
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

CLIP-ASN: A Multi-Model Deep Learning Approach to Recognize Dog Breeds
1 College of Information Technology, Amman Arab University, Amman, 11953, Jordan
2 University of Institute Information Technology, PMAS-Arid Agriculture University Rawalpindi, Rawalpindi, 46000, Pakistan
3 Department of Computer Science, College of Computer & Information Sciences, King Saud University, Riyadh, 11543, Saudi Arabia
4 School of Computer Science and Engineering, Central South University, Changsha, 410083, China
* Corresponding Author: Asif Nawaz. Email:
Computers, Materials & Continua 2025, 85(3), 4777-4793. https://doi.org/10.32604/cmc.2025.064088
Received 05 February 2025; Accepted 05 June 2025; Issue published 23 October 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The kingdom Animalia encompasses multicellular, eukaryotic organisms known as animals. Currently, there are approximately 1.5 million identified species of living animals, including over 195 distinct breeds of dogs. Each breed possesses unique characteristics that can be challenging to distinguish. Each breed has its own characteristics that are difficult to identify. Various computer-based methods, including machine learning, deep learning, transfer learning, and robotics, are employed to identify dog breeds, focusing mainly on image or voice data. Voice-based techniques often face challenges such as noise, distortion, and changes in frequency or pitch, which can impair the model’s performance. Conversely, image-based methods may fail when dealing with blurred images, which can result from poor camera quality or photos taken from a distance. This research presents a hybrid model combining voice and image data for dog breed identification. The proposed method Contrastive Language-Image Pre-Training-Audio Stacked Network (CLIP-ASN) improves robustness, compensating when one data type is compromised by noise or poor quality. By integrating diverse data types, the model can more effectively identify unique breed characteristics, making it superior to methods relying on a single data type. The key steps of the proposed model are data collection, feature extraction based on Contrastive Language Image for image-based feature extraction and Audio stacked-based voice features extraction, co-attention-based classification, and federated learning-based training and distribution. From the experimental evaluation, it has been concluded that the performance of the proposed work in terms of accuracy 89.75% and is far better than the existing benchmark methods.Keywords
An animal breed refers to a specific type or variety of domestic animal that has been selectively bred by humans for particular traits or characteristics. These traits can include physical appearance, size, behavior, temperament, and production of milk, meat, wool, or other useful products [1,2]. Some of the most common animal breeds are vital such as, there are more than 195 recognized breeds of dogs, each with unique physical and behavioral characteristics [3]. Cats have more than 100 recognized breeds, each with unique physical and behavioral characteristics. There are more than 300 breeds of horses, each with its own unique size, shape, and characteristics [4]. Cattle have more than 800 breeds which are raised for meat, dairy, and other agricultural products [5]. These are only a few of the numerous animal breeds that people have kept as pets throughout history. Each breed has its own distinct set of qualities and traits that humans have deliberately chosen to suit demands and serve functions.
One of the most well-liked and well-known pets in the world is the dog which is the focus of this study. They occur in a variety of breeds, each with their own special traits and characteristics. It can be challenging to determine a dog’s breed, especially for those unfamiliar with them. Most Machine learning techniques for animal breed identification are either image or voice-based [6]. The image-based technique requires high-quality and dimension pictures for accurate identification, which is a difficult and challenging task. Whereas, in the voice-based technique, the frequency or pitch may vary from device to device which makes it quite difficult to recognize animal breeds. This research tries to design an ensemble strategy with high accuracy to identify the animal breed using both image and their voices.
The dog is one of the most popular and well-known pets in the world. As seen in Fig. 1, they come in a variety of breeds, each with their own unique qualities and characteristics. Knowing a dog’s breed can be challenging, especially for individuals who are not familiar with them. Physical inspection or DNA testing are two common traditional methods for identifying a dog’s breed, but they can be time-consuming, expensive, and unreliable. Since the development of artificial intelligence and machine learning in recent years, there has been an increase in interest in applying these technologies to categorize various dog breeds [7]. The identification of lost or found dogs, encouraging the breeding of dogs for desirable characteristics, and aiding in medical diagnosis and treatment are just a few practical uses for knowing a dog’s breed. Historically, experts have classified breeds manually using physical traits including size, shape, and color. However, this procedure can be time-consuming and error-prone, particularly when dealing with breeds that appear to be similar [8].

Figure 1: Famous dog breeds adopted from [1]
In recent years, a number of studies have been conducted to identify dog breeds using a variety of techniques, such as the synthetic method and machine learning techniques. The synthetic breed identification method looks at genetic markers in a dog’s DNA to determine its breed. This method uses DNA testing to identify specific genetic markers connected to specific breed groups [9]. As part of the procedure, a blood sample may be utilized to collect a sample of the dog’s DNA. Then, specific genetic markers, such as single nucleotide polymorphisms (SNPs) connected to different breeds, are found using this DNA sample. By contrasting these genetic markers with a reference database of recognized breed markers, the breed of the dog can be distinguished with a high level of accuracy.
The synthetic methodology is considered to be a fairly reliable method for identifying breeds because it is based on the genetic makeup of the dog rather than a subjective visual judgment of physical attributes It is important to remember that breed identification by DNA testing is not always accurate, making it difficult to identify a breed, even if several breeds may have comparable genetic markers. Furthermore, because DNA testing only identifies breeds that are mentioned in the reference database, this technology cannot likely recognize rare or obscure breeds [10].
Despite the promising results of machine learning approaches in dog breed identification, several key challenges remain unresolved. One major limitation is the generation and use of synthetic data, which may fail to capture the full complexity and diversity of real-world visual and auditory features associated with different breeds. This mismatch can lead to poor generalization, causing biases and inaccuracies in breed classification models. Furthermore, ensuring that synthetic datasets are truly representative of natural conditions is difficult, which compromises the robustness and reliability of trained models. Variability in lighting conditions, background noise, occlusions, and intra-breed differences can further complicate accurate recognition. These issues highlight the need for more advanced and reliable approaches that can integrate and generalize across multiple data modalities in realistic scenarios.
In this article, we propose a deep learning-based ensemble technique (CLIP-ANS) to recognize dog breeds using both image and voice. CLIP-ANS is a hybrid technique having data collection, multi-data feature extraction, feature fusion, classification, and federated learning-based distribution. The proposed technique is evaluated on various datasets and the experimental results reveal that the performance of CLIP-ANS is far better than the existing research.
Research Contribution
The key contributions of the proposed work are as follows:
• The proposed work is non-invasive, which means it does not require physical contact with the dog. Moreover, the proposed work is useful in situations where the dog is difficult to capture or may be aggressive.
• The utilization of CLIP and Audio stack network with Stacked Block (SB) Mobile inverted Bottleneck Coevolution provides a more robust model by focusing voice and image-based data for accurate breed identification.
• Secondly, the system is cost-effective and can be easily deployed on a wide range of devices, including smartphones and tablets.
• The experimental evaluation portrays that the proposed research is highly accurate and can recognize dog breeds with a high degree of precision.
The remainder of the article is structured as follows. Section 2 is about literature review. Section 3 presents CLIP-ANS. Section 4 discusses the experimental results, and Section 5 concludes the article.
This section presents the state-of-the-art methods of animal breed identification. Due to the diverse nature of the problem some of the technique has also be presented in Table 1. First study [11] presents a model for grading canine cataracts using images taken with standard mobile phone cameras. The approach leverages a Support Vector Machine (SVM) algorithm for accurate cataract classification, with K-fold cross-validation confirming the reliability of the image-based assessments. Similar work has also been presented by Shah et al. [12], whose research focuses on the classification of dog breeds using a deep convolutional neural network, which is a challenging task. To achieve this, a dataset comprising sample images of both dogs and humans was used to identify and learn breed-specific features.

Borwarnginn et al. [13] discussed a number of issues related to the huge number of dogs, such as population control, illness management (such as rabies), vaccination administration, and legal ownership. Accurate identification of individual dogs and their respective breeds is crucial for giving proper treatments and training because there are over 180 dog breeds, each with unique traits and specialized health issues. A deep learning-based strategy using convolutional neural networks (CNN) with transfer learning was proposed in the study report in addition to two conventional methods using Local Binary Pattern (LBP) and Histogram of Oriented Gradient (HOG). The retrained CNN model outperformed the traditional methods in the study’s evaluation of how well these methods classified dog breeds. In particular, the suggested method greatly outperformed the accuracy of 79.25% obtained using the HOG descriptor, achieving an amazing accuracy of 96.75%.
From the above discussion, we concluded that there exist a lot of deficiencies in animal breed recognition. The majority of machine learning methods for identifying animal breeds are based on either voice or image. High-quality and dimension-based photos are required for image-based approaches. Whereas, the voice-based technique may lead to poor results due to the frequency and pitch of the recorded voice on different devices. The primary goal of CLIP-ANS is to determine the animal breed from speech and image mash-ups. The proposed technique will be capable of identifying dog breeds as well as all other Animalia. The experimental results indicate that the proposed work is more precise in identification when compared to current best practices.
This section discusses the proposed conceptual model. Whereas Fig. 2 shows the architecture of the proposed work. The CLIP-ANS framework has been optimized for efficiency, with a computational cost that is well-suited for edge devices. The model achieves an optimal training time of approximately 12 h for the initial phase, utilizing transfer learning to minimize the need for large-scale data processing. For deployment, the model requires minimal computational resources, with an estimated memory footprint of 150 MB and an inference time of 150 ms per image or audio input. These optimized resource requirements ensure the model can run smoothly on devices with limited processing power.

Figure 2: Proposed CLIP-ASN architecture for dog breed identification
Collecting high-quality data for breed identification is crucial for the development of accurate and reliable machine-learning models. In this context, data collection for breed identification using both image and voice presents a unique set of challenges, as it requires the collection and labeling of both visual and audio data.
Table 2 shows a detailed description of the dog breed dataset. The Image datasets (DS-I) consist of many high-quality images of dogs labeled with their respective breeds. The web link to the dataset has also been mentioned. The images are already rotated and flipped, that helps to increase the size and diversity of the datasets. This contains over 20,000 images of 120 dog breeds. The publicly accessible dataset has been extensively utilized in studies on computer vision and breed recognition.

The DS-II is a voice recorder that comes with a lot of dog voice clips. The types of animals in this collection are also labeled. It might take a lot of work to reliably tell the difference between dog types based on their sound, since this dataset was made using a thorough and varied recording method. It is important to use a range of dog types and audio clips taken in a range of settings to make sure that these models are reliable and can be used in other situations. This set has more than 500 sound clips of different types of dogs growling and barking. A lot of research on animal behaviour and breed spotting has used the information that is available to everyone. The DS-III, which blends voice and picture, can help people learn more about dog types and how they sound and look.
Voice and picture analysis both need feature extraction in order to achieve reliable breed identification. In the field of voice analysis, distinguishing between various dog breeds may be accomplished by extracting characteristics such as the length, pitch, and intensity of the bark [19]. For the purpose of picture analysis, the suggested model may be assisted in precisely recognizing patterns and classifying breeds by extracting information such as the color of the fore, the shape of the ear, and the size of the snout. Identifying the distinctive characteristics of each breed would be difficult in the absence of feature extraction, which would increase the difficulty of proper identification.
3.2.1 Image Based Feature Extraction
CLIP (Contrastive Language-Image Pre-Training) provides distinct benefits over other deep learning models for tasks such as image-text association and semantic comprehension [20]. On the other hand, there are an excessive number of deep learning algorithms that extract characteristics from pictures. CLIP makes use of contrastive learning to learn from large-scale picture-text pairings without explicit labels, which enables it to generalize over a wide range of domains and tasks. This is in contrast to typical image classification models, which need labelled datasets for particular tasks [21]. Furthermore, CLIP’s design, which simultaneously learns to encode pictures and text into a common embedding space, enables it to capture deep semantic links between visual and textual ideas. This is made possible by the fact that CLIP also learns to encode text. Because of this, CLIP is particularly well-suited for tasks that involve understanding the context and meaning of images and text. Some examples of these tasks include cross-modal retrieval, image captioning, and natural language understanding. CLIP provides a solution that is both versatile and efficient for a variety of applications in computer vision and natural language processing.
As depicted in Algorithm 1, CLIP uses a neural network architecture to encode both images and text into feature vectors in a shared embedding space. These feature vectors capture semantic information about the content of images and text. The CLIP model consists of an image encoder and a text encoder. The image encoder is typically a convolutional neural network (CNN), while the text encoder is usually a transformer-based model. Let “I” represent the input image and “T” represent the input text. The image encoder produces a feature vector

CLIP learns to associate images and text by training on a contrastive learning objective. The objective is to maximize the similarity between feature vectors of matching image-text pairs and minimize the similarity between feature vectors of non-matching pairs. Let Sim (fI, fT) denote the similarity between the feature vectors of an image I and its corresponding text T. The contrastive loss is defined as in Eq. (1):
where f, j represent the feature vector of a non-matching text for the given image.
3.2.2 Audio Based Feature Extraction
The audio based feature extraction process is presented in Algorithm 2 that start with the normalization of audio data to ensure consistent amplitude levels across recordings. Additionally, this division of the audio into short-time frames using techniques Hamming window with fixed size frame size has also be done. After which a Short-Time Fourier Transform (STFT) [22] has been applied to convert the audio frames into the time-frequency domain representation. The STFT of a signal χ(t) is given by Eq. (2):
where X(f,t) is the STFT, χ(t) is the input signal, ω(t) is the window function, and f is frequency. After the conversion of audio frames into time-frequency representation the Mel-Frequency Cepstral Coefficients (MFCCs) [23] has been applied to extract relevant features from the spectrogram. MFCCs are computed in Eq. (3) by taking the Discrete Cosine Transform (DCT) [24] of the log filter-bank energies.
where MFCCi is the ith MFCC coefficient, Ek is the energy in the kth Mel filterbank.

A sophisticated architecture designed to efficiently extract discriminative features from dog voice data. This architecture comprises a series of SB stacked blocks, each housing Mobile Inverted Bottleneck (MB) structures. The Mobile Inverted Bottleneck block employs depth-wise separable convolution followed by point-wise convolution, facilitating the extraction of spatial and channel-wise information while minimizing computational overhead. Through the SB stacking, multiple Mobile Inverted Bottleneck blocks are sequentially arranged to enhance the model’s representational capacity. Co-evolutionary techniques are then employed to adaptively optimize the parameters of these stacked blocks, ensuring the network learns to capture intricate patterns and nuances present in the dog vocalizations, thereby facilitating accurate breed recognition.
3.2.3 Co-Attention Based Fusion and Classification
The Co-Attention fusion network integrates audio and text features for precise dog breed classification as described in Algorithm 3, leveraging a dynamic attention mechanism to align and fuse information from both modalities. Mathematically, the attention weights for the audio features (A) and text features (T) are computed using compatibility functions, denoted as Att(⋅). These attention weights capture the importance of each modality’s features in the classification task. The fused representation FF is obtained by combining the audio features (X) and text features (Y) with their respective attention weights, weighted by AA and TT, respectively. This fusion process is represented in Eq. (4).

The fused representation is then fed into a classification layer, where the fully connected layer applies a linear transformation to the fused representation, followed by an activation function to introduce non-linearity. Denoting the fully connected layer parameters as W and b, the output of the fully connected layer (z) can be expressed as z = W ⋅ F + b. Finally, the softmax activation function is applied to the output of the fully connected layer to obtain the probabilities of each dog breed. The softmax function is a commonly used activation function in multi-class classification tasks, including dog breed classification. Mathematically, given a vector of raw scores or logits z, the softmax function computes the probabilities of each class as depicted in Eq. (5):
where P(yi|z) represents the probability of class i given the input logits z. e denotes the base of the natural logarithm (Euler’s number). zi is the raw score or logit for class i and C is the total number of classes.
The softmax function normalizes the logits by exponentiating each score and dividing it by the sum of all exponentiated scores across all classes. This normalization ensures that the output probabilities lie in the range [0, 1] and sum up to 1, making them interpretable as class probabilities. This property enables the model to perform multi-class classification effectively, as the output can be directly interpreted as the likelihood of each class being the correct label.
3.2.4 Federated Learning Based Distribution
Due to the intricacy and diversity of these inputs, it has proven difficult to identify different dog breeds at each door step. Federated learning has become a potential method for developing any newly designed models in a distributed setting while maintaining the confidentiality and privacy of the data [24]. The proposed Federated learning offers a decentralized approach to model training, enabling collaboration among multiple edge devices or clients while preserving data privacy. In the context of distributing the proposed Co-Attention fusion network for dog breed classification, federated learning presents a compelling solution to address data privacy concerns and leverage diverse datasets distributed across different locations or devices. The distribution of the proposed model in a federated learning setting involves several key steps.
Initially, the server initializes the global parameters of the Co-Attention fusion network and distributes them to participating clients. Each client locally trains the model using its own data, which in this case, includes both audio recordings and textual descriptions of dog breeds. During local training, clients update the model parameters based on their respective datasets using techniques like stochastic gradient descent (SGD) or variants such as Federated Averaging. Instead of sending raw data to the central server, clients send only the model updates (i.e., gradients) back to the server. This approach preserves the privacy of client data as sensitive information never leaves the client’s device. The server aggregates the model updates from all clients using federated averaging, adjusting the global model parameters accordingly.
To ensure robustness and fairness, the proposed federated learning employs strategies of weighted aggregation, where clients with more representative or diverse data contribute more to the global model update. This helps mitigate the effects of data heterogeneity and non-IID (non-identically distributed) data across clients. Finally, the updated global model is then redistributed to the clients for further iterations of local training. The model is shown in Fig. 3. This iterative process continues until convergence criteria are met or a predefined number of communication rounds is completed. By distributing the training process across multiple clients and aggregating their contributions in a privacy-preserving manner, federated learning facilitates the development of a robust and generalized Co-Attention fusion network for dog breed classification, capable of capturing diverse patterns and nuances present in distributed datasets while respecting user privacy.

Figure 3: Proposed federated learning mechanism for dog breed classification
This section details the experimental outcomes and evaluates the effectiveness of the proposed method. Numerous experiments were conducted to assess the accuracy and efficiency of the proposed system. The experimental evaluation demonstrated that the proposed technique significantly outperforms existing cutting-edge methods.
The baseline method establishes a starting point for evaluating advanced algorithms. It is simple and transparent, providing a basic level of performance. It guides research, highlights limitations, and sets a minimum threshold for success, fostering fairness in comparisons and driving innovation.
• Existing 1: Ráduly et al. [25] proposed a technique that was based on the deep learning model.
• Existing 2: Abdel-Hamid et al. [26] proposed a technique that was based on the Convolutional Neural Networks (Hidden Markov Model, Deep Neural Networks).
• Existing 3: Sinnott et al. [27] proposed a technique that was based on the Machine Learning techniques.
In the very first step, the experiment performed the efficacy of a novel method for breed identification, by measuring its precision, accuracy, and recall. The experimental results are presented graphically in Fig. 4 which depicts the performance of the proposed approach across different datasets (namely, Dog Images and Dogs Voice) in terms of precision, accuracy, and recall. Fig. 4 demonstrates that the proposed technique achieved high scores on all datasets, indicating impressive results in terms of precision, accuracy, and recall across each dataset.

Figure 4: Performance measure of CLIP-ANS in term of precision, recall and F-score
The graphical representation in Fig. 4 indicates that the proposed technique achieved high precision, recall, and accuracy scores across the different datasets. The precision, recall, and accuracy of the suggested technique were specifically 82.74%, 75.15%, and 87.45% when used on the Images dataset, demonstrating outstanding results. Similar results were obtained when the suggested method was applied to the Voice dataset, yielding impressive precision, recall, and accuracy scores of 85.47%, 77.2%, and 84.24%. Another experiment was conducted to observe the confusion matrix for the prediction of the top three breeds as numbered (1, 2, 3) in the matrix. The results of DS-I, DS-II, and DS-III in Fig. 5a–c demonstrate the confusion matrix of DS-I, DS-II, and DS-III, respectively.


Figure 5: Confusion matrix on DS-I, DS-II and DS-III. (a) Actual-predicted response rate of the proposed CLIP-ASN on DS-I; (b) Actual-predicted response rate of the proposed CLIP-ASN on DS-II; (c) Actual-predicted response rate of the proposed CLIP-ASN on DS-III
Furthermore, the proposed technique also performed well on the Miscellaneous (DS3) dataset, with a precision of 88.42% and recall and accuracy scores of 80% and 84%, respectively. Overall, these results demonstrate that the proposed approach is efficient and exhibits superior performance in terms of recall, accuracy, F-score and precision, for the task of dog breed identification. The results are shown in Fig. 6.

Figure 6: Comparison of the CLIP-ANS with the baselines approaches
Using the Inception Net-V2 and CNN models that were suggested in [20], the Dogs dataset was assessed. Their findings showed that other organizations had an accuracy of 84.24%, whereas CNN had 78.12% accuracy. With scores of 87.45% and 88.05%, the proposed method demonstrated greater accuracy, which is exceptional and emphasizes the uniqueness of the suggested methodology in terms of accuracy. The proposed method also performed better than the Inception Net-V2 and CNN models, which had accuracy values of 78.12%, 84.24%, and 80.95%, respectively. Because Inception Net-V2 uses probabilistic methods and significantly depends on the quality of training data, the higher accuracy attained by the proposed strategy on the Voice dataset can be attributable to this. Due to inadequate training data, Inception Net-V2 was unable to correctly detect breed identity in the Voice dataset. The accuracy attained by the CLIP-ANS and other alternatives (DS1, DS2, and DS3) is depicted in Fig. 7. The accuracy bar of the proposed method clearly outperforms the alternatives, demonstrating their superior performance.

Figure 7: Comparative analysis of CLIP-ASD with existing benchmark methods
Ethical considerations play a crucial role in the development and deployment of AI-driven breed identification systems, particularly when such technologies are used for purposes such as pet adoption, breeding, and veterinary care. One key ethical concern is ensuring fairness and avoiding bias in the model’s predictions, as AI systems can unintentionally reinforce existing prejudices, such as promoting certain breeds over others or misidentifying animals based on incomplete or skewed data. Furthermore, privacy concerns may arise, especially if voice or image data is collected from pets without proper consent or transparency regarding its use. The implementation of federated learning in our model addresses some of these concerns by keeping sensitive data decentralized and private. However, it is also essential to ensure that such systems are used responsibly, with proper guidelines for data handling, informed consent, and transparency in algorithmic decision-making, to avoid unintended consequences and ensure ethical deployment in real-world scenarios.
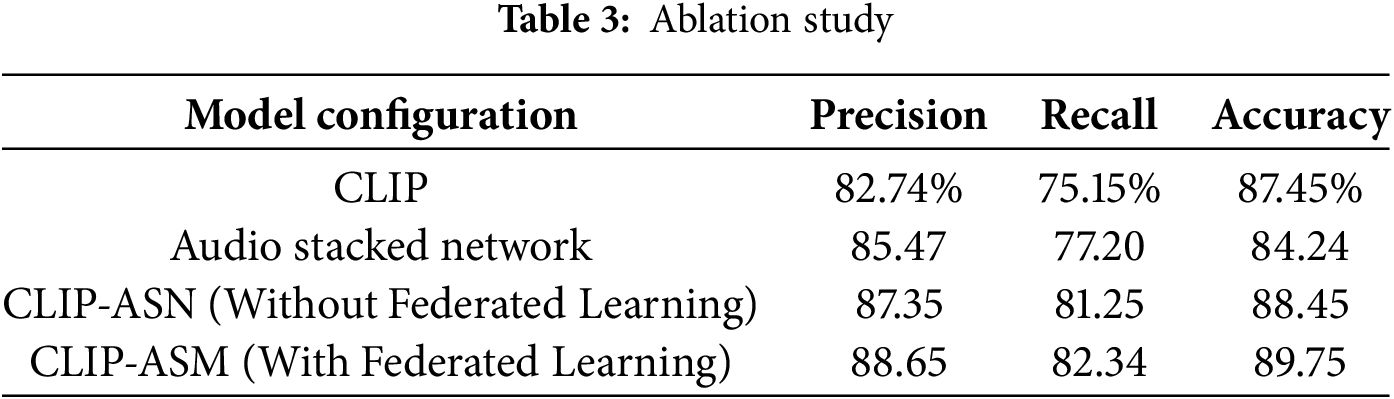
The ablation study demonstrates a clear performance improvement as different components are added to the model as shown in Table 3. The image-only (CLIP) and audio-only (Audio Stacked Network) models achieved decent results, but their limitations were evident in terms of recall and accuracy. Introducing multimodal fusion in CLIP-ASN significantly enhanced performance, and the addition of Federated Learning in CLIP-ASM further boosted the results to the highest accuracy of 89.75%, showcasing improved generalization, robustness, and privacy-aware learning.
This study presents CLIP-ANS, a hybrid model that combines both image and voice data for more accurate dog breed identification, overcoming the limitations of single-modal approaches. By leveraging the complementary strengths of visual and auditory data, the model achieves greater robustness in identifying unique breed characteristics, which is particularly valuable in real-world scenarios where data quality may vary. The experimental results demonstrate that CLIP-ANS outperforms existing benchmark methods with an accuracy rate of 89.75%, highlighting its potential as a reliable tool for breed identification. The integration of federated learning further enhances the model’s privacy and scalability, making it suitable for deployment in distributed environments. This work provides a significant step forward in multi-modal recognition and offers a foundation for future applications in the broader animal identification domain.
Future research will focus on refining CLIP-ANS by incorporating advanced deep learning techniques, such as self-supervised learning, to improve representation learning and reduce the reliance on labeled data. Additionally, further exploration of fusion strategies for combining image and voice data more effectively could enhance model performance, particularly in challenging environments with noisy or incomplete data. Extending the framework to include more animal species and evaluating its adaptability to various environmental conditions will be essential for broadening its real-world applicability. Moreover, improving the scalability of the federated learning approach could facilitate the deployment of the model in large-scale, decentralized systems while ensuring privacy and security in sensitive applications.
Acknowledgement: The authors gratefully acknowledge the support of King Saud University, Saudi Arabia.
Funding Statement: The authors extend their appreciation to King Saud University, Saudi Arabia for funding this work through Ongoing Research Funding Program (ORF-2025-953), King Saud University, Riyadh, Saudi Arabia.
Author Contributions: All authors contributed equally. The authors confirm their contribution to the paper as follows: Study conception and design, Supervision and Methodology: Asif Nawaz; Data collection: Rana Saud Shoukat; Conceptualization: Khalil El Hindi; Analysis and interpretation of results: Mohammad Shehab; Draft manuscript preparation: Zohair Ahmed. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data is available with the corresponding author and can be shared on request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Ahuja M. Life sciences. Delhi, India: Gyan Publishing House; 2006. [Google Scholar]
2. Singh A, Kothari R, Arulalan V. Dog breed detection using YOLOv7 and WOA-CNN. In: Proceedings of the 2024 10th International Conference on Communication and Signal Processing (ICCSP); 2014 Apr 12–14; Melmaruvathur, India. doi:10.1109/ICCSP60870.2024.10543599. [Google Scholar] [CrossRef]
3. van Boom KM, Schoeman JP, Steyl JCA, Kohn TA. Fiber type and metabolic characteristics of skeletal muscle in 16 breeds of domestic dogs. Anat Rec. 2023;306(10):2572–86. doi:10.1002/ar.25207. [Google Scholar] [PubMed] [CrossRef]
4. Ameen C, Benkert H, Fraser T, Gordon R, Holmes M, Johnson W, et al. In search of the ‘great horse’: a zooarchaeological assessment of horses from England (AD 300-1650). Int J Osteoarchaeol. 2021;31(6):1247–57. doi:10.1002/oa.3038. [Google Scholar] [CrossRef]
5. Amirhosseini MH, Yadav V, Serpell JA, Pettigrew P, Kain P. An artificial intelligence approach to predicting personality types in dogs. Sci Rep. 2024;14(1):2404. doi:10.1038/s41598-024-52920-9. [Google Scholar] [PubMed] [CrossRef]
6. Benz-Schwarzburg J, Monsó S, Huber L. How dogs perceive humans and how humans should treat their pet dogs: linking cognition with ethics. Front Psychol. 2020;11:584037. doi:10.3389/fpsyg.2020.584037. [Google Scholar] [PubMed] [CrossRef]
7. Mulligan K, Rivas P. Dog breed identification with a neural network over learned representations from the xception cnn architecture. In: Proceedings of the 21st International Conference on Artificial Intelligence (ICAI 2019); 2019 Feb 11–13; Okinawa, Japan. [Google Scholar]
8. Cao Q, Yu L, Wang Z, Zhan S, Quan H, Yu Y, et al. Wild animal information collection based on depthwise separable convolution in software defined IoT networks. Electronics. 2021;10(17):2091. doi:10.3390/electronics10172091. [Google Scholar] [CrossRef]
9. Lai K, Tu X, Yanushkevich S. Dog identification using soft biometrics and neural networks. In: Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN); 2019 Jul 14–19; Budapest, Hungary. doi:10.1109/ijcnn.2019.8851971. [Google Scholar] [CrossRef]
10. Chan YK, Lin CH, Wang CL, Tu KC, Yang SC, Tsai MH, et al. Dog identification based on textural features and spatial relation of noseprint. Pattern Recognit. 2024;151(25):110353. doi:10.1016/j.patcog.2024.110353. [Google Scholar] [CrossRef]
11. Jones A, Vijayan TB. AI-driven canine cataract detection: a machine learning approach using support vector machine. J Chin Inst Eng. 2025;48(1):94–102. doi:10.1080/02533839.2024.2420100. [Google Scholar] [CrossRef]
12. Shah SK, Tariq Z, Lee Y. IoT based urban noise monitoring in deep learning using historical reports. In: Proceedings of the 2019 IEEE International Conference on Big Data (Big Data); 2019 Dec 9–12; Los Angeles, CA, USA. doi:10.1109/bigdata47090.2019.9006176. [Google Scholar] [CrossRef]
13. Borwarnginn P, Thongkanchorn K, Kanchanapreechakorn S, Kusakunniran W. Breakthrough conventional based approach for dog breed classification using CNN with transfer learning. In: Proceedings of the 2019 11th International Conference on Information Technology and Electrical Engineering (ICITEE); 2019 Oct 10–11; Pattaya, Thailand. doi:10.1109/iciteed.2019.8929955. [Google Scholar] [CrossRef]
14. Turab A, Mlaiki N, Fatima N, Mitrović ZD, Ali W. Analysis of a class of stochastic animal behavior models under specific choice preferences. Mathematics. 2022;10(12):1975. doi:10.3390/math10121975. [Google Scholar] [CrossRef]
15. Stowell D, Benetos E, Gill LF. On-bird sound recordings: automatic acoustic recognition of activities and contexts. IEEE/ACM Trans Audio Speech Lang Process. 2017;25(6):1193–206. doi:10.1109/TASLP.2017.2690565. [Google Scholar] [CrossRef]
16. Li J, Zhang Y. Regressive vision transformer for dog cardiomegaly assessment. Sci Rep. 2024;14(1):1539. doi:10.1038/s41598-023-50063-x. [Google Scholar] [PubMed] [CrossRef]
17. Borwarnginn P, Kusakunniran W, Karnjanapreechakorn S, Thongkanchorn K. Knowing your dog breed: identifying a dog breed with deep learning. Int J Autom Comput. 2021;18(1):45–54. doi:10.1007/s11633-020-1261-0. [Google Scholar] [CrossRef]
18. Dutrow EV, Serpell JA, Ostrander EA. Domestic dog lineages reveal genetic drivers of behavioral diversification. Cell. 2022;185(25):4737–55.e18. doi:10.1016/j.cell.2022.11.003. [Google Scholar] [PubMed] [CrossRef]
19. Zou DN, Zhang SH, Mu TJ, Zhang M. A new dataset of dog breed images and a benchmark for finegrained classification. Comput Vis Medium. 2020;6(4):477–87. doi:10.1007/s41095-020-0184-6. [Google Scholar] [CrossRef]
20. Pan X, Ye T, Han D, Song S, Huang G. Contrastive language-image pre-training with knowledge graphs. Adv Neural Inf Process Syst. 2022;35:22895–910. [Google Scholar]
21. Rana K, Randhawa SS, Mohindroo J, Sethi RS, Mukhopadhyay CS. Biocomputational identification of microRNAs from indigenous Gaddi dog genome. Gene Rep. 2025;39(10):102167. doi:10.1016/j.genrep.2025.102167. [Google Scholar] [CrossRef]
22. Zuo P, Ma D, Chen Y. Short-time Fourier transform based on stimulated Brillouin scattering. J Light Technol. 2022;40(15):5052–61. doi:10.1109/JLT.2022.3174552. [Google Scholar] [CrossRef]
23. Gul E, Toprak AN. Contourlet and discrete cosine transform based quality guaranteed robust image watermarking method using artificial bee colony algorithm. Expert Syst Appl. 2023;212(1):118730. doi:10.1016/j.eswa.2022.118730. [Google Scholar] [CrossRef]
24. Li L, Fan Y, Tse M, Lin KY. A review of applications in federated learning. Comput Ind Eng. 2020;149(5):106854. doi:10.1016/j.cie.2020.106854. [Google Scholar] [CrossRef]
25. Ráduly Z, Sulyok C, Vadászi Z, Zölde A. Dog breed identification using deep learning. In: Proceedings of the 2018 IEEE 16th International Symposium on Intelligent Systems and Informatics (SISY); 2018 Sep 13–15; Subotica, Serbia. doi:10.1109/SISY.2018.8524715. [Google Scholar] [CrossRef]
26. Abdel-Hamid O, Mohamed AR, Jiang H, Deng L, Penn G, Yu D. Convolutional neural networks for speech recognition. IEEE/ACM Trans Audio Speech Lang Process. 2014;22(10):1533–45. doi:10.1109/TASLP.2014.2339736. [Google Scholar] [CrossRef]
27. Sinnott RO, Wu F, Chen W. A mobile application for dog breed detection and recognition based on deep learning. In: Proceedings of the 2018 IEEE/ACM 5th International Conference on Big Data Computing Applications and Technologies (BDCAT); 2018 Dec 17–20; Zurich, Switzerland. doi:10.1109/BDCAT.2018.00019. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools