
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Ensemble Deep Learning Framework for Situational Aspects-Based Annotation and Classification of International Student’s Tweets during COVID-19
1 School of Information Engineering, Zhengzhou University, Zhengzhou, China
2 School of Computer Science and Engineering, Central South University, Changsha, China
3 Department of Data Science, The Islamia University of Bahawalpur, Bahawalpur, Pakistan
4 Clausthal University of Technology, Clausthal-Zellerfeld, Germany
* Corresponding Author: Hou Weiyan. Email:
Computers, Materials & Continua 2023, 75(3), 5355-5377. https://doi.org/10.32604/cmc.2023.036779
Received 12 October 2022; Accepted 29 January 2023; Issue published 29 April 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
As the COVID-19 pandemic swept the globe, social media platforms became an essential source of information and communication for many. International students, particularly, turned to Twitter to express their struggles and hardships during this difficult time. To better understand the sentiments and experiences of these international students, we developed the Situational Aspect-Based Annotation and Classification (SABAC) text mining framework. This framework uses a three-layer approach, combining baseline Deep Learning (DL) models with Machine Learning (ML) models as meta-classifiers to accurately predict the sentiments and aspects expressed in tweets from our collected Student-COVID-19 dataset. Using the proposed aspect2class annotation algorithm, we labeled bulk unlabeled tweets according to their contained aspect terms. However, we also recognized the challenges of reducing data’s high dimensionality and sparsity to improve performance and annotation on unlabeled datasets. To address this issue, we proposed the Volatile Stopwords Filtering (VSF) technique to reduce sparsity and enhance classifier performance. The resulting Student-COVID Twitter dataset achieved a sophisticated accuracy of 93.21% when using the random forest as a meta-classifier. Through testing on three benchmark datasets, we found that the SABAC ensemble framework performed exceptionally well. Our findings showed that international students during the pandemic faced various issues, including stress, uncertainty, health concerns, financial stress, and difficulties with online classes and returning to school. By analyzing and summarizing these annotated tweets, decision-makers can better understand and address the real-time problems international students face during the ongoing pandemic.Keywords
The COVID-19 pandemic affected the whole world and changed every human life. Its devastation begins in China Wuhan and spreads worldwide, ruining human lives, health, and economies. The World Health Organization (WHO) [1] declared the COVID-19 pandemic on March 11, 2020, due to its destructive behavior. After discerning the rapid spread of COVID-19 [2], all nations and their governments adopted harsh preventive measures to manage this terrible epidemic and stop it from spreading. About 3.9 billion people have been affected and under lockdown or quarantined in their houses, and international travelers have been quarantined in quarantine centers reserved by different countries to contain the virus [3]. After the surge of COVID-19 cases, every field of life has faced troubles, and this disease disturbed their lives. Its aftershocks will be observed and felt for many years. The student community is one of the influential groups that has been disturbed pathetically and is missing from the vulnerable group’s list. This vulnerable group of international students has been facing social and economic obstacles, and no one has addressed their issues globally [4]. Globally lockdown policies were also affected, and universities shut down their campuses by following the government’s directives. Developed countries financially helped their citizens in this time of pandemic emergency. Unluckily, international students suffer social and economic costs and are ignored by the authorities [5,6]. International students from developing countries have already experienced difficulties with financial circumstances to continue their studies abroad [7]. The sudden shutdown of university campuses has created problems for students from developing countries. Most of the work found in the literature is survey-based, and the researchers performed statistical analysis on the collected data. A study revealed that 13% of students had faced late graduation concerns, and 4% of students lost their jobs due to the COVID-19 pandemic. Another survey [8] was conducted at “education.com” to evaluate “how COVID-19 affected your study abroad plans”, in which they estimated that 4.7% of students intend to cancel their study abroad plans. The number of students who returned to their homes due to the shutdown of university campuses and now want to return to their universities to resume their studies is 47.2%. Moreover, 68.2% of students are interested in studying abroad online. Before the COVID-19 situation, a global investment of $18.66 billion in 2019 and $350 was estimated to reach 2025 in educational technology. Over the decades, social media has become an active technological tool and a news and communication channel for the general public worldwide. It plays an influential role in the COVID-19 pandemic by dismantling information around the globe [9]. The public has used the social media platform more frequently during the COVID-19 pandemic to express their sentiments. The information about any issue and trends on social media spread as COVID-19 spread rapidly. We analyzed many trends that international students influence by using different hashtags like “#takeusback” to address their study regarding issues [4,10]. They want to return to their universities to continue their studies. To the best of our knowledge, there is no study yet to analyze and understand international students’ perceptions and problems during the COVID-19 pandemic using text mining. This paper has addressed and explored students’ sentiments and aspects regarding their financial distress, emotional distress, self-worth, and academic performance distress. The effect of COVID-19 on international students is heterogeneous. This study aims to answer the following research questions.
• How does international students’ perception change due to COVID-19, and what problems do they face in this pandemic?
• Using Natural Language Processing (NLP), how do we mine and explore students’ issues from their given textual feedback on different social media platforms?
To answer the above research questions and uncover international students’ issues and views, NLP and Artificial Intelligence (AI) models are used widely to process textual data [11]. We proposed an ensemble deep learning framework (SABAC) for topic extraction, annotation, and classification. The purpose of SABAC is to annotate a large amount of unlabeled textual data automatically according to the situational aspects. In traditional text mining, most of the data is labeled and balanced, and labeling the unbalanced data according to the situational aspects is a laborious and time-consuming task. Therefore, we proposed three layers based SABAC framework. In the first layer of SABAC, we used an ensemble deep learning-based four different models to analyze international students’ tweets to explore and extract their situational emotions regarding their situation in the COVID-19 pandemic. We proposed and implemented an annotation algorithm in the second layer to annotate the extracted aspect terms as class labels. The third layer of SABAC used annotated tweets, which were annotated from the previous layer for the classification using deep learning algorithms in an ensemble learning manner to classify students’ textual data according to extracted class labels. In addition to the above-mentioned two research questions, we aim to answer the following research questions to examine issues of international students.
• Does our proposed framework improve the aspect extraction process from textual feedback given by international students?
• Does our proposed SABAC framework improve topic classification and annotation process accuracy?
Analyzing the student’s tweets about the uncertainty in their future goals due to the COVID-19 pandemic is necessary to uncover hidden aspects in their feedback. Higher authorities can take essential measures regarding their study plans by analyzing international students’ views. This study will help understand the factors and issues regarding students’ situational information. Our main contributions to this paper are as follows:
• We scrapped and collected Twitter dataset in which international students expressed their situational perceptions and opinion, and we named our dataset Student-COVID-19.
• We have proposed a novel ensemble deep learning-based topic modeling and classification framework named SABAC to mine the accurate and robust aspect terms from the international students’ feedback dataset.
• We also proposed a new ensemble machine learning-based model to perform topic classification and annotate unlabeled Twitter datasets using mined topic terms.
• We proposed and implemented a data filtering technique. We analyzed that using Volatile Stop words Filtering (VSF) improved the performance of machine learning classifiers.
• The results of this study may help international universities and governments to understand the situational aspect and sentiments of international students.
In the next section of this paper, we discussed related works. It is followed by a description of the research methodology, procedures, and data collection in Section 3. Results and discussion are presented in Section 4. Finally, the research conclusion is in Section 5.
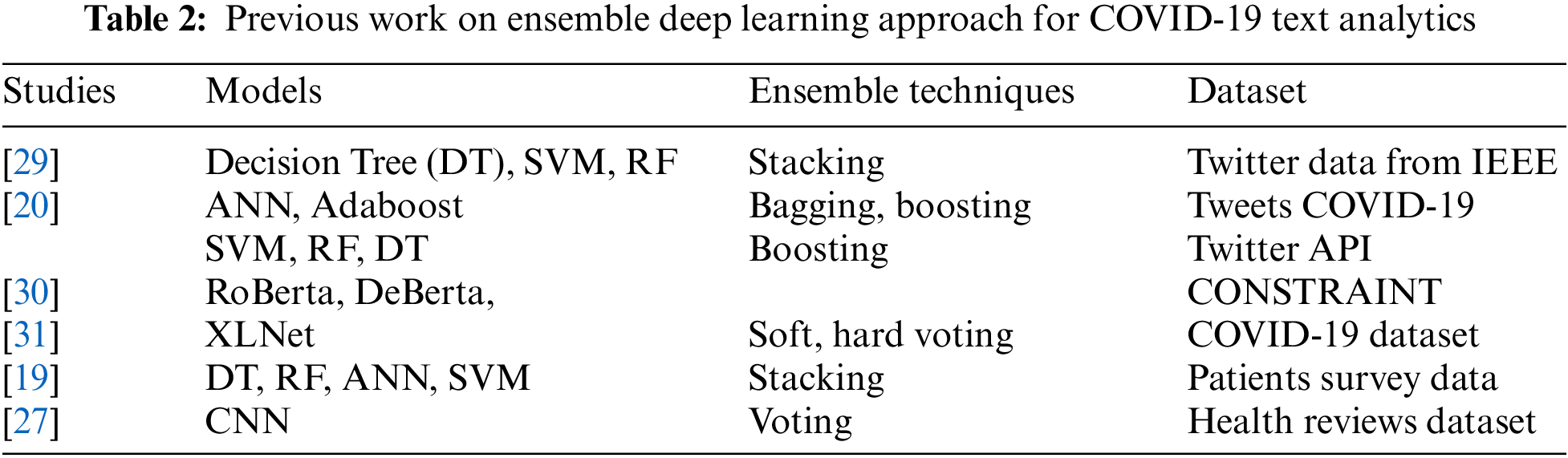
Since the COVID-19 pandemic started, the interest of researchers has diverted to explore and analyze the effect of COVID-19 from many perspectives. China was the first country to force the regional lockdown strategy in Hubei province, especially Wuhan city, for 76 days [12]. Quarantine centers use IoT systems to monitor the suspected individuals and restrict them from interactions [13]. According to [14], the absence of these social connections leads to depression, anxiety, extreme mental stress, and many other aspects of life. In contrast to mental health, the authors [15] surveyed Liaoning Province, mainland China, to assess the influence of COVID-19 on people’s mental health. According to their findings, 52.1% of the 263 participants were terrified and worried due to the epidemic. However, 53.3% of those polled did not feel helpless due to the pandemic. Nowadays, deep learning is being used in various domains of life to improve performance, including face emotion recognition [16], comparative analysis of social communication apps [17], to evaluate the business insides [18], and many more. In this study, we reviewed previous work on text classification using ensemble deep learning techniques Table 1.
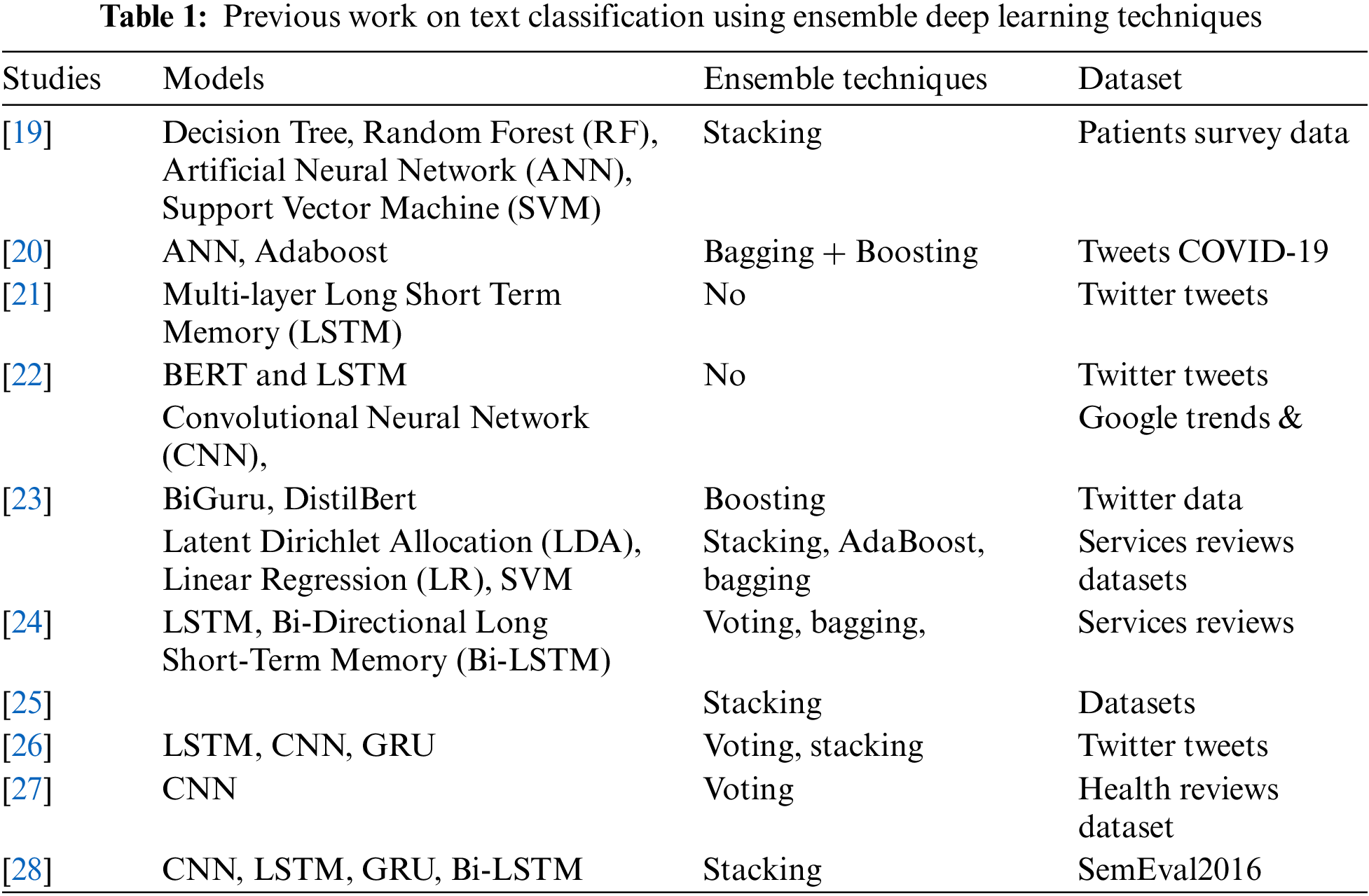
The authors [3,32] used machine learning and natural language processing techniques to analyze the 840000 tweets. Their sentiment results showed that the death and lockdown due to the COVID-19 are the aspects that mainly caused stress, anxiety, and Trauma among Indian citizens. COVID-19 increased depression, anxiety, and stress levels in individual life. Their results showed that the lockdown in the country increased depression in individuals. To understand the sentiment of an individual through social media posts, the authors of [33] used an adaptive model for automatic hate speech identification that is ensemble learning-based, enhancing cross-dataset generalization. Base learners in ensemble learning are reliant on the outcomes of base learners in the past. Furthermore, we reported previous ensemble studies and their implementation for text classification using machine learning, as shown in Table 2. As COVID-19 was declared a pandemic by WHO, people started sharing their opinion about mental stress and anxiety due to COVID-19 on Twitter [34]. Meanwhile, to analyze the students’ mental health and behavior toward COVID-19, the authors [35] surveyed 1182 students of different age groups. Their findings revealed that students used various social media platforms and other coping techniques to minimize worry and mental stress and obtained aid from their friends and family. Due to COVID-19, universities led to online classes, and students were asked to leave dorms; hence, students faced mental health issues. To examine the students’ mental health and evaluate their online academic performance, the study [36] conducted a general health Questionnaire-based survey among 1123 participants. The results of their experiments were considered significant at a p-value set of 0.05. 76.96% of the participants manifested psycho-pathological symptoms measured by this survey. To address and predict international students’ satisfaction, the researchers [37] gathered survey data from 425 students from different departments in Hong Kong. They performed different machine learning algorithms like regression and random forest; however, they achieved the highest accuracy using elastic net regression, and 65.2% explained variance. Their findings reported that it is critical to rule out the underlying reasons why students from different programs prefer face-to-face learning.
This section has discussed significant components of the manuscript, including dataset collection, pre-processing, feature extraction using several NLP techniques, and statistical analysis. The current study consists of two parts: In the first part, we performed aspect extraction using an ensemble learning approach to explore students’ situational perceptions or aspect terms from the Tweets. The proposed Emergency Situational Awareness (ESA) model is a fusion of different deep learning and machine learning models to improve Situational Understanding (SU), as shown in Fig. 1. We further divided our approach into three layers; in the first layer, we used different deep learning models as weak learners (weak classifiers) for Aspect Extraction (AE) from textual data using the ensemble learning approach. After extracting situational aspects from the dataset, we performed annotation of each tweet according to its extracted aspect term using aspect2class Algorithm 1 in the second layer of the proposed SABAC framework. The third layer includes training of deep learning weak classifiers using annotated Tweets according to aspect terms as class labels to perform classification. In this manner, our proposed model is different from other existing solutions, and the results of deep weak classifiers are passed to machine learning-based meta-classifiers as the proposed ensemble technique for the final prediction of class labels on the test dataset.

Figure 1: Ensemble learning framework for situational awareness
All experiments in this paper are conducted on Intel(R) Celeron(R) CPU N3150 @ 1.60 GHz. The operating system is Windows 64-bit, Python 3.6.6, TensorFlow deep Learning framework 1.8.0, and CUDA 10.1.
3.1 Data Collection and Pre-processing
The dataset used for this study is obtained from Twitter. The Twitter dataset was collected using Twitter API from March 2020 to December 2021, and we extracted 13.4k tweets using diffident hashtags represented by trends of international students. We named our collected Twitter dataset Student-COVID-19. The process of collecting data is shown in Fig. 2.

Figure 2: Student-COVID-19 dataset collection
We analyzed different studies [38,39] in this domain and also analyzed various tweets by international students on Twitter and collected “back to school”, “open border”, “online education”, “stress”, and “uncertainty” hashtags based on the previous studies and trends of international students tweets [4,5,6]. The combination of these hashtags only posed by the international students who were suffering from mental stress and no study outcome due to online education and requesting for the border opening to go back to school for physical classes, and these hashtags were also considered of the scope by previous studies as well [38,39]. We also performed experiments on our collected and previous benchmark datasets to evaluate the proposed ensemble deep learning framework (SABAC). A detailed description of the benchmark and our collected datasets is shown in Table 3.

Data pre-processing involves many techniques to make data consistent to perform the experiments. We removed @ symbol, which represents the user’s name, RT used for retweets, and the hashtag symbol. We replaced slang words with actual words using n-gram according to the procedure defined by [42]. For the second and third datasets, we performed traditional data pre-processing, in which we performed the following techniques to remove the noise from the data.
• We performed basic pre-processing techniques to clean the data by removing unnecessary and irrelevant information and text, i.e., from these hashtags #takeusback, and #openborders, we removed # symbols.
• We observed that students use many words in combination to create hashtags, such as “takeusback”, but these words need to be separate for processing take us back. We performed segmentation to void such kinds of issues.
• Stopword removal is also a prevalent method to remove noisy data from the text without affecting the sentence’s meaning. We also removed Stopwords from the data in the aspect extraction module.
• Next, we used the lemmatization technique to preserve morphological aspects of words by converting them into their basic form. We performed this task by using the “nltk” library in python.
• We also removed punctuation, numbers, hyphens, and special symbols from raw text to make data consistent and noise-free.
• To capture and preserve syntactic features from the texts, we performed Part of Speech (POS) tagging to denote each word, i.e., noun, verb, adjective, and adverb.
We used the Volatile Stopwords Filtering (VSF) technique to reduce the sparsity problem. The VSF list is generated from the current dataset and is not pre-defined. According to our data’s vocabulary analysis, 79% of the terms appeared less than five times in the corpus. Exploring these terms revealed that almost all words with a frequency of fewer than five are less significant, so we excluded all these terms from the feature space. Using the VSF technique improved the accuracy of the classification process.
In the traditional machine learning classification process, a single classifier is trained on training data at one time [43]. Usually, every classifier produces a different result in accuracy on the same training dataset. It is more complex to determine which classifier could attain adequate accuracy on a particular training dataset if we use multiple classifiers [44] as a base or weak classifier to obtain optimal results. In the ensemble machine learning approach, meta-classifiers produce an optimal generalized output by aggregating the results of weak classifiers [45]. The workflow of our proposed situational awareness ensemble deep learning topic modeling for aspect classification is shown in Fig. 3. To ensemble the weak learner’s predictions, there are three commonly applicable techniques, bagging, boosting, and stacking. This paper uses a stacking ensemble deep learning approach for topic modeling and aspect classification. The reason for not choosing the bagging and boosting is that it works only with weak homogeneous learners, leading to more bias in models and being computationally expensive. However, we implemented heterogeneous weak classifiers and performed training parallelly using the stacking approach. We parallelly trained multiple deep learning models in our stacked ensemble approach and combined weak learners’ output. The output of the weak learners is finally used as input for the meta-classifier for the final prediction. We have used Naive Bayes (NB), Logistic Regression (LR), and Support Vector Machines (SVM) as meta-classifiers for the final prediction.

Figure 3: Aspect extraction using ensemble learning framework for situational awareness
3.3 Aspect Extraction as Ensemble Learning
To extract the best and most accurate topic terms as aspect terms from the tweets, we first need to constitute the topic models as baseline classifiers used for topic modeling. We used the first baseline model, Latent Dirichlet allocation (LDA) [34], and a generative probabilistic corpus model, which can identify and describe latent thematic structures within collections of text documents. LDA inputs our document-term matrix and generates an output yielding an NXN topic matrix, in which N is the number of topics assigned to six topics. The LDA algorithm [46] attempts to build a complete representation of the corpus by inferring latent content variables known as topics. For instance, a given corpus D consisting of M documents, with document d having Nd words
• Select a multinomial distribution
• From a Dirichlet distribution with parameter
• Choose a topic
The probability of observed data D of a corpus is computed and acquired as shown in Eq. (1).
In Eq. (1),
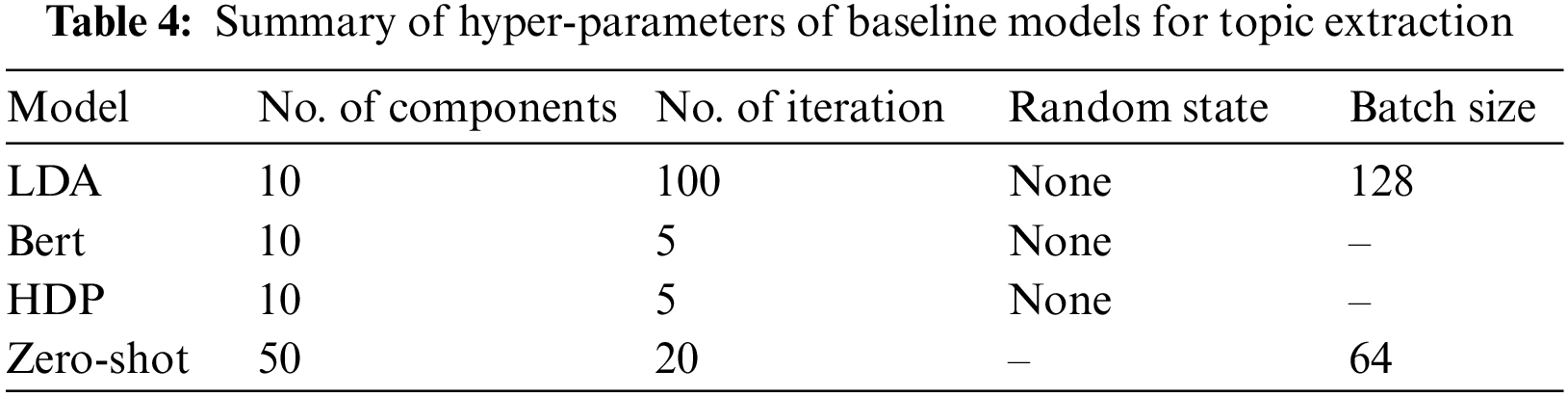

The second baseline model used for topic modeling is the Hierarchical Dirichlet Process (HDP), which uses a Dirichlet process for each data group, with the Dirichlet processes for all groups sharing a base distribution drawn from a Dirichlet process [48]. We used a hierarchical Dirichlet process from the gensim library. We used cosine similarity to compute the feature vector’s similarity, as shown in Eq. (2).
In Eq. (2), A and B are the feature vector, n is each feature vector’s size, and i is the index of each feature value in the feature vector. We also adjust the hyper-parameters of the HDP model according to our dataset, as shown in Table 4. The experimental results in extracted topics, their relevant terms, and coherence score are shown in Table 8. The third technique used for topic extraction is the Zero-Shot Learning transfer learning approach [49]. We have also adjusted hyper-parameters of Zero-Shot Learning according to our dataset, as shown in Table 4. The experimental results in extracted topics, their relevant terms, and coherence score are shown in Table 9. Last but not least Bidirectional Encoder Representations from Transformers (BERT) is used as a base learner for topic extraction. BERT uses a transformer, an attention mechanism that learns contextual relations between words (or sub-words) in a text. We also adjust the hyper-parameters of BERT according to our dataset, as shown in Table 4. The experimental results in extracted topics, their relevant terms, and coherence score are shown in Table 6. Algorithm 1 shows the formal procedure of aspect terms annotation on the unlabeled dataset. The output of the first layer is used as input for the second layer. We extracted six topics and their related terms {ti1, ti2, ti3…tn} by using different deep learning models. As a result of each topic term, we mapped each aspect term with a related tweet and assigned where the relevant terms and associated synonyms matched.
3.4 Text Classification as Ensemble Learning
The classification process used as an ensemble approach is illustrated in Fig. 4. We construct a set of deep baseline models based on several architectures of networks for each benchmark dataset. The first weak classifier used for extracted aspect classification is the Convolutional Neural Network Model (CNN) [50], which stimulates biological neurons. In recent years it has been widely used for NLP tasks. We adjust the hyper-parameters of CNN according to our classification task, as shown in Table 5. The confusion matrix’s experimental results are shown in Fig. 6, which shows the classification values. Fig. 6a reported the highest classification accuracy by accurately classifying the text into topic 2. The second model for classification as base learner Long Short-Term Memory (LSTM) is a three-gated neural network. We also adjust hyper-parameters of LSTM according to our classification task for six topics, as shown in Table 5. The experimental results in terms of the confusion matrix as shown in Fig. 6b. The third base learner for classification is Bi-Directional Long Short-Term Memory (Bi-LSTM). Its bi-directional approach increases efficiency and effectively results in text classification as forward and preceding text [51]. However, in bi-directional, we can flow the input in both directions to preserve future and past information. We also adjust the hyper-parameters of Bi-LSTM according to our classification task for six topics, as shown in Table 6 and the confusion matrix in Fig. 6c. The fourth weak learner used for classification tasks is the Robustly Optimized BERT pre-trained approach (RoBERTa); BERT’s extension changes the pre-training procedure. The base version of the model has 12 layers and 110M parameters. We also adjust hyper-parameters of Bi-LSTM according to our classification task for six topics, as shown in Table 5. The experimental results in the confusion matrix as shown in Fig. 6d, show the classification values for all six topics using the RoBERTa on our Twitter tweet datasets.

Figure 4: Aspect terms classification using ensemble learning framework for situational awareness


This study focuses on a novel Situational Aspect-Based Annotation and Classification (SABAC) framework to uncover international students’ situational aspects. As discussed in the methodology section, our proposed framework consists of three layers. The dataset used for this study was collected from Twitter using diffident hashtags represented by trends on Twitter from international students.
In the first layer, we used four deep learning models, such as LDA, BERT, HDP, and Zero-Shot Learning, as base learner (weak classifiers) models in the ensemble technique to mine accurate aspect terms from the Twitter dataset. The experimental results in extracted topics with their relevant terms and coherence score are shown in Tables 6–9.



Assessing the results shown in Tables 6–9, we can conclude that on the Student-COVID-19 dataset, the SABAC provides better results and coherent topics by selecting six topics and five relevant terms. Our topic modeling techniques’ performance according to each extracted topic is reported using a word cloud. In addition, the words that dominate the word cloud are most likely directly related to the topic term of the word cloud, as we can see in Fig. 5a reporting Topic-0, which talks about the “returning to school” of international students.

Figure 5: Word cloud representation of each extracted topic
There are some dominant words in Fig. 5a that represent the topic of returning to school, such as “school” “open” “back” and “border” these words illustrate the issue of international students about their returning to school for physical classes.
Similarly, Figs. 5b, 5c, 5d and 5f represents Topic-1, Topic-2, Topic-3, Topic-4, and Topic-5, which show Financial Stress, Health, Online Education, Stress, and uncertainty, respectively. In contrast, the word cloud for each topic (Topic-1 to Topic5) contains dominant words representing each topic’s authenticity and relevant term score for each topic term. The topic extraction and relevant terms extraction results are shown below using Bert-Topic Library. For the topic extraction and modeling, we used different deep-learning approaches. The complete list of models and their parameters used in this study is shown in Table 4. Similarly, we used other deep learning models to evaluate the topic modeling results. The complete list of models and their architecture summary is shown in Table 5. The coherence score is for accessing the quality of learned topics through different models. We used a coherence score as it is essential to find the optimal number of topics because these topics will ultimately convert into labels for annotating the dataset. As shown in Eq. (3), for one topic, the words i, j is scored in
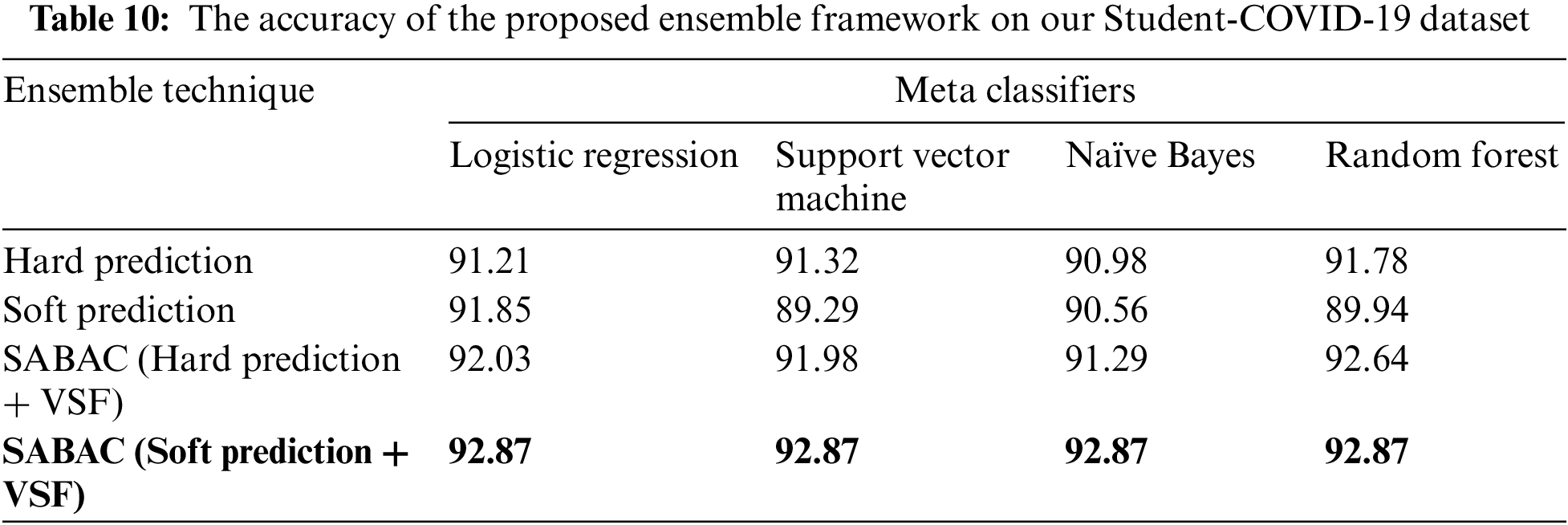
Moreover, the extracted topics have also demonstrated the situation of international students, such as mental stress or fear in the students whose degree is delayed due to lab work. Hence Table 8 also represents these terms as relevant terms, similar to Table 6, demonstrating the fear and being stuck. These terms also represent the international student’s situation as they are stuck in their rooms and home countries. Hence it represents fear of being late for graduation and unemployment. To better understand the extracted terms from the tweets, we also represent the co-occurrence of words within sentences, as shown in Fig. 7. We can conclude that our proposed SABAC model accurately extracts the situational aspects of international students to uncover their issues during the pandemic. The second layer of the proposed SABAC framework used Algorithm 1 to annotate a more significant number of unlabeled tweets into six mined aspect terms. Our proposed framework used the aspect2class algorithm and text similarity matrix to annotate unlabeled tweets into six mined aspect terms. In the third layer of the proposed framework, we used ensemble learning techniques to classify unlabeled Twitter tweets into six mined aspect terms. Using the ensemble technique, we used CNN, LSTM, Bi-LSTM, and RoBERTa models as base-learner classifiers in the third layer to classify our Twitter dataset into six mined aspect terms. The results of the base-learner classifier in the form of precision, recall, and f1-support are shown in Table 11. We used four different ensemble learning techniques in this classification layer of the proposed SABAC. These ensemble techniques include soft prediction, hard prediction, SABAC (soft prediction + VSF), and SABAC (Hard prediction + VSF). Moreover, we used logistic regression, support vector machine, naive Bayes, and random forest machine learning models as meta-classifiers in Layer-1 to evaluate the final prediction for aspect classification. The results of meta-classifiers’ using different ensemble techniques are shown in Table 10. We plotted the confusion matrix to depict our four meta-classifiers’ performances on the test dataset shown in Fig. 6.

Figure 6: Confusion matrix for each aspect topic using meta-classifiers (a) LR, (b) NB, (c) RF, (d) SVM

Figure 7: Co-occurrences within sentences and words following one another
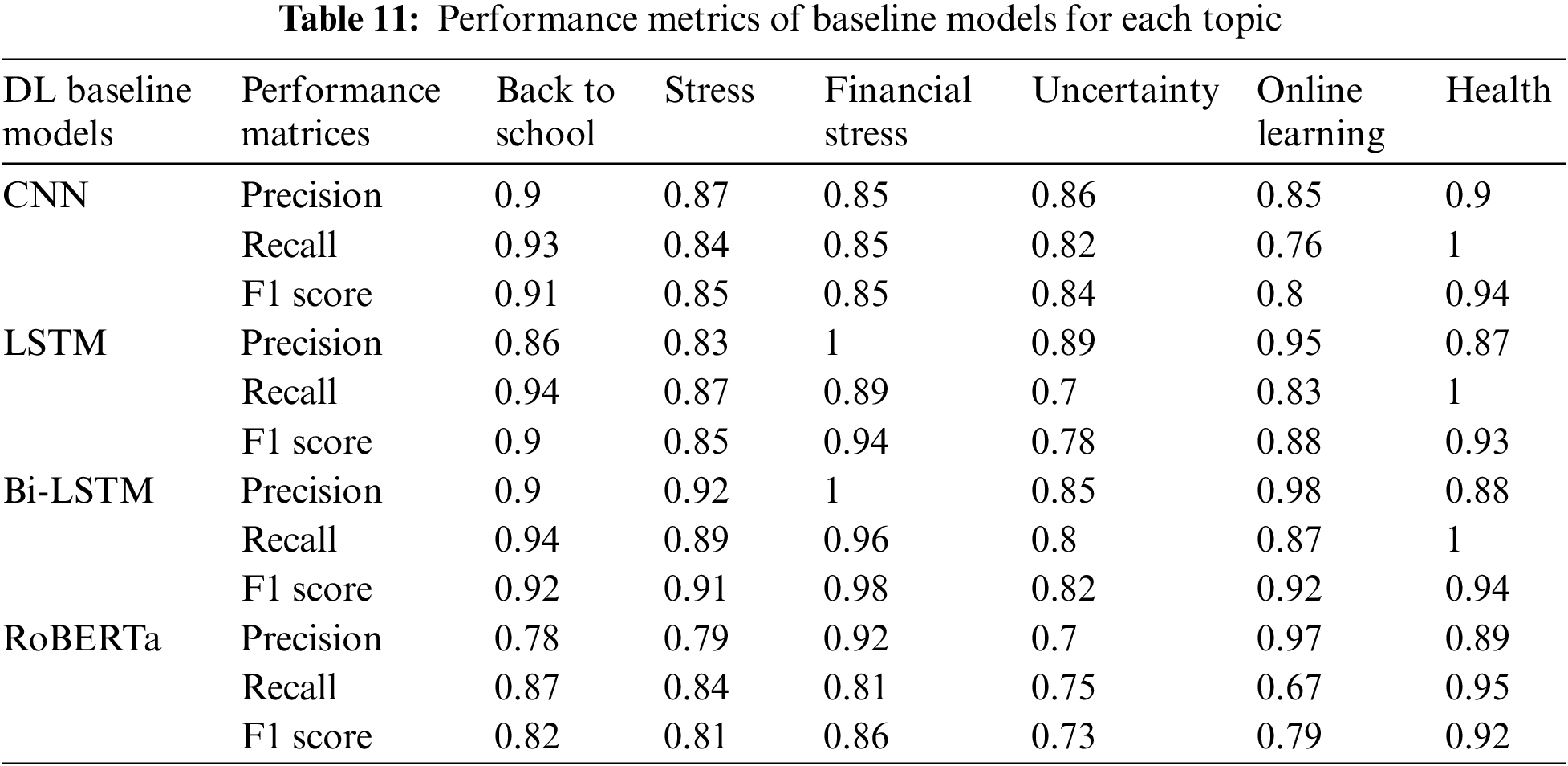
Finally, to evaluate the performance of baseline models and the ensemble approach for each topic, we used different performance metrics such as precision, recall, and F1 score. The comparative values of performance metrics for each topic are shown in Table 11. We conducted several experiments on the previous benchmark datasets to validate our proposed model in the text classification task and compared the ensemble’s performance to the best individual baseline models. According to the Pareto principle, we divided each benchmark dataset into training and validation test sets with a ratio of 80% and 20%. The comparative result of an ensemble model on different benchmark datasets is shown in Table 12.
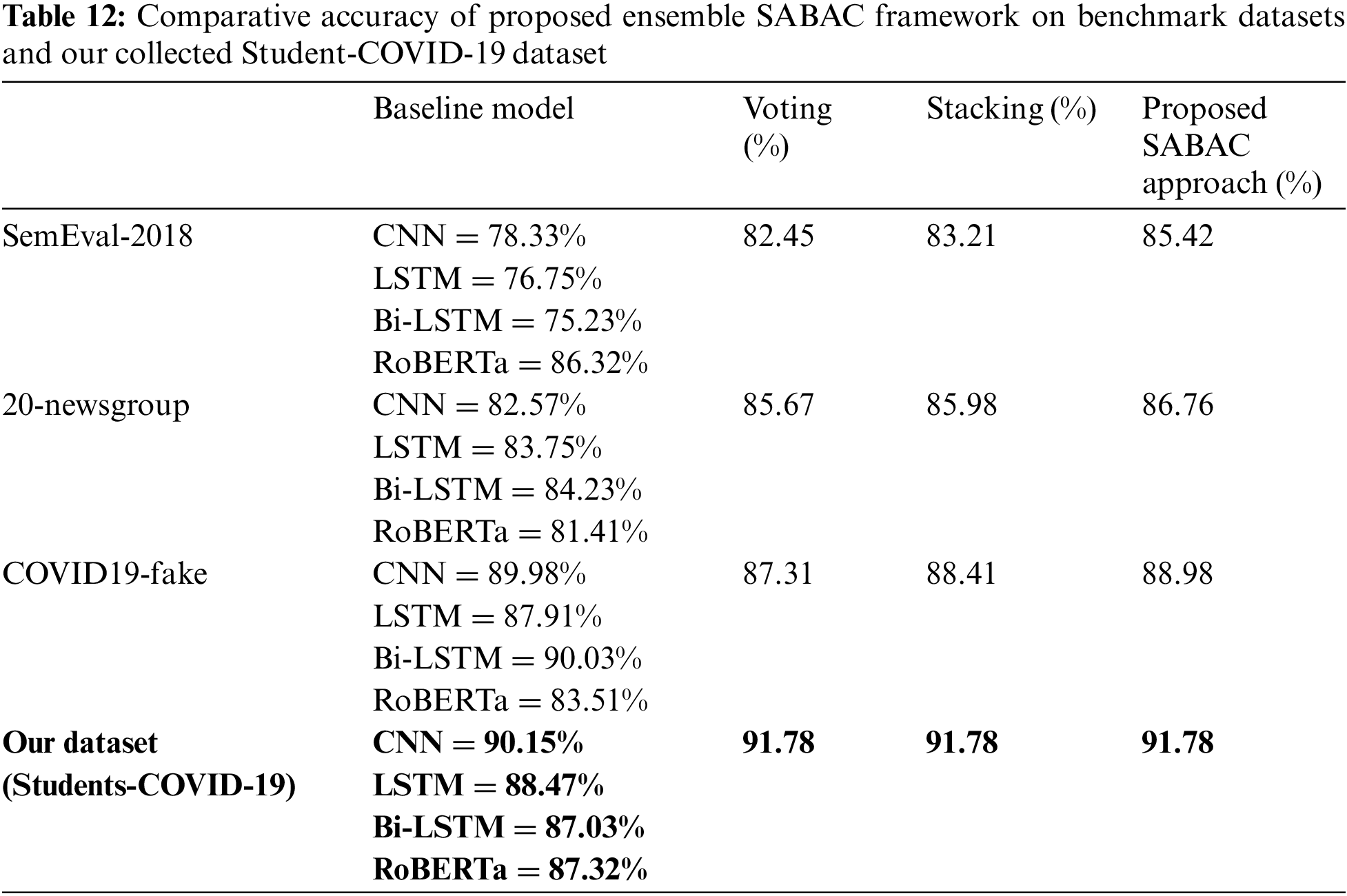
The proposed ensemble SABAC approach results on the previous benchmark datasets and our Students-COVID-19 dataset are demonstrated in Table 12, improving accuracy. Compared to the baseline models, the ensemble approaches improved the class prediction accuracy. Using the voting ensemble technique for final prediction, we achieved 82.45% accuracy on the SemEval-2018 dataset, 85.65% on the 20-newsgroup, 87.31% on the COVID19-Fake, and 91.31% on our collected Student-COVID dataset. Furthermore, using the stacking approach for final prediction, we achieved 83.21% accuracy on the SemEval-2018 dataset, 85.98% on the 20-newsgroup, 88.41% on the COVID19-Fake dataset, and 92.47 on our collected Student-COVID dataset. Likewise, we achieved the best results using the proposed SABAC approach in which we used ML models as meta-classifiers for final prediction, and we achieved 85.52% accuracy on the SemEval-2018 dataset, 86.76% accuracy on the 20-newsgroup, 88.98% accuracy on the COVID19-Fake dataset, and 93.21% on our collected Student-COVID-19 dataset. Moreover, Fig. 8 demonstrates the comparative results of used ensemble techniques on different datasets. The results reveal that the proposed SABAC framework is an improved approach that can perform robust topic extraction, annotation, and classification tasks. Finally, we compared the performance of our proposed approach with previous studies using ensemble techniques, as shown in Table 13.

Figure 8: The comparative performance evaluation of different ensemble techniques on three benchmarks and our (Student-COVID) datasets

In this study, we proposed an improved text mining approach named SABAC to uncover the situational topic terms from the international students’ tweets. Our findings show that international students face uncertainty, health, financial stress, job stress, online classes stress, and returning to school-related issues. To uncover these findings, an ensemble deep learning framework is proposed and implemented in this paper. Using our proposed framework, we have performed topic modeling to extract aspect terms and performed annotation on unlabeled tweets. After labeling the unlabeled dataset, we performed classification using deep learning models using ensemble stacking and boosting techniques. We achieved 89.94% accuracy on our proposed baseline soft prediction, and performance has been enhanced using Volatile Stopwords Filtering (VSF) method. We gained promising results using our proposed SABAC + VSF technique. We achieved 93.21% accuracy on our proposed model and compared our results with the latest reported work in the text mining domain. The study concluded that our proposed SABAC framework would help the authorities appropriately understand international students’ situational aspects and take the necessary steps for students in the COVID-19 pandemic. In future work, we will like to improve the accuracy of SABAC by handling high dimensional feature space on textual datasets transfer-learning techniques.
Funding Statement:: This research work is supported by the National Natural Science Foundation of China [Grant Number: 92067106] and the Ministry of Education of the People’s Republic of China [Grant Number: E-GCCRC20200309].
Conflicts of Interest: The authors declare they have no conflicts of interest to report regarding the present study.
References
1. B. Kheovichai and A. R. Network, “Collocation and discursive construction of COVID-19 in WHO director general’s discourse: A corpus-based study,” LEARN Journal, vol. 15, no. 1, pp. 10–32, 2022. [Google Scholar]
2. S. Hussain, Y. Yu, M. Ayoub, A. Khan, R. Rehman et al., “IoT and deep learning based approach for rapid screening and face mask detection for infection spread control of COVID-19,” Applied Sciences, vol. 11, no. 8, pp. 3495, 2021. [Google Scholar]
3. S. Praveen, R. Ittamalla and G. Deepak, “Analyzing Indian general public’s perspective on anxiety, stress and trauma during COVID-19-a machine learning study of 840,000 tweets,” Diabetes & Metabolic Syndrome: Clinical Research & Reviews, vol. 15, no. 3, pp. 667–671, 2021. [Google Scholar]
4. H. Ma and C. J. H. C. Miller, “Trapped in a double bind: Chinese overseas student anxiety during the COVID-19 pandemic,” Health Communication, vol. 36, no. 13, pp. 1598–1605, 2021. [Google Scholar] [PubMed]
5. D. Firang, “The impact of COVID-19 pandemic on international students in Canada,” International Social Work, vol. 63, no. 6, pp. 820–824, 2020. [Google Scholar]
6. M. A. Islam, S. D. Barna, H. Raihan, M. N. A. Khan and M. T. J. P. O. Hossain, “Depression and anxiety among university students during the COVID-19 pandemic in Bangladesh: A web-based cross-sectional survey,” PLoS One, vol. 15, no. 8, pp. e0238162, 2020. [Google Scholar] [PubMed]
7. R. Choudaha, “Three waves of international student mobility (1999–2020),” Studies in Higher Education, vol. 42, no. 5, pp. 825–832, 2017. [Google Scholar]
8. E. M. Aucejo, J. French, M. P. U. Araya and B. J. J. O. P. E. Zafar, “The impact of COVID-19 on student experiences and expectations: Evidence from a survey,” Journal of Public Economics, vol. 191, no. 3, pp. 104271, 2020. [Google Scholar] [PubMed]
9. T. Kaya, “The changes in the effects of social media use of Cypriots due to COVID-19 pandemic,” Technology in Society, vol. 63, no. 4, pp. 101380, 2020. [Google Scholar] [PubMed]
10. A. K. Yadav, “Impact of online teaching on students’ education and health in India during the pandemic of COVID-19,” Ingenta, vol. 2, no. 4, pp. 516–520, 2021. [Google Scholar]
11. J. A. Wahid, S. Hussain, H. Wang, Z. Wu, L. Shi et al., “Aspect oriented sentiment classification of COVID-19 twitter data; an enhanced LDA based text analytic approach,” in 2021 Int. Conf. on Computer Engineering and Artificial Intelligence (ICCEAI), Shanghai, China, IEEE, pp. 271–275, 2021. [Google Scholar]
12. T. Zhou, T. -V. T. Nguyen, J. Zhong and J. Liu, “A COVID-19 descriptive study of life after lockdown in Wuhan, China,” Royal Society of Open Science, vol. 7, no. 9, pp. 200705, 2020. [Google Scholar]
13. Y. Yu, X. Qin, S. Hussain, W. Hou and T. Weis, “Pedestrian counting based on piezoelectric vibration sensor,” Applied Sciences, vol. 12, no. 4, pp. 1920, 2022. [Google Scholar]
14. J. Singh and S. Singh, “COVID-19 and its impact on society,” Electronic Research Journal of Social Sciences and Humanities, vol. 2, no. 1, pp. 168–172, 2020. [Google Scholar]
15. Y. Zhang and Z. F. Ma, “Impact of the COVID-19 pandemic on mental health and quality of life among local residents in Liaoning Province, China: A cross-sectional study,” International Journal of Environmental Research and Public Health, vol. 17, no. 7, pp. 2381, 2020. [Google Scholar] [PubMed]
16. N. Bukhari, S. Hussain, M. Ayoub, Y. Yu, A. Khan et al., “Deep learning based framework for emotion recognition using facial expression,” Pakistan Journal of Engineering and Technology, vol. 5, no. 3, pp. 51–57, 2022. [Google Scholar]
17. L. Irfan, S. Hussain, M. Ayoub, Y. Yu, A. Khan et al., “A comparative analysis of social communication applications using aspect based sentiment analysis,” Pakistan Journal of Engineering and Technology, vol. 5, no. 3, pp. 44–50, 2022. [Google Scholar]
18. A. Sahar, M. Ayoub, S. Hussain, Y. Yu, A. Khan et al., “Transfer learning-based framework for sentiment classification of cosmetics products reviews,” Pakistan Journal of Engineering and Technology, vol. 5, no. 3, pp. 38–43, 2022. [Google Scholar]
19. A. Gupta, V. Jain and A. J. N. G. C. Singh, “Stacking ensemble-based intelligent machine learning model for predicting post-COVID-19 complications,” New Generation Computing, vol. 40, no. 1, pp. 1–21, 2021. [Google Scholar]
20. P. Vaishali and P. Kumari, “Ensemble learning baThe impact of policymeasures on human mobilitysed classifier to predict depression caused due to pandemic,” Journal of Physics: Conference Series, IOP Publishing, vol. 2089, no. 1, pp. 012026, 2021. [Google Scholar]
21. A. S. Imran, S. M. Daudpota, Z. Kastrati and R. J. I. A. Batra, “Cross-cultural polarity and emotion detection using sentiment analysis and deep learning on COVID-19 related tweets,” IEEE Access, vol. 8, pp. 181074–181090, 2020. [Google Scholar] [PubMed]
22. N. Chintalapudi, G. Battineni and F. J. I. D. R. Amenta, “Sentimental analysis of COVID-19 tweets using deep learning models,” Infectious Disease Reports, vol. 13, no. 2, pp. 329–339, 2021. [Google Scholar] [PubMed]
23. M. E. Basiri, S. Nemati, M. Abdar, S. Asadi and U. R. J. K. -B. S. Acharrya, “A novel fusion-based deep learning model for sentiment analysis of COVID-19 tweets,” Knowledge-Based Systems, vol. 228, no. 2020, pp. 107242, 2021. [Google Scholar] [PubMed]
24. A. Onan, S. Korukoğlu and H. J. E. S. W. A. Bulut, “A multiobjective weighted voting ensemble classifier based on differential evolution algorithm for text sentiment classification,” Expert Systems with Applications, vol. 62, no. 21, pp. 1–16, 2016. [Google Scholar]
25. I. E. Livieris, L. Iliadis and P. J. E. S. Pintelas, “On ensemble techniques of weight-constrained neural networks,” Evolving Systems, vol. 12, no. 1, pp. 155–167, 2021. [Google Scholar]
26. M. S. Akhtar, D. Ghosal, A. Ekbal, P. Bhattacharyya and S. J. A. P. A. Kurohashi, “A multi-task ensemble framework for emotion, sentiment and intensity prediction,” arXiv preprint arXiv:1808.01216, 2018. [Google Scholar]
27. L. Akhtyamova, A. Ignatov and J. Cardiff, “A large-scale CNN ensemble for medication safety analysis,” in Int. Conf. on Applications of Natural Language to Information Systems, Saarbrücken, Germany, Springer, pp. 247–253, 2017. [Google Scholar]
28. S. Mohammad, F. Bravo-Marquez, M. Salameh and S. Kiritchenko, “Semeval-2018 task 1: Affect in tweets,” in Proc. of the 12th Int. Workshop on Semantic Evaluation, New Orleans, United States, pp. 1–17, 2018. [Google Scholar]
29. V. Kandasamy, P. Trojovský, F. A. Machot, K. Kyamakya, N. Bacanin et al., “Sentimental analysis of COVID-19 related messages in social networks by involving an N-gram stacked autoencoder integrated in an ensemble learning scheme,” Sensors, vol. 21, no. 22, pp. 7582, 2021. [Google Scholar] [PubMed]
30. M. Ra, B. Ab and S. J. G. O. R. Kc, “COVID-19 outbreak: Tweet based analysis and visualization towards the influence of coronavirus in the world,” Gedrag. Organ, vol. 33, pp. 8–9, 2020. [Google Scholar]
31. S. D. Das, A. Basak and S. Dutta, “A heuristic-driven ensemble framework for COVID-19 fake news detection,” in Int. Workshop on Combating Online Hostile Posts in Regional Languages During Emergency Situation, Dublin, Ireland, Springer, pp. 164–176, 2021. [Google Scholar]
32. S. Hussain, M. Ayoub, G. Jilani, Y. Yu, A. Khan et al., “Aspect2Labels: A novelistic decision support system for higher educational institutions by using multi-layer topic modelling approach,” Expert Systems with Applications, vol. 209, no. 1, pp. 118119, 2022. [Google Scholar]
33. S. Agarwal and C. R. Chowdary, “Combating hate speech using an adaptive ensemble learning model with a case study on COVID-19,” Expert Systems with Applications, vol. 185, pp. 115632, 2021. [Google Scholar] [PubMed]
34. J. A. Wahid, L. Shi, Y. Gao, B. Yang, L. Wei et al., “Topic2Labels: A framework to annotate and classify the social media data through LDA topics and deep learning models for crisis response,” Expert Systems with Applications, vol. 195, no. 1, pp. 116562, 2022. [Google Scholar]
35. K. Chaturvedi, D. K. Vishwakarma, N. J. C. Singh and Y. S. Review, “COVID-19 and its impact on education, social life and mental health of students: A survey,” Children and Youth Services Review, vol. 121, pp. 105866, 2021. [Google Scholar] [PubMed]
36. Y. Li, M. Li, M. Rice, H. Zhang, D. Sha et al., “The impact of policy measures on human mobility, COVID-19 cases, and mortality in the US: A spatiotemporal perspective,” Children and Youth Services Review, vol. 18, no. 3, pp. 996, 2021. [Google Scholar]
37. C. Hou, J. Chen, Y. Zhou, L. Hua, J. Yuan et al., “The effectiveness of quarantine of Wuhan city against the Corona Virus Disease 2019 (COVID-19A well-mixed SEIR model analysis,” Journal of Medical Virology, vol. 92, no. 7, pp. 841–848, 2020. [Google Scholar] [PubMed]
38. K. Kedraka and C. J. E. J. O. E. S. Kaltsidis, “Effects of the COVID-19 pandemic on university pedagogy: Students’ experiences and considerations,” European Journal of Education Studies, vol. 7, no. 8, pp. 17–30, 2020. [Google Scholar]
39. J. Mittelmeier and H. J. A. A. S. Cockayne, “Global depictions of international students in a time of crisis: A thematic analysis of Twitter data during COVID-19,” International Studies in Sociology of Education, vol. 1, no. 1, pp. 1–24, 2022. [Google Scholar]
40. Q. Du, N. Li, W. Liu, D. Sun, S. Yang et al., “A topic recognition method of news text based on word embedding enhancement,” Computational Intelligence and Neuroscience, vol. 2022, no. 7, pp. 1–15, 2022. [Google Scholar]
41. S. Srivastava, R. Raj and S. Saumya, “COVID-19 fake news identification using multi-layer convolutional neural network,” in Advanced Computational Paradigms and Hybrid Intelligent Computing, Singapore: Springer, pp. 149–157, 2022. [Google Scholar]
42. T. Singh and M. J. P. C. S. Kumari, “Role of text pre-processing in Twitter sentiment analysis,” Procedia Computer Science, vol. 89, pp. 549–554, 2016. [Google Scholar]
43. L. K. Shrivastav and S. K. J. A. I. Jha, “A gradient boosting machine learning approach in modeling the impact of temperature and humidity on the transmission rate of COVID-19 in India,” Applied Intelligence, vol. 51, no. 5, pp. 2727–2739, 2021. [Google Scholar] [PubMed]
44. C. Janiesch, P. Zschech and K. J. E. M. Heinrich, “Machine learning and deep learning,” Electronic Markets, vol. 31, no. 3, pp. 685–695, 2021. [Google Scholar]
45. A. Onan, S. Korukoğlu and H. J. E. S. W. A. Bulut, “Ensemble of keyword extraction methods and classifiers in text classification,” Expert Systems with Applications, vol. 57, no. 8, pp. 232–247, 2016. [Google Scholar]
46. H. Jelodar, Y. Wang, C. Yuan, X. Feng, X. Jiang et al., “Latent dirichlet allocation (LDA) and topic modeling: Models, applications, a survey,” Multimedia Tools and Applications, vol. 78, no. 11, pp. 15169–15211, 2019. [Google Scholar]
47. D. Maier, A. Waldherr, P. Miltner, G. Wiedemann, A. Niekler et al., “Applying LDA topic modeling in communication research: Toward a valid and reliable methodology,” Communication Methods and Measures, vol. 12, no. 2–3, pp. 93–118, 2018. [Google Scholar]
48. S. Park, D. Lee, J. Choi, S. Ryu, Y. Kim et al., “Hierarchical Dirichlet process topic modeling for large number of answer types classification in open domain question answering,” in Asia Information Retrieval Symp., Sarawak, Malaysia, Springer, pp. 418–428, 2014. [Google Scholar]
49. T. Long, X. Xu, F. Shen, L. Liu, N. Xie et al., “Zero-shot learning via discriminative representation extraction,” Pattern Recognition Letters, vol. 109, no. 10, pp. 27–34, 2018. [Google Scholar]
50. M. Ayoub, S. Hussain, A. Khan, M. Zahid, J. A. Wahid et al., “A predictive machine learning and deep learning approach on agriculture datasets for new moringa oleifera varieties prediction,” Pakistan Journal of Engineering and Technology, vol. 5, no. 1, pp. 68–77, 2022. [Google Scholar]
51. B. Jang, M. Kim, G. Harerimana, S. -U Kang and J. W. J. A. S. Kim, “Bi-LSTM model to increase accuracy in text classification: Combining Word2vec CNN and attention mechanism,” Applied Sciences, vol. 10, no. 17, pp. 5841, 2020. [Google Scholar]
52. A. Elnagar, O. Einea and R. Al-Debsi, “Automatic text tagging of Arabic news articles using ensemble deep learning models,” in Proc. of the 3rd Int. Conf. on Natural Language and Speech Processing, Trento, Italy, pp. 59–66, 2019. [Google Scholar]
53. M. Kang, J. Ahn and K. J. E. S. W. A. Lee, “Opinion mining using ensemble text hidden Markov models for text classification,” Expert Systems with Applications, vol. 94, no. 6, pp. 218–227, 2018. [Google Scholar]
54. K. Zeng, Z. Pan, Y. Xu and Y. Qu, “An ensemble learning strategy for eligibility criteria text classification for clinical trial recruitment: Algorithm development and validation,” JMIR Medical Informatics, vol. 8, no. 7, pp. e17832, 2020. [Google Scholar] [PubMed]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools