
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

LCDM-Mono: Lightweight Conditional Diffusion Model for Self-Supervised Monocular Depth Estimation
1 University of Electronic Science and Technology of China, Chengdu, China
2 Shenzhen Institute for Advanced Study, University of Electronic Science and Technology of China, Shenzhen, China
* Corresponding Author: Shicai Fan. Email:
(This article belongs to the Special Issue: Advances in Intelligent Video Object Tracking and Scene Understanding)
Computers, Materials & Continua 2026, 87(3), 55 https://doi.org/10.32604/cmc.2026.076784
Received 26 November 2025; Accepted 04 February 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Self-supervised monocular depth estimation has attracted considerable attention due to its ability to learn without ground-truth depth annotations and its strong scalability. However, existing approaches still suffer from inaccurate object boundaries and limited inference efficiency. To address these issues, we present a Lightweight Conditional Diffusion Model for Monocular Depth Estimation (LCDM-Mono). The proposed framework integrates an efficient diffusion inference strategy with a knowledge distillation scheme, enabling the model to generate high-quality depth maps with only two sampling steps during inference. This design substantially reduces computational overhead and ensures real-time performance on resource-constrained platforms. In addition, we introduce a surface normal-based distillation loss to transfer geometric priors from the teacher network to the student network, enhancing its ability to recover local 3D structures and boundary details. Extensive experiments demonstrate that LCDM-Mono achieves a well-balanced trade-off between accuracy and efficiency. On the Jetson Orin NX platform, it achieves real-time inference at approximately 28 FPS, validating its practical deployability and effectiveness.Keywords
Monocular depth estimation (MDE) serves as a crucial approach for perceiving and understanding 3D scenes, aiming to infer pixel-wise depth information from a single image. As one of the fundamental tasks in 3D vision, MDE holds broad applicability across numerous domains, including autonomous driving [1], augmented reality [2], navigation and localization [3], and 3D reconstruction [4]. Deep learning-based monocular depth estimation algorithms can be broadly categorized into two types: supervised and self-supervised approaches. Supervised methods rely on large-scale paired data with ground-truth depth annotations and are trained by minimizing the error between the predicted and true depth, typically achieving high depth prediction accuracy. However, the substantial cost of data acquisition and annotation limits their large-scale deployment in real-world scenarios.
In contrast, self-supervised monocular depth estimation does not require ground-truth depth labels. Instead, it leverages view reconstruction constraints to train the network, significantly reducing data acquisition costs and attracting extensive attention in applications such as autonomous driving and robotic vision. Typical self-supervised frameworks optimize depth and pose networks jointly by minimizing the photometric consistency error between adjacent frames. Garg et al. [5] proposed a pioneering self-supervised monocular depth estimation method, which reprojects the right image in a stereo pair back to the left image and uses the photometric reconstruction error as the supervisory signal. This approach enabled end-to-end depth learning without requiring ground-truth depth, laying the foundation for subsequent research in self-supervised depth estimation. Building on this, Zhou et al. [6] introduced the first complete framework for self-supervised monocular depth estimation, establishing the modern paradigm by predicting depth and motion directly from monocular sequences.
Subsequently, Godard et al. [7] further refined the training process and proposed the classical Monodepth2 algorithm. This method addresses challenges arising from dynamic objects and occlusions through a minimum reprojection loss and an auto-masking strategy. In recent years, to further improve the performance of monocular depth estimation algorithms, researchers have mainly explored several directions: some studies focus on the refinement of loss functions [8,9]; others incorporate additional semantic information to assist monocular depth estimation [10,11]; meanwhile, some works attempt to leverage geometric priors [1,12] and feature representation learning [13] to enhance depth inference capabilities. In addition, a number of studies have devoted efforts to designing lightweight depth estimation architectures [14–16] to reduce model size and computational complexity, achieving notable progress. As a result, these algorithms generally belong to the discriminative paradigm.
Diffusion models [17,18], as powerful generative models, have demonstrated remarkable modeling capability and generation quality in tasks such as image generation, reconstruction, and visual understanding. Their core principle is to progressively add noise to the data and learn the reverse process to recover high-quality images or feature distributions from the noisy input. Compared with discriminative models, incorporating denoising diffusion models into depth estimation enables the capture of the underlying probabilistic distribution of the data, allowing better recovery of complex geometric structures and fine details. This, in turn, facilitates the generation of more accurate and realistic depth predictions, thereby improving depth estimation accuracy and detail fidelity. Consequently, in recent years, numerous studies have attempted to apply diffusion models to depth estimation tasks [19–21].
However, denoising diffusion models typically require multiple sampling steps during inference (e.g., dozens or even hundreds of steps), resulting in high computational complexity and slow speed, which limits their use in real-time and resource-constrained edge applications. To this end, we propose a Lightweight Conditional Diffusion Model for Monocular Depth Estimation (LCDM-Mono), combined with a knowledge distillation strategy for self-supervised monocular depth estimation. During inference, LCDM-Mono requires only two sampling steps to generate high-quality depth maps in real time, effectively reducing the multi-step sampling overhead of conventional diffusion models and significantly enhancing the real-time inference capability on resource-constrained devices. Furthermore, we introduce a surface normal-based knowledge distillation loss to explicitly enforce local geometric consistency in the 3D structure, allowing the network to better capture scene structure and object boundaries. As a result, it reduces boundary blurring in depth maps and enhances both overall depth prediction accuracy and detail fidelity.
Our main contributions are summarized as follows:
• A lightweight conditional denoising diffusion model, LCDM-Mono, is proposed for self-supervised monocular depth estimation. During inference, the model requires only two sampling steps to rapidly generate high-quality depth maps in real time, significantly reducing computational overhead and enabling real-time inference on resource-constrained edge devices.
• We introduce a surface normal-based knowledge distillation loss to enhance geometric consistency between the teacher and student networks. This loss explicitly aligns the normal directions of the depth predictions from the teacher and student networks, guiding the student to capture more accurate 3D scene geometry and achieving higher-quality depth predictions in boundary and detailed regions.
• Extensive experiments are conducted on multiple public datasets and real-world scenarios. The results confirm that the proposed method achieves superior depth estimation accuracy while maintaining a lightweight model architecture and efficient inference. On resource-constrained platforms, it achieves real-time inference at approximately 29 FPS on the Jetson Xavier NX and approximately 28 FPS on the Jetson Orin NX, demonstrating consistent real-time performance across different edge devices.
2.1 Monocular Depth Estimation
Depth estimation from a single image is an ill-posed problem, as multiple distinct 3D scenes can correspond to the same 2D image. Deep learning-based approaches for monocular depth estimation can be broadly divided into two main categories.
Supervised depth estimation. Supervised monocular depth estimation aims to leverage ground-truth depth information to guide the training of neural networks, thereby learning the mapping between RGB images and depth values. Eigen et al. [22] were the first to use deep neural networks to predict depth from a single image. Subsequent studies have employed more sophisticated network architectures and post-processing techniques. Liu et al. [23] formulated depth estimation as a learning problem within a continuous conditional random field (CRF). Yuan et al. [24] further optimized the application of CRFs by computing fully connected CRFs within local windows to reduce computational cost. Wang et al. [25] proposed a more effective loss function, designing a hierarchical embedding loss to measure the semantic distance between predicted and ground-truth depth values. Lee and Ki [26] introduced a method to automatically balance the weights of different loss terms, dynamically adjusting each term’s contribution to the overall monocular depth estimation loss and model parameter updates based on its performance during training. Although supervised monocular depth estimation methods often achieve high precision, the cost of acquiring annotated datasets with ground-truth depth is extremely high, which largely limits the widespread applicability of these algorithms.
Self-supervised depth estimation. Self-supervised monocular depth estimation does not require costly depth annotations, significantly reducing training costs. As a result, this research area has attracted substantial attention. Garg et al. [5] first proposed a self-supervised framework for monocular depth estimation that trains a depth convolutional network without ground-truth depth labels. They formulated depth estimation as an image synthesis problem and used the photometric error between the reconstructed and original source images as the supervisory signal. Subsequently, Godard et al. [27] further refined this training framework by introducing a left-right disparity consistency loss to improve monocular depth estimation accuracy. Later, Zhou et al. [6] designed an end-to-end self-supervised training framework consisting of a DepthNet and a PoseNet, jointly optimized using image synthesis as the supervisory signal to enable depth prediction from a single image. Furthermore, Godard et al. [7] proposed the classical Monodepth2 algorithm, introducing a novel appearance matching loss to address occluded pixels, a simple auto-masking approach to ignore pixels exhibiting motion similar to the camera during training, and a multi-scale appearance matching loss to reduce depth artifacts. Zhang et al. [14] designed an efficient hybrid architecture combining CNNs and Transformers to achieve lightweight end-to-end monocular depth estimation.
Diffusion models have attracted widespread attention due to their remarkable generative capabilities. These models iteratively generate data by adding a certain level of noise in the forward process (diffusion) and then training a neural network in the reverse process (denoising) to progressively predict and remove the noise. However, since DDPMs employ a Markov chain during sampling, their inference speed is extremely slow, severely limiting practical applicability. Later, DDIM [18] improved upon DDPM by adopting a non-Markovian sampling strategy, significantly reducing sampling time while maintaining generation quality, thereby greatly advancing the application of diffusion models in computer vision and image processing tasks.
Building on this, conditional denoising diffusion models have been further developed. By introducing additional conditional information during the denoising sampling process, they enable controllable image generation. Duan et al. [19] reformulated monocular depth estimation as a conditional denoising diffusion process, progressively denoising a random depth distribution under monocular visual guidance to generate high-quality depth maps, where the diffusion model is trained in a supervised manner using ground-truth depth as guidance. Patni et al. [28] optimized the conditioning module and proposed a novel monocular depth estimation architecture. This architecture uses ViT embeddings as conditioning inputs and adopts a diffusion model as the backbone, achieving high-precision depth estimation. Fu et al. [29] introduced an algorithm called GeoWizard, which models depth estimation as a denoising diffusion process. It also utilizes a knowledge-rich diffusion prior to jointly predict scene depth and surface normals, accurately capturing complex geometric details. Shao et al. [30] also reformulated monocular depth estimation as a denoising diffusion process in their proposed Monodiffusion algorithm, employing a pseudo ground-truth diffusion strategy to assist the model’s forward diffusion during training and adopting a coarse-to-fine, multi-scale diffusion approach to further improve depth estimation accuracy.
However, despite significant progress in modeling monocular depth estimation as a generative denoising diffusion task, most of the aforementioned algorithms rely on ground-truth depth (except Monodiffusion). This reliance limits their applicability in scenarios lacking depth annotations, as they cannot directly leverage the forward diffusion process. In addition, these methods focus primarily on accuracy optimization, often involving excessive denoising steps, resulting in slow inference and insufficient consideration of real-time performance and deployability in practical applications. To address these challenges, this paper proposes a lightweight conditional denoising diffusion model for self-supervised monocular depth estimation that requires only two sampling steps during inference. Without the need for ground-truth depth, our method models depth estimation as a denoising diffusion process while achieving a favorable balance between depth prediction accuracy and inference speed, thereby supporting real-time inference and deployment on resource-constrained platforms.
Knowledge distillation is an efficient model compression technique that transfers knowledge from a large teacher network to a smaller student network, achieving both effective compression and knowledge transfer. This results in a compact and lightweight student network suitable for resource-constrained scenarios. The concept of knowledge distillation was first introduced by Buciluǎ et al. [31] and later popularized by Hinton et al. [32]. Recently, an increasing number of studies have applied knowledge distillation to the field of self-supervised monocular depth estimation, achieving significant results. He et al. [33] proposed a complementary multi-teacher distillation framework, leveraging the advantages of multiple teacher models to obtain more robust and accurate depth estimation. Liu et al. [34] presented a self-reference knowledge distillation framework for monocular depth estimation, employing online distillation learning to efficiently transfer knowledge during student network training. Gao et al. [15] proposed a lightweight monocular depth estimation method combined with knowledge distillation, using offline distillation to transfer pseudo depth knowledge generated by the teacher network MonoViT [35] to the student network, achieving effective prediction-level distillation.
In this section, we introduce the proposed lightweight conditional denoising diffusion model, LCDM-Mono, for self-supervised monocular depth estimation. As illustrated in Fig. 1, LCDM-Mono comprises Knowledge Distillation, DepthNet, and PoseNet. We then present the overall training strategy of the network and the composition of its loss functions.
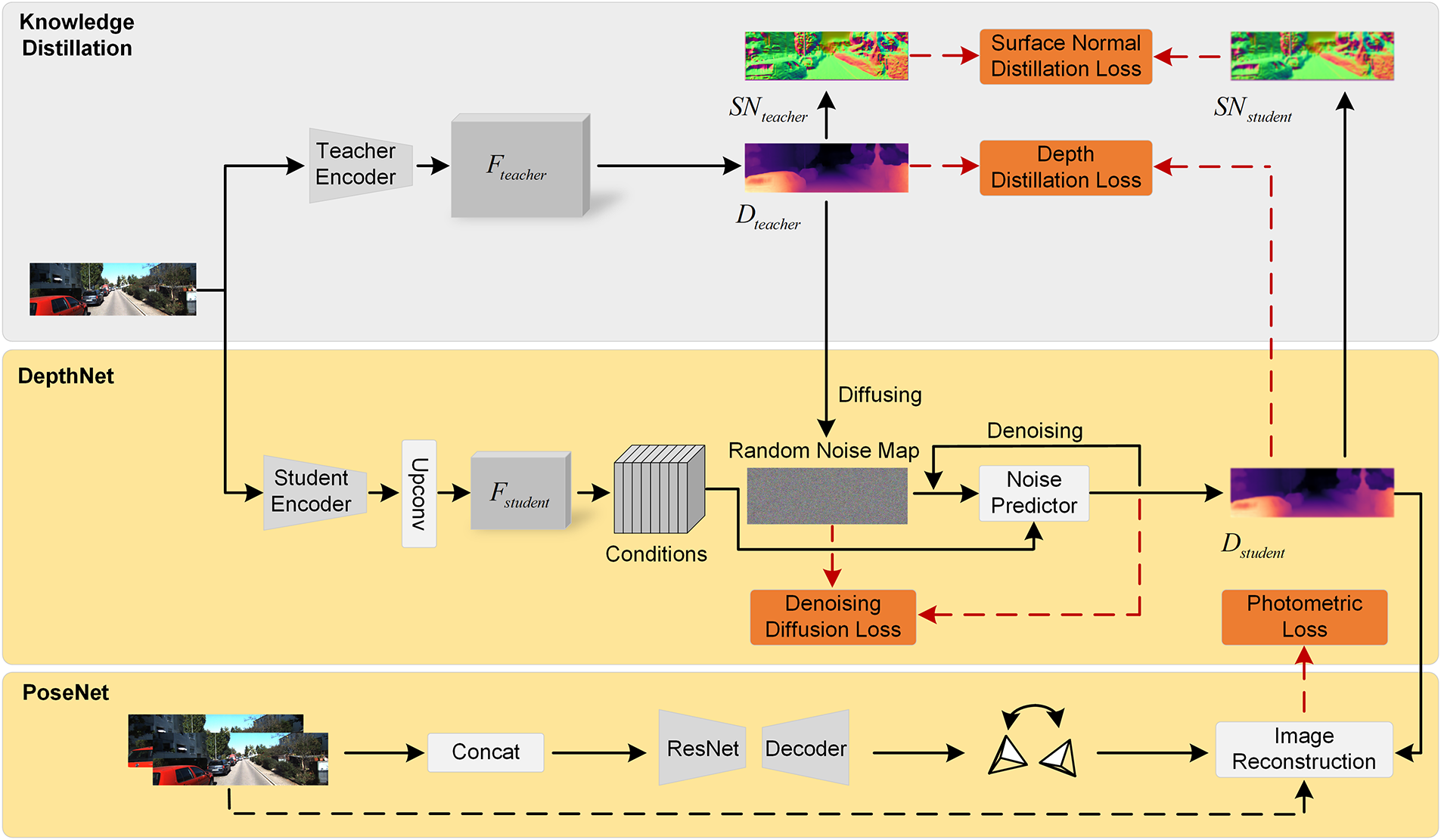
Figure 1: The overall architecture of LCDM-Mono, comprising Knowledge Distillation, DepthNet, and PoseNet.
To jointly model the global distribution and local details of depth maps, LCDM-Mono adopts a diffusion model as its core framework. Through the forward noising and reverse denoising processes during training, the model learns the conditional distribution of depth maps, thereby effectively capturing both global geometric structures and local texture information. During inference, a two-step sampling strategy is employed to meet real-time requirements. This process performs conditional denoising and global feature integration rather than simple local residual refinement. It significantly reduces computational overhead while preserving the diffusion model’s capability to model the global depth distribution. As a result, a favorable balance between global consistency and local detail recovery is achieved.
Despite its relatively small model size, LCDM-Mono achieves competitive performance through a series of lightweight yet effective design choices. Specifically, a MobileViT-based encoder-decoder architecture is adopted to replace computationally expensive backbones, enabling efficient extraction of both local features and global contextual information at a low computational cost. Second, the diffusion process is conditioned on image features, with only two denoising steps used during inference. As a result, computational overhead and inference latency are significantly reduced, while stable depth predictions are preserved. Finally, a knowledge distillation strategy is introduced to transfer geometric structure and boundary information from the teacher network to the student network, thereby compensating for the limited model capacity. The synergy of these components allows LCDM-Mono to achieve a favorable balance among model compactness, computational efficiency, and depth estimation accuracy.
Knowledge distillation is an efficient model compression technique. It transfers knowledge from a pre-trained teacher network to a lighter student network, achieving an effective balance between performance and complexity. As shown in Fig. 2, in this paper, knowledge distillation includes both depth map distillation loss and surface normal distillation loss. Specifically, the teacher network’s predicted depth maps are treated as pseudo ground-truth, and the L1 loss between these maps and the student network’s depth estimates provides direct supervisory signals for the student network. To further enhance the accuracy and robustness of the student’s depth estimation, we introduce a novel surface normal knowledge distillation loss.

Figure 2: The illustration of depth knowledge distillation and surface normal knowledge distillation.
The pseudo-labels utilized in this work are generated by the teacher network, MonoViT, which achieves high performance on the KITTI dataset. MonoViT is specifically selected as the teacher due to its ability to capture long-range global dependencies and fine-grained structural details through its hybrid Transformer-CNN architecture, providing the rich geometric priors necessary to guide our diffusion-based student model. The high fidelity of these teacher-generated labels ensures the reliability of the supervision signal. Under this guidance, the student network is enabled to effectively learn complex scene depth structures through the proposed distillation and optimization strategies, achieving robust depth prediction while maintaining a lightweight footprint.
The core idea is to use surface normals as key geometric descriptors, representing the orientation of object surfaces at each pixel. Surface normals capture local 3D geometric shapes and spatial directional characteristics, making them essential for representing 3D scene structure. Importantly, a well-defined geometric relationship exists between depth values and surface normals: the depth map defines an implicit 3D surface, from which surface normals can be derived. When the student network’s predicted normals align with those of the teacher, it indicates geometric consistency in local depth variations and 3D structures, enhancing depth estimation accuracy. Based on this relationship, we design a surface normal distillation loss to explicitly align the derived surface normal distributions, encouraging the student to learn smoother, more continuous depth structures with sharper boundaries. This is particularly effective in object contours and foreground-background boundaries, mitigating depth errors in boundary regions.
Specifically, surface normals are computed from the predicted depth maps following GeoNet++ [36]. For each pixel
where
with a closed-form solution:
where
In DepthNet, we adopt the pre-trained MonoViT as the teacher network. Its predicted depth maps serve a dual purpose: they act as pseudo ground-truth for the diffusion model’s noise injection process and simultaneously provide supervisory signals to guide the student network’s monocular depth prediction. The encoder of DepthNet employs MobileViT [37]. We choose MobileViT as the student model due to its favorable balance between lightweight design and global context modeling, which is important for monocular depth estimation. MobileViT combines a lightweight convolutional backbone (MobileNetV2) with a lightweight Vision Transformer, enabling it to capture long-range dependencies while maintaining low computational cost, suitable for real-time inference on embedded platforms. It is worth noting that our method is not restricted to a specific student network. In this work, we use MobileViT as a representative lightweight encoder for validation.
In the student network, the decoder of DepthNet employs a lightweight conditional denoising diffusion model to progressively recover depth. As shown in Fig. 3, the decoder performs noise injection and denoising only at the original resolution scale, integrating visual conditional features from the encoder at each sampling step to enable fast and efficient noise prediction and depth reconstruction. Notably, during inference, the model requires only two sampling steps to complete the denoising process, significantly reducing computational overhead and greatly improving inference speed. Thanks to this architectural design, our method can achieve real-time monocular depth estimation on resource-constrained edge computing devices, demonstrating excellent lightweight characteristics and deployment friendliness.
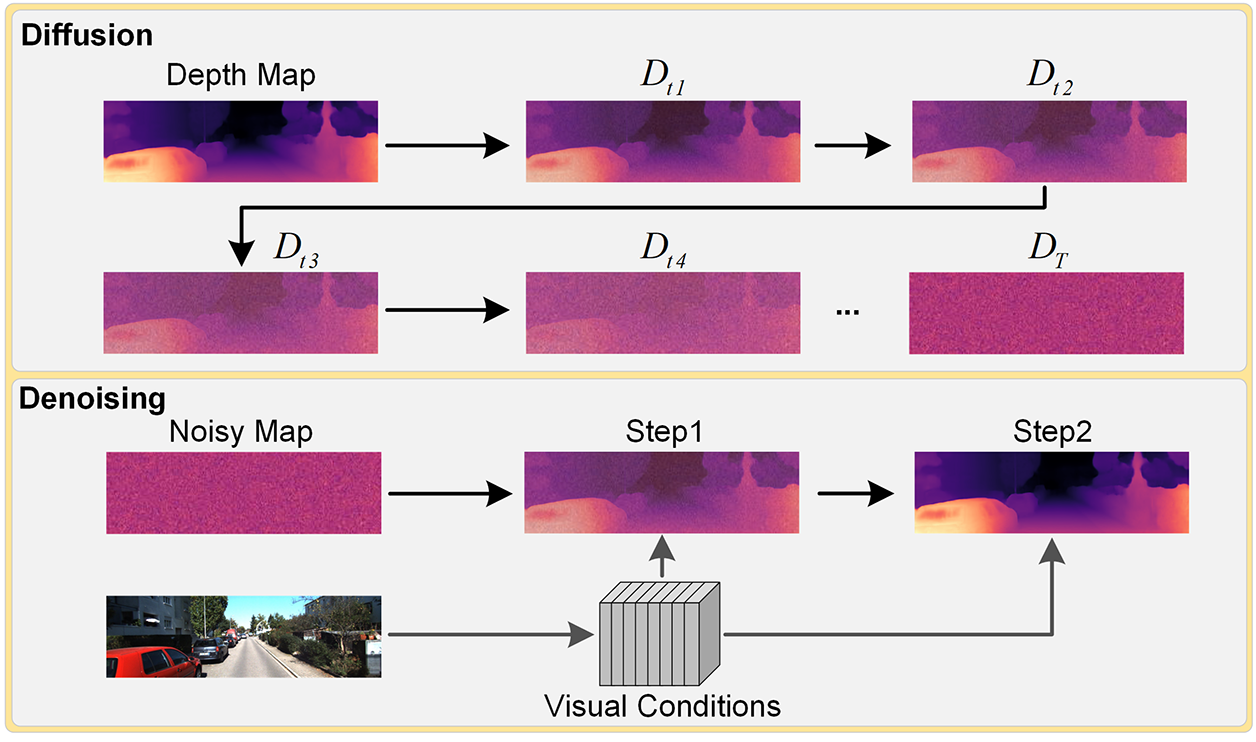
Figure 3: The illustration of the lightweight denoising diffusion process. The forward diffusion process requires T steps, while the reverse denoising process requires only two steps.
Following the approach in [7], we adopt the same network architecture for pose prediction. In PoseNet, the input consists of two consecutive frames concatenated along the channel dimension, and the network predicts the relative pose transformation from the target frame to the source frame. This provides the necessary pose information for subsequent image reconstruction, enabling the synthesis of novel viewpoints. The PoseNet encoder is based on ResNet18, and the decoder comprises four convolutional layers to predict the 6 degrees of freedom (6-DoF) pose. During training, PoseNet and DepthNet are jointly optimized to ensure consistency between pose and depth estimation.
3.2 Training Strategy and Loss Functions
In self-supervised monocular depth estimation, ground-truth depth labels are unavailable. Inspired by Monodiffusion, we use the depth predictions from the pre-trained teacher network MonoViT as pseudo ground-truth to construct the forward diffusion process and provide depth priors. To address the high computational cost associated with multi-step iterative generation in diffusion models, we constrain the diffusion process to the high-resolution scale and employ only two sampling steps during inference to complete denoising and depth reconstruction. This approach significantly reduces computational complexity while effectively improving inference speed and enabling real-time deployment.
During the training (noise injection) process, Gaussian noise is added to the highest-resolution pseudo ground-truth generated by the teacher model to obtain noisy samples. Let
where
During the inference (denoising) phase, our algorithm starts from a random noise map sampled from a Gaussian distribution. The sampled noise is combined with the test image as conditional features and the timestep embedding to obtain fused feature representations. At each sampling step, the fused features are fed into the noise predictor to estimate the noise, and the noise map for the next step is computed using a reparameterization trick, iterating until the sampling process is complete. The conditional denoising can be formulated as follows:
where
During training, the model learns the full step-wise denoising trajectory, recovering clean depth maps from noisy inputs with each step explicitly supervised. During inference, with the help of a DDIM sampling strategy, the denoising process can be completed in only 2 steps. Although training involves 150 steps, the model has learned the conditional denoising distribution. Combined with a data-driven training strategy, it is capable of approximating the full multi-step denoising trajectory even when the number of denoising steps is greatly reduced. This fast inference strategy effectively preserves key denoising information, generating high-quality depth maps while substantially reducing inference time.
Meanwhile, to further enhance the depth estimation capability of the student network, this work employs a knowledge distillation mechanism to strengthen the knowledge transfer from the teacher network. Specifically, distillation is applied at both the predicted depth map level and the surface normals level. The surface normals are derived from the depth maps predicted by both the teacher and student networks, representing the orientation of object surfaces in 3D scene. Together with depth information, they encode the geometric properties of the scene. Through this distillation process, the 3D geometric structural knowledge embedded in the teacher network is effectively transferred to the student network, ensuring geometric consistency in depth estimation and significantly improving the accuracy of depth prediction in object boundaries and geometrically detailed regions.
Specifically, the loss function in this work consists of the photometric reprojection loss (Lph), edge-aware smoothness loss (Lsm), denoising diffusion loss (Ldd), and knowledge distillation loss, which include the depth distillation loss (Lkd_depth) and surface normal distillation loss (Lkd_sn), as detailed below:
(1) Photometric Reprojection Loss: This loss measures the pixel-wise photometric difference between the target image and the source image warped into the target view, serving as a self-supervised signal to train the depth network. Following prior work [7], the photometric reprojection loss is formulated as:
where α is a weighting coefficient, set to 0.85.
(2) Edge-Aware Smoothness Loss: An edge-aware smoothness loss is employed to enforce smoothness in the predicted depth maps, defined as follows:
where
(3) Denoising Diffusion Loss: Following the formulation in previous diffusion models [18], the denoising diffusion loss used in this work is defined as:
where xt and c denote the noisy sample at timestep t and the image condition, respectively.
(4) Knowledge Distillation Loss: The knowledge distillation in this work consists of two components: the distillation loss on the predicted depth map Lkd_depth and the distillation loss on the surface normal Lkd_sn, defined as follows:
where
(5) Overall Loss: In summary, the overall loss function is formulated as follows:
where the weighting coefficients
4.1 Benchmark Datasets and Evaluation Metrics
The KITTI dataset [38] is a widely used standard benchmark in monocular depth estimation, consisting of 61 stereo road scenes. In this paper, we adopt the Eigen split [39] for training our self-supervised monocular depth estimation model. Under this split, the dataset contains 39,810 monocular triplets for training, 4424 samples for evaluation, and 697 images for testing. The Make3D dataset [40] provides 134 outdoor scene images with ground-truth depth and is commonly used to evaluate the generalization ability of self-supervised monocular depth estimation models. The NYU Depth V2 [41] dataset is a widely used indoor RGB-D dataset, containing paired RGB images and depth maps captured from a variety of indoor scenes. It consists of 24,231 training images and 654 test images. In this work, we directly evaluate our model on both datasets without additional fine-tuning to assess its generalization performance on previously unseen outdoor and indoor environments.
Regarding the evaluation metrics, we follow the depth estimation error and accuracy measures proposed in [22] to quantitatively evaluate the model’s depth prediction performance. The metrics include Absolute Relative Error (Abs Rel), Squared Relative Error (Sq Rel), Root Mean Squared Error (RMSE), and Root Mean Squared Log Error (RMSE log), as well as the accuracy thresholds δ1 < 1.25, δ2 < 1.252, and δ3 < 1.253. In addition, we use the number of parameters (Params.) to indicate the model size and the number of floating point operations (FLOPs) to represent the computational complexity.
LCDM-Mono is implemented using the PyTorch deep learning framework and trained on a single NVIDIA GeForce RTX 4090 GPU. We adopt the AdamW optimizer with a weight decay of 1e−2 and an initial learning rate of 1e−4, following a cosine annealing schedule. The batch size is set to 12. PoseNet uses a pre-trained ResNet18 as its backbone. In addition, all network weights are initialized with ImageNet-pretrained parameters, and the entire model is trained for 30 epochs.
4.3 Evaluation on Benchmark Datasets
We conduct both qualitative and quantitative comparison on the KITTI dataset with several representative self-supervised monocular depth estimation methods. We select lightweight approaches with no more than 35M parameters, and the input image resolution is set to 640 × 192 unless otherwise specified. As shown in Fig. 4, our method achieves an excellent balance between accuracy and model complexity.
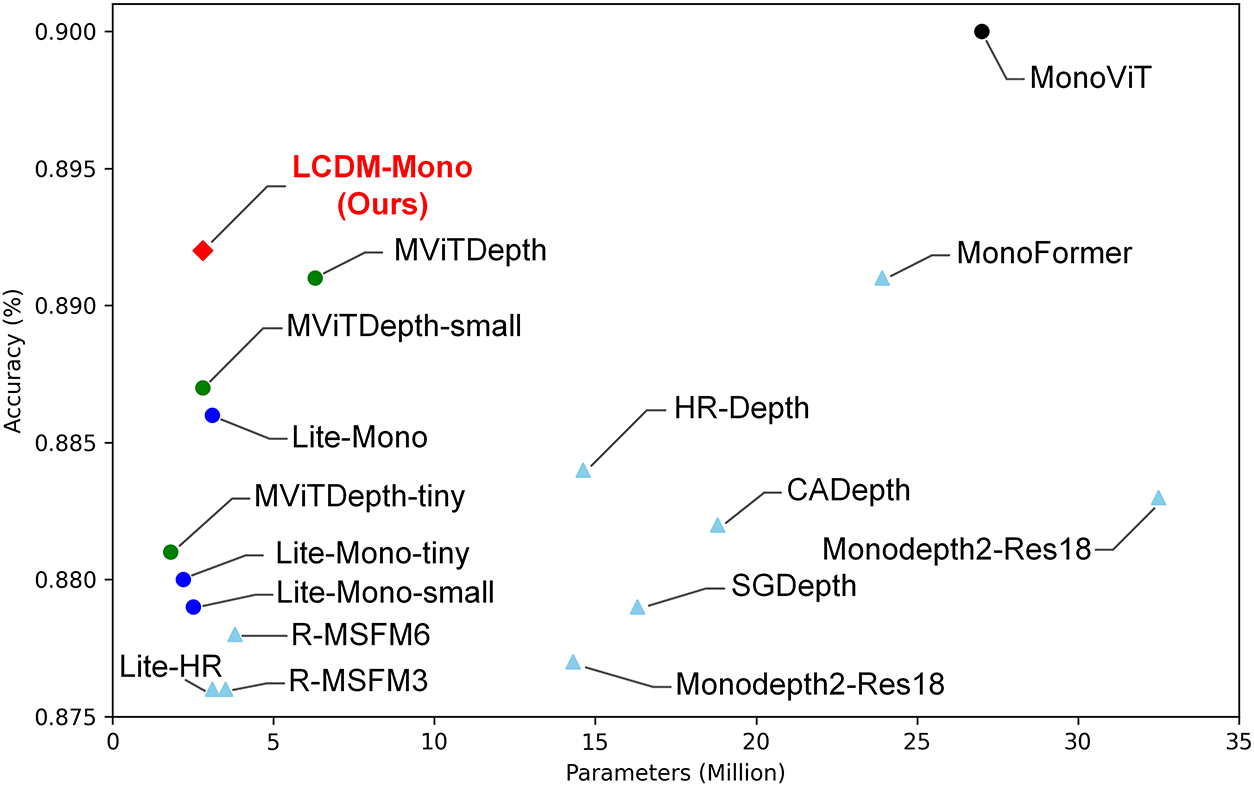
Figure 4: Comparison of model parameters and δ1 accuracy among different lightweight self-supervised monocular depth estimation methods. All models are trained and tested on the KITTI dataset with an image resolution of 640 × 192. Our method (marked in red) achieves a much better balance between model complexity and accuracy.
The detailed quantitative results on the KITTI dataset are presented in Table 1. Compared with other self-supervised monocular depth estimation methods, LCDM-Mono not only achieves highly competitive depth prediction accuracy but also significantly reduces the number of model parameters, highlighting its favorable accuracy-efficiency trade-off. Specifically, LCDM-Mono substantially outperforms the classical Monodepth2-Res18, despite the latter having a considerably larger parameter size, indicating a more effective utilization of model capacity. Moreover, compared with the recent lightweight Lite-Mono, LCDM-Mono consistently surpasses it across both error metrics and accuracy metrics, demonstrating superior overall performance under identical hardware conditions. More importantly, relative to the latest lightweight method MViTDepth, LCDM-Mono achieves comprehensive improvements in both model compactness and overall performance metrics, validating the effectiveness of the proposed conditional diffusion-based design. Table 2 reports results at a higher input image resolution of 1024 × 320. The results demonstrate that when the input resolution increases, LCDM-Mono continues to exhibit superior performance across most evaluation metrics while maintaining its lightweight architecture, further validating its robustness, scalability, and effectiveness under higher-resolution inference settings.
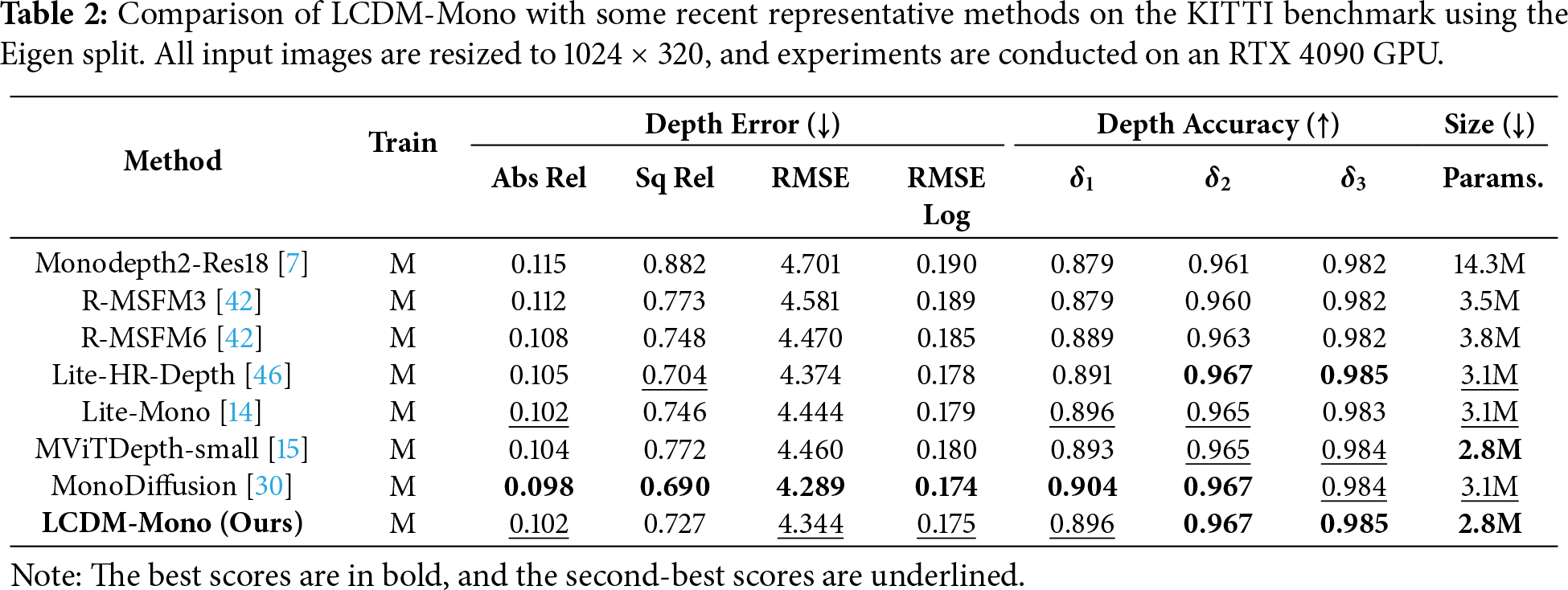
Fig. 5 further presents the qualitative depth estimation results on the KITTI dataset. As shown, our method produces noticeably sharper depth predictions around object boundaries (e.g., the traffic sign in column 4) and accurately recovers fine-grained structures such as the poles in column 2 and the tree trunk in column 3. These qualitative and quantitative results collectively suggest that the proposed LCDM-Mono achieves a superior balance between accuracy and model compactness. In particular, it significantly enhances depth prediction quality around object edges and detailed structures while maintaining a lightweight network design, ultimately yielding depth maps that exhibit stronger geometric consistency and structural coherence across the entire scene.
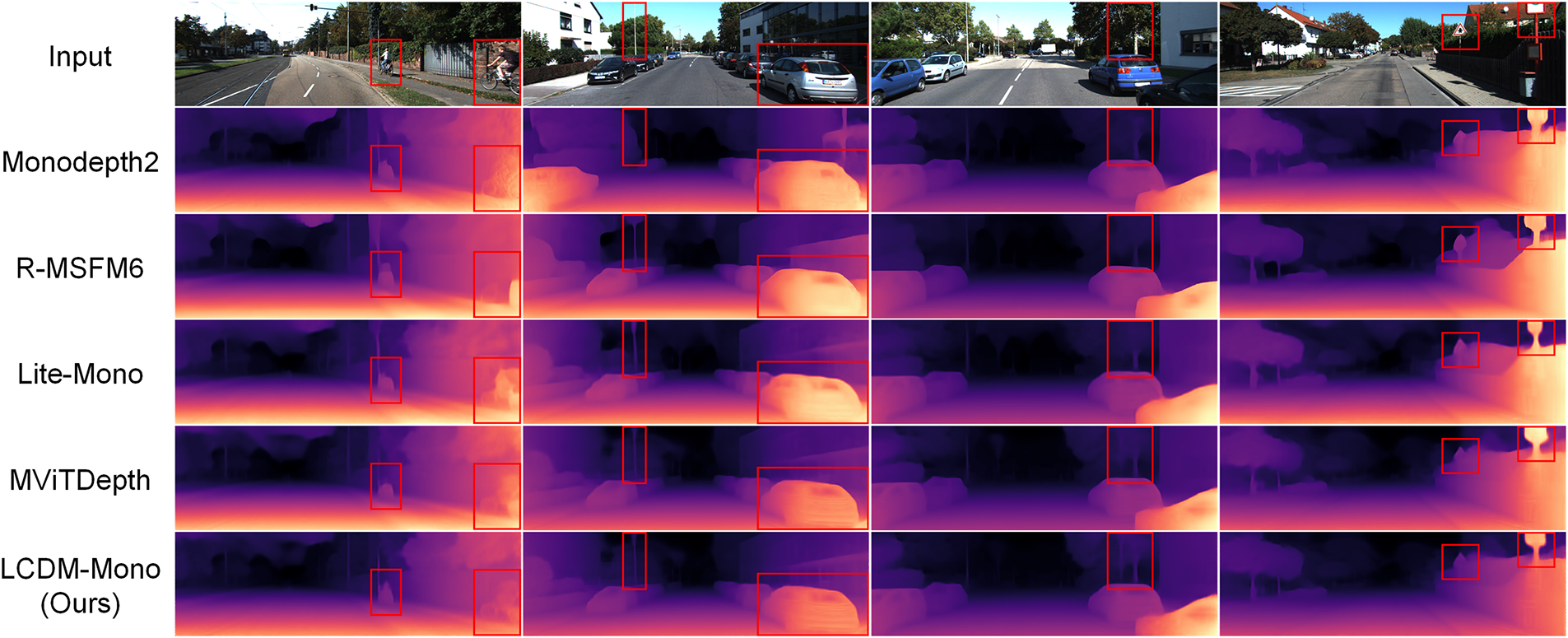
Figure 5: Qualitative results on the KITTI dataset. Compared to other methods, our method preserves sharper object boundaries.
The Make3D dataset is further employed to evaluate the generalization capability of the proposed LCDM-Mono across diverse outdoor environments. Specifically, LCDM-Mono is trained on the KITTI dataset using an input resolution of 640 × 192 and then directly tested on the Make3D dataset without any additional fine-tuning. As summarized in Table 3, our method achieves superior generalization performance compared with existing approaches, demonstrating the robustness and reliability of the proposed depth estimation framework. Fig. 6 provides qualitative comparisons on the Make3D test set. Benefiting from the introduced surface normal-based knowledge distillation loss, LCDM-Mono generates high-quality depth maps across the entire 3D scene, producing clearer and more accurate predictions around object boundaries and fine structures (e.g., the tree trunk in columns 1 and 3 and the door contours in column 2).
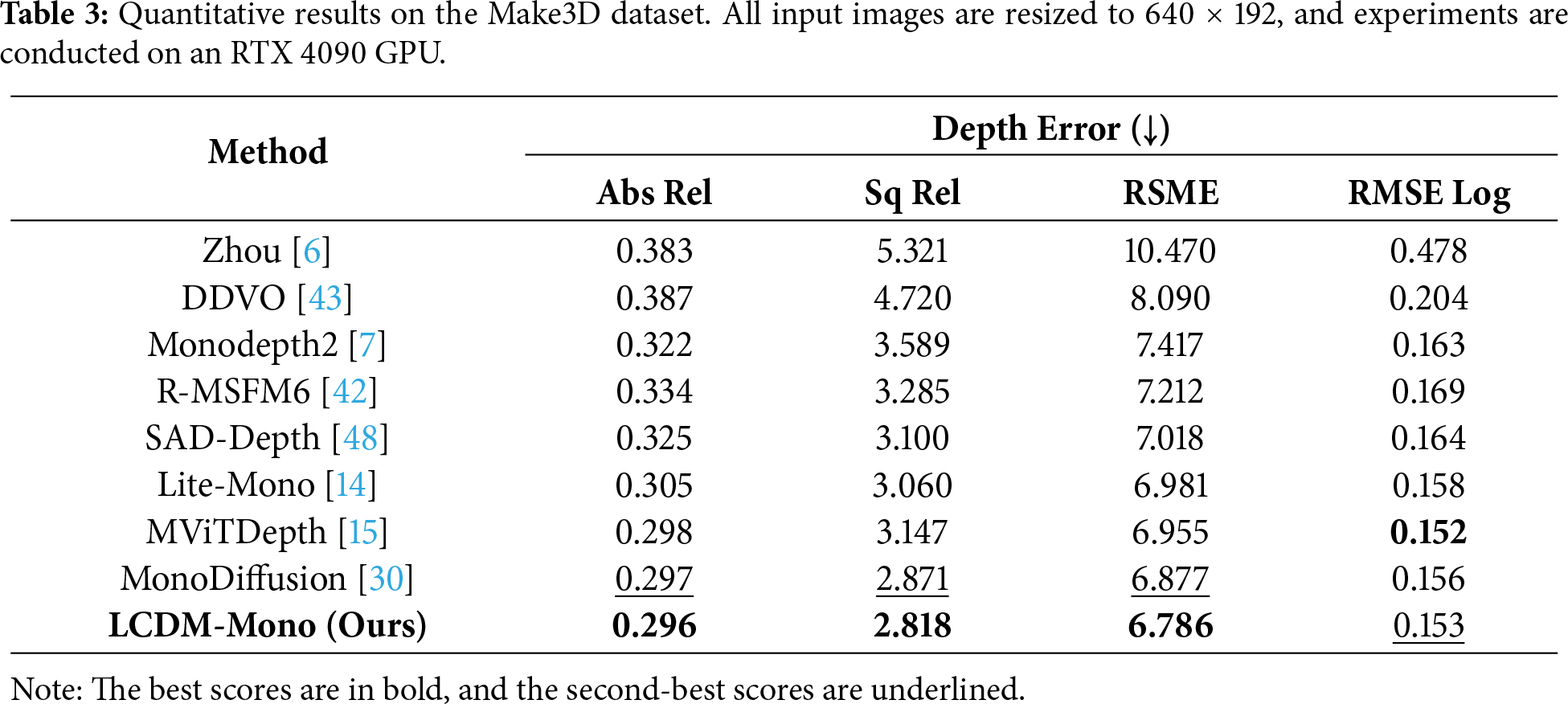
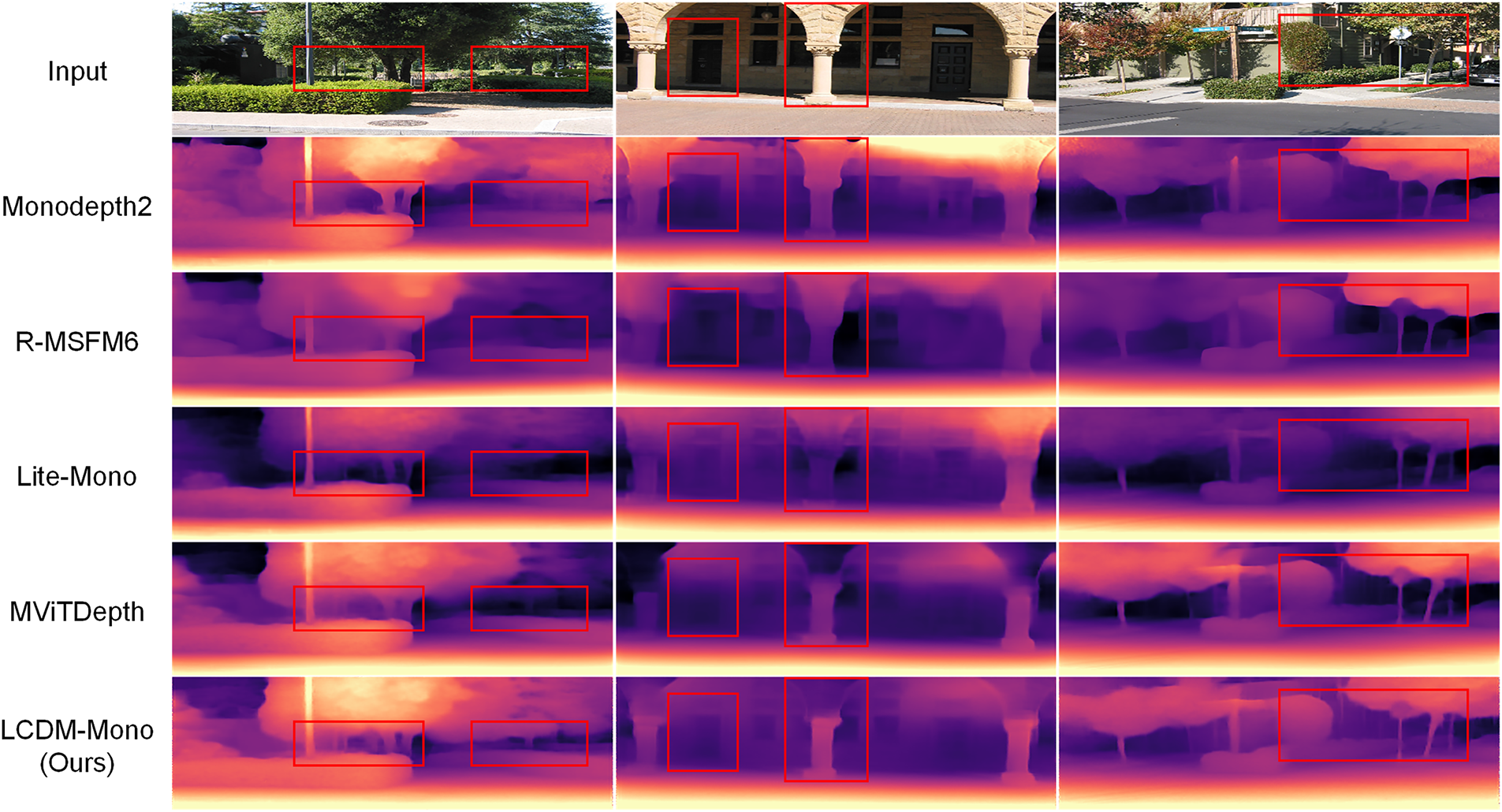
Figure 6: Qualitative results on the Make3D dataset. Compared to other methods, our method preserves more fine-grained details and sharper edges in the depth maps.
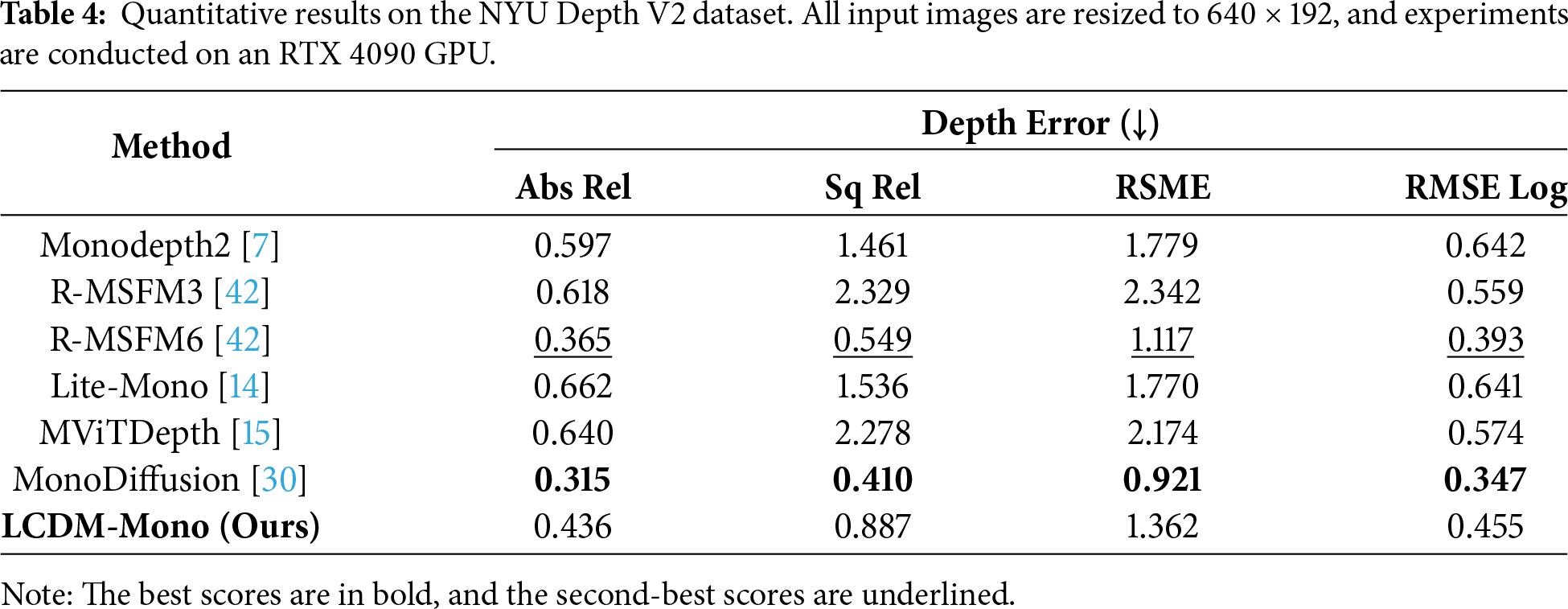
Furthermore, to evaluate the performance of the proposed method in indoor environments, we conduct experiments on the NYU Depth V2 dataset. The model is directly inferred on this dataset without any additional fine-tuning. As shown in Table 4, although some methods achieve lower absolute errors, they often come at the cost of increased model complexity or computational overhead. In contrast, our LCDM-Mono achieves relatively low depth estimation errors while being specifically designed for resource-constrained settings, demonstrating a favorable balance between performance and efficiency.
4.4 Evaluation on Real-World Scenarios
To further evaluate the runtime performance of LCDM-Mono on resource-constrained edge devices, we build a real-world UAV experimental platform. The overall structure of the UAV is illustrated in Fig. 7. The platform is equipped with an 8-core Cortex-A78AE processor and 16 GB of RAM, and integrates an NVIDIA Jetson Orin NX module as the onboard edge computing unit. Image acquisition is performed using an SY020HD monocular camera, with an input resolution of 640 × 480.

Figure 7: The custom-built drone equipped with an SY020HD monocular camera and an NVIDIA Jetson Orin NX edge computing module.
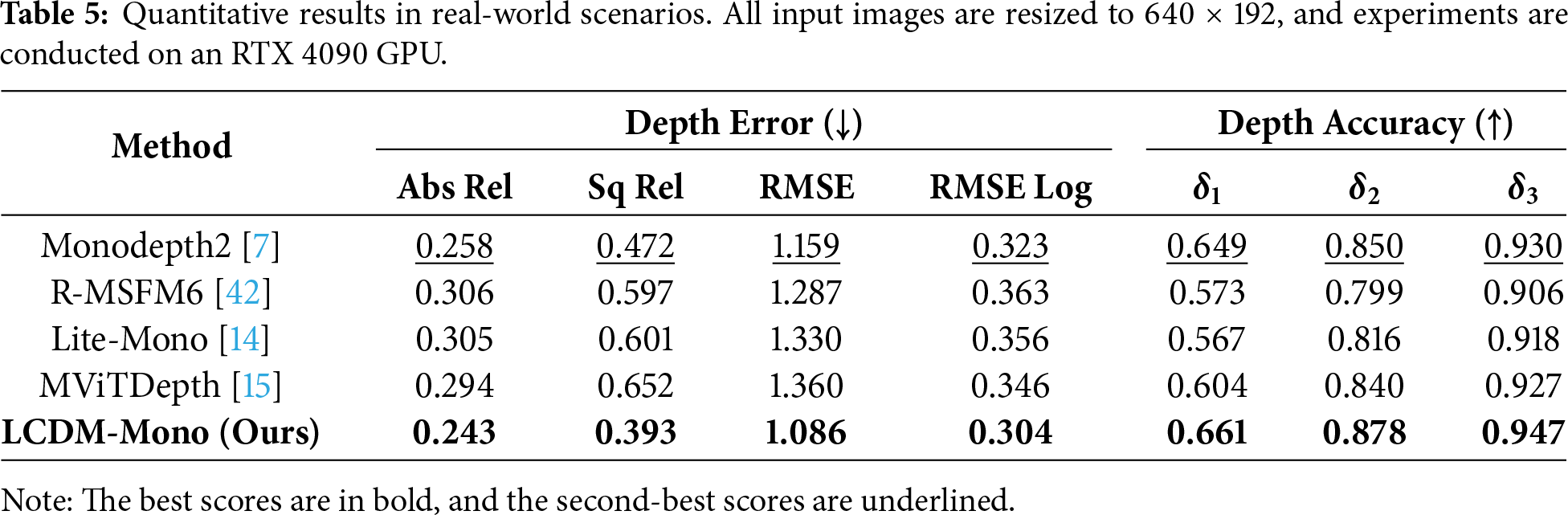
To evaluate the performance of the proposed LCDM-Mono in real-world environments, we collect RGB-D data using an Intel RealSense D435i depth sensor. A total of 1000 RGB images and their corresponding depth maps are captured at a resolution of 640 × 480. Specifically, the acquisition is conducted within a dedicated indoor flight arena enclosed by protective netting, utilizing consistent artificial overhead lighting. To ensure high scene diversity, the environment is populated with diverse structural elements, including boxes, shelves, artificial trees, aerial hoops and moving pedestrians. Based on this indoor test set with ground-truth depth, we conduct comprehensive quantitative and qualitative evaluations of LCDM-Mono and several recent lightweight depth estimation methods, without applying any fine-tuning. The evaluations include depth estimation error and accuracy metrics, as well as visual comparisons of the predicted depth maps. The results are summarized in Table 5. LCDM-Mono consistently outperforms competing methods across all depth estimation metrics in real-world scenarios, further demonstrating its strong generalization ability and robustness.
Furthermore, we conduct a detailed comparison based on visualized depth maps. As shown in Fig. 8, the proposed LCDM-Mono generates clearer and more accurate depth maps, particularly around object boundaries. Compared with recent lightweight methods such as Lite-Mono and MViTDepth, our LCDM-Mono produces sharper and more precise depth predictions around objects with distinct structural edges, such as the aerial hoops (column 2), pedestrians (columns 3 and 4), and artificial trees (columns 3 and 5). Additionally, the overall depth map exhibits higher accuracy and improved geometric consistency across the scene. This superior performance can be attributed to the introduced surface normal distillation loss. Through this loss, the student model is able to capture finer geometric and spatial structure information in the 3D scene, including object orientations and boundary structures. Such enhancements effectively preserve geometric consistency in depth estimation and improve the accuracy of both object boundaries and the overall scene.

Figure 8: Qualitative results in real-world scenarios. Our method produces depth maps with clearer structural details and better-preserved object boundaries than competing methods.
4.5 Complexity and Speed Evaluation
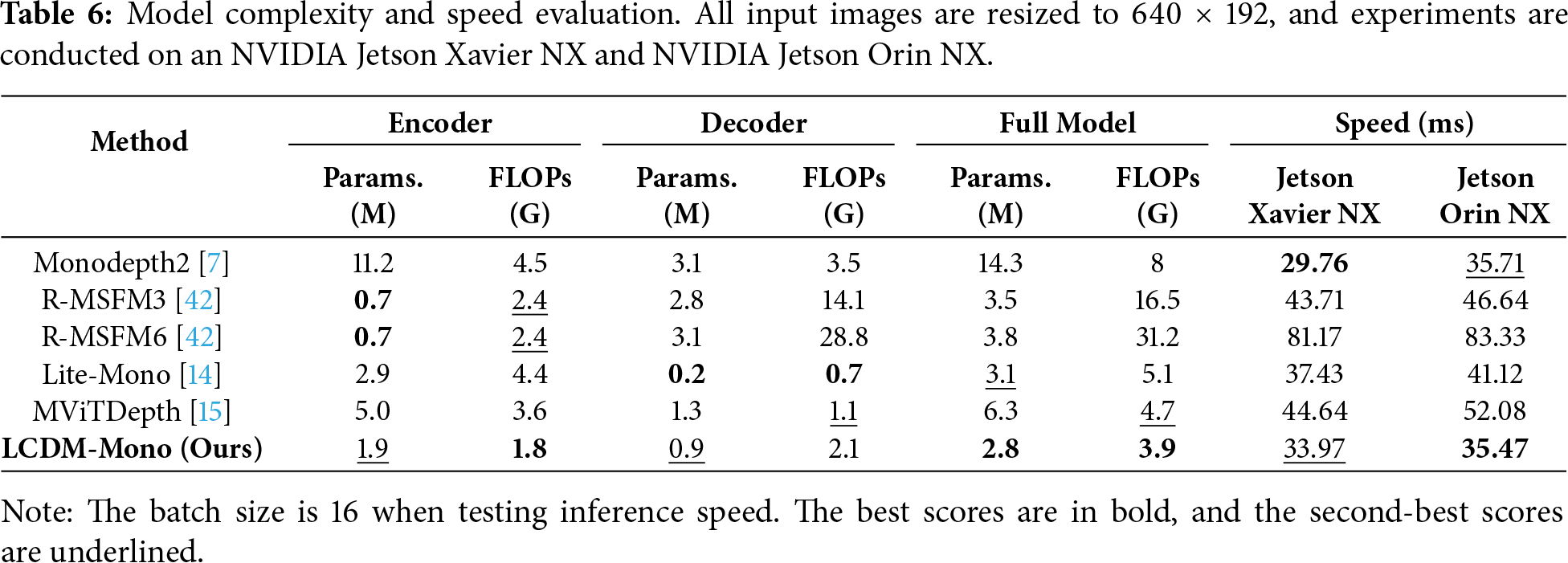
The model size and inference speed are critical considerations for practical deployment of depth estimation model. To evaluate the lightweight characteristics of our proposed method, LCDM-Mono is comprehensively compared with several representative lightweight monocular depth estimation algorithms, including Monodepth2, R-MSFM3, R-MSFM6, Lite-Mono, and MViTDepth. The comparison metrics include the Params., the FLOPs, and the inference speed. All experiments are conducted on resource-constrained edge computing platforms, including the NVIDIA Jetson Xavier NX and Jetson Orin NX. Specifically, the Jetson Xavier NX is powered by a 6-core NVIDIA Carmel ARM v8.2 64-bit CPU and a 384-core NVIDIA Volta GPU with 48 Tensor Cores. It is equipped with 8 GB of 128-bit LPDDR4x memory, operating at a configurable power range of 10–20 W, and providing 32 GB of storage. The Jetson Orin NX features an 8-core Arm Cortex-A78AE v8.2 64-bit CPU and a 1024-core NVIDIA Ampere GPU with 32 Tensor Cores. It comes with 16 GB of 128-bit LPDDR5 memory, operating at a configurable power range of 10–25 W, and providing 128 GB of storage.
As shown in Table 6, LCDM-Mono achieves a favorable balance between model complexity and inference speed, making it highly suitable for deployment on resource-constrained edge devices. Among the compared methods, R-MSFM6 exhibits the highest inference latency and slowest speed due to its recurrent multi-scale feature modulation architecture. In contrast, the proposed LCDM-Mono requires only two sampling steps during inference to generate high-quality depth maps. On the Jetson Xavier NX platform, its inference speed ranks second, while on the Jetson Orin NX platform, it achieves the lowest inference time, making it the fastest among all evaluated methods overall.
The significantly reduced inference latency not only enhances real-time processing capability but also lowers computational cost and energy consumption, thereby meeting the performance requirements of most real-time depth estimation applications. Moreover, these results show that the proposed lightweight conditional diffusion inference strategy exhibits strong generality and robustness across different Jetson embedded platforms, achieving a favorable balance between accuracy and efficiency. This further confirms that LCDM-Mono is not specifically optimized for a single Jetson device but possesses strong practical deployment potential across various Jetson embedded platforms. Overall, LCDM-Mono substantially improves inference efficiency while maintaining prediction accuracy, demonstrating high practical deployment value, particularly for platforms with limited computational resources, such as UAVs, smart cameras, and mobile robots.
To further validate the effectiveness of the proposed LCDM-Mono, comprehensive ablation studies on model architectures are conducted on the KITTI dataset, with the corresponding results summarized in Table 7.
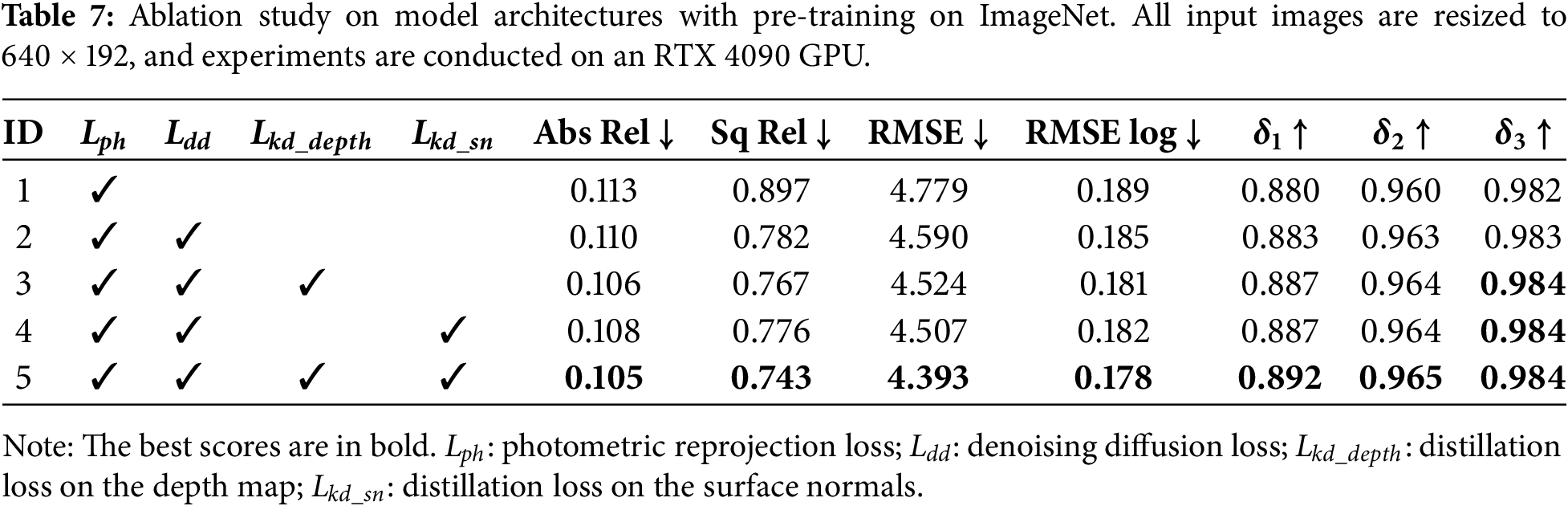
The experiments start with a baseline model (ID 1), which employs only the basic photometric reprojection loss as the supervision signal. Subsequently, the effectiveness of each component is analyzed step by step. When the proposed denoising diffusion loss is added (ID 2), the overall error tends to decrease, suggesting that this term enhances the reliability of depth predictions. Further introducing depth map knowledge distillation (ID 3) leads to a significant improvement in depth estimation accuracy, suggesting that supervision from the pseudo ground-truth depth generated by the teacher network can directly enhance the precision of depth predictions. Replacing depth map distillation with surface normal knowledge distillation (ID 4) also yields a comparable improvement, demonstrating that surface normal distillation can serve as a geometry-guided supervision signal that help the network capture 3D structural information. Finally, when all components are employed simultaneously (ID 5), the student network achieves the most significant improvements across all depth estimation metrics, especially in the Abs Rel error and δ1 accuracy.
It is demonstrated by these results that the combined use of Lkd_depth and Lkd_sn is superior to the isolated application of either loss. The reason is that Lkd_depth alone supervises the predicted depth values but provides limited guidance for capturing geometric details around object boundaries and fine structures. Conversely, Lkd_sn alone can maintain geometric consistency by constraining surface normals, but it lacks direct supervision on depth values, limiting improvements in overall depth estimation. Combining both losses provides both precise global depth guidance and local geometric and edge constraints. These complementary effects enable the student network to produce accurate depth predictions while maintaining geometric consistency around object boundaries and fine details, thereby significantly enhancing depth estimation performance.
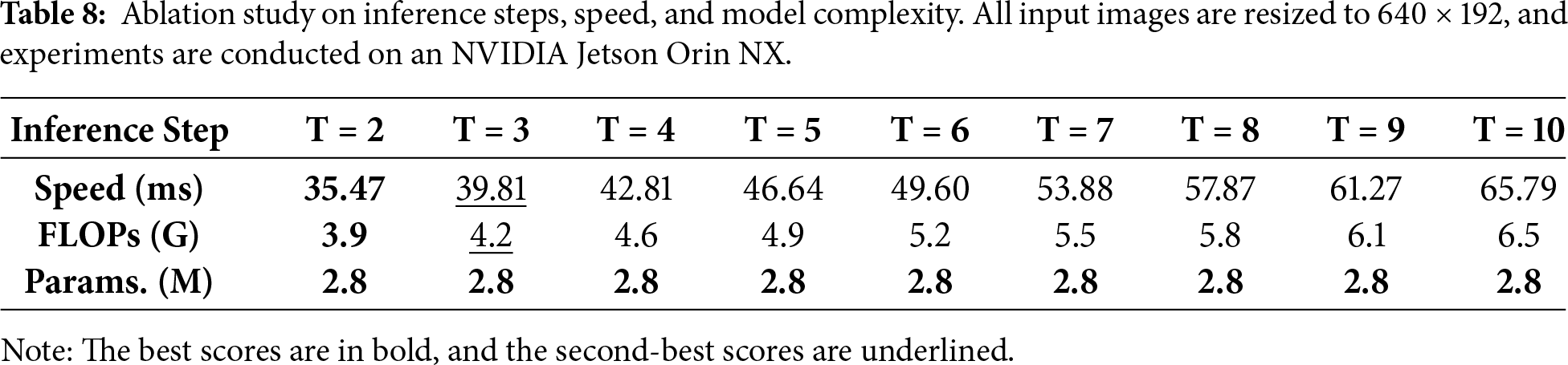
To evaluate the impact of the number of inference steps on model efficiency, we conduct an ablation study and report the inference time, FLOPs and parameter counts across different step settings (T), as summarized in Table 8. It is evident from the results that the inference time increases approximately linearly with the number of steps, while the parameter count remains constant. Although increasing sampling steps is theoretically associated with improved generation quality, the computational overhead is found to increase disproportionately, thereby severely compromising real-time capabilities on computationally limited edge devices. Therefore, the configuration of T = 2 is identified as an efficient inference setting, making it suitable for resource-constrained edge computing and real-time applications.
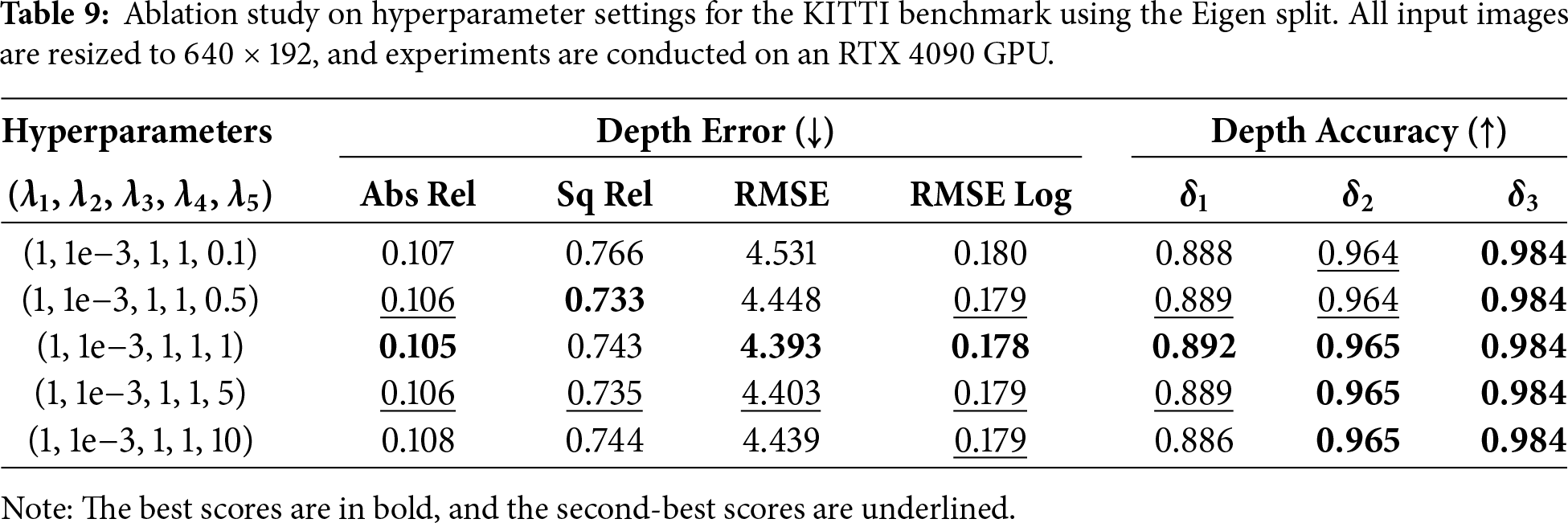
To investigate the sensitivity of depth estimation performance to loss weighting, a series of hyperparameter ablation experiments is conducted (see Table 9). By varying λ5 (corresponding to Lkd_sn) while fixing the remaining coefficients, a trend of high performance stability is demonstrated, suggesting that the proposed framework is not overly sensitive to specific parameter tuning. The peak performance across all accuracy and error metrics is consistently observed when a balanced weighting strategy is employed. Consequently, this optimal configuration is selected for all subsequent experiments, as it provides a harmonious trade-off between the diverse loss terms and ensures reliable depth map generation.
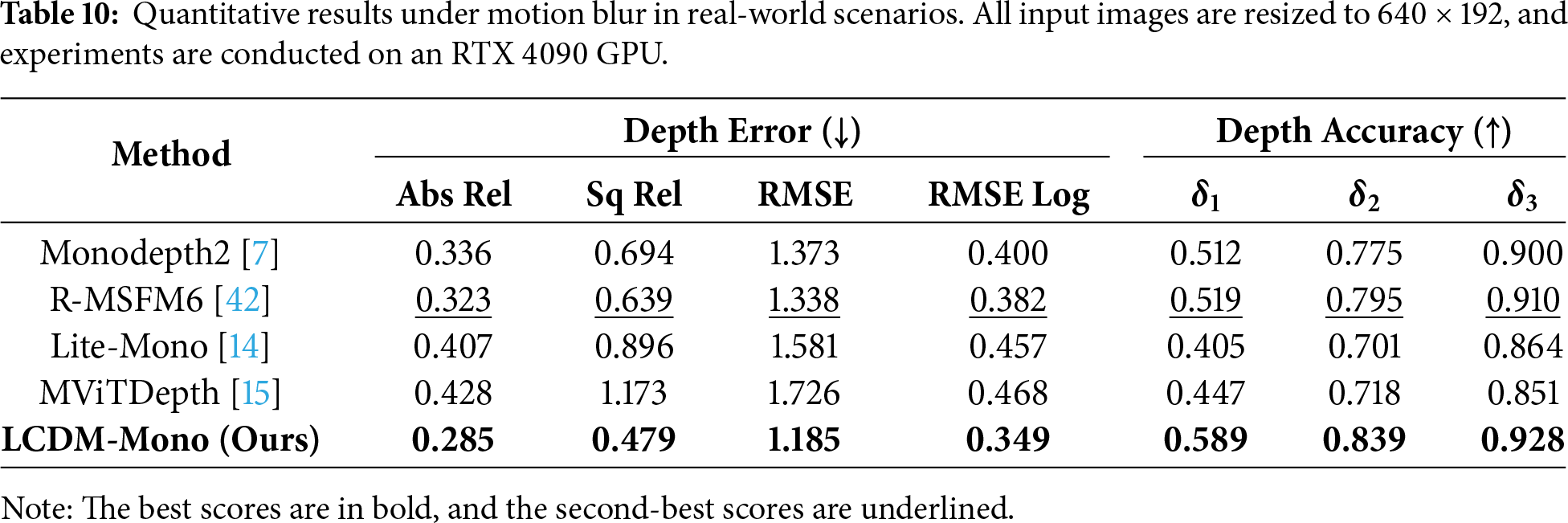
As a self-supervised monocular depth estimation method, our approach relies on the photometric consistency assumption during training. Therefore, similar to most existing self-supervised methods, its performance may degrade in complex scenarios such as extreme illumination changes or scenes containing fast-moving dynamic objects, where this assumption is violated. In this work, motion-blurred scenes are used as a representative example of such extreme conditions to further investigate the robustness of monocular depth estimation. Specifically, we collect 100 images exhibiting motion blur and conduct both quantitative and qualitative comparative analyses against various state-of-the-art methods.
As shown in Fig. 9 and Table 10, a degradation in depth estimation accuracy is observed across all compared methods under extreme motion scenarios, characterized by unstable camera motion and severe motion blur. In contrast, the proposed LCDM-Mono maintains relatively optimal overall performance in motion-blurred scenes and outperforms all competing methods. This advantage is mainly attributed to the diffusion-based modeling framework and the knowledge distillation strategy that incorporates geometric structural priors. These components help improve the stability of depth prediction under motion blur conditions. Nevertheless, there remains room for further improvement in such extreme cases, and future work will explore the incorporation of explicit motion modeling or illumination-aware constraints to further enhance the robustness of the model.
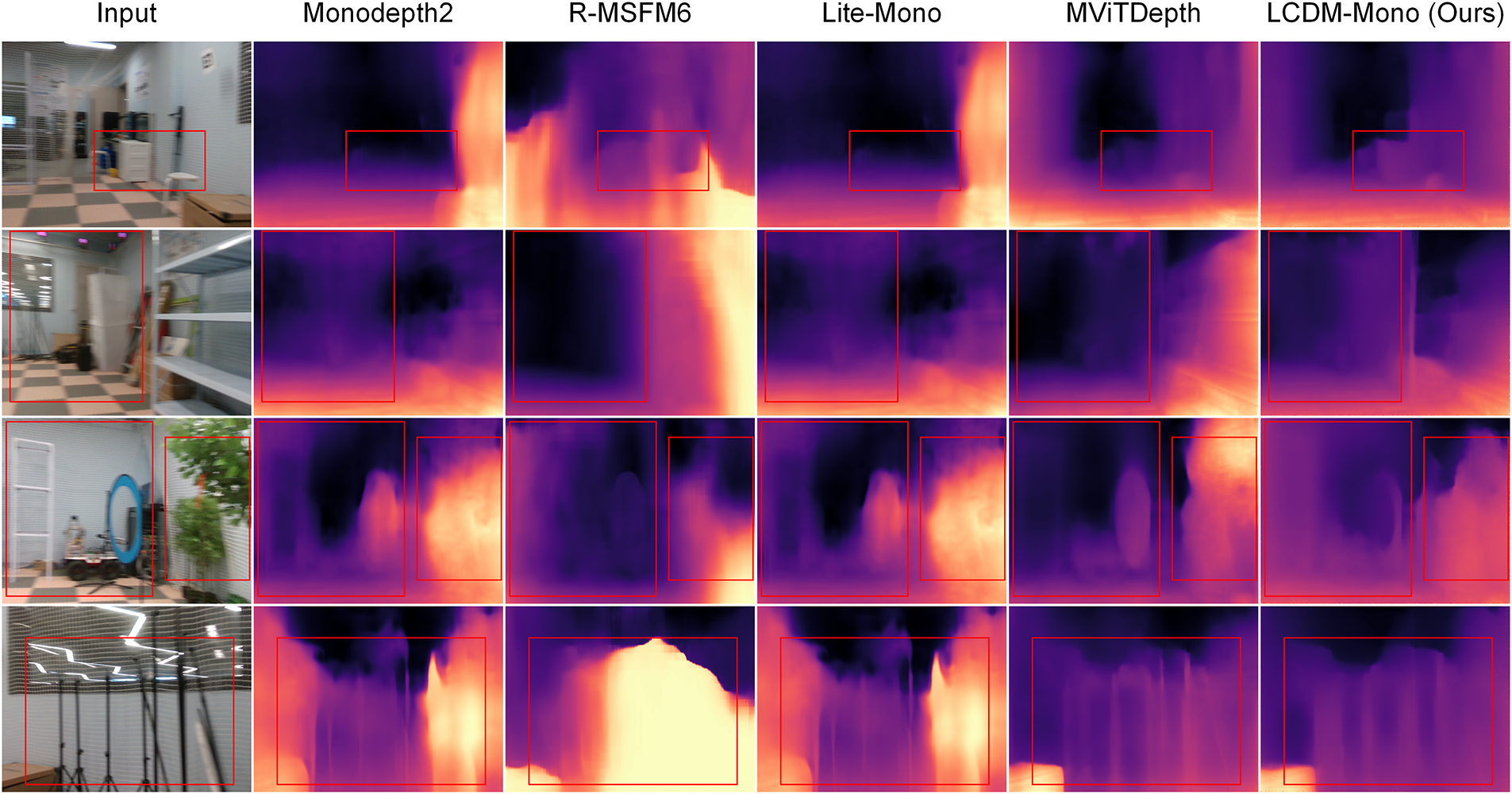
Figure 9: Qualitative results under extreme motion blur conditions. Our method produces more stable depth predictions with clearer structural details and better-preserved object boundaries compared with competing methods.
Beyond robustness, the practical deployability of LCDM-Mono relies on the edge-level efficiency trade-offs between task-specific accuracy, latency, and power consumption. As highlighted in the recent study on drone-based AI deployment [49], incorporating tiny machine learning principles helps achieve high-performance monitoring on resource-constrained platforms. Specifically, Bakirci [49] conducts an extensive evaluation of lightweight YOLO variants, emphasizing that metrics such as GPU usage and power consumption are as critical as conventional accuracy for autonomous aerial systems. Their findings demonstrate that while complex models offer superior precision, the resulting computational overhead can severely degrade the operational endurance and decision-making speed of UAVs. Therefore, deploying lightweight and energy-efficient models is essential for UAV-based AI systems, ensuring real-time performance, fast decision-making, and sustainable operation under limited onboard resources.
Drawing inspiration from this multi-dimensional evaluation framework, we argue that self-supervised depth estimation should similarly move towards streamlined pipelines. This trend is further supported by the LITI framework [50], which advocates for lightweight training and inference for depth estimation on edge devices such as the NVIDIA Jetson Orin Nano. Our LCDM-Mono aligns with these philosophies by optimizing the inference process to only two sampling steps. This strategic reduction not only ensures real-time latency on embedded hardware but also minimizes the thermal and energy load. By balancing structural fidelity with low power consumption, our approach provides a practical solution for real-time environmental perception and scene understanding on resource-constrained edge devices.
In this paper, we propose a Lightweight Conditional Diffusion Model for Monocular Depth Estimation (LCDM-Mono). The method formulates depth estimation as a conditional denoising process. During training, a teacher network is introduced to guide the forward diffusion process using pseudo ground-truth, while during inference, only two sampling steps are required to generate high-quality depth maps in real time, significantly reducing inference latency and ensuring real-time performance. Additionally, we introduce a surface normal distillation loss to guide the student network in capturing more accurate geometric structure information of 3D scenes, enhancing structural awareness in object boundary regions and producing depth predictions with sharper edges. Experimental results on benchmark datasets and real-world scenarios validate that LCDM-Mono achieves a favorable balance between depth estimation accuracy and model complexity, exhibiting excellent lightweight characteristics suitable for resource-constrained edge devices. Future work will investigate the integration of monocular depth estimation with real-time video object tracking. This integration is expected to further enhance the algorithm’s perception and understanding capabilities in complex 3D scenes.
Acknowledgement: Not applicable.
Funding Statement: This work was supported by the National Natural Science Foundation of China (Grant No. 62203480).
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization and methodology, Hao Li; data curation and investigation, Hao Li and Haojie Wu; writing—original draft preparation, Hao Li; writing—review and editing, Zhoujingzi Qiu and Shicai Fan; supervision, Shicai Fan; funding acquisition, Zhoujingzi Qiu, Shicai Fan and Jianxiao Zou. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data are available from the corresponding author upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Xiang J, Wang Y, An L, Liu H, Wang Z, Liu J. Visual attention-based self-supervised absolute depth estimation using geometric priors in autonomous driving. IEEE Robot Autom Lett. 2022;7(4):11998–2005. doi:10.1109/LRA.2022.3210298. [Google Scholar] [CrossRef]
2. Valentin J, Kowdle A, Barron JT, Wadhwa N, Dzitsiuk M, Schoenberg M, et al. Depth from motion for smartphone AR. ACM Trans Graph. 2018;37(6):1–19. doi:10.1145/3272127.3275041. [Google Scholar] [CrossRef]
3. Schmid K, Tomic T, Ruess F, Hirschmuller H, Suppa M. Stereo vision based indoor/outdoor navigation for flying robots. In: Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems; 2013 Nov 3–7; Tokyo, Japan. doi:10.1109/iros.2013.6696922. [Google Scholar] [CrossRef]
4. Zhang C, Liang L, Zhou J, Xu Y. Multi-view depth estimation based on multi-feature aggregation for 3D reconstruction. Comput Graph. 2024;122(4):103954. doi:10.1016/j.cag.2024.103954. [Google Scholar] [CrossRef]
5. Garg R, Vijay Kumar BG, Carneiro G, Reid I. Unsupervised CNN for single view depth estimation: geometry to the rescue. In: Proceedings of the Computer Vision—ECCV 2016: 14th European Conference; 2016 Oct 11–14; Amsterdam, The Netherlands. doi:10.1007/978-3-319-46484-8_45. [Google Scholar] [CrossRef]
6. Zhou T, Brown M, Snavely N, Lowe DG. Unsupervised learning of depth and ego-motion from video. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017 Jul 21–26; Honolulu, HI, USA. doi:10.1109/cvpr.2017.700. [Google Scholar] [CrossRef]
7. Godard C, Mac Aodha O, Firman M, Brostow G. Digging into self-supervised monocular depth estimation. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. doi:10.1109/iccv.2019.00393. [Google Scholar] [CrossRef]
8. Zou Y, Luo Z, Huang JB. DF-net: unsupervised joint learning of depth and flow using cross-task consistency. In: Computer vision—ECCV 2018. Berlin/Heidelberg, Germany: Springer; 2018. p. 38–55. doi:10.1007/978-3-030-01228-1_3. [Google Scholar] [CrossRef]
9. Bian JW, Li Z, Wang N, Zhan H, Shen C, Cheng MM, et al. Unsupervised scale-consistent depth and ego-motion learning from monocular video. arXiv:1908.10553. 2019. [Google Scholar]
10. Klingner M, Termöhlen JA, Mikolajczyk J, Fingscheidt T. Self-supervised monocular depth estimation: solving the dynamic object problem by semantic guidance. In: Proceedings of the Computer Vision—ECCV 2020: 16th European Conference; 2020 Aug 23–28; Glasgow, UK. doi:10.1007/978-3-030-58565-5_35. [Google Scholar] [CrossRef]
11. Jung H, Park E, Yoo S. Fine-grained semantics-aware representation enhancement for self-supervised monocular depth estimation. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 10–17; Montreal, QC, Canada. doi:10.1109/iccv48922.2021.01241. [Google Scholar] [CrossRef]
12. Liu J, Cao Z, Liu X, Wang S, Yu J. Self-supervised monocular depth estimation with geometric prior and pixel-level sensitivity. IEEE Trans Intell Veh. 2023;8(3):2244–56. doi:10.1109/TIV.2022.3210274. [Google Scholar] [CrossRef]
13. Spencer J, Bowden R, Hadfield S. DeFeat-net: general monocular depth via simultaneous unsupervised representation learning. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. doi:10.1109/cvpr42600.2020.01441. [Google Scholar] [CrossRef]
14. Zhang N, Nex F, Vosselman G, Kerle N. Lite-mono: a lightweight CNN and transformer architecture for self-supervised monocular depth estimation. In: Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. doi:10.1109/CVPR52729.2023.01778. [Google Scholar] [CrossRef]
15. Gao W, Rao D, Yang Y, Chen J. Edge devices friendly self-supervised monocular depth estimation via knowledge distillation. IEEE Robot Autom Lett. 2023;8(12):8470–7. doi:10.1109/LRA.2023.3330054. [Google Scholar] [CrossRef]
16. Rudolph M, Dawoud Y, Güldenring R, Nalpantidis L, Belagiannis V. Lightweight monocular depth estimation through guided decoding. In: Proceedings of the 2022 International Conference on Robotics and Automation (ICRA); 2022 May 23–27; Philadelphia, PA, USA. doi:10.1109/ICRA46639.2022.9812220. [Google Scholar] [CrossRef]
17. Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models. arXiv:2006.11239. 2020. [Google Scholar]
18. Song J, Meng C, Ermon S. Denoising diffusion implicit models. arXiv:2010.02502. 2020. [Google Scholar]
19. Duan Y, Guo X, Zhu Z. DiffusionDepth: diffusion denoising approach for monocular depth estimation. In: Computer vision—ECCV 2024. Berlin/Heidelberg, Germany: Springer; 2024. p. 432–49. doi:10.1007/978-3-031-73247-8_25. [Google Scholar] [CrossRef]
20. Saxena S, Herrmann C, Hur J, Kar A, Norouzi M, Sun D, et al. The surprising effectiveness of diffusion models for optical flow and monocular depth estimation. arXiv:2306.01923. 2023. [Google Scholar]
21. Wang J, Lin C, Nie L, Liao K, Shao S, Zhao Y. Digging into contrastive learning for robust depth estimation with diffusion models. In: Proceedings of the 32nd ACM International Conference on Multimedia; 2024 Oct 28–Nov 1; Melbourne, VIC, Australia. doi:10.1145/3664647.3681168. [Google Scholar] [CrossRef]
22. Eigen D, Puhrsch C, Fergus R. Depth map prediction from a single image using a multi-scale deep network. arXiv:1406.2283. 2014. [Google Scholar]
23. Liu F, Shen C, Lin G. Deep convolutional neural fields for depth estimation from a single image. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2015 Jun 7–12; Boston, MA, USA. doi:10.1109/cvpr.2015.7299152. [Google Scholar] [CrossRef]
24. Yuan W, Gu X, Dai Z, Zhu S, Tan P. Neural window fully-connected CRFs for monocular depth estimation. In: Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. doi:10.1109/cvpr52688.2022.00389. [Google Scholar] [CrossRef]
25. Wang L, Zhang J, Wang Y, Lu H, Ruan X. CLIFFNet for monocular depth estimation with hierarchical embedding loss. In: Computer vision—ECCV 2020. Berlin/Heidelberg, Germany: Springer; 2020. p. 316–31. doi:10.1007/978-3-030-58558-7_19. [Google Scholar] [CrossRef]
26. Lee JH, Kim CS. Multi-loss rebalancing algorithm for monocular depth estimation. In: Computer vision—ECCV 2020. Berlin/Heidelberg, Germany: Springer; 2020. p. 785–801. doi:10.1007/978-3-030-58520-4_46. [Google Scholar] [CrossRef]
27. Godard C, Mac Aodha O, Brostow GJ. Unsupervised monocular depth estimation with left-right consistency. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017 Jul 21–26; Honolulu, HI, USA. doi:10.1109/CVPR.2017.699. [Google Scholar] [CrossRef]
28. Patni S, Agarwal A, Arora C. ECoDepth: effective conditioning of diffusion models for monocular depth estimation. In: Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024 Jun 16–22; Seattle, WA, USA. doi:10.1109/CVPR52733.2024.02672. [Google Scholar] [CrossRef]
29. Fu X, Yin W, Hu M, Wang K, Ma Y, Tan P, et al. GeoWizard: unleashing the diffusion priors for 3D geometry estimation from a single image. In: Computer vision—ECCV 2024. Berlin/Heidelberg, Germany: Springer; 2024. p. 241–58. doi:10.1007/978-3-031-72670-5_14. [Google Scholar] [CrossRef]
30. Shao S, Pei Z, Chen W, Sun D, Chen PCY, Li Z. MonoDiffusion: self-supervised monocular depth estimation using diffusion model. IEEE Trans Circuits Syst Video Technol. 2025;35(4):3664–78. doi:10.1109/TCSVT.2024.3509619. [Google Scholar] [CrossRef]
31. Buciluǎ C, Caruana R, Niculescu-Mizil A. Model compression. In: Proceedings of the KDD ′06: Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; 2006 Aug 20–23; Philadelphia, PA, USA. doi:10.1145/1150402.1150464. [Google Scholar] [CrossRef]
32. Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network. arXiv:1503.02531. 2015. [Google Scholar]
33. He X, Guo D, Li H, Li R, Cui Y, Zhang C. Distill any depth: distillation creates a stronger monocular depth estimator. arXiv:2502.19204. 2025. [Google Scholar]
34. Liu Z, Li R, Shao S, Wu X, Chen W. Self-supervised monocular depth estimation with self-reference distillation and disparity offset refinement. IEEE Trans Circuits Syst Video Technol. 2023;33(12):7565–77. doi:10.1109/TCSVT.2023.3275584. [Google Scholar] [CrossRef]
35. Zhao C, Zhang Y, Poggi M, Tosi F, Guo X, Zhu Z, et al. MonoViT: self-supervised monocular depth estimation with a vision transformer. In: Proceedings of the 2022 International Conference on 3D Vision (3DV); 2022 Sep 12–16; Prague, Czech Republic. doi:10.1109/3DV57658.2022.00077. [Google Scholar] [CrossRef]
36. Qi X, Liu Z, Liao R, Torr PHS, Urtasun R, Jia J. GeoNet: iterative geometric neural network with edge-aware refinement for joint depth and surface normal estimation. IEEE Trans Pattern Anal Mach Intell. 2022;44(2):969–84. doi:10.1109/TPAMI.2020.3020800. [Google Scholar] [PubMed] [CrossRef]
37. Mehta S, Rastegari M. MobileViT: light-weight, general-purpose, and mobile-friendly vision transformer. arXiv:2110.02178. 2021. [Google Scholar]
38. Geiger A, Lenz P, Stiller C, Urtasun R. Vision meets robotics: the KITTI dataset. Int J Robot Res. 2013;32(11):1231–7. doi:10.1177/0278364913491297. [Google Scholar] [CrossRef]
39. Eigen D, Fergus R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV); 2015 Dec 7–13; Santiago, Chile. doi:10.1109/ICCV.2015.304. [Google Scholar] [CrossRef]
40. Saxena A, Sun M, Ng AY. Make3D: learning 3D scene structure from a single still image. IEEE Trans Pattern Anal Mach Intell. 2009;31(5):824–40. doi:10.1109/TPAMI.2008.132. [Google Scholar] [PubMed] [CrossRef]
41. Silberman N, Hoiem D, Kohli P, Fergus R. Indoor segmentation and support inference from RGBD images. In: Computer vision—ECCV 2012. Berlin/Heidelberg, Germany: Springer; 2012. p. 746–60. doi:10.1007/978-3-642-33715-4_54. [Google Scholar] [CrossRef]
42. Zhou Z, Fan X, Shi P, Xin Y. R-MSFM: recurrent multi-scale feature modulation for monocular depth estimating. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 10–17; Montreal, QC, Canada. doi:10.1109/ICCV48922.2021.01254. [Google Scholar] [CrossRef]
43. Wang C, Buenaposada JM, Zhu R, Lucey S. Learning depth from monocular videos using direct methods. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. doi:10.1109/CVPR.2018.00216. [Google Scholar] [CrossRef]
44. Yin Z, Shi J. GeoNet: unsupervised learning of dense depth, optical flow and camera pose. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. doi:10.1109/CVPR.2018.00212. [Google Scholar] [CrossRef]
45. Yan J, Zhao H, Bu P, Jin Y. Channel-wise attention-based network for self-supervised monocular depth estimation. In: Proceedings of the 2021 International Conference on 3D Vision (3DV); 2021 Dec 1–3; London, UK. doi:10.1109/3DV53792.2021.00056. [Google Scholar] [CrossRef]
46. Lyu X, Liu L, Wang M, Kong X, Liu L, Liu Y, et al. HR-depth: high resolution self-supervised monocular depth estimation. Proc AAAI Conf Artif Intell. 2021;35(3):2294–301. doi:10.1609/aaai.v35i3.16329. [Google Scholar] [CrossRef]
47. Bae J, Moon S, Im S. Deep digging into the generalization of self-supervised monocular depth estimation. Proc AAAI Conf Artif Intell. 2023;37(1):187–96. doi:10.1609/aaai.v37i1.25090. [Google Scholar] [CrossRef]
48. Song L, Shi D, Xia J, Ouyang Q, Qiao Z, Jin S, et al. Spatial-aware dynamic lightweight self-supervised monocular depth estimation. IEEE Robot Autom Lett. 2024;9(1):883–90. doi:10.1109/LRA.2023.3337991. [Google Scholar] [CrossRef]
49. Bakirci M. Performance evaluation of low-power and lightweight object detectors for real-time monitoring in resource-constrained drone systems. Eng Appl Artif Intell. 2025;159:111775. doi:10.1016/j.engappai.2025.111775. [Google Scholar] [CrossRef]
50. Farcas AJ, Marculescu R. Demo abstract: lightweight training and inference for self-supervised depth estimation on edge devices. In: Proceedings of the 23rd ACM Conference on Embedded Networked Sensor Systems; 2025 May 6–9; Irvine, CA, USA. doi:10.1145/3715014.3724373. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools