
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

You KAN See through the Sand in the Dark: Uncertainty-Aware Meets KAN in Joint Low-Light Image Enhancement and Sand-Dust Removal
1 School of Computer Science, Wuhan University, Wuhan, 430072, China
2 Intelligent Transport Systems Research Center, Wuhan University of Technology, Wuhan, 430062, China
3 GNSS Research Center, Wuhan University, Wuhan, 430072, China
* Corresponding Author: Hui Liu. Email:
(This article belongs to the Special Issue: Computer Vision and Image Processing: Feature Selection, Image Enhancement and Recognition)
Computers, Materials & Continua 2025, 84(3), 5095-5109. https://doi.org/10.32604/cmc.2025.065812
Received 21 March 2025; Accepted 11 June 2025; Issue published 30 July 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Within the domain of low-level vision, enhancing low-light images and removing sand-dust from single images are both critical tasks. These challenges are particularly pronounced in real-world applications such as autonomous driving, surveillance systems, and remote sensing, where adverse lighting and environmental conditions often degrade image quality. Various neural network models, including MLPs, CNNs, GANs, and Transformers, have been proposed to tackle these challenges, with the Vision KAN models showing particular promise. However, existing models, including the Vision KAN models use deterministic neural networks that do not address the uncertainties inherent in these processes. To overcome this, we introduce the Uncertainty-Aware Kolmogorov-Arnold Network (UAKAN), a novel structure that integrates KAN with uncertainty estimation. Our approach uniquely employs Tokenized KANs for sampling within a U-Net architecture’s encoder and decoder layers, enhancing the network’s ability to learn complex representations. Furthermore, for aleatoric uncertainty, we propose an uncertainty coupling certainty module that couples uncertainty distribution learning and residual learning in a feature fusion manner. For epistemic uncertainty, we propose a feature selection mechanism for spatial and pixel dimension uncertainty modeling, which captures and models uncertainty by learning the uncertainty contained between feature maps. Notably, our uncertainty-aware framework enables the model to produce both high-quality enhanced images and reliable uncertainty maps, which are crucial for downstream applications requiring confidence estimation. Through comparative and ablation studies on our synthetic SLLIE6K dataset, designed for low-light enhancement and sand-dust removal, we validate the effectiveness and theoretical robustness of our methodology.Keywords
The presence of sand-dust in the atmosphere severely degrades image quality through complex optical interactions [1]. Sand particles scatter and absorb light, which causes reduced contrast, hazy appearance, and color distortion in images. These degradations profoundly impact subsequent visual tasks [2,3]. For example, in object detection, obscured edges and diminished visibility hinder accurate object identification and localization. In instance segmentation, unclear boundaries due to sand-dust interference result in inaccurate pixel-level classification. In scene recognition, the weakening of critical visual cues such as texture and color gradients leads to unreliable semantic interpretation. Insufficient lighting compounds these issues by introducing high noise, narrow dynamic range, and loss of fine details that render feature extraction unreliable, as seen in low-light object detection where inadequate illumination challenges the detection of small or dark objects [4–6]. The core challenge arises when sand-dust degradation and low-light conditions coexist. Existing methods either focus on dust removal under natural light or low-light enhancement without addressing dust contamination. These methods, however, are ill-equipped to disentangle the synergistic deteriorations caused by dust-induced light scattering and low-light photon starvation, as the two phenomena exacerbate each other in complex ways. Addressing this gap is critical for real-world applications, which include autonomous driving in desert sandstorms and remote sensing in arid regions. In these regions, both dust and low light frequently compromise camera visibility. Developing a method to jointly mitigate dust contamination and enhance low-light visibility while preserving fine details is essential.
To tackle these challenges, various neural network architectures have been developed. Convolutional Neural Networks (CNNs) exploit local spatial correlations via convolutional operations, performing well in many visual tasks. However, their fixed receptive fields limit the capture of long-range dependencies. Multi-Layer Perceptrons (MLPs), with fully connected structures, model complex nonlinear relationships but suffer from high computational costs and overfitting. Generative Adversarial Networks (GANs), comprising generators and discriminators, generate realistic images but face unstable training. Transformers leverage self-attention mechanisms to model global dependencies, enabling exceptional performance in long-range contextual reasoning. However, their effectiveness is often constrained by significant data dependency, necessitating substantial training datasets for optimal results.
Recently, Kolmogorov-Arnold Networks (KANs) have emerged as a promising alternative to traditional MLPs. Rooted in the Kolmogorov-Arnold superposition theorems, KANs offer distinct advantages in accuracy and interpretability. Unlike MLPs, KANs employ a more compact architecture to represent complex functions, thereby reducing computational complexity. Their design enables superior feature representation, enhancing performance in visual tasks. Moreover, KANs’ interpretability allows researchers to decipher how the network processes information.
However, within the domain of low-level vision, the application of KANs remains relatively unexplored, and their potential benefits are yet to be fully harnessed. In the realm of low-level vision, complex tasks that encompass substantial uncertainty, such as simultaneous low-light image enhancement and single-image sand-dust removal, have received scant attention in research. These tasks pose unique challenges due to the inherent variability and unpredictability of the data. Specifically, traditional methods often fail to adequately address these complexities. To address the aforementioned challenges, this paper introduces an uncertainty-aware KAN framework, designated as UAKAN. Specifically, we propose Downsample Tokenized KAN (DTKAN) and Upsample Tokenized KAN (UTKAN) that utilize KAN for the downsampling and upsampling process in U-Net. Unlike the interpolate operation in traditional U-Net, our DTKAN and UTKAN offer enhanced flexibility and interoperability. Concurrently, to tackle aleatoric uncertainty in joint low-light image enhancement and sand-dust removal, we introduce an uncertainty coupling certainty module. This mechanism leverages distribution modeling that is used to capture the uncertainty and a residual learning branch for certainty. By coupling these two branches, our module effectively utilizes uncertainty and certainty across data dimensions. Furthermore, to address the epistemic uncertainty associated with model dimensions, we propose an uncertainty-aware distributional spatial modulator. This mechanism selectively filters features through uncertainty modeling, identifying and discarding redundant features with high uncertainty to refine the model’s feature selection.
In summary, the primary contributions of this paper can be categorized into four main aspects:
• To the best of our knowledge, we are the first to explore the task of single-image Joint Low-Light Image Enhancement and Sand-dust Removal (JLLIESR), we are also the first to utilize uncertainty estimation and KAN for this task.
• This is the first work to utilize tokenized KAN in the low-level vision task and we propose Downsample Tokenized KAN (DTKAN) and Upsample Tokenized KAN (UTKAN) implanted in a U-Net.
• We propose an Uncertainty Coupling Certainty Module (UCCM) to handle the data uncertainty of the JLLIESR task, and we propose an Uncertainty-aware Distributional Spatial Modulator (UDSM) to model the uncertainty in the epistemic dimension for our model.
• We propose a framework called Uncertainty-Aware KAN (UAKAN) for accurate single-image joint low-light image enhancement and sand removal. Through comprehensive experiments conducted on our proposed SLLIE6K dataset, we demonstrate that our proposed method outperforms current state-of-the-art techniques.
The widely utilized physical model for explaining the formation of an image affected by light transmission hazed [7] is typically defined as follows:
where
where
where
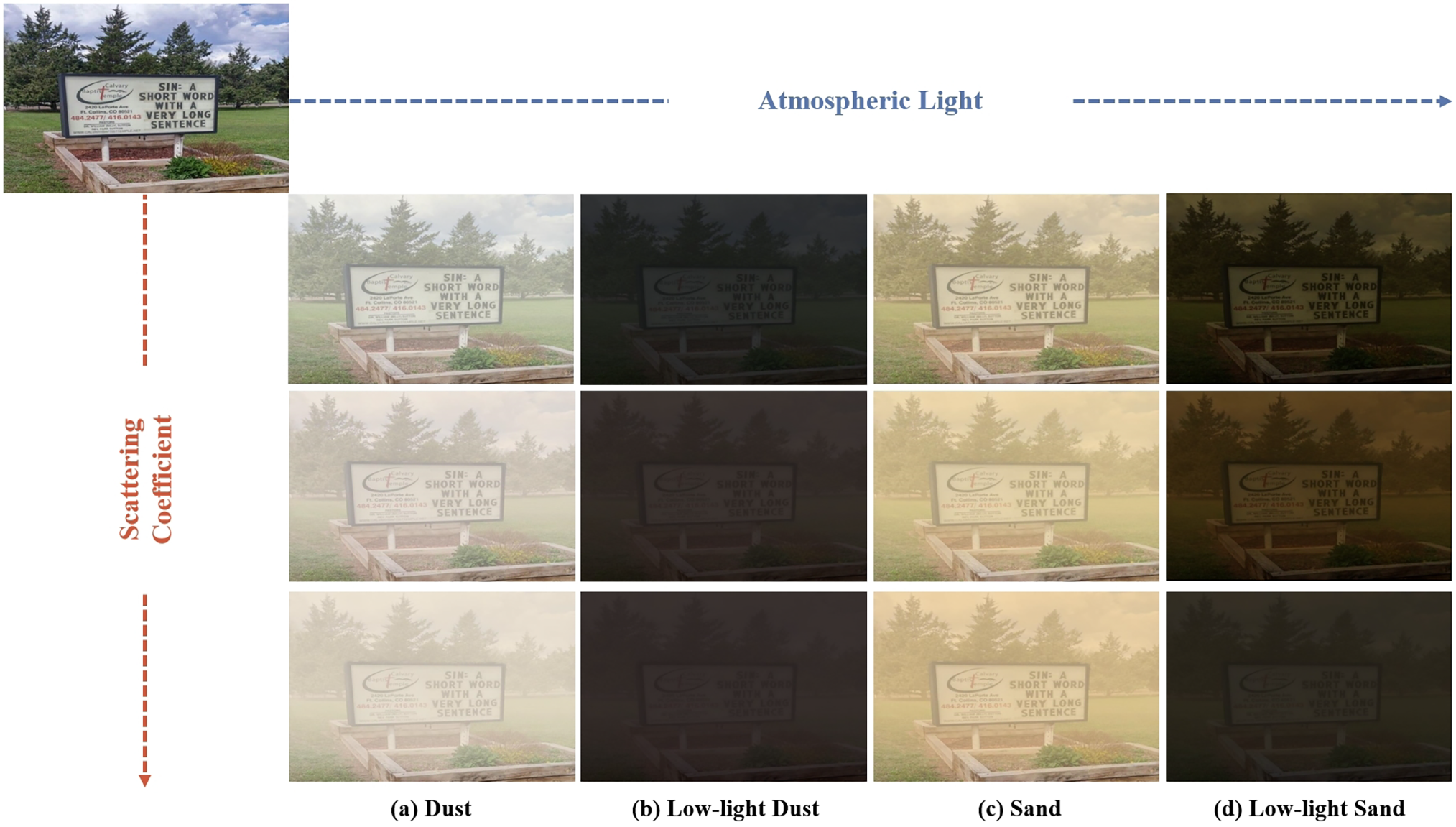
Figure 1: Visual examples of the used synthetic low-light sand-dust images in this paper
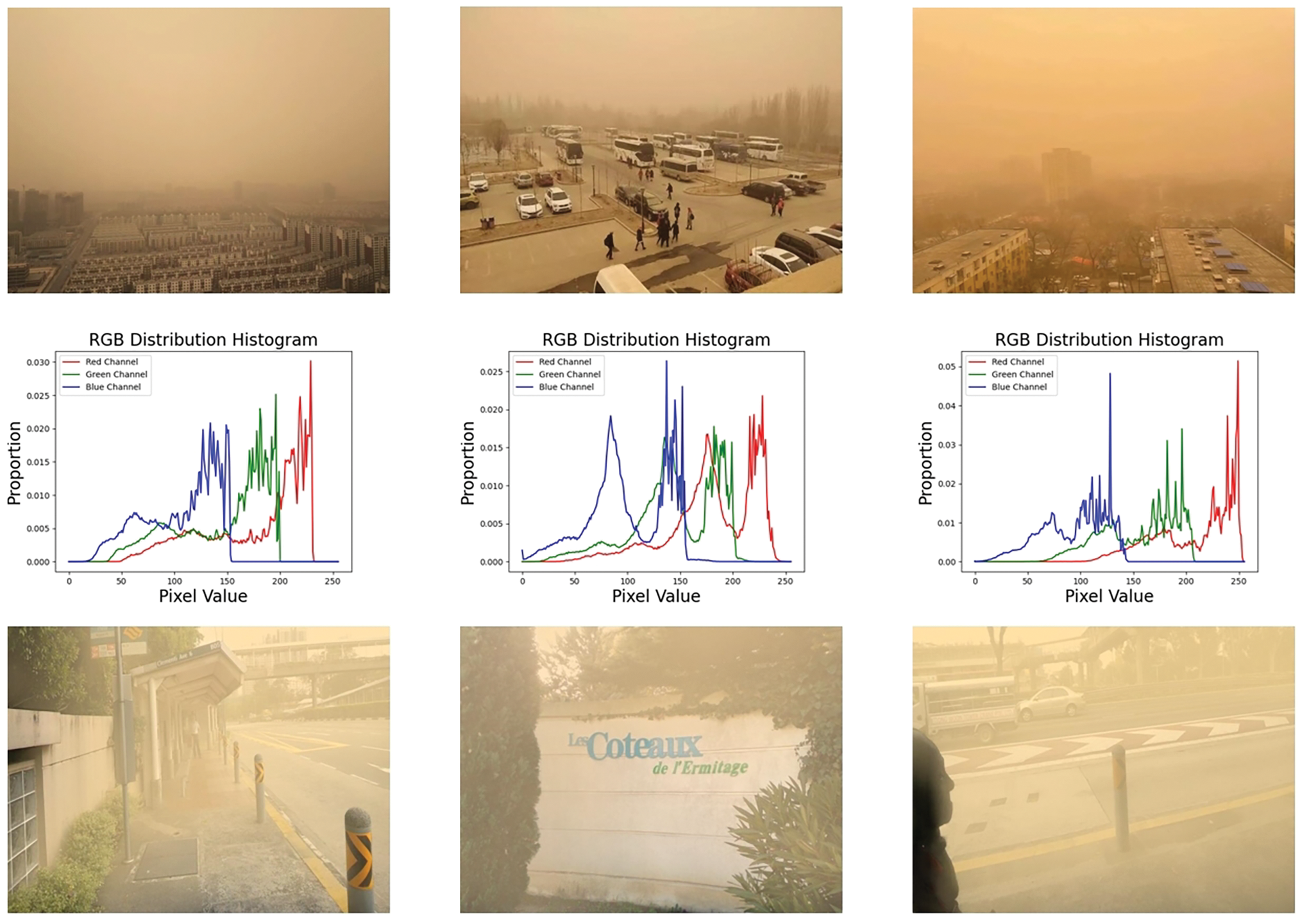
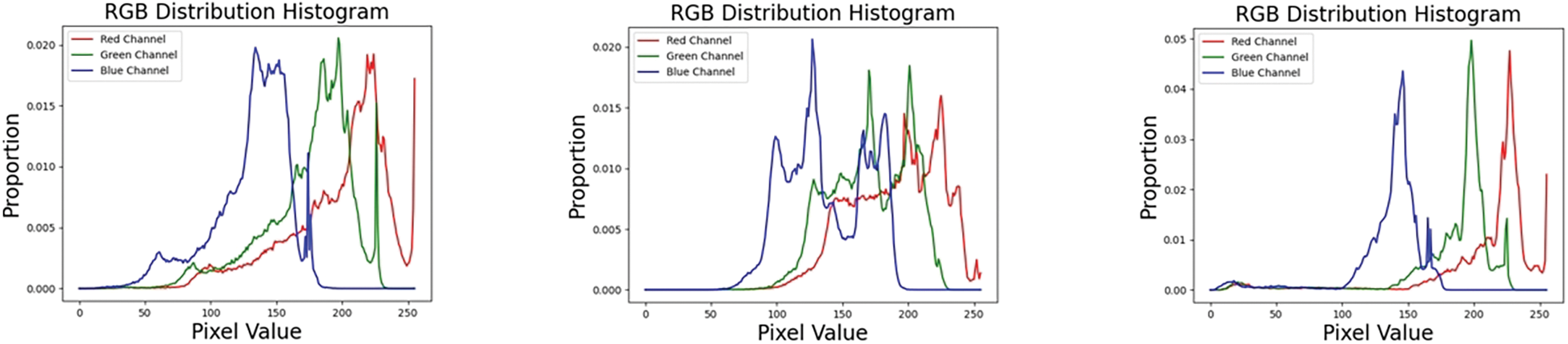
Figure 2: Pixel distribution comparison examples of real-world and synthetic sand dust images
2.2 Image Recovery from Degraded Weather
Li et al. [9] introduced AOD-Net, a pioneering end-to-end CNN model for image dehazing, highlighting its potential for enhancing computer vision tasks in hazy conditions. Chen et al. [10] present NAFNet, a pioneering approach that simplifies image restoration by eliminating nonlinear activations, achieving comparable state-of-the-art results with reduced computational complexity. Cui et al. [11] introduced OKNet, an efficient convolutional network for image restoration that leverages an omni-kernel module to capture multi-scale receptive fields, demonstrating state-of-the-art performance across various restoration tasks including dehazing, desnowing, and defocus deblurring. Gao et al. [12] propose a single-stage design, based on a simple U-Net architecture, with a mountain-shaped structure. The DSANet proposed by Cui and Knoll [13] enhances representation learning through spatial and frequency strip attention units, offering a significant advancement in image restoration efficiency and effectiveness. Gao et al. [14] introduced ECFNet, an efficient image restoration framework that combines spatial and frequency attention mechanisms with multi-scale blocks to adaptively handle varying degradation levels across image regions, achieving superior performance on multiple benchmark datasets. Cui et al. [15] introduced FSNet, an image restoration framework that employs frequency selection mechanisms to dynamically decompose and emphasize frequency components for effective image recovery.
2.3 Uncertainty-Aware Probabilistic Modeling
Data uncertainty and model uncertainty in deep learning are key factors influencing performance, and probabilistic modeling approaches to address data and model uncertainty are gaining growing attention. Bayesian SegNet [16] leverages Monte Carlo Dropout [17] at test time to approximate posterior distributions, offering a measure of uncertainty crucial for decision-making in applications such as autonomous driving and robotic interaction. Wang et al. [18] introduce a data-uncertainty guided multi-phase learning approach for semi-supervised object detection that effectively leverages unlabeled data across varying difficulty levels. Zhou et al. [19] introduced an Uncertainty-Aware Edge Detector (UAED) that leverages the ambiguity in multiple annotations to enhance edge detection performance, representing a significant advancement in the field. Yang et al. [20] present UGTR, a pioneering approach that integrates Bayesian learning with Transformer-based [21] reasoning to enhance camouflaged object detection. Zhang et al. [22] introduced GLENet, a generative framework for modeling label uncertainty in 3D object detection using conditional variational autoencoders, which improves detection accuracy by capturing the diversity of potential bounding boxes for objects. Tang et al. [23] proposed UA-Track, an uncertainty-aware framework for 3D multi-object tracking that introduces probabilistic attention, query denoising, and uncertainty-reduced query initialization to address tracking challenges in complex scenarios. Dong et al. [24] proposed UAC, a semi-supervised learning method that combines multi-perturbation strategies and uncertainty estimation to improve medical image segmentation performance. Shao et al. [25] proposed UA-Fusion, an uncertainty-aware multimodal data fusion framework for 3-D object detection in autonomous vehicles. This framework effectively addresses challenges related to uncertainty in dynamic traffic environments through probabilistic cross-modal attention and query denoising strategies.
We propose UAKAN for the removal of sand-dust in a single-image under low-light conditions, as shown in Fig. 3. To expand the application of Kolmogorov-Arnold Networks (KANs) in low-level vision, we propose novel Tokenized KAN modules, namely the Downsampling Tokenized KAN (DTKAN) and Upsampling Tokenized KAN (UTKAN) modules. These modules leverage Patch Embedding and Patch Unembedding techniques for tokenization, followed by the application of KAN layers for further embedding, thereby enhancing the representational capabilities of the network. Furthermore, to tackle the aleatoric uncertainty inherent in the data dimensions of the concurrent task of single-image low-light enhancement and sand-dust removal, we introduce a module that couples uncertainty awareness with deterministic representation termed the Uncertainty Coupling Certainty Module (UCCM). The UCCM achieves the integration of uncertainty and determinism by feature coupling between a distribution modeling representation module and a residual learning module, thereby characterizing the fusion of uncertainty and determinism. Finally, addressing uncertainties of the epistemic dimension, we introduce the Uncertainty-aware Distributional Spatial Modulator (UDSM) and integrate it into the backbone of our framework, which we term the Uncertainty-aware Feature Modeling Block (UFMBlock). The incorporation of UFMBlock equips our framework with the capability to model comprehensive uncertainty, subsequently augmenting its ability to encapsulate the intrinsic uncertainties associated with the dual tasks of low-light image enhancement and image sand-dust removal. Our network adopts the same MIMOUNet [26] architecture, which is a multi-input multi-output U-shaped encoder-decoder structure. The total structure of our proposed UAKAN is shown in Fig. 3.
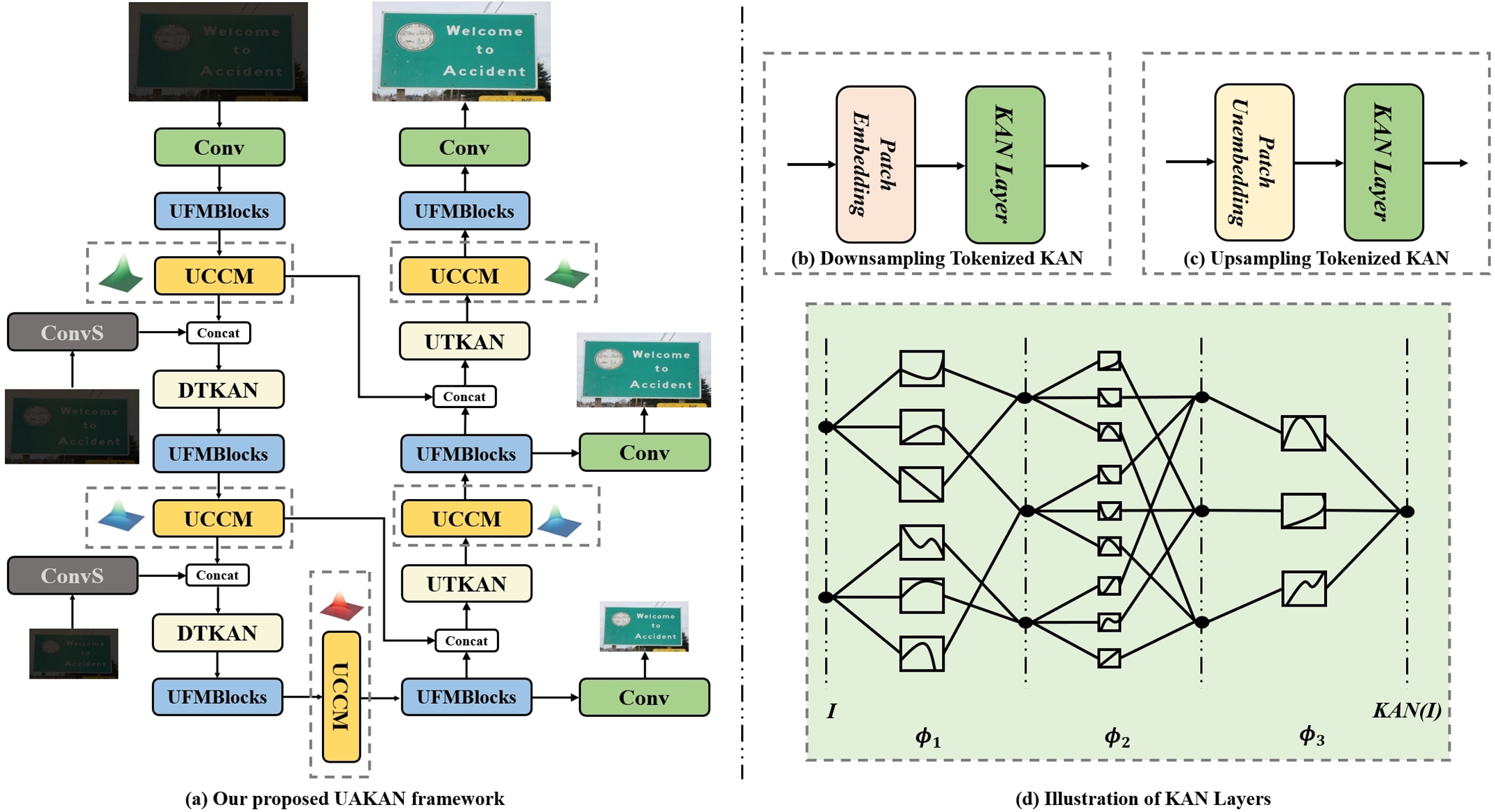
Figure 3: Overall structure of the proposed method. Our UAKAN employs the classic MIMOUNet [26] as its basic framework. MIMOUNet is a multi-input multi-output UNet architecture that is commonly seen in recent image restoration frameworks. The encoder accepts input images at three scales, and the decoder outputs images at three scales. We use UFMBlocks as the backbone network. In the encoder stage, we use DTKAN for feature downsampling, and in the decoder stage, we use UTKAN for feature upsampling
3.2 Tokenized KAN for Sampling
Analogous to a Multilayer Perceptron (MLP), a KAN with K layers can be described as a composition of successive KAN layers, this process can be formulated as following:
where I is the input feature;
where
by employing edge-learned activation functions and parameterized activation functions in place of weights, KAN distinguishes itself from traditional MLP, thereby eliminating the need for linear weight matrices. The architectural design bolsters the interpretability of KAN while maintaining high performance, rendering them apt for a broad spectrum of applications. The detailed framework of KAN layers is shown in Fig. 3d.
To expand the application of KAN in low-level vision, we introduce a novel approach that integrates KANs with the sampling layers within the U-Net architecture, specifically the Down-sampling Tokenized KAN (DTKAN) and Up-sampling Tokenized KAN (UTKAN) modules. These modules utilize Patch Embedding (PE) and Patch Unembedding (PU) techniques for tokenization, followed by the application of KAN layers for advanced embedding processes, thereby enhancing the network’s capability to handle complex visual tasks. The detailed structure of DTKAN and UTKAN is shown in Fig. 3b,c. For DTKAN, this process can be formulated as:
meanwhile, for UTKAN, it can be expressed as:
where
3.3 Uncertainty Coupling Certainty Module
To address the aleatoric uncertainty inherent in the data dimensions of the intricate visual task encompassing joint low-light image enhancement and sand-dust removal, we introduce the Uncertainty Coupling Certainty Module (UCCM). This module is designed to manage the stochastic elements present in these challenging image-processing tasks, thereby enhancing the robustness and reliability of the visual system. The detailed structure of our UCCM is shown in Fig. 4. In the UCCM, we employ a coupling mechanism between an uncertainty modeling branch and a deterministic representation branch to estimate the stochastic uncertainty present in the data. For the deterministic branch, we utilize a residual block from the ResNet [27] architecture for certain representations. As a quintessential component within convolutional neural networks, residual blocks possess formidable learning capabilities. The detailed process of the residual block can be articulated through the following formula:
meanwhile, for the uncertainty branch, we utilize a distribution modeling module for learning the uncertainty inside data-wise, it can be expressed as:
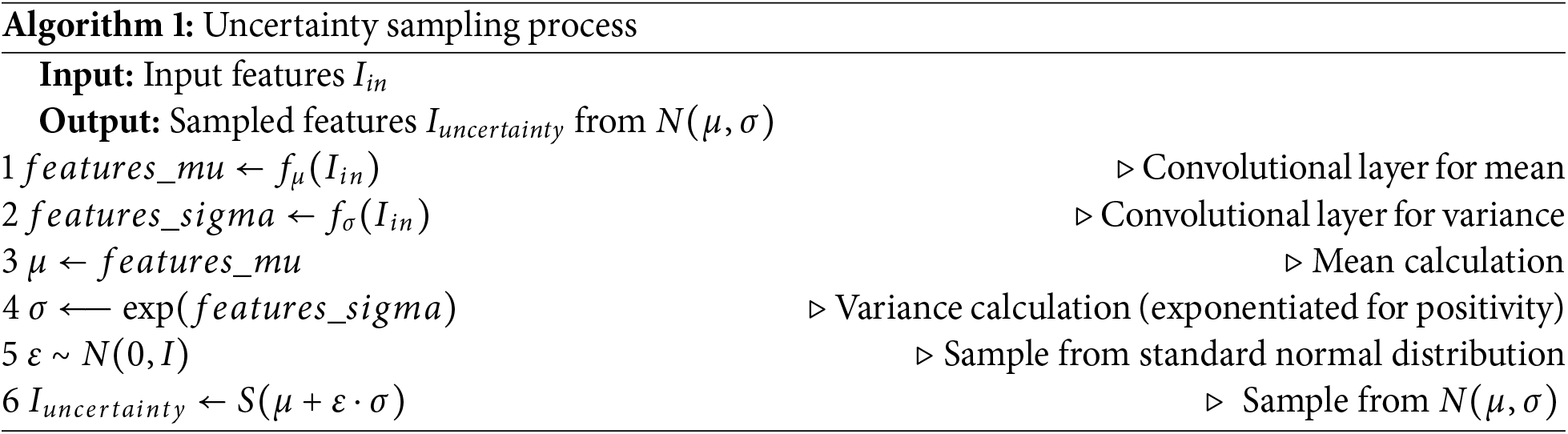
where S is the sampling operator from the Gaussian distribution by the parameterization trick [19],
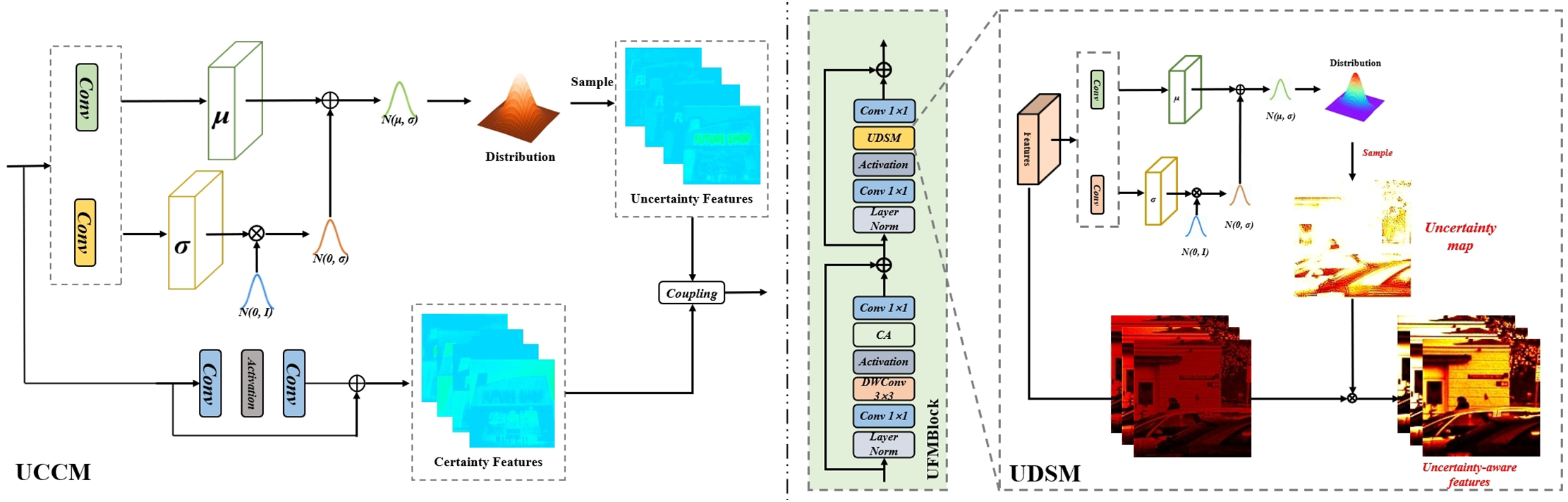
Figure 4: Detailed process of the uncertainty coupling certainty module (UCCM), uncertainty-aware distributional spatial modulator (UDSM), and uncertainty-aware feature modeling block (UFMBlock) in our UAKAN
3.4 Uncertainty-Aware Distributional Spatial Modulator
In order to make a proper response to the epistemic uncertainty in neural networks, that is, the model uncertainty, we embed an uncertainty-aware feature selective distribution learning module. This module is called the Uncertainty-aware Distributional Spatial Module (UDSM). We incorporate a distribution representation learning module, enabling our model to learn both a mean feature and a standard deviation feature. These two features are then combined to form a distribution from which we sample to obtain a single-channel selective map. This selective feature map is subsequently used to refine the expression of the input features selectively, yielding the final feature map for low-light enhancement and simultaneous sand-dust removal. The detailed structure of our proposed UDSM is shown in Fig. 4, and the whole process of UDSM can be described in Eq. (12):
Furthermore, we embed UDSM in the backbone of our UAKAN and call the backbone Uncertainty-aware Feature Modeling Block (UFMBlock). Inspired by the architecture of Transformers [21], our backbone structure can be divided into two analogous stages, each initiated with a layer normalization. Drawing from the design of residual blocks [27], we incorporate two convolutional layers within each stage, with an activation function interposed between them. Influenced by the NAFBlock [10], we introduce channel attention [28] and depth-wise convolution in the first stage to enhance the network’s fitting and learning capabilities. Consequently, we integrate the UDSM into the second stage of our backbone to balance the computational load between the two stages. The specific process of our backbone can be delineated by the following formula:
where
All the experiments are performed on the Ubuntu 20.04 operating system with a NVIDIA RTX4090 GPU (24 GB) and an Intel i7-13700k CPU processor. The network training and testing processes are implemented by using Python 3.10 language environment and encompass torch 2.3.1+cu118 in conjunction with Anaconda. We train all the models for 200 epochs with the AdamW optimizer. The initial learning rate is set to
For synthetic images used to train neural networks, we use a dataset named SLLIE6K that contains 6000 images for training and validation, and 2397 images for testing. We chose the Pascal VOC 2012 [30] dataset as clear images. For the training set, we picked 799 sharp images from the Pascal VOC 2012 dataset. Then, according to different Atmospheric Light, we synthesized three types of degraded images: dust, sand and sandstorm, and each type of image contained five degraded images with different degrees according to the Scattering Coefficient. As a result, 11,985 degraded images were obtained. Finally, in order to reduce the training data set and remove some training data with similar training effects, we selected 6000 images from all degraded images as training data. Then, for the test set, we also selected 799 clear images from the Pascal VOC 2012 dataset, and then, according to different Atmospheric Light, we synthesized three types of degraded images: Dust, Sand and Sandstorm. Therefore, the test data totals 2397 image pairs.
We use the Char loss [31] as the loss function for training all the neural networks. The Char loss [31] can be formulated as:
where
4.2 Quantitative and Qualitative Results
In the comparative experiments with other state-of-the-art methods, we compare our proposed method with various cutting-edge approaches and compute PSNR, SSIM, MAE, and LPIPS scores using the RGB channel following [1]. In addition, to compare the computational complexity of these learning-based methods, we have also listed relevant measurement metrics, including Params, FLOPs, inference tims, and memory cost. As shown in Table 1, our method achieves significant performance gains that are more than the state-of-the-art methods. Our method outperforms all comparison methods in all indicators. It outperforms the second-best FSNet by 0.11 dB in PSNR, and shows significant superiority in MAE and LPIPS. For the running time and memory consumption, we use a server equipped with an RTX4090 graphics card for inference time evaluation, and the image size is 128
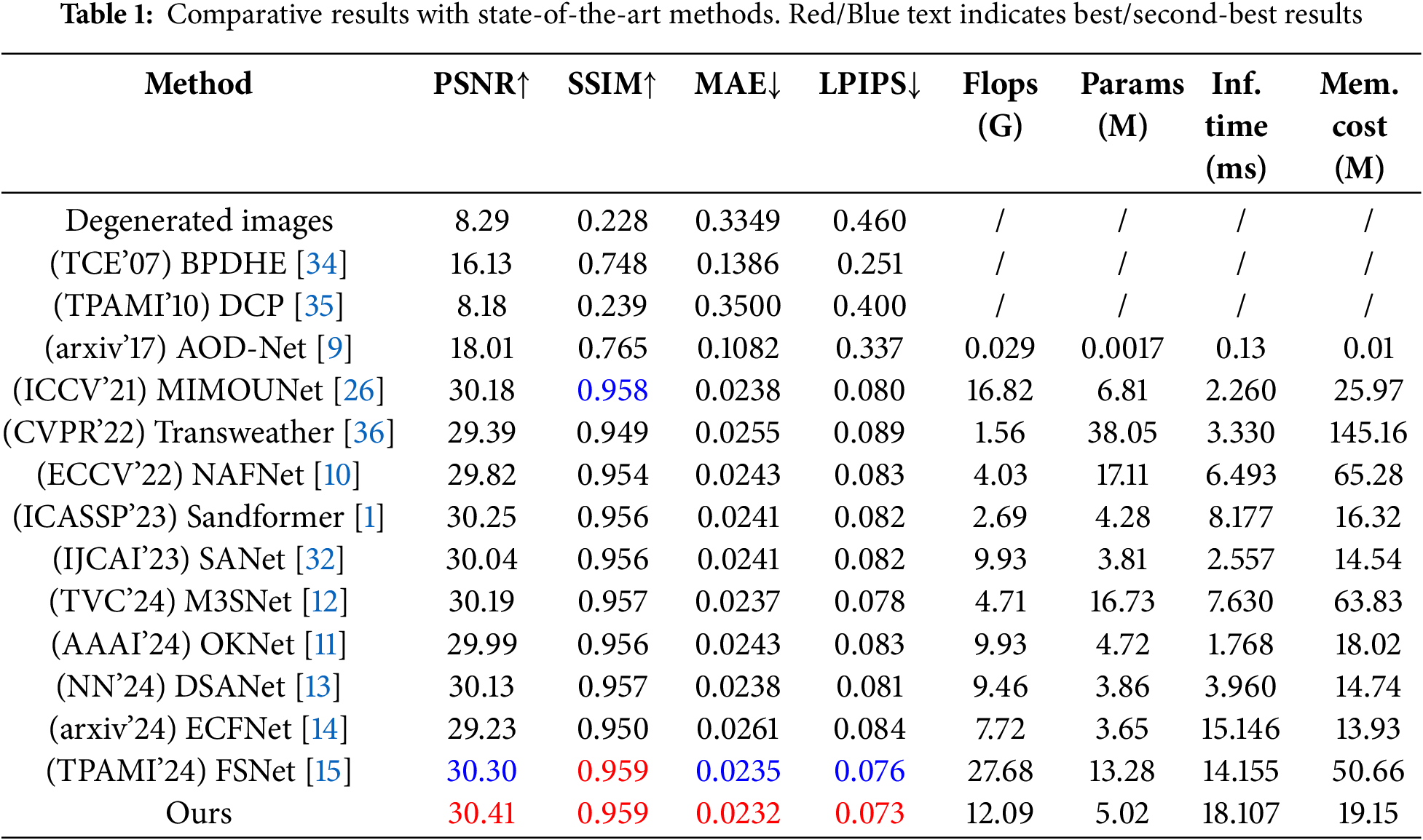

Figure 5: Joint low-light image enhancement and sand-dust removal results on SLLIE6K Dataset
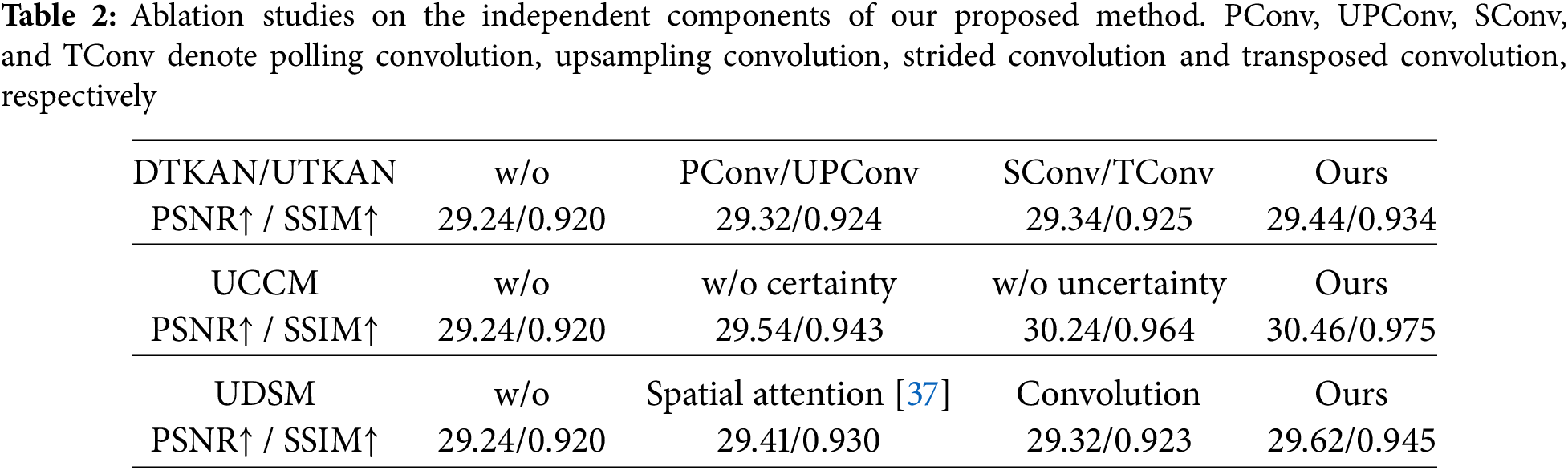
Table 2 presents ablation experimental metrics for our proposed DTKAN, UTKAN, UCCM, and UDSM. We conducted detailed ablation experiments on the components proposed in this paper. For the convenience and efficiency of the experiment, only 60% of the 6000 images used for training and validation in the SLLIE6K dataset were used for model training in the ablation experiment section, and the remaining images were used for testing. As Table 2 shown, it demonstrates that our proposed component enhances the performance of the model, underscoring the rationality of the model. For example, replacing the pooling convolution or strided convolution with the tokeniz KAN can enhance the network’s ability of image restoration. Embedding the UCCM module can increase PSNR by 1.22 dB. Our proposed UDSM module outperforms the spatial attention module and plain convolution layers by 0.21 and 0.30 dB, respectively. Therefore, Table 2 also indicates the superiority of our proposed individual modules.
In this paper, we introduce the concept of uncertainty learning in the joint removal of sand-dust and low-light enhancement in a single-image. Building upon this, we present the UAKAN framework that integrates our innovative Downsampling Tokenized KAN (DTKAN) and Upsampling Tokenized KAN (UTKAN) with Uncertainty-aware Distribution Spatial Modulator (UDSM) and Uncertainty Coupling Certainty Module (UCCM). Extensive evaluations confirm our method’s superiority over state-of-the-art image restoration techniques, with significant advantages in low-light sand-dust scenes. By modeling uncertainties in the JLLIESR task, UAKAN effectively addresses aleatoric uncertainty (data-level randomness) and epistemic uncertainty (model-level cognitive limitations). Meanwhile, UAKAN employs Tokenized KAN for sampling. Therefore, UAKAN can effectively perform the JLLIESR task and can effectively restore the original clear image from images where both sand-dust adhesion and low-light degradation occur simultaneously. However, our proposed method still has limitations. For example, our method still has room for improvement in image processing speed while keeping low computational complexity and memory occupation. This may lead to some potential failure cases or scenarios in which our proposed UAKAN may perform poorly, such as when deployed in terminals with high real-time requirements. Therefore, in the future, we will further optimize the running time of the reduced model and improve the performance of the model in order to achieve faster and more accurate image restoration.
Acknowledgement: Thanks for all the help of the teachers and students of the related universities.
Funding Statement: This research is supported by National Key R&D Program of China (2023YFB2504400).
Author Contributions: Study conception and design: Bingcai Wei, Hui Liu, Chuang Qian; data collection: Bingcai Wei, Haoliang Shen, Yibiao Chen; analysis and interpretation of results: Bingcai Wei, Haoliang Shen, Yixin Wang; draft manuscript preparation: Bingcai Wei, Hui Liu. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding author, Hui Liu, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Shi J, Wei B, Zhou G, Zhang L. Sandformer: CNN and transformer under gated fusion for sand dust image restoration. In: ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2023 Jun 4–10; Rhodes Island, Greece. p. 1–5. doi:10.1109/ICASSP49357.2023.10095242. [Google Scholar] [CrossRef]
2. Tian Y, Ye Q, Doermann D. YOLOv12: Attention-centric real-time object detectors. arXiv:2502.12524. 2025. doi:10.48550/arXiv.2502.12524. [Google Scholar] [CrossRef]
3. Chen Y, Yuan X, Wang J, Wu R, Li X, Hou Q, et al. YOLO-MS: rethinking multi-scale representation learning for real-time object detection. IEEE Trans Pattern Anal Mach Intell. 2025;47(6):4240–52. doi:10.1109/TPAMI.2025.3538473. [Google Scholar] [PubMed] [CrossRef]
4. Guo C, Li C, Guo J, Change Loy C, Hou J, Kwong S, et al. Zero-reference deep curve estimation for low-light image enhancement. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020 Jun 13–19; Seattle, WA, USA. p. 1780–9. doi:10.1109/CVPR42600.2020.00185. [Google Scholar] [CrossRef]
5. Wang W, Yin B, Li L, Li L, Liu H. A low light image enhancement method based on dehazing physical model. Comput Model Eng Sci. 2025;143(2):1595–616. doi:10.32604/cmes.2025.063595. [Google Scholar] [CrossRef]
6. Wang M, Li J, Zhang C. Low-light image enhancement by deep learning network for improved illumination map. Comput Vis Image Underst. 2023;232(4):103681. doi:10.1016/j.cviu.2023.103681. [Google Scholar] [CrossRef]
7. Narasimhan SG, Nayar SK. Vision and the atmosphere. Int J Comput Vis. 2002;48(3):233–54. doi:10.1023/A:1016328200723. [Google Scholar] [CrossRef]
8. Si Y, Yang F, Guo Y, Zhang W, Yang Y. A comprehensive benchmark analysis for sand dust image reconstruction. J Vis Commun Image Represent. 2022;89(12):103638. doi:10.1016/j.jvcir.2022.103638. [Google Scholar] [CrossRef]
9. Li B, Peng X, Wang Z, Xu J, Feng D. An all-in-one network for dehazing and beyond. arXiv:1707.06543. 2017. doi:10.48550/arXiv.1707.06543. [Google Scholar] [CrossRef]
10. Chen L, Chu X, Zhang X, Sun J. Simple baselines for image restoration. In: European Conference on Computer Vision; 2022 Oct 23–27; Tel Aviv, Israel. p. 17–33. doi:10.1007/978-3-031-20071-7_2. [Google Scholar] [CrossRef]
11. Cui Y, Ren W, Knoll A. Omni-kernel network for image restoration. Proc AAAI Conf Artif Intell 2024;38(2):1426–34. doi:10.1609/aaai.v38i2.27907. [Google Scholar] [CrossRef]
12. Gao H, Yang J, Zhang Y, Wang N, Yang J, Dang D. A novel single-stage network for accurate image restoration. Vis Comput. 2024;40(10):7385–98. doi:10.1007/s00371-024-03599-6. [Google Scholar] [CrossRef]
13. Cui Y, Knoll A. Dual-domain strip attention for image restoration. Neural Netw. 2024;171(5):429–39. doi:10.1016/j.neunet.2023.12.003. [Google Scholar] [PubMed] [CrossRef]
14. Gao H, Ma B, Zhang Y, Yang J, Yang J, Dang D. Emphasizing crucial features for efficient image restoration. arXiv:2405.11468. 2024. doi:10.48550/arXiv.2405.11468. [Google Scholar] [CrossRef]
15. Cui Y, Ren W, Cao X, Knoll A. Image restoration via frequency selection. IEEE Trans Pattern Anal Mach Intell. 2024;46(2):1093–108. doi:10.1109/TPAMI.2023.3330416. [Google Scholar] [PubMed] [CrossRef]
16. Kendall A, Badrinarayanan V, Cipolla R. Bayesian segnet: model uncertainty in deep convolutional encoder-decoder architectures for scene understanding. arXiv:1511.02680. 2015. doi:10.48550/arXiv.1511.02680. [Google Scholar] [CrossRef]
17. Gal Y, Ghahramani Z. Dropout as a bayesian approximation: representing model uncertainty in deep learning. In: Proceedings of The 33rd International Conference on Machine Learning; 2016 Jun 19–24; New York, NY, USA. Vol. 48, p. 1050–9. [Google Scholar]
18. Wang Z, Li Y, Guo Y, Fang L, Wang S. Data-uncertainty guided multi-phase learning for semi-supervised object detection. In: Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition; 2021 Jun 20–25; Nashville, TN, USA. p. 4568–77. doi:10.1109/CVPR46437.2021.00454. [Google Scholar] [CrossRef]
19. Zhou C, Huang Y, Pu M, Guan Q, Huang L, Ling H. The treasure beneath multiple annotations: an uncertainty-aware edge detector. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2023 Jun 17–24; Vancouver, BC, Canada. p. 15507–17. doi:10.1109/CVPR52729.2023.01488. [Google Scholar] [CrossRef]
20. Yang F, Zhai Q, Li X, Huang R, Luo A, Cheng H, et al. Uncertainty-guided transformer reasoning for camouflaged object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2021 Oct 11–17; Montreal, QC, Canada. p. 4146–55. doi:10.1109/ICCV48922.2021.00411. [Google Scholar] [CrossRef]
21. Vaswani A. Attention is all you need. In: Advances in neural information processing systems. 2017 [Internet]. [cited 2025 Jun 10]. Available from: https://proceedings.neurips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html. [Google Scholar]
22. Zhang Y, Zhang Q, Zhu Z, Hou J, Yuan Y. Glenet: boosting 3D object detectors with generative label uncertainty estimation. Int J Comput Vis. 2023;131(12):3332–52. doi:10.1007/s11263-023-01869-9. [Google Scholar] [CrossRef]
23. Tang T, Zhou L, Hao P, He Z, Ho K, Gu S, et al. S2-Track: a simple yet strong approach for end-to-end 3D multi-object tracking. arXiv:2406.02147. 2024. doi:10.48550/arXiv.2406.02147. [Google Scholar] [CrossRef]
24. Dong M, Yang A, Wang Z, Li D, Yang J, Zhao R. Uncertainty-aware consistency learning for semi-supervised medical image segmentation. Knowl Based Syst. 2025;309(1):112890. doi:10.1016/j.knosys.2024.112890. [Google Scholar] [CrossRef]
25. Shao Z, Wang H, Cai Y, Chen L, Li Y. UA-fusion: uncertainty-aware multimodal data fusion framework for 3d object detection of autonomous vehicles. IEEE Trans Instrum Meas. 2025;74:2514916. doi:10.1109/TIM.2025.3548184. [Google Scholar] [CrossRef]
26. Cho SJ, Ji SW, Hong JP, Jung SW, Ko SJ. Rethinking coarse-to-fine approach in single image deblurring. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2021 Oct 11–17; Montreal, QC, Canada. p. 4641–50. doi:10.1109/ICCV48922.2021.00460. [Google Scholar] [CrossRef]
27. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2016 Jun 27–30; Las Vegas, NV, USA. p. 770–8. doi:10.1109/CVPR.2016.90. [Google Scholar] [CrossRef]
28. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 7132–41. doi:10.1109/CVPR.2018.00745. [Google Scholar] [CrossRef]
29. Ba JL, Kiros JR, Hinton GE. Layer normalization. arXiv:1607.06450. 2016.doi:10.48550/arXiv.1607.06450. [Google Scholar] [CrossRef]
30. Everingham M, Gool LV, Williams CKI, Winn J, Zisserman A. The pascal visual object classes (voc) challenge. Int J Comput Vis. 2010;88(2):303–38. doi:10.1007/s11263-009-0275-4. [Google Scholar] [CrossRef]
31. Charbonnier P, Blanc-Feraud L, Aubert G, Barlaud M. Two deterministic half-quadratic regularization algorithms for computed imaging. In: Proceedings of 1st International Conference on Image Processing; 1994 Nov 13–16; Austin, TX, USA. p. 168–72. doi:10.1109/ICIP.1994.413553. [Google Scholar] [CrossRef]
32. Cui Y, Tao Y, Jing L, Knoll A. Strip attention for image restoration. In: Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence Main Track; 2023 Aug 19–25; Macao, China. p. 645–53. doi:10.24963/ijcai.2023/72. [Google Scholar] [CrossRef]
33. Zheng C, Shi D, Liu Y. Windowing decomposition convolutional neural network for image enhancement. In: Proceedings of the 29th ACM International Conference on Multimedia; 2021 Oct 20–24; Virtual Event, China. p. 424–32. doi:10.1145/3474085.3475181. [Google Scholar] [CrossRef]
34. Ibrahim H, Kong NSP. Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans Consum Electron. 2007;53(4):1752–8. doi:10.1109/TCE.2007.4429280. [Google Scholar] [CrossRef]
35. He K, Sun J, Tang X. Single image haze removal using dark channel prior. IEEE Trans Pattern Anal Mach Intell. 2010;33(12):2341–53. doi:10.1109/TPAMI.2010.168. [Google Scholar] [PubMed] [CrossRef]
36. Valanarasu JMJ, Yasarla R, Patel VM. Transweather: transformer-based restoration of images degraded by adverse weather conditions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022 Jun 18–24; New Orleans, LA, USA. p. 2353–63. doi:10.1109/CVPR52688.2022.00239. [Google Scholar] [CrossRef]
37. Woo S, Park J, Lee JY, Kweon IS. Cbam: convolutional block attention module. In: Proceedings of the European Conference on Computer Vision (ECCV); 2018 Sep 8–14; Munich, Germany. p. 3–19. doi:10.1007/978-3-030-01234-2_1. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools