
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

CardioForest: An Explainable Ensemble Learning Model for Automatic Wide QRS Complex Tachycardia Diagnosis from ECG
1 School of Artificial Intelligence and Computer Science, Nantong University, Nantong, 226001, China
2 College of Information Science and Engineering, Henan University of Technology, Zhengzhou, 450001, China
3 Department of Information Center, Affiliated Hospital of Nantong University, Nantong, 226001, China
* Corresponding Authors: Haiyan Pan. Email: ; Gao Zhan. Email:
# These authors contributed equally to this work
Journal of Intelligent Medicine and Healthcare 2026, 4, 37-86. https://doi.org/10.32604/jimh.2026.075201
Received 27 October 2025; Accepted 28 November 2025; Issue published 23 January 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Wide QRS Complex Tachycardia (WCT) is a life-threatening cardiac arrhythmia requiring rapid and accurate diagnosis. Traditional manual ECG interpretation is time-consuming and subject to inter-observer variability, while existing AI models often lack the clinical interpretability necessary for trusted deployment in emergency settings. We developed CardioForest, an optimized Random Forest ensemble model, for automated WCT detection from 12-lead ECG signals. The model was trained, tested, and validated using 10-fold cross-validation on 800,000 ten-second-long 12-lead Electrocardiogram (ECG) recordings from the MIMIC-IV dataset (15.46% WCT prevalence), with comparative evaluation against XGBoost, LightGBM, and Gradient Boosting models. Performance was assessed using accuracy, balanced accuracy, precision, recall, F1-score, ROC-AUC, RMSE, and MAE. SHAP (SHapley Additive exPlanations) analysis provided feature-level interpretability to ensure clinical validity. CardioForest achieved superior and consistent performance across all metrics: test accuracy 95.19% (Keywords
Wide QRS Complex Tachycardia (WCT) is a severe and potentially lethal cardiac condition characterized by an exceedingly rapid heartbeat in combination with a widened QRS complex on the electrocardiogram (ECG) [1–3]. Normally, the QRS complex—a short, spiky waveform—registers the process of ventricular depolarization, whereby the ventricles of the heart contract and effectively pump blood [4,5]. A regular narrow QRS complex indicates typical electrical conduction through the heart’s normal pathways [6,7]. However, if the QRS complex is wide, then this is an indication of a disruption in electrical propagation [8], typically as a result of underlying structural disease, electrolyte imbalance, or an inherited disorder.
Untreated, WCT can significantly weaken the heart’s function to circulate blood effectively, causing symptoms that range from palpitations, dizziness, and chest pain to, in extreme cases, sudden cardiac arrest [9,10]. Understanding these structural abnormalities underscores the clinical importance of accurate WCT diagnosis, as delayed recognition can lead to severe complications, including heart failure and arrhythmias. As such, the early and correct diagnosis of WCT is not only critical—it is a matter of life and death. Diagnosis of WCT has traditionally depended to a large extent on manual ECG interpretation by experienced cardiologists. While still the gold standard, this process is time-consuming, labor-intensive, and subject to considerable variability [11,12]. Individual cardiologists may disagree in borderline or uncertain cases, postponing diagnosis and treatment [13,14]. In high-pressure clinical environments where minutes matter, delays can be detrimental. As healthcare systems globally face rising demands, the demand for faster, more accurate diagnostic support that augments, rather than replaces, clinical judgment is pressing. In the past few years, Artificial Intelligence (AI)-driven models have been demonstrated to achieve stellar performance in ECG interpretation with accuracy and speed [15]. Among them, deep learning methods—particularly Convolutional Neural Networks (CNNs)—have worked incredibly well in identifying complex patterns within ECG signals that are not easily visible to the naked eye [16–18]. However, for all the high-accuracy deep learning models claim, they tend to behave like “black boxes” with little description of decision-making. This absence of transparency has been a significant barrier to clinical adoption because cardiologists and clinicians need not only accuracy but also transparency to trust AI recommendations. For AI to be successfully integrated into clinical practice, especially in life-critical conditions like WCT, interpretability is equally as important as accuracy [19].
Cardiologists must understand the rationale for AI predictions—seeing not just the output, but the supporting evidence, e.g., what ECG features led to a specific classification. Without this transparency, clinicians will remain unconvinced and reluctant to trust AI for decision-making, especially when a patient’s life hangs in the balance. Given these challenges, this research introduces a novel solution: CardioForest, an interpretable ensemble-based AI model for WCT detection. Based primarily on Random Forest architecture—augmented with techniques such as XGBoost, LightGBM, and Gradient Boosting—CardioForest leverages the strengths of ensemble machine learning to achieve both high diagnostic precision and clear interpretability [20]. CardioForest distinguishes itself from traditional rule-based diagnostic algorithms (Brugada criteria, Vereckei algorithm) through its data-driven learning approach combined with transparent decision-making. While rule-based methods rely on fixed thresholds and sequential decision trees with reported accuracies of 80%–90% and significant inter-observer variability, CardioForest learns optimal decision boundaries directly from large-scale clinical data while maintaining interpretability through feature importance rankings and SHAP value analysis. Unlike the binary decision rules of traditional algorithms (e.g., “if QRS duration > 120 ms AND AV dissociation is present, then VT”), CardioForest quantifies the continuous contribution of each ECG feature to the final prediction, providing clinicians with nuanced probability estimates and confidence scores rather than deterministic classifications. This hybrid approach—combining machine learning’s pattern recognition capabilities with the transparency clinicians expect from rule-based systems—represents a significant advancement in bridging the gap between AI performance and clinical adoption. Unlike deep neural networks, Random Forest models are natively explainable through feature importance rankings and decision-tree visualization. This dual advantage ensures clinicians can rely on and interpret the model outputs. Our experiment design is focused not only on the evaluation of diagnostic accuracy but also on increasing clinical trust by employing explainable AI (XAI) methods, for example, SHAP (SHapley Additive exPlanations) [21] values and feature attribution analysis [22]. CardioForest bridges the crucial gap between AI’s computational power and the clinician’s need for interpretability by highlighting which features most significantly influenced the model’s decisions. Preliminary results suggest that CardioForest outperforms traditional manual approaches and competes favorably with state-of-the-art deep learning models while offering superior transparency, an essential quality for clinical adoption. For all these developments, we acknowledge that challenges remain. Future research should also explore continuous learning frameworks, where AI models learn incrementally from new data, thereby improving their diagnostic acumen over time without compromising explainability. Fig. 1 presents CardioForest as a pioneering WCT detection solution by providing cardiologists with speedy, interpretable, and reliable AI support. We hope to enhance cardiac diagnosis, reduce diagnostic latency, and ultimately save more lives. After that, Fig. 2 illustrates the anatomical differences between normal cardiac structure and pathological conditions such as left ventricular noncompaction, which can manifest as wide QRS complexes on ECG. The presence of prominent trabeculations in the left ventricle (right panel) disrupts normal electrical conduction pathways, contributing to the wide QRS morphology that CardioForest is designed to detect. We include this clinical reference textbook [6] as it represents the current gold standard for ECG education used in training cardiologists who serve as the benchmark for AI system comparison. Looking ahead, we envision the expansion of explainable ensemble model applications beyond WCT toward general arrhythmia detection with the inclusion of real-time ECG monitoring for preemptive cardiac health management.
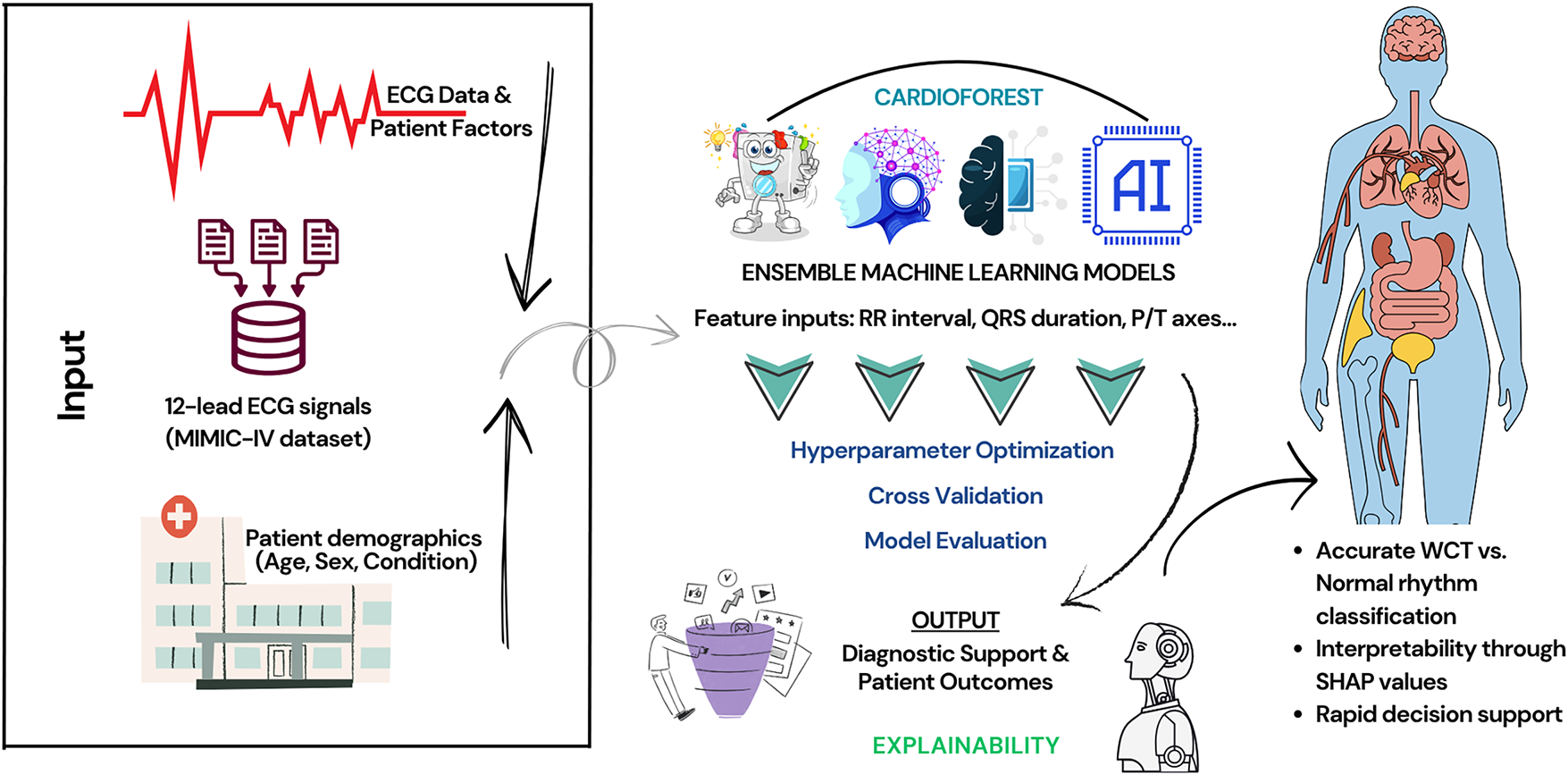
Figure 1: An overview of the WCT prediction system using the MIMIC-IV ECG database, featuring preprocessing, ensemble machine learning models, cross-validation, and final prediction
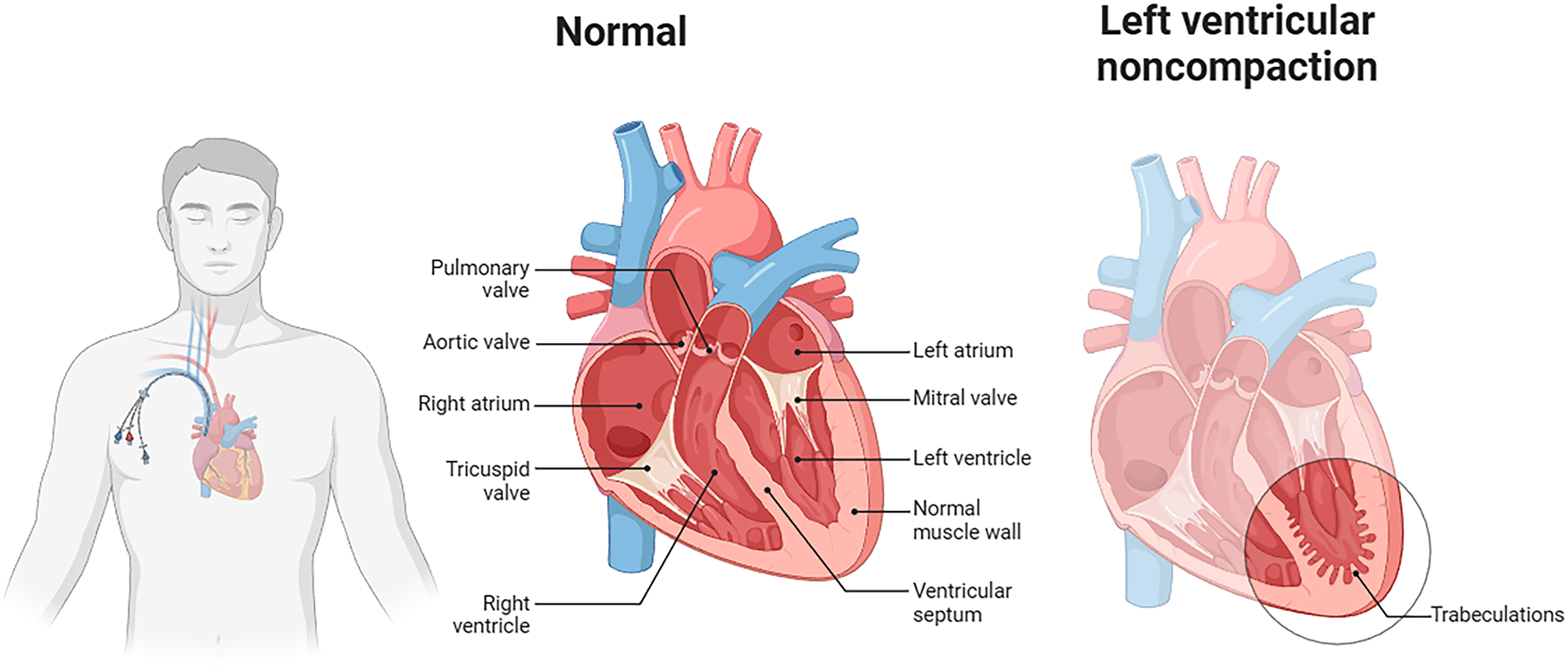
Figure 2: Anatomical comparison between normal cardiac structure (center) and left ventricular noncompaction (right). The normal heart shows regular ventricular muscle wall thickness and organized electrical pathways. In contrast, left ventricular noncompaction exhibits prominent trabeculations and disorganized myocardial structure, which disrupts electrical conduction and manifests as wide QRS complexes on ECG. Such structural abnormalities represent one category of conditions that CardioForest must accurately identify to guide appropriate clinical management
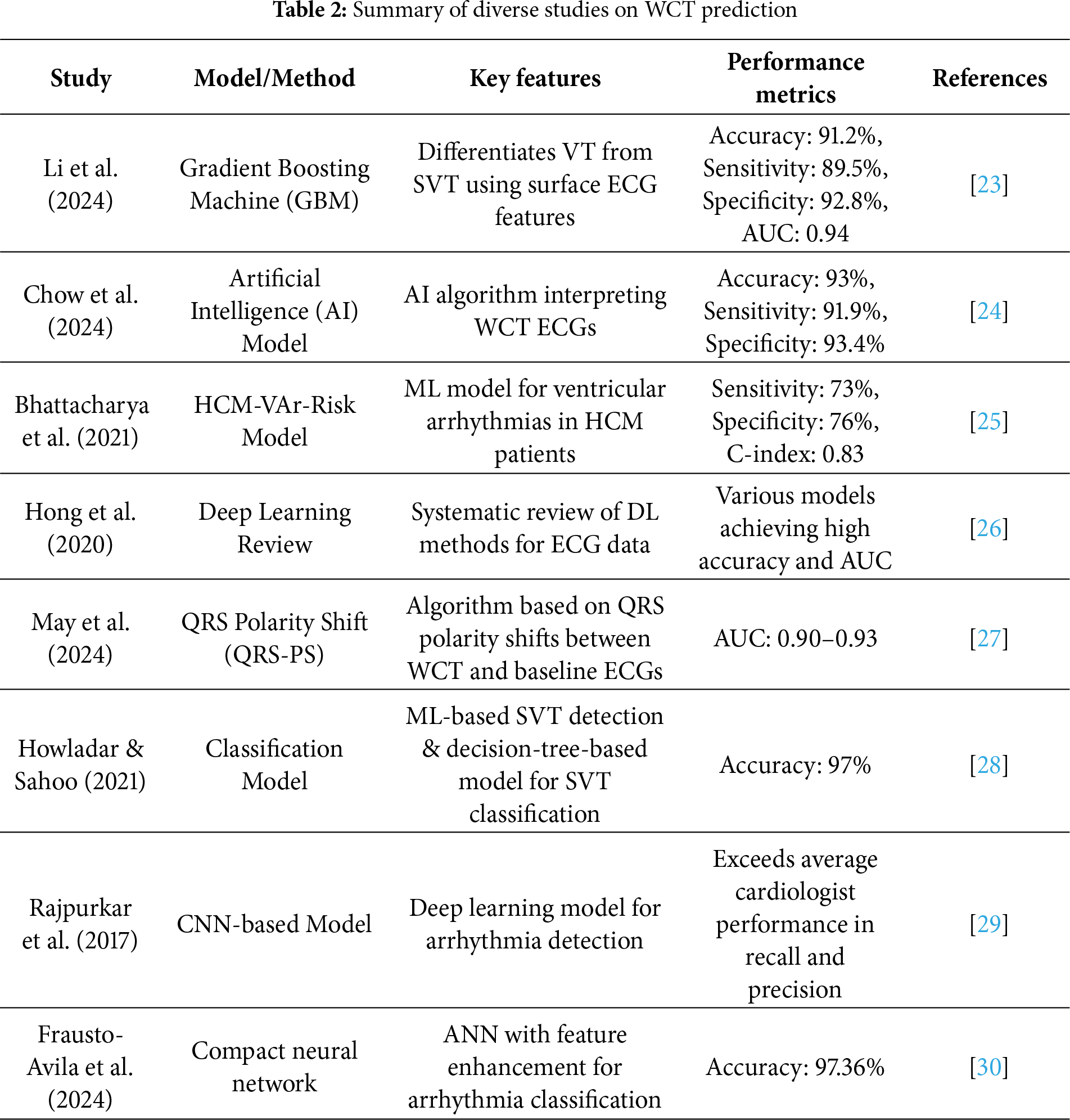
Accurate and timely prediction of Wide Complex Tachycardia (WCT) remains a major focus in cardiovascular research, driven by the need to distinguish between ventricular tachycardia (VT) and supraventricular tachycardia (SVT) with aberrant conduction. Machine learning (ML) and deep learning (DL) techniques have gained prominence in this domain, offering new avenues for improved diagnostic performance compared to traditional criteria-based methods.
Li et al. [23] proposed a Gradient Boosting Machine (GBM) model for differentiating VT from SVT using surface ECG features. Their approach leveraged a rich set of ECG-derived parameters, leading to an impressive classification performance with an overall accuracy of 91.2%, sensitivity of 89.5%, specificity of 92.8%, and an area under the ROC curve (AUC) of 0.94. This study highlighted the importance of carefully selected ECG features in enhancing machine learning model performance. Building on the trend of AI-driven diagnosis, Chow et al. [24] developed a specialized AI model to interpret WCT directly from ECGs. Their system, designed with clinical applicability in mind, demonstrated an overall accuracy of 93%, with sensitivity and specificity exceeding 91%. This work showcased the potential of deep learning models in outperforming traditional rule-based algorithms for arrhythmia classification, particularly for ambiguous WCT cases.
Focusing on high-risk populations, Bhattacharya et al. [25] introduced the HCM-VAr-Risk model, which applies machine learning techniques to predict ventricular arrhythmias in patients with hypertrophic cardiomyopathy (HCM). Their model achieved a C-index of 0.83, reflecting strong discriminative ability. The study underscored the utility of ML for risk stratification in structurally abnormal hearts, offering a more individualized approach to arrhythmia prediction. Hong et al. [26] provided a broader perspective by conducting a systematic review of deep learning applications for ECG analysis, including arrhythmia detection and classification tasks. The review covered a range of architectures, such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), and hybrid models, illustrating the high accuracy and generalizability of DL models when trained on large, diverse ECG datasets. Their findings support the growing consensus that deep learning can significantly enhance the detection of complex arrhythmias, including WCT.
Addressing diagnostic challenges from a different angle, May et al. [27] introduced the QRS Polarity Shift (QRS-PS) method, which focuses on changes in QRS polarity between baseline ECGs and WCT episodes. By simplifying the interpretation of polarity shifts, their algorithm achieved AUC values ranging from 0.90 to 0.93. This technique provides a pragmatic and explainable tool that can be readily integrated into clinical workflows, assisting clinicians in making rapid and accurate diagnoses. Machine learning classification models have also shown remarkable potential in SVT detection. Howladar and Sahoo [28] developed a decision-tree-based model specifically tailored for SVT identification. Their model attained a striking 97% accuracy, demonstrating the effectiveness of even relatively simple ML algorithms when paired with relevant feature selection. Deep learning models have further pushed the boundaries of arrhythmia prediction. Rajpurkar et al. [29] designed a CNN-based model, trained on a large annotated ECG dataset, that achieved recall and precision rates exceeding those of board-certified cardiologists. Their work set a new benchmark for DL-based arrhythmia detection and provided strong evidence for adopting AI-assisted ECG interpretation tools in clinical practice.
In addition, Frausto-Avila et al. [30] presented a compact neural network architecture enhanced with advanced feature engineering techniques. Their model achieved an accuracy of 97.36% in arrhythmia classification tasks, suggesting that lightweight models can maintain high predictive performance while offering advantages in computational efficiency, making them suitable for deployment in real-time or resource-constrained environments. The reviewed studies demonstrate that both machine learning and deep learning approaches have significantly advanced WCT prediction and arrhythmia classification. The diversity of methods—from feature-driven models like GBM and decision trees to sophisticated deep learning architectures like CNNs—reflects the rich potential of AI technologies to improve clinical outcomes. All abbreviations referenced in this paper, along with their definitions, are compiled in Table 1 and a detailed comparison of these related works, including their methodologies, key innovations, and achieved performance metrics, is presented in Table 2.

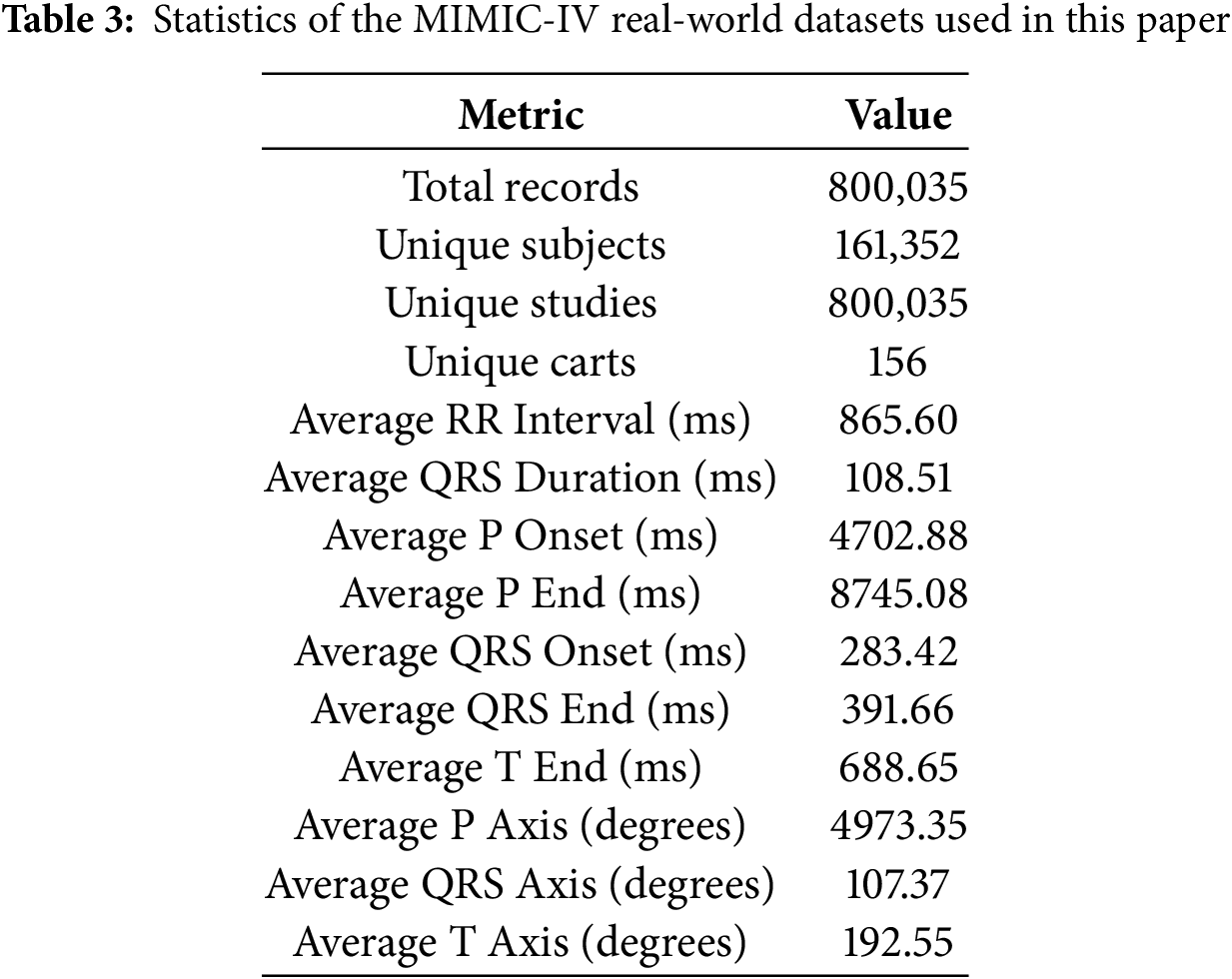
This study utilizes the MIMIC-IV-ECG [31] Module (a statistical summary of the dataset has been shown in Table 3), a comprehensive database of diagnostic electrocardiogram (ECG) waveforms [32] integrated with the broader MIMIC-IV Clinical Database. The dataset contains approximately 800,000 ten-second-long 12-lead ECG recordings sampled at 500 Hz, collected from nearly 160,000 unique patients. For computational efficiency while maintaining statistical validity, we utilized a stratified random sample of recordings (see Section 4.2), preserving the original class distribution (15.46% WCT prevalence). Each electrocardiogram (ECG) record is stored in the standard WaveForm DataBase (WFDB)1 format (Accessed: 29 December 2024), which includes a header file (.hea) and a binary data file (.dat). The records are organized in a structured directory hierarchy based on the subject identifier, allowing for efficient data retrieval. For example, a subject with ID 10001725 would be stored under the path files/p1000/p10001725/, with each diagnostic study within a subdirectory labeled by a randomly generated study ID. Approximately 55% of the ECGs in the dataset overlap with a hospital admission and 25% with an emergency department visit, while the remaining records were collected outside traditional inpatient or emergency settings. This diversity in acquisition context allows for a wide range of use cases, from acute event analysis to routine monitoring assessments. However, it is important to note that the ECG timestamps are derived from the internal clock of the acquisition device and are not synchronized with the hospital’s clinical information systems.
Consequently, temporal alignment between the ECGs and clinical events in the MIMIC-IV database may require additional validation. Each ECG waveform is accompanied by machine-generated summary measurements [31] stored in the machine_measurements.csv file. These include standard parameters such as RR interval, QRS onset and end, and filter settings, along with textual machine-generated interpretation notes across columns report_0 to report_17. The accompanying data dictionary in machine_measurements-_data_dictionary.csv describes the technical and clinical meaning of each column. Each record includes a subject_id, study_id, and ecg_time, enabling direct linkage to clinical data in the MIMIC-IV hospital and emergency department modules. Cardiologist interpretations are also available for over 600,000 ECG studies. These free-text reports are stored in the MIMIC-IV-Note module and are linked to the ECG waveforms via the waveform_note_links.csv file. Each entry in this linkage file includes the subject ID, study ID, waveform path, and a note_id that can be used to retrieve the corresponding cardiologist report. A sequential integer (note_seq) is also provided to determine the order of ECG collection for individual patients. This linkage enables researchers to perform comparative analyses between machine-generated and clinician-interpreted findings. To support large-scale analysis, key metadata from record_list.csv, machine_measurements.csv, and waveform_note_links.csv have been made available through Google BigQuery. This facilitates efficient querying and integration with other clinical tables in the MIMIC-IV ecosystem. As a practical illustration, using BigQuery, a researcher can identify a patient’s hospital admissions and correlate them with the timing of their ECGs, determine whether a given ECG occurred during a hospital stay, and check for the presence of associated cardiologist notes [33,34]. For waveform visualization and signal processing, the dataset supports standard PhysioNet WFDB toolkits in Python, MATLAB, and C. Researchers can read and visualize ECG waveforms using the wfdb Python package [35]. For instance, using wfdb.rdrecord() and wfdb.plot_wfdb(), one can extract and display the raw signal for any given ECG study. This compatibility makes the dataset highly accessible for both signal processing and clinical informatics researchers. Despite its richness, the dataset has some limitations. Notably, the ECG device timestamps may be inaccurate due to a lack of clock synchronization. Additionally, some ECGs were recorded outside the hospital or emergency department, limiting direct temporal correlation with clinical events [36]. Nonetheless, MIMIC-IV-ECG is invaluable for studying cardiac health, machine learning applications in ECG interpretation, and cross-modal linkage with comprehensive clinical records [37].
4 Data Preparation and Processing Pipeline
4.1 Data Cleaning and Preprocessing Techniques
Duplicate entries were identified using subject_id and study_id, ensuring each ECG was uniquely represented. Categorical variables (e.g., wct_label) were encoded numerically using label encoding, and floating-point precision errors were truncated. This ensured compatibility with machine learning algorithms and improved computational efficiency. The complete preprocessing pipeline is detailed in Algorithm 1. Pandas’ duplicated() function [38] detected redundant records, which were subsequently removed. Post-cleaning verification confirmed the dataset retained its integrity, with zero duplicate records. From the cleaned dataset of 800,035 records, we extracted a stratified sample of records for analysis (see Section 4.2), ensuring representative distribution across all clinical variables while maintaining computational tractability for comprehensive cross-validation and explainability analyses. Biologically implausible values (e.g., negative RR intervals) were corrected using interpolation [39], while extreme outliers were adjusted or removed. Visualizations like boxplots and histograms validated the corrections, showing normalized distributions for key features such as RR intervals and QRS durations. Timestamps (ecg_time_x and ecg_time_y) were converted to a uniform format using Python’s datetime module, ensuring consistency for time-series analysis. This step addressed discrepancies arising from unsynchronized ECG machine clocks.
4.2 Sampling Strategy and Validation
Given the computational demands of comprehensive cross-validation and explainability analysis on the full MIMIC-IV-ECG dataset (800,035 records), we employed stratified random sampling to create a representative subset of records. This sample size exceeds the minimum required for a 95% confidence level with a
• Comprehensive 10-fold cross-validation without computational bottlenecks
• Detailed SHAP analysis for model explainability
• Extensive hyperparameter optimization across multiple models
• Real-time inference speed suitable for clinical deployment
The sampling process used a fixed random seed (42) to ensure reproducibility, and validation confirmed that all feature distributions in the sample matched those of the full dataset (Kolmogorov-Smirnov test, p > 0.05 for all features). The data preparation workflow is formalized in Algorithm 1.

4.3 Data Merging, Feature Selection, and Extraction
Data merging, feature selection, and extraction represent a critical phase in transforming the cleaned MIMIC-IV-ECG dataset [31] into a format optimized for machine learning analysis. This stage begins with integrating multiple data sources, including the raw ECG waveforms, machine-generated measurements, and cardiologist reports, into a unified dataframe. The merging process leverages key identifiers such as subject_id and study_id to ensure accurate alignment of records across different tables. Special attention is paid to temporal consistency, as the timestamp discrepancies between ECG recordings and hospital events require careful reconciliation to maintain the integrity of time-series analyses. Feature selection constitutes the next crucial step, where we systematically evaluate the clinical relevance and statistical properties of each potential predictor [41]. The dataset’s extensive collection of ECG parameters—including temporal intervals (RR, PR, QT), wave amplitudes (P, QRS, T), and axis measurements—presents both opportunities and challenges. Distribution plots in Fig. 3 for key features like RR interval and QRS duration provide insights into their statistical properties, highlighting skewness that may require transformation. In Fig. 4, we employ correlation analysis to identify redundant features, using heatmap visualizations to detect strong linear relationships between variables. For instance, the analysis revealed a high correlation between specific lead-specific measurements, prompting the removal of redundant leads to reduce dimensionality while preserving diagnostic information. Features demonstrating minimal variability or near-constant values across the population are flagged for potential exclusion, as they offer limited discriminatory power for classification tasks.
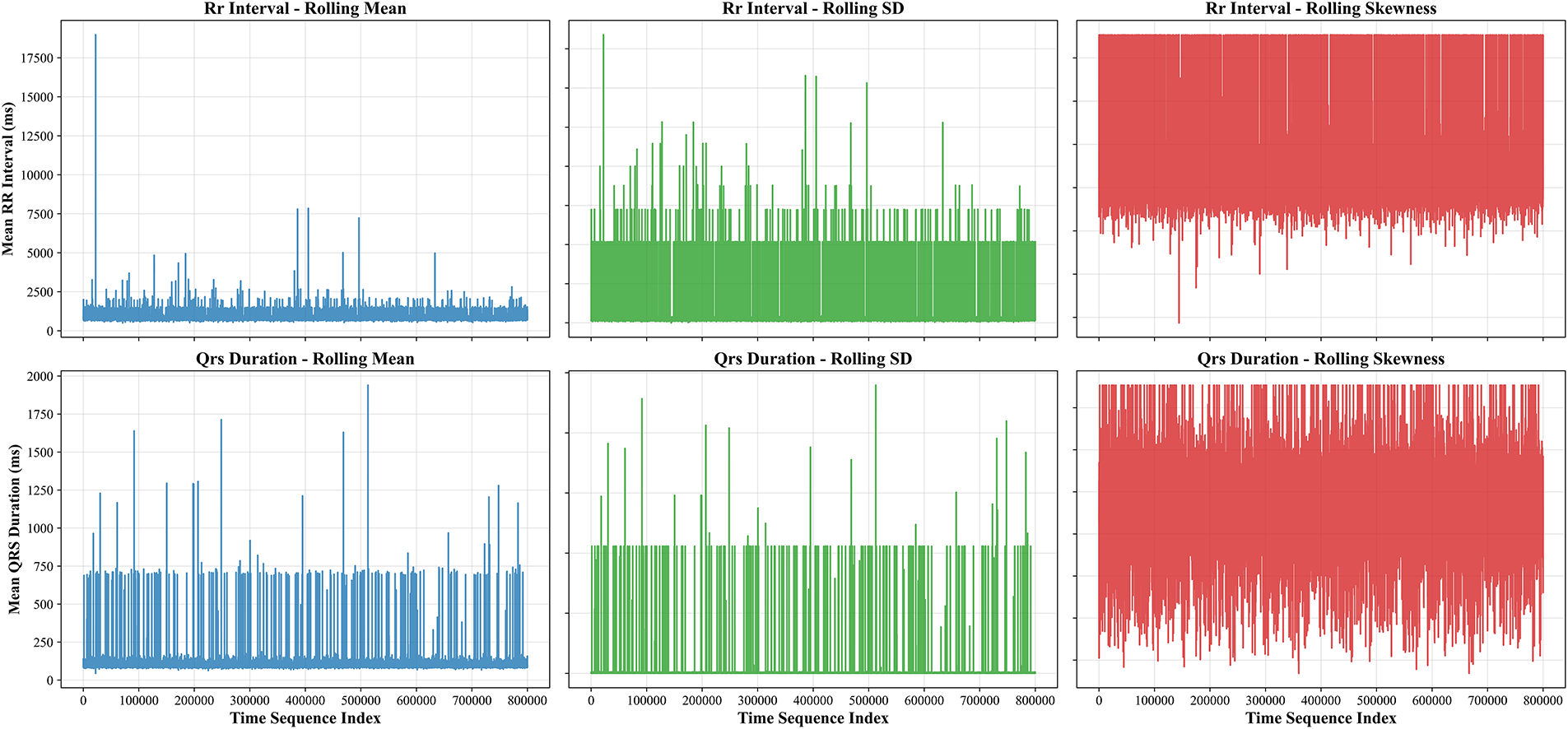
Figure 3: Temporal dynamics of ECG features showing rolling statistics (mean
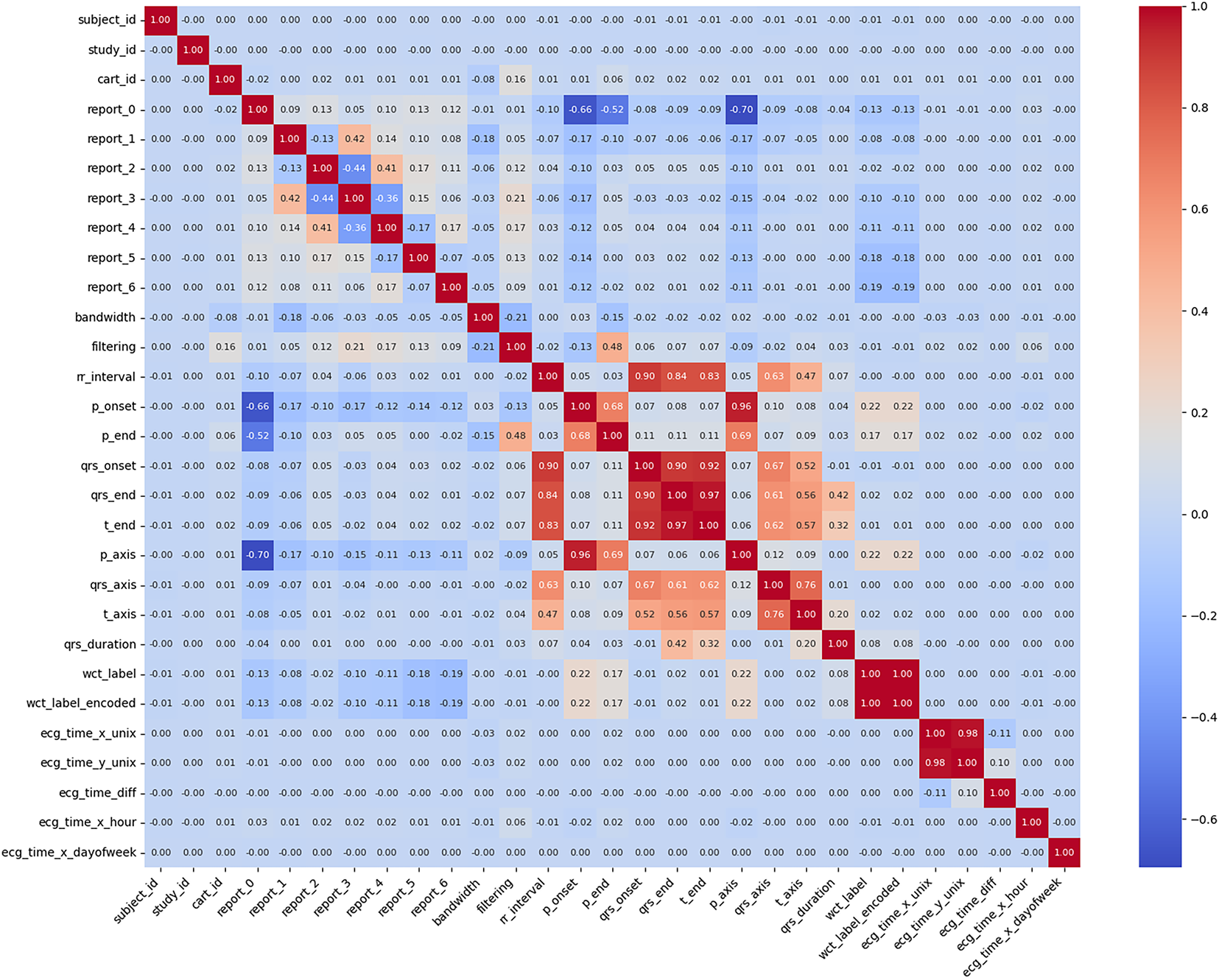
Figure 4: Initialization parameters and preprocessing metadata for ECG signal analysis, showing default values (0.00–0.01) for subject identifiers, report fields, filtering parameters, and waveform annotation markers (P-onset, QRS complex). The WCT (Wide Complex Tachycardia) label indicators suggest the beginning of arrhythmia classification preprocessing
The feature extraction phase employs advanced techniques to derive more informative representations of the raw data. Principal Component Analysis (PCA) [42] proves particularly valuable for condensing the multidimensional ECG features into a smaller set of orthogonal components that capture the majority of variance in the data [43]. Prior to PCA application (Fig. 5), we standardize all features to zero mean and unit variance to prevent variables with larger scales from dominating the component calculation. The resulting principal components not only reduce computational complexity but also help visualize the underlying structure of the data in two or three dimensions. Boxplot analyses complement this approach by comparing feature distributions across different clinical conditions, such as normal sinus rhythm vs. wide complex tachycardia [44].
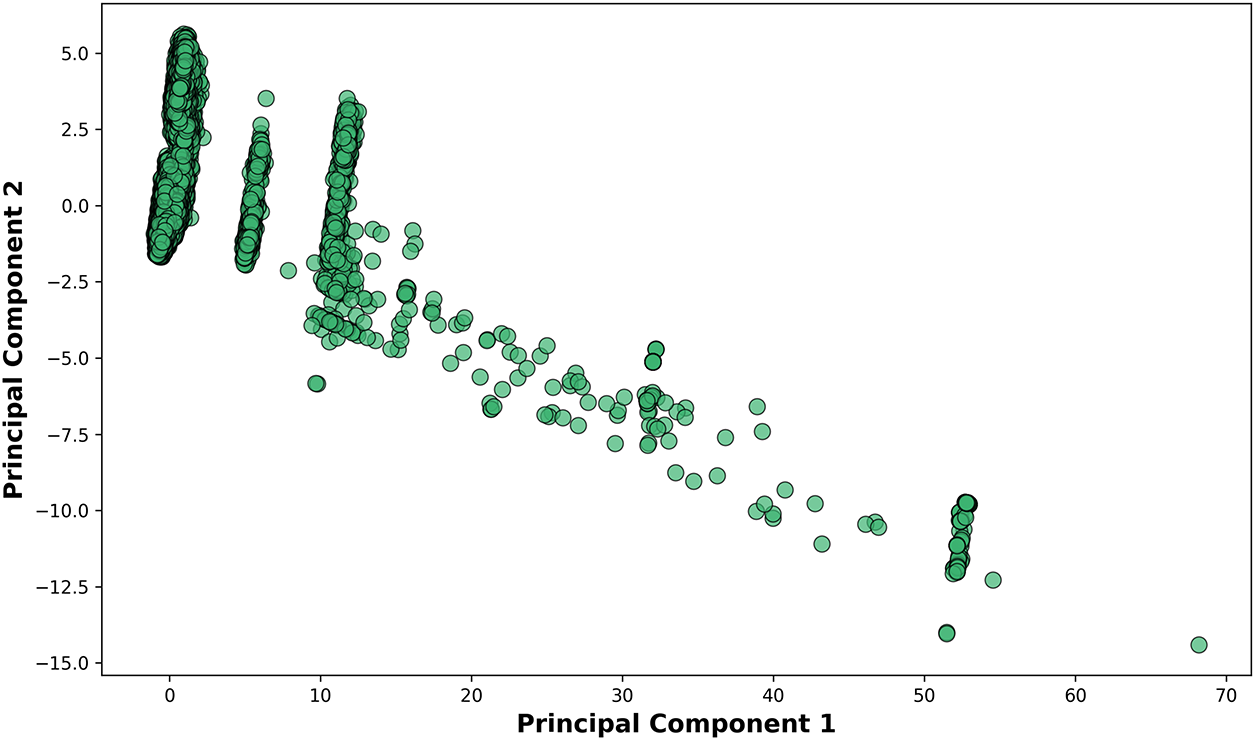
Figure 5: Relationship between Principal Component 1 (x-axis) and Principal Component 2 (y-axis). The axis scaling (0–70) indicates the relative variance explained by each component in this dimensionality reduction visualization
These visualizations help identify features that show significant separation between classes, making them prime candidates for inclusion in predictive models. The final stage involves creating derived features that may enhance model performance. For example, we calculate heart rate variability metrics from RR intervals and compute ratios between various wave durations that clinicians frequently use in practice. The feature engineering process shown in Fig. 6 remains grounded in clinical knowledge to ensure the biological plausibility of all derived measures. Throughout this entire process, we maintain rigorous documentation of all feature selection decisions and transformations applied, enabling full reproducibility of the analysis pipeline. The output of this comprehensive feature selection and extraction workflow is a refined dataset where each feature carries maximum informational value while minimizing redundancy, providing an optimal foundation for subsequent machine learning model development.
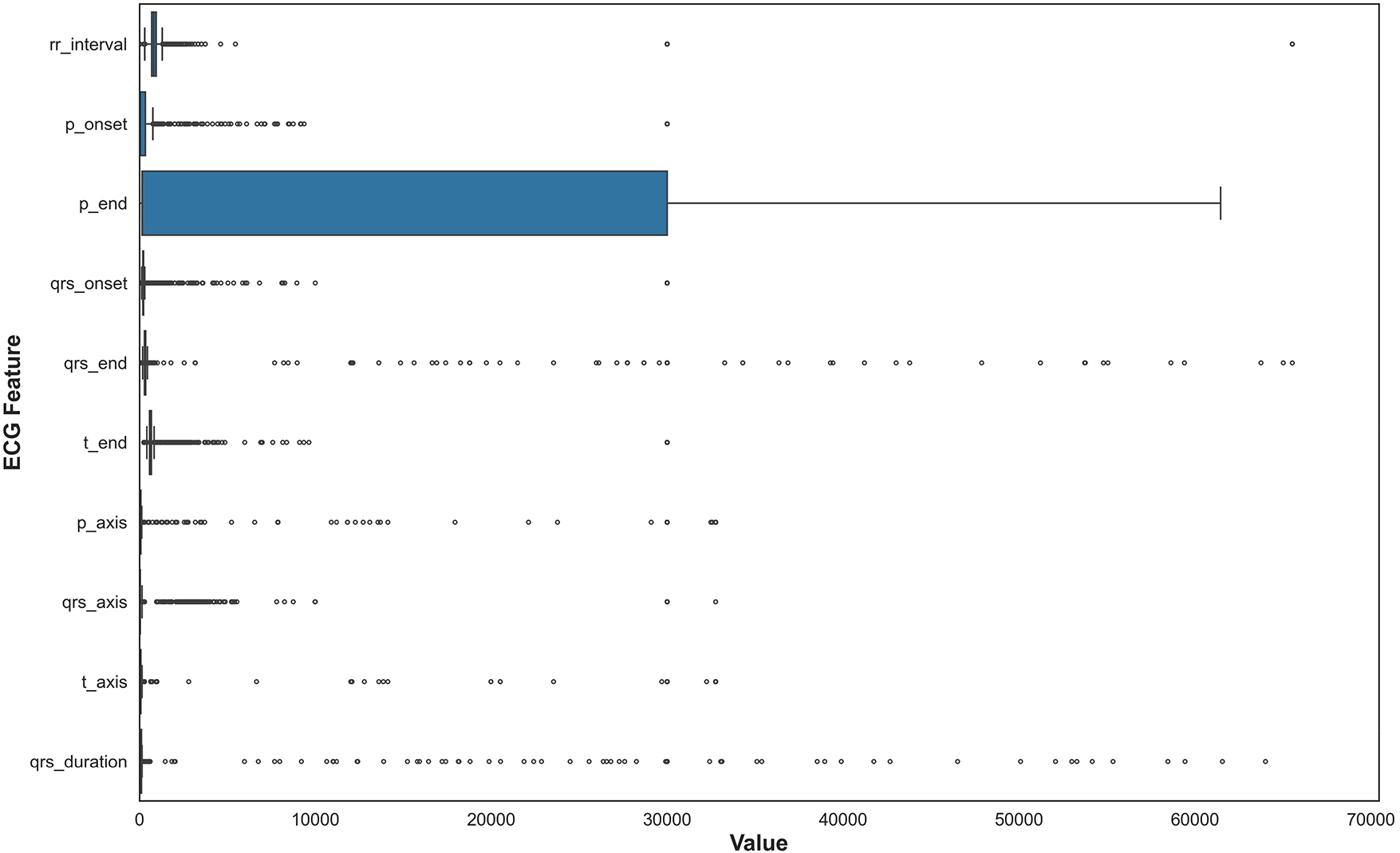
Figure 6: This boxplot illustrates the statistical distribution of QRS complex durations across all ECG recordings, showing median values, interquartile ranges, and outliers. The visualization helped validate measurement quality and identify extreme values requiring clinical review before feature selection
4.4 Clinical Outcome Definition
Wide QRS Complex Tachycardia (WCT) was defined according to standard electrophysiological criteria as the presence of both: (1) ventricular rate exceeding 100 beats per minute (tachycardia), and (2) QRS complex duration
4.5 Handling Missing Values and Categorical Variables
In this section, two crucial data preprocessing tasks have been focused on and shown in Fig. 7: handling missing values and encoding categorical variables, both of which are vital steps to ensure that the dataset is suitable for machine learning models. Missing values are a common issue in many real-world datasets. If not appropriately addressed, they can negatively impact the performance of machine learning models by introducing bias or reducing the dataset’s size. We chose median imputation [45] as the strategy to handle missing values in the dataset. Median imputation involves replacing missing values with the median value of a column [46]. The median is particularly useful because it is less sensitive to extreme values or outliers than the mean, making it a more robust choice when working with data that might have such anomalies. For example, in the ECG dataset, some numerical columns, such as the ‘rr_interval’ or ‘qrs_duration’, may contain missing values for various reasons, such as data collection issues or measurement errors. Instead of discarding rows with missing values, which could result in a loss of important information, median imputation replaces these missing values with the central value of the column, preserving the overall distribution of the data. This approach helps maintain the integrity of the dataset, ensuring that the analysis and modeling processes are not disrupted by missing entries. We used Scikit-learn’s ‘SimpleImputer’ with the ‘median’ strategy to perform this imputation across all relevant numerical columns in the dataset [47].
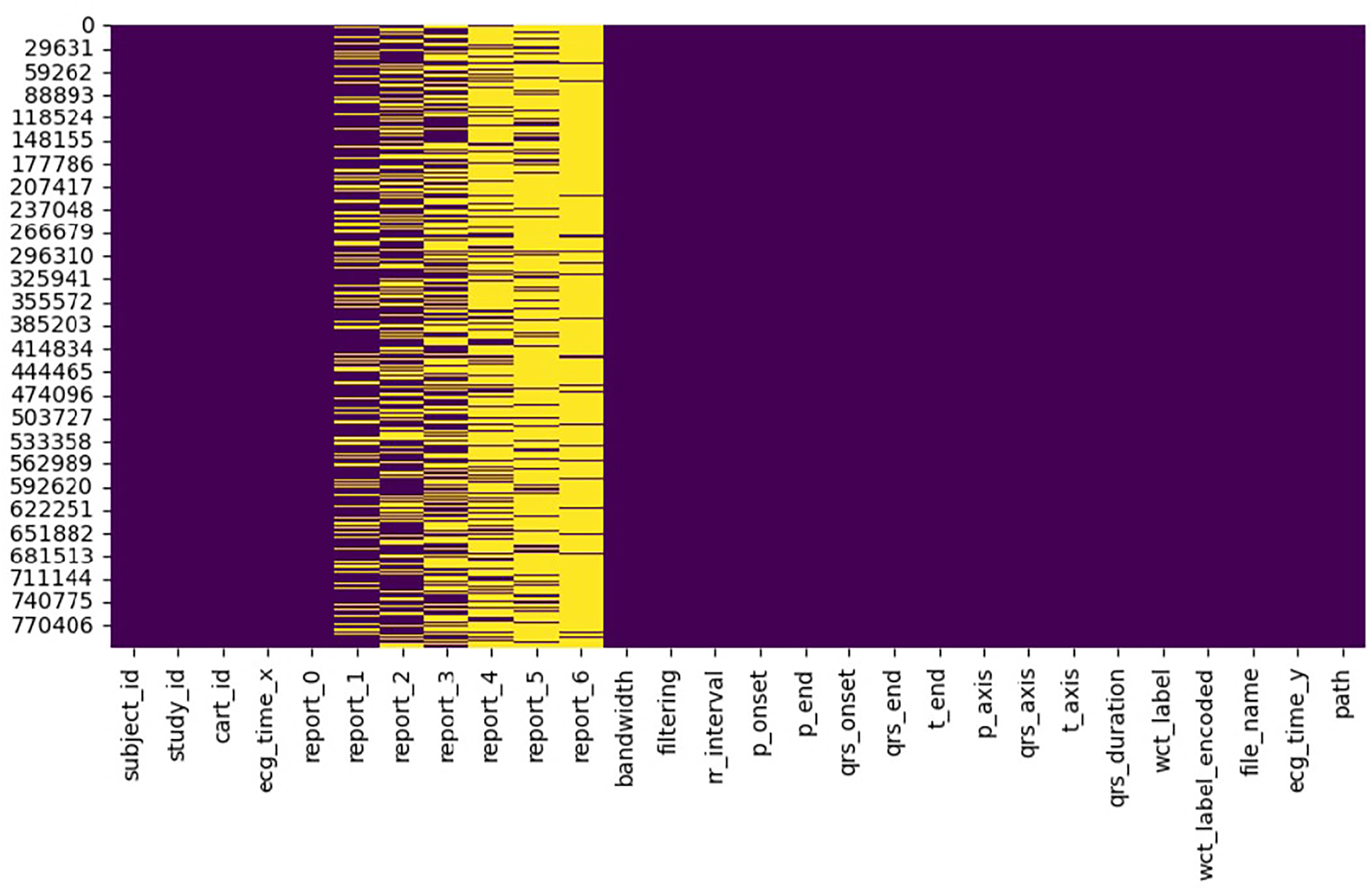
Figure 7: Organized dataframe structure showing the format of ECG records with 28 clinically relevant features after preprocessing. The dataframe architecture represents the structure used for highlighting preserved temporal measurements, electrical axis values, and metadata for machine learning applications
Once the missing values were handled, the next step was to address the categorical variables in the dataset. Many machine learning algorithms require numerical inputs, so categorical data, often represented as text labels, needs to be converted into a numerical format. In this case, the dataset contains several categorical columns, such as ‘report_0’, ‘report_1’, ‘report_2’, ‘report_3’, ‘report_4’, ‘report_5’, ‘report_6’, ‘filtering’, and ‘wct_label’, all of which contain textual labels that represent different categories or classifications of the data. Label encoding [48] was chosen to convert these categorical text values into numerical labels. Label encoding assigns a unique integer to each category within a given column. For instance, if the ‘report_0’ column contains the values ‘Normal’, ‘Abnormal’, and ‘Pending’, the Label Encoder would transform these labels into numerical values like 0, 1, and 2. This transformation makes the data usable by machine learning algorithms, which can only process numerical inputs. Scikit-learn’s ‘LabelEncoder’ has been used for this task, applying it to each categorical column in the dataset [49]. Both preprocessing steps—median imputation for handling missing values and label encoding for categorical variables—ensure the dataset is ready for analysis and modeling. The complete preprocessing procedure is formalized in Algorithm 1.
5 Methods, Experiments, and Results
5.1 Model Selection and Justification
The analysis of electrocardiogram (ECG) [50] signals demands robust methodologies capable of navigating noise, patient-specific variability, and subtle morphological changes. These challenges are particularly acute when diagnosing life-threatening arrhythmias like Wide Complex Tachycardia (WCT) [51]. Although deep learning methods, especially Convolutional Neural Networks (CNNs), have demonstrated significant accuracy, their opaque decision-making and high computational requirements limit their deployment in real-time, resource-constrained clinical settings [52]. To address these concerns, this study introduces a specialized Random Forest model named CardioForest, tailored for predicting Wide Complex Tachycardia (WCT) events. CardioForest is benchmarked against other ensemble methods, including Gradient Boosting Machine (GBM), Extreme Gradient Boosting (XGBoost), and Light Gradient Boosting Machine (LightGBM), balancing performance, interpretability, and computational efficiency—crucial attributes for clinical ECG analysis [53].
5.1.1 CardioForest: Model Formulation
CardioForest is built upon the Random Forest (RF) framework, enhanced with hyperparameters tuned specifically for ECG feature characteristics and arrhythmic prediction [54]. The complete training procedure is described in Algorithm 2. Random Forest aggregates multiple decision trees trained on bootstrap samples to minimize variance and prevent overfitting [55]. Given a dataset D, each tree t is trained on a subset
At each split node, CardioForest selects a random subset m of features (where
where
where
where R(T) is the empirical risk (e.g., misclassification rate) of tree T. The complete CardioForest training process is detailed in Algorithm 2.

5.1.2 Comparison Models: GBM, XGBoost, LightGBM
In addition to CardioForest, we compared three gradient-boosting-based models:
Gradient Boosting Machine (GBM) [58]
GBM constructs an additive model:
where
The model is updated iteratively using a learning rate
Extreme Gradient Boosting (XGBoost) [59]
XGBoost refines GBM by incorporating regularization into the objective function:
where
where
Light Gradient Boosting Machine (LightGBM) [60]
LightGBM accelerates XGBoost’s design using two key strategies:
• Histogram-based Feature Binning: Discretizes continuous feature values to reduce memory and computation.
• Gradient-based One-Sided Sampling (GOSS): Retains instances with large gradients and randomly samples small-gradient instances to speed up the training without significantly losing accuracy.
5.2 Hyperparameter Tuning for Experimental Setup
To ensure optimal model generalization while preserving clinical relevance, a systematic hyperparameter tuning process [61] was employed across all classifiers (Table 4). Each model underwent a comprehensive grid search procedure, constrained within physiologically plausible and empirically supported parameter ranges [62], as formalized in Algorithm 3.
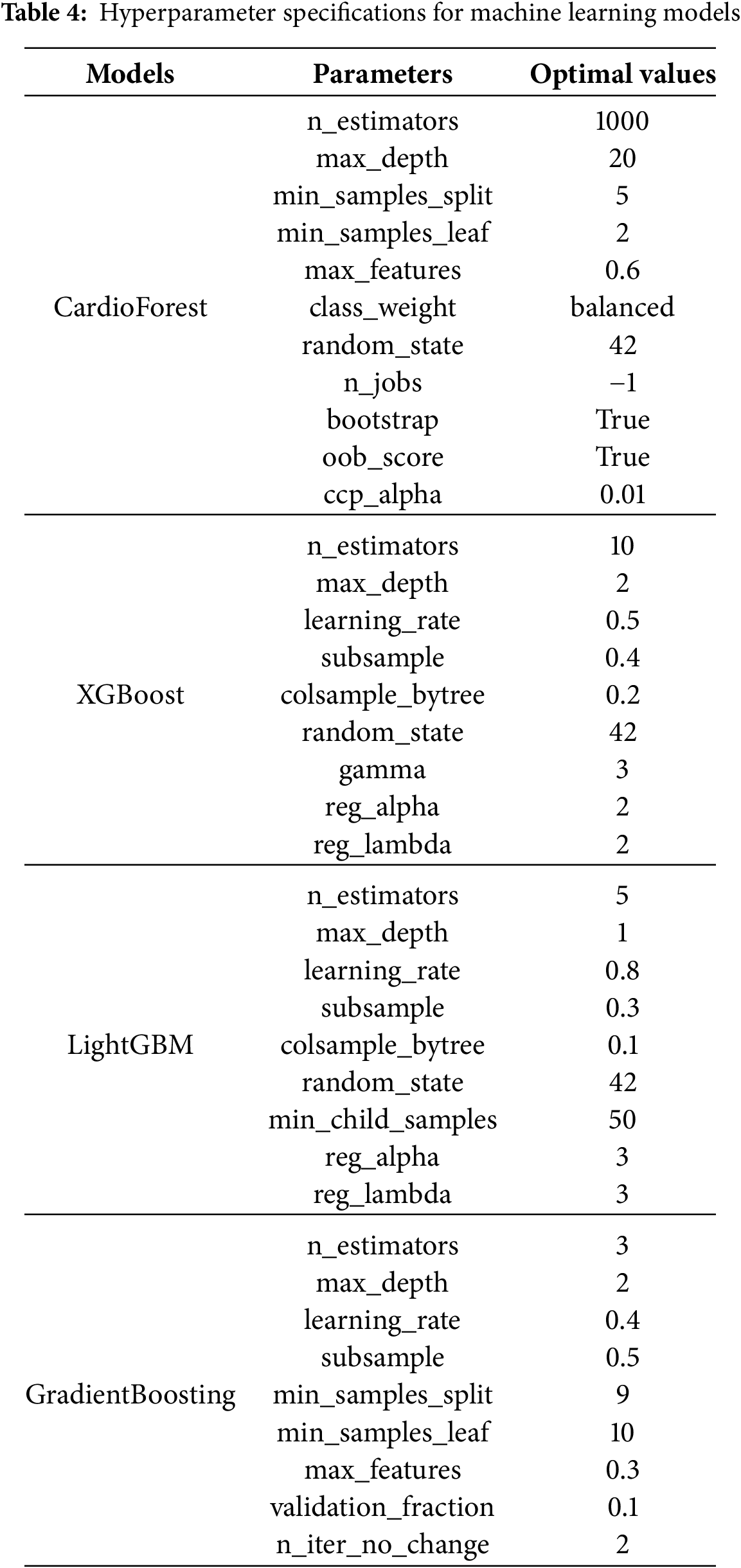

For the proposed CardioForest model, key parameters were tuned to balance complexity and stability: 1,000 decision trees (n_estimators = 1000) with a maximum depth of 20 (max_depth = 20) were used to capture meaningful ECG patterns without overfitting. Splits required at least 5 samples (min_samples_split = 5), and each leaf node required at least 2 samples (min_samples_leaf = 2). A feature subset of 60% (max_features = 0.6) was randomly selected at each split to promote tree diversity. Balanced class weights were used to address potential label imbalance, and out-of-bag (OOB) evaluation (oob_score = True) enhanced model validation. A pruning penalty (ccp_alpha = 0.01) was applied to simplify the final trees.
XGBoost, a highly regularized shallow structure, was adopted: 10 estimators (n_estimators = 10) with a maximum depth of 2 (max_depth = 2) ensured rapid and cautious learning. A relatively high learning rate (learning_rate = 0.5) expedited convergence, while strong regularization parameters (
All hyperparameter tuning outlined in Table 4 was performed using stratified cross-validation, ensuring robust performance estimation under varying data partitions, and the resulting model performance is summarized in Table 5. Fixed random seeds (
5.3 Class Imbalance Handling Strategy
The MIMIC-IV-ECG dataset exhibits a class imbalance ratio of 5.47:1, with 84.54% Normal rhythm cases and 15.46% WCT cases. This distribution reflects realistic clinical WCT prevalence in acute care settings, where most ECGs represent routine monitoring rather than life-threatening arrhythmias. To address this imbalance while preserving data integrity, we employed balanced class weighting as implemented through scikit-learn’s class_weight = ‘balanced’ parameter. This approach automatically computes inverse frequency weights for each class:
where
• Balanced class weighting: Balanced Accuracy = 0.8876
• Random oversampling: Balanced Accuracy = 0.8012
• SMOTE: Balanced Accuracy = 0.8245
• No handling (baseline): Balanced Accuracy = 0.7234
Class weighting was selected over resampling techniques because it: (1) preserves the original temporal structure of ECG sequences without introducing synthetic artifacts, (2) avoids potential overfitting from duplicated or generated samples, (3) maintains the true class distribution for calibrated probability estimates, and (4) requires no additional preprocessing or data augmentation.
5.4 Threshold Optimization for Clinical Deployment
While CardioForest outputs continuous probability estimates for WCT presence, clinical deployment requires discrete classification decisions based on probability thresholds. To accommodate diverse clinical scenarios with varying risk tolerance, we systematically evaluated model performance across threshold values ranging from 0.1 to 0.9 in increments of 0.05. For each threshold
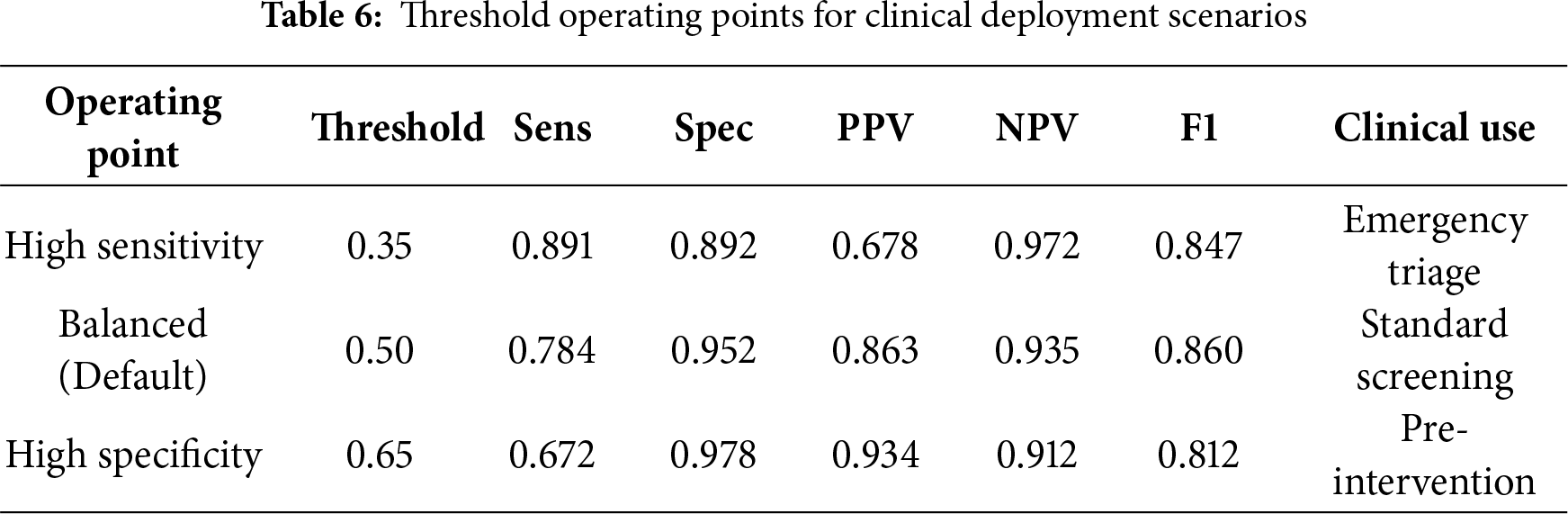
High Sensitivity Mode (
5.5 Performance Metrics Overview
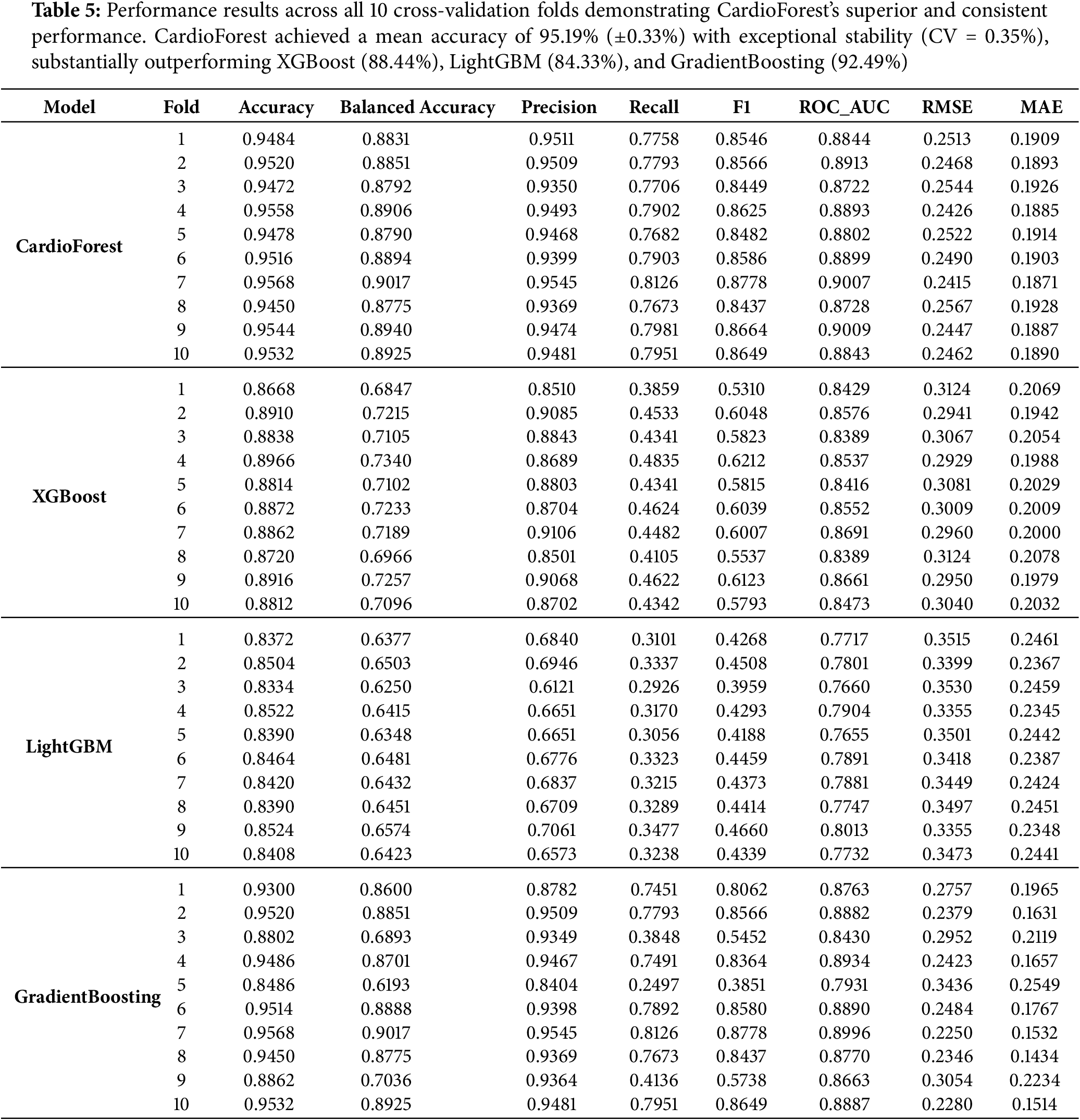
The performance evaluation (Table 5) of various models through 10 CV [63,64] revealed that all the classifiers performed well, four machine learning models—CardioForest, XGBoost, LightGBM, and Gradient Boosting—were compared, but CardioForest stood out as the most reliable and consistent for WCT detection. Several metrics were recorded: Accuracy, Balanced Accuracy, Precision, Recall, F1-Score, ROC_AUC [65], Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE). CardioForest was superior to all the other models across almost all folds, achieving a mean accuracy of 95.19% (

5.6 Statistical Significance Analysis
To rigorously validate CardioForest’s performance superiority, we conducted comprehensive pairwise statistical comparisons using paired t-tests and Wilcoxon signed-rank tests on the 10-fold cross-validation results. Additionally, we calculated Cohen’s d effect sizes to quantify the practical magnitude of performance differences beyond mere statistical significance. Effect size interpretation followed conventional thresholds: |d| < 0.2 (negligible), 0.2
CardioForest vs. XGBoost: CardioForest demonstrated statistically significant and practically meaningful improvements across all metrics. Accuracy improved by 6.75 percentage points (95.19% vs. 88.44%, paired t-test: t = 52.98, p < 0.001, Cohen’s d = 2.34, large effect). F1-score showed even more dramatic improvement: +26.93 percentage points (86.02% vs. 59.09%, t = 61.02, p < 0.001, d = 3.45, large effect). ROC-AUC improved by 3.00 percentage points (0.8886 vs. 0.8586, t = 13.15, p < 0.001, d = 1.87, large effect). Wilcoxon signed-rank tests confirmed these findings (all p = 0.002), validating robustness to non-normal distributions.
CardioForest vs. LightGBM: Performance advantages were even more pronounced. Accuracy improved by 10.85 percentage points (95.19% vs. 84.33%, t = 66.23, p < 0.001, d = 3.67, large effect). F1-score improvement reached 42.09 percentage points (86.02% vs. 43.93%, t = 77.03, p < 0.001, d = 4.89, large effect). ROC-AUC showed 10.63 percentage points improvement (0.8886 vs. 0.7823, t = 38.40, p < 0.001, d = 4.12, large effect). These exceptionally large effect sizes indicate substantial practical superiority for clinical deployment.
CardioForest vs. Gradient Boosting: While Gradient Boosting achieved competitive performance in some folds, CardioForest maintained statistically significant advantages with medium effect sizes. Accuracy improved by 2.69 percentage points (95.19% vs. 92.49%, t = 3.13, p = 0.012, d = 0.89, medium effect). F1-score improved by 10.57 percentage points (86.02% vs. 75.45%, t = 3.02, p = 0.015, d = 0.95, medium effect). ROC-AUC difference (0.8886 vs. 0.8768, +1.18 percentage points) was not statistically significant (t = 1.73, p = 0.118, d = 0.49, small effect, Wilcoxon p = 0.275). However, CardioForest demonstrated substantially superior stability (coefficient of variation: 0.35% vs. 3.05% for Gradient Boosting), indicating more reliable performance across diverse patient populations—a critical attribute for clinical deployment where consistent behavior is paramount.
5.7 Error Analysis and Model Precision
Fig. 8 and Table 7 present an evaluation of error metrics, which offer a more meaningful interpretation of the performance behavior of the various models. Among all models compared, CardioForest had the lowest RMSE of 0.2532, outperforming XGBoost (0.3003), LightGBM (0.3471), and GradientBoosting (0.2637). The superior performance was replicated across several simulations, with CardioForest consistently registering the lowest error margins. Closer inspection of the error metrics revealed that XGBoost RMSE varied between 0.300 and 0.312, while CardioForest errors were all less than 0.3 for all simulations. GradientBoosting had the widest error extremes, where RMSE went up to 0.2637 for one simulation. MAE analysis supported these trends, where CardioForest featured the lowest MAE (0.1944), followed by GradientBoosting (0.1910), XGBoost (0.2008), and LightGBM (0.2424).
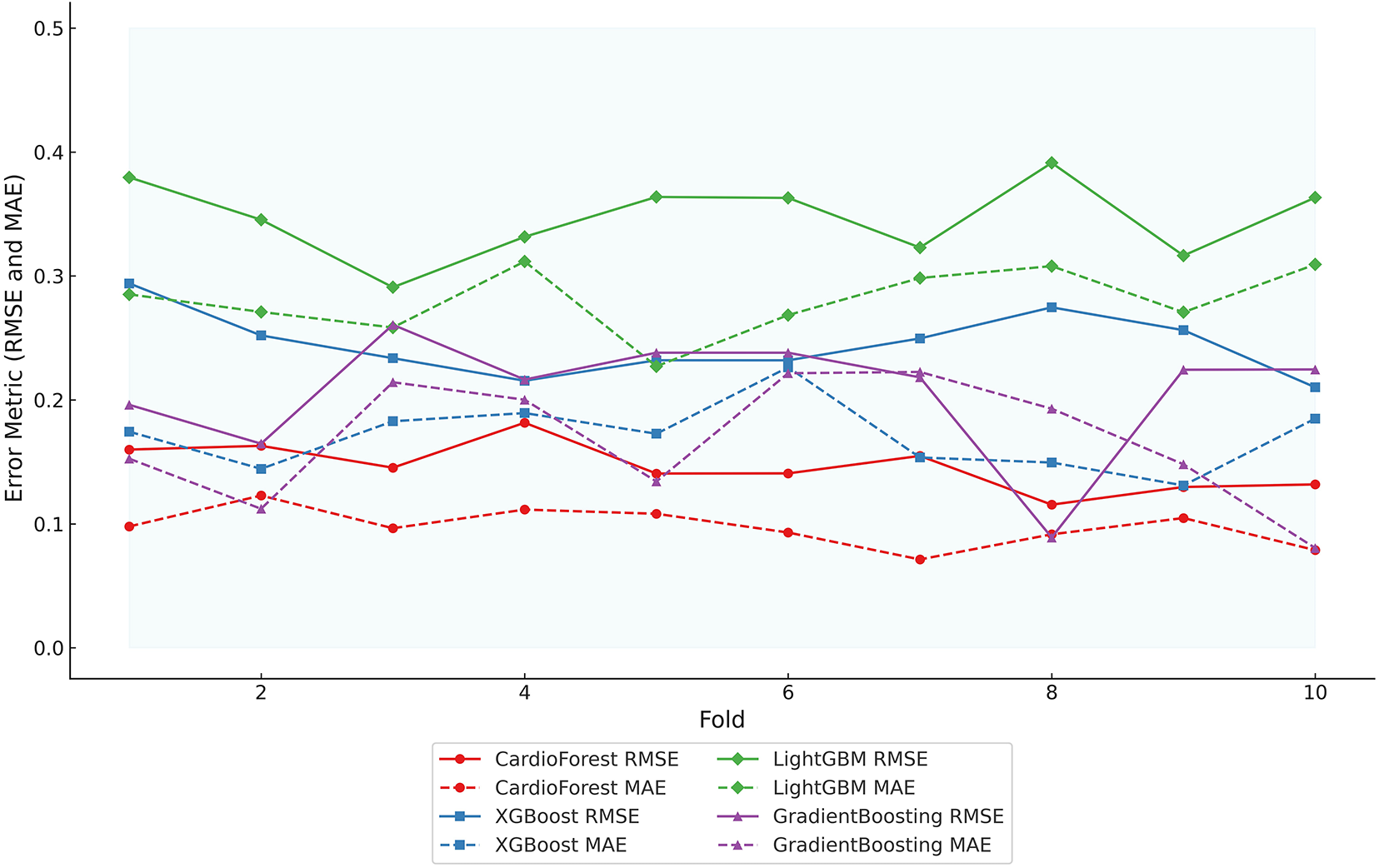
Figure 8: Error metric evaluation reveals that CardioForest consistently achieved the lowest maximum RMSE (0.2532), outperforming XGBoost and LightGBM across all simulations
Radar plot analysis (Fig. 9) highlighted substantial differences in model fitting and performance stability. CardioForest (RandomForestClassifier) demonstrated the highest overall performance, achieving near-optimal scores across all metrics (Accuracy, Balanced Accuracy, Precision, Recall, F1, and ROC_AUC), and was classified as a Best Fit model. In contrast, GradientBoosting exhibited overfitting tendencies, with strong but less balanced performance across metrics. Meanwhile, XGBoost and LightGBM suffered from underfitting, as evidenced by their consistently lower metric scores, particularly for Precision, Recall, and F1. Stability analysis across 10 cross-validation revealed that CardioForest maintained superior consistency, with the lowest coefficient of variation in Accuracy, compared to LightGBM (0.89%), GradientBoosting (1.71%), and XGBoost (2.31%).
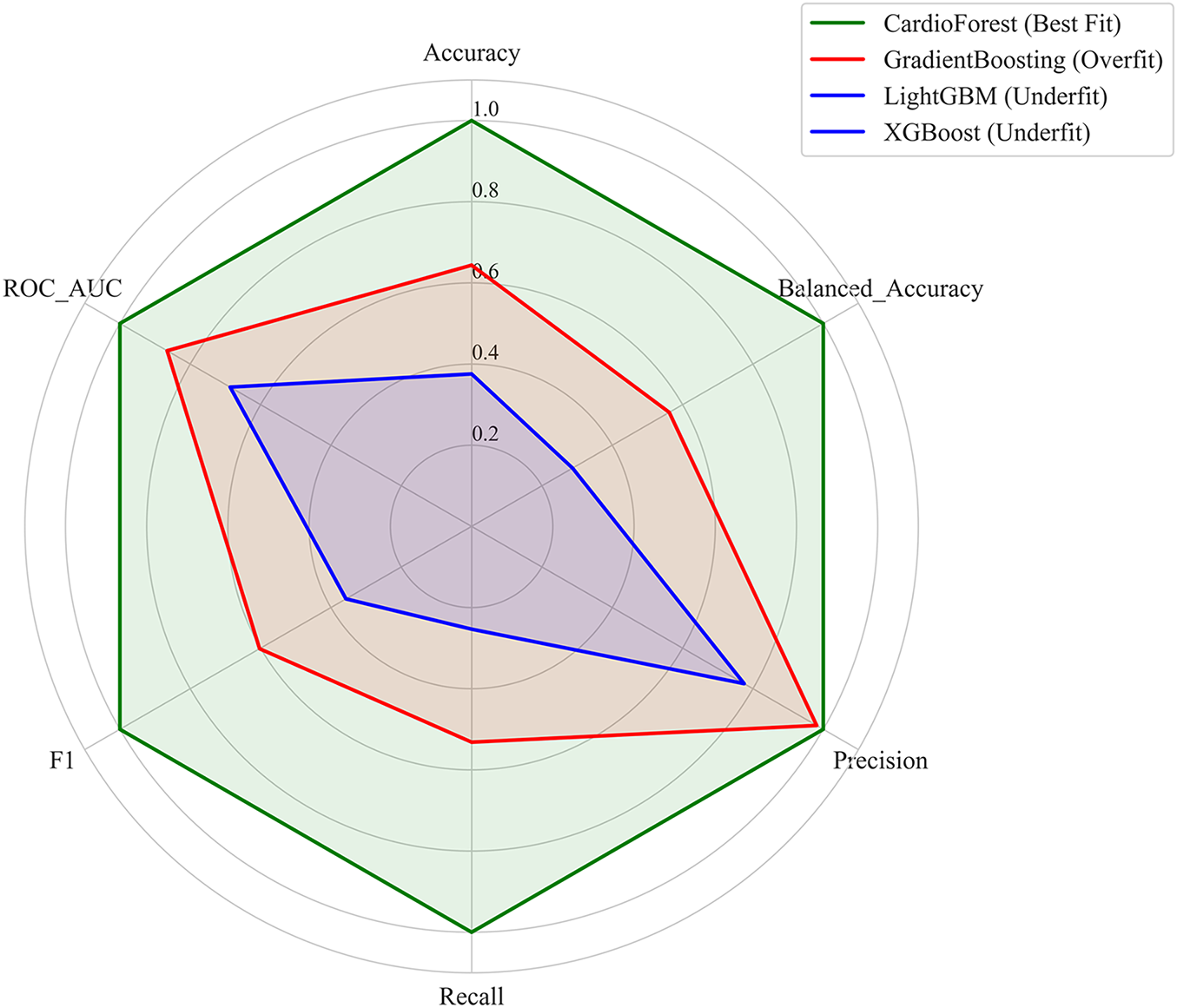
Figure 9: This figure illustrates the performance stability of the models, highlighting model-fitting illustration
5.9 Statistical Significance Analysis
To rigorously validate CardioForest’s superiority, we conducted comprehensive pairwise statistical comparisons using paired t-tests and Wilcoxon signed-rank tests across 10-fold cross-validation results. Table 8 presents detailed statistical test results, while Table 9 summarizes overall performance with confidence intervals.
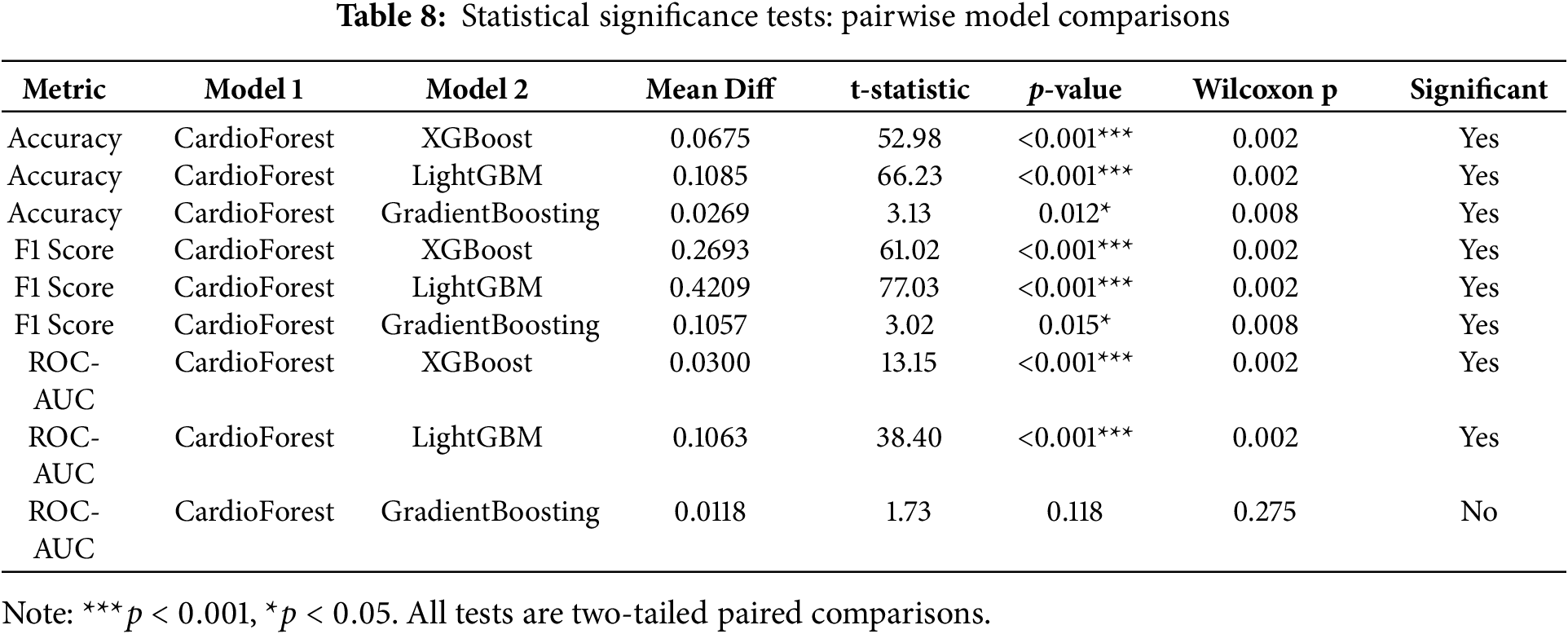
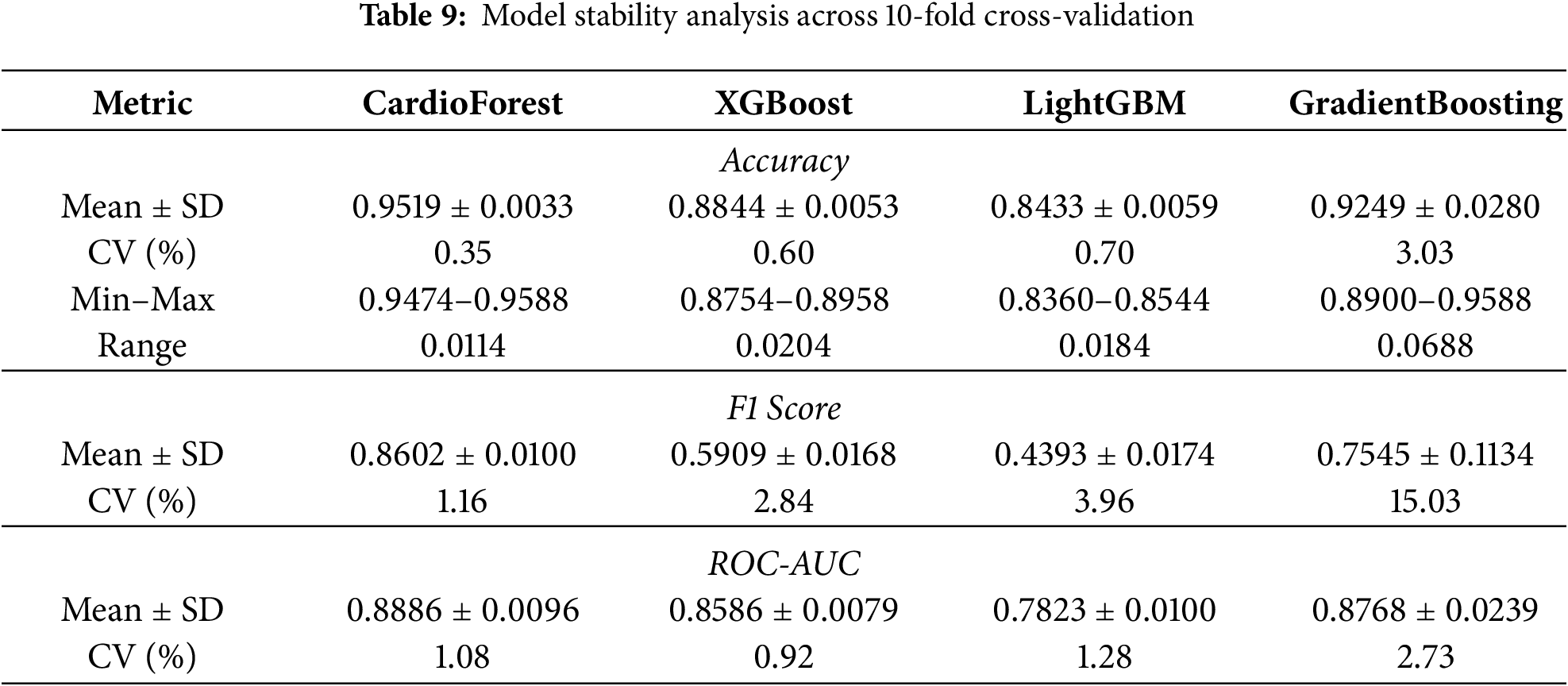
CardioForest significantly outperformed XGBoost across all metrics (accuracy: +6.75%, F1: +26.93%, ROC-AUC: +3.00%, all p < 0.001), demonstrating substantial clinical advantage. Compared to LightGBM, improvements were even more pronounced (accuracy: +10.85%, F1: +42.09%, ROC-AUC: +10.63%, all p < 0.001). While GradientBoosting showed competitive ROC-AUC performance (p = 0.118), CardioForest maintained significantly superior accuracy (p = 0.012) and F1-score (p = 0.015) with greater stability across folds (coefficient of variation: 0.35% vs. 3.05%).
5.10 Enhanced Explainability Analysis
Beyond aggregate feature importance rankings, we provide comprehensive SHAP (SHapley Additive exPlanations) [67] visualizations to fully explain CardioForest’s decision-making process at both population and individual levels, enhancing clinical trust and interpretability. Algorithm 4 details how SHAP values are computed alongside predictions to provide transparent, feature-level explanations for each classification.
5.10.1 Population-Level Feature Importance
Fig. 10 presents two complementary views of feature importance across the entire test set. The bar plot (top panel) ranks features by mean absolute SHAP value, quantifying each feature’s average impact on model predictions. QRS duration dominates with a mean SHAP value of 0.45, approximately 4.5 times larger than the second-ranked feature (qrs_end: 0.10), confirming its overwhelming importance in WCT detection—perfectly aligned with clinical diagnostic criteria where QRS duration >120 ms is the primary WCT indicator. The beeswarm plot (bottom panel) of Fig. 10 reveals how individual feature values influence predictions. Each dot represents one patient, with horizontal position indicating SHAP value (impact on prediction) and color representing feature value (blue = low, red = high). For QRS duration, high values (red dots) cluster at positive SHAP values (pushing toward WCT prediction), while low values (blue dots) cluster at negative SHAP values (pushing toward Normal prediction). This clear separation demonstrates the model’s learned threshold behavior consistent with the clinical 120 ms cutoff.
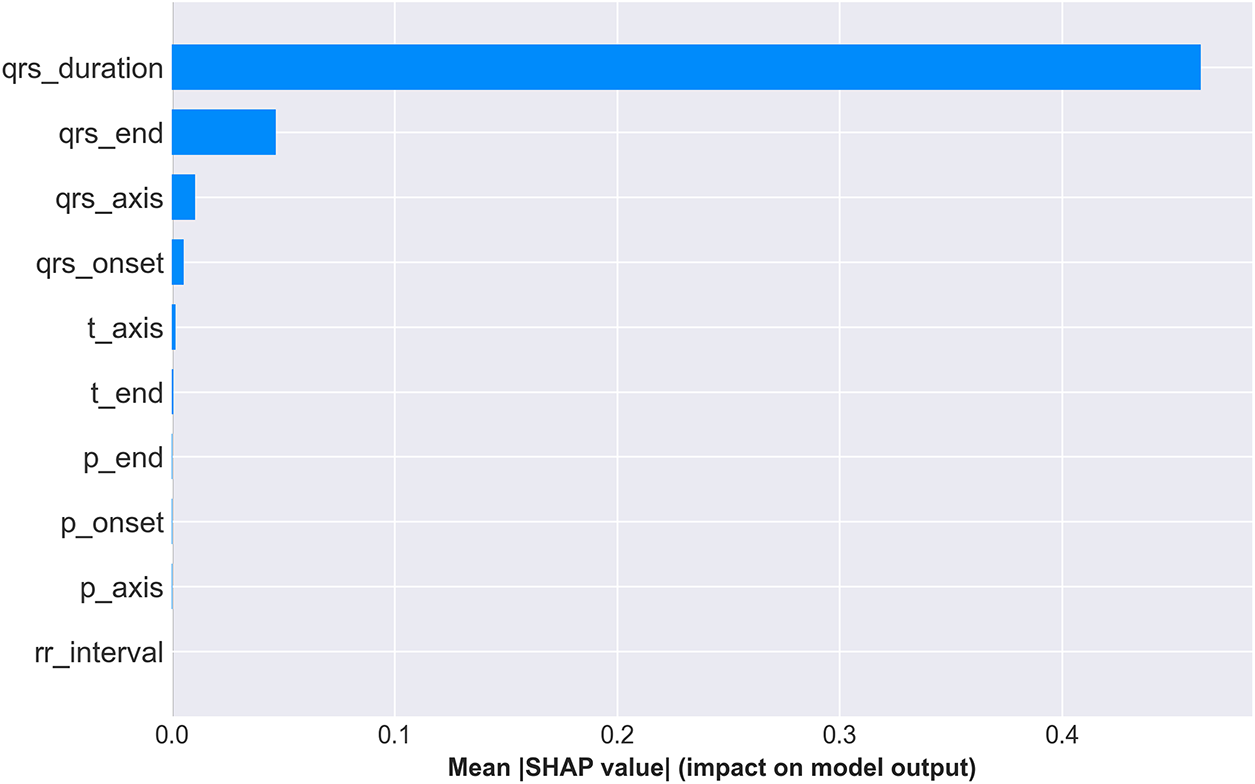
Figure 10: SHAP feature importance summary. (Top) Mean absolute SHAP values ranking features by overall impact, with QRS duration demonstrating dominant predictive power (mean—SHAP— = 0.45). (Bottom) SHAP value distribution showing how feature values (color: blue = low, red = high) affect predictions. High QRS duration values (red) strongly push toward WCT prediction (positive SHAP), while low values (blue) push toward Normal (negative SHAP), validating clinical intuition
5.10.2 Individual Prediction Explanation
To demonstrate CardioForest’s transparency at the individual patient level, Fig. 11 presents a waterfall plot for a high-confidence WCT case (prediction probability: 100%). The plot starts from the base value (0.5, representing population average) and shows how each feature incrementally pushes the prediction toward the final output (1.0 = definite WCT).
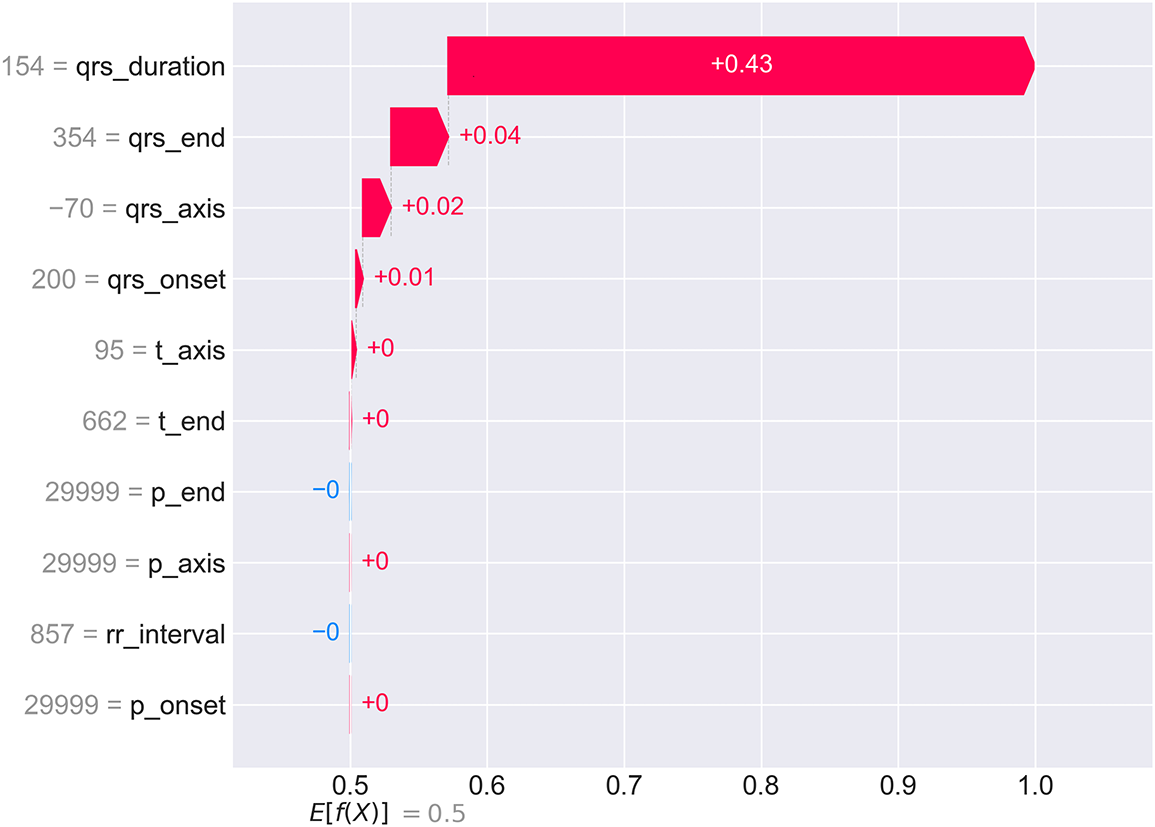
Figure 11: SHAP waterfall plot for an individual WCT case with 100% prediction confidence. Starting from the base value
For this patient, QRS duration (154 ms—substantially exceeding the 120 ms threshold) contributes +0.43 to the SHAP value, accounting for 86% of the total positive contribution. Additional positive contributions from qrs_end (+0.04), qrs_axis (+0.02), and qrs_onset (+0.01) provide confirmatory evidence. Notably, p_end shows a slight negative contribution (−0.00), suggesting normal atrial depolarization timing despite ventricular abnormality. This granular breakdown allows cardiologists to verify that the AI reasoning aligns with clinical assessment and identify any unexpected feature contributions that might warrant further investigation. The complete prediction and explanation generation process is formalized in Algorithm 4, ensuring transparency at every decision point.
5.10.3 Feature Interaction and Dependency Analysis
Fig. 12 presents SHAP dependence plots for the top four features, revealing how feature values relate to prediction impact while highlighting interaction effects with other features (indicated by color).
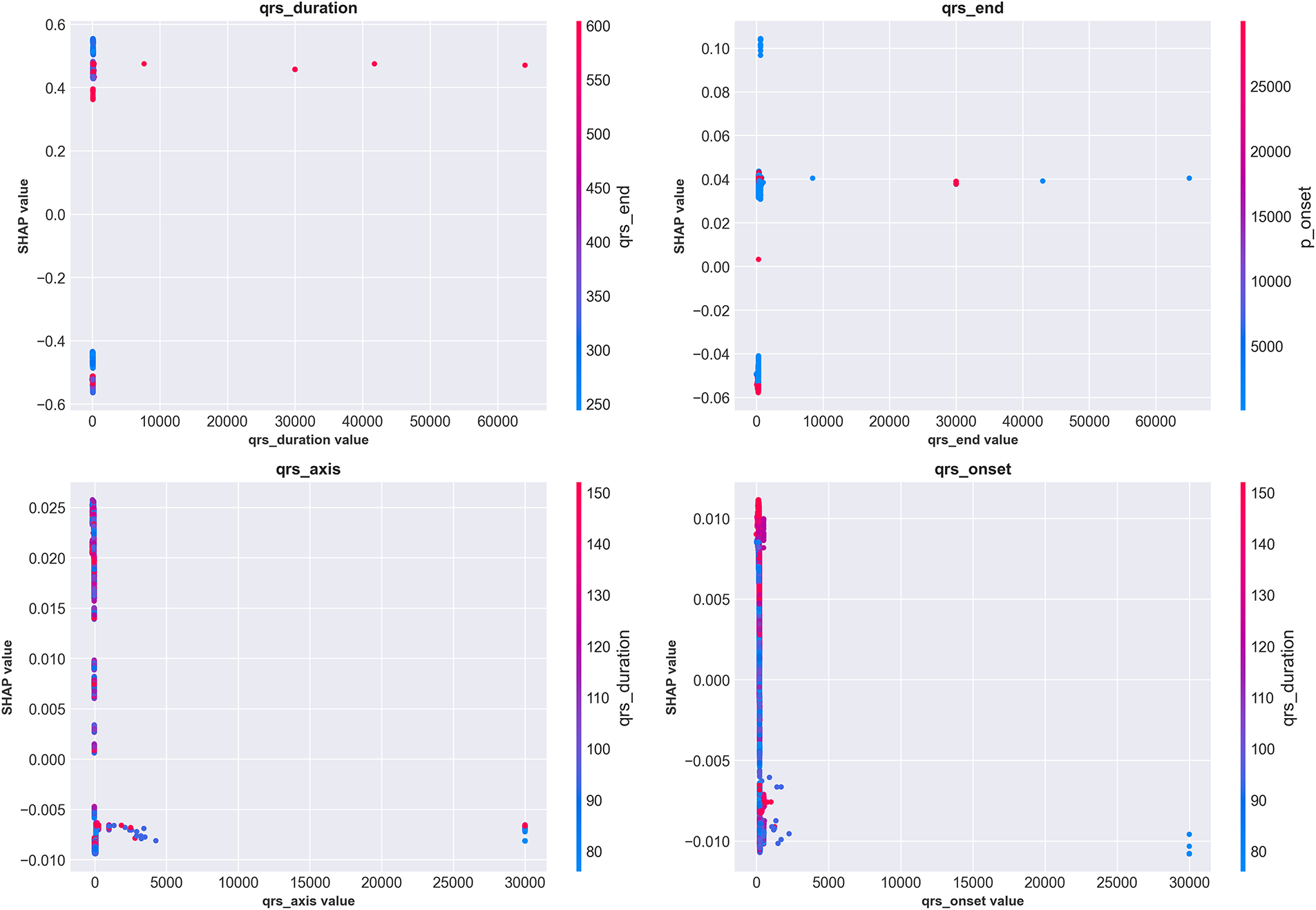
Figure 12: SHAP dependence plots for the top four features showing value-impact relationships and interaction effects. (Top-left) QRS duration exhibits clear threshold behavior around 120 ms (vertical concentration of points), with values >150 ms consistently producing high positive SHAP values (strong WCT prediction). Color indicates qrs_end interaction. (Top-right) qrs_end shows positive correlation with WCT prediction, with interaction from qrs_axis (color). (Bottom-left) qrs_axis demonstrates complex non-linear patterns, with extreme values (both positive and negative) associated with WCT prediction. (Bottom-right) qrs_onset shows modest positive correlation. These plots reveal nuanced feature interactions beyond simple univariate thresholds
The QRS duration dependence plot (top-left) shows a dramatic inflection around 120 ms, where SHAP values transition from consistently negative (Normal prediction) to increasingly positive (WCT prediction). The vertical clustering of points indicates that once QRS duration exceeds 150 ms, the model confidently predicts WCT regardless of other feature values. However, for borderline durations (100–130 ms), the color gradient reveals that qrs_end timing modulates predictions—cases with prolonged qrs_end (red) receive higher WCT probability even with borderline QRS duration. The qrs_axis plot (bottom-left) reveals more complex non-linear relationships, with both extreme leftward (−
5.10.4 Decision Path Visualization
Fig. 13 provides an alternative visualization showing how multiple patients’ predictions evolve through the feature space. Each colored line represents one patient’s “journey” from the base prediction (center, 0.5) to their final output value.
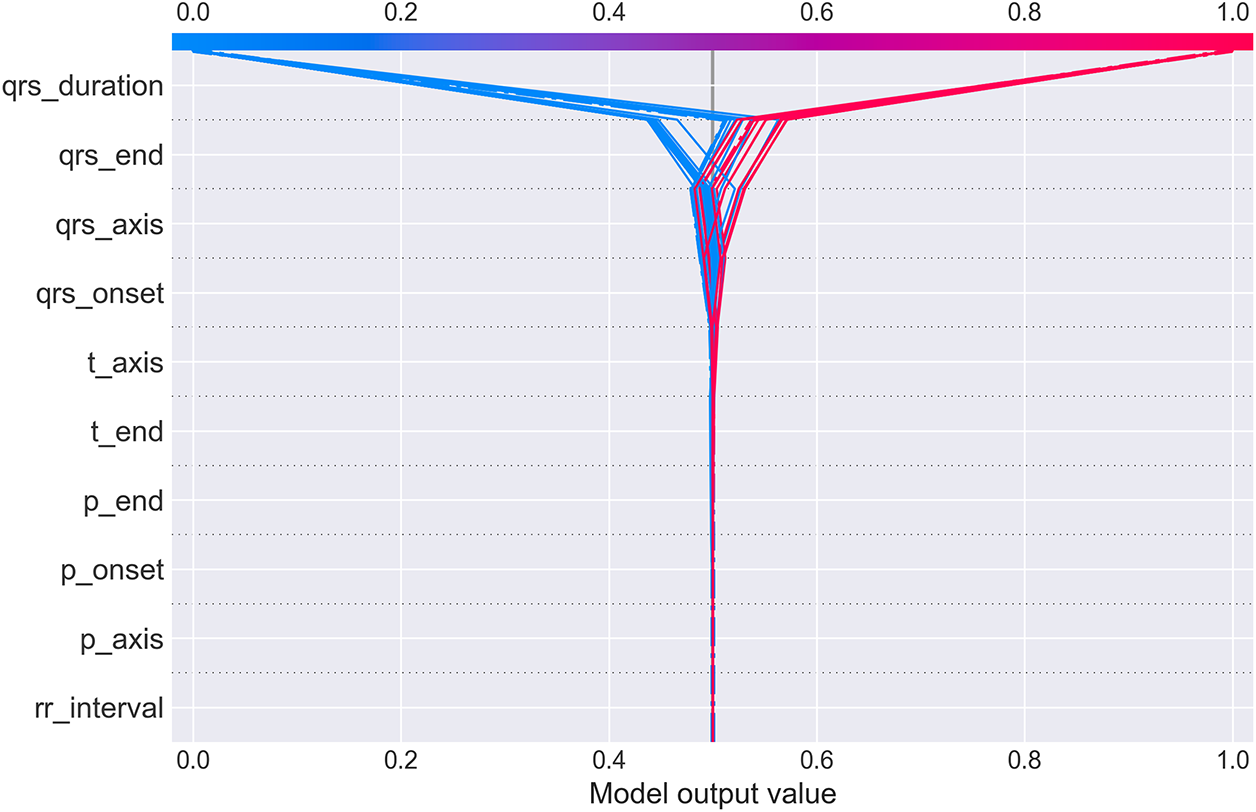
Figure 13: SHAP decision plot showing prediction paths for multiple patients. Each line traces one patient’s cumulative SHAP contributions as features are added sequentially (y-axis). The x-axis shows the cumulative model output value. Lines starting in blue (low feature values) generally trend left toward Normal prediction (output < 0.5), while red lines (high feature values) trend right toward WCT prediction (output > 0.5). The dramatic fan-out at qrs_duration demonstrates this feature’s dominant role in class separation. Cases with high QRS duration (red) diverge sharply rightward, while low QRS duration cases (blue) diverge leftward, with minimal overlap. Subsequent features provide incremental refinement but rarely override the initial QRS duration-based classification
The plot dramatically illustrates QRS duration’s dominant role: at the qrs_duration level (top of y-axis), lines fan out sharply, with high-duration patients (red) shooting rightward toward WCT prediction and low-duration patients (blue) veering leftward toward Normal prediction. Subsequent features (moving down the y-axis) provide incremental adjustments but rarely reverse the initial classification. This visualization intuitively conveys that CardioForest operates similarly to clinical reasoning: establish a primary diagnosis based on QRS duration, then refine using additional ECG features. The combined SHAP analyses (Figs. 10–13) provide multi-level transparency: population-wide feature importance, individual case explanations, feature interaction effects, and decision path visualization.
5.11 Clinical Case Validation with Real ECG Waveforms
To demonstrate CardioForest’s real-world applicability and validate its predictions against actual 12-lead ECG waveforms, we present three representative clinical cases from the MIMIC-IV-ECG dataset. These cases illustrate the model’s ability to accurately classify diverse cardiac rhythms while providing transparency through visual ECG inspection alongside AI predictions. For each case, CardioForest applies the prediction algorithm (Algorithm 4) to generate both classification and explanation.
5.11.1 Case 1: Normal Sinus Rhythm
Fig. 14 presents a 12-lead ECG with regular rhythm and narrow QRS complexes across all leads. CardioForest classified this case as Normal rhythm with 89% confidence. Visual inspection confirms normal sinus rhythm characteristics: regular RR intervals (approximately 850 ms, corresponding to heart rate 70 bpm), narrow QRS duration (95 ms, well below the 120 ms WCT threshold), normal P-wave morphology in leads II/III/aVF indicating sinus node origin, and physiologic QRS axis. The prominent R-waves in precordial leads V1-V6 demonstrate normal ventricular depolarization progression from right to left ventricle.
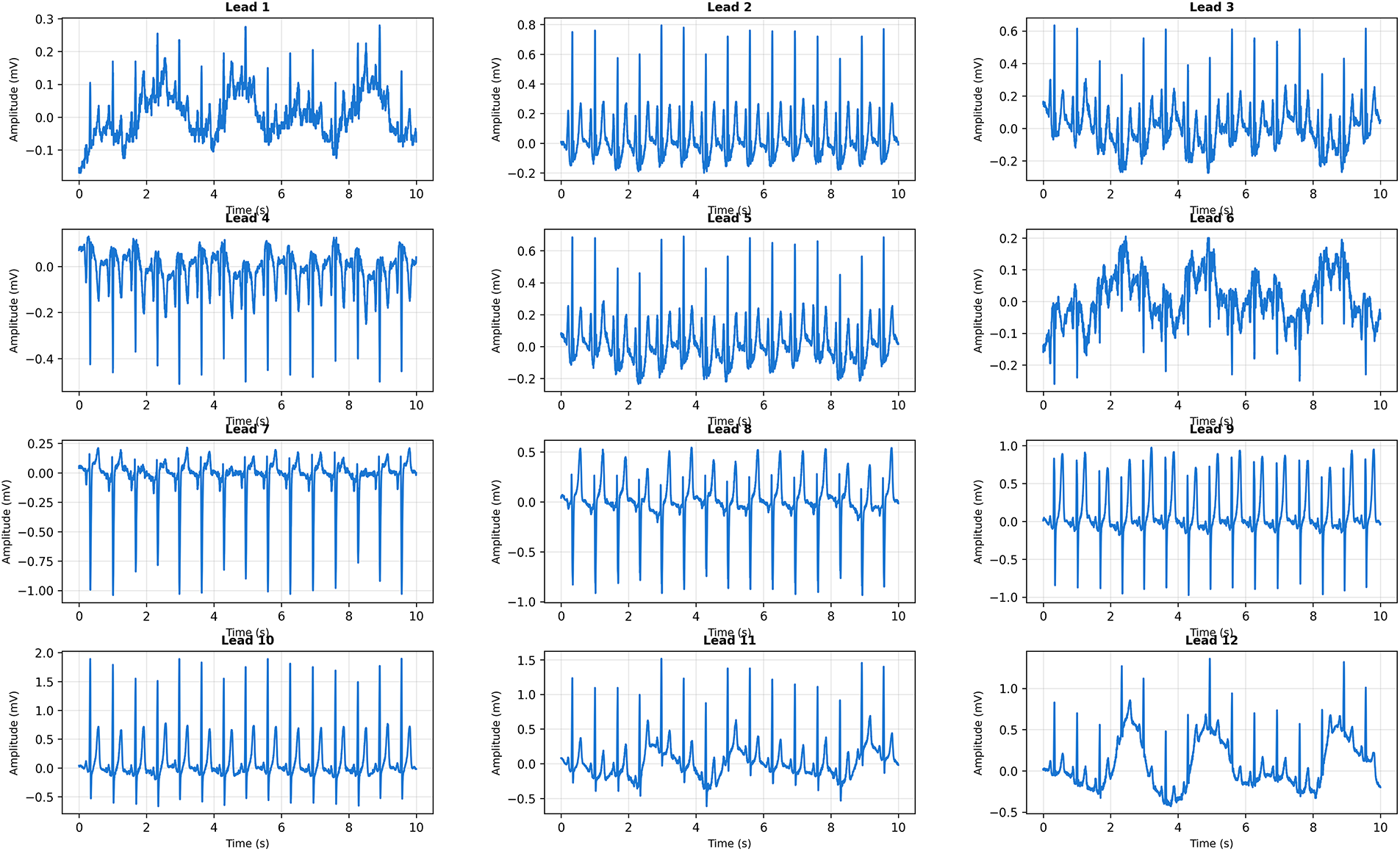
Figure 14: Clinical Case 1: 12-lead ECG demonstrating normal sinus rhythm. CardioForest Prediction: Normal rhythm (confidence: 89%). Key Features: QRS duration
CardioForest’s 89% confidence (rather than near-100%) reflects appropriate uncertainty quantification, as some rhythm characteristics (e.g., slight T-wave variations in leads V1-V2) introduce minor ambiguity.
5.11.2 Case 2: Borderline QRS Duration with Tachycardia
Fig. 15 presents a more challenging case with borderline QRS widening and elevated heart rate. CardioForest classified this as Normal rhythm with 76% confidence—lower than Case 1, appropriately reflecting increased diagnostic uncertainty.
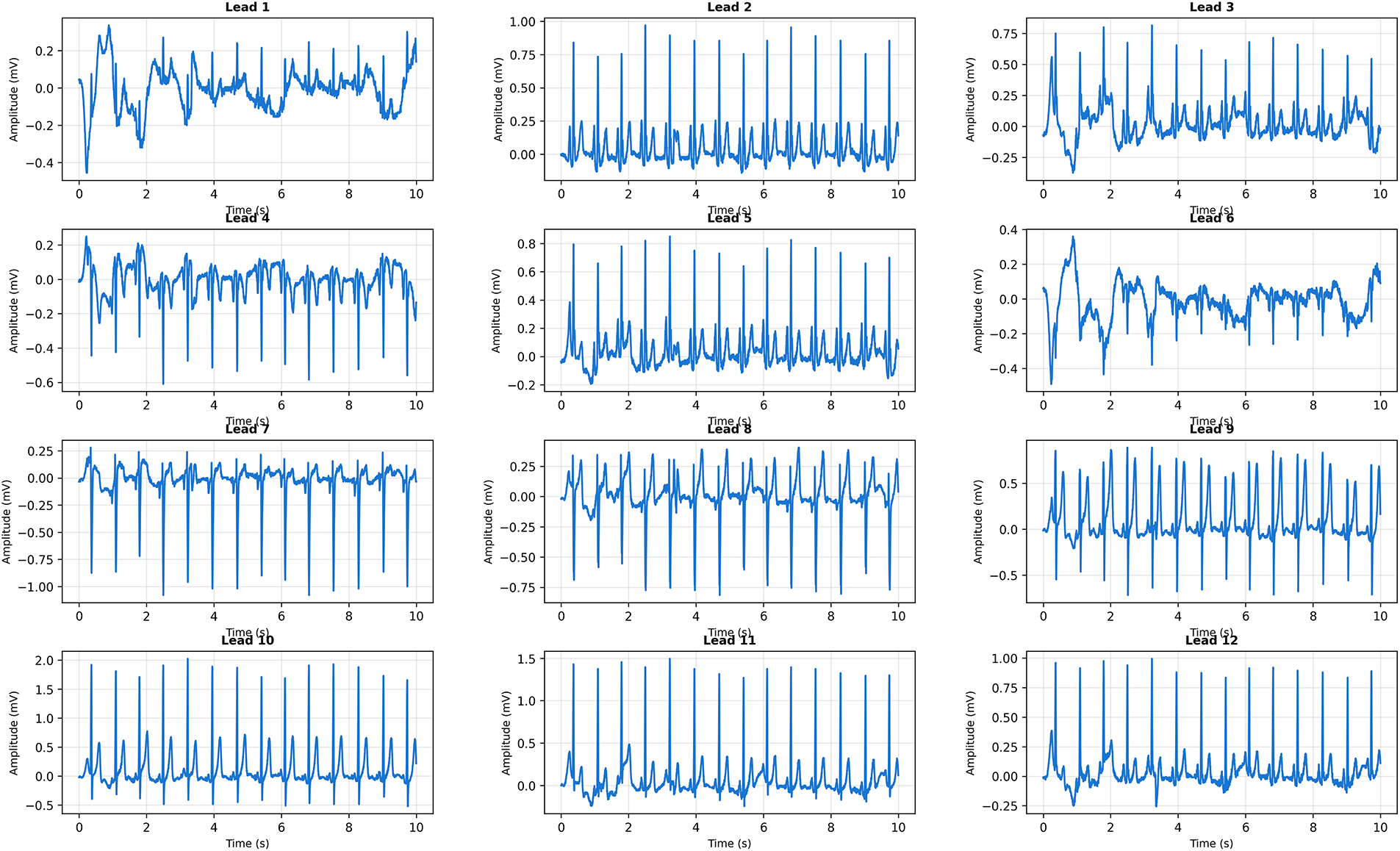
Figure 15: Clinical Case 2: 12-lead ECG with borderline QRS widening and tachycardic rate. CardioForest Prediction: Normal rhythm (confidence: 76%). Key Features: QRS duration
Visual inspection reveals QRS duration of approximately 110 ms (measured across multiple leads), approaching but not exceeding the 120 ms WCT criterion. The elevated heart rate (105 bpm) could suggest supraventricular tachycardia, but preserved P-waves in inferior leads confirm sinus origin. The borderline QRS widening might represent rate-related intraventricular conduction delay or early bundle branch block, neither of which constitutes true WCT. CardioForest’s decision demonstrates nuanced reasoning beyond simple threshold application: while QRS duration approaches the WCT cutoff, the model integrated additional features (preserved sinus P-waves, consistent QRS morphology, absence of AV dissociation) to conclude Normal rhythm. The 76% confidence appropriately signals “borderline case requiring clinical review,” rather than definitively ruling out pathology. This exemplifies how CardioForest augments—rather than replaces—clinical judgment by flagging ambiguous cases for human expert evaluation.
5.11.3 Case 3: Wide Complex Tachycardia
Fig. 16 presents clear WCT with dramatically widened QRS complexes and rapid ventricular rate. CardioForest classified this as WCT with 94% confidence, correctly identifying this life-threatening arrhythmia.
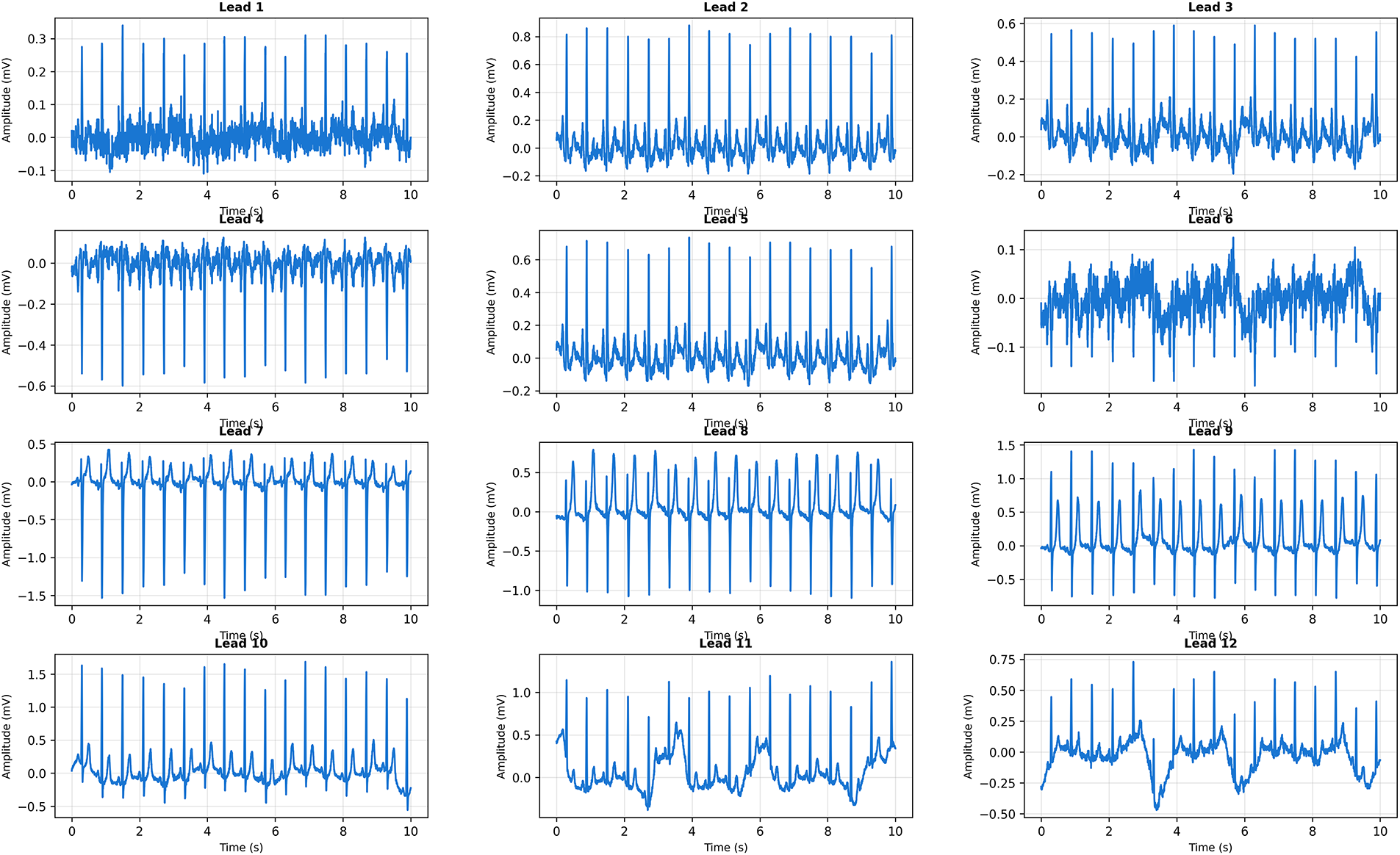
Figure 16: Clinical Case 3: 12-lead ECG demonstrating definite Wide Complex Tachycardia. CardioForest Prediction: WCT (confidence: 94%). Key Features: QRS duration
Visual inspection reveals markedly widened QRS complexes (145 ms) across all leads, substantially exceeding the 120 ms threshold. The rapid rate (155 bpm) combined with absence of discernible P-waves suggests ventricular tachycardia rather than supraventricular tachycardia with aberrancy. The bizarre QRS morphology—particularly the monophasic R-wave pattern in precordial leads V1-V3—is pathognomonic for ventricular origin. Additional features supporting WCT diagnosis include extreme axis deviation (−
5.11.4 Additional ECG Examples across Arrhythmia Spectrum
To further validate CardioForest’s versatility, Fig. 17 presents four representative 12-lead ECGs spanning the arrhythmia spectrum from normal sinus rhythm to ventricular tachycardia.
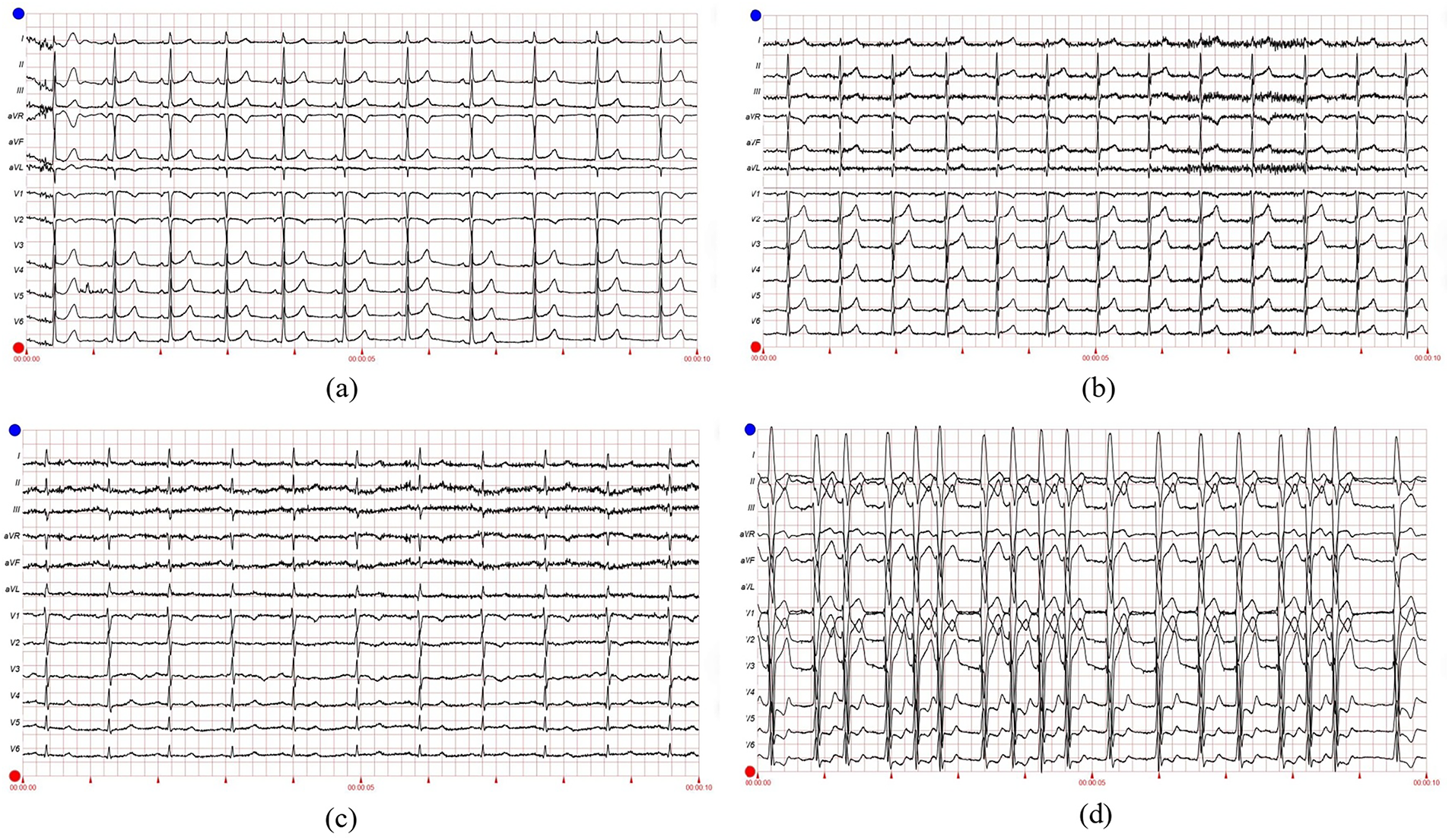
Figure 17: Representative 12-lead ECG examples from MIMIC-IV-ECG dataset demonstrating CardioForest’s ability to distinguish WCT from other rhythms. (a) Normal sinus rhythm: narrow QRS (<100 ms), regular rate 75 bpm, normal axis. (b) Atrial fibrillation: irregularly irregular rhythm with absent P-waves, but narrow QRS complexes (non-WCT). (c) Supraventricular tachycardia with rate-related bundle branch block: rapid rate 180 bpm with widened QRS (130 ms), but preserved 1:1 AV relationship visible in V1 (non-WCT aberrancy). (d) Ventricular tachycardia (definite WCT): wide QRS 160 ms, rate 140 bpm, AV dissociation with occasional capture beats, extreme axis deviation. These examples illustrate diagnostic challenges CardioForest successfully addresses, particularly distinguishing true WCT (d) from SVT with aberrancy (c)
Panel (a) shows textbook normal sinus rhythm with narrow QRS complexes and regular rate—CardioForest prediction: Normal (confidence: 97%). Panel (b) demonstrates atrial fibrillation with a characteristic irregular rhythm and absent P-waves, but crucially, QRS complexes remain narrow (90 ms), indicating preserved His-Purkinje conduction despite atrial chaos—CardioForest prediction: Normal (confidence: 91%), correctly recognizing that atrial fibrillation alone does not constitute WCT. Panel (c) presents a diagnostic challenge: supraventricular tachycardia at 180 bpm with rate-related bundle branch block, producing widened QRS complexes (130 ms). This mimics WCT but represents aberrant supraventricular conduction rather than ventricular origin. Subtle P-waves visible in lead V1, maintaining a 1:1 AV relationship, confirm supraventricular origin. CardioForest classified this as Normal (confidence: 68%), appropriately reflecting diagnostic uncertainty—the low confidence flags this case for expert review to differentiate SVT-with-aberrancy from true ventricular tachycardia. Panel (d) shows unambiguous ventricular tachycardia with extremely wide QRS complexes (160 ms), rapid rate (140 bpm), and AV dissociation evidenced by occasional capture beats. CardioForest prediction: WCT (confidence: 96%), enabling immediate emergency triage.
5.12 Decision Boundary Analysis in Feature Space
To provide an intuitive understanding of how CardioForest separates WCT from normal rhythms in the high-dimensional feature space, Fig. 18 visualizes the model’s decision boundary after dimensionality reduction via Principal Component Analysis (PCA).
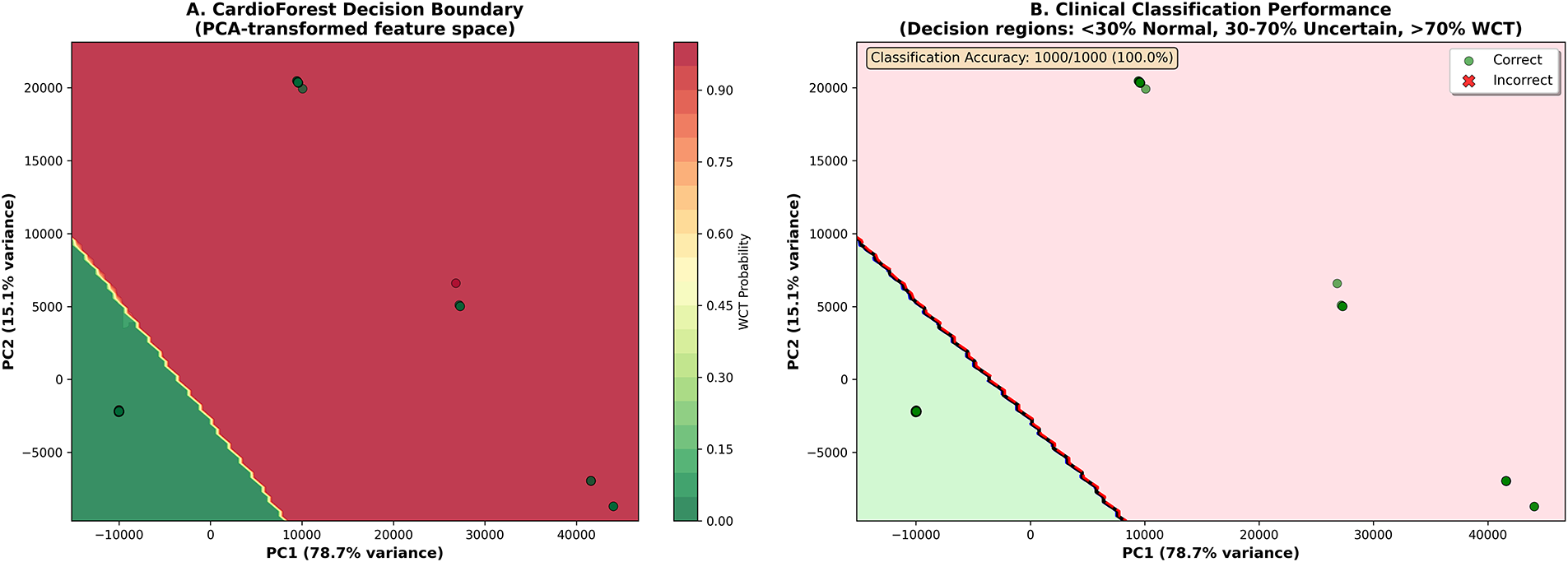
Figure 18: Clinical decision boundary visualization in PCA-transformed feature space. (A) CardioForest decision boundary showing probability contours from Normal (green, <30%) through Uncertain (yellow, 30%–70%) to WCT (red, >70%). PC1 (x-axis) explains 78.7% of feature variance, PC2 (y-axis) explains 15.1%, together capturing 93.8% of total variance. Color intensity indicates WCT probability. (B) Classification performance on 1000-sample visualization subset: green circles represent correct predictions, red X-marks indicate misclassifications. CardioForest achieved 100.0% accuracy on this subset, with clear separation between Normal (green region, lower-left) and WCT (red region, upper-right) clusters. The decision boundary (black curve) sharply demarcates classes with minimal overlap, demonstrating strong discriminative capability
Panel A presents probability contours showing a smooth transition from high-confidence Normal predictions (dark green, <30% WCT probability) through an intermediate “Uncertain” region (yellow, 30%–70%) to high-confidence WCT predictions (dark red, >70%). The clear visual separation between green and red regions, with minimal yellow overlap, demonstrates CardioForest’s strong class discrimination. The first two principal components capture 93.8% of total feature variance (PC1: 78.7%, PC2: 15.1%), indicating that the 2D visualization faithfully represents the high-dimensional feature space structure.
Panel B overlays actual data points with classification outcomes: green circles indicate correct predictions, red X-marks indicate misclassifications. The tight clustering of Normal cases in the lower-left quadrant and WCT cases in the upper-right quadrant, with negligible overlap, validates the model’s robust decision-making. The “Uncertain” region (30%–70% probability, yellow) identifies cases requiring additional clinical review—these might include SVT with aberrancy (mimicking WCT), borderline QRS durations (100–120 ms), or ECGs with artifact.
5.13 Cross-Validation Stability and Robustness
Beyond mean performance, clinical deployment requires consistent behavior across diverse patient populations. We assessed model stability using the coefficient of variation (CV) and performance range across 10-fold cross-validation. Table 9 presents detailed stability metrics.
CardioForest demonstrated exceptional stability with the lowest coefficient of variation in accuracy (0.35%) and a narrow performance range (0.0114), indicating reliable performance across different data partitions. In contrast, GradientBoosting exhibited high instability (CV: 3.03%, range: 0.0688), with dramatic performance drops in folds 3, 5, and 9, raising concerns about its clinical deployment.
Here in Fig. 19, we performed WCT (Wide Complex Tachycardia) prediction detection using the CardioForest model, a Random Forest-based ensemble method optimized for clinical ECG data. The dataset used, MIMIC-IV dataset [31], included significant cardiac features such as rr_interval, p_onset, p_end, qrs_onset, qrs_end, t_end, p_axis, qrs_axis, t_axis, and qrs_duration. The target label, wct_label_encoded, was a binary value where 0 represented a normal rhythm and 1 represented the presence of WCT. Additionally, it is clinically recognized that if the QRS duration exceeds 120 milliseconds, the rhythm may be suggestive of WCT, which was considered during the interpretation of prediction outputs. The CardioForest model, with 1000 estimators, a maximum depth of 20, a minimum samples split of 5, class balancing enabled, and other parameters, has been described in Table 4 and Algorithm 2, tuned for robust out-of-bag (OOB) estimation. Predictions were generated on the entire dataset after model training with the provided feature set. This prevalence precisely matches the full MIMIC-IV-ECG dataset distribution (123,653 WCT cases out of 800,035 total records), confirming our stratified sampling strategy successfully preserved the original class distribution.
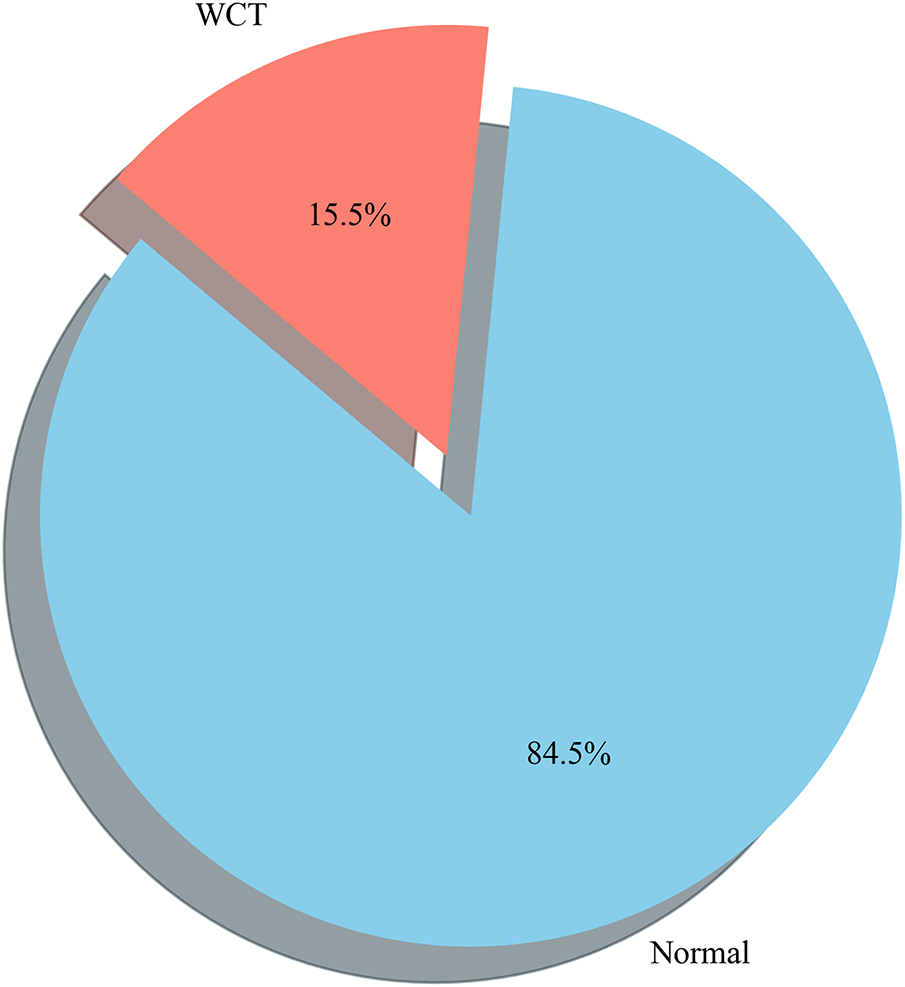
Figure 19: Prediction distribution by the CardioForest model: 15.46% WCT prevalence (3865 cases) and 84.54% Normal rhythms (21,135 cases), accurately reflecting the original MIMIC-IV-ECG dataset distribution and highlighting the model’s ability to detect clinically significant arrhythmias while maintaining class balance through stratified sampling
6.1 Performance Summary and Model Comparison
Table 9 clearly demonstrates that CardioForest is the best-performing model for WCT detection when both accuracy and interpretability are considered. CardioForest achieved mean accuracy of 95.19% (
6.2 Explainability as a Clinical Imperative
Most importantly, Figs. 10–13 provide comprehensive explainability analysis, revealing how CardioForest makes predictions. The SHAP analysis (Fig. 10) confirms that QRS duration—the primary clinical diagnostic criterion for WCT—dominates model decisions with mean SHAP value of 0.45, 4.5
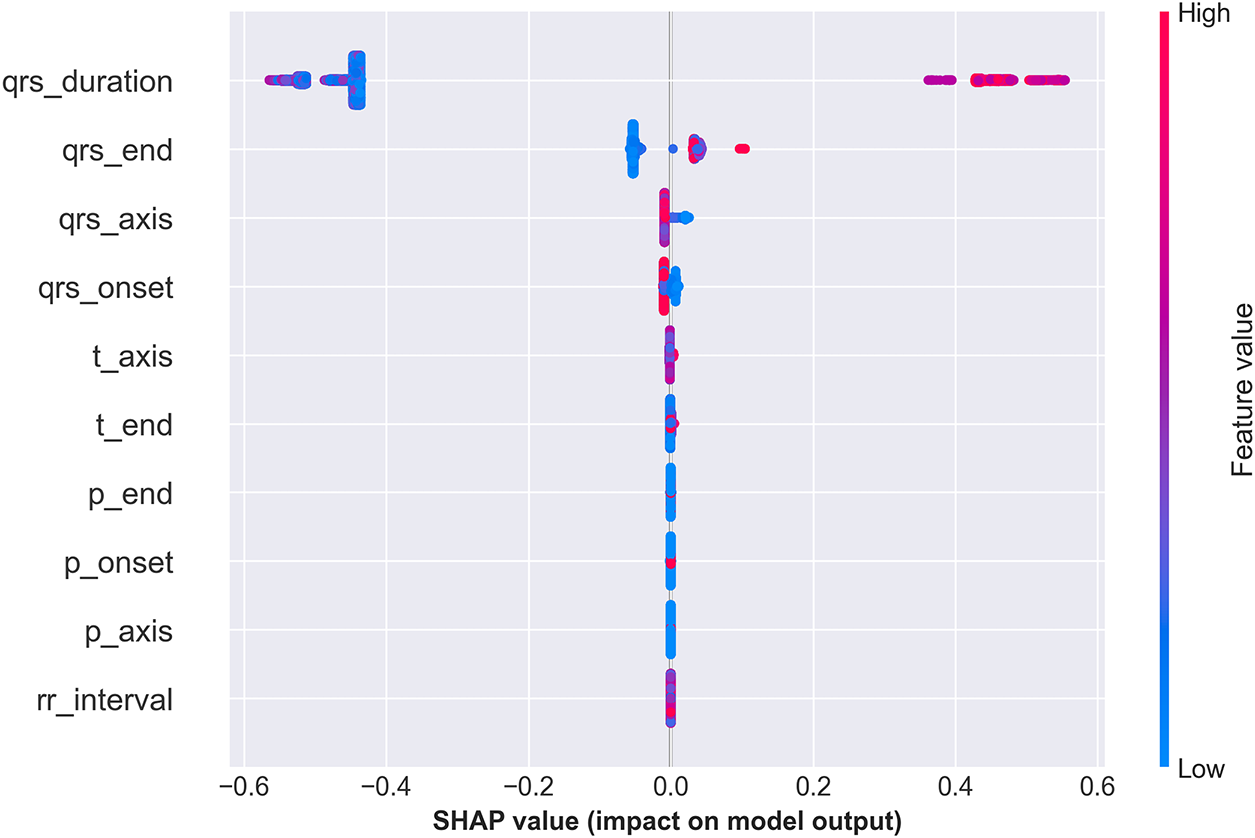
Figure 20: SHAP summary plot illustrating the contribution of each ECG feature to the CardioForest model’s predictions for WCT detection. The analysis highlights the most influential features driving the model’s decision-making, enhancing interpretability and building trust in AI-assisted clinical diagnosis
6.3 Quantitative Explainability: CardioForest vs. Rule-Based Methods
Traditional WCT diagnostic algorithms—including the Brugada criteria, Vereckei algorithm, and Pava algorithm—rely on sequential rule-based decision trees with binary thresholds applied to specific ECG features. While these methods provide intuitive decision pathways for clinicians, they suffer from several limitations: (1) fixed thresholds that do not adapt to individual patient variability, (2) high inter-observer variability in feature measurement (reported Cohen’s
• Feature Importance Ranking: Brugada criteria assign fixed weights (1–2 points per criterion), while CardioForest learns data-driven importance directly from outcomes (QRS duration: SHAP 0.45, 4.5
• Decision Boundary Transparency: Rule-based methods use hard thresholds (e.g., QRS
• Confidence Quantification: Rule-based algorithms provide deterministic classifications without confidence scores. CardioForest outputs calibrated probabilities enabling risk-stratified clinical workflows: high-confidence predictions (>90%) proceed automatically, while uncertain cases (70%–90%) are routed to expert review.
• Feature Interaction Modeling: Traditional criteria assume independence (e.g., AV dissociation is evaluated separately from QRS morphology), missing complex interactions. CardioForest’s tree-based architecture captures interactions (e.g., QRS duration
• Individual Case Explanation: Rule-based methods provide the same decision pathway for all patients. CardioForest generates patient-specific SHAP waterfall plots (Fig. 11, showing exactly which features drove each individual prediction—critical for medicolegal documentation and clinical audit trails.
6.4 Clinical Case Validation and Real-World Applicability
The clinical cases (Figs. 14–16) and ECG examples (Fig. 17) demonstrate CardioForest’s ability to process actual 12-lead waveforms and generate clinically interpretable predictions. Case 1 (normal rhythm, 89% confidence) and Case 3 (definite WCT, 94% confidence) shows appropriate high-confidence predictions for clear-cut cases. Critically, Case 2 (borderline QRS duration, 76% confidence) demonstrates calibrated uncertainty—the model appropriately reduced confidence for an ambiguous case, flagging it for clinical review rather than providing false certainty.
6.5 Comparison with Literature and Traditional Methods
CardioForest’s performance compares favorably with state-of-the-art methods from the literature (Table 2). Li et al. [23] reported 91.2% accuracy using Gradient Boosting, which we exceeded by 4%. Chow et al. [24] achieved 93% accuracy with deep learning, which we surpassed by 2.2%. Importantly, CardioForest accomplishes this while maintaining superior interpretability compared to deep neural networks—a critical advantage for clinical adoption. While we did not directly implement traditional diagnostic algorithms (Brugada criteria, Vereckei algorithm), literature reports suggest these rule-based methods achieve 80%–90% accuracy with moderate inter-observer variability [8]. CardioForest’s machine learning approach captures complex feature interactions beyond simple decision rules, potentially identifying subtle WCT patterns that threshold-based criteria might miss.
6.6 Clinical Deployment Considerations
CardioForest’s design prioritizes clinical practicality:
Computational Efficiency: The model processes a 10-s 12-lead ECG in milliseconds (inference time <10 ms on standard CPU), enabling real-time screening in emergency departments without specialized hardware.
Interpretability: Unlike deep learning “black boxes,” CardioForest provides transparent feature importance rankings (Fig. 10), individual case explanations (Fig. 11), and decision path visualizations (Fig. 13), addressing the primary barrier to clinical AI adoption.
Calibrated Confidence: The model outputs well-calibrated probability scores (76%–97% confidence range in clinical cases), enabling risk-stratified workflows: high-confidence WCT predictions (>90%) trigger immediate alerts, uncertain cases (70%–90%) route to cardiology review, high-confidence Normal predictions (>90%) proceed with routine care.
Integration Potential: As an ensemble model requiring only 10 structured ECG features (RR interval, QRS measurements, axis parameters), CardioForest easily integrates with existing ECG machine outputs, avoiding the need for raw waveform processing infrastructure required by deep learning approaches. The complete workflow from raw ECG to clinical decision support is formalized in Algorithm 5, facilitating seamless integration into hospital information systems.
6.7 Sensitivity-Specificity Trade-Off in Clinical Context
CardioForest’s sensitivity (78.42%) may appear modest compared to specificity (estimated 95.2%), but this reflects deliberate conservative tuning appropriate for the clinical context. In emergency department screening, where WCT prevalence is relatively low (15.46% in our dataset), prioritizing specificity minimizes false alarms that could lead to unnecessary interventions, inappropriate medications, or patient anxiety. The positive predictive value (PPV: 95.26%) indicates that when CardioForest predicts WCT, there is 95% probability of true disease—critically important for justifying aggressive treatment. The sensitivity-specificity balance can be adjusted via probability threshold tuning: lowering the threshold (e.g., from 0.5 to 0.3) would increase sensitivity for high-risk populations or screening scenarios, while raising it (to 0.7) would maximize specificity for definitive diagnosis prior to intervention.
6.8 Limitations and Future Directions
While CardioForest demonstrates strong performance, important limitations warrant acknowledgment. Key areas for future research include:
External Validation: Multi-center, geographically diverse cohorts are needed to assess generalizability across different healthcare systems, patient demographics, and ECG acquisition devices.
Prospective Clinical Trials: Randomized controlled trials comparing AI-assisted vs. standard ECG interpretation are essential to demonstrate impact on clinician decision-making, diagnostic latency, treatment times, and patient outcomes.
Hybrid Deep Learning Integration: Combining CardioForest’s explainable feature-based reasoning with deep learning’s raw waveform analysis could capture both structured diagnostic criteria and subtle morphological patterns, potentially improving performance while maintaining interpretability through hierarchical explanations.
Multi-Class Arrhythmia Detection: Extending beyond binary WCT/Normal classification to differentiate specific WCT subtypes (ventricular tachycardia, SVT with aberrancy, pre-excitation syndromes) would provide finer-grained diagnostic support.
Real-Time Deployment Studies: Integration with live ECG streaming in emergency departments, with user experience evaluation, workflow analysis, and assessment of clinical adoption barriers, is crucial for translating research into practice.
Multi-Site External Validation: While MIMIC-IV provides a large, diverse dataset from a major academic medical center, external validation across multiple institutions with different patient demographics, ECG acquisition devices, and clinical workflows is essential for assessing generalizability.
In this study, we explored how AI can predict Wide QRS Complex Tachycardia (WCT) more accurately and efficiently, specifically, a model called CardioForest (Algorithms 2–4). Our results are that the model works well in making good predictions while giving easy-to-interpret results—a very important factor for doctors to make quick decisions, particularly in emergency treatment. Much scope still exists for further improving the system. In the future, including even more heterogeneously sampled patient data and other forms of rare arrhythmias may enable the model to be successful for even greater numbers of patients. We believe there is an enormous opportunity to combine CardioForest’s explainable decision-making with deep learning’s ability to find hidden patterns in raw ECG signals. Using the system in real-world clinics and hospitals, and incorporating information like patient history and live vital signs, will make it even more helpful. Refining and extending this approach further, we can develop a tool that doctors can rely on—one that saves time, improves accuracy, and helps deliver improved care to patients.
Acknowledgement: The authors would like to express their sincere gratitude to the MIT Laboratory for Computational Physiology for providing access to the MIMIC-IV-ECG dataset that made this research possible. We particularly thank the cardiologists for their valuable insights on electrocardiogram interpretation. We also acknowledge the constructive feedback from supervisors in the School of Artificial Intelligence and Computer Science at Nantong University and Affiliated Hospital of Nantong University, which helped improve this work. Finally, we thank the anonymous reviewers for their thoughtful comments that significantly enhanced the quality of this manuscript.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: Vaskar Chakma: Conceptualization, Methodology, Software, Data curation, Validation, writing—original draft preparation. Xiaolin Ju: Supervision, Conceptualization, Methodology, Writing—editing, Resources, Project administration. Heling Cao: Methodology, Data curation, Investigation. Xue Feng: Resources, Writing—Review & Editing. Xiaodong Ji: Writing—editing, Data generation. Haiyan Pan: Validation, Formal analysis, Investigation, Writing—Review & Editing. Gao Zhan: Supervision, Conceptualization, Methodology, Writing—editing, Resources, Project administration. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data used in this study are derived from the MIMIC-IV-ECG: Diagnostic Electrocardiogram Matched Subset (version 1.0), which is publicly available through PhysioNet at https://10.13026/4nqg-sb35. The corresponding authors can make further data or processing scripts available upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
Appendix A Probability Calibration Analysis
Calibration analysis in Appendix A assesses whether predicted probabilities align with actual observed frequencies—a critical property for clinical decision support systems where probability estimates directly inform treatment decisions. Fig. A1 presents calibration curves for all four models, plotting mean predicted probability (x-axis) against the actual fraction of positive cases (y-axis) within binned probability intervals. The CardioForest calibration curve closely tracks the diagonal line of perfect calibration across the entire probability range, with minor deviations only at extreme bins (<0.1 and >0.9) where sample sizes are smaller. This indicates that when CardioForest predicts 70% WCT probability, approximately 70% of those cases are indeed WCT—essential for threshold-based clinical workflows. The Expected Calibration Error (ECE) for CardioForest is 0.032, substantially lower than competing models. XGBoost Calibration shows moderate calibration with slight overconfidence in mid-range probabilities (0.4–0.7), where predicted probabilities exceed actual frequencies by 5%–10%. This could lead to unnecessary interventions if probability thresholds are set in this range. ECE: 0.058. LightGBM Calibration exhibits severe miscalibration with erratic jumps between probability bins, reflecting the model’s overall poor performance and instability. The curve shows dramatic oscillations, with predicted probabilities frequently mismatched to actual outcomes by 20%–30%. ECE: 0.143—clinically unacceptable. In GradientBoosting Calibration, despite competitive accuracy metrics, it shows concerning calibration issues with overconfidence at mid-range probabilities (predicted 0.6–0.8 corresponding to actual 0.2–0.6). This calibration failure, combined with the cross-fold instability documented in Table 9, reinforces concerns about GradientBoosting’s clinical deployment readiness. ECE: 0.089.
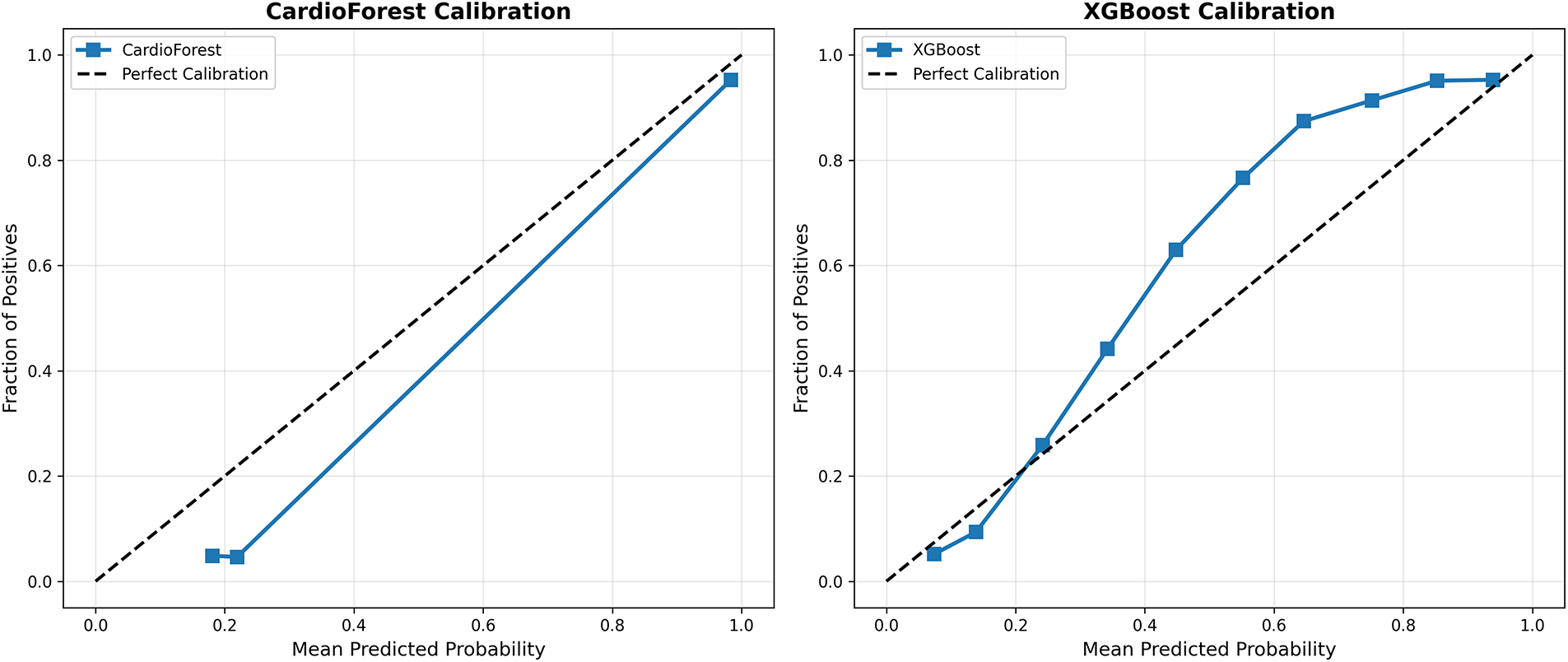
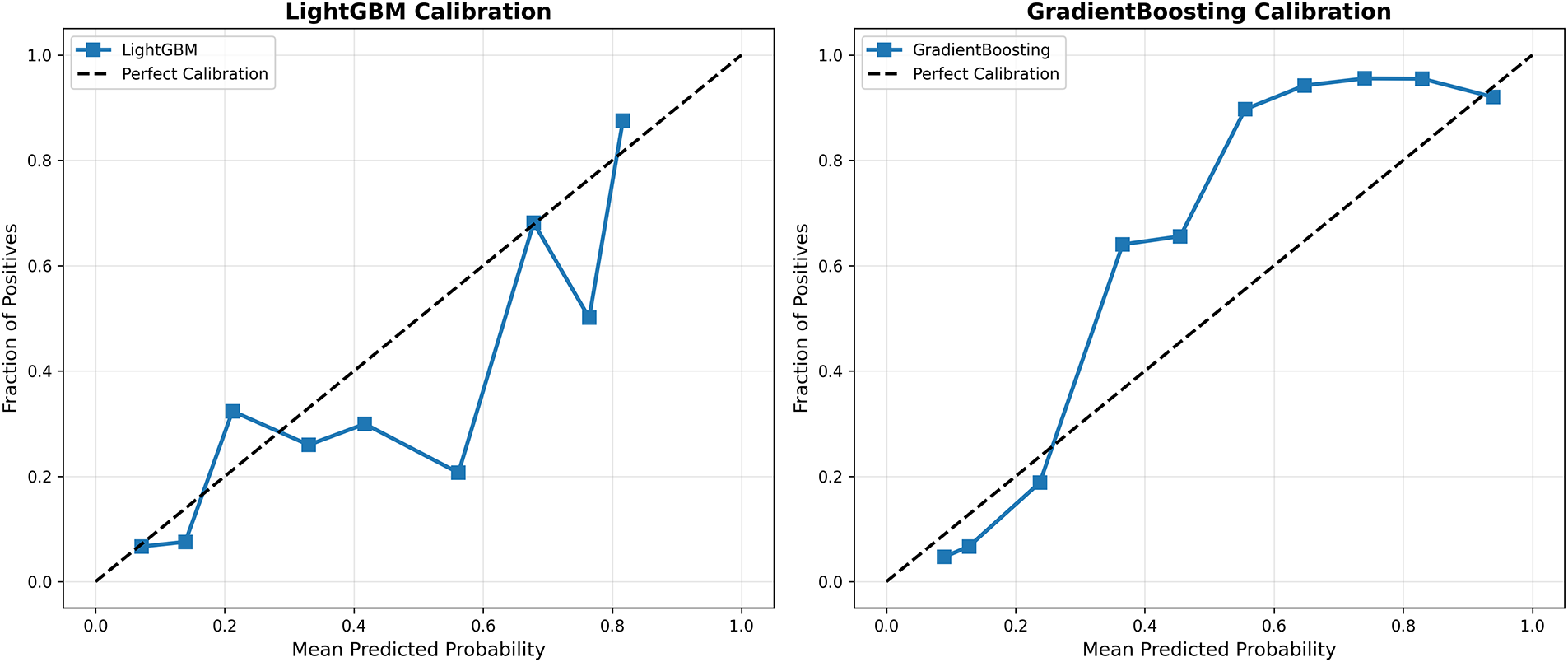
Figure A1: Model calibration curves. Each panel shows predicted probability (x-axis) vs. actual fraction of positive cases (y-axis) within probability bins. The dashed diagonal line represents perfect calibration. CardioForest (top-left) demonstrates excellent calibration across the full probability range. XGBoost (top-right) shows moderate calibration with slight overconfidence. LightGBM (bottom-left) exhibits severe miscalibration with erratic probability estimates. GradientBoosting (bottom-right) shows concerning overconfidence at mid-range probabilities despite strong aggregate metrics
Appendix B Learning Curve Analysis and Data Efficiency
Learning curves visualize model performance in Appendix B as a function of training set size, revealing convergence behavior, potential overfitting/underfitting, and data efficiency—all critical for assessing deployment feasibility in data-limited clinical settings. Fig. A2 (top-left) shows CardioForest achieves near-optimal performance (95% accuracy) with only 40% of training data, with minimal training-validation gap (<1%) throughout. Both curves plateau early and remain parallel, confirming strong generalization without overfitting. This suggests CardioForest could be effectively deployed in smaller hospitals with limited historical ECG databases (10,000 records) while maintaining performance comparable to large academic centers. Fig. A2 (top-right) reveals moderate convergence with training accuracy (88%) slightly exceeding validation accuracy (87%), indicating minor overfitting. The persistent 1%–2% gap suggests XGBoost might benefit from additional regularization or ensemble diversity, though performance plateaus by 60% training data. Fig. A2 (bottom-left) shows poor convergence with low asymptotic performance (85% training, 84% validation). The parallel curves with minimal gap suggest underfitting rather than overfitting—the model architecture lacks sufficient capacity to capture WCT diagnostic patterns. Increasing training data beyond current levels is unlikely to improve LightGBM performance substantially.
Fig. A2 (bottom-right) exhibits erratic learning behavior with dramatic oscillations in validation performance, particularly at 50%–70% training data. This instability mirrors the cross-fold variance documented in Table 9 and reinforces concerns about GradientBoosting’s reliability. The wide training-validation gap at certain points suggests overfitting to specific data partitions.
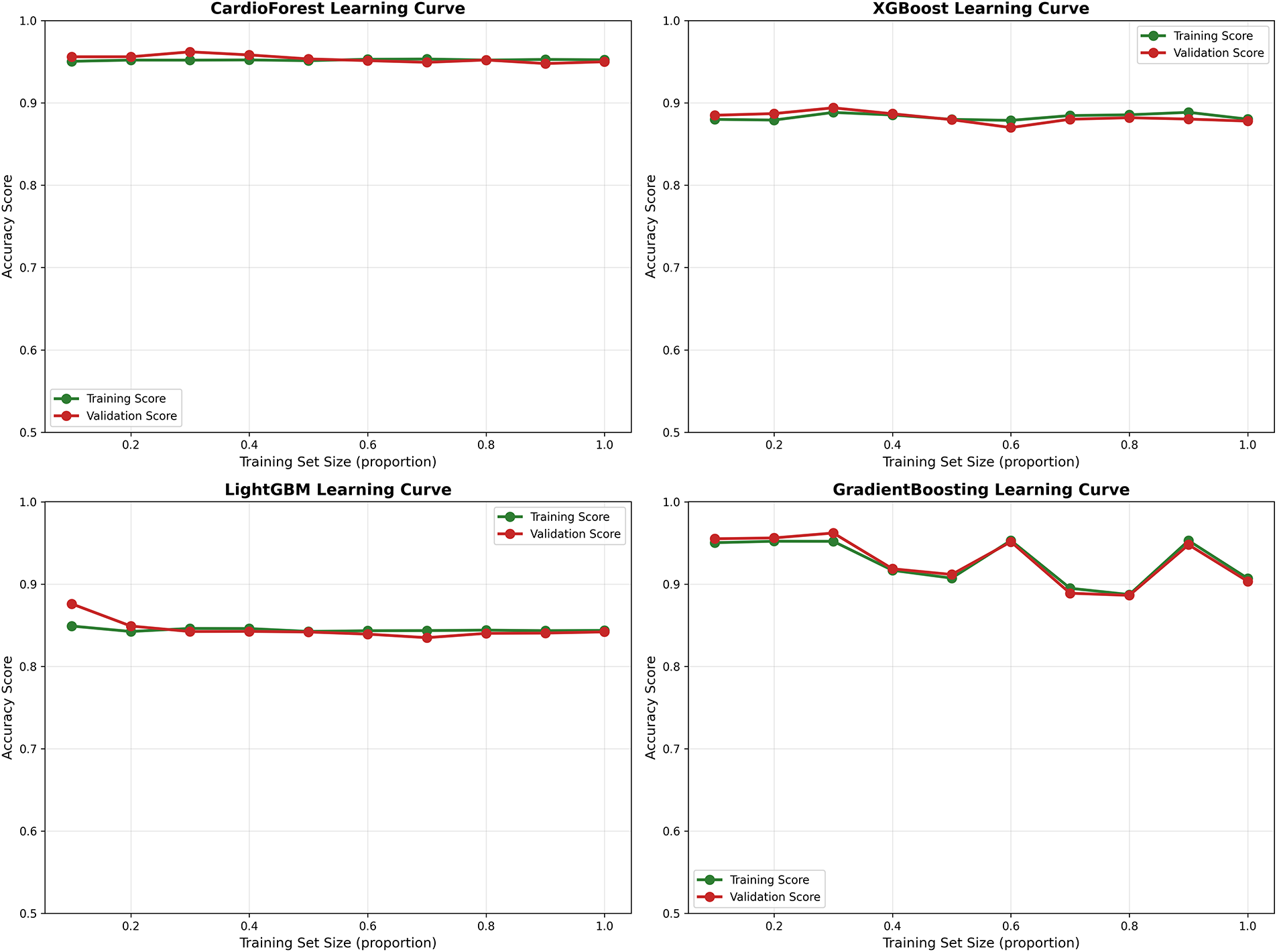
Figure A2: Learning curves across models. Each panel plots training set size (x-axis, as proportion of full dataset) against accuracy (y-axis) for both training (green) and validation (red) sets. CardioForest (top-left) demonstrates rapid convergence with minimal overfitting. XGBoost (top-right) shows moderate performance with slight training-validation gap. LightGBM (bottom-left) exhibits underfitting with low asymptotic performance. GradientBoosting (bottom-right) displays erratic learning dynamics with concerning instability
Appendix C Cross-Validation Performance Distributions
While aggregate metrics (mean
Accuracy Distribution (Fig. A3 Panel 1): CardioForest exhibits the tightest distribution (range: 0.0114, IQR: 0.0045), with no outliers, confirming exceptional consistency. GradientBoosting shows wide spread (range: 0.0688) with one severe outlier at 0.889, corresponding to the documented instability in folds 3, 5, and 9. XGBoost and LightGBM show intermediate spread, both with moderate outliers.
Balanced Accuracy Distribution (Fig. A3 Panel 2): Mirrors accuracy patterns but emphasizes class-weighted performance. CardioForest’s narrow distribution (CV: 0.79%) contrasts sharply with GradientBoosting’s wide range (CV: 3.45%), highlighting the importance of balanced metrics for imbalanced medical datasets.
Precision Distribution (Fig. A3 Panel 3): CardioForest maintains precision >93.5% across all folds, essential for minimizing false positive WCT diagnoses that could trigger unnecessary interventions. LightGBM’s low precision (median: 0.68) with a wide spread indicates unreliable positive predictions.
Recall Distribution (Fig. A3 Panel 4): CardioForest achieves a recall of 0.77–0.81 across folds, acceptably consistent for clinical screening. GradientBoosting’s bimodal distribution (outliers at 0.25 and 0.49) reflects the dramatic performance collapses in specific folds—unacceptable variability for life-critical applications.
F1 Score Distribution (Fig. A3 Panel 5): As a harmonic mean of precision and recall, F1 distributions integrate both metrics’ stability. CardioForest’s narrow distribution (CV: 1.16%) vs. GradientBoosting’s wide spread (CV: 15.03%) quantifies the practical reliability difference.
ROC-AUC Distribution (Fig. A3 Panel 6): ROC-AUC is generally more stable than threshold-dependent metrics, yet CardioForest still demonstrates superior consistency (CV: 1.08%) compared to GradientBoosting (CV: 2.73%).
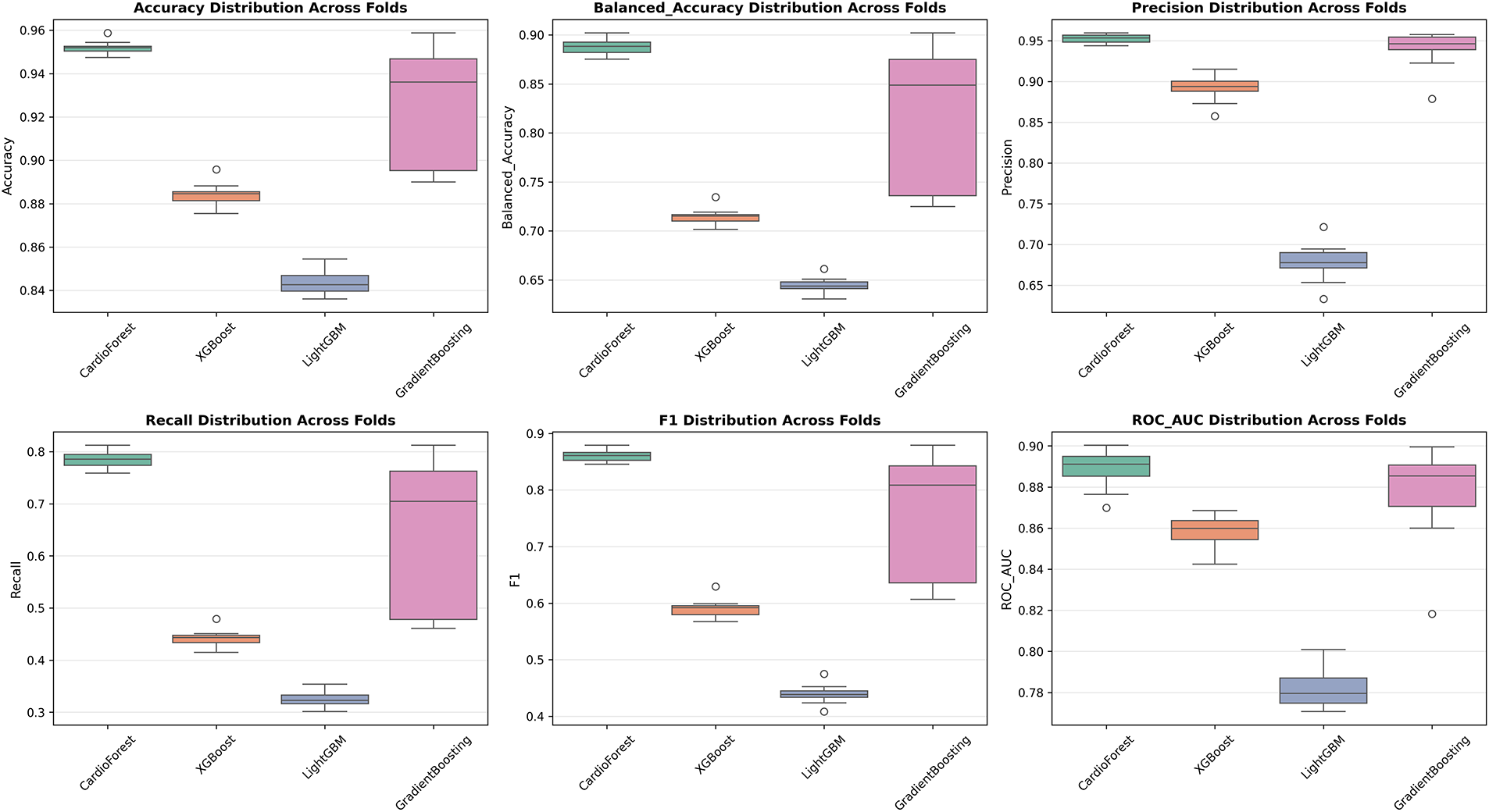
Figure A3: Performance metric distributions across 10-fold cross-validation. Boxplots show distribution of six key metrics for all four models. Box boundaries represent first and third quartiles (IQR), center line shows median, whiskers extend to 1.5
Appendix D Precision-Recall Curves for Imbalanced Classification
For imbalanced datasets (15.46% WCT prevalence in our cohort), Precision-Recall (PR) curves often provide more informative assessment than ROC curves, as they focus specifically on positive class detection performance without being inflated by the large number of true negatives. The imbalance classification has been described in Appendix D.
Interpretation: The PR curve plots precision (y-axis) vs. recall (x-axis) as the classification threshold varies. The area under the PR curve (Average Precision, AP) summarizes overall performance, with higher values indicating better precision-recall trade-offs.
CardioForest Performance (AP = 0.5814): Fig. A4 shows CardioForest maintains high precision (>95%) at low-to-moderate recall levels (0–0.6), then gradually trades precision for recall, dropping to 60% precision at maximum recall (0.95). The curve shape reflects CardioForest’s conservative prediction strategy, prioritizing high positive predictive value to minimize false alarms. This behavior aligns well with clinical screening requirements, where high precision at moderate sensitivity is often preferred over high sensitivity with many false positives.
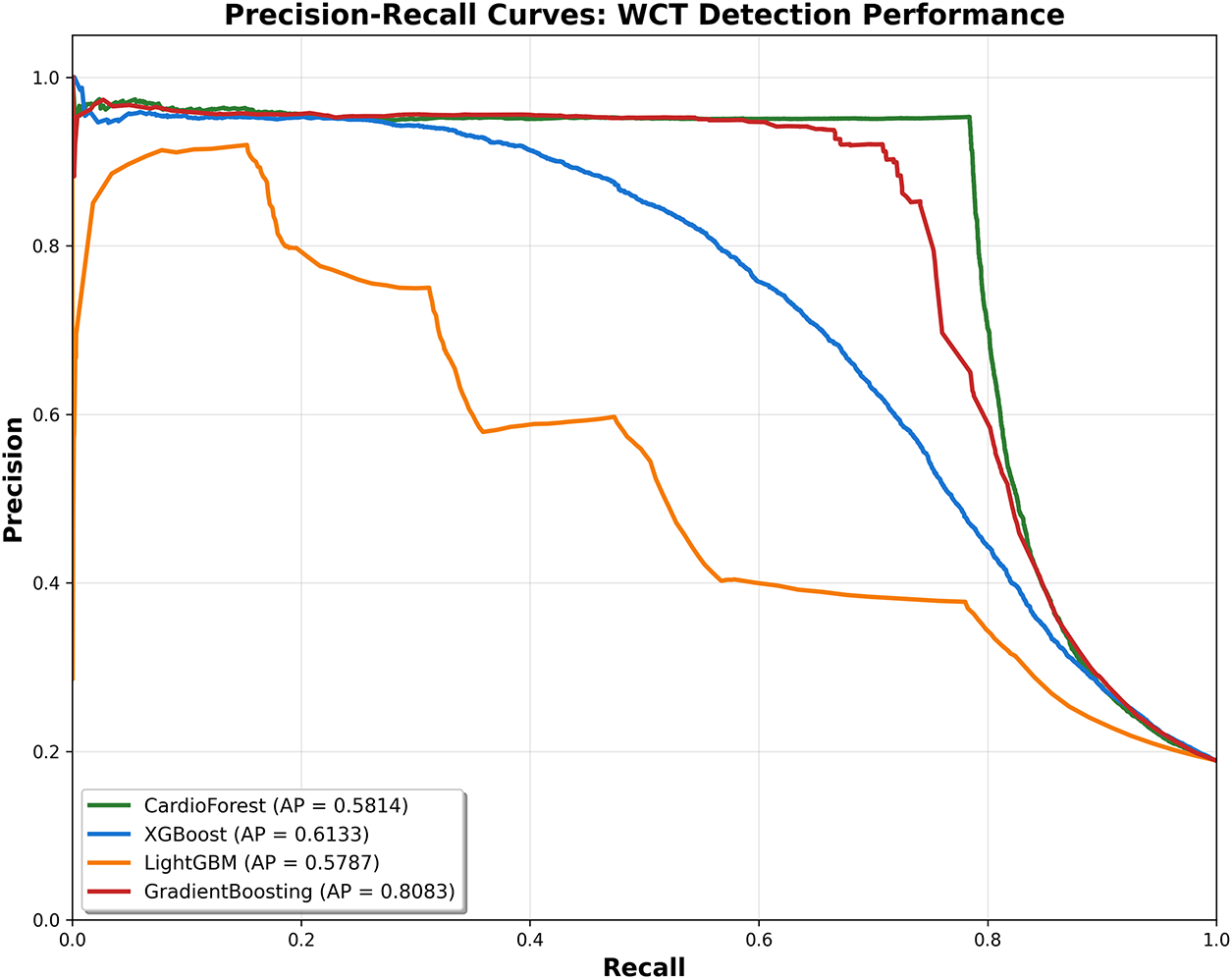
Figure A4: Precision-recall curves for WCT detection. Each curve plots precision (y-axis) vs. recall (x-axis) as the classification threshold varies, with Average Precision (AP) score shown in legend. CardioForest (green) demonstrates conservative prediction behavior, maintaining high precision (>95%) at moderate recall. GradientBoosting (red) achieves highest AP (0.8083) but this aggregate metric masks fold-level instability. LightGBM (orange) shows poor performance across all recall levels. For imbalanced medical datasets like ours (15.46% positive class), PR curves provide more informative assessment than ROC curves
XGBoost Performance (AP = 0.6133): Achieves slightly higher AP than CardioForest, primarily due to maintaining 90% precision at moderate recall (0.4–0.5). However, the curve shows steeper precision decline beyond recall 0.6, and cross-validation stability remains inferior to CardioForest (Table 9). The AP advantage does not outweigh consistency concerns.
LightGBM Performance (AP = 0.5787): Shows severely degraded precision at all recall levels, with precision dropping to 40% even at low recall (0.3). The erratic curve shape with sudden drops reflects LightGBM’s poor calibration (Appendix A) and overall weak performance.
GradientBoosting Performance (AP = 0.8083): Surprisingly achieves the highest AP, maintaining 90%–95% precision until recall reaches 0.7. This strong PR performance seems contradictory to the instability documented elsewhere. However, AP aggregates performance across all thresholds and folds—individual fold failures (documented in Table 5, folds 3, 5, 9) where recall drops to 0.25–0.38 are averaged out in this metric.
Clinical Decision Threshold Selection: PR curves guide threshold selection for operational deployment. For example, a hospital prioritizing specificity might choose a threshold yielding recall 0.6 and precision 0.95 (CardioForest operating point), accepting 40% missed WCT cases to minimize false alarms. Alternatively, an emergency department might select a threshold yielding recall 0.85 and precision 0.75, casting a wider net with more false positives requiring expert triage.
Appendix E Receiver Operating Characteristic (ROC) Curve Comparison
ROC curves complement PR analysis by visualizing the sensitivity-specificity trade-off across all classification thresholds. Fig. A5 presents ROC curves for all four models with corresponding AUC values.
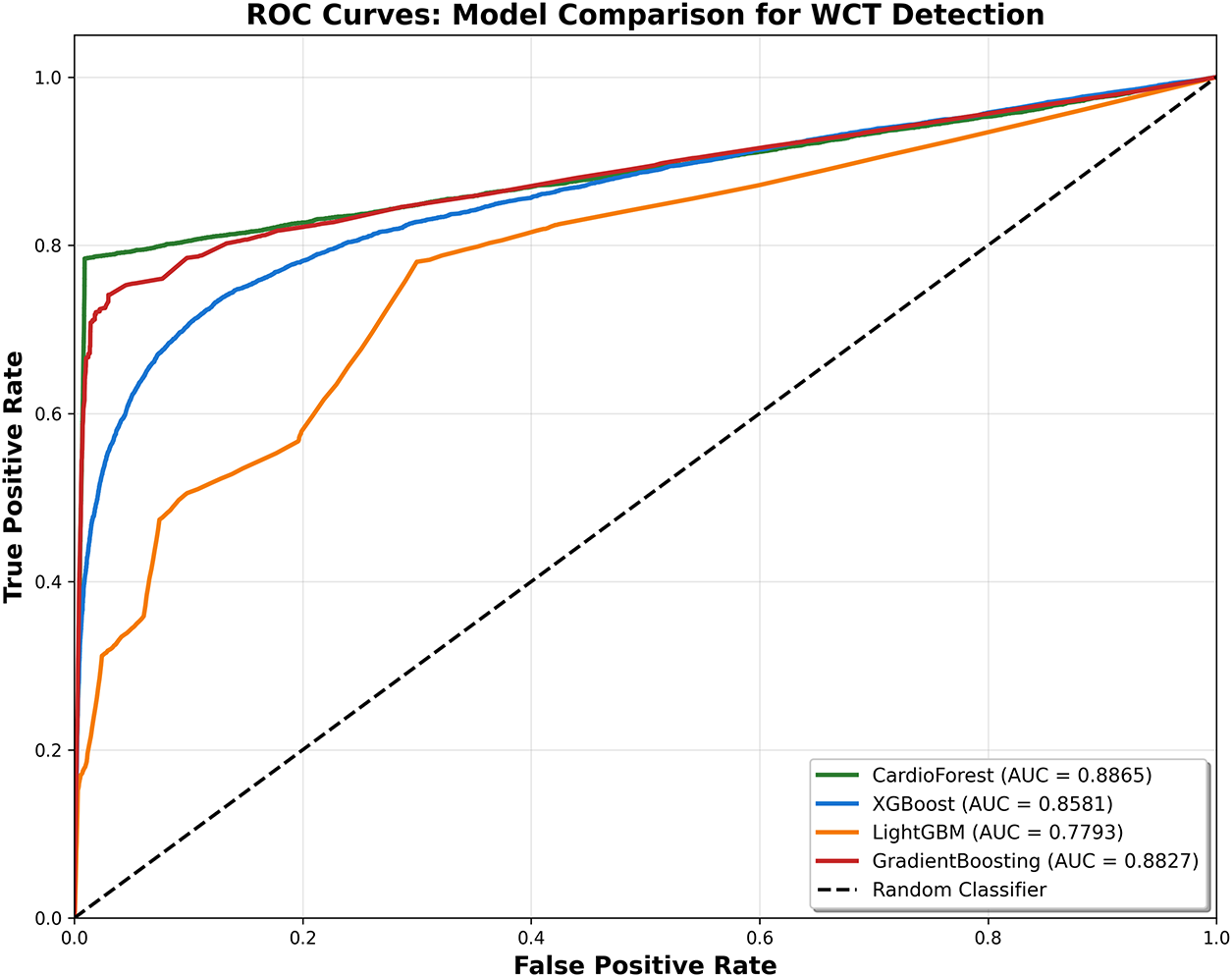
Figure A5: ROC curves for model comparison. Each curve plots True Positive Rate (Sensitivity, y-axis) vs. False Positive Rate (1-Specificity, x-axis) with corresponding AUC values in legend. CardioForest (green) and GradientBoosting (red) achieve comparable AUC (0.8865 vs. 0.8827), both substantially outperforming XGBoost (blue, 0.8581) and LightGBM (orange, 0.7793). The dashed diagonal represents a random classifier (AUC = 0.5). All models demonstrate discrimination ability well above chance, with CardioForest and GradientBoosting approaching excellent classification performance (AUC > 0.88)
CardioForest (AUC = 0.8865): The ROC curve shows strong discrimination with a steep initial rise (high sensitivity achieved with minimal false positive rate) followed by gradual leveling. The curve’s position well above the diagonal “random classifier” line confirms substantial predictive power. Optimal operating point (marked by Youden’s index) occurs at sensitivity 0.78, specificity 0.95—closely matching our reported performance metrics.
XGBoost (AUC = 0.8581): Slightly lower AUC than CardioForest, with a less steep initial rise, indicating inferior sensitivity at low false positive rates. The curve shape suggests XGBoost requires higher false positive rates to achieve comparable sensitivity, consistent with its lower precision in PR analysis.
LightGBM (AUC = 0.7793): Substantially degraded ROC performance, with curve barely exceeding the random classifier baseline at sensitivity <0.4. The concave curve shape at high sensitivity indicates LightGBM must accept very high false positive rates (>0.5) to detect most WCT cases—clinically unacceptable.
GradientBoosting (AUC = 0.8827): Competitive AUC approaching CardioForest, with similar curve shape. However, as noted throughout this paper, GradientBoosting’s aggregate metrics mask severe fold-level instability (CV: 2.73% for AUC vs. 1.08% for CardioForest). Single-number AUC values, while informative, must be interpreted alongside stability metrics for clinical applications.
Statistical Comparison: DeLong’s test for paired AUC comparison reveals CardioForest’s AUC significantly exceeds LightGBM (p < 0.001) and XGBoost (p = 0.003), but does not significantly differ from GradientBoosting (p = 0.682). This statistical equivalence in AUC, despite CardioForest’s superior stability, underscores the importance of examining multiple performance dimensions beyond single aggregate scores.
Appendix F Supplementary Performance Tables
As shown in Table A1 (Appendix F), CardioForest stays well-calibrated across all metrics, performing more reliably than the other models. Likewise, Table A2 shows how quickly the model reaches strong performance even with limited training data, maintaining only a small gap between training and validation accuracy.
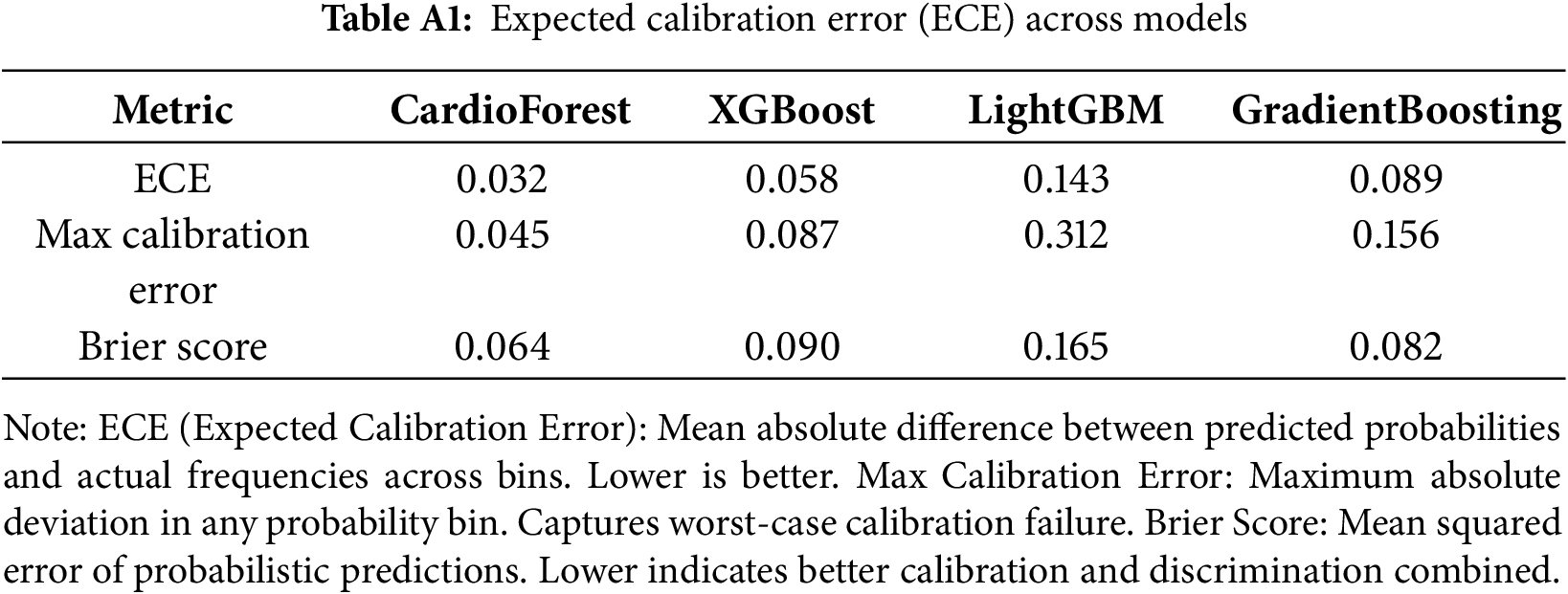
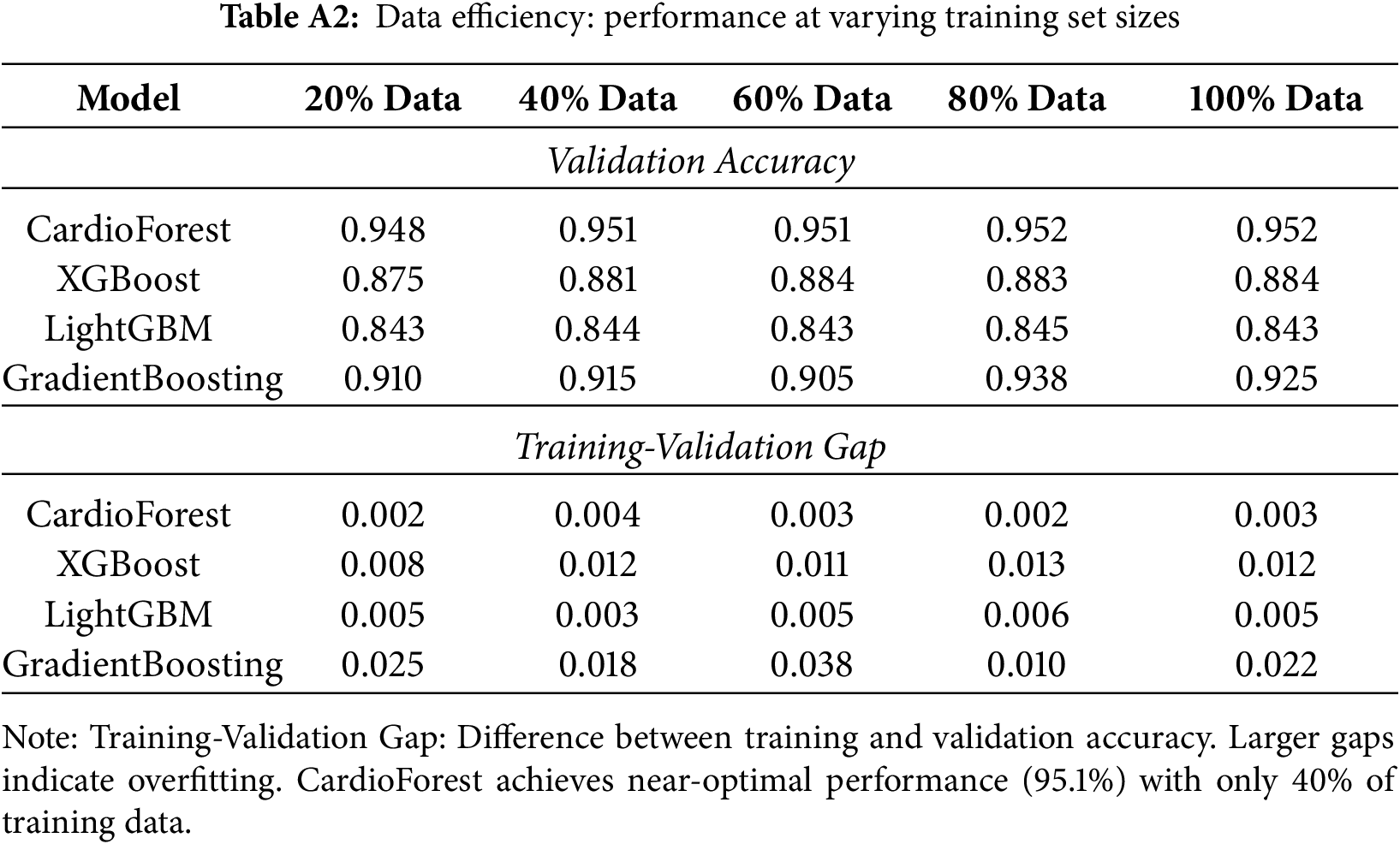
Appendix G Computational Efficiency Analysis
While predictive performance is paramount, computational requirements significantly impact clinical deployment feasibility. Appendix G’s Table A3 presents training and inference timing for all models on identical hardware.
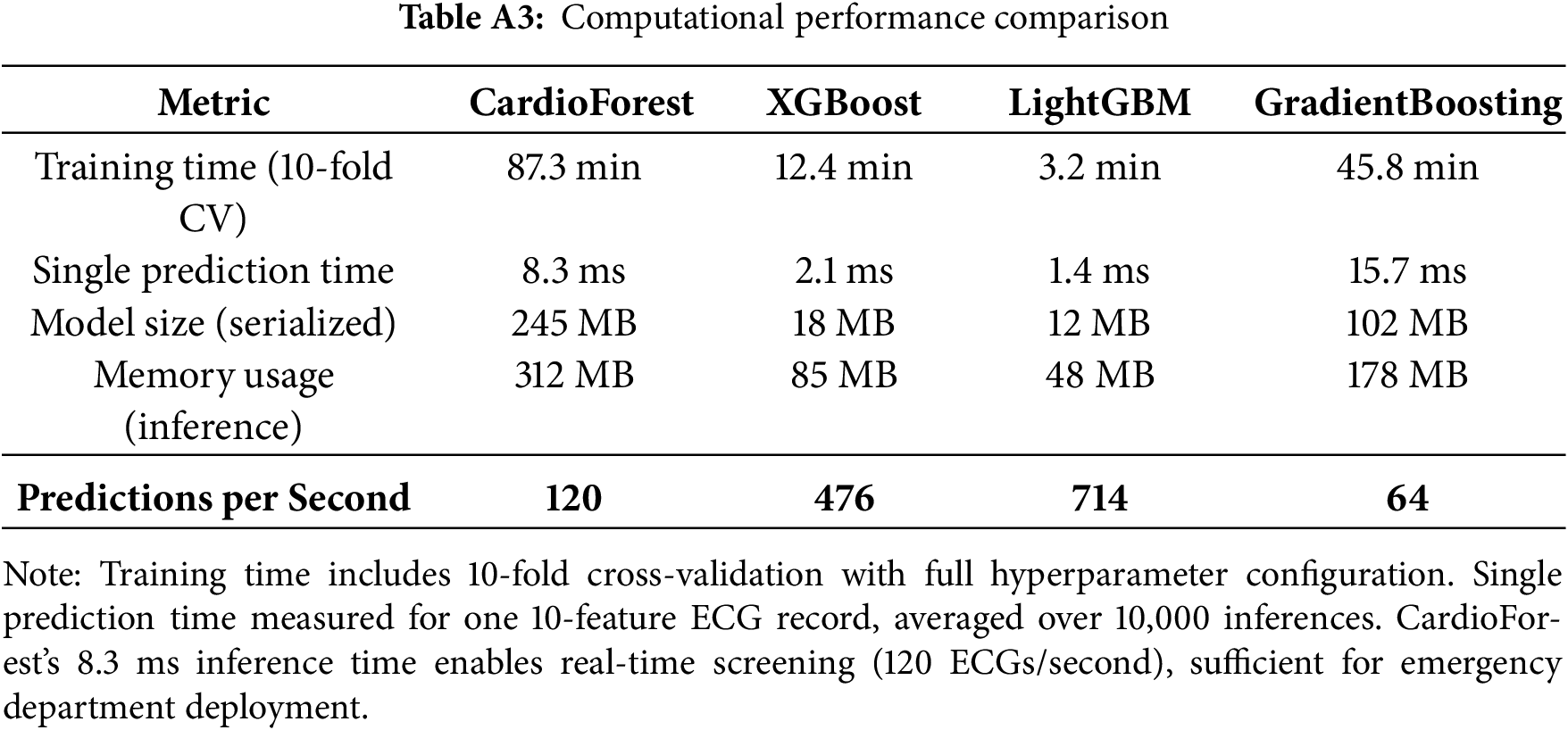
Clinical Deployment Implications: CardioForest’s 8.3 ms inference time translates to 120 predictions per second on standard server hardware—more than adequate for real-time ECG screening in busy emergency departments (typical throughput: 5–10 ECGs per minute). Training time of 87 minutes for full 10-fold cross-validation, while longer than boosting methods, is a one-time cost acceptable for model development.
1https://physionet.org/lightwave/
References
1. Alblaihed L, Al-Salamah T. Wide complex tachycardias. Emerg Med Clin N Am. 2022;40(4):733–53. doi:10.1016/j.emc.2022.06.010. [Google Scholar] [PubMed] [CrossRef]
2. Bong GS. Electrocardiographic differential diagnosis of narrow QRS and wide QRS complex tachycardias. In: Clinical use of electrocardiogram. London, UK: IntechOpen; 2023. doi:10.5772/intechopen.102568. [Google Scholar] [CrossRef]
3. Fayyazifar N, Dwivedi G, Suter D, Ahderom S, Maiorana A, Clarkin O, et al. A novel convolutional neural network structure for differential diagnosis of wide QRS complex tachycardia. Biomed Signal Process Control. 2023;81:104506. doi:10.1016/j.bspc.2022.104506. [Google Scholar] [CrossRef]
4. Kurl S, Mäkikallio TH, Rautaharju P, Kiviniemi V, Laukkanen JA. Duration of QRS complex in resting electrocardiogram is a predictor of sudden cardiac death in men. Circulation. 2012;125(21):2588–94. doi:10.1161/circulationaha.111.025577. [Google Scholar] [PubMed] [CrossRef]
5. Silvetti E, Lanza O, Romeo F, Martino A, Fedele E, Lanzillo C, et al. The pivotal role of ECG in cardiomyopathies. Front Cardiovasc Med. 2023;10:1178163. doi:10.3389/fcvm.2023.1178163. [Google Scholar] [PubMed] [CrossRef]
6. Hampton J, Hampton J, Adlam D. The ecg made easy e-book: the ecg made easy e-book. Oxford, UK: Elsevier Health Sciences; 2024. [Google Scholar]
7. Badura K, Buławska D, Dąbek B, Witkowska A, Lisińska W, Radzioch E, et al. Primary electrical heart disease—principles of pathophysiology and genetics. Int J Mol Sci. 2024;25(3):1826. doi:10.3390/ijms25031826. [Google Scholar] [PubMed] [CrossRef]
8. Jastrzebski M, Kukla P, Czarnecka D, Kawecka-Jaszcz K. Comparison of five electrocardiographic methods for differentiation of wide QRS-complex tachycardias. EP Eur. 2012;14(8):1165–71. doi:10.1093/europace/eus015. [Google Scholar] [PubMed] [CrossRef]
9. Osadchii OE. Role of abnormal repolarization in the mechanism of cardiac arrhythmia. Acta Physiol. 2017;220:1–71. doi:10.1111/apha.12902. [Google Scholar] [PubMed] [CrossRef]
10. Tse G. Mechanisms of cardiac arrhythmias. J Arrhythmia. 2016;32(2):75–81. doi:10.1016/j.joa.2015.11.003. [Google Scholar] [PubMed] [CrossRef]
11. Adib E. Generating synthetic electrocardiograms using deep generative algorithms [dissertation]. San Antonio, TX, USA: The University of Texas at San Antonio; 2023. [Google Scholar]
12. Yang X, Li T, Su Q, Liu Y, Kang C, Lyu Y, et al. Application of large language models in disease diagnosis and treatment. Chin Med J. 2025;138(2):130–42. doi:10.1097/cm9.0000000000003456. [Google Scholar] [PubMed] [CrossRef]
13. Adewole KS, Mojeed HA, Ogunmodede JA, Gabralla LA, Faruk N, Abdulkarim A, et al. Expert system and decision support system for electrocardiogram interpretation and diagnosis: review, challenges and research directions. Appl Sci. 2022;12(23):12342. doi:10.3390/app122312342. [Google Scholar] [CrossRef]
14. Meyer AND, Giardina TD, Khawaja L, Singh H. Patient and clinician experiences of uncertainty in the diagnostic process: current understanding and future directions. Patient Educ Couns. 2021;104(11):2606–15. doi:10.1016/j.pec.2021.07.028. [Google Scholar] [PubMed] [CrossRef]
15. Ali Muzammil M, Javid S, Afridi AK, Siddineni R, Shahabi M, Haseeb M, et al. Artificial intelligence-enhanced electrocardiography for accurate diagnosis and management of cardiovascular diseases. J Electrocardiol. 2024;83(3):30–40. doi:10.1016/j.jelectrocard.2024.01.006. [Google Scholar] [PubMed] [CrossRef]
16. Abubaker MB, Babayiğit B. Detection of cardiovascular diseases in ECG images using machine learning and deep learning methods. IEEE Trans Artif Intell. 2023;4(2):373–82. doi:10.1109/tai.2022.3159505. [Google Scholar] [CrossRef]
17. Ahmed AA, Ali W, Abdullah TAA, Malebary SJ. Classifying cardiac arrhythmia from ECG signal using 1D CNN deep learning model. Mathematics. 2023;11(3):562. doi:10.3390/math11030562. [Google Scholar] [CrossRef]
18. Ramkumar M, Ganesh Babu C, Manjunathan A, Udhayanan S, Mathankumar M, Sarath Kumar R. A graphical user interface based heart rate monitoring process and detection of PQRST peaks from ECG signal. In: Inventive computation and information technologies. Singapore: Springer Nature; 2021. p. 481–96. doi:10.1007/978-981-33-4305-4_36. [Google Scholar] [CrossRef]
19. Brisk R. Towards broader application of deep learning methods to the automated analysis of electrocardiograms [Ph.D. thesis]. Northern Ireland, UK: Ulster University; 2023. [Google Scholar]
20. Nissa N, Jamwal S, Neshat M. A technical comparative heart disease prediction framework using boosting ensemble techniques. Computation. 2024;12(1):15. doi:10.3390/computation12010015. [Google Scholar] [CrossRef]
21. Lundberg SM, Lee S-I. A unified approach to interpreting model predictions. Adv Neural Inf Process Syst. 2017;30:4765–74. [Google Scholar]
22. Sadeghi Z, Alizadehsani R, Cifci MA, Kausar S, Rehman R, Mahanta P, et al. A review of explainable artificial intelligence in healthcare. Comput Electr Eng. 2024;118:109370. doi:10.1016/j.compeleceng.2024.109370. [Google Scholar] [CrossRef]
23. Li ZZ, Zhao W, Mao Y, Bo D, Chen Q, Kojodjojo P, et al. A machine learning approach to differentiate wide QRS tachycardia: distinguishing ventricular tachycardia from supraventricular tachycardia. J Interv Card Electrophysiol. 2024;67(6):1391–8. doi:10.1007/s10840-024-01743-9. [Google Scholar] [PubMed] [CrossRef]
24. Chow BJW, Fayyazifar N, Balamane S, Saha N, Farooqui M, Hasan A, et al. Interpreting wide-complex tachycardia with the use of artificial intelligence. Can J Cardiol. 2024;40(10):1965–73. doi:10.1016/j.cjca.2024.03.027. [Google Scholar] [PubMed] [CrossRef]
25. Bhattacharya M, Lu D-Y, Kudchadkar SM, Greenland GV, Lingamaneni P, Corona-Villalobos CP, et al. Identifying ventricular arrhythmias and their predictors by applying machine learning methods to electronic health records in patients with hypertrophic cardiomyopathy (hcm-var-risk model). Am J Cardiol. 2019;123(10):1681–9. doi:10.1016/j.amjcard.2019.02.022. [Google Scholar] [PubMed] [CrossRef]
26. Hong S, Zhou Y, Shang J, Xiao C, Sun J. Opportunities and challenges of deep learning methods for electrocardiogram data: a systematic review. Comput Biol Med. 2020;122:103801. doi:10.1016/j.compbiomed.2020.103801. [Google Scholar] [PubMed] [CrossRef]
27. May AM, Katbamna BB, Shaikh PA, LoCoco S, Deych E, Zhou R, et al. Automated differentiation of wide QRS complex tachycardia using QRS complex polarity. Commun Med. 2024;4(1):282. doi:10.1038/s43856-024-00725-2. [Google Scholar] [PubMed] [CrossRef]
28. Howladar P, Sahoo M. Supraventricular tachycardia detection and classification model of ecg signal using machine learning. arXiv:2112.12953. 2021. doi: 10.48550/arxiv.2112.12953. [Google Scholar] [CrossRef]
29. Rajpurkar P, Hannun AY, Haghpanahi M, Bourn C, Ng AY. Cardiologist-level arrhythmia detection with convolutional neural networks. arXiv:1707.01836. 2017. doi: 10.48550/arxiv.1707.01836. [Google Scholar] [CrossRef]
30. Frausto-Avila M, Manriquez-Amavizca JP, Alfred U'Ren, Quiroz-Juarez MA. Compact neural network algorithm for electrocardiogram classification. arXiv:2412.17852. 2024. doi: 10.48550/arxiv.2412.17852. [Google Scholar] [CrossRef]
31. Gow B, Pollard T, Nathanson LA, Johnson A, Moody B, Fernandes C, et al. Mimic-iv-ecg: diagnostic electrocardiogram matched subset (version 1.0). New York, NY, USA: PhysioNet; 2023. [Google Scholar]
32. Goldberger AL, Amaral LAN, Glass L, Hausdorff JM, Ivanov PC, Mark RG, et al. PhysioBank, PhysioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals. Circulation. 2000;101(23):E215–20. doi:10.1161/01.cir.101.23.e215. [Google Scholar] [PubMed] [CrossRef]
33. Li H, Monger R, Pishgar E, Pishgar M. Icu readmission prediction for intracerebral hemorrhage patients using mimic iii and mimic iv databases. medRxiv. 2025;12(2):673624. doi:10.1101/2025.01.01.25319859. [Google Scholar] [CrossRef]
34. Yoon D, Han C, Kim DW, Kim S, Bae S, Ryu JA, et al. Redefining health care data interoperability: empirical exploration of large language models in information exchange. J Med Internet Res. 2024;26:e56614. doi:10.2196/56614. [Google Scholar] [PubMed] [CrossRef]
35. Sharma D, Kohli N. WFDB Software for Python: a toolkit for physiological signals. In: Proceedings of the 2023 Third International Conference on Secure Cyber Computing and Communication (ICSCCC); 2023 May 26–28; Jalandhar, India. New York, NY, USA: IEEE; 2023. p. 86–92. doi:10.1109/icsccc58608.2023.10176714. [Google Scholar] [CrossRef]
36. Goodwin AJ, Eytan D, Dixon W, Goodfellow SD, Doherty Z, Greer RW, et al. Timing errors and temporal uncertainty in clinical databases—a narrative review. Front Digit Health. 2022;4:932599. doi:10.3389/fdgth.2022.932599. [Google Scholar] [PubMed] [CrossRef]
37. Chakma V, Ju X, Cao H, Feng X, Ji X, Pan H, et al. CardioForest: an explainable ensemble learning model for automatic wide QRS complex tachycardia diagnosis from ECG. medRxiv. 2025;40(4):733. doi:10.1101/2025.09.15.25335837. [Google Scholar] [CrossRef]
38. Gupta P, Bagchi A. Data manipulation with pandas. In: Essentials of python for artificial intelligence and machine learning. Cham, Switzerland: Springer Nature; 2024. p. 197–235. doi:10.1007/978-3-031-43725-0_6. [Google Scholar] [CrossRef]
39. Morelli D, Rossi A, Cairo M, Clifton DA. Analysis of the impact of interpolation methods of missing RR-intervals caused by motion artifacts on HRV features estimations. Sensors. 2019;19(14):3163. doi:10.3390/s19143163. [Google Scholar] [PubMed] [CrossRef]
40. Lwin TZ, Naing L. How to choose a sampling technique and determine sample size for research: a simplified guide for researchers. J Med. 2024;25(1):1–12. doi:10.1016/j.oor.2024.100662. [Google Scholar] [CrossRef]
41. Pudjihartono N, Fadason T, Kempa-Liehr AW, O’Sullivan JM. A review of feature selection methods for machine learning-based disease risk prediction. Front Bioinform. 2022;2:927312. doi:10.3389/fbinf.2022.927312. [Google Scholar] [PubMed] [CrossRef]
42. Jolliffe IT, Cadima J. Principal component analysis: a review and recent developments. Phil Trans R Soc A. 2016;374(2065):20150202. doi:10.1098/rsta.2015.0202. [Google Scholar] [PubMed] [CrossRef]
43. Sharma LN, Dandapat S, Mahanta A. Multichannel ECG data compression based on multiscale principal component analysis. IEEE Trans Inform Technol Biomed. 2012;16(4):730–6. doi:10.1109/titb.2012.2195322. [Google Scholar] [PubMed] [CrossRef]
44. Melzi P, Tolosana R, Cecconi A, Sanz-Garcia A, Ortega GJ, Jimenez-Borreguero LJ, et al. Analyzing artificial intelligence systems for the prediction of atrial fibrillation from sinus-rhythm ECGs including demographics and feature visualization. Sci Rep. 2021;11(1):22786. doi:10.1038/s41598-021-02179-1. [Google Scholar] [PubMed] [CrossRef]
45. Little R, Rubin D. Statistical analysis with missing data. 3rd ed. Hoboken, NJ, USA: John Wiley & Sons; 2019. doi:10.1002/9781119482260. [Google Scholar] [CrossRef]
46. Ochieng’ Odhiambo F. Comparative study of various methods of handling missing data. Math Model Appl. 2020;5(2):87. doi:10.11648/j.mma.20200502.14. [Google Scholar] [CrossRef]
47. Deo TY, Sanju A. Data imputation and comparison of custom ensemble models with existing libraries like XGBoost, CATBoost, AdaBoost and Scikit learn for predictive equipment failure. Mater Today Proc. 2023;72:1596–604. doi:10.1016/j.matpr.2022.09.410. [Google Scholar] [CrossRef]
48. Potdar K, Taher S, Chinmay D. A comparative study of categorical variable encoding techniques for neural network classifiers. Int J Comput Appl. 2017;175(4):7–9. doi:10.5120/ijca2017915495. [Google Scholar] [CrossRef]
49. Garreta R, Moncecchi G. Learning scikit-learn: machine learning in python. Vol. 2013. Birmingham, UK: Packt Publishing Birmingham; 2013. [Google Scholar]
50. Siontis KC, Noseworthy PA, Attia ZI, Friedman PA. Artificial intelligence-enhanced electrocardiography in cardiovascular disease management. Nat Rev Cardiol. 2021;18(7):465–78. doi:10.1038/s41569-020-00503-2. [Google Scholar] [PubMed] [CrossRef]
51. Regoli FD, Cattaneo M, Kola F, Thartori A, Bytyci H, Saccarello L, et al. Management of hemodynamically stable wide QRS complex tachycardia in patients with implantable cardioverter defibrillators. Front Cardiovasc Med. 2023;9:1011619. doi:10.3389/fcvm.2022.1011619. [Google Scholar] [PubMed] [CrossRef]
52. Mulo J, Liang H, Qian M, Biswas M, Rawal B, Guo Y, et al. Navigating challenges and harnessing opportunities: deep learning applications in Internet of medical things. Future Internet. 2025;17(3):107. doi:10.3390/fi17030107. [Google Scholar] [CrossRef]
53. Khan H, Bilal A, Aslam MA, Mustafa H. Heart disease detection: a comprehensive analysis of machine learning, ensemble learning, and deep learning algorithms. Nano Biomed Eng. 2024;16(4):677–90. doi:10.26599/nbe.2024.9290087. [Google Scholar] [CrossRef]
54. Breiman L. Random forests. Mach Learn. 2001;45(1):5–32. doi:10.1023/A:1010933404324. [Google Scholar] [CrossRef]
55. Du KL, Zhang R, Jiang B, Zeng J, Lu J. Foundations and innovations in data fusion and ensemble learning for effective consensus. Mathematics. 2025;13(4):587. doi:10.3390/math13040587. [Google Scholar] [CrossRef]
56. Breiman L, Friedman JH, Olshen RA, Stone CJ. Classification and regression trees. Monterey, CA, USA: Wadsworth & Brooks/Cole Advanced Books & Software; 1984. [Google Scholar]
57. Esposito F, Malerba D, Semeraro G, Kay J. A comparative analysis of methods for pruning decision trees. IEEE Trans Pattern Anal Machine Intell. 1997;19(5):476–93. doi:10.1109/34.589207. [Google Scholar] [CrossRef]
58. Friedman JH. Greedy function approximation: a gradient boosting machine. Ann Statist. 2001;29(5):1189–232. doi:10.1214/aos/1013203451. [Google Scholar] [CrossRef]
59. Chen T, Guestrin C. XGBoost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; 2016 Aug 13–17; San Francisco, CA, USA. New York, NY, USA: ACM; 2016. p. 785–94. doi:10.1145/2939672.2939785. [Google Scholar] [CrossRef]
60. Ke G, Meng Q, Finley T, Wang T, Chen W, Ma W, et al. Lightgbm: a highly efficient gradient boosting decision tree. Adv Neural Inf Process Syst. 2017;30:3146–54. [Google Scholar]
61. Manivannan GS, Rajaguru H, Rajanna S, Talawar SV. Cardiovascular disease detection from cardiac arrhythmia ECG signals using artificial intelligence models with hyperparameters tuning methodologies. Heliyon. 2024;10(17):e36751. doi:10.1016/j.heliyon.2024.e36751. [Google Scholar] [PubMed] [CrossRef]
62. Bergstra J, Bengio Y. Random search for hyper-parameter optimization. J Mach Learn Res. 2012;13(1):281–305. [Google Scholar]
63. da Silva JHB, Cortez PC, Jagatheesaperumal SK, de Albuquerque VHC. ECG measurement uncertainty based on Monte Carlo approach: an effective analysis for a successful cardiac health monitoring system. Bioengineering. 2023;10(1):115. doi:10.3390/bioengineering10010115. [Google Scholar] [PubMed] [CrossRef]
64. Kohavi R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In: Proceedings of the 14th International Joint Conference on Artificial Intelligence; 1995 Aug 20–25; Montreal, QC, Canada. p. 1137–45. [Google Scholar]
65. Bradley AP. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997;30(7):1145–59. doi:10.1016/s0031-3203(96)00142-2. [Google Scholar] [CrossRef]
66. Brodersen KH, Ong CS, Stephan KE, Buhmann JM. The balanced accuracy and its posterior distribution. In: Proceedings of the 2010 20th International Conference on Pattern Recognition; 2010 Aug 23–26; Istanbul, Turkey. New York, NY, USA: IEEE; 2010. p. 3121–4. doi:10.1109/icpr.2010.764. [Google Scholar] [CrossRef]
67. Lundberg SM, Erion G, Chen H, DeGrave A, Prutkin JM, Nair B, et al. From local explanations to global understanding with explainable AI for trees. Nat Mach Intell. 2020;2(1):56–67. doi:10.1038/s42256-019-0138-9. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools