
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Parameter Tuned Machine Learning Based Emotion Recognition on Arabic Twitter Data
1 Department of Computer Science, College of Science and Arts, Sharurah, Najran University, Najran, 55461, Saudi Arabia
2 Department of Language Preparation, Arabic Language Teaching Institute, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3 Department of Industrial Engineering, College of Engineering at Alqunfudah, Umm Al-Qura University, Najran, 24211, Saudi Arabia
4 Computer Department, Applied College, Najran University, Najran, 66462, Saudi Arabia
5 Department of Computer Science, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11835, Egypt
6 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Abdelwahed Motwakel. Email:
Computer Systems Science and Engineering 2023, 46(3), 3423-3438. https://doi.org/10.32604/csse.2023.033834
Received 29 June 2022; Accepted 03 November 2022; Issue published 03 April 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Arabic is one of the most spoken languages across the globe. However, there are fewer studies concerning Sentiment Analysis (SA) in Arabic. In recent years, the detected sentiments and emotions expressed in tweets have received significant interest. The substantial role played by the Arab region in international politics and the global economy has urged the need to examine the sentiments and emotions in the Arabic language. Two common models are available: Machine Learning and lexicon-based approaches to address emotion classification problems. With this motivation, the current research article develops a Teaching and Learning Optimization with Machine Learning Based Emotion Recognition and Classification (TLBOML-ERC) model for Sentiment Analysis on tweets made in the Arabic language. The presented TLBOML-ERC model focuses on recognising emotions and sentiments expressed in Arabic tweets. To attain this, the proposed TLBOML-ERC model initially carries out data pre-processing and a Continuous Bag Of Words (CBOW)-based word embedding process. In addition, Denoising Autoencoder (DAE) model is also exploited to categorise different emotions expressed in Arabic tweets. To improve the efficacy of the DAE model, the Teaching and Learning-based Optimization (TLBO) algorithm is utilized to optimize the parameters. The proposed TLBOML-ERC method was experimentally validated with the help of an Arabic tweets dataset. The obtained results show the promising performance of the proposed TLBOML-ERC model on Arabic emotion classification.Keywords
Arabic is one of the six official languages of the United Nations. As an official language in 27 nations, Arabic is spoken by nearly 422 million people worldwide [1]. Arabic has rich morphology and is highly complex since every word carries significant meaning. Since space is one of the delimited tokens, the terms in the Arabic language expose numerous morphological prospects such as agglutination, derivation, and inflection [2]. Unlike Latin languages, Arabic is written from right to left and can be distinguished by the absence of lower or upper case. Its alphabet has 28 letters, of which 25 are consonants and 3 are vowels [3,4]. However, the Arabic script employs diacritical marks as short vowels and vocal parts. This can be positioned either below or above the letters to ensure the right pronunciation and convey clear meaning for the words [5]. Most Arabic texts are written without shorter vowels. So, proficient speakers do not require diacritical marks to understand the presented text [6]. But, it is frequently utilized in books written for Arabic learners and children. The lack of diacritical marks in most textbooks brings lexical ambiguity issues that challenge the computational mechanisms [7,8].
There is a shortage of studies or linguistics research in Arabic, especially social emotion analysis. Further, no structured methods exist for extracting and classifying emotions in Arabic tweets. If available, such mechanisms can be applied to improve customer service management, E-learning applications, product quality, detection techniques for psychologists to identify terrorist conduct, and so on [9,10]. The emotion analysis process allows the analysis and classification of more complex emotions. Emotion is a part of the nervous system function and is associated with different mental states, such as sadness, joy, or annoyance. Emotion analysis can identify whether the content under study has emotions and can categorize the emotions under appropriate emotion categories [11]. The data for sentiment analysis is available on Twitter in the form of tweets. This Twitter data has text in several languages, whereas users post around 4.00 billion tweets daily. The tweets posted on Twitter exhibit the feelings and emotions of the users in distinct languages. Several challenges are associated with the emotional analysis of Twitter data since the tweets contain several social shortcuts, grammatical mistakes, multimedia content, misspellings, and slang [12]. Various authors have investigated emotions in English-language tweets. However, no single author has categorized the emotions exhibited in Arabic language tweets since the language has intricate difficulties. Many sentiment analysis studies on Arabic tweets merely categorized a sentiment as either positive or negative [13]. As mentioned, there is a lack of resources and studies in Arabic language social emotion analysis. In contrast, such studies or mechanisms need the hour to be applied in different fields [14], for instance, support psychiatrists in understanding terrorist conduct, improving E-learning applications, enhancing customer service and product quality, etc.
The current study develops a Teaching and Learning Optimization with Machine Learning Based Emotion Recognition and Classification (TLBOML-ERC) model on Arabic Twitter data. The presented TLBOML-ERC model focuses on recognising emotions and sentiments expressed in Arabic tweets. To attain this, the proposed TLBOML-ERC model initially carries out data pre-processing and Continuous Bag Of Words (CBOW)-based word embedding. The Denoising Autoencoder (DAE) model is exploited for emotion recognition, which categorizes the emotions found in Arabic tweets. To improve the efficacy of the DAE model, the Teaching and Learning Based Optimization (TLBO) algorithm is utilized for parameter optimization. The experimental analysis of the proposed TLBOML-ERC model was conducted using the Arabic tweets dataset.
Baali et al. [15] proposed a classification method for emotions found in Arabic tweets. In this technique, Deep Convolution Neural Network (DCNN) was trained on top of a training word vector for sentence classification, especially upon the dataset. The outcomes of the proposed method were compared with three other Machine Learning (ML) techniques, such as Multilayer Perceptron (MLP), Support Vector Machine (SVM), and Naïve Bayes (NB). The structure of the deep learning algorithm was an end-to-end network with sentence, word, and document vectorization steps. Khalil et al. [16] developed a new multi-layer Bidirectional Long Short Term Memory (BiLSTM) that was trained on top of pre-trained word-embedded vectors. This method obtained excellent performance improvement and was also related to other techniques for similar tasks, such as SVM, Random Forest (RF), and Fully Convolution Neural Network (FCNN). In the study conducted earlier [17], empirical research was executed on the progression of language methods from conventional Term Frequency–Inverse Document Frequency (TF–IDF) to highly-sophisticated word embedding word2vec and finally to the existing pre-trained language method, i.e., Bidirectional Encoder Representations from Transformers (BERT). It observed and examined how the performance can be increased to bring a change in language methods. Additionally, various BERT techniques were inspected for the Arabic language earlier.
Poorna et al. [18] developed a speech emotion recognition mechanism for the Arabic population. A speech database elicited emotions such as surprise, anger, disgust, happiness, neutrality, and sadness was developed from 14 non-native yet efficient speakers of the language. Spectral, cepstral, and prosodic features were derived after preprocessing the data. Then, the features were exposed to single-stage classification using supervised learning techniques. SVM and Extreme Learning Machine (ELM). Al-Hagery et al. [19] intended to achieve optimal performance in emotion classification upon the tweets made in Arabic. In this background, it is evident that various research investigations have been conducted earlier to investigate the impact of feature extraction methods and the N-gram method on the performances of three supervised ML techniques, such as SVM, NB, and Logistic Regression (LR).
In the current study, a new TLBOML-ERC model is proposed for the recognition of emotions and sentiments found in Arabic tweets. The TLBOML-ERC model initially carries out data pre-processing and the CBOW-based word embedding process to attain this. For emotion recognition, TLBO is exploited along with the DAE model that identifies and categorizes the emotions found in Arabic tweets. Fig. 1 showcases the block diagram of the TLBOML-ERC approach.
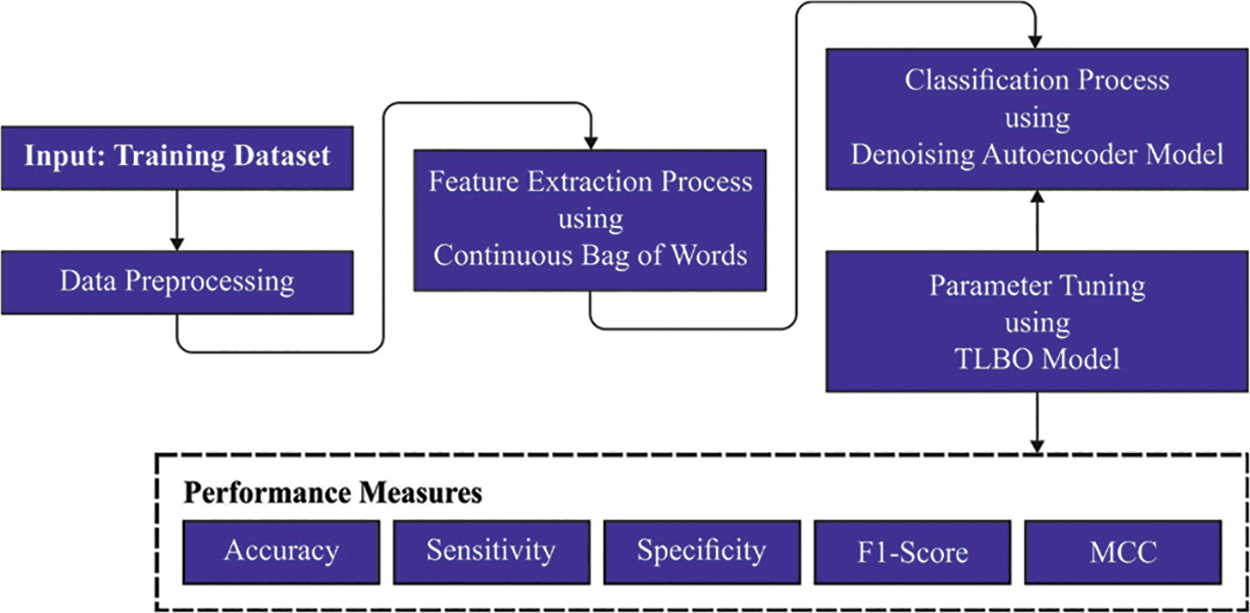
Figure 1: Block diagram of TLBOML-ERC approach
The original Arabic tweets from training and testing datasets are tokenized. After removing the white spaces, the punctuation marks are preserved as individual words (”.,?!:;()[]#@’). It is worth declaring that the pre-processing approaches not present in the current study model have normalized the Arabic characters, whereas diacritics, punctuations, and repetitive characters are eliminated.
CBOW approach employs Bag-of-Word models in which every word shares a prediction layer. Furthermore, the nonlinear hidden state is detached to reduce the computational time. CBOW employs the word from history and the future, whereas
In Eq. (1),
3.3 DAE-Based Emotion Classification
For emotion recognition, the DAE model is exploited, which identifies and categorizes the emotions found in Arabic tweets. Autoencoder (AE) is a Fully Connected (FC) layer of the unsupervised ML process, implying the Backpropagation (BP) model [21]. AE comprises an input layer, several hidden states, and a single output layer. The resultant of the neural network is denoted in Eq. (2) by permitting bold letters to indicate the vector.
whereas
As stated earlier, AE operates as an unsupervised learning method, i.e., backpropagation. Unsupervised learning refers to the training stage in which the basic features are merely needed without labelling. At the same time, backpropagation is the fault in the foretold resultant. In contrast, the target resultant propagates back from the resultant to every neuron in the network to update the weights based on a certain learning rate
whereas i refers to the index of trained epochs and
Here, E denotes the cost function. In such cases, Mean Square Error (MSE) is employed as an error measure, calculated as given below.
Here, N denotes the training set size,
Here,
3.4 Parameter Tuning Using TLBO Algorithm
To improve the efficacy of the DAE model, the TLBO algorithm is utilized for parameter optimization. TLBO is a population-based metaheuristic approach in which the optimum solution is characterized in terms of the population [22]. The TLBO approach works based on classroom learning mechanisms. Here, the teacher is presented to teach the learner with a goal, i.e., to increase the learning ability of the learner. However, in the classroom learning mechanism, learners can improve their skills by obtaining knowledge from others. The TLBO approach comprises two stages learner and teacher stages. A comprehensive discussion of both stages is summarized herewith. The teacher phase aims to impart the student’s learning skills so that the entire class’s outcomes are considerably enhanced. This results in an increased mean outcome of the class. Generally, a teacher improves the outcomes of the class learning process to a certain extent. Various limitations are accountable for the outcomes: the learner’s grasping ability, teaching technique, teacher’s capability, knowledge of the learners, and interaction of the learners with others. In the teacher stage,
Now,
The learner phase aims at boosting the learner’s knowledge from other learners. Therefore, to increase one’s learning capability, a learner should interact randomly with others. In the learner stage of the TLBO approach, the learner also gains knowledge from other learners. The learning ability of a learner is formulated herewith. Once an
Once the fitness of the novel location of the
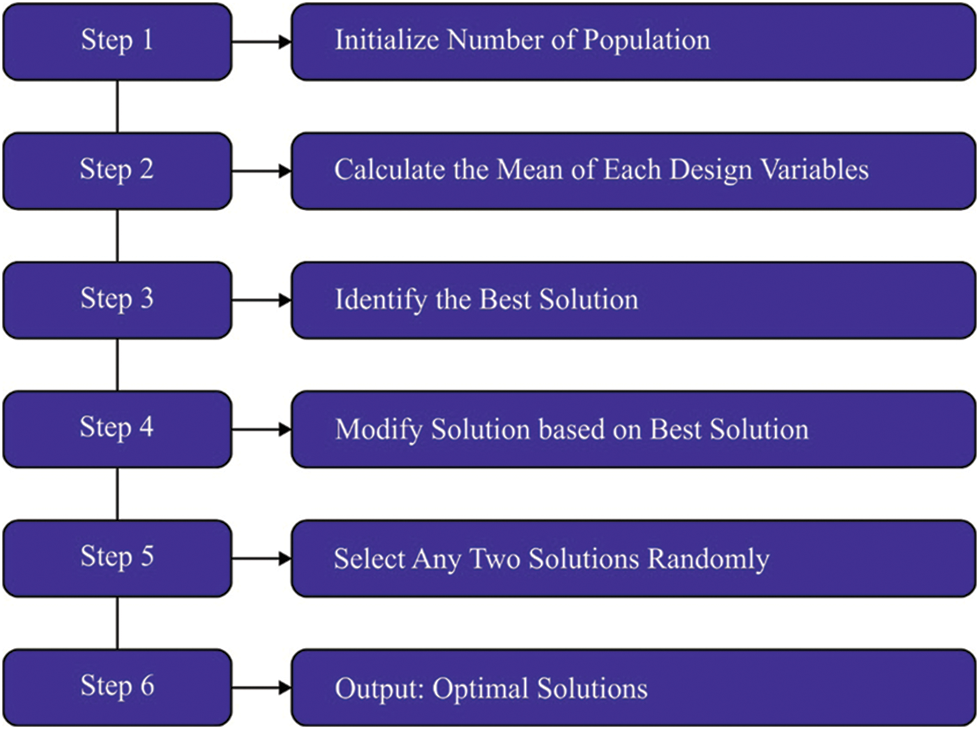
Figure 2: Steps involved in TLBO

The proposed TLBOML-ERC model was experimentally validated using a dataset that contains 5,600 Arabic tweets under four class labels, as depicted in Table 1. Each class holds a set of 1,400 samples.
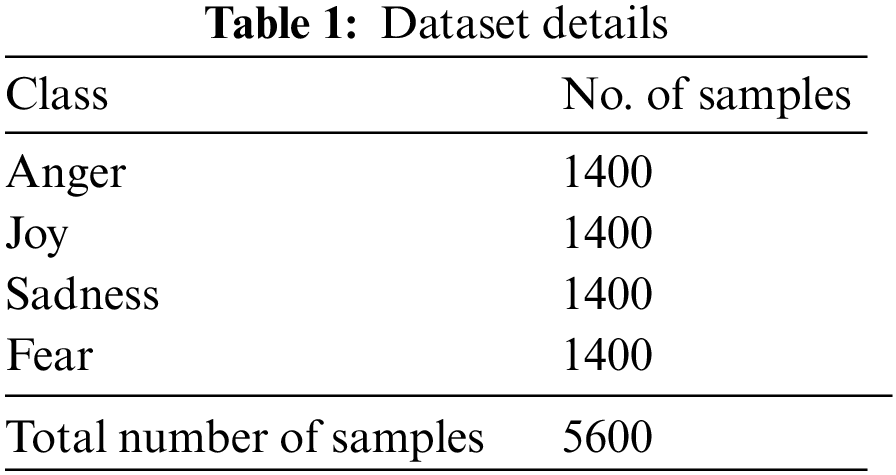
Fig. 3 illustrates the confusion matrices generated by the TLBOML-ERC model on Arabic tweets using Training Set (TRS) and Testing Set (TSS). On 90% of TRS, the proposed TLBOML-ERC model categorized 1,218 samples under anger, 1,217 samples under joy, 1,179 samples under sadness, and 1,212 samples under fear classes, respectively. Also, on 10% of TSS, the presented TLBOML-ERC approach classified 138 samples under anger, 120 samples under joy, 139 samples under sadness, and 139 samples under fear classes correspondingly. Additionally, on 70% of TRS, the proposed TLBOML-ERC technique recognized 970 samples as anger, 926 samples as joy, 918 samples as sadness, and 968 samples as fear classes, respectively. Followed by 30% of TSS, the TLBOML-ERC algorithm classified 383 samples under anger, 405 samples under joy, 436 samples under sadness and 397 samples under fear categories correspondingly.
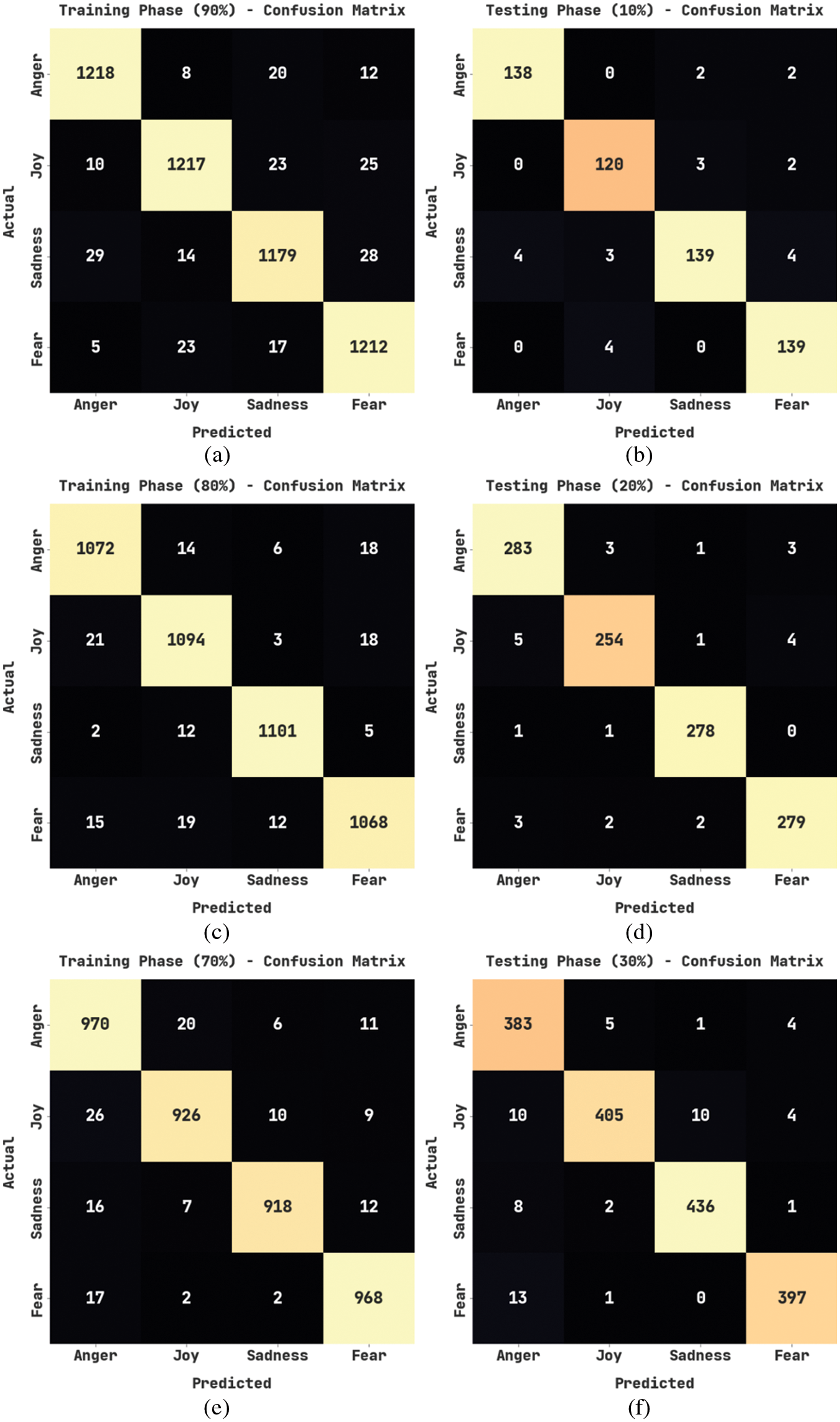
Figure 3: Confusion matrices of TLBOML-ERC approach for (a) 90% of TRS, (b) 10% of TSS, (c) 80% of TRS, (d) 20% of TSS, (e) 70% of TRS, and (f) 30% of TSS
Table 2 and Fig. 4 portray the results attained by the proposed TLBOML-ERC model on 90% of TRS and 10% of TSS. With 90% of TRS, the proposed TLBOML-ERC model achieved an average
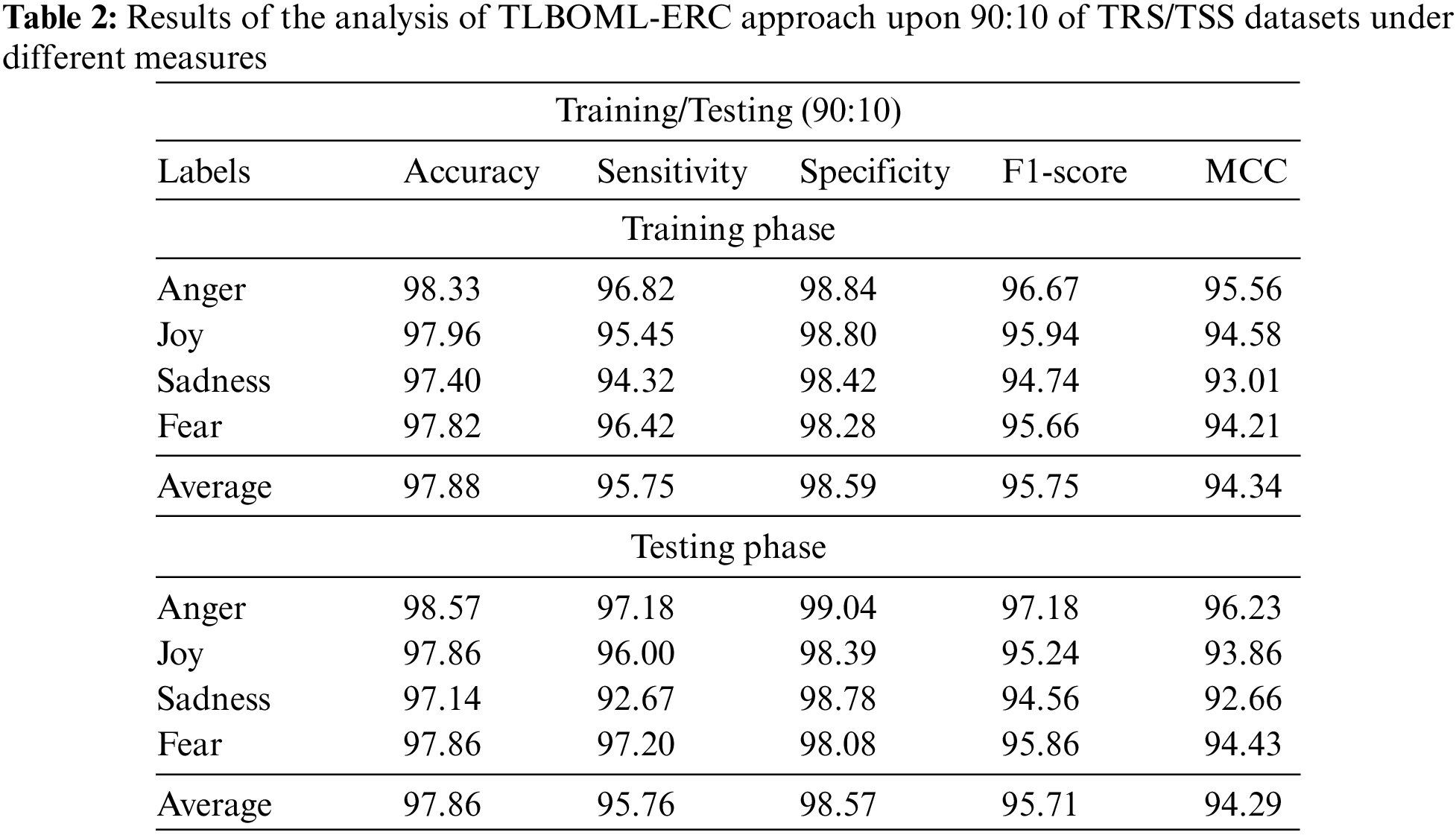
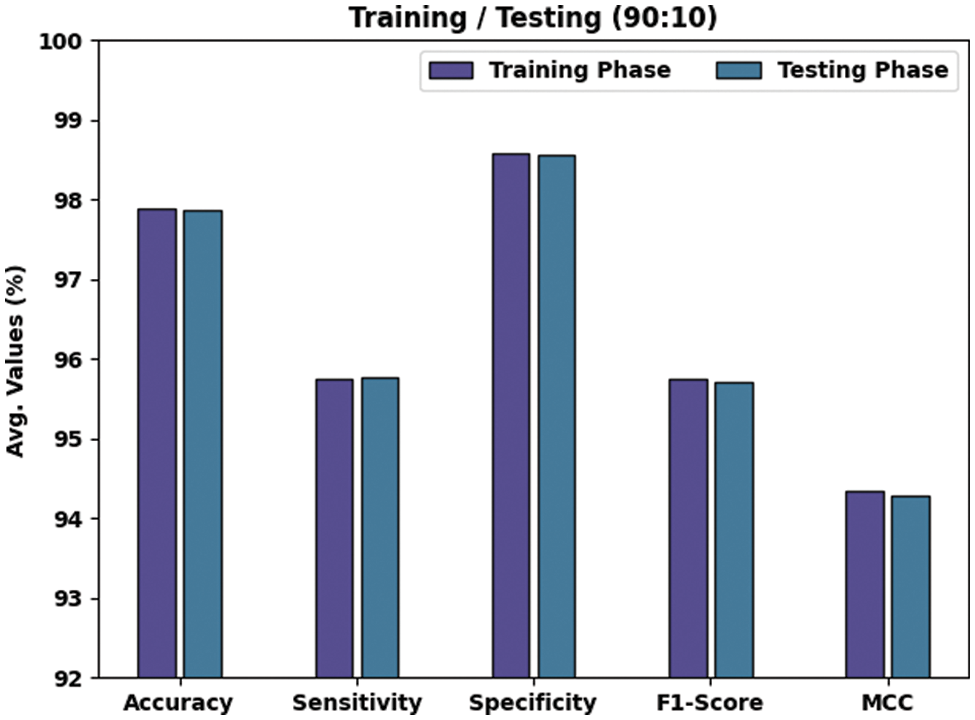
Figure 4: Results of the analysis of TLBOML-ERC approach upon 90:10 of TRS/TSS datasets
Table 3 and Fig. 5 depict the results accomplished by the proposed TLBOML-ERC model on 80% of TRS and 20% of TSS datasets. With 80% of TRS, the TLBOML-ERC method achieved an average
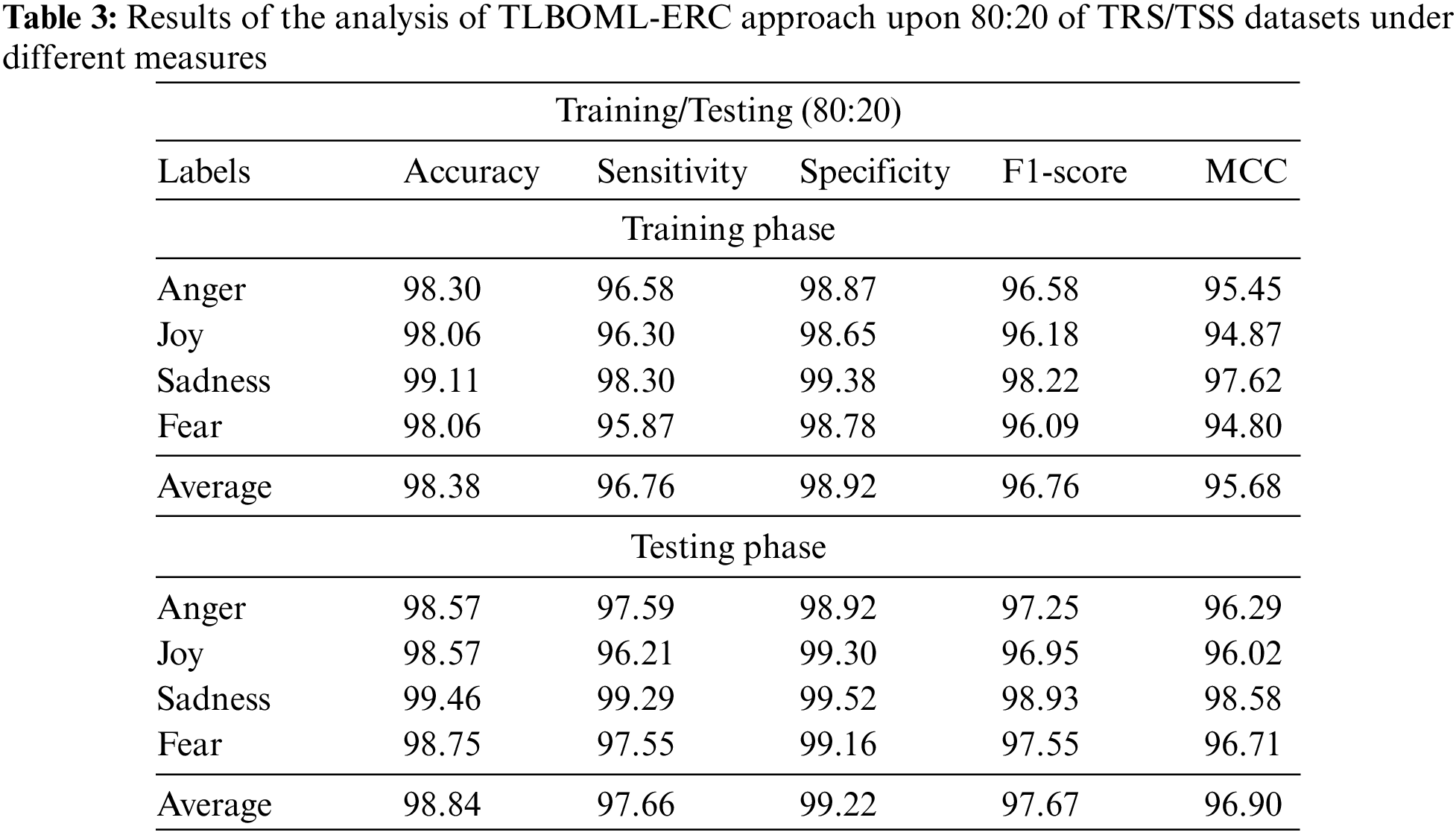
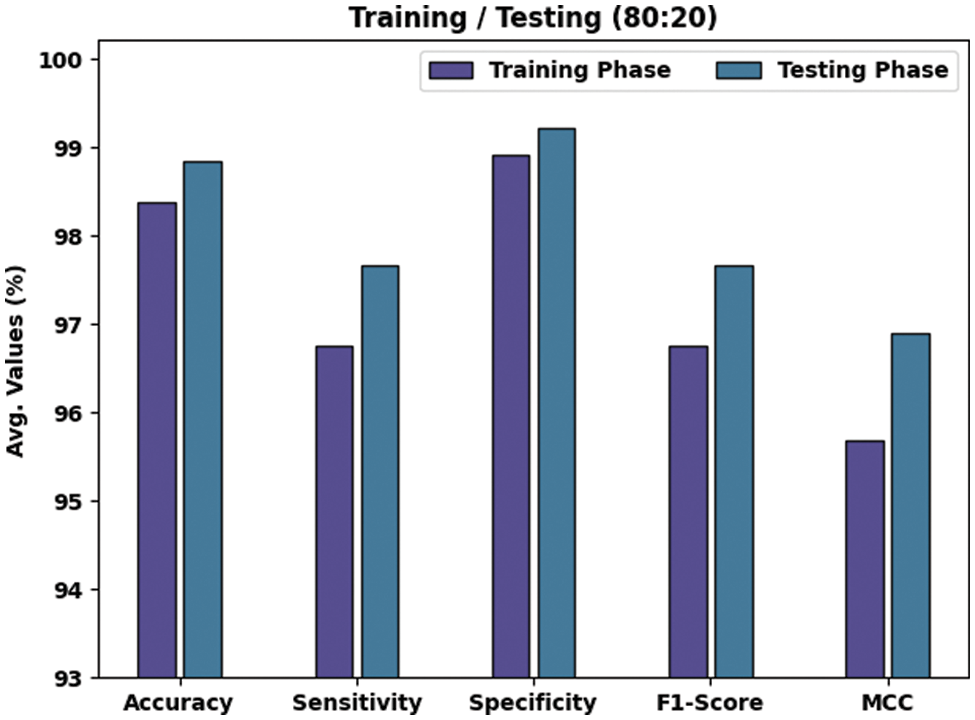
Figure 5: Results of the analysis of TLBOML-ERC approach upon 80:20 of TRS/TSS datasets
Table 4 and Fig. 6 illustrate the results of the proposed TLBOML-ERC model on 80% of TRS and 20% of TSS datasets. With 80% of TRS, the TLBOML-ERC approach yielded an average
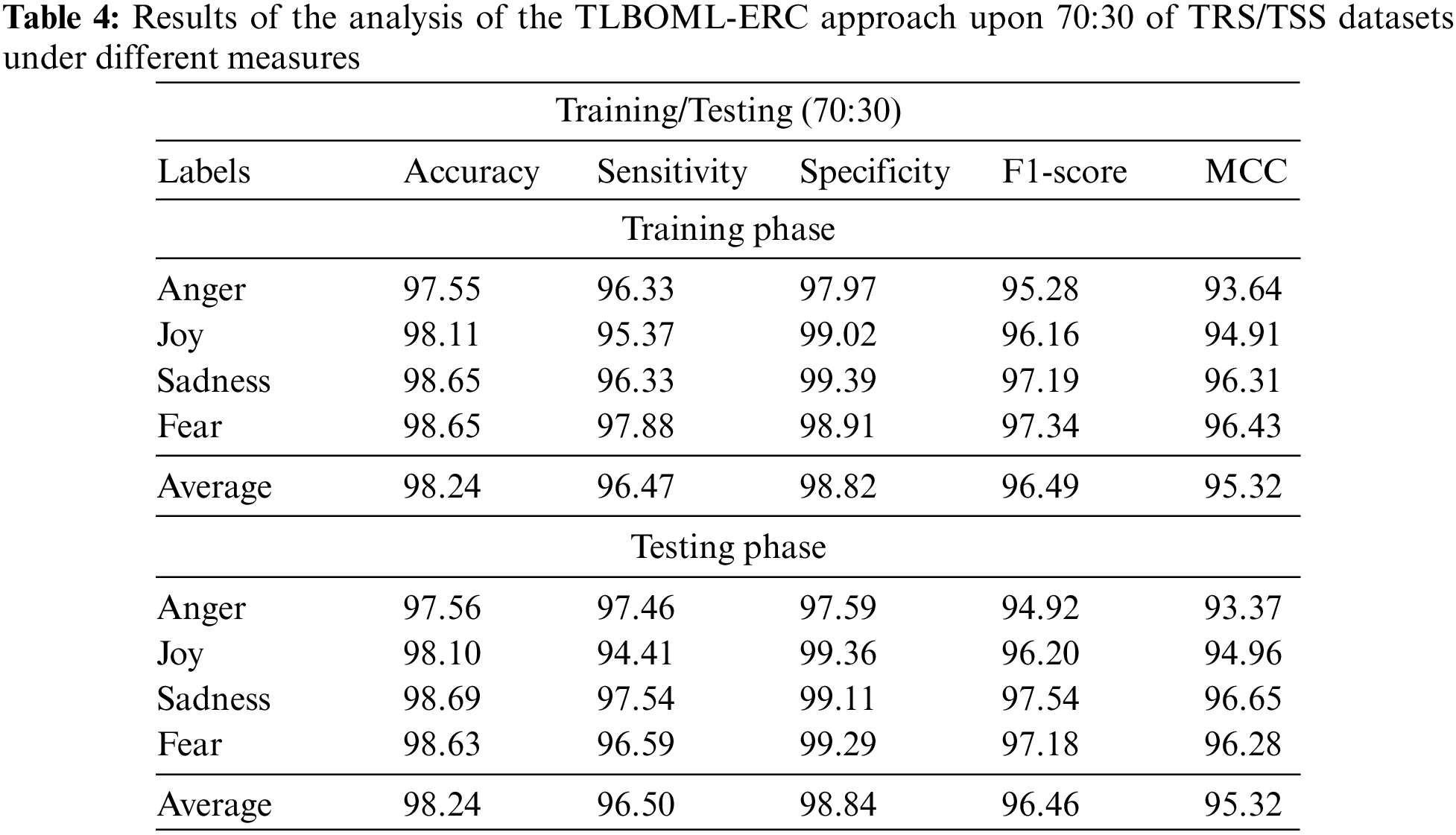
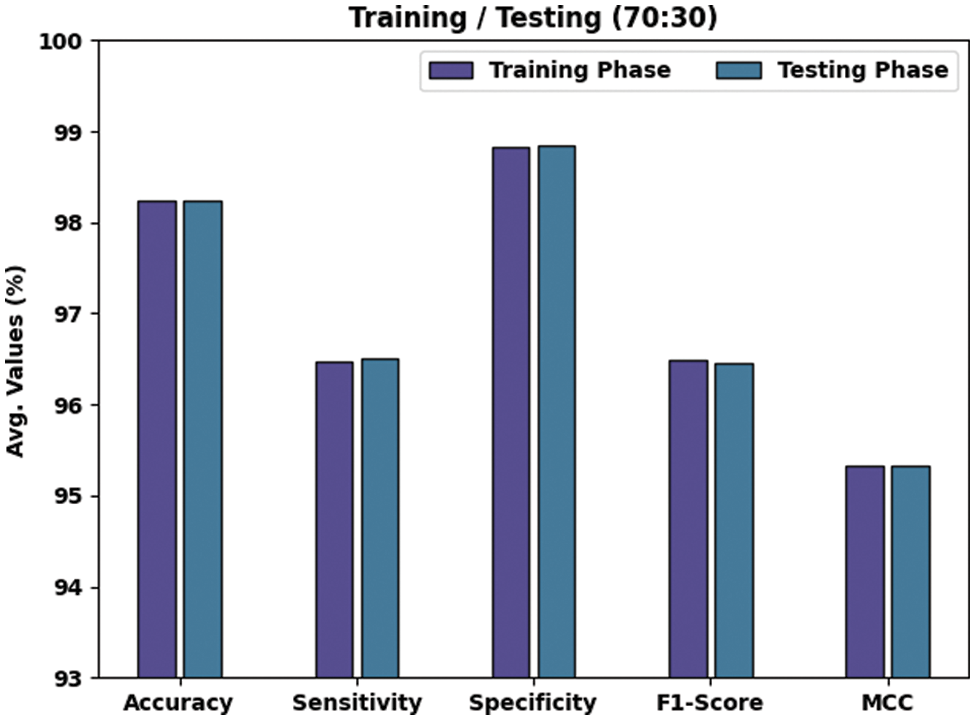
Figure 6: Results of the analysis of the TLBOML-ERC approach upon 70:30 of TRS/TSS datasets
Training Accuracy (TA) and Validation Accuracy (VA) values acquired by the proposed TLBOML-ERC method on the test dataset are shown in Fig. 7. The experimental outcomes imply that the proposed TLBOML-ERC method achieved the highest TA and VA values, while VA values were higher than TA.
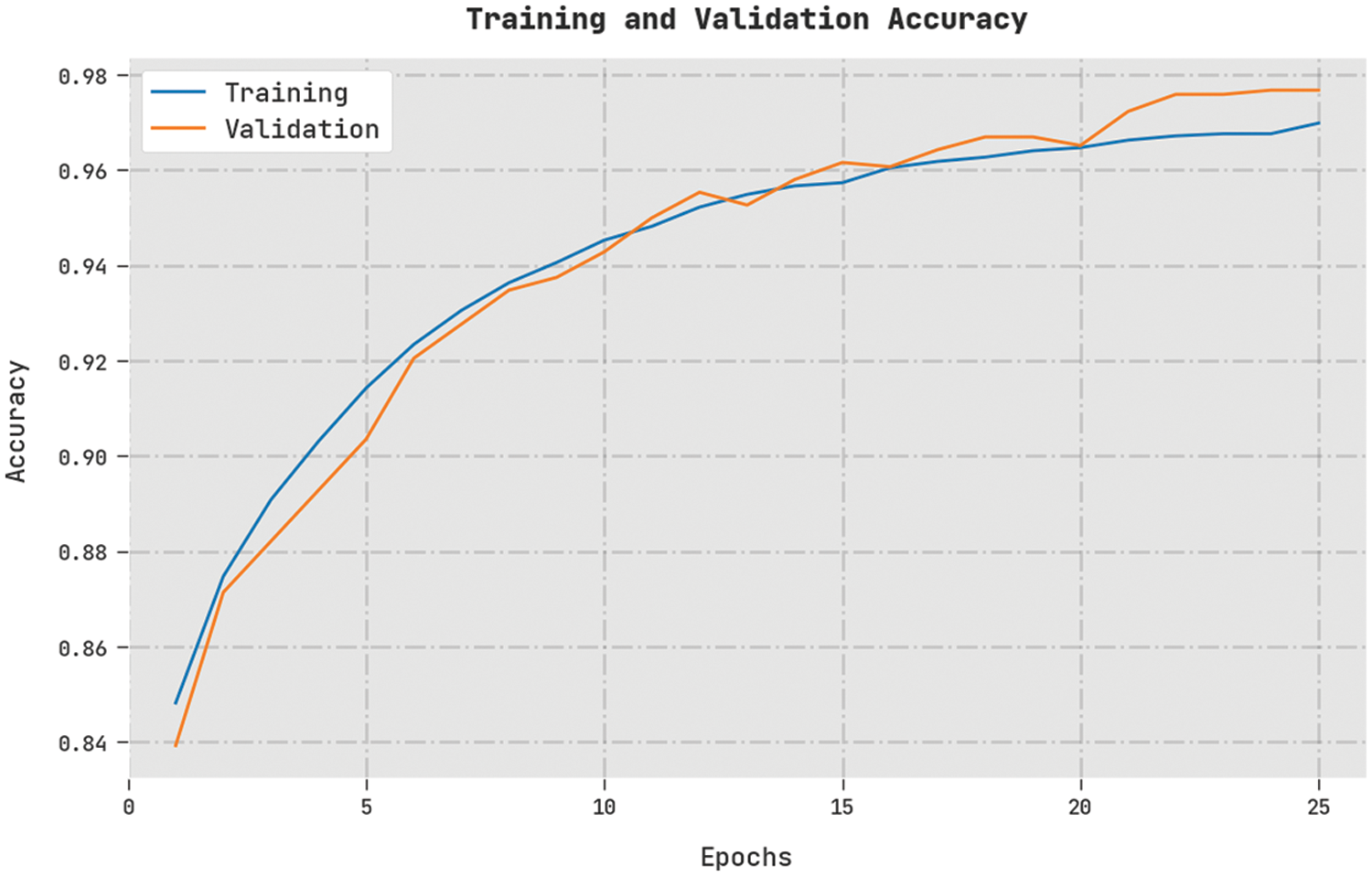
Figure 7: TA and VA analyses results of TLBOML-ERC approach
Both Training Loss (TL) and Validation Loss (VL) values, achieved by the proposed TLBOML-ERC approach on the test dataset, are displayed in Fig. 8. The experimental outcomes infer that the proposed TLBOML-ERC algorithm exhibited the least TL and VL values, while VL values were lower compared to TL.
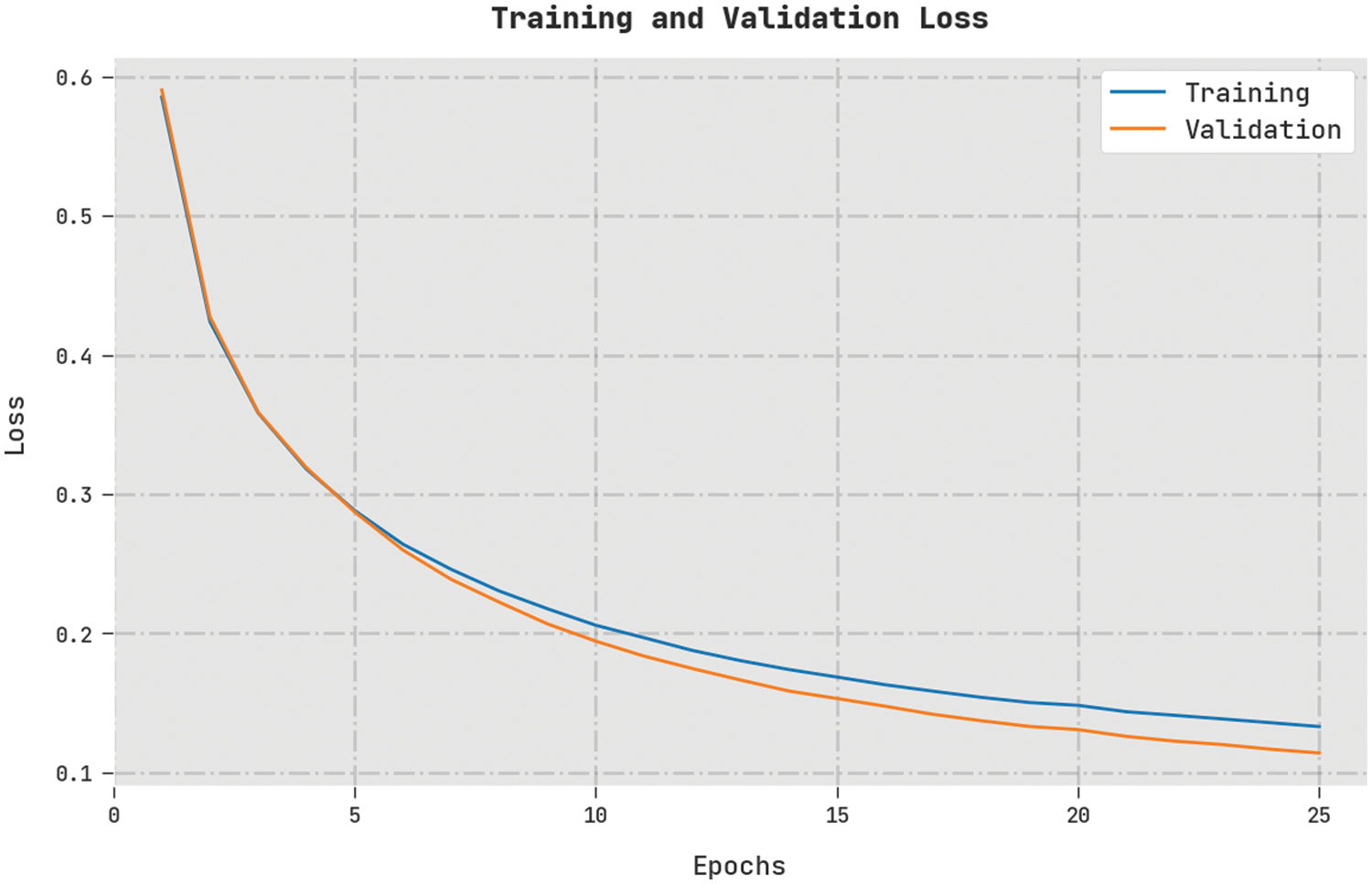
Figure 8: TL and VL analyses results of TLBOML-ERC approach
A clear precision-recall analysis was conducted on the TLBOML-ERC method using the test dataset, and the results are shown in Fig. 9. The figure indicates that the proposed TLBOML-ERC method produced enhanced precision-recall values under all the classes.
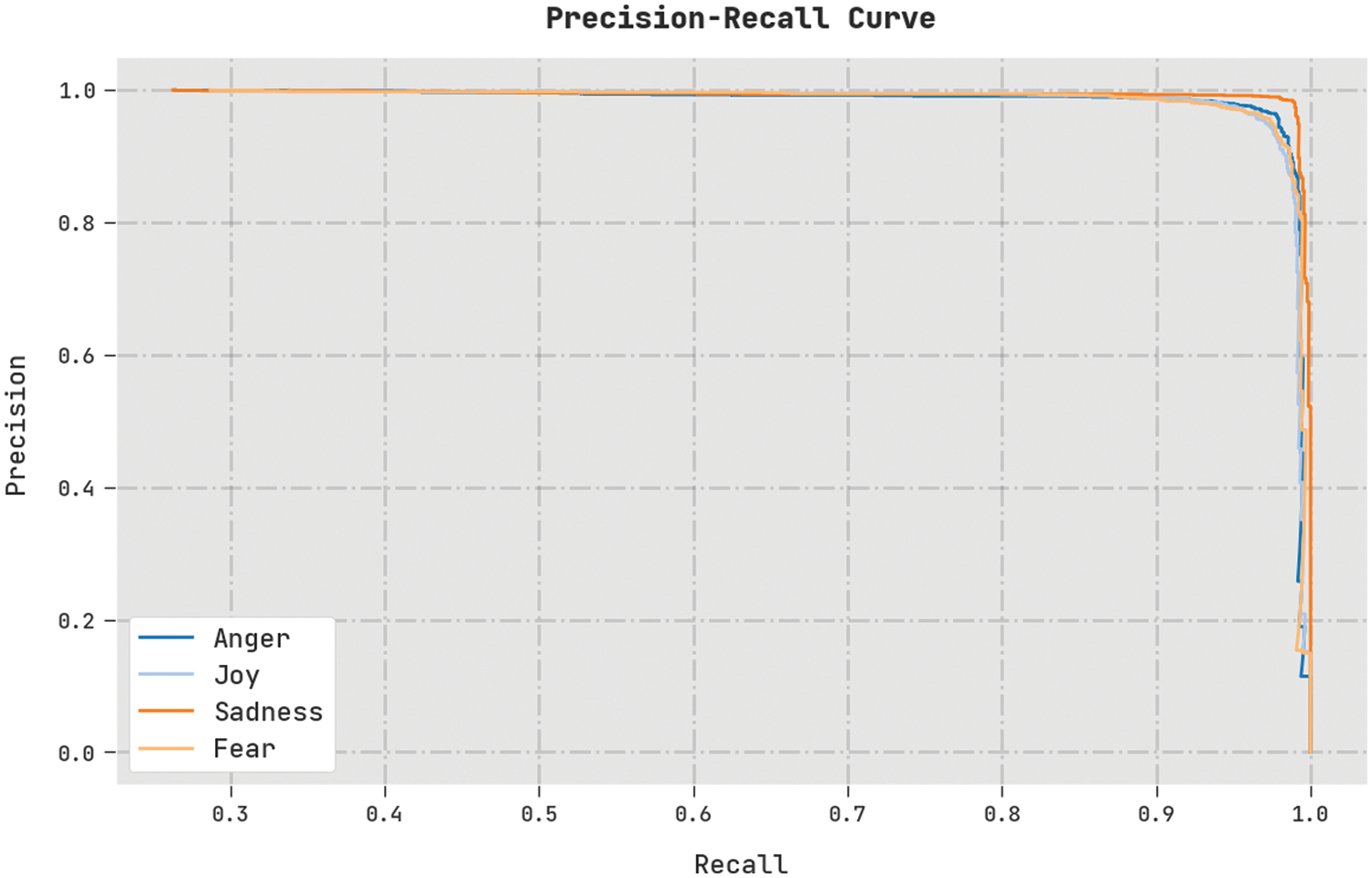
Figure 9: Precision-recall curve analysis of TLBOML-ERC approach
A brief Receiver Operating Characteristic (ROC) analysis was conducted on the TLBOML-ERC method using the test dataset, and the results are displayed in Fig. 10. The results infer that the proposed TLBOML-ERC approach excelled in categorizing distinct classes on the test dataset.
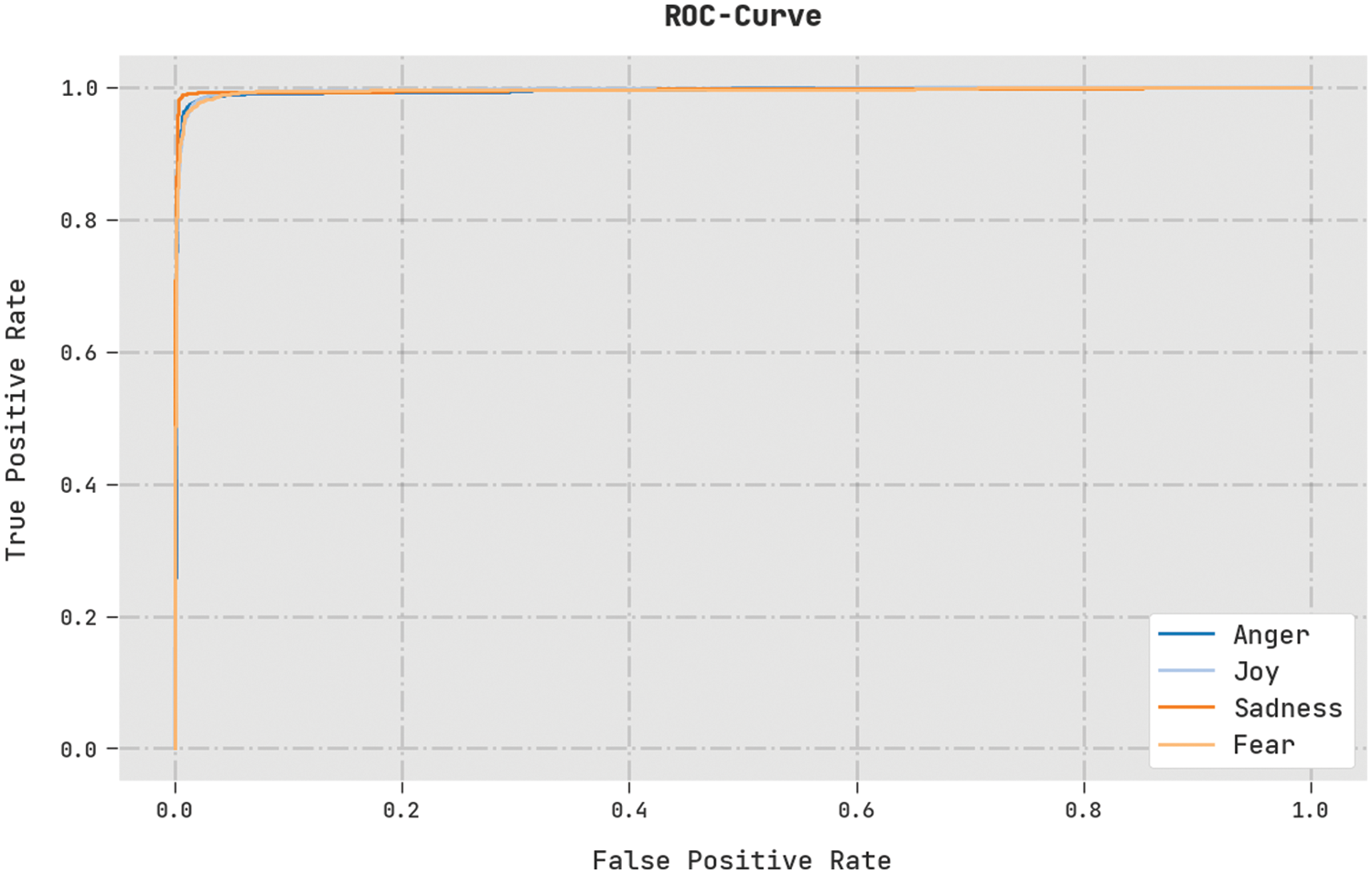
Figure 10: ROC curve analysis of TLBOML-ERC approach
Table 5 and Fig. 11 show the comprehensive comparison study outcomes accomplished by the proposed TLBOML-ERC model and other existing models [23]. The results infer that the TLBOML-ERC model outperformed other models. With respect to
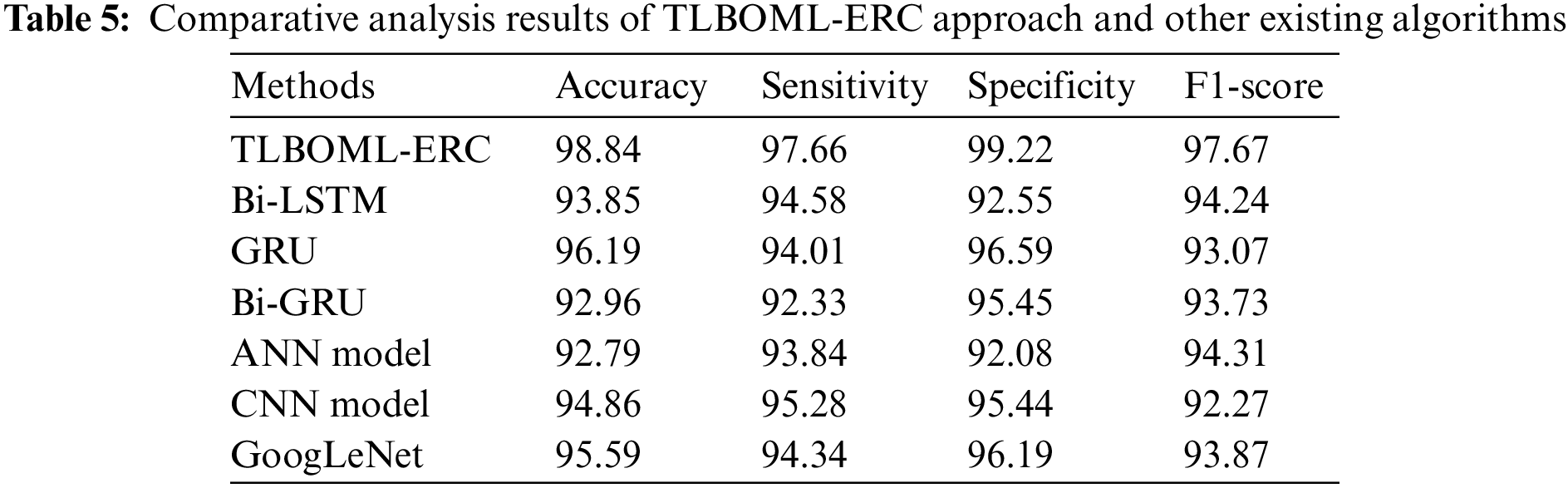
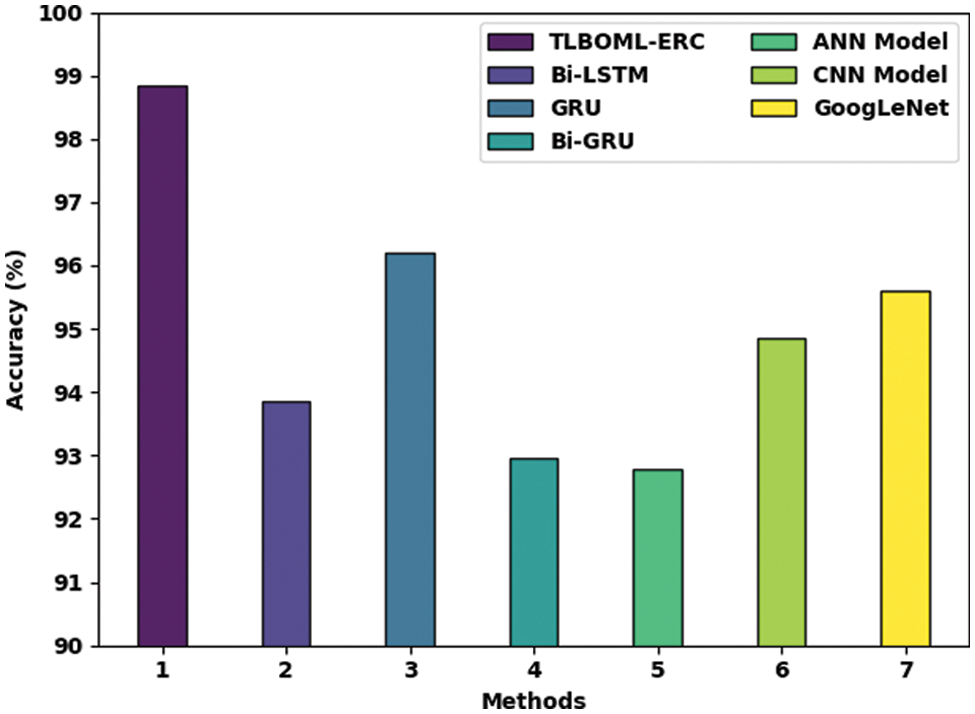
Figure 11: Comparative analysis of TLBOML-ERC approach and other existing algorithms
At last, with respect to
In current study, a new TLBOML-ERC method has been devised for the recognition of emotions and sentiments found in Arabic tweets. To attain this, TLBOML-ERC model initially carries out data pre-processing and CBOW-based word embedding process. For emotion recognition, DAE model is exploited which identifies the categories of emotions found in Arabic tweets. In order to improve the efficacy of DAE model, TLBO algorithm is utilized for parameter optimization. The experimental analysis was conducted upon the proposed TLBOML-ERC approach using Arabic tweets’ dataset. The obtained results show the promising performance of TLBOML-ERC model on Arabic emotion classification. In the future, TLBOML-ERC model can be modified to utilize Feature Selection approaches to boost the classification results.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: 22UQU4340237DSR36. The authors are thankful to the Deanship of Scientific Research at Najran University for funding this work under the Research Groups Funding program grant code (NU/RG/SERC/11/7).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. A. Elnagar, R. A. Debsi and O. Einea, “Arabic text classification using deep learning models,” Information Processing & Management, vol. 57, no. 1, pp. 102121, 2020. [Google Scholar]
2. S. Klaylat, Z. Osman, L. Hamandi and R. Zantout, “Emotion recognition in Arabic speech,” Analog Integrated Circuits and Signal Processing, vol. 96, no. 2, pp. 337–351, 2018. [Google Scholar]
3. P. Nandwani and R. Verma, “A review on sentiment analysis and emotion detection from text,” Social Network Analysis and Mining, vol. 11, no. 1, pp. 81, 2021. [Google Scholar] [PubMed]
4. F. N. Al-Wesabi, “Proposing high-smart approach for content authentication and tampering detection of arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. [Google Scholar]
5. A. Alharbi, M. Taileb and M. Kalkatawi, “Deep learning in Arabic sentiment analysis: An overview,” Journal of Information Science, vol. 47, no. 1, pp. 129–140, 2021. [Google Scholar]
6. F. N. Al-Wesabi, “A hybrid intelligent approach for content authentication and tampering detection of Arabic text transmitted via internet,” Computers, Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. [Google Scholar]
7. T. S. Kumar, “Construction of hybrid deep learning model for predicting children behavior based on their emotional reaction,” Journal of Information Technology and Digital World, vol. 3, no. 1, pp. 29–43, 2021. [Google Scholar]
8. F. N. Al-Wesabi, A. Abdelmaboud, A. A. Zain, M. M. Almazah and A. Zahary, “Tampering detection approach of Arabic-text based on contents interrelationship,” Intelligent Automation & Soft Computing, vol. 27, no. 2, pp. 483–498, 2021. [Google Scholar]
9. M. A. Ahmed, R. A. Hasan, A. H. Ali and M. A. Mohammed, “The classification of the modern Arabic poetry using machine learning,” TELKOMNIKA, vol. 17, no. 5, pp. 2667, 2019. [Google Scholar]
10. F. N. Al-Wesabi, “Entropy-based watermarking approach for sensitive tamper detection of Arabic text,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. [Google Scholar]
11. F. A. Acheampong, C. Wenyu and H. N. Mensah, “Text-based emotion detection: Advances, challenges, and opportunities,” Engineering Reports, vol. 2, no. 7, pp. 1–24, 2020. [Google Scholar]
12. M. Abdullah, M. AlMasawa, I. Makki, M. Alsolmi and S. Mahrous, “Emotions extraction from Arabic tweets,” International Journal of Computers and Applications, vol. 42, no. 7, pp. 661–675, 2018. [Google Scholar]
13. E. Lieskovská, M. Jakubec, R. Jarina and M. Chmulík, “A review on speech emotion recognition using deep learning and attention mechanism,” Electronics, vol. 10, no. 10, pp. 1163, 2021. [Google Scholar]
14. I. Aljarah, M. Habib, N. Hijazi, H. Faris, R. Qaddoura et al., “Intelligent detection of hate speech in Arabic social network: A machine learning approach,” Journal of Information Science, vol. 47, no. 4, pp. 483–501, 2021. [Google Scholar]
15. M. Baali and N. Ghneim, “Emotion analysis of Arabic tweets using deep learning approach,” Journal of Big Data, vol. 6, no. 1, pp. 89, 2019. [Google Scholar]
16. E. A. H. Khalil, E. M. F. E. Houby and H. K. Mohamed, “Deep learning for emotion analysis in Arabic tweets,” Journal of Big Data, vol. 8, no. 1, pp. 136, 2021. [Google Scholar]
17. N. Al-Twairesh, “The evolution of language models applied to emotion analysis of Arabic tweets,” Information, vol. 12, no. 2, pp. 84, 2021. [Google Scholar]
18. S. S. Poorna and G. J. Nair, “Multistage classification scheme to enhance speech emotion recognition,” International Journal of Speech Technology, vol. 22, no. 2, pp. 327–340, 2019. [Google Scholar]
19. M. A. Al-Hagery, M. A. Al-assaf and F. M. Al-kharboush, “Exploration of the best performance method of emotions classification for Arabic tweets,” Indonesian Journal of Electrical Engineering and Computer Science, vol. 19, no. 2, pp. 1010, 2020. [Google Scholar]
20. D. Qiu, H. Jiang and S. Chen, “Fuzzy information retrieval based on continuous bag-of-words model,” Symmetry, vol. 12, no. 2, pp. 225, 2020. [Google Scholar]
21. Z. Shang, L. Sun, Y. Xia and W. Zhang, “Vibration-based damage detection for bridges by deep convolutional denoising autoencoder,” Structural Health Monitoring, vol. 20, no. 4, pp. 1880–1903, 2021. [Google Scholar]
22. W. Chen, X. Chen, J. Peng, M. Panahi and S. Lee, “Landslide susceptibility modeling based on ANFIS with teaching-learning-based optimization and satin bowerbird optimizer,” Geoscience Frontiers, vol. 12, no. 1, pp. 93–107, 2021. [Google Scholar]
23. M. Abdullah, M. Hadzikadicy and S. Shaikhz, “SEDAT: Sentiment and emotion detection in Arabic text using cnn-lstm deep learning,” in 2018 17th IEEE Int. Conf. on Machine Learning and Applications (ICMLA), Orlando, FL, USA, pp. 835–840, 2018. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools