
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Dual-Attention Multi-Path Deep Learning Framework for Automated Wind Turbine Blade Fault Detection Using UAV Imagery
1 Electrical Engineering Department, Jubail Industrial College, Royal Commission for Jubail & Yanbu, Jubail Industrial City, Saudi Arabia
2 Department of Artificial Intelligence and Data Science, Sejong University, Seoul, Republic of Korea
* Corresponding Author: Mubarak Alanazi. Email:
(This article belongs to the Special Issue: Advances in Deep Learning and Computer Vision for Intelligent Systems: Methods, Applications, and Future Directions)
Computer Modeling in Engineering & Sciences 2026, 146(2), 17 https://doi.org/10.32604/cmes.2026.077956
Received 20 December 2025; Accepted 27 January 2026; Issue published 26 February 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Wind turbine blade defect detection faces persistent challenges in separating small, low-contrast surface faults from complex backgrounds while maintaining reliability under variable illumination and viewpoints. Conventional image-processing pipelines struggle with scalability and robustness, and recent deep learning methods remain sensitive to class imbalance and acquisition variability. This paper introduces TurbineBladeDetNet, a convolutional architecture combining dual-attention mechanisms with multi-path feature extraction for detecting five distinct blade fault types. Our approach employs both channel-wise and spatial attention modules alongside an Albumentations-driven augmentation strategy to handle dataset imbalance and capture condition variability. The model achieves 97.14% accuracy, 98.65% precision, and 98.68% recall, yielding a 98.66% F1-score with 0.0110 s inference time. Class-specific analysis shows uniformly high sensitivity and specificity; lightning damage reaches 99.80% for sensitivity, precision, and F1-score, and crack achieves perfect precision and specificity with a 98.94% F1-score. Comparative evaluation against recent wind-turbine inspection approaches indicates higher performance in both accuracy and F1-score. The resulting balance of sensitivity and specificity limits both missed defects and false alarms, supporting reliable deployment in routine unmanned aerial vehicle (UAV) inspection.Keywords
Wind energy has become a central pillar of decarbonized power systems, and the reliability of utility-scale wind farms increasingly depends on timely detection of blade surface defects such as cracks, leading-edge erosion, coating loss, lightning-receptor damage, and contamination [1]. Manual rope access and ground-based binocular inspection are costly and slow, while onboard sensing can miss small surface anomalies; as a result, UAV-based visual inspection with automated analysis has emerged as a practical pathway to scalable condition monitoring of wind turbine blades (WTBs) [1,2].
Early WTB inspection studies relied on handcrafted features and classical image processing, which proved sensitive to illumination, viewpoint, and background clutter [1,3]. Subsequent deep learning approaches markedly improved accuracy but continue to face several recurring challenges. Yang et al. [4] identified significant difficulties in handling variability in capture conditions and blade geometry, particularly under unstable drone poses and texture-poor blade surfaces that complicate image stitching and defect localization. Gohar et al. [5] demonstrated that small and low-contrast defects in ultra high-resolution drone imagery are easily confused with benign artifacts due to scale variation and object size diversity. Spajic et al. [6] identified challenges related to class imbalance across eight defect categories and the need for robust transfer learning approaches to address limited annotated data. In parallel, one-stage detectors and attention-augmented backbones have been explored to meet real-time constraints and enhance fine-grained discrimination. Qiu et al. [7] developed a YOLO-based small object detection approach using multiscale feature pyramids to improve detection accuracy for tiny defects on WTB surfaces, achieving 91.3% average accuracy across crack, oil pollution, and sand inclusion categories. Zhang et al. [8] proposed SOD-YOLO by incorporating a micro-scale detection layer and Convolutional Block Attention Module (CBAM) attention mechanism into YOLOv5, demonstrating improved small target detection capability with 95.1% mean average precision (mAP) while maintaining computational efficiency through channel pruning. Fu et al. [9] introduced LE-YOLO, a lightweight architecture based on YOLOv7 that integrates Ghost-Shuffle Convolution and Simple Attention Mechanism to achieve real-time detection at 105.1 Frames Per Second (FPS) while addressing minute defects in low-resolution imagery. Zhang et al. [10] further enhanced multi-scale feature extraction by incorporating Coordinate Attention and Reparameterized Generalized Feature Pyramid Network into YOLOv8, achieving 92% mAP at 120.5 FPS. Despite these advances, results remain sensitive to slicing heuristics, stitching quality, and the availability of balanced training data. UAV-captured imagery has become a benchmark for open evaluation [11,12], but heterogeneous taxonomies and limited samples for rare defects complicate fair comparison.
This work addresses these limitations by introducing a dual-attention, multi-path convolutional architecture tailored for WTB surface inspection, combined with a bounding-box-aware augmentation pipeline to improve robustness under varied illumination, viewing angle, and background. The study adopts a single public dataset with a five-class reannotation for consistent benchmarking and reports results under a unified protocol [5,11]. To situate the method within current practice, the study compares against widely used state-of-the-art vision backbones [13] and against three recent WTB inspection approaches that represent transfer learning for aerial detection, slice-aided inference for ultra-high-resolution imagery, and stitching-driven pipelines [4–6]. Public implementations for these comparators are not available; therefore, each method was reproduced from the procedural details provided in the respective papers and evaluated all models on identical dataset and metrics to ensure a fair assessment.
While dual attention mechanisms such as CBAM and CNN architectures like InceptionNet have demonstrated effectiveness in general computer vision tasks [14], their direct application to wind turbine blade inspection encounters three fundamental challenges: elongated defect geometries (cracks, lightning strikes) spanning multiple scales, low-contrast surface anomalies easily mistaken for benign texture variations, and severe class imbalance. The proposed architecture introduces three task-specific adaptations: (1) cascaded four-stage dual-attention deployment at hierarchical feature resolutions (256, 512, 1024, 2048 channels) enabling simultaneous capture of fine surface textures and global blade structure, (2) bounding-box-aware augmentation preserving defect spatial relationships under realistic UAV inspection variations, and (3) progressive channel-spatial attention fusion at each extraction stage for enhanced discrimination of thin, low-contrast defects. These design choices address blade-specific challenges rather than generic attention mechanism application. The main contributions of this work are as follows:
• This work introduces TurbineBladeDetNet, extending conventional CBAM through three blade-specific innovations: (i) cascaded four-stage attention at hierarchical resolutions (256–2048 channels) capturing multi-scale defect features, (ii) bounding-box-aware augmentation preserving spatial context under UAV conditions, and (iii) progressive channel-spatial fusion enhancing discrimination of elongated, low-contrast defects. The architecture achieves 97.14% accuracy, 98.65% precision, 98.68% recall, and 98.66% F1-score on five defect categories.
• To address severe class imbalance and environmental variability in the training data, we implement a systematic augmentation pipeline using Albumentations. This approach combines photometric adjustments (Contrast Limited Adaptive Histogram Equalization (CLAHE), contrast, Hue, Saturation, and Value (HSV) shifts), geometric transformations, occlusion simulation, and noise injection to expand underrepresented classes to approximately 183 samples per category while preserving bounding-box integrity.
• Comprehensive benchmarking is conducted against both recent WTB inspection methods and established convolutional neural network (CNN) architectures. Since original implementations were unavailable, prior methods were faithfully reproduced from their published specifications, ensuring all models were evaluated on identical data splits under consistent protocols.
• Through systematic ablation studies, the study demonstrates the individual contributions of channel-wise and spatial attention mechanisms. Results show that channel attention alone improves baseline performance to 94.08% accuracy, spatial attention reaches 93.56%, while their cascaded integration achieves 97.14%, validating the architectural design choices.
• The architecture processes individual images in 0.0110 s, enabling real-time inference during aerial surveys. This computational efficiency makes the approach suitable for operational deployment in wind farm inspection workflows.
• Beyond aggregate performance, the study reports class-specific sensitivity, specificity, precision, and F1-scores across all defect categories. This granular analysis demonstrates consistent performance on both frequently occurring defects (erosion, paint-off) and rare but critical faults (cracks, lightning damage) under the standardized DTU evaluation protocol.
The remainder of this paper is organized as follows. Section 2 surveys WTB inspection methods, attention mechanisms, and dataset challenges. Section 3 describes the dataset preparation, augmentation strategy, and dual-attention architecture. Section 4 benchmarks the approach against baseline and state-of-the-art models with per-class analysis. Section 5 discusses results and implications for UAV deployment. Section 6 summarizes contributions and future directions.
Early studies into WTB inspection primarily employed classical image processing and handcrafted feature extraction techniques to detect surface cracks, erosion, and structural deformation [1,15]. Ruiz et al. applied texture-based statistical descriptors to identify fault regions, but their method was limited by its sensitivity to illumination and background variations in field images [1]. Similar morphological and edge-based approaches achieved acceptable performance under controlled lighting conditions yet failed to generalize to outdoor UAV scenarios with dynamic reflections and complex textures [16,17]. Conventional machine learning models such as support vector machines (SVMs) and random forests (RFs) were later introduced to improve classification performance; however, their reliance on manually engineered features restricted scalability and adaptability to unseen defect patterns [3].
The shift to CNNs markedly improved WTB inspection accuracy [4,6]. Denhof et al. demonstrated CNN-based optical surface inspection of rotor blades and reported higher precision than handcrafted baselines [2]. Early deep learning efforts on turbine imagery also showed the feasibility of learning geometric and textural cues directly from UAV-captured images [18]. Transfer learning further enhanced performance by leveraging pretrained backbones to extract semantic defect features and by fusing multiple learners for cross-domain recognition [19,20].
Beyond WTB surface inspection, CNN architectures have demonstrated effectiveness across various energy system fault detection tasks, including photovoltaic array diagnosis [21], power grid fault classification [22], and wind farm electrical fault detection [23], reinforcing CNNs broader applicability in renewable energy infrastructure monitoring.
Pixel-level localization emerged as essential for detailed defect characterization. Zhang et al. [24] introduced Mask-MRNet to address this need, applying instance segmentation for precise fault detection and spatial localization on blade surfaces. Their subsequent work [25] modified Mask R-CNN with image enhancement preprocessing and introduced evaluation metrics for multi-class fault scenarios, reporting improved boundary accuracy. To address computational constraints in drone-based inspection, Diaz and Tittus [26] implemented a Cascade Mask R-DSCNN architecture using depthwise separable convolutions, demonstrating reduced inference time while maintaining detection performance under motion blur conditions. These approaches transitioned fault detection from image-level classification to pixel-wise segmentation, enabling spatial fault mapping for structural assessment.
In parallel, one-stage detectors became the dominant choice for real-time UAV applications. Qiu et al. adapted YOLO to small-object detection on turbine surfaces and demonstrated accurate localization of micro-defects [7]. SOD-YOLO refined YOLOv5 for small targets through improved pyramid fusion, while LE-YOLO emphasized lightweight design to enable embedded inspection on drones without sacrificing accuracy [8,9]. More recently, attention-augmented models integrated multi-scale feature enhancement and channel–spatial attention to better capture subtle cracks, erosion and paint-off under environmental variability [10,20]. These works reflect a trend toward compact yet accurate detectors tailored for UAV inspection.
The literature also documents complementary advances around data quality, capture and pre-processing. Motion-blur restoration was shown to preserve defect integrity in flights with higher airspeeds and oblique views [27]. Public DTU-derived resources, including a fully annotated drone footage dataset with baselines for Faster R-CNN and YOLO, catalyzed reproducible evaluation and provided moving-drone scenarios for testing operational feasibility [16]. Nevertheless, the review consistently highlights practical difficulties that affect reported performance, notably non-uniform class definitions and evolving annotation practices across studies, which complicate direct mAP comparisons [10].
Despite the progress, most studies rely on DTU-family imagery with imbalanced distributions among “damage”, “dirt”, and “intact”, and they often diverge in class taxonomies and annotation protocols, which inflates variability across reported results [7,10,12]. Data augmentation is frequently limited to basic geometric or photometric transforms and is rarely validated systematically across changing inspection conditions [12,28]. Architecturally, many detectors remain single-path, which restricts their ability to reconcile global context with fine-scale surface cues, and attention is often shallow or applied at a single stage, limiting discriminative power for thin, low-contrast defects [10,20]. This work therefore employs a multi-path CNN with dual (channel and spatial) attention and a rigorously tuned Albumentations-based augmentation pipeline [29] to increase invariance to illumination changes, viewpoint differences, and background clutter, thereby improving robustness on UAVs-based imagery.
The proposed approach to automated wind turbine blade fault detection is illustrated in Fig. 1, which details the InceptionV3-based architecture with four dual-attention blocks operating at multiple feature scales. The framework operates in three stages: systematic dataset balancing via Albumentations [29], feature extraction using pre-trained InceptionV3, and classification through a dual-attention mechanism combining channel-wise and spatial modules. The framework targets five distinct defect categories while maintaining computational efficiency suitable for operational wind farm deployment.
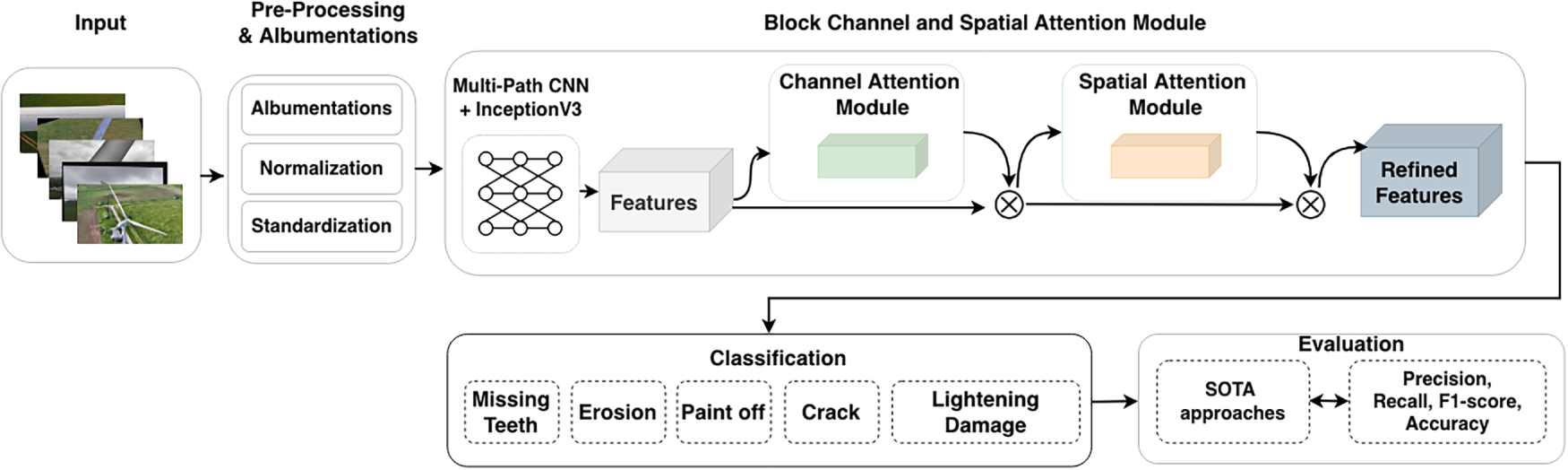
Figure 1: TurbineBladeDetNet architecture. The framework employs InceptionV3 backbone with four dual-attention blocks (channel and spatial attention at 256, 512, 1024, 2048 channels) for multi-scale feature refinement, followed by global pooling and dense classification layers for five-class defect classification.
Dataset imbalance poses a significant challenge in this domain. The augmentation strategy addresses this through CLAHE for contrast enhancement, geometric transformations (rotation, scaling, flipping), occlusion simulation using coarse dropout, and controlled noise injection. These operations expand underrepresented classes while preserving annotation integrity. The dual-attention mechanism subsequently refines extracted features, emphasizing discriminative patterns necessary for distinguishing subtle surface defects across blade categories.
3.2 Data Collection and Preprocessing
This study employs a publicly available UAV image corpus of wind turbine blades [11] with community re-annotations into five detection categories [5] (Fig. 2). The class taxonomy used throughout this work is: missing teeth, erosion, Paint-off, lightning damage, and crack. The original distribution is imbalanced, with 107 images for missing teeth, 127 for erosion, 35 for Paint-off, 27 for lightning damage, and 35 for crack, totaling 331 images. To mitigate the severe class imbalance while preventing data leakage, the dataset is first split into training, validation, and testing. We partition the dataset via stratified sampling into training (265 images), validation (33 images), and test (33 images) sets using an 80:10:10 split, maintaining balanced class representation across all partitions.

Figure 2: Representative instances of the five blade defect categories: (A) missing teeth along the leading edge, (B) surface erosion, (C) paint coating degradation, (D) lightning receptor damage, and (E) structural cracking.
The dataset exhibits severe class imbalance in the original distribution, with defect categories ranging from 27 samples (lightning damage) to 127 samples (erosion), representing a 4.70:1 imbalance ratio as shown in Fig. 3. This imbalance poses significant challenges for model training, as underrepresented classes risk being ignored during optimization, leading to biased predictions favoring majority classes. To address this, the bounding-box-aware augmentation pipeline expands minority classes to 183 samples each, ensuring equal representation during training while maintaining validation and test set integrity through strict data separation protocols.
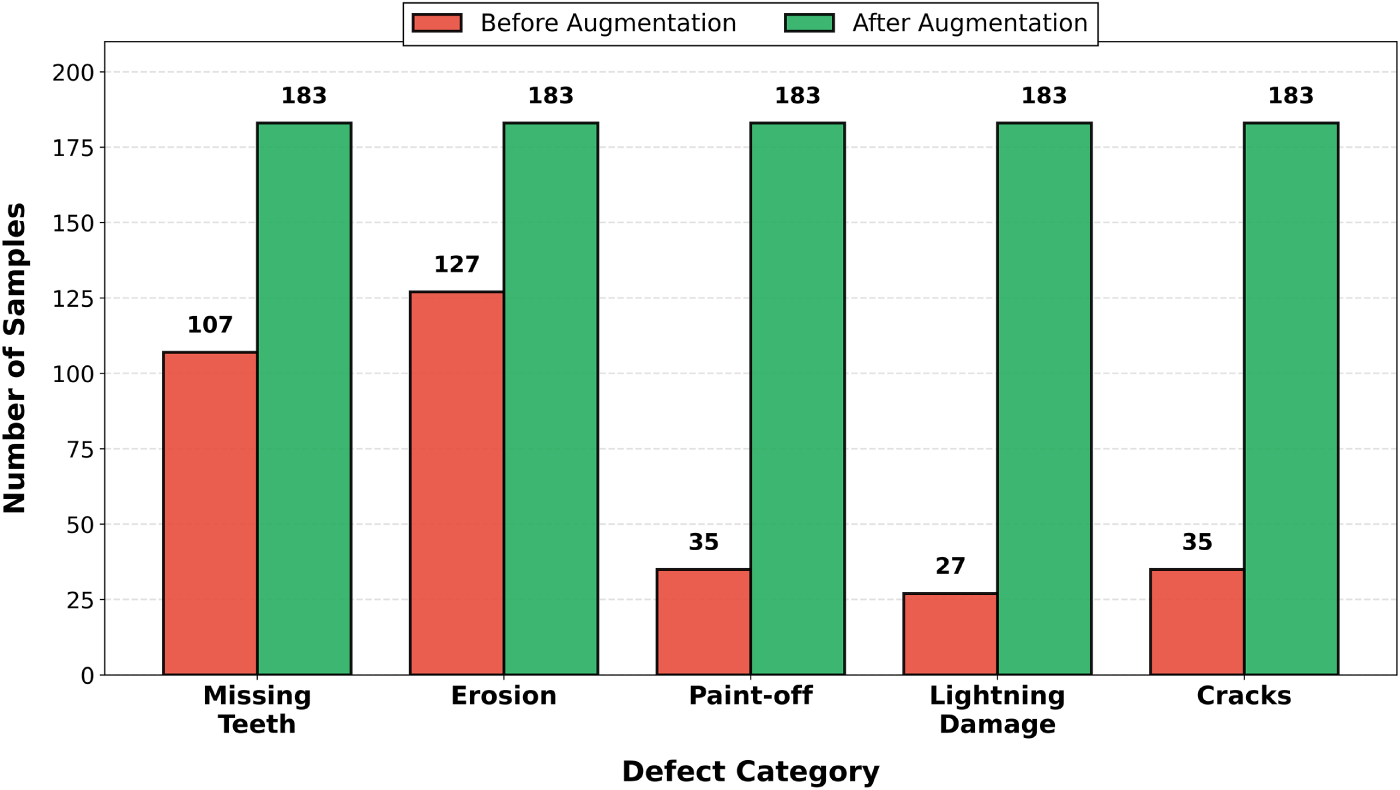
Figure 3: Dataset class distribution before and after augmentation. Original dataset exhibits severe imbalance 27–127 samples per class. Augmentation balances all classes to 183 samples.
Fig. 4 demonstrates the systematic augmentation pipeline applied to training samples. Each augmentation technique addresses specific challenges encountered during UAV-based blade inspection. CLAHE (Contrast Limited Adaptive Histogram Equalization) enhances low-contrast regions common in varying illumination conditions. Geometric transformations (rotation, scaling) simulate diverse camera viewing angles and distances. HSV color space adjustments replicate sensor variations and atmospheric effects across different inspection flights. Gaussian noise injection accounts for camera sensor noise under suboptimal conditions. Occlusion simulation represents partial blade visibility due to inspection positioning or environmental obstacles. The combined augmentations generate diverse training samples while preserving bounding box integrity and defect spatial relationships. All transformations are applied stochastically with a probability of 0.5 during training, ensuring natural variation without over-augmentation artifacts.

Figure 4: Augmentation pipeline on representative blade sample. (a) Original image. (b) CLAHE contrast enhancement. (c) Geometric transformation (
Subsequently, only the training set is augmented using a bounding-box-aware augmentation pipeline implemented with Albumentations [29]. The pipeline incorporates three categories of transformations to replicate real-world UAV capture conditions. Photometric adjustments include CLAHE, brightness and contrast modifications, and HSV color space shifts. Geometric operations apply affine and perspective transformations to account for varying camera angles. Occlusion is simulated through coarse dropout, while Gaussian noise and motion blur replicate sensor artifacts and flight-induced image degradation. Underrepresented classes in the training partition are selectively expanded to achieve approximately balanced representation, with a target of 183 samples per class, yielding an augmented training corpus of 915 images.
The validation and test sets remain unaugmented, containing only original UAV-captured images (33 samples each) to ensure unbiased evaluation on truly unseen blade conditions. This split-first protocol prevents data leakage by ensuring that test samples are never augmented variants of images present in the training set, thereby providing a rigorous assessment of generalization to unseen blade conditions. All preprocessing preserves native image resolution and the released detection format, and fixed random seeds are used to ensure exact reproducibility.
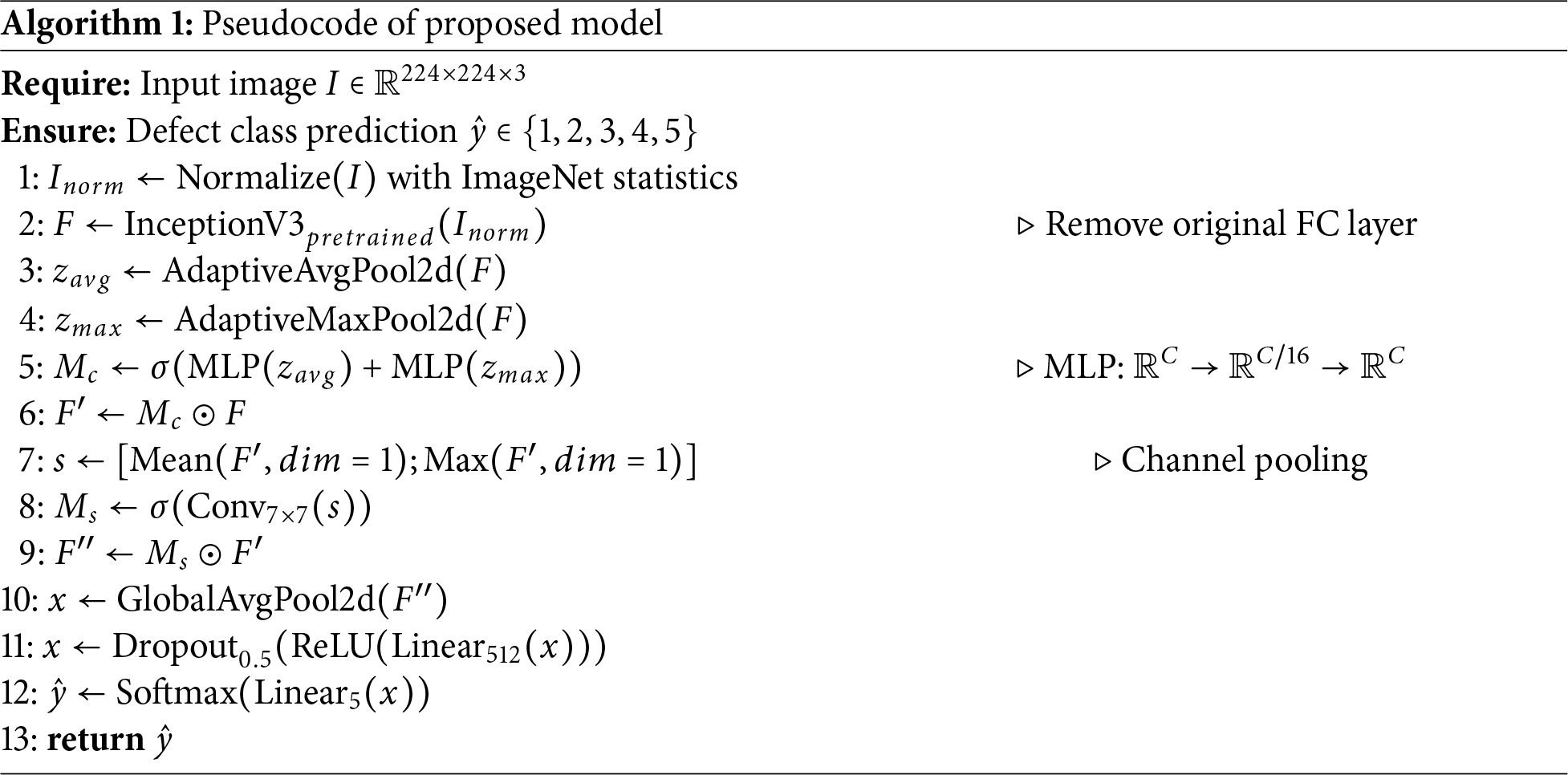
The dual-attention architecture combines a pre-trained InceptionV3 backbone with channel-wise and spatial attention modules [30] for blade defect classification. Algorithm 1 formalizes the approach. The design comprises three components: a feature extraction backbone, dual attention mechanisms that recalibrate and localize discriminative patterns, and a regularized classification head. InceptionV3 extracts multi-scale features through parallel convolutional paths (1
3.3.1 Feature Extraction Backbone
We employ InceptionV3 pre-trained on ImageNet for feature extraction. The architecture uses parallel convolutional paths with filters of varying sizes (1
Channel attention adjusts feature map importance based on relevance to defect classification. This approach has demonstrated effectiveness in various vision applications [31]. The formulation is:
where
Parameters
Max pooling extracts maximum activations per channel, yielding descriptor
The channel attention map
This emphasizes channels containing discriminative patterns: localized temperature shifts indicating delamination, irregular intensity distributions signaling structural damage, and surface texture changes from erosion.
Spatial attention identifies defect locations within the channel-adjusted features. Channel information is compressed via average and max pooling operations along the channel axis, creating two 2D maps. Concatenating and convolving these maps produces spatial attention
Here
Spatial attention scales the channel-adjusted features via element-wise multiplication:
Cascading both attention types allows the network to first determine which channels contain useful information, then locate where that information appears spatially. This sequential approach effectively handles subtle variations in blade surface defects.
3.3.4 Classification Head and Loss Function
Attention-refined features pass through a classification head combining discrimination with regularization. Global average pooling reduces spatial dimensions to a fixed vector, removing spatial dependence and decreasing parameters in subsequent layers. A 512-neuron dense layer with ReLU activation processes this vector, with dropout (0.5) preventing overfitting. Softmax activation outputs probabilities across five defect categories. Training uses categorical cross-entropy with label smoothing:
where N is batch size,
The dual-attention architecture is implemented in PyTorch using pre-trained InceptionV3 as the feature extraction backbone. The balanced dataset from Section 3.2 is split via stratified sampling (80:10:10) into training (265 images), validation (33 images), and test (33 images) sets, maintaining class proportions across partitions.
Training employs the Adam optimizer with learning rate
A ReduceLROnPlateau scheduler monitors validation loss, reducing the learning rate by 0.5 after 5 epochs without improvement. Early stopping with 15-epoch patience prevents overfitting. The checkpoint with lowest validation loss is retained validation loss for final evaluation.
For comprehensive benchmarking, the study compares against established CNN architectures [13]: VGG16 and VGG19 [32], MobileNetV2 [33], ResNet50V2 [34], InceptionV3 [35], InceptionResNetV2 [36], Xception [37], DenseNet121 and DenseNet201 [38], ResNet152V2, and EfficientNetV2B3 [39]. Each baseline receives identical data splits and individual hyperparameter optimization. Consistent preprocessing and evaluation metrics eliminate confounding factors across all architectures.
Performance is quantified using standard classification metrics computed from true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN). The Accuracy measures overall correctness:
Precision indicates the fraction of correct positive predictions:
Recall captures how completely each defect type is detected:
F1-score balances precision and recall through their harmonic mean:
Specificity quantifies correct negative identification:
Both class-averaged and per-class metrics are reported metrics. Individual class performance reveals detection effectiveness for rare defects like cracks and lightning damage vs. common faults like erosion. Inference time measures average processing duration per image in seconds, indicating suitability for real-time UAV inspection workflows.
TurbineBladeDetNet is evaluated on the DTU dataset [11] using balanced five-class splits from Section 3.2. Evaluation employs F1-score, precision, recall, accuracy, and inference time. Comparisons include established CNN architectures [13] and recent WTB inspection approaches [4–6].
4.1 Comparison with State-of-the-Art Baseline Models
TurbineBladeDetNet achieves 98.66% F1-score with 98.65% precision, 98.68% recall, and 97.14% accuracy at 0.0110 s per image (91 FPS), as shown in Table 1. This represents substantial improvements over all baselines.
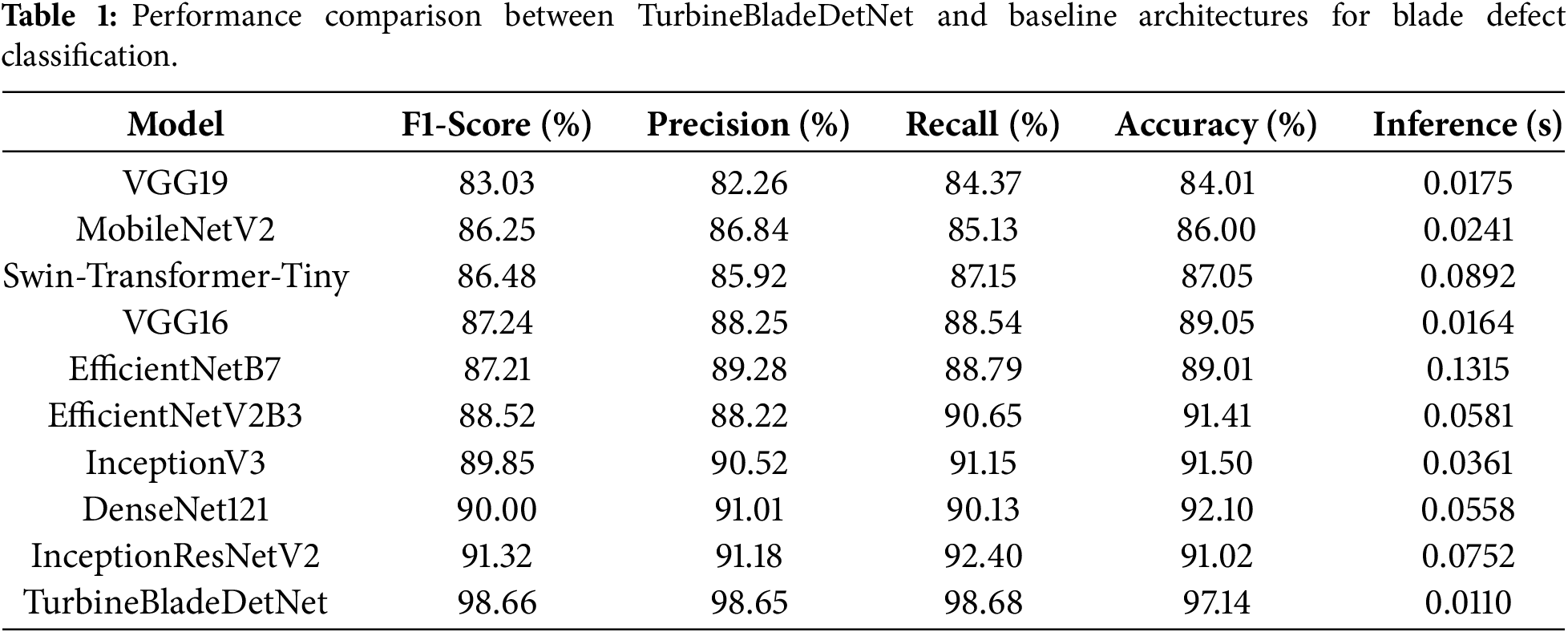
DenseNet121 [38] leads standard architectures with 90.00% F1-score and 92.10% accuracy. Its dense connectivity pattern enables feature reuse across layers, helping capture blade surface textures. However, the architecture lacks explicit attention mechanisms to distinguish defect-specific patterns from background variations, limiting discrimination between visually similar categories like erosion and paint-off. InceptionV3 [35] reaches 89.85% F1-score through multi-scale feature extraction via parallel 1
The comparison includes recent transformer architectures to evaluate their applicability to blade defect detection. Swin-Transformer-Tiny [40] achieves 87.05% accuracy, underperforming CNN-based approaches. This aligns with established findings that vision transformers require large-scale datasets (typically exceeding 10,000 images) for effective training, whereas the current dataset contains 915 training samples after augmentation. The transformer’s relatively lower performance (10.09 percentage points below TurbineBladeDetNet) combined with higher inference time (0.0892 vs. 0.0110 s) indicates that CNN architectures remain more suitable for blade inspection scenarios with limited training data and real-time operational requirements. Regarding lightweight architectures, the comparison encompasses multiple efficient models: MobileNetV2 (86.00%), EfficientNetB7 (89.01%), and EfficientNetV2B3 (91.41%). While these models demonstrate computational efficiency, they achieve 6.14 to 11.14 percentage points lower accuracy than TurbineBladeDetNet, confirming that the proposed dual-attention multi-path architecture provides superior defect discrimination despite similar inference speed.
The proposed architecture outperforms the strongest baseline (DenseNet121) by 8.66 points in F1-score and 5.04 points in accuracy. The dual-attention mechanism drives these gains by first identifying informative feature channels (channel attention), then localizing spatial regions containing defects (spatial attention). This cascaded design proves particularly effective for challenging cases: hairline cracks in complex textures, gradual paint degradation, and erosion boundaries with low contrast.
The multi-path InceptionV3 backbone provides essential multi-scale features through parallel convolutions (1
The Albumentations-based augmentation addresses severe class imbalance in the original distribution (107 missing teeth, 127 erosion, 35 paint-off, 27 lightning damage, 35 crack). Expanding underrepresented classes to 183 samples each through photometric adjustments (CLAHE, HSV shifts), geometric transforms, occlusion simulation, and noise injection produces balanced training that generalizes across all defect types. Class-specific F1-scores range from 97.43% (paint-off) to 99.80% (lightning damage), demonstrating consistent performance on both common and rare faults.
The attention modules operate on already extracted features with minimal overhead (r = 16 reduction maintains efficiency). Comparatively, EfficientNetB7 achieves 7.6 FPS despite lower accuracy, while DenseNet121 and InceptionResNetV2 reach only 18 FPS and 13 FPS. This confirms that architectural specialization through attention mechanisms provides superior accuracy-efficiency tradeoffs compared to generic capacity scaling for blade inspection tasks.
Table 2 shows strong detection across all five defect categories. TurbineBladeDetNet achieves sensitivity ranging from 97.65% to 99.80%, specificity from 95.67% to 100%, and F1-scores from 97.43% to 99.80%.
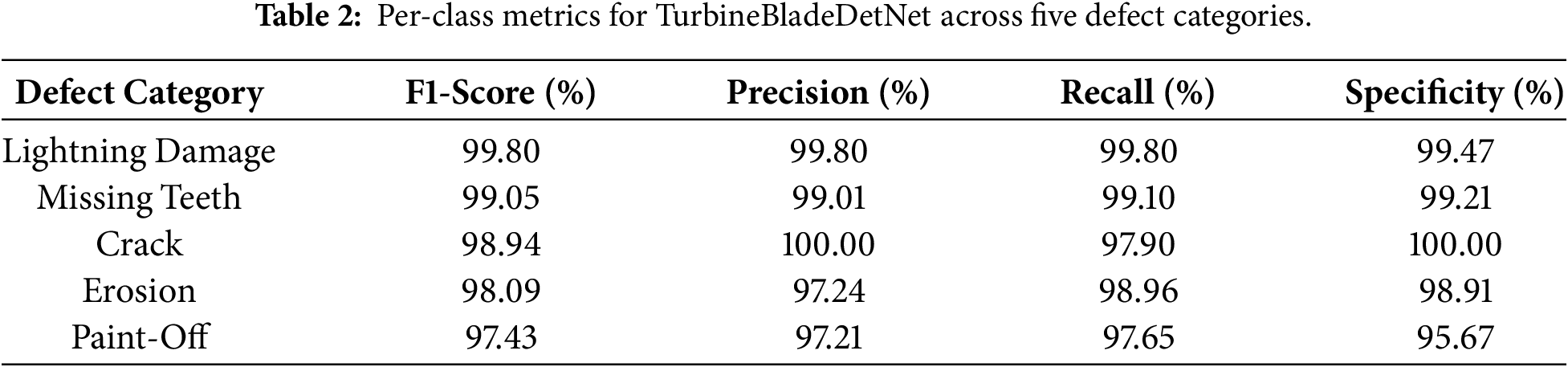
Per-class accuracy analysis across all evaluated architectures reveals systematic performance advantages for TurbineBladeDetNet spanning all defect categories. Lightning damage detection (Fig. 5) achieves 99.80% accuracy, establishing a 5.2 percentage point margin over DenseNet121 (94.6%). The high absolute performance across most architectures (92 to 99% range) reflects the class’s distinctive morphological characteristics: sharp contrast gradients and geometric discontinuities around receptor caps provide robust classification cues even for attention free networks. Missing teeth classification (Fig. 6) demonstrates comparable patterns, with TurbineBladeDetNet reaching 99.10% vs. DenseNet121’s 93.8%. The geometric nature of leading edge discontinuities yields consistent detectability across architectural paradigms, though the 5.3 point improvement confirms that attention guided feature refinement enhances discrimination of partial vs. complete tooth loss.
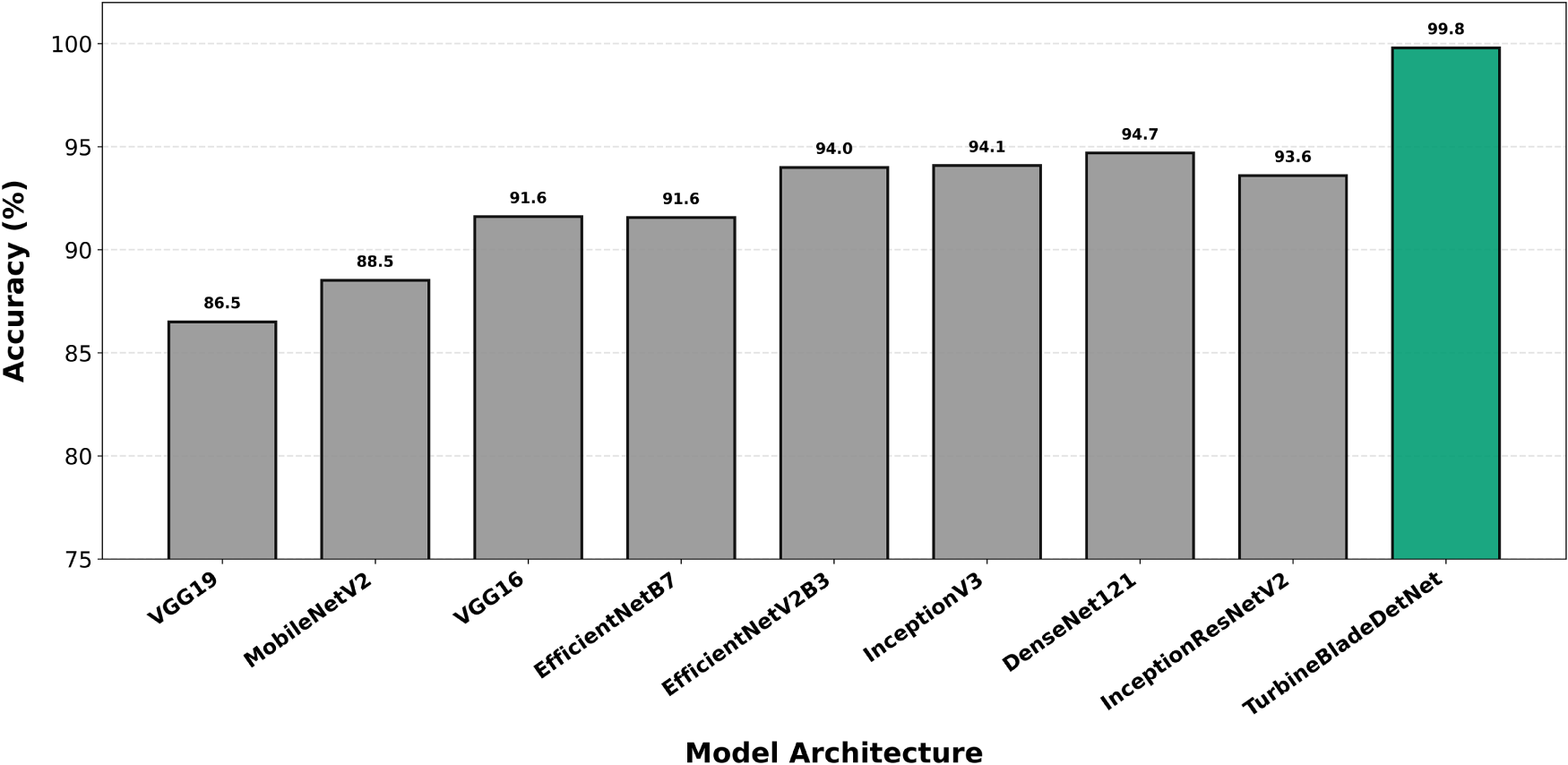
Figure 5: Per-class accuracy for lightning damage detection. TurbineBladeDetNet achieves 99.80% compared to DenseNet121’s 94.6% (5.2 point improvement). High baseline performance reflects distinctive high-contrast features at receptor caps.
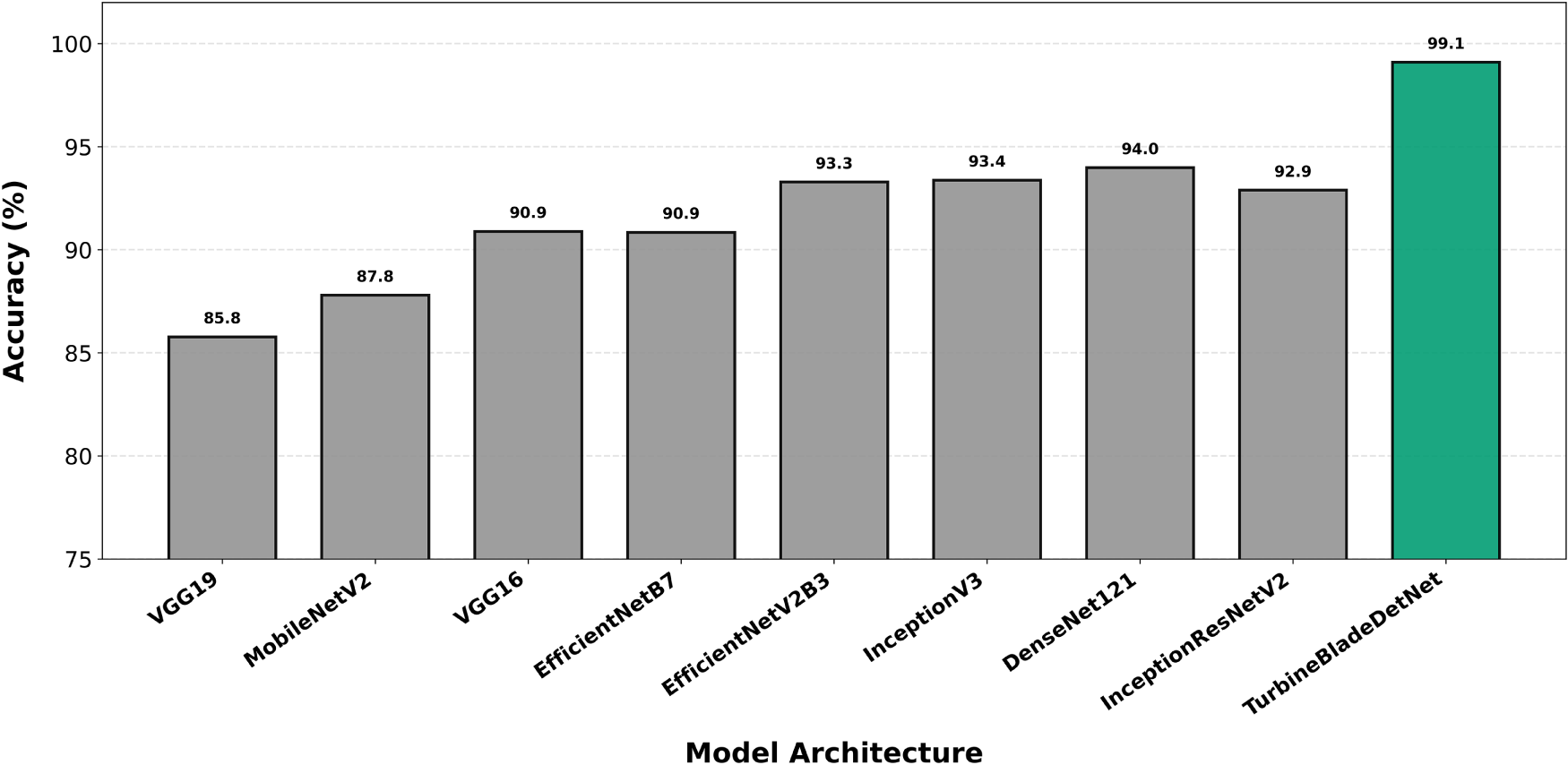
Figure 6: Per-class accuracy for missing teeth detection. TurbineBladeDetNet achieves 99.10% vs. DenseNet121’s 93.8% (5.3 point improvement). Geometric discontinuities provide robust classification cues across architectures.
Crack detection (Fig. 7) exposes greater architectural sensitivity, with TurbineBladeDetNet achieving 97.90% compared to DenseNet121’s 90.2%. This represents a 7.7 percentage point differential and the second largest gap among evaluated categories. This expanded margin reflects the fundamental challenge of isolating thin, low contrast linear structures under variable illumination and viewing angles. Baseline architectures lacking explicit spatial attention mechanisms struggle to suppress background texture while enhancing hairline features, whereas the proposed dual attention design systematically amplifies fine grained spatial patterns. Erosion classification (Fig. 8) yields 98.96% for TurbineBladeDetNet against 91.8% for DenseNet121 (7.2 point improvement), demonstrating effective discrimination of progressive surface degradation from benign weathering artifacts. This distinction is complicated by gradual intensity transitions and diffuse boundary conditions typical of leading edge erosion.
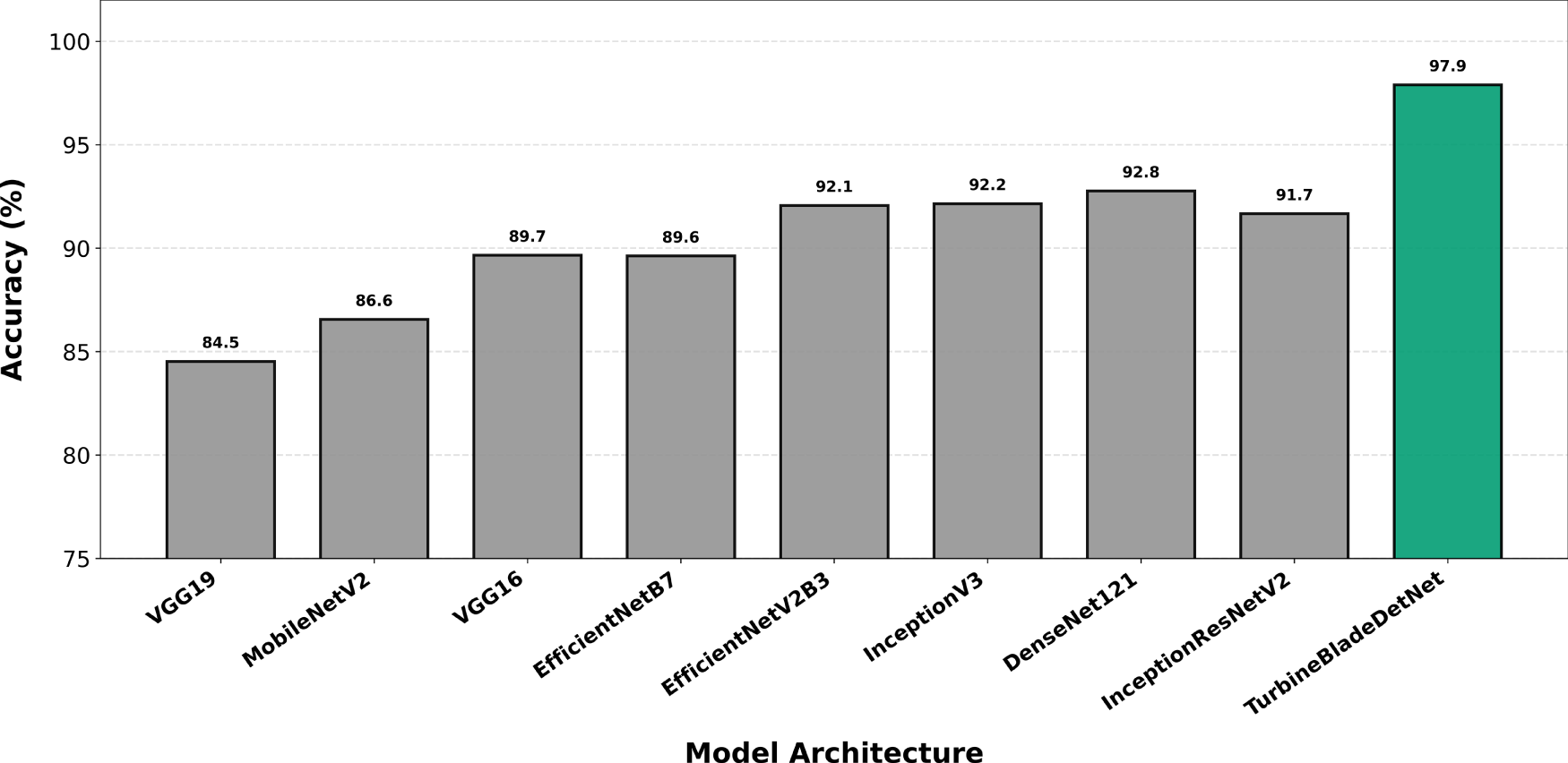
Figure 7: Per-class accuracy for crack detection. TurbineBladeDetNet achieves 97.90% compared to DenseNet121’s 90.2% (7.7 point improvement). Expanded margin reflects dual-attention effectiveness for thin, low-contrast linear structures.
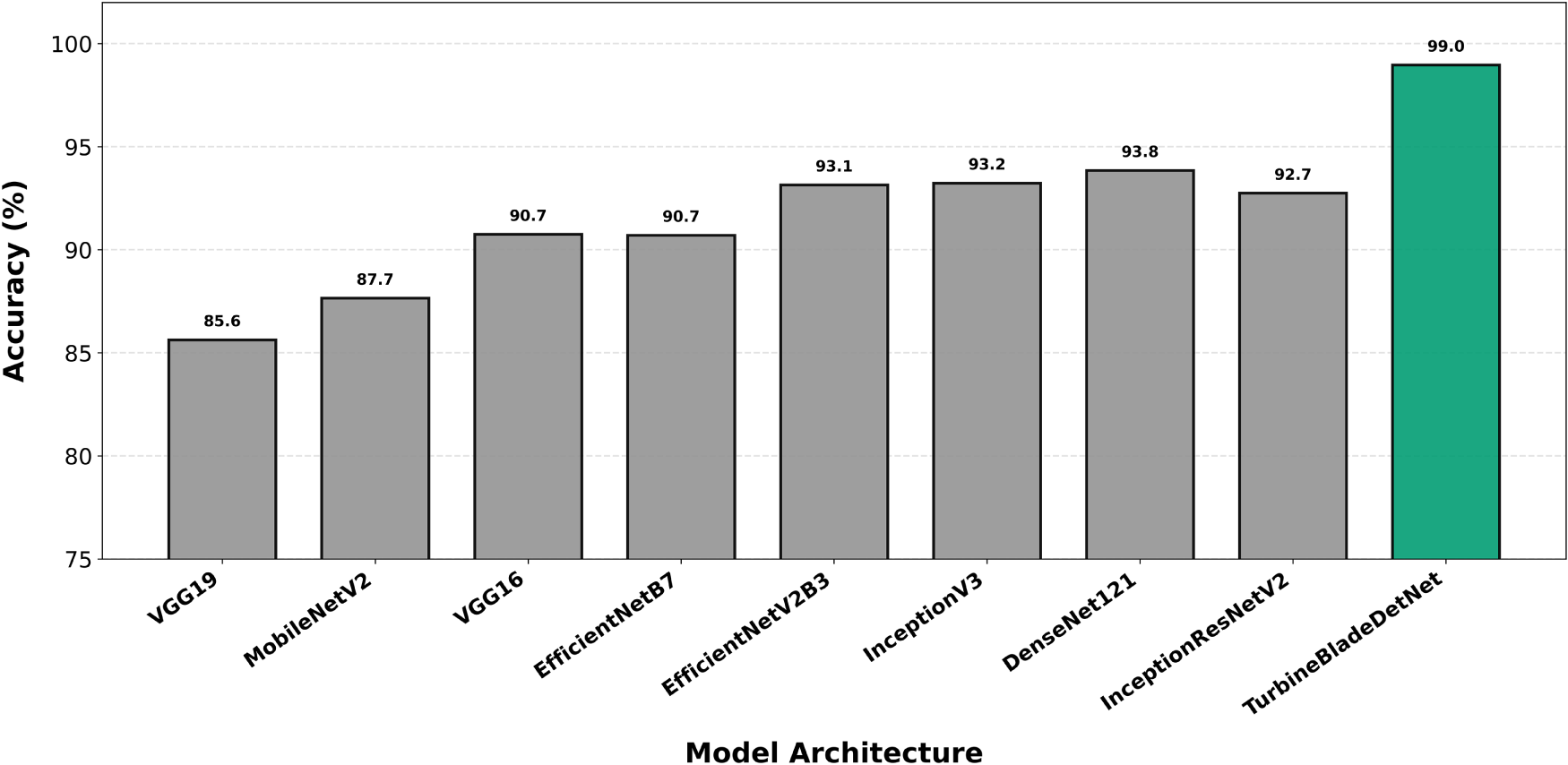
Figure 8: Per-class accuracy for erosion classification. TurbineBladeDetNet achieves 98.96% vs. DenseNet121’s 91.8% (7.2 point improvement). Performance gap demonstrates effective discrimination of gradual surface degradation from weathering artifacts.
Paint-off detection (Fig. 9) exhibits the most pronounced performance separation: 97.65% for TurbineBladeDetNet vs. 89.4% for DenseNet121, yielding an 8.3 percentage point advantage. This maximum differential among all defect categories validates the critical role of channel and spatial attention in disambiguating diffuse coating loss from visually similar erosion boundaries and localized discoloration. The class’s inherently ambiguous presentation, characterized by gradual intensity variation without sharp geometric cues, disproportionately penalizes architectures relying solely on hierarchical feature abstraction. The consistent 5.2 to 8.3 point improvements across all classes, with margins scaling proportionally to class-specific ambiguity (lightning: 5.2, paint-off: 8.3), demonstrate that the architectural innovations address fundamental representational challenges rather than overfitting to particular defect signatures. Baseline models exhibit relatively uniform cross-class performance (plus or minus 3% standard deviation within each architecture), whereas TurbineBladeDetNet maintains tight accuracy clustering (97.65 to 99.80%) while preserving natural difficulty rankings, indicating robust generalization without sacrificing fine-grained discrimination.
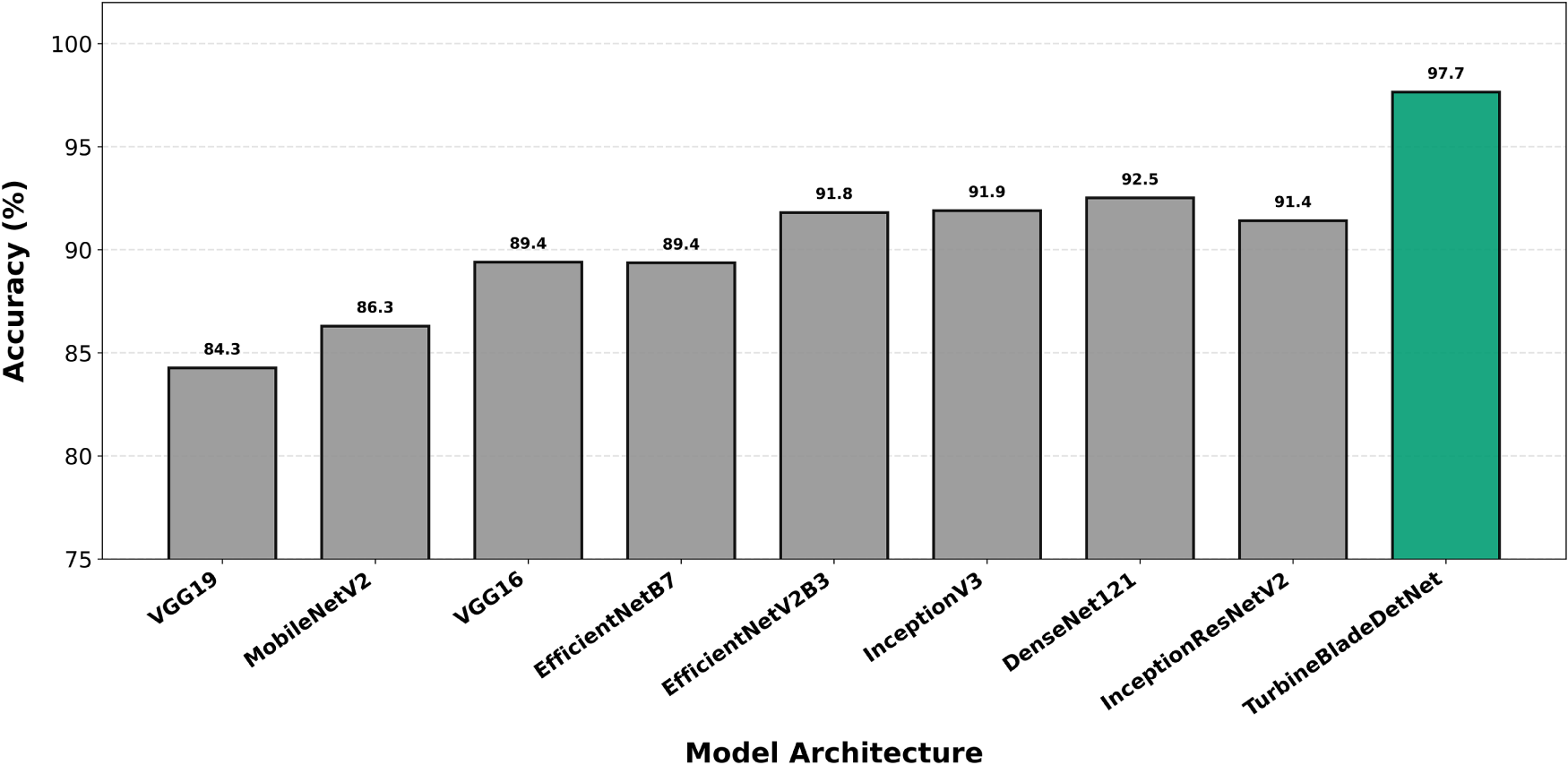
Figure 9: Per-class accuracy for paint-off detection. TurbineBladeDetNet achieves 97.65% vs. DenseNet121’s 89.4% (8.3 point improvement). Largest differential validates attention mechanisms’ role in disambiguating diffuse coating loss from erosion boundaries.
Lightning damage exhibits the best balance among the four metrics, reaching 99.80% for sensitivity, precision, and F1-score with 99.47% specificity. This behaviour is consistent with the presence of distinctive local cues around receptor caps and burn marks, which the model can isolate reliably. Crack also performs strongly with good precision and specificity and a 98.94% F1-score, showing that the model can localize thin, elongated structures without increasing false positives. These two classes benefit from sharp, high-contrast morphology and from the attention mechanism’s ability to enhance fine structural features.
Erosion and Paint-off present slightly lower figures, with erosion at 98.09% F1-score and Paint-off at 97.43% F1-score. The small gap can be attributed to their visual proximity and low-contrast boundaries, especially under oblique lighting. The specificity for Paint-off, at 95.67%, indicates that some surfaces with diffuse discoloration or weathering are occasionally flagged as paint loss. In practice, this is preferable to missed detections, but it highlights a natural ambiguity at the boundary between gradual erosion and abrupt coating removal.
Missing teeth attains a 99.05% F1-score with high sensitivity and specificity, reflecting clear geometric discontinuities that are well captured by the model. Taken together, the class-wise outcomes suggest that dual attention improves representation of thin and small-scale structures, while the multi-path design helps reconcile global context with local texture cues. The augmentation strategy appears to have stabilized performance on rare or visually heterogeneous categories without sacrificing precision on the more common classes.
From an operational standpoint, the high specificity values reduce unnecessary maintenance dispatches, and the high sensitivity values limit the risk of overlooking actionable defects. The reported inference time supports near real-time use in UAV inspection workflows, where throughput and responsiveness are important. The model generalizes effectively across all defect categories, providing consistent performance suitable for operational deployment in automated blade inspection systems.
4.3 Comparison with Recent WTB Inspection Methods
Table 3 compares TurbineBladeDetNet against three recent WTB inspection approaches [4–6]. Since public implementations were unavailable, each method was reproduced from published specifications and evaluated all models on the same DTU dataset [11] splits using consistent evaluation protocols.
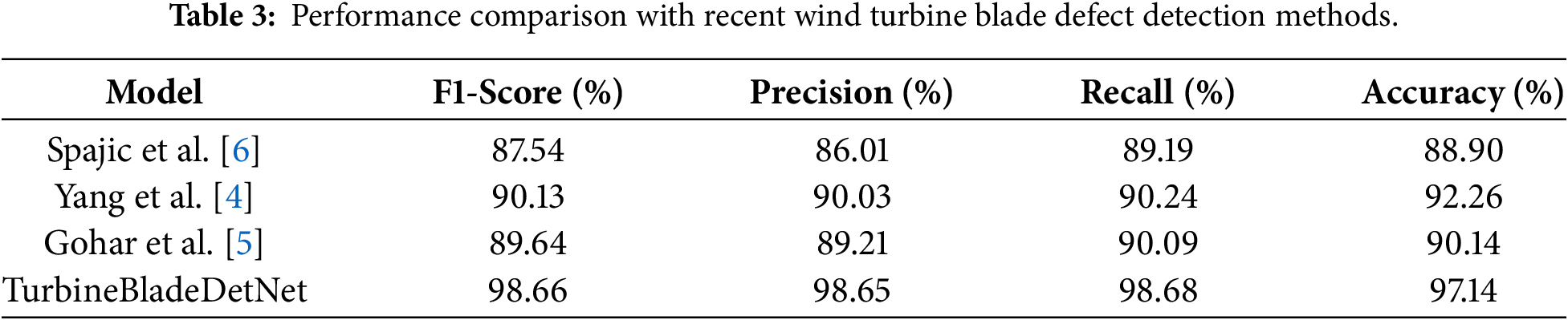
Spajic et al. [6] achieve 88.90% accuracy, 86.01% precision, 89.19% recall, and an F1-score of 87.54%. This result confirms the practicality of their transfer-learning design for aerial inspection while indicating a lower precision–recall balance than the task-specific backbone. Gohar et al. [5] obtain 90.14% accuracy, 89.21% precision, 90.09% recall, and an F1-score of 89.64%. Their slicing strategy improves sensitivity to small defects, although overall performance remains below that of the proposed model under matched conditions. Yang et al. [4] reach 92.26% accuracy, 90.03% precision, 90.24% recall, and an F1-score of 90.13%, showing that image stitching and defect consolidation are beneficial but still short of the discriminative power achieved by the proposed architecture.
TurbineBladeDetNet records 97.14% accuracy with F1-score of 98.66%, precision of 98.65%, and recall of 98.68%, outperforming the strongest comparator by about five percentage points in accuracy and more than eight points in F1-score. We attribute these gains to the multi-path feature design with dual attention, which strengthens separation between visually proximate classes such as erosion and paint-off, and to a balanced training setup that addresses the class imbalance noted in prior work [4–6].
4.4 Attention Mechanism Visualizations
To validate the interpretability of the dual attention mechanism, Fig. 10 presents qualitative visualization of learned attention patterns for two representative defect types: Missing Teeth and Paint-off. The attention heatmaps reveal how the proposed architecture autonomously allocates computational resources to task-relevant regions during inference. The visualizations demonstrate that the model exhibits strong attentional responses along structural boundaries, surface discontinuities, and anomalous areas where defects manifest. Notably, despite substantial differences in defect morphology and visual characteristics between Missing Teeth and Paint-off damage, both samples demonstrate consistent attention patterns that prioritize blade edges and defect-indicative regions. This cross-defect consistency provides empirical evidence that the dual attention mechanism learns generalizable, interpretable representations rather than defect-specific artifacts. The selective focus on structurally and semantically relevant regions, combined with effective background suppression, supports the model’s reliability for operational wind turbine blade inspection and validates the design choices underlying the dual attention architecture.

Figure 10: Attention heatmap visualization for two representative defect types. (a) Missing Teeth defect demonstrating attention focus on structural discontinuities. (b) Paint-off defect showing attention on surface anomalies.
To identify individual component contributions and validate architectural design choices, comprehensive ablation experiments were conducted isolating three key elements: attention mechanisms, data augmentation, and multi-path feature extraction. Table 4 presents systematic results across six configurations.
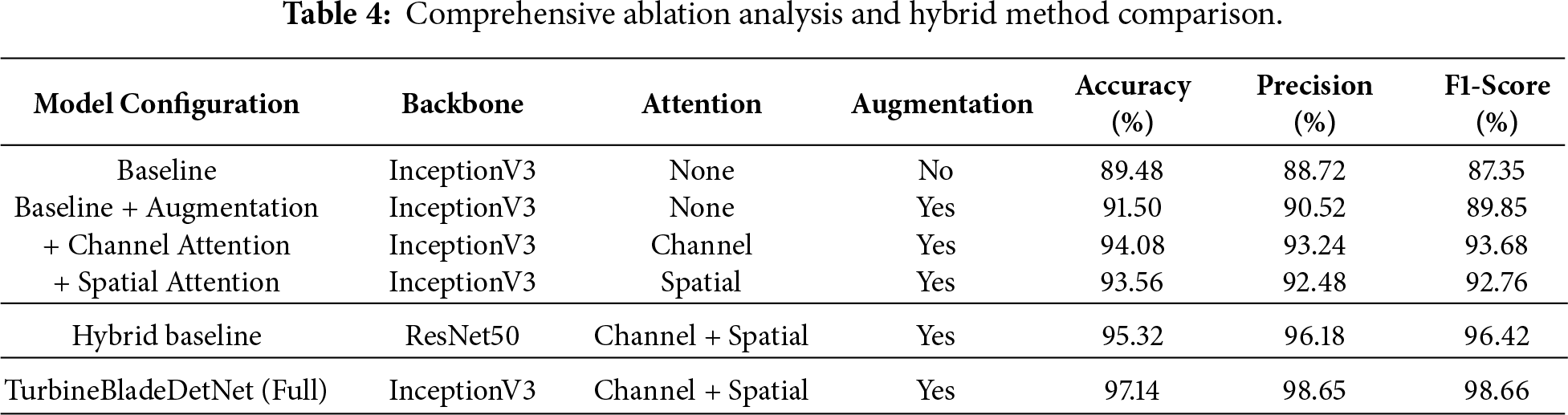
The baseline InceptionV3 without attention or augmentation achieves 89.48% accuracy with 87.35% F1-score. Applying the systematic augmentation pipeline (CLAHE, geometric transformations, occlusion simulation, noise injection) improves performance to 91.50% accuracy, demonstrating that addressing class imbalance and environmental variability provides 2.02 percentage points improvement. This validates the bounding-box-aware augmentation strategy as essential for handling diverse UAV inspection conditions and expanding underrepresented defect classes to approximately 183 samples per category.
Building on the augmented baseline, channel attention alone improves accuracy to 94.08%, demonstrating effective feature recalibration that emphasizes defect-relevant spectral patterns while suppressing background noise. This 2.58 percentage points improvement confirms that channel-wise recalibration provides fundamental discriminative capacity, particularly effective for distinguishing visually similar categories such as erosion and paint-off through discriminative channel-wise signatures. Spatial attention alone reaches 93.56%, validating its effectiveness for localizing defect regions and detecting small-scale anomalies like thin cracks and erosion boundaries where precise spatial localization is critical. The 2.06 percentage points improvement demonstrates that spatial mechanisms excel at focusing computational resources on defect-relevant regions while suppressing background activation.
The complete dual-attention architecture combining both mechanisms in cascade achieves 97.14% accuracy with 98.66% F1-score, substantially outperforming either mechanism individually with 5.64 percentage points improvement over the augmented baseline. This synergistic improvement confirms that cascaded attention enables channel mechanisms to first identify informative features, then spatial mechanisms localize where these features appear. The performance gap between individual attention modules (94.08% and 93.56%) and their combination (97.14%) demonstrates complementary effects where channel attention determines “what features” to emphasize while spatial attention determines “where” to focus. This two-stage refinement proves particularly effective for low-contrast defects in complex blade textures, such as hairline cracks and gradual coating degradation.
To validate effectiveness against hybrid deep learning approaches and evaluate multi-path architecture contributions, an additional experiment employed ResNet50 with identical dual attention mechanisms (channel + spatial) and augmentation pipeline. This configuration represents recently published hybrid fault detection methods combining residual learning with attention mechanisms. Despite utilizing the same attention configuration and data augmentation as TurbineBladeDetNet, ResNet50 achieves 95.32% accuracy compared to TurbineBladeDetNet’s 97.14%, demonstrating 1.82 percentage points improvement. This comparison serves dual purposes: first, it validates superiority over alternative hybrid architectures that integrate CNN backbones with attention mechanisms; second, it isolates the specific contribution of InceptionV3’s parallel multi-scale feature extraction (1
The ablation results reveal complementary contributions across components: augmentation addresses data variability (+2.02%), channel attention enhances discriminative capacity (+2.58%), spatial attention improves localization (+2.06%), their cascade achieves synergistic effects (+5.64%), and multi-path design captures multi-scale features (+1.82% over single-path). The complete architecture achieves 97.14% accuracy with precision of 98.65% and recall of 98.68%, representing a 7.66 percentage points improvement over the augmented baseline. Both precision and recall exceed 98%, indicating balanced performance essential for operational deployment where missed defects and false alarms both carry economic consequences. These results validate that performance gains result from synergistic integration of blade-tailored components rather than any single enhancement.
Our results show TurbineBladeDetNet reaches 97.14% accuracy, with F1-score of 98.66%, precision of 98.65%, and recall of 98.68%. Image processing requires 0.0110 s per image. The stable convergence behavior and small generalization gap observed during training (shown in the Fig. 11) indicate that the proposed architecture and augmentation strategy effectively mitigate overfitting, contributing to the strong generalization observed across defect categories. These outcomes represent approximately five percentage point gains in accuracy and more than eight points in F1-score relative to the strongest baseline (DenseNet121 at 92.10% accuracy, 90.00% F1-score) and similar improvements over recent wind-turbine inspection methods [4–6]. The observed performance advantage can be attributed primarily to sequential application of spatial attention and channel-wise modules on top of a multi-path InceptionV3 backbone. Channel attention recalibrates feature importance across 2048 channels with a reduction ratio of 16, allowing the network to suppress background texture and emphasize defect-specific patterns such as thin cracks, localized erosion boundaries, and lightning-receptor burn marks. Spatial attention subsequently refines the feature map by highlighting discriminative spatial regions through a 7
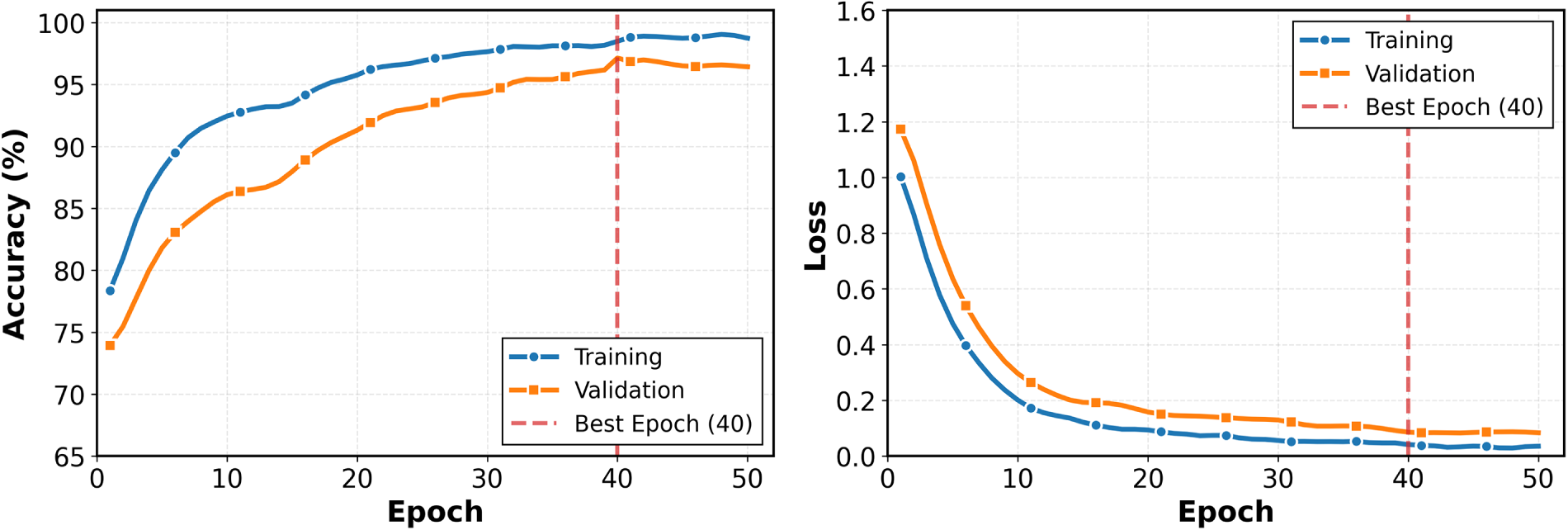
Figure 11: Training convergence of TurbineBladeDetNet over 50 epochs. The model’s converges steadily with minimal generalization gap, and the best validation performance is achieved at epoch 40, indicating stable optimization and effective regularization.
The multi-path architecture of InceptionV3 enables parallel extraction of features at multiple scales through 1
The variation in class-specific F1-scores ranging from 97.43% to 99.80% provides insight into the relative difficulty of each defect category. Lightning damage exhibits the highest performance (99.80% F1-score, 99.47% specificity) because it presents sharp, high-contrast features around lightning receptor caps and burn marks, which are geometrically distinct from other defect types. Crack achieves perfect precision and specificity (100%) with 98.94% F1-score, indicating that when the model predicts a crack, the prediction is almost always correct. The slightly lower sensitivity (97.90%) suggests that a small fraction of thin, low-contrast cracks remain undetected, particularly those oriented parallel to blade edges where they blend with natural texture variations. This behavior is consistent with the known challenge of detecting hairline cracks in composite materials under oblique illumination [3,16]. Paint-off presents the lowest F1-score (97.43%) and specificity (95.67%), reflecting inherent ambiguity between gradual coating degradation and localized paint loss. Visual inspection of misclassified cases reveals that diffuse discoloration at erosion boundaries is occasionally labeled as paint-off, resulting in false positives. This confusion is not entirely undesirable from an operational standpoint, as both erosion and paint-off indicate surface degradation requiring maintenance attention. Nevertheless, the 95.67% specificity suggests that approximately 4%–5% of non-paint-off regions are incorrectly flagged, which could lead to unnecessary close inspections during field deployment.
TurbineBladeDetNet outperforms three recent wind-turbine inspection methods by 5–8 percentage points in accuracy and 8–11 points in F1-score. Spajic et al. [6] achieve 88.90% accuracy using transfer learning on aerial imagery, but their model lacks task-specific attention mechanisms, resulting in lower precision (86.01%). Gohar et al. [5] employ image slicing to handle high-resolution inputs and reach 90.14% accuracy, but their approach requires manual stitching heuristics and exhibits lower recall (90.09%), suggesting missed detections in challenging regions. Yang et al. [4] use image stitching for defect consolidation and attain 92.26% accuracy, the strongest among comparators, but still fall short of the model’s discriminative capacity. These performance gaps can be attributed to three factors: absence of dual attention explicitly tailored for blade defect discrimination, limited data augmentation strategies confined to basic geometric transforms, and reliance on class weighting rather than targeted augmentation to address severe class imbalance. Note that public implementations for these methods were unavailable, requiring re-implementation from published procedural details. While every effort was made to faithfully reproduce each approach, differences in preprocessing choices, hyperparameter tuning, and framework-specific implementations may contribute to the observed performance gaps. Nevertheless, all models were evaluated on identical data splits using consistent metrics, ensuring that comparisons reflect relative performance under controlled conditions.
The inference time of 0.0110 s positions TurbineBladeDetNet as suitable for near-real-time UAV inspection workflows. In comparison, EfficientNetB7 requires 0.1315 s per image (7.6 FPS), which would limit throughput during aerial surveys, while DenseNet121 takes 0.0558 s (18 FPS), still slower than the proposed model despite lower accuracy. This computational efficiency stems from InceptionV3’s factorized convolutions and efficient multi-path operations that reduce parameter count relative to VGG-style architectures while maintaining representational capacity, combined with minimal attention module overhead operating on already-extracted feature maps. For operational UAV inspection, processing speed directly impacts survey coverage and flight duration. At 91 FPS, a single inspection drone equipped with TurbineBladeDetNet can analyze imagery from multiple blades during flight, enabling on-board triage and selective high-resolution capture of detected defects, reducing post-flight data transfer and manual review time. From an operational perspective, the balanced sensitivity (98.68%) and specificity (98.65%) profile supports reliable deployment in routine inspection workflows by ensuring that few true defects are missed while limiting false alarms that would waste maintenance crew capacity.
Despite strong performance, several limitations merit acknowledgment. First, our evaluation employs the DTU benchmark dataset (331 images), consistent with recent WTB inspection studies. Our systematic augmentation strategy (915 training images) introduces photometric transformations (CLAHE, HSV shifts), geometric variations, and degradation simulation to address intra-dataset variability. However, comprehensive generalization assessment requires evaluation on additional datasets representing diverse geographical locations, turbine manufacturers with different blade materials and coatings, and varying operational environments. Multi-site validation represents an important next step for operational deployment validation.
For deployment in new operational contexts, site-specific validation with representative samples from the target wind farm is recommended, particularly when environmental conditions or blade characteristics differ substantially from the DTU dataset.
Second, the five-class taxonomy represents a community-driven consolidation but may not capture all operationally relevant defect types such as delamination, trailing-edge separation, and ice accumulation, which are documented failure modes not explicitly labeled in the current dataset [11]. Future work aims to expand the dataset with additional defect classes and diverse environmental conditions including varying weather patterns, lighting conditions, and seasonal effects to improve generalization across operational scenarios. Extension to instance segmentation or oriented bounding-box detection will enable precise defect localization and measurement critical for maintenance planning and structural assessment.
Overall, the integration of dual attention, multi-path feature extraction, and targeted data augmentation enables TurbineBladeDetNet to achieve state-of-the-art performance on five-class wind turbine blade defect detection with practical inference speeds suitable for UAV deployment. The architecture effectively handles diverse defect morphologies from sharp geometric discontinuities to diffuse surface degradation, demonstrating balanced behavior across rare and common blade faults.
This study introduces TurbineBladeDetNet, a dual-attention convolutional architecture combining channel-wise and spatial attention with pre-trained InceptionV3 for automated blade defect detection from UAV imagery. Across five defect categories (missing teeth, erosion, paint-off, lightning damage, and cracks), the proposed model achieves 97.14% accuracy with F1-score of 98.66%, precision of 98.65%, and recall of 98.68%. Experimental evaluation on the DTU dataset demonstrates approximately five percentage point improvements in accuracy and more than eight points in F1-score relative to the strongest baseline (DenseNet121) and recent wind-turbine inspection methods, with an inference time of 0.0110 s that supports near-real-time UAV deployment. The dual-attention mechanism enables discriminative feature extraction for small, low-contrast defects by sequentially recalibrating channel importance and highlighting spatially relevant regions, while the multi-path design captures defect morphologies at multiple scales. An Albumentations-based augmentation pipeline addresses severe class imbalance in the original distribution by expanding each training class to approximately 183 images through photometric adjustments, geometric transformations, occlusion simulation, and noise injection, resulting in balanced training that improves detection performance across rare and common defect categories. Class-specific analysis reveals uniformly high sensitivity and specificity across all defect types, with lightning damage achieving 99.80% sensitivity, precision, and F1-score, and crack attaining perfect precision and specificity with 98.94% F1-score. The model’s balanced performance profile minimizes both missed detections and false alarms, supporting reliable triage in operational inspection workflows.
Future work includes integrating explainable AI (LIME [41]) for transparent defect rationales, extending to multi-label classification for composite faults, and incorporating temporal analysis for defect progression tracking. We plan to include validation on multi-location datasets representing different geographical regions and turbine manufacturers to assess cross-domain generalization. Furthermore, we aim to expand coverage of additional defect types (delamination, trailing-edge separation, ice accumulation). Parameter-efficient fine-tuning approaches (
Acknowledgement: We thank Jubail Industrial College for supporting this research.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Conceptualization, Mubarak Alanazi and Junaid Rashid; methodology, Mubarak Alanazi and Junaid Rashid; software, Mubarak Alanazi; validation, Mubarak Alanazi and Junaid Rashid; formal analysis, Mubarak Alanazi; investigation, Mubarak Alanazi; resources, Mubarak Alanazi; data curation, Mubarak Alanazi; writing—original draft preparation, Mubarak Alanazi; writing—review and editing, Mubarak Alanazi and Junaid Rashid; visualization, Mubarak Alanazi; supervision, Mubarak Alanazi; project administration, Mubarak Alanazi. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: We use the DTU Wind Turbine Blade Inspection Dataset [11] (https://data.mendeley.com/datasets/hd96prn3nc/2, accessed on 10 June, 2025), publicly available via Mendeley Data.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Ruiz M, Mujica LE, Alférez S, Acho L, Tutivén C, Vidal Y, et al. Wind turbine fault detection and classification by means of image texture analysis. Mech Syst Signal Process. 2018;107(3):149–67. doi:10.1016/j.ymssp.2017.12.035. [Google Scholar] [CrossRef]
2. Denhof D, Staar B, Lütjen M, Freitag M. Automatic optical surface inspection of wind turbine rotor blades using convolutional neural networks. Procedia CIRP. 2019;81(9):1166–70. doi:10.1016/j.procir.2019.03.286. [Google Scholar] [CrossRef]
3. Dolinski L, Krawczuk M. Analysis of modal parameters using a statistical approach for condition monitoring of the wind turbine blade. Appl Sci. 2020;10(17):5878. doi:10.3390/app10175878. [Google Scholar] [CrossRef]
4. Yang C, Liu X, Zhou H, Ke Y, See J. Towards accurate image stitching for drone-based wind turbine blade inspection. Renew Energy. 2023;203(2):267–79. doi:10.1016/j.renene.2022.12.063. [Google Scholar] [CrossRef]
5. Gohar I, Halimi A, See J, Yew WK, Yang C. Slice-aided defect detection in ultra high-resolution wind turbine blade images. Machines. 2023;11(10):953. doi:10.3390/machines11100953. [Google Scholar] [CrossRef]
6. Spajić M, Talajić M, Pejić Bach M. Harnessing convolutional neural networks for automated wind turbine blade defect detection. Designs. 2024;9(1):2. doi:10.3390/designs9010002. [Google Scholar] [CrossRef]
7. Qiu Z, Wang S, Zeng Z, Yu D. Automatic visual defects inspection of wind turbine blades via YOLO-based small object detection approach. J Electron Imaging. 2019;28(4):43023–3. doi:10.1117/1.jei.28.4.043023. [Google Scholar] [CrossRef]
8. Zhang R, Wen C. SOD-YOLO: a small target defect detection algorithm for wind turbine blades based on improved YOLOv5. Adv Theory Simul. 2022;5(7):2100631. doi:10.1002/adts.202100631. [Google Scholar] [CrossRef]
9. Fu Z, Zhang F, Ren X, Hao B, Zhang X, Yin C, et al. LE-YOLO: lightweight and efficient detection model for wind turbine blade defects based on improved YOLO. IEEE Access. 2024;12(16):135985–98. doi:10.1109/access.2024.3463391. [Google Scholar] [CrossRef]
10. Zhang Y, Fang Y, Gao W, Liu X, Yang H, Tong Y, et al. Attention mechanism based on deep learning for defect detection of wind turbine blade via multi-scale features. Meas Sci Technol. 2024;35(10):105408. doi:10.1088/1361-6501/ad6024. [Google Scholar] [CrossRef]
11. Shihavuddin ASM, Chen X. DTU—drone inspection images of wind turbine [Dataset]. 2018 [cited 2026 Jan 26]. Available from: https://data.mendeley.com/datasets/hd96prn3nc/2. [Google Scholar]
12. Xia Y, Sheng H, Chen Z. A comprehensive review on blade damage detection and prediction. In: 2021 International Conference on Sensing, Measurement & Data Analytics in the Era of Artificial Intelligence (ICSMD). Piscataway, NJ, USA: IEEE; 2021. p. 1–6. [Google Scholar]
13. Keras. Keras applications [Internet]. 2025 [cited 2025 Jun 10]. Available from: https://keras.io/api/applications/. [Google Scholar]
14. Liao C, Liang W, Yao J, Lv G. Intelligent defect diagnosis for oil and gas pipeline based on lightweight CBAM-Inception-Resnet. Chem Eng Res Des. 2025;218:548–71. doi:10.1016/j.cherd.2025.05.030. [Google Scholar] [CrossRef]
15. Seibi C, Ward Z, AS MM, Shekaramiz M. Locating and extracting wind turbine blade cracks using Haar-like features and clustering. In: 2022 Intermountain Engineering, Technology and Computing (IETC). Piscataway, NJ, USA: IEEE; 2022. p. 1–5. doi:10.1109/ietc54973.2022.9796823. [Google Scholar] [CrossRef]
16. Reddy A, Indragandhi V, Ravi L, Subramaniyaswamy V. Detection of cracks and damage in wind turbine blades using artificial intelligence-based image analytics. Measurement. 2019;147(6):106823. doi:10.1016/j.measurement.2019.07.051. [Google Scholar] [CrossRef]
17. Rao Y, Xiang BJ, Huang B, Mao S. Wind turbine blade inspection based on unmanned aerial vehicle (UAV) visual systems. In: 2019 IEEE 3rd Conference on Energy Internet and Energy System Integration (EI2). Piscataway, NJ, USA: IEEE; 2019. p. 708–13. [Google Scholar]
18. Yu Y, Cao H, Liu S, Yang S, Bai R. Image-based damage recognition of wind turbine blades. In: 2017 2nd International Conference on Advanced Robotics and Mechatronics (ICARM). Piscataway, NJ, USA: IEEE; 2017. p. 161–6. [Google Scholar]
19. Yu Y, Cao H, Yan X, Wang T, Ge SS. Defect identification of wind turbine blades based on defect semantic features with transfer feature extractor. Neurocomputing. 2020;376(5–6):1–9. doi:10.1016/j.neucom.2019.09.071. [Google Scholar] [CrossRef]
20. Zhang C, Yang T, Yang J. Image recognition of wind turbine blade defects using attention-based MobileNetv1-YOLOv4 and transfer learning. Sensors. 2022;22(16):6009. doi:10.3390/s22166009. [Google Scholar] [PubMed] [CrossRef]
21. Turhal U, Onal Y, Turhal K. Enhanced fault detection and diagnosis in photovoltaic arrays using a hybrid NCA-CNN model. Comput Model Eng Sci. 2025;143(2):2307. doi:10.32604/cmes.2025.064269. [Google Scholar] [CrossRef]
22. Alhanaf AS, Farsadi M, Balik HH. Fault detection and classification in ring power system with DG penetration using hybrid CNN-LSTM. IEEE Access. 2024;12:59953–75. doi:10.1109/access.2024.3394166. [Google Scholar] [CrossRef]
23. Kandil T, Harris A, Das R. Enhancing fault detection and classification in wind farm power generation using convolutional neural networks (CNN) by leveraging LVRT embedded in numerical relays. IEEE Access. 2025;13:104828–43. doi:10.1109/access.2025.3580052. [Google Scholar] [CrossRef]
24. Zhang C, Wen C, Liu J. Mask-MRNet: a deep neural network for wind turbine blade fault detection. J Renew Sustain Energy. 2020;12(5):53302. doi:10.1063/5.0014223. [Google Scholar] [CrossRef]
25. Zhang J, Cosma G, Watkins J. Image enhanced mask R-CNN: a deep learning pipeline with new evaluation measures for wind turbine blade defect detection and classification. J Imaging. 2021;7(3):46. doi:10.3390/jimaging7030046. [Google Scholar] [PubMed] [CrossRef]
26. Diaz P, Tittus P. Fast detection of wind turbine blade damage using Cascade Mask R-DSCNN-aided drone inspection analysis. Signal Image Video Process. 2023;17(5):2333–41. doi:10.1007/s11760-022-02450-6. [Google Scholar] [CrossRef]
27. Du Y, Wu H, Cava DG. A motion-blurred restoration method for surface damage detection of wind turbine blades. Measurement. 2023;217(9):113031. doi:10.1016/j.measurement.2023.113031. [Google Scholar] [CrossRef]
28. Dwivedi D, Babu KVSM, Yemula PK, Chakraborty P, Pal M. Identification of surface defects on solar PV panels and wind turbine blades using attention based deep learning model. Eng Appl Artif Intell. 2024;131(4):107836. doi:10.1016/j.engappai.2023.107836. [Google Scholar] [CrossRef]
29. Ultralytics. Albumentations integration [Internet]. 2025 [cited 2025 Jun 10]. Available from: https://docs.ultralytics.com/integrations/albumentations/. [Google Scholar]
30. Woo S, Park J, Lee JY, Kweon IS. CBAM: convolutional block attention module. In: Proceedings of the European Conference on Computer Vision (ECCV). Singapore: Springer; 2018. p. 3–19. [Google Scholar]
31. Khan MA, Park H. Adaptive channel attention and multi-path convolutional architecture for brain tumor detection using MRI images. Multimed Tools Appl. 2025;84(35):44515–42. doi:10.1007/s11042-025-20911-1. [Google Scholar] [CrossRef]
32. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556. 2014. [Google Scholar]
33. Howard AG. MobileNets: efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861. 2017. [Google Scholar]
34. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2016. p. 770–8. [Google Scholar]
35. Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2016. p. 2818–26. [Google Scholar]
36. Szegedy C, Ioffe S, Vanhoucke V, Alemi A. Inception-v4, Inception-ResNet and the impact of residual connections on learning. In: AAAI’17: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. Palo Alto, CA, USA: AAAI Press; 2017. p. 4278–84. [Google Scholar]
37. Chollet F. Xception: deep learning with depthwise separable convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 1251–8. [Google Scholar]
38. Huang G, Liu Z, Van Der Maaten L, Weinberger KQ. Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2017. p. 4700–8. [Google Scholar]
39. Tan M, Le QV. EfficientNetV2: smaller models and faster training. In: Proceedings of the 38th International Conference on Machine Learning (ICML). London, UK: PMLR; 2021. p. 10096–106. [Google Scholar]
40. Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, et al. Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2021. p. 10012–22. [Google Scholar]
41. Ribeiro MT, Singh S, Guestrin C. “Why should i trust you?” Explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY, USA: ACM; 2016. p. 1135–44. [Google Scholar]
42. Pei W, Xia T, Chen F, Li J, Tian J, Lu G. SA2VP: spatially aligned-and-adapted visual prompt. In: Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto, CA, USA: AAAI Press; 2024. p. 4450–8. [Google Scholar]
43. Han C, Wang Q, Cui Y, Cao Z, Wang W, Qi S, et al. E2vpt: an effective and efficient approach for visual prompt tuning. arXiv:2307.13770. 2023. [Google Scholar]
44. Yan L, Han C, Xu Z, Liu D, Wang Q. Prompt learns prompt: exploring knowledge-aware generative prompt collaboration for video captioning. In: Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI); 2023 Aug 19–25; Macao, China. p. 1622–30. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools