
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
MRFNet: A Progressive Residual Fusion Network for Blind Multiscale Image Deblurring
1 School of Mechanical Engineering, Qinghai University, Xining, 810000, China
2 School of Computer Technology and Applications, Qinghai University, Xining, 810000, China
* Corresponding Author: Qiangqiang Yao. Email:
# These authors contributed to the work equally and should be regarded as co-first authors
Computers, Materials & Continua 2026, 86(3), 80 https://doi.org/10.32604/cmc.2025.072948
Received 07 September 2025; Accepted 05 November 2025; Issue published 12 January 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Recent advances in deep learning have significantly improved image deblurring; however, existing approaches still suffer from limited global context modeling, inadequate detail restoration, and poor texture or edge perception, especially under complex dynamic blur. To address these challenges, we propose the Multi-Resolution Fusion Network (MRFNet), a blind multi-scale deblurring framework that integrates progressive residual connectivity for hierarchical feature fusion. The network employs a three-stage design: (1) TransformerBlocks capture long-range dependencies and reconstruct coarse global structures; (2) Nonlinear Activation Free Blocks (NAFBlocks) enhance local detail representation and mid-level feature fusion; and (3) an optimized residual subnetwork based on gated feature modulation refines texture and edge details for high-fidelity restoration. Extensive experiments demonstrate that MRFNet achieves superior performance compared to state-of-the-art methods. On GoPro, it attains 32.52 dB Peak Signal-to-Noise Ratio (PSNR) and 0.071 Learned Perceptual Image Patch Similarity (LPIPS), outperforming MIMO-WNet (32.50 dB, 0.075). On HIDE, it achieves 30.25 dB PSNR and 0.945 Structural Similarity Index Measure (SSIM), representing gains of +0.26 dB and +0.015 SSIM over MIMO-UNet (29.99 dB, 0.930). On RealBlur-J, it reaches 28.82 dB PSNR and 0.872 SSIM, surpassing MIMO-UNet by +1.19 dB and +0.035 SSIM (27.63 dB, 0.837). These results validate the effectiveness of the proposed progressive residual fusion and hybrid attention mechanisms in balancing global context understanding and local detail recovery for blind image deblurring.Keywords
In recent years, with the continuous development of multimedia technologies such as image and video, image deblurring techniques have been increasingly applied in various fields. These include video restoration [1], general-purpose image restoration frameworks such as DeblurGAN [2], and object detection [3]. These tasks impose extremely high requirements on image quality. However, during the actual image acquisition process, images frequently exhibit varying degrees of dynamic blurring due to factors such as camera jitter, target motion, or out-of-focus conditions [4]. This blurring has been shown to cause a significant loss of high-frequency details, such as edges and textures, which can compromise the accuracy and robustness of subsequent high-level vision tasks [5]. Consequently, the recovery of clear images from degraded images has emerged as a significant research challenge in the domain of image restoration.
A range of solutions has been examined for the purpose of image deblurring. In the early stages of this investigation, the prior-based deblurring methods were proposed [6–8]. These methods primarily rely on the statistical analysis of a large number of image features to extract prior information related to natural images. They then introduce these priors as regular terms into the model to guide it towards a specific solution space. This effectively narrows the range of the solution and results in restoration results that are closer to the real image. Among them, Ren et al. [9] introduced an advanced deblurring prior in the image deblurring task, which enhances the estimation accuracy of the blurring kernel by adeptly preserving the image edge information through the minimization of a weighted kernel paradigm. As Joshi et al. [10] first demonstrated, the incorporation of color statistics a priori into the joint modeling process of image deblurring and denoising effectively mitigates the inaccurate estimation of blurring kernels and over-smoothing of images caused by missing texture or noise interference in traditional methods. Mai et al. [11] proposed a kernel estimation strategy incorporating eight deblurring methods to construct a fuzzy kernel capable of modeling complex structures. However, traditional methods generally exhibit limited adaptability to non-uniform blur and highly dynamic scenes.
The efficacy of deep learning techniques in addressing image deblurring tasks has been demonstrated to exceed that of conventional methodologies. Nah et al. [12] proposed a pioneering Multi-Scale Convolutional Neural Network (MSCNN) method that can perform end-to-end image restoration at different scales in a “coarse-to-fine” manner without the need to estimate fuzzy kernels. This method is effective in restoring images of various scales, offering a novel approach to image restoration that is both efficient and accurate. Zhang et al. [13] proposed an image deblurring method called the Deep Hierarchical Multi-Patch Network (DMPHN). This method employs a hierarchical multi-region strategy to make full use of the blurring information of the image at different scales. As a result, it effectively improves the deblurring performance of the network. Chen et al. [14] introduced a novel normalization method and combined it with a coding-decoding structure to effectively achieve multi-scale and multi-stage image restoration. However, these methods utilize a multitude of network parameters, which complicates the process of network training. Consequently, to mitigate these limitations, Ji et al. [15] proposed an XYDeblur method, which enhances the efficacy of deblurring while concurrently reducing network parameters. This method employs a division of the image into multiple regions, with deblurring being performed on these regions individually. However, the constrained acceptance field also imposes limitations on the efficacy of dealing with severe blurring, and there is considerable potential for enhancement in advanced contextual information, texture, and edge perception capabilities.
To address the aforementioned issues, the present study puts forth a blind image deblurring network with multi-scale feature fusion and progressive residuals and connectivity, herein referred to as Multi-Resolution Fusion Network (MRFNet). The fundamental premise of this study is that image deblurring should fundamentally adhere to a coarse-to-fine, staged progressive recovery mechanism. However, to address the weaknesses in advanced contextual information, texture and edge perception capabilities, and global modeling capabilities, it is appropriate to use different feature extraction strategies for each of our phases to suit their specific needs. The MRFNet architecture is comprised of a three-stage cascade of encoder-decoder components. In the initial phase, the model functions at the lowest resolution, thereby leveraging the global modeling capacity of the TransformerBlock to facilitate expeditious parsing and coarse recovery of the overall fuzzy patterns. In the second stage, the model processes medium-resolution features. Concurrently, the encoder continues to employ the TransformerBlock to maintain global semantic consistency. Concurrently, the decoder introduces the Nonlinear Activation Free Block (NAFBlock) module, which adopts a local convolutional operation instead of the complex attention mechanism. This module focuses more on extracting neighborhood texture and edge information. It also cooperates with the Spatial Attention Module (SAM), which effectively fuses the recovery results of the previous stage to improve mesoscale details. In the final third stage, the model operates at full resolution, and with the assistance of the Optimized Residual Subnetwork (ORSNet) composed of NAFBlock, all features from all preceding stages are profoundly integrated to facilitate the culminating reconstruction of high-precision texture and edge particulars. The primary contributions of this paper can be enumerated as follows:
Firstly, a Multi-Stage Residual Fusion (MSRF) is proposed. This mechanism combines a spatial attention mechanism to achieve cross-stage feature compensation and contextual information propagation.
Secondly, Hybrid Attention-based Tokenization (HAT) is employed, a method that integrates the long-range dependency modeling capability of the TransformerBlock and the local texture enhancement capability of NAFBlock. HAT is implemented in various stages of the encoder and decoder, respectively.
The third Gated Feature Modulation (GFM) module has been introduced to enhance the perception of high-frequency information, such as texture and edges, through the synergistic effect of SimpleGate and Simplified Channel Attention (SCA), which provides adaptive weighting of key channels.
2.1 Multi-Scale Structural Deblurring Methods
Multi-scale deblurring methods process images at different resolutions to estimate motion blur or generate smoother images at low resolutions. These results are then used as a prior for high-resolution processing. Purohit et al. [16] proposed a regionally adaptive dense network that allocates computational resources based on blur severity, enabling efficient motion blur removal. Cui et al. [17] enhanced image recovery by optimizing Convolutional Neural Network (CNN) architectures and integrating deep features. Jiang et al. [18] proposed the Multi-Scale Progressive Fusion Network (MSPFN) for single-image deraining, employing recurrent computation in the Coarse Fusion Module (CFM) and channel attention in the Fine Fusion Module (FFM) to integrate multi-scale rain streak information.
Although MSPFN and MRFNet share the multi-stage progressive paradigm, they target fundamentally different degradation types with distinct technical solutions. MSPFN addresses rain removal, where rain streaks are additive and spatially localized with predictable directions. It employs uniform convolutional feature extraction across all stages, with recurrent computation in CFM for global texture capture and channel attention in FFM for scale-wise integration. In contrast, MRFNet tackles motion blur, which involves spatially varying convolution with complex global dependencies and severe high-frequency loss. To address these challenges, MRFNet introduces: (1) HAT that combines TransformerBlocks for global blur modeling with NAFBlocks for local detail recovery; (2) MSRF with SAM for pixel-wise adaptive cross-stage fusion rather than recurrent operations; (3) GFM for enhanced high-frequency texture and edge recovery beyond channel attention; and (4) stage-specific optimization strategies (global structure at 1/4, semantic refinement at 1/2, detail reconstruction at full resolution) instead of uniform processing. These deblurring-specific designs enable MRFNet to effectively handle motion blur’s unique characteristics. However, these methods struggle with advanced semantic context modeling and fine-grained texture recovery. To address this, we introduce the Gated Feature Modulation Module, which enhances high-frequency information (textures and edges) using SimpleGate and SCA, with adaptive channel weighting.
Gate-like fusion has been widely used in image restoration to regulate information flow. Zhang et al. [19] proposed a Gated Fusion Network (GFN) that jointly performs image deblurring and super-resolution through adaptive feature fusion using learnable gates. Chen et al. [20] introduced a Gated Context Aggregation Network (GCANet) for dehazing and deraining, which aggregates multi-scale contextual features via dilated convolutions and gating control. Xiao et al. [21] presented a Frequency-Assisted Mamba (FAMamba) network for remote-sensing super-resolution, combining spectral priors with state-space modeling to enhance high-frequency detail recovery. Chen et al. [22] proposed a Dual Gated Attention Network, a feedback-mechanism-based encoder-decoder network (FMNet), that combines a feedback mechanism and gated attention to refine features and enhance global dependency modeling for image deblurring. Compared with these gate-based methods, our MRFNet differs fundamentally in both structure and learning strategy. While previous approaches rely on static or task-specific gating to control feature flow, MRFNet integrates a Hybrid Attention Transformer (HAT) and Multi-Stage Residual Fusion (MSRF) to dynamically balance global blur modeling and local detail restoration. Instead of gating individual feature channels, MRFNet models long-range dependencies through self-attention and adaptively fuses multi-scale representations across stages. This design allows MRFNet to handle spatially varying motion blur more effectively, achieving superior perceptual fidelity and generalization compared to gated or frequency-assisted architectures.
2.3 Transformer-Based Deblurring
Transformer-based Deblurring. Recent works leverage Transformers to enhance long-range dependency modeling for deblurring. Liu et al. [23] combined local attention with a global Transformer to improve global context modeling. While these methods have improved performance, they often use single-stage structures and lack effective inter-stage feature adaptation. Xiao et al. [24] proposed a top-k token selective transformer (TTST) for remote sensing image super-resolution, which adopts a top-k token selection mechanism to prioritize critical image information and boost super-resolution performance. While TTST uses a top-k token selection for super-resolution, our MRFNet adopts a multi-stage approach with Hybrid Attention Transformer (HAT) and Multi-Stage Residual Fusion (MSRF) to address the unique challenges in motion blur deblurring. Restormer [25] proposed a Transformer architecture utilizing pixel self-attention and gated feed-forward networks. Mao et al. [26] proposed LoFormer, a Local Frequency Transformer that applies Local Frequency Self-Attention by converting spatial tokens into DCT-frequency tokens, effectively capturing global correlations while preserving high-frequency details. In contrast, our MRFNet adopts diversified feature extraction across three resolution stages, with HAT to decouple the Transformer and NAFBlock, while MSRF exchanges contextual information across stages through residual compensation and spatial attention.
2.4 Frequency-Domain & Spatial-Frequency Hybrid Methods
Cui et al. [27] proposed the Selective Frequency Network, which decomposes image features into frequency sub-bands via the Fourier transform and selectively enhances informative components through attention, effectively recovering fine textures. Kong et al. [28] introduced the FFTformer, a Transformer framework operating in the frequency domain that performs FFT-based self-attention to capture long-range dependencies efficiently and produce sharper deblurring results. Xiang et al. [29] developed the Multi-scale Frequency Enhancement Network, which integrates multi-scale spatial features with wavelet-based frequency enhancement to balance global structure and local detail, achieving strong performance on non-uniform motion blur datasets.
A novel blind image deblurring network, termed the Multi-Resolution Fusion Network (MRFNet), is proposed in this work. MRFNet integrates multi-scale residual pathways, hybrid attention mechanisms, and channel modulation within a unified architecture. The network is designed based on a coarse-to-fine, stage-wise optimization paradigm, aiming to progressively restore both global semantics and local details of degraded images.
As illustrated in Fig. 1, the three-stage progressive architecture addresses the multi-scale nature of motion blur, from global motion to local texture degradation. Unlike single-stage methods that struggle with conflicting optimization objectives, MRFNet decouples these tasks: Stage 1 (1/4 resolution) captures global semantics using TransformerBlocks with large receptive fields; Stage 2 (1/2 resolution) refines mid-scale features with hybrid attention mechanisms; and Stage 3 (full resolution) recovers high-frequency details through Gated Feature Modulation. This staged design offers key advantages: (1) task-specific modules, where TransformerBlocks model long-range dependencies and NAFBlocks handle local textures; (2) improved generalization across datasets, enabling robust adaptation to varied real-world conditions. The progressive approach mimics human visual perception, simplifying the restoration process at each stage.
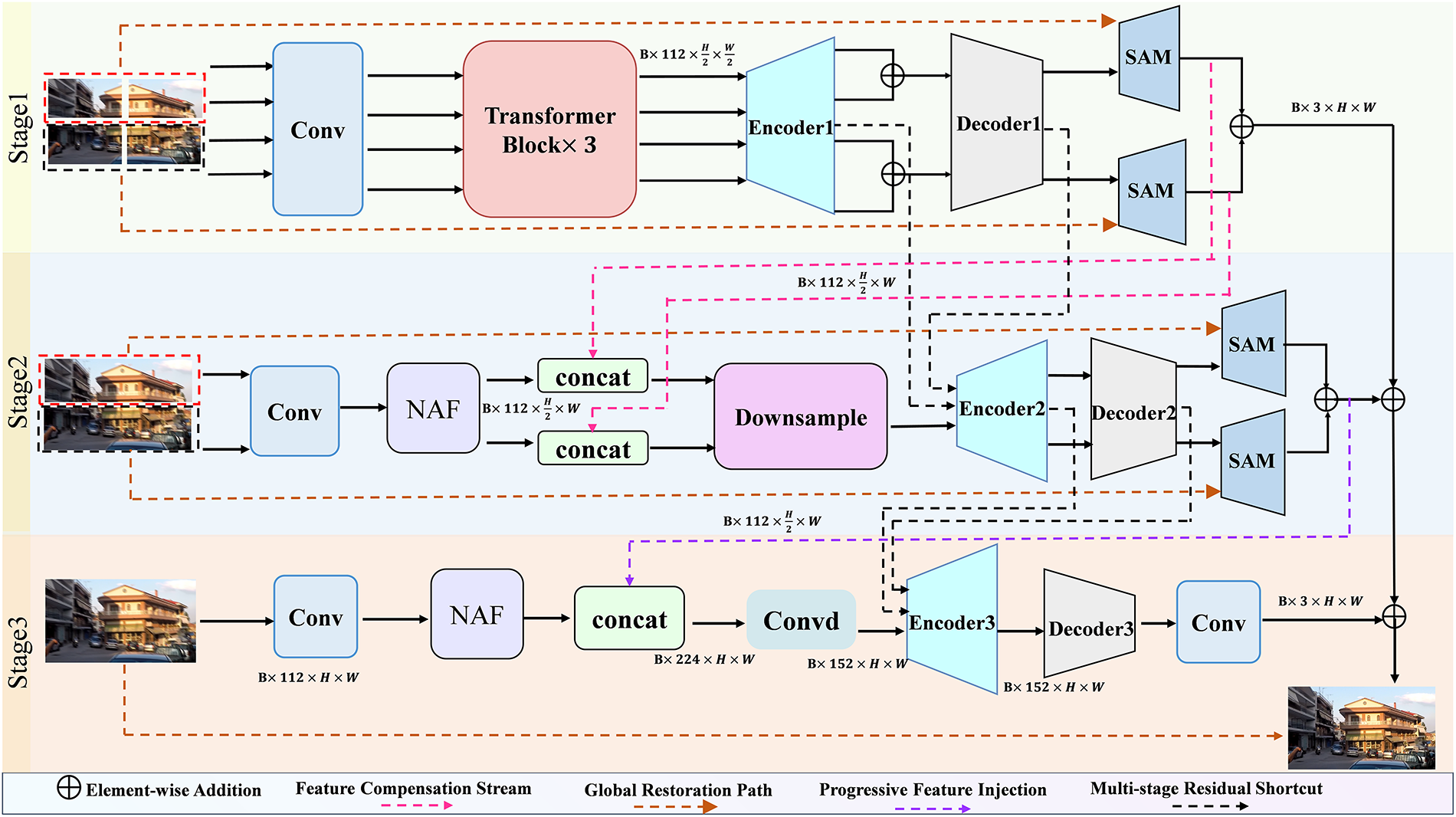
Figure 1: Overall architecture of the proposed Multi-Resolution Fusion Network (MRFNet)
The three-stage processing strategy is fundamentally designed to progressively address motion blur at different semantic and spatial scales, each requiring distinct feature extraction capabilities. Stage 1 prioritizes global context modeling to establish coarse blur structure, Stage 2 focuses on mid-level semantic refinement, while Stage 3 specializes in high-frequency detail reconstruction. To enable optimal module deployment tailored to these stage-specific requirements, MRFNet incorporates three critical components: Multi-Stage Residual Fusion (MSRF), Hybrid Attention-based Tokenization (HAT), and Gated Feature Modulation (GFM). These modules collaboratively enable efficient feature propagation, adaptive attention deployment, and detail-aware modulation.
3.2.1 Multi-Stage Residual Fusion
To address the issue of contextual information loss due to resolution changes in multi-stage architectures, we propose the MSRF mechanism. At the core of the mechanism is a Spatial Attention Module (SAM), which serves as a bridge connecting two neighboring phases. The SAM uses the recovery results of the previous phase as a priori information to guide the feature refinement of the current phase in a spatial attention manner. By generating the attention map pixel by pixel, SAM can regulate the fusion intensity across stages based on the local feature response at each location, while avoiding the high computational burden of non-local operations; this complements the local feature modeling of NAFBlock is a significant contribution of this study. Conversely, Channel Attention (CA) merely performs global weighting for each channel, thus lacking the capacity to process information from disparate spatial locations with the requisite fine granularity.
Let
Subsequently, a spatial attention mask, designated as
where
In conclusion, the utilization of this mask is intended to modulate the original decoder features. The mask is then combined with residual concatenation to output the refined feature
where
3.2.2 Hybrid Attention-Based Tokenization
In order to achieve equilibrium between the global modeling capability and the local processing efficiency in disparate recovery stages, the HAT mechanism was devised. The mechanism attains feature extraction capability through the differential deployment of two base modules, TransformerBlock and NAFBlock, within the encoder and decoder, respectively.
TransformerBlock: Inspired by the Restormer framework [25], TransformerBlocks leverage Multi-Head Self-Attention (MHSA) to capture non-local dependencies, which are essential for suppressing large-scale motion blur. The core operation is defined as:
where
NAFBlock: Adopted from Nonlinear Activation Free Network (NAFNet) [30], this efficient convolution-based module is utilized in the second-stage decoder and throughout the third stage. It excels in reconstructing fine-grained local textures and edges. The core feature update rule is:
where
3.2.3 Gated Feature Modulation
The GFM module represents a subsequent evolution and implementation of NAFBlock, conceived for the culminating high-resolution reconstruction phase. It serves as the fundamental constituent of ORSNet. The system functions through the synergy of SimpleGate and Simplified Channel Attention (SCA). This simple design offers distinct advantages, including its computational efficiency and its ability to circumvent training instability caused by complex operations. The system demonstrates flexible feature modulation capability, which involves the enhancement of significant features and the suppression of superfluous ones. A comparison of SimpleGate with common activation functions (e.g., ReLU and GELU) reveals its primary advantages: the capacity to provide precise, nuanced tuning to circumvent the undesirable suppression of pertinent information, and the ability to achieve more seamless feature tuning, thereby ensuring the preservation of intricate details during the processing of intricate inputs, such as images. Consequently, the gating mechanism of SimpleGate does not introduce significant computational complexity. In addition, it enhances the network’s precision in processing image details and textures through efficient feature adjustment.
Given an input feature map
SimpleGate: The input is split into two along the channel dimension
SCA: A channel attention map
3.3 Staged Processing Strategy
3.3.1 Stage 1: Global Semantic Modeling and Coarse Restoration
In the initial stage, global contextual information is rapidly captured at a low resolution to eliminate large-scale motion blur. The input blurry image
The decoded features
3.3.2 Stage 2: Context-Aware Fine Enhancement
At a medium resolution, the second stage refines structure and texture by leveraging the contextual priors from Stage 1. The original image is vertically split into two parts and processed by a separate shallow feature extractor
The encoder continues to utilize TransformerBlocks to preserve semantic consistency, while the decoder switches to lightweight NAF Blocks, focusing on localized detail enhancement. The transformation is expressed as:
The output features
3.3.3 Stage 3: Full-Resolution High-Quality Reconstruction
The third stage operates at full input resolution and is responsible for reconstructing high-frequency textures and sharp edges. The original image is first passed through the final shallow feature extractor
These fused features are then fed into the Optimized Residual Subnetwork (ORSNet), constructed entirely with Gated Feature Modulation (GFM) blocks. This subnetwork further incorporates skip connections to integrate encoder and decoder features from the previous stage
The final output is generated by applying a convolution layer followed by a residual addition to the original input image:
This stage fully exploits the capacity of the GFM modules for detail-aware modulation, enabling accurate reconstruction of textures and contours. Experimental results demonstrate that this final stage is critical for achieving high PSNR and SSIM scores, as validated in ablation studies.
To evaluate the performance of MRFNet, two commonly used image restoration metrics—Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM)—are adopted. These metrics are widely recognized for their ability to quantify image fidelity and perceptual quality. In addition, we also evaluate the perceptual performance using Mean Absolute Error (MAE) and Learned Perceptual Image Patch Similarity (LPIPS), which are more aligned with human visual perception.
The PSNR metric evaluates the pixel-level reconstruction accuracy between the restored image R and the ground truth Y, and is defined as:
where the Mean Squared Error (MSE) is given by:
Representing the total number of pixels, and
The SSIM metric assesses structural similarity by jointly considering luminance, contrast, and structural information, and is computed as:
where
The Mean Absolute Error (MAE) measures the average absolute difference between the pixel values of the restored image and the ground truth. It is calculated as:
where
Through this dual-perspective evaluation framework, the superiority of MRFNet is substantiated in terms of both reconstruction accuracy and perceptual quality, confirming its robustness and generalizability across diverse deblurring scenarios.
To comprehensively evaluate the proposed method under diverse real-world blur scenarios, three public datasets were used:
GoPro [12]: A widely used benchmark with 3214 image pairs covering natural, indoor, and urban scenes. Images are resized to 1280 × 720 for fair comparison. Human-aware Image Deblurring (HIDE) [31]: A synthetic dataset with realistic camera trajectories and depth-of-field effects, used to verify generalization. RealBlur [32]: Real-captured blurry images with diverse motion patterns, suitable for testing robustness in practical conditions. Together, these datasets provide a comprehensive and rigorous assessment of the proposed method.
All experiments were conducted in an environment configured with Ubuntu 20.04.5, PyTorch 2.1, and Python 3.11. The hardware consisted of four NVIDIA RTX 4090 GPUs.
A step-wise training strategy was adopted to build an efficient optimization pipeline for MRFNet. The initial learning rate was set to 0.001 with a batch size of 4, and random flipping and rotation were applied for data augmentation to enhance the model’s robustness to viewpoint variations. The Adam optimizer was employed, benefiting from its adaptive learning rate mechanism to accelerate convergence.
To mitigate the risk of local minima during later training stages, a cosine annealing learning rate schedule was applied to gradually decay the learning rate from 0.001 to 0.000001, ensuring smooth parameter updates and stable convergence.
On the GoPro benchmark, MRFNet achieves competitive PSNR (32.52 dB) with the best LPIPS (0.071) among compared methods of similar complexity, offering a favorable perceptual–distortion trade-off. As shown in Table 1, MRFNet keeps the model size and computation moderate—18.08 M parameters and 156 GFLOPs—which is substantially lighter than early multi-scale baselines (e.g., Nah et al. [12], 1660 GFLOPs) and even lower compute than BANet (264 GFLOPs) at a similar parameter scale. Although some methods report slightly higher SSIM, MRFNet provides the best PSNR-LPIPS trade-off, yielding sharper reconstructions with stronger perceptual fidelity while maintaining practical efficiency.
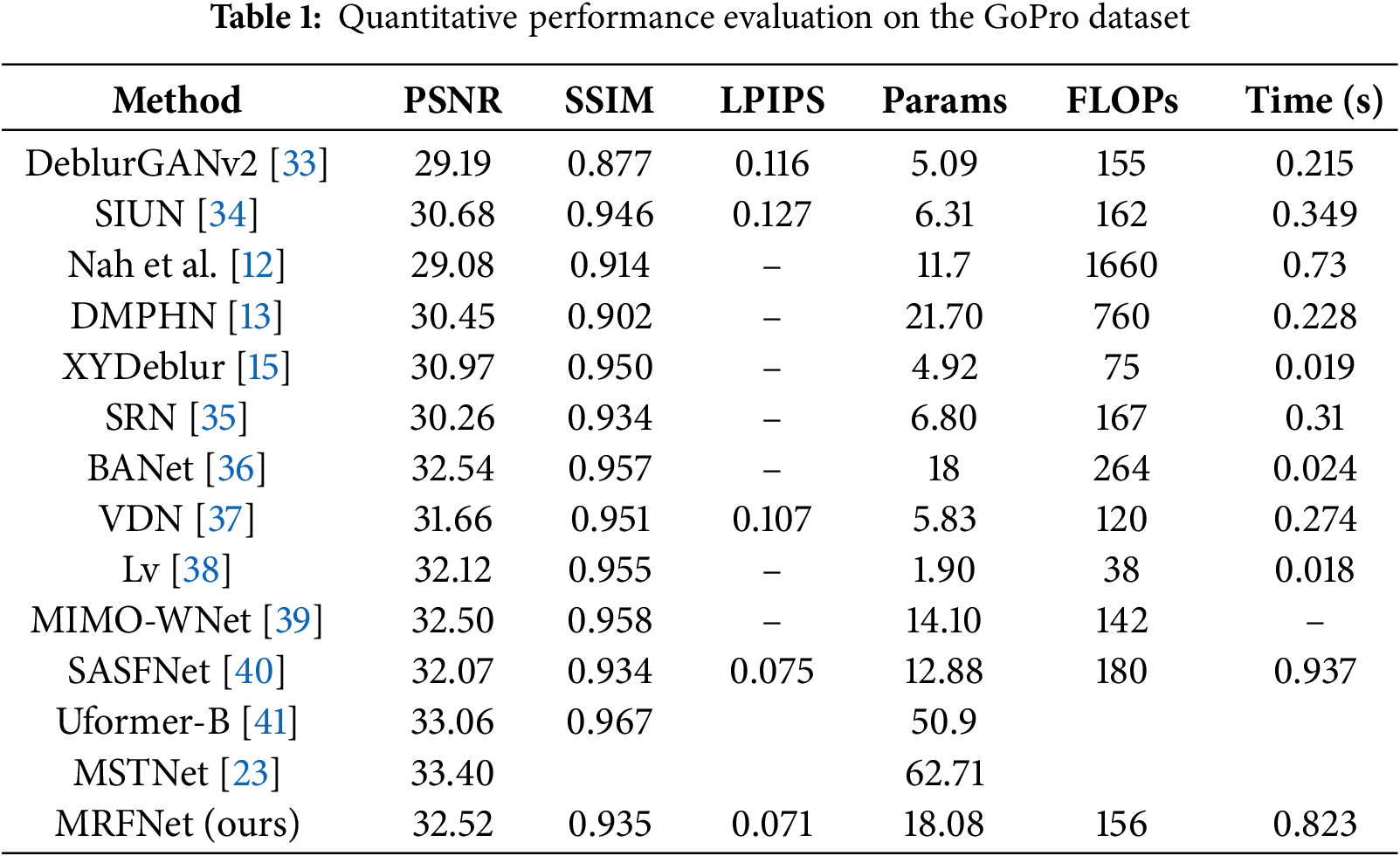
On more challenging datasets, MRFNet exhibits strong generalization capability. Notably, on the HIDE dataset (Table 2), MRFNet achieves 30.25 dB PSNR, significantly outperforming single-stage baselines, indicating that our hierarchical blur decomposition strategy enables more robust adaptation to diverse blur patterns. The cross-dataset evaluation further validates this advantage: on RealBlur-J datasets, MRFNet maintains consistently high performance (28.82 dB, respectively), demonstrating that multi-scale staged processing facilitates better generalization to real-world scenarios compared to single-stage alternatives.
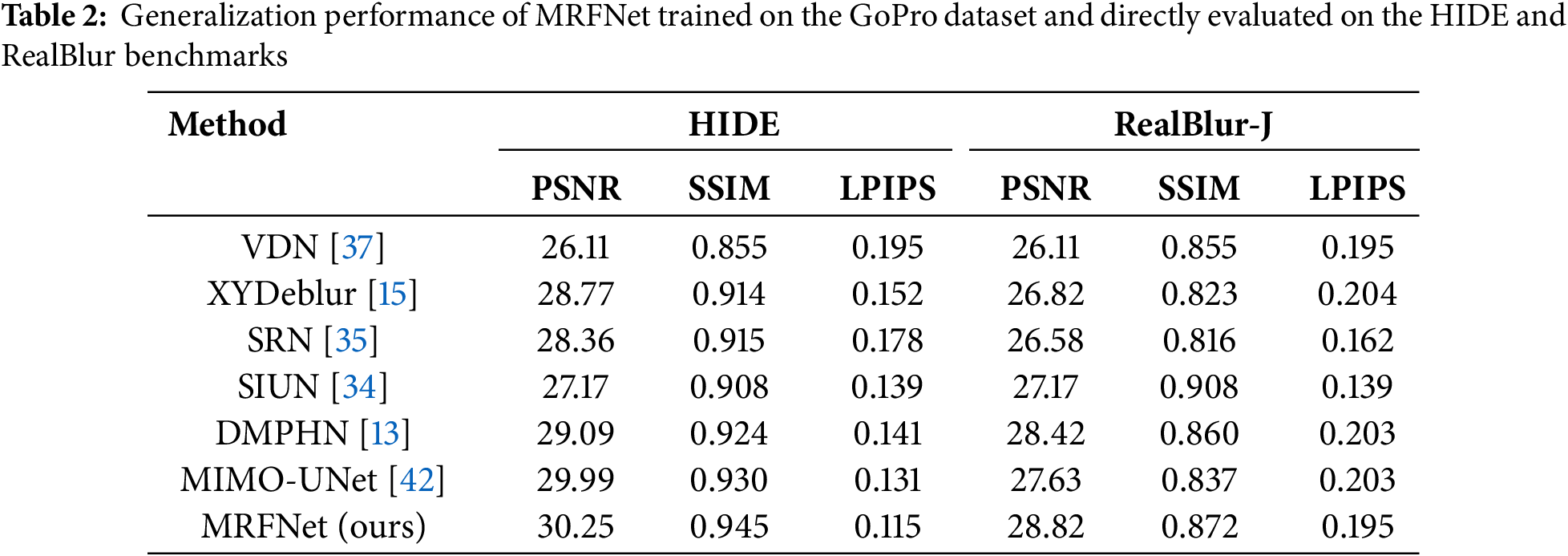
To further demonstrate the deblurring effectiveness of the proposed MRFNet, qualitative comparisons are provided in Fig. 2, showcasing visual results on the GoPro dataset. MRFNet is evaluated against several state-of-the-art methods, including Restormer, MSRF, MPRNet, DMPHN, GFM, MIMO-UNet, and NAFNet, with key regions magnified to highlight differences in edge clarity, texture reconstruction, and artifact suppression.

Figure 2: Visual comparisons of deblurring results and corresponding PSNR values on the GoPro dataset using different methods
In the first scenario featuring architectural structures, existing models such as Restormer and MSRF exhibit noticeable structural distortions due to residual blur, while MPRNet and DMPHN offer limited improvements. GFM and NAFNet achieve better texture restoration; however, high-frequency details like window frames remain partially lost. In contrast, MRFNet yields sharper edges and enhanced structural consistency, achieving a PSNR of 33.61 dB, thereby validating the benefits of its multi-scale residual guidance design.
In the second case involving dynamic human motion, many methods compromise subject clarity while removing background blur. MRFNet successfully maintains background sharpness while accurately reconstructing the contours and fine details of moving subjects, achieving 32.63 dB PSNR. This highlights the effectiveness of its gated residual fusion mechanism in handling dynamic scenes.
To assess cross-domain generalizability, additional visual comparisons are conducted on the HIDE dataset (Fig. 3). Across scenes involving human motion and camera shake, MRFNet consistently delivers sharper contours, cleaner textures, and more perceptually coherent outputs than competing methods.

Figure 3: Visual comparisons of deblurring results and corresponding PSNR values on the HIDE dataset using different methods
The results of the qualitative analysis demonstrate the effectiveness of the proposed MRFNet in improving the accuracy and generalization ability of deblurring operations. The MRFNet network exhibits a significant ability to preserve details, enhance edges, and recover texture, thereby ensuring image deblurring capability. Furthermore, it has been demonstrated to exhibit superior performance in scenarios involving non-uniform blurring and complex dynamic scenes.
4.6 Ablation Study and Component-Wise Analysis
To evaluate the effectiveness of each component in MRFNet, an ablation study was conducted on the GoPro dataset. The analysis examines three modules: Multi-Stage Residual Fusion (MSRF), Hybrid Attention-based Tokenization (HAT), and Gated Feature Modulation (GFM). Results are summarized in Table 3. The baseline removes all modules and adopts a simple encoder-decoder with skip connections. It achieves 31.98 dB PSNR and 0.935 SSIM as a reference. Adding MSRF improves PSNR by 0.48 dB. Multi-scale residual pathways enhance feature propagation and context aggregation, benefiting detail restoration under motion blur. With HAT, performance increases to 33.12 dB PSNR and 0.943 SSIM. Dual-branch interaction strengthens feature exchange between shallow and deep layers, balancing textures and semantics. GFM, inspired by NAFNet, applies gating and lightweight channel attention to further enhance detail recovery. Overall, each module contributes independently and complementarily. Their combination significantly improves both quantitative results and visual quality, validating the design of MRFNet.
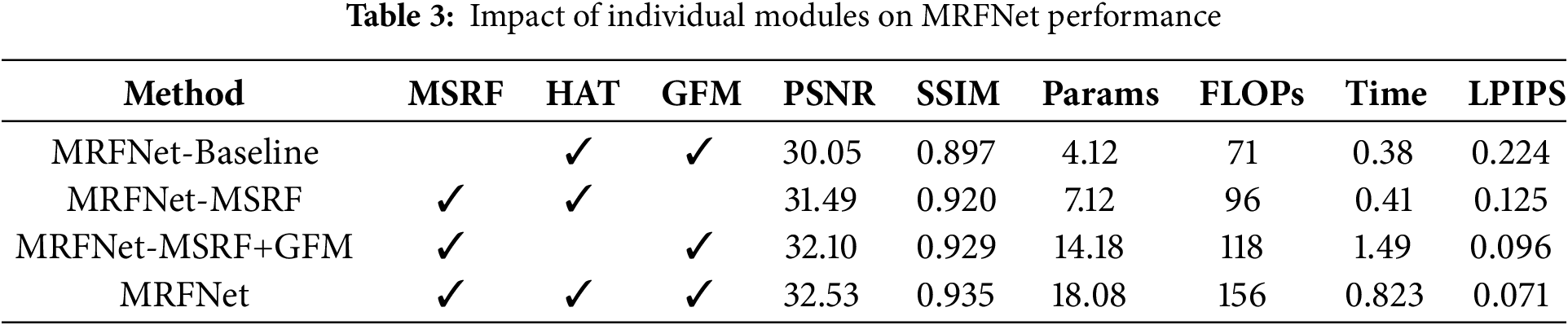
Fig. 4 shows the error heatmaps of different models. The visualization indicates that the baseline model exhibits significant errors in the elevator and edge regions (highlighted in red). After incorporating the MSRF and GFM modules, the errors in these areas are noticeably reduced. The error map of the full model shows overall darker colors, suggesting that its predictions are closer to the ground truth, particularly in the edge and texture regions.

Figure 4: Error heatmaps comparing different models. Warmer colors indicate larger errors. The full model shows significantly reduced errors (darker regions) compared to the baseline, particularly in the elevator and edge areas. The complete model performs especially well in these regions, highlighting the improvement in prediction accuracy
We hereby propose a novel multi-stage progressive image deblurring method, designated as MRFNet, which fully combines a coarse-to-fine feature processing strategy with an efficient feature modeling mechanism to enhance the image reconstruction quality in the blind deblurring task. The proposed methodology comprises three principal innovations. First, a multi-stage residual fusion mechanism is constructed, which effectively promotes the feature transfer between different scales and enhances the structural consistency and expressive coherence of the blurred region. Secondly, an efficient mixed-attention feature extraction module has been designed to be adapted to the encoder and decoder. This module integrates local perceptual and global dependency information in different resolutions, thereby enhancing the model’s ability to model complex blurred patterns. Thirdly, a gated feature fusion strategy is introduced to achieve accurate capture and selective enhancement of key details, which helps to improve the restoration of high-frequency information in images. The experimental results on the GoPro, HIDE, and RealBlur datasets demonstrate that the proposed MRFNet-based method exhibits significantly superior performance in comparison to existing methods on mainstream objective evaluation metrics, such as PSNR and SSIM. The efficacy of the method in motion blur removal tasks is further substantiated by a comparison of subjective visualization results. Subsequent endeavors will prioritize the reduction of model complexity and the expansion of its functionality across diverse sensory domains, thereby enhancing its practical applicability.
Acknowledgement: Not applicable.
Funding Statement: This research was funded by Qinghai University Postgraduate Research and Practice Innovation Program of Funder, grant number 2025-GMKY-42.
Author Contributions: Methodology, Wang Zhang and Haozhuo Cao; resources, Wang Zhang; writing—original draft preparation, Wang Zhang; writing—review, Qiangqiang Yao; funding acquisition, Wang Zhang and Qiangqiang Yao. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the Corresponding Author, QY, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Zhang K, Luo W, Zhong Y. Adversarial spatio-temporal learning for video deblurring. IEEE Trans Image Process. 2018;28(1):291–301. doi:10.1109/tip.2018.2867733. [Google Scholar] [PubMed] [CrossRef]
2. Kupyn O, Budzan V, Mykhailych M, Mishkin D, Matas J. DeblurGAN: blind motion deblurring using conditional adversarial networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 8183–92. [Google Scholar]
3. Zhao ZQ, Zheng P, Xu S, Wu X. Object detection with deep learning: a review. IEEE Trans Neural Netw Learn Syst. 2019;30(11):3212–32. doi:10.1109/tnnls.2018.2876865. [Google Scholar] [PubMed] [CrossRef]
4. Xu L, Zheng S, Jia J. Unnatural L0 sparse representation for natural image deblurring. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2013 Jun 23–28; Portland, OR, USA. p. 1107–14. [Google Scholar]
5. Wang P, Zhu Y, Xue D, Yan Q, Sun J, Yoon S, et al. Take a prior from other tasks for severe blur removal. Comput Vis Image Underst. 2024;245:104027. [Google Scholar]
6. Pan J, Sun D, Pfister H, Yang MH. Blind image deblurring using dark channel prior. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2016 Jun 27–30; Las Vegas, NV, USA. p. 1628–36. [Google Scholar]
7. Shan Q, Jia J, Agarwala A. High-quality motion deblurring from a single image. ACM Trans Graph. 2008;27(3):1–10. doi:10.1145/1360612.1360672. [Google Scholar] [CrossRef]
8. Biyouki SA, Hwangbo H. Blind image deblurring based on kernel mixture. arXiv:2101.06241. 2021. [Google Scholar]
9. Ren W, Cao X, Pan J, Guo X, Zuo W, Yang MH, et al. Image deblurring via enhanced low-rank prior. IEEE Trans Image Process. 2016;25(7):3426–37. doi:10.1109/tip.2016.2571062. [Google Scholar] [PubMed] [CrossRef]
10. Joshi N, Zitnick CL, Szeliski R, Kriegman DJ. Image deblurring and denoising using color priors. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition; 2009 Jun 20–25; Miami, FL, USA. p. 1550–7. [Google Scholar]
11. Mai L, Liu F. Kernel fusion for better image deblurring. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015 Jun 7–12; Boston, MA, USA. p. 371–80. [Google Scholar]
12. Nah S, Kim TH, Lee KM. Deep multi-scale convolutional neural network for dynamic scene deblurring. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2017 Jul 21–26; Honolulu, HI, USA. p. 3883–91. [Google Scholar]
13. Zhang H, Dai Y, Li H, Koniusz P. Deep stacked hierarchical multi-patch network for image deblurring. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019 Jun 15–20; Long Beach, CA, USA. p. 5978–86. [Google Scholar]
14. Chen L, Lu X, Zhang J, Chu X, Chen C. HINet: half instance normalization network for image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021 Jun 20–25; Nashville, TN, USA. p. 182–92. [Google Scholar]
15. Ji SW, Lee J, Kim SW, Hong J-P, Baek S-J, Jung S-W, et al. XYDeblur: divide and conquer for single image deblurring. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022 Jun 18–24; New Orleans, LA, USA. p. 17421–30. [Google Scholar]
16. Purohit K, Rajagopalan AN. Region-adaptive dense network for efficient motion deblurring. In: Proceedings of the AAAI Conference on Artificial Intelligence; 2025 Feb 25–Mar 4; Philadelphia, PA, USA. Washington, DC, USA: AAAI Press; 2020. p. 11882–9. [Google Scholar]
17. Cui Y, Ren W, Cao X, Knoll A. Revitalizing convolutional network for image restoration. IEEE Trans Pattern Anal Mach Intell. 2024;46(12):9423–38. doi:10.1109/tpami.2024.3419007. [Google Scholar] [PubMed] [CrossRef]
18. Jiang K, Wang Z, Yi P, Chen C, Huang B, Luo Y, et al. Multi-scale progressive fusion network for single image deraining. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020 Jun 13–19; Seattle, WA, USA. p. 8346–55. [Google Scholar]
19. Zhang X, Dong H, Hu Z, Lai WS, Wang F, Yang MH. Gated fusion network for joint image deblurring and super-resolution. arXiv:1807.10806. 2018. [Google Scholar]
20. Chen D, He M, Fan Q, Liao J, Zhang L, Hou D, et al. Gated context aggregation network for image dehazing and deraining. In: Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV); 2019 Jan 7–10; Snowmass Village, CO, USA. p. 1375–83. [Google Scholar]
21. Xiao Y, Yuan Q, Jiang K, Chen Y, Zhang Q, Lin CW. Frequency-assisted Mamba for remote sensing image super-resolution. IEEE Trans Multimedia. 2024;26:1458–70. doi:10.1109/tmm.2024.3521798. [Google Scholar] [CrossRef]
22. Chen J, Ye S, Jiang Z, Fang Z. Image deblurring using feedback mechanism and dual gated attention network. Neural Process Lett. 2024;56(2):88. doi:10.1007/s11063-024-11462-x. [Google Scholar] [CrossRef]
23. Liu R, Wang L, He J, Wang J, Zhang J, Liu X, et al. MSTNet: a multi-stage progressive network with local-global transformer fusion for image restoration. Complex Intell Syst. 2025;11(6):1–16. doi:10.1007/s40747-025-01892-y. [Google Scholar] [CrossRef]
24. Xiao Y, Yuan Q, Jiang K, He J, Lin CW, Zhang L. TTST: a top-k token selective transformer for remote sensing image super-resolution. IEEE Trans Image Process. 2024;33:738–52. doi:10.1109/tip.2023.3349004. [Google Scholar] [PubMed] [CrossRef]
25. Zamir SW, Arora A, Khan S, Hayat M, Shahbaz Khan F, Yang M-H, et al. Restormer: efficient transformer for high-resolution image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022 Jun 18–24; New Orleans, LA, USA. p. 5728–39. [Google Scholar]
26. Mao X, Wang J, Xie X, Li Q, Wang Y. Loformer: local frequency transformer for image deblurring. In: Proceedings of the 32nd ACM International Conference on Multimedia; 2024 Oct 12–16; San Francisco, CA, USA. p. 10382–91. [Google Scholar]
27. Cui Y, Tao Y, Bing Z, Ren W, Gao X, Cao X, et al. Selective frequency network for image restoration. In: Proceedings of the Eleventh International Conference on Learning Representations (ICLR); 2023 Apr 27–May 1; Kigali, Rwanda. p. 1–13. [Google Scholar]
28. Kong L, Dong J, Ge J, Li M, Pan J. Efficient frequency domain-based transformers for high-quality image deblurring. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2013 Jun 17–24; Vancouver, BC, Canada. p. 5886–95. [Google Scholar]
29. Xiang Y, Zhou H, Zhang X, Li C, Li Z, Xie Y. Multi-scale frequency enhancement network for blind image deblurring. IET Image Process. 2025;19(1):e70036. doi:10.1049/ipr2.70036. [Google Scholar] [CrossRef]
30. Chen L, Chu X, Zhang X, Sun J. Simple baselines for image restoration. In: Proceedings of the European Conference on Computer Vision; 2022 Oct 23–27; Tel Aviv, Israel. Cham, Switzerland: Springer Nature Switzerland; 2022. p. 17–33. [Google Scholar]
31. Shen Z, Wang W, Lu X, Shen J, Ling H, Xu T, et al. Human-aware motion deblurring. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2019 Jun 15–20; Long Beach, CA, USA. p. 5572–81. [Google Scholar]
32. Rim J, Lee H, Won J, Cho S. Real-world blur dataset for learning and benchmarking deblurring algorithms. In: Proceedings of the Computer Vision—ECCV 2020: 16th European Conference on Computer Vision; 2020 Aug 23–28; Glasgow, UK. Cham, Switzerland: Springer; 2020. p. 184–201. [Google Scholar]
33. Kupyn O, Martyniuk T, Wu J, Wang Z. DeblurGAN-v2: deblurring (orders-of-magnitude) faster and better. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2019 Jun 15–20; Long Beach, CA, USA. p. 8878–88. [Google Scholar]
34. Ye M, Lyu D, Chen G. Scale-iterative upscaling network for image deblurring. IEEE Access. 2020;8:18316–25. doi:10.1109/access.2020.2967823. [Google Scholar] [CrossRef]
35. Tao X, Gao H, Shen X, Wang J, Jia J. Scale-recurrent network for deep image deblurring. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 8174–82. [Google Scholar]
36. Tsai FJ, Peng YT, Tsai CC, Lin YY, Lin CW. BANet: a blur-aware attention network for dynamic scene deblurring. IEEE Trans Image Process. 2022;31:6789–99. doi:10.1109/tip.2022.3216216. [Google Scholar] [PubMed] [CrossRef]
37. Guo C, Wang Q, Dai H-N, Li P. VDN: variant-depth network for motion deblurring. Comput Animat Virtual Worlds. 2022;33(3–4):e2066. doi:10.1002/cav.2066. [Google Scholar] [CrossRef]
38. Lv J, Pan J. Lightweight deep deblurring model with discriminative multi-scale feature fusion. In: Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP); 2023 Oct 8–11; Kuala Lumpur, Malaysia. p. 3065–9. [Google Scholar]
39. Liu M, Yu Y, Li Y, Ji Z, Chen W, Peng Y. Lightweight MIMO-WNet for single image deblurring. Neurocomputing. 2023;516(1):106–14. doi:10.1016/j.neucom.2022.10.028. [Google Scholar] [CrossRef]
40. Cheng J, Zhang K, Hou J, Zhang Y. SASFNet: soft-edge awareness and spatial-attention feedback deep network for blind image deblurring. Comput Vis Image Underst. 2025;259:104408. doi:10.1016/j.cviu.2025.104408. [Google Scholar] [CrossRef]
41. Wang Z, Cun X, Bao J, Zhou W, Liu J, Li H. Uformer: a general U-shaped transformer for image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022 Jun 18–24; New Orleans, LA, USA. p. 17683–93. [Google Scholar]
42. Cho SJ, Ji SW, Hong JP, Jung SW, Ko SJ. Rethinking coarse-to-fine approach in single image deblurring. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2021 Jun 20–25; Nashville, TN, USA. p. 4641–50. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools