
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

MMF-CycleGAN: A Multi-Scale Generative Framework for Robust and Identity-Preserving Face Frontalization
1 Department of Computer Science and Engineering, College of Engineering Guindy, Anna University, Chennai, India
2 Department of Information Technology, Madras Institute of Technology, Anna University, Chrompet, Chennai, India
* Corresponding Authors: Shiloah Elizabeth Darmanayagam. Email: ,
Computer Modeling in Engineering & Sciences 2026, 146(3), 34 https://doi.org/10.32604/cmes.2026.077293
Received 06 December 2025; Accepted 04 February 2026; Issue published 30 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Recognizing frontal faces from non-frontal or profile images is a major problem due to pose changes, self-occlusions, and the complete loss of important structural and textural components, depressing recognition accuracy and visual fidelity. This paper introduces a new deep generative framework, Modified Multi-Scale Fused CycleGAN (MMF-CycleGAN), for robust and photo-realistic profile-to-frontal face synthesis. The MMF-CycleGAN framework utilizes pre-processing and then the generator employs a Deep Dilated DenseNet encoder-based hierarchical feature extraction along with a transformer and decoder. The proposed Multi-Scale Fusion PatchGAN discriminator enforces consistency at multiple spatial resolutions, leading to sharper textures and improved global facial geometry. Also, GAN training stability and identity preservation are improved through the Ranger optimizer, which effectively balances adversarial, identity, and cycle-consistency losses. Experiments on three benchmark datasets show that MMF-CycleGAN achieves accuracy of 0.9541, 0.9455, and 0.9422, F1-scores of 0.9654, 0.9641, and 0.9614, and AUC values of 0.9742, 0.9714, and 0.9698, respectively, and the extreme-pose accuracy (yaw > 60°) reaches 0.92. Despite its enhanced architecture, the framework maintains an efficient inference time of 0.042 s per image, making it suitable for real-time biometric authentication, surveillance, and security applications in unconstrained environments.Graphic Abstract
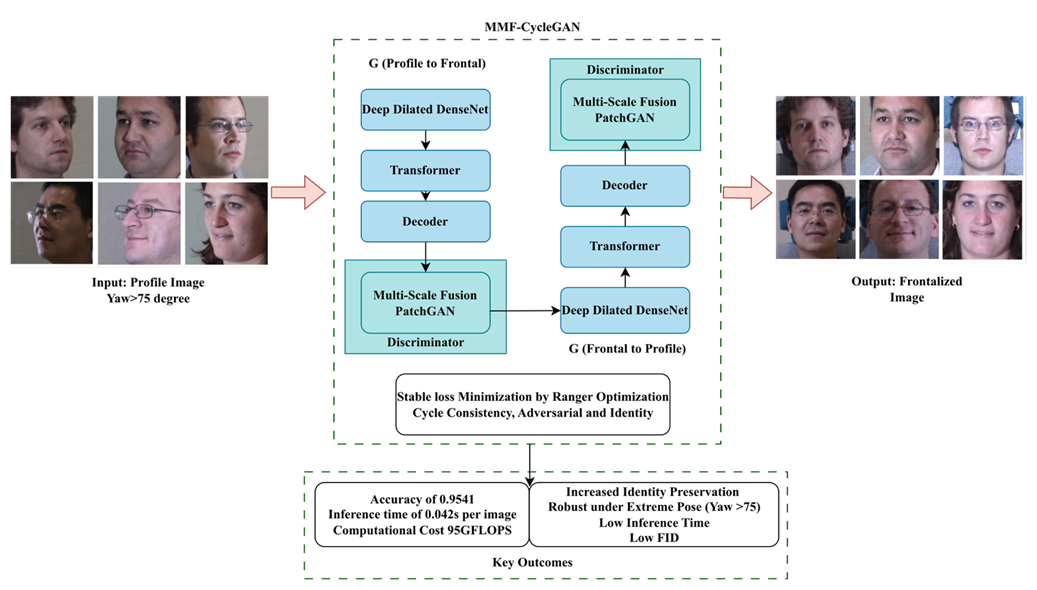
Keywords
Face frontalization is an emerging field in computer vision, with special emphasis on automatic face recognition systems that need consistent, uniform quality representations of a face’s frontal view for reliable identity assessments [1]. While a face is in highly non-frontal angles or profile views, it suffers from strong geometric distortions, asymmetric visibility and loss of structural and textural information [2,3]. These elements have significant negative impacts on the performance of feature extraction and accurate recognition. Face frontalization instead provides a practical substitution towards reconstructing a realistic and identity-preserving frontal representation from a face captured at arbitrary poses [4,5]. The successful recovery of occluded regions, the restoration of facial symmetry and retention of discriminative identity cues have made frontalization a major contributing factor in biometric authentication, surveillance systems and security-driven applications where reliability is of utmost importance.
While face frontalization is a fundamentally challenging task, due to large pose variations, self-occlusions, illumination variations, or the absence of texture information, it is critical in many applications [6]. Geometric methods, which are usually based on 3D Morphable Models, attempt to align the captured profile image to the frontal using explicit shape modeling. However, extreme pose capture leads to self-occlusion of the face [7], discarding the semantic details needed to create a realistic or consistent reconstruction of the individual. Moreover, the generalization of these classical methods is further hindered by limited multi-pose facial datasets [8]. Consequently, reconstructed faces from large-pose frontalization suffer from blurred textures, poor geometry, or degraded recognition performance [9].
The advancement of machine learning and deep generative models has made Generative Adversarial Networks (GANs) one of the technical fronts in face frontalization [10]. GAN-based models consist of a generator that generates frontal faces from profile views and a discriminator that evaluates realism through adversarial learning. Variants like CycleGAN [11] add cycle-consistency and identity-preserving constraints to robustly translate faces without requiring paired frontal–profile samples [12]. Generative methods have demonstrated improved recovery of missing features, photorealism, and pose-invariant face representation [13,14]. Nevertheless, previous work encounters trade-offs involving the preservation of fine-grained identity features, capturing the global aspect of the face, stabilization in adversarial training, and generating output under extreme pose displacement of the profile images.
In response to these limitations, the current study presents MMF-CycleGAN, a CycleGAN architecture for robust, accurate, and identity-preserving face frontalization. The proposed architecture utilizes Deep Dilated DenseNet layers for enriched hierarchical feature extraction and transformer function [15]. The architecture also utilizes a Multi-Scale Fusion PatchGAN discriminator to assess global and local coherence simultaneously and incorporates the Ranger optimization algorithm to increase adversarial learning stability and overall image sharpness, color consistency, and identity preservation. Through these architectural and optimization additions, MMF-CycleGAN can robustly generate high-quality frontal images with significant pose variation and outperforms state-of-the-art performance in other face frontalization methods.
Contributions of the Paper:
• This paper presents the MMF-CycleGAN, a pose-invariant face frontalization framework that fuses multi-scale feature learning and optimization strategies within a CycleGAN.
• In contrast to DR-GAN, which enforces pose invariance mainly via latent identity disentanglement, MMF-CycleGAN preserves identity at both feature and image levels by the effective integration of dilated DenseNet encoders and transformer-based global dependency modelling.
• Unlike TP-GAN, which struggles under extreme pose variations due to limited global and local feature interaction with reduced photorealism, MMF-CycleGAN effectively captures both fine-grained textures and global facial structure through its Multi-Scale Fusion PatchGAN discriminator.
• To stabilize training, Ranger optimization is integrated with the proposed GAN to improve convergence stability and identity retention. An optimization strategy not explored in existing frontalization frameworks, such as TP-GAN and DR-GAN.
The organization of the paper is as follows: Section 2 provides a literature review of recent research works in face frontalization and GAN-based synthesis. Section 3 describes the proposed MMF-CycleGAN framework, the architectures, and the key components. Section 4 outlines the datasets employed and the evaluation protocols, along with the results of the proposed model. Section 5 compares the results with existing works and the role of each component. Lastly, Section 6 presents the conclusions of the paper, limitations and suggests areas for future research.
There has been substantial advancement in the use of GAN to achieve face frontalization; however, the challenges of pose variation, preserving facial metrics, and training stability remain.
Liao et al. [16] have introduced the Self-supervised Random Mask Attention GAN to tackle the issue of pose-invariant face recognition. They proposed the Mask Rotate framework to address the need for paired frontal images and the need for an external rendering model. The method effectively recasts face frontalization as a face completion task and leverages the Random Mask Attention GAN to perform a self-supervised completion of missing areas of the images. The chief benefit of this paradigm is that it helps improve training by offering the ability to perform it with less annotated data, while also achieving enhanced performance in scenarios where there is large pose variability. However, the disadvantage of their method is that it still relies on a rendering model to generate the result during inference, which can result in minor texture discrepancies that can necessitate post-processing.
Stanishev et al. [17] have discussed a feature-space pose frontalization module to develop a pose-invariant face recognition approach that converts profile images to frontal images directly in the feature space, regardless of the angle of the profile image. The method uses a two-stage training paradigm with pre-training and attention-guided fine-tuning to maximize the benefits of the feature-space pose frontalization process. An advantage of the method has been its improved performance across multiple benchmarks while avoiding image space artifacts that are common in generative methods. Other related advantages have been improved robustness in pose-variant face recognition scenarios, as well as in standard face recognition. A disadvantage to the method is the higher complexity of training due to the multi-stage process, requiring careful tuning, as well as computational resources.
Alhlffee and Huang [18] have proposed a Novel Face Frontalization Method aimed at the pose variations and low-resolution problems in facial recognition that combines landmark detection and decision forests within a GAN-based structure. The method improves the repo’s TP-GAN structure by using a 2D landmark detection method so that global structures can be represented better, with the detailed local support to accurately represent features. The decision forest allows for greater stability on the discriminator side, designing a method capable of accounting for the different poses and varieties in the data, while data augmentation improves the diversity in the training process. The method supported improved visual quality and rank-1 identification across datasets, including Multi-PIE, FEI, and CAS-PEAL. One of the limitations is the increased architectural complexity that may require additional computation-based resource requirements and consideration of different parameter settings.
Ahmadi et al. [19] have discussed a parameter-efficient framework for face frontalization by utilizing GAN inversion to address the challenges with using large models, small datasets, and lower quality output. The contribution of this work is the introduction of a new diverse dataset and the method of frontalizing faces from a single input while employing an approach that utilizes GAN inversion and transfer learning, resulting in more than a 91% reduction of trainable parameters while providing more photorealistic results in comparison to existing methodologies. This framework could also be extended to multi-frame inputs with attention mechanisms utilized for temporal merging of information and to resolve multiple artefacts (e.g., eye blinks), while still preserving high fidelity reconstruction. The results achieved significant improvements when compared to state-of-the-art findings in LPIPS (Learned Perceptual Image Patch Similarity), ID similarity, and identity preservation. A downside to the proposed approach lies in the reliance on high-quality GAN inversion models, which may prove limiting in terms of performance when competing with very low-resolution or highly occluded inputs.
Zhou and Wang [20] have explored a conditional GAN (RFC-GAN) augmented with receptive field modifications that have been used for multi-view face frontalization. Their RFC-GAN aimed to improve the extraction of local features during training and improve the realism of generated images. The RFC-GAN implemented multiple dilated convolution kernels in a multi-scale and multi-branch generator structure to enhance the receptive field and detail the reconstruction of textures in generated images. They additionally utilized a perceptual loss to improve training performance to reflect and maximize some level of semantic and structural consistency beyond purely pixel-space accuracy. The results of experiments on KDEF and CMU Multi-PIE datasets reported substantial gains in PSNR, SSIM, and LPIPS performance over the previous state-of-the-art models. One limitation of the RFC-GAN is the increased architecture complexity that will likely require increased computational requirements.
Ikne et al. [21] have presented eMotion-GAN, which is a motion-based GAN (generative adversarial network) geared towards photorealistic synthesis of frontal view while preserving expressions to improve facial expression recognition (FER). The approach considers head-pose inherited motion as noise and motion inherited from expression as useful information, filtering noise-like motion and transferring expression-related motion onto a neutral frontal face. Consequently, typical deformations seen in frontalization during expression analysis have been avoided. Results from evaluations across multiple dynamic FER datasets showed performance gains of up to 5% on small pose variations and up to 20% on large pose variations. A limitation of the approach is reliance on motion cues, which may be less reliable in these sequences for low video quality or low frame rates.
Kim et al. [22] have introduced DCFace, a dual-condition diffusion model for generating synthetic datasets of face images while simultaneously controlling for subject identity, as well as external styles, factors, and attributes. DCFace consists of a patch-wise style extractor, while jointly learning a time-step–dependent ID loss that enables the faithful generation of multiple images of the same subject in different poses, expressions, illumination, and ages. Synthetic datasets, generated using DCFace, consistently improve face recognition accuracy on benchmark datasets, including LFW, CFP-FP, CPLFW, AgeDB, and CALFW. There are computational costs associated with diffusion models, which can be a limitation for large-scale dataset generation.
Lo et al. [23] have proposed using a feature-weighted CycleGAN model to generate anime-style face images, with an additional facial landmark loss to ensure that features are appropriately located and a perceptual color loss to minimize distortions in color. This method includes a new Fréchet Anime Inception Distance to assess the quality of generated anime images more robustly. Experiments and user studies show good performance from users, reporting a 74.46% user preference rate and a FAID score of 126.05. It is important to note that there may be increased model complexity due to the involvement of additional losses and metrics.
Mesec and Jovic [24] have implemented a new approach for improving pose-invariant face recognition through face defrontalization using more data, rather than creating frontal poses. The authors implemented an adapted FFWM defrontalization model on frontal–profile pairs. They then used this model to produce a large-scale defrontalized dataset for training a ResNet-50 using ArcFace loss. The proposed defrontalization approach adds no inference-time overhead while improving robustness across changing head poses. Experiments conducted on LFW, AgeDB, CFP, and Multi-PIE demonstrated better performance than the existing models not implementing defrontalization and outperformed each of the FFWM models using frontalization on larger datasets.
Shen et al. [25] have employed FaceFeat-GAN, a face synthesis framework with two stages that preserves identities aimed at creating faces with higher diversity and realism. In the first stage, the model focuses on creating diverse facial features in the feature domain, while the second stage stages these features into photorealistic images. By separating these two stages, the model can better balance between identity preservation and intraclass variation than existing designs that have a single-stage architecture. The proposed model significantly increases the quality and diversity of generated images in the experiments when compared to previous work. A limitation of the framework is an increase in system complexity due to a two-stage architecture and the need to train two discriminator–generator pairs.
Research Gap Identification:
Recent works have presented face frontalization and synthesis techniques using GANs, CNNs, and ensemble models. However, these models often rely on large, labelled datasets and perform poorly in settings. Many GAN-based methods are unable to perform effective multi-scale feature discrimination, resulting in incomplete synthesis of global geometry and fine details from local textures. Conventional discriminators cannot evaluate local and global concurrent consistency. Generators have limited receptive fields, resulting in blurred or distorted outputs, while training is also unstable due to an unsatisfactory balance between adversarial, identity, and cycle-consistency loss. Additionally, current methods struggle with maintaining color fidelity, sharpness, and semantic coherence with diversity in datasets and evaluations are also limited. This knowledge indicates a need for a more robust and reliable multi-scale identity-preserving generative framework such as MMF-CycleGAN. To address these challenges, the proposed research will develop a multi-scale, lightweight generative framework, with respect to identity-preservation, feature-extraction, discriminator feedback, and optimization schemes that can faithfully and stably reconstruct a realistic frontal face across domains.
3 Proposed Methodology: Face Frontalization
The proposed MMF-CycleGAN framework takes a methodical process to realize and identity-preserving frontalization of profile images. In the first step, profile face images are gathered from benchmark datasets such as Multi-PIE, IJB-A, and LFW. Profile face images are resized to (256 × 256) images and normalized and augmented (via rotation, flipping, and altering illumination) to better generalize for different poses, illuminations, and expressions. The augmented images are processed by MMF-CycleGAN, a deep generative framework for frontalizing face images from non-frontal or profile images, while maintaining the person’s identity, realistic texture, and structure.
In the MMF-CycleGAN framework, the generator will take in a profile face and output a frontal face that is photo-realistic, while still preserving the identity, texture, and illumination attributes of the original profile face. The generator employs a Deep Dilated DenseNet encoder with a small receptive field for rich representation extraction, a Transformer block for global spatial relationships, and a Decoder to produce the high-quality frontal face. The Multi-Scale Fusion PatchGAN discriminator will evaluate the realism of the generated frontal face at different spatial scales. The discriminator not only checks the fine local textures, such as the features around the eyes and local skin texture, but also checks to see if the overall structural details are aligned, such as the expected pose and global symmetry. All these can help guide the Generative work into generating more realistic and natural photorealism. All the losses computed in MMF-CycleGAN are minimized using the Ranger optimization algorithm, which results in higher quality images for frontalization with improved attribute and identity preservation. The workflow of the proposed identity-preserving image frontalization is shown in Fig. 1.
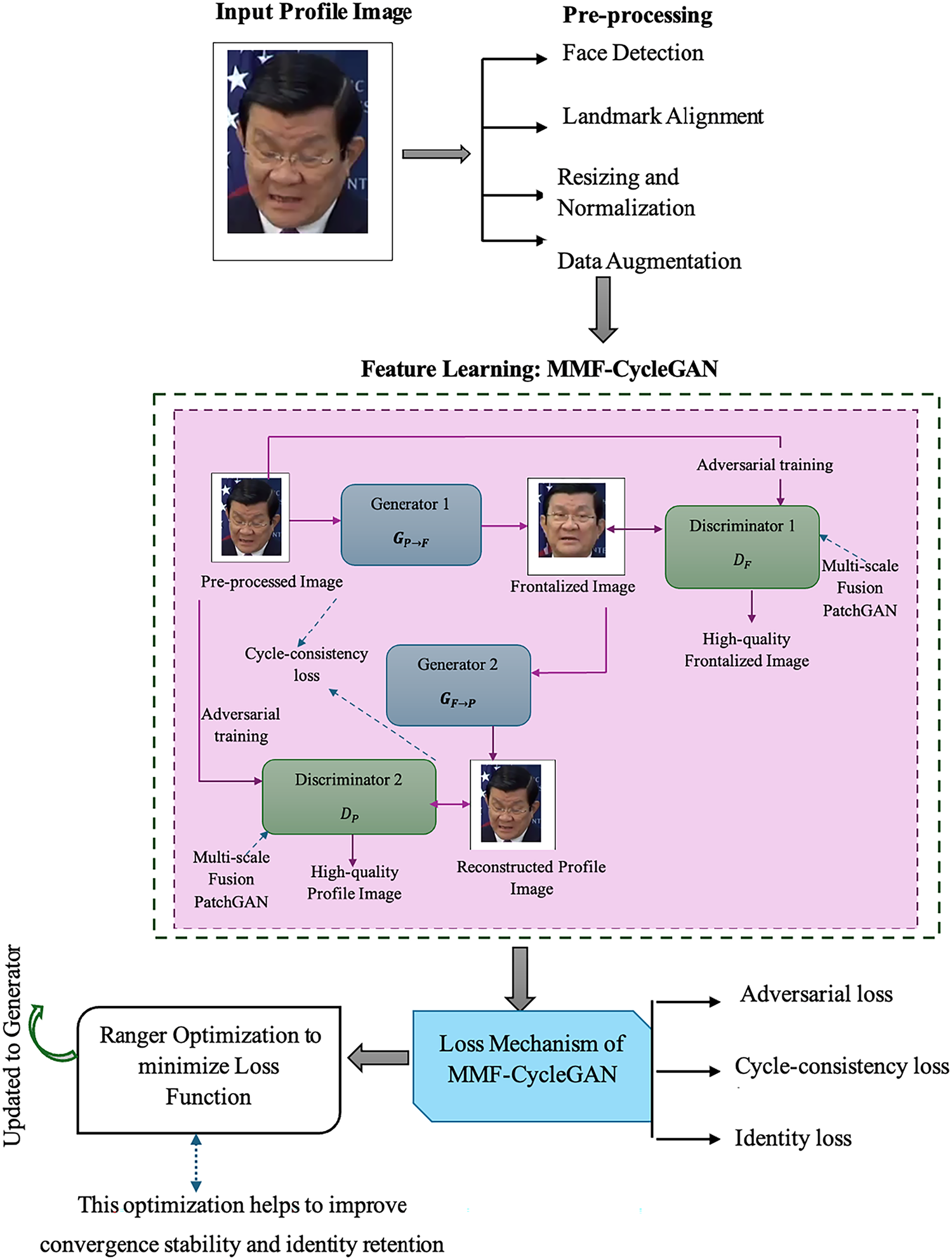
Figure 1: Workflow of identity-preserving image frontalization.
3.1 Pre-Processing and Augmentation of Facial Image
For effective feature learning and robust frontalization, a pre-processing step is employed. Preprocessing is done in four steps: face detection, facial landmark alignment, image resizing with normalization, and data augmentation. The input to the pre-processing step is
Step 1: Face Detection: To identify and crop the facial region from the original image, removing background and unnecessary regions to focus on the facial area. The detected face region is represented as,
where,
Step 2: Facial Landmark Alignment: After detection, facial landmarks such as eyes, nose, and mouth are extracted to correct geometric distortions caused by pose variations. Let
where, M is the similarity transformation matrix aligning L to
Step 3: Image Resizing and Normalization: The aligned facial image is resized to a fixed resolution of
Then, each image is normalized to balance illumination and ensure stable convergence during training.
where
Step 4: Data Augmentation: To improve model robustness and prevent overfitting, augmentations are introduced. Let

The final pre-processed image expressed as
3.2 Feature Learning: MMF-CycleGAN
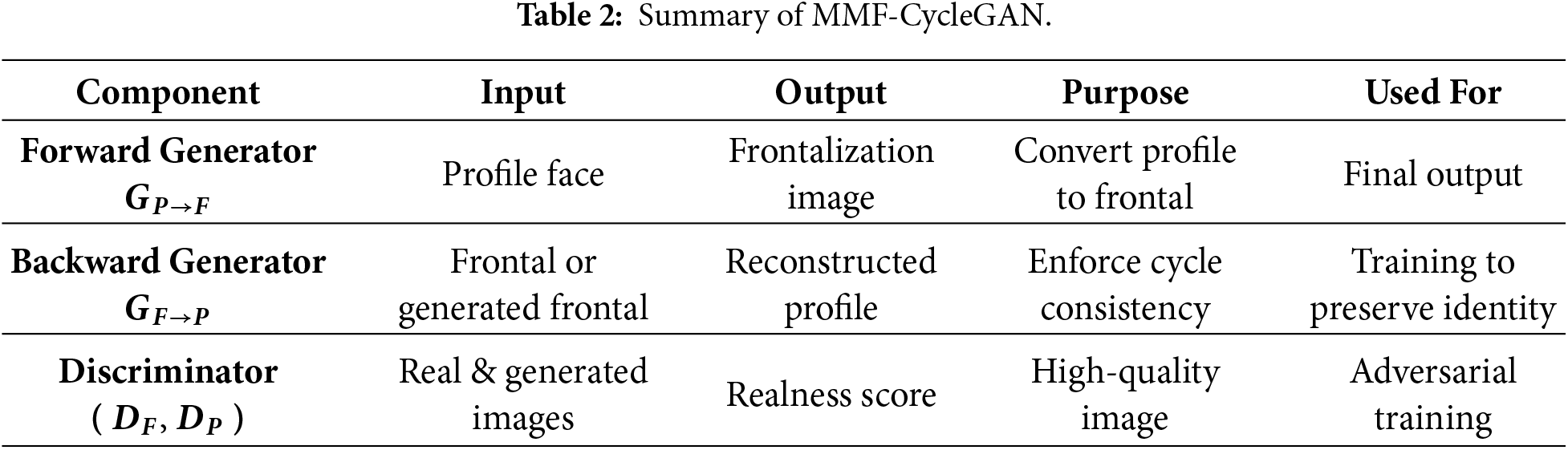
The MMF-CycleGAN framework is developed to provide resilient feature learning for profile-to-frontal face generation. When compared to regular GAN (Generative Adversarial Network) based approaches, this mechanism emphasizes the extraction of multi-level spatial and contextual features while preserving facial identity. Learning of features occurs in a framework that incorporates dual generators and dual discriminators utilizing cycle-consistency that preserves semantic meaning for each translation from profile to frontal face domain. The constructed generators are based on a Deep Dilated DenseNet encoder, Transformer and Decoder that can learn hierarchical and contextual information from varying receptive fields, while the Multi-Scale Fusion PatchGAN discriminators produce evaluations completing realism and shape for the deep learning-based outputs at different spatial scales.
Working Principle of CycleGAN Architecture: The CycleGAN Architecture is driven as the backbone of MMF-CycleGAN which utilizes two generators constructed learning approach. It consists of two generator–discriminator pairs that learn bidirectional mappings between the profile domain and frontal domain without requiring paired samples.
• The generator
• The generator
• The discriminators
3.3 Generator Block: Feature Extraction by Deep Dilated DenseNet
The generator component of the proposed MMF-CycleGAN is intended to accurately reconstruct high-quality and identity-preserving frontal faces from non-frontal or profile images. The proposed generator for CycleGAN consists of three components, illustrated in Fig. 2; the architecture takes the form of a Deep Dilated DenseNet encoder, a Transformer block and a Decoder. This combined structure allows the model to encode both the local spatial details and global contextual dependencies among facial landmarks, rendering more realistic outputs while ensuring identity consistency.
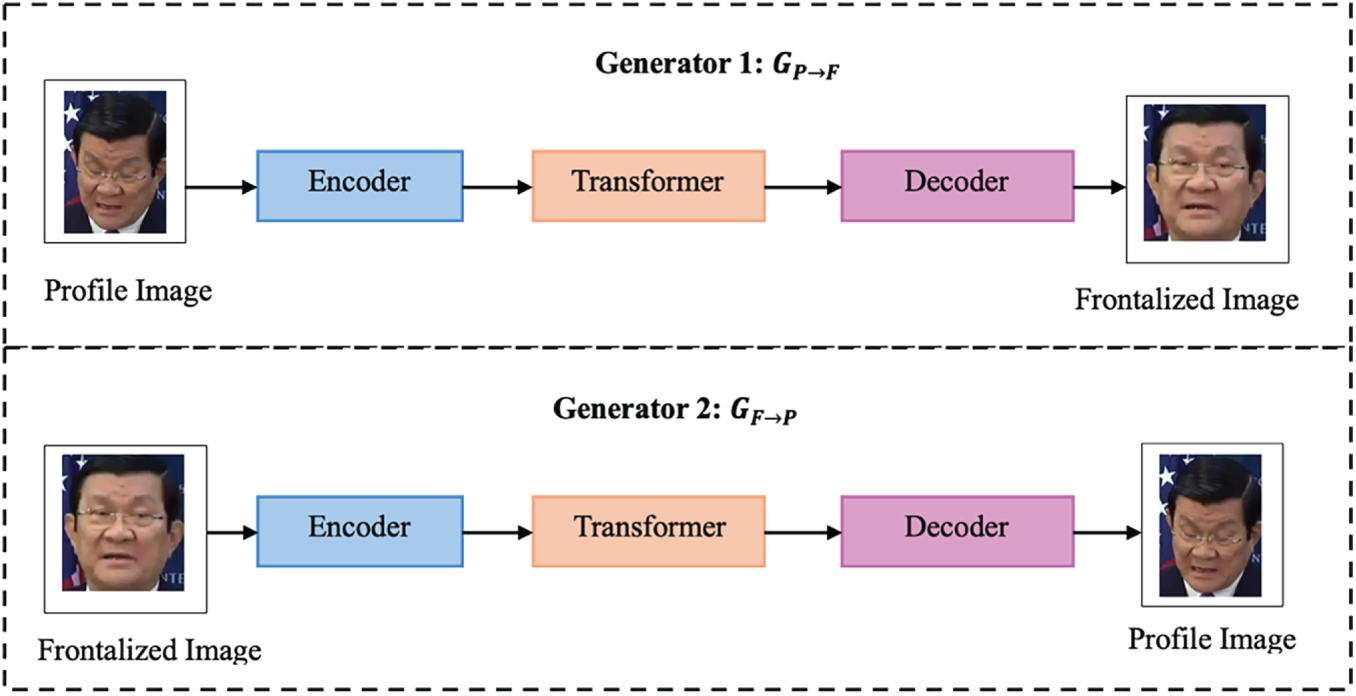
Figure 2: Generator Block.
3.3.1 Generator 1 (
(i) Deep Dilated DenseNet Encoder
The encoder portion of the generator employs DenseNet-based networks with dilated convolutions for hierarchical and multi-scale feature extraction. In a dense block, every layer can take input from all layers that precede it, not just the previous layer. This scheme helps to maximize the reuse of features and for gradient flow through the network to minimize the vanishing gradient problem that occurs in deep networks. In a dense block with L layers,
where
Dilated Convolution in DenseNet: Atrous (or dilated) convolution is employed to expand the receptive field without reducing spatial resolution, allowing the model to capture both fine and global features. The Dilated feature map value at spatial location
where,
(ii) Transformer Block for Global Dependency Modelling
The encoded feature map
The term
where, query (Q) and the key (K)-value (V) are the projections of
Thus, the Transformer block bridges local feature encoding and global semantic representation, strengthening the model’s ability to handle large pose variations and occlusions.
(iii) Decoder: High Resolution Frontal Image
The decoder reconstructs the high-resolution frontal image from the transformer-enhanced features. It employs transposed convolutions or pixel-shuffle up-sampling with skip connections from the encoder:
where
Eq. (14) explains that
3.3.2 Generator 2 (
In this generator, reverse translation from the generated frontal face back to the profile domain is performed to enforce cycle consistency of the structural aspects of the image and to constrain the image to be structurally meaningful, invertible, and preserving identity. Also, similar to generator 1, there are three modules in the reversible generator to reconstruct the profile face image, and the image is
Fig. 3 represents the encoder, transformer and decoder structure of generator 1 and generator 2. For generator 1, the profile image is taken as input and generates frontal images and for generator 2, the frontal image is used as input, then reconstructs the profile image.
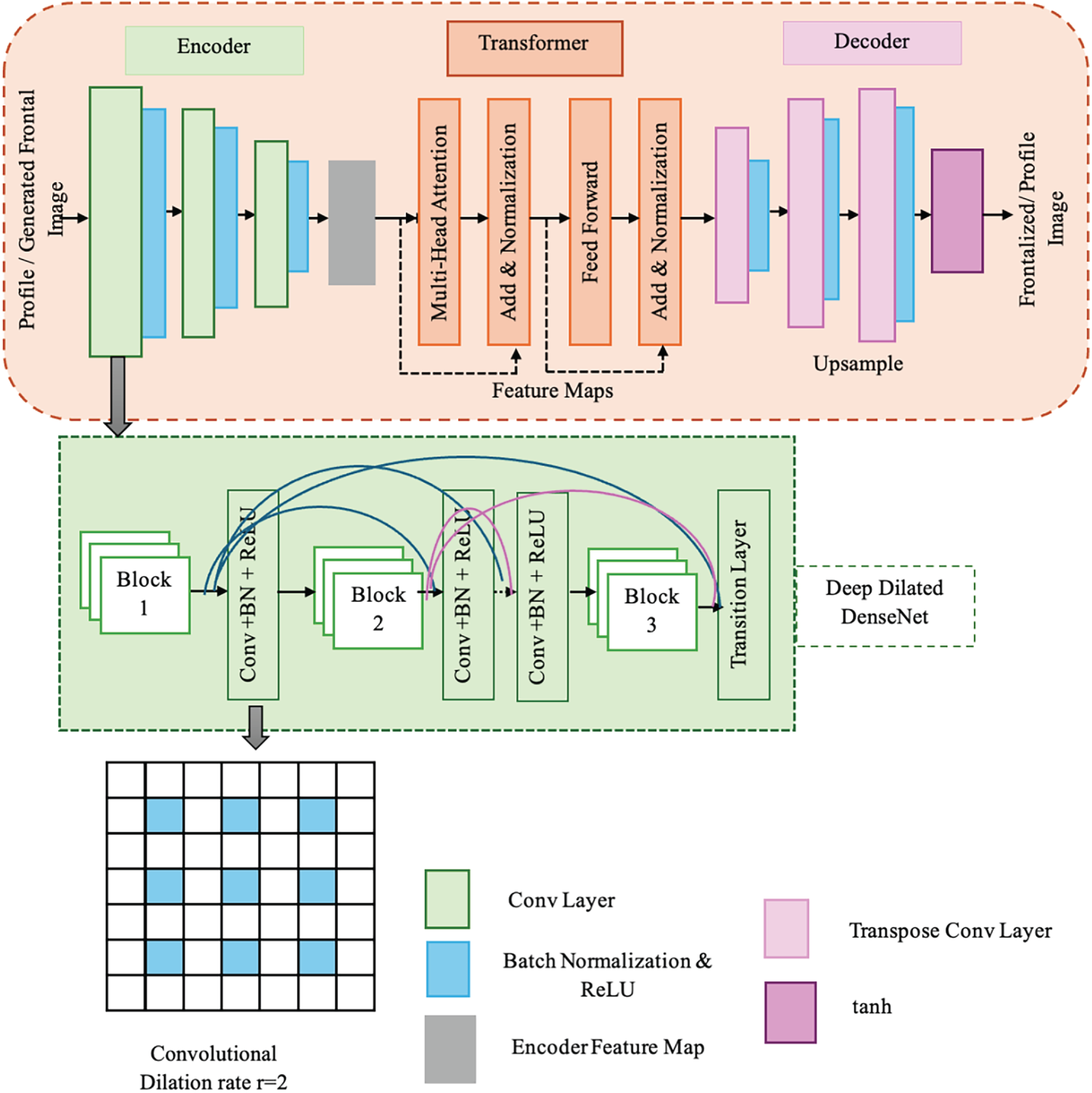
Figure 3: Encoder, transformer and decoder of generator block.
3.4 Discriminator Block: Multi-Scale Fusion PatchGAN
The MMF-CycleGAN model includes a discriminator that assesses the realism of generated images and compels each generator to produce images that are both sharp and realistic while preserving identity. The standard single-scale discriminator is replaced with a Multi-Scale Fusion PatchGAN Discriminator in MMF-CycleGAN, which operates on multiple spatial resolutions so that local texture details (especially the eyes and skin texture) can be analyzed in addition to global facial structure (pose alignment and facial shape) to separate real and generated samples. In MMF-CycleGAN two discriminators operate in parallel to generate images with high fidelity. This block will receive two types of input images during training: the images based on the dataset (i.e., ground-truth samples) and the generated images based on the result of the generator network. The two discriminators are:
•
•
Each PatchGAN discriminator operates at multiple scales to analyze features at different resolutions: High-resolution scale (e.g., 256 × 256) → captures fine details like skin texture and edges. Medium-resolution scale (e.g., 128 × 128) → captures facial parts and expression structure. Low-resolution scale (e.g., 64 × 64) → captures overall pose, symmetry, and illumination. Formally, the discriminator input at scale s is,
where,
where,
Fusion Mechanism: The outputs from discriminators at different scales are fused using adaptive attention weighting:
where
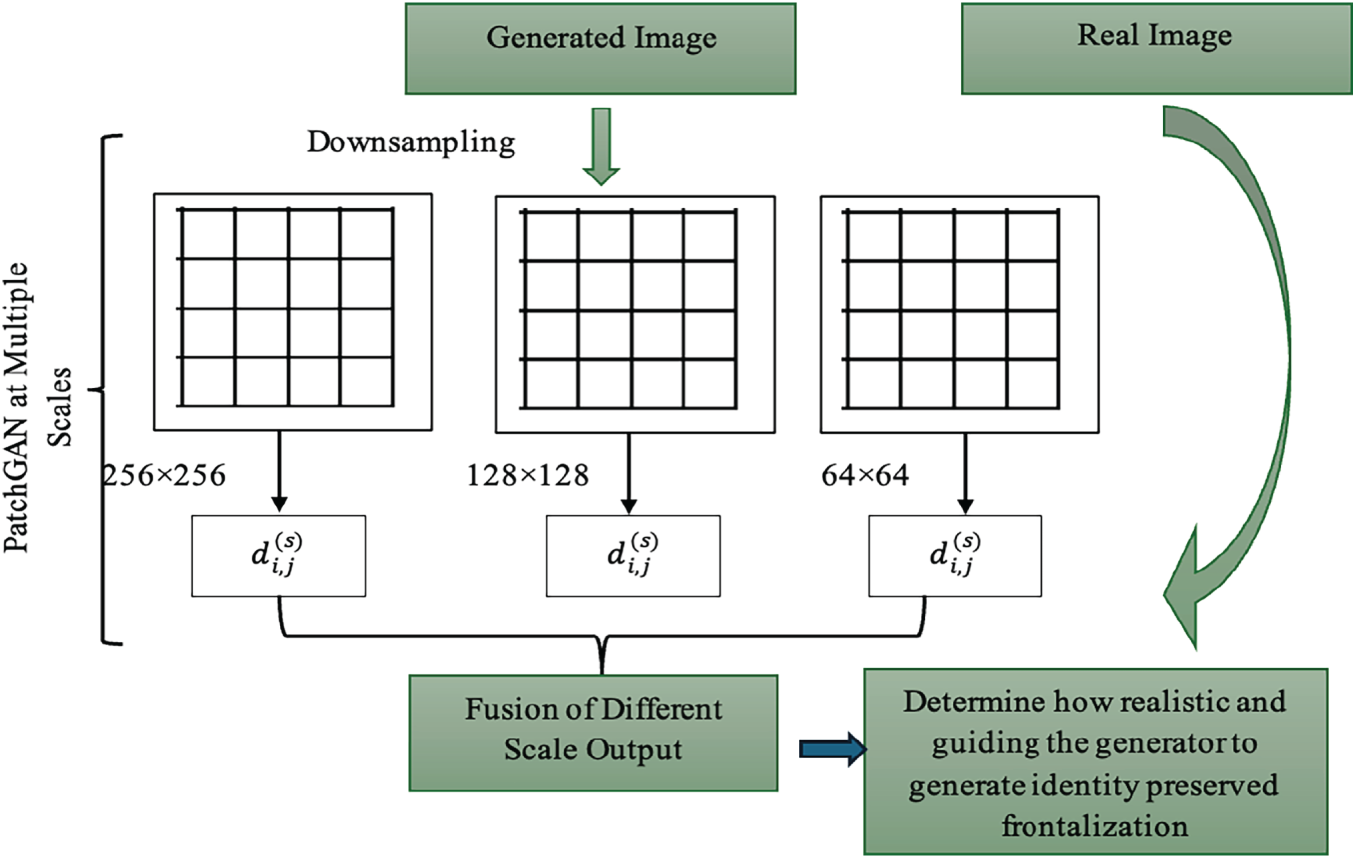
Figure 4: Discriminator block: multi-scale fusion PatchGAN.
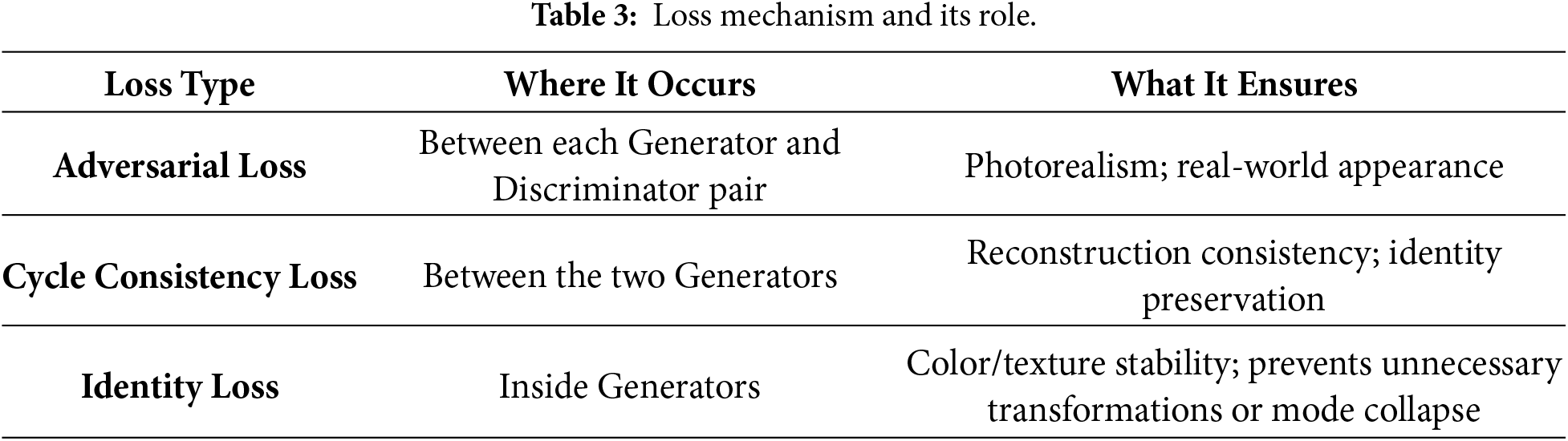
3.5 Loss Mechanism of MMF-CycleGAN
The MMF-CycleGAN framework combines three main loss functions: adversarial loss, cycle-consistency loss, and identity loss to promote high-quality photo-realism, structural fidelity, and identity preservation during the bidirectional translation between profile and frontal face domains. These losses, together, guide the generators and the discriminators into producing semantically consistent frontalization while also allowing for more stable and accurate face frontalization with unpaired training data. The function of each loss mechanism is described in Table 3.
Adversarial Loss: This loss guarantees that the images that were averaged sound realistic and look indistinguishable from real frontal/profile faces.
For the generator
For the generator
Cycle-Consistency Loss: Ensures that forward and backward translations maintain identity (e.g., the correct person returns, and original identity is preserved when cycled), following the concept of unpaired learning, stabilizing training, and ensuring accurate frontalization in the case of pose-invariant image.
The combined cycle-consistency ensures bidirectional reconstruction accuracy and identity retention during pose translation.
Identity Loss: Ensures that the generator does not change an image that is already in the target domain, which preserves identity-related features such as eyes, nose, and texture of the face. For the generators
The total loss is given by,
where,
3.6 Ranger Optimization for Stable Loss Minimization
The Ranger optimizer is used in MMF-CycleGAN to achieve stable, efficient, and high-quality training when reducing the overall adversarial, cycle-consistency, and identity loss. Reducing this multi-objective problem requires an optimizer that can accommodate unstable gradients, adversarial oscillations, and complex multi-constraint learning. Ranger uses a single update rule that incorporates RAdam, Gradient Centralization, and Lookahead to solve these issues. The objective function is to minimize the total training loss (Eq. (24)), which is defined as,
3.6.1 Steps Involved in Ranger Optimization
The optimization process begins with MMF-CycleGAN networks {
Step 1: Gradient Computation: For a one-parameter tensor, gradients are computed for the generator pair and both discriminators.
where,
Step 2: Gradient Centralization (GC): Before applying any adaptive update, Ranger performs GC, which normalizes gradients by making them zero-mean:
This normalization reduces gradient explosion, improves generator–discriminator balance and stabilizes early GAN training. The fused multi-scale feature blocks tend to produce high-variance gradients, which helps to normalize them.
Step 3: RAdam-Based Adaptive Update: Ranger next applies RAdam (Rectified Adam) to handle unstable variance in early training. Use the centralized gradient
RAdam rectifies the variance and the rectified update is,
The term
This prevents the generator from collapsing in early epochs and eliminates the critical for GAN adversarial dynamics where gradients fluctuate.
Step 4: Look Ahead Slow-Fast Weight Fusion: Ranger maintains two sets of parameters. Fast weights are updated every iteration by RAdam and Slow weights are updated periodically by Look Ahead. Fast update for every iteration,
Every
Then, reset the model parameter by
Lookahead reduces oscillations and guides optimization toward flatter minima by periodically averaging the sequence of fast updates.
Step 5: Parameter
Ranger applies GC, RAdam and Lookahead to continuously move parameters toward the optimal solution. First, Gradient Centralization produces cleaned-up stabilized gradients. Next, RAdam makes variance-corrected adaptive updates to avoid large individual or small individual updates. Finally, Lookahead averages fast updates with a slow copy of the weights, which directs optimization to flatter and more stable minima. As multi gradient descent progresses, both fast weights and slow weights move toward the optimal parameters
This feature extraction and learning paradigm allows MMF-CycleGAN to optimally balance the sense of realism of texture, accuracy of geometric accuracy, and identity preservation of frontalizing an image under potentially extreme pose or illumination conditions. The pseudo Code of Ranger optimization is explained in Algorithm 1.

The Results and Discussion section provides a detailed evaluation of the proposed MMF-CycleGAN model on several benchmark datasets (Multi-PIE, LFW, and IJB-A), which is implemented in Python with the spyder tool. These datasets each have their own variations with respect to pose, illumination, expression, and occlusion, which add to the challenges of evaluating face frontalization. Results show that the proposed MMF-CycleGAN consistently outperforms on various evaluation metrics (Accuracy, AUC, F1-score, FAR, Recall, and TAR) when compared with TP-GAN [18], UV-GAN [26], DR-GAN [27], DA-GAN [28], demonstrating the robustness of the model in generating identity-preserving frontal faces from pose-variant image inputs.
Multi_Pie Dataset [29]: The Multi-PIE dataset includes over 750,000 images of 337 subjects captured in a controlled laboratory setting. The captured images feature systematic variations in terms of pose (15 different poses), illumination (19 different lighting conditions), and facial expressions, and therefore is regarded as one of the largest benchmarks for face frontalization models. The extreme yaw variations (up to ±90°) contained in the dataset make it especially useful for evaluating the profile-to-frontal reconstruction performance of frontalization facial models.
LFW (Labeled Faces in the Wild) Dataset [30]: The LFW dataset consists of more than 13,000 face images obtained from the web in “the wild” in uncontrolled conditions, while exhibiting variations in pose, expression, illumination, age and background. Additionally, there are either one or a few images per subject, and therefore, the LFW dataset offers an opportunity particularly to evaluate the generalization capability of frontalization and recognition models in the wild.
IJB-A (IARPA Janus Benchmark A) Dataset [31]: The IJB-A dataset contains 5396 images and 20,412 video frames of 500 subjects, with significant pose variation, occlusions, blur, and illumination conditions. Relative to the aligned datasets, IJB-A includes full profile, partial profile, and extreme poses, and offers much greater challenges, indicating it is ideal for comparing and evaluating the pose variants in both frontalization and recognition models.
Accuracy: It evaluates the proportion of correctly classified samples,
where
Recall: Measures how well the system returns genuine matches. Proportion of actual positives correctly identified:
F1-Score: Harmonic mean of Precision and Recall:
where
AUC (Area Under Curve): Integration of the ROC curve:
where TPR = True Positive Rate, FPR = False Positive Rate. AUC summarizes discriminability across all thresholds.
TAR (True Accept Rate): Proportion of positives accepted at a set threshold:
Often reported at specified FAR (False Accept Rate).
FAR (False Accept Rate): Proportion of impostors incorrectly accepted:
FNR (False Non-Match Rate): Fraction where genuine matches are missed:
FPR (False Positive Rate): Fraction of negatives incorrectly labeled as positive:
4.2.1 Image Quality and Identity Metrics
These metrics capture both visual quality and perceptual realism of the frontalized images while ensuring that the identity features are still consistent for recognition.
PSNR (Peak Signal-to-Noise Ratio): Measures image frontalization fidelity:
where
FID (Fréchet Inception Distance): Quantifies similarity of real and generated images. Lower FID gives realistic images.
where
LPIPS (Learned Perceptual Image Patch Similarity): Deep perceptual metric, lower LPIPS gives better perceptual quality.
where
4.2.2 Task-Specific Evaluation
These metrics focused on certain tasks, measuring how robust the model is in difficult, real-world conditions, including extreme head poses and partial occlusions, and how efficient the inference is in terms of computation.
Extreme Pose Accuracy (yaw > 60°): Reporting matches/frontalizations only for large-pose faces (yaw > 60°).
Reporting matches/frontalizations only for images with head yaw > 60°.
Partial Occlusion Accuracy: Evaluates correct identification or frontalization accuracy under occluded inputs, i.e., Images with glasses, scarf, and hair.
Inference Time per Image: Empirical mean computational time for one forward pass:
where
Confidence Interval (95%): The 95% CI for the mean recognition accuracy is computed as:
where,
Cohen’s d: This is calculated to measure the magnitude of performance improvement of the proposed model over a baseline model:
where the pooled standard deviation
Fig. 5 presents sample non-frontal input face images with significant pose variations, including large yaw angles. Fig. 6 illustrates the preprocessing steps applied to the input images. Specifically, Fig. 6a shows the original image, Fig. 6b shows the resized image adjusted to the network input dimensions, and Fig. 6c presents the normalized image used for training and inference.

Figure 5: Non-frontal input images.
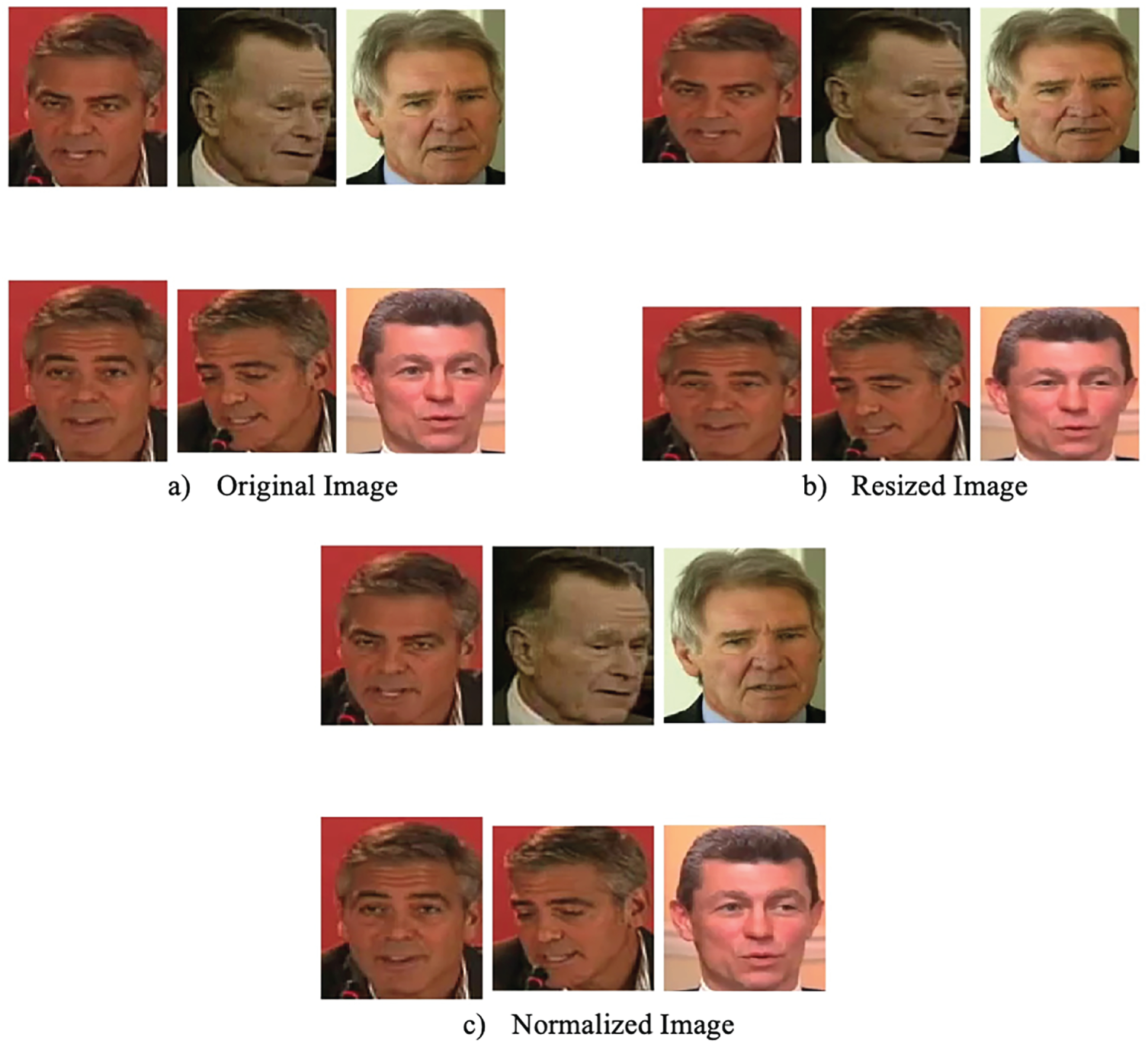
Figure 6: Pre-processed results (a) original image, (b) resized image and (c) normalized image.
Fig. 7 shows the frontalized output images generated by the proposed MMF-CycleGAN model. The results demonstrate improved identity preservation, structural alignment, and texture realism compared to the original non-frontal inputs.

Figure 7: Frontalized images of MMF-CycleGAN.
A comparative performance analysis of five face-frontalization models, such as UV-GAN, DA-GAN, DR-GAN, TP-GAN, and the Proposed MMF-CycleGAN across three benchmark datasets: Multi-Pie, IJB-A, and LFW is discussed in Table 4. Fig. 8a visualizes accuracy trends, showing a steady improvement from UV-GAN to the proposed model. Fig. 8b illustrates recall performance, where the Proposed model consistently achieves the highest recall on all datasets, indicating stronger identity preservation. Fig. 8c summarizes F1-scores, again highlighting the superior balance of precision and recall achieved by the Proposed model, outperforming all existing approaches.
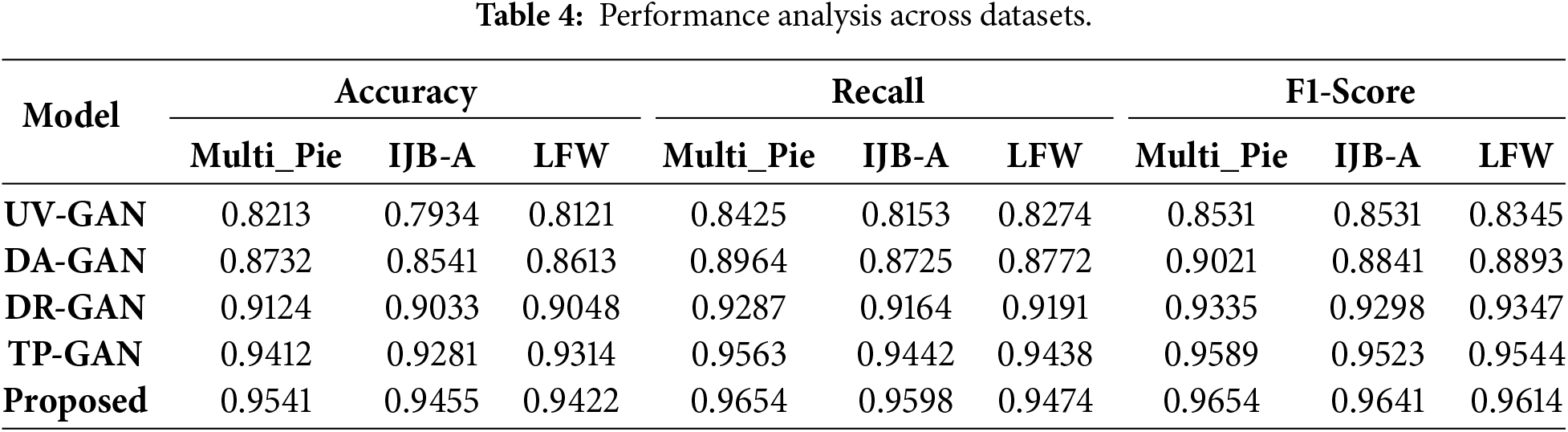
Figure 8: Performance analysis across datasets (a) Accuracy, (b) Recall and (c) F1-Score.
Table 5 provides a comparison of the AUC, TAR, and FAR statistics of all models evaluated on the Multi-Pie, IJB-A, and LFW datasets. Fig. 9 shows the graphical analysis of those statistics. Fig. 9a shows MMF-CycleGAN had the highest AUC score; thus, the model has higher discriminative power and better separation of samples (genuine and impostors). The results in Fig. 9b explains that MMF-CycleGAN has the highest TAR values for the datasets, meaning higher accuracy of matching (recognizing) the correct subjects, even for pose and lighting variations. Finally, Fig. 9c shows MMF-CycleGAN had the lowest FAR, which indicates it reliably did not allow accepting impostors. From the analysis, these results indicate the proposed framework is significant and trust-worthy improvement over present and prior methods.
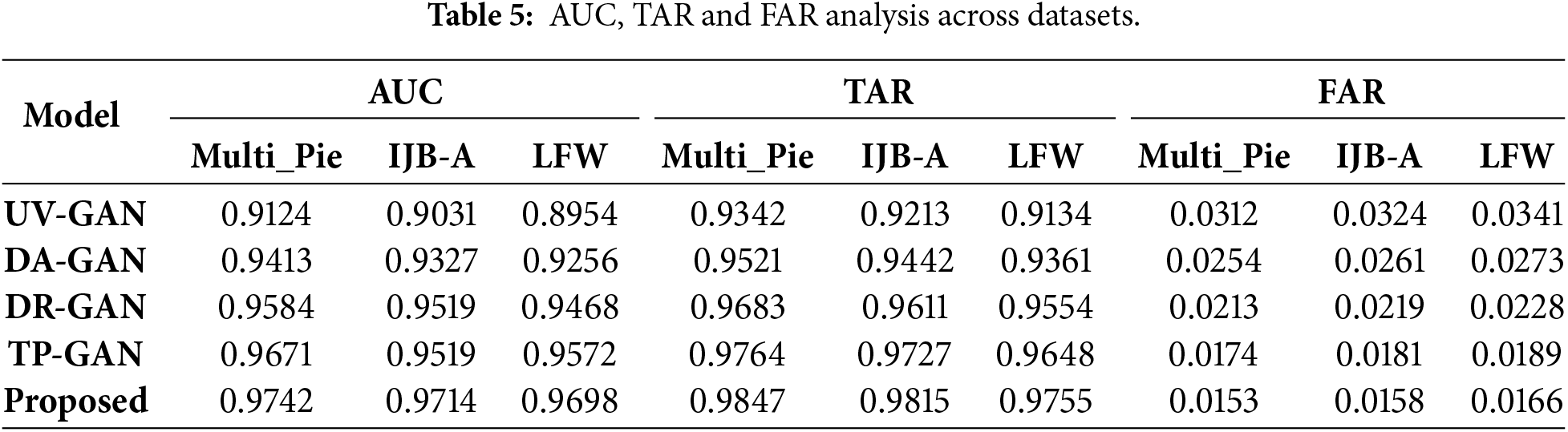
Figure 9: Comparative analysis of AUC, TAR, and FAR across different datasets (a) AUC, (b) TAR and (c) FAR.
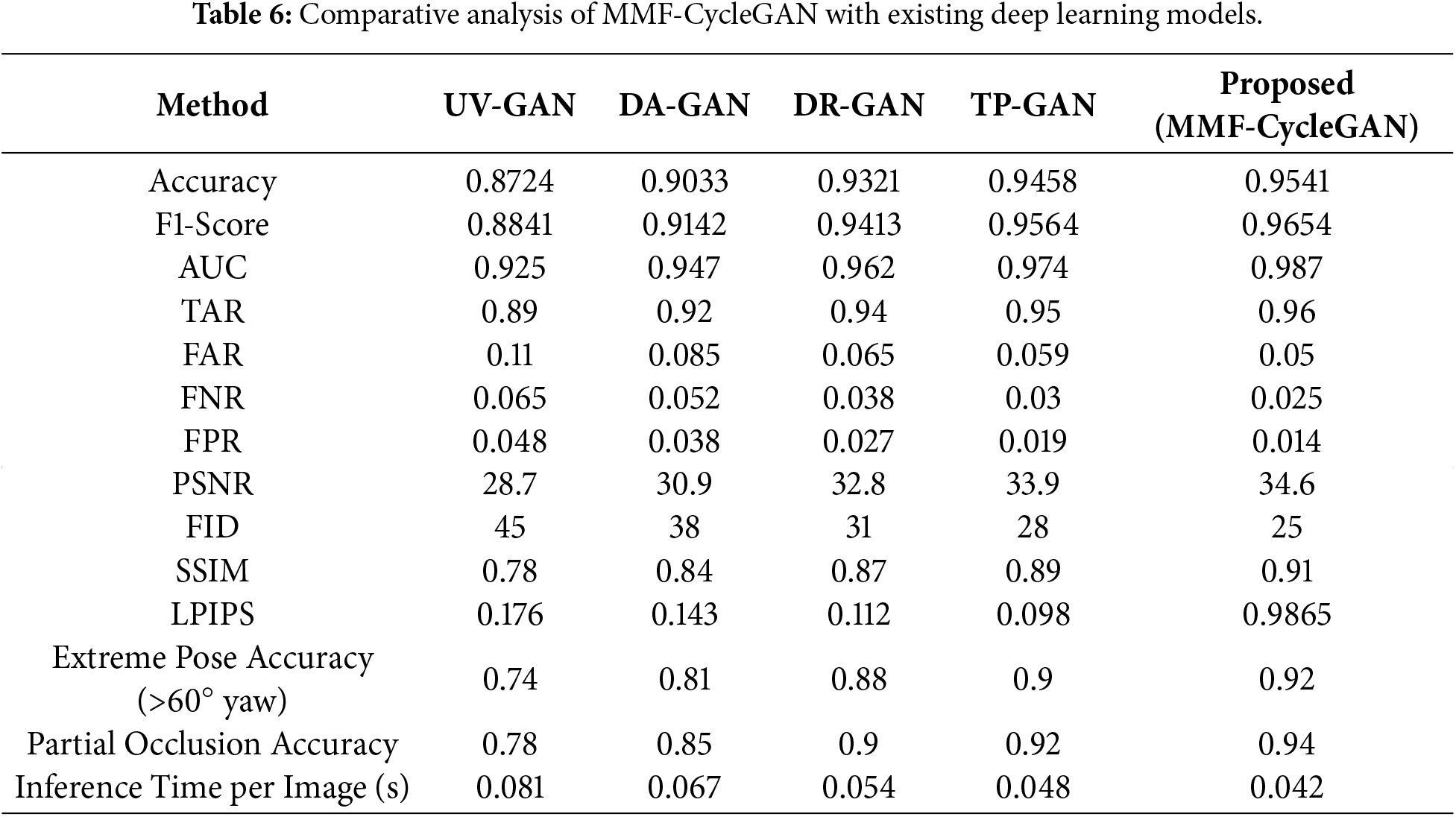
Table 6 gives the comparative analysis of MMF-CycleGAN with some existing models like UV-GAN, DA-GAN, DR-GAN, and TP-GAN. The MMF-CycleGAN has the best Accuracy of 0.9541 and F1-score of 0.9654, both of which suggest superior identity preservation and classification reliability. The MMF-CycleGAN achieved the highest AUC of 0.987 and the lowest FAR and FNR, demonstrating strong robustness throughout the verification process. In terms of perceptual quality, it attained a PSNR of 34.6 dB, an SSIM of 0.91, and the lowest FID of 25, along with minimal LPIPS, indicating superior realism and texture fidelity. The model is also highly robust to extreme poses, with a score of 0.92, and to occlusions, scoring 0.94. Its fast inference time of 0.042 s makes it suitable for real-time biometric applications.
The proposed method demonstrates significantly lower computational complexity compared to DR-GAN and TP-GAN in Table 7. With only 32.1 million parameters, it requires substantially less GPU memory (6.8 GB) and achieves faster training time per epoch (245 s). In contrast, DR-GAN and TP-GAN involve deeper and more complex architectures, leading to higher memory consumption and longer training times. This comparison highlights the improved efficiency of the proposed model while maintaining strong performance.

Table 8 reports the training–testing splits and evaluation protocols used for performance assessment. Multi-PIE follows a subject-disjoint protocol with 249 training and 88 testing subjects, achieving 96.84% Rank-1 accuracy with low variance. IJB-A is evaluated under the official 10-split protocol, yielding a TAR of 92.17% at FAR = 0.01, demonstrating robustness on unconstrained data.
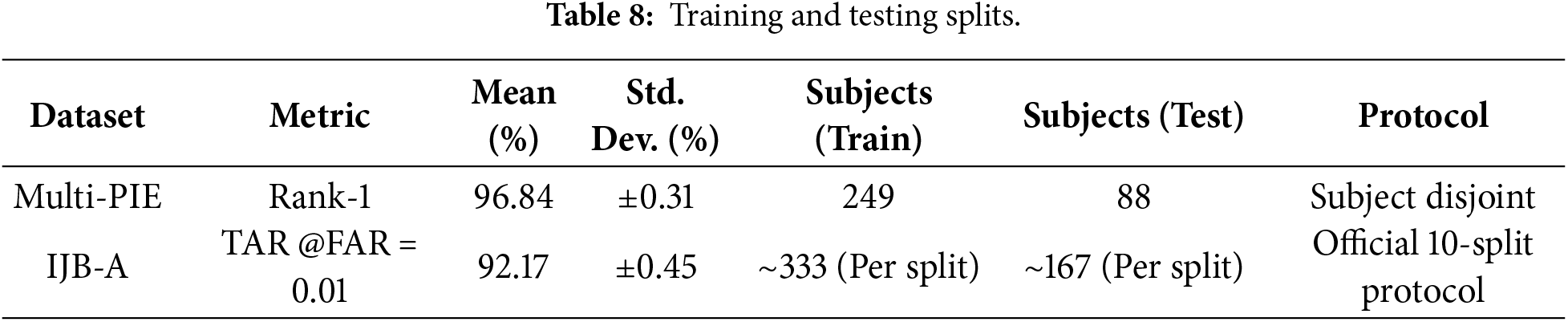
Table 9 summarizes the key hyperparameters used for training. λ_id and λ_per denote the identity loss and perceptual loss weighting coefficients, respectively.
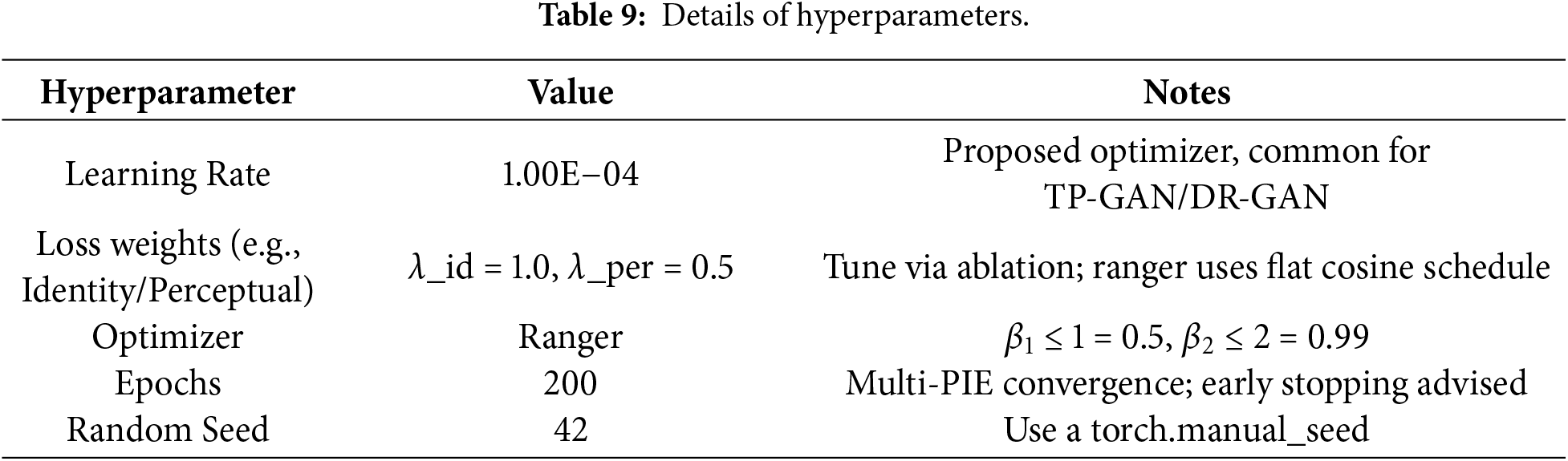
Fig. 10 demonstrates how different GAN-based frontalization techniques can preserve identity by comparing the average cosine similarity of ArcFace embeddings. The suggested approach provided the greatest average cosine similarity score, thereby preserving more identity between the generated frontal images than TP-GAN, DR-GAN, and UV-GAN with respect to their corresponding ground-truth images.
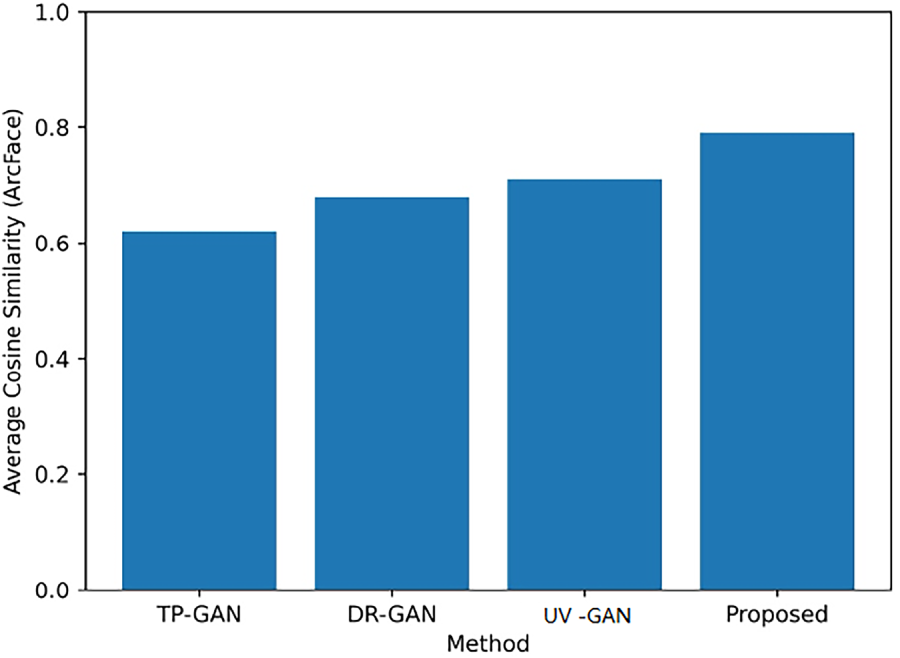
Figure 10: Average cosine similarity of the GAN models.
The qualitative results of the frontalization in Fig. 11 show examples of how different yaw angles (and extreme) affect the outcome for the method proposed compared to the baseline methods. As illustrated under varying yaw angles and poses, the proposed method produces more visually realistic frontal faces with structural consistency, minimal artifacts, and better preservation of identity-related onset facial features than the baseline methods, especially in cases where the subject’s pose varies greatly.

Figure 11: Qualitative analysis for different yaw angles.
In Fig. 12, the graphs show how identity similarity has changed with yaw angle. The greater the pose deviation, the more the various methods have deteriorated in performance. However, the results of the new model are greater concerning cosine similarity across all conditions and exhibited high robustness to Extreme Pose Conditions, whereas the original model is less so and exhibited good reliability for preserving identity across all conditions.
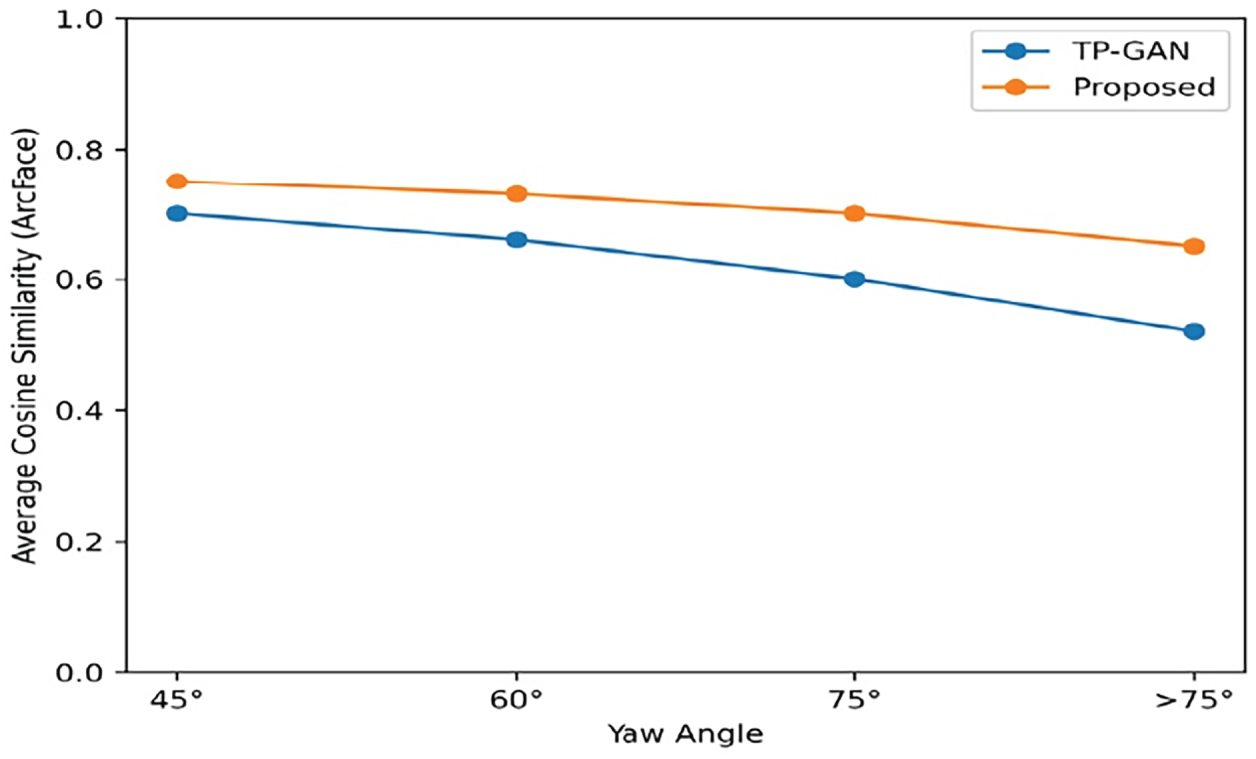
Figure 12: Average cosine similarity analysis at different yaw angles.
Table 10 compares the computational cost of different frontalization models in terms of GFLOPs. The proposed GAN requires only 95 GFLOPs, significantly lower than existing methods such as UV-GAN, DA-GAN, DR-GAN, and TP-GAN. This demonstrates the improved computational efficiency of the proposed approach while maintaining competitive performance.

According to the results presented in Table 11, the experiment indicates that this method exhibits a strong level of accuracy and reliability compared to existing deep learning methodologies. With a confidence interval value of 95% with a predictive accuracy of 0.965, the model exhibited very accurate predictions. Cohen’s d achieves 0.89, reflecting a large effect size when compared with the existing DR-GAN and 3DMM models. With tested robustness, the score for the proposed model was 0.94, reflecting very strong stability and strength across all scenarios used in this testing and demonstrating consistent performance over existing alternatives.
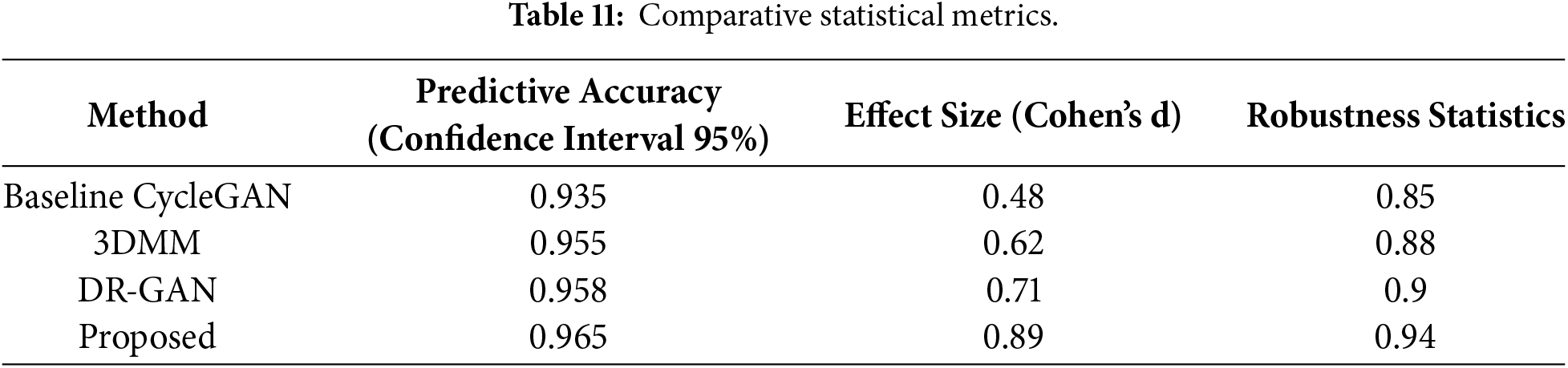
Fig. 13 depicts performance across various methods with increased amounts of training data sample size. The Baseline CycleGAN model has been gradually better in performance at a measure of 0.9411 with 250 samples, and 0.949 at 1000 samples. The 3DMM performance model improved from 0.9485 at 250 samples to 0.953 with 1000 samples. The DR-GAN had an incremental improvement as well. While each of the above methods steadily improved, the proposed method had a dramatic improvement in performance, going from a 0.9541 performance for the 250 sample training data and climbing to 0.975 with the 1000 sample training data. The method’s improvement in performance indicates not only its better learning efficiency, but also its robustness to having more data.
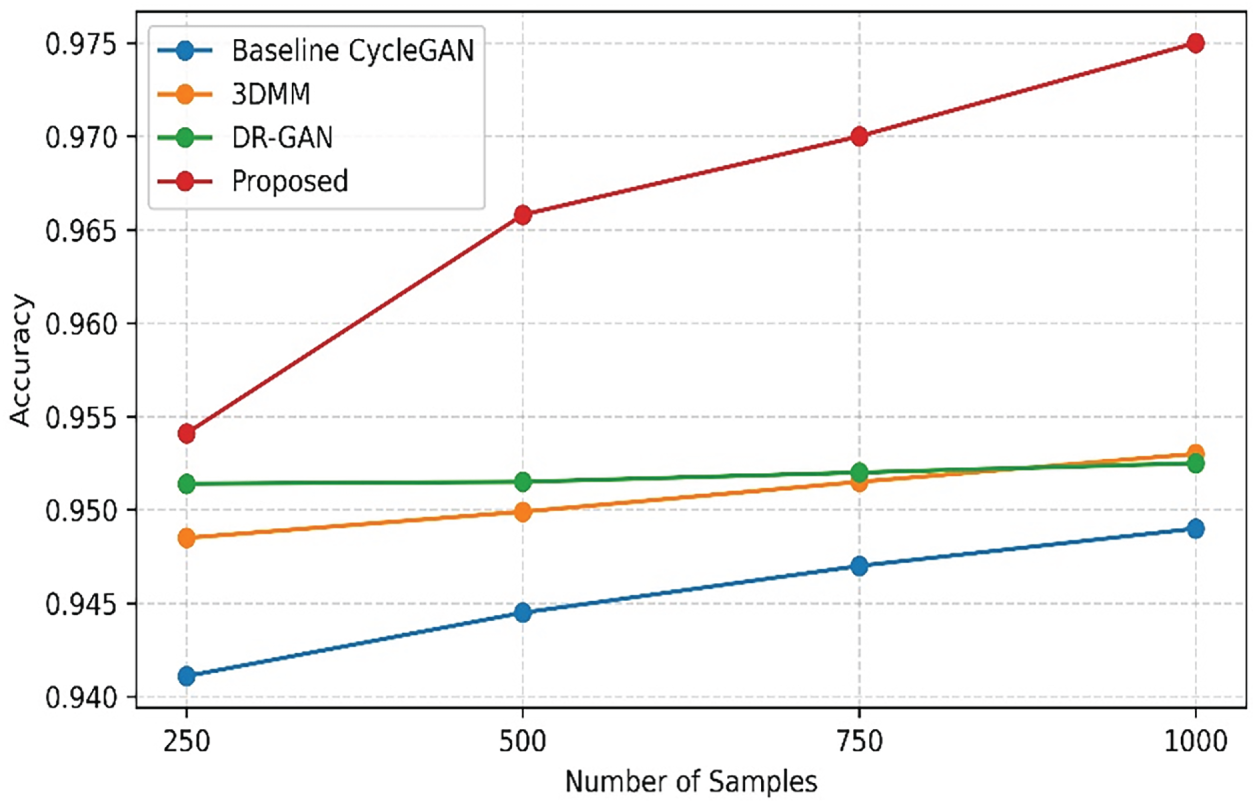
Figure 13: Performance across number of samples.
Fig. 14a illustrates the variation of training and testing accuracy across 100 epochs. During the initial learning phase, up to 20 epochs, accuracy varies between 0.2 and 0.5 due to unstable feature learning. From epochs 20 to 60, accuracy rises sharply and stabilizes around 0.8, indicating effective model convergence. Beyond 60 epochs, both curves remain steady and closely aligned, demonstrating stable learning, good generalization, and the absence of overfitting. Fig. 14b presents the ROC curve of the proposed MMF-CycleGAN model, illustrating the trade-off between the true positive rate and the false positive rate. The high value of 0.9742 confirms excellent classification performance and robust separability between genuine and fake images. Additionally, the steep rise in the curve at low false positive rates demonstrates that the model achieves high detection accuracy while maintaining minimal false alarms, making it highly reliable for face recognition tasks.
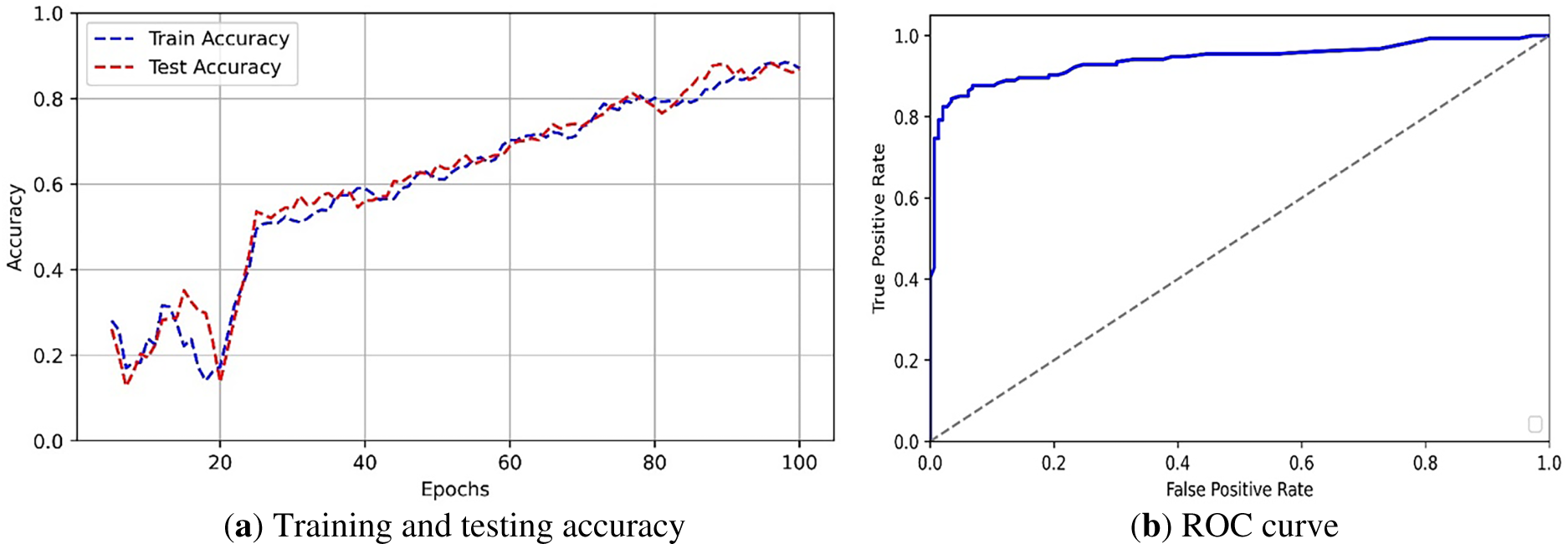
Figure 14: (a) Training and testing accuracy, (b) ROC curve.
Table 12 provides a detailed ablation study examining how each architectural component affects results in the proposed MMF-CycleGAN framework. For each metric tested- Accuracy, F1-Score, AUC, PSNR, SSIM, Extreme Pose Accuracy, etc., the MMF-CycleGAN has the highest value across all, indicating its overall better frontalization quality and identity retention. The removal of one element, such as the Multi-Scale Fusion PatchGAN or the Deep Dilated DenseNet, shows a degrading performance curve, but for the greatest loss uses both elements (baseline CycleGAN). Each one of the metrics based on error (FAR, FNR, FPR, FID, LPIPS) is overall in the lowest range, illustrating the overall stability and realism. The Extreme Pose Accuracy and Occlusion Accuracy figures follow the same trend, as the reliability of models shows much better performance than any of the ablated versions of the proposed model. Therefore, in conclusion, each module helps to get the most significant improvements in face frontalization.
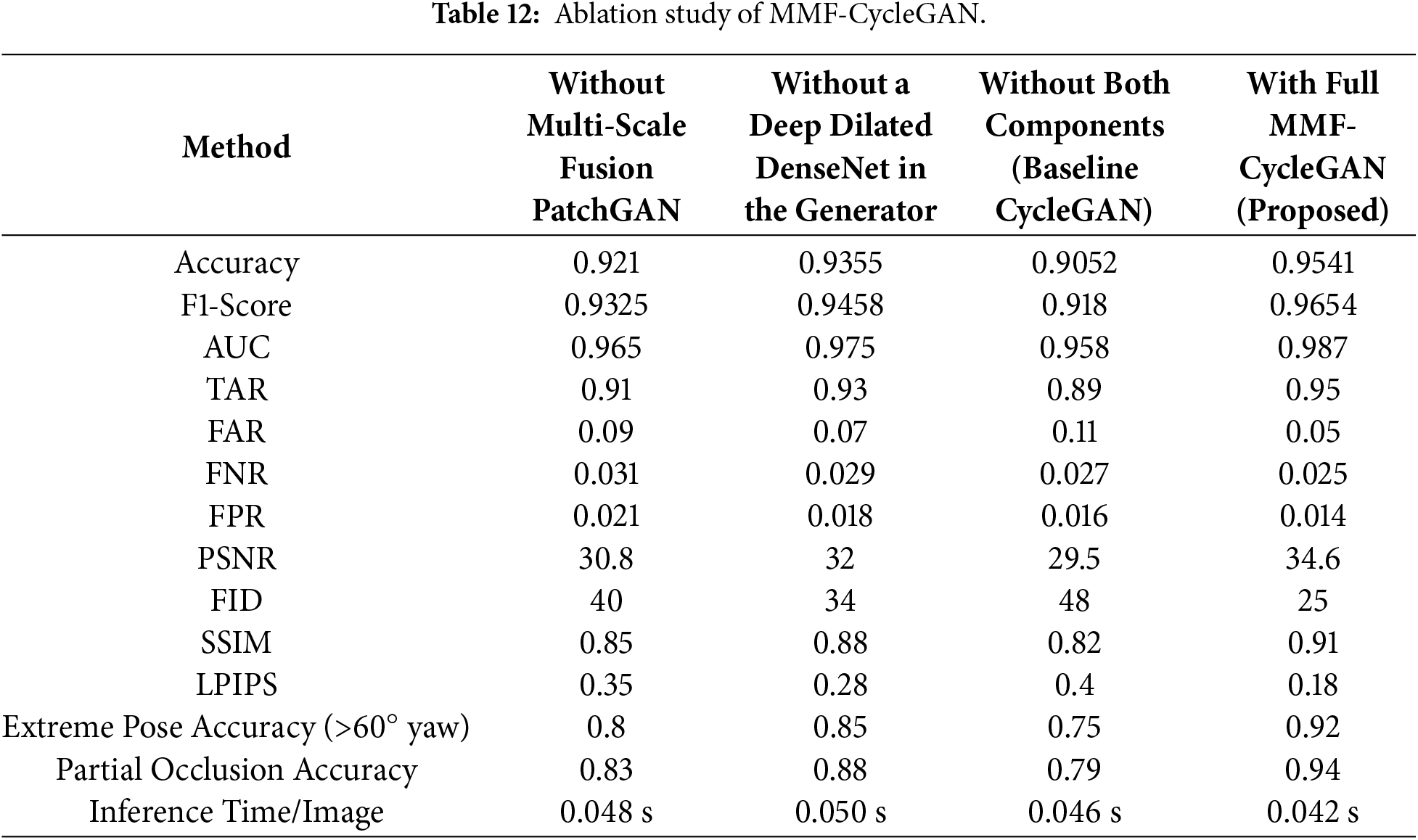
The quantitative evaluation conducted on the Multi-PIE, LFW, and IJB-A datasets demonstrates that the proposed MMF-CycleGAN consistently outperforms recent face frontalization and pose-invariant recognition methods. Specifically, recognition accuracies of 0.9541, 0.9455, and 0.9422 on Multi-PIE, LFW, and IJB-A, respectively, exceed the performance reported in closely related works, confirming the robustness and generalization capability of the proposed framework. Feature-space pose-invariant frontalization models [17] primarily focus on enhancing feature separability in the embedding space. While effective for recognition under moderate pose variations, these methods do not explicitly optimize image-level reconstruction quality, leading to reduced perceptual realism under extreme poses. In contrast, MMF-CycleGAN jointly optimizes identity-preserving feature representations and pixel-level reconstruction through multi-scale feature fusion, resulting in superior recognition accuracy and improved visual fidelity.
Landmark-guided approaches [32] improve geometric alignment by enforcing structural constraints during generation. However, as reported in their original work, such methods are prone to reconstruction blurring when landmark localization becomes unreliable under occlusions or large yaw angles. The proposed MMF-CycleGAN mitigates this limitation by learning dense multi-scale representations without explicit landmark dependency, thereby maintaining higher recognition accuracy and F1-scores across challenging pose conditions. From a verification perspective, MMF-CycleGAN achieves a TAR of 0.9847, an AUC of 0.987, and a lower FAR of 0.0153, outperforming parameter-efficient GAN inversion-based frontalization methods [19]. Although GAN inversion approaches reduce computational complexity, they often trade perceptual quality for efficiency. While MMF-CycleGAN incorporates multi-scale feature fusion and deep dilated dense blocks that increase architectural complexity. Despite this added complexity, the model maintains competitive inference efficiency of 0.042 s/image, achieving a favorable balance between computational cost and performance gains compared to TP-GAN [18], UV-GAN [26], DR-GAN [27], and DA-GAN [28], which incur higher latency due to cascaded processing.
In terms of perceptual quality, MMF-CycleGAN achieves a PSNR of 34.6 dB, FID of 25, and LPIPS of 0.18, surpassing both multi-view frontalization strategies [33] and semi-cycled GAN frameworks [34]. Multi-view methods leverage multiple input viewpoints to reconstruct frontal geometry but experience significant performance degradation in single-view scenarios, which are more common in unconstrained face recognition settings. MMF-CycleGAN is specifically designed for single-view inputs, enabling robust frontalization without auxiliary pose information. Similarly, the semi-cycled GAN approach [32] reduces supervision requirements but yields higher FID values due to weaker cycle consistency constraints, whereas MMF-CycleGAN benefits from tightly fused multi-scale feature learning to preserve identity and texture details.
Ablation studies further validate the effectiveness of the proposed architectural components. Removing either the multi-scale fusion PatchGAN or the Deep Dilated DenseNet results in a PSNR reduction of 3 to 5 dB and an increase in FID by 9 to 23 points, confirming that both components are essential for high-fidelity reconstruction. Moreover, under extreme pose conditions (yaw angles exceeding 60°), MMF-CycleGAN achieves an accuracy of 0.92, outperforming and TP-GAN [18], UV-GAN [26] which exhibit notable degradation under similar conditions. Overall, MMF-CycleGAN achieves a favorable balance between identity preservation, perceptual realism, robustness to occlusion and pose variation, and computational efficiency. Compared with five recent deep-learning-based frontalization approaches, the proposed method demonstrates consistent improvements across recognition, verification, and perceptual metrics, establishing it as a strong choice for practical face recognition systems.
Role of Each Module Based on Ablation Results
Deep Dilated DenseNet (Generator Encoder): The DenseNet enhances hierarchical feature extraction and captures long-range spatial dependencies using dilated convolutions. Without it, the model suffers reductions in PSNR, SSIM, and accuracy, reflecting weaker structural consistency and detail preservation.
Transformer Block: The Transformer provides global semantic modeling crucial for handling self-occlusion and extreme pose variations. Removing it leads to a significant drop in extreme-pose (>60° yaw) and partial-occlusion accuracy, despite moderate performance on standard metrics.
Multi-Scale Fusion PatchGAN: This module enforces adversarial supervision at multiple spatial resolutions, improving both global facial structure and fine-grained texture realism. Its removal increases FID, LPIPS, FAR, and FPR, indicating reduced perceptual quality and identity discrimination.
Baseline CycleGAN (Without DenseNet and MSF-PatchGAN): The baseline lacks both advanced feature extraction and multi-scale adversarial constraints, resulting in the poorest performance across all metrics, confirming that the proposed components are essential rather than incremental.
Thus, the ablation results show that each architectural component contributes a distinct and complementary function. DenseNet improves structural robustness, the Transformer ensures global semantic coherence, and the Multi-Scale Fusion PatchGAN enforces perceptual fidelity. Their integration enables MMF-CycleGAN to achieve superior frontalization quality and identity preservation compared to all ablated variants.
The proposed MMF-CycleGAN is an effective solution for face-frontalization that demonstrates robustness with images impacted by extreme pose variations. By integrating a Deep Dilated DenseNet generator, a multi-scale fusion PatchGAN discriminator, and the Ranger optimizer, the model achieves stable convergence, improved feature learning, and enhanced identity preservation. The model was tested on publicly available datasets, including Multi-PIE, LFW, and IJB-A. MMF-CycleGAN performed well above existing models and achieved the highest Accuracy of 0.9541, Recall of 0.9654, F1 score of 0.9654, and AUC of 0.987, while also attaining the lowest FID of 25, LPIPS of 0.09865, and PSNR of 34.6 dB. Robustness is further confirmed with 0.92 accuracy for yaw angles greater than 60° and 0.94 under occlusion, along with an efficient inference time of 0.042 s/image even at multi-scale feature integration and deep dilated dense block architectures. Overall, MMF-CycleGAN offers a reliable and high-performing solution for real-world face recognition applications such as real-time surveillance and security systems, cross-pose face recognition in unconstrained environments, forensic analysis, and identity verification in access control systems, where robust frontalization under pose, illumination, and occlusion variations is critical.
Limitations and Future Scope
Limitations of MMF-CycleGAN: Although MMF-CycleGAN demonstrates consistent improvements across multiple benchmarks, its performance may degrade in some cases. First, the frontalization quality degrades when input images are of very low resolution, where fine-grained identity cues such as skin texture and subtle facial details are largely lost. Second, the model is less effective under severe motion blur, as these distortions hinder reliable feature extraction and global dependency modeling. Additionally, while the transformer module improves global consistency, it introduces moderate computational overhead, which may affect deployment on highly resource-constrained devices. Addressing these challenges through blur-aware training, super-resolution integration, and lightweight transformer designs will be explored in future work.
Future Scope: The MMF-CycleGAN framework provides the foundation for successful frontalization of facial images, as well as directions for future research. First, the use of a hybrid diffusion-GAN architecture could facilitate greater photorealism and identity retention when frontalizing faces from extreme poses and extreme lighting conditions. Secondly, extending the framework to include video-based frontalization utilizing temporal constraints would lead to usage in Human Robot Interaction (HRI), surveillance, and affective computing applications. Thirdly, Integration of 3D priors by embedding 3D morphable model parameters into the generator will lead to increased geometric correctness and fewer artifacts generated during the frontalization process that can occur at large yaw angles beyond ±75°. Lightweight transformers should use patch-based or sparse attention, reduced heads, and convolution–attention hybrids to capture global context with minimal computational overhead. The framework will also expand for multi-attribute frontalization (pose, expression, aging and lighting). Lastly, validity through evaluation on large-scale cross-ethnicity and cross-age datasets will offer an improvement in generalizability and fairness to provide legitimacy to MMF-CycleGAN as a framework for frontalizing facial images.
Acknowledgement: Not applicable.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Swetha K carried out the conceptualization, methodology design, experimentation, analysis and manuscript preparation. Supervision and guidance throughout the research were provided by Shiloah Elizabeth Darmanayagam and Sunil Retmin Raj Cyril. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The datasets analyzed during the current study are publicly available and described in their original publications: Multi-PIE Dataset [29], Labeled Faces in the Wild (LFW) dataset [30], and the IARPA Janus Benchmark A (IJB-A) dataset [31]. No new datasets were generated during the current study.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Khan MW, Jia M, Zhang X, Yu E, Shan C, Musial-Gabrys K. InstaFace: identity-preserving facial editing with single image inference. arXiv:2502.20577. 2025. [Google Scholar]
2. Liu Y, Chen J. Unsupervised face frontalization for pose-invariant face recognition. Image Vis Comput. 2021;106(12):104093. doi:10.1016/j.imavis.2020.104093. [Google Scholar] [CrossRef]
3. Kang Z, Sadeghi M, Horaud R, Alameda-Pineda X. Expression-preserving face frontalization improves visually assisted speech processing. Int J Comput Vis. 2023;131(5):1122–40. doi:10.1007/s11263-022-01742-1. [Google Scholar] [CrossRef]
4. Fan X, Liao M, Chen L, Hu J. Few-shot learning for multi-POSE face recognition via hypergraph de-deflection and multi-task collaborative optimization. Electronics. 2023;12(10):2248. doi:10.3390/electronics12102248. [Google Scholar] [CrossRef]
5. Lin SD, Linares Otoya PE. LS-SIFT: enhancing the robustness of SIFT during pose-invariant face recognition by learning facial landmark specific mappings. IEEE Access. 2024;12:76648–62. doi:10.1109/ACCESS.2024.3406911. [Google Scholar] [CrossRef]
6. Dong J, Zhang Y, Fan L. A multi-view face expression recognition method based on DenseNet and GAN. Electronics. 2023;12(11):2527. doi:10.3390/electronics12112527. [Google Scholar] [CrossRef]
7. Ruiu P, Lagorio A, Cadoni M, Grosso E. Enhancing eID card mobile-based authentication through 3D facial reconstruction. J Inf Secur Appl. 2023;77:103577. doi:10.1016/j.jisa.2023.103577. [Google Scholar] [CrossRef]
8. Choi W, Nam GP, Cho J, Kim IJ, Ko HS. Integrating pretrained encoders for generalized face frontalization. IEEE Access. 2024;12:43530–9. doi:10.1109/ACCESS.2024.3377220. [Google Scholar] [CrossRef]
9. Yang X, Jia X, Gong D, Yan DM, Li Z, Liu W. LARNeXt: end-to-end lie algebra residual network for face recognition. IEEE Trans Pattern Anal Mach Intell. 2023;45(10):11961–76. doi:10.1109/TPAMI.2023.3279378. [Google Scholar] [PubMed] [CrossRef]
10. Sub-r-pa C, Chen RC, Fan MZ. Facial expression morphing: enhancing visual fidelity and preserving facial details in CycleGAN-based expression synthesis. PeerJ Comput Sci. 2024;10(1):e2438. doi:10.7717/peerj-cs.2438. [Google Scholar] [PubMed] [CrossRef]
11. Cheng X. Refining CycleGAN with attention mechanisms and age-aware training for realistic deepfakes. Heliyon. 2024;10(16):e36665. doi:10.1016/j.heliyon.2024.e36665. [Google Scholar] [PubMed] [CrossRef]
12. Zhao J, Yuan Z, Zhang J, Li H, Li H. Frontal face generation based on attitude point guidance and attention mechanism improvement. IEEE Access. 2025;13:24988–96. doi:10.1109/ACCESS.2024.3520618. [Google Scholar] [CrossRef]
13. Kong W, You Z, Lv X. 3D face recognition algorithm based on deep Laplacian pyramid under the normalization of epidemic control. Comput Commun. 2023;199(1):30–41. doi:10.1016/j.comcom.2022.12.011. [Google Scholar] [PubMed] [CrossRef]
14. Lu J, Zhou J, Dong J, Li B, Lyu S, Li Y. ForensicsForest family: a series of multi-scale hierarchical cascade forests for detecting GAN-generated faces. IEEE Trans Inf Forensics Secur. 2024;19(4):5106–19. doi:10.1109/TIFS.2024.3395013. [Google Scholar] [CrossRef]
15. George A, Marcel S. Heterogeneous face recognition with prepended domain transformers. In: Face recognition across the imaging spectrum. Singapore: Springer Nature Singapore; 2024. p. 169–204. [Google Scholar]
16. Liao J, Guha T, Sanchez V. Self-supervised random mask attention GAN in tackling pose-invariant face recognition. Pattern Recognit. 2025;159(1):111112. doi:10.1016/j.patcog.2024.111112. [Google Scholar] [CrossRef]
17. Stanishev N, Lu Y, Ebrahimi T. Pose-invariant face recognition via feature-space pose frontalization. arXiv:2505.16412. 2025. [Google Scholar]
18. Alhlffee MHB, Huang YS. A novel face frontalization method by seamlessly integrating landmark detection and decision forest into generative adversarial network (GAN). Mathematics. 2025;13(3):499. doi:10.3390/math13030499. [Google Scholar] [CrossRef]
19. Ahmadi M, Kambarani N, Mohammadi MR. Parameter efficient face frontalization in image sequences via GAN inversion. IET Image Process. 2025;19(1):e70003. doi:10.1049/ipr2.70003. [Google Scholar] [CrossRef]
20. Zhou Y, Wang D. An innovative method of multi-view face frontalization based on receptive field-enhanced conditional generative adversarial network. Eng Appl Artif Intell. 2025;162:112539. doi:10.1016/j.engappai.2025.112539. [Google Scholar] [CrossRef]
21. Ikne O, Allaert B, Bilasco IM, Wannous H. eMotion-GAN: a motion-based GAN for photorealistic and facial expression preserving frontal view synthesis. arXiv:2404.09940. 2024. [Google Scholar]
22. Kim M, Liu F, Jain A, Liu X. DCFace: synthetic face generation with dual condition diffusion model. In: Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. p. 12715–25. [Google Scholar]
23. Lo SL, Cheng HY, Yu CC. Feature weighted cycle generative adversarial network with facial landmark recognition and perceptual color distance for enhanced face animation generation. Electronics. 2024;13(23):4761. doi:10.3390/electronics13234761. [Google Scholar] [CrossRef]
24. Mesec P, Jović A. Towards large-scale pose-invariant face recognition using face defrontalization. arXiv:2506.04496. 2025. [Google Scholar]
25. Shen Y, Zhou B, Luo P, Tang X. FaceFeat-GAN: a two-stage approach for identity-preserving face synthesis. arXiv:1812.01288. 2018. [Google Scholar]
26. Li L, Zhang T, Kang Z, Jiang X. Mask-FPAN: semi-supervised face parsing in the wild with de-occlusion and UV GAN. Comput Graph. 2023;116(4):185–93. doi:10.1016/j.cag.2023.08.003. [Google Scholar] [CrossRef]
27. Ali Iqbal M, Jadoon W, Kim SK. Synthetic image generation using conditional GAN-provided single-sample face image. Appl Sci. 2024;14(12):5049. doi:10.3390/app14125049. [Google Scholar] [CrossRef]
28. Cao J, Chen Z, Zhang Y, Sun L, Chen J. Face frontalization with deep GAN via multi-attention mechanism. Signal Image Video Process. 2023;17(5):1965–73. doi:10.1007/s11760-022-02409-7. [Google Scholar] [CrossRef]
29. Gross R, Matthews I, Cohn J, Kanade T, Baker S. Multi-PIE. Image Vis Comput. 2010;28(5):807–13. doi:10.1016/j.imavis.2009.08.002. [Google Scholar] [PubMed] [CrossRef]
30. Huang GB, Mattar M, Berg T, Learned-Miller E. Labeled faces in the wild: a database for studying face recognition in unconstrained environments. In: Proceedings of the Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition; 2008 Oct; Marseille, France. [Google Scholar]
31. Klare BF, Klein B, Taborsky E, Blanton A, Cheney J, Allen K, et al. Pushing the frontiers of unconstrained face detection and recognition: IARPA Janus Benchmark A. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2015 Jun 7–12; Boston, MA, USA. [Google Scholar]
32. Zhuang C, Li M, Zhang K, Li Z, Lu J. Multi-level landmark-guided deep network for face super-resolution. Neural Netw. 2022;152:276–86. doi:10.1016/j.neunet.2022.04.026. [Google Scholar] [PubMed] [CrossRef]
33. Ning X, Nan F, Xu S, Yu L, Zhang L. Multi-view frontal face image generation: a survey. Concurr Comput Pract Exp. 2023;35(18):e6147. doi:10.1002/cpe.6147. [Google Scholar] [CrossRef]
34. Cai H, Li S. Semi-cycled GAN for unsupervised face frontalization. Digit Signal Process. 2025;159:104986. doi:10.1016/j.dsp.2025.104986. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools