
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Identification of a Printed Anti-Counterfeiting Code Based on Feature Guidance Double Pool Attention Networks
1 School of Cyber Science and Engineering, Wuhan University, Wuhan, 430000, China
2 School of Electronic Information, Wuhan University, Wuhan, 430000, China
3 College of Artificial Intelligence, Nanchang Institute of Science and Technology, Nanchang, 330108, China
* Corresponding Author: Hong Zheng. Email:
Computers, Materials & Continua 2023, 75(2), 3431-3452. https://doi.org/10.32604/cmc.2023.035897
Received 08 September 2022; Accepted 14 December 2022; Issue published 31 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The authenticity identification of anti-counterfeiting codes based on mobile phone platforms is affected by lighting environment, photographing habits, camera resolution and other factors, resulting in poor collection quality of anti-counterfeiting codes and weak differentiation of anti-counterfeiting codes for high-quality counterfeits. Developing an anti-counterfeiting code authentication algorithm based on mobile phones is of great commercial value. Although the existing algorithms developed based on special equipment can effectively identify forged anti-counterfeiting codes, the anti-counterfeiting code identification scheme based on mobile phones is still in its infancy. To address the small differences in texture features, low response speed and excessively large deep learning models used in mobile phone anti-counterfeiting and identification scenarios, we propose a feature-guided double pool attention network (FG-DPANet) to solve the reprinting forgery problem of printing anti-counterfeiting codes. To address the slight differences in texture features in high-quality reprinted anti-counterfeiting codes, we propose a feature guidance algorithm that creatively combines the texture features and the inherent noise feature of the scanner and printer introduced in the reprinting process to identify anti-counterfeiting code authenticity. The introduction of noise features effectively makes up for the small texture difference of high-quality anti-counterfeiting codes. The double pool attention network (DPANet) is a lightweight double pool attention residual network. Under the condition of ensuring detection accuracy, DPANet can simplify the network structure as much as possible, improve the network reasoning speed, and run better on mobile devices with low computing power. We conducted a series of experiments to evaluate the FG-DPANet proposed in this paper. Experimental results show that the proposed FG-DPANet can resist high-quality and small-size anti-counterfeiting code reprint forgery. By comparing with the existing algorithm based on texture, it is shown that the proposed method has a higher authentication accuracy. Last but not least, the proposed scheme has been evaluated in the anti-counterfeiting code blurring scene, and the results show that our proposed method can well resist slight blurring of anti-counterfeiting images.Keywords
With the rapid development of the market economy and the rise in internet shopping, product counterfeiting, forgery and piracy are becoming increasingly rampant. Fake and inferior products will not only disrupt the market order and affect the reputations of businesses but also damage the legitimate rights and interests of consumers, and even endanger consumers’ health and safety. Anti-counterfeiting technology is an effective means of eliminating fake and inferior products. Traditional anti-counterfeiting technologies include uncovering-left-word anti-counterfeiting [1], ink anti-counterfeiting [2], laser anti-counterfeiting [3–5], papers of embedding security thread [6], and Internet of Things (IoT) anti-counterfeiting [7–9]. Although traditional anti-counterfeiting methods can prevent the proliferation of fake and inferior products to a certain extent, most of them have problems such as high cost, difficult user operation, short anti-counterfeiting period, being easy to crack, and after-sales anti-counterfeiting. For example, the cost of uncovering-left-word anti-counterfeiting is not high, but it is damaged once it is uncovered, making it impossible to realize presales anti-counterfeiting. Although ink anti-counterfeiting has a high-performance anti-counterfeiting ability, with the increase in the number of anti-counterfeiting ink manufacturers, anti-counterfeiting ink manufacturing technology is easy to obtain by counterfeiters. The special embedded security thread technology paper has a complex production process that is technically difficult and has a high manufacturing cost. In recent years, increasing attention has been given to research on anti-counterfeiting technology based on digital image information. It integrates data information storage, image processing, internet communication and other technologies, and can automatically determine authenticity. Compared with traditional anti-counterfeiting methods, the digital image anti-counterfeiting method not only has a low production cost and cannot be imitated by attackers but can also be customized. Additionally, it is combined with networks and communication to facilitate consumers queries and identification. Compared with traditional anti-counterfeiting methods, this anti-counterfeiting method not only has a low production cost and cannot be imitated by attackers but can also be customized.
Quick response (QR) codes have been widely used in commodity packaging. Users can quickly obtain a wealth of product information by scanning QR codes with mobile phones, but QR codes do not have anti-counterfeiting functions [10]. Recent studies have shown that a corresponding original digital QR code can be reconstructed from a QR code printed image through the deep learning method. Therefore, it is necessary to endow the texture anti-counterfeiting area with an anti-counterfeiting function to ensure that an attacker cannot construct the original digital anti-counterfeiting code [11]. We embed a randomly generated texture pattern into a QR code, and named this new combined pattern an anti-counterfeiting code. The random texture pattern in the anti-counterfeiting code ensures the uniqueness of the anti-counterfeiting code. An attacker cannot generate a digital anti-counterfeiting code that is the same as the genuine anti-counterfeiting code, which effectively makes up for the QR code digital file being easy to imitate. We design a textured anti-counterfeiting area according to the characteristics of random texture introduced by printer ink diffusion and combine the textured anti-counterfeiting area with a QR code to form an anti-counterfeiting code with anti-counterfeiting ability. The anti-counterfeiting code is shown in Fig. 1. The unique design of anti-counterfeiting codes makes it impossible for attackers to reconstruct genuine digital anti-counterfeiting codes. Existing anti-counterfeiting code forgery methods scan a genuine printed anti-counterfeiting code through high-definition scanning equipment and then print it into a forged anti-counterfeiting code. This forgery method is called reprint forgery. Therefore, how to prevent attackers from reprinting anti-counterfeiting codes through high-definition scanning equipment and high-precision printers has important theoretical research significance and commercial application prospects. In the form of one commodity and one anti-counterfeiting code, each commodity corresponds to a unique anti-counterfeiting code, and each anti-counterfeiting code has a unique sample image on the server. Using the QR code semantics as the index, we can quickly find the corresponding stored samples of the anti-counterfeiting code on the commodity to be tested in the server. Because the diffusion of ink on paper is random, the reprinted anti-counterfeiting code will experience secondary diffusion when printed again, and the fine random texture pattern in the anti-counterfeiting area is quite different from the original printed image in terms of texture details. Therefore, the texture feature of the anti-counterfeiting area is the key feature that distinguishes the original anti-counterfeiting code from the reprinted anti-counterfeiting code. The QR code area is a black-and-white image block. The black image block will form a more obvious burr phenomenon after secondary ink diffusion. Secondary printing of the white image block will not cause changes in texture, but the white part of the image will retain more inherent scanner and printer noise introduced by recapturing. Generally, the difference in texture features in the QR code area is relatively weak, and the difference in noise features is more obvious. The traditional anti-counterfeiting code identification algorithm extracts the texture features of the anti-counterfeiting code, analyzes the texture feature difference between the genuine anti-counterfeiting code and the reprinted anti-counterfeiting code, and identifies the authenticity of the anti-counterfeiting code. Although the authenticity of the anti-counterfeiting code can be identified to some extent by analyzing the difference in texture features, with the development of high-definition scanning equipment and high-precision printing equipment, the forgery quality of the fake anti-counterfeiting code is increasing, and the texture difference between the original anti-counterfeiting code and the secondary printed anti-counterfeiting code is decreasing. Existing texture-based anti-counterfeiting algorithms have difficulty meeting the needs of anti-counterfeiting identification. To address the small texture difference of high-quality forgery anti-counterfeiting codes, we propose a feature guidance algorithm that uses the texture features caused by ink diffusion and the inherent scanner and printer noise introduced in the secondary printing process of anti-counterfeiting codes to identify the authenticity of anti-counterfeiting codes.

Figure 1: Example of an anti-counterfeiting code: the outer part of the anti-counterfeiting code is a QR code area, and the inner part is an anti-counterfeiting area with a random texture
Although digital image anti-counterfeiting technology has incomparable advantages over traditional methods, it is also very easy for attackers to attack the anti-counterfeiting system by scanning and reprinting the genuine anti-counterfeiting codes and then attaching it to counterfeit goods [12–14]. Therefore, how to identify genuine anti-counterfeiting codes and reprinted anti-counterfeiting codes has become the key to digital image anti-counterfeiting technology. Research on secondary printing of printed images is still relatively limited and is still in its infancy. The existing reprinting detection algorithms can be divided into active detection and passive detection. The active detection algorithm adds special anti-counterfeiting information in the image generation process and identifies image reprinting by analyzing the integrity of anti-counterfeiting information. For example, a semifragile weak watermark is added to an anti-counterfeiting code to detect image reprinting. The reprinting operation destroys the watermark hidden in the image [15,16]. References [17–20] use the copy detection mode (CDP) to identify the authenticity of printed documents. CDP is a digital image filled with random gray pixels. It is embedded in a digital document and printed as a legal document. CDP is distorted during scanning and printing operations. Researchers detect counterfeit products by measuring the degree of distortion. The passive identification method of reprinted images distinguishes the printed image from the reprinted image by extracting the texture features of the anti-counterfeiting code image. In the texture classification method of anti-counterfeiting images, Mikkilineni uses the gray level co-occurrence matrix to estimate 22 statistics, combined with the nearest neighbor classifier for classification, and then performs a majority vote to determine the authenticity of the printed image [21]. Jie proposed an extended contrast local binary pattern for texture classification, extracted frontal symbol features, energy features and central pixel features, and then used the chi square distance and nearest neighbor classifier for texture classification [22]. Song et al. proposed two new texture description operators: local grouping ordered mode and nonlocal binary mode. By combining the local grouped order pattern (LGOP) and non-local binary pattern (NLBP) through central pixel coding, a distinctive histogram feature is constructed as a texture descriptor for image texture classification [23]. Mohammad proposed a new descriptor to process high-noise texture images by capturing the texture information of microstructure and macro structure to improve the discrimination performance of texture images [24]. Reference [12] extracted the frequency domain and spatial domain features introduced by a scanner to distinguish the original file from the reprinted file. Albert Berenguel used a texture analysis method to extract the corresponding features from the print pattern to be tested and designed an end-to-end mobile server, which can provide detection services for ordinary users [25]. Reference [26] uses the features from accelerated segment test (FAST) corner detection algorithm with an adaptive threshold and nonmaximum suppression processing to extract noncluster feature points and detect the authenticity of security codes according to feature point matching results. A two-level QR code with a public layer and a private layer was developed in [27,28] for general document authentication purposes. The private layers, which featured three textured patterns, were demonstrated to be sensitive to the illegal copying operation. Wong et al. [29] used mobile phone cameras to acquire paper textures and achieved good detection performance.
Although the above methods have made great progress in the reprinting detection of printed images, there are still some deficiencies. A semifragile watermark in the scene of a small anti-counterfeiting image will make it difficult to identify the original watermark. The CDP method in low-quality imaging scenes such as mobile phones and CDP traces will become very weak. Reference [12] identified an original document and a reprinted document to a certain extent by manually extracting the frequency domain and spatial domain features, but this method only achieves a good effect on halftone documents, the size of the tested anti-counterfeiting code is too large, and the anti-counterfeiting performance on small anti-counterfeiting codes has not been verified. Although the image anti-counterfeiting method based on texture can identify the authenticity of anti-counterfeiting codes to a certain extent, with the development of high-definition scanning equipment and printing equipment, the forgery quality of anti-counterfeiting codes is increasing, the texture difference between the original anti-counterfeiting code and the secondary printing anti-counterfeiting code is small, and its identification performance is increasingly worse. The scheme based on two-level QR codes and feature point matching becomes much more challenging after introducing a mobile imaging device as the authenticator. Reference [29] proposed a method based on mobile phones, however, the proposed method requires several fixed illumination angles, which is not friendly to nonprofessional users.
Although the existing anti-counterfeiting authentication schemes have been tried in many aspects, such as anti-counterfeiting texture extraction, copy detection mode, anti-counterfeiting watermark, and anti-counterfeiting code design, they all have defects such as high cost, low security, and strict anti-counterfeiting conditions. In a word, the existing anti-counterfeiting methods are difficult to identify high-quality anti-counterfeiting code forgery in the mobile phone imaging scene. In order to solve the problem of weak texture features in mobile phone imaging scenes, we creatively introduced printer noise features, which effectively solved the defect of weak texture features. In addition, we propose a new attention model to enhance the ability of network feature expression ability.
In this paper, a lightweight double pooling attention network based on feature guidance (FG-DPANet) is proposed to identify the authenticity of anti-counterfeiting codes. First, we divide the anti-counterfeiting image into image patches with a size of pixels that do not overlap each other, and then divide all image patches into two subdatasets according to features (texture features and noise features). Each subdataset trains a double pool attention residual network (DPANet) to classify specific types of anti-counterfeiting images. To extract more abundant features, we design DPANet as a parallel double branch network. Each branch is composed of an adaptive filtering module and two residual modules. To combine the features between channels, we embed the double pool attention module proposed in this paper into the residual module. Finally, we fuse the features extracted by the two branch networks for authenticity identification.
The contributions of this paper can be summarized as follows:
• To meet the anti-counterfeiting requirements of mobile devices with low computing power, we propose a lightweight dual-pool attention network (DPANet), which outperforms existing methods in identification performance.
• To address the small differences of texture features in high-quality reprinted anti-counterfeiting codes, we propose a feature guidance algorithm that creatively combines the traditional texture features and the inherent noise of scanners and printers introduced in the reprinting process to identify the authenticity of anti-counterfeiting codes.
• To make full use of the correlation features between channels, we propose a double pool attention model to improve the feature extraction ability of the proposed DPANet.
The framework of the proposed method is shown in Fig. 2, which includes two parts: the training and testing stages. For the training stage, three steps are executed in order. First, we need to process the dataset collected by the mobile phone. For this stage, all anti-counterfeiting code images are normalized to
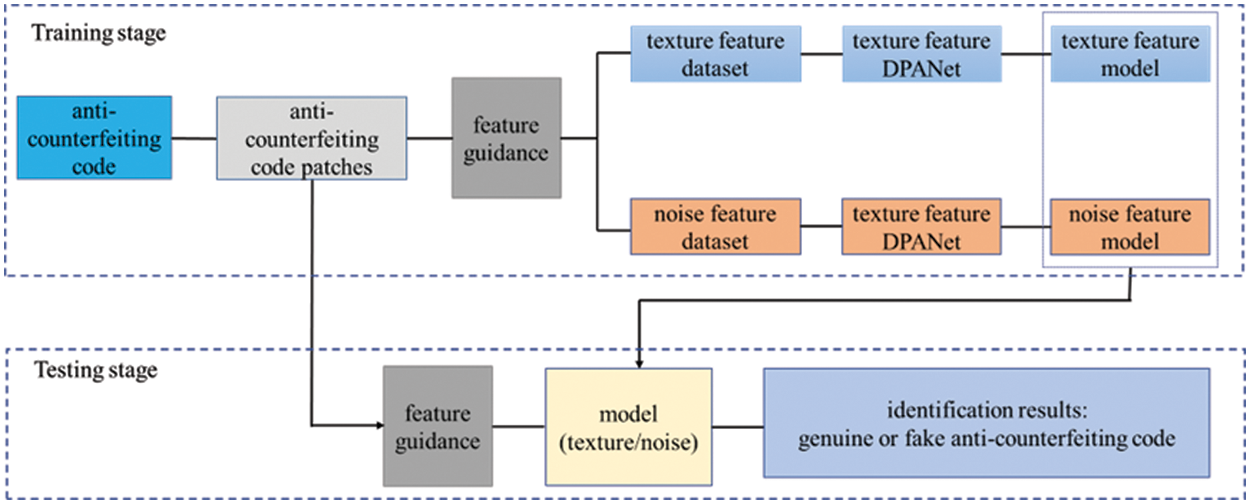
Figure 2: Framework of the feature-guided double pool attention network

Figure 3: Anti-counterfeiting code image patches. The upper row is the two-dimensional code area image patch, and the lower row is the anti-counterfeiting area image patch
The feature guidance algorithm divides the dataset into a texture feature dataset and a noise feature dataset according to the feature type through formula (1) mentioned below, then uses the texture dataset guidance model to focus on learning the texture features of the image, and use the noise feature dataset guidance network model to focus on learning the noise features of the image. The anti-counterfeiting code is divided into QR codes and anti-counterfeiting areas. The features of the two areas are very different. The QR code area consists mainly of noise features, and the anti-counterfeiting area consists mainly of texture features. The texture feature dataset and noise feature dataset are shown in Fig. 3. The upper 6 images in the figure are QR code image patches, and the lower 6 images are anti-counterfeiting image patches. The QR code area is an ordinary QR code that is composed of a large number of black-and-white blocks. The QR code has a single texture feature, which will not cause obvious changes in texture after secondary printing. However, due to the simple texture of QR code images, the noise features of scanners and printers can be better extracted. A large number of studies have shown that complex image content information will seriously interfere with the extraction of noise features. The QR code area has a single pattern, which is suitable for extracting the inherent noise features of scanners and printers. The pattern of the anti-counterfeiting area is a randomly generated fine texture pattern, and its anti-counterfeiting mechanism is the random diffusion of printer ink. The random diffusion of ink will lead to local multiple image blocks being connected into areas, resulting in obvious changes in texture. After reprinting the printed image, the ink diffusion phenomenon is more serious, the local areas connected into pieces will increase, and the area of the white slit image in the anti-counterfeiting area will decrease. In the reprinted image, the ink diffusion phenomenon is more serious, and a large number of white areas become gray areas. The anticounterfeit code pattern texture has changed significantly. Specifically, the feature differences between genuine printing and reprinting mainly include pattern shape, texture roughness and edge sharpness. From the above analysis, we can see that the noise features are mainly concentrated in the QR code area, and the texture features are mainly concentrated in the anti-counterfeiting code area. According to this distribution rule of features, the feature guidance algorithm distinguishes texture features and noise features according to the image patch location. According to the difference in image features, the feature guidance algorithm proposed in this paper trains two feature extraction networks, namely, the noise feature network and the texture feature network. The noise feature network is responsible for scanner and printer noise feature extraction in the QR code area, and the texture network is responsible for texture feature extraction in the anti-counterfeiting code area. Experimental results show that the introduction of noise features can effectively improve the classification performance of the network.
Although the locations of the anti-counterfeiting area and QR code area are relatively fixed, it is difficult to extract the anti-counterfeiting area and QR code area due to the randomness of the shooting position and angle of the anti-counterfeiting code. Therefore, guiding different feature image patches to the corresponding network model has become the key to feature guidance algorithms. Because there are a large number of white background areas in the QR code area, there is a single texture feature, the ink diffusion ability of the QR code image patch is weak after printing, and the pixels of the printed image are still distributed at approximately 0 and 255. The anti-counterfeiting code area is composed of a large number of fine textures. After the anti-counterfeiting code image is printed, the ink diffusion ability is strong. Due to ink diffusion, a large number of intermediate pixels are generated, so the pixel value of the anti-counterfeiting code area is richer. Inspired by this, the anti-counterfeiting image patches (texture image patches) are distinguished from the QR code image patches (noise image patches) through the pixel distribution of the image patches. Fig. 4 shows the pixel distribution of the anti-counterfeiting code image patches. In the figure, (a)–(c) are the gray histograms of the image patches in the QR code area, and (d)–(f) are the gray histograms of the image patches in the anti-counterfeiting area. The histogram results in (a), (b) and (c) show that the picture block pixels in the QR code area are mainly distributed near black and white, and (e), (d), (f) show that there are a large number of intermediate pixels in the picture block pixels in the anti-counterfeiting area. According to the distribution law of anti-counterfeiting code pixels, pixel patches with different characteristics can be distinguished by counting the number of pixels in a certain interval. The feature guidance algorithm is shown in formula (1):
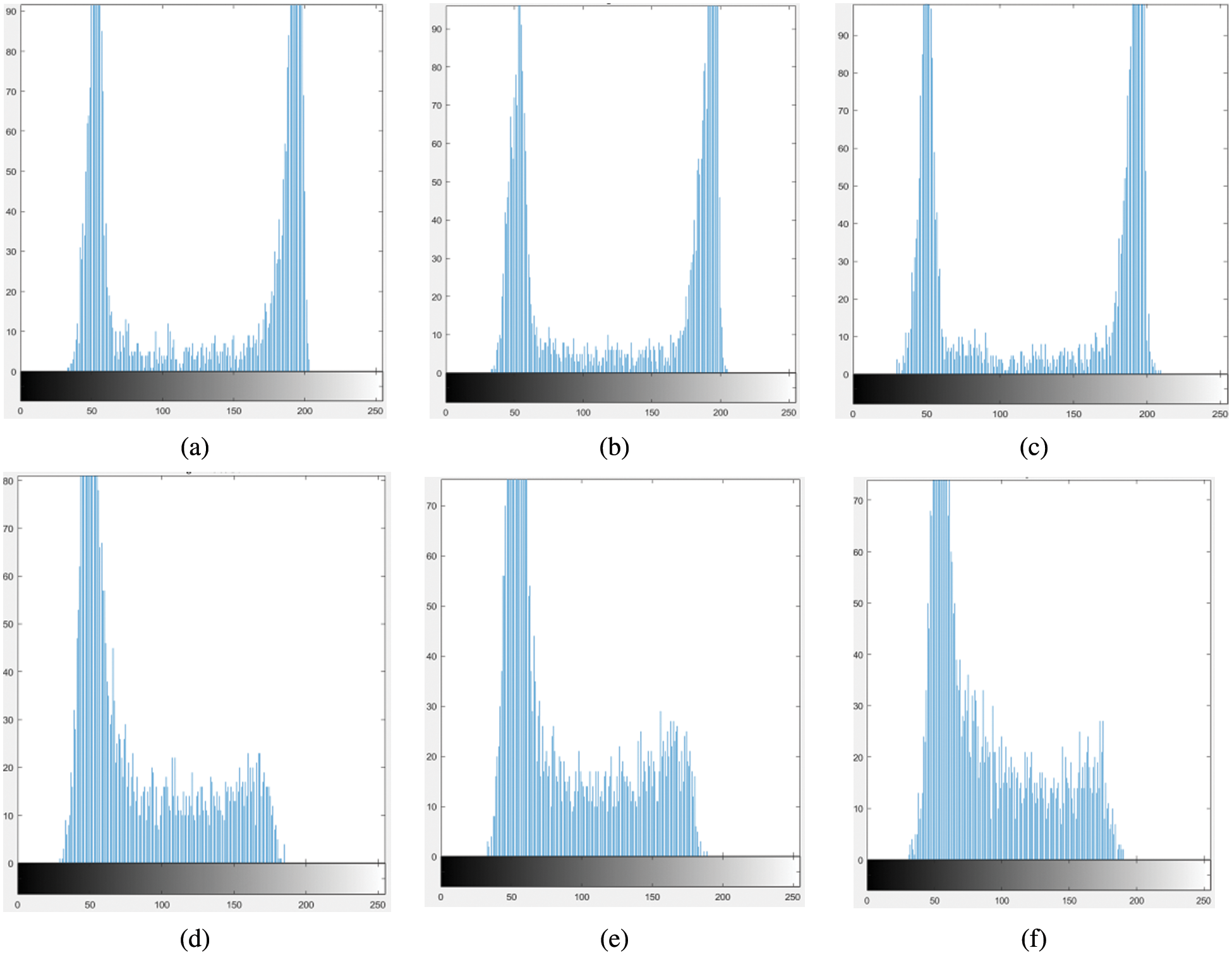
Figure 4: Gray histogram of the anti-counterfeiting code image patch, (a)–(c) gray histogram of the image patch in the QR code area, and (d)–(f) gray histogram of the image patch in the anti-counterfeiting code area
3.2 Double Pool Attention Network
In the past decade, the development of deep learning has made amazing achievements, which has not only caused a research upsurge in academia, but has also been widely used in industry. In academia, deep learning has become a research hotspot in natural language processing [30], object detection [31,32], human activity recognition [33,34], and image denoising [35,36] and has achieved better results than traditional methods. In industry, deep learning has been successfully applied to product defect detection [37,38], image restoration [39], speech recognition [40] and other fields. Although deep learning has been successfully applied in many fields, as far as we know, deep learning has not been applied to image anti-counterfeiting. In this paper, deep learning is applied to image anti-counterfeiting for the first time, and the identification performance is better than that of exist methods. To pursue classification accuracy, the existing deep learning networks are getting deeper and more complex. For example, the number of layers of the deep residual network (ResNet) has reached 152 [41]. Digital image anti-counterfeiting technology is a new anti-counterfeiting technology developed based on mobile phones. It requires high classification accuracy, high response speed and a small deep learning model. Therefore, it is very important to design a deep learning network with a simplified structure and high classification accuracy. A large number of studies show that the residual unit can directly transfer the shallow features back, protect the integrity of information, reduce the loss of key features with the same network depth, and have strong feature extraction ability. Therefore, we select the residual structure as the basic module of DPANet. Although the ResNet structure can integrate the features of each convolution layer, research on channel attention such as squeeze-and-excitation networks (SENet) [42] and convolutional block attention module (CBAM) [43] also shows that the information between channels also has relevance. For shallow networks, making full use of the information between channels is the key to improving the network performance. However, existing research shows that there is a certain degree of information loss in SENet. Therefore, we improve the existing SENet and propose a double pool attention (DPA) module. To make full use of the feature information between channels, the double pool attention model is embedded into the residual module and used as the basic unit of DPANet. DPANet is shown in Fig. 5.
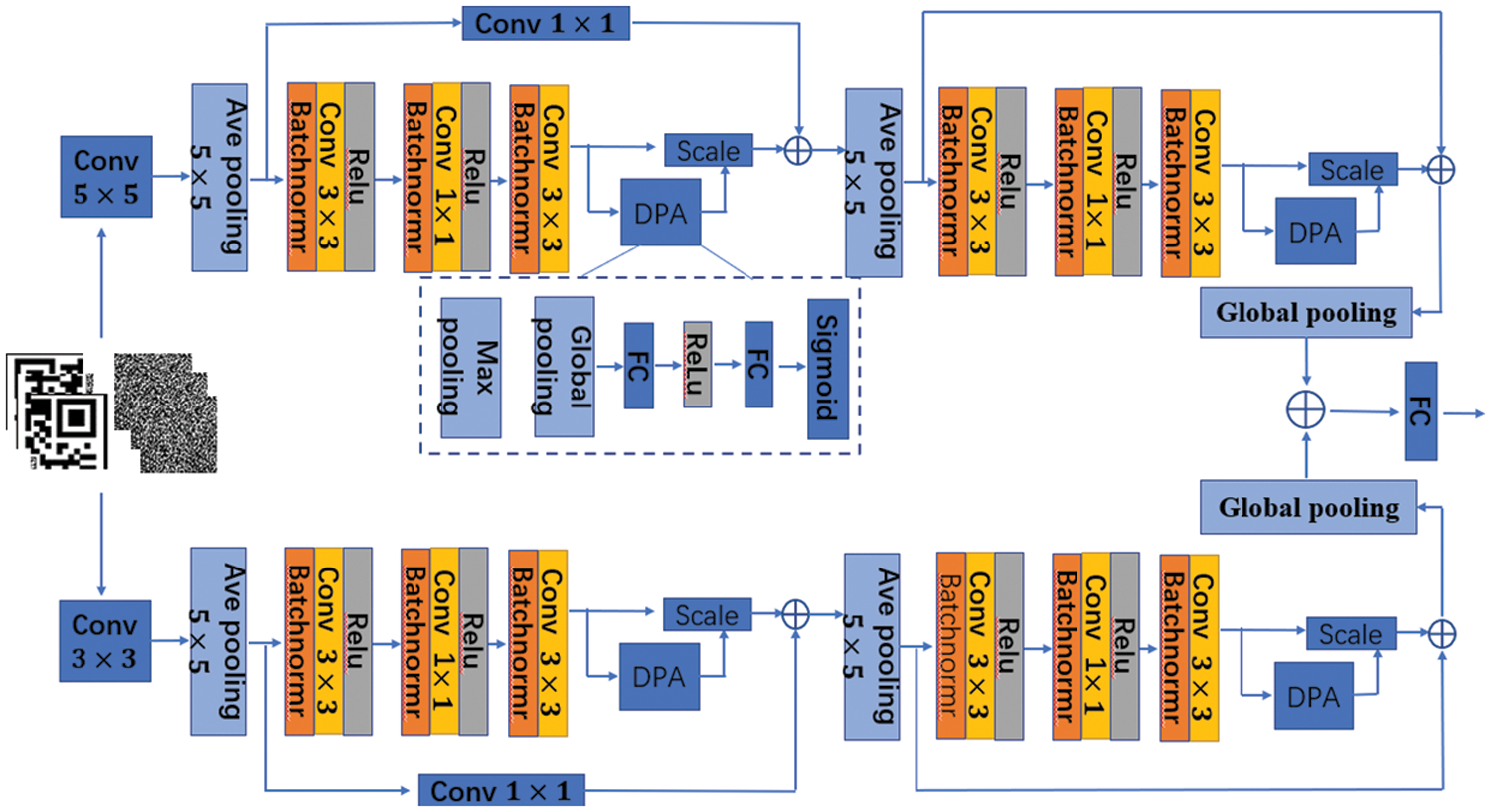
Figure 5: DPANet network structure
As shown in Fig. 5, to extract more abundant features, we parallel two DPA networks. The input image is processed to fully amplify the subtle difference features between genuine anti-counterfeiting codes and fake anti-counterfeiting codes in preprocessing layer by two kinds of convolutional kernel sizes:
The attention mechanism comes from the study of human vision. In cognitive science, due to the bottleneck of information processing, human beings selectively pay attention to part of the information and ignore other visible information. Attention models have become an important research direction in deep learning and have been fully studied in many fields, such as image recognition, speech recognition, and natural language processing. The squeeze-and-excitation (SE) structure is one of the most widely used and representative attention models in image vision. The SE module first performs the squeeze operation on the feature map obtained by convolution to obtain the channel-level global features, then performs the excitation operation on the global features to learn the relationship between various channels and obtain the weights of different channels, and finally multiplies the original feature map to obtain the final features. The structure of the SE module is shown in Fig. 6a. The DPA module proposed in this paper is shown in Fig. 6b.
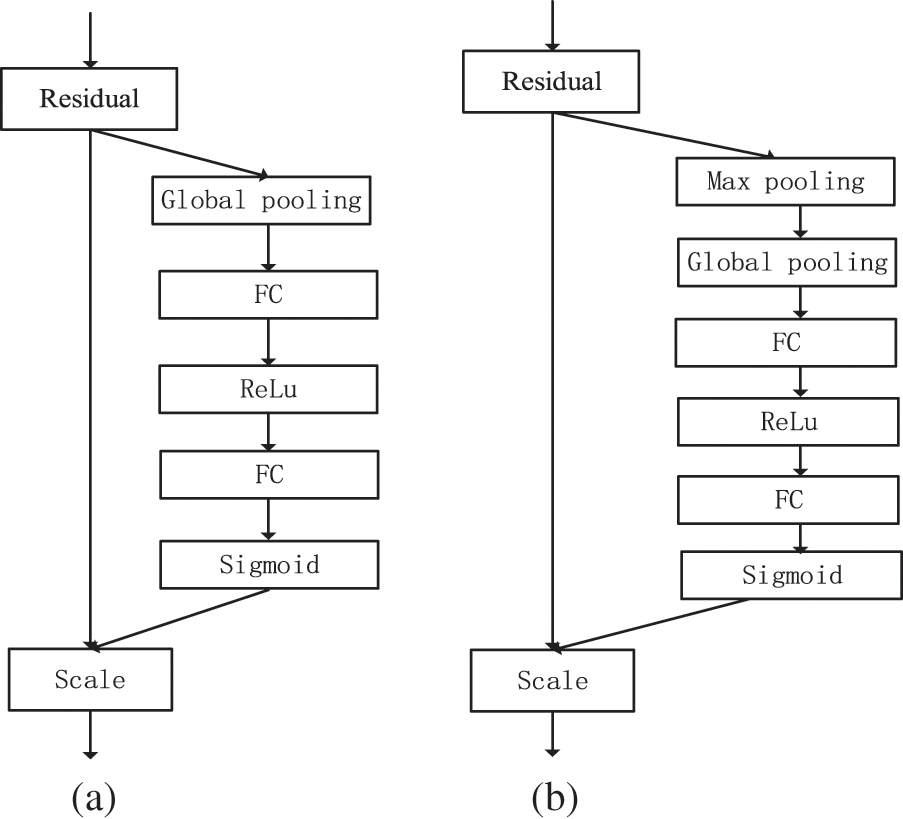
Figure 6: Structure of the attention module. a is the SE module and b is the DPA module
As shown in Fig. 6, the SE module sends the high-dimensional feature map into a global average pool, and directly compresses the
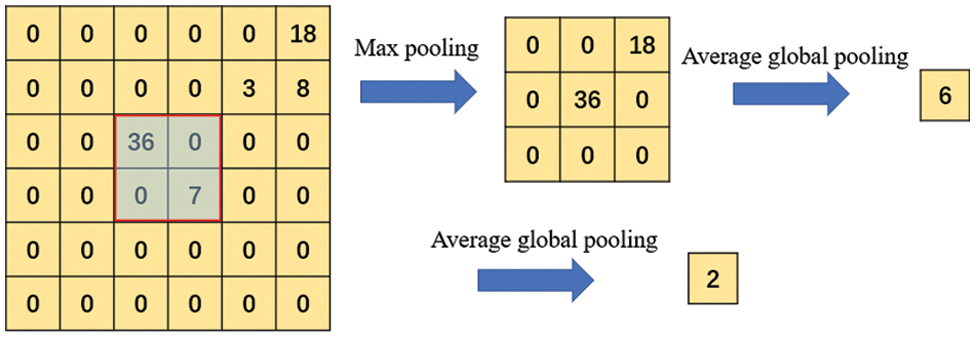
Figure 7: Comparison of pooling between the SE model and the DPA model
This section evaluates the performance of the FG-DPANet algorithm proposed in this paper and compares FG-DPANet with existing texture based anti-counterfeiting methods.
The preparation of the dataset is an important part of the experiment and the quality of dataset determines whether the experiment will be successful. As research on digital image anti-counterfeiting is still in its infancy, there is no available printed anti-counterfeiting code image dataset at present. Therefore, we need to establish a high-quality printed anti-counterfeiting code image dataset to evaluate the FG-DPANet algorithm proposed in this paper.
The anti-counterfeiting code datasets are divided into two categories: genuine anti-counterfeiting codes and reprinted anti-counterfeiting codes. For convenience, we call the reprinted anti-counterfeiti-ng code the fake anti-counterfeiting code. The generation process of the two categories of datasets is shown in Fig. 8. First, a batch of genuine digital anti-counterfeiting image files are generated and printed as genuine paper anti-counterfeiting code by using the printing equipment authorized by the merchant, and then, the genuine paper documents are photographed by mobile camera devices such as mobile phones to obtain the corresponding genuine digital anti-counterfeiting code dataset. For the acquisition process of the fake digit anti-counterfeiting code dataset, the genuine printing anti-counterfeiting code is first scanned through illegal high-definition (HD) scanning equipment, the fake anti-counterfeiting code is printed with illegal printing equipment, and photos of the fake printing anti-counterfeiting code are finally taken with mobile camera devices such as mobile phones to obtain the corresponding fake anti-counterfeiting code dataset.
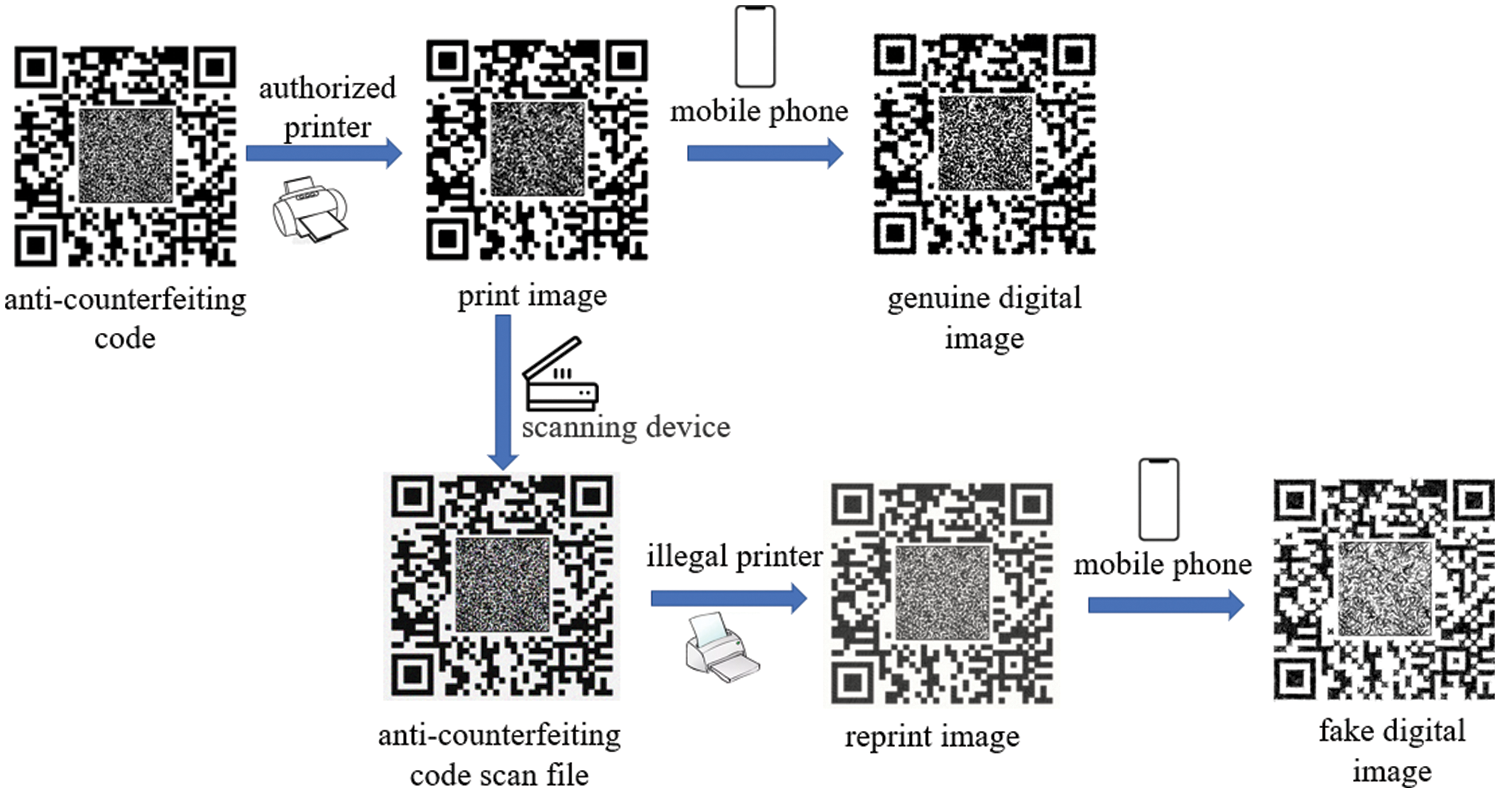
Figure 8: Production process of the paper anti-counterfeiting image dataset
Considering the diversity of HD scanning equipment and mobile camera equipment, we decided to use 1 printer authorized by the manufacturer to print genuine anti-counterfeiting codes, 3 scanners to scan the genuine anti-counterfeiting codes, and 8 illegal printers to print the fake anti-counterfeiting codes. The printing, scanning and mobile photographing devices of the anti-counterfeiting code dataset and the model information of the anti-counterfeiting code are shown in Table 1. Different anti-counterfeiting codes have different texture image densities. Multiple anti-counterfeiting code types are chosen to verify that the algorithm proposed in this paper can be applied to printed anti-counterfeiting codes with different texture image densities. In the anti-counterfeiting code model, C represents the QR code type, D represents the anti-counterfeiting area density, and Ft represents the fault tolerance level. Each type of anti-counterfeiting code contains 200 anti-counterfeiting codes, so the anti-counterfeiting code dataset includes 1,600 genuine anti-counterfeiting codes and 1,600 fake anti-counterfeiting codes. The size of the printed anti-counterfeiting code is set to
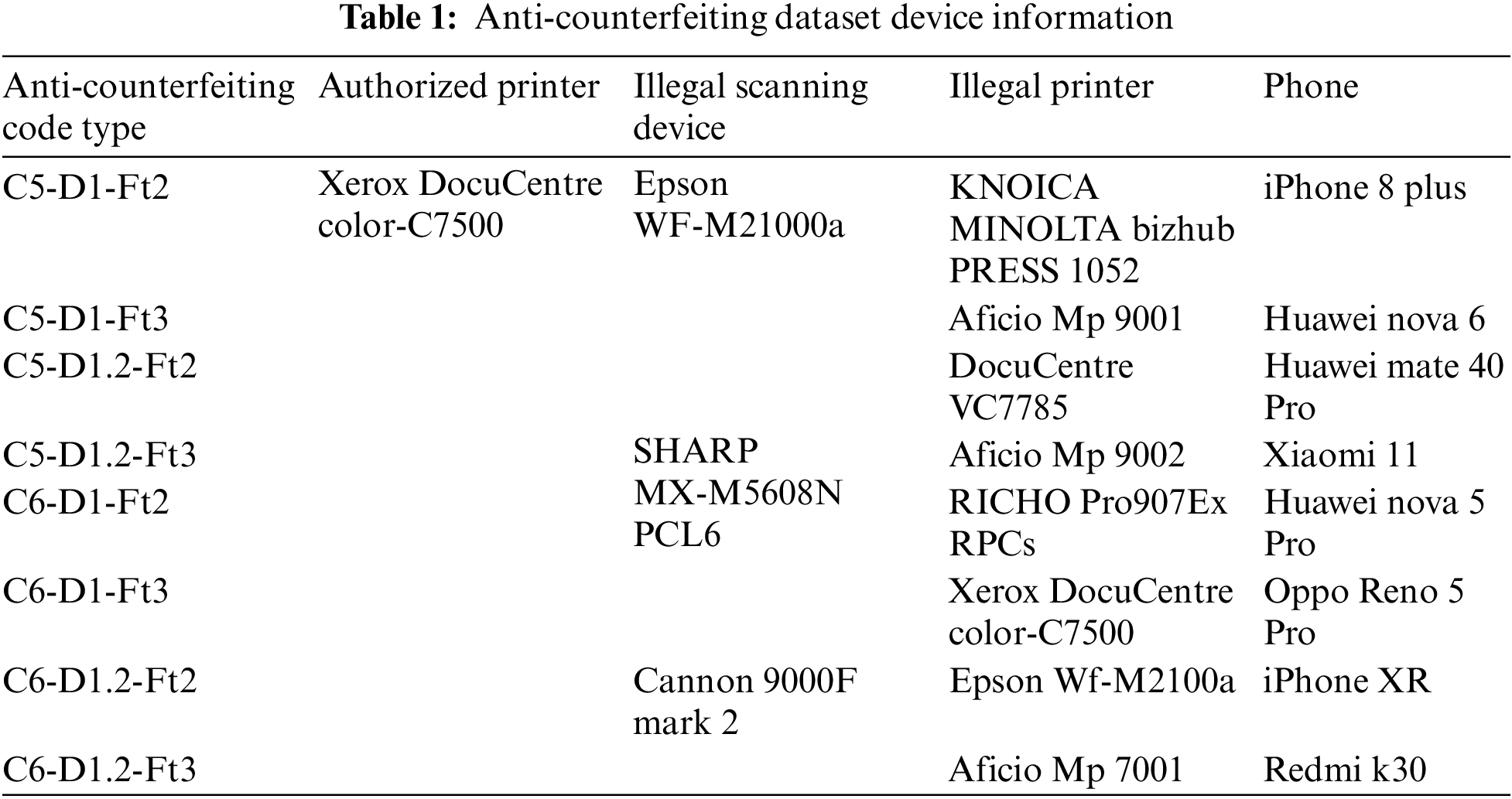
As shown in Table 1, we used a printer (Xerox DocuCentre color-C7500) authorized by the manufacturer to print authentic paper anticounterfeit codes and then use 8 illegal printers of different models to reprint the counterfeit anticounterfeit codes. To imitate the use scenario confirmed by users, we selected 8 smartphones of different models to take photos of authentic and counterfeit paper anticounterfeit codes. We use one mobile phone to collect 200 authentic anticounterfeit codes and their corresponding counterfeit anticounterfeit codes. Finally, all the collected anti-counterfeiting codes are normalized to
To evaluate the algorithm proposed in this paper, a series of experiments are carried out on the anti-counterfeiting code dataset. The anti-counterfeiting code dataset includes 1,600 genuine anti-counterfeiting codes and 1,600 fake anti-counterfeiting codes. A total of 3,200 anti-counterfeiting code images are cut into image patches with a size of
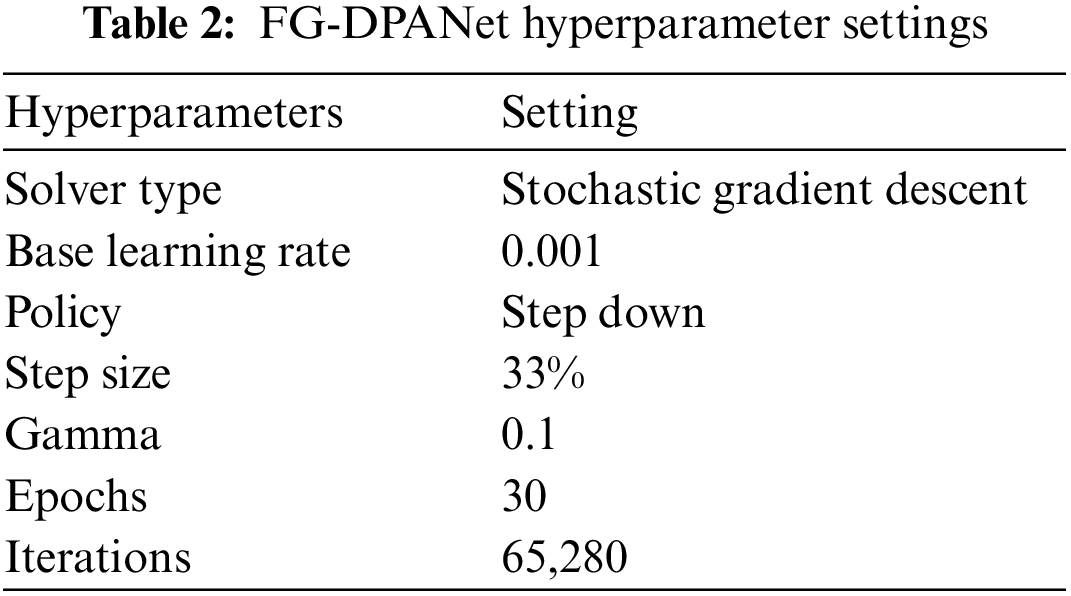
In the evaluation experiment of DPANet’s anti-counterfeiting performance, the default hyperparameters are as follows: the training steps and epochs are 65,280 and 30, respectively, the training batch size is 32, the base learning rate is 0.001, the momentum and weight decay are 0.9 and 0.001 respectively, and the model optimization algorithm is stochastic gradient descent (SGD). The hyperparameter settings of FG-DPANet are shown in Table 2.
The notebook platform used in the experiment is HP OMEN, the central processing unit (CPU) model is i7-9750H (2.60 GHz, 16 GB), the graphics processing unit (GPU) graphics card model is an NVIDIA GeForce RTX2070 (8 GB), the deep learning framework used is Caffe, the compute unified device architecture (CUDA) version is 10.0, and the CUDA deep neural network library (CUDNN) version is 7.6.0. The specific software and hardware parameters are shown in Table 3.

Existing anti-counterfeiting code identification methods are based on the whole anti-counterfeiti- ng image. However, the authenticity identification method based on the whole image is not robust. Commodities will be stained and rubbed in the process of transportation and sales, resulting in the destruction of anti-counterfeiting code images. However, the identification performance of existing anti-counterfeiting code identification methods declines sharply when the anti-counterfeiting code image is damaged. The quality of anti-counterfeiting code images usually decreases due to factors such as dirt, friction, reflection and blurring, so the anti-counterfeiting requirements are not met. However, there are usually some image areas with high quality in anti-counterfeiting images. Therefore, developing an area-based anti-counterfeiting method can effectively combat the decline in anti-counterfeiting code quality. For the above reasons, the anti-counterfeiting code is divided into image patches with a size of
4.4 Performance Evaluation and Analysis of the Double Pool Attention Network
To test the impact of the double pool attention module proposed in this paper on the network, DPANet is considered the basic network, the existing attention model channel attention module [43] (CAM) and SE are embedded into DPANet, and the impacts of various attention models on the classification performance of the basic network are compared. The experimental test dataset is the above anti-counterfeiting code dataset, and the input image size of the network is
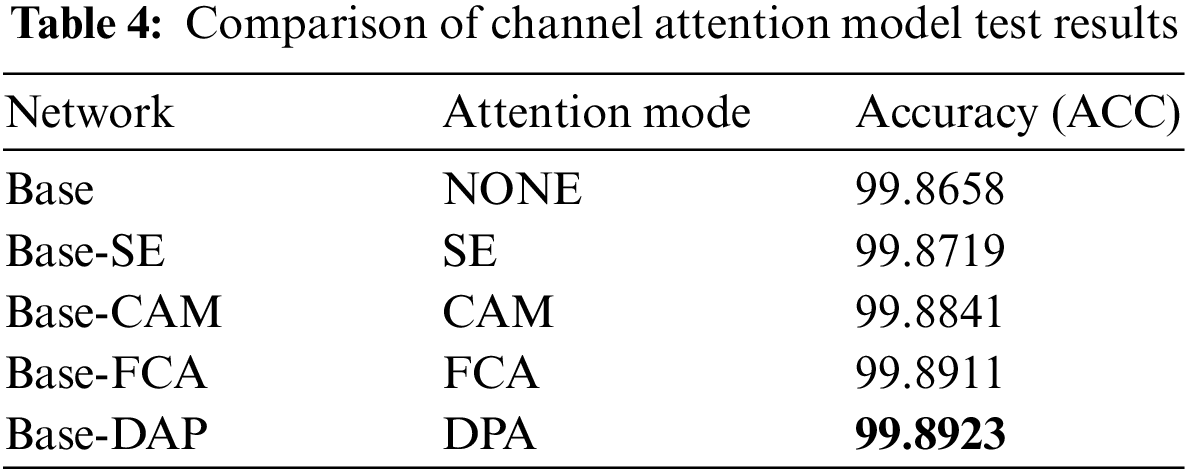
The Base network in Table 4 represents the residual network in DPANet, Base-SE indicates that the DPA module in DAPNet is replaced with SE [42], Base-CAM indicates that the DPA module in DPA-Net is replaced with CAM [43], and Base-FCA indicates that the DPA module in DPA-Net is replaced with FCA. Base-DPA is a double pool attention network proposed in this paper. According to the test results in Table 4, the Base network has the lowest classification accuracy, which proves that embedding the attention model in the network can make full use of the features between channels and improve the network classification performance. According to the test results of Base-SE, Base-CAM and Base-DAP, the DPA model proposed in this paper can address the information loss of the attention model to a certain extent. In addition, although Base-FCA has achieved good classification results, its network performance is largely affected by the top-k frequency combination, and the selection of frequency combination will bring great uncertainty.
4.5 Performance Analysis of the Feature-Guided Double Pool Attention Network
To evaluate the classification performance of the feature-guided DPA network proposed in this paper, authenticity identification experiments are carried out on anti-counterfeiting code datasets. Because the DPANet proposed in this paper is the first deep learning network in digital image anti-counterfeiting, and there is no digital image anti-counterfeiting network that can be used for comparison, the existing sophisticated network widely used in image classification is chosen for comparison. Considering the industrial application limitation of anti-counterfeiting code authentication, we should take the complexity of the network model and the inference speed into consideration. We select the existing networks with simple structures and high classification accuracy for comparison. Therefore, we compare DAPNet with LeNet, AlexNet, ResNet18 and GoogLeNet. The existing ResNet, GoogLeNet and other networks are very deep, and the input image size is large. The image with a size of
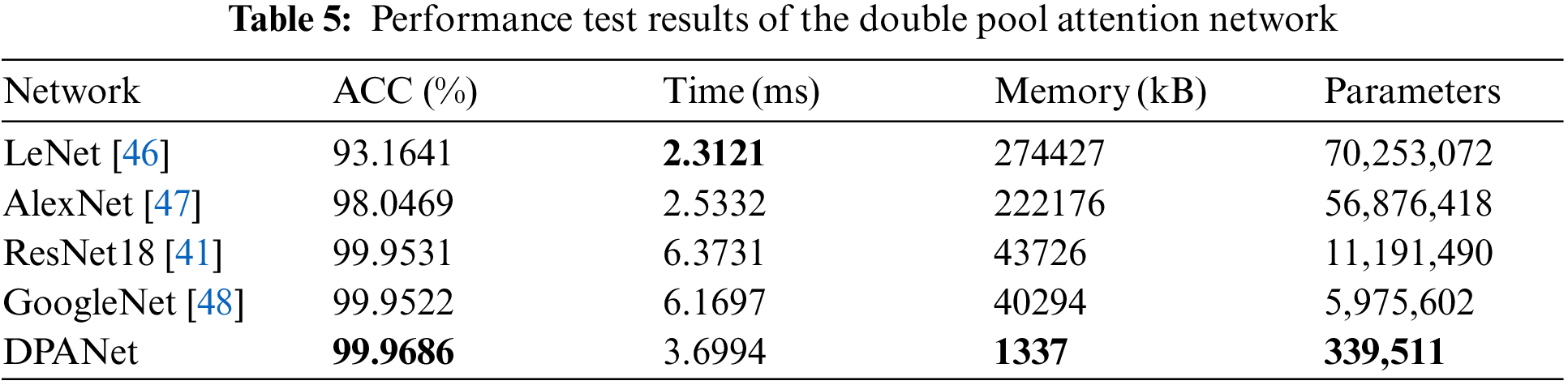
We compare the classification accuracy, test time of a single image, model memory and network parameters of several classical networks. As seen from Table 5, the DPANet proposed in this paper achieved the highest classification accuracy of 99.9686, slightly higher than that of ResNet18 and that of GoogleNet, and much higher than that of LeNet and that of AlexNet. In terms of memory and network parameters, DPANet is much better than other existing sophisticated networks. A comprehensive evaluation of various test indicators shows that DPANet has the best classification performance and can meet the operation requirements of mobile platforms in terms of memory and test time.
4.6 Compared to the Textural Anti-Counterfeiting Algorithms
At present, research on the authenticity identification of anti-counterfeiting code mainly focuses on traditional image processing and machine learning algorithms. To evaluate the classification performance of the FG-DPANet network, the 13 most common and advanced existing methods, CLBC [49], CLBP [50], COV-LBPD [51], ECLBP [22], LBP [52], LDEP [53], LGONBP [23], MCDR [54], MRELBP [55], RALBGC [56], RAMBP [24], MMLR [57] and GCLBP [58] are chosen for comparison to the FG-DPANet network. To comprehensively evaluate the performance of the digital image anti-counterfeiting algorithm, we test the classification accuracy, recall and F1 value of each digital image anti-counterfeiting algorithm. The accuracy, recall and F1 value of the calculation methods are shown in formulas (2), (3) and (4), respectively:
where
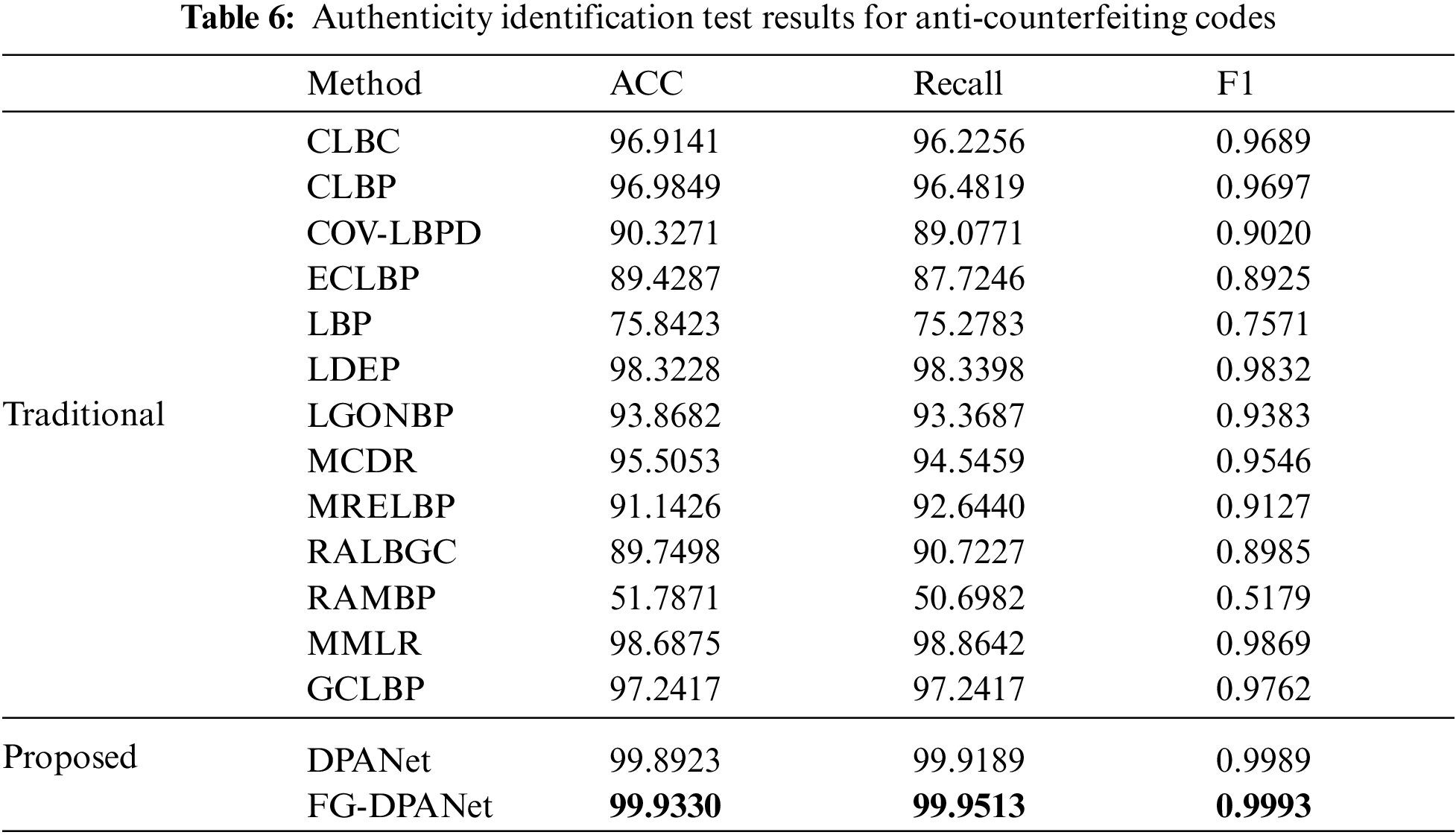
The test results in Table 6 show that FG-DPANet has achieved the best performance in the authenticity identification of anti-counterfeiting code, and the three indices of accuracy, recall and F1 are much higher than those of the existing image anti-counterfeiting algorithm. The above experiments prove the effectiveness and superiority of FG-DPANet.
4.7 Experimental Details Display
In this section, we show the details of the experiment, including training and test results. Fig. 9 shows the training details of DPANet, and Fig. 10 shows the (receiver operating characteristic) ROC curve and confusion matrix of DPANet test results on the anti-counterfeiting dataset.
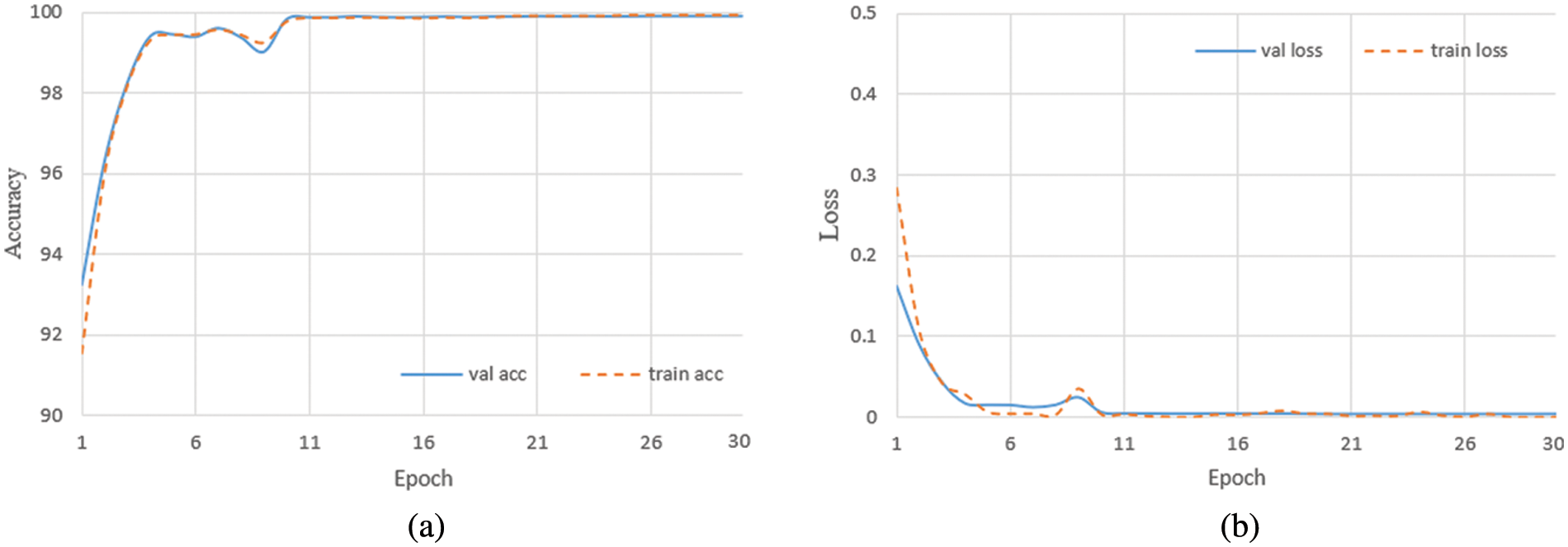
Figure 9: DPANet training details. Panel a is the DPANet accuracy curve and Panel b is the DPANet loss curve
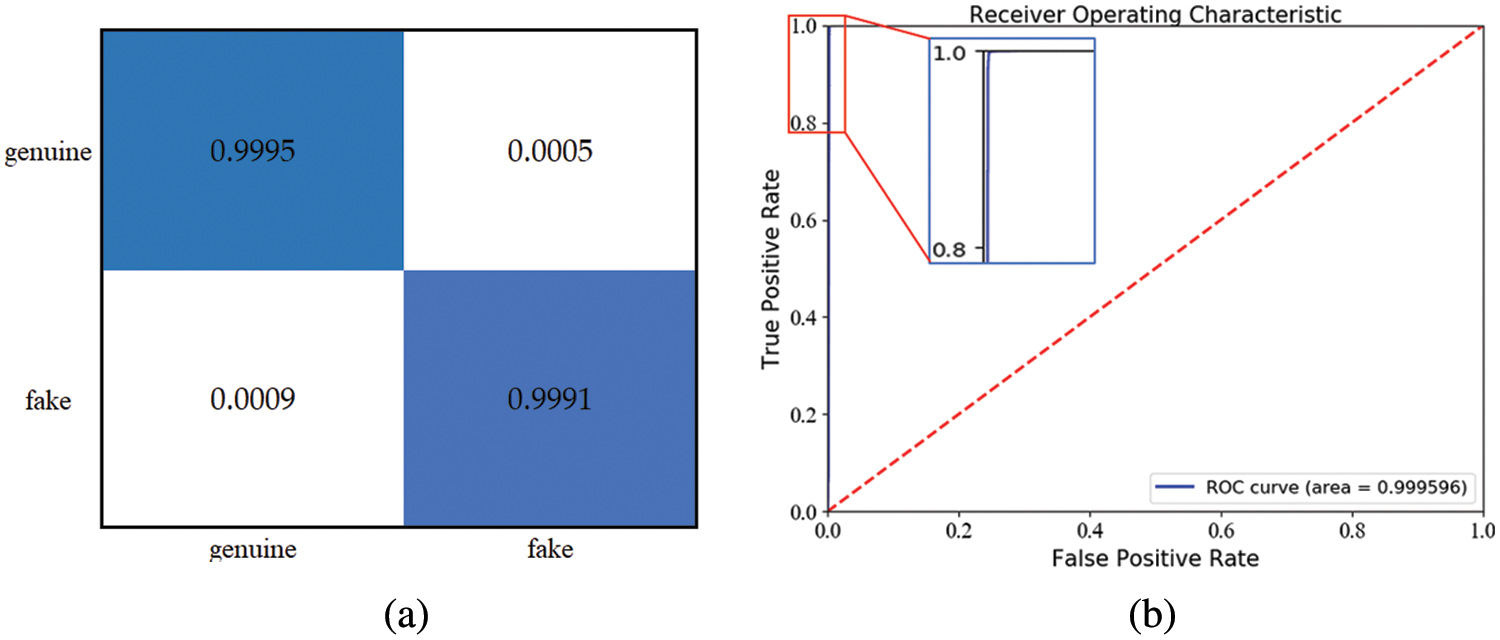
Figure 10: DPANet Test Results. Panel a is DPANet test confusion matrix and Panel b is DPANet test ROC curve
Fig. 9 shows the training details of the DPANet network model, Fig. 9a is the training and verification accuracy curve, and Fig. 9b is the training and verification loss curve. From the accuracy curve and loss curve in the figure, it can be seen that the model proposed in this paper can converge quickly and achieve high classification accuracy.
Fig. 10 shows the test results of DPANet on the anti-counterfeiting dataset. Fig. 10a is the confusion matrix of the test results. It can be seen from the figure that the accuracy rate of genuine products is 0.9995 and that of counterfeit products is 0.9991. Fig. 10b is the ROC curve of the test results, with the false positive rate as the horizontal axis and the true positive rate as the vertical axis. The ROC curve in the figure is very close to the upper left corner, and the area below the curve is 0.999596. The confusion matrix and ROC curve of the DPANet test results show that the proposed model has superior classification performance.
4.8 Authenticity Identification of Anti-Counterfeiting Codes for Blurred Images
In the process of using mobile phones to scan and identify anti-counterfeiting codes, due to the relative motion between mobile phones and anti-counterfeiting codes, the scanned anti-counterfeiting code image is easily blurred by motion. The blurred anti-counterfeiting code image has a great impact on the discrimination performance, so it is necessary to test the antiblur ability of the network proposed in this paper. To test the antiblur performance of the FG-DPANet network, five different degrees of motion blur with blurring kernel lengths of 2, 4, 6, 8 and 10 and angles of 45% are added to the anti-counterfeiting dataset above. An example of an anti-counterfeiting code blurred image is shown in Fig. 11. The antiblur test results of FG-DPANet are shown in Table 7.

Figure 11: Examples of anti-counterfeiting code fuzziness, where L represents the length of the blurring kernel, L(a) = 0, L(b) = 2, L(c) = 4, L(d) = 6, L(e) = 8 and L(f) = 10
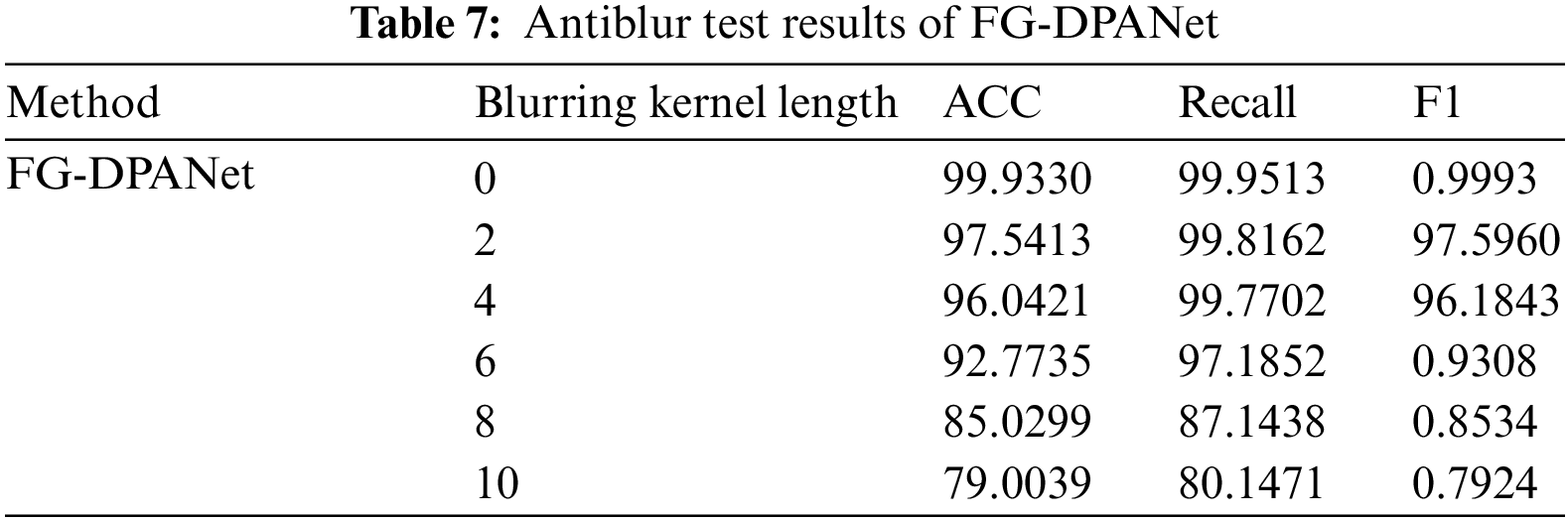
The three test indices ACC, recall and F1 in Table 7 show that the detection performance of the FG-DPANet algorithm decreases gradually with increasing blur, but FG-DPANet still maintains a high detection accuracy in the case of slight blur (2, 4). In the case of severe ambiguity, the detection accuracy is reduced to less than 96%. The above detection results show that the algorithm proposed in this paper can accurately identify the authenticity of the anti-counterfeiting code when it is slightly blurred.
In this paper, we propose a lightweight anticounterfeit code recognition network, which is a two branches attention residual network. The introduction of noise features effectively solves the problem of weak texture features of anti-counterfeiting code in high-quality forgery and image blur scenes. In addition, the DPA model further improves the network’s feature expression ability. The experimental results show that our scheme is superior to the existing anticounterfeit code authentication algorithm, and the authentication accuracy reaches 99.95%. In addition, our algorithm can accurately identify the authenticity of the anti-counterfeit code in the mobile phone imaging scene and the slightly blurred scene of the anti-counterfeit code, which solves a major problem in the commercialization of the anti-counterfeit code authentication scheme. Although our algorithm can identify the authenticity of the anti-counterfeit code under slight ambiguity, if the anti-counterfeit code encounters severe ambiguity, the identification effect will be seriously affected. Our next step is to solve the problem of authenticating the anti-counterfeit code in the heavily blurred scene.
Funding Statement: This work is supported by Supported by the National Key Research and Development Program of China under Grant No.2020YFF0304902 and the Science and Technology Research Project of Jiangxi Provincial Department of Education under Grant No. GJJ202511
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. E. Pilania and B. Arora, “Recognition of fake currency based on security thread feature of currency,” International Journal of Engineering Computer Science, vol. 5, no. 7, pp. 17136–17140, 2016. [Google Scholar]
2. M. Chen and S. Yin, “Anti-counterfeit printing technique and chemistry,” Chinese Journal of Chemical Education, vol. 2008, no. 2, pp. 1–5, 2018. [Google Scholar]
3. C. T. Sun, P. C. Kuan, Y. M. Wang, C. S. Lu and H. C. Wang, “Integration of graphic QR code and identity documents by laser perforation to enhance anti-counterfeiting features,” in 2018 IEEE Int. Conf. on Multimedia & Expo Workshops (ICMEW), San Diego, CA, USA, pp. 1–6, 2018. [Google Scholar]
4. J. Miao, X. Ding, S. Zhou and C. Gui, “Fabrication of dynamic holograms on polymer surface by direct laser writing for high-security anti-counterfeit applications,” IEEE Access, vol. 7, pp. 142926–142933, 2019. [Google Scholar]
5. D. U. Mengyuan, L. I. Han, L. V. Fei and X. Zhang, “The recognition of laser anti-counterfeiting code with complex background,” in Int. Conf. on Innovative Design & Manufacturing, Montreal, QC, Canada, pp. 288–293, 2014. [Google Scholar]
6. L. Wang, “Research on detecting method of security area covered by anti-counterfeit paper based on machine vision,” M.S. Theses, Shanghai Jiao Tong University, Shanghai, China, 2018. [Google Scholar]
7. Y. Yan, Z. Zou, H. Xie, Y. Gao and L. R. Zheng, “An IoT-based anti-counterfeiting system using visual features on QR code,” IEEE Internet of Things Journal, vol. 8, no. 8, pp. 6789–6799, 2020. [Google Scholar]
8. B. A. Alzahrani, K. Mahmood and S. Kumari, “Lightweight authentication protocol for NFC based anti-counterfeiting system in IoT infrastructure,” IEEE Access, vol. 8, pp. 76357–76367, 2020. [Google Scholar]
9. M. Al-Bahri, A. Yankovsky, R. Kirichek and A. Borodin, “Smart system based on DOA & IoT for products monitoring & anti-counterfeiting,” in 2019 4th MEC Int. Conf. on Big Data and Smart City (ICBDSC), Muscat, Oman, pp. 1–5, 2019. [Google Scholar]
10. C. Xiaohe, L. Feng, P. Cao and J. Hu, “Secure QR code scheme based on visual cryptography,” in 2016 2nd Int. Conf. on Artifical Intelligence and Industrial Engineering (AIIE2016), Beijing China, pp. 444–447, 2016. [Google Scholar]
11. O. Taran, S. Bonev and S. Voloshynovskiy, “Clonability of anti-counterfeiting printable graphical codes: A machine learning approach,” in IEEE Int. Conf. on Acoustics, Brighton, UK, pp. 2482–2486, 2019. [Google Scholar]
12. C. Chen, M. Li, A. Ferreira, J. Huang and R. Cai, “A copy-proof scheme based on the spectral and spatial barcoding channel models,” IEEE Transactions on Information Forensics and Security, vol. 15, pp. 1056–1071, 2020. [Google Scholar]
13. F. Chen and P. Cao, “Research on dual anti duplication and anti-counterfeiting technology of QR code based on metamerism characteristics,” in 2020 IEEE 5th Int. Conf. on Image, Vision and Computing (ICIVC), Beijing, China, pp. 303–306, 2020. [Google Scholar]
14. Y. M. Wang, C. T. Sun, P. C. Kuan, C. S. Lu and H. C. Wang, “Secured graphic QR code with infrared watermark,” in 2018 IEEE Int. Conf. on Applied System Innovation (ICASI), Chiba, Japan, IEEE, pp. 690–693, 2018. [Google Scholar]
15. R. Xie, C. Hong, S. Zhu and D. Tao, “Anti-counterfeiting digital watermarking algorithm for printed QR barcode,” Neurocomputing, vol. 167, pp. 625–635, 2015. [Google Scholar]
16. H. P. Nguyen, A. Delahaies, F. Retraint, D. H. Nguyen, M. Pic et al., “A watermarking technique to secure printed QR codes using a statistical test,” in Proc. IEEE Global Conf. Signal Inf.Process. (GlobalSIP), Montreal, QC, Canada, pp. 288–292, 2017. [Google Scholar]
17. J. Picard, “Digital authentication with copy-detection patterns,” in Conf. on Optical Security and Counterfeit Deterrence Techniques V, San Jose, CA, US, pp. 176–184, 2004. [Google Scholar]
18. J. Picard, J. P. Massicot, A. Foucou and Z. Sagan, “Document Securization method and a document securization device using printing a distribution of dots on said document,” U.S. Patent 8 913 299, Dec. 16, 2014. [Google Scholar]
19. J. Picard, Z. Sagan, A. Foucou and J. -P. Massicot, “Method and device for authenticating geometrical codes,” U.S. Patent 8 727 222, 2014. [Google Scholar]
20. J. Picard and P. Landry, “Two dimensional barcode and method of authentication of such barcode,” U.S. Patent 9 594 993, 2017. [Google Scholar]
21. A. K. Mikkilineni, P. J. Chiang, G. N. Ali, G. T. C. Chiu, J. P. Allebach et al., “Printer identification based on gray level cooccurrence features for security and forensic applications,” in Conf. on Security, Strganography, and Watermarking of Multimedia Contents VII, San JoseCA, US, pp. 430–440, 2005. [Google Scholar]
22. S. Jie, Y. Dong, T. Wang and J. Pu, “Extended contrast local binary pattern for texture classification,” International Journal of New Technology and Research, vol. 4, no. 3, pp. 15–20, 2018. [Google Scholar]
23. T. C. Song, J. Feng, L. Luo, C. Q. Gao and H. L. Li, “Robust texture description using local grouped order pattern and non-local binary pattern,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 1, pp. 189–202, 2021. [Google Scholar]
24. M. Alkhatib and A. Hafiane, “Robust adaptive median binary pattern for noisy texture classification and retrieval,” IEEE Transactions on Image Processing, vol. 28, no. 11, pp. 5407–5418, 2019. [Google Scholar] [PubMed]
25. A. Berenguel, O. R. Terrades, J. Lladós and C. Cristina, “E-Counterfeit: A mobile-server platform for document counterfeit detection,” in 2017 14th IAPR Int. Conf. on Document Analysis and Recognition (ICDAR), Kyoto, Japan, pp. 15–20, 2018. [Google Scholar]
26. Z. Huahong, L. Qin and H. Qin, “The anti counterfeiting algorithm for overall security code based on registration principle,” in 2021 IEEE 6th Int. Conf. on Signal and Image Processing (ICSIP), Nanjing, China, pp. 995–998, 2021. [Google Scholar]
27. I. Tkachenko, W. Puech, O. Strauss, C. Destruel and J. -M. Gaudin, “Printed document authentication using two level or code,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), Shanghai, China, pp. 2149–2153, 2016. [Google Scholar]
28. I. Tkachenko, W. Puech, C. Destruel, O. Strauss, J. -M. Gaudin et al., “Two-level QR code for private message sharing anddocument authentication,” IEEE Trans. Inf. Forensics Security, vol. 11, no. 3, pp. 571–583, 2016. [Google Scholar]
29. C. -W. Wong and M. Wu, “Counterfeit detection based on unclonable feature of paper using mobile camera,” IEEE Trans. Inf. Forensics Security, vol. 12, no no. 8, pp. 1885–1899, 2017. [Google Scholar]
30. D. Otter, J. Medina and J. Kalita, “A survey of the usages of deep learning for natural language processing,” IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 2, pp. 604–624, 2020. [Google Scholar]
31. A. K. Shetty, I. Saha, R. M. Sanghvi, S. A. Save and Y. J. Patel, “A review: Object detection models,” in 2021 6th Int. Conf. for Convergence in Technology (I2CT), Maharashtra, India, pp. 1–8, 2021. [Google Scholar]
32. M. Pandiya, S. Dassani and D. Mangalraj, “Analysis of deep learning architectures for object detection-A critical review,” in IEEE HYDCON. Hyderabad, India, pp. 978–983, 2020. [Google Scholar]
33. Y. Tang, L. Zhang, F. Min and J. He, “Multiscale deep feature learning for human activity recognition using wearable sensors,” IEEE Transactions on Industrial Electronics, vol. 70, no. 2, pp. 2106–2116, 2023. [Google Scholar]
34. X. Cheng, L. Zhang, Y. Tang, Y. Liu, H. Wu et al., “Real-time human activity recognition using conditionally parametrized convolutions on mobile and wearable devices,” IEEE Sensors Journal, vol. 22, no. 6, pp. 5889–5901, 2022. [Google Scholar]
35. A. Yapici, M. Ali and Akcayol, “A review of image denoising with deep learning,” in 2021 2nd Int. Informatics and Software Engineering Conf. (IISEC), Ankara, Turkey, pp. 1–39, 2021. [Google Scholar]
36. S. Ghose, N. Singh and P. Singh, “Image denoising using deep learning: Convolutional neural network,” in 2022 30th Int. Conf. on Electrical Engineering (ICEE), Tehran, Islamic Republic of Iran, pp. 185–190, 2022. [Google Scholar]
37. G. Liu, “Surface defect detection methods based on deep learning: A brief review,” in 2020 2nd Int. Conf. on Information Technology and Computer Application (ITCA), Guangzhou, China, pp. 200–203, 2020. [Google Scholar]
38. X. Wu, Y. Ge, Q. Zhang and D. Zhang, “PCB defect detection using deep learning methods,” in 2021 IEEE 24th Int. Conf. on Computer Supported Cooperative Work in Design (CSCWD), Dalian, China, pp. 873–876, 2021. [Google Scholar]
39. Z. Yang, P. Shi and D. Pan, “A survey of super-resolution based on deep learning,” in 2020 Int. Conf. on Culture-Oriented Science & Technology (ICCST), Beijing, China, pp. 514–518, 2020. [Google Scholar]
40. A. B. Nassif, I. Shahin, I. Attili, M. Azzeh and K. Shaalan, “Speech recognition using deep neural networks: A systematic review,” IEEE Access, vol. 7, no. 99, pp. 19143–19165, 2019. [Google Scholar]
41. K. He, X. Zhang, S. Ren and J. Sun, “Deep residual learning for image recognition,” in 2016 IEEE Computer Vision and Pattern Recognition, Las Vegas, NV, USA, pp. 770–778, 2016. [Google Scholar]
42. J. Hu, S. Li, A. Samuel, S. Gang and W. Wu, “Squeeze-and-excitation networks,” in 2018 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, pp. 7132–7141, 2019. [Google Scholar]
43. S. Woo, J. Park, J. Y. Lee and I. S. Kweon, “CBAM: Convolutional block attention module,” in Proc. of the European Conf. on Computer Vision (ECCV), San Jose, CA, USA, pp. 3–19, 2018. [Google Scholar]
44. Z. Qin, P. Zhang, F. Wu and X. Li, “FcaNet: Frequency channel attention networks,” in 2021 IEEE/CVF Int. Conf. on Computer Vision, Montreal, QC, Canada, pp. 763–772, 2021. [Google Scholar]
45. Noble W S, “What is a support vector machine?,” Nature Biotechnology, vol. 24, no. 12, pp. 1565–1567, 2006. [Google Scholar] [PubMed]
46. L. Yann, N. Leon, B. Yoshua and H. Patrick, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998. [Google Scholar]
47. A. Krizhevsky, I. Sutskever and G. Hinton, “ImageNet classification with deep convolutional neural networks,” Advances in Neural Information Processing Systems, vol. 25, no. 2, pp. 84–90, 2012. [Google Scholar]
48. C. Szegedy, W. Liu, Y. Jia, S., Pierre and R. Scott, “Going deeper with convolutions,” in 2015 IEEE Computer Vision and Pattern Recognition, Boston, MA, pp. 1–12, 2015. [Google Scholar]
49. Y. Zhao, S. Huang and W. Jia, “Completed local binary count for rotation invariant texture classification,” IEEE Transactions on Image Processing, vol. 21, no. 10, pp. 4492–4497, 2012. [Google Scholar] [PubMed]
50. Z. H. Guo, L. Zhang and D. Zhang, “A completed modeling of local binary pattern operator for texture classification,” IEEE Transactions on Image Processing, vol. 19, no. 6, pp. 1657–1663, 2012. [Google Scholar]
51. X. Hong, G. Zhao and M. Pietikainen, “Combining LBP difference and feature correlation for texture description,” IEEE Trans Image Process, vol. 23, no. 6, pp. 2557–2568, 2014. [Google Scholar] [PubMed]
52. T. Ojala, M. Pietikinen and T. Menp, “Multiresolution gray scale and rotation invariant texture classification with local binary patterns,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 24, no. 7, pp. 971–987, 2017. [Google Scholar]
53. Y. Dong, T. Wang, C. Yang, L. Zheng and M. Jin, “Locally directional and extremal pattern for texture classification,” IEEE Access, vol. 7, no. 99, pp. 87931–87942, 2019. [Google Scholar]
54. Y. Dong, J. Feng, C. Yang, X. Wang and J. Pu, “Multi-scale counting and difference representation for texture classification,” VISUAL COMPUTER, vol. 34, no. 10, pp. 1315–1324, 2017. [Google Scholar]
55. L. Liu, P. Fieguth, M. Pietikäinen and S. Lao, “Median robust extended local binary pattern for texture classification,” IEEE Transactions on Image Processing, vol. 25, no. 3, pp. 1368–1381, 2015. [Google Scholar]
56. I. E. Khadiri, M. Kas, Y. E. Merabet, Y. Ruichek and R. Touahni, “Repulsive-and-attractive local binary gradient contours: New and efficient feature descriptors for texture classification,” Information Sciences, vol. 467, no. 2015, pp. 634–653, 2018. [Google Scholar]
57. A. Sharma, V. Srinivasan, V. Kanchan and L. Subramanian, “The fake vs real goods problem: Microscopy and machine learning to the rescue,” in Proc. of KDD, Halifax, NS, Canada, pp. 2011–2019, 2017. [Google Scholar]
58. W. Wang, Q. Kou, S. Zhou, K. Luo and L. Zhang, “Geometry-based completed local binary pattern for texture image classification,” in 2020 IEEE 3rd Int. Conf. on Information Communication and Signal Processing (ICICSP), Shanghai, China, pp. 274–278, 2020. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools