
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Enhanced Coverage Path Planning Strategies for UAV Swarms Based on SADQN Algorithm
1 School of Computer Science and Engineering, Jiangsu University of Science and Technology, Zhenjiang, 212003, China
2 Experimental Centre of Forestry in North China, Chinese Academy of Forestry, Beijing, 102300, China
* Corresponding Authors: Qi Wang. Email: ; Bin Kong. Email:
Computers, Materials & Continua 2025, 84(2), 3013-3027. https://doi.org/10.32604/cmc.2025.064147
Received 06 February 2025; Accepted 06 May 2025; Issue published 03 July 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In the current era of intelligent technologies, comprehensive and precise regional coverage path planning is critical for tasks such as environmental monitoring, emergency rescue, and agricultural plant protection. Owing to their exceptional flexibility and rapid deployment capabilities, unmanned aerial vehicles (UAVs) have emerged as the ideal platforms for accomplishing these tasks. This study proposes a swarm A*-guided Deep Q-Network (SADQN) algorithm to address the coverage path planning (CPP) problem for UAV swarms in complex environments. Firstly, to overcome the dependency of traditional modeling methods on regular terrain environments, this study proposes an improved cellular decomposition method for map discretization. Simultaneously, a distributed UAV swarm system architecture is adopted, which, through the integration of multi-scale maps, addresses the issues of redundant operations and flight conflicts in multi-UAV cooperative coverage. Secondly, the heuristic mechanism of the A* algorithm is combined with full-coverage path planning, and this approach is incorporated at the initial stage of Deep Q-Network (DQN) algorithm training to provide effective guidance in action selection, thereby accelerating convergence. Additionally, a prioritized experience replay mechanism is introduced to further enhance the coverage performance of the algorithm. To evaluate the efficacy of the proposed algorithm, simulation experiments were conducted in several irregular environments and compared with several popular algorithms. Simulation results show that the SADQN algorithm outperforms other methods, achieving performance comparable to that of the baseline prior algorithm, with an average coverage efficiency exceeding 2.6 and fewer turning maneuvers. In addition, the algorithm demonstrates excellent generalization ability, enabling it to adapt to different environments.Keywords
In recent years, due to their efficiency, flexibility, safety, and other advantages, unmanned aerial vehicles (UAVs) have been widely applied in various fields such as surveillance, agriculture, disaster management, and power line inspections [1–5]. These applications require UAV to quickly cover the target area while acquiring environmental information and avoiding obstacles [6]. Therefore, efficient coverage path planning (CPP) is critical to determining the operational efficiency and quality of the UAV. However, in practical applications, a single UAV is limited by its endurance and is suitable only for small-scale tasks [7]. For large-scale missions, UAV swarm are typically used. This paper focuses on the coverage task of the UAV swarm in order to further improve efficiency and reduce time and energy consumption.
Researchers have proposed various methods to address the UAV swarm coverage path planning problem, which can be broadly classified into centralized and distributed approaches. In centralized methods, a central planner allocates tasks based on prior environmental knowledge and mathematical optimization to find the optimal path [8]. However, these methods assume that environmental information is available, which underestimates the complexity of the CPP problem. Distributed methods, on the other hand, enable collaborative decision-making through communication between UAVs and a ground station, avoiding collisions [9], but still face challenges in complex and irregular environments. With the development of artificial intelligence, more and more researchers are applying machine learning to path planning problems, with reinforcement learning (RL) being the most representative approach [10]. However, its research in coverage path planning is still in the early stages [11].
This paper proposes a UAV swarm-based Coverage Path Planning methodology, aiming to ensure complete coverage of the target area while minimizing time and energy consumption, taking into account factors such as no-fly zones, boundary constraints, and flight conflicts. The main contributions of this paper include:
(1) We proffer an enhanced cell decomposition method, discretizing the irregular target area into grids whilst concurrently minimizing the grid-based target area to curtail the task execution time to the greatest extent possible.
(2) We put forward a multi-scale map fusion method, which amalgamates and updates local environment maps perceived by individual UAVs through communication among UAVs, augmenting the observation range of UAVs and further augmenting coverage efficiency.
(3) We present a distributed SADQN algorithm, leveraging the A* algorithm to assist in initial action selection for UAV swarm DQN training, expediting the training process, and employing prioritized experience replay to train neural networks, hastening the convergence of the algorithm.
The remainder of this work is structured as follows. Section 2 furnishes an overview of germane work in the field of multi-UAV coverage path planning. Section 3 introduces the model of UAV swarm coverage tasks and delineates objectives and constraints. Section 4 presents the SADQN algorithm for UAV swarm coverage along with its minutiae. Section 5 showcases the simulation results of the algorithm. Finally, Section 6 concludes the paper and deliberates on future research directions.
At present, a copious amount of research efforts have been dedicated to the coverage path planning problem concerning UAV swarms. This part undertakes a comprehensive survey of pertinent work from both centralized and distributed perspectives.
In [12], a grid decomposition-based coverage method is proposed, which optimizes the allocation of coverage areas for multiple UAVs by constructing a linear programming model. Lu et al. introduced a turning-minimization multi-robot spanning tree coverage algorithm that transforms the problem into one of finding the maximum independent set in a bipartite graph and then employs a greedy strategy to minimize the number of turns in the spanning tree’s circumnavigation coverage path [13]. Maza and Ollero presented a cooperative strategy in which the ground control station divides the target area into multiple non-overlapping, obstacle-free subregions and assigns each subregion to a UAV based on its relative capabilities and initial position [14]. However, since this method initiates task assignments from the center of each subregion, it may result in considerable redundant coverage. Building upon this, Chen et al. proposed a novel path planning method based on a success-history-adaptive differential evolution variant combined with linear population reduction. This approach establishes the relationship between all possible starting points of subregion paths and the overall multi-region path to enhance the efficiency of multi-region coverage tasks [15].
These methods rely on the availability of environmental information, underestimating the complexity of the CPP problem and being applicable only to deterministic scenarios. To augment UAVs’ robustness in complex environments, distributed algorithms can be enlisted. In [16], a coordinated search scheme based on model predictive control and communication constraints was designed to effectively enable UAV swarms to search for both static and dynamic targets in uncertain scenarios. Qiu et al. proposed a novel complete coverage path planning method for mobile robot obstacle avoidance based on bio-inspired neural networks, rolling path planning, and heuristic search approaches [17]. Bine et al. introduced an energy-aware ant colony optimization algorithm that leverages multi-UAV Internet technologies to coordinate and organize UAVs in order to avoid airspace collisions and congestion [18]. Li et al. proposed a DQN-based coverage path planning method that approximates the optimal action values via DQN, while combining a sliding window approach with probabilistic statistics to handle unknown environments. This method optimizes coverage decisions and enhances the adaptability and performance of multi-UAV missions in unknown scenarios [19]. Moreover, in [20], a comprehensive coverage path planning framework was constructed using deep reinforcement learning techniques, which integrates convolutional neural networks with long short-term memory networks. The framework simultaneously maximizes cumulative rewards and optimizes an overall cost weight based on kinetic energy.
Although the above research results have obvious application effects in their respective research fields, there is still significant room for improvement in solving the problem of collaborative coverage path planning for UAV swarms in discrete environments, while simultaneously reducing path repetition rate and energy consumption.
3.1 Enhanced Approximate Cell Decomposition
The coverage task in this study is conducted on a discretized map. However, real-world environments are often irregular, which results in many redundant grids during the discretization process. In irregular terrain environments, to improve task execution efficiency, we have adopted an innovative strategy: rotating the target area to minimize the decomposed grid map, thereby minimizing task execution time.
Fig. 1 illustrates this enhanced approximate cell decomposition method, where black lines represent the boundaries of the irregular target area, red grids represent the area that UAVs need to cover, black blocks represent obstacles in the environment, and gray grids represent no-fly zones. Fig. 1a illustrates the initial situation of cell decomposition in an irregular area. To optimize the terrain redundancy issue, we first identify all vertices
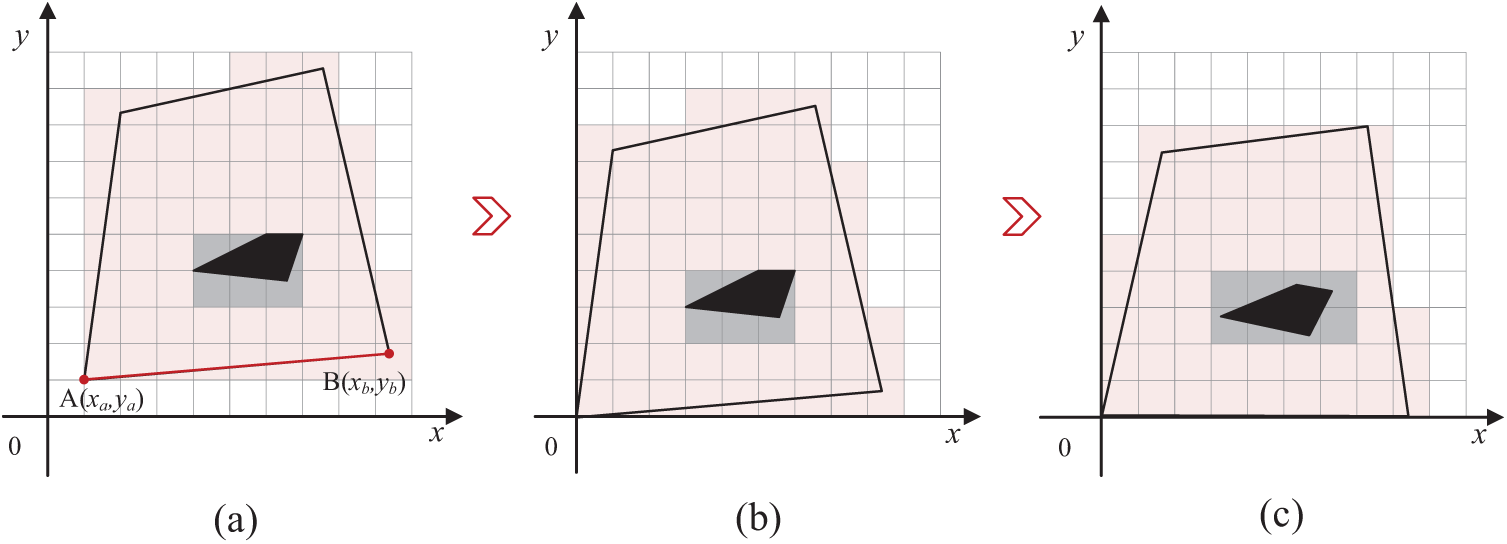
Figure 1: Illustration of enhanced approximate cell decomposition in irregular terrain
UAV swarms often face issues such as trajectory overlap, coverage gaps, and collisions when performing coverage path planning in complex environments with obstacles. To address these challenges, we propose a method for integrating and updating multi-scale maps to achieve close cooperation among UAVs.
Specifically, a UAV swarm system consisting of
In this equation,
Fig. 2 shows the system framework for three UAVs working together on the CPP task. UAVs interact with the environment, choose actions, and receive rewards. Specifically, we use local environmental maps to record the areas covered by each UAV and no-fly zones. At each time step, UAVs exchange local environmental map information with the ground station and update the multi-scale maps, enabling action decisions based on global observations.
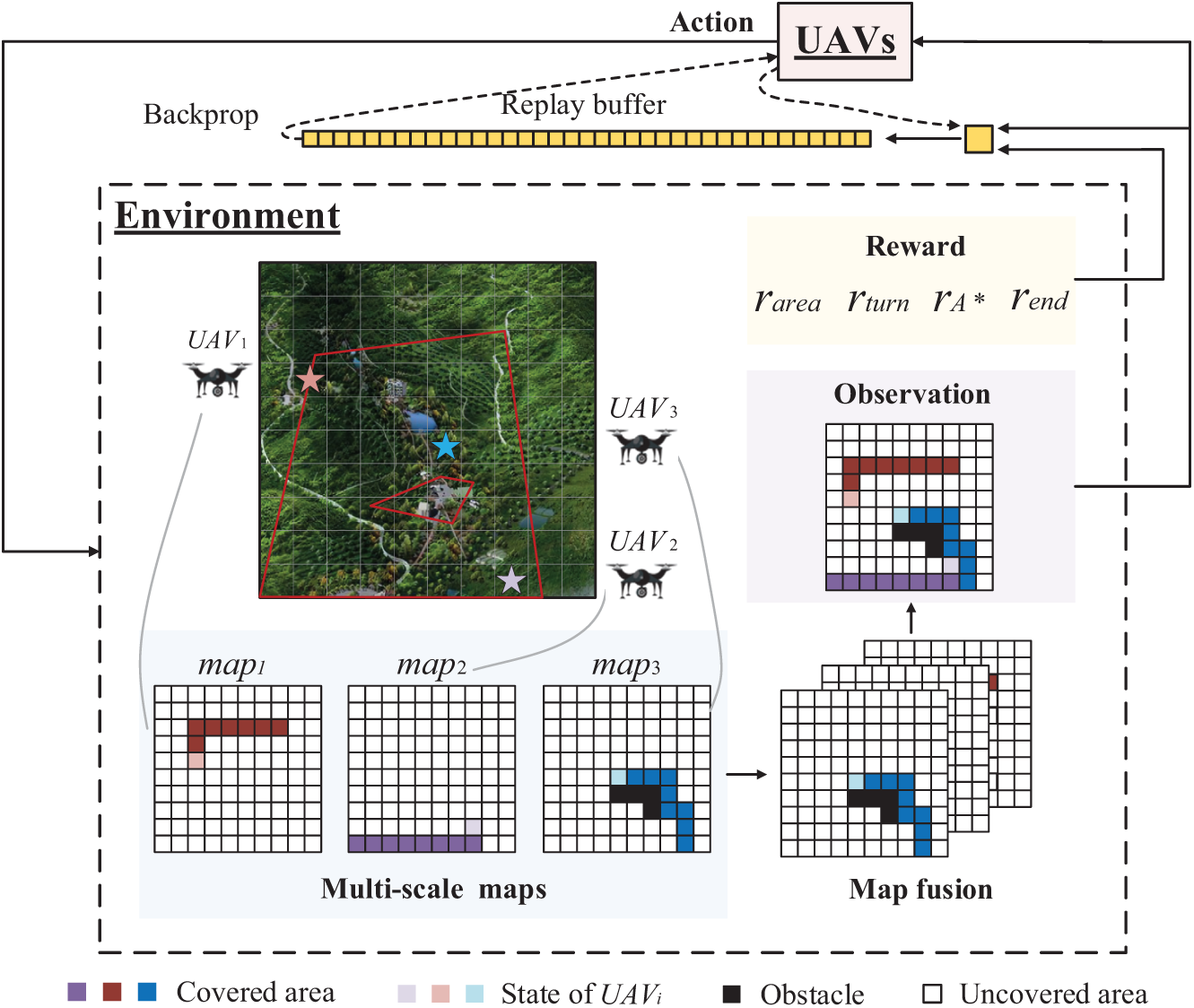
Figure 2: Illustration of the CPP system framework
In summary, this paper adopts a distributed approach, allowing each UAV to take off simultaneously from different initial positions. At each step, UAVs collaborate using multi-scale map integration while independently making action decisions. During this process, each UAV only needs to cover a portion of the target area, completing its sub-task. Therefore, the completion time of the last UAV’s sub-task determines the total completion time of the CPP task. This paper assumes that the UAV maintains a constant speed during flight and uses the number of task completion steps
where
where the function
The Deep Q-Network (DQN) algorithm aims to learn the state-action value (Q-value) function through a deep neural network to find the optimal policy, enabling the agent to take appropriate actions in each state to maximize future cumulative rewards. The update process of its Q-value function is as follows:
The parameters
Specifically, DQN uses two neural networks with the same structure but different parameters: the online network and the target network. In Eq. (8),
In a given state, the agent in a reinforcement learning task can only choose one action, either exploitation or exploration. Therefore, a balance between the two needs to be achieved in order to obtain the optimal task outcome. To further improve learning efficiency, this paper improves the
where
where
4.2 State Space, Action Space, Reward
The state space, action space, and instantaneous reward for the
a. State space and action space
In a discrete grid map, the position of the
The algorithm discretizes the UAV’s action space, where the UAV can move diagonally through horizontal and vertical actions. Thus, the action set of the UAVs is represented as
b. Reward
The core objective of the CPP for the UAV swarm is to maximize coverage efficiency while ensuring safe flight operations. To achieve this goal, we have designed multiple task-oriented reward functions to guide the UAV swarm in achieving optimal collision-free coverage. Specifically, to avoid path repetition and collisions, we have designed a reward based on effective coverage, denoted as
In Eq. (11),
In Eq. (12), the
The total reward
4.3 Prioritized Experience Replay
The SADQN algorithm of this paper deployed on
To effectively utilize learning experiences, we adopt a prioritized experience replay strategy to improve learning efficiency and stability during training, accelerating the algorithm’s convergence. In the SADQN algorithm proposed in this paper, the
Eq. (16) defines the sampling probability for each sample, where
Eq. (20) is used to update the parameters

This section validates the correctness and effectiveness of the proposed SADQN method by comparing its results with those of six other solutions, including GBNN, A*, TMSTC*, SADQN-nA, SADQN-nP, and DDPG. All algorithms were run on Python 3.9 on a Windows 11 system. The specific parameter settings of the algorithm are as follows: the learning rate
5.1 Analysis Performance of SADQN
We map the UAV flight trajectories onto a two-dimensional plane. Fig. 3a shows the irregular environment, where the initial discretized map is shown in Fig. 3b, and the final optimized map is presented in Fig. 3c. And in the irregular environment depicted in Fig. 3c, three UAVs are deployed to perform the coverage path planning task. The green dashed lines represent the starting positions of the UAVs.
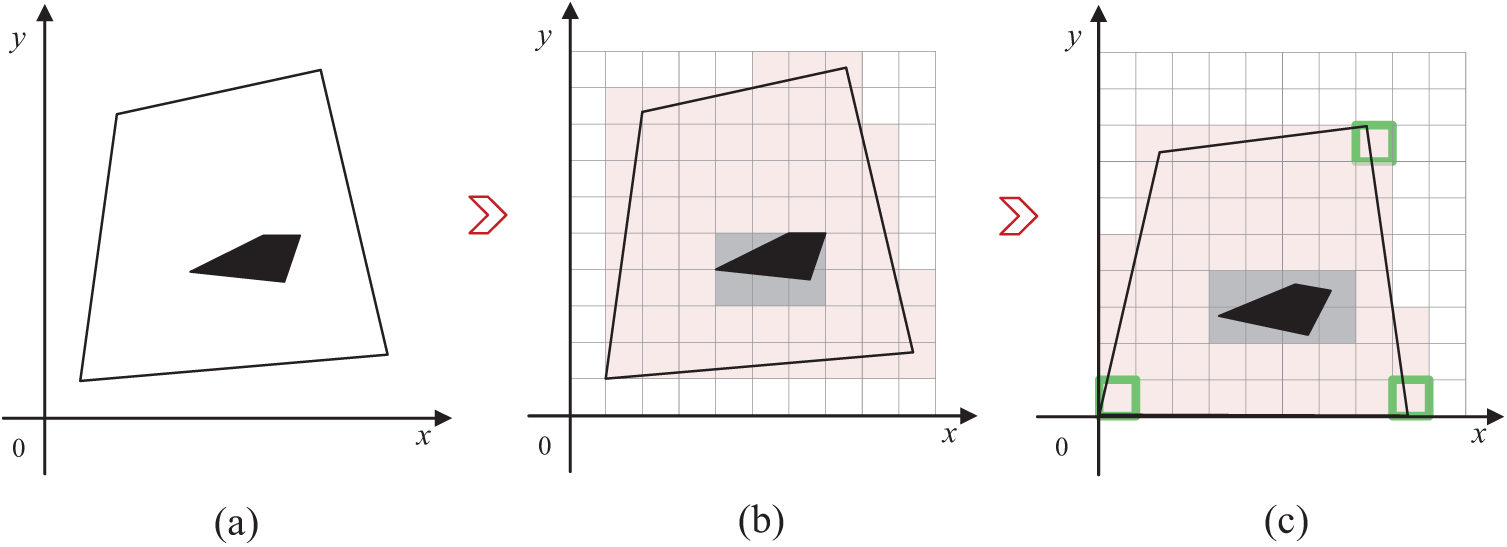
Figure 3: Schematic diagram of the discretized target area
As shown in Fig. 4, the final coverage results of different algorithms are presented. We can observe that all the algorithms have completed the coverage task. Moreover, the paths generated by the proposed SADQN method and the A* algorithm show no overlapping segments, while significant repeated coverage is observed in the path maps of the other algorithms.
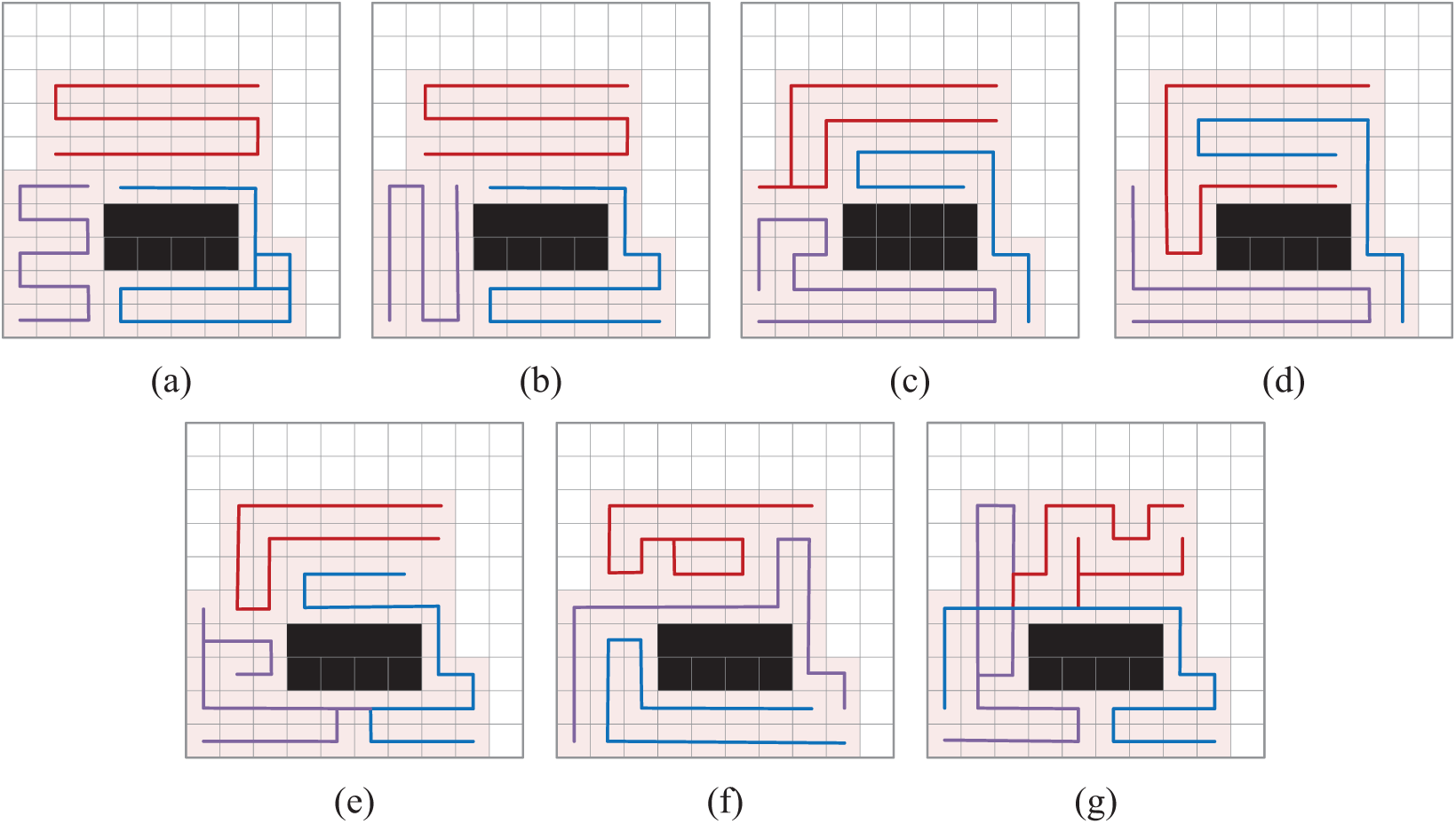
Figure 4: Comparison of coverage results for different algorithms. (a) GBNN; (b) A*, (c) TMSTC*; (d) SADQN; (e) SADQN_nP; (f) SADQN_nA; (g) DDPG
As shown in Table 1, the average results of the CPP task under different algorithms are presented. From this, we can observe that in the irregular environment, the average coverage efficiency of the proposed SADQN method can reach 2.798, which indicates that it effectively balances the workload distribution among the UAVs while minimizing repeated coverage. Notably, the task completion efficiency of our method is superior to that of the GBNN, A*, and TMSTC* algorithms. Where the GBNN algorithm exhibits a significant amount of redundant path planning. While the A* and TMSTC algorithms demonstrate high coverage efficiency, they fall short of the SADQN algorithm in terms of the number of task completion steps, primarily due to their lack of a collaborative mechanism. Our SADQN algorithm achieves cooperative coverage among UAVs by sharing environmental information through multi-scale maps, making it better suited for complex environments and resulting in superior path planning. Additionally, the SADQN algorithm performs better in terms of step count and number of turns, benefiting from our turn reward mechanism, which effectively reduces energy consumption caused by frequent turns. DDPG adopts a deterministic policy, making it prone to getting stuck in local optima during exploration. Although it enhances exploration by adding noise, this mechanism is insufficient in large state spaces and irregular environments, resulting in slow learning and suboptimal performance.
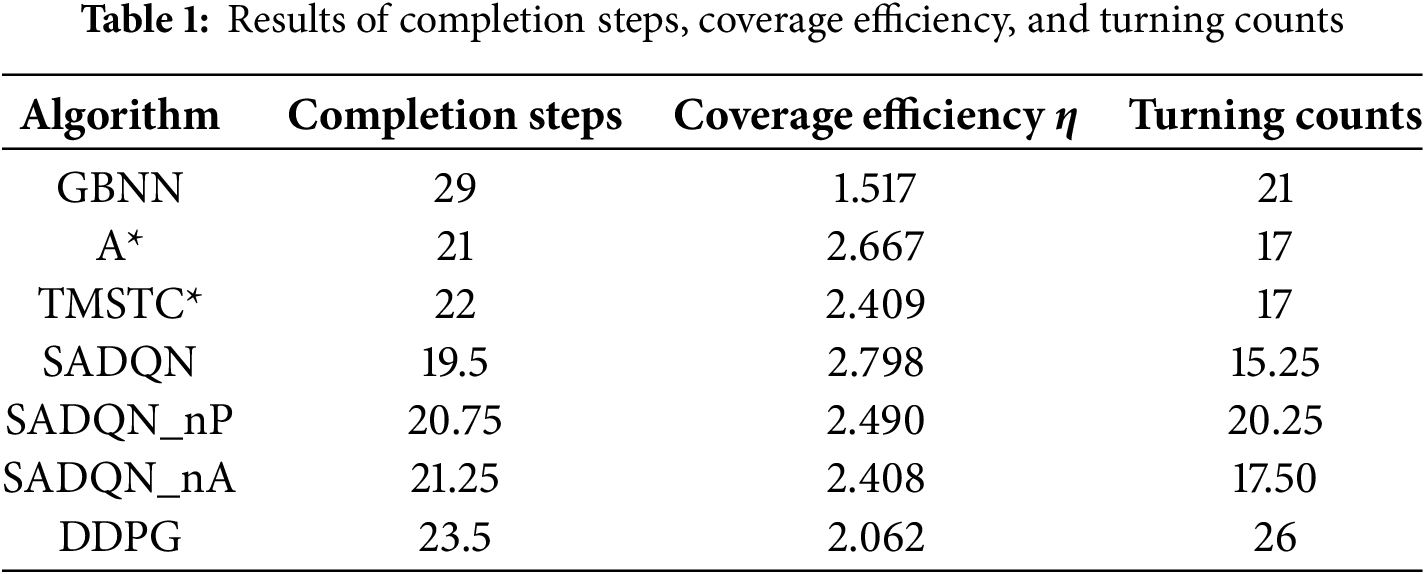
Fig. 5 illustrates the reward variation curves of four different algorithms during training, with the shaded areas representing the standard deviation of the reward values, reflecting the range of reward fluctuations. From Fig. 5, we can observe that the SADQN algorithm converges the fastest, stabilizing after 200 episodes. The reward values of the SADQN_nA algorithm are relatively low, indicating that the A*-guided algorithm provides effective prior knowledge, accelerating the training process. The reward increase of the SADQN_nP algorithm is slower, suggesting that prioritized experience replay effectively utilizes important experiences, enhancing training efficiency. The combination of the A* algorithm and prioritized experience replay makes the SADQN algorithm perform the best. The DDPG algorithm converges slowly with lower reward values, primarily because its exploration mechanism and action selection methods are unsuitable for complex environments, resulting in significantly inferior performance.
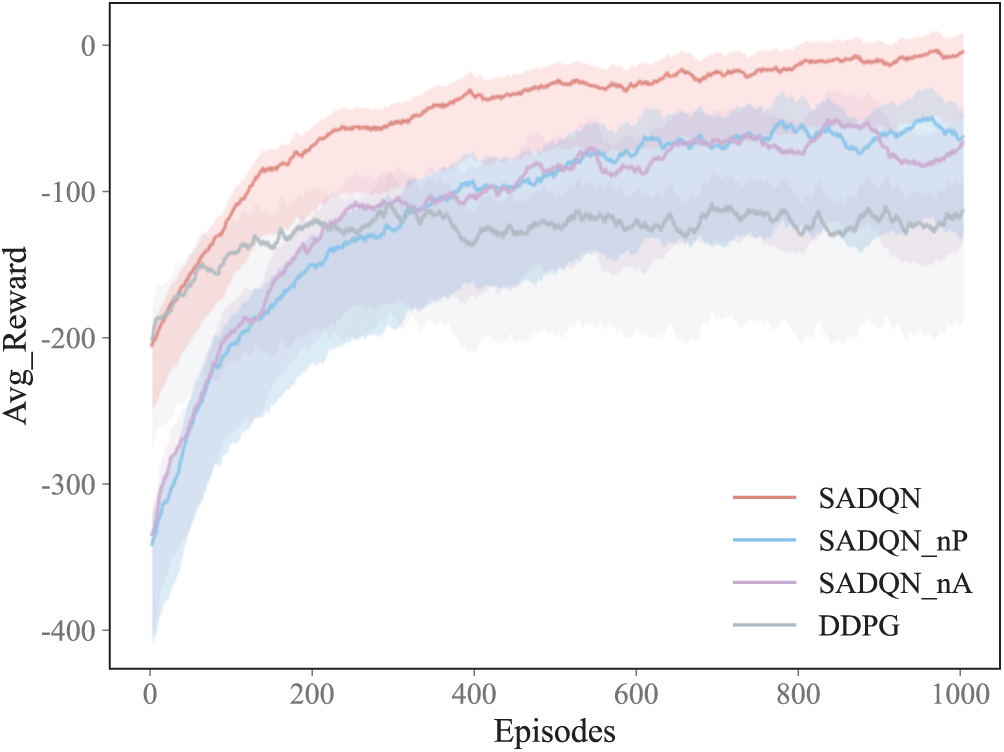
Figure 5: Reward curve comparison graph
The UAV swarm may encounter unexpected situations such as malfunctions, energy depletion, or communication interruptions while performing complex tasks, causing some UAVs to stop working. In such cases, ensuring full coverage becomes crucial. As shown in Fig. 6, in a coverage task coordinated by three UAVs, one UAV stops working due to an unexpected issue. The remaining two UAVs can quickly adjust their strategies and take over the coverage task for the entire area to ensure the successful completion of full coverage.
Figure 6: Response of the UAV swarm to the failure situation
To validate the algorithm’s generalization ability, this section compares the results of the CPP problem in two irregular environments, Env1 and Env2, as shown in Fig. 7a,b. It can be observed that the number of coverage grids in the target area was reduced by 10.1% and 9.1%, respectively, after processing with the improved cell decomposition method. In this section, three UAVs were deployed to perform coverage path planning tasks in two experimental scenarios shown in Fig. 7a,b. The green lines outline the starting positions of each UAV, and they will collaborate to achieve full coverage of the target area.
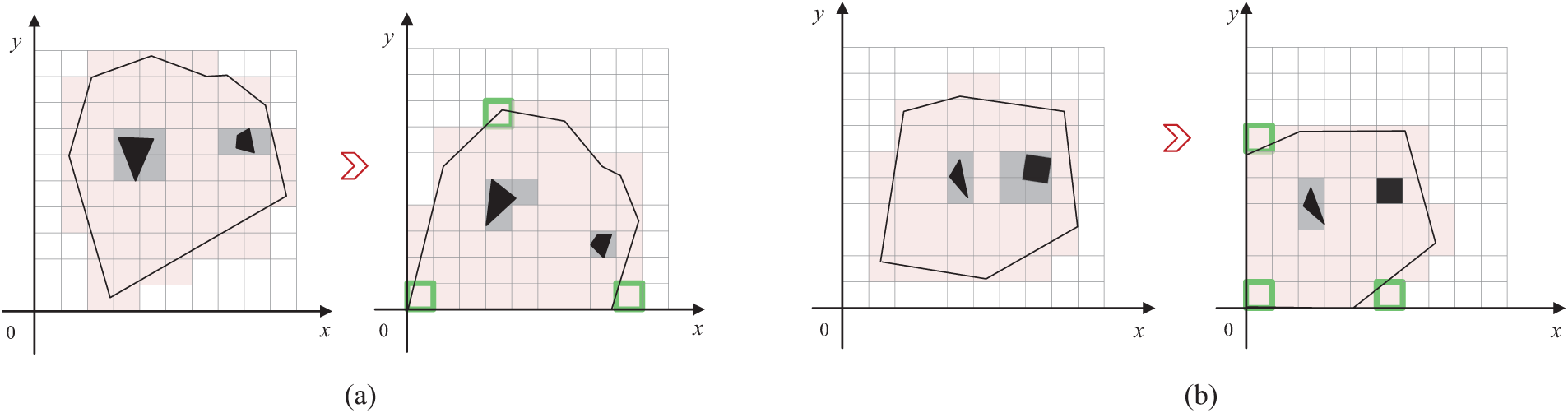
Figure 7: Discretization of irregular environments
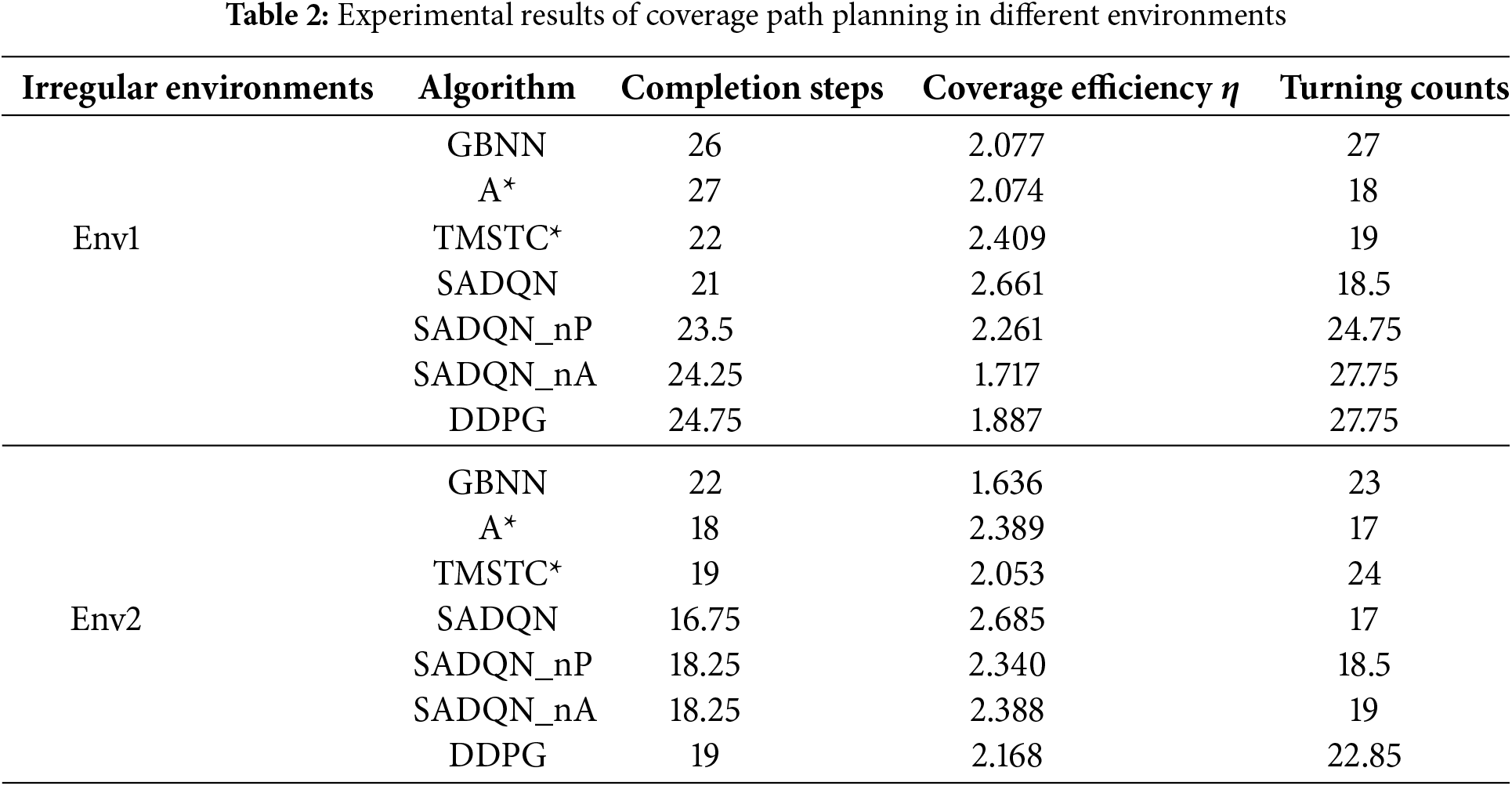
Table 2 presents the completion steps, coverage efficiency, and turning counts. From Table 2, it can be observed that all algorithms achieved complete coverage. Our proposed SADQN method performed well in both environments, with minimal occurrence of duplicate coverage. Compared to other algorithms, SADQN demonstrated lower average steps to completion steps, further enhancing its coverage efficiency, with an average coverage efficiency exceeding 2.6. Moreover, while our method ensures a high coverage efficiency through reasonable path planning, it also involves fewer turns, enabling more efficient coverage path planning.
This research initiates with the discretization of irregular environments through an enhanced cell decomposition technique, thereby effectively partitioning the complex terrains into manageable grids. Simultaneously, the observation scope of UAVs is expanded by leveraging multi-scale maps, endowing them with a broader field of view to better perceive and adapt to the surroundings. An inventive SADQN algorithm is put forth, which ingeniously incorporates the A* algorithm to bolster the DQN process, specifically devised to tackle the intricate coverage path planning challenges that UAV swarms encounter in complex and irregular settings. The proposed algorithm has been rigorously validated within obstacle-ridden irregular environments. The experimental outcomes unequivocally demonstrate its superiority over existing benchmark algorithms. In terms of convergence speed, it exhibits a remarkable acceleration, swiftly arriving at optimal solutions and reducing the computational burden. Regarding completion steps, it streamlines the overall process, minimizing unnecessary maneuvers and enhancing operational efficiency. The coverage efficiency soars to an impressive 2.6, signifying a significant leap in the thoroughness of area coverage. Moreover, the algorithm also considers the turning counts, optimizing flight paths to curtail energy consumption associated with frequent directional changes. Notably, in the face of sudden failures, the resilience of the system shines through. The remaining UAVs are still capable of tenaciously adhering to the original CPP task objectives, ensuring the continuity and integrity of the mission. This robustness adds an extra layer of reliability to UAV swarm operations, especially in critical or unpredictable scenarios.
Acknowledgement: The authors are thankful to researchers in Jiangsu University of Science and Technology for the helpful discussion.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Zhuoyan Xie, Qi Wang; data collection: Zhuoyan Xie; analysis and interpretation of results: Zhuoyan Xie, Bin Kong; draft manuscript preparation: Zhuoyan Xie, Shang Gao. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding authors, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
Nomenclature
| Length and width of the target area | |
| Target area coordinate | |
| Target grid area | |
| Total number of Unmanned Aerial | |
| The | |
| The | |
| Environmental information state value | |
| The | |
| The | |
| Coverage efficiency | |
| Set of the UAV actions | |
| State, action, and reward of the DQN algorithm | |
| State, action, and reward of the | |
| DQN neural network parameters | |
| Value function of the DQN algorithm | |
| Target Q-value | |
| Loss function | |
| Greedy algorithm parameters |
References
1. Cabreira TM, Brisolara LB, Paulo RFJ. Survey on coverage path planning with unmanned aerial vehicles. Drones. 2019;3(1):4. doi:10.3390/drones3010004. [Google Scholar] [CrossRef]
2. Mukhamediev RI, Yakunin K, Aubakirov M, Assanov I, Kuchin Y, Symagulov A, et al. Coverage path planning optimization of heterogeneous UAVs group for precision agriculture. IEEE Access. 2023;11:5789–803. doi:10.1109/access.2023.3235207. [Google Scholar] [CrossRef]
3. Pérez-González A, Benítez-Montoya N, Jaramillo-Duque Á, Cano-Quintero JB. Coverage path planning with semantic segmentation for UAV in PV plants. Appl Sci. 2021;11(24):12093. doi:10.3390/app112412093. [Google Scholar] [CrossRef]
4. Muñoz J, López B, Quevedo F, Monje CA, Garrido S, Moreno LE. Multi UAV coverage path planning in urban environments. Sensors. 2021;21(21):7365. doi:10.3390/s21217365. [Google Scholar] [PubMed] [CrossRef]
5. Cabreira TM, Di Franco C, Ferreira PR, Buttazzo GC. Energy-aware spiral coverage path planning for UAV photogrammetric applications. IEEE Robot Autom Lett. 2018;3(4):3662–8. doi:10.1109/lra.2018.2854967. [Google Scholar] [CrossRef]
6. Nedjati A, Izbirak G, Vizvari B, Arkat J. Complete coverage path planning for a multi-UAV response system in post-earthquake assessment. Robotics. 2016;5(4):26. doi:10.3390/robotics5040026. [Google Scholar] [CrossRef]
7. Collins L, Ghassemi P, Esfahani ET, Doermann D, Dantu K, Chowdhury S. Scalable coverage path planning of multi-robot teams for monitoring non-convex areas. In: Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA); 2021 May 30–Jun 5; Xi’an, China. Piscataway, NJ, USA: IEEE; 2021. p. 7393–9. [Google Scholar]
8. Bolu A, Korçak Ö. Path planning for multiple mobile robots in smart warehouse. In: Proceedings of the 2019 7th International Conference on Control, Mechatronics and Automation (ICCMA); 2019 Nov 6–8; Piscataway, NJ, USA: IEEE; 2019. p. 144–50. [Google Scholar]
9. Luna MA, Molina M, Da-Silva-Gomez R, Melero-Deza J, Arias-Perez P, Campoy P. A multi-UAV system for coverage path planning applications with in-flight re-planning capabilities. J Field Robot. 2024;41(5):1480–97. doi:10.1002/rob.22342. [Google Scholar] [CrossRef]
10. Jonnarth A, Zhao J, Felsberg M. End-to-end reinforcement learning for online coverage path planning in unknown environments. arXiv:2306.16978. 2023. [Google Scholar]
11. Heydari J, Saha O, Ganapathy V. Reinforcement learning-based coverage path planning with implicit cellular decomposition. arXiv:2110.09018. 2021. [Google Scholar]
12. Cho SW, Park JH, Park HJ, Kim S. Multi-uav coverage path planning based on hexagonal grid decomposition in maritime search and rescue. Mathematics. 2021;10(1):83. doi:10.3390/math10010083. [Google Scholar] [CrossRef]
13. Lu J, Zeng B, Tang J, Lam TL, Wen J. TMSTC*: a path planning algorithm for minimizing turns in multi-robot coverage. IEEE Robot Autom Lett. 2023;8(8):5275–82. doi:10.1109/lra.2023.3293319. [Google Scholar] [CrossRef]
14. Maza I, Ollero A. Multiple UAV cooperative searching operation using polygon area decomposition and efficient coverage algorithms. In: Distributed autonomous robotic systems. Vol. 6. Tokyo, Japan: Springer; 2007. p. 221–30 doi: 10.1007/978-4-431-35873-2_22. [Google Scholar] [CrossRef]
15. Chen G, Shen Y, Zhang Y, Zhang W, Wang D, He B. 2D multi-area coverage path planning using L-SHADE in simulated ocean survey. Appl Soft Comput. 2021;112(7):107754. doi:10.1016/j.asoc.2021.107754. [Google Scholar] [CrossRef]
16. Xu S, Zhou Z, Li J, Wang L, Zhang X, Gao H. Communication-constrained UAVs coverage search method in uncertain scenarios. IEEE Sens J. 2024;24(10):17092–101. doi:10.1109/jsen.2024.3384261. [Google Scholar] [CrossRef]
17. Qiu X, Song J, Zhang X, Liu S. A complete coverage path planning method for mobile robot in uncertain environments. In: Proceedings of the 2006 6th World Congress on Intelligent Control and Automation; 2006 Jun 21–23; Dalian, China. Piscataway, NJ, USA: IEEE; 2006. p. 8892–6. [Google Scholar]
18. Bine LM, Boukerche A, Ruiz LB, Loureiro AA. A novel ant colony-inspired coverage path planning for internet of drones. Comput Netw. 2023;235:109963. doi:10.1016/j.comnet.2023.109963. [Google Scholar] [CrossRef]
19. Li W, Zhao T, Dian S. Multirobot coverage path planning based on deep Q-network in unknown environment. J Robot. 2022;2022(1):6825902. doi:10.1155/2022/6825902. [Google Scholar] [CrossRef]
20. Le AV, Vo DT, Dat NT, Vu MB, Elara MR. Complete coverage planning using Deep Reinforcement Learning for polyiamonds-based reconfigurable robot. Eng Appl Artif Intell. 2024;138(4):109424. doi:10.1016/j.engappai.2024.109424. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools