
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

High-Performance Segmentation of Power Lines in Aerial Images Using a Wavelet-Guided Hybrid Transformer Network
Department of Electrical and Electronics Engineering, Sakarya University, Sakarya, Türkiye
* Corresponding Author: Ahmet Küçüker. Email:
(This article belongs to the Special Issue: Advanced Artificial Intelligence and Machine Learning Methods Applied to Energy Systems)
Computer Modeling in Engineering & Sciences 2026, 146(2), 26 https://doi.org/10.32604/cmes.2026.077872
Received 18 December 2025; Accepted 04 February 2026; Issue published 26 February 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Inspections of power transmission lines (PTLs) conducted using unmanned aerial vehicles (UAVs) are complicated by the fine structure of the lines and complex backgrounds, making accurate and efficient segmentation challenging. This study presents the Wavelet-Guided Transformer U-Net (WGT-UNet) model, a new hybrid network that combines Convolutional Neural Networks (CNNs), Discrete Wavelet Transform (DWT), and Transformer architectures. The model’s primary contribution is based on spatial and channel attention mechanisms derived from wavelet subbands to guide the Transformer’s self-attention structure. Thus, low and high frequency components are separated at each stage using DWT, suppressing structural noise and making linear objects more prominent. The developed design is supported by multi-component hybrid cost functions that simultaneously solve class imbalance, edge sharpness, structural integrity, and spatial regularity issues. Furthermore, high segmentation success has been achieved in producing sharp boundaries and continuous line structures with the DWT-guided attention mechanism. Experiments conducted on the TTPLA dataset reveal that the version using the ConvNeXt backbone outperforms the current state-of-the-art approaches with an F1-Score of 79.33% and an Intersection over Union (IoU) value of 68.38%. The models and visual outputs of the developed method and all compared models can be accessed at https://github.com/burhanbarakli/WGT-UNET.Keywords
Reliable energy transmission is a critical component of modern industrial and societal infrastructure [1,2]. Power transmission lines (PTLs), which are the most crucial among such systems, often traverse difficult and hazardous terrains for miles; therefore, their regular inspection becomes a necessity [3,4]. Traditional manual inspection methods are not only costly but also time-consuming, inefficient, and potentially hazardous for workers [5,6]. In recent years, the increasing use of Unmanned Aerial Vehicles (UAVs) has significantly advanced inspection processes and created new opportunities for computer vision-based automation systems [7,8]. The automatic detection and segmentation of PTLs from high-resolution aerial images captured by UAVs has become an important task for ensuring both the operational safety of the network and the flight safety of the UAVs [9,10].
However, segmentation from aerial images presents unique challenges. PTLs are thin, elongated objects that occupy a very small pixel area compared to the entire image, as shown in Fig. 1 [11–13]. Such conditions lead to a serious class imbalance problem between the background (vegetation, buildings, roads) and the foreground (power lines) [14,15]. Additionally, complex and variable backgrounds, differences in lighting conditions, and even weather conditions (fog, rain, etc.) weaken the visual characteristics of the lines, making the detection process even more complex [16,17].

Figure 1: Power transmission line image samples from transmission towers and power lines (TTPLA) dataset.
Literature has proposed several methods to address the above challenges. Early studies relied on traditional image processing techniques for edge and line detection, such as the Hough transform, Radon transform, and Line Segment Detector, among others [18,19]. Although such techniques are straightforward and computationally inexpensive, they often exhibit limited robustness in complex backgrounds and are sensitive to noise [20]. With the rise of deep learning, research has increasingly focused on convolutional neural networks (CNN)-based semantic segmentation models [21]. Encoder–decoder architectures such as Fully Convolutional Network (FCN), U-Net, and DeepLabv3+ enable accurate pixel-wise classification and have been widely adopted for semantic segmentation [11,22–24]. Furthermore, fundamental architectures have been adapted for PTL detection in various works, and loss functions such as Focal Loss have been employed to better handle class imbalance.
Recent advanced approaches go beyond standard CNN architectures. Hybrid models that combine the local feature extraction power of CNNs with the global context modeling capability of transformers have become increasingly influential in the field [21]. DUFormer proposed a structure where CNN-based rich features feed a transformer block using the heavy token encoder concept [10]. Conversely, the combination of signal processing methods with deep learning has resulted in promising outcomes. Generative Adversarial Networks for Power-Line Segmentation (PLGAN) forces linear consistency in the output by using the Hough transform as a loss function [7], while PLNet uses information obtained from Hough space as an attention mechanism [9]. WaveGNet uses wavelet transform to suppress low-frequency background noise and highlight high-frequency (HF) details [4]. Collectively, the studies highlight the importance of integrating domain-specific prior knowledge into deep learning models.
The existing literature on PTL segmentation largely focuses on wavelet/frequency-based approaches, transformers, and CNN-transformer hybrids. Wavelet-based studies typically aim to suppress the background and strengthen fine line/edge cues using HF components; for example, WaveGNet uses HF coefficients to weaken background information and emphasize edge regions via wavelet decomposition [4]. Similarly, the Wavelet Feature Enhancement (WFE) module in remote sensing segmentation can be seen as a representative feature enhancement approach that feeds detail back to network layers by enhancing HF sub-bands with multiscale Discrete Wavelet Transform (DWT) [25]. However, these wavelet techniques are most often applied at the feature-map level (e.g., enhancement or convolutional/gating attention), rather than being incorporated as an explicit bias within the transformer’s self-attention scoring that governs token-to-token interactions. On the other hand, transformer-based/hybrid methods are effective at modeling the long-range persistence of PTLs. For instance, DUFormer performs global context modeling by converting CNN-based features into tokens with a heavy token encoder and feeding them into a transformer block [10]. Nevertheless, in most transformer designs, attention is primarily shaped by learned content representations and tokenization, and it is less common to use frequency-domain fine-line/edge characteristics as an explicit structural premise to guide self-attention. Overall, frequency information is often introduced as input/feature refinement, while PTL segmentation approaches that directly inject a frequency-derived bias into transformer self-attention scoring appear less explored [11].
The Wavelet-Guided Transformer U-Net (WGT-UNet) proposed in this study aims to address this gap in the literature not only by incorporating a transformer component, but also by establishing a connection at the mechanism level. A spatial attention map is produced with the high frequency components obtained from the wavelet transform and this map is injected directly into the self-attention scores of the windowed transformer block as a bias. Thus, while maintaining the global context power of DUFormer-like hybrids [10], the model enhances the focus on fine structures by bringing the fine-edge cues provided by wavelet-based methods [4] into the self-attention decision; this integration is realized with the Wavelet-Guided Transformer (WGT) blocks and Wavelet Attention Module (WAM) architectures that form the core of WGT-UNet. The key contributions of the study are outlined below:
• A novel hybrid encoder-decoder network is proposed, which synergistically integrates a multi-scale CNN backbone with a decoder built from WGT blocks.
• A Wavelet Attention Module is introduced, which generates Spatial Attention from HF wavelet sub-bands and uses it to directly bias the self-attention mechanism of a windowed transformer block, thereby improving focus on relevant fine structures with low overhead.
• A five-component hybrid loss function is designed to jointly address class imbalance, regional consistency, and line continuity. The loss combines a primary segmentation term (Dice + BCE/Focal) with an auxiliary edge supervision loss, a wavelet-domain loss matching HF components, a low-frequency structural similarity (SSIM) loss, and a Total Variation (TV) regularization term for output smoothness.
• Through extensive experiments, it is demonstrated that the proposed model, particularly using the ConvNeXt backbone, surpasses state-of-the-art (SOTA) methods on the TTPLA dataset, achieving an F1-Score of 79.33%, an IoU of 68.38%, and 43.84 giga floating-point operations per second (GFLOPs), indicating a favorable accuracy-efficiency trade-off.
The structure of the paper is as follows: Related work is discussed in Section 2. The proposed WGT-UNet methodology is explained in detail in Section 3. Section 4 presents the experiment design, dataset, evaluation metrics, and the results obtained, and finally, Section 5 summarizes the work and suggests future research lines.
The automatic detection and segmentation of PTLs from aerial images has become an important research topic in computer vision in recent years. Research in the area spans a broad range, from traditional image processing techniques to advanced deep learning-based architectures. The following section examines the fundamental approaches in the existing literature, discusses their strengths and weaknesses, and defines the position of the proposed methodology within that framework.
Before deep learning became the dominant approach, PTL detection was largely dependent on handcrafted feature extractors and geometric models. Various techniques like the Hough transform, Radon transform, and Line Segment Detector were often utilized as they could efficiently pick out linear forms in the pictures [18–20,26]. Traditional methods typically operate on images that have been preprocessed using edge detection algorithms such as Canny or Sobel [1]. Approaches like Otsu thresholding and k-means clustering have been used to separate the image into simple background and foreground [1,18]. The main advantage of such techniques is their low computational cost and simple applicability [18]. However, they are quite sensitive to lighting changes, shadows, complex background textures (e.g., tree branches, road edges), and image noise [13,22]. Thus, their accuracy in practical use is restricted and they generally produce many false positives [20].
The rise of deep learning has brought about a paradigm shift in segmentation [21]. Encoder–decoder architectures such as FCN, U-Net, and DeepLabv3+ have become standard approaches in the field [11,18,22,23]. In addition, the Pyramid Scene Parsing Network (PSPNet) [27] introduced a pyramid pooling module to aggregate global context information at multiple scales, improving the segmentation of objects with varying sizes. Similarly, the Feature Pyramid Network [28] architecture, originally developed for object detection, has been widely adopted in segmentation for its effective mechanism of combining semantically strong, low-resolution features with semantically weak, high-resolution features via a top-down pathway and lateral connections. These models enable precise segmentation of lines by classifying the image at the pixel level [22]. The encoder layer extracts hierarchical semantic features, while the decoder layer upsamples the extracted features to create a segmentation map at the original image resolution [11]. The skip connections introduced by the U-Net architecture have been quite effective in improving the segmentation accuracy of fine structures, by transferring low-level fine details (such as edges) from the encoder to the decoder [12,14].
Basic architectures have been specifically improved for the similar tasks in various studies. For example BASNet [29], which, although primarily designed for salient object detection, introduces a predict–refine framework with boundary quality awareness as its central focus. The emphasis on sharp edge definition is highly relevant to the challenge of segmenting thin power lines. For instance, ResNet-Ghost-SIMAM-UNet (RGS-UNet) enhances the U-Net backbone with Residual Network and achieves a lightweight structure by reducing the number of model parameters with Ghost Modules [12]. PL-Deeplab extends the DeepLabv3+ architecture with a multi-branch concatenation network for stronger feature extraction and a one-shot concatenation feature pyramid to provide a wider receptive field [8]. PLE-Net captures rich contextual relationships by adding a multi-scale feature enhancement block to the U-Net architecture [5]. Collectively, the studies demonstrate how effective basic encoder–decoder structures can be in PTL detection with the right modifications.
The literature has extensively utilized attention mechanisms to enhance the performance of models based on CNNs [20,21]. The introduction of attention mechanisms allows the model to focus on relevant regions of the image, thereby improving the detection of objects that are often obscured by complex backgrounds [15,30].
PLE-Net has highlighted regions using a self-attention block [5]. RGS-UNet has used a Simple-Parameter-Free Attention (SimAM) mechanism, which handles channel and spatial dimensions together and does not require additional parameters [12]. PL-UNet has proposed a multi-scale attention gate to improve feature extraction in key regions [11]. More recently, the Axial-UNet++ adopted a gated axial-attention method which applies the attention function one after the other to the x and y axes to reduce the computational cost of the regular attention mechanisms [31]. All the research findings show that the power of attention mechanisms can be exploited fully by virtue of the models’ increased representational strength which consequently leads to better accuracy in segmentation tasks.
Several studies suggested to use hybrid or multi-stage methods that would involve combining different algorithms rather than relying on a single end-to-end model. Taking one study as an instance, components were initially located in bounding boxes through an efficient object detection model like YOLO (You Only Look Once), and subsequently, the center points of those boxes were merged in order to reconstruct the whole lines in a post-processing step [17]. Another hybrid scenario starts with the extraction of a region of interest by means of classical methods like Canny/Sobel, and then a more robust deep learning model like Mask Region-based Convolutional Neural Network is applied to that region only [18]. Similarly, another study proposed a technique that integrates line detection and semantic segmentation [26]. Generally, such methods are directed towards a practical compromise between speed and accuracy; however, because of their multi-stage nature, they not only have a risk of error propagation but also cannot fully exploit the benefits of end-to-end learning [18].
Some innovative studies inspired by the linear and HF nature of PTLs have integrated signal processing techniques into deep learning pipelines. PLGAN and PLNet have utilized the Hough transform to ensure the global linear consistency. While PLGAN regulates the model’s outputs with a loss function defined in Hough space, PLNet uses the information obtained from Hough space as an attention mechanism [7,9]. On the other hand, WaveGNet and a recent Amplitude Stretch Transform–based approach use the Wavelet Transform and the Amplitude Stretch Transform, respectively, to emphasize HF details [4,32]. Such methods effectively suppress low-frequency background noise while highlighting edge details. These approaches suggest that integrating domain-specific information into deep learning models can improve robustness and accuracy compared to standard architectures.
In recent years, transformer architectures have become popular in computer vision because of their strong ability to model global dependencies. DUFormer is among the first studies to apply the potential of transformers to PTL detection [10]. The proposed model is a hybrid architecture that merges the strong local feature extraction capability of CNNs with the broad contextual understanding of transformers. By generating rich semantic tokens using a CNN-based module called the ”heavy token encoder”, the subsequent transformer block operates more efficiently [10]. Hybrid approaches offer potential for preserving local details while maintaining global consistency.
Although the studies summarized above have made significant progress in the field, there are still some gaps that need to be addressed. Hough transform-based methods may experience difficulties in modeling curved lines based on the assumption that lines are straight [9]. Approaches using wavelet transform have not yet fully leveraged the powerful global context modeling capability offered by transformer architectures [4]. Hybrid models combining CNN and transformer do not make use of the extensive edge information that the frequency domain offers to direct the attention mechanism of the transformer, which could possibly result in the loss of both efficiency and accuracy [10].
3 Proposed Method: Wavelet-Guided Transformer U-Net
The WGT-UNet is built around an encoder–decoder architecture. The CNN backbone extracts hierarchical multi-scale features, and the WGT decoder progressively recovers spatial details at full resolution to obtain precise segmentation masks. The general structure is shown in Fig. 2.
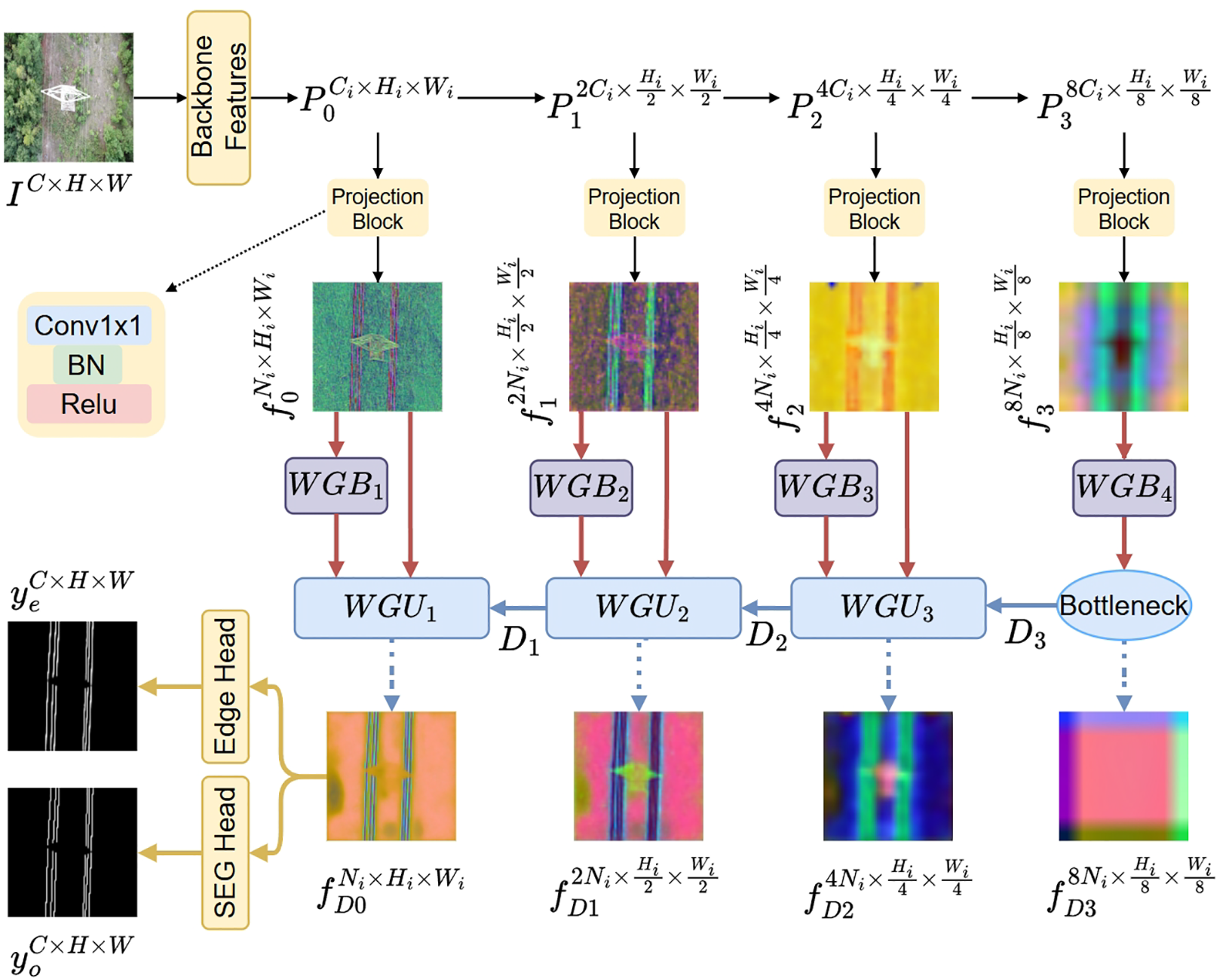
Figure 2: Overall architecture of the proposed WGT-UNet. A CNN backbone extracts four multi-scale feature maps
A pre-trained CNN backbone receives an image of size
To account for variations in channel dimensions across backbones,
The core component is a decoder that receives the projected multi-scale features and progressively upsamples them to produce the final segmentation mask. Skip connections from the encoder are leveraged, and wavelet-derived attention is used to modulate these skip pathways to emphasize PTL structures.
The decoder ends with two output heads: a primary segmentation head that predicts the mask and an auxiliary edge head that predicts an edge map. The dual-head design provides explicit boundary supervision, thereby improving contour sharpness. The auxiliary edge head is used only during training to enforce boundary-aware representations via deep supervision; it is removed at inference, leaving only the primary segmentation head. As a result, the edge branch introduces no additional FLOPs or latency during deployment on UAV hardware.
3.1 Multi-Scale Backbone Encoder
The encoder serves as the primary feature extractor, mapping an input image
EfficientNet [33] is included as an efficient convolutional baseline. The network is composed of mobile inverted bottleneck blocks with depthwise separable convolutions, reducing parameters while preserving feature expressiveness. In addition, compound scaling jointly adjusts depth, width, and input resolution. EfficientNet provides a purely convolutional baseline under a lightweight computational budget for the target task.
An attention-based backbone is considered to capture long-range context for continuous PTLs. Swin Transformer [34] employs hierarchical window-based self-attention (W-MSA), where attention is computed within non-overlapping windows and propagated across regions through shifted windows in deeper layers. The resulting features combine local texture cues with broader structural context, with a manageable computational cost.
ConvNeXt [35] is also considered a modernized CNN backbone with transformer-inspired design choices. The architecture retains a purely convolutional formulation while adopting elements such as
Regardless of the chosen backbone, the encoder processes the input image I and outputs four multi-scale feature maps
To provide a backbone-agnostic interface to the decoder, each
In the main pipeline (Fig. 2), the decoder is instantiated as a sequence of
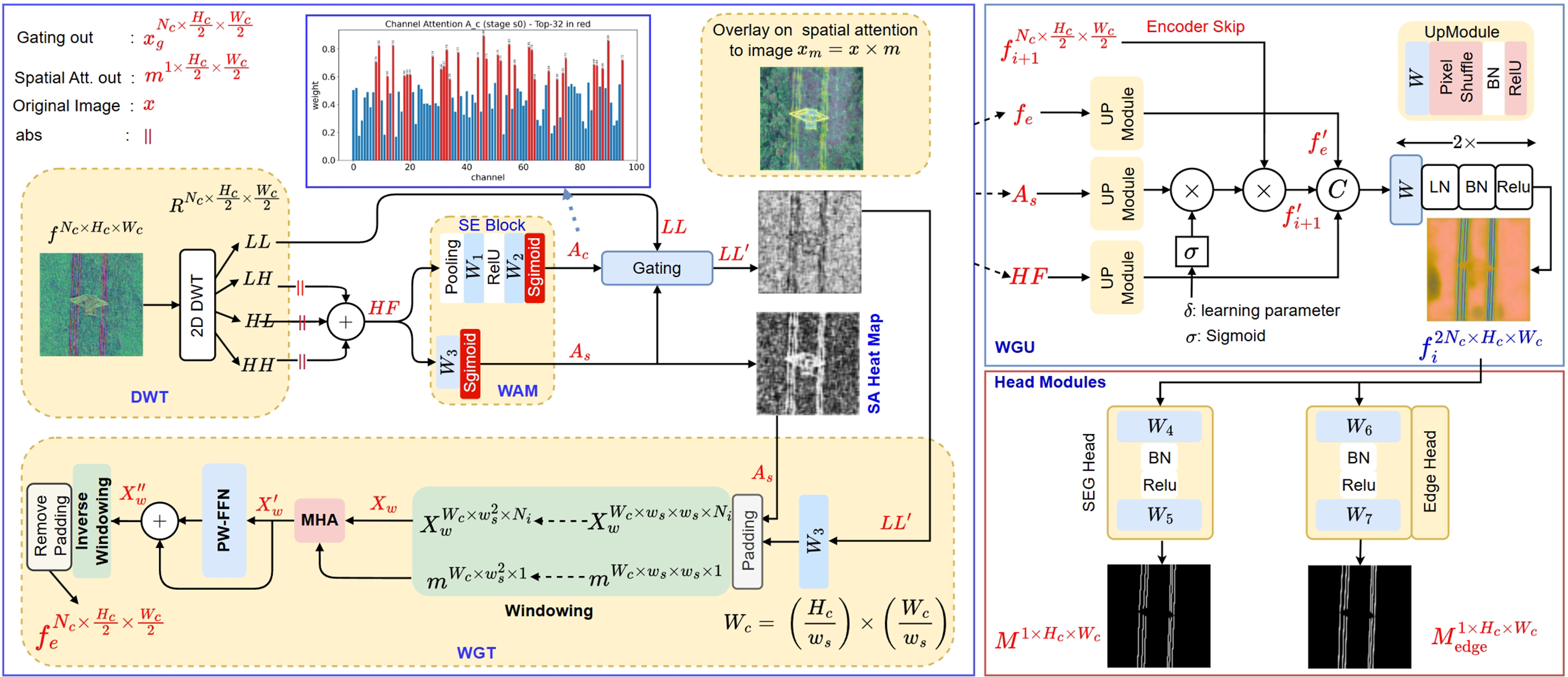
Figure 3: Overview of a single wavelet-guided decoder stage at level
Notation
In this section,
At each decoder stage, the 2D Haar DWT is applied to the corresponding feature map
For each stage
3.2.1 Wavelet Attention Module
WAM derives complementary channel (
Here,
WAM produces two attention maps. The
where
Complementary to
The procedure for generating the
The resulting map
3.2.2 Wavelet-Guided Transformer Block
The transformer block is used to model global context and long-range dependencies. Unlike standard transformers, the WGT block is explicitly guided by the
The full architecture of the WGT block follows a standard transformer block structure, augmented with a wavelet-guided attention mechanism.
First, the input feature map
To improve computational efficiency, the projected feature map
W-MHA represents Wavelet-Guided Multi-Head Attention, and PW-FFN represents the position-wise feed-forward network in Eq. (6). The output of each sublayer is added to its input via a residual connection.
The PW-FFN is a two-layer MLP applied independently to each token (each position), providing additional nonlinearity and channel mixing. The computation is given in Eq. (6).
The attention score connecting two tokens
Here,
Here, Q and K denote the query and key matrices, respectively, and
Wavelet features are used in the WGT block in two complementary roles. First, the wavelet-derived channel and
In approaches that rely only on multiplicative gating/masking, the signal may be attenuated when the gating map suppresses relevant regions (e.g., low-contrast or partially occluded thin line segments), which can reduce the continuity of linear structures such as PTLs. The additive bias in Eq. (8) provides a soft structural cue by shifting the scores before the softmax operation. Content-based similarity is retained, while the attention distribution is encouraged toward line/edge regions indicated by the wavelet response. Even when wavelet cues are weak in some areas, global context can still help maintain long-range PTL continuity, and the bias can improve stability with respect to line integrity.
The final output of the block,
In the decoder synthesis path (Fig. 3), each WGU block increases the spatial resolution by a factor of 2 and fuses the upsampled decoder stream with the corresponding projected encoder feature via a skip pathway. Specifically, the decoder feature
The contribution of the skip feature
The term
To support the reconstruction of fine details (e.g., edges and textures), the HF wavelet component
The UpModule denotes a sequence of operations that upsamples an input tensor
Here
Two different head layers have been implemented in the final stage of the decoder for the generation of the final segmentation and edge maps. The outputs produced by the two heads have the same spatial resolution as the input image and share the same architectural template (Conv–BN–ReLU–Conv), but are generated by separate parameter sets.
The segmentation mask M is obtained from the shared feature map
The edge map
For efficient supervision during training, a composite total loss is defined,
where
The main segmentation loss combines two widely used terms to jointly encourage pixel-wise accuracy and region overlap. It consists of Binary Cross-Entropy (BCE) loss and Dice loss. The BCE term penalizes per-pixel classification errors, while the Dice term measures region-level overlap between the predicted and ground-truth masks and is generally more robust to class imbalance. Let M denote the predicted mask after sigmoid activation and Y the ground-truth mask. The resulting loss is given in Eq. (14).
where
with N being the total number of pixels and
To enforce the generation of sharp and precise boundaries, an auxiliary edge head is supervised with an explicit edge loss. The ground truth edge map,
To ensure sharpness at the signal level, the loss operates in the frequency domain. It penalizes discrepancies between the HF details of the prediction and the ground truth. A Haar DWT is applied to both the predicted mask M and the ground truth Y to obtain their respective HF sub-bands {LH, HL, HH}.
The loss is defined as the L1 distance between the absolute values of the components, as shown in Eq. (17).
In addition to the HF term,
Finally, a TV loss is used as a regularization term to favor spatial smoothness in the predicted mask. By doing so, it punishes large differences between neighboring pixels in the output which aids in getting rid of noise and reducing spurious isolated predictions. It is described with Eq. (19) as the total of the absolute differences over the neighbor pixels in the horizontal and vertical lines.
Having detailed the architectural innovations of WGT-UNet, including its multi-scale encoder design, the wavelet-guided decoder, and the comprehensive hybrid loss function, the subsequent section is dedicated to the empirical validation of the proposed method. The following experiments quantify the performance of WGT-UNet, analyze the contribution of its key components, and benchmark it against existing models on the challenging TTPLA dataset.
The section outlines the experimental setup used to evaluate the WGT-UNet model. We describe the dataset, evaluation metrics, implementation details, and present a comprehensive comparison of the model’s performance against several methods.
4.1 Dataset and Evaluation Metrics
All experiments are conducted on two public benchmarks: the TTPLA dataset [36] and the VLIR (Ground Truth of Powerline) dataset [37]. Both are challenging and widely used benchmarks for power line segmentation. TTPLA dataset comprises 1260 high-resolution aerial images captured by UAVs under diverse and complex conditions, including varying backgrounds (mountains, forests, urban areas), different lighting, and weather. The fine, sparse nature of the power lines in the images makes it an ideal testbed for evaluating the robustness and precision of segmentation models. For the TTPLA experiments, the standard split was followed, using 1008 images for training and 252 images for validation and testing. To further assess the model’s robustness and generalization capability on unseen data domains, the VLIR dataset was additionally employed as an external test set. This dataset consists of 200 aerial images and was used exclusively for testing purposes without any training involvement.
To provide a comprehensive assessment of the model’s performance, a set of standard and task-specific metrics is employed:
• Intersection over Union (IoU): IoU, also referred to as the Jaccard index, serves as the primary metric for assessing semantic segmentation performance. It measures the ratio between the intersection and the union of the predicted and ground truth masks. As a stringent metric that penalizes both false positives and false negatives, it offers a reliable indication of the model’s capability to accurately delineate power lines. For a binary segmentation task, it is computed using Eq. (20) for the foreground class (power lines), and is defined in terms of True Positives (TP), False Positives (FP), and False Negatives (FN).
where TP represents the pixels correctly identified as power lines, FP represents background pixels incorrectly classified as power lines, and FN represents power line pixels that were missed by the model.
• F1-Score: The F1-Score is the harmonic mean of Precision and Recall, and it is a crucial metric for tasks with significant class imbalance, such as power line segmentation where line pixels are a small fraction of the total image area. It provides a more balanced assessment than accuracy alone, as it requires both high precision (the model’s predictions are correct) and high recall (the model finds most of the actual lines).
First, Precision and Recall are defined with Eqs. (21) and (22).
The F1-Score is then calculated with Eq. (23):
• Parameters: The total number of trainable parameters in the model (in millions, M), indicating its size and complexity.
• FLOPs: Floating Point Operations per second (in Giga-FLOPs, G), measuring the computational cost of a single forward pass.
All models were implemented using the PyTorch framework and trained on a single NVIDIA RTX 3090 GPU. Input images were resized to
For the DWT calculation, it is implemented as a standard CNN operation. In the implementation, a separable 2D Haar filter bank—corresponding to the LL (low-low), LH (low-high), HL (high-low), and HH (high-high) subbands—is formulated as a single convolutional layer configured with stride = 2. The single Conv2d operation executes both the filtering and 2D subsampling (decimation) steps of the transformation. Setting the number of groups (groups = C) to match the number of input channels changes the operation to a depthwise convolution. Thus, each input channel is processed independently of the others and decomposed into four subband outputs. Fig. 4 shows the DWT analysis of the features in the encoder layers. At the lowest encoder level (

Figure 4: Visual analysis of 2D Haar DWT subbands at different network levels.
To validate the effectiveness of WGT-UNet, a comprehensive comparison was conducted against several SOTA segmentation models. All methods were re-executed using identical configuration and dataset settings, employing the original code repositories provided in their respective studies. The evaluation includes both quantitative and qualitative analyses, which is common practice in segmentation studies.
The detailed quantitative results are summarized in Table 1. The results indicate that WGT-UNet with the ConvNeXt backbone achieves competitive performance on the TTPLA dataset among the evaluated methods. Specifically, proposed model reaches an IoU of 68.38% and an F1-Score of 79.33%, exceeding the next best competitor, U-Net++, by more than 5 percentage points in IoU.
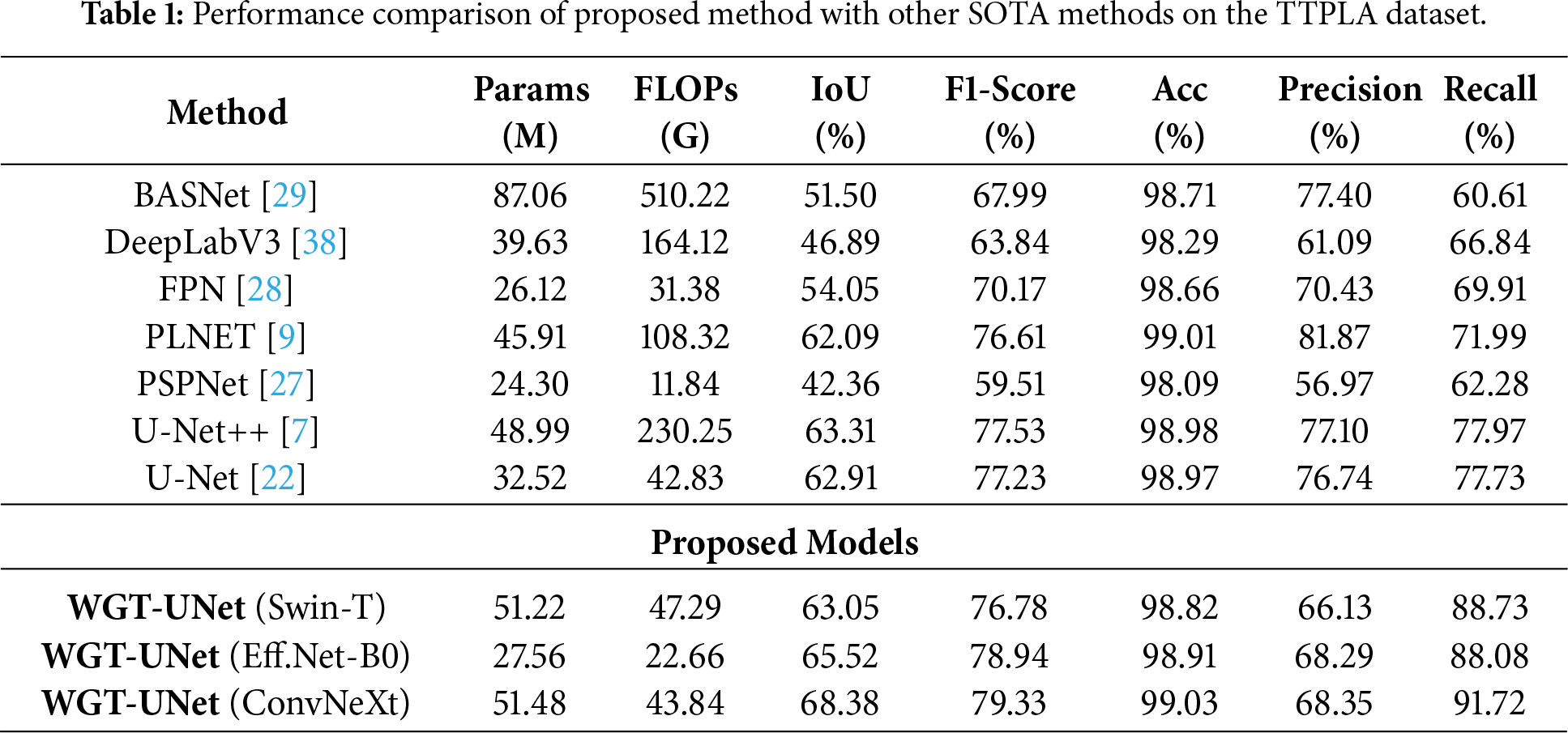
Table 2 presents the evaluation results on the external VLIR dataset, which was used exclusively for testing to assess generalization to an unseen domain. Despite the domain shift and challenging conditions in VLIR (e.g., blur and partially invisible lines), the proposed WGT-UNet (ConvNeXt) maintains robust performance, achieving an IoU of 58.75% and an F1-Score of 71.83%. The model exceeds the closest competitors, PLNet and U-Net++, by approximately 5% in IoU. Notably, WGT-UNet attains a high Recall of 97.62%, suggesting improved sensitivity to faint and disconnected power lines that may be missed by other models. Overall, these results support the effectiveness of the wavelet-guided attention mechanism in capturing structural cues that transfer across domains.
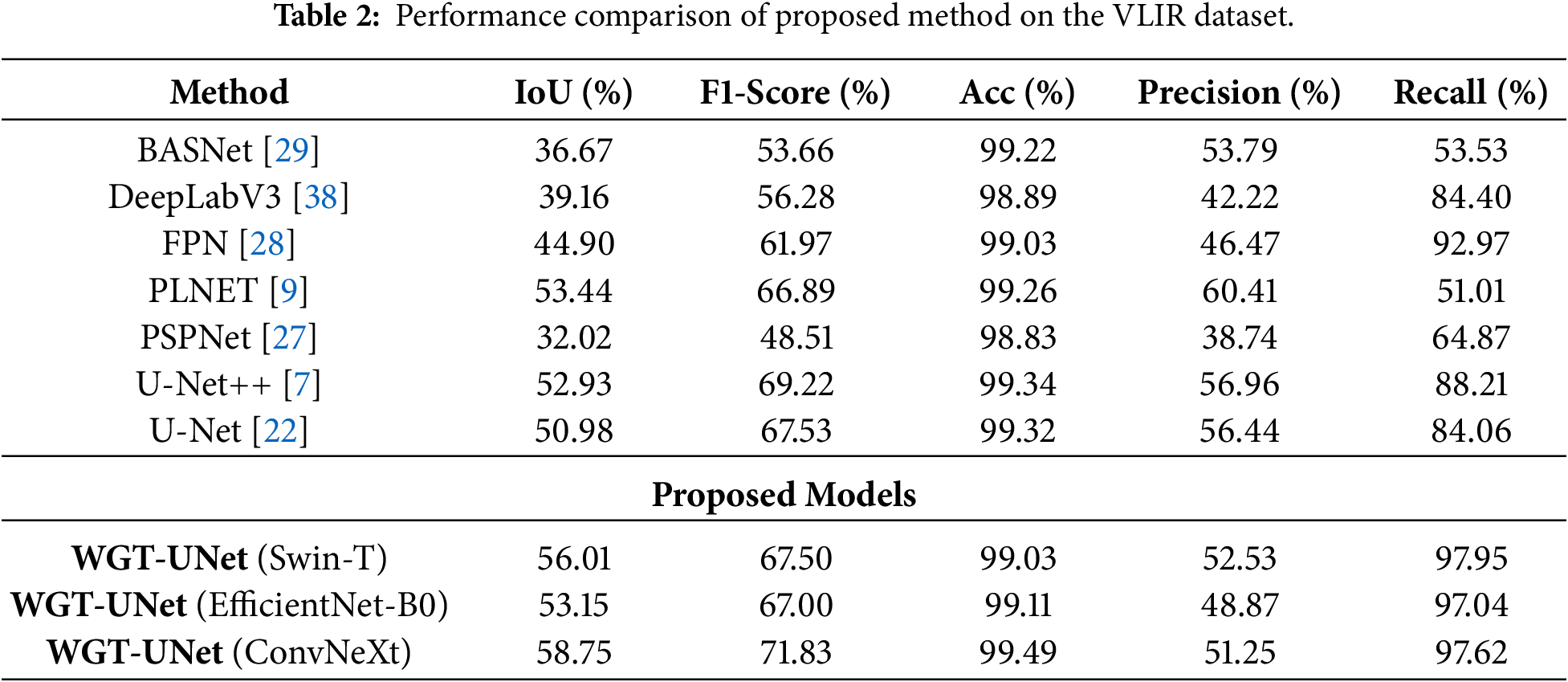
The observed accuracy can be attributed to the combination of the wavelet-guided attention mechanism and the hybrid loss function. By leveraging the wavelet transform, the model can better emphasize HF details associated with power lines, while the transformer block helps capture their global and continuous structure.
A detailed comparison of inference latency, Frames Per Second (FPS), and memory usage is reported for both GPU and CPU settings in Table 3. For UAV applications that target real-time processing, a frame rate of around 30 FPS is often considered a practical minimum. WGT-UNet (ConvNeXt) achieves 74.51 FPS with a latency of 13.42 ms on the GPU setup described in the implementation details, suggesting its suitability for real-time processing in practice. While models such as FPN and PSPNet can achieve faster inference due to their lightweight designs, their segmentation accuracy is notably lower in the evaluation (Table 1). Overall, the proposed model offers a favorable accuracy efficiency trade-off by maintaining high inference speed while achieving competitive segmentation accuracy on the TTPLA benchmark.
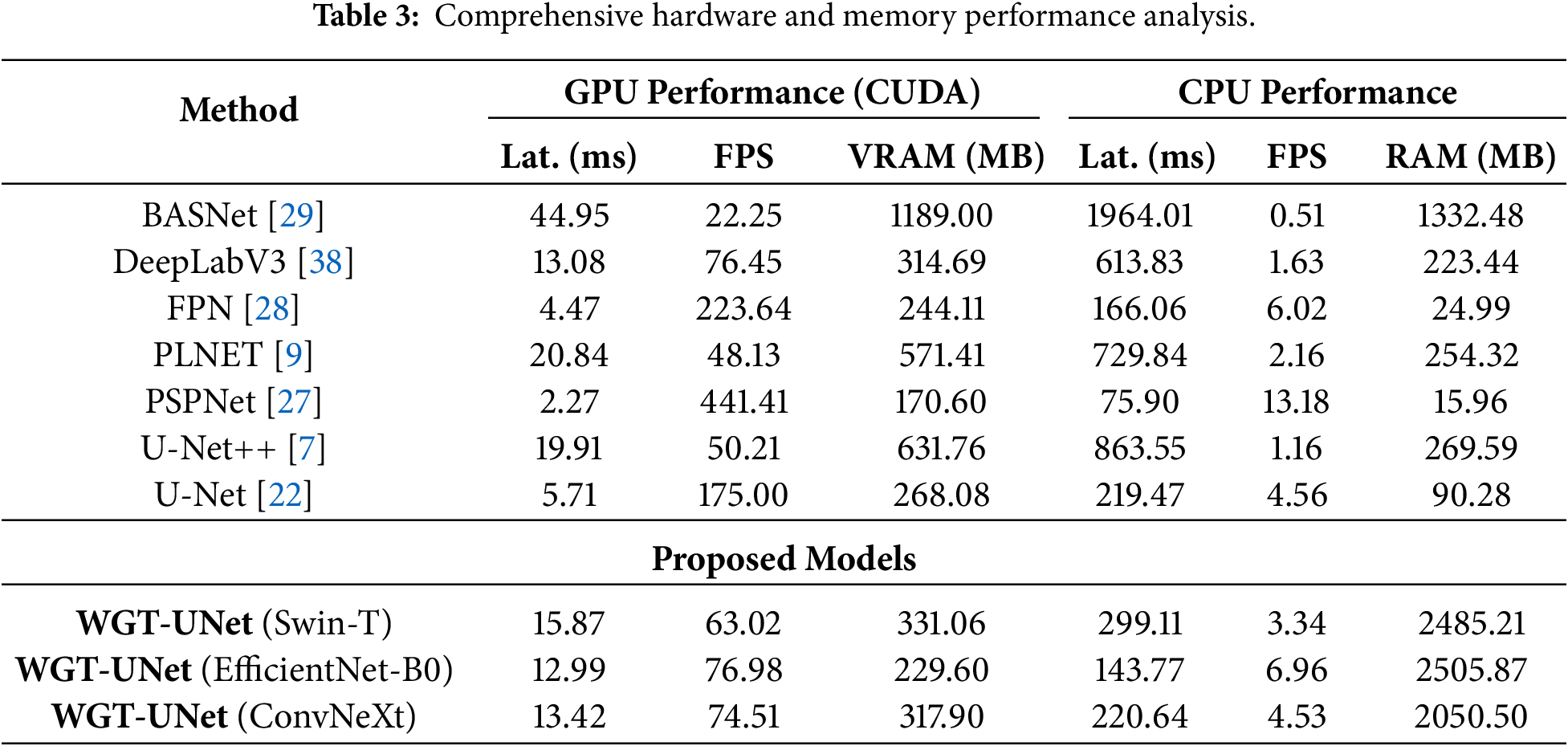
This section provides a qualitative evaluation to visually demonstrate the segmentation quality and behavior of proposed WGT-UNet model in challenging scenarios. The analysis aims to highlight the model’s ability to suppress complex background noise and maintain line continuity. Fig. 5 presents a visual comparison of the segmentation results obtained by WGT-UNet variants against several classic and SOTA models ((c) PSPnet, (d) FPN, (e) DeepLabV3, (f) BASNet, (g) PLNET, (h) U-Net, (i) U-Net++) on challenging samples from the TTPLA and VLIR dataset. The input images (column a) effectively illustrate the core challenges of the task: complex and visually noisy backgrounds, often containing linear features (e.g., road edges, shadows), and the fine, low-contrast nature of the power lines themselves.

Figure 5: Qualitative results on the TTPLA dataset: (a) Input Image, (b) Ground Truth, (c) PSPnet, (d) FPN (e) DeepLabV3, (f) BASNet, (g) PLNET, (h) U-Net, (i) U-Net++, (j) WGT-Unet-EfficientNet, (k) WGT-Unet-Swin-T, (l) WGT-Unet-ConvNeXt Prediction.
When considering the input images in column (a) and the ground truth masks in column (b) of Fig. 5, it is observed that the compared models (c–i) exhibit various failure modes. Segmentation models such as PSPNet (c), FPN (d), and DeepLabV3 (e) experience pronounced line fragmentation and false-positive detections, especially in noisy backgrounds such as the vegetation in the 5th column and the complex urban texture in the 7th column. Although advanced encoder–decoder architectures such as U-Net (h) and U-Net++ (i) offer better continuity, they still misclassify deceptive linear features that are structurally similar to power lines, such as road edges in the 2nd column and roof edges in the 7th column. The WGT-UNet models (j–l), particularly the one with the ConvNeXt backbone (l), show consistently improved predictions across the entire set of challenging scenarios, in line with the quantitative comparison. These qualitative gains are attributable to the core architectural components of the proposed model.
To validate the generalization capability of the proposed model on unseen data, we further evaluated it on the VLIR dataset (Fig. 6). This dataset introduces environmental challenges that are not fully represented in the training set. Specifically, the images in columns 1, 2, and 3 suffer from significant blur, which degrades edge-related cues. While baseline models struggle to delineate boundaries under these low-sharpness conditions, WGT-UNet preserves the structural integrity of the lines more consistently. In columns 6 and 7, where the power lines are extremely faint and barely visible, the proposed model recovers line topology that competing models miss. Furthermore, the grassy textures in columns 4 and 5 create repetitive linear noise patterns that mimic power lines. Unlike standard models that tend to produce false positives under this vegetative clutter, the frequency-selective nature of proposed method distinguishes the target PTLs from repetitive background patterns.

Figure 6: Qualitative results on the VLIR dataset: (a) Input Image, (b) Ground Truth, (c) PSPnet, (d) FPN, (e) DeepLabV3, (f) BASNet, (g) U-Net, (h) U-Net++, (i) WGT-Unet-EfficientNet, (j) WGT-Unet-Swin-T, (k) WGT-Unet-ConvNeXt Prediction.
The proposed attention-based decoder is an important component of the model’s overall performance. Spatial attention is generated by processing the HF components obtained via 2D-DWT. The resulting map is injected as a bias into the self-attention mechanism of the transformer block. This design guides the transformer’s context modeling capability toward HF cues, reducing attention to irrelevant background structures such as road signs in the second column or roof edges in the seventh column. Through multi-head self-attention, the WGT block can capture global context and long-range structural dependencies. As a result, it produces more continuous line segmentation in low-contrast images (e.g., the 3rd and 4th columns) and in partially occluded cases (e.g., the 5th column with tree branches), where competing models tend to fragment the lines. In addition, the five-component hybrid loss function contributes to the sharp boundaries observed in row (l) of Fig. 5 and their high structural similarity to the ground truth in column (b). Auxiliary edge supervision with
In contrast, WGT-UNet variants (columns j–l), particularly the ConvNeXt-T backbone model (l), show improved performance in these cases. With the proposed WAM, the model suppresses background clutter and maintains the structural continuity of the lines, producing masks that closely match the Ground Truth (b). The ability to extract line structures with both precision and continuity supports the effectiveness of the proposed hybrid architecture and the five-component loss function used for supervision.
Fig. 7 qualitatively analyzes the incremental refinement process of the model’s multi-stage attention mechanism. The rows show the hierarchical progression from the model’s deepest and coarsest level (

Figure 7: The model’s attention gradually evolves from a coarse level (
The visual representation of the qualitative results in Fig. 5 illustrates that the WGT-UNet model (j–l) outperforms the others (c–i) under difficult conditions. The architectural innovations of the model appear to contribute substantially to this improvement. Despite the overall high performance, the model exhibits limitations in certain specific and challenging scenarios, as illustrated in Fig. 8. Such failures are particularly observed in images captured from a direct top-down perspective, where the PTLs blend with complex ground textures (e.g., dense vegetation or urban structures). In such cases, the distinguishing features of the lines are weakened by the ground complexity, which can confuse the model. The issue likely stems from the insufficient number of such rare and challenging top-down examples in the TTPLA dataset. The model may not have generalized adequately for these specific orientations and ground conditions, highlighting an area for improvement in future data collection and augmentation strategies.

Figure 8: Failure cases of the WGT-Unet-ConvNeXt model in some challenging scenarios. (a) Original Image, (b) Ground Truth, (c) Model Prediction.
Although the proposed WGT architecture provides high accuracy, some characteristic failure modes are encountered in challenging field conditions (Fig. 7). To systematically evaluate the limitations, the observed errors are analyzed in terms of viewpoint imbalance and texture bias, low contrast/low signal-to-noise ratio (SNR), partial occlusion, curvilinear topology, and perspective distortion.
In overhead or near-vertical scenes, PTLs are visually integrated with complex ground textures such as dense vegetation, road lines, and building edges. Due to the texture bias in the visual models, thin and long edges in the background can be confused with PTLs, increasing both false negatives and false positives. The under-representation of extreme viewpoints in the long-tailed distribution in the TTPLA dataset makes it difficult to generalize the model to these variations.
Discontinuities in PTL estimates are observed in fog, backlight/glare, or low-contrast conditions. Although DWT-based features enhance edges, when SNR is significantly reduced, HF components are mixed with noise, and discrimination is reduced. Partial obscuration by vegetation or structural obstructions forces mask continuity, resulting in fragmented outputs.
Perspective effects and the curvature of the PTL geometry (e.g., deflection curves) in the image plane create a tendency for over-smoothing or refraction of the estimates. The fact that common pixel-based loss functions do not directly target topological integrity and centerline continuity causes the model to tend towards piecewise or flat solutions instead of following the curvature.
Fig. 9 illustrates a detailed performance comparison of the models on a specific zoomed-in area. Both images used as examples show how power transmission lines are perceived at different levels of complexity in natural and urban environments. In the first example, PTLs with weak contrast and a broken appearance are located among dense tree branches. In the second example, road lines and intersecting lines on the asphalt create structurally similar but semantically different edges for the model. In both cases, classical CNN-based methods (DeepLabV3, PSPNet, BASNet, etc.) exhibited noticeable erratic behavior, mixing the PTL with the background or mistakenly labeling road lines as PTL.
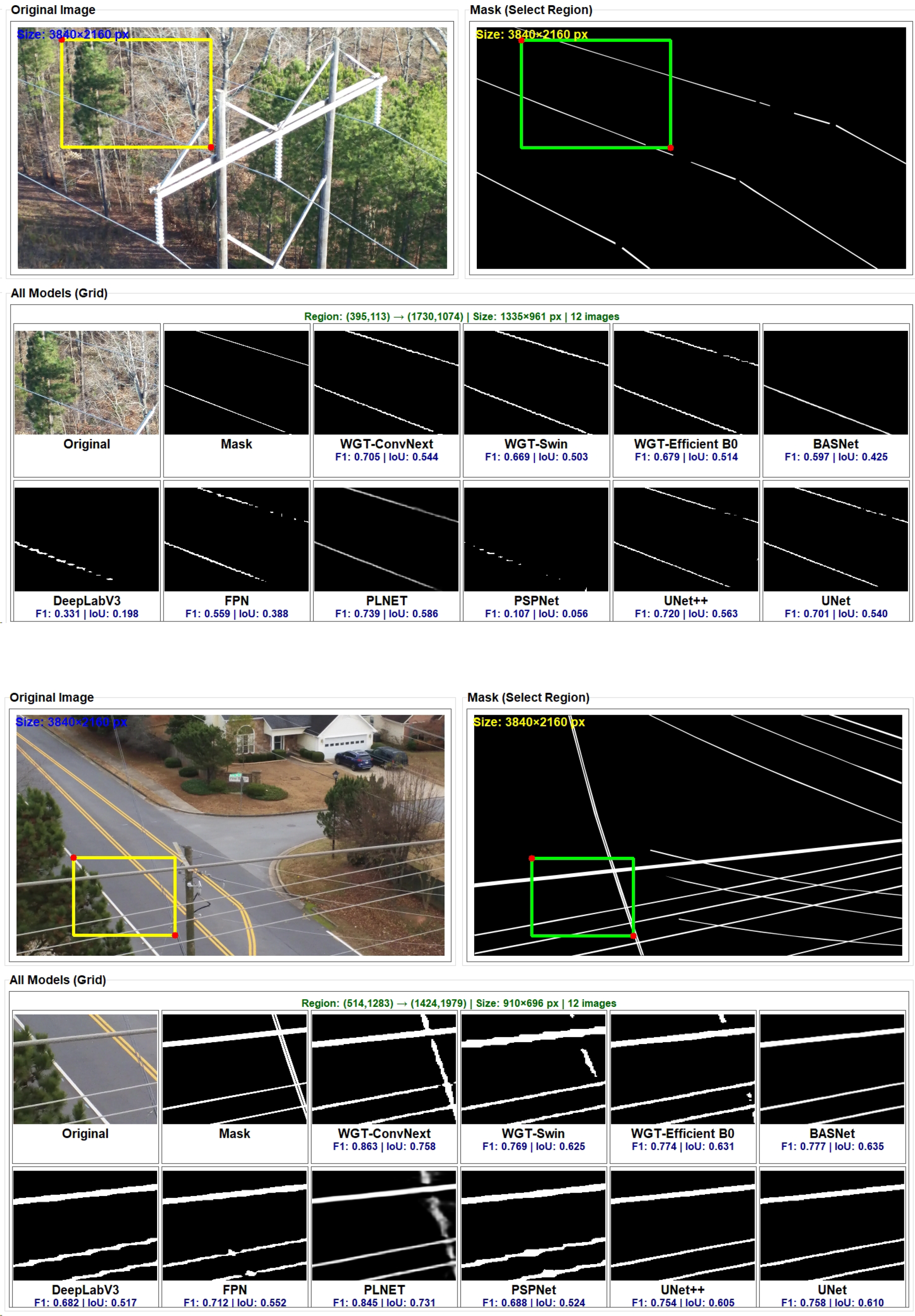
Figure 9: Comparative analysis of model performance on zoomed-in regions.
WGT-UNet (Swin) and WGT-UNet (Efficient-B0) offered wider context but had difficulty with the continuity and especially with the thin or intersecting lines. Meanwhile, the WGT-UNet (ConvNeXt) model showed the best performance in both cases, consistently capturing the PTL structure more accurately, even in the complex backgrounds (F1-score = 0.705/0.863, IoU = 0.544/0.768).
4.3.3 High-Frequency Detail Sensitivity Evaluation
The visualization presented in Fig. 10 demonstrates the robustness of the proposed WGT module against HF noise. Located in column 3, it captures not only the wavelet appearance distribution and power distribution, but also hidden HF details such as building sections, road lines, and vegetation. Therefore, the model’s false positive predictions may increase.
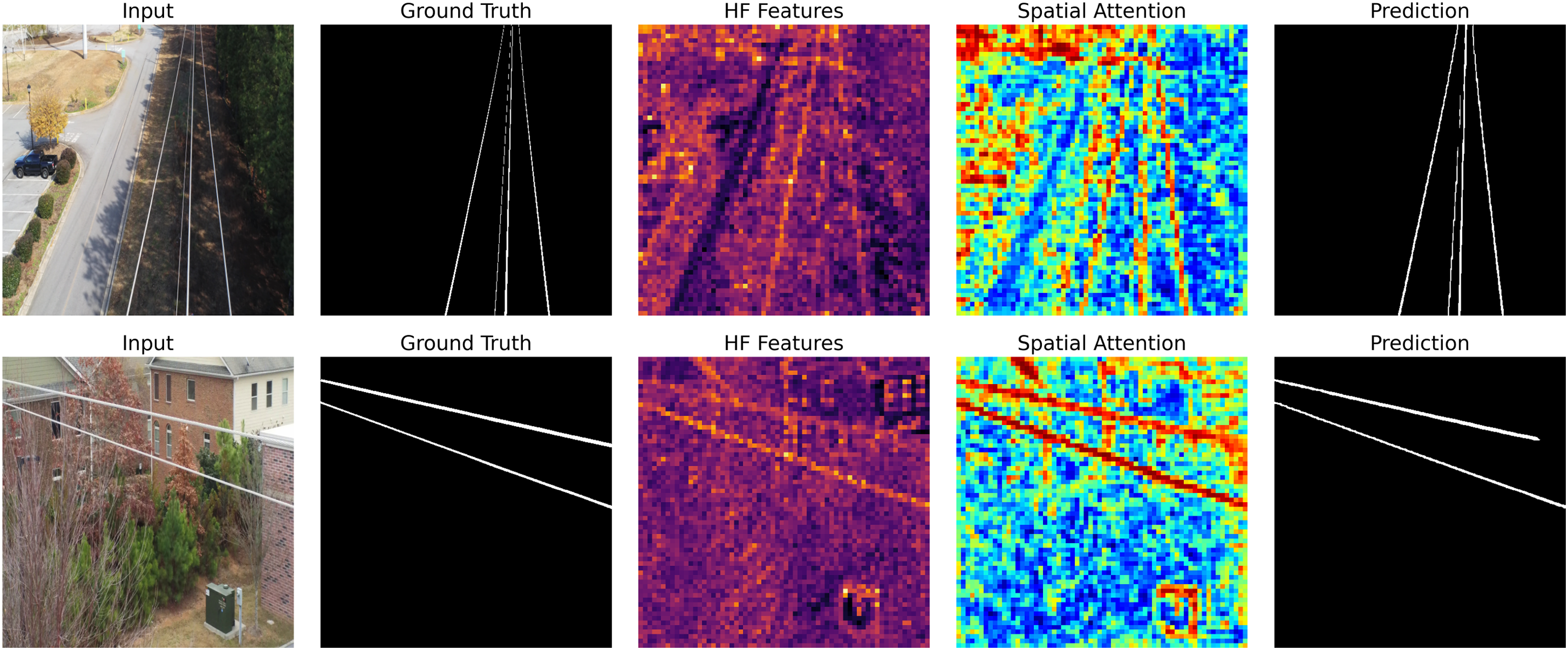
Figure 10: Visual performance analysis of the proposed model including spatial attention and HF features. Sample visualizations: Input, Ground Truth, HF Features, Spatial Attention, and Prediction.
However, when examining the learned spatial attention in the fourth column, it is evident that the model successfully suppresses these complex background noises. The attention mechanism has specifically concentrated the modulation weights (red/hot regions) on PTLs. Other HF features, such as building and road edges, have been filtered out by being given low weights (blue/cold regions) in the attention map. This result indicates that the proposed gamma-controlled sigmoid mechanism enables the model to focus primarily on relevant fine structural details and reduces its sensitivity to environmental noise.
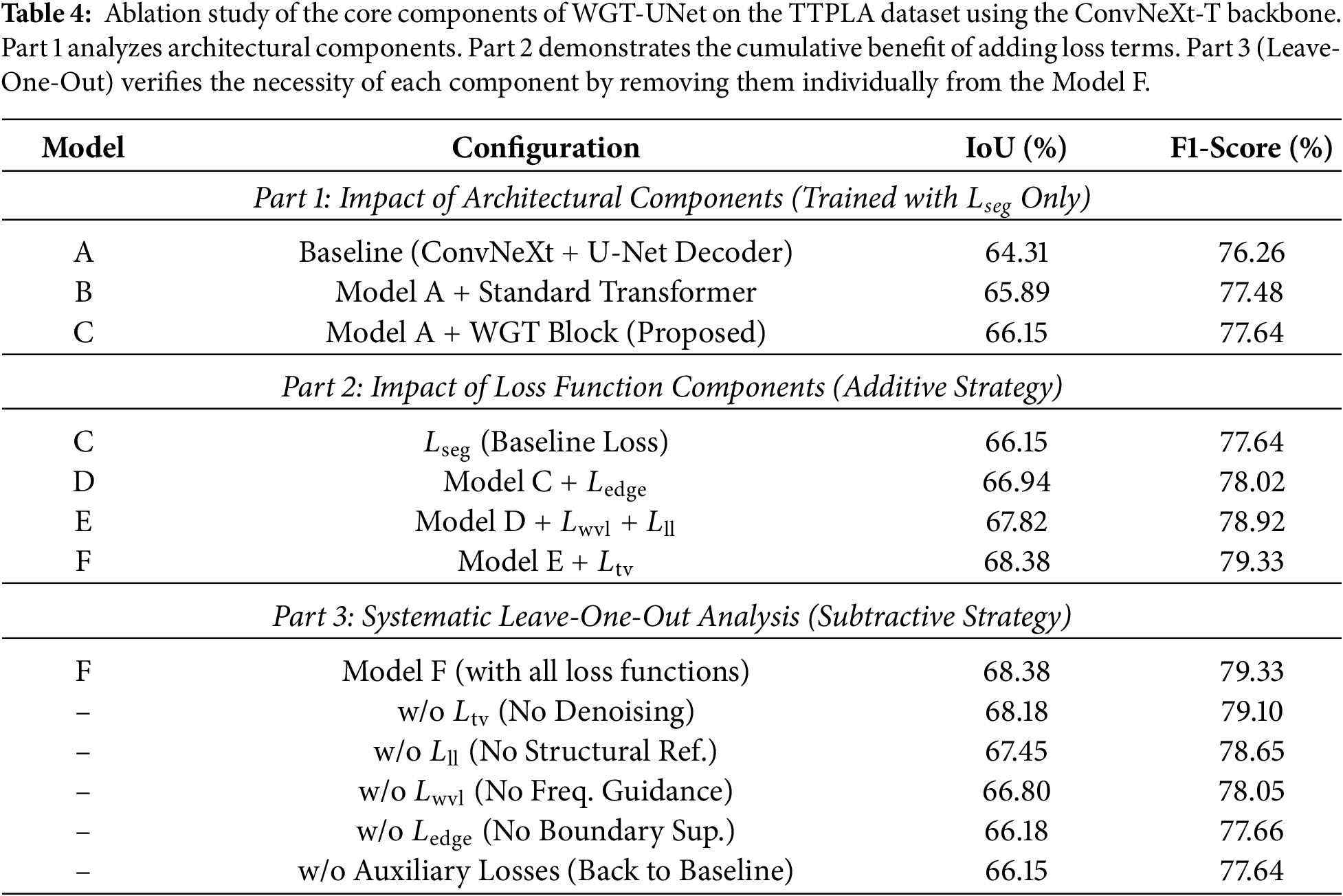
In order to confirm the efficiency of the proposed WGT-UNet and to measure the contribution of its essential components, a thorough ablation study was performed. The study methodically evaluates the influence of the two major contributions: the architectural design of WGT block and the role of each component within the multi-component hybrid loss function. The results are summarized in Table 4.
4.4.1 Impact of the Wavelet-Guided Architecture
First, an analysis was performed regarding the contribution of the new architectural elements in the proposed decoder. and stepwise generated the model, starting with a basic one to the complete model structure, in order to distinguish the advantages of every segment.
Model A (Baseline): The model serves as the baseline, representing a standard U-Net architecture. It uses the ConvNeXt-T backbone as an encoder, while the decoder is constructed with standard convolutional and up-sampling layers, without any transformer or wavelet guidance mechanisms. The configuration establishes the performance foundation upon which the proposed innovations are built.
Model B (Baseline + Standard Transformer): To the decoder of Model A, a standard, non-guided transformer block (e.g., a vanilla Swin Transformer block) was added. The purpose of the model is to measure the performance gain attributable solely to the global context modeling capability of a transformer.
Model C (Baseline + WGT Block): The standard transformer was replaced with the proposed WGT block. The effectiveness of the attention map produced by the WAM in guiding the self-attention mechanism of the transformer was directly evaluated under the given configuration. During the corresponding training stage, only the main segmentation loss was applied to all models.
The results in Table 4 demonstrate the architectural advantages. The baseline (Model A) achieves a respectable IoU of 64.31%. Incorporating a standard transformer (Model B) improves the IoU to 65.89%, confirming the value of long-range dependency modeling. A notable improvement is observed with Model C, where the proposed WGT block performance raises up to 66.15% in IoU. The improvement of more than 1.2 percentage points is consistent with our main assumption. Guiding the transformer’s focus with HF data from the wavelet domain appears more effective than a standard transformer for segmenting fine structures.
4.4.2 Impact of Transformer Block
A controlled ablation study was conducted to assess the contribution of the WGT block to overall segmentation performance. The WGT block, which employs window-based self-attention to capture long-range dependencies guided by wavelet-derived cues, was removed and replaced with an Atrous Spatial Pyramid Pooling (ASPP) based context module. Unlike a standard CNN block with a limited local receptive field, the ASPP baseline leverages multi-scale atrous convolutions to provide a wider effective receptive field and better capture elongated line structures. All other components of the architecture (Haar Wavelet Encoder, HF Attention Module, and the remaining decoder structure) were kept identical.
Specifically, the WGT block was replaced with a residual ASPP block that matches the input and output dimensions. The ASPP block aggregates multi-scale contextual information through parallel atrous convolutions with different dilation rates, together with a global pooling branch, as defined in Eq. (24). The resulting multi-branch features are concatenated and projected back to the original channel dimension. A residual connection is preserved to ensure a fair comparison with the residual nature of the original transformer block. The overall structure of the residual ASPP ablation block is given in Eq. (25). Here, the
We use dilation rates
As seen in Fig. 11a and 11b, the proposed model consistently performs better than the ASPP-based baseline. When the WGT block is used, the F1-score increases by about 10%. The transformer-based variant also converges faster and reaches a lower final validation loss, indicating improved generalization and reduced segmentation error. Moreover, the higher F1-score scores obtained with the proposed method are important for preserving the structural integrity of long and thin objects such as PTLs, where capturing global context via self-attention is challenging to achieve with convolution-only baselines, even with multi-scale atrous receptive fields.
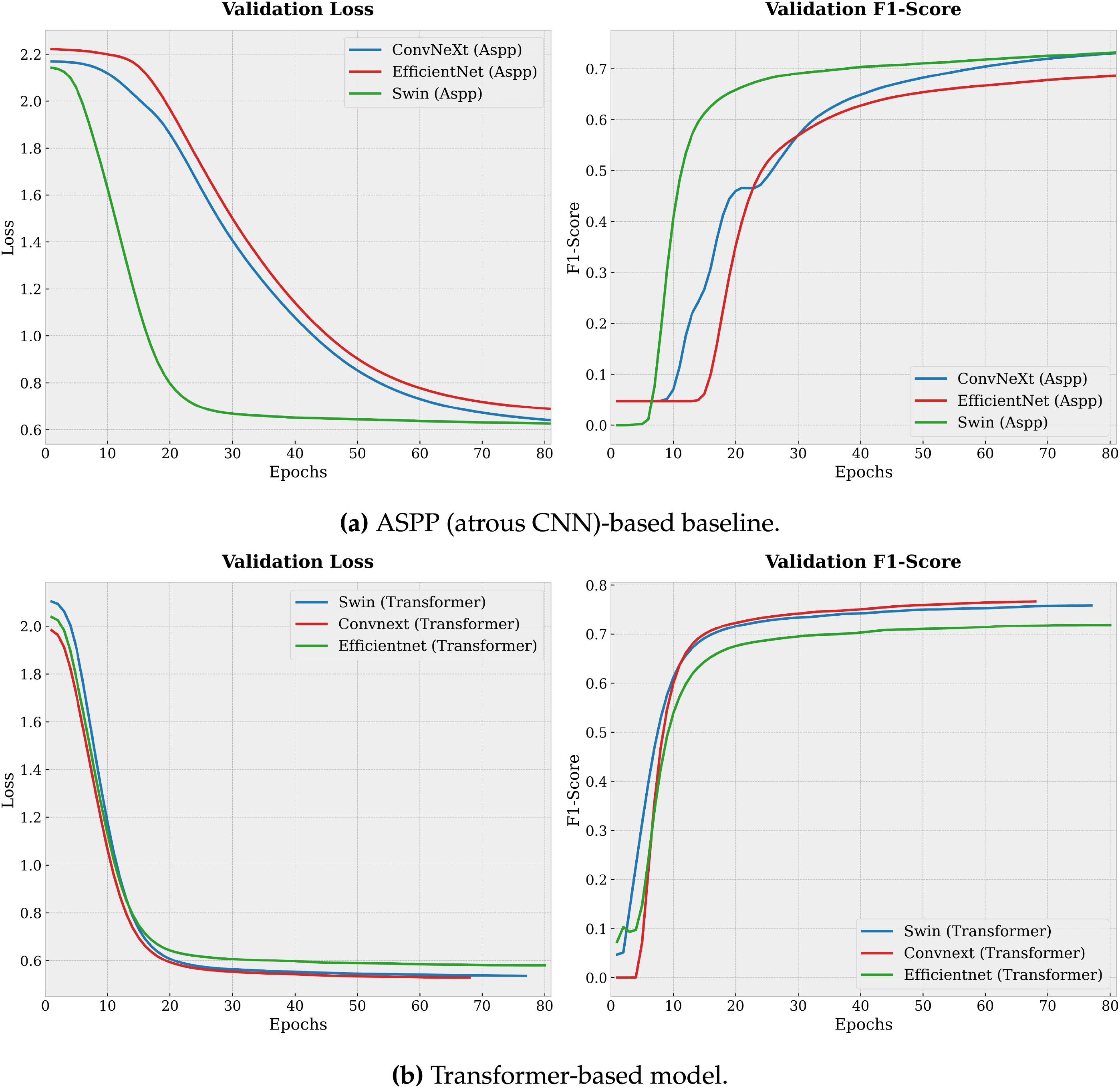
Figure 11: Validation loss and validation F1-score curves over training epochs.
4.4.3 Impact of the Hybrid Loss Function Components
After demonstrating the benefits of the proposed WGT architecture, the incremental benefit of each component in the hybrid loss function was evaluated. The experiments started with Model C (the best architecture) and progressively added the loss terms.
Model C (
Model D (+
Model E (+
Model F (+
All components of the loss function contribute measurably to performance improvement. The inclusion of edge loss in Model D results in an IoU increase to 66.94%, indicating that explicit boundary supervision is effective. Adding the frequency-domain losses in Model E further raises the IoU to 67.82%, revealing a strong synergy between the wavelet-guided architecture and the wavelet-domain loss functions.
Leave-One-Out Analysis: To address concerns regarding potential redundancy, we performed a subtractive analysis starting from the Model F.
• Removing
• Removing
• Removing
This dual-validation confirms that all components contribute uniquely to the final performance.
Finally, the inclusion of the TV loss as a regularizer provides a final boost to 68.38 IoU, suggesting that all five components work in concert to achieve the reported performance level, which is competitive with state-of-the-art methods on the TTPLA dataset. These analyses indicate that the strong performance of WGT-UNet is closely related to its carefully designed architecture and supervision strategy.
4.4.4 Sensitivity Analysis of the Learnable Parameters:
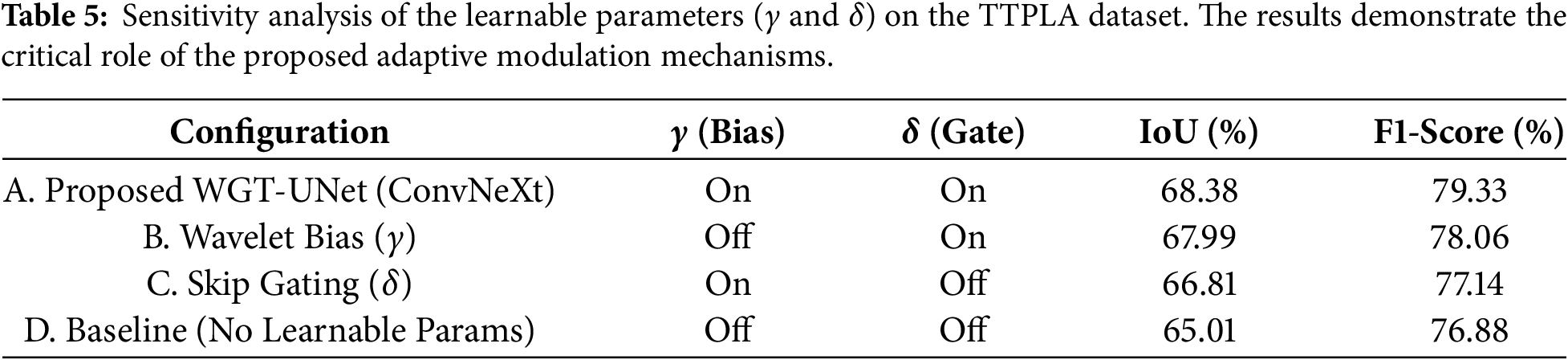
A controlled ablation study was performed to quantitatively evaluate the contribution of the parameters
Table 5 shows how the performance changes under individual and combined disabling scenarios. The results suggest that both
4.4.5 Impact of Low Image Resolution
The resolution of

In this work, we present a hybrid deep learning architecture, WGT-UNet, for PTL segmentation in aerial images acquired by UAVs. The proposed model combines the feature extraction capability of CNN-based multiscale backbones with a wavelet-guided transformer decoder. The key innovation, the Wavelet Attention Module, explicitly guides the self-attention mechanism by utilizing HF details from the wavelet domain, enhancing focus on fine, linear structures that are often obscured by complex backgrounds. This architectural design is further supported by a five-component hybrid loss function that jointly addresses class imbalance, edge sharpness, and structural coherence.
Experimental results on the TTPLA and external VLIR datasets indicate that WGT-UNet achieves strong performance, particularly with the ConvNeXt backbone, reaching an IoU of 68.38% and an F1-Score of 79.33%. The evaluation across different backbones also suggests that the framework is adaptable. The EfficientNet variant provides a competitive and lightweight alternative for resource-constrained scenarios. However, there are also limitations to this work. The model exhibits performance degradation in certain top-down perspectives where complex ground textures (e.g., road signs) structurally mimic power lines, and the current supervised approach relies on large-scale labeled datasets that are labor-intensive to acquire.
Future research will focus on overcoming the limitations of the existing work and broadening the scope of the proposed framework. To enhance the depiction of the scenes with different viewpoints and difficult textures, we will apply specific data augmentation techniques, which will involve stronger perspective distortions and background complexity as well. Furthermore, exploiting multi-view temporal fusion from consecutive UAV frames and integrating geometric regularizers into the loss function will be explored to strengthen signal coherence and topological stability in curvilinear segments. Beyond these algorithmic enhancements, priority will be given to the optimization of lightweight variants for real-time processing in embedded UAV systems using hardware acceleration libraries such as NVIDIA TensorRT and quantization techniques. In addition, the integration of self-supervised learning techniques will be investigated in order to minimize the dependency on large-scale labeled data sets. Finally, the universal nature of the proposed frequency-based attention mechanism suggests that it has strong application potential in similar linear segmentation problems, such as crack detection in civil structures or vessel segmentation in medical imaging.
Acknowledgement: Not applicable.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm their contributions to the paper as follows: Ahmet Küçüker was responsible for investigation, visualization, and writing (original draft, review and editing). Burhan Baraklı contributed to conceptualization, methodology, software, validation, and writing (original draft). All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The source code and the masks generated in this study will be publicly available at https://github.com/burhanbarakli/WGT-UNET. All other datasets used in the experiments are publicly available and have been referenced in the experimental section of the manuscript.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Faisal MAA, Mecheter I, Qiblawey Y, Fernandez JH, Chowdhury MEH, Kiranyaz S. Deep learning in automated power line inspection: a review. Appl Energy. 2025;385:125507. doi:10.1016/j.apenergy.2025.125507. [Google Scholar] [CrossRef]
2. Yang L, Fan J, Liu Y, Li E, Peng J, Liang Z. A review on state-of-the-art power line inspection techniques. IEEE Trans Instrum Meas. 2020;69(12):9350–65. doi:10.1109/tim.2020.3031194. [Google Scholar] [CrossRef]
3. Zou K, Jiang Z. Power line extraction framework based on edge structure and scene constraints. Remote Sens. 2022;14(18):4575. doi:10.3390/rs14184575. [Google Scholar] [CrossRef]
4. An D, Chao J, Li T, Fang L. WaveGNet: wavelet-guided deep learning for efficient aerial power line detection. IEEE Sens J. 2024;24(14):22037–44. doi:10.1109/jsen.2023.3330331. [Google Scholar] [CrossRef]
5. Afanaseva OV, Tulyakov TF. Comparative analysis of image segmentation methods in power line monitoring systems. Int J Eng Trans A Basics. 2026;39(1):1–11. doi:10.5829/ije.2026.39.01a.01. [Google Scholar] [CrossRef]
6. Nguyen VN, Jenssen R, Roverso D. Automatic autonomous vision-based power line inspection: a review of current status and the potential role of deep learning. Int J Elect Power Energy Syst. 2018;99:107–20. [Google Scholar]
7. Abdelfattah R, Wang X, Wang S. PLGAN: generative adversarial networks for power-line segmentation in aerial images. IEEE Trans Image Process. 2023;32:6248–59. doi:10.1109/TIP.2023.3321465. [Google Scholar] [PubMed] [CrossRef]
8. Chen G, Hao K, Wang B, Li Z, Zhao X. A power line segmentation model in aerial images based on an efficient multibranch concatenation network. Expert Syst Appl. 2023;228:120359. doi:10.1016/j.eswa.2023.120359. [Google Scholar] [CrossRef]
9. Wei N, Jin Y, Dan Z, Liu N, Peng F, Sun S. Power line segmentation by multilevel attention from hough domain. IEEE Trans Instrum Meas. 2025;74:5005711. doi:10.1109/tim.2024.3522395. [Google Scholar] [CrossRef]
10. An D, Zhang Q, Chao J, Li T, Qiao F, Bian Z, et al. DUFormer: solving power line detection task in aerial images using semantic segmentation. In: Pattern recognition and computer vision (PRCV 2023). Singapore: Springer; 2023. p. 54–66. doi:10.1007/978-981-99-8543-2_5. [Google Scholar] [CrossRef]
11. Zhao Q, Ji T, Liang S, Yu W, Yan C. Real-time power line segmentation detection based on multi-attention with strong semantic feature extractor. J Real Time Image Process. 2023;20:117. doi:10.1007/s11554-023-01367-8. [Google Scholar] [CrossRef]
12. Zhu W, Ding H, Han G, Wang W, Li M, Qin L. Power line segmentation algorithm based on lightweight network and residue-like cross-layer feature fusion. Sensors. 2025;25(11):3551. doi:10.3390/s25113551. [Google Scholar] [PubMed] [CrossRef]
13. Son HS, Kim DK, Yang SH, Choi YK. Recognition of the shape and location of multiple power lines based on deep learning with post-processing. IEEE Access. 2023;11:57895–904. doi:10.1109/access.2023.3283613. [Google Scholar] [CrossRef]
14. Yang L, Fan J, Huo B, Li E, Liu Y. PLE-Net: automatic power line extraction method using deep learning from aerial images. Expert Syst Appl. 2022;198:116771. [Google Scholar]
15. Yang L, Fan J, Xu S, Li E, Liu Y. Vision-based power line segmentation with an attention fusion network. IEEE Sens J. 2022;22(8):8196–205. doi:10.1109/jsen.2022.3157336. [Google Scholar] [CrossRef]
16. Ardis P, Voulodimos A, Doulamis N. Detecting cables and power lines in Small-UAS (Unmanned Aircraft Systems) images through deep learning. Drones. 2021;5(4):115. doi:10.1109/dasc52595.2021.9594405. [Google Scholar] [CrossRef]
17. Yetgin OE, Gerek ON. Automatic recognition of scenes with power line wires in real life aerial images using DCT-based features. Digit Signal Process. 2018;77:102–19. doi:10.1016/j.dsp.2017.10.012. [Google Scholar] [CrossRef]
18. Zhao W, Dong Q, Zuo Z. A method combining line detection and semantic segmentation for power line extraction from unmanned aerial vehicle images. Remote Sens. 2022;14(6):1367. doi:10.3390/rs14061367. [Google Scholar] [CrossRef]
19. Nguyen VN, Jenssen R, Roverso D. LS-Net: fast single-shot line-segment detector. Mach Vision Appl. 2021;32(1):12. doi:10.1007/s00138-020-01138-6. [Google Scholar] [CrossRef]
20. Li Y, Pan C, Cao X, Wu D. Power line detection by pyramidal patch classification. IEEE Trans Emerg Topics Comput Intell. 2019;3(6):416–26. doi:10.1109/tetci.2018.2849414. [Google Scholar] [CrossRef]
21. Huang L, Jiang B, Lv S, Liu Y, Fu Y. Deep-learning-based semantic segmentation of remote sensing images: a survey. IEEE J Select Topics Appl Earth Observ Remote Sens. 2024;17:8370–98. doi:10.1109/jstars.2023.3335891. [Google Scholar] [CrossRef]
22. Zhao Q, Fang H, Pang Y, Zhu G, Qian Z. PL-UNet: a real-time power line segmentation model for aerial images based on adaptive fusion and cross-stage multi-scale analysis. J Real Time Image Process. 2025;22(1):39. doi:10.1007/s11554-024-01615-5. [Google Scholar] [CrossRef]
23. Hota M, Kumar U. Power lines detection and segmentation in multi-spectral UAV images using convolutional neural network. In: 2020 IEEE India Geoscience and Remote Sensing Symposium (InGARSS). Piscataway, NJ, USA: IEEE; 2020. p. 154–7. [Google Scholar]
24. Jaffari R, Hashmani MA, Reyes-Aldasoro CC. A novel focal phi loss for power line segmentation with auxiliary classifier U-Net. Sensors. 2021;21(8):2803. doi:10.3390/s21082803. [Google Scholar] [PubMed] [CrossRef]
25. Li Y, Liu Z, Yang J, Zhang H. Wavelet transform feature enhancement for semantic segmentation of remote sensing images. Remote Sens. 2023;15(24):5644. doi:10.3390/rs15245644. [Google Scholar] [CrossRef]
26. Premachandra MH, Salaan C, Funada MRD, Vea MT, Kawanaka H. Detecting power lines using point instance network for distribution line inspection. Appl Sci. 2021;11(21):10174. doi:10.1109/access.2021.3101490. [Google Scholar] [CrossRef]
27. Zhao H, Shi J, Qi X, Wang X, Jia J. Pyramid scene parsing network. In: Proceedings of the IEEE/CVF Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2017. p. 2881–90. [Google Scholar]
28. Lin TY, Dollár P, Girshick R, He K, Hariharan B, Belongie S. Feature pyramid networks for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2017. p. 2117–25. [Google Scholar]
29. Qin X, Zhang Z, Huang C, Gao C, Dehghan M, Jagersand M. Basnet: boundary-aware salient object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2019. p. 7479–89. [Google Scholar]
30. Han G, Zhang M, Li Q, Liu X, Li T, Zhao L, et al. A lightweight aerial power line segmentation algorithm based on attention mechanism. Machines. 2022;10(10):881. doi:10.3390/machines10100881. [Google Scholar] [CrossRef]
31. Hu D, Zheng Z, Liu Y, Liu C, Zhang X. Axial-UNet++ power line detection network based on gated axial attention mechanism. Remote Sens. 2024;16(23):4585. doi:10.3390/rs16234585. [Google Scholar] [CrossRef]
32. Xu P, Sulaiman NAA, Ding Y, Zhao J. Innovative segmentation technique for aerial power lines via amplitude stretching transform. Sci Rep. 2025;15(1):2468. doi:10.1038/s41598-025-86753-x. [Google Scholar] [PubMed] [CrossRef]
33. Tan M, Le QV. Efficientnet: rethinking model scaling for convolutional neural networks. In: International Conference on Machine Learning (ICML). London, UK: PMLR; 2019. p. 6105–14. [Google Scholar]
34. Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, et al. Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE; 2021. p. 10012–22. [Google Scholar]
35. Liu Z, Mao H, Wu CY, Feichtenhofer C, Darrell T, Xie S. A ConvNet for the 2020s. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2022. p. 11976–86. [Google Scholar]
36. Abdelfattah R, Wang X, Wang S. TTPLA: an aerial-image dataset for detection and segmentation of transmission towers and power lines. arXiv:2010.10032. 2020. [Google Scholar]
37. Yetgin OE, Gerek ON. Ground truth of powerline dataset (Infrared-IR and Visible Light-VL). Mendeley Data. 2019. [cited 2026 Jan 21]. Available from: https://data.mendeley.com/datasets/twxp8xccsw/9. [Google Scholar]
38. Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL. Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans Pattern Anal Mach Intell. 2017;40(4):834–48. [Google Scholar] [PubMed]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools