
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Ghost-Attention You Only Look Once (GA-YOLO): Enhancing Small Object Detection for Traffic Monitoring
1 School of Advanced Technology, Xi’an Jiaotong-Liverpool University, Suzhou, China
2 School of AI and Advanced Computing, Xi’an Jiaotong-Liverpool University, Suzhou, China
3 Department of Electrical Engineering and Electronics, University of Liverpool, Liverpool, UK
4 Department of Information Science and Technology, Sanda University, Shanghai, China
5 School of Information Engineering, Wenzhou Business College, Wenzhou, China
6 Thrust of Artificial Intelligence and Thrust of Intelligent Transportation, The Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China
7 Institute of Deep Perception Technology, JITRI, Wuxi, China
8 XJTLU-JITRI Academy of Industrial Technology, Xi’an Jiaotong-Liverpool University, Suzhou, China
9 Department of Mathematical Science Technology, University of Liverpool, Liverpool, UK
10 Department of Artificial Intelligence Software Technology, Sun Moon University, Chung-nam, Republic of Korea
* Corresponding Author: Young-Ae Jung. Email:
Computers, Materials & Continua 2026, 87(2), 75 https://doi.org/10.32604/cmc.2026.075415
Received 31 October 2025; Accepted 13 January 2026; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Intelligent Transportation Systems (ITS) represent a cornerstone in modern traffic management, leveraging surveillance cameras as primary visual sensors to monitor road conditions. However, the fixed characteristics of public surveillance cameras, coupled with inherent image resolution limitations, pose significant challenges for Small Object Detection (SOD) in traffic surveillance. To address these challenges, this paper proposes Ghost-Attention YOLO (GA-YOLO), a lightweight model derived from YOLOv8 and specifically designed for traffic SOD. To enhance the attention of small targets and critical features, a novel channel-spatial attention mechanism, termed Small-object Extend Attention (SEA), is introduced. In addition, the original C2f module is replaced with a more efficient Cross-Stage Partial (CSP) module, C3k2, to achieve improved feature processing with lower cost. Building upon these designs, a CSP-based Ghost Bottleneck with Attention (CGBA) module is further developed by integrating SEA into C3k2 and is deployed within the FPN–PAN network to strengthen feature extraction and fusion. Compared with similar-scale baseline models YOLOv8n and YOLOv11n, GA-YOLO demonstrates clear performance advantages on the UA-DETRAC dataset. Specifically, GA-YOLO achieves over 3% improvements in precision and mAP@50, along with a 5.6% gain in mAP@50-95, while reducing the parameter count by nearly 10% and computational complexity by 0.5 GFLOPS compared with YOLOv8n. In addition, GA-YOLO outperforms YOLOv11n by 8.6% in precision and 3.2% in mAP@50-95. These results indicate that GA-YOLO effectively balances detection accuracy and computational efficiency. Furthermore, additional evaluations across varying occlusion levels and representative detection models indicate the effectiveness and practicality of GA-YOLO for traffic-oriented SOD tasks.Keywords
Considering the rapid advancement of urbanisation and personal vehicle ownership, traffic management and safety are facing significant challenges. Intelligent Transportation Systems (ITS), a crucial component of smart cities, enhance traffic management by providing real-time detection and decision-making through deep learning approaches [1,2]. The effectiveness of ITS directly impacts the safety of citizens and the reliability and law enforcement credibility of the government. Among various sensors, fixed surveillance cameras serve as the primary data source for real-time monitoring of traffic conditions [2].
However, the fixed positions and viewing angles of public surveillance cameras limit their monitoring capabilities, making detection performance highly relevant to the distance between vehicles and cameras. Nearby vehicles appear larger and more distinct, whereas distant vehicles tend to appear small and easily merge with background noise. The limited pixel representation further exacerbates this issue, causing small targets to blend more easily into background noise [3]. Moreover, fixed camera angles may result in occlusions, where targets are blocked by other elements, further complicating the detection. These intrinsic constraints of surveillance cameras substantially exacerbate the challenge of Small Object Detection (SOD), as the reduced visibility of distant or partially obscured objects compromises the overall monitoring accuracy of ITS. Thus, enhancing SOD capability is essential for ITS monitoring, ensuring the detection performance is less influenced by image quality, object size and spatial position.
As the representative of popular real-time detectors that balance accuracy and speed, the You Only Look Once (YOLO) series, notably YOLOv8, has demonstrated outstanding performance in real-time object detection tasks [4]. However, their capability in detecting small objects remains constrained [4,5]. Specifically, the standard YOLOv8 architecture struggles to preserve minor features due to its hierarchical feature extractions and fusion designs, which hinder adequate SOD handling [6]. In addition, the high computational demand of most existing detectors restricts the real-time deployment on resource-constrained edge devices in practical traffic monitoring systems. Recent studies have compared different scales of YOLOv8 in ITS scenarios. Bakirci [7] evaluated YOLOv8 variants in aerial traffic monitoring and found that, although YOLOv8n yields relatively lower detection accuracy than other larger-scale variants, it offers significantly outstanding inference speed. Consequently, YOLOv8n is adopted as the baseline model due to its strong real-time potential.
To alleviate the above limitations, we propose Ghost-Attention YOLO (GA-YOLO), an optimised YOLOv8 tailored to improve small object detection and lightweight implementation in real-time ITS monitoring. The main contributions of this work include:
• We design a novel plug-and-play Small-object Extend Attention (SEA) module to enhance feature representation for small objects. By emphasising fine details and critical features, SEA improves the extraction of features for tiny or partially visible targets, enabling more robust detection in complex traffic scenes.
• We improve the backbone by replacing the standard ‘faster implementation of CSP Bottleneck with two convolutions (C2f)’ modules with the more efficient ‘faster CSP Bottleneck with two convolutions and optional C3k blocks (C3k2)’ modules. This modification enhances multiscale feature processing while mitigating computational redundancy, resulting in a faster and more cost-efficient solution without sacrificing detection accuracy.
• We propose the CSP-based Ghost Bottleneck with Attention (CGBA) module, which integrates the SEA mechanism into a lightweight CSP bottleneck structure. This module strengthens multiscale feature extraction and fusion, thereby improving small object detection performance while maintaining computational efficiency.
• We demonstrate the effectiveness and robustness of GA-YOLO by comparing it with diverse models under both general detection and occlusion scenarios. Additionally, we analyse the impact of attention insert positions and kernel designs in SEA.
In the rest of this paper, related works in small object detection, attention mechanisms and lightweight techniques are reviewed in Section 2. Then, Section 3 presents our proposed model framework and details the improved modules. After that, experimental details and results are presented and discussed in Section 4. Eventually, the conclusion and potential future research directions are outlined in Section 5.
Small-Object Detection (SOD) is a challenging topic in computer vision because of the difficulties in correctly localising and classifying small objects in pixel-limited images. Objects smaller than or equal to 32
With the emergence of Convolutional Neural Network (CNN), object detection based on deep learning has rapidly developed; as a branch of object detection, the performance of SOD has also improved. The CNN-based detection method can be divided into two types: the two-step stage, like Faster-RCNN, and the one-step stage, like YOLO [4,12,13]. These models commonly enhance SOD by using multiscale feature extraction and fusion techniques, such as the feature pyramid method and region proposal network [14–17]. Additionally, context-aware methods have been proposed to enhance the feature representation by integrating contextual information and expanding the receptive fields. For instance, Cai et al. [18] extended the proposal region by 1.5 times and stacked the extended context information with the original small object features. Many YOLO-based models have also proposed adding an extra detection head to capture smaller objects by a finer receptive field [16,17,19].
Another popular approach is the Transformer-based SOD method, which utilises the encoder-decoder structure for object detection, such as the DEtection TRansformer (DETR) [20]. However, the complexity of the encoder-decoder structure limits DETR’s performance on SOD tasks [20]. Deformable-DETR alleviates this issue by proposing a deformable multiscale attention block and only focusing on a few points surrounding the reference point strategy [21]. Also, Xu et al. [22] propose that the Bidirectional Feature Pyramid Network (BiFPN) be used to more effectively retain features relevant to the target small objects. Moreover, researchers also aim to fuse the two structures, such as UA-YOLOv5 imports the Swin Transformer v2 (STR-V2) and BiFormer to YOLOv5, and PVswin-YOLOv8s combines the Swin Transformer to the backbone [19,23].
Overall, the SOD has significantly advanced with the development of deep learning. Both CNN-based and Transformer-based models have shown the potential to enhance SOD performance through multi-scale feature extraction and context-aware improvement. Our model aims to further enhance the SOD by integrating the attention mechanism into the CNN-based model, combining the powerful feature extraction mechanism from the Transformer without significantly increasing the model’s complexity.
Humans can accurately and quickly identify the more interested or important information from vast data by focusing on key aspects with limited cognitive resources. Inspired by this cognition mechanism, the attention mechanism has become a popular research approach in resource-limited computer systems to improve the performance of deep learning models [24–26]. By selectively emphasising the critical part of input data, the attention mechanism allows models to process large data more effectively, thereby improving overall efficiency and accuracy. Currently, attention mechanisms have been applied across multiple tasks, particularly in visual recognition [27,28]. This paper reviews attention mechanisms in visual recognition tasks, such as image classification and object detection.
Based on the various operating domains, the attention mechanisms in static images can be categorised as channel attention, spatial attention and combinations of both [24,26]. Channel attention determines “which” feature channel deserves more focus. As pioneers, Hu et al. [29] propose the Squeeze-and-Excitation (SE) block, which uses global average pooling to squeeze input features into a global information vector; this vector then undergoes an excitation process to generate channel weights; when the weights are multiplied with the original input, the important channel will be emphasised. However, the excitation in SE involves both dimensionality reduction and expansion, disrupting the direct correspondence between channels and weights and introducing unnecessary dependency across all channels [24,30]. To alleviate these limitations, researchers have proposed several structures. For example, Wang et al. [30] introduced the Efficient Channel Attention (ECA) block, which uses a 1D convolution to realise the interaction between the channel and its k neighbours without dimensionality reduction, improving the excitation process.
Besides channels, the spatial position is also a considerable dimension for analysing static images. Researchers can use spatial attention choice “where” to focus, highlighting the areas that are more relevant to the task [26,31]. For instance, Jaderberg et al. [32] proposed the Spatial Transformer Network (STN), which adaptively adjusts the spatial structure of the input feature map to focus on the most relevant region while learning affine transformations, such as translation, rotation, and cropping. STN contains three components: firstly, a localisation network predicts the affine transformation parameter (
Beyond individual attention mechanisms, since important information in the images is often distributed in different channels and spatial positions, combining both can capture complementary information, supporting more comprehensive feature learning. The Convolutional Block Attention Module (CBAM) is a typical and popular combinational instance [33]. The CBAM sequentially applies channel and spatial attention to enhance the feature representation. Channel attention first refines input features by applying global average pooling and max pooling to aggregate channel information, then utilises a Multi-Layer Perceptron (MLP) to generate weights for highlighting important channels. Spatial attention emphasises crucial regions by applying a 7
While current attention mechanisms excel in general detection tasks, they still face SOD challenges due to the limited size and partial visibility of small objects. Most existing mechanisms primarily focus on enhancing the overall feature extraction, whereas fail to effectively address the issues specific to SOD. In detail, channel attention often neglects small object channels due to the low response. For example, SE applies global average pooling compresses the features, and the global information is dominated by large objects and background channels, overshadowing the contribution of small object features [29]. Similarly, spatial attention also faces such issues, as the focus allocated to small objects is diminished due to the limited spatial occupied areas. Moreover, small area objects are easily confused with the background noise and are difficult to distinguish. For instance, if the localisation network fails to recognise the small object regions, the STN might unconsciously crop the small object during affine transformation, causing the loss of the small local features [32]. Furthermore, combination attention might inherit limitations from channel and spatial attention; different combined strategies determine the specific challenges. For CBAM, while the max pooling operation in the channel side somewhat helps preserve small object features, the spatial part still potentially fails to capture the small features with low occupancy. This is because the spatial part only utilises a large receptive field (7
Overall, existing attention mechanisms primarily focus on optimising general feature extraction, even in attention mechanisms applied to SOD models. For instance, DANet directly incorporates CBAM to enhance feature representation [34]. There is still a lack of attention specifically designed to optimise the small object features. Therefore, considering the complementary channel and spatial attention in images, our research proposes a combination attention mechanism tailored to the limited representation of small objects. This aims to enhance the focus on small objects with low response channels and fewer occupancy regions, thereby improving overall detection performance by balancing global and local features and considering adaptiveness across varying conditions.
To deploy deep learning models on resource-limited devices, lightweight models are proposed to reduce computational burden while balancing performance and cost. This enables the model to perform similarly to the original when deployed on edge devices [35]. Common lightweight approaches include compression techniques like pruning, quantisation, and knowledge distillation. However, this paper focuses on designing efficient architectures, which is another lightweight approach [36]. Below, two renowned lightweight models from recent years are introduced:
• MobileNetV1-V3: MobileNetV1 uses depthwise separable convolutions, which combine depthwise and pointwise convolutions, to significantly reduce computations with minimal accuracy loss [37]. Then, MobileNetV2 introduces the inverted residual block, improves accuracy and reduces the model size [38]. MobileNetV3 further optimises the network by incorporating the MobileNetV2 block and SE attention, enhancing the depth-wise separable convolution and inverted residual block [39].
• GhostNet: Reduces model size and computational complexity by replacing standard convolution with ghost convolution (GhostConv), which uses fewer parameters to generate more valid features [36]. GhostNet has been shown to outperform both MobileNet and ShuffleNet [36].
Many later lightweight models have been developed based on the above architectures. Beyond these, due to considerations of search efficiency and hardware deployment, researchers have proposed lightweight models based on the enhanced Neural Architecture Search (NAS), which aims to alleviate the dependency on manual design, enabling models to automatically search for the optimal architecture on current devices [40]. Observing these well-performing lightweight networks, some are realised based on lightweight convolution blocks, such as DSConv in MobileNet and GhostConv in GhostNet [36,37]. Instead of replacing the entire backbone with a lightweight network like GhostNet, we propose integrating efficient convolution blocks into the improved YOLO model. This approach aims to achieve lightweight properties while maintaining the performance and well-developed structure of the YOLO series.
Considering the requirements of high-density traffic scenarios, YOLOv8 is selected as the baseline model due to its balanced trade-off among detection accuracy, computational cost, and real-time performance. However, beyond the general challenges posed by dense traffic scenes and limitations of public surveillance cameras, YOLOv8 also faces intrinsic structural constraints in SOD tasks. First, as the network depth increases, progressively larger down-sampling rates reduce the feature map resolution, leading to the loss or suppression of low-level detailed features that are critical for representing small objects. These fine-grained features are often overwhelmed by dominant large-object information. Second, the standardised operation during preprocessing further shrinks the small objects in larger resolution inputs, increasing the difficulty of fine-grained detection. These factors highlight the limitations of the original YOLOv8 architecture in handling SOD tasks. To address these challenges, we optimise the YOLOv8 architecture to improve both SOD performance and computational efficiency. The key improvements include:
• Composite attention module: A novel plug-and-play attention module is designed by integrating channel attention (CA) and spatial attention (SA) mechanisms and is tailored for SOD. By dynamically allocating attention to small targets through size-sensitive channels and spatial weighting, this module enhances the representation and robustness of small-object features under occlusion and scale variation.
• Cross-Stage Partial (CSP) module optimisation: A more efficient CSP module is introduced to enhance feature extraction and fusion in both backbone and neck, while reducing redundant computations on high-level features.
• CSP-based lightweight bottleneck module: A novel CSP-based bottleneck is proposed by embedding the designed attention mechanism into a lightweight structure. By being deployed in the neck, this module strengthens multiscale feature aggregation, mitigates feature loss, and effectively preserves fine-grained details for SOD.
The overall architecture of GA-YOLO is illustrated in Fig. 1, which consists of three main components: Backbone, Neck, and Head. The proposed architecture enhances SOD performance by reconfiguring CSP modules and selectively introducing the SEA attention mechanisms. In the backbone, the original C2f modules are replaced with more efficient C3k2 modules, enabling faster and more effective feature extraction. The neck adopts a Feature Pyramid Network–Path Aggregation Network (FPN–PAN) structure to fuse multiscale features. Semantic information is enhanced through the top-down FPN pathway, while localisation information is refined via the bottom-up PAN pathway. To further strengthen multiscale feature representation, particularly for small-scale objects, the proposed CGBA module with embedded SEA is incorporated into the neck. Finally, similar to YOLOv8, the refined features are fed into decoupled detection heads to predict objects at three scales: small, medium, and large. The proposed modules are detailed in the following subsections.
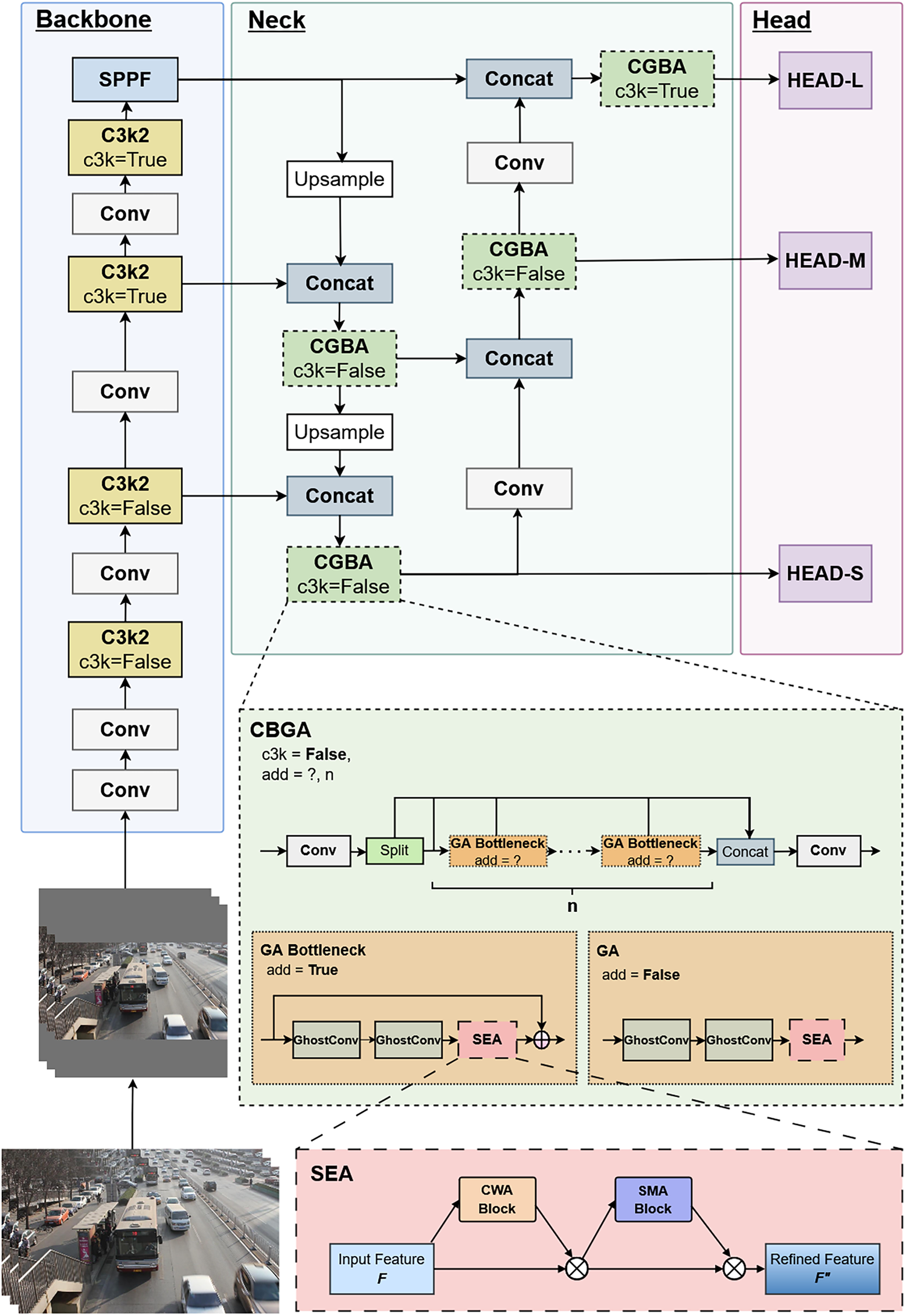
Figure 1: The overall architecture of the proposed Ghost-Attention YOLO (GA-YOLO) model.
3.1 Small-Object Extend Attention (SEA) Module
To enhance feature representation for small objects, we propose the SEA module, which is inspired by the channel-spatial structure of CBAM. SEA is further redesigned utilising established principles of multi-scale representation and hierarchical refinement to overcome the typical limitations of CBAM in small-object responses and scale generalisation. As shown in Fig. 1, SEA consists of two sub-blocks: Channel Weighted Attention (CWA) and Spatial Multi-Attention (SMA). This sequential design follows the feature subspace refinement paradigm, which progressively suppresses irrelevant feature dimensions before redistributing attention spatially. From a theoretical perspective, the CWA block is grounded in statistical feature theory, while the SMA block is guided by scale-space theory. Although the sequential multiplications in Eq. (1) introduce additional inference latency, each operation is lightweight (with
where the overall calculation is divided into two stages: the channel stage (
The CWA map
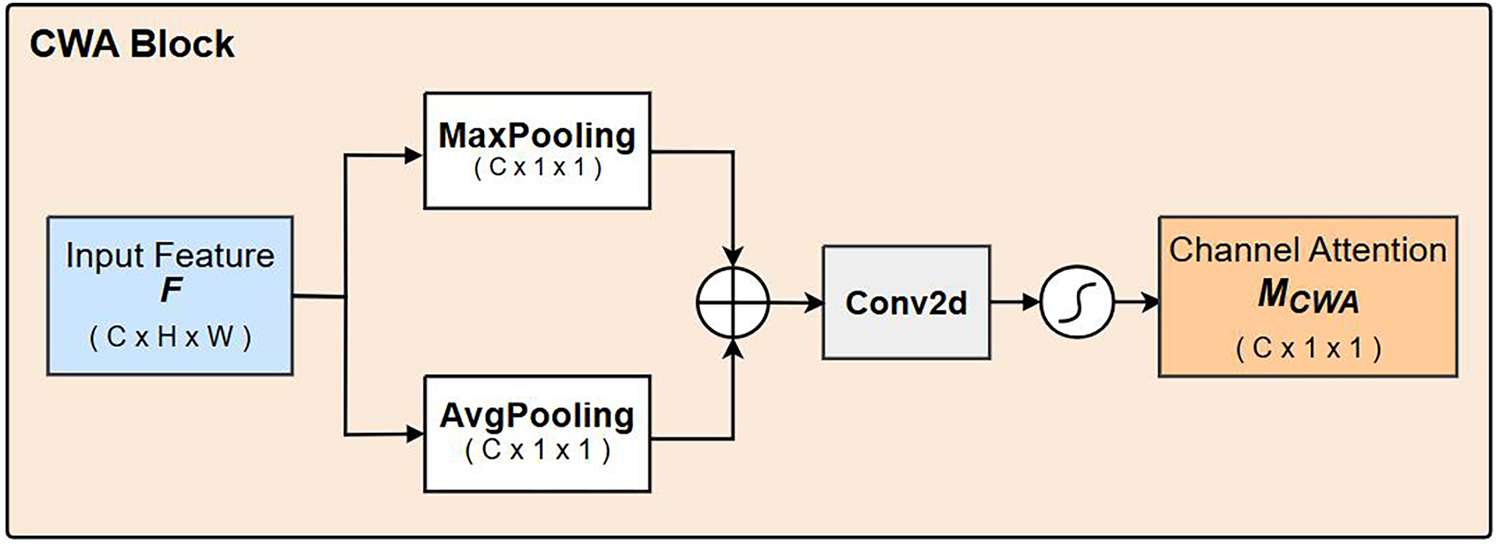
Figure 2: Detailed structure of the Channel Weighted Attention (CWA) block.
As illustrated in Fig. 3, the channel-refined feature
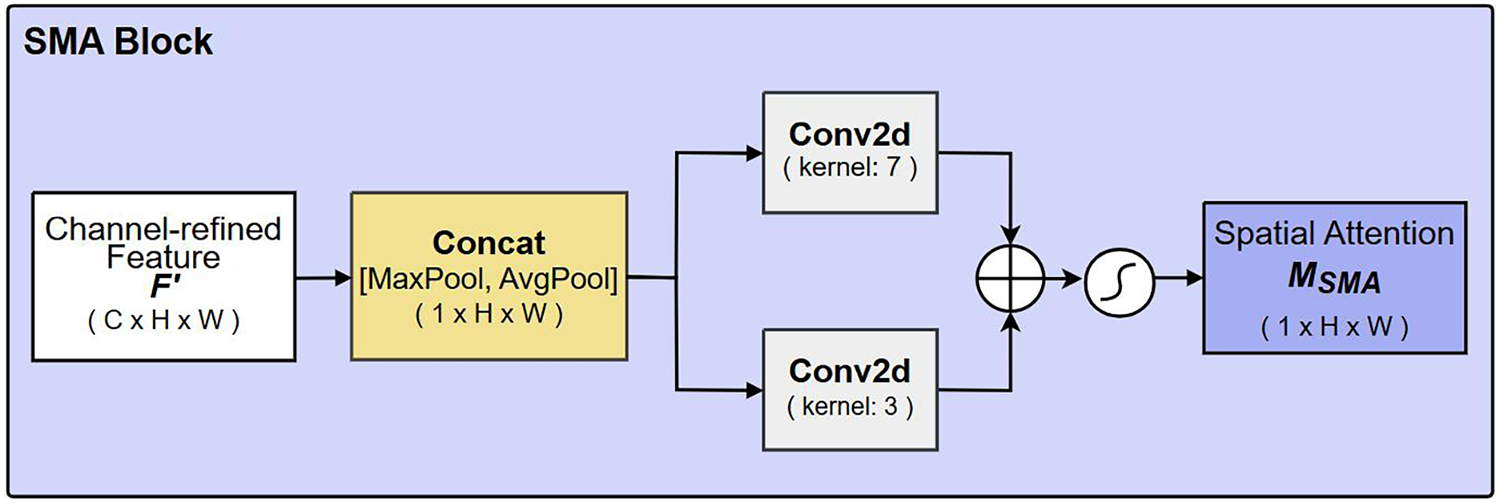
Figure 3: Detailed structure of the Spatial Multi-Attention (SMA) block.
In summary, the proposed SEA module is specifically tailored for SOD tasks. The module leverages mixed pooling in the channel domain and dynamically weighted multiscale kernels in the spatial domain to emphasise fine features while preserving global contextual information. This design mitigates feature loss during down-sampling extraction and multiscale fusion, increases the relative importance of small object features, and improves model’s ability to distinguish small or occluded targets from background distractions. The quantitative and qualitative analyses in Sections 4.4.2 and 4.6 further demonstrate the effectiveness of SEA.
3.2 Feature Extraction Layers Replacement: C3k2 Module
To improve feature aggregation efficiency while reducing computational redundancy, we replace the original C2f modules with the C3k2 module. Both C2f and C3k2 belong to the CSP family, which employs partial connections to decompose feature processing into a feature-refining main branch and a feature-preserving bypass branch. This design effectively reduces computations without damaging model understanding capability and alleviating gradient degradation issues [43]. Early YOLO adopted CSP-based backbone first, like CSPDarkNet-53, and later introduced the C3 module to both backbone and neck to improve computational efficiency [4,44]. However, the C3 module relies on fixed bottleneck stacking with limited cross-layer interaction, which constrains feature diversity in deeper layers and may lead to insufficient preservation of fine details such as small-object features.
To address this issue, YOLOv8 introduced the C2f module, which enriches feature interaction by adding cross-connections between bottlenecks and the concatenation layer. This design enhances cross-layer interaction, effectively increases multiscale feature fusion and improves detail preservation. Nevertheless, the repeated reuse and concatenation of low-level features also introduce meaningless redundant calculations, impacting parameter efficiency and computational loads [45].
The C3k2 module offers a more compact alternative by providing a configurable CSP bottleneck that selectively removes redundant cross-layer interactions. As shown in Fig. 4, when the c3k is false, C3k2 bottleneck behaves similarly to C2f; whereas when c3k is true, it is simplified into the C3 structure with a customised kernel size k. This flexible design removes redundant cross-layer interactions while preserving essential CSP principles. In YOLOv11, c3k is enabled in the deeper backbone layers and the fusion stage leading to the large-scale detection head [46]. This reflects that high-computation processing of already well-processed high-level features is redundant. Guided by this thinking, as shown in Fig. 1, we enable c3k = True only in the deep-level extraction layers of the backbone and the feature fusing and refining layer for the large-scale head. This selective replacement enables more efficient allocation of computational resources while maintaining robust multiscale feature representation.
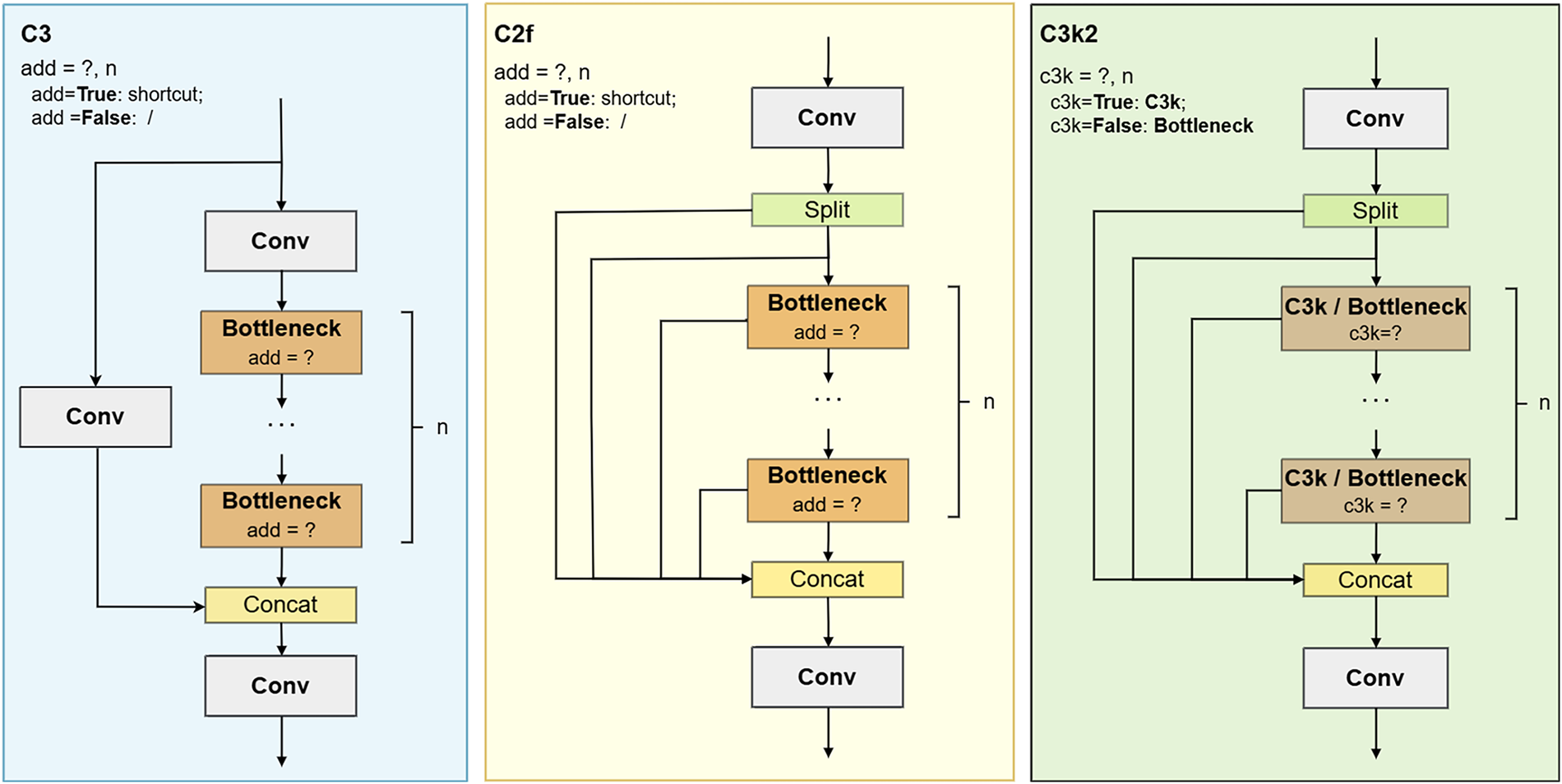
Figure 4: Structures of CSP modules, including C3, C2f and C3k2.
3.3 Improved Feature Extraction and Fusion Module: CGBA
The YOLOv8 architecture achieves effective feature extraction and fusion through CSP variants and the PAN–FPN structure [4,5]. To enhance SOD performance without introducing substantial computational overhead, such as that introduced by importing a Transformer-based encoder–decoder, we refine the CSP bottleneck by embedding an attention mechanism. By integrating attention within the bottleneck, the response to low-saliency small-object cues is strengthened, thereby improving the overall feature aggregation within the PAN-FPN structure.
Theoretically, the design of CGBA also follows the principle of hierarchical feature refinement. The CSP bottleneck is inherently a hierarchical refinement structure that compresses features into a compact semantic subspace. Integrating the attention mechanism into the bottleneck enables the model to selectively amplify features that may be suppressed during bottleneck dimensional changes. This attention-combined hierarchical structure further enhances the preservation possibility of small features while maintaining the structural efficiency of the CSP framework. As discussed in Section 3.1, SEA provides a channel–spatial mechanism for highlighting small-object responses. To exploit this property efficiently, SEA is embedded inside the CSP bottleneck, forming a CSP-based Bottleneck with Attention (CBA) module.
While embedding attention improves small feature representation, it inevitably introduces additional computational cost, as each attention has weights and biases. To preserve the lightweight nature of the bottleneck, we incorporate GhostConv as the convolutional operator. GhostConv is grounded in low-rank feature approximation, which posits that the high-dimensional feature map can be reconstructed from a small set of intrinsic features through multiple inexpensive linear transformations. In GhostConv, the intrinsic features are generated by a primary 1
Combining the above considerations yields the proposed CSP-based Ghost Bottleneck with Attention (CGBA) module. CGBA integrates SEA for selective feature emphasis and GhostConv for efficient feature transformation. In GA-YOLO, we adopt the C3k2-based CGBA. As detailed in Fig. 1, this novel CGBA module incorporates SEA attention and lightweight GhostConv, enabling efficient processing of critical features while managing computational resources effectively.
This section first states the datasets, equipment setups and evaluation metrics used in the following experiments. Afterwards, present validation, comparative, and ablation experimental results to assess the effectiveness of the proposed modules and the overall performance of the GA-YOLO model. Notably, the experiments are based on the UA-DETRAC dataset unless otherwise specified. Finally, we further provide intuitive assessments through occlusion-level SOD performance and attention heatmap comparisons.
We conducted experiments on two challenging public traffic image datasets: UA-DETRAC and KITTI-2D [47,48]. Both datasets involve images captured under varying brightness, weather conditions and traffic scenarios, and exhibit scale variation and occlusion caused by camera viewpoints. The details of the datasets are shown in Table 1. The datasets assess model performance from different perspectives and resolutions. Notably, the original labels were converted to YOLO format, and categories representing uncertain or invalid areas (such as ‘DontCare’ in KITTI-2D) were filtered out to avoid introducing training noise. Thus, in our experiments, the UA-DETRAC contains four classes (car, bus, van, truck), and KITTI-2D contains eight classes (car, van, truck, pedestrian, person sitting, cyclist, tram and misc). Additionally, as both datasets are medium scale, we followed the standard practice of 70% training, 20% validation, and 10% test split to balance training sufficiency, hyperparameter tuning, and reliable performance evaluation.

Experiments were conducted under the PyTorch framework using a single NVIDIA RTX 4090 GPU card with a 24 GB GDDR6X frame buffer. All the images were preprocessed to 640
Model performance is mainly evaluated in two aspects: computational cost and detection accuracy. Computational cost, reflecting the resource requirements and execution efficiency of the model, is measured by the number of parameters and Giga Floating Point Operations Per Second (GFLOPS). The number of parameters affects the model size and memory needs, while GFLOPS measures the computational complexity.
Detection accuracy, which reflects the bounding box (bbox) detection and classification ability of the model, is assessed using precision (P) and mean Average Precision (mAP). mAP computes the mean of Average Precision (AP) values across all classes, providing an overall measure of the model’s detection performance. The evaluation utilises mAP@50 and mAP@50-95 metrics, where mAP@50 represents the mAP at an Intersection over Union (IoU) threshold of 50%, and mAP@50-95 represents the mAP on the IoU threshold ranging from 50% to 95%. IoU is the overlap between the predicted and ground-truth bounding boxes.
Additionally, the model deployment performance is also evaluated in comparative experiments. This reflects the practical runtime performance of the detectors and is measured by Frame Per Second (FPS), peak end-to-end memory usage and model loading time. Normally, real-time processing is defined as a throughput of more than 30 FPS [49].
In this section, we verified the effectiveness of several detailed designs in GA-YOLO. Specifically, we validated the insertion of the attention mechanism in the YOLO neck and the use of a 3
4.3.1 Impact of Attention Mechanism Placement
To optimise feature extraction and fusion efficiency, we experimented with the placement of the improved C2f module, C2f-based Bottleneck with Attention (CBA) in YOLOv8. The original YOLOv8 employs the C2f module in the backbone for feature extraction and the neck for multiscale feature fusion and refinement. In this experiment, we insert CBAM as the attention mechanism to evaluate the performance impact of placing the CBA module in three different configurations: backbone-only, backbone and neck, and neck-only.
The experiment results in Table 2 show that incorporating the attention mechanism in any position can improve accuracy metrics. Notably, placing in the neck-only position achieved the highest mAP values (mAP@50 and mAP@50-95). This is theoretically rational because the neck stage processes and fuses multiscale features extracted from the backbone, where these multiscale features already represent the essential information from the base layers. Thus, inserting attention only at the neck stage refines the multiscale features, avoids redundant feature processing in the backbone layers, and effectively further reinforces the feature representation before detection. Additionally, compared to the original YOLOv8, incorporating the attention mechanism increases the parameter count, while GFLOPS remain relatively stable, indicating that the additional parameters caused by the attention mechanism do not significantly impact the computational complexity of the model. The stability of GFLOPS indicates that integrating attention does not increase the computational complexity of the model.
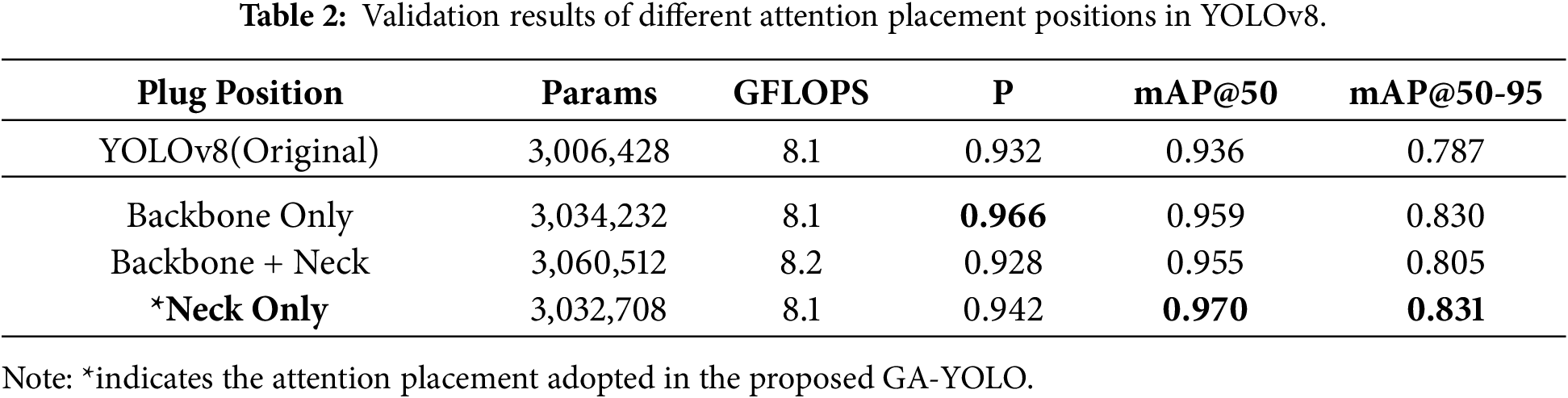
The results show that incorporating attention improves model performance, and placing it only in the neck stage yields the best trade-off between accuracy and efficiency, achieving a 4% mAP gain with only a 0.08% increase in computational cost.
4.3.2 Impact of Kernel Size Selection and Weight Allocation in SEA Mechanism
In the proposed SEA attention mechanism, we process the feature using learnable kernel size combinations in its SMA block. To validate and evaluate the correctness of the 3
As mentioned in Section 3.1, the GA-YOLO employs an attention mechanism configured with learnable weighted multiscale convolutions (3
According to the results shown in Table 3, GA-YOLO with ‘3
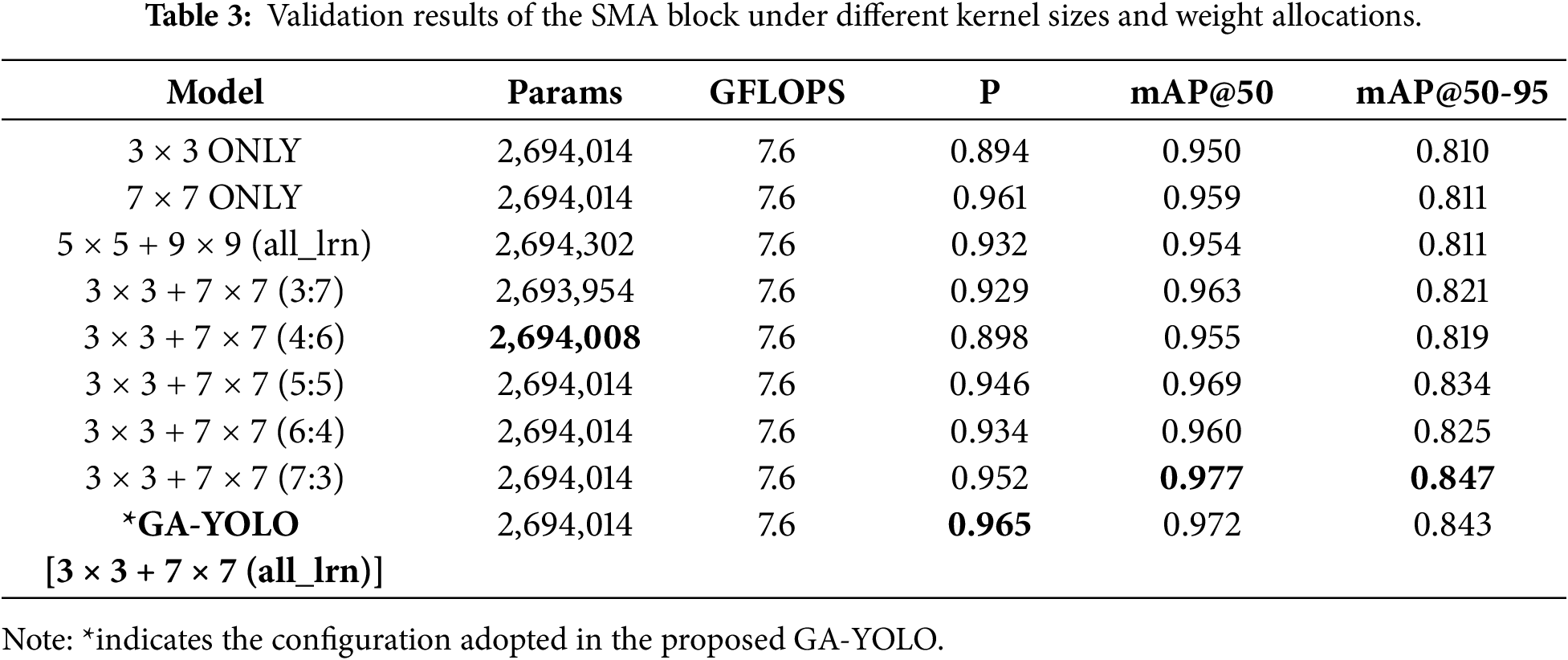
Building on the validation of the 3-7 combination’s effectiveness, we further investigate the weight allocation design for the two kernels. The experiments were conducted using two strategies: fixed weights and dynamic learnable weights. As shown in Table 3, the learnable weights GA-YOLO model holds the highest precision while its mAP metrics are only slightly lower than the fixed weights 7:3 configuration. However, the mAP differences are both less than 1%, indicating that GA-YOLO has a very similar detection accuracy to the fixed 7:3. Furthermore, the fixed weight strategies are fragile, and the performance might degrade on different datasets. In contrast, the dynamic learnable weight strategies offer a more flexible weight; the weights are adjusted based on different data distributions, demonstrating the greater potential for adaptability and generalisation. Moreover, observing the computational costs and introducing the two learnable weights does not introduce any additional burden. Thus, the learnable strategy achieves the highest precision and nearly the highest mAP, offering a more robust and efficient weight allocation that ensures flexibility with strong detection performance.
Additionally, observing among the fixed-weight kernels in similar-scale weight groups (such as 7:3 and 3:7, 6:4 and 4:6), weight bias towards small kernels typically yields better detection performance, highlighting the importance of local detail extraction by small kernels. Compared with the configuration that only uses 3
This section compares GA-YOLO with other representative models across different datasets to evaluate the overall performance. Then, we assessed the SEA module by conducting a comparison between SEA and a similar combinational attention mechanism, CBAM.
4.4.1 Comparison of GA-YOLO with Other Models
The comparative experiment is conducted on the proposed GA-YOLO model alongside other similar-scale representative models across three categories: CNN-based, Transformer-based, and YOLO-based. In addition to comparing with recent similar scales YOLOs, the YOLO-based category further includes two specialised SOD models: Improved YOLOv8 and SOD-YOLO, to evaluate the effectiveness of GA-YOLO against both general-purpose and SOD-oriented YOLO architectures. Furthermore, GA-YOLO is evaluated against representative CNN-based detection paradigms, including the two-stage FasterRCNN, the one-stage RetinaNet, and the lightweight EfficientDet [12,50,51]. Considering the substantial training time differences between GA-YOLO and other Transformer-based models, only the Real-Time DEtection TRansformer (RT-DETR) is included for comparison to ensure fairness and practicality [52].
Additionally, the comparison focuses on computation loads, accuracy and deployment metrics to assess the effectiveness and lightweight advantages of the GA-YOLO model, where lightweight is determined by four aspects: model complexity (GFLOPS), model size (parameters), inference speed (FPS and model loading time), and hardware consumption (peak memory usage). Furthermore, to assess the generalisation capability of GA-YOLO, experiments are conducted with the same configurations on both UA-DETRAC and KITTI-2D datasets, involving diverse traffic scenarios with varying viewpoints, weather and lighting conditions, and geographic environments.
As the comparison results across the UA-DETRAC dataset shown in Table 4, the YOLO series outperform most CNN-based and Transformer-based models. Particularly, the proposed GA-YOLO achieves the highest Precision, mAP@50, and mAP@50-95 values, demonstrating better overall detection performance that benefits from the SOD enhancements. In comparison with various YOLO models, including other nano-size, larger-size models and the improved YOLOv8, the proposed GA-YOLO outperforms others in the overall detection accuracy metrics, even surpassing the SOTA YOLOv11, which benefits from the proposed attention-optimised and cross-stage efficiently integrated CGBA mechanism. However, GA-YOLO exhibits a slightly higher computational load than YOLOv5 and YOLOv11 at the same scale, which can be attributed to the inclusion of relatively more complex modules, such as the CSP module and the detection head. YOLOv5 has a lighter parameter load because its C3 module only concatenates the final bottleneck output with the initial feature map. In contrast, the C3k2 modules applied in GA-YOLO, when c3k is False (equivalent to the C2f module), concatenate each bottleneck output with the initial feature map, leading to an increase in parameters. Additionally, YOLOv11 benefits from the lightweight DWConv, which is introduced in the detection head structure and reduces computational costs (GFLOPS) [46]. This advantage is also highlighted in the comparison between the ‘YOLOv8’ and ‘YOLOv8+v11Head’ items in Table 4, where replacing the head from v8Head (which only uses normal Conv) with lightweight v11Head (which uses the DWConv) results in a decrease of 1.3 GFLOPS. The higher GFLOPS of GA-YOLO can be attributed to the use of the more computationally intensive v8Head. Thus, even though GA-YOLO does not hold the lowest computational load, it still maintains a competitive computational cost while outperforming other YOLOs in detection performance.
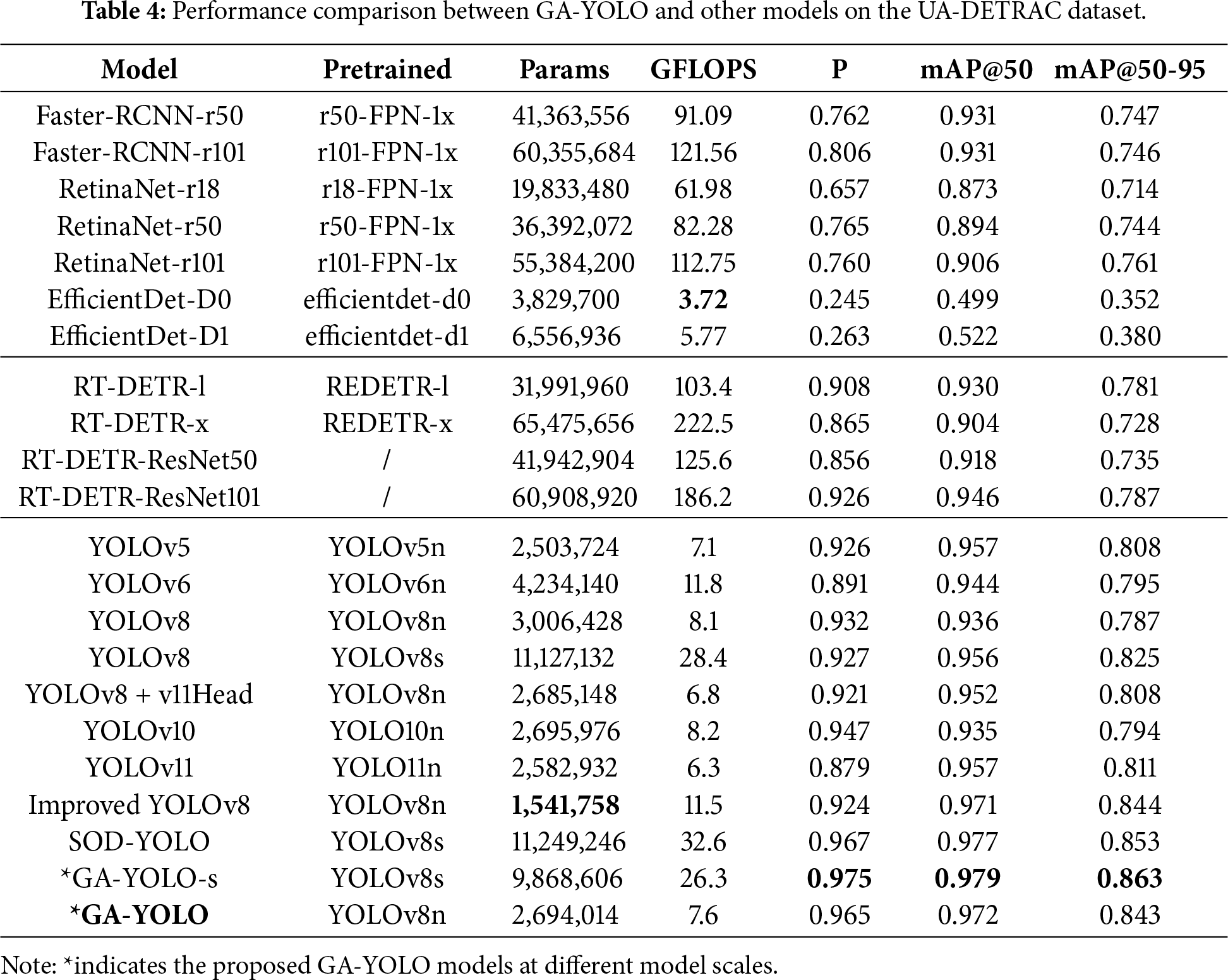
Following the comparison with the YOLO series, it is also necessary to evaluate GA-YOLO against another mainstream detector, Transformer-based models. To ensure a comprehensive and fair comparison, we selected four RT-DETR models that represent different model sizes (large and extra-large) and diverse backbones (pure Transformer-based and ResNet-based). Observing the detection performance in Table 4, our proposed GA-YOLO achieves superior detection performance, especially with an increase of more than 5% in mAP@50-95, while maintaining a computational load at least 12 times lighter. Considering the high computational demands of Transformer-efficient structures, such as Multi-Head Self-Attention (MHSA) and Feed-Forward Networks (FFN), the proposed GA-YOLO offers a more efficient alternative in both accuracy and computational efficiency.
Beyond these emerging detectors, we have also conducted experiments on representative CNN-based models. Classic CNN-based models generally perform well in detection tasks; however, high computational loads are an issue because performance is highly dependent on convolutional operations. Analysing the results in Table 4, the proposed GA-YOLO outperforms the conventional CNN-based models (i.e., Faster-RCNN and RetinaNet) in accuracy indexes with 15.9% Precision and 8.2% mAP@50-95 improvement, while decreasing the computational cost at least 8
In addition to the typical and lightweight detector comparisons above, two recently published YOLO-based models, Improved YOLOv8 [53] and SOD-YOLO [54], are also included to strengthen the evaluation. Improved YOLO is built on YOLOv8n, while SOD-YOLO is derived from YOLOv8s, but both aim to improve small-target detection. As shown in Table 4, although these SOD models achieve noticeable gains over the corresponding baseline models, similar-scale GA-YOLOs still deliver better accuracy, especially in precision. GA-YOLO-s achieves the best accuracy among all detectors while maintaining a comparable computational cost. Compared with nano size GA-YOLO, SOD-YOLO gains only a minor improvement (less than 1%) in accuracy at the cost of 5000k additional parameters and over 3.2
Building upon the comparative analysis on the UA-DETRAC dataset, we further assess the reliability and generalisation of GA-YOLO through similar experiments on the KITTI-2D dataset, which offers a diverse perspective in terms of camera viewpoints, dynamic scenes, and background complexity, thereby evaluating the robustness of the proposed model beyond fixed surveillance scenarios.
As shown in Table 5, in general, models exhibit slightly higher computational requirements and lower detection performance on KITTI-2D compared to results on UA-DETRAC. This performance decline is attributed to differences in the collection equipment and annotation categories between the two datasets. Firstly, KITTI-2D is captured by the onboard cameras, with the scene changing dynamically as the vehicle moves, resulting in more dynamic and complex scenarios in the dataset. In contrast, UA-DETRAC uses fixed cameras mounted on public facilities, capturing relatively more stable and simpler scenarios. The complex scenarios in KITTI-2D may pose additional challenges for models, including increased background interference and occlusions. Secondly, compared to UA-DETRAC, which only annotates four different types of vehicles, KITTI-2D labels a broader range of target sizes, including trams, pedestrians, and cyclists. The increased variety of target sizes, particularly with smaller objects like people, raises the difficulty of the detection task. Thus, the complexity of both scenarios and target sizes leads to a more challenging detection on KITTI-2D, resulting in lower performance compared to UA-DETRAC.
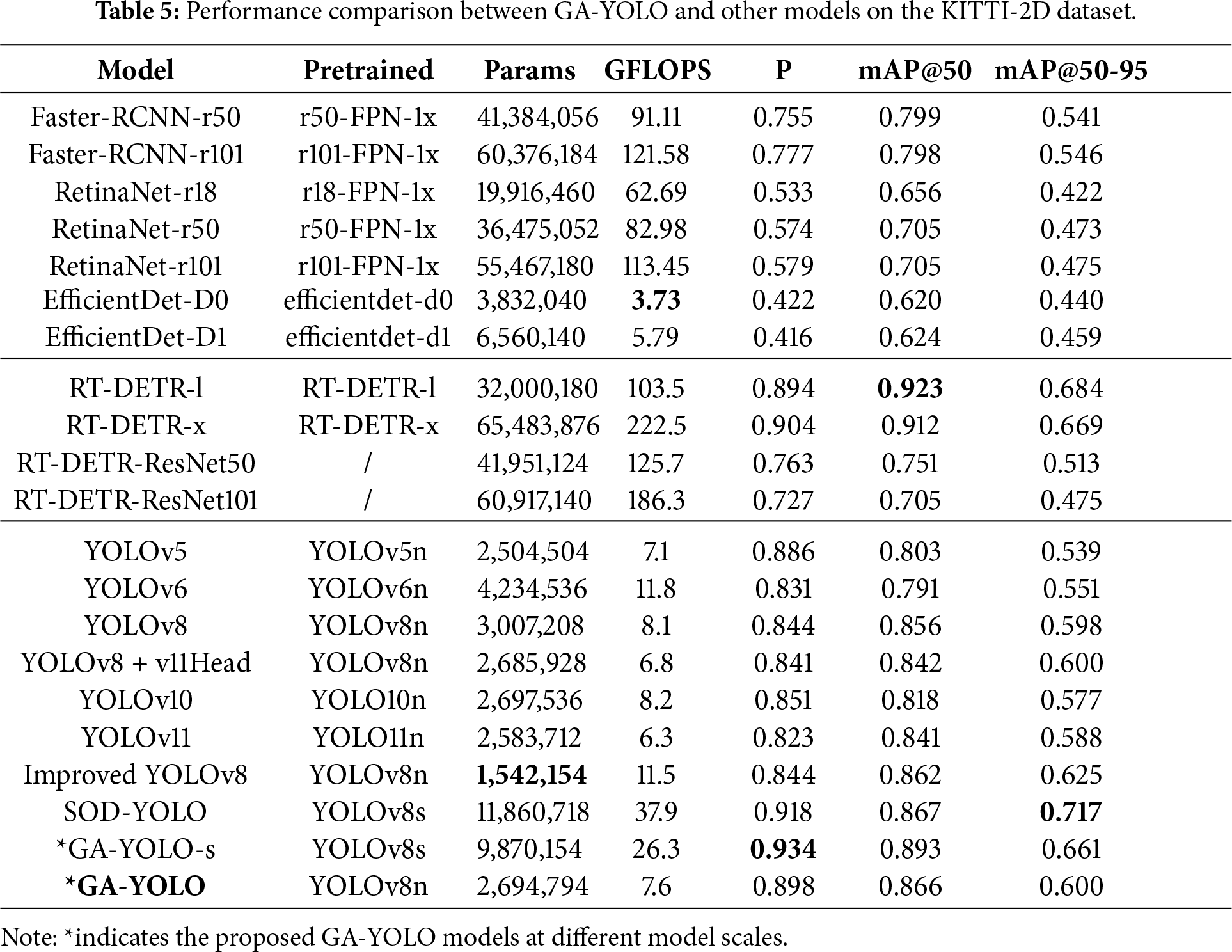
On KITTI-2D, GA-YOLO maintains a similar performance pattern as on UA-DETRAC, achieving the highest accuracy among the YOLO series while maintaining a relatively low computational cost, and retains its significant advantage in both accuracy and computational efficiency over CNN-based models. However, in KITTI-2D, instead of GA-YOLO, Transformer-based models achieve the highest accuracy metrics. This is because the MHSA mechanism in Transformer enables the capture of long dependencies and global context, thereby better distinguishing the dynamic, varying background and providing robust detection performance under dynamic scenarios. Although GA-YOLO does not achieve the highest accuracy, it offers a substantially lower computational overhead, with at least 11.8
Consistent with the UA-DETRAC experiments, we also compare GA-YOLO with the two latest YOLO-based SOD models on the KITTI-2D dataset. As presented in Table 5, Improved YOLOv8 and SOD-YOLO still provide improvements over their original YOLOv8 baselines, and GA-YOLO shows superior detection performance in precision and mAP@50. However, these two SOD models presented a better mAP@50-95. This change is primarily due to differences in architectural designs. Both SOD models introduce more feature fusion operations and skip connections into their framework, enabling the model to produce more precise bbox targets. Although GA-YOLO has minor shortcomings in bbox precise localisation in KITTI 2D, the consistently higher precision and mAP@50 indicate the overall advantages of GA-YOLO in detection performance and favourable trade-off of performance and efficiency. These advancements are maintained across datasets and across scales, demonstrating the robustness and generalisation of our model.
In addition to comparing the model-level performance, we also conduct a comparison regarding deployment-level performance. Real-time traffic monitoring scenarios require detectors that can operate efficiently on resource-constrained edge devices. Therefore, the three practical indicators are important: inference speed (FPS), peak memory usage, and model loading time. These metrics provide a more comprehensive assessment of lightweight and real-time performance beyond parameters and GFLOPS, and reflect the actual runtime behaviour of a detector. Generally, higher FPS, lower peak memory usage, and shorter loading time indicate better deployment efficiency.
As shown in Table 6, GA-YOLO consistently exceeds 65 FPS on both datasets, which is well above the common threshold for real-time processing. Meanwhile, GA-YOLO also maintains competitive peak memory usage and loading time. Compared with heavier CNN-based and Transformer-based models, GA-YOLO demonstrates substantially lower memory consumption and faster initialisation, making it more suitable for deployment on embedded or edge platforms. Although some lightweight YOLO variants achieve higher FPS, GA-YOLO presents a more balanced trade-off between accuracy and efficiency, retaining superior detection performance while keeping the runtime overhead within practical real-time constraints. These results further confirm the practical value and deployment readiness of GA-YOLO in real-world traffic monitoring systems.
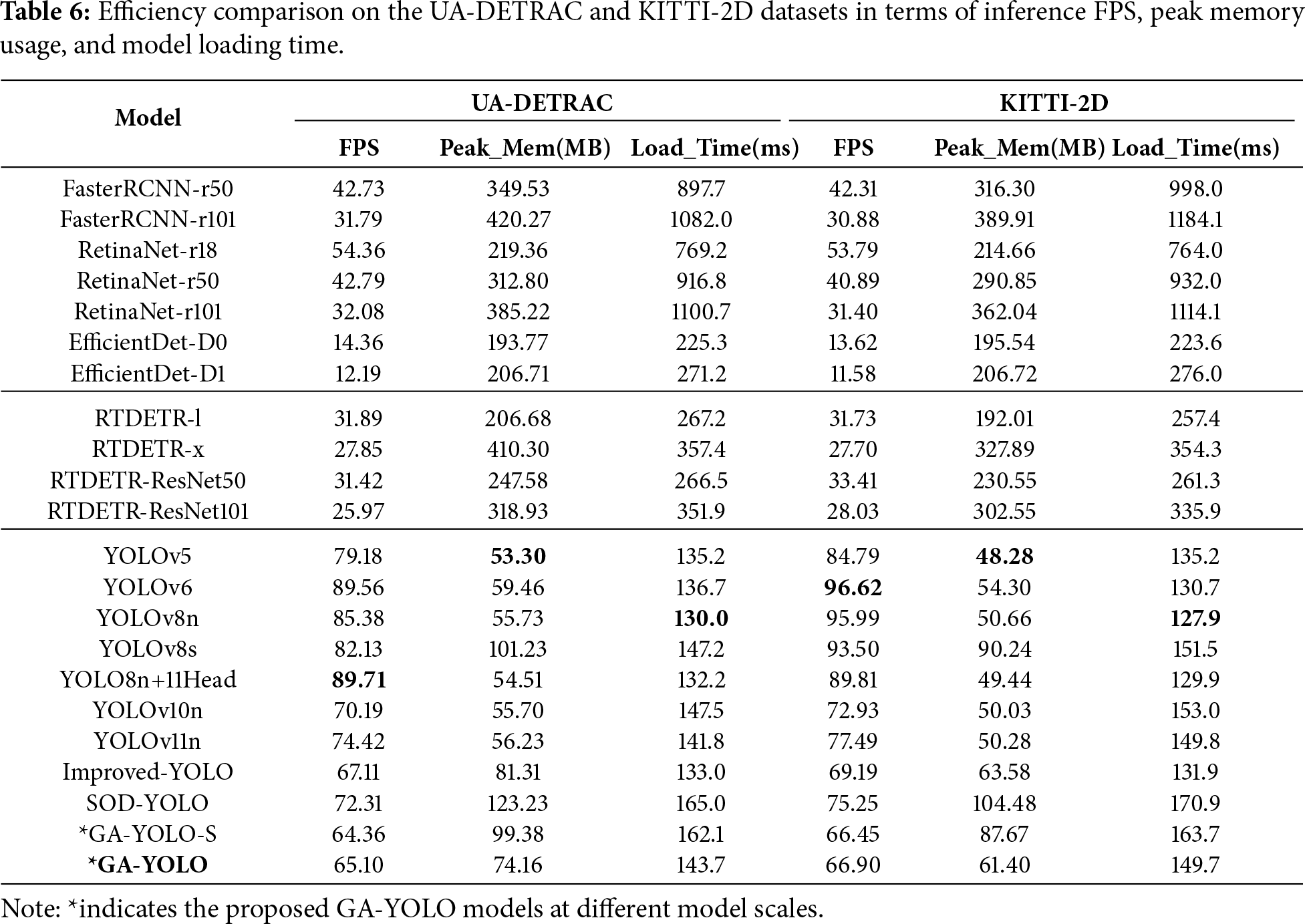
Overall, the comparative experiments demonstrate that GA-YOLO consistently achieves competitive detection accuracy across diverse model categories and datasets, while maintaining significantly lower computational overhead. Although there exist limitations in quickly understanding the highly dynamic backgrounds, GA-YOLO presents a favourable trade-off between accuracy and efficiency. These results highlight the reliability and lightweight nature of GA-YOLO’s detection capability, as well as its robustness, adaptability, and deployment potential in various traffic scenarios.
4.4.2 Comparison of Attention Mechanisms
To evaluate the performance of our proposed attention mechanism, SEA, a comparison experiment is conducted across different configurations of the CGBA module. The experiments focused on:
a. Different CSP modules: Two versions of YOLOv8 were tested, one with the original C2f modules version (Base-8) and the other with the replaced C3k2 modules version (Base-8-C3K2).
b. Different channel-spatial attention mechanisms: The experiments compared the CBAM attention mechanism with the proposed SEA to determine their impact on detection performance, particularly for small object detection.
Table 7 illustrates that integrating the attention mechanism into the original YOLOv8 structure (C2f-based) increases accuracy indexes while decreasing the computational indexes. Demonstrate the effectiveness of attention in improving the detection performance. Furthermore, compared to the two attention mechanisms, CBAM achieves higher precision but slightly lower mAP values than SEA with similar computation requirements. This superior mAP is attributed to the SEA’s enhanced sensitivity to minor targets. However, this high sensitivity carries the risk of increasing false positives, which can potentially impact precision. Thus, although the precision of SEA is slightly lower than that of CBAM in certain conditions, the overall higher mAP scores indicate a stronger overall detection capability of SEA within the original YOLO structure.
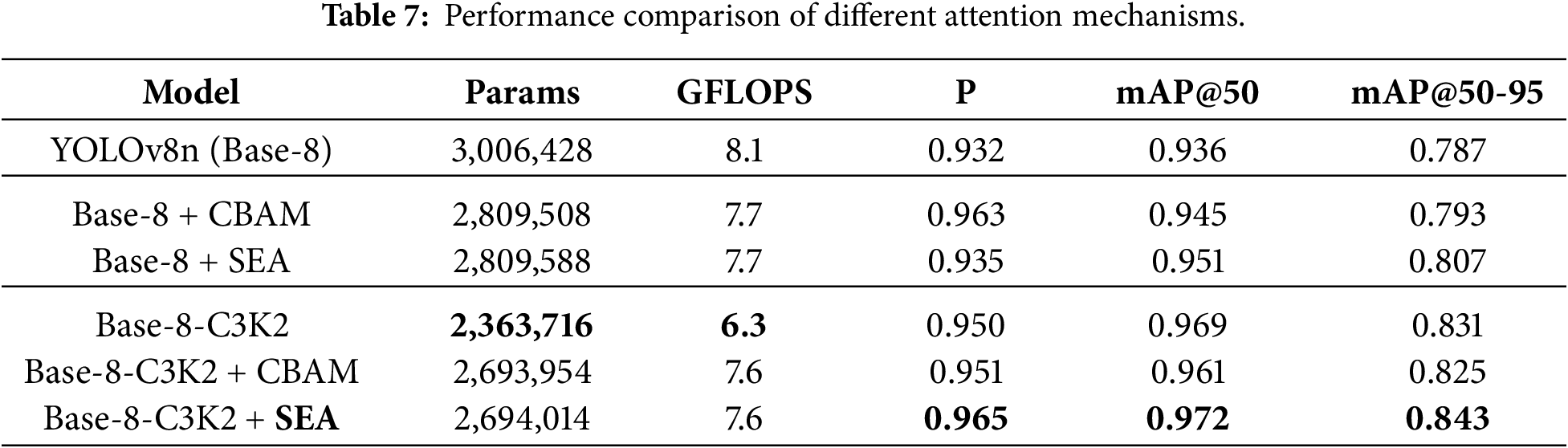
In the replaced YOLOv8 (C3k2-based) structure, the C3k2-based CGBA module received the best performance among all the YOLOv8 configurations. While inserting attention increases computational complexity, the replaced YOLOv8 with C3k2 and SEA maintains lower computational complexity than the original YOLOv8. This confirmed that the CSP module replacement and SEA integration are feasible and effective, and the detection accuracy improves with a decrease in computational loads. Additionally, the superior performance of SEA compared to CBAM in the lightweight YOLOv8 replacement indicates that SEA is more efficient in lightweight models.
Therefore, SEA outperforms CBAM in both the original and lightweight YOLOv8 models. The best configuration (‘Base-8-C3K2+SEA’) indicates that embedding SEA into C3k2 modules effectively boosts the SOD capabilities while maintaining lower computational demand. In summary, integrating SEA yields a 1%–2% gain in mAP over both CBAM and the corresponding baseline under similar computational overhead, confirming the utility of SEA. Such modest gains are expected, as the baseline already achieves strong performance. Nevertheless, the consistent improvements, particularly over CBAM attention, demonstrate the advantage of SEA in enhancing fine-grained cues such as small targets.
In the ablation studies, we first evaluate the attention blocks within the SEA module, investigating the individual contributions of the CWA and SMA. Then, we conduct ablation experiments on the entire GA-YOLO model, analysing the impact of proposed components and justifying the exclusion of the popular 4_Heads structure.
4.5.1 Ablations of the SEA Attention Module
To assess the contributions of the SEA module, we conducted ablation experiments by progressively replacing the corresponding channel and spatial attention blocks in CBAM with our CWA and SMA blocks. Each experiment isolates the impact of the individual components, allowing us to evaluate how the CWA and SMA blocks improve the model’s overall performance.
As shown in Table 8, the two improved blocks introduced new parameters for weighting, but the weighting mechanism is normally lightweight, just realised by some simple computations, and will not significantly increase computational costs. As a result, the cost indexes remain similar in the experiments. The analysis of accuracy indexes reveals an interesting observation: the CWA block mainly enhances the mAP values, while the SMA block primarily boosts the Precision. When combined in SEA, the GA-YOLO model achieves improvements in both mAP and Precision indexes, with the improving trend of each corresponding block.
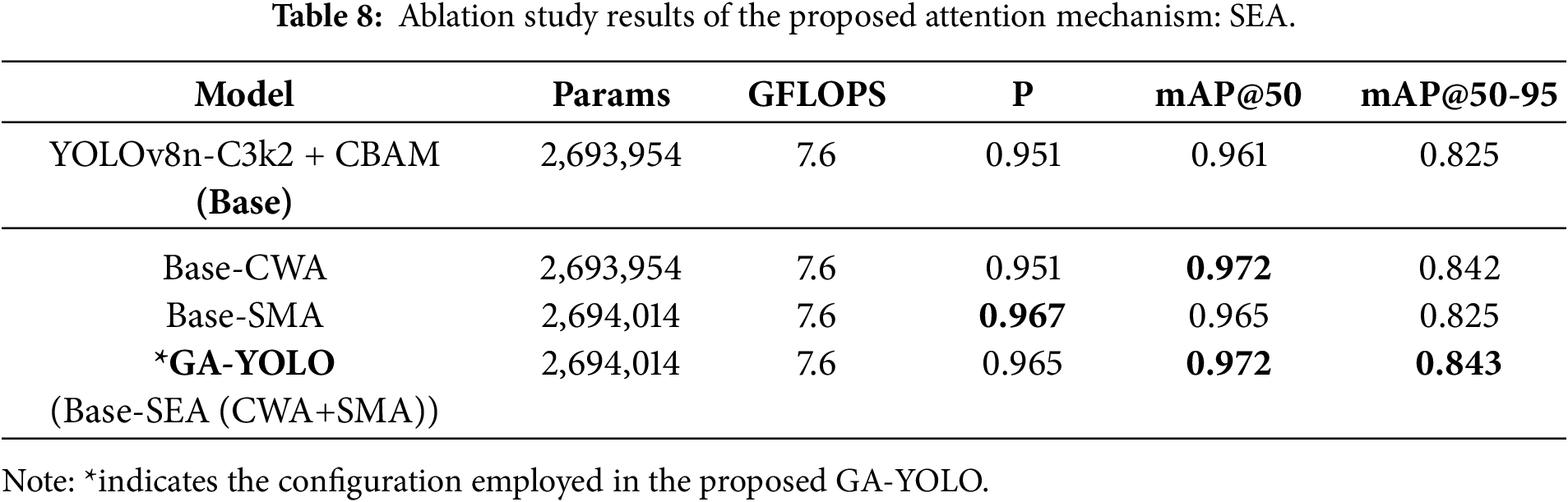
The CWA block reinforces attention on important feature channels, improving multiscale detection performance, and enhancing feature representation capacity of the model, which is highly relevant to multiple classes and scales in target detection, contributing to a higher mAP. The SMA block emphasises the target regions in the image, reducing the effect of background noise. Distributing more attention to target regions helps decrease the probability of misrecognising noises as targets, which mitigates false-positive events and increases the Precision score. Since CWA and SMA are sequentially applied in SEA, the module retains both advantages, thereby enhancing overall performance in both the Precision and mAP metrics.
4.5.2 Ablations of the GA-YOLO Model
Ablation experiments were conducted to assess the contributions of each component in the GA-YOLO model. We mainly evaluate the impact of the C3k2, CBA (i.e., CSP with SEA attention) and CGBA modules (i.e., lightweight CSP with SEA attention). In addition to conducting experiments on YOLOv8, we also performed ablation studies on YOLOv11, as the YOLOv11 proposed the C3k2 module.
The original YOLOv8 head detects objects at three scales: small (8
The ablation results are shown in Table 9. Firstly, observe the difference between the three blocks. When comparing all corresponding combinations between the Base-8 block and Base-8-C3K2 block, all configurations in Base-8-C3K2 consistently show reduced computational costs while improving all accuracy metrics. This indicates that YOLOv8 with the lightweight C3k2 modules can faster and more efficiently increase the feature capturing and analysis capability of the model. Due to one of the major improvements in YOLOv11 being the C3k2 module, the noticeable performance difference between Base-8 and Base-11, as well as the similar performance between Base-8-C3K2 and Base-11, further proves the effectiveness of replacing the CSP module with C3k2.
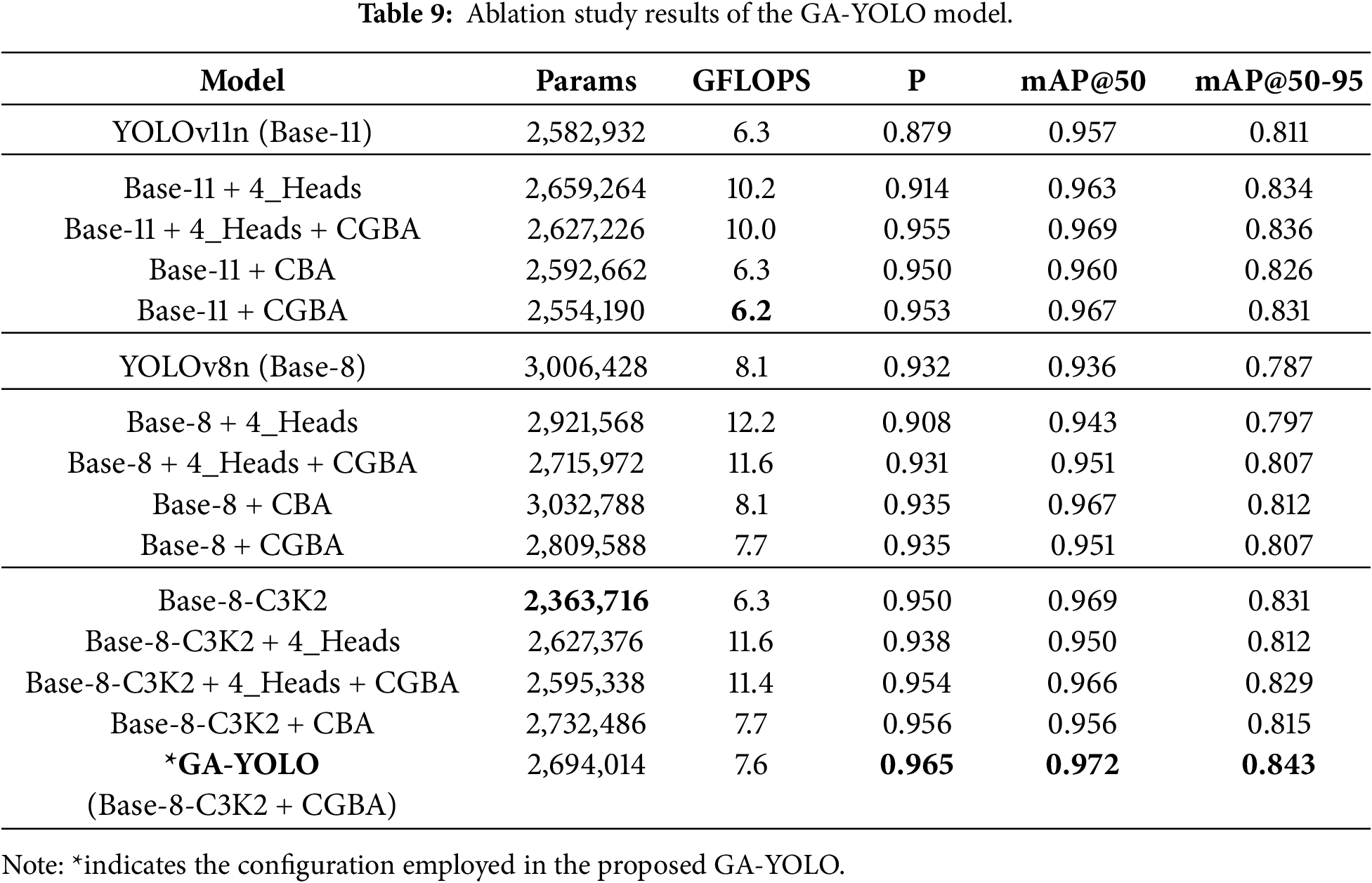
Then, the configurations within the three blocks (Base-11, Base-8 and Base-8-C3K2) will be analysed. Introducing 4_Heads consistently increases the GFLOPS by at least 50%, regardless of the presence of the CGBA module. When combining CGBA with 4_Heads, the performance is significantly enhanced compared to the 4_Heads-only configuration. Nevertheless, simply integrating the SEA attention into the C3k2 bottleneck structure (which means only configuring CGBA) also achieves comparable or even better performance than the combination configurations, while requiring far fewer computations. These findings demonstrate the efficiency and importance of the CGBA module in enhancing SOD performance, revealing its capability to provide a lightweight solution while increasing accuracy. The significant increase in GFLOPS caused by the 4_Heads structure indicates that the additional detection head introduces higher computational costs and increases the model’s complexity. This is primarily due to the extra convolution operations and feature fusion that the extra head brings. Therefore, compared with 4_Heads only and the combination configurations, the CGBA module is the key component for improving the model’s SOD performance more cost-effectively in different frameworks.
Moreover, to further isolate the effect of combining GhostConv with SEA attention, we additionally evaluated the CBA variants, in which the bottleneck retains standard convolutions. The results show that CBA can provide accuracy gains over the baseline, confirming that applying attention alone is beneficial. However, CGBA provided consistently lower computational cost while maintaining similar or even better accuracy. For the pure C2f-based Base-8-CBA and Base-8-CGBA, the computational reduction brought by GhostConv is particularly evident. In contrast, the C3k2-based structures (Base-11 and Base-8-C3K2) inherently reduce redundancy through the bottleneck reconfiguration, leaving less space for further saving. Nevertheless, the C3k2-based structures produce more compact features, which is beneficial for the cheap operation of GhostConv, resulting in the extra accuracy gains. Thus, the SEA-only configuration (i.e., CBA) isolates and evaluates the effect brought solely by the attention mechanism. Furthermore, the comparison between CBA and CGBA further demonstrates the additional gains introduced by the lightweight GhostConv.
Overall, the ablation experiments across different blocks and configurations effectively confirm the efficiency and positive impact of the replaced C3k2 module, CGBA module, SEA attention and GhostConv. The best performance combination in the table also validates that our proposed GA-YOLO model (YOLOv8-C3k2 with CGBA) successfully optimised YOLOs in balancing the computational load and high performance, providing a feasible solution for small object detection.
4.6 Visualisation and Analysis
To intuitively demonstrate the effectiveness of GA-YOLO in SOD tasks, we present visual analyses from two perspectives: model behavior under varying occlusion conditions, and attention visualisation based on Gradient-weighted Class Activation Mapping (Grad-CAM) [56].
In the SOD task, occlusion presents challenges to model detection, especially when objects are partially or largely covered. As the occlusion level increases, the difficulty of accurately identifying target objects also rises, and small objects are particularly vulnerable to background interference. To quantitatively evaluate model robustness under various occlusion conditions, we assess model performance with official occlusion annotations provided by the KITTI-2D dataset. KITTI-2D categorises instances into four occlusion levels: Occ0 represents fully visible, Occ1 for partially occluded, Occ2 for largely occluded and Occ3 for unknown. No extra manual simulation has been introduced.
Considering the data validity, we processed the test set (749 images with 4196 instances) into three valid occlusion subsets: Occ0 (723 images with 1937 instances), Occ1 (477 images with 1127 instances), and Occ2 (341 images with 901 instances). We evaluate the accuracy performance on each subset individually, provide normalised confusion matrices, and further visualise the cross-model performance comparison.
To directly illustrate model performance on different classes, we provide the normalised confusion matrices. Fig. 5 shows that GA-YOLO maintains strong diagonal dominance across all occlusion levels, indicating stable detection performance. With the occlusion level increasing from Occ0 to Occ2, a slight increase occurred in the off-diagonal items, mainly between the similar objects such as the occluded ‘Pedestrian’, ‘Person_sitting’ and ‘Cyclist’. However, for vehicle-related classes (Car, Van, Truck, and Tram), GA-YOLO maintains a high performance and strong robustness to partial and large occlusions.
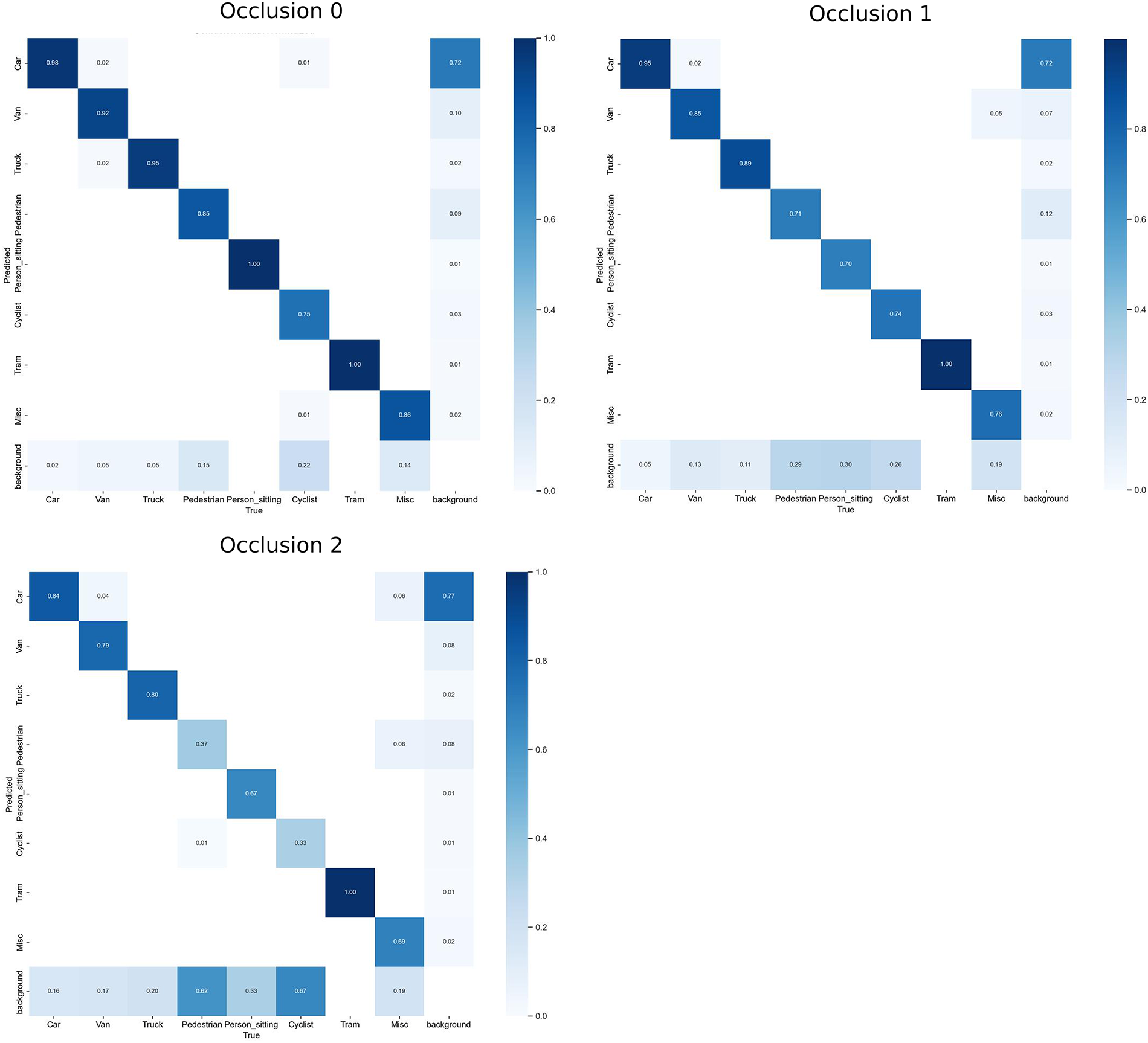
Figure 5: Normalised confusion matrices of GA-YOLO under different occlusion levels (0 = Fully visible, 1 = Partly occluded, 2 = Largely occluded).
To further validate the effectiveness of GA-YOLO in SOD, we conducted a comparison against other YOLO detectors under varying occlusion conditions, ensuring an architecturally consistent and fair assessment of our proposed model. As shown in Fig. 6a–c, the GA-YOLO model (red diamonds) outperforms other YOLO versions (coloured circles) in most conditions, particularly in terms of mAP metrics at the highest occlusion level (Occ2). This superior performance demonstrates the enhanced detection capability of GA-YOLO, especially for small and occluded objects. The notable improvement at Occ2 further highlights its enhanced local feature extraction ability, which is crucial for distinguishing small objects from complex backgrounds, given that small target detection is highly susceptible to background interference. These improvements implicitly validate the effectiveness of the proposed SEA attention in enhancing local feature perception and mitigating background distractions. Additionally, the increased Precision values across different occlusion levels indicate a lower FPR of GA-YOLO, suggesting a reduction in False Positives (FP) and an enhancement in its detection accuracy and reliability for SOD tasks.
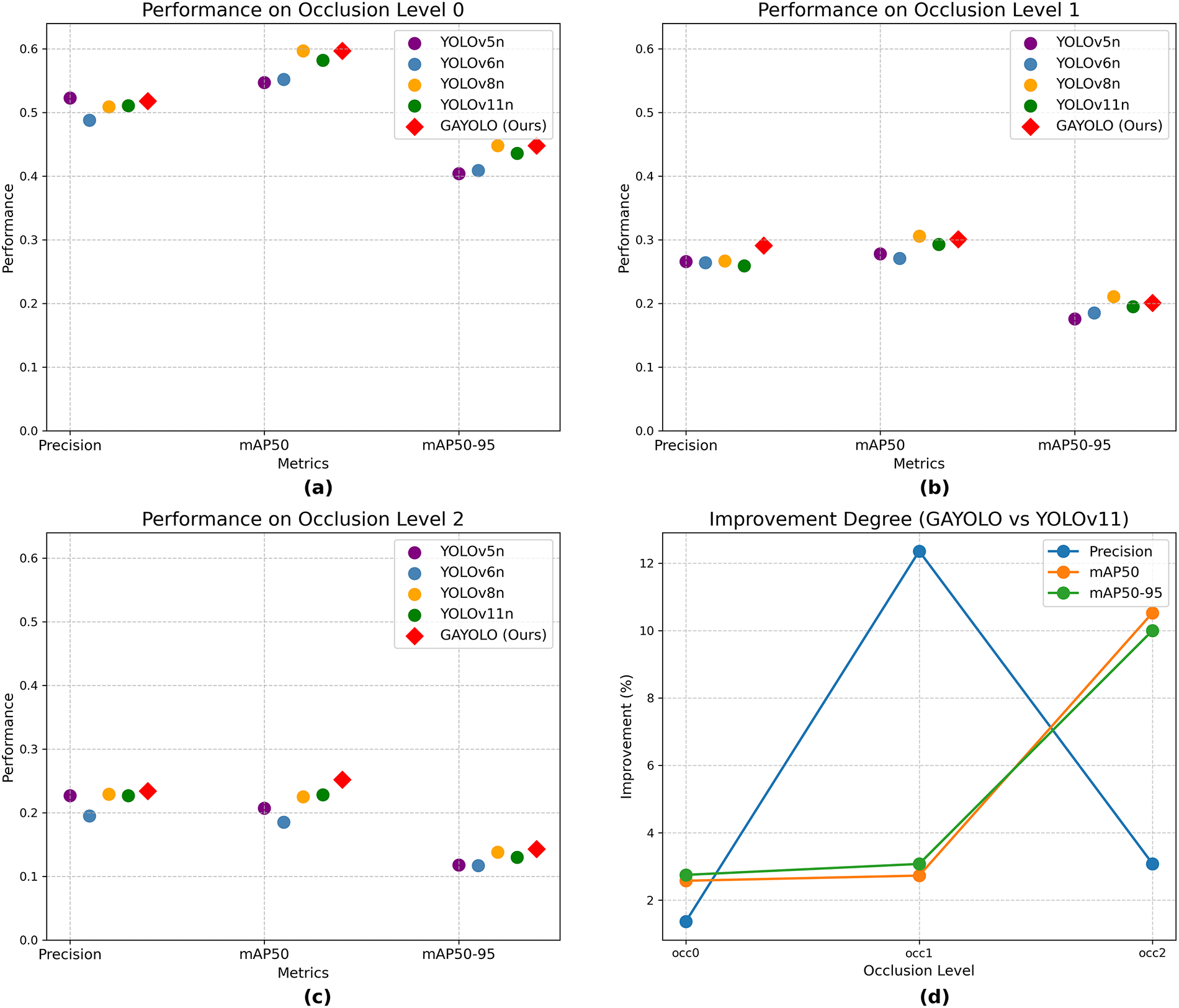
Figure 6: (a–c): Detection performance of different models under varying occlusion levels (0 = Fully visible, 1 = Partly occluded, 2 = Largely occluded). (d): Improvement of GA-YOLO compared to the latest YOLO model: YOLOv11.
Nevertheless, despite the outstanding performance at Occ2, GA-YOLO exhibits slightly lower than YOLOv8 at Occ1 in terms of mAP@50 and mAP@50-95. This discrepancy arises because GA-YOLO prioritises prediction accuracy by reducing the FPR, which consequently increases the FNR and leads to more missed detections, lowering recall and further impacting the overall mAP performance. In contrast, YOLOv8 adopts a less strict approach to accuracy, capturing more potential targets but also introducing more FP, which is evidenced by the higher Precision of GA-YOLO. As shown in Fig. 6, GA-YOLO performs slightly better than YOLOv8 at Occ0, indicating its reliability in non-occluded scenarios. Furthermore, in the highly occluded scenarios (Occ2), the superior performance of GA-YOLO across all metrics suggests that its approach to balancing FPR and FNR enables GA-YOLO to extract sufficient feature information even under severe occlusion. These results demonstrate GAYOLO’s stronger detection capability for small objects and enhanced robustness across various occlusion levels, highlighting its ability to effectively handle severe occlusions.
Moreover, to showcase a more intuitive comparison, we have further quantified GA-YOLO improvements relative to the latest YOLOv11. As shown in Fig. 6d, the improvement amplitudes are consistently positive, demonstrating the effectiveness and generalisation ability of GA-YOLO under varying occlusion conditions in detection tasks. The upward trend in mAP metrics further validates the adaptability of GA-YOLO in multiple scenarios, with the most significant improvement observed at the Occ2 occlusion level, highlighting its advancement in handling severe occlusions and capturing representative features from small, partially occluded targets.
Except for occlusion comparison, we also conducted a heatmap visualisation to further prove the effect of the proposed improvements. The heatmaps are superimposed on the original inputs, highlighting model-sensitive regions in varying colours, with areas closer to red indicating stronger focus from the model. Fig. 7 displays four CGBA module outputs combined with heatmaps from the test set, illustrating results under various models and scenarios, including different vehicle densities, weather and lighting conditions. In sparse environments, as shown in Fig. 7A, the YOLOv8, YOLOv11 and GA-YOLO all demonstrate good performance and precise attention on target vehicles. However, as vehicle density increases, model performance is affected. For example, in Fig. 7B,C, YOLOv8 and YOLOv11 allocate limited computer attention to the background, focusing on irrelevant road information rather than vehicles. By contrast, the GA-YOLO model, which incorporates an attention mechanism, effectively mitigates the background noise effect while maintaining a more precise focus on target vehicles.

Figure 7: Grad-CAM visualisations comparing YOLOv8, YOLOv11, and GA-YOLO in traffic scenes *denotes the proposed GA-YOLO.
In scenarios involving occluded objects, as illustrated in Fig. 7D, GA-YOLO successfully detects a partially obscured yellow vehicle that YOLOv8 fails to identify. Compared with YOLOv11, GA-YOLO also produces a more concentrated and semantically aligned attention distribution around the target region. Across all four instances, GA-YOLO showcases stronger robustness in detecting distant and occluded vehicles under both sparse and dense traffic conditions. These results highlight the model’s improved target-focusing capability over YOLOv8 and YOLOv11, further evidencing the effectiveness of the proposed SEA attention mechanism and CGBA module.
However, despite these advantages, Fig. 7B,C also reveal two general issues: the misclassification caused by class imbalance in the dataset and the inadequate detection of distant vehicles. The class imbalance problem leads to a higher likelihood of misclassification of the classes with limited training samples. Meanwhile, the insufficient detection issue becomes apparent when the model pays attention to the irrelevant background, especially affecting the detection of distant vehicles in dense conditions. Although GA-YOLO alleviates the distracted issue by importing the attention mechanism, the visualisation results still indicate that further improvements are needed to enhance the detection of distant vehicles and mitigate the class imbalance problem.
Overall, the visualisation results provide strong evidence of GA-YOLO’s enhanced performance in the occluded SOD tasks and intuitively demonstrate the effectiveness of the proposed attention and CGBA modules.
In this paper, we presented Ghost-Attention YOLO (GA-YOLO), an improved and scalable variant of YOLOv8 tailored for efficient SOD in traffic monitoring. GA-YOLO integrates a plug-and-play channel-spatial attention mechanism to enhance the representation of small yet informative features, and replaces the original C2f with a more computationally efficient C3k2 to alleviate computational burden without sacrificing detection accuracy. Building upon these designs, a lightweight CGBA module is introduced to further improve feature extraction and fusion efficiency. Notably, GA-YOLO is inherently scalable and can be deployed across different model sizes (n, s, m, l). Although our implementation and evaluations are mainly conducted on the lightweight YOLOv8n variant, the proposed architectural design allows direct extension to larger models when constraints permit.
The experimental results and comparative analysis demonstrate the effectiveness and efficiency of GA-YOLO and its key components, outperforming YOLOv8 and YOLOv11 variants at similar scales. On the UA-DETRAC dataset, GA-YOLO achieves improvements over YOLOv8n, with increases of 3.3% in precision, 3.6% in mAP@50, and 5.6% in mAP@50-95, while reducing the number of parameters by approximately 10%. The computational cost is also reduced from 8.1 to 7.6 GFLOPS. Compared with YOLOv11n, GA-YOLO achieves gains of 8.6% in precision, 1.5% in mAP@50, and 3.2% in mAP@50-95. Considering the accuracy improvements, the 4% parameter increase and around 1 GFLOPS of extra computations are acceptable for deployment. Similar performance improvements are also observed on the KITTI-2D dataset, further demonstrating the generalisation capability of GA-YOLO across diverse traffic scenes. Furthermore, visualisations under varying occlusion levels highlight the effectiveness and robustness of GA-YOLO in SOD scenarios, showcasing its improved feature discrimination capability with insufficient visual information.
Future work will explore three directions: (1) utilising parameter-efficient fine-tuning techniques and addressing class imbalance issues in traffic datasets to further improve model detection performance on resource-constrained devices; (2) exploring quantum computing to optimise the SEA mechanism and the Non-Maximum Suppression (NMS) algorithm, with the potential to accelerate attention computation and bounding box selection, thereby further enhancing real-time capability; (3) extending GA-YOLO toward video anomaly detection and multimodal fusion by incorporating temporal features or complementary sensing modalities, such as LiDAR and radar, to support reliable traffic perception under adverse weather and complex traffic conditions.
Acknowledgement: Not applicable.
Funding Statement: This research did not receive specific funding from public, commercial, or nonprofit sectors. The article processing charge (APC) for this open-access publication was covered by the corresponding author’s personal funds.
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Xinyue Zhang, Yuxuan Zhao and Ka Lok Man; methodology, Xinyue Zhang, Yuxuan Zhao and Ka Lok Man; software, Xinyue Zhang and Jeremy S. Smith; validation, Yuxuan Zhao, Jeremy S. Smith, Yuechun Wang, Gabriela Mogos, Ka Lok Man and Young-Ae Jung; formal analysis, Xinyue Zhang, Yuxuan Zhao and Ka Lok Man; investigation, Xinyue Zhang, Yuxuan Zhao, Gabriela Mogos, Yutao Yue and Young-Ae Jung; resources, Yuxuan Zhao, Ka Lok Man and Yutao Yue; data curation, Xinyue Zhang and Jeremy S. Smith; writing—original draft preparation, Xinyue Zhang; writing—review and editing, Yuxuan Zhao, Jeremy S. Smith, Yuechun Wang, Gabriela Mogos, Ka Lok Man, Yutao Yue and Young-Ae Jung; visualization, Xinyue Zhang and Yuechun Wang; supervision, Yuxuan Zhao, Jeremy S. Smith, Yuechun Wang, Gabriela Mogos, Ka Lok Man, Yutao Yue and Young-Ae Jung; project administration, Ka Lok Man; funding acquisition, Young-Ae Jung. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The datasets generated and analyzed during the current study are not publicly available due to data-use agreements and privacy considerations.
Ethics Approval: This article does not contain any studies with human participants or animals performed by any of the authors. Therefore, formal ethical approval and informed consent were not required.
Conflicts of Interest: The authors declares no conflicts of interest.
Abbreviations
| AP | Average Precision |
| bbox | bounding box |
| BiFPN | Bidirectional Feature Pyramid Network |
| C2f | Faster implementation of CSP Bottleneck with two convolutions |
| C3k2 | Faster CSP Bottleneck with two convolutions and optional C3k blocks |
| CA | Channel Attention |
| CBA | CSP-based Bottleneck with Attention |
| CBAM | Convolutional Block Attention Module |
| CGBA | CSP-based Ghost Bottleneck with Attention |
| CNN | Convolutional Neural Network |
| CSP | Cross-Stage Partial |
| CWA | Channel Weighted Attention |
| DETR | DEtection TRansformer |
| ECA | Efficient Channel Attention |
| FFN | Feed-Forward Networks |
| FNR | False Negative Rate |
| FP | False Positives |
| FPN-PAN | Feature Pyramid Network-Path Aggregation Network |
| FPR | False Positive Rate |
| FPS | Frames Per Second |
| GA-YOLO | Ghost-Attention You Only Look Once |
| GFLOPS | Giga Floating Point Operations Per Second |
| GhostConv | Ghost Convolution |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
| IoU | Intersection over the Union |
| ITS | Intelligent Transportation Systems |
| mAP | mean Average Precision |
| MHSA | Multi-Head Self-Attention |
| MLP | Multi-Layer Perceptron |
| NAS | Neural Architecture Search |
| NMS | Non-Maximum Suppression |
| P | Precision |
| Param | Parameter |
| RT-DETR | Real-Time DEtection TRansformer |
| SA | Spatial Attention |
| SE | Squeeze-and-Excitation |
| SEA | Small-object Extend Attention |
| SMA | Spatial Multi-Attention |
| SOD | Small Object Detection |
| STN | Spatial Transformer Network |
| STR-V2 | Swin Transformer v2 |
| YOLO | You Only Look Once |
References
1. Qureshi KN, Abdullah H. A survey on intelligent transportation systems. 2013;15(5):629–42. doi:10.5829/idosi.mejsr.2013.15.5.11215. [Google Scholar] [CrossRef]
2. Guerrero-Ibáñez J, Zeadally S, Contreras-Castillo J. Sensor technologies for intelligent transportation systems. Sensors. 2018;18(4):1212. doi:10.3390/s18041212 1212. [Google Scholar] [PubMed] [CrossRef]
3. Iqra, Giri KJ, Javed M. Small object detection in diverse application landscapes: a survey. Multimed Tools Appl. 2024;83(41):88645–80. doi:10.1007/s11042-024-18866-w. [Google Scholar] [CrossRef]
4. Home-Ultralytics YOLO Docs [Internet]. [cited 2026 Jan 12]. Available from: https://docs.ultralytics.com/. [Google Scholar]
5. Terven JR, Cordova-Esparza DM. A comprehensive review of YOLO architectures in computer vision: from YOLOv1 to YOLOv8 and YOLO-NAS. Mach Learn Knowl Extr. 2023;5(4):1680–716. doi:10.3390/make5040083. [Google Scholar] [CrossRef]
6. Huang H, Wang B, Xiao J, Zhu T. Improved small-object detection using YOLOv8: a comparative study. Appl Comput Eng. 2024 2;41(1):80–8. doi:10.54254/2755-2721/41/20230714. [Google Scholar] [CrossRef]
7. Bakirci M. Advanced aerial monitoring and vehicle classification for intelligent transportation systems with YOLOv8 variants. J Netw Comput Appl. 2025;237(B):104134. doi:10.1016/j.jnca.2025.104134. [Google Scholar] [CrossRef]
8. Lin TY, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: common objects in context. arXiv:1405.0312. 2014. [Google Scholar]
9. Krishna H, Jawahar CV. Improving small object detection. In: 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR). Piscataway, NJ, USA: IEEE; 2017. p. 340–5. [Google Scholar]
10. Chen G, Wang H, Chen K, Li Z, Member S, Song Z, et al. A survey of the four pillars for small object detection: multiscale representation, contextual information, super-resolution, and region proposal. IEEE Trans Syst Man Cybern Syst. 2022;52(2):936–53. doi:10.1109/TSMC.2020.3005231. [Google Scholar] [CrossRef]
11. Lowe DG. Object recognition from local scale-invariant features. In: Proceedings of the IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 1999. p. 1150–7. [Google Scholar]
12. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2017;39(6):1137–49. doi:10.1109/tpami.2016.2577031. [Google Scholar] [PubMed] [CrossRef]
13. Liu Y, Sun P, Wergeles N, Shang Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst Appl. 2021;172(4):114602. doi:10.1016/j.eswa.2021.114602. [Google Scholar] [CrossRef]
14. Ma P, He X, Chen Y, Liu Y. ISOD: improved small object detection based on extended scale feature pyramid network. Visual Comput. 2025;41(1):465–79. doi:10.1007/s00371-024-03341-2. [Google Scholar] [CrossRef]
15. Wang H, Liu C, Cai Y, Chen L, Li Y. YOLOv8-QSD: an improved small object detection algorithm for autonomous vehicles based on YOLOv8. IEEE Trans Instrum Meas. 2024;73:1–16. doi:10.1109/tim.2024.3379090. [Google Scholar] [CrossRef]
16. Li X, Wei Y, Li J, Duan W, Zhang X, Huang Y. Improved YOLOv7 algorithm for small object detection in unmanned aerial vehicle image scenarios. Appl Sci. 2024;14(4):1664. doi:10.1109/aiotsys58602.2023.00031. [Google Scholar] [CrossRef]
17. Xiao Y, Di N. SOD-YOLO: a lightweight small object detection framework. Sci Rep. 2024;14(1):25624. doi:10.1038/s41598-024-77513-4. [Google Scholar] [PubMed] [CrossRef]
18. Cai Z, Fan Q, Feris RS, Vasconcelos N. A unified multi-scale deep convolutional neural network for fast object detection. In: Computer Vision—ECCV 2016 (ECCV 2016). Cham, Switzerland: Springer; 2016. p. 354–70. [Google Scholar]
19. Li J, Xie C, Wu S, Ren Y. UAV-YOLOv5: a swin-transformer-enabled small object detection model for long-range UAV images. Ann Data Sci. 2024;11:1109–38. doi:10.1007/s40745-024-00546-z. [Google Scholar] [CrossRef]
20. Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. End-to-end object detection with transformers. Cham, Switzerland: Springer International Publishing; 2020. [Google Scholar]
21. Zhu X, Su W, Lu L, Li B, Wang X, Dai J, et al. Deformable transformers for end-to-end object detection. arXiv:2010.04159. 2020. [Google Scholar]
22. Xu W, Zhang C, Wang Q, Dai P. FEA-swin: foreground enhancement attention swin transformer network for accurate UAV-based dense object detection. Sensors. 2022;22(18):6993. doi:10.3390/s22186993. [Google Scholar] [PubMed] [CrossRef]
23. Tahir NUA, Long Z, Zhang Z, Asim M, ELAffendi M. PVswin-YOLOv8s: UAV-based pedestrian and vehicle detection for traffic management in smart cities using improved YOLOv8. Drones. 2024;8(3):84. doi:10.3390/drones8030084. [Google Scholar] [CrossRef]
24. Hassanin M, Anwar S, Radwan I, Khan FS, Mian A. Visual attention methods in deep learning: an in-depth survey. Inf Fusion. 2024 8;108(3):102417. doi:10.1016/j.inffus.2024.102417. [Google Scholar] [CrossRef]
25. Niu Z, Zhong G, Yu H. A review on the attention mechanism of deep learning. Neurocomputing. 2021 9;452:48–62. doi:10.1016/j.neucom.2021.03.091. [Google Scholar] [CrossRef]
26. Guo MH, Xu TX, Liu JJ, Liu ZN, Jiang PT, Mu TJ, et al. Attention mechanisms in computer vision: a survey. Comput Visual Media. 2021;8(3):331–68. doi:10.1007/s41095-022-0271-y. [Google Scholar] [CrossRef]
27. Zhao H, Jia J, Koltun V. Exploring self-attention for image recognition. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2020. p. 10073–82. [Google Scholar]
28. Fukui H, Hirakawa T, Yamashita T, Fujiyoshi H. Attention branch network: learning of attention mechanism for visual explanation. arXiv:1812.10025. 2019. [Google Scholar]
29. Hu J, Shen L, Albanie S, Sun G, Wu E. Squeeze-and-excitation networks. arXiv:1709.01507. 2017. [Google Scholar]
30. Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q. ECA-Net: efficient channel attention for deep convolutional neural networks. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2020. p. 11531–9. [Google Scholar]
31. Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al. An image is worth 16 × 16 words: transformers for image recognition at scale. arXiv:2010.11929. 2021. [Google Scholar]
32. Jaderberg M, Simonyan K, Zisserman A, Kavukcuoglu K. Spatial transformer networks. Advances in neural information processing systems. arXiv:1506.02025. 2015. [Google Scholar]
33. Woo S, Park J, Lee JY, Kweon IS. CBAM: convolutional block attention module. arXiv:1807.06521. 2018. [Google Scholar]
34. Mia MS, Voban AAB, Arnob ABH, Naim A, Ahmed MK, Islam MS. DANet: enhancing small object detection through an efficient deformable attention network. In: 2023 International Conference on Cognitive Computing and Complex Data, ICCD 2023. Piscataway, NJ, USA: IEEE; 2023. p. 51–62. [Google Scholar]
35. Wang CH, Huang KY, Yao Y, Chen JC, Shuai HH, Cheng WH. Lightweight deep learning: an overview. IEEE Consum Electron Mag. 2024;13(4):51–64. doi:10.1109/mce.2022.3181759. [Google Scholar] [CrossRef]
36. Han K, Wang Y, Tian Q, Guo J, Xu C. GhostNet: more features from cheap operations. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2019. p. 1577–86. [Google Scholar]
37. Howard AG, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T, et al. MobileNets: efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861. 2017. [Google Scholar]
38. Sandler M, Howard A, Zhu M, Zhmoginov A, Chen LC. MobileNetV2: inverted residuals and linear bottlenecks. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2018. p. 4510–20. [Google Scholar]
39. Howard A, Sandler M, Chen B, Wang W, Chen LC, Tan M, et al. Searching for mobileNetV3. In: Proceedings of the 2019 IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2019. p. 1314–24. [Google Scholar]
40. Wei W, Cheng Y, He J, Zhu X. A review of small object detection based on deep learning. Neural Comput Appl. 2024;36(12):6283–303. doi:10.1007/s00521-024-09422-6. [Google Scholar] [CrossRef]
41. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556. 2015. [Google Scholar]
42. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2016. p. 770–8. [Google Scholar]
43. Wang CY, Liao HYM, Wu YH, Chen PY, Hsieh JW, Yeh IH. CSPNet: a new backbone that can enhance learning capability of CNN. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ, USA: IEEE; 2019. p. 1571–80. [Google Scholar]
44. Bochkovskiy A, Wang CY, Liao HYM. YOLOv4: optimal speed and accuracy of object detection. arXiv:2004.10934. 2020. [Google Scholar]
45. Ultralytics/ultralytics. Residual connection is redundant in c2f module #14931. [cited 2026 Jan 11]. Available from: https://github.com/ultralytics/ultralytics/issues/14931. [Google Scholar]
46. Khanam R, Hussain M. YOLOv11: an overview of the key architectural enhancements. arXiv:2410.17725. 2024. [Google Scholar]
47. Wen L, Du D, Cai Z, Lei Z, Chang MC, Qi H, et al. UA-DETRAC: a new benchmark and protocol for multi-object detection and tracking. Comput Vis Image Underst. 2020;193(9):102907. doi:10.1016/j.cviu.2020.102907. [Google Scholar] [CrossRef]
48. Geiger A, Lenz P, Urtasun R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2012. p. 3354–61. [Google Scholar]
49. Guerrouj FZ, Florez SAR, El Ouardi A, Abouzahir M, Ramzi M. Quantized object detection for real-time inference on embedded GPU architectures. Int J Adv Comput Sci Appl. 2025;16(5):hal-05102885. [Google Scholar]
50. Lin TY, Goyal P, Girshick R, He K, Dollar P. Focal loss for dense object detection. IEEE Trans Pattern Anal Mach Intell. 2020;42(2):318–27. doi:10.1109/tpami.2018.2858826. [Google Scholar] [PubMed] [CrossRef]
51. Tan M, Pang R, Le QV. EfficientDet: scalable and efficient object detection. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2019. p. 10778–87. [Google Scholar]
52. Zhao Y, Lv W, Xu S, Wei J, Wang G, Dang Q, et al. DETRs beat YOLOs on real-time object detection. arXiv:2304.08069. 2023. [Google Scholar]
53. Krasnov DI, Yarishev SN, Ryzhova VA, Djamiykov TS. Improved YOLOv8 network for small objects detection. In: 2024 33rd International Scientific Conference Electronics, ET 2024. Piscataway, NJ, USA: IEEE; 2024. p. 1–4. [Google Scholar]
54. Khalili B, Smyth AW. SOD-YOLOv8—enhancing YOLOv8 for small object detection in aerial imagery and traffic scenes. Sensors. 2024;24(19):6209. doi:10.3390/s24196209. [Google Scholar] [PubMed] [CrossRef]
55. Ultralytics/ultralytics. Regarding the calculation of the number of YOLOv8 detection head parameters #13189. [cited 2026 Jan 12]. Available from: https://github.com/ultralytics/ultralytics/issues/13189. [Google Scholar]
56. Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: visual explanations from deep networks via gradient-based localization. In: 2017 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ, USA: IEEE; 2017. p. 618–26. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools