
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Regional Distribution Network Coordinated Optimization Strategy for Electric Vehicle Clusters Based on Parametric Deep Reinforcement Learning
1 State Grid Hubei Electric Power Research Institute, Wuhan, 430000, China
2 Hubei Key Laboratory of Regional New Power Systems and Rural Energy System Configuration, Wuhan, 430000, China
3 Hubei Engineering Research Center of the Construction and Operation Control Technology of New Power Systems, Wuhan, 430000, China
4 School of Electrical Engineering and Automation, Anhui University, Hefei, 230601, China
5 School of Artificial Intelligence, Anhui University, Hefei, 230601, China
* Corresponding Author: Lingxiao Yang. Email:
(This article belongs to the Special Issue: Grid Integration of Intermittent Renewable Energy Resources: Technologies, Policies, and Operational Strategies)
Energy Engineering 2026, 123(3), 10 https://doi.org/10.32604/ee.2025.071006
Received 29 July 2025; Accepted 17 October 2025; Issue published 27 February 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
To address the high costs and operational instability of distribution networks caused by the large-scale integration of distributed energy resources (DERs) (such as photovoltaic (PV) systems, wind turbines (WT), and energy storage (ES) devices), and the increased grid load fluctuations and safety risks due to uncoordinated electric vehicles (EVs) charging, this paper proposes a novel dual-scale hierarchical collaborative optimization strategy. This strategy decouples system-level economic dispatch from distributed EV agent control, effectively solving the resource coordination conflicts arising from the high computational complexity, poor scalability of existing centralized optimization, or the reliance on local information decision-making in fully decentralized frameworks. At the lower level, an EV charging and discharging model with a hybrid discrete-continuous action space is established, and optimized using an improved Parameterized Deep Q-Network (PDQN) algorithm, which directly handles mode selection and power regulation while embedding physical constraints to ensure safety. At the upper level, microgrid (MG) operators adopt a dynamic pricing strategy optimized through Deep Reinforcement Learning (DRL) to maximize economic benefits and achieve peak-valley shaving. Simulation results show that the proposed strategy outperforms traditional methods, reducing the total operating cost of the MG by 21.6%, decreasing the peak-to-valley load difference by 33.7%, reducing the number of voltage limit violations by 88.9%, and lowering the average electricity cost for EV users by 15.2%. This method brings a win-win result for operators and users, providing a reliable and efficient scheduling solution for distribution networks with high renewable energy penetration rates.Keywords
The comprehensive advancement of the “Dual Carbon” (Carbon Peak and Carbon Neutrality) strategic goals has accelerated the transition toward a new power system dominated by renewable energy. Within this paradigm, the distribution network, a critical link between energy production and consumption, is evolving into a more active and complex system. The increasing penetration of DERs, such as PV, WT, and EVs, is shifting the operational paradigm from the traditional passive “generation following load” mode to an active control framework featuring synergistic “Generation-Grid-Load-Storage” interactions [1,2]. While this integration enhances sustainability, it also introduces significant uncertainties from real-time electricity prices [3], intermittent renewable generation [4], and stochastic EV user behaviors [5]. These challenges complicate optimal scheduling, achieving economically efficient operation while ensuring power supply security, a paramount concern for modern distribution network management [6].
Extensive research has been conducted to achieve synergistic optimization of “Generation-Grid-Load-Storage” in modern power systems, with various advanced methodologies proposed to improve coordination among these components. For example, hybrid policy-based reinforcement learning (HPRL) has effectively managed transmission constraints and enhanced decision-making under uncertainty [7]. Other studies have developed event-triggered distributed hybrid control (DHC) frameworks to reduce regulation frequency and improve operational efficiency in integrated energy systems (IES) [8]. Power distance-based correction indices (CI) have also been introduced for dynamic control variable selection, enabling more adaptive and precise system adjustments [9]. Further approaches include two-layer optimization models integrating energy management with pricing strategies to balance economic and operational objectives better [10]. While these contributions offer valuable insights for enhancing system flexibility, reliability, and economy, they remain insufficient in addressing the heightened complexities arising from high penetration levels of DERs and EVs. Key challenges include increased unpredictability, scalability limitations, and the need for real-time adaptive coordination beyond the capabilities of existing frameworks.
Artificial intelligence, particularly reinforcement learning (RL), has recently shown transformative potential in handling high-dimensional, nonlinear, and uncertain systems [11,12]. Techniques such as DRL-based indirect multi-energy transaction (IMET) schemes [13], expert-knowledge-integrated RL for real-time scheduling [14], curtailment deadline line (CDL) strategies for renewable energy consumption [15], and multi-task RL for MG restoration [16] have demonstrated improvements in flexibility, economy, and reliability. Literature [17] combined GRU prediction with DDPG to develop a DRL framework for multiple agents in the day-ahead. Although RL has shown potential in handling complex scheduling problems, it still has limitations when applied to real-time scheduling of distribution networks with high penetration of DERs [18]. This is mainly due to the fact that each EV’s decision involves discrete mode selection and continuous power adjustment [19]. When EVs perform independent optimization based on local information in the distribution network, their behavior of concentrated charging during low-price periods causes mutual interference, leading to resource competition, which in turn hinders the system from achieving global optimality [20]. This ’strategy conflict’ [21] makes it difficult for agents to stably coordinate, resulting in existing algorithms being unable to meet the stringent requirements of real-time scheduling for stability and reliability.
Significant research efforts have been devoted to several key areas in the domain of EV and grid interaction. These include modeling EVs’ charging loads to predict and manage electricity demand accurately [22] and developing collaborative EV-grid energy management frameworks to optimize bidirectional energy flow [23]. Additionally, multi-agent algorithms have been explored to reduce operational costs and user range anxiety [24], while market-based strategies are designed for DER aggregators to enhance participation in electricity markets [25]. Furthermore, DRL has been increasingly utilized in applications such as energy management for hybrid EVs [26] and the planning of active distribution networks that incorporate high penetration of EVs, highlighting its growing role in addressing complex coordination challenges in modern power systems [27].
Despite these advancements, key limitations persist when these methods are applied to distribution networks with high penetration of DERs and widespread EV access:
• Multi-Resource Coordination Challenge: Integrating resources with diverse dynamic characteristics into a unified optimization framework remains complex, often leading to suboptimal scheduling.
• Hybrid Action Space Conflict in Multi-Agent Environments: The decision-making for EVs scheduling inherently involves hybrid action spaces (discrete charging modes and continuous power parameters). In multi-agent settings, the independent learning of such hybrid actions can lead to policy conflicts and hinder the convergence to a global optimum.
• Balancing Economy and Stability: Achieving cost-effective operations while maintaining voltage stability and respecting equipment constraints under uncertainty requires highly adaptive and robust algorithms.
To address these gaps, this paper proposes a novel dual-scale hierarchical coordinated optimization strategy designed for the balanced and stable operation of distribution networks with high DER and EVs integration. The main contributions of this work are threefold:
• We develop a dynamic model for key DERs and design a hierarchical control architecture with flexible network functions to enable coordinated multi-resource management.
• We propose an improved PDQN algorithm to handle the discrete-continuous hybrid action space inherent in EVs scheduling. This algorithm models discrete decisions and associated continuous parameters within a unified RL framework, effectively resolving strategy conflicts.
• We embed key physical constraints directly into the learning process to prevent infeasible actions and ensure operational safety, enhancing economic efficiency and system stability.
The remainder of this paper is organized as follows: Section 2 details the DER modeling, hierarchical control architecture, and optimization framework. Section 3 introduces the core PDQN algorithm and its application to the energy system MDP. Section 4 presents simulation results and performance analysis. Finally, Section 5 concludes the paper.
2 Resource Modeling and Scheduling Framework
This section details the mathematical foundation of our coordinated optimization strategy. We describe the MG management framework and the dynamic models of key DERs (PV, WT, ES, and EVs). Finally, we formulate the bi-level optimization problem and introduce the hierarchical control architecture to solve it.
2.1 Microgrid Management Framework
An MG is a small-scale power system comprising DERs, ES, electrical loads, and EVs. As a unique entity in the network, EVs are consumers of electrical energy and can also serve as providers of electrical energy under specific conditions. With the continuous advancement of EV technology, their battery capacity and performance have been steadily improving, enabling them to participate in grid interactions. DERs provide the MG with clean and renewable energy sources. The ES system plays a role in regulating the microgrid. It can store excess electrical energy, absorbing power during periods of energy surplus and releasing power during energy shortages or peak load times, thereby balancing the grid’s supply-demand relationship. These interconnected components work synergistically to provide energy support and services for the MG collectively.
The coordinated scheduling framework proposed in this paper is designed for a grid-connected MG, aiming to optimize the operation of internal distributed resources through a hierarchical control structure, as illustrated in Fig. 1.
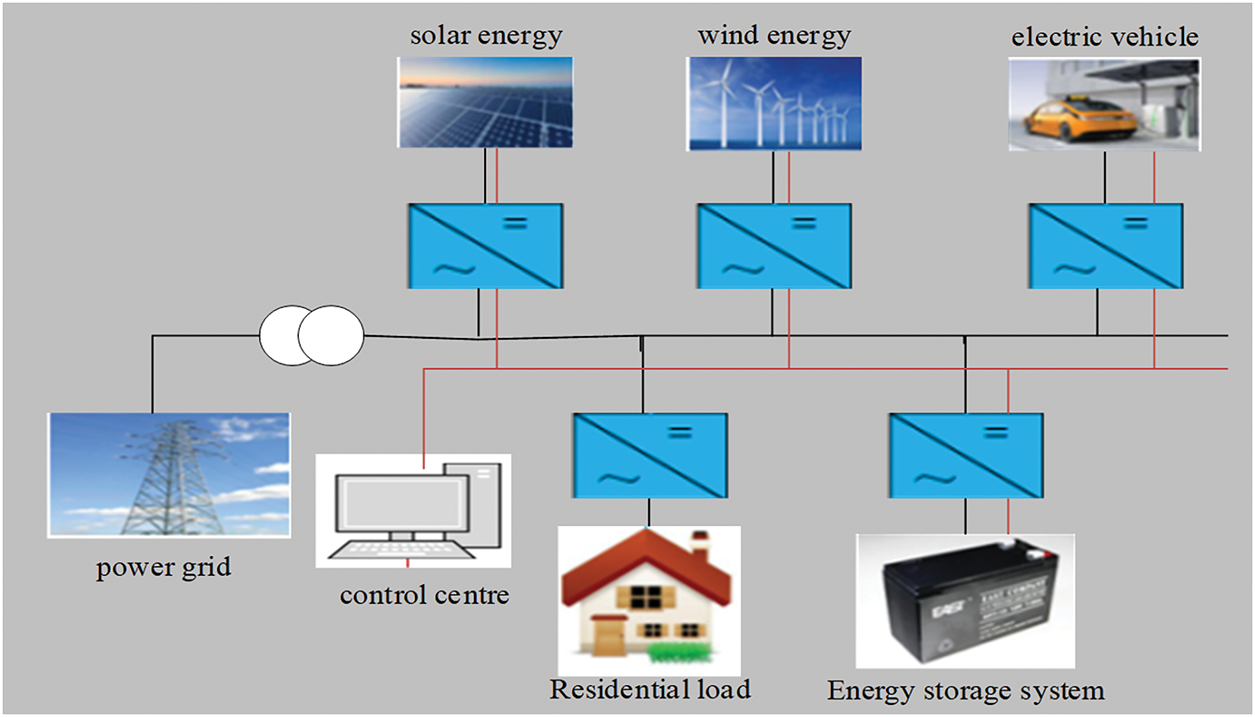
Figure 1: Microgrid model
1. The power generation of the PV system is affected by many factors, and the following mathematical model is established:
In the formula,
2. The power generation of WT is closely related to wind speed, and its mathematical model is as follows:
where
3. The following model expresses the power change of the ES system model:
where
4. EVs charge and discharge model SOC is usually used to simulate the ES capacity of a user’s EVs. The time-domain evolution model of charging and discharging can be expressed as:
where
2.3 Hierarchical Network Solutions
To coordinate multi-scale dynamic resources, address the limitations of centralized control, and mitigate the negative impacts of disordered EVs charging on distribution networks, this paper proposes a two-layer control architecture, illustrated in Fig. 2. Unlike purely decentralized schemes [5], where agents relying solely on local information may lead to system instability caused by conflicting objectives and incomplete observations, the proposed two-layer approach converts system-wide objectives into economic incentives through the introduction of a dynamic pricing mechanism.
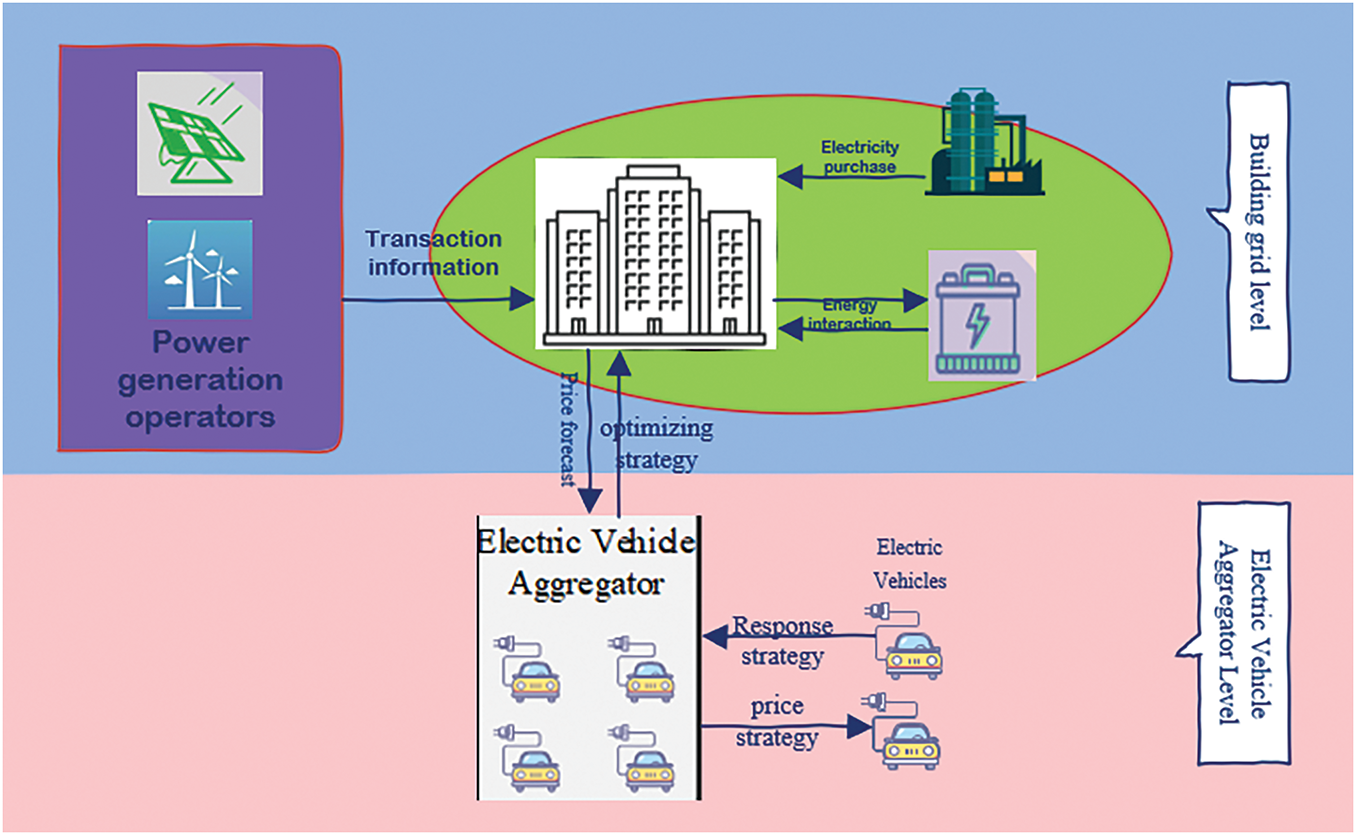
Figure 2: Hierarchical control architecture
The upper control core is the microgrid operator, which possesses global system information and can dynamically adjust the price signal based on the overall system status (i.e., renewable energy generation and total load demand). The goal of this level is to guide the collective behavior of EV agents towards coordinated development towards system-level objectives (i.e., maximization of economic benefits and smoothing of load curves as defined by Eqs. (11)–(13)). The lower level consists of individual EV agents. Each agent, upon receiving the price signal issued by the upper level, independently decides its charging and discharging actions based on its own state, aiming to minimize its individual electricity cost (defined by Eq. (5)) while strictly adhering to its local operational constraints (Eqs. (6)–(10)).
The hierarchical structure proposed a closed-loop feedback loop, where the electricity price signal affects EVs behavior, which in turn alters the system load curve. After operators observe these changes in system states, they adjust the electricity price signal. Through this price-based coordination mechanism, the aforementioned strategic conflicts are resolved. This method avoids the large amount of computation and communication requirements needed for fully centralized control, while addressing the inherent global optimization challenges in fully distributed schemes, ultimately representing a practical and efficient balanced solution.
2.4 Bi-Level Optimization Problem Formulation
1. Objective function
The objective for each EV agent is to minimize its daily electricity cost, which includes the cost of charging and the revenue from discharging. The objective function of EVs is shown:
where
2. Relevant constraints
(1) EVs Charging/Discharging Logic Constraint: Simultaneous charging and discharging are prohibited.
(2) EVs Power Limits:
where
(3) EVs Energy Dynamics.
(4) SOC Boundaries:
(5) Driving Energy Demand Constraint: The SOC at departure must meet the user’s expected driving needs.
1. Objective function
The upper level aims to maximize the economic benefits of the MG operator and flatten the load profile. The specific expressions are shown in Eqs. (11) and (12):
Here,
2. Optimizing constraints
The physical limitations of batteries; the SOC safety boundary, which prevents overcharging or deep discharging; the power line energy balance equation; energy conservation: the sum of grid supply, PV output, and EVs discharge power must equal the load demand plus ES charging power; and electricity price constraints. In summary, the constraints are respectively shown in Eqs. (13)–(15).
Through optimized resource modeling, multi-objective economic scheduling, and hierarchical control architecture, this paper provides theoretical support and technical path for the optimal operation of a power grid with a high proportion of distributed energy access, to balance economy, reliability, and resource flexibility, which is suitable for MG scenarios.
3 Deep Reinforcement Learning Setup
DRL combines the perceptual capability of deep learning with the decision-making ability of reinforcement learning, enabling agents to learn optimal strategies through interaction with complex environments. This study employs DRL to address the challenges of coordinated scheduling in MG with high penetrations of DERs and EVs, specifically the hybrid discrete-continuous action space and multi-agent collaboration problems.
3.1 Markov Decision Process Formulation
The optimization problem is formulated as a Markov Decision Process (MDP), defined by the tuple
State S: The state observable by each EV agent includes the current time, electricity price, and the EVs’ own power state:
Action A: The action space is hybrid, consisting of a discrete charging mode and a continuous power parameter. The discrete action set is
Reward R: The reward function is designed to minimize electricity cost while penalizing constraint violations:
where
The upper layer aims to optimize MG-wide economic efficiency and load profile smoothing through dynamic pricing:
State S: The system-level state encompasses renewable generation, load demand, aggregate EVs’ power, and time:
Action A: The action is the dynamic electricity price signal issued to the EV agents:
Reward R: The reward function is designed to maximize economic revenue for the operator and achieve load flattening.
3.2 PDQN Algorithm and Its Improvement
To natively handle the hybrid discrete-continuous action space inherent in the EVs scheduling problem, we adopt an improved PDQN algorithm. The standard PDQN framework extends Deep Q-Networks by associating each discrete action with continuous parameters, allowing joint learning within a unified policy.
3.2.1 Algorithmic Improvements
1. The key enhancements to the standard PDQN are as follows: Advantage-Based Discrete Action Selection: To mitigate state-value bias and improve the discernibility of discrete actions, we calculate the advantage value for each discrete action using Eq. (21).
This focuses the learning on the relative value of an action compared to the average.
2. Adaptive
3. Directed Parameter Noise Injection: We inject structured noise during action sampling to foster more effective exploration in the continuous parameter space. For a selected discrete action
where
4. Physical Action Clipping: Generated continuous parameters are immediately clipped to their feasible physical ranges to ensure all actions respect system constraints, guaranteeing safe operation during both training and execution:
3.2.2 Loss Functions and Training
The agent is trained by minimizing the following loss functions:
Critic Loss: The critic network
where the target
Actor Loss (Policy Gradient with Entropy Regularization): The actor network
H is the entropy of the policy distribution and
The training workflow of the improved PDQN algorithm is summarized in Table 1, and the overall architecture is depicted in Fig. 3.

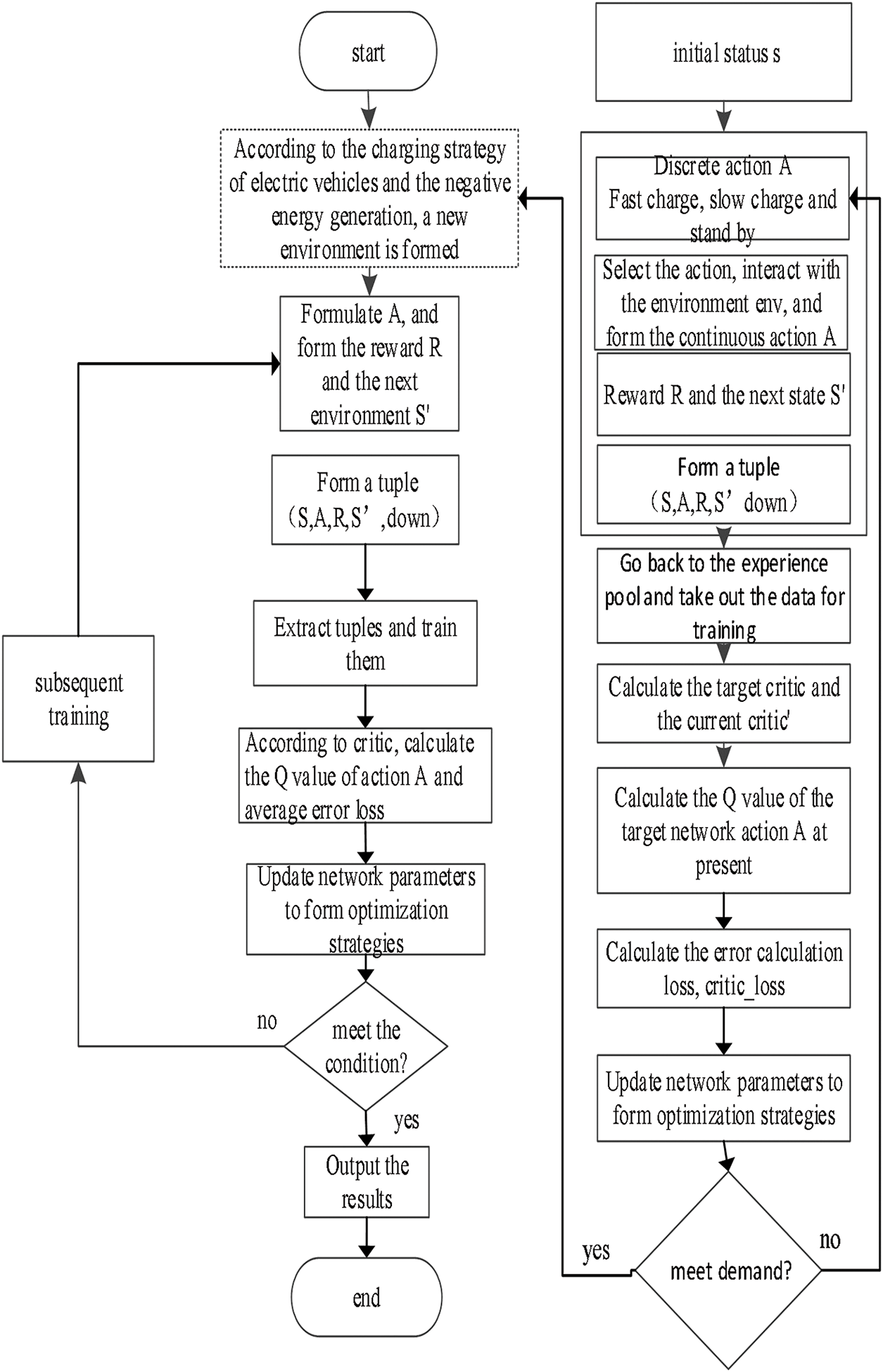
Figure 3: Training process
4 Experimental Results and Analysis
4.1 Environmental Configuration
To validate the effectiveness of the proposed hierarchical optimization framework and the improved PDQN algorithm, a simulation environment based on the residential MG model described in Section 2 was constructed. The system comprises 10 wind turbines (100 kW each), 10 PV units (40 kW each), and 100 EVs (24 kWh battery capacity each). The time-of-use electricity price is listed in Table 2, and key state parameters are detailed in Table 3. Fig. 4 illustrates the residential PV, WT, and load configuration.
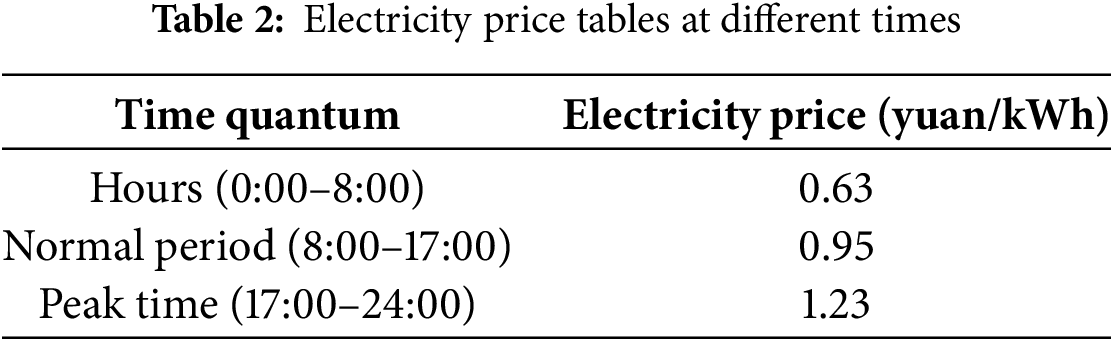
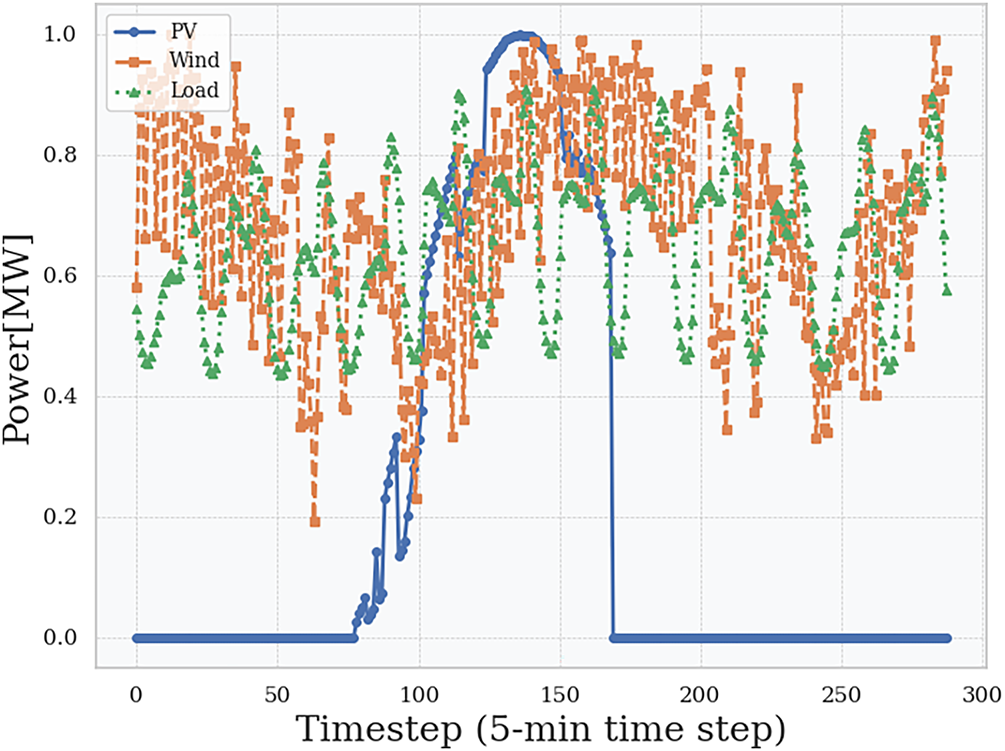
Figure 4: DERs generation power and load power
The performance is evaluated using the following metrics:
1. Cumulative Reward: the primary indicator of overall performance and learning efficiency of the DRL agents;
2. Total Operating Cost
3. Peak-to-Valley Difference
4. Convergence: the number of training episodes required for the algorithm’s reward to approach and stabilize near its maximum value.
To verify the performance of the proposed PDQN algorithm, we selected DDPG and PPO as baseline algorithms. DDPG is a classic algorithm in continuous control tasks, and its performance can effectively test the ability of PDQN in power fine adjustment [13]; PPO is renowned for its stable training and strong adaptability, capable of handling both discrete and continuous actions simultaneously, making it a strong baseline for evaluating mixed action space problems [15]. By selecting these two representative algorithms, different technical routes can be comprehensively covered, and the advantage of PDQN in natively processing mixed action spaces can be highlighted through comparison with them.
4.2 Results Analysis and Discussion
This section presents a comprehensive analysis of the simulation results to validate the effectiveness of the proposed hierarchical optimization framework and the improved PDQN algorithm. The discussion covers training performance, scheduling strategies, algorithm comparison, and quantitative economic benefits.
4.2.1 Analysis of Training Performance
Fig. 5 illustrates the cumulative rewards obtained during training for both the upper-layer and lower-layer strategies.
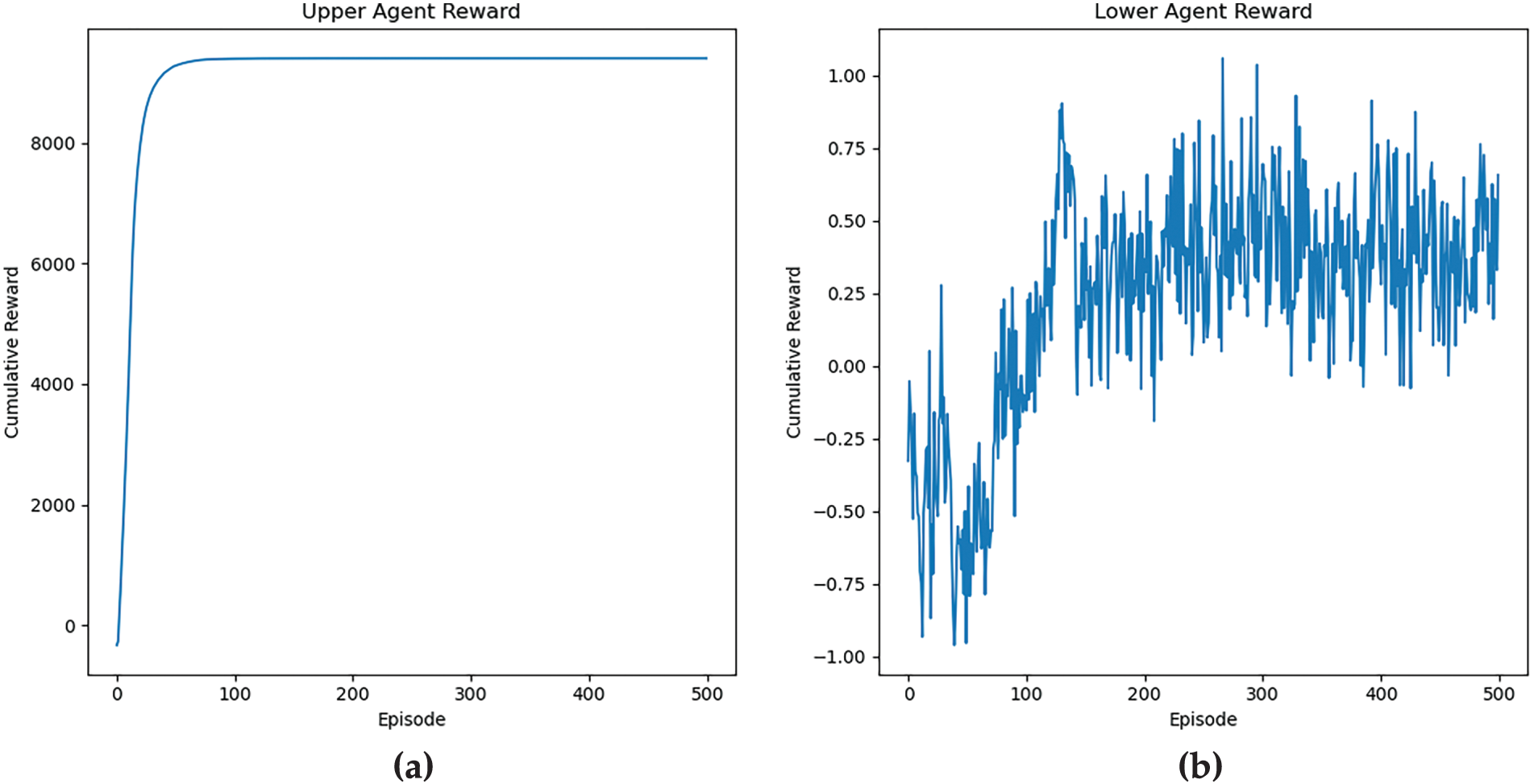
Figure 5: Algorithmic cumulative rewards
Fig. 5a shows that the MG operator’s reward converges rapidly to a stable near-optimal value within approximately 50 episodes. This swift convergence demonstrates the effectiveness of the dynamic pricing strategy in achieving its dual objectives: maximizing economic benefits (
In contrast, as shown in Fig. 5b, the learning process for the EV agents is more volatile, with rewards fluctuating throughout the training period before gradually increasing. This behavior is rational and expected for two reasons: (1) Environmental Dynamics: The EVs agents must adapt to fluctuating renewable generation and load demand, and the dynamic electricity prices issued by the upper-layer agent. (2) Exploration-Exploitation Trade-off: The continued fluctuations indicate sustained exploration, as EVs probe different charging/discharging strategies to maximize their long-term rewards within operational constraints. This ultimately leads to a superior cooperative strategy. The contrasting learning curves between the two layers validate the hierarchical design: a stable, global price signal from the upper layer enables a population of distributed agents at the lower layer to learn complex behaviors coherently.
The contrasting learning curves between the two layers validate the hierarchical design: a stable, centrally-guided pricing signal from the upper layer enables a population of distributed agents at the lower layer to learn complex behaviors without collapsing into chaos.
4.2.2 Analysis of Scheduling Strategies
Fig. 6 presents the dynamic electricity pricing strategy learned by the MG operator. The results align perfectly with economic and grid operation principles:
Figure 6: Electricity price change chart
Valley Period (0:00–8:00): The price is lowest, incentivizing EVs to charge when renewable energy might be abundant and overall grid demand is low. Peak Period (17:00–24:00): The price remains high and close to the original peak price, discouraging additional load from EVs charging during high general electricity demand. Dawn Period, the slight dip in price near dawn could be a strategy to encourage final charging before the morning peak begins, utilizing any remaining surplus generation.
This intelligent pricing pattern demonstrates that the upper-layer agent successfully learned to use price signals to shift EVs’ load away from peak times and toward valley times, thereby achieving the goal of peak shaving and valley filling.
4.2.3 EVs Scheduling Strategy Analysis
The scheduling strategy that emerged from the lower-layer EV agents is the direct result of the price signal issued by the upper-layer agent. Figs. 7–9 comprehensively visualizes this demand response process over 24 h.
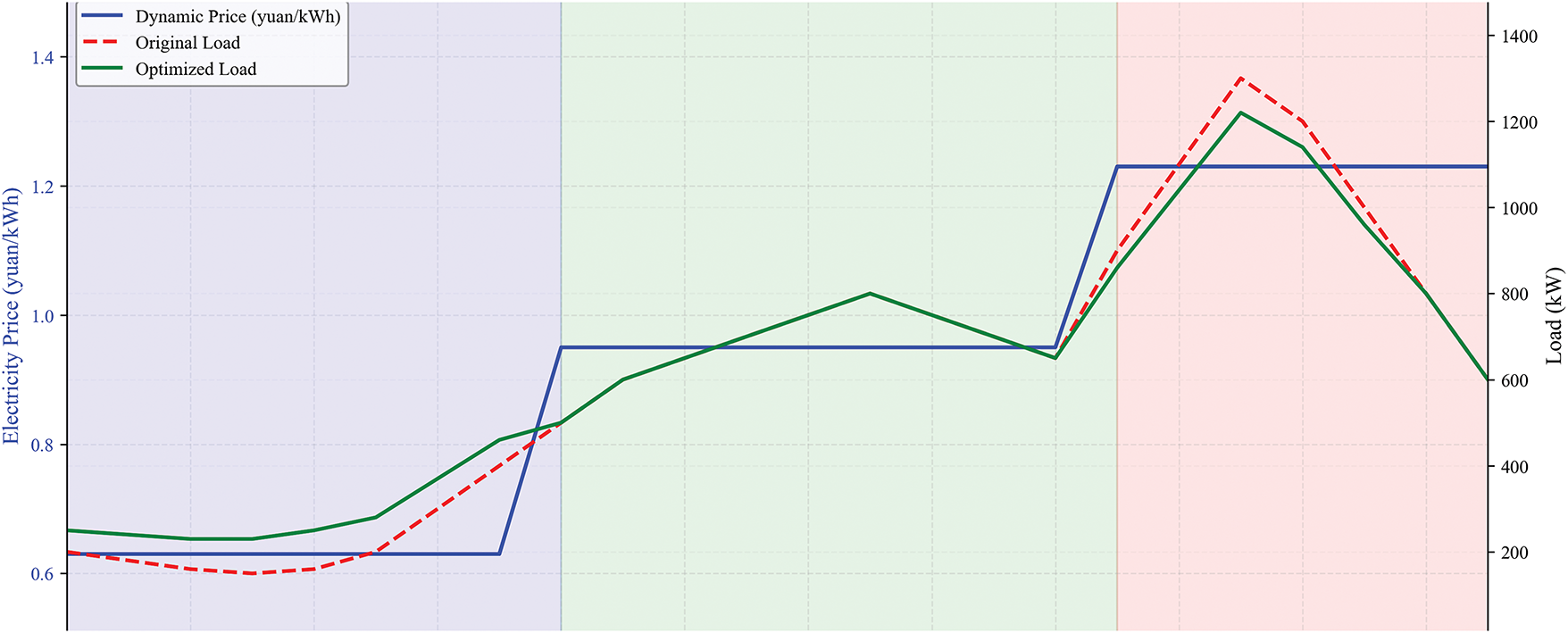
Figure 7: Upper-layer dynamic price signal and the resultant total load profile
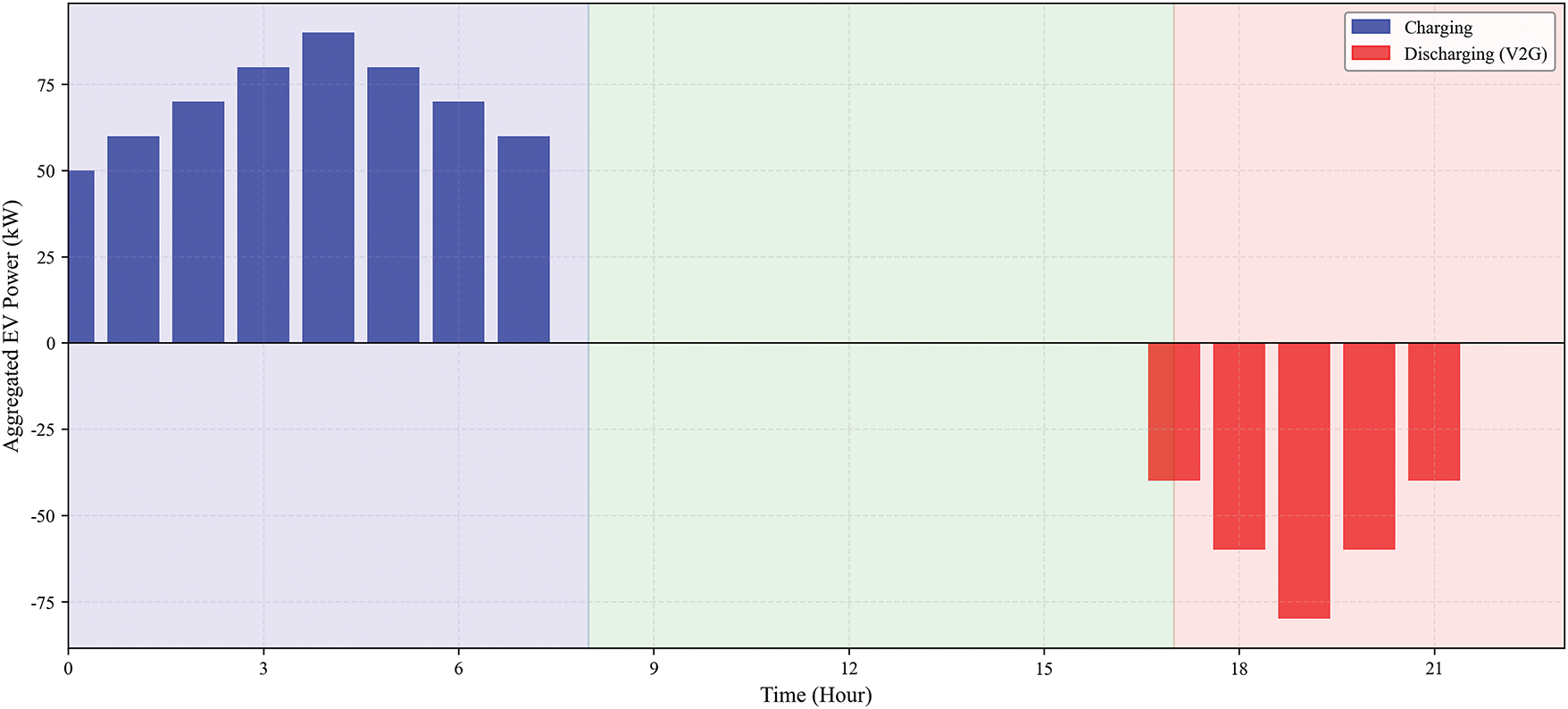
Figure 8: Aggregated charging/discharging power of the EV cluster
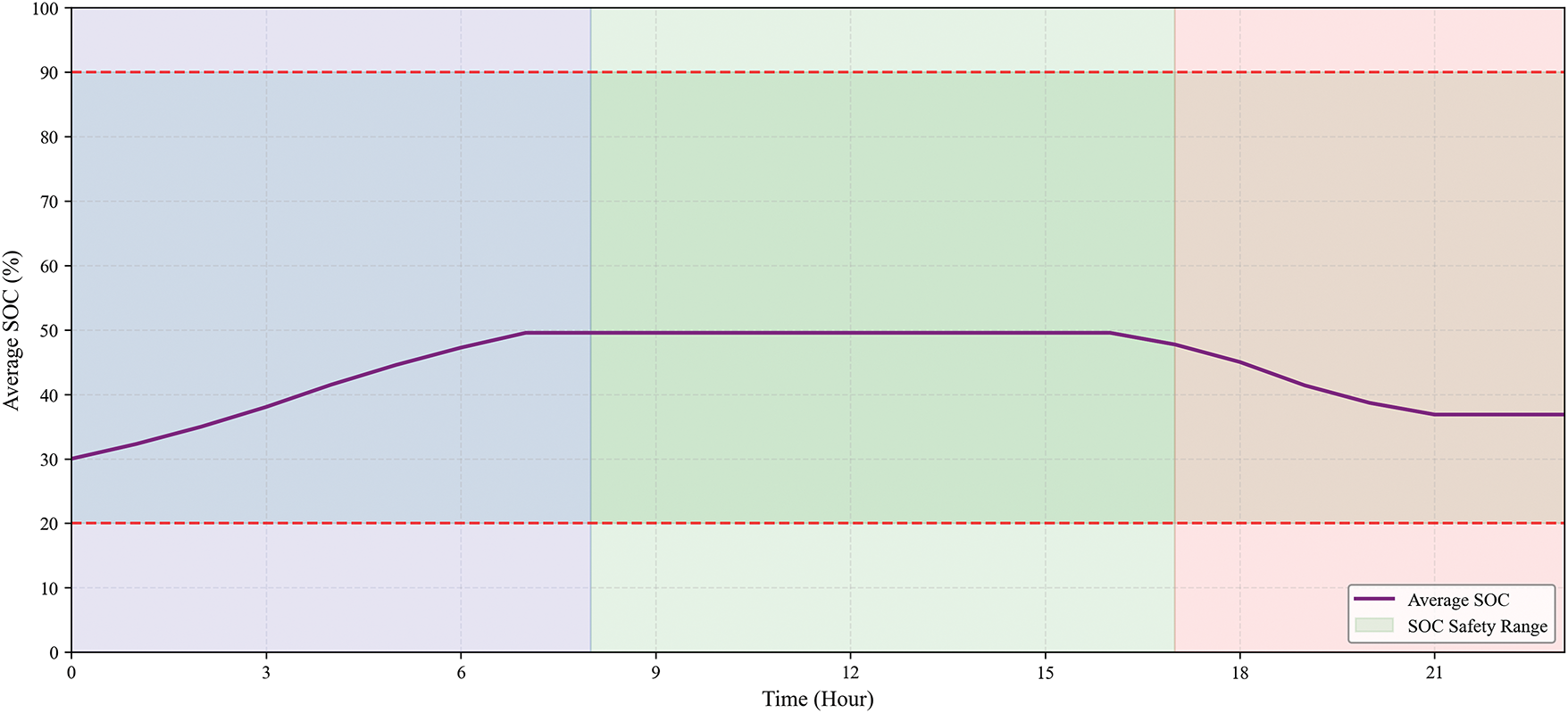
Figure 9: Average SOC evolution of the EV fleet
As illustrated in Fig. 7, the dynamic price signal (blue line) clearly defines the peak (17:00–22:00), regular (08:00–17:00), and valley (00:00–08:00) periods. The red line shows the total load profile of the MG without EVs charging, which exhibits a natural evening peak. After integrating the coordinated EVs charging and discharging, the green line demonstrates the optimized total load profile. The most significant effect is the dramatic reduction of the evening peak load and the elevation of the overnight valley load, visually confirming the achievement of “peak shaving and valley filling.”
The aggregated behavior of the EVs, depicted in Fig. 8, explains how this load shaping is achieved. During Valley Periods (00:00–08:00, Low Price): The EVs exhibit significant charging power (positive values), absorbing the excess renewable energy and efficiently storing it at the lowest cost. During Peak Periods (17:00–22:00, High Price): The EVs switch to a discharging mode (negative values), acting as a distributed power source to feed energy back into the grid. This EV action provides power during the most expensive and congested hours, directly reducing the net load peak. During Normal Daytime Hours: The charging power is minimal or zero, as the price is not low enough to incentivize charging nor high enough to justify discharging.
Fig. 9 tracks the average SOC of the EV fleet. It shows a clear cyclical pattern: the SOC replenishes during the night, remains relatively stable during the day (assuming vehicles are away for commuting), and decreases during the evening peak due to EVs’ discharge. Crucially, the algorithm successfully maintains the fleet’s average SOC within the safe bounds (20%–90%), ensuring battery health and satisfying user driving needs for the next day.
This collective, price-responsive behavior demonstrates that the selfish cost-minimization objective of each EV agent, under the guidance of a well-designed global price signal, leads to an emergent system-level optimal outcome. This effectively resolves the strategic conflict between individual and system objectives.
4.2.4 Algorithm Performance Comparison
Fig. 10 compares the average reward performance of the proposed PDQN algorithm against DDPG and PPO over 200 training episodes.
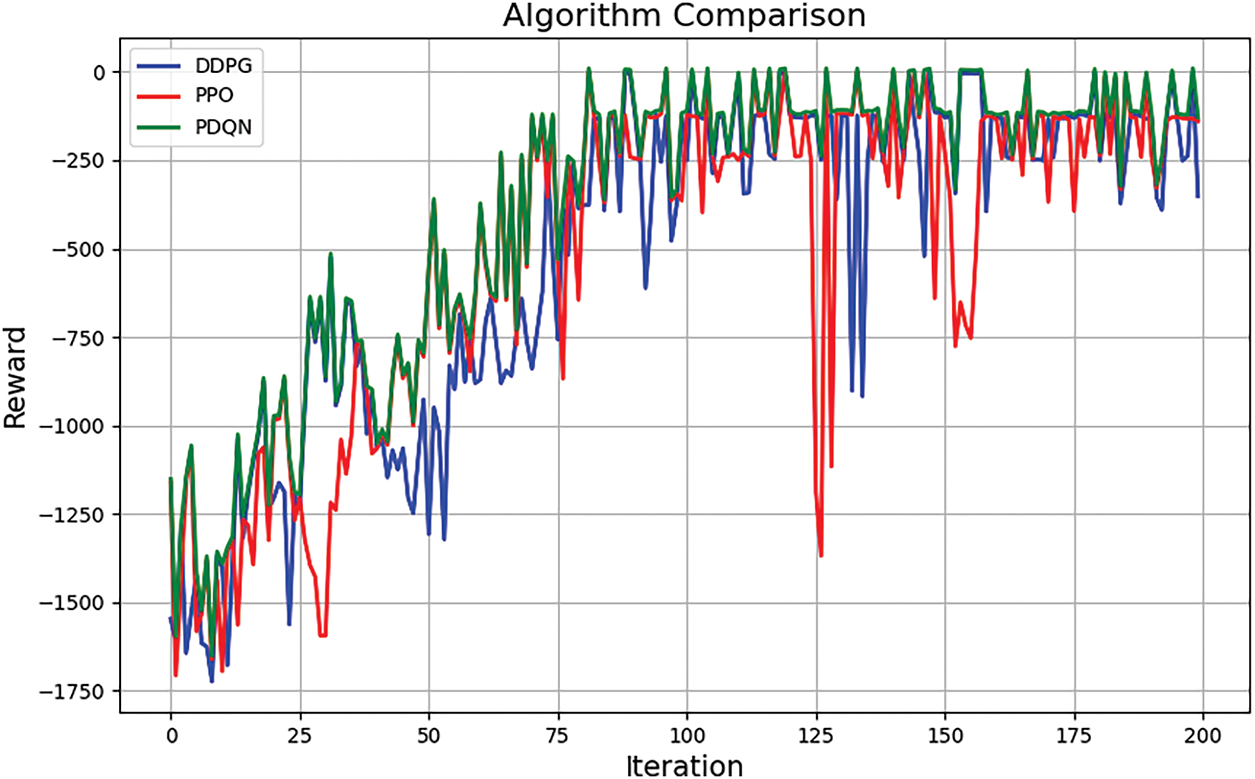
Figure 10: Algorithm comparison graph
The proposed PDQN algorithm demonstrates superior performance in terms of. PDQN’s reward curve is significantly smoother and exhibits less variance than DDPG and PPO, indicating more stable learning and higher sample efficiency. Final Performance: PDQN achieves a higher final average reward (
4.2.5 Quantitative Performance Analysis
Table 4 summarizes the key performance indicators under the optimized PDQN strategy compared to a baseline scenario with no coordinated scheduling to further quantify the economic and operational benefits.
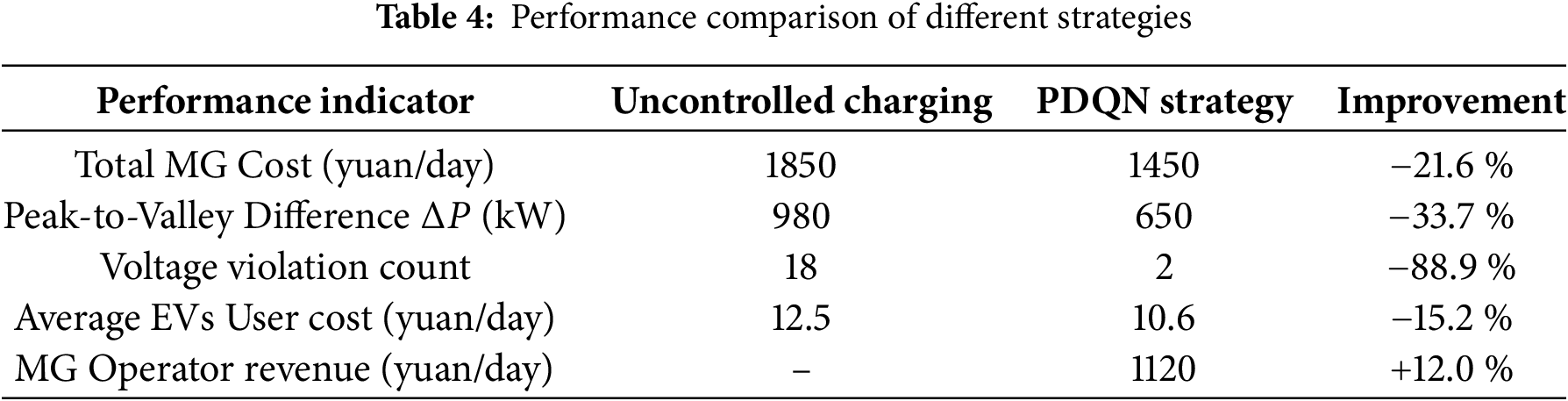
The results demonstrate that the proposed strategy significantly reduces system operating costs, flattens the load profile, and enhances grid stability. Simultaneously, it reduces electricity costs for EV users, creating a win-win situation for both the MG operator and the consumers. This quantitatively validates the effectiveness of our hierarchical coordinated optimization approach.
In conclusion, this paper proposes a two-layer optimization strategy based on the PDQN framework for regional distribution networks with high penetration of EVs and DERs. The proposed method effectively decouples system-level economic dispatch from distributed EV control through a dynamic pricing mechanism, successfully coordinating multi-agent decision-making in a hybrid action space. Simulation results show that the strategy significantly improves economic and operational performance: reducing the total operating cost of the MG by 21.6%, decreasing the peak-to-valley load difference by 33.7%, reducing the number of voltage limit violations by 88.9%, lowering the average electricity cost for EV users by 15.2%, thus achieving a win-win situation between MG operators and EV users.
In future and practical applications, we can further explore several important directions. First, the intermittency of DERs and the reliability of communication networks are obstacles in the real world. Issues such as communication delays, packet loss, and inaccuracies in renewable energy and load demand forecasting may affect scheduling. Future work will explore integrating technologies to enhance robustness, such as adopting model predictive control (MPC) to compensate for communication delays, utilizing probabilistic forecasting to better characterize uncertainties, and training DRL algorithms in diverse environments with high prediction errors, thereby improving their generalization ability under unforeseen real-world conditions and comprehensively enhancing the algorithm’s adaptability and resilience. Second, we can incorporate more complex power market factors to enhance the economic applicability of the strategy. Future research will extend the current model to operate in mixed market environments involving regulated electricity prices and liberalized trading. We should analyze how market signals affect the coordination strategies of DERs to promote the practical deployment of the proposed method.
Acknowledgement: Not applicable.
Funding Statement: This work was supported in part by the Research on Key Technologies for the Development of an Active Balancing Cooperative Control System for Distribution Networks and the National Natural Science Foundation of China under Grant 521532240029, Grant 62303006.
Author Contributions: Conceptualization, Lei Su and Wanli Feng; methodology, Lei Su; software, Cao Kan; validation, Mingjiang Wei; formal analysis, Lingxiao Yang; investigation, Pan Yu; resources, Pan Yu; data curation, Lei Su; writing—original draft preparation, Jihai Wang; writing—review and editing, Jihai Wang; visualization, Lei Su; supervision, Lingxiao Yang; project administration, Lei Su; funding acquisition, Lei Su. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the Corresponding Author, [Lingxiao Yang], upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Zhang N, Yan J, Hu C, Sun Q, Yang L, Gao DW, et al. Price-matching-based regional energy market with hierarchical reinforcement learning algorithm. IEEE Trans Ind Inform. 2024;20(9):11103–14. doi:10.1109/tii.2024.3390595. [Google Scholar] [CrossRef]
2. Lee S, Seon J, Sun YG, Kim SH, Kyeong C, Kim DI, et al. Novel architecture of energy management systems based on deep reinforcement learning in microgrid. IEEE Trans Smart Grid. 2024;15(2):1646–58. doi:10.1109/tsg.2023.3317096. [Google Scholar] [CrossRef]
3. Ge XL, Hu WZ, Fu Y, Cao SP. Electric vehicle optimal scheduling strategy based on user response willingness 3D sigmoid cloud model. Proc CSEE. 2024;44(22):8874–83. (In Chinese). [Google Scholar]
4. Zhao Y, Zhang G, Hu W, Huang Q, Chen Z, Blaabjerg F. Meta-learning based voltage control for renewable energy integrated active distribution network against topology change. IEEE Trans Power Syst. 2023;38(6):5937–40. doi:10.1109/tpwrs.2023.3309536. [Google Scholar] [CrossRef]
5. Prasad M, Rather ZH, Razzaghi R, Doolla S. Real-time reduced model of active distribution networks for grid support applications. IEEE Trans Power Del. 2023;38(5):3531–40. doi:10.1109/tpwrd.2023.3293791. [Google Scholar] [CrossRef]
6. Li X, Han Q. An EV charging station load prediction method considering distribution network upgrade. IEEE Trans Power Syst. 2024;39(2):4360–71. doi:10.1109/tpwrs.2023.3311795. [Google Scholar] [CrossRef]
7. Yang L, Li X, Sun M, Sun C. Hybrid policy-based reinforcement learning of adaptive energy management for the energy transmission-constrained Island group. IEEE Trans Ind Inform. 2023;19(11):10751–62. doi:10.1109/tii.2023.3241682. [Google Scholar] [CrossRef]
8. Zhang N, Sun Q, Yang L, Li Y. Event-triggered distributed hybrid control scheme for the integrated energy system. IEEE Trans Ind Inform. 2022;18(2):835–46. doi:10.1109/tii.2021.3075718. [Google Scholar] [CrossRef]
9. Wang J, Zheng Y, Ding J, Zhang H, Sun J. Memory-based event-triggered fault-tolerant consensus control of nonlinear multi-agent systems and its applications. IEEE Trans Autom Sci Eng. 2025;22:7941–54. doi:10.1109/tase.2024.3474968. [Google Scholar] [CrossRef]
10. Shang WQ, Li GL, Ding YM, Du SH, Tan QY, Pang BW, et al. Collaborative scheduling method for integrated energy system considering source-load uncertainty and renewable energy consumption. Power Syst Technol. 2024;48(2):517–26. doi:10.13335/j.1000-3673.pst.2023.0577. [Google Scholar] [CrossRef]
11. Ali A, Li C, Hredzak B. Dynamic voltage regulation in active distribution networks using day-ahead multi-agent deep reinforcement learning. IEEE Trans Power Del. 2024;39(2):1186–97. doi:10.1109/tpwrd.2024.3358262. [Google Scholar] [CrossRef]
12. Alzaareer K, Saad M, Mehrjerdi H, Asber D, Lefebvre S. Development of new identification method for global group of controls for online coordinated voltage control in active distribution networks. IEEE Trans Smart Grid. 2020;11(5):3921–31. doi:10.1109/tsg.2020.2981145. [Google Scholar] [CrossRef]
13. Yang L, Sun Q, Zhang N, Li Y. Indirect multi-agent transactions of energy internet with deep reinforcement learning approach. IEEE Trans Power Syst. 2022;37(5):4067–77. doi:10.1109/tpwrs.2022.3142969. [Google Scholar] [CrossRef]
14. Sui Q, Zhang J, Sun L, Liang J, Wei F, Lin X. Optimal scheduling of mobile energy storage capable of variable speed energy transmission. IEEE Trans Smart Grid. 2024;15(3):2710–22. doi:10.1109/tsg.2023.3329294. [Google Scholar] [CrossRef]
15. Liu UX, Qiao RY, Liang N, Chen Y, Yu K, Wu HX. Renewable energy consumption strategy for electric vehicle cluster system based on curtailment deadline line and deep reinforcement learning. J Shanghai Jiaotong Univ. 2025;59(10):1464–75. (In Chinese). doi:10.16183/j.cnki.jsjtu.2023.529. [Google Scholar] [CrossRef]
16. Wang Y, Qiu D, Sun X, Bie Z, Strbac G. Coordinating multi-energy microgrids for integrated energy system resilience: a multi-task learning approach. IEEE Trans Sustain Energy. 2024;15(2):920–37. doi:10.1109/tste.2023.3317133. [Google Scholar] [CrossRef]
17. Dolatabadi A, Adelavab H, Mohamed YAI. A novel model-free deep reinforcement learning framework for energy management of a PV integrated energy hub. IEEE Trans Power Syst. 2023;38(5):4840–52. doi:10.1109/tpwrs.2022.3212938. [Google Scholar] [CrossRef]
18. Prakhar P, Jaiswal R, Gupta S, Tiwari AK. Electric vehicles in transition: opportunities, challenges, and research agenda—a systematic literature review. J Environ Manage. 2024;372:12345. doi:10.1016/j.jenvman.2024.123415. [Google Scholar] [PubMed] [CrossRef]
19. Cao D, Hu W, Zhao J, Zhang G, Zhang B, Liu Z, et al. Reinforcement learning and its applications in modern power and energy systems: a review. J Mod Power Syst Clean Energy. 2020;8(6):1029–42. [Google Scholar]
20. Li Z, Wei Y, Park JH. An improved bilevel algorithm based on ant colony optimization and adaptive large neighborhood search for routing and charging scheduling of electric vehicles. IEEE Trans Transp Electrif. 2025;11(1):934–44. doi:10.1109/tte.2024.3398113. [Google Scholar] [CrossRef]
21. Xu W, Fang B, Zhang Q, Li W, Liu H. Electric vehicle charging load optimization strategy based on staged time-of-use price response. Hunan Electric Power. 2024;44(1):94–100. (In Chinese). doi:10.21203/rs.3.rs-2916080/v1. [Google Scholar] [CrossRef]
22. Peng Z, He Z. Optimization of regenerative braking control strategy for dual-motor electric vehicles based on deep reinforcement learning. IEEE Trans Intell Transp Syst. 2025 Jul;26(7):10954–67. doi:10.1109/tits.2025.3553875. [Google Scholar] [CrossRef]
23. Liu L, Huang Z, Xu J. Multi-agent deep reinforcement learning based scheduling approach for mobile charging in internet of electric vehicles. IEEE Trans Mobile Comput. 2024 Oct;23(10):10130–45. doi:10.1109/tmc.2024.3373410. [Google Scholar] [CrossRef]
24. Liu P, Liu Z, Zhang N, Lin F. Cooperative game-based charging-discharging efficiency optimization of electric vehicles in 6G-enabled V2G. IEEE Trans Green Commun Netw. 2023 Jun;7(2):1078–89. doi:10.1109/tgcn.2022.3191699. [Google Scholar] [CrossRef]
25. Lee S, Choi D-H. Multilevel deep reinforcement learning for secure reservation-based electric vehicle charging via differential privacy and energy storage system. IEEE Trans Veh Technol. 2024 Aug;73(8):11097–109. doi:10.1109/tvt.2024.3372517. [Google Scholar] [CrossRef]
26. Qian J, Jiang Y, Liu X, Wang Q, Wang T, Shi Y, et al. Federated reinforcement learning for electric vehicles charging control on distribution networks. IEEE Internet Things J. 2024 Feb;11(3):5511–25. doi:10.1109/jiot.2023.3306826. [Google Scholar] [CrossRef]
27. Liu ZE, Li Y, Zhou Q, Li Y, Shuai B, Xu H, et al. Deep reinforcement learning-based energy management for heavy duty HEV considering discrete-continuous hybrid action space. IEEE Trans Transp Electrif. 2024;10(4):9864–76. doi:10.1109/tte.2024.3363650. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools