
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

FedGLP-ADP: Federated Learning with Gradient-Based Layer-Wise Personalization and Adaptive Differential Privacy
College of Computer Science, Chongqing University, Chongqing, China
* Corresponding Author: Di Xiao. Email:
(This article belongs to the Special Issue: Privacy-Preserving and Secure Federated Learning for IoT, Cyber-Physical, and Maritime Systems)
Computers, Materials & Continua 2026, 87(3), 102 https://doi.org/10.32604/cmc.2026.079808
Received 28 January 2026; Accepted 09 March 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The rapid advancement of the Internet of Things (IoT) has transformed edge devices from simple data collectors into intelligent units capable of local processing and collaborative learning. However, the vast amounts of sensitive data generated by these devices face severe constraints from “data silos” and risks of privacy breaches. Federated learning (FL), as a distributed collaborative paradigm that avoids sharing raw data, holds great promise in the IoT domain. Nevertheless, it remains vulnerable to gradient leakage threats. While traditional differential privacy (DP) techniques mitigate privacy risks, they often come at the cost of significantly reduced model performance—a limitation particularly pronounced in resource-constrained IoT environments characterised by non-independent and identically distributed (non-IID) data distribution. To bridge the gap between privacy preservation and high performance on heterogeneous data, this paper proposes a novel personalized federated learning (PFL) method, FedGLP-ADP. This method leverages historical gradient information to provide a more detailed partitioning of parameters, aiming to prevent personalized knowledge from being affected by noise as much as possible, thereby reducing model degradation. Building on this, we propose an adaptive DP mechanism that optimizes both the clipping and noising steps to minimize the impact of noise on global knowledge. Experimental results show that FedGLP-ADP exhibits superior performance compared to other representative methods under different privacy levels and non-IID degrees.Keywords
With the rapid advancement of information technology, the Internet of Things (IoT) has become an essential component of digital infrastructure, connecting billions of distributed devices. This evolution marks a significant transformation: edge devices are no longer mere data collectors but intelligent units equipped with local processing and collaborative capabilities. These devices continuously generate vast amounts of data at the network edge, powering various applications in industries, cities, healthcare, maritime sectors, and beyond. However, under traditional centralized machine learning frameworks, data aggregation faces significant practical challenges. The raw data collected by distributed IoT nodes often involves users’ sensitive information, making the sharing of such data increasingly difficult due to the dual constraints of strict privacy regulations and intense commercial competition. This has led to the “data silo” problem, which greatly hinders the collaborative development of distributed intelligence. To break these silos, Federated Learning (FL) [1] has emerged. As a novel distributed paradigm, FL allows IoT participants to retain their data locally and only share model parameters or gradients with a central server. However, research has shown that the model parameters or gradients shared by clients may still leak information about their private training data [2,3].
In recent years, researchers have proposed various methods to enhance privacy protection in FL, including homomorphic encryption (HE) [4], secure multiparty computation (SMC) [5], and differential privacy (DP) [6]. Compared with HE, which has high computational complexity in encryption and decryption, and SMC, which requires complex protocols and frequent communication, DP only needs to perturb the original data by adding a small amount of noise to provide substantial privacy protection, making it more suitable for resource-constrained scenarios such as the IoT. FL based on DP obscures individual client contributions through random noise perturbation, but this often comes at the cost of model performance. In addition, in heterogeneous IoT environments, data across different nodes exhibits non-independent and identically distributed (non-IID) characteristics. In such cases, the significantly divergent gradient values among clients are more sensitive to noise, leading to a sharp decline in both model accuracy and convergence speed.
To address these challenges, this paper proposes a novel personalized federated learning (PFL) method, FedGLP-ADP. We propose a gradient-based layer-wise personalization (GLP) strategy. GLP regards parameters that undergo significant changes before and after local training as personalized ones, keeps them locally without adding noise, thereby effectively handling non-IID data and alleviating convergence difficulties caused by noise. Meanwhile, we adopt an adaptive clipping-and-noising DP (ACNDP) mechanism. ACNDP dynamically allocates layer-wise clipping thresholds based on the variation trend of shared gradients and adaptively adjusts the noise scale according to the degree of personalization, accelerating model convergence while preserving privacy. We summarize our contributions as follows:
• We propose a parameter-granularity personalized strategy, which achieves layer-wise personalized partitioning based on the parameter variation during local training. It quantifies the contribution of clients to the global model and implements weighted aggregation, thereby enhancing robustness to heterogeneous data and noise.
• We design an adaptive DP mechanism that optimizes both the clipping and noising steps, improving model performance under privacy protection.
• We conduct extensive experiments on three datasets, and the results validate the effectiveness of our proposed method.
FL based on DP obscures individual client contributions through random noise perturbation, but this often comes at the cost of model performance. To minimize the impact of DP on model performance, researchers have proposed various methods. AE-DPFL [7] uses a voting-based mechanism to avoid dimension dependency issues, thereby ensuring secure aggregation and significantly reducing communication costs. Fed-SMP [8] sparsifies model gradients before adding Gaussian noise, mitigating the impact of privacy protection on model accuracy. Beyond local update sparsification (LUS), BLUR+LUS [9] further constrains the norm of local updates via bounded local update regularization (BLUR) to reduce the amount of noise added, thus improving model convergence. FedDPA [10] applies different levels of constraint to different parameters, minimizing the negative effects of clipping. Although effective, these methods apply a uniform clipping threshold, overlooking significant variation in parameter/update magnitudes across layers in FL. This often leads to improper clipping and noising, harming convergence and performance. Moreover, as parameter updates shrink during training, the relative impact of added noise increases [11], making convergence difficult in later stages, especially under a small privacy budget.
2.2 Personalized Federated Learning
In real-world non-IID scenarios, the local objectives of clients deviate from the global objective, leading to an increasing gradient discrepancy. This makes the model more sensitive to noise and ultimately makes it challenging for the global model to achieve usable accuracy. PFL aims to address the issue of data heterogeneity by enabling clients to adapt to their local data distributions [12]. Current PFL methods mainly adopt parameter decoupling to divide the model into two components: a feature extractor (the backbone) and a classifier (the head). FedPer [13], FedBABU [14], FedRep [15], FedPAC [16], FedAS [17], PPFed [18], and FedMPS [19] treat the head as the personalized part and the backbone as the shared part, so that different clients facing heterogeneous data share the same feature extraction process while applying their own classification strategies. In contrast, methods like LG-FedAvg [20], FedClassAvg [21], and FedSSA [22] regard the backbone as the personalized part and the head as the shared part, they share a consistent classification strategy but employ client-specific feature extractors locally. Nevertheless, recent studies [23] have shown that even within the same layer, parameters can differ significantly in their importance for prediction. The above methods rely on preselecting personalized partitions, which lack flexibility in adapting to diverse data characteristics and thus limit the potential of parameter decoupling.
To address these issues, we propose a novel PFL method with adaptive DP. Our method dynamically selects personalized parameters based on the variation of parameter change before and after local training on the client side. This strategy not only addresses the inflexibility of fixed parameter partitioning, but also avoids potential degradation in generalization performance caused by personalizing too many parameters at once by progressively expanding the personalized portion. To prevent personalized parameters from being affected by noise, we only upload the gradients of the shared portion and allocate different clipping thresholds to each layer of the model based on the gradient variation trend. Furthermore, as the training progresses, the number of gradients in the shared portion decreases, and the scale of the added noise is reduced, thereby facilitating model convergence.
3.1 Federated Learning and Personalized Federated Learning
In the training process of the standard FL framework, there exist multiple clients and one central server. When the number of clients is N, the set
where
In standard FL, all clients share a global model with parameter
In practical applications, the data distributions of clients in FL may differ, a phenomenon known as data heterogeneity. In such circumstances, merely minimizing the average local loss with no personalization will result in poor performance. In contrast, in PFL,
PFL can achieve this goal through a two-step iteration:
• Local Update: During the local update phase, each client
• Global Aggregation: In the aggregation phase, all clients send their local updates
3.2 User-Level Differential Privacy
DP, as a lightweight privacy-preserving approach, can achieve strong privacy protection by simply adding a small amount of random noise to the data. It is formally defined as follows:
Definition 1 Differential Privacy: A randomized algorithm M satisfies
where
This definition implies that adjacent datasets cannot be distinguished merely by observing the output of M, thereby protecting individual records in the dataset from being identified. The most commonly used method to achieve
Definition 2 L2 Sensitivity: Let
In this paper, we adopt user-level DP, which is a stronger privacy requirement suitable for IoT environments. We define the adjacency of datasets at the user granularity.
Definition 3 User-Level Adjacency: Let
DP-FedAvg [24] achieved user-level DP in FL for the first time by applying the Gaussian mechanism, protecting the participation of individual clients from being identified. To guarantee user-level DP, DP-FedAvg constrains the norm of each client’s local model update
where C denotes the clipping bound, which controls the maximum contribution of a single client to the global update, and
The proposed FL scheme is illustrated in Fig. 1. In general, each client receives the global model and combines its local personalized parameters with the global parameters using the binary mask of the current round to obtain the initialized model. Then, the client trains the model on its local data to generate updated gradients, and segregates the shared gradients. Before uploading the shared gradients to the central server, each client perturbs the shared gradients according to the clipping threshold weights and the binary mask. Subsequently, the binary mask for the next round is computed using the perturbed shared gradients, and the clipping threshold weights are updated based on the gradient variation trend. Finally, the central server receives the perturbed shared gradients and masks from all clients, and aggregates the gradients via weighted aggregation based on their masks, thereby obtaining the updated global model.
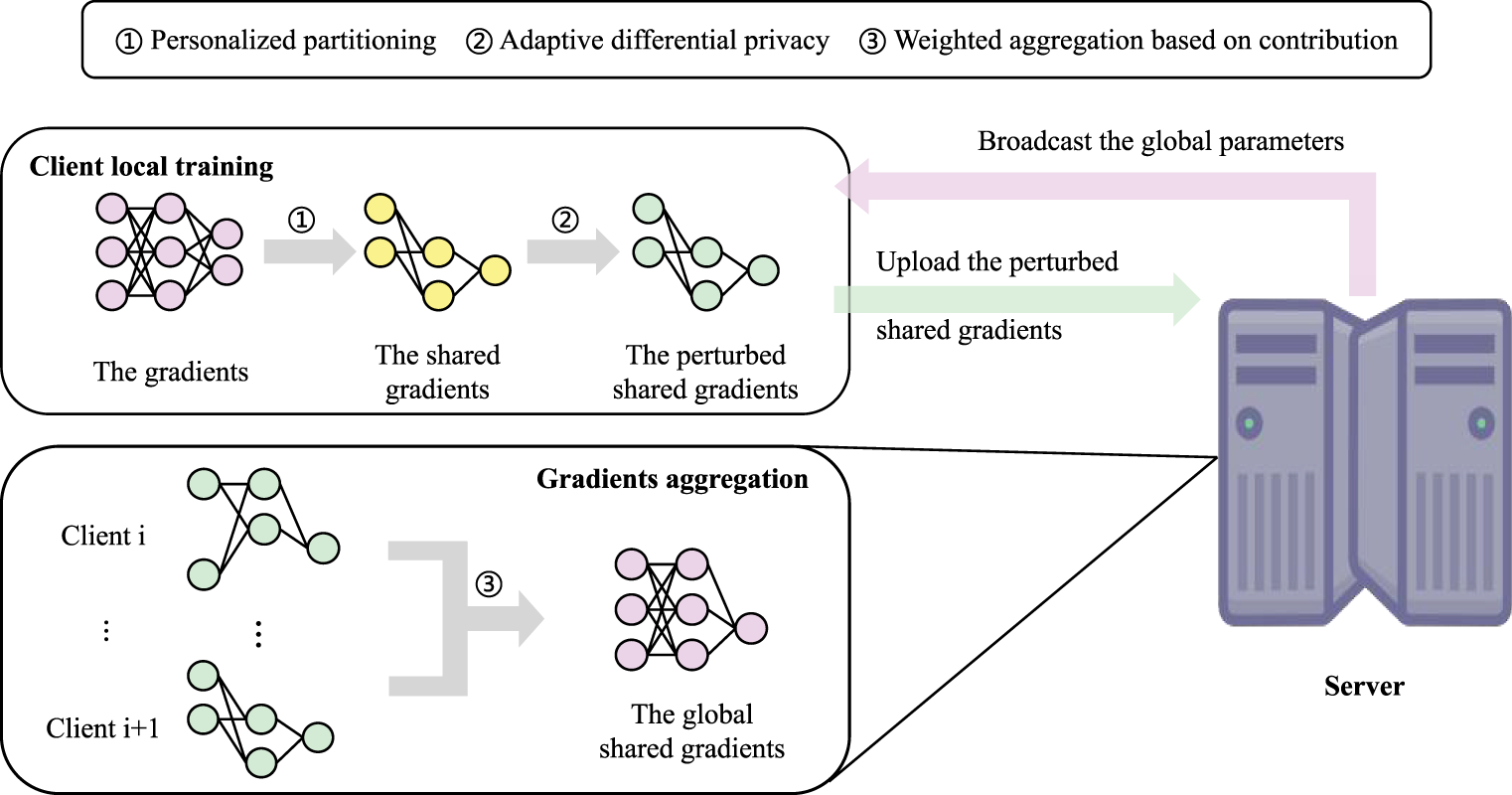
Figure 1: Overall architecture of the FedGLP-ADP algorithm.
4.1 Gradient-Based Layer-Wise Personalization
In previous works on PFL, specific layers of the model are usually preselected as the personalized part to adapt to the local data distribution. However, such an inflexible partitioning limits the potential of parameter decoupling and fails to account for the varying importance of parameters within the same layer. Our intuition is that if a subset of parameters in the client model exhibits greater changes during local training compared to others, it indicates that these parameters are more likely to capture personalized features fitting the unique local data distribution, and thus should be designated as personalized parameters. Conversely, the remaining parameters, which capture more generic and generalizable features, should be treated as shared parameters for global aggregation. Thus we propose a GLP strategy, achieving personalized partitioning via simple traversal with nearly negligible computation cost. Specifically, after local training, parameters with smallest variations are global knowledge contributors (their gradients uploaded as shared ones to the server for aggregation), while those with largest variations are retained locally to learn personalized knowledge. However, to prevent the mask from revealing the most active features in the local dataset, we postpone the computation of the mask until after the perturbation of the shared gradients. At this stage, the generation of the mask can be interpreted as a utility-based randomized selection process: under the guarantee of DP, parameters with larger gradients are assigned a higher probability of being selected. In the following, we provide a detailed description of this module.
In communication round
where
In other words, the mask
Subsequently, the process enters the local update phase, during which, with reference to [10], the two sets of parameters are updated using two different loss functions, respectively.
where
After the local update, the perturbed gradients are denoted as
Moreover, we argue the personalization threshold
where
Client
4.2 Adaptive Clipping-and-Noising Differential Privacy
In client models, the update norms across different layers may vary significantly, making a uniform clipping threshold no longer an appropriate solution. A uniform threshold leads to insufficient clipping for layers with small update norms, introducing disproportionately large noise relative to their scale, while layers with large update norms suffer from excessive clipping, resulting in the loss of important information. Ultimately, this imbalance prevents the system from converging stably and degrades overall model performance. Furthermore, as parameter changes become smaller during training, the impact of added noise grows [11]. To overcome these challenges, we design an ACNDP mechanism, which assigns an appropriate clipping threshold and noise scale to each layer’s gradient, thereby improving the utility of the model.
In communication round
where the clipping threshold
When computing the noise to be added to the shared gradients for layer
where
The next round’s clipping threshold weights

The pseudocode of FedGLP-ADP is outlined in Algorithm 2.

In this subsection, we will prove that the proposed method satisfies the
Lemma 1 (Gaussian Mechanism of Rényi Differential Privacy (RDP)): Let
Lemma 2 (Sequential Composition of RDP): Let
Lemma 3 (Parallel Composition of RDP): Let a dataset D be partitioned into disjoint subsets
Lemma 4 (From RDP to DP): If a mechanism
Lemma 5 (Post-Processing): If a algorithm
Theorem 1 (Privacy Guarantee of FedGLP-ADP): The proposed algorithm satisfies
Proof of Theorem 1: In FedGLP-ADP, the mask
At round
According to Lemma 2, the RDP loss for client
Due to the additivity of Gaussian noise, the total noise is
Therefore, according to Lemma 4, our proposed method overall satisfies
We employ the RDP algorithm provided by Opacus as the privacy accountant to compute the optimal noise multiplier
In this section, we compare FedGLP-ADP with different methods of FL with DP. We use various datasets and learning settings to demonstrate the superiority of FedGLP-ADP.
Datasets and Models. To evaluate the performance of FedGLP-ADP in diverse IoT visual perception scenarios, we conduct experiments on three representative datasets: Fashion-MNIST [26], SVHN [27], and CIFAR-10 [28]. These datasets simulate various data types captured by distributed edge sensors:
• Fashion-MNIST: Fashion-MNIST represents grayscale sensor data in smart retail or logistics inventory systems, containing
• SVHN: SVHN mimics smart city surveillance tasks such as automated street address recognition, consisting of color images of house numbers (
• CIFAR-10: CIFAR-10 serves as a proxy for general-purpose object recognition at the network edge, covering
To align with the limited computational resources and memory capacity of typical IoT devices, we adopt lightweight Convolutional Neural Network (CNN) architectures: Fashion-MNIST and SVHN both use networks with two convolution layers followed by two fully connected layers, while CIFAR-10 uses a CNN with three convolution layers and three fully connected layers, as well as ResNet-18.
Comparison Methods. Our goal is to improve the performance of DP-FedAvg [24], so we select it as the baseline. In addition, we compare our method with three state-of-the-art methods of FL with DP. There is a brief description of these methods as follows:
• DP-FedAvg [24]: It is the first method to implement user-level DP in FL by applying the Gaussian mechanism, and provides a baseline level of model performance under privacy protection.
• BLUR+LUS [9]: This algorithm improves model quality without sacrificing privacy by combining bounded local update regularization and local update sparsification.
• FedDPA [10]: FedDPA achieves flexible personalization via dynamic fisher personalization and adaptive constraints, mitigating slow convergence caused by clipping operations and improving both performance and clipping resilience.
• FedADDP [29]: FedADDP proposes a PFL algorithm with adaptive dimensional DP, which reduces the accuracy loss of personalized models caused by DP.
Evaluation Metrics. We use average accuracy as the performance metric for the models. Specifically, each client trains a local model on its own dataset, and the accuracy of each client’s model is computed individually. The average of these accuracies serves as the final evaluation metric. To thoroughly validate the effectiveness of our method, we designed corresponding evaluation schemes for different datasets. For Fashion-MNIST and SVHN, we measure average accuracy under varying privacy budgets to demonstrate our method’s advantages in noise resilience. For CIFAR-10, we evaluate average accuracy under different degrees of non-IID data distributions, highlighting the strengths of our personalized algorithm in handling heterogeneous data.
Implementation Details. For a fair comparison, all methods adopt the same network architecture and hyperparameter settings. We set the number of clients to
For FedGLP-ADP, the initial personalization threshold
Results under Different Privacy Budgets. We evaluate the performance of each method on the Fashion-MNIST and SVHN datasets under various privacy budgets, and the results are summarized in Table 1. The experimental results show that FedGLP-ADP achieves higher accuracy than other methods under all privacy budgets. Particularly in high-noise environments, the accuracy of FedGLP-ADP still outperforms the best method by
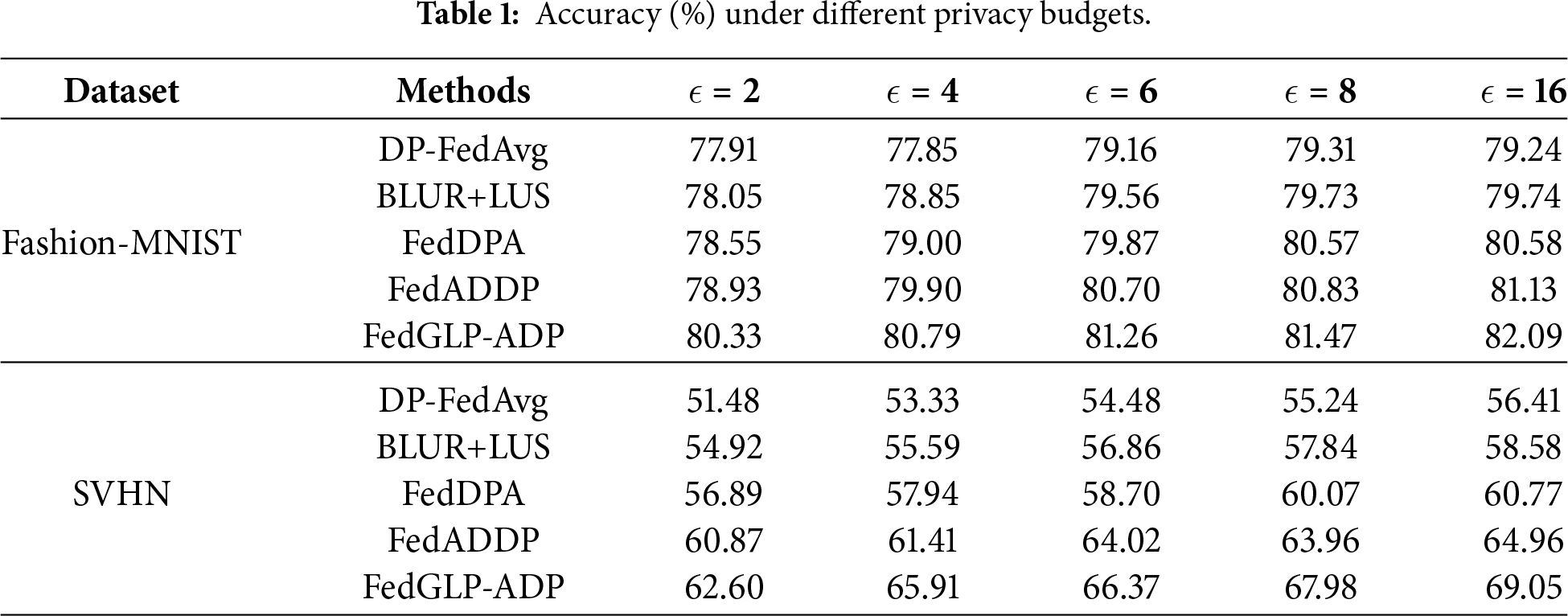
Figure 2: Comparison of model accuracy and loss variation.
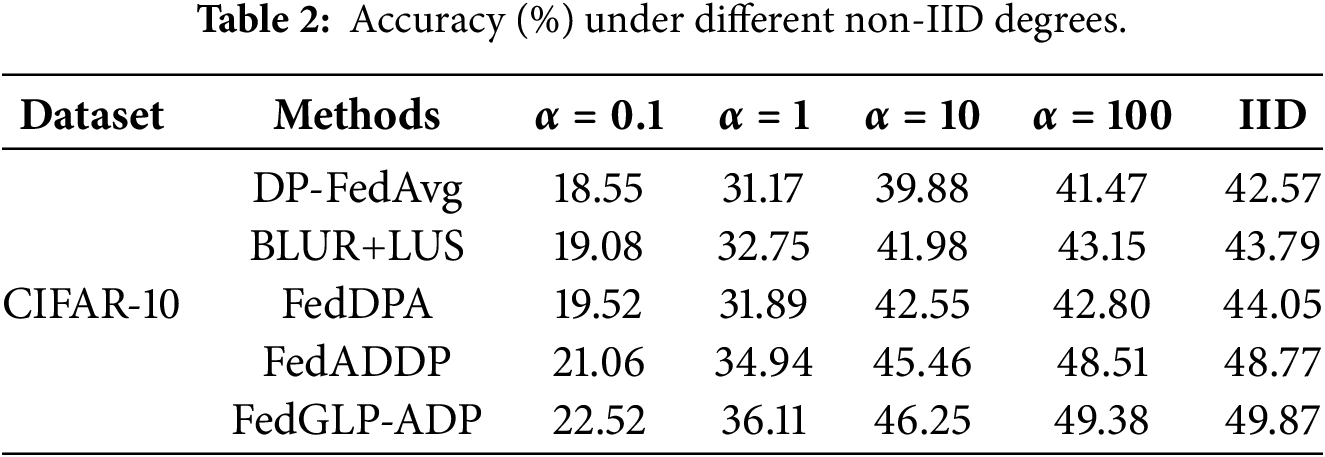
Results under Different Non-IID Degrees. We evaluate the performance of each method under different non-IID degrees, with results in Table 2. The results indicate that FedGLP-ADP achieves the highest accuracy under all non-IID degrees, demonstrating that it enhances the robustness agaist non-IID data.
To further investigate the robustness of FedGLP-ADP under complex architectures, we conduct supplementary experiments using the ResNet-18 model on the CIFAR-10 dataset (
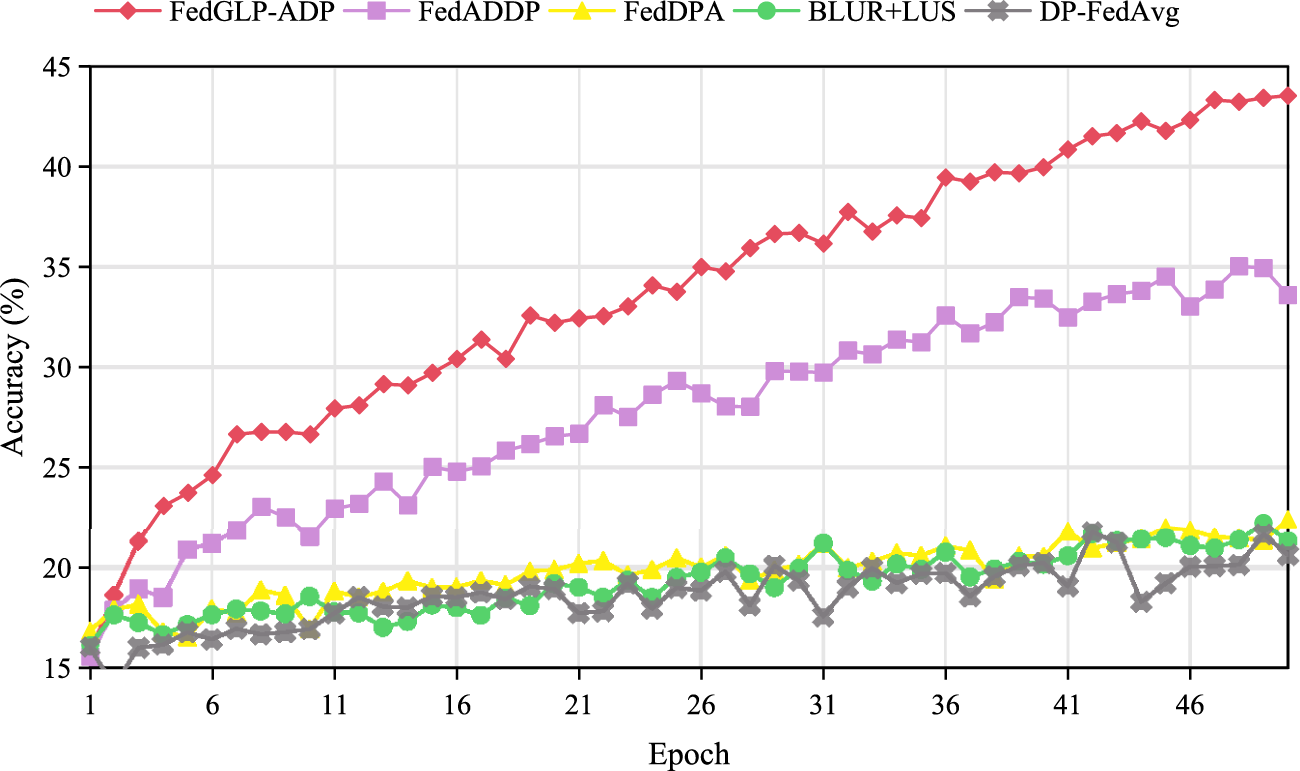
Figure 3: Performance comparison on CIFAR-10 dataset (
Study on the Personalization Threshold. We compare the model accuracy when the personalization threshold
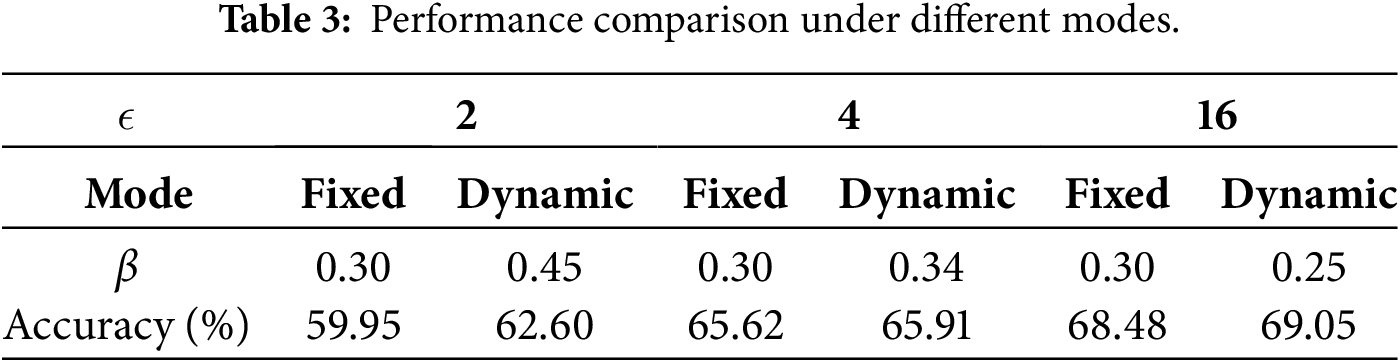
Study on the Log-Odds Update Step Size. We investigate the impact of the log-odds update step size

Ablation Experiments. To investigate the contribution of each component in FedGLP-ADP to the overall performance, we conduct a series of ablation experiments on the SVHN dataset (
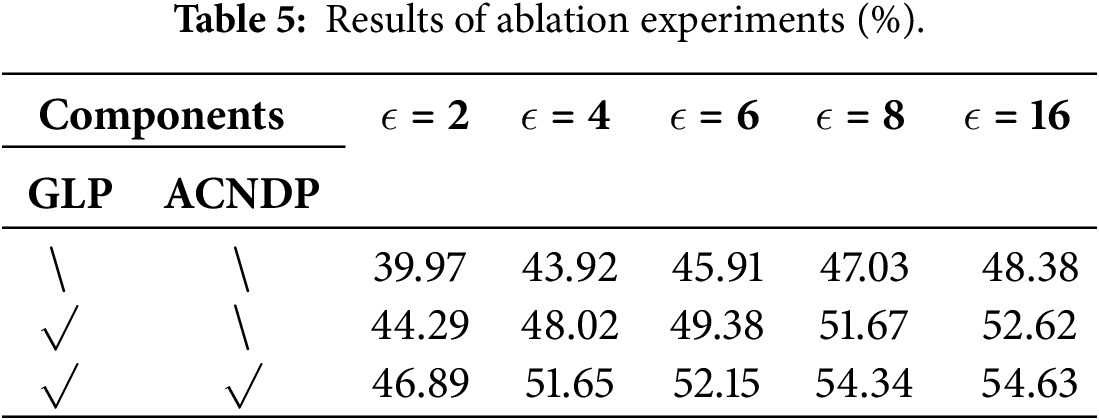
Gradient-Based Layer-Wise Personalization (GLP). Compared with DP-FedAvg (first row in the table), DP-FedAvg+GLP (second row) achieves significant improvements in model performance under all privacy budgets, demonstrating the effectiveness of GLP in enhancing model accuracy under privacy protection.
Adaptive Clipping and Noising Differential Privacy (ACNDP). ACNDP is inherently and closely coupled with the GLP strategy. Specifically, the adaptive logic of ACNDP—both the allocation of clipping thresholds based on shared gradients and the noise injection scaled by the current degree of personalization—is specifically designed in response to the evolving personalization boundary established by GLP. Therefore, we did not report results for DP-FedAvg+ACNDP alone. Instead, ACNDP was applied on top of GLP, forming the complete FedGLP-ADP method (third row in the table). The results show that the addition of ACNDP further improves model accuracy, confirming that the synergy between ACNDP and GLP can significantly enhance the overall performance of the method.
Analysis of Communication Overhead. Unlike standard FL approaches (such as DP-FedAvg), which require uploading the full model parameters in each round, FedGLP-ADP reduces uplink communication overhead through its progressive personalization strategy. Let M be the total number of model parameters. In round
As the training progresses, the communication overhead decreases linearly. By the final round T, the per-round communication volume is reduced to (
The total communication cost over T rounds is
Study on Computational Overhead. To evaluate the computational overhead of FedGLP-ADP, we measure the average wall-clock time required per local training round for different methods and model architectures on the CIFAR-10 dataset. The result in Table 6 shows a significant efficiency gap between FedGLP-ADP and other state-of-the-art methods. While other advanced methods incur substantial computational overhead (ranging from 4.22

This paper proposes a novel FL method, FedGLP-ADP, which consists of two core components: gradient-based layer-wise personalization (GLP) and adaptive clipping-and-noising DP (ACNDP). GLP leverages the variation of model parameters before and after local training to perform personalized partitioning of the model, while ACNDP implements adaptive allocation of clipping thresholds and determines the magnitude of added noise based on the personalization degree achieved by GLP. This design overcomes the limitations of coarse-grained parameter decoupling and the convergence challenges faced by traditional DP. Experimental results demonstrate that FedGLP-ADP consistently outperforms existing methods under various privacy budgets and different degrees of non-IID data distributions.
Acknowledgement: None.
Funding Statement: The work was supported by the Chongqing Research Program of Basic Research and Frontier Technology (Chongqing Talent) (Grant No. cstc2024ycjh-bgzxm0048).
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Di Xiao; methodology, Wenting Jiang and Min Li; software, Wenting Jiang and Min Li; validation, Di Xiao and Wenting Jiang; writing—original draft preparation, Wenting Jiang; writing—review and editing, Di Xiao; visualization, Wenting Jiang and Min Li; supervision, Wenting Jiang; project administration, Di Xiao. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The datasets used in this paper are respectively in references [26–28].
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. McMahan B, Moore E, Ramage D, Hampson S, Arcas BA. Communication-efficient learning of deep networks from decentralized data. In: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS); 2017 Apr 20–22; Fort Lauderdale, FL, USA. Westminster, UK: PMLR; 2017. Vol. 54, p. 1273–82. [Google Scholar]
2. Fredrikson M, Jha S, Ristenpart T. Model inversion attacks that exploit confidence information and basic countermeasures. In: Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security; 2015 Oct 12–16; Denver, CO, USA. New York, NY, USA: ACM; 2015. p. 1322–33. doi:10.1145/2810103.2813677. [Google Scholar] [CrossRef]
3. Geiping J, Bauermeister H, Dröge H, Moeller M. Inverting gradients-how easy is it to break privacy in federated learning? In: Advances in Neural Information Processing Systems; 2020 Dec 6–12; Virtual Event. Vol. 33, p. 16937–47. [Google Scholar]
4. Xie Q, Jiang S, Jiang L, Huang Y, Zhao Z, Khan S, et al. Efficiency optimization techniques in privacy-preserving federated learning with homomorphic encryption: a brief survey. IEEE Internet Things J. 2024;11(14):24569–80. doi:10.1109/JIOT.2024.3382875. [Google Scholar] [CrossRef]
5. Mohassel P, Zhang Y. Secureml: a system for scalable privacy-preserving machine learning. In: Proceedings of the 38th IEEE Symposium on Security and Privacy (SP); 2017 May 22–26; San Jose, CA, USA. p. 19–38. doi:10.1109/SP.2017.12. [Google Scholar] [CrossRef]
6. Dwork C, Roth A. The algorithmic foundations of differential privacy. Found Trends® Theor Comput Sci. 2014;9(3–4):211–407. doi:10.1561/0400000042. [Google Scholar] [CrossRef]
7. Zhu Y, Yu X, Tsai YH, Pittaluga F, Faraki M, Wang YX, et al. Voting-based approaches for differentially private federated learning. arXiv:2010.04851. 2020. [Google Scholar]
8. Hu R, Guo Y, Gong Y. Federated learning with sparsified model perturbation: improving accuracy under client-level differential privacy. IEEE Trans Mobile Comput. 2023;23(8):8242–55. doi:10.1109/TMC.2023.3343288. [Google Scholar] [CrossRef]
9. Cheng A, Wang P, Zhang XS, Cheng J. Differentially private federated learning with local regularization and sparsification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 21–24; New Orleans, LA, USA. p. 10122–31. doi:10.1109/CVPR52688.2022.00988. [Google Scholar] [CrossRef]
10. Yang X, Huang W, Ye M. Dynamic personalized federated learning with adaptive differential privacy. In: Advances in Neural Information Processing Systems; 2023 Dec 10–16; New Orleans, LA, USA. Vol. 36, p. 72181–92. doi:10.52202/075280-3160. [Google Scholar] [CrossRef]
11. Jiao S, Cai L, Wang X, Cheng K, Gao X. A differential privacy federated learning scheme based on adaptive gaussian noise. Comp Model Eng Sci. 2024;140(2):1679–94. doi:10.32604/cmes.2023.030512. [Google Scholar] [CrossRef]
12. Tan AZ, Yu H, Cui L, Yang Q. Towards personalized federated learning. IEEE Trans Neural Netw Learn Syst. 2022;34(12):9587–603. doi:10.1109/TNNLS.2022.3160699. [Google Scholar] [PubMed] [CrossRef]
13. Arivazhagan MG, Aggarwal V, Singh AK, Choudhary S. Federated learning with personalization layers. arXiv:1912.00818. 2019. [Google Scholar]
14. Oh J, Kim S, Yun SY. Fedbabu: towards enhanced representation for federated image classification. In: Proceedings of the 9th International Conference on Learning Representations (ICLR); 2021 May 3–7; Virtual Event. [Google Scholar]
15. Collins L, Hassani H, Mokhtari A, Shakkottai S. Exploiting shared representations for personalized federated learning. In: Proceedings of the 38th International Conference on Machine Learning (ICML); 2021 Jul 18–24; Virtual Event. Westminster, UK: PMLR. Vol. 139, p. 2089–99. [Google Scholar]
16. Xu J, Tong X, Huang SL. Personalized federated learning with feature alignment and classifier collaboration. In: Proceedings of the 11th International Conference on Learning Representations (ICLR); 2023 May 1–5; Kigali, Rwanda. [Google Scholar]
17. Yang X, Huang W, Ye M. Fedas: bridging inconsistency in personalized federated learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024 Jun 17–21; Seattle, WA, USA. p. 11986–95. [Google Scholar]
18. Zhang G, Liu B, Zhu T, Ding M, Zhou W. PPFed: a privacy-preserving and personalized federated learning framework. IEEE Internet Things J. 2024;11(11):19380–93. doi:10.1109/JIOT.2024.3360153. [Google Scholar] [CrossRef]
19. Wang D, Gao Y, Pang S, Zhang C, Zhang X, Li M. FedMPS: a robust differential privacy federated learning based on local model partition and sparsification for heterogeneous IIoT data. IEEE Internet Things J. 2025;12(10):13757–68. doi:10.1109/JIOT.2025.3536035. [Google Scholar] [CrossRef]
20. Liang PP, Liu T, Liu Z, Allen NB, Auerbach RP, Brent D, et al. Think locally, act globally: federated learning with local and global representations. arXiv:2001.01523. 2020. [Google Scholar]
21. Jang J, Ha H, Jung D, Yoon S. Fedclassavg: local representation learning for personalized federated learning on heterogeneous neural networks. In: Proceedings of the 51st International Conference on Parallel Processing (ICPP); 2022 Aug 29–Sep 1; Bordeaux, France. p. 1–10. doi:10.1145/3545008.3545073. [Google Scholar] [CrossRef]
22. Yi L, Yu H, Shi Z, Wang G, Liu X, Cui L, et al. FedSSA: semantic similarity-based aggregation for efficient model-heterogeneous personalized federated learning. arXiv:2312.09006. 2023. [Google Scholar]
23. Renda A, Frankle J, Carbin M. Comparing rewinding and fine-tuning in neural network pruning. In: Proceedings of the 8th International Conference on Learning Representations (ICLR); 2020 Apr 26–30; Addis Ababa, Ethiopia (Virtual Event). [Google Scholar]
24. McMahan HB, Ramage D, Talwar K, Zhang L. Learning differentially private recurrent language models. In: Proceedings of the 6th International Conference on Learning Representations (ICLR); 2018 Apr 30–May 3; Vancouver, BC, Canada. [Google Scholar]
25. Mironov I. Rényi differential privacy. In: 2017 IEEE 30th Computer Security Foundations Symposium (CSF); 2017 Aug 21–25; Santa Barbara, CA, USA. p. 263–75. doi:10.1109/CSF.2017.11. [Google Scholar] [CrossRef]
26. Xiao H, Rasul K, Vollgraf R. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv:1708.07747. 2017. [Google Scholar]
27. Netzer Y, Wang T, Coates A, Bissacco A, Wu B, Ng AY, et al. Reading digits in natural images with unsupervised feature learning. In: NIPS 2011 Workshop on Deep Learning and Unsupervised Feature Learning; 2011 Dec 12–17; Granada, Spain. [Google Scholar]
28. Krizhevsky A. Learning multiple layers of features from tiny images [master’s thesis]. Toronto, ON, Canada: University of Toronto; 2009. [Google Scholar]
29. Guo Y, Zhang T, Mu X, Li H, Dong X, Li Q. FedADDP: privacy-preserving personalized federated learning with adaptive dimensional differential privacy. In: Proceedings of the 24th International Conference on Algorithms and Architectures for Parallel Processing (ICA3PP); 2024 Oct 25–27; Guilin, China. p. 22–40. doi:10.1007/978-981-96-1548-3_3. [Google Scholar] [CrossRef]
30. Hsu TMH, Qi H, Brown M. Measuring the effects of non-identical data distribution for federated visual classification. arXiv:1909.06335. 2019. [Google Scholar]
31. Zhu Z, Hong J, Zhou J. Data-free knowledge distillation for heterogeneous federated learning. In: Proceedings of the 38th International Conference on Machine Learning (ICML); 2021 Jul 18–24; Virtual Event. Westminster, UK: PMLR. Vol. 139, p. 12878–89. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools