
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Optimal Quad Channel Long Short-Term Memory Based Fake News Classification on English Corpus
1 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
2 Department of Applied Linguistics, College of Languages, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3 Department of Computer Sciences, College of Computing and Information System, Umm Al-Qura University, Saudi Arabia
4 Department of Information Systems, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, Saudi Arabia
5 Department of Digital Media, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11845, Egypt
6 Department of Information System, College of Computer Engineering and Sciences, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Manar Ahmed Hamza. Email:
Computer Systems Science and Engineering 2023, 46(3), 3303-3319. https://doi.org/10.32604/csse.2023.034823
Received 28 July 2022; Accepted 07 November 2022; Issue published 03 April 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The term ‘corpus’ refers to a huge volume of structured datasets containing machine-readable texts. Such texts are generated in a natural communicative setting. The explosion of social media permitted individuals to spread data with minimal examination and filters freely. Due to this, the old problem of fake news has resurfaced. It has become an important concern due to its negative impact on the community. To manage the spread of fake news, automatic recognition approaches have been investigated earlier using Artificial Intelligence (AI) and Machine Learning (ML) techniques. To perform the medicinal text classification tasks, the ML approaches were applied, and they performed quite effectively. Still, a huge effort is required from the human side to generate the labelled training data. The recent progress of the Deep Learning (DL) methods seems to be a promising solution to tackle difficult types of Natural Language Processing (NLP) tasks, especially fake news detection. To unlock social media data, an automatic text classifier is highly helpful in the domain of NLP. The current research article focuses on the design of the Optimal Quad Channel Hybrid Long Short-Term Memory-based Fake News Classification (QCLSTM-FNC) approach. The presented QCLSTM-FNC approach aims to identify and differentiate fake news from actual news. To attain this, the proposed QCLSTM-FNC approach follows two methods such as the pre-processing data method and the Glove-based word embedding process. Besides, the QCLSTM model is utilized for classification. To boost the classification results of the QCLSTM model, a Quasi-Oppositional Sandpiper Optimization (QOSPO) algorithm is utilized to fine-tune the hyperparameters. The proposed QCLSTM-FNC approach was experimentally validated against a benchmark dataset. The QCLSTM-FNC approach successfully outperformed all other existing DL models under different measures.Keywords
Fake news is a supreme threat to democracy, commerce and journalism across the globe, and it results in massive collateral damages. Fake news is frequently used to denote ‘rumours’, ‘misinformation’, ‘hoax’ and ‘disinformation’, or it can be classified as false information [1]. Various research works, applications and tools have been developed earlier to find fake news by checking the facts about the news. Most tools scrutinize the complexity as a veracity classification [2,3]. The distribution of fake news via various mediums, particularly social media platforms, cannot be stopped completely or shut down to reduce the opposing effects caused by the fake news. This is attributed to the fact that no proper system can control fake news with some or no human participation [4].
Advanced technologies such as Natural Language Processing (NLP) and Artificial Intelligence (AI) tools provide promising outcomes for authors who attempt to build automatic fake news detection mechanisms [5,6]. However, it is challenging to identify fake news since the process needs dynamic methods that can summarize the news and compare it with the actual news so that it can be classified as fake or not [7]. Several Machine Learning (ML) approaches, such as Sentiment Analysis (SA), NLP and Knowledge verification, are highly helpful in the identification of false information spread across the internet [8,9]. In literature, the authors have focused on using textual data extracted from an article’s content, such as emotional information and statistical text features [10]. Deep Learning (DL) is a developing technology in this research domain and it has already proved to be highly effective in finding fake news than the classical techniques [11]. It has a few specific benefits over the ML techniques, such as the capability of extracting high-dimensional features, automated feature extraction, optimum accuracy and minimal dependency on data pre-processing techniques.
Additionally, the extensive accessibility of the data in recent times and the programming structures fostered the robustness and utility of the DL-related techniques [12]. Therefore, numerous research articles have been published in the past five years on fake news identification, typically related to DL techniques. The authors attempted to compare the recent literature on DL-related fake news identification techniques [13]. Despite the quick surge in its fame, the subject is still in a nascent stage among the research groups. Though several studies emphasize the analysis of rumours and fake news to find and expose false information correctly, no unified solution has been developed in this research field [14].
In this background, the current research article focuses on the design of the Optimal Quad Channel Hybrid Long Short-Term Memory-based Fake News Classification (QCLSTM-FNC) approach. The presented QCLSTM-FNC approach aims to identify and differentiate fake news from actual news. To attain this, the proposed QCLSTM-FNC approach follows two processes such as the pre-processing data method and the Glove-based word embedding process. Besides, the QCLSTM model is utilized for classification. To boost the classification results of the QCLSTM model, a Quasi-Oppositional Sandpiper Optimization (QOSPO) technique is employed to fine-tune the hyperparameters. The proposed QCLSTM-FNC approach was experimentally validated against a benchmark dataset.
Nasir et al. [15] developed a hybrid DL method integrating the Recurrent Neural Network (RNN) and the Convolutional Neural Network (CNN) for the classification of fake news. The proposed method was validated for its effectiveness on two fake news datasets (FA-KES and ISO). The recognition outcomes were superior to other non-hybrid models. Agarwal et al. [16] proposed a DL method to forecast the nature of a study when it is provided as an input value. In this study, the researchers experimented with the word embedded (GloVe) process for text pre-processing to establish a linguistic relationship and make a vector space of the words. The suggested technique was developed using CNN and RNN frameworks and accomplished standard outcomes in predicting fake news. Further, the word embedding model supplemented the proposed model in terms of effectiveness and efficacy.
The study author conducted earlier [17] collected 1,356 news instances from different sources, such as Twitter users and news reports like PolitiFact, to generate two different datasets for fake and real news articles. This work was correlated with many advanced techniques, such as the attention mechanism, CNN, Long Short Term Memory (LSTM) and the ensemble method. Ahmad et al. [18] focused on identifying the latest news rumours spread on social networking platforms instead of long-term rumours. The study presented a new content-based and social-based characteristic to detect rumours on social networking platforms. Moreover, the results demonstrate that the presented feature is highly helpful in the classification of the rumours in comparison with the advanced features. Furthermore, this study applied the bi-directional LSTM-RNN on text to predict the rumours. This simple method was effective in the detection of rumours. Most earlier rumour recognition studies emphasized long-term rumours and considered fake news most of the time.
In literature [19], a DL-based method was applied to discriminate the false news from the original one. An LSTM-Neural Network (NN) was employed to construct the presented method. In addition to the NN model, a gloVe word embedding method was exploited to describe the vectors of the textual words. Likewise, the tokenisation method was employed for the vectorization or feature extraction process. Further, the N-grams model was also employed to enhance the outcomes. Jin et al. [20] developed a fine-grained reasoning architecture by succeeding in the user-data processing method. This method presented a mutual reinforcement-based methodology to incorporate human knowledge about prioritization and designed a prior-aware bi-channel kernel graph network to model the subtle modifications in the information. Mouratidis et al. [21] proposed a recent technique for the automated recognition of fake news on Twitter. This technique included (i) a pairwise text input, (ii) a novel Deep Neural Network (DNN) learning framework that allows the adaptable fusion of input at different network layers, and (iii) different input modes such as the word embedding, network account and the linguistic feature. In addition, the tweets were creatively detached from the news text and its headers. This study conducted a wide range of experiments on text classification using news text and headers.
In this article, a novel QCLSTM-FNC approach has been developed for fake news detection and classification. The presented QCLSTM-FNC approach aims to identify and differentiate fake news from original news. The QCLSTM-FNC approach follows a series of operations, as shown in Fig. 1.
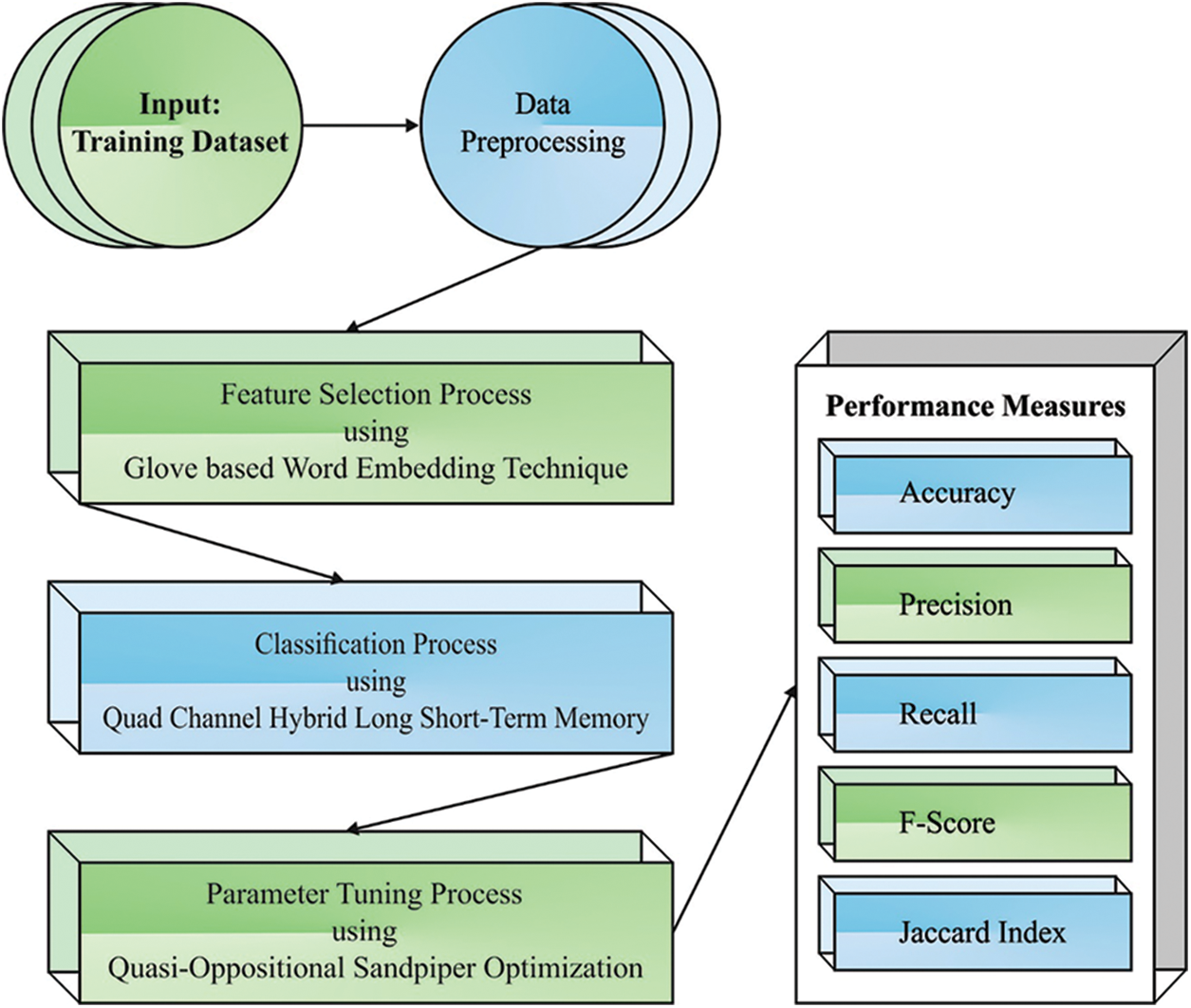
Figure 1: Overall process of the QCLSTM-FNC approach
3.1 Data Pre-processing and Word Embedding
Initially, the QCLSTM-FNC approach follows two processes such as the data pre-processing process and the Glove-based word embedding process. The sequential models that use the pre-processing steps are given below.
– Elimination of the HyperText Markup Language (HTML) tags: In data collection, screen or web scraping often results in incorporating the HTML tags in texts. Though no attention is paid to those entities, there is a need to eliminate the tags.
– Transform the accented characters to align with the American Standard Code for Information Interchange (ASCII) characters: To prevent the NLP module from handling the accented words such as “latte”, “resume”, and so on that are distinct from the common spelling, the text must be passed over this step.
– Extend the contractions: Apostrophe is a classical approach to shorten a group of words or an entire word. Let’s say, ‘it’s’ stands for ‘it is’ and does not denote ‘do not’. The shortened form is extended in these steps.
– Elimination of the special characters: The special characters are unreadable and involve the characters such as ‘&’, ‘$’, ‘*’ and so on.
– Removal of the noise: It involves the removal of white spaces, unwanted new lines and so on. Such texts are filtered in this step.
– Normalization: The whole text is transformed into lowercase characters since the NLP libraries are case-sensitive in nature.
– Removal of the stop-words: In this step, the removal of stop-words such as ‘a’, ‘an’, ‘the’, ‘of’, ‘is’, and so on is executed. Though these words widely appear in sentences, it typically adds less value to the whole meaning of the sentence. To guarantee a lesser processing time, the stop words should be eliminated, and the model should be assisted to focus on the words that convey the leading focus of the sentence.
– Stemming: In this step, a word is reduced to its root word afterward eliminating the suffixes. However, it does not guarantee that the resultant word is significant. Porter’s stemmer model is used in this study out of the several stemming approaches available in this domain.
3.2 QCLSTM Based Fake News Detection
In this study, the QCLSTM model is utilized for the purpose of classification. The explosion gradient problem certainly happens, when the length of the input sequence is higher. This phenomenon increases the learning time of the model about the data in a long-time context [22]. To resolve these issues, the LSTM model is applied. This is the most commonly-applied dissimilar version of the RNN method. Due to the introduction of the gating models in all the LSTM units, the problems mentioned above get resolved easily. Here, the discarded data of a cell state is determined using the forget gate whereas the novel input is calculated using the input gate. According to the existing cell state, the output values are described on the basis of the data included in the cell’s state. A four-channel model is proposed from the CNN-LSTM method by providing different labels of embedding as input instantaneously, at a provided time point such that various factors of the characteristics are assimilated. Consequently, the extraction of the word and the character levels are easily implemented. In all the channels, the model architecture is consecutive and can be separated into two exclusive distinct parts such as LSTM-NN and CNN. Fig. 2 illustrates the infrastructure of the LSTM model.
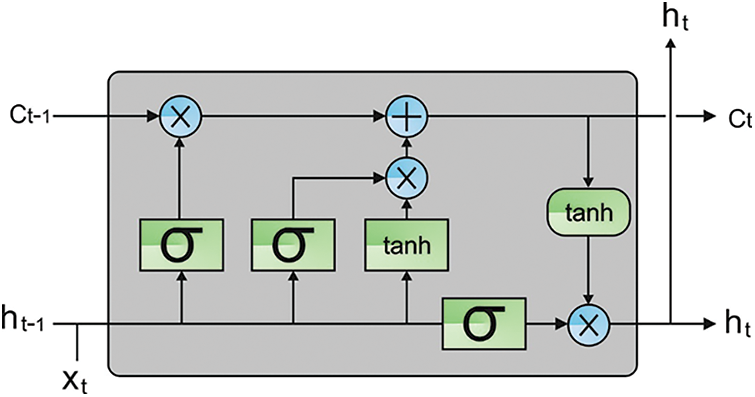
Figure 2: Structure of the LSTM model
For the input sequence
For a simple presentation, the LSTM technique is combined as LSTM (x). Both parallel and the series architectures are employed for LSTM-NN and CNN techniques. In general, the series structure is extensively employed regardless of the data loss, owing to the nature of the convolutional procedure. Several time series features are missing from the series structures due to which the compressed data can be obtained using the LSTM-NN model. Then, the series architecture is substituted with the parallel architecture and the outcomes achieved are relatively well-established. In all the channels, the recordings of the architecture are performed and formulated using the Eq. (2):
A rudimentary description of the word and the character level is acquired from the Eq. (2). Through x demonstrates the output and the input values formulated by
Here,
For a Fully Connected (FC) layer, the hidden state outcome is transmitted. At last, for the classification output, the
A four-channel demonstration is described herewith. A key component of the dynamic pliable weight model is characterized by weight score w and its calculation is as follows.
In Eq. (6),
In Eq. (7), the series length is formulated by x. An adaptive weight is calculated towards the resultant vector
In the QCLSTM algorithm, the input text is first embedded. Then, the vector depiction of the sequence is attained to achieve a good semantic representation and the optimum text feature is extracted. Afterwards, the vector representation of the sequence is achieved. Later, the sequence is convolved through the convolutional layer. A word-level semantic feature is extracted from these models thereby, the output size and the input dataset are reduced by alleviating the over-fitting features. The convolution layer processes the dataset proficiently and sends it to the LSTM layer in such a way that the timing features of the dataset are examined well. Consequently, to improve the classification performance and prevent the subordinate data of the contextual semantics, this structure is accomplished.
To boost the classification results of the QCLSTM model, the QOSPO algorithm is utilized for fine-tuning the hyperparameters. The SPO technique randomly generates an initial population that includes a group of positions for the bower [23]. Each location (pop(i).Pos) is defined as a variable that must be improved. It should be noted that the values of the initial population lie within the pre-defined maximal and minimal boundaries.
For a specific range, the likelihood of attracting a male or a female
Alike the evolutionary-based optimizer, the elitism approach is applied herewith to store the optimum solutions during every iteration of the optimization methodology. It is obvious that other older and experienced males attract the consideration of the others to the bower. In other words, these bowers have additional fitness compared to others. In the SPO method, the position of an optimum bower, constructed by the bird, is forecasted as an elite value of the
It is to be noted that the roulette wheel selection method is applied to select the bowers with a large probability, (
The arbitrary changes are applied to
Finally, the older population and the population accomplished from the variations mentioned earlier, are integrated, sorted, measured and a novel population is generated. It is to be noted that if the SPO features are to be changed, five controlling parameters should be adapted, namely,
In these expressions,

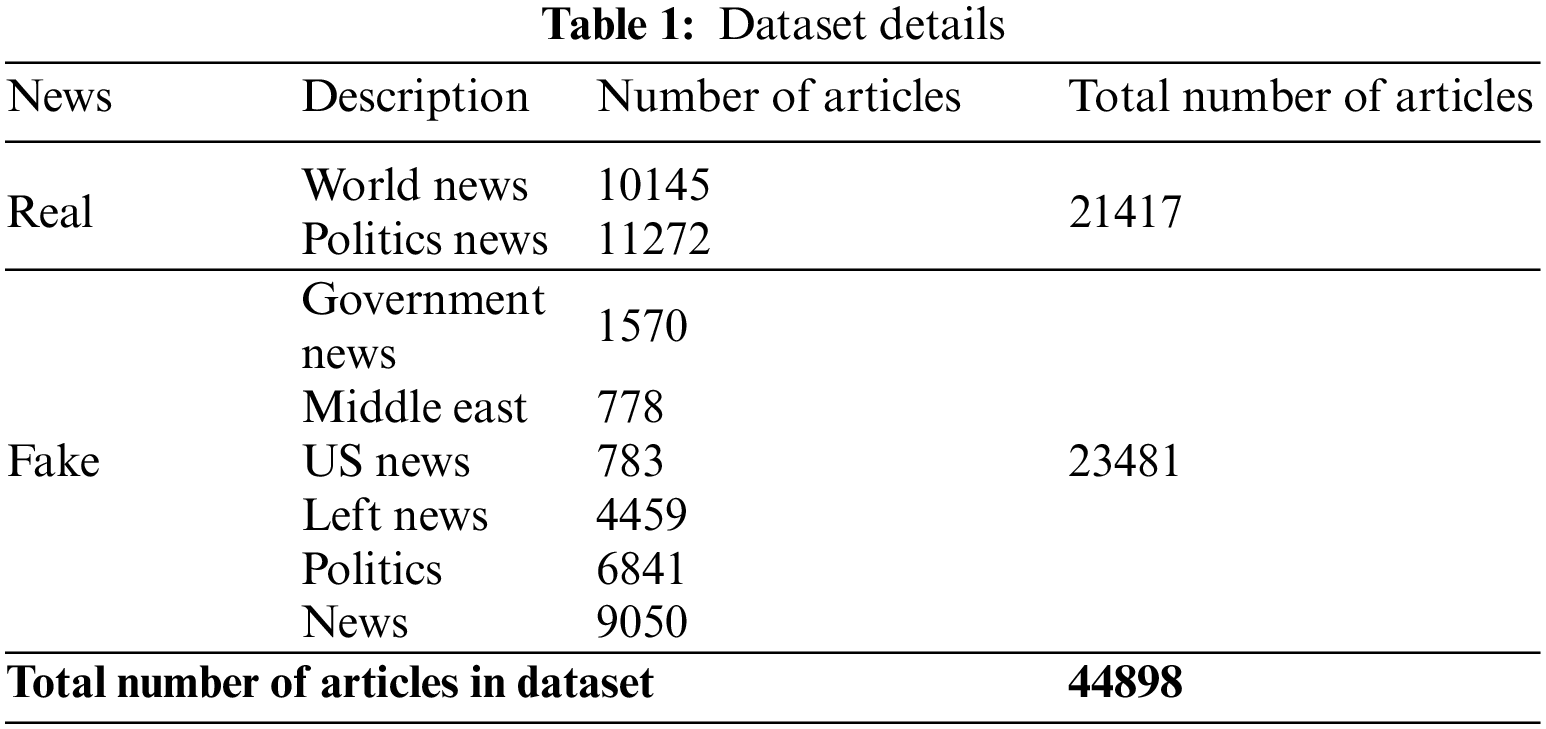
The proposed QCLSTM-FNC model was experimentally validated using a fake news dataset. The dataset contains the samples under two classes namely, real and fake. Table 1 showcases a detailed description of the dataset.
The classification results of the QCLSTM-FNC model are represented by means of confusion matrices in Fig. 3. With the entire dataset, the QCLSTM-FNC model recognized 21,254 samples under real class and 23,267 samples under fake class. In contrast, with 70% of the training (TR) dataset, the QCLSTM-FNC technique classified 14,849 samples under real class and 16,302 samples under fake class. Eventually, with 30% of the testing (TS) dataset, the proposed QCLSTM-FNC approach categorized 6,405 samples under real class and 6,965 samples under fake class.
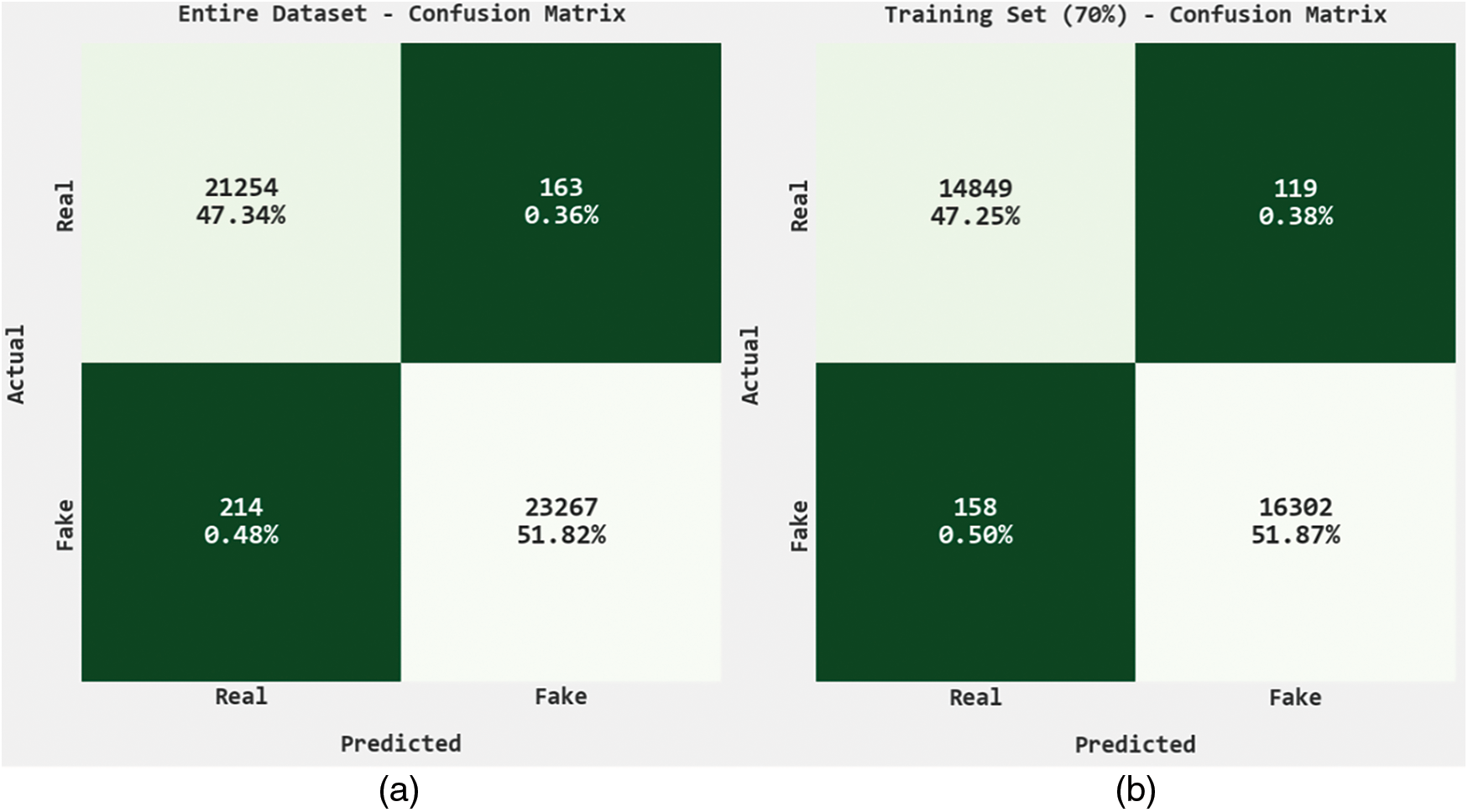
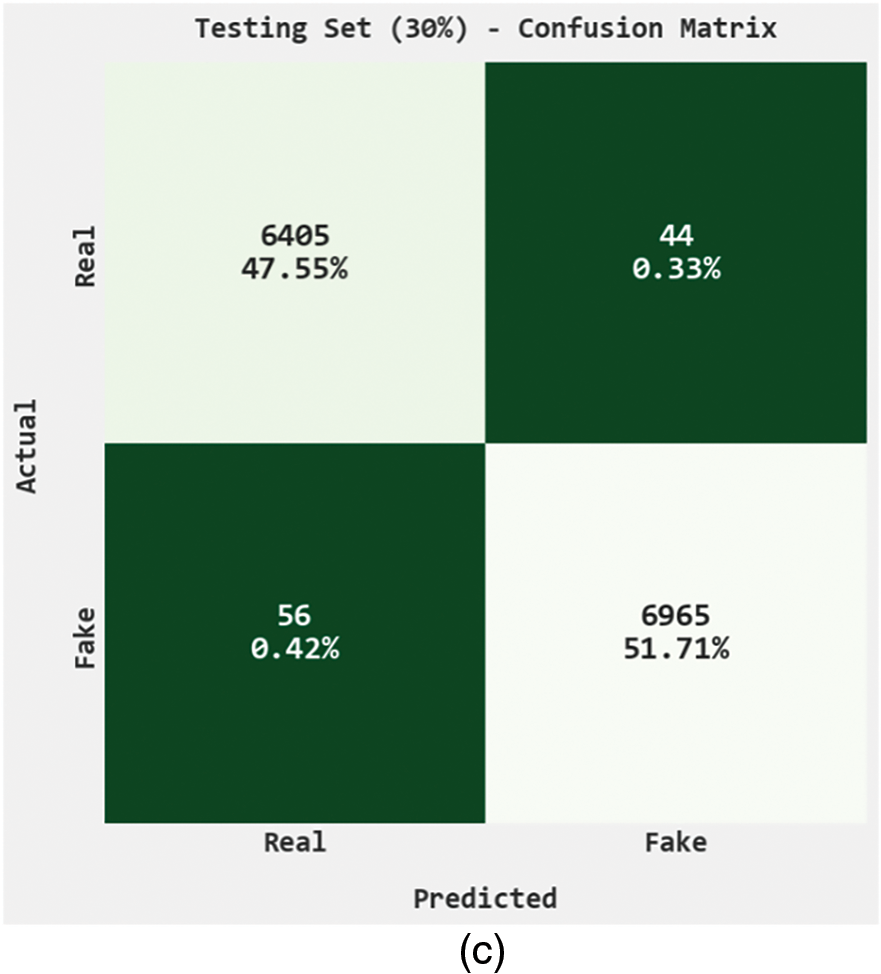
Figure 3: Confusion matrices of the QCLSTM-FNC approach (a) Entire dataset, (b) 70% of the TR data, and (c) 30% of the TS data
Table 2: Fake news Classification results of the QCLSTM-FNC model in terms of different measures namely Accuracy (ACC), Precision (PRE), Recall (RS), F-Score (FS), and Jaccard Index (JI). Fig. 4 highlights the overall fake news classification performance of the QCLSTM-FNC model on the entire dataset. The figure reports that the QCLSTM-FNC model accomplished the improved classification outcomes. For instance, the QCLSTM-FNC model recognized the real class instances with an ACC of 99.16%, PRE of 99%, REC of 99.24%, FS of 99.12% and a JI of 98.26%. Meanwhile, the QCLSTM-FNC technique classified the fake class instances with an ACC of 99.16%, PRE of 99.30%, REC of 99.09%, FS of 99.20% and a JI of 98.41%.
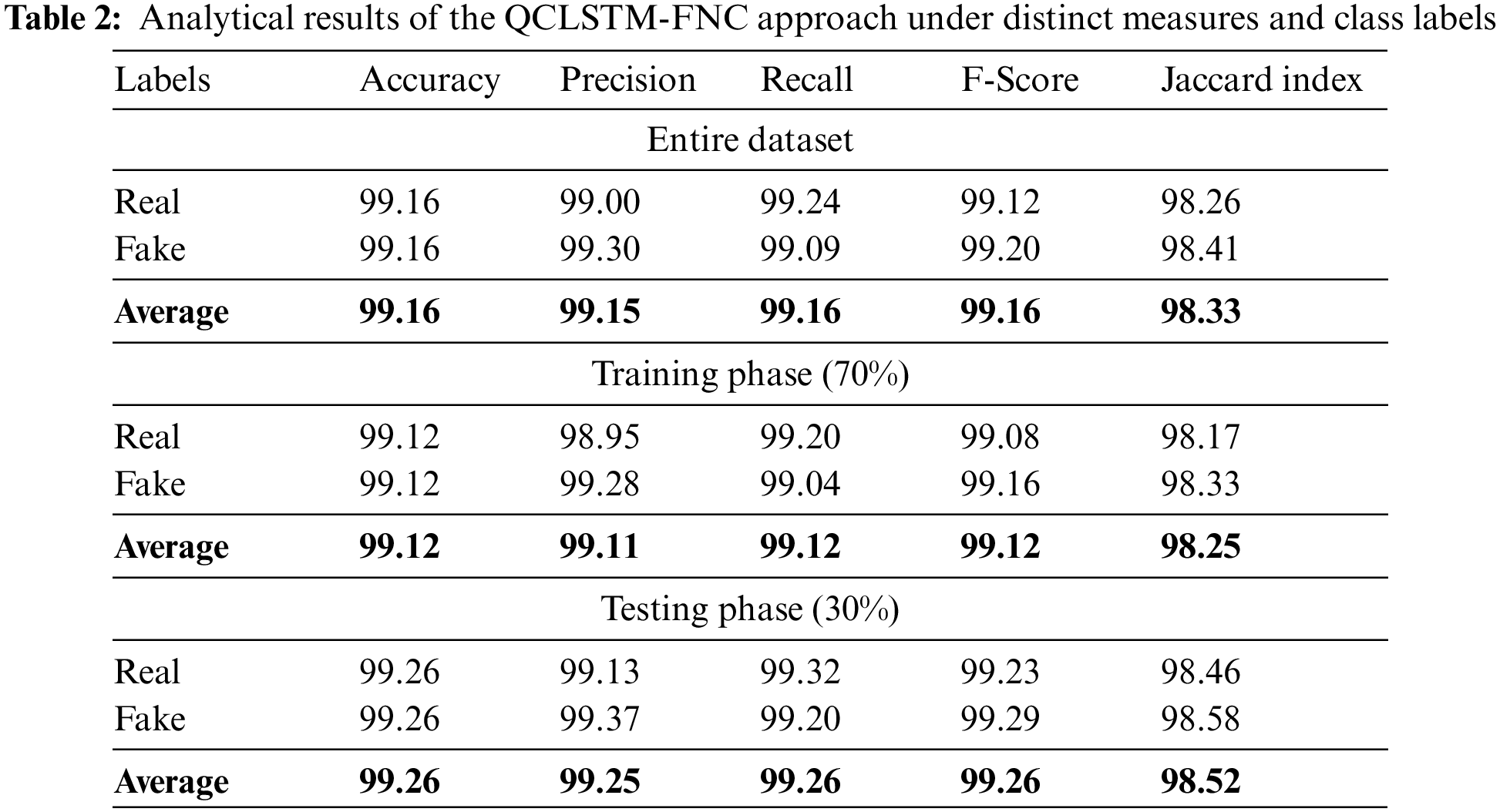
Figure 4: Analytical results of the QCLSTM-FNC approach on the entire dataset
Fig. 5 portrays the complete fake news classification performance of the proposed QCLSTM-FNC approach on 70% of the TR data. The figure states that the QCLSTM-FNC algorithm exhibited the enhanced classification outcomes. For example, the QCLSTM-FNC method recognized the real class instances with an ACC of 99.12%, PRE of 98.95%, REC of 99.20%, FS of 99.08% and a JI of 98.17%. Eventually, the proposed QCLSTM-FNC technique recognized the fake class instances with an ACC of 99.12%, PRE of 99.28%, REC of 99.04%, FS of 99.16% and a JI of 98.33%.
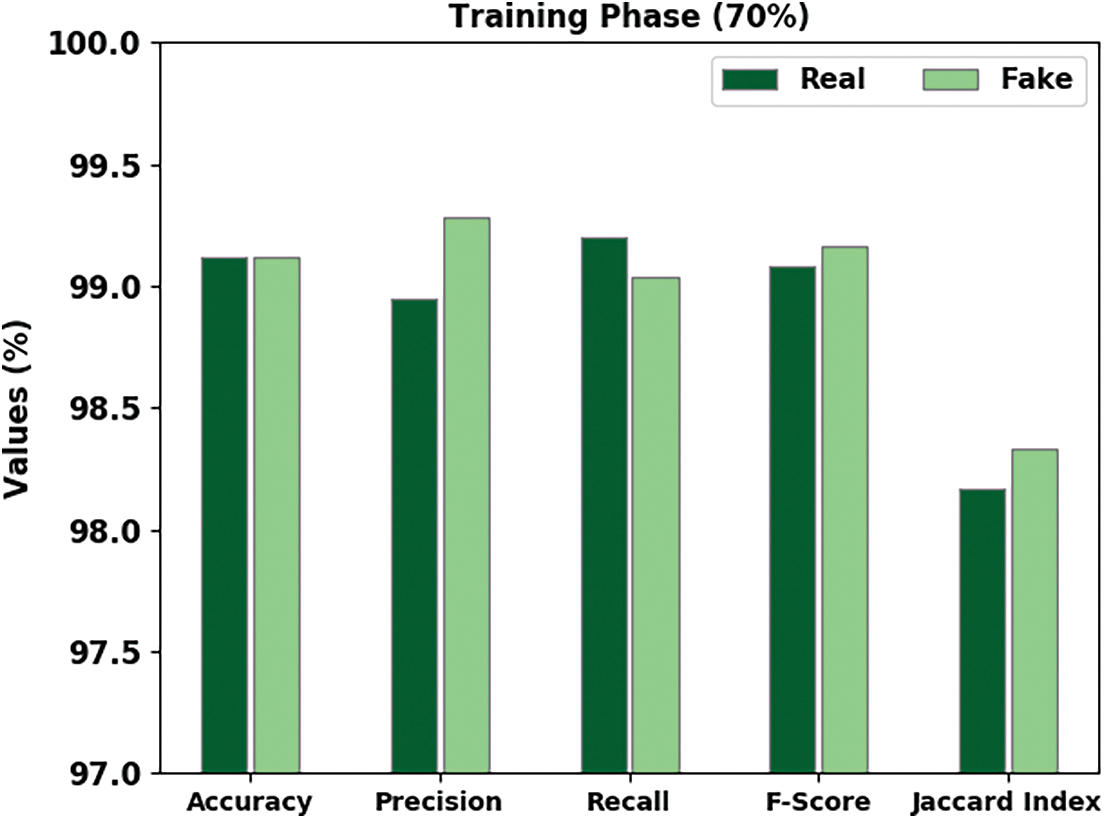
Figure 5: Analytical results of the QCLSTM-FNC approach on 70% of the TR data
Fig. 6 demonstrates the comprehensive fake news classification performance of the proposed QCLSTM-FNC technique on 30% of the TS data. The figure expresses that the QCLSTM-FNC method achieved the improved classification outcomes. For example, the QCLSTM-FNC methodology recognized the real class instances with an ACC of 99.26%, PRE of 99.13%, REC of 99.32%, FS of 99.23% and a JI of 98.46%. Meanwhile, the proposed QCLSTM-FNC approach categorized the fake class instances with an ACC of 99.26%, REC of 99.37%, REC of 99.20%, FS of 99.29% and a JI of 98.58%.
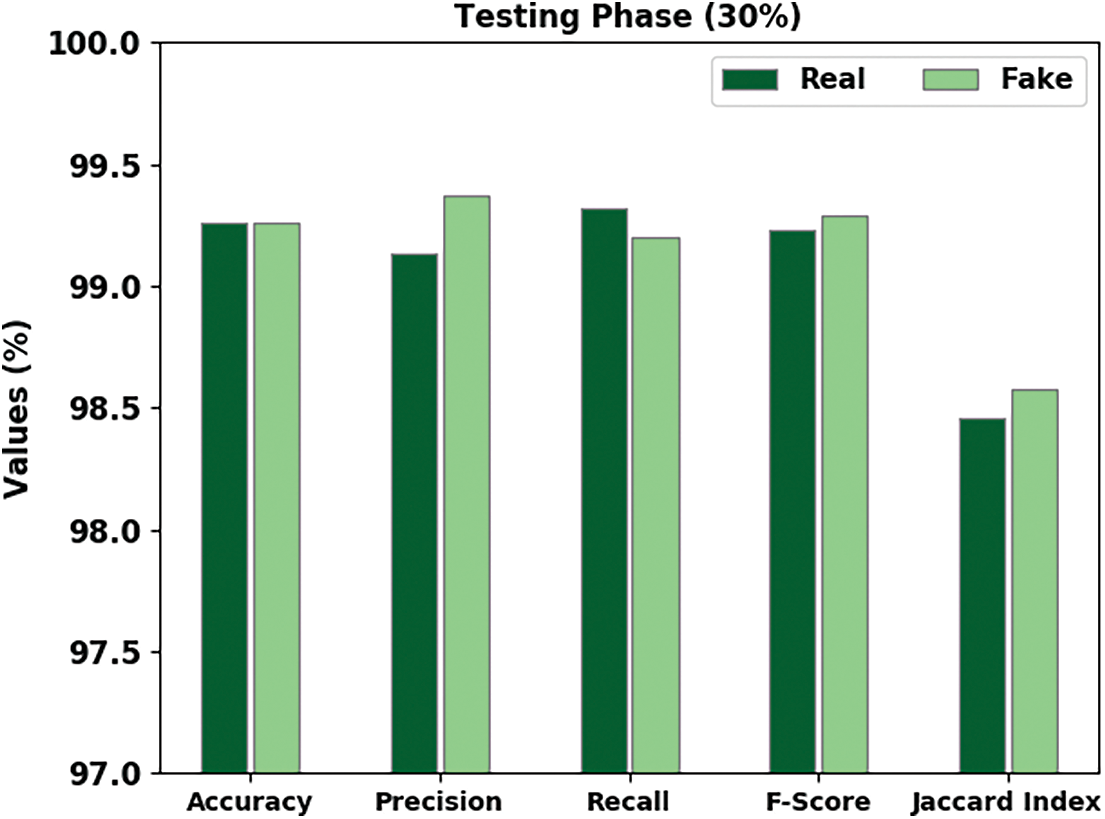
Figure 6: Analytical results of the QCLSTM-FNC approach on 30% of the TS data
Both Training Accuracy (TRA) and Validation Accuracy (VLA) values, gained by the QCLSTM-FNC methodology on the test dataset, are presented in Fig. 7. The experimental outcomes denote that the proposed QCLSTM-FNC approach attained the maximal TRA and VLA values whereas the VLA values were superior to TRA values.
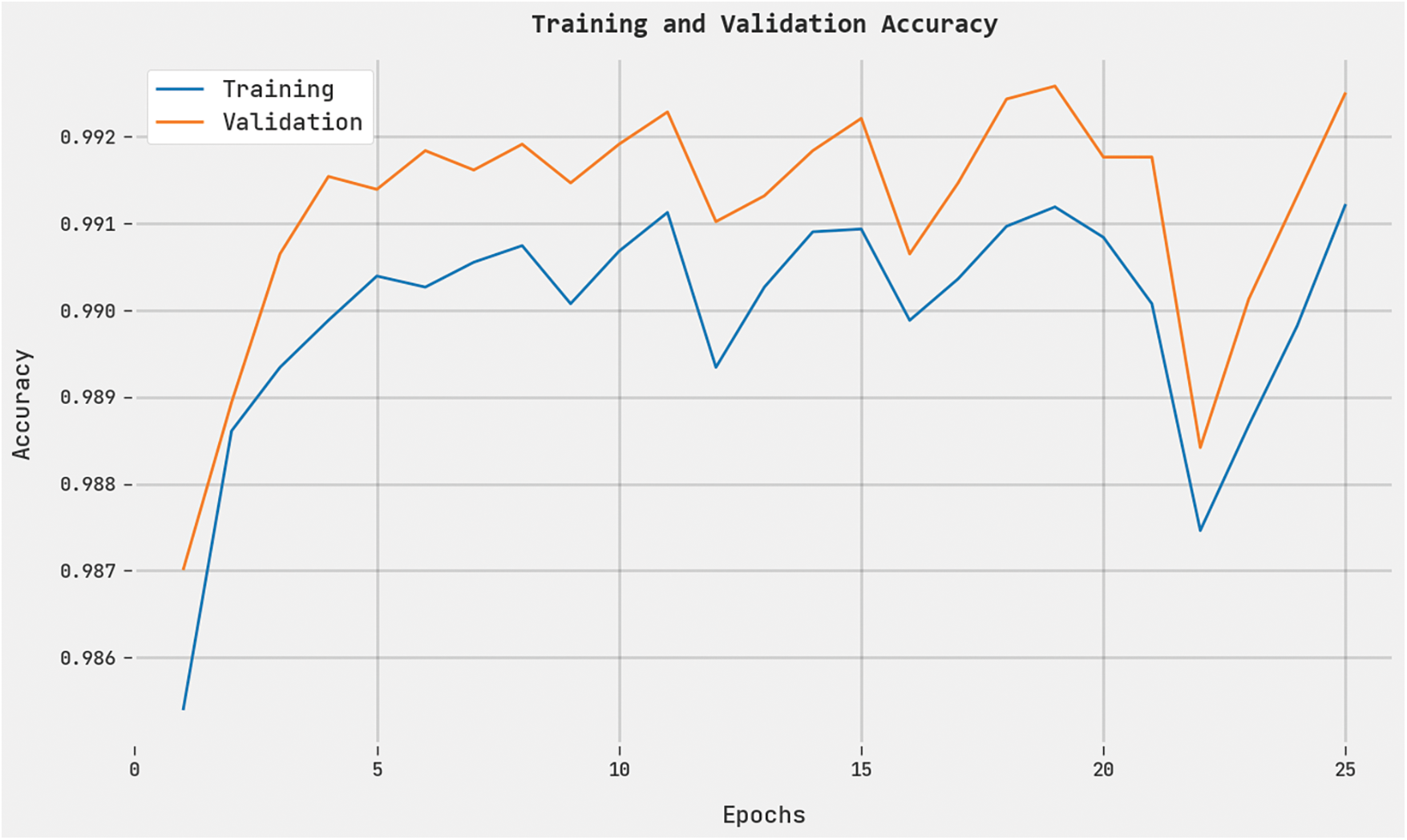
Figure 7: TRA and VLA analyses results of the QCLSTM-FNC approach
Both Training Loss (TRL) and Validation Loss (VLL) values, acquired by the QCLSTM-FNC method on the test dataset, are given in Fig. 8. The experimental outcomes imply that the proposed QCLSTM-FNC approach exhibited the least TRL and VLL values whereas the VLL values were lesser than the TRL values.
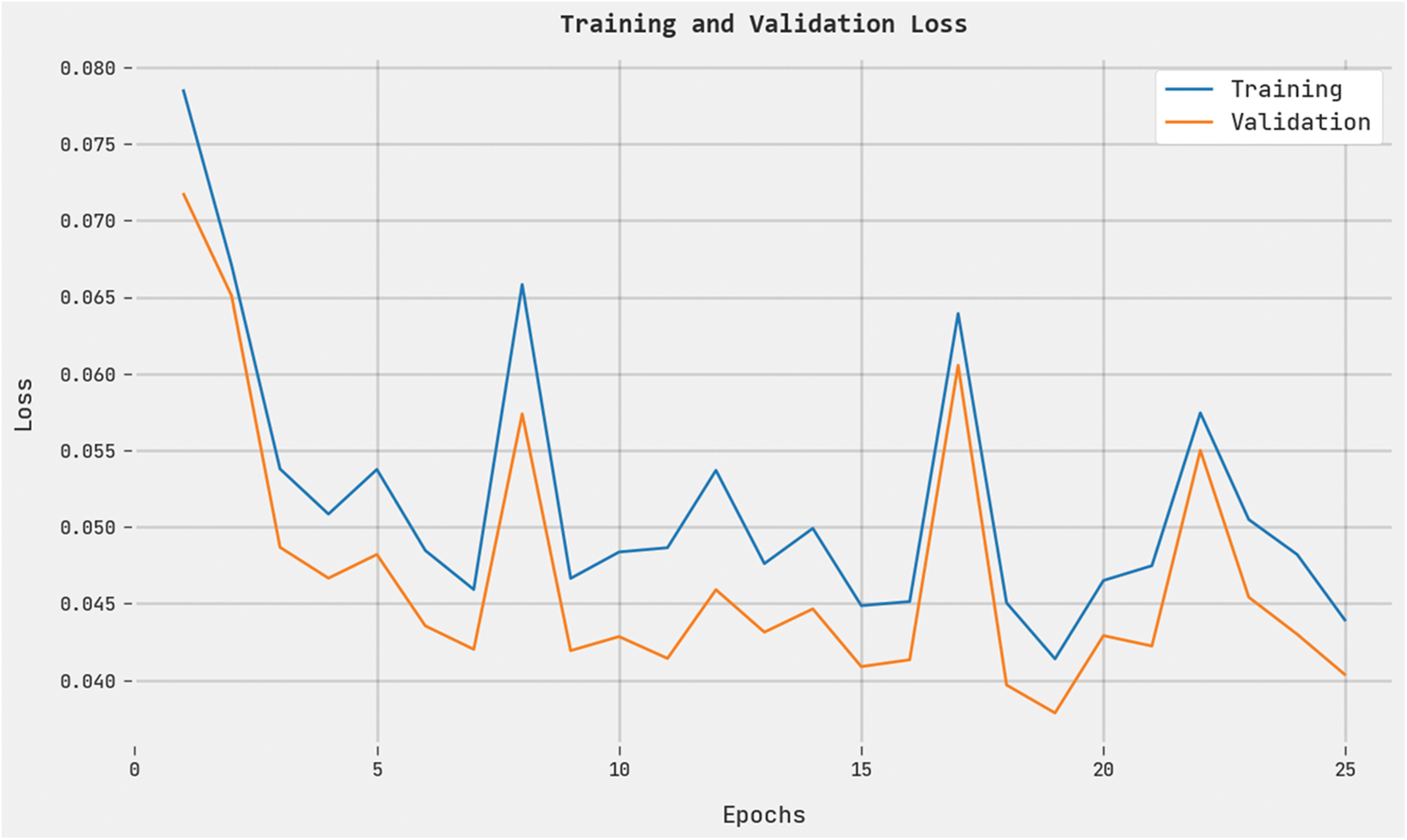
Figure 8: TRL and VLL analyses results of the QCLSTM-FNC approach
In order to showcase the enhanced performance of the proposed QCLSTM-FNC model, a comprehensive comparison study was conducted and the results are shown in Table 3 [11]. Fig. 9 reports the comparative ACC assessment outcomes achieved by the proposed QCLSTM-FNC model over other models such as the Random Forest (RF) method, Decision Tree (DT), AB, CNN, RNN and the hybrid CNN-RNN model. These results imply that the RF and AB models achieved the least ACC values such as 91.48% and 92.02% respectively whereas the DT model attained a certainly improved ACC of 95.59%. Moreover, the CNN, RNN, and the hybrid CNN-RNN model accomplished moderately closer
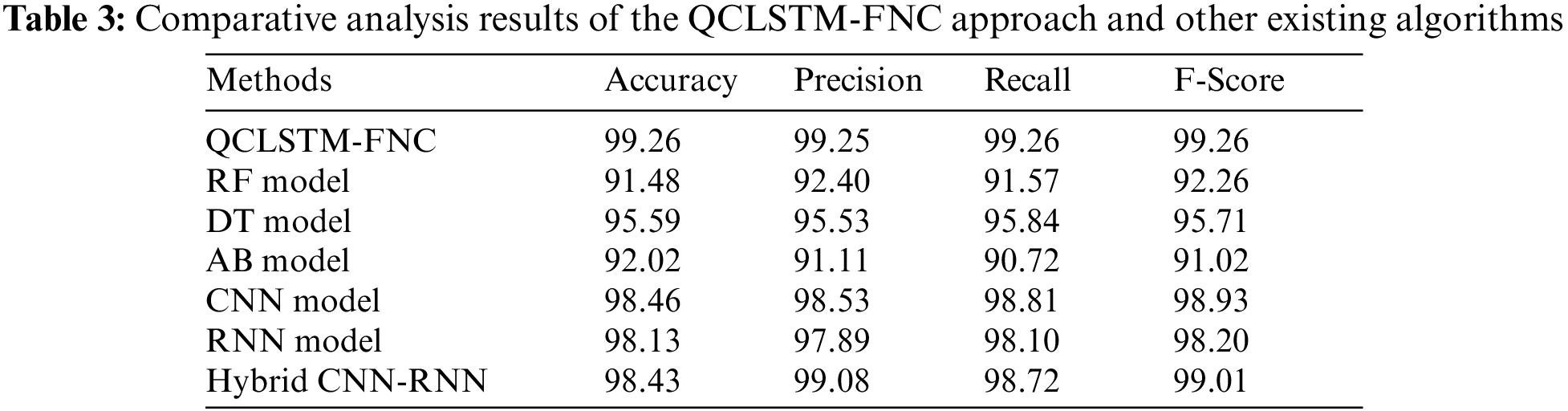
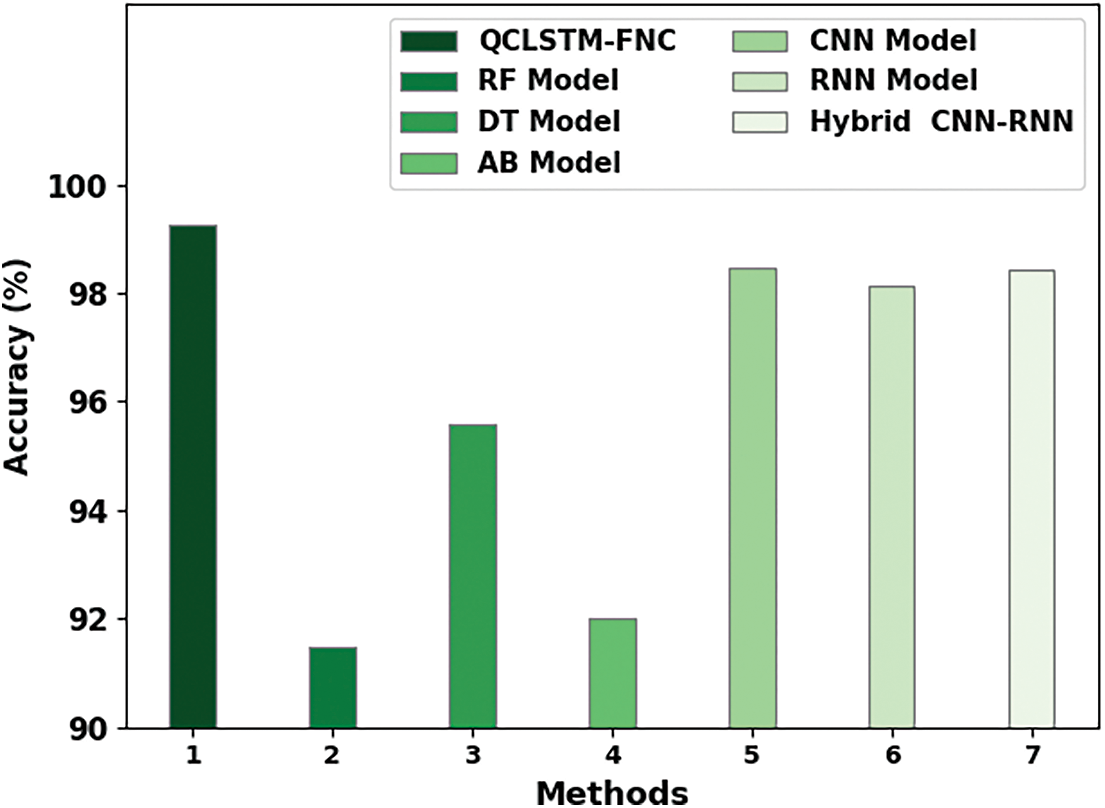
Figure 9:
Fig. 10 illustrates the brief PRE assessment outcomes of the QCLSTM-FNC approach over other models. These results imply that the RF and the AB methodologies accomplished the least PRE values such as 92.40% and 91.11% correspondingly whereas the DT technique gained a certainly improved PRE of 95.53%. In addition, the CNN, RNN and the hybrid CNN-RNN technique displayed moderately closer PRE values such as 98.53%, 97.89%, and 99.08%, respectively. But the figure confirmed the outstanding performance of the QCLSTM-FNC method with a maximum PRE of 99.25%.
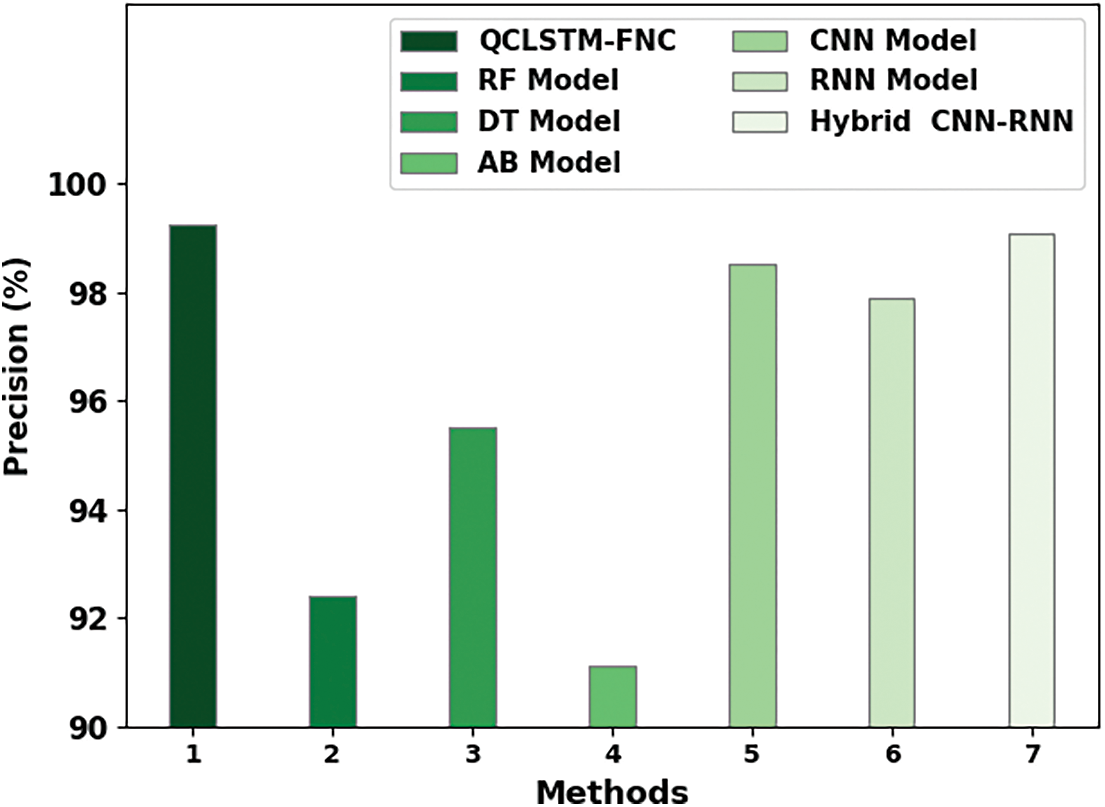
Figure 10:
Fig. 11 signifies the detailed REC analysis outcomes of the proposed QCLSTM-FNC technique over other models. These results represent that the RF and the AB methods displayed the least REC values such as 91.57% and 90.72% correspondingly whereas the DT model attained a certainly improved REC of 95.84%. Furthermore, the CNN, RNN and the hybrid CNN-RNN technique established the moderately closer REC values such as 98.81%, 98.10%, and 98.72% respectively. But the figure confirmed the better performance of the QCLSTM-FNC method with a maximum REC of 99.26%. Thus, it can be inferred that the proposed QCLSTM-FNC model can be used to recognize the fake news on social media.
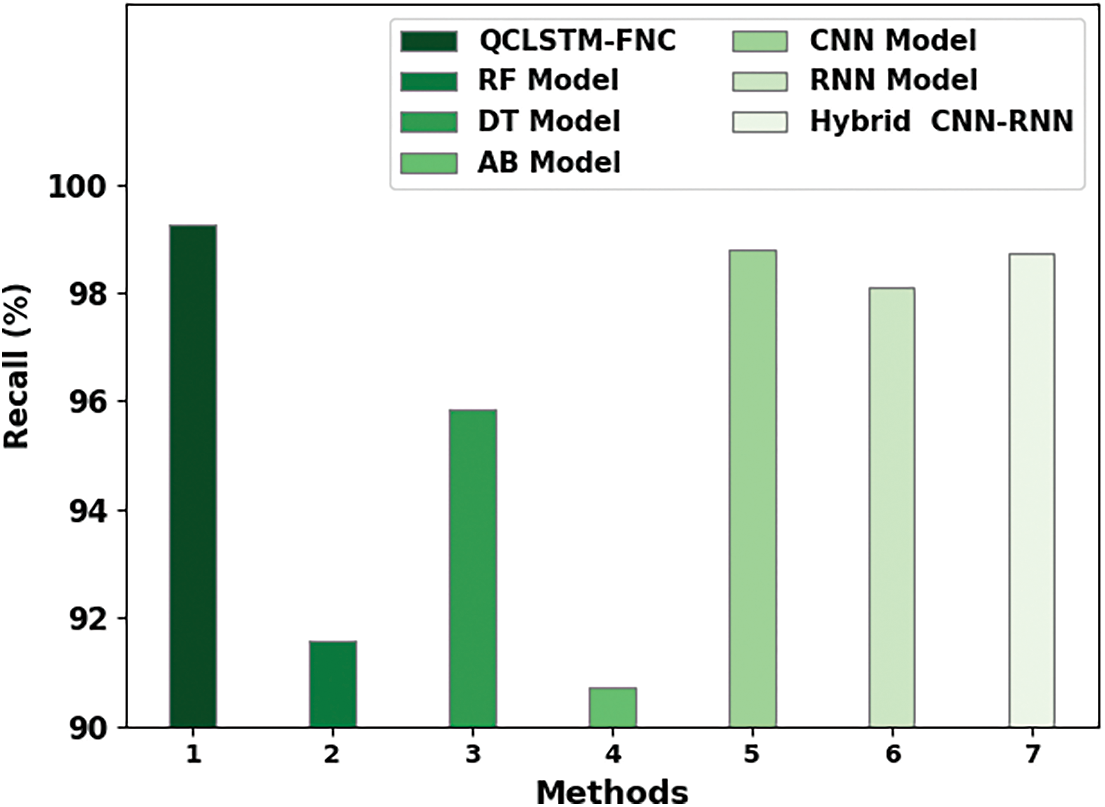
Figure 11:
In this article, a novel QCLSTM-FNC approach has been established for the identification and classification of the fake news. The aim of the presented QCLSTM-FNC approach is to identify and differentiate the fake news from original news. To attain this, the QCLSTM-FNC approach follows two processes such as the data pre-processing process and the Glove-based word embedding process. Besides, the QCLSTM model is utilized for the purpose of classification. To boost the classification results of the QCLSTM model, the QOSPO algorithm is utilized for fine-tuning the hyperparameters. The QCLSTM-FNC approach was experimentally validated against a benchmark dataset. The QCLSTM-FNC approach successfully outperformed the existing DL models under different measures. In the future, the presented approach can be extended to examine the fake COVID-19 tweets in a real-time environment.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R281), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4331004DSR41).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. R. K. Kaliyar, A. Goswami and P. Narang, “FakeBERT: Fake news detection in social media with a BERT-based deep learning approach,” Multimedia Tools and Applications, vol. 80, no. 8, pp. 11765–11788, 2021. [Google Scholar] [PubMed]
2. M. Sarnovský, V. M. Krešňáková and K. Ivancová, “Fake news detection related to the COVID-19 in slovak language using deep learning methods,” Acta Polytechnica Hungarica, vol. 19, no. 2, pp. 43–57, 2022. [Google Scholar]
3. F. N. Al-Wesabi, “A smart English text zero-watermarking approach based on third-level order and word mechanism of markov model,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1137–1156, 2020. [Google Scholar]
4. D. H. Lee, Y. R. Kim, H. J. Kim, S. M. Park and Y. J. Yang, “Fake news detection using deep learning,” Journal of Information Processing Systems, vol. 15, no. 5, pp. 1119–1130, 2019. [Google Scholar]
5. A. Zervopoulos, A. G. Alvanou, K. Bezas, A. Papamichail, M. Maragoudakis et al., “Deep learning for fake news detection on Twitter regarding the 2019 Hong Kong protests,” Neural Computing and Applications, vol. 34, no. 2, pp. 969–982, 2022. [Google Scholar]
6. F. N. Al-Wesabi, “A hybrid intelligent approach for content authentication and tampering detection of arabic text transmitted via internet,” Computers, Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. [Google Scholar]
7. E. Amer, K. S. Kwak and S. El-Sappagh, “Context-based fake news detection model relying on deep learning models,” Electronics, vol. 11, no. 8, pp. 1255, 2022. [Google Scholar]
8. F. N. Al-Wesabi, “Entropy-based watermarking approach for sensitive tamper detection of Arabic text,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. [Google Scholar]
9. R. K. Kaliyar, A. Goswami and P. Narang, “EchoFakeD: Improving fake news detection in social media with an efficient deep neural network,” Neural Computing and Applications, vol. 33, no. 14, pp. 8597–8613, 2021. [Google Scholar] [PubMed]
10. F. N. Al-Wesabi, “Proposing high-smart approach for content authentication and tampering detection of Arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. [Google Scholar]
11. A. Kumar, J. P. Singh and A. K. Singh, “COVID-19 Fake news detection using ensemble-based deep learning model,” IT Professional, vol. 24, no. 2, pp. 32–37, 2022. [Google Scholar]
12. F. Harrag and M. K. Djahli, “Arabic fake news detection: A fact-checking based deep learning approach,” Transactions on Asian and Low-Resource Language Information Processing, vol. 21, no. 4, pp. 1–34, 2022. [Google Scholar]
13. A. Thota, P. Tilak, S. Ahluwalia and N. Lohia, “Fake news detection: A deep learning approach,” SMU Data Science Review, vol. 1, no. 3, pp. 10, 2018. [Google Scholar]
14. B. Palani, S. Elango and V. K. Viswanathan, “CB-Fake: A multimodal deep learning framework for automatic fake news detection using capsule neural network and BERT,” Multimedia Tools and Applications, vol. 81, no. 4, pp. 5587–5620, 2022. [Google Scholar] [PubMed]
15. J. A. Nasir, O. S. Khan and I. Varlamis, “Fake news detection: A hybrid CNN-RNN based deep learning approach,” International Journal of Information Management Data Insights, vol. 1, no. 1, pp. 100007, 2021. [Google Scholar]
16. A. Agarwal, M. Mittal, A. Pathak and L. M. Goyal, “Fake news detection using a blend of neural networks: An application of deep learning,” SN Computer Science, vol. 1, no. 3, pp. 1–9, 2020. [Google Scholar]
17. S. Kumar, R. Asthana, S. Upadhyay, N. Upreti and M. Akbar, “Fake news detection using deep learning models: A novel approach,” Transactions on Emerging Telecommunications Technologies, vol. 31, no. 2, pp. e3767, 2020. [Google Scholar]
18. T. Ahmad, M. S. Faisal, A. Rizwan, R. Alkanhel, P. W. Khan et al., “Efficient fake news detection mechanism using enhanced deep learning model,” Applied Sciences, vol. 12, no. 3, pp. 1743, 2022. [Google Scholar]
19. T. Chauhan and H. Palivela, “Optimization and improvement of fake news detection using deep learning approaches for societal benefit,” International Journal of Information Management Data Insights, vol. 1, no. 2, pp. 100051, 2021. [Google Scholar]
20. Y. Jin, X. Wang, R. Yang, Y. Sun, W. Wang et al., “Towards fine-grained reasoning for fake news detection,” in Proc. of the AAAI Conf. on Artificial Intelligence, USA, vol. 36, no. 5, pp. 5746–5754, 2022. [Google Scholar]
21. D. Mouratidis, M. N. Nikiforos and K. L. Kermanidis, “Deep learning for fake news detection in a pairwise textual input schema,” Computation, vol. 9, no. 2, pp. 20, 2021. [Google Scholar]
22. S. K. Prabhakar and D. O. Won, “Medical text classification using hybrid deep learning models with multihead attention,” Computational Intelligence and Neuroscience, vol. 2021, pp. 1–16, 2021. [Google Scholar]
23. A. Kaur, S. Jain and S. Goel, “Sandpiper optimization algorithm: A novel approach for solving real-life engineering problems,” Applied Intelligence, vol. 50, no. 2, pp. 582–619, 2020. [Google Scholar]
24. R. V. Rao and D. P. Rai, “Optimization of submerged arc welding process parameters using quasi-oppositional based Jaya algorithm,” Journal of Mechanical Science and Technology, vol. 31, no. 5, pp. 2513–2522, 2017. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools