
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Robust Automated Framework for Classification of CT Covid-19 Images Using MSI-ResNet
1 Department of Computer Science and Business Systems, Sethu Institute of Technology, Kariapatti, Virudhunagar, 626115, Tamilnadu, India
2 Department of Computer Science, College of Computer Engineering and Sciences, Prince Sattam Bin Abdulaziz University, Alkharj, 11942, Saudi Arabia
3 Department of Computer Science and Engineering, School of Engineering, Kathmandu University, Banepa, Kathmandu, Nepal
4 Department of CSE, University College of Engineering, Panruti, Tamilnadu, India
5 Department of Information Technology, College of Computers and Information Technology, Taif University, Taif, 21944, Saudi Arabia
6 Department of Computer Science, College of Computers and Information Technology, Taif University, Taif, 21944, Saudi Arabia
* Corresponding Author: Sultan Ahmad. Email:
Computer Systems Science and Engineering 2023, 45(3), 3215-3229. https://doi.org/10.32604/csse.2023.025705
Received 02 December 2021; Accepted 04 July 2022; Issue published 21 December 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Nowadays, the COVID-19 virus disease is spreading rampantly. There are some testing tools and kits available for diagnosing the virus, but it is in a limited count. To diagnose the presence of disease from radiological images, automated COVID-19 diagnosis techniques are needed. The enhancement of AI (Artificial Intelligence) has been focused in previous research, which uses X-ray images for detecting COVID-19. The most common symptoms of COVID-19 are fever, dry cough and sore throat. These symptoms may lead to an increase in the rigorous type of pneumonia with a severe barrier. Since medical imaging is not suggested recently in Canada for critical COVID-19 diagnosis, computer-aided systems are implemented for the early identification of COVID-19, which aids in noticing the disease progression and thus decreases the death rate. Here, a deep learning-based automated method for the extraction of features and classification is enhanced for the detection of COVID-19 from the images of computer tomography (CT). The suggested method functions on the basis of three main processes: data preprocessing, the extraction of features and classification. This approach integrates the union of deep features with the help of Inception 14 and VGG-16 models. At last, a classifier of Multi-scale Improved ResNet (MSI-ResNet) is developed to detect and classify the CT images into unique labels of class. With the support of available open-source COVID-CT datasets that consists of 760 CT pictures, the investigational validation of the suggested method is estimated. The experimental results reveal that the proposed approach offers greater performance with high specificity, accuracy and sensitivity.Keywords
Recently, the Corona virus pandemic, which is widely known as COVID-19 has threatened the people globally. It is an extremely harmful disease instigated by a virus that comes under the Beta coronavirus, named Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2). Earlier, it was called as 2019 new coronavirus (2019-nCoV), which transmitted from animals to humans in Wuhan province, China, in November and December 2019. Currently, for COVID-19, medicines and vaccines are not available, thereby leading to a huge worldwide death rate to the toll of 244 K. The coronavirus affects the respiratory system and lungs of humans, resulting in Pneumonia and many lungs associated illnesses. Mostly reddened fluid is filled inside the lungs and arranged patches called Ground-Glass Opacity (GGO).
Available medical facilities and services are not enough to find and diagnose the symptoms of infections recently. It is vital to enhance some more medical amenities. Although, several developers have made varied efforts in actual analysis, regular hand washing, mask wearing, self-quarantined and social distancing are mentioned as good suppositories to avoid COVID-19. Several other nations also follow the above mentioned precautions. Consequently, the biggest shortcoming of self-quarantine and lockdown is that they extremely influence the country’s GDP (Gross Domestic Product) and several people are psychologically affected. The extremely and adversely affected countries like Spain, USA and Italy have crossed the mortal rate of China, indicating an extreme death rate across the world.
In Wuhan, China, a novel infectious viral (primary atypical) pneumonia bust out in December 2019. It has been seen as a zoonotic coronavirus, like coronavirus SARS and coronavirus MERS and termed as COVID-19. In the discussed screening methodologies, the accuracy rate of the prediction is very much difficult. There is always a deviation in the lung cells that predicts the specific lung type cancer. So far, the scanning technology of computerized tomography has become the most effective way to treat the disease, as there is much as there would be increasing the rate of the prediction and follows all of the technology guidelines interface. A computerized tomography (CT) scan integrates an X-ray image series that are taken from various angles in the body and employs computer processing for creating cross-sectional (slices) of soft tissues, bones, and blood vessels inside the body. The CT scan image offers more detailed data by comparing normal or plain X-rays. Various modes of CT scans are as follows: CT Scan Arthrography, CT Scan Abdomen, CT Scan Pelvis, CT Angiography, CT Scan Brain/CT Scan Head, CT Scan Bones, CT Scan Chest (CT Scan Lung), CT Scan Neck. This could be done by passing the X-rays through the human body that examines the whole human body [1]. At present, there exists officially no anti-viral treatments or vaccines permitted for the management or prevention of the disease [2,3].
Subsequently, the input images get into the process of removing the noises in the images, acquiring the images and thus selecting desired features such as organs, and lines, equivalent to the procedure for detecting the lung cancer affected cases that were taken from the dataset. After that process, the features are then segmented using region segmentation and feature classification. The generalized ML methods are of two types: supervised and unsupervised learning models. Some machine learning techniques are as follows: naïve Bayes, SVM (support vector machine), random forest, Decision tree, regression model, etc. Some of the reliable classifiers that could be used in the case of the classification process to find the increased prediction rate would be k-NN (k-nearest neighbors), RNN (recurrent neural network) and other most neural net classifiers to detect covid-19 [4,5]. To process the large volume of data, the automatic system that was employed in the traditional techniques thus helps in the successful enhancement of accuracy rate.
The remaining part of this paper is drafted as follows: Section 2 is the detailed survey analysis of various existing techniques employed till date. Section 3 describes a detailed explanation of the proposed work. Section 4 is the narration of the performance analysis of the proposed system. Finally, the conclusion is provided in Section 5.
The author of the work [6] offered a scheme of fusion depiction with the usage of classical and deep machine learning for face mask detection. The anticipated representation encompasses two mechanisms. The first constituent was intended with the use of Resnet50 for feature extraction. While the second component was intended for the face masks classification process utilizing Support Vector Machine (SVM), ensemble, and decision tree techniques.
The author in [7] presented a scheme for predicting a particular tumor that has insufficient gene expressions; this case has trained the DNN (Deep Neural Network), which might lead to a diagnosis of bad cancer performance. Consequently, the work is projected with the data analysis technique by using the multi-task deep learning method, which gives out a way for the insufficiency of data.
In [8] an idea was presented regarding several methodologies for the prediction and diagnosis. This work is considered for the various methodologies analyzed to detect skin, lung, and brain tumors. In view of the cancer detection works, diabetes includes the major cause, which leads to the foremost health concern. However, deep learning methods [9] for the detection of lung cancer were presented by the deep reinforcement methodology. This approach is applied to the medical internet of things world.
In [10], the approach deals with the detection of lung nodules, which is the preliminary step for the detection of cancer. As mentioned in [11], lung cancer detection is carried out by feature extraction and classification by using the minimum redundancy maximum relevance that chooses the most efficient features and k-NN classifier. While in [12], the methods were determined with the attacks on the neural networks that make the adverbial effects on the overall detecting scheme.
In [13], the internet of things technology scheme was used for the modelling and classification through continuous monitoring. This approach is used to categorize the transitional region features from the feature of the lung cancer image. In [14] presented a Deep 2D neural convolution network and suggested convolutional neural network (CNNs). The problems imposed on the 3D data are primarily attributable to varying volume and Graphics processing unit (GPU) optimization exhaustion. The author in [15] presented an electronic noise that is introduced for the prediction of lung cancer. The outcoming data is analyzed with the help of k nearest neighbors for the non-conformity measurement in the offline prediction. Nonetheless, in work [16] a scheme gets accounted for the automated pulmonary detection in the (computer-aided design) CAD scanning. In [17] this includes extensive image analysis, accompanied by the extraction of the function using tensor flow and 3-D CNN in order to further supplement the metadata with the derived features from the image data. In [18] presented the Deep Denoising Auto-Encoder (Deep AMR) end-to-end multi-task model for the multiple classifications of medications and the Deep AMR cluster, a Deep AMR cluster, for the latent data space learning clusters. Study about the Covid-19 virus pandemic was initiated in December 2019 and has been very low. These limited researches are utilized only to detect the COVID-19 virus. In addition, many other analyses were done to find several illnesses in humans. At the same time, the methods and treatments were considered for the virus diagnosis and it has been carried out for the same [19]. The patient recovered from the Coronavirus pandemic, was discharged from the hospital and observed regularly. Covid-19 was examined [20] by dermatologists with the properties of hygienic measures on the skin. In [21] focused on the Covid-19 preventive measures and the effectiveness of novel treatments. In [22] developed a scheme to study and analyze the tool and kit arranged by the doctors in case of emergency to protect against the virus. In [23] the method of automatic segmentation was presented depending on Convolution Neural Networks (CNN) for 3 × 3 kernels exploration. For better classification, the author proposes extracted texture features from every segment using the advantages of histogram and co-occurrence matrix and the hybrid kernel through the fuzzy logic. This method was designed and the Residual Neural Net training was applied for the classification purpose. The seed points are then fed into the region growing algorithm for the segmentation process.
This section deals with the negotiation of comprehensive elucidation of the proposed system. Fig. 1 displays the overall flow of the presented system.
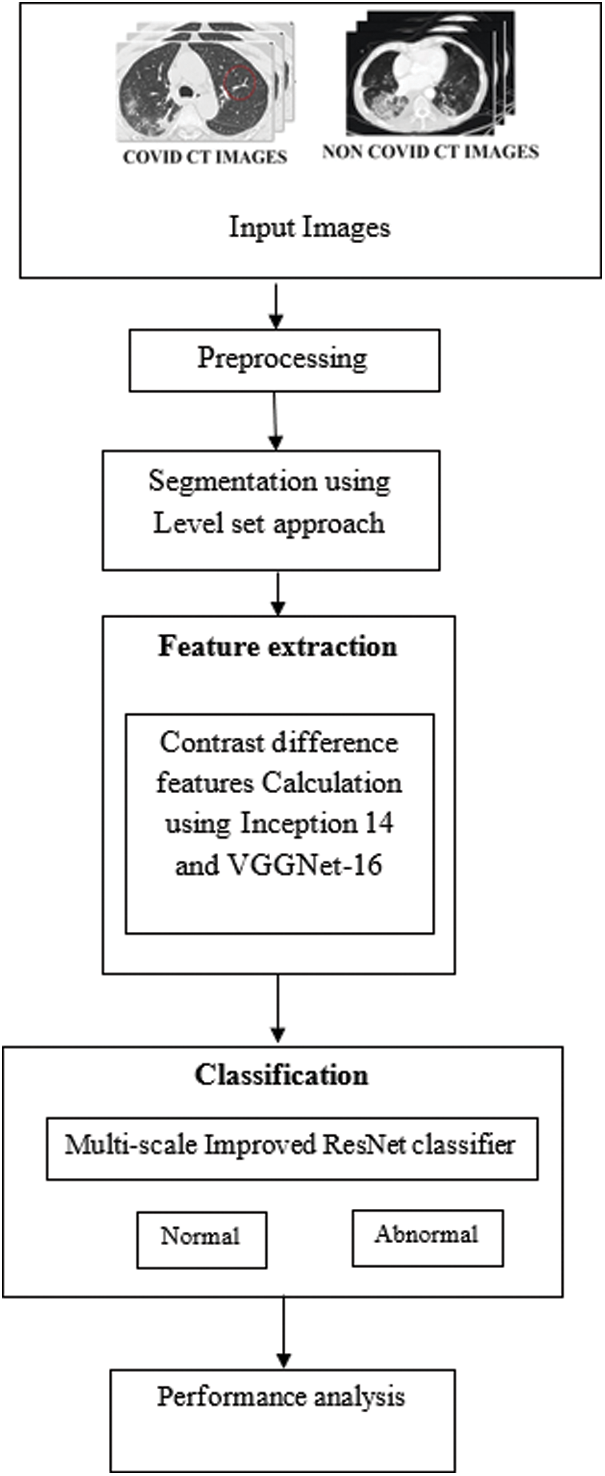
Figure 1: Flow of the proposed system
At first, the input images of covid and non-covid CT images are taken and is followed by preprocessing to denoise the input images. The image de-noising is performed with the use of a filtering scheme. For this, a collaborative non-local means (CNLM) technique is employed, which offers a better result in the uniform regions, but it fails in the region in which the number of equivalent patches is tiny, mostly at edges. This rare patch effect phenomenon can be overwhelmed by encompassing CNLM to commonly equivalent information happening in dissimilar images rather than employing only self-similar information for the estimation of noise-free value enhancements of each image. This offers a new idea of enhanced collaborative CNLM Means filter.
The output of this presented filter at any pixel ‘j’ is given by NL(j) as shown in Eq. (1)
Here, i denotes j and j denotes the set of entire pixels.
The weight w (j, i) standards depend on the equivalent information amongst j and i pixels. For effectual structure-preserving de-noising, it employs a self-similar approach. The CNLM can be expanded, which also occurs in mutually-similar information that are dissimilar abnormal images for maximizing the sample size, thus enhancing the calculation of each noise-free image.
Just in case to target the noisy image and the co- de-noising images to be grouped with indices represented as set S (this sentence is not clear). Let
The output of the CNLM filter of any pixel ‘i’ is represented by C(i) as in Eq. (2). The pre-processed output is then given as input for the segmentation process. Fig. 2 displays masking effect of CT covid 19 images.
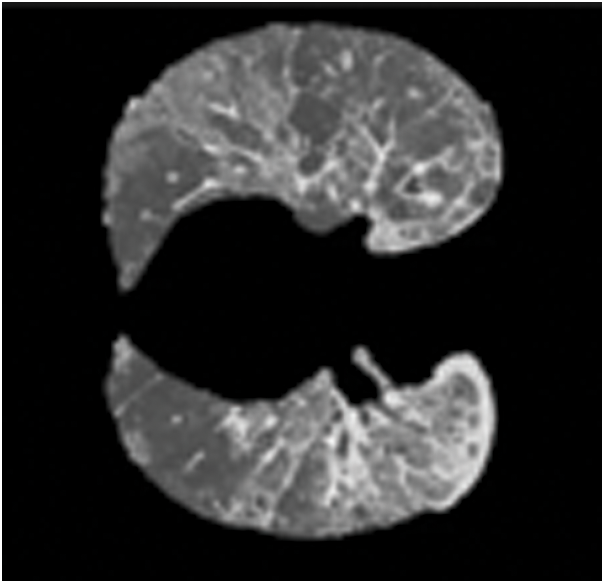
Figure 2: Masking effect of CT covid 19 images
Segmentation is the method of separating an image into many segments. It is typically used to locate objects and boundaries in images. In terms of features, objects and scenes, the high-level image descriptions such as the image which in the order of color image that gets into the low level transforming in the image of grayscale becomes the process of meaningful segmentation. The achievement of image analysis depends on the reliability of segmentation. But an, accurate image partitioning is usually a very interesting issue. After de-noising, the texture-based segmentation is performed on noise-free CT images. Here, four different methods are used to segment the tumor. They are the active contour method, Region growing method, watershed segmentation and a hybrid method combining the region growing method and active contour method. The performance matrices Dice and Jaccard are calculated and the hybrid method performs better than the other three methods. Then, the multiscale level set method of segmentation is used for segmentation. The set of levels basic concept predicts the curves of hyper-surface and zero level range of surface.
It gives many fast and numerical tests. The model of surface smoothing
The shortest distance between the point a on the surface and the curve is denoted as S.
The common function of the level set is provided as in Eq. (4)
where F is the function that depends on the image information.
To enhance the process of segmentation, the internal independent term and external independent term will be declared. The gradient flow that minimizes the power of cumulative function growth is expressed as:
Here P is the controlling parameter. The Dirac delta function is
Here, I is an image, and gj is the Gaussian kernel and standard deviation.
3.3 Feature Extraction Using Inception V4 Models
Inception v4 CNN models include a set of convolutional layers for finding the patterns that occur in the image. The advantage of Inception v4 CNN is that it is useful in implementing and designing a deep network and minimizing the complexity and the duration of the task of training. In addition, Inception v4 CNN comprises various layers such as pooling, activation, fully connected and layers of SoftMax.
The main concept is that in the classification of images, the vertical or horizontal edge findings are achieved by executing a convolution function. A small window is considered a filter and starts to enhance the image. The filter induces Inception v4 CNN to detect the specified patterns in the image. Fig. 3 shows segmented outcome of covid 19 CT images.
• An Inception v4 CNN model is organized into different layers such as Convolutional layers, ReLU layers, Fully connected and Pooling layers. While comparing other classification algorithms, the Inception v4 CNN model has very few pre-processing steps. This Inception v4 CNN model was used in various fields for several different purposes.
Figure 3: Segmented outcome of covid 19 CT image
Convolution
In this, the highlights in the data set must be focused. The convolutional layer is the initial stage of GoogLeNet model. The characteristics are detected, and the function map is created in this process from the input dataset.
ReLU layer
The subsequent step of the convolution surface is the ReLU layer. To increase the nonlinearity in the network, the application method was implemented on the device maps. In this scenario, the negatives can be eliminated.
Pooling
Gradually pooling will alleviate the input size. The phase of pooling will reduce overfitting. This can quickly identify the appropriate variables by minimizing the count of variables needed.
Flattening
It is a rather easy way to flatten the polled characteristics map in the following number line.
Fully Connected Layer
At this stage, all the features are joined with the attributes. The process of classification could be completed with more percent of precision. The error could be calculated and reported.
SoftMax
This SoftMax layer was developed for analyzing several issues in various fields. The decimal chances must mean 1.0. Let us consider the associated variations of SoftMax. The SoftMax that can calculate the similarity for every conceivable class is Full SoftMax. SoftMax estimates a probability for all the names that are positive but only an arbitrary example of negative names.
Lastly, the type of features can be detected and extracted easily using Inception 14 and VGG-16.
Inception 14 Model
The basic idea of the Inception model is that it is utilized in various parts of training in which the repetitive blocks are grouped as different sub-networks that fit to represent an entire model in the space store. Therefore, Inception modules are flexible to change and that denotes the chance of altering the number of filters from special layers. It is preferred that it does not affect the power of the trained network. The development in the speed of the process is achieved by changing the size of the layers appropriately to get a trade-off among varied sub-networks. The recent models of Inception were created without identical segmentation with the help of Tensor Flow. The operation can optimize the memory for backpropagation (BP), which is grasped by triggering the tensors that are important to determine gradient and in the calculation of the limited values. This approach also removes the unnecessary function, which is the same as other modules to the blocks of inception in all sizes of grid.
Residual Blocks of Inception
In this method, the filter expansion layer that is applied to the blocks of Inception is used to develop the size of the filter, before estimating the input depth. It is significant while changing the dimensionality cutback which is enforced by the block of Inception. It comprises different forms of Inception. Due to the presence of several layers, Inception v4 is reasonable. The updation among residual and non-residual is defined as batch-normalization (BN), which is used for the layers of convention. Therefore, in Tensor flow, the method of BN requires more memory.
Residuals Scaling
In this, the residual models represent its unsteadiness and at the initial stage, the network is not continued if the number of filters is more than a thousand. The final terminal layer, which is prior to the layer of pooling, induces to make zeros from varied repetitions. So, it cannot be eliminated by controlling the measures of training. In general, some factors of scaling range from 0.1 to 0.3, which is implied in scaling accumulated layers.
Model of VGG-16
It is one of the best-known CNN techniques with layers of 16 offered by Oxford Visual Geometry Group in 2014. It has been revealed that the best outputs under different applications of image processing. This approach replaces maximum size filters with small-sized filters during the enhancement of system depth. The accuracy of this classification is improved because of the tiny filters of CNN. VGG-16 CNN model used in this method is pretrained on datasets of ImageNet and front layers are a reasonable low-level feature which matches the tasks of image processing.
3.4 Classification Using Multi-scale Improved ResNet Algorithm
In the classification process, the method of Multi-scale Improved ResNet (MSI-ResNet) is utilized for better accuracy. This learning model is offered for robust detection at which both noisy and clean information is classified. The MSI-ResNet technique incorporates various semantic and learned features in a comprehensive and deep network for the detection of decisions. At this time, the classification stage is based on Multi-scale Improved ResNet (MSI-ResNet) and the Conditional Random Fields (CRFs) for segmentation of covid images at different scales and layers, thus trusting the assurance among the balancing information and the neighboring pixels.
The projected MSI-ResNet links several networks for making a multi-cascaded network style. Firstly, the MSI-ResNet Input means has been accomplished in the lung CT image segmentation method. The MSI-ResNet classification aids in enhancing the precise classification over two structures that are cascaded. In the input, one structure cascades off the network beneath and the one that is preserved as the primary network is the output for the accompanying image channel of another network to conduct the training and is termed as simple progression (this sentence is not clear, please check). Prior to the estimation of feature map through simple progression, other network is allocated to assign a cascaded method, which is being nourished to the last layer of classification, thus creating a multi-cascaded MSI-ResNet strategy. By utilizing the soft-max output layer’s neurons that cascade directly with the previous output, the network learning is biased further to envisage the central pixel label that is ought to be similar to its adjacent, consequently leading to the formation of flatter margins. Now, the two multi-cascaded network designs are named: 1. MSI-ResNet 1 and 2. MSI-ResNet 2, consistently.
1. MSI-ResNet 1 exploits the Two-Stage ResNet (TS ResNet) method as a simple progression. In this way, a Two-Path system of higher image areas is favoured to extract features and accomplish a deep Single-Path system to learn the lesser image patch features. Also, an additional single-path network was related to finding the information of edge in the abnormal image, which supports taking information that is related and additional local info.
2. From the basis of the Single Stage ResNet (SS-ResNet) manner, the MSI-ResNet 2 produces the greater image patches as input to an alternative Single-path system for recognizing local features of the CT image, for instance, the details (information) of the image edge. The intended provisional outcome is linked to the previous layer of the output of the final stage. Consistent with the explicit necessities, the cropping patch size is delimited. By concerning this way, it is considered that it not only the dependence labels but also enhances the lung CT image segmentation performance by integrating several cascaded structures and uniting the multi-scale image details.
The single-stage and two-stage combination of ResNet connection is applied to the fusion technique. The fusion technique aids in identifying accurately predicted image classification as lung CT image that are covid affected regions. The performance outcomes demonstrate conquer feasibility depending on the given manner assessed to other models and the complexity in the acquisition of data and computational cost. Furthermore, this model can share the CT images slice by slice in the testing phase. This delivers speedy segmentation through the image patches. Using image patches for segmentation purposes, they are trained by the concern of the three models, which are estimated from three diverse directions. On combining all the diverse directions, the final result is attained.
Consider, total image features as ‘M’ provided to the MSI-ResNet input capitulates the unit of total output as ‘K’ and the hidden layer unit in s is Ms. The jth unit weight in s layer the ith unit in s + 1 is exemplified by Wij. The ith unit activation in layer s is
Here, tp is the training phase instance. The evaluation of the non-input unit’s activation is in accordance with the given equation:
The successive hidden layer’s activation units with a prior modernization equation till a network response is given below:
The training aim gets the set of weights located in the network and the total squared error is shown as:
Depending on the gradient error, the error value(e) gets decreased and the weights vary incrementally in the direction corresponding to weights:
The new weight estimation is given as:
It is the batch learning mode equation at which the new weights of input images are computed after enabling the entire samples for training. One such thing gets throughout all the samples mentioned in an era. Reliant on the first era, weight initialization is typically done to the insignificant random numbers. For enabling the variant incremental learning depiction and to alter the weights after giving the specific samples of training, it is expressed as:
Once the error gets smaller than a settled threshold value, or if an error variation has a different fixed threshold change or excess value of the fixed threshold, the function will be stopped. Still the minor fault was gratified and accomplished in many similar eras. On concerning this process, attaining the score value is effective in deciding whether the specific image is abnormal or normal. If the score value exceeds the threshold value, the specific image is normal. If the threshold value is lesser than or equal, the specific image is considered abnormal. The assessment of the score value computed regarding the specified condition is shown as follows:
Outcome = Th

The proposed design is simulated with the use of the Python Programming Tool. The outcomes are guaranteed on testing the projected model on CT images. Fig. 4 represents the sample test images of COVID CT and Non-COVID CT images.
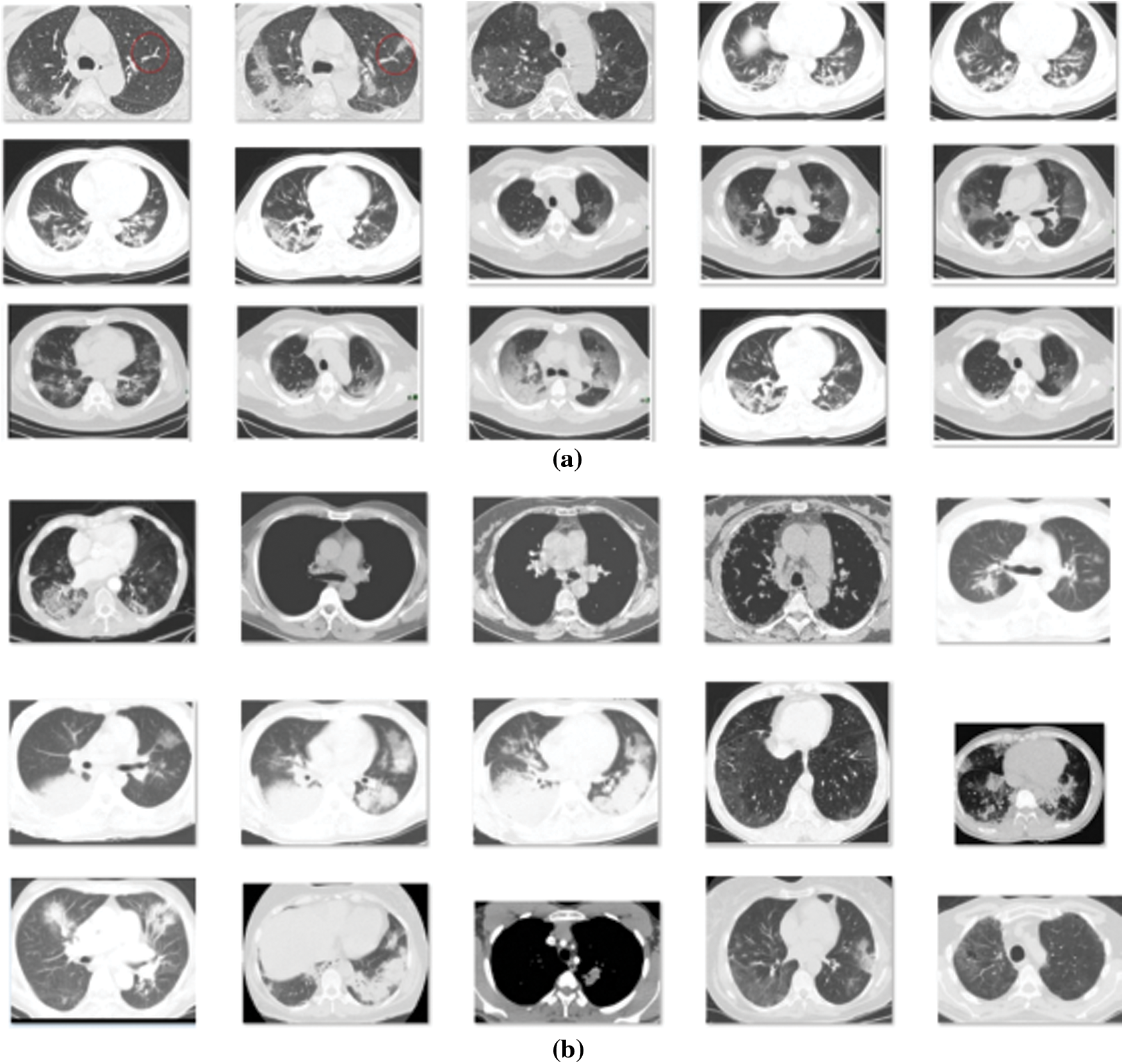
Figure 4: Sample images (a) COVID CT Images (b) Non-COVID CT Images
The performance is estimated and the outcomes are compared with traditional ResNet and other models, as shown in the Table 1 provided below:
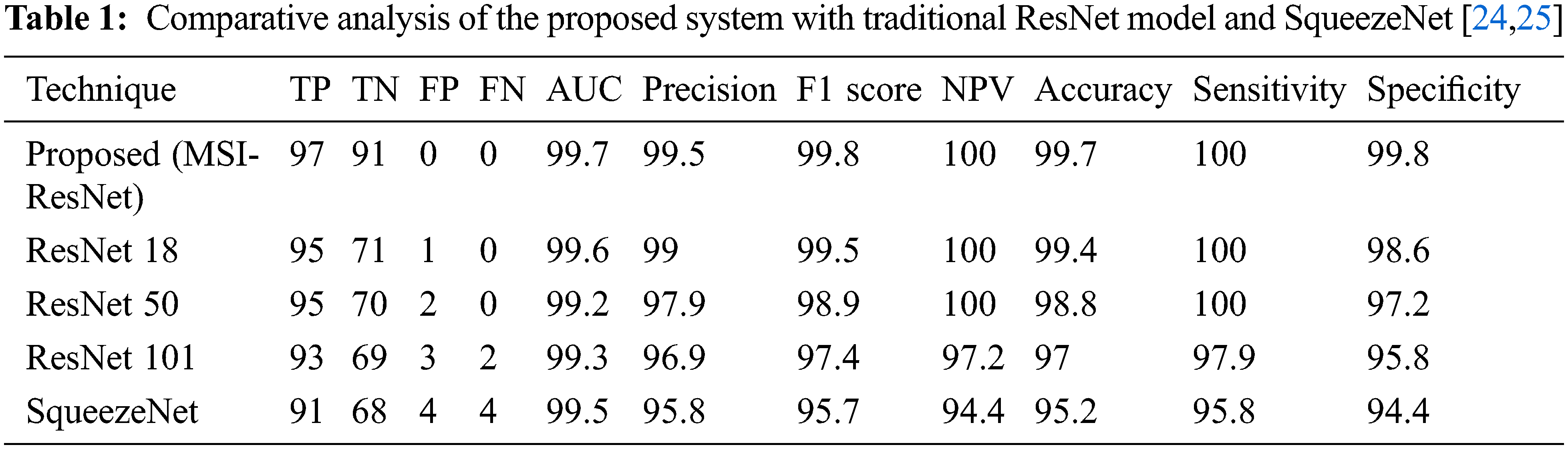
The comparative analysis of the proposed method in terms of AUC, Precision, F1-score, and NPV over other prevailing methods is shown in Fig. 5. From the analysis, it is evident that the proposed technique is better than the existing ones.
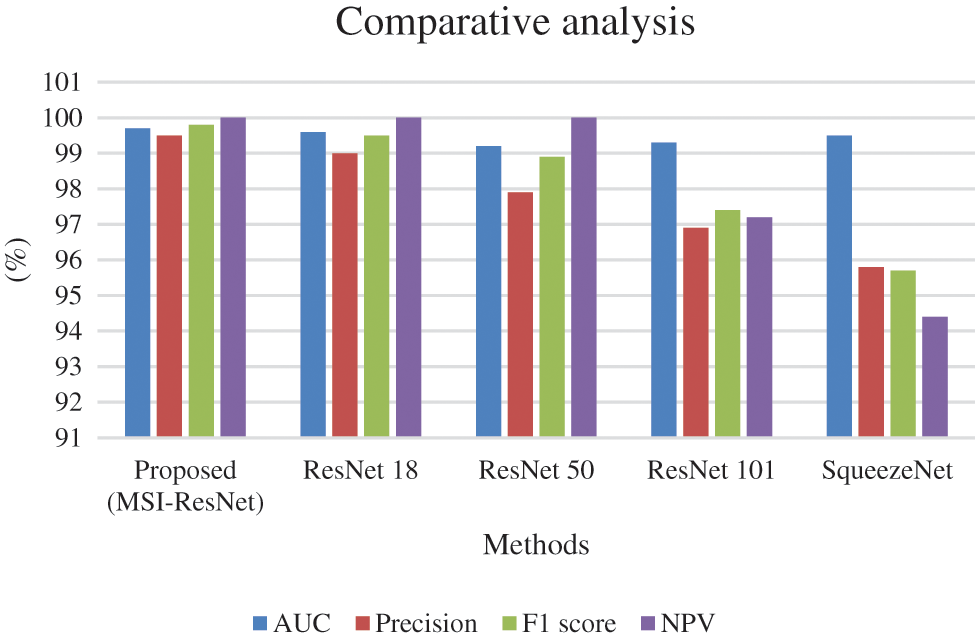
Figure 5: Comparative analysis of the proposed system with traditional ResNet model and SqueezeNet in terms of AUC, Precision, F1-score, NPV
The comparative analysis of the proposed method in terms of TN and TP over other prevailing methods is shown in Fig. 6. From the analysis, it is evident that the proposed technique is better than the existing ones.
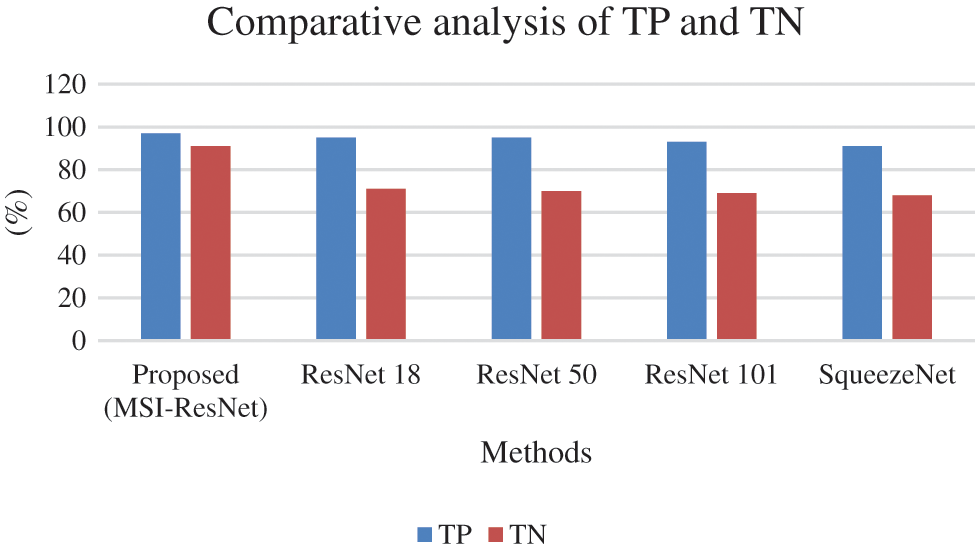
Figure 6: Comparative analysis of the proposed system with traditional ResNet model and SqueezeNet in terms of TN and TP
The overall accuracy, sensitivity, and selectivity of the proposed technique and the other existing methods are listed in Table 2.
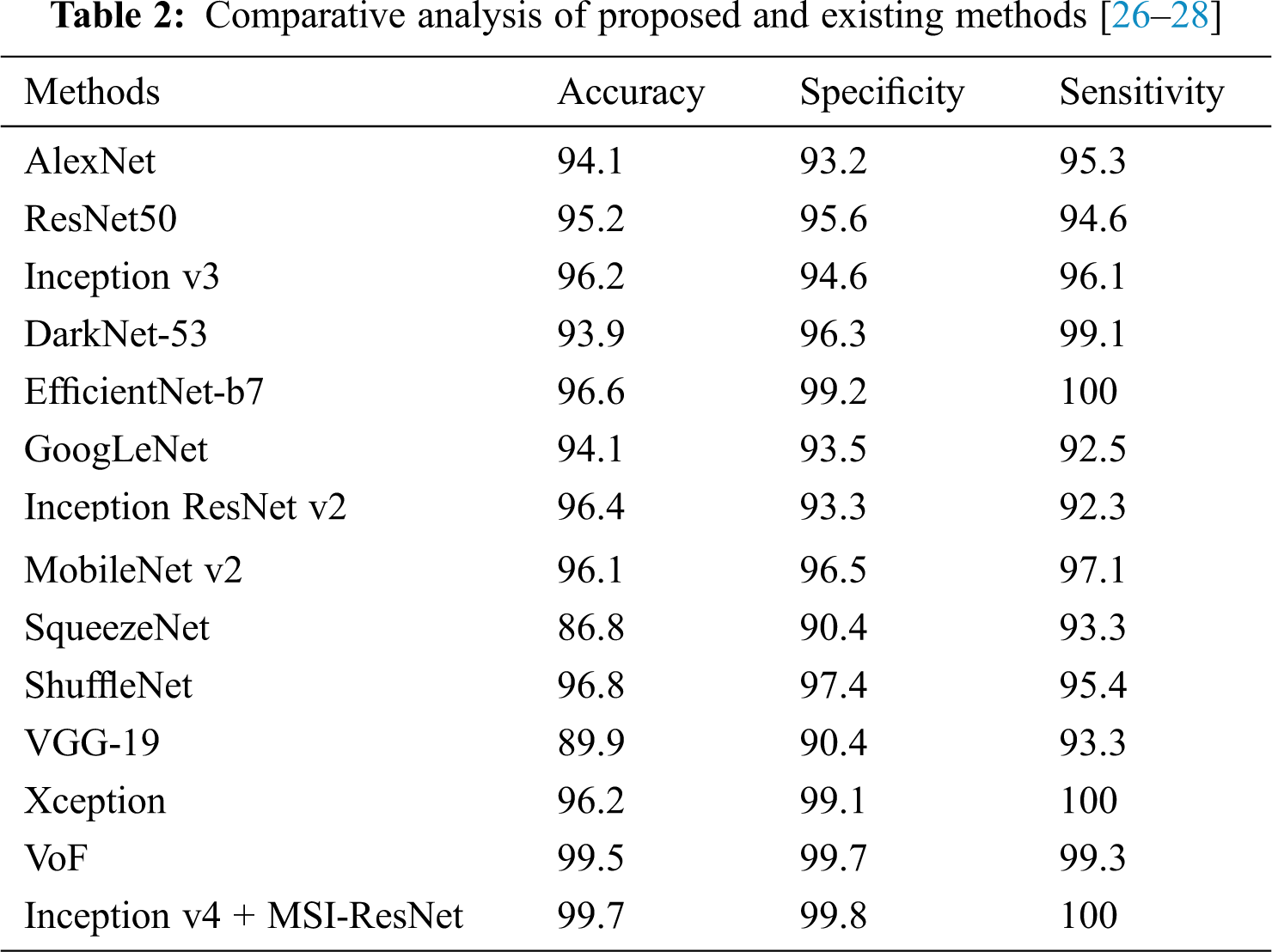
The comparative analysis of the proposed method in terms of accuracy, sensitivity, and specificity over other prevailing methods is shown in Fig. 7. From the analysis, it is evident that the proposed technique is better than the existing ones.
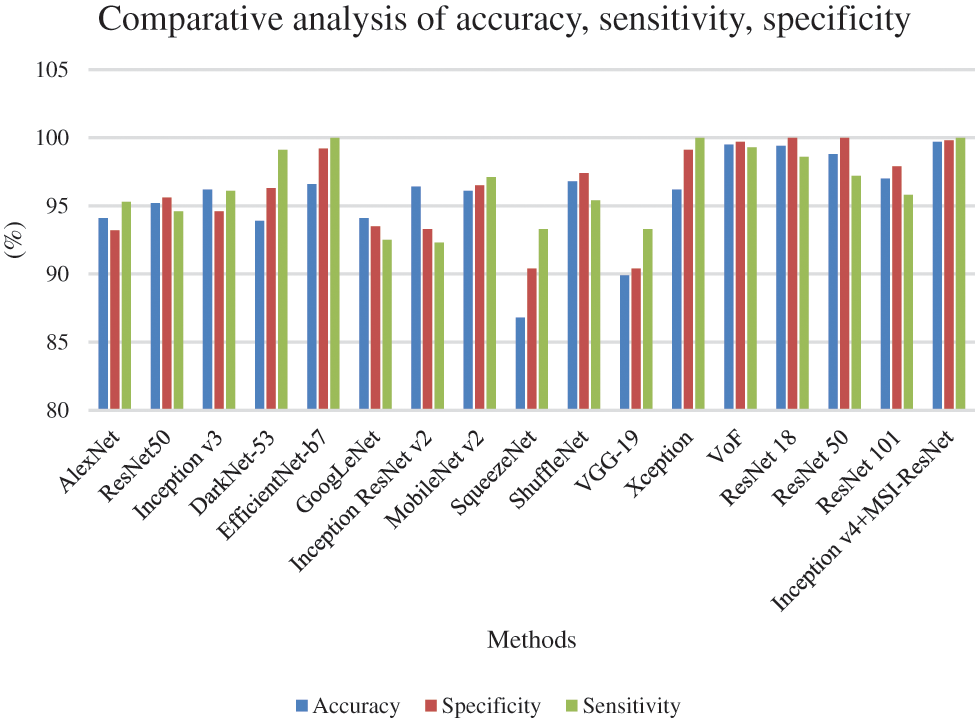
Figure 7: Comparative analysis of the proposed system with traditional models in terms of accuracy, sensitivity, and specificity
This paper offers a deep learning-based feature extraction, segmentation and classifier method for CT images for CAD diagnosis of covid-19. Various ML methods have been functional so far. As there was some need to improve the detection performance, the proposed model was presented. The proposed model employs the deep features using Inception 14 and VGG-16 models. Then, a Multi-scale Recurrent Neural network (MS-RNN) based classifier was employed for identifying and classifying the test CT images into distinct class labels. The investigational outcomes were carried out on the available CT dataset to demonstrate that the extracted features by Inception 14 and VGG-16 models and classified through Multi-scale RNN are effective. From the consequences, it was obvious that the proposed model provides a better outcome than the traditional techniques.
Acknowledgement: We deeply acknowledge Taif University for Supporting this research through Taif University Researchers Supporting Project number (TURSP-2020/231), Taif University, Taif, Saudi Arabia.
Funding Statement: This research was supported by Researchers Supporting Project number (TURSP-2020/231), Taif University, Taif, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. J. Dong, Y. Zhou, Y. Zhang, T. Flaherty and D. Franz, “A meta analysis for the basic reproduction number of COVID-19 with application in evaluating the effectiveness of isolation measures in different countries,” Journal of Data Science, vol. 18, no. 3, pp. 496–510, 2020. [Google Scholar]
2. B. Tang, N. L. Bragazzi, Q. Li, S. Tang, Y. Xiao et al., “An updated estimation of the risk of transmission of the novel coronavirus (2019-nCov),” Infectious Disease Modelling, vol. 5, pp. 248–255, 2020. [Google Scholar]
3. Y. Zhao, R. Wang, J. Li, Y. Zhang, H. Yang et al., “Analysis of the transmissibility change of 2019-novel coronavirus pneumonia and its potential factors in China from 2019 to 2020,” BioMed Research International, vol. 2020, Article ID 3842470, 2020. [Google Scholar]
4. B. Raju, D. Sumathi and B. Chandra, “A machine learning approach to analyze COVID 2019,” in Proc. of Int. Conf. on Computational Intelligence and Data Engineering, vol. 2021, Hyderabad, India, pp. 237–248, 2019. [Google Scholar]
5. Q. Li, X. Guan, P. Wu, X. Wang, L. Zhou et al., “Early transmission dynamics in Wuhan, China, of novel coronavirus–infected pneumonia,” New England Journal of Medicine, vol. 382, pp. 1199–1207, 2020. [Google Scholar]
6. M. Loey, G. Manogaran, M. H. N. Taha and N. E. M. Khalifa, “A hybrid deep transfer learning model with machine learning methods for face mask detection in the era of the COVID-19 pandemic,” Measurement, vol. 167, pp. 108288, 2021. [Google Scholar]
7. Q. Liao, Y. Ding, Z. L. Jiang, X. Wang, C. Zhang et al., “Multi-task deep convolutional neural network for cancer diagnosis,” Neurocomputing, vol. 348, pp. 66–73, 2019. [Google Scholar]
8. D. Szczesniak, M. Ciulkowicz, J. Maciaszek, B. Misiak, D. Luc et al., “Psychopathological responses and face mask restrictions during the COVID-19 outbreak: Results from a nationwide survey,” Brain, Behavior, and Immunity, vol. 87, pp. 161, 2020. [Google Scholar]
9. X. Li, L. Shen, X. Xie, S. Huang, Z. Xie et al., “Multi-resolution convolutional networks for chest X-ray radiograph based lung nodule detection,” Artificial Intelligence in Medicine, vol. 103, pp. 101744, 2020. [Google Scholar]
10. G. H. Gunasekaran, S. S. S. Gunasekaran, S. S. Gunasekaran, F. H. A. Halim and N. S. I. Zaimi, “Prevalence and acceptance of glove wearing practice among general population when visiting high risk are during local COVID-19 outbreak,” MedRxiv, 2020. https://dx.doi.org/10.1101/2020.05.30.20117564. [Google Scholar]
11. M. Toğaçar, B. Ergen and Z. Cömert, “Detection of lung cancer on chest CT images using minimum redundancy maximum relevance feature selection method with convolutional neural networks,” Biocybernetics and Biomedical Engineering, vol. 40, pp. 23–39, 2020. [Google Scholar]
12. X. Ma, Y. Niu, L. Gu, Y. Wang, Y. Zhao et al., “Understanding adversarial attacks on deep learning based medical image analysis systems,” Pattern Recognition, vol. 110, Article ID 107332, 2021. [Google Scholar]
13. D. Palani and K. Venkatalakshmi, “An IoT based predictive modelling for predicting lung cancer using fuzzy cluster based segmentation and classification,” Journal of Medical Systems, vol. 43, pp. 1–12, 2019. [Google Scholar]
14. H. Zunair, A. Rahman, N. Mohammed and J. P. Cohen, “Uniformizing techniques to process CT scans with 3D CNNs for tuberculosis prediction,” International Workshop on Predictive Intelligence in Medicine, vol. 12329, pp. 156–168, 2020. [Google Scholar]
15. J. Kantor, “Behavioral considerations and impact on personal protective equipment use: Early lessons from the coronavirus (COVID-19) pandemic,” Journal of the American Academy of Dermatology, vol. 82, pp. 1087–1088, 2020. [Google Scholar]
16. H. Xie, D. Yang, N. Sun, Z. Chen and Y. Zhang, “Automated pulmonary nodule detection in CT images using deep convolutional neural networks,"Pattern Recognition, vol. 85, pp. 109–119, 2019. [Google Scholar]
17. A. Pattnaik, S. Kanodia, R. Chowdhury and S. Mohanty, “Predicting tuberculosis related lung deformities from CT scan images using 3D CNN,” CLEF (Working Notes), vol. 2380, Article ID Paper_144, 2019. http://ceur-ws.org/Vol-2380/paper_144.pdf. [Google Scholar]
18. Y. Yang, T. M. Walker, A. S. Walker, D. J. Wilson, T. E. Peto et al., “DeepAMR for predicting co-occurrent resistance of mycobacterium tuberculosis,” Bioinformatics, vol. 35, pp. 3240–3249, 2019. [Google Scholar]
19. J. -F. Zhang, K. Yan, H. -H. Ye, J. Lin, J. -J. Zheng et al., “SARS-CoV-2 turned positive in a discharged patient with COVID-19 arouses concern regarding the present standards for discharge,” International Journal of Infectious Diseases, vol. 97, pp. 212–214, 2020. [Google Scholar]
20. R. Darlenski and N. Tsankov, “COVID-19 pandemic and the skin: What should dermatologists know?,” Clinics in Dermatology, vol. 38, pp. 785–787, 2020. [Google Scholar]
21. J. Chen, C. Hu, L. Chen, L. Tang, Y. Zhu et al., “Clinical study of mesenchymal stem cell treatment for acute respiratory distress syndrome induced by epidemic influenza A (H7N9) infection: A hint for COVID-19 treatment,” Engineering, vol. 6, pp. 1153–1161, 2020. [Google Scholar]
22. M. Holland, D. J. Zaloga and C. S. Friderici, “COVID-19 personal protective equipment (PPE) for the emergency physician,” Visual Journal of Emergency Medicine, vol. 19, pp. 100740, 2020. [Google Scholar]
23. K. Wang, B. K. Patel, L. Wang, T. Wu, B. Zheng et al., “A Dual-mode deep transfer learning (D2TL) system for breast cancer detection using contrast enhanced digital mammograms,” IISE Transactions on Healthcare Systems Engineering, vol. 9, pp. 357–370, 2019. [Google Scholar]
24. Ahuja, S., B. K. Panigrahi, N. Dey, V. Rajinikanth et al., “Deep transfer learning-based automated detection of COVID-19 from lung CT scan slices.” Applied Intelligence, vol. 51, no. 1, pp. 571–585, 2021. [Google Scholar]
25. A. Alharbi, K. Equbal, S. Ahmad, H. Rahman and H. Alyami, “Human gait analysis and prediction using the levenberg-marquardt method.” Journal of Healthcare Engineering, vol. 2021, Article ID 5541255, 2021. [Google Scholar]
26. S. Jamil and M. Rahman, “A Dual-stage vocabulary of features (VoF)-based technique for COVID-19 variant’s classification.” Applied Sciences, vol. 11, no. 24, pp. 11902, 2021. [Google Scholar]
27. A. U. Haq, J. P. Li, S. Ahmad, S. Khan, M. A. Alshara et al., “Diagnostic approach for accurate diagnosis of COVID-19 employing deep learning and transfer learning techniques through chest X-ray images clinical data in E-healthcare,” Sensors (Basel), vol. 21, no. 24, pp. 8219, 2021. [Google Scholar]
28. S. Ahmad, H. A. Abdeljaber, J. Nazeer, M. Y. Uddin, V. Lingamuthu et al., “Issues of clinical identity verification for healthcare applications over mobile terminal platform,” Wireless Communications and Mobile Computing, vol. 2022, Article ID 6245397, 2022. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools