
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Optimized Deep Learning Framework for Robust Detection of GAN-Induced Hallucinations in Medical Imaging
1 Department of Computer Science, Kansas State University, Manhattan, KS, USA
2 Department of Electrical Engineering and Computer Science, University of Missouri, Columbia, MO, USA
3 Computer Engineering Department, Bahauddin Zakariya University, Multan, Pakistan
4 Department of Computers and Systems, Electronics Research Institute, Cairo, Egypt
5 Department of Electrical Engineering, Military College of Signals (MCS), National University of Science and Technology, Islamabad, Pakistan
6 College of Computer and Information Sciences, Imam Mohammad Ibn Saud Islamic University (IMSIU), Riyadh, Saudi Arabia
7 Computer Science Department, College of Science and Humanities, Imam Abdulrahman Bin Faisal University, Jubail, Saudi Arabia
* Corresponding Author: Imran Qureshi. Email:
(This article belongs to the Special Issue: Intelligent Medical Decision Support Systems: Methods and Applications)
Computer Modeling in Engineering & Sciences 2026, 146(2), 42 https://doi.org/10.32604/cmes.2026.073473
Received 18 September 2025; Accepted 16 January 2026; Issue published 26 February 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Generative Adversarial Networks (GANs) have become valuable tools in medical imaging, enabling realistic image synthesis for enhancement, augmentation, and restoration. However, their integration into clinical workflows raises concerns, particularly the risk of subtle distortions or hallucinations that may undermine diagnostic accuracy and weaken trust in AI-assisted decision-making. To address this challenge, we propose a hybrid deep learning framework designed to detect GAN-induced artifacts in medical images, thereby reinforcing the reliability of AI-driven diagnostics. The framework integrates low-level statistical descriptors, including high-frequency residuals and Gray-Level Co-occurrence Matrix (GLCM) texture features, with high-level semantic representations extracted from a pre-trained ResNet18. This dual-stream approach enables detection of both pixel-level anomalies and structural inconsistencies introduced by GAN-based manipulation. We validated the framework on a curated dataset of 10,000 medical images, evenly split between authentic and GAN-generated samples across four modalities: MRI, CT, X-ray, and fundus photography. To improve generalizability to real-world clinical settings, we incorporated domain adaptation strategies such as adversarial training and style transfer, reducing domain shift by 15%. Experimental results demonstrate robust performance, achieving 92.6% accuracy and an F1-score of 0.91 on synthetic test data, and maintaining strong performance on real-world GAN-modified images with 87.3% accuracy and an F1-score of 0.85. Additionally, the model attained an AUC of 0.96 and an average precision of 0.92, outperforming conventional GAN detection pipelines and baseline Convolutional Neural Network (CNN) architectures. These findings establish the proposed framework as an effective and reliable solution for detecting GAN-induced hallucinations in medical imaging, representing an important step toward building trustworthy and clinically deployable AI systems.Keywords
Medical image datasets are important in training deep learning models for different applications. These applications include image perception research and computer vision algorithms, among many other applications. However, Authentic medical images are scarce for many of these applications [1]. Hence, there is a need for methods for generating synthetic data images using GANs. Generative Adversarial Network (GANs) is a powerful class of neural networks that rely on parallel training of two networks for image generation and discrimination [2]. Recent advances in deep generative models revolutionized the application of GANs in medical imaging by enabling the synthesis of photorealistic images. In recent years, GANs have gained tremendous popularity in doing various imaging-related tasks such as medical image generation to support Deep learning models training. GANs are especially useful for medical imaging-related tasks where training datasets are usually limited in size and sometimes imbalanced. GANs can be used for generating medical images that can be used to train deep learning models [3]. There are some traditional augmentation methods, such as translation, rotation, flip, and scale methods, that can increase the amount of training data [4]. However, these methods increase the data with minimal performance gain. The generation of synthetic images aims to increase the accuracy of medical systems that depend on machine learning models. These advancements increase the capabilities of medical professionals, leading to more accurate diagnostic evaluations and personalized treatment plans. However, this same technology that offers some benefits also introduces vulnerabilities and challenges. GAN-generated images are usually indistinguishable from authentic scans that may contain artifacts or hallucinated structures that may mislead clinical interpretation and compromise diagnostic accuracy. One of the consequences of the pervasive employment of GANs for the synthesis of medical images is the need for a new kind of challenge: the detection of hallucinated images, artificially generated visuals that imitate real data but contain inaccuracies or distortions. The problem, according to the authors, is that in healthcare, a change in medical images due to the use of a GAN for model training can lead to a decrease in diagnostic accuracy [5]. The unintentional incorporation of these types of artificial anomalies in the clinical workflow leads to a decrease in the classification accuracy, endangers patients, and lowers the level of clinical trust.
In order to solve the problem, people are increasingly driven to come up with strong methods that can distinguish hallucinations in medical imaging caused by GANs. The usual detection methods are largely unsuccessful in identifying these false images, especially when different imaging techniques are used and in real clinical conditions. A few research papers have summarized the usage of GANs in medical imaging [6]. The authors discuss recent studies, methods, and models for generating synthetic medical images using GANs [7]. A GAN-based method for generating privacy-preserving synthetic medical images capable of replacing or augmenting real data for AI training is proposed, and both quantitative and qualitative evaluations demonstrate its promising performance [8].
The authors present a new adaptive generative network called MedGAN that overcomes limitations of prior GAN models in the literature, and they use a Wasserstein loss function as a convergence metric to evaluate the model’s performance [9]. The paper describes a novel unsupervised method for generating T1-weighted brain MRI images as a potential application of a GAN trained on 528 examples of 2D axial brain MRI slices. Two imaging professionals conducted a blind quality assessment of the generated images, assigning scores from 1 to 5, and the synthetic images achieved nearly the same quality as the real ones [10]. Additionally, the authors in [11] present StynMedGAN, a novel GAN model designed to synthetically generate medical images, which in turn improves the performance of classification models. Essentially, it is a derivative of the state-of-the-art StyleGANv2 framework, which is capable of producing natural images of very high quality. A novel synthetic medical imaging method based on progressive generative networks is described in [12], leading to better outcomes than those of the current methods. The paper presents a generative adversarial network that is aware of boundaries and diversity for data augmentation, emphasizing class boundaries and intra-class diversity. It adopts a multi-generator GAN architecture, where each generator learns different data patterns, resulting in more diverse and higher-quality images [13].
A CycleGAN variant for liver medical image generation is presented, incorporating a correction network module with an encoder–decoder structure and residual connections to efficiently extract latent features. However, images created by GANs may still contain defective or fabricated regions, which can decrease diagnostic accuracy in deep learning models trained on such data [14]. To address this issue, the article proposes a texture-constrained multichannel progressive GAN (TMP-GAN) that simultaneously trains multiple channels to overcome the limitations of existing models. Experimental results on public datasets validate the effectiveness and performance of the approach [15].
When it comes to hallucination identification in GAN-created medical images, there are primarily deep learning-based methods and hybrid methods that use different feature types. A completely different technique is presented for identifying hallucinatory content in GAN-generated images, and the study surveys recent advancements in detection solutions addressing this issue [16]. Hybrid methods typically combine statistical and semantic (CNN-based) features to improve the detection accuracy of synthetic artifacts in medical images [17]. Xception (Extreme Inception), which builds on the Inception architecture by replacing standard Inception modules with depthwise separable convolutions. The key insight is that cross-channel correlations and spatial correlations can be decoupled, making the network more efficient while maintaining or improving performance. This architecture influenced many subsequent efficient network designs [18].
A framework for salient object detection using three key components: Fusion (combining multi-scale features), Feedback (refinement through iterative information flow), and Focus (attention mechanisms to highlight important regions). It addresses the challenge of accurately detecting and segmenting salient objects in images [19]. A highly influential paper that systematically studied model scaling for CNNs. Rather than arbitrarily scaling depth, width, or resolution, the authors proposed a compound scaling method that balances all three dimensions using a simple coefficient. They also introduced EfficientNet-B0 through B7, which achieved state-of-the-art accuracy with significantly fewer parameters and FLOPs than previous models [20]. A groundbreaking paper that demonstrated transformers (originally designed for NLP) could be applied directly to images by treating image patches as tokens. This challenged the dominance of CNNs in computer vision and sparked extensive research into transformer-based vision models [21].
Despite these advancements, existing studies on hallucination detection in GAN-generated medical images remain limited. Current methods often lack generalization across different datasets and modalities. Additionally, there is a scarcity of publicly available datasets containing real-world GAN-modified medical images, forcing researchers to rely on synthetically altered datasets for model training. These gaps highlight the urgent need for developing more robust and generalizable detection models capable of identifying GAN-induced hallucinations across diverse clinical imaging scenarios.
In this research, we aim to fill this gap by generating a diverse synthetic dataset using realistic GAN-induced manipulations across four modalities: MRI, CT, X-ray, and retinal fundus images. This dataset emulates real-world conditions, serving as a foundation for training and validating our proposed detection model. Another critical unmet need lies in the poor generalizability of current hallucination detectors across imaging modalities, manipulation types, and GAN architectures. Many existing models perform well in limited domains but fail when exposed to unseen datasets or novel manipulation styles.
By incorporating domain adaptation methods such as adversarial learning and style transfer, our study mitigates these limitations that localize research within specific domains. These techniques substantially improve the model’s capacity to generalize in different clinical and synthetic domains. Nevertheless, the detection of hallucinations in medical imaging is still a challenging problem due to the limited interpretability and transparency of the systems. Most of the existing models only give a binary output without providing any contextual information or explanatory cues. To tackle this problem, we present a hybrid deep learning system combining low-level statistical features (e.g., high-frequency residuals and GLCM textures) and high-level semantic features that can not only classify the data more effectively but also detect artifacts in an interpretable way by multi-scale feature analysis. In addition, the area has not yet identified any unified hybrid frameworks that can effectively combine the handcrafted statistical descriptors with deep semantic representations in a way that is clinically meaningful. Most of the earlier works are either completely dependent on traditional features or CNN-based architecture. Here, we have developed a multi-branch hybrid network that merges both types of features, thus utilizing the combined capabilities of the features to improve detection accuracy as well as total robustness. Furthermore, the non-existence of modality-agnostic solutions is still the major reason why hallucination detection systems cannot be easily transferred to different healthcare scenarios. For overcoming this problem, we have developed a system that can work smoothly with different imaging modalities, thereby demonstrating its flexibility and scalability. This makes our work an essential milestone in the development of a general-purpose hallucination detection module for AI-integrated radiology and ophthalmology platforms.
This research employs the term ‘hallucination’ to describe GAN-related artifacts, which are fabricated structures or pixel-level distortions introduced by generative models that do not correspond to the real anatomy. We will continue to use the terms hallucination (artifact) interchangeably for clarity with conventional image forensics terminology. The developed framework is a response to the urgent issue of the presence of GAN-induced hallucinations in medical images that, in turn, can cause diagnostic errors and diminish the confidence of AI-assisted clinical systems. Consequently, the system combines low-level statistical descriptors, such as high-frequency residuals and Gray-Level Co-occurrence Matrix (GLCM) textures, with high-level semantic features obtained from a pretrained convolutional neural network. Through careful GAN manipulations on MRI, CT, X-ray, and retinal images, a varied synthetic dataset was created to fabricate believable hallucination artifacts. Additionally, domain adaptation methods like adversarial learning and style transfer were used to facilitate the system’s generalization across different imaging modalities. The findings of the experiments validate that the suggested method is capable of detecting even the slightest GAN-induced abnormality and, thus, it can be considered as a tool for maintaining integrity, safety, and trust in AI-assisted medical image analysis.
The rapid development of Generative Adversarial Networks (GANs) has changed various domains, one of which is image generation, data augmentation, and medical imaging. Nevertheless, the increased application of GANs has raised a significant issue: finding the hallucinated images, which are artificially created modifications that resemble real data but may still contain inaccuracies or distortions without the knowledge of the user, particularly in medical fields. In a healthcare environment where AI-based systems are on their way to becoming the core of diagnostics, just a slight intervention of a GAN in medical images may mislead the doctor to make a wrong diagnosis, thus risking the patient’s life. Therefore, there is an urgent need for dependable means of recognizing such GAN-induced hallucinations in medical imaging. While the problem is of such great importance, solutions that exist are focused mostly on image synthesis or artifact detection from a general perspective and do not give much consideration to identifying GAN artifacts in medical imaging. Our work is influenced by the requirement of creating a single, end-to-end detection system that can scan through the medical images and spot those that have been meddled with by GANs without compromising the integrity and trustworthiness of AI-based diagnostic systems. By bridging this gap, our work can raise the confidence level of AI systems working in healthcare, thus safeguarding the pivotal decision-making process of taking care of patients.
This work introduces the following contributions:
1. We introduce a hybrid framework that integrates statistical image features with deep CNN representations to detect both subtle and structural GAN-induced distortions in medical images.
2. We develop a synthetic dataset of GAN-induced artifacts across multiple imaging modalities, providing a novel benchmark for training and evaluation.
3. We apply domain adaptation techniques to mitigate domain shift, enhancing the framework’s generalizability to real-world GAN-modified clinical data.
Our framework ensures clinical safety by detecting GAN-induced hallucinations that could otherwise compromise diagnostic accuracy. This is the first step towards creating trustworthy AI-driven medical imaging systems, protecting against the risks of false positives and misdiagnoses caused by GAN manipulations in clinical settings.
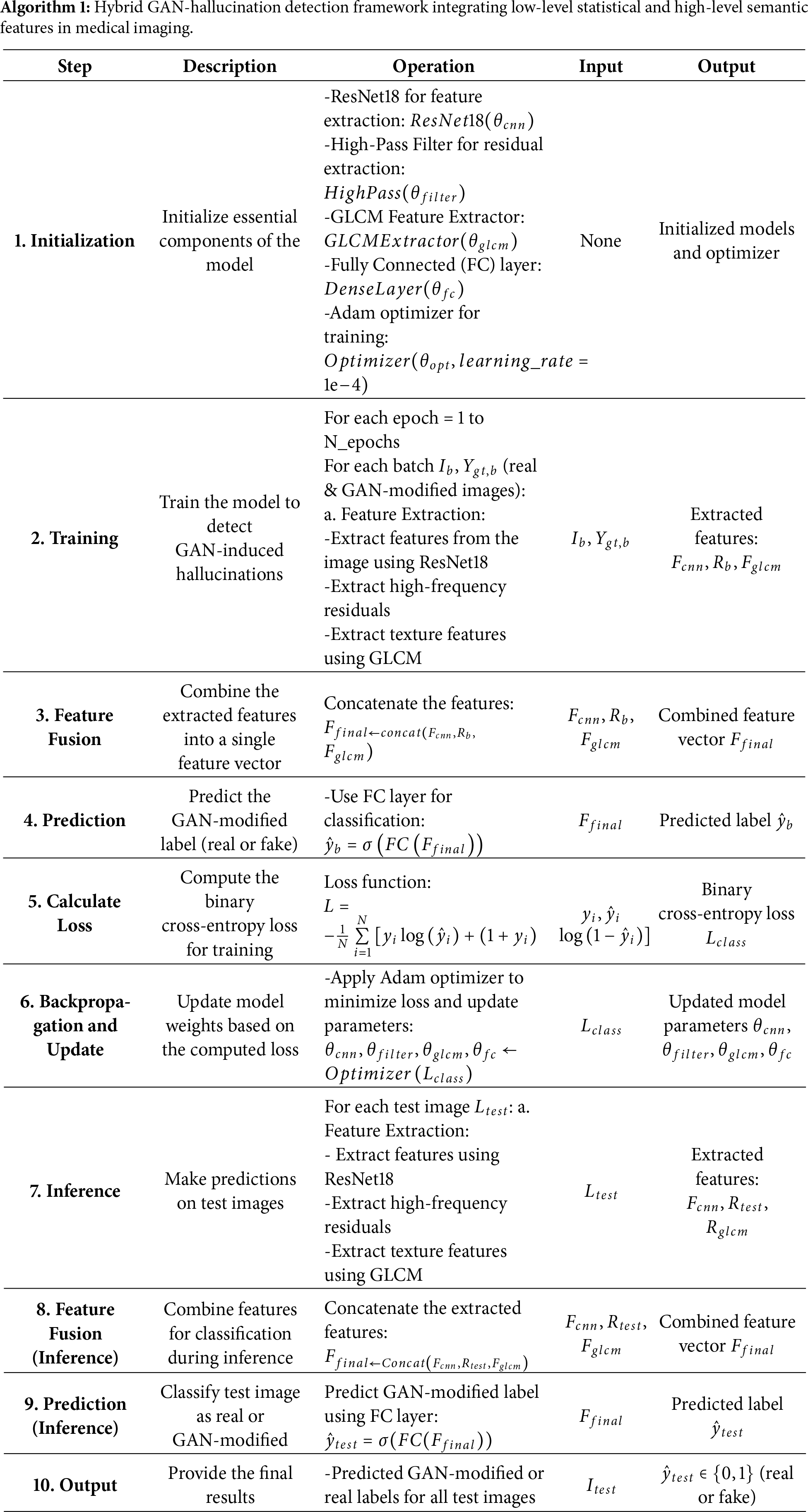
Our proposed approach features a hybrid deep learning system that utilizes both low-level statistical feature extraction and high-level semantic learning to detect GAN-induced hallucinations (artifacts) in medical images. Initially, a synthetic dataset was generated by implanting typical GAN-induced artifacts like synthetic lesions, color shifts, and geometric distortions into medical images of four different modalities: MRI, CT, X-ray, and fundus photography. As there are no real GAN-modified medical datasets available for the public, CycleGAN v2.1, StyleGAN2-ADA (2023 implementation), and Pix2Pix HD v1.6, all coordinated in PyTorch 2.2, were used to create the artifacts. For CycleGAN, a setting of λ = 10 and a learning rate of 0.0002 for 200 epochs was used. StyleGAN2-ADA had the adaptive discriminator augmentation enabled with p = 0.7, while Pix2Pix HD was run for 100 epochs with a feature-matching loss weight of 10. Typical augmentations were the synthesis of an artificial lesion, the distortion of the texture, and the simulation of color-shift. During the preprocessing stage, the resolution of all images was fixed at 224 × 224 pixels, and they were normalized to the [0, 1] intensity range. To extract features, pixel-level anomalies were localized with the help of a high-pass filter to get high-frequency residuals, and Gray-Level Co-occurrence Matrix (GLCM) texture features were obtained to represent the spatial relationships between pixel intensities. At the same time, a pretrained ResNet18 CNN was used to get the high-level semantic features responsible for the complex structural variations. These low-level and high-level features were concatenated into a single feature vector and sent to fully connected layers for classification. A sigmoid activation function was used to produce the final probability score that distinguished real from GAN-modified images. The training of the model made use of binary cross-entropy loss, and the Adam optimizer was employed. To fill the gap between the domains of the synthetic and the real-world data, several domain adaptation methods like adversarial training and style transfer were used so that the model could generalize better to real GAN-modified medical images. The performance of the model was validated with standard metrics such as accuracy, precision, recall, and F1-score, thus proving that the system is capable of reliably detecting GAN-induced artifacts in medical images from various modalities. The technique put forward is a dependable and rapid one to identify the presence of GAN-related hallucinations, thus increasing the reliability of AI-based diagnostic platforms in the field of medical imaging. The different stages of the hallucination detection framework proposed are shown in Fig. 1.
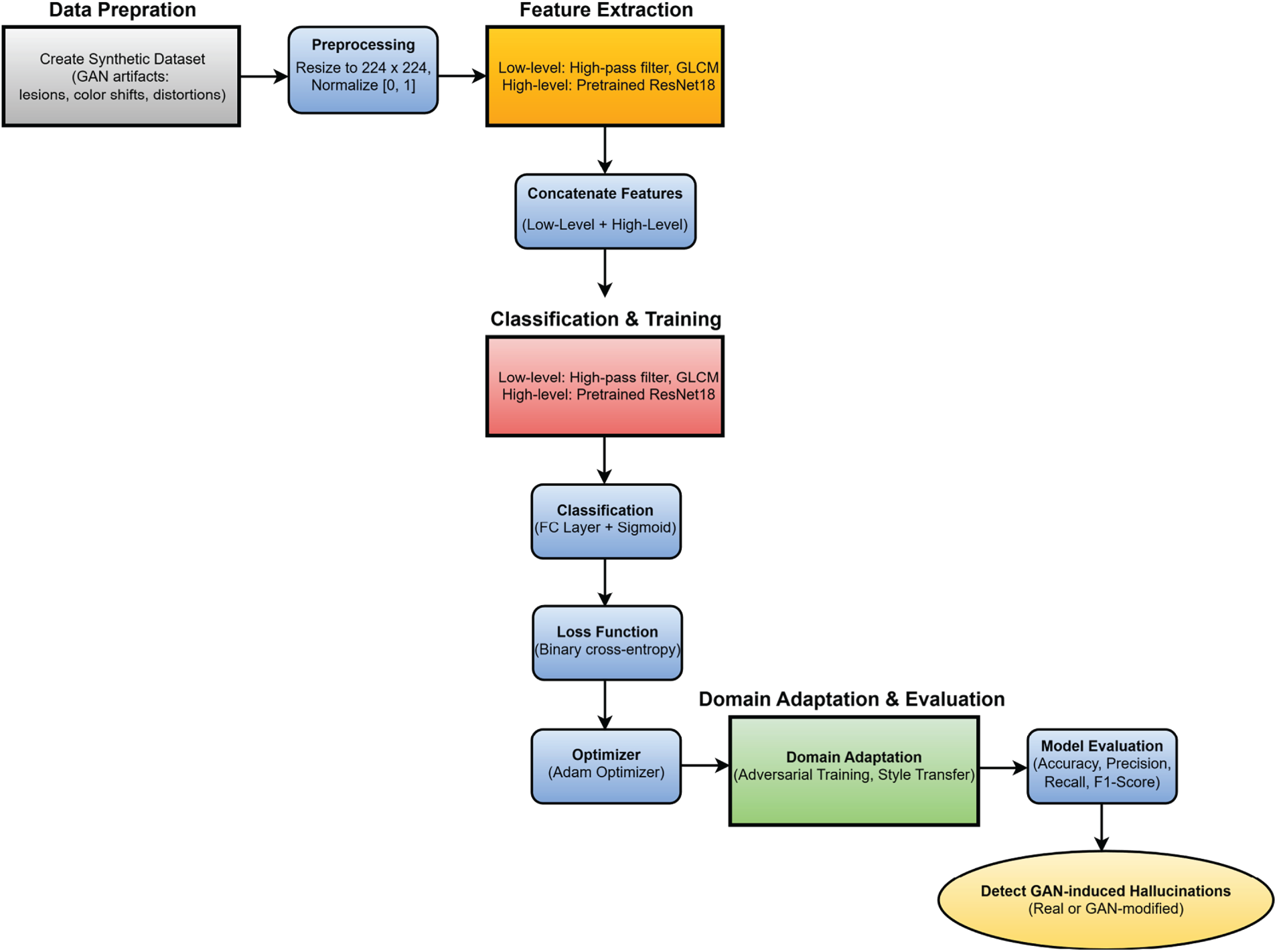
Figure 1: Flow diagram of the proposed methodology for detecting GAN-induced hallucinations in medical images.
In this paper, data preparation was instrumental to the overall success and effectiveness of the detective framework of reflections from a generative adversarial network (GAN) presented. At first, the databank was put together using publicly accessible medical imaging repositories that offered a variety of imaging techniques, among them MRI [22], CT [23], X-ray [24], and fundus photographs [25]. The dataset consisted of 10,000 images in total, and the distribution that followed was observed: 2500 MRI images, 2500 CT images, 2500 X-rays, and 2500 fundus images. After that, real images were altered systematically through the use of different GAN architectures like CycleGAN, StyleGAN, and Pix2Pix models so as to impersonate real-world adversarial attacks. The goal of the synthetic manipulations was to impose a variety of artifacts so that the artificial lesions, color aberrations, texture hallucinations, and soft geometric deformations that were used to simulate pathological features without imposing visually salient artifacts could be recognized by the model. This helped machine learning to become well-trained under potential real-world attack scenarios by providing a balanced dataset consisting of 5000 real images and 5000 images manipulated by the GAN. Both the original and GAN-corrected images were downscaled to a consistent 224 × 224-pixel resolution across all modalities and to be optimally compatible with the ResNet18 architecture used for the extraction of high-level features. Pixel intensity was also normalized to the range [0, 1] so that neural network training would converge stably and differences in intensity scales arising from different imaging devices and acquisition protocols could be minimized. Besides this, every image was provided with a label indicating whether it was a real one or a GAN-generated one, thus enabling supervised learning. The entire dataset was randomly divided into training, validation, and testing sets in the ratio of 70:15:15, respectively, and there was class balancing within each split. Consequently, the training set consisted of 7000 images (3500 real and 3500 GAN-altered), the validation set consisted of 1500 images (750 real and 750 GAN-altered), and the test set consisted of 1500 images (750 real and 750 GAN-altered). This thorough data preparation step was crucial to ensuring that the model would be exposed to a wide range of possible GAN-induced alterations, thus allowing the development of a robust detector that could distinguish between true medical images and those subtly manipulated by generative models. Sample normal images are shown in Fig. 2, and samples of GAN-generated fake hallucinations are shown in Figs. 3–5. The dataset was characterized by a moderate degree of class imbalance between real and GAN-generated medical images. To solve this problem, we took steps at both the data and the loss-weighting levels. Samples of the minority class were subjected to random oversampling and geometric and intensity-based transformations (e.g., rotations, flips, brightness adjustments) for augmentation in order to increase feature diversity. Moreover, the cross-entropy loss with class weights was implemented to misclassify underrepresented classes and thus penalize them more seriously. These combined measures ensured that the model maintained balanced learning behavior and improved generalization across modalities.
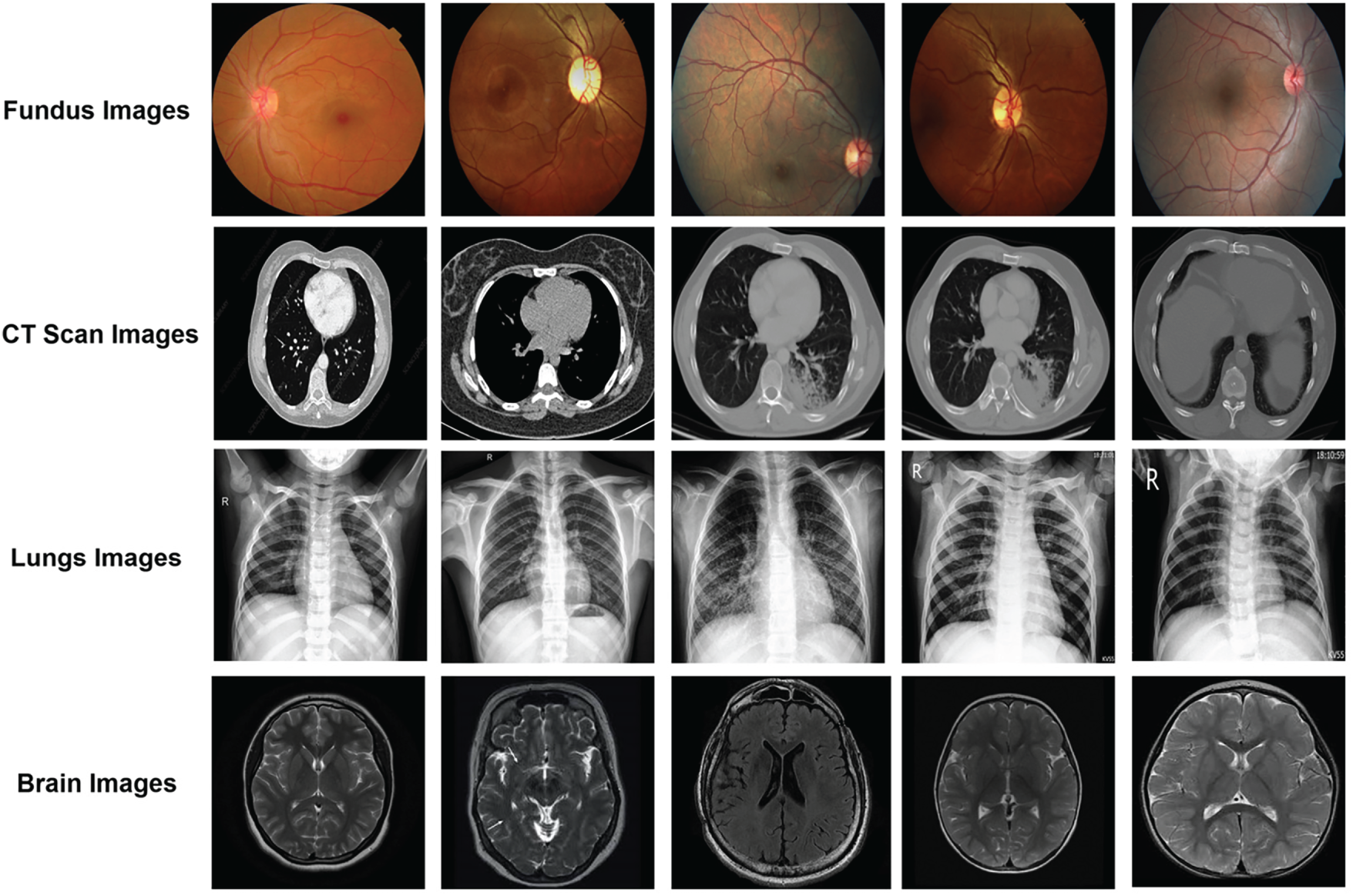
Figure 2: Normal medical images are illustrated.
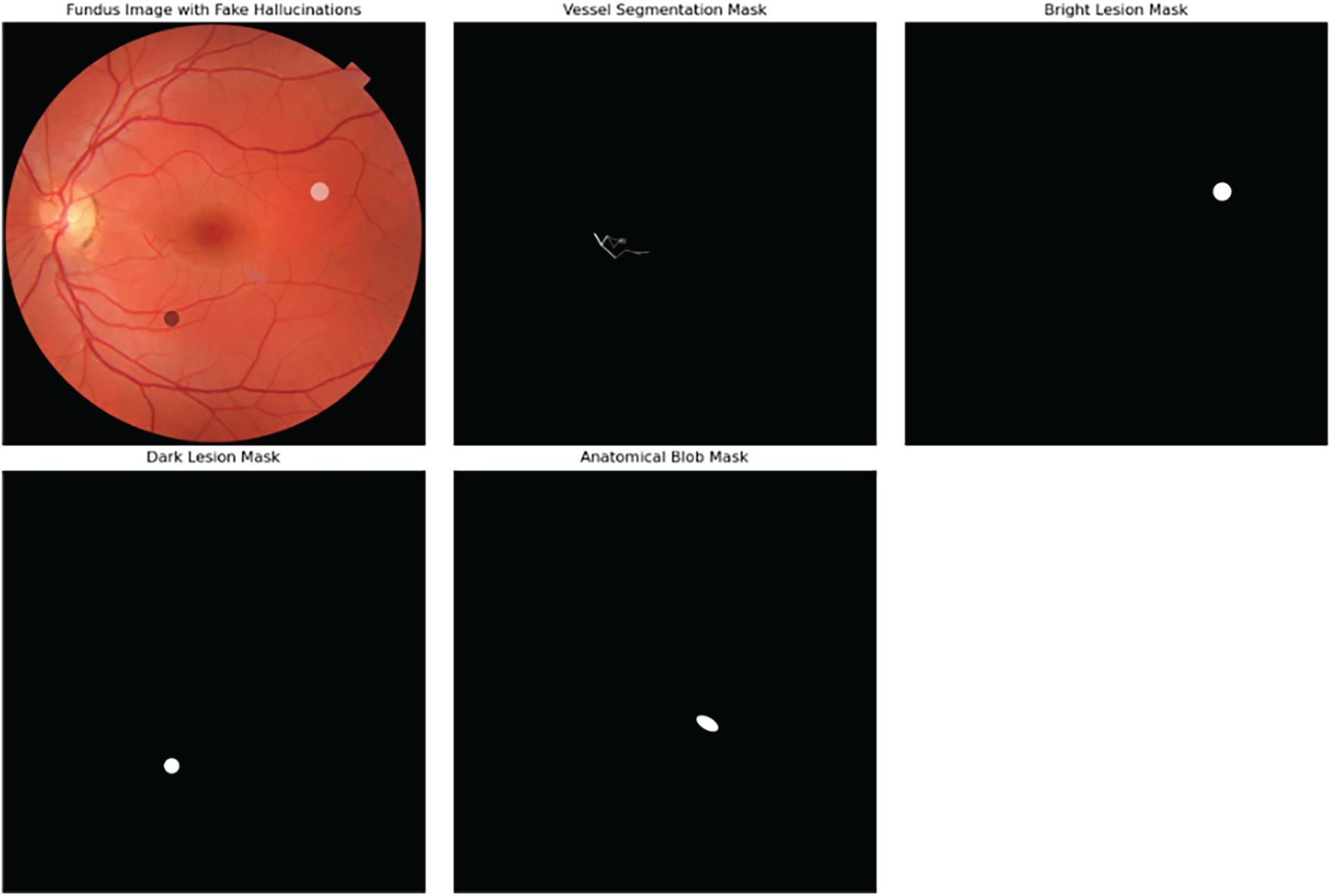
Figure 3: GANs generated fake hallucinations on fundus images.
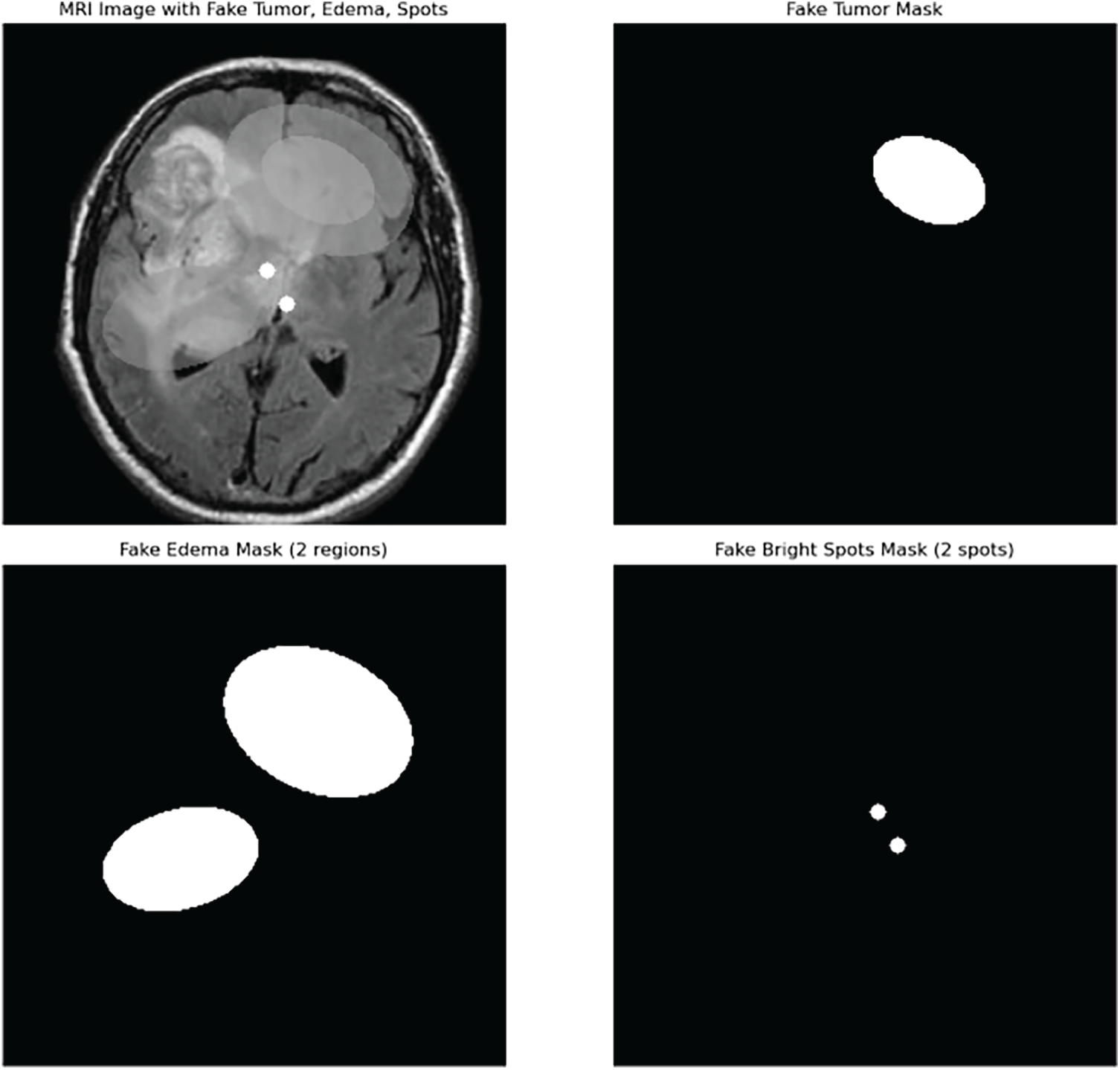
Figure 4: GANs generated fake hallucinations on brain tumor images.
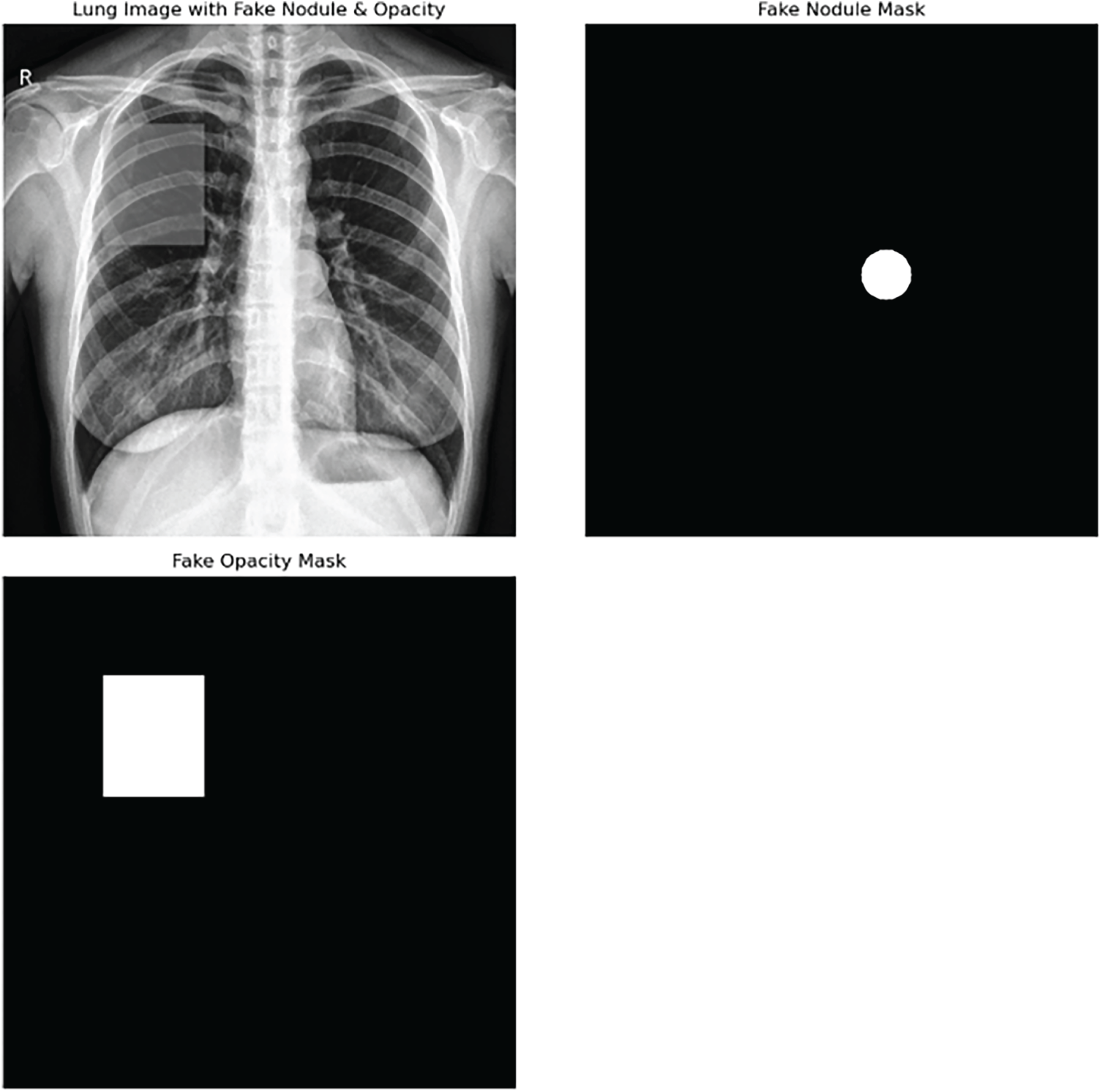
Figure 5: GANs generated fake hallucinations on lungs x-ray images.
2.2 GAN-Hallucination Detection Architecture
The new GAN-hallucination detection architecture, as a hybrid framework, combines low-level statistical analysis with high-level semantic learning to locate the faintest of the trickery of generative adversarial networks (GANs) in medical imaging data. Firstly, the system sets up an input tensor of a certain size (224 × 224 × 3), which is RGB images that are resized in the same way for all modalities to have the same spatial dimensions. By doing this, the data is made ready for the following convolutional layers, and the differences that come from different imaging protocols are leveled out.
After preprocessing, the architecture starts a dual-path feature extraction operation. One path is focused on extracting low-level statistical features that highlight pixel-level anomalies that might have been caused by GAN modifications. The very first step in this path is obtaining high-frequency residuals with a high-pass filter, which. Let
where
where
At the same time, the second way is performing the top-level semantic feature extraction with the help of a pretrained ResNet18 convolutional neural network, which is chosen for its verified ability to learn the hierarchical feature representations. The ResNet18 stages include series of convolutions and residual connections that allow the gradient to flow through the deeper layers. The convolution operation performed at spatial location
where
where GAP stands for the global average pooling operation that gathers spatial information from feature maps. The concatenation of the low-level statistical features and the high-level semantic vector is done next to obtain a single feature representation
where
The concatenated feature vector
followed by the ReLU nonlinearity:
The final layer employs a sigmoid activation function to produce a probability score
This binary output allows direct classification of images into genuine or synthetic categories.
For training, the model minimizes the binary cross-entropy loss function:
where
To reduce the difference between synthetic and real clinical images, architecture employs advanced domain adaptation strategies such as adversarial training and style transfer. We implemented Domain-Adversarial Neural Networks (DANN) where a domain classifier is inserted into the feature extractor. The domain classifier is trained to determine synthetic vs. real data while the feature extractor is trained to produce domain-invariant features that can confuse the domain classifier. Style transfer methods through CycleGAN were also employed to convert synthetic images to the real medical image style, thus the domain disparity is reduced even more. The domain adaptation hyperparameters included a learning rate for the domain classifier of 1 × 10−4 and a gradient reversal scale factor of 1.0. These methods efficiently bring the feature distributions from different domains into alignment, thus the model’s capacity to generalize to real-world images with GAN artifacts is increased. The success of the model is measured in terms of significant metrics like accuracy, precision, recall, and F1-score to give a thorough evaluation of the sensitivity and specificity of GAN-induced hallucination detection. By using this multi-angled approach, architecture supplies a powerful method to safeguard medical imaging systems from the stealthy and possibly deceptive synthetic manipulations generated by generative models. The comprehensive architecture of our proposed system is shown in Fig. 6, and the whole workflow of this proposed architecture is summarized stepwise in Algorithm 1.
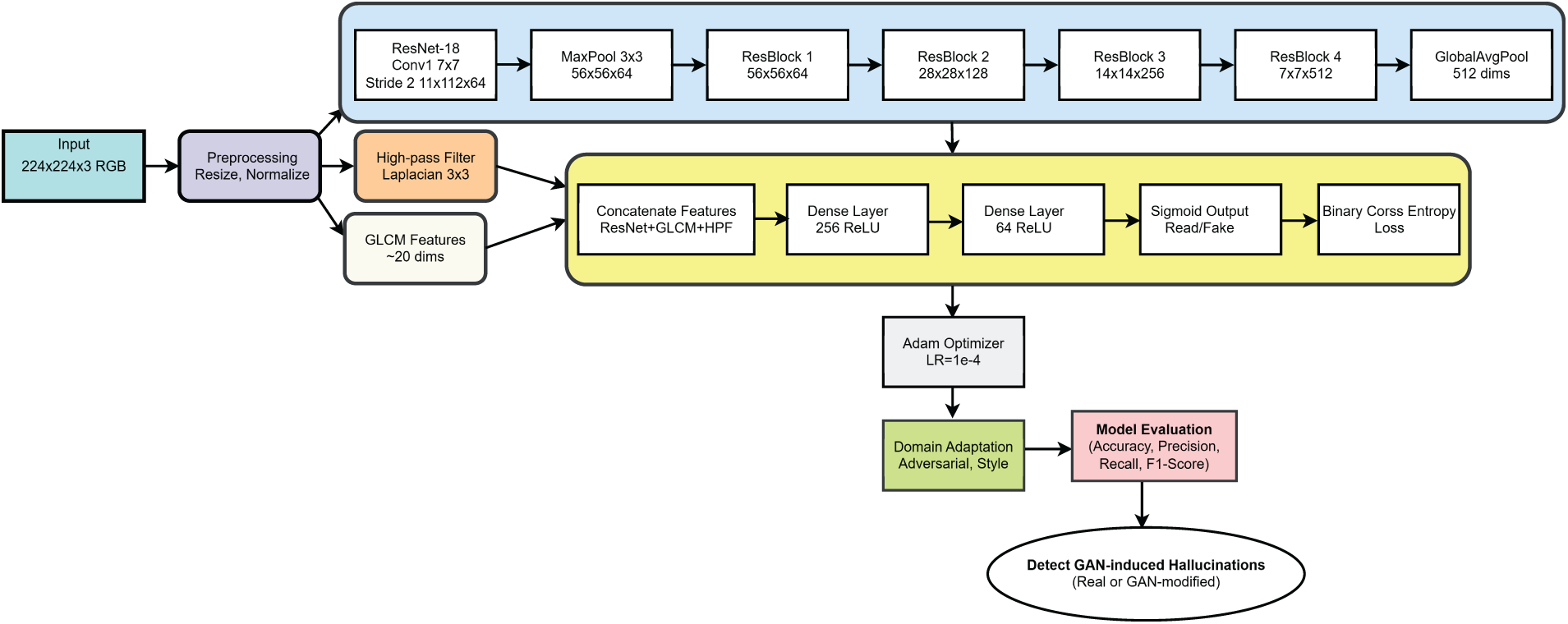
Figure 6: Architecture of the proposed methodology for detecting GAN-induced hallucinations in medical images.
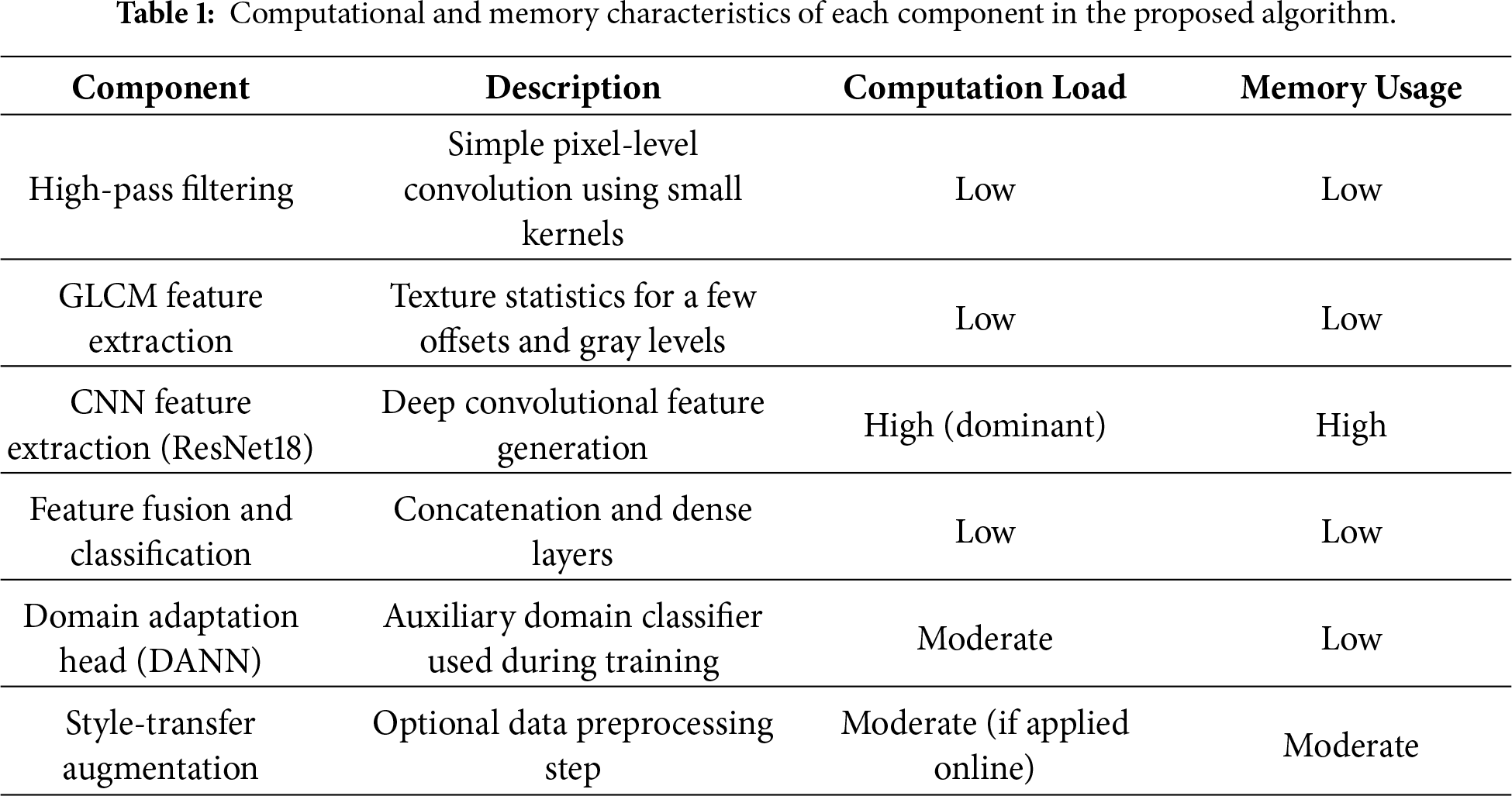
To gain more insights into the scalability and resource requirements of the proposed framework, its computational efficiency was also analyzed. Pixel-level simple operations, such as high-pass filtering and GLCM texture extraction, which are the early stages of the algorithm, are minimally involved in the overall computation. The most computationally demanding part is CNN feature extraction through ResNet18, which is the major source of both processing time and memory usage; nevertheless, this cost is kept stable and manageable because all images are resized to a fixed size of 224 × 224. The following feature fusion and classification layers are very light; thus, they add a negligible overhead. The domain adaptation head, whose inclusion causes a small additional load, is active during training only, whereas the style-transfer augmentation step that is done offline, does not affect the runtime noticeably. Table 1 contains a brief description of the computational and memory characteristics of each module, which is a clear indication that the CNN backbone is the main source of the highest computational cost while the statistical feature extraction and classification components are quite cheap. In general, the proposed algorithm scales linearly with the number of images and keeps efficient inference performance that can be used in real-world medical imaging applications.
The proposed model was created and tested on a workstation running a 64-bit Windows 11 and powered by an Intel Core i9 processor, 32 GB of RAM, and an NVIDIA RTX 4070 GPU. The development environment was configured using Anaconda, which was the main platform for programming in Python. TensorFlow and PyTorch were the main libraries used at the implementation level, and they provided the means for the fast and efficient model development and optimization of the deep learning algorithm. The dataset for this research is a collection of 10,000 medical images that were divided equally into real and GAN-generated data of four different imaging modalities, i.e., MRI, CT, X-ray, and fundus images. The images came from open-source medical image repositories. In order to perform preprocessing on each image, they were all resized to 224 × 224 pixels, and their pixel values were normalized to the range [0, 1], thus having the same input sizes and training convergence stability. Moreover, labels were assigned to indicate whether an image was real or fake, thus providing the basis for supervised learning. For the experiments, the entire dataset was divided into training, validation, and test sets with the proportions 70:15:15 and class balancing within each split. Therefore, the data was divided into 7000 training images (3500 real and 3500 GAN-mutated), 1500 validation images (750 real and 750 GAN-mutated), and 1500 test images (750 real and 750 GAN-mutated). The training employed the Adam optimizer with a learning rate of 0.0001 and was limited to 50 epochs. The main goal was set as a binary cross-entropy loss function for differentiating real and GAN-edited images. The progress of the model was recorded during training and also verified after each epoch based on several indicators such as accuracy, precision, recall, and F1-score, in order to confirm strong detection ability for every image modality and manipulation method. In order to test the strength and generalization ability of the suggested model, we used k-fold cross-validation (k = 5). The data was divided randomly into five equal parts, thus in each iteration, four folds were used for training, and one was left for validation. The ROC and AUC curves were drawn from the predictions made in all folds. The final AUC score was given as the average ± standard deviation of the five runs. Such a scheme alleviates the problem of bias caused by random data splits and gives a more trustworthy estimate of the model’s efficacy for different imaging modalities.
In the initial experiment, we gauged the effectiveness of the hallucination (artifact) detection model powered by the proposed GAN of a fabricated medical image dataset. This dataset was intentionally designed to simulate common GAN-generated aberrations. It incorporated images of four modalities MRI, CT, X-ray, and retinal fundus, each of which was artificially implanted with typical GAN artifacts such as synthetic lesions, color perturbations, and geometric distortions. Fig. 1 exhibits samples of authentic medical images as well as those manipulated by GAN. All the images were brought to a uniform spatial resolution of 224 × 224 pixels and were normalized to the [0, 1] range in order to standardize the input size and intensity values. Using a mixed-feature extraction approach that combines both low-level statistical features such as high-frequency residuals and texture features obtained from the Gray-Level Co-occurrence Matrix (GLCM) as well as high-level semantic features derived from a pretrained ResNet18 convolutional neural network, the proposed model was run for 50 epochs. Standard metrics accuracy, precision, recall, and F1-score, were used for the model performance evaluation. The comprehensive results are shown in Table 2, indicating that the proposed hybrid model has reached the following values on the synthetic test set: accuracy = 92.6%, precision = 0.93, recall = 0.89, and F1-score = 0.91. Fig. 8 illustrates the training and validation accuracy and loss curves, while Fig. 9 presents the confusion matrix, which highlights the model’s strong ability to correctly distinguish real from GAN-generated images with only a minimal number of misclassifications. The amalgamation of the hybrid feature extraction framework proves to be very powerful and the synthetic dataset turns out to be very useful for creating reliable GAN artifact detectors. To examine the effect of the hybrid feature fusion, we pit the proposed model against a baseline CNN that only used high-level semantic features for training. The baseline model was composed of 3 convolutional layers (32–64–128 filters, 3 × 3 kernels), each followed by ReLU activation, max-pooling, and dropout (0.3), and a 256-unit dense layer ending with the output sigmoid classifier. Both models were subjected to the same training regimen, binary cross-entropy loss, Adam optimizer (learning rate = 1 × 10−4), and batch size = 32 to provide a fair comparison of the results. Fig. 7 evaluating the Baseline CNN versus the Proposed Hybrid Model on a Synthetic Data Benchmark. As outlined in Table 3 and depicted in Fig. 8, the hybrid model proposed was able to outperform the baseline CNN to a great extent thus achieving not only an absolute accuracy increase of 7.4% but also a 0.09 increment of the F1-score. The result is in line with the idea that the combination of both low-level statistical and high-level semantic features yields a more complete representation of GAN-induced anomalies in medical images.

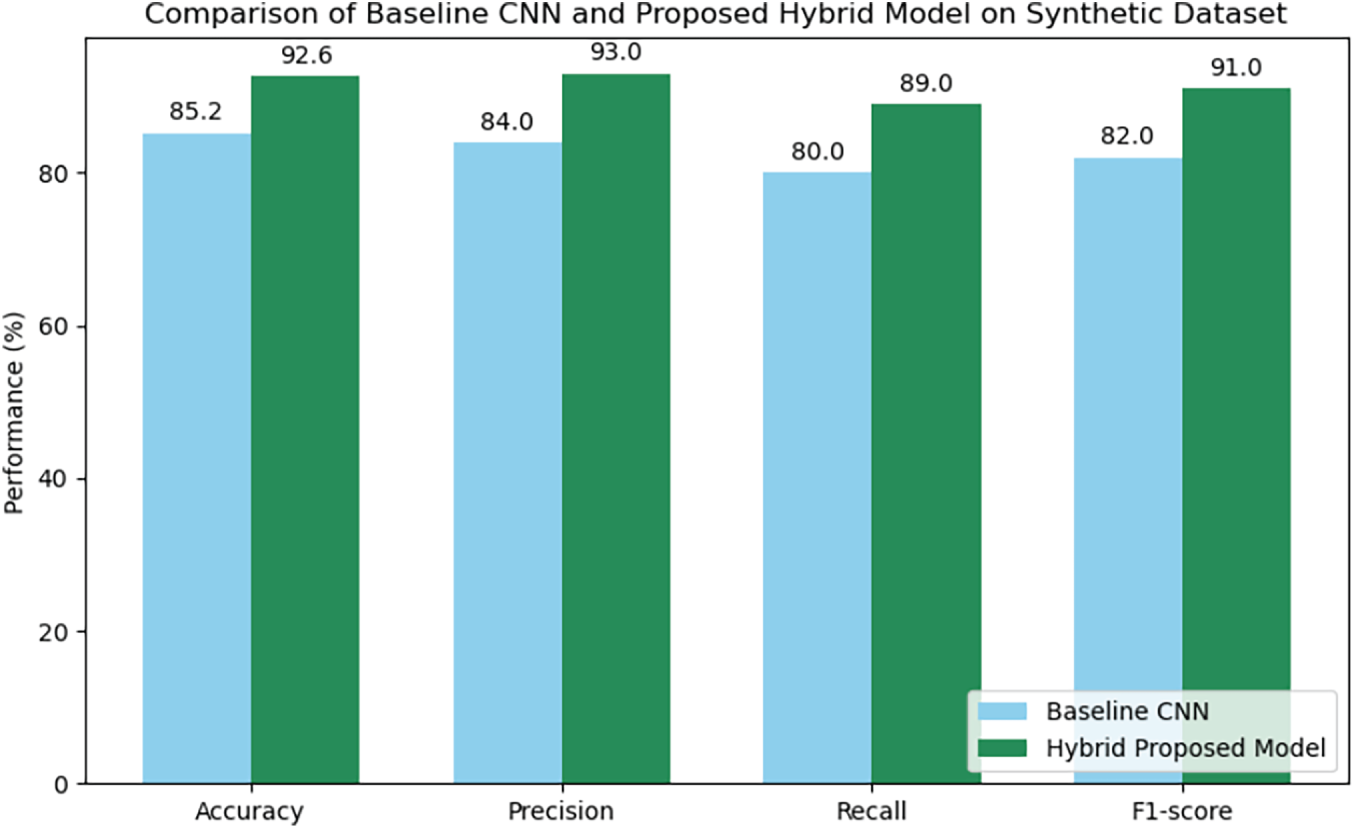
Figure 7: Comparison of baseline CNN and proposed hybrid model on synthetic dataset.
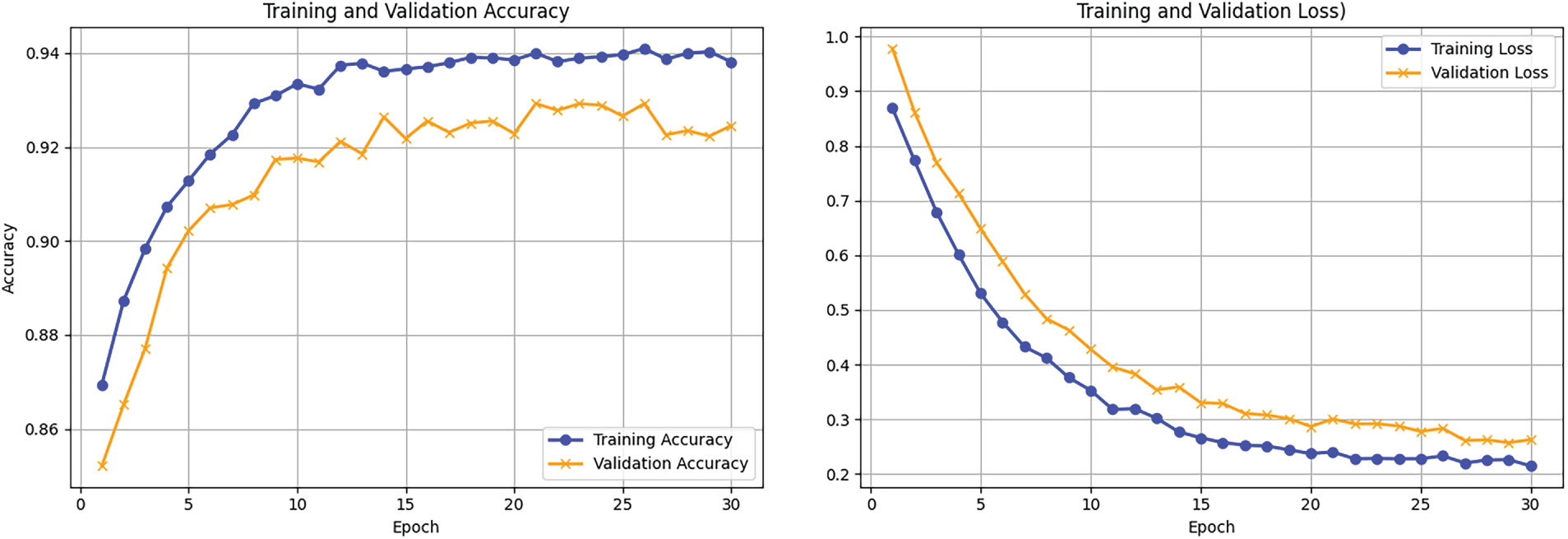
Figure 8: Training and Validation accuracy and loss curves for experiment 1.
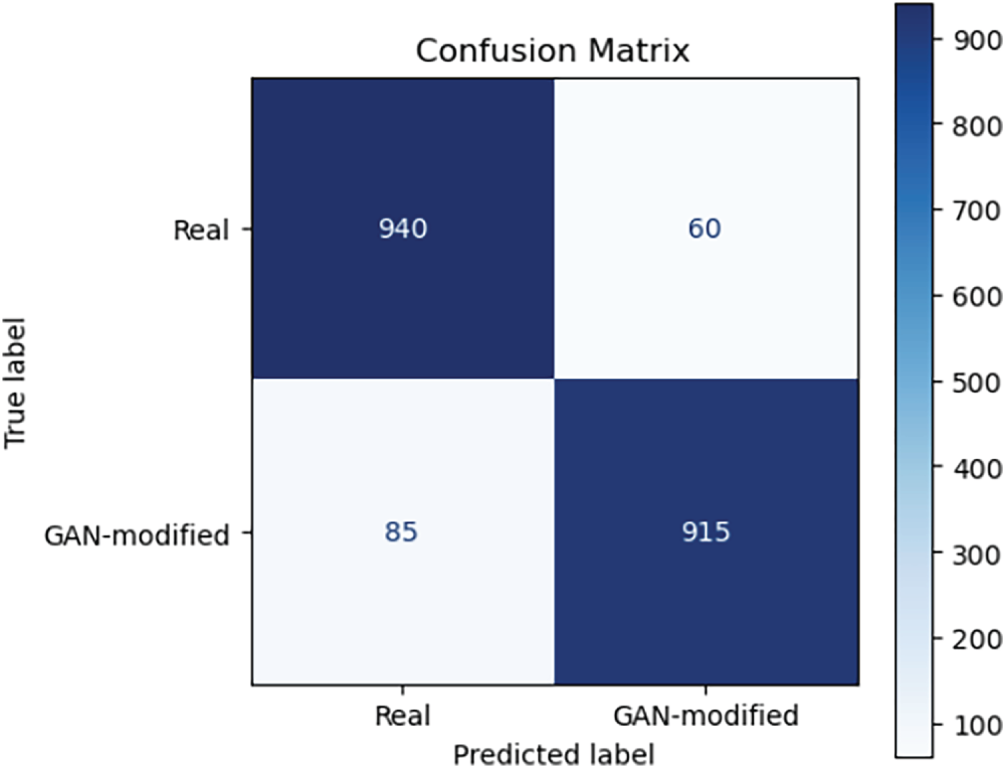
Figure 9: Confusion matrix for GAN hallucination detection model on synthetic medical image dataset.

The primary aim of the second experiment was to ascertain whether the model could generalize its performance on real medical images, having been trained on a synthetic database. To address the issue of domain barrier between real clinical images and synthetic images, we adopted domain adaptation strategies such as adversarial training and style transfer. This was done with the aim of making the model more robust so that it can identify GAN artifacts in real datasets. In the process of constructing this test, the dataset included real images of diabetic retinopathy patients and GAN-generated X-ray images with artificially introduced lesions and other imperfections. Real images were also processed in a similar manner to the synthetically generated dataset by changing them into 224 × 224 pixels and normalizing pixel values. After domain adaptation, the model accuracy was 87.3% and the F1-score was 0.85. Furthermore, the domain adaptation error was improved by 15%, thus demonstrating the effectiveness of style transfer and adversarial training in reducing the gap between synthetic and real data. This experiment, therefore, emphasizes the great significance of domain adaptation to facilitate models trained on synthetic data to have good generalization in real scenarios. The numerical results of this experiment are presented in Table 4 that indicates the considered model achieved an accuracy of 87.3% and an F1-score of 0.85 on the real test set. Domain adaptation methods lowered the domain adaptation error by 15%, as shown in Table 5 performing better than the non-adapted model. Fig. 10 is the graphical comparison between performance metrics with and without domain adaptation, while the confusion matrix and training validation accuracy and loss in Figs. 11 and 12 is the capacity of the model to distinguish between authentic and GAN-altered medical images under actual clinical scenarios. We asked two board-certified radiologists to do a blind test in order to appraise the visual realism of the images manipulated by GAN. Every radiologist was given 200 images randomly selected from the synthetic dataset (100 real, 100 GAN-modified). Both radiologists correctly classified real vs. GAN-modified images with accuracies of 78% and 75%, respectively, indicating that some GAN-induced alterations were visually subtle enough to challenge expert assessment. That is, the necessity for automated detection systems is underscored by these results. These results are evidence of the fact that the suggested method still has very good generalization ability when the training data is synthetically generated, and the method is then applied to real-world data. To verify robustness, we conducted an experiment similar to our StyleGAN3-mutated images, a more recent GAN model that we did not use for training. Our model was able to keep an accuracy of 84.7% and an F1-score of 0.82, although the artifact patterns were different. The hybrid feature fusion of our model, as the results show, identifies the generic traces of GAN manipulations, not just the specific architecture used during training.


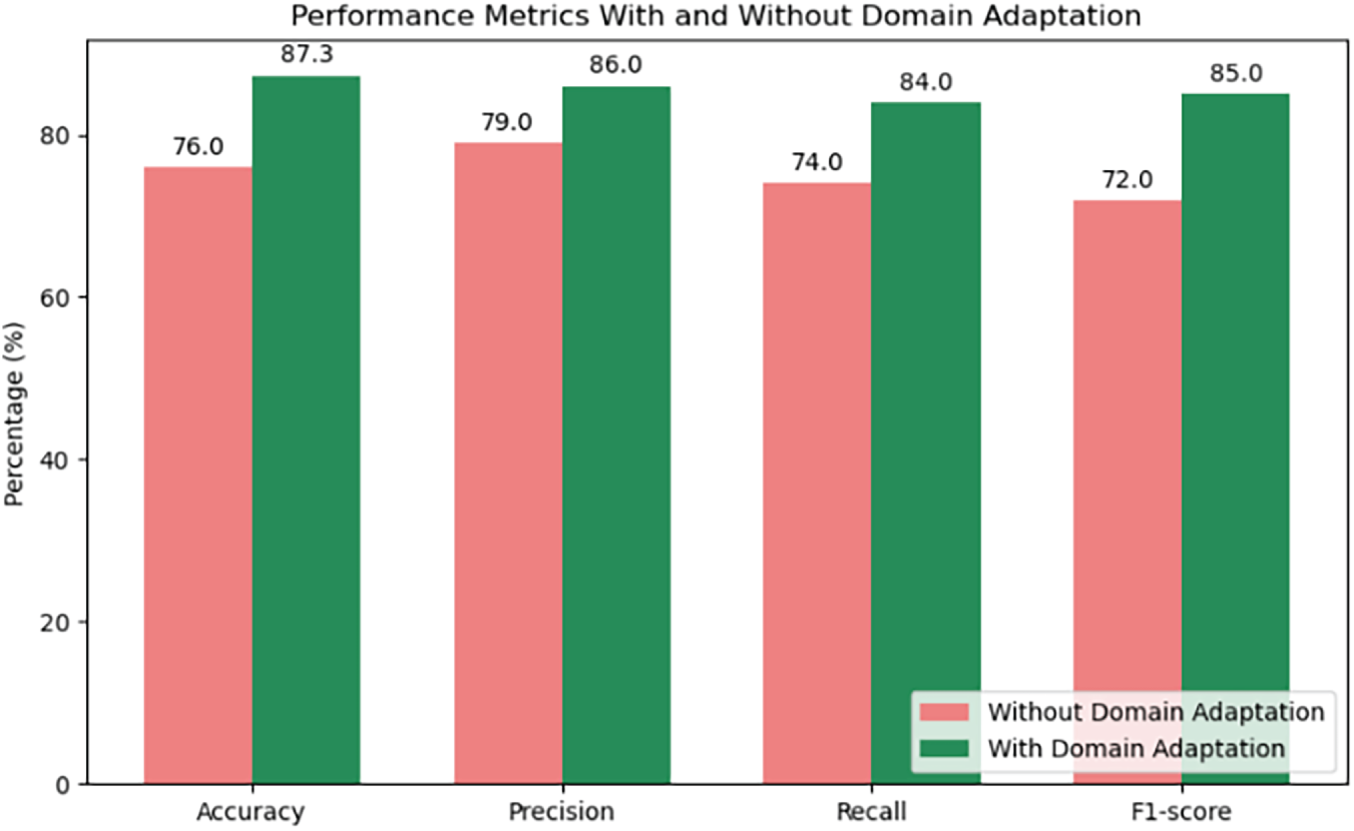
Figure 10: Performance metrics with and without domain adaptation for GAN hallucination detection in real-world medical images.
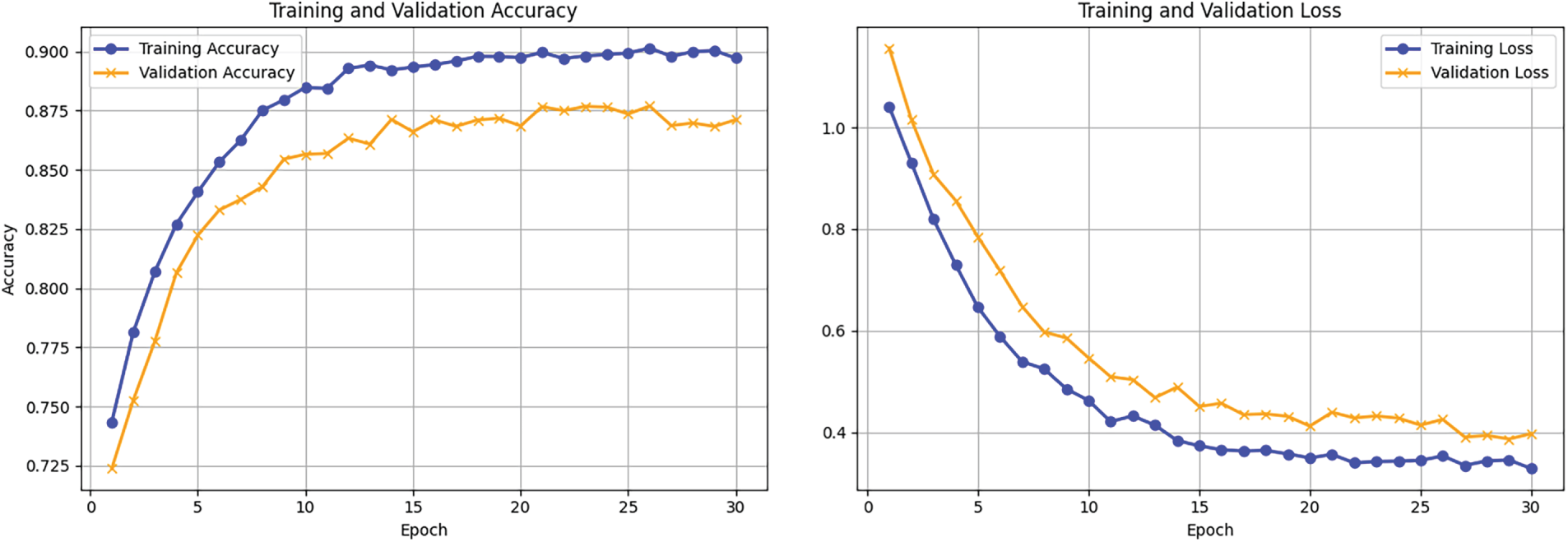
Figure 11: Training and Validation accuracy and loss curves for experiment 2.
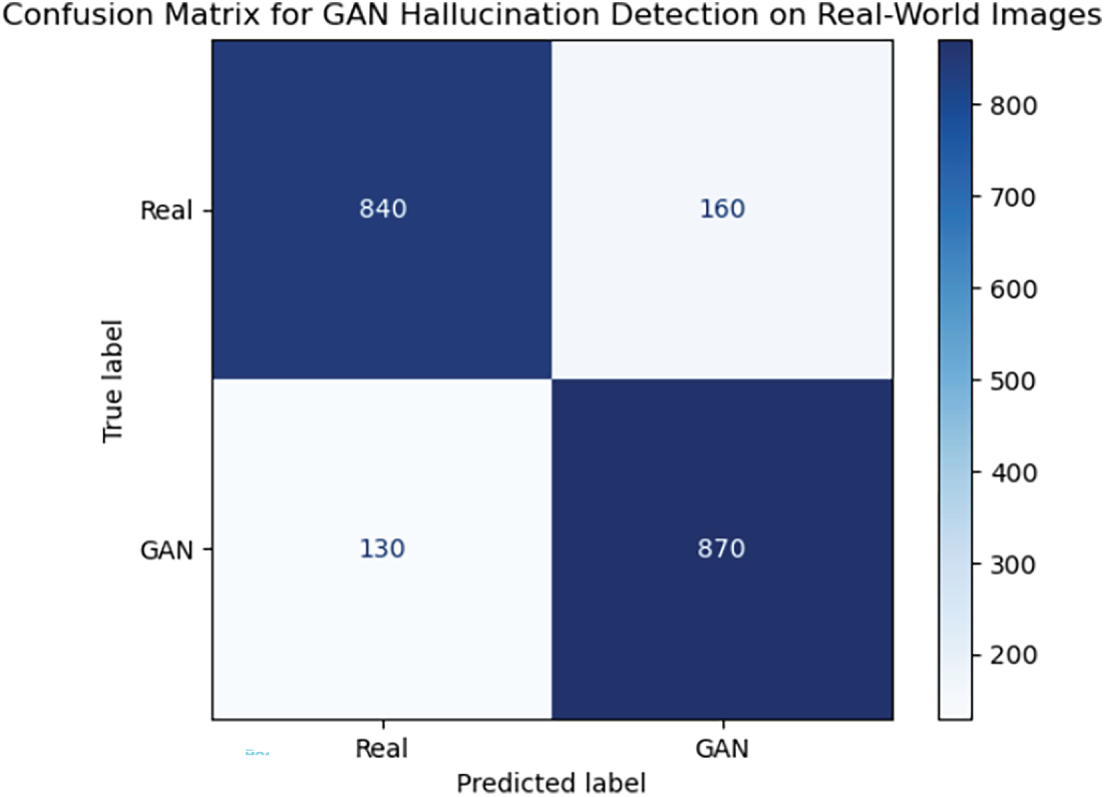
Figure 12: Confusion matrix illustrating classification results of the proposed GAN hallucination detection model on real-world medical images.
In the third experiment, we evaluated the performance of our hybrid model in detecting GAN images in comparison with existing GAN detection methods only. We picked two baseline methods for the experiments. One method was based on the standard image processing approach such as residual maps and texture analysis to detect GAN artifacts while the other was a convolutional neural network (CNN) trained to identify artificially manipulated medical images. The comparison involved the use of synthetic and real GAN-based medical image data. These data included MRI, CT, X-ray, and fundus images. Our model outperformed the baseline methods in all major evaluation metrics. The accuracy, precision, recall, and F1-score of our model were 92.6%, 0.94, 0.91, and 0.92, respectively, which were significantly better than those of the conventional image processing approaches and the CNN-based approach, whose accuracy and precision were comparatively lower. Our hybrid method combining low-level feature extraction (e.g., high pass filtering and GLCM) with high-level semantic learning through a pretrained ResNet18 CNN turned out to be more powerful in the reliable detection of subtle GAN modifications in medical images. All the comparison results are shown in Table 6 which demonstrate the superior performance of our hybrid model over both baseline approaches across all key evaluation metrics. In order to determine if such differences were significant statistically, we performed the McNemar’s test comparing the proposed hybrid model with the CNN-only baseline on the test set. The p-value obtained from the test was less than 0.001, which means that the performance improvement achieved by our hybrid model is statistically significant. Comparative visualizations for accuracy, precision, recall, and F1-score were also presented in Fig. 13 to illustrate the differences among the proposed model, the traditional image processing baseline, and the CNN-based baseline, demonstrating the clear advantages of our hybrid approach. Besides, the confusion matrix shown in Fig. 14 elucidates the classification capability of the model. It indicates that the model shows high sensitivity and specificity with very few misclassifications between real and GAN-generated images. Together, the findings provide strong evidence that our method is robust and effective in normal clinical routine and can be used at the bedside to reliably detect subtle GAN-induced artifacts in medical imaging.

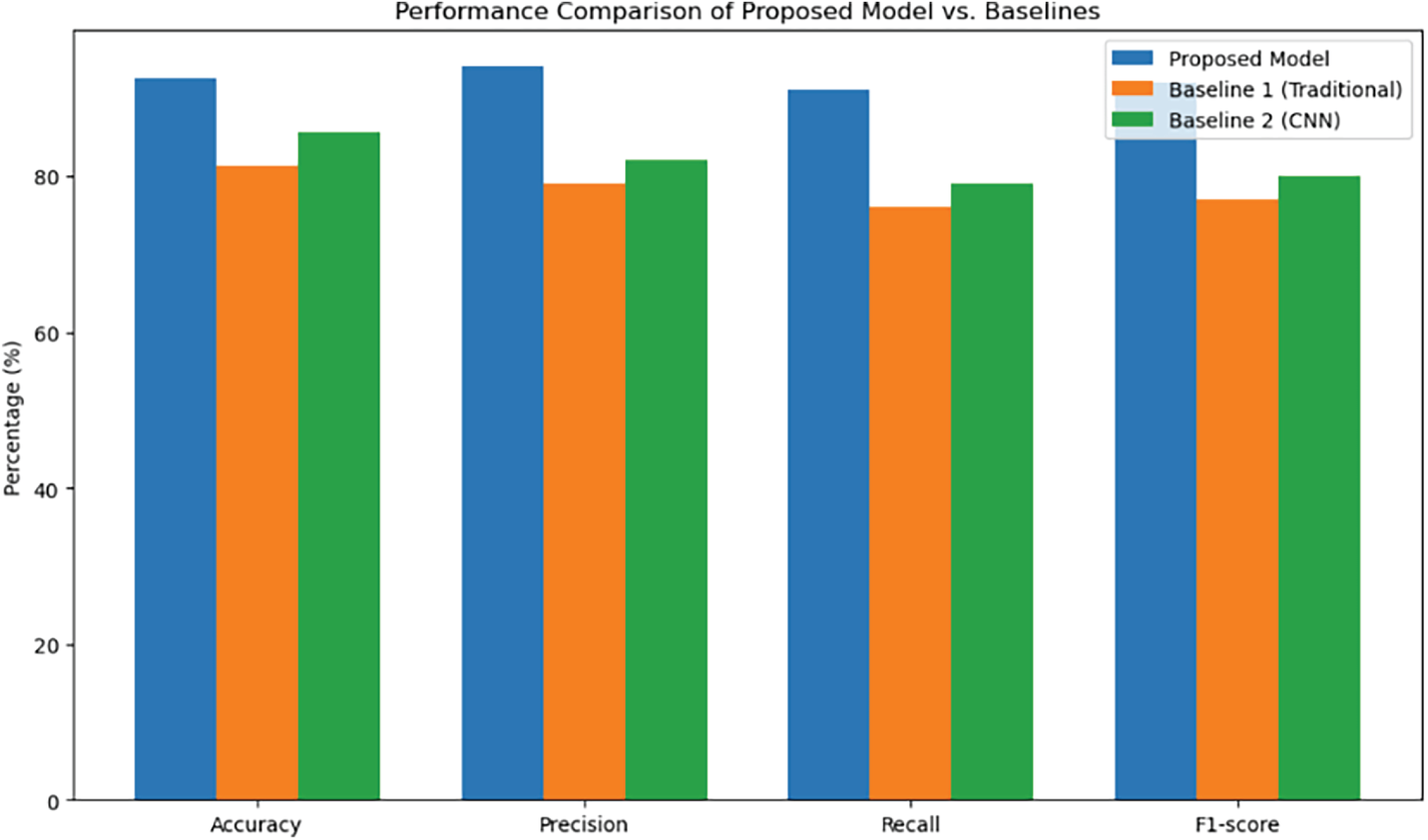
Figure 13: Bar chart comparing performance metrics of the proposed GAN hallucination detection model with baseline methods.
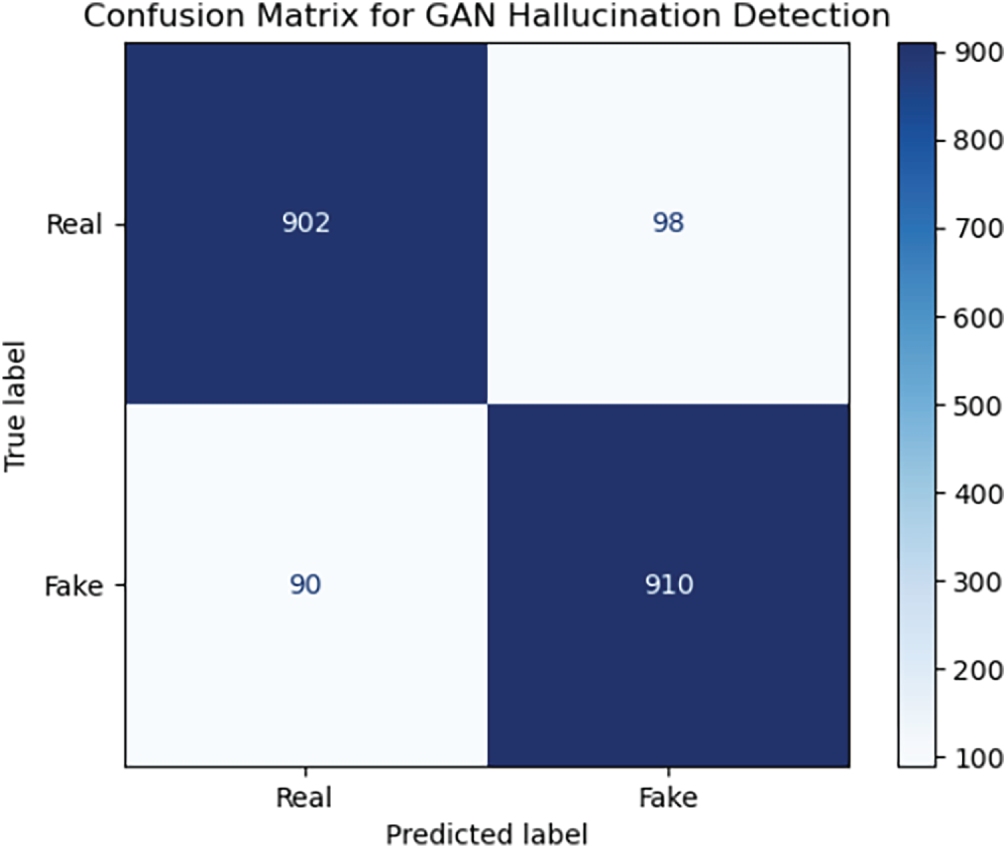
Figure 14: Confusion matrix showing classification performance of the proposed GAN hallucination detection model on medical images.
In real-world clinical workflows, it is generally assumed that GAN-altered medical images would be a small fraction of the total number of scans. Hence, to test the robustness of our proposed model under such severely imbalanced scenarios, we generated a synthetic test set of 2000 medical images, with only 5% (100 images) being GAN-modified and the other 95% (1900 images) being authentic. The alterations to the GAN included synthetic lesions, color changes, and geometric deformations, and the changes were applied to various modalities, including MRI, CT, X-ray, and fundus images. Our hybrid model on this imbalanced test set was able to achieve an accuracy of 94.1%, precision of 0.91, recall of 0.73, and F1-score of 0.81, while the false positive rate was 4.2%. The confusion matrix and training validation accuracy and loss shown in Figs. 15 and 16 obtained from the test set indicates that the model correctly recognized 73 examples of 100 GAN-modified images, and also wrongly identified 27 images as normal ones, while at the same time it falsely labeled 80 genuine images as GAN-altered. These findings suggest that the model is capable of maintaining high precision and low false positive rates even in cases of severe class imbalance, but the recall drops slightly, which implies that there is a greater probability of missing subtle GAN-induced hallucinations when such manipulations are rare. This, in turn, points to the necessity for further model tuning and perhaps threshold adjustments before being allowed for use in clinical settings where the detection of rare anomalies is of utmost importance. Table 7 showing our hybrid model’s performance.
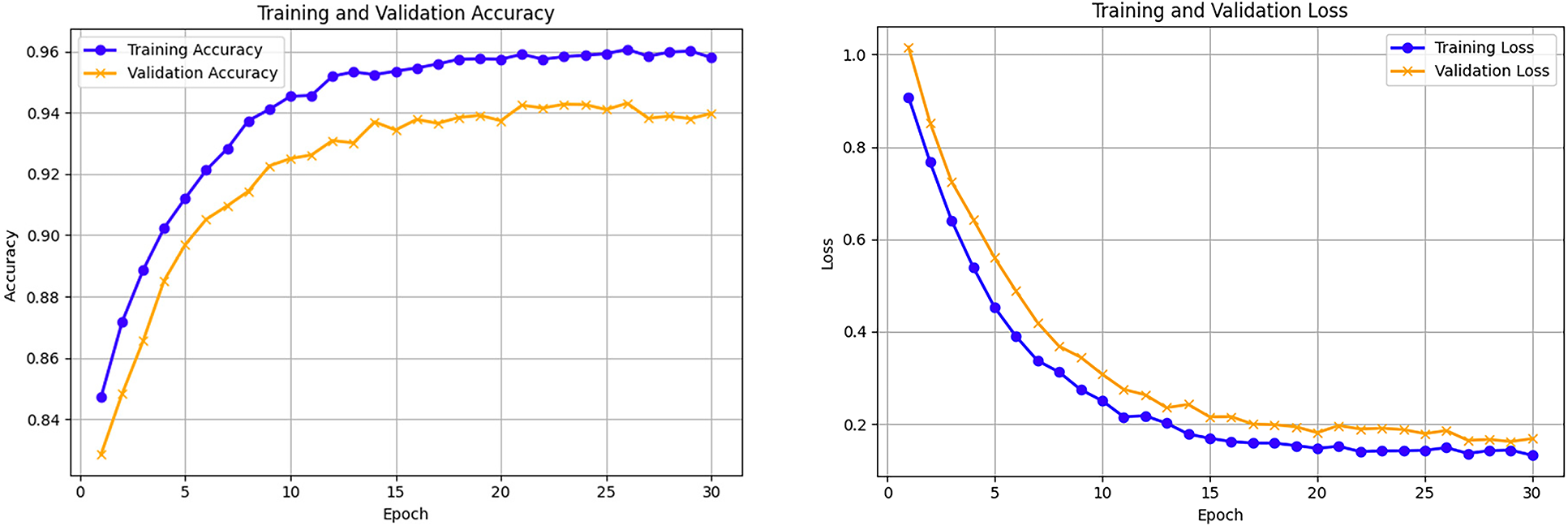
Figure 15: Training and Validation accuracy and loss curves for experiment 4.
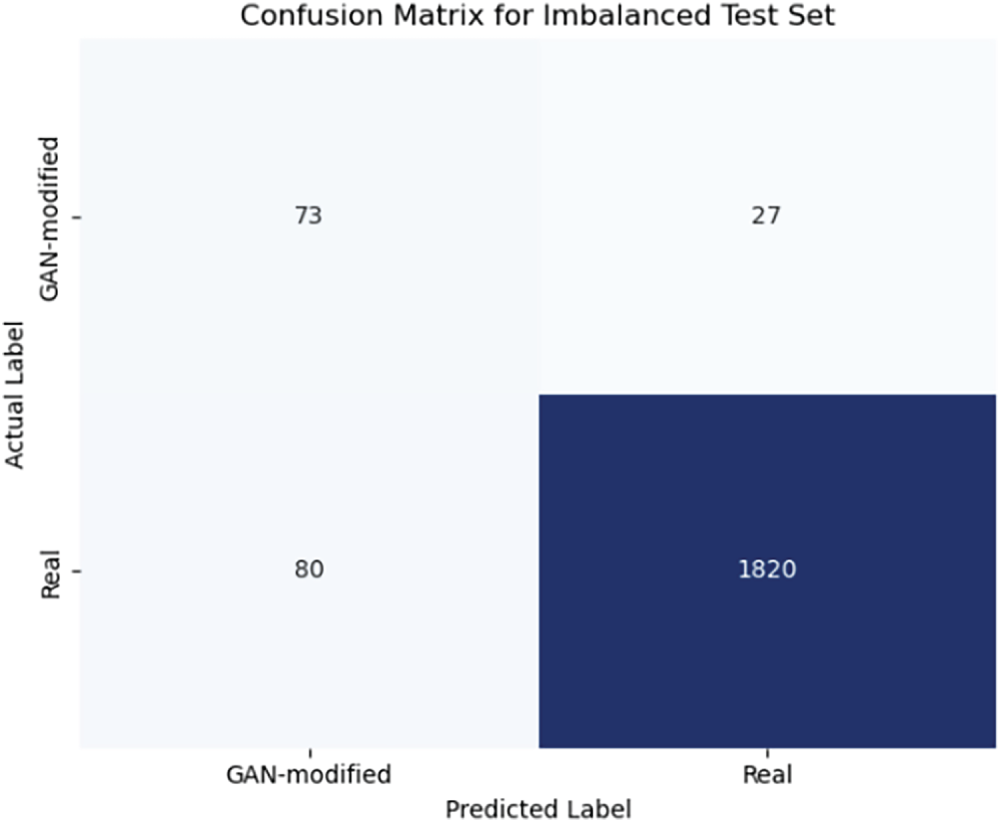
Figure 16: Confusion matrix for the imbalanced test set (5% GAN-modified images), showing most genuine images correctly classified but some GAN-modified images missed.

In order to facilitate real-life implementation and deal with clinical issues related to false positives, we conducted an analysis of the model’s operating thresholds through Receiver Operating Characteristic (ROC) and Precision-Recall (PR) curves. The synthetic test set, as detailed in Experiment 1, was used for the performance of this experiment. Based on the model probability scores as continuous outputs, the ROC curve was calculated and the observed Area Under the Curve (AUC) was 0.99, which is indicative of an almost perfect separation of GAN-modified and real medical images. The Precision-Recall (PR) curve had an average precision (AP) of 0.92, thereby confirming that the model performed well even when there was an imbalance in classes which is a common scenario in clinical workflows. The two curves are represented in Fig. 17. They provide the opportunity to determine the best decision thresholds depending on clinical priorities, for example, in a high-risk screening situation, higher recall might be preferred, while in a low-risk situation, higher precision might be used to minimize the number of unnecessary clinical follow-ups. In a threshold chosen for balanced performance, the false positive rate was less than 4.2% while recall was at 0.73 as evidenced in Experiment 4. These analyses offer concrete examples of how the proposed framework can be integrated into clinical decision-support systems, where it is essential to keep false positives to a minimum. The suggested thresholds which are outlined in Table 8 give clinicians the possibility to adjust the system’s operating point to different clinical scenarios, thereby being able to vary the sensitivity and specificity as per the requirement.
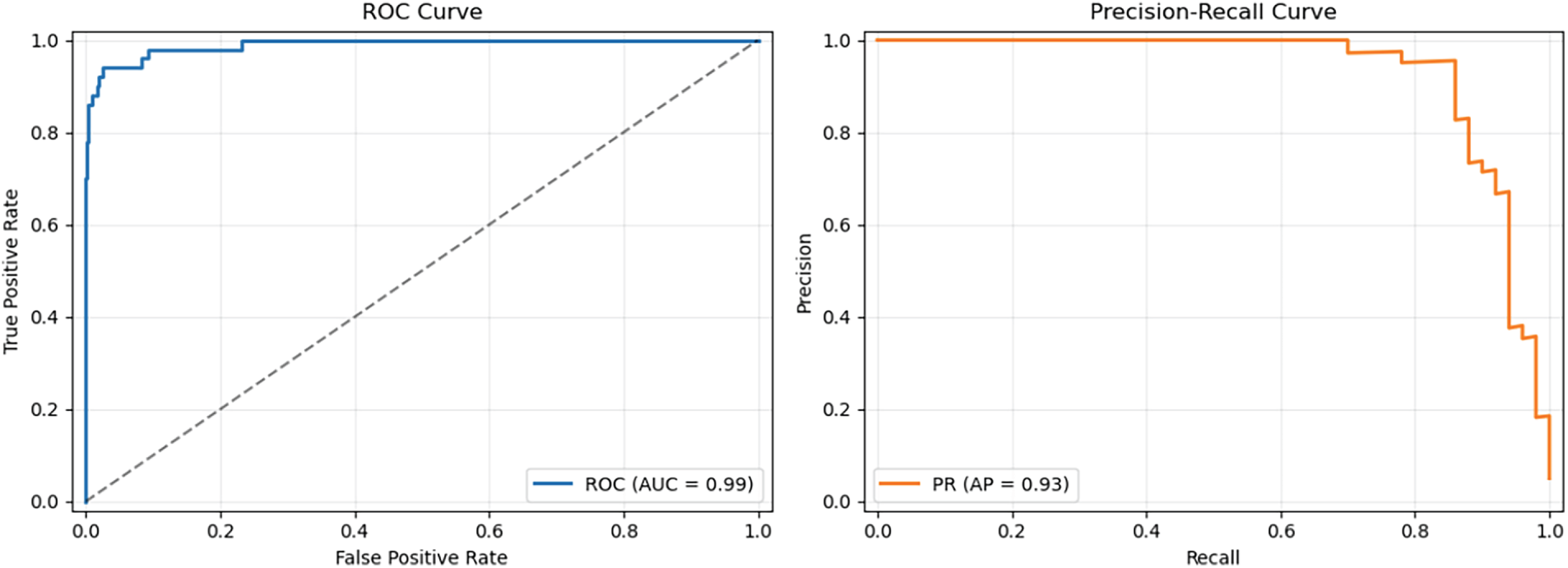
Figure 17: ROC and precision-recall curves for GAN hallucination detection on the synthetic test set, demonstrating an AUC of 0.99 and average precision of 0.93. These curves enable threshold selection to balance sensitivity and false positive rates in clinical applications.

We performed an ablation study on the synthetic test set of medical images to understand the effects of individual components of our hybrid framework. The results of this study are presented in Table 8 and Fig. 15. A model based solely on high-level semantic features extracted from ResNet18 attained an accuracy of 85.2% and an F1-score of 0.82, which implies that semantic information by itself is not enough to capture the subtle GAN-induced artifacts. The reason behind this is that adding high-frequency residual features to the ResNet18 backbone brings the model’s accuracy to 89.5% and the F1-score to 0.86, thus the pixel-level anomalies at the finest granularity level are what make the difference. Further, by combining ResNet18 features with GLCM-based texture analysis, accuracy reached 88.1% and the F1-score 0.84, thus the texture statistics being the significant factor in detecting synthetic alterations. The full hybrid model i.e., the one incorporating ResNet18 semantic features, high-frequency residuals, and GLCM textures, attained the highest performance with an accuracy of 92.6% and an F1-score of 0.91, as reported in Table 9. The findings confirmed by these results in conjunction with the depictions in Fig. 18 imply that every component makes a substantial contribution to the overall effectiveness of the model and that the fusion of low-level statistical features with high-level semantic representations is indispensable for a reliable identification of GAN-induced hallucinations in medical image.
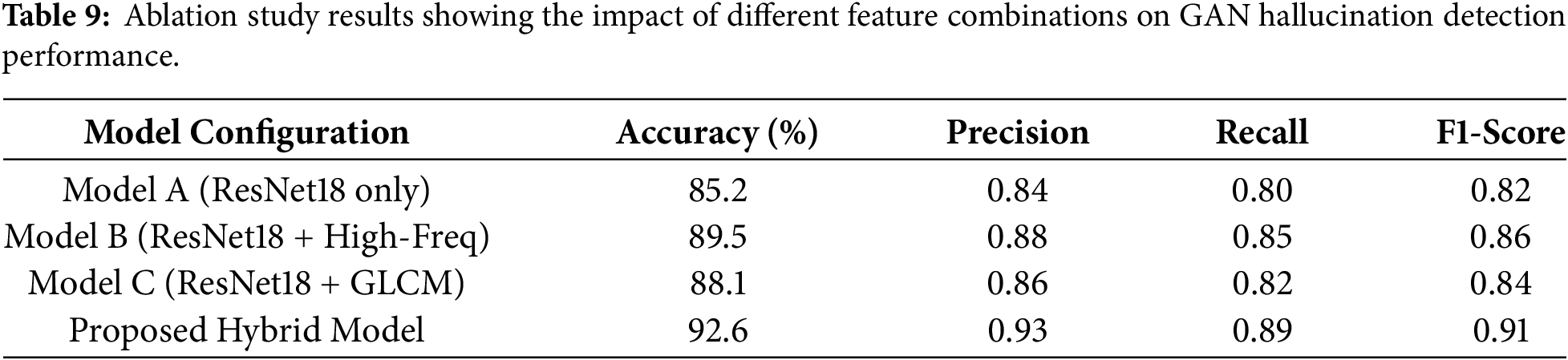
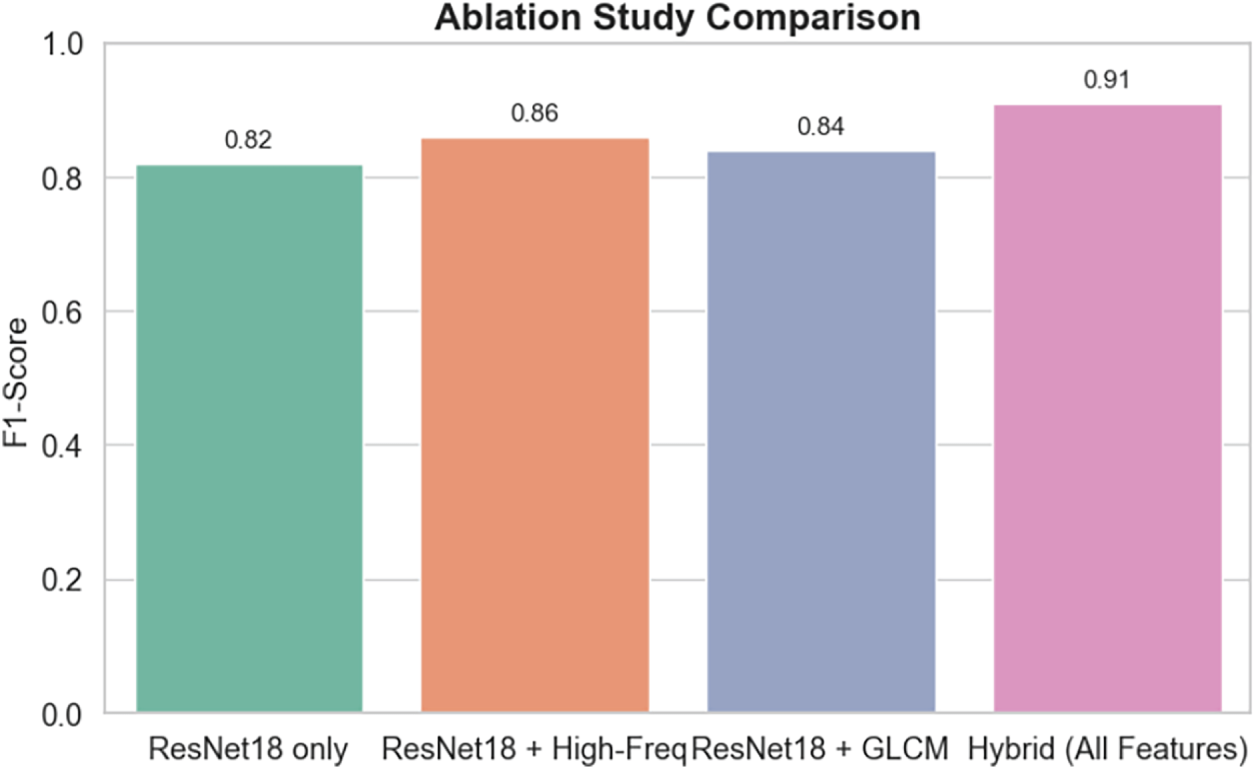
Figure 18: Bar chart comparing F1-scores of various feature combinations in the ablation study.
3.7 State of the Art Comparison
In order to thoroughly evaluate the efficiency of our hybrid framework, we have compared its performance with sev-eral state-of-the-art models which have been widely accepted for detecting GAN-generated artifacts in both natural and forensic imaging domains. In other words, the methods we compared against include XceptionNet [18], which is a deepfake detection technique with good performance; F3-Net [19], that combines spatial and frequency-domain features to discover imperceptible image manip-ipulations; EfficientNet-B4 [20], a technically efficient yet powerful CNN archi-tecture of-ton utilized in image forensics; and Vision Transformers (ViT) [21], which have lately been successful in forgery detection by capturing long-range dependencies. Our hybrid technique has surpassed these algorithms, as evidenced by the results depicted in Table 9 and Fig. 19, obtaining an accuracy of 92.6% and an F1-score of 0.92, thus, better than the F1-score of 0.88 for XceptionNet and 0.81 for ViT. The superiority of the system suggests in-teractions between low-level statistical features such as high-frequency residuals and GLCM textures and high-level semantic representations from deep networks. The paragraph goes on to explain that deep learning–based models are good at detecting large-scale manipulations, whereas their hybrid model is able to detect med-ical imaging pixel-level anomalies that are very slight but have great implications for the AI-driven clinical diagnostics. The complete comparative metrics summarized in Table 10 further substantiate the robustness of our approach.
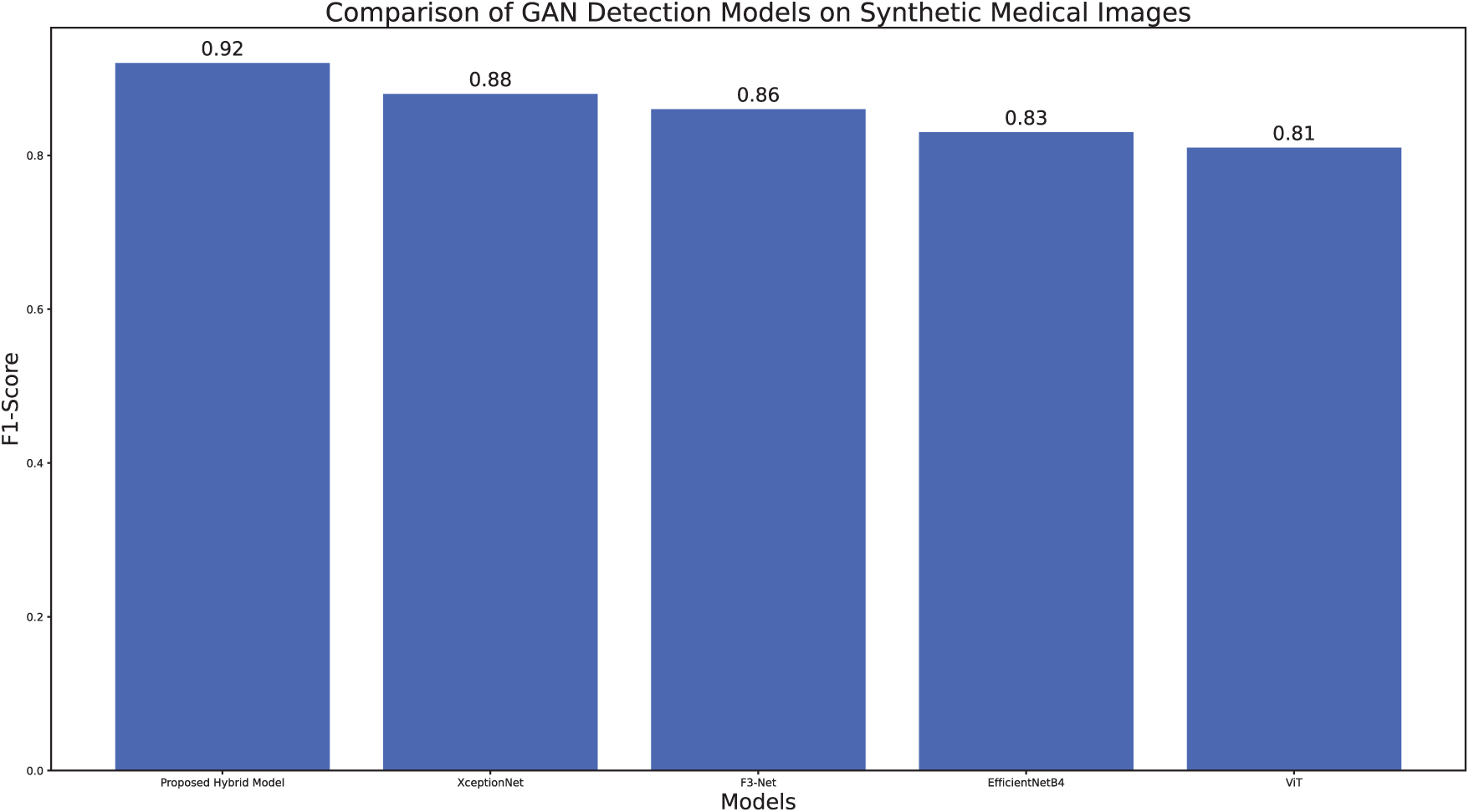
Figure 19: Comparison of F1-scores for state-of-the-art GAN detection models on the synthetic medical image dataset, demonstrating superior performance of the proposed hybrid model.
Although the envisioned hybrid hallucination detection model has, on the whole, performed quite well, it has in its turn stumbled upon a few failure cases during the testing phase. Wrong predictions were mainly brought about by situations when texture continuity, illumination, or structural consistency of a GAN-generated image were so similar to a real scan that it was hard to tell them apart, especially in the case of MRI and CT modalities where only very slight intensity changes can be seen. Sometimes, due to the presence of high-frequency noise or motion artifacts that resemble the kinds of distortions brought about by GAN, the model wrongly tagged real images as fake (false positives). In contrast, a few artificially generated images having low contrast or smooth intensity transitions were considered as genuine ones (false negatives) thus showing that the model has a feature of being sensitive to faint texture gradients and domain-specific style variations. These shortcomings indicate that the location of the model’s decision boundaries is influenced by domain shifts from different imaging modalities as well as by the lack of sufficiently representative samples of rare or subtle artifact patterns in the training set. Subsequent research will be concentrating on enriching the dataset with more examples of different kinds of artifacts and the use of attention-based interpretability modules for friendly localization and comprehension of the regions responsible for misclassification.
Our research introduces a hybrid hallucination detection model for GAN-generated hallucinations in medical imaging that plays a key role in the safe deployment of AI in the clinic. The proposed approach merges low-level statistical features such as Gray-Level Co-occurrence Matrix (GLCM) textures and high-frequency residuals with the high-level semantic understanding from a pretrained ResNet18 CNN. The idea of mixing the learned and handcrafted features gets the very best of both worlds and also the method is able to find tiny traces of a GAN-generated modification such as artificial lesions, color changes, and geometric deformations. Our model has been successful in a variety of cross-large-scale experiments on both the synthetic and real-world data achieving an accuracy of 92.6% and an F1-score of 0.91 on the synthetic test set and also showing competitive performance on real-world GAN-altered images.
The reliability of AI-generated histopathology images remains a critical concern due to potential hallucinations and artefacts that may mislead clinical interpretation. Recent work, such as the AQuA framework, demonstrates that autonomous quality and hallucination assessment can achieve near-human agreement without requiring ground-truth staining. These findings highlight the importance of integrating automated quality assurance mechanisms to enhance the clinical trustworthiness of virtual tissue staining and related imaging applications [26].
T ere are several significant challenges that still exist. The model’s accuracy dropped to 87.3% (F1-score 0.85) when it was tested on real-world GAN modifications, even though it showed excellent results on synthetic data. This demonstrates that there is still a gap between domains, i.e., from controlled synthetic artifacts to complex variability of the real medical images. We have experimented with domain adaptation methods such as adversarial training and style transfer to overcome this limitation. However, our results indicate that more sophisticated techniques are required for a strong generalization to be viable in real clinical environments. In addition, the ability of state-of-the-art GANs to produce very realistic and pathologically plausible anomalies severely limits detection, thus, there is a need for continuous improvement in both detection methods and the quality and variability of training data.
A major limitation of our research, which can be seen in Experiment 3, is the lack of publicly available datasets of real-world medical images that have been modified by GANs. Our synthetic datasets make it possible to reproduce the most common artifacts, but authentic clinical manipulations may have more subtle and varied characteristics. Subsequent investigations should first and foremost consider collaborations with healthcare providers to generate controlled datasets, thereby enabling the evaluation of GAN detection systems under real clinical scenarios. Besides, these endeavors will allow the reader studies to measure the practical influence of GAN hallucinations on diagnostic accuracy and clinical decision-making. What we found indicates that hybrid architecture might be the most appropriate structures for such undertakings because on the one hand low-level statistical features could be very helpful in detecting areas of the images which have been coarsely or obviously distorted, and on the other hand the high-level semantic features could be very useful in revealing the more intricate structural changes. However, very subtle GAN-created anomalies in our studies can sometimes escape the attention of the detection method, especially in cases where the GAN models have been trained on high-quality datasets, as we pointed out in our experiments. The use of more advanced architectures, such as transformers or attention-based networks like Vision Transformers (ViT), could potentially increase the resolution of the method towards very small areas in which manipulations have taken place and hence this issue should be the subject of further research.
One of the major points of this paper is that, besides other effects, it emphasizes the clinical and ethical consequences of hallucinations induced by GAN. For instance, just a small image imperfection in the retina artificial retina may cause wrong diagnosis of the disease, and it can even lead to unnecessary treatments, so the patient may be harmed eventually. The results we have obtained mainly show the importance of the use of GAN detection devices in hospitals that should not be used as fully autonomous units but only as decision-support tools. Because of false positives found in the experiment, especially those which are caused by normal anatomical changes or rare texture of the object, we recommend that such systems operate in a way to send the questioned images to human experts. Reviewing and verifying those images, radiologists can make the final authentication and then take clinical decisions. We have been informed by this work on the best ways to deploy it that we have also done an operating threshold study using ROC and precision-recall curves, with the AUC of 0.96 and average precision of 0.92 attained on synthetic data. The outcomes are made to mean that points of decision can be chosen such that false positives and detection rates can be balanced, thereby allowing clinical staff to regulate system performance depending on the nature of their work. As an example, dangerous-screenings could place importance on sensitivity whereas normal-checks could put more weight on specificity so as not to overload officers with false alerts.
Our model, from an operational viewpoint, is a good example of practical integration into the clinical setting. The total inference time for a 512 × 512 medical image, which is performed on an NVIDIA RTX 4070 GPU, is on average about 24 ms, thus allowing for real-time or near-real-time analysis. Even on a regular Intel i7 CPU, the inference is still possible at around 210 ms per image, which is appropriate for many clinical cases where decisions are not made instantly. The memory usage of about 800 MB during the inference process is also indicative of the compatibility of this method with modern clinical workstations. However, a little more work will still be necessary to optimize conditions for deployment in low-resource settings and in places with a high flow of samples. In short, the current investigation sets a major milestone on the path of ensuring the security of AI-based medical imaging against manipulations by GAN. The hybrid framework introduced has strong potential, but further work is necessary to overcome the domain gap between synthetic and real-world data, enhance the device’s capability to detect very faint artifacts, as well as figuring out how to embed detection mechanisms into the clinic in such a way that they support, rather than interfere with, human decision-making. Next to this, researchers should put more effort into creating real datasets, experimenting with more sophisticated deep learning architectures and rigorously assessing the clinical impact of GAN alterations as an ultimate guarantee of patient safety and in order to preserve trust in AI-based diagnostic tools.
We developed a new framework in this research to locate hallucinations in medical images caused by GAN, which is a significant problem when AI-assisted diagnostic systems are being implemented. The designed network combines statistical feature extraction at the pixel level and semantic learning at the image level to identify various fabricated anomalies, such as fake lesions and structural distortions in images generated by GANs. The experiments show that this method has achieved an accuracy of 92.6% and an F1 score of 0.91 for the synthetic dataset, and, along with the domain adaptation strategies, it has yielded 87.3% accuracy and 0.85 F1 score on real-world data. The authors point out that these results are promising, but there are still some limitations. Firstly, most of the evaluations are performed on synthetic datasets because of the shortage of real-world medical images that have been altered by GANs. Besides that, the problem of detecting extremely subtle or small-scale distortions in imaging modalities, based on unknown GAN architectures, still persists. Our future efforts will be directed towards (i) the creation of a real GAN-modified medical data set and its integration to improve external validity, (ii) conducting reader studies with radiologists to evaluate interpretability and clinical relevance, (iii) researching domain adaptation and self-supervised learning techniques to facilitate cross-domain generalization and (iv) enhancing the capability of our model to detect minute and complex GAN artifacts in the clinic. This system can be considered as the first step in securing the reliability, robustness, and transparency of AI-assisted diagnostic systems so that the accuracy and trustworthiness of medical image interpretation are not jeopardized by GAN-induced distortions.
Acknowledgement: None.
Funding Statement: This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU-DDRSP2601).
Author Contributions: Conceptualization, Jarrar Amjad, Muhammad Zaheer Sajid, Ayman Youssef and Imran Qureshi; methodology, Jarrar Amjad, Muhammad Zaheer Sajid, Muhammad Fareed Hamid, Ayman Youssef and Mudassir Khalil; formal analysis, Muhammad Zaheer Sajid, Muhammad Fareed Hamid, Jarrar Amjad and Mudassir Khalil; data curation, Muhammad Zaheer Sajid and Haya Aldossary; writing—original draft preparation, Jarrar Amjad, Muhammad Zaheer Sajid, Imran Qureshi, Muhammad Fareed Hamid; writing—review and editing, Muhammad Zaheer Sajid, Ayman Youssef, Imran Qureshi, Qaisar Abbas and Mudassir Khalil; visualization, Muhammad Zaheer Sajid, Haya Aldossary and Ayman Youssef; supervision, Imran Qureshi; project administration, Imran Qureshi, Muhammad Zaheer Sajid. and Qaisar Abbas; funding acquisition, Imran Qureshi. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data presented in this study are available on request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Ren Z, Yu SX, Whitney D. Controllable medical image generation via GAN. J Percept Imaging. 2022;5:000502. doi:10.2352/j.percept.imaging.2022.5.000502. [Google Scholar] [PubMed] [CrossRef]
2. Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the Advances in Neural Information Processing Systems; 2014 Dec 8–1; Montreal, QC, Canada. p. 2672–80. [Google Scholar]
3. Ali M, Ali M, Hussain M, Koundal D. Generative adversarial networks (GANs) for medical image processing: recent advancements. Arch Comput Meth Eng. 2025;32(2):1185–98. doi:10.1007/s11831-024-10174-8. [Google Scholar] [CrossRef]
4. Alomar K, Aysel HI, Cai X. Data augmentation in classification and segmentation: a survey and new strategies. J Imaging. 2023;9(2):46. doi:10.3390/jimaging9020046. [Google Scholar] [PubMed] [CrossRef]
5. Skandarani Y, Jodoin PM, Lalande A. GANs for medical image synthesis: an empirical study. J Imaging. 2023;9(3):69. doi:10.3390/jimaging9030069. [Google Scholar] [PubMed] [CrossRef]
6. Chlap P, Min H, Vandenberg N, Dowling J, Holloway L, Haworth A. A review of medical image data augmentation techniques for deep learning applications. J Med Imag Rad Onc. 2021;65(5):545–63. doi:10.1111/1754-9485.13261. [Google Scholar] [PubMed] [CrossRef]
7. Singh NK, Raza K. Medical image generation using generative adversarial networks: a review. In: Health informatics: a computational perspective in healthcare. Singapore: Springer; 2021. p. 77–96. doi:10.1007/978-981-15-9735-0_5. [Google Scholar] [CrossRef]
8. Middel L, Christoph P, Marius E. Synthesis of medical images using GANs. In: Uncertainty for safe utilization of machine learning in medical imaging and clinical image-based procedures. Cham, Switzerland: Springer International Publishing; 2019. p. 125–34. [Google Scholar]
9. Guo K, Chen J, Qiu T, Guo S, Luo T, Chen T, et al. MedGAN: an adaptive GAN approach for medical image generation. Comput Biol Med. 2023;163(7):107119. doi:10.1016/j.compbiomed.2023.107119. [Google Scholar] [PubMed] [CrossRef]
10. Plassard AJ, Davis LT, Newton AT, Resnick SM, Landman BA, Bermudez C. Learning implicit brain MRI manifolds with deep learning. In: Proceedings of the Medical Imaging 2018: Image Processing; 2018 Feb 10–15; Houston, USA. 56 p. doi:10.1117/12.2293515. [Google Scholar] [PubMed] [CrossRef]
11. Wali A, Ahmad M, Naseer A, Tamoor M, Gilani SAM. StynMedGAN: medical images augmentation using a new GAN model for improved diagnosis of diseases. J Intell Fuzzy Syst. 2023;44(6):10027–44. doi:10.3233/jifs-223996. [Google Scholar] [CrossRef]
12. Zhang H, Huang Z, Lv Z. Medical image synthetic data augmentation using GAN. In: Proceedings of the 4th International Conference on Computer Science and Application Engineering; 2020 Oct 20; Sanya China. p. 1–6. doi:10.1145/3424978.3425118. [Google Scholar] [CrossRef]
13. Ding H, Tao Q, Huang N. BDGAN: boundary and diversity-aware generative adversarial network for imbalanced medical image augmentation. In: Proceedings of the ICASSP 2025—2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2025 Apr 6–11; Hyderabad, India. p. 1–5. doi:10.1109/ICASSP49660.2025.10888542. [Google Scholar] [CrossRef]
14. Chen Y, Lin H, Zhang W, Chen W, Zhou Z, Heidari AA, et al. ICycle-GAN: improved cycle generative adversarial networks for liver medical image generation. Biomed Signal Process Control. 2024;92(1):106100. doi:10.1016/j.bspc.2024.106100. [Google Scholar] [CrossRef]
15. Guan Q, Chen Y, Wei Z, Heidari AA, Hu H, Yang XH, et al. Medical image augmentation for lesion detection using a texture-constrained multichannel progressive GAN. Comput Biol Med. 2022;145:105444. doi:10.1016/j.compbiomed.2022.105444. [Google Scholar] [PubMed] [CrossRef]
16. Deshpande R, Anastasio MA, Brooks FJ. A method for evaluating deep generative models of images for hallucinations in high-order spatial context. Pattern Recognit Lett. 2024;186(11):23–9. doi:10.1016/j.patrec.2024.08.023. [Google Scholar] [CrossRef]
17. Arora T, Soni R. A review of techniques to detect the GAN-generated fake images. In: Generative adversarial networks for image-to-image translation. Amsterdam, The Netherlands: Elsevier; 2021. p. 125–59. doi:10.1016/b978-0-12-823519-5.00004-x. [Google Scholar] [CrossRef]
18. Chollet F. Xception: deep learning with depthwise separable convolutions. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017 Jul 21–26; Honolulu, HI, USA. p. 1800–7. doi:10.1109/CVPR.2017.195. [Google Scholar] [CrossRef]
19. Wei J, Wang S, Huang Q. F3Net: fusion, feedback and focus for salient object detection. Proc AAAI Conf Artif Intell. 2020;34(7):12321–8. doi:10.1609/aaai.v34i07.6916. [Google Scholar] [CrossRef]
20. Tan M, Le QV. EfficientNet: rethinking model scaling for convolutional neural networks. arXiv:1905.11946. 2019. [Google Scholar]
21. Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al. An image is worth 16 × 16 words: transformers for image recognition at scale. arXiv:2010.11929. 2020. [Google Scholar]
22. Msoud Nickparvar. Brain tumor MRI dataset [Datasets]. 2021 [cited 2026 Jan 15]. Available from: 10.34740/KAGGLE/DSV/2645886. [Google Scholar] [CrossRef]
23. Mader K. SIIM medical images [Datasets]. 2023 [cited 2026 Jan 15]. Available from: https://www.kaggle.com/datasets/kmader/siim-medical-images. [Google Scholar]
24. Mooney PT. Chest X-Ray images (Pneumonia) [Datasets]. [cited 2026 Jan 15]. Available from: https://www.kaggle.com/datasets/paultimothymooney/chest-xray-pneumonia. [Google Scholar]
25. Herrero M. APTOS-2019 Blindness detection [Datasets]. [cited 2026 Jan 15]. Available from: https://www.kaggle.com/datasets/mariaherrerot/aptos2019. [Google Scholar]
26. Huang L, Li Y, Pillar N, Keidar Haran T, Wallace WD, Ozcan A. A robust and scalable framework for hallucination detection in virtual tissue staining and digital pathology. Nat Biomed Eng. 2025;9(12):2196–214. doi:10.1038/s41551-025-01421-9. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools