
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Eye Strain Detection During Online Learning
1 Faculty of Physics, VNU University of Science, Hanoi, 100000, Vietnam
2 University of Science, Vietnam National University, Hanoi, 100000, Vietnam
3 VNU-HUS, High School for Gifted Students, Hanoi, 100000, Vietnam
4 Hanoi-Amsterdam High School for the Gifted, Hanoi, 100000, Vietnam
* Corresponding Author: Le Quang Thao. Email:
Intelligent Automation & Soft Computing 2023, 35(3), 3517-3530. https://doi.org/10.32604/iasc.2023.031026
Received 08 April 2022; Accepted 08 June 2022; Issue published 17 August 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The recent outbreak of the coronavirus disease of 2019 (Covid-19) has been causing many disruptions among the education systems worldwide, most of them due to the abrupt transition to online learning. The sudden upsurge in digital electronic devices usage, namely personal computers, laptops, tablets and smartphones is unprecedented, which leads to a new wave of both mental and physical health problems among students, for example eye-related illnesses. The overexposure to electronic devices, extended screen time usage and lack of outdoor sunlight have put a consequential strain on the student’s ophthalmic health because of their young age and a relative lack of responsibility on their own health. Failure to take appropriate external measures to mitigate the negative effects of this process could lead to common ophthalmic illnesses such as myopia or more serious conditions. To remedy this situation, we propose a software solution that is able to track and capture images of its users’ eyes to detect symptoms of eye illnesses while simultaneously giving them warnings and even offering treatments. To meet the requirements of a small and light model that is operable on low-end devices without information loss, we optimized the original MobileNetV2 model with depth-wise separable convolutions by altering the parameters in the last layers with an aim to minimize the resizing of the input image and obtained a new model which we call EyeNet. Combined with applying the knowledge distillation technique and ResNet-18 as a teacher model to train the student model, we have successfully increased the accuracy of the EyeNet model up to 87.16% and support the development of a model compatible with embedded systems with limited computing power, accessible to all students.Keywords
In many countries, schools have been closed indefinitely to stop the spread of the new coronavirus disease (Covid-19) [1]. As stated in Sahu [2], the outbreak of this pandemic has had a devastating impact on the education and mental health of students and academic staff. The traditional teaching method has been replaced by online classes through digital devices such as computers, laptops and smartphones. When using these devices, not only do students have trouble looking at a short distance, but teachers, who usually have to switch between several tabs, are also concerned about constant eye regulation. The amount of time they are exposed to digital screens is a lot longer than usual, which can easily lead to various eye problems. Due to numerous factors such as the brightness of the environment, the flickering light, multiple simultaneously moving images, or visible light which comes from digital electronic devices, human eyes are incapable of accommodating consecutively for long periods of time, therefore unable to block their wavelengths. The most prevalent eye condition associated with prolonged use of digital devices is digital eye strain, which is characterized by symptoms such as dry eyes, itching, foreign body sensation, watering, blurred vision, and headaches [3]. Unfortunately, the majority of computer users are not aware of the accumulation of eye fatigue when working with an electronic display. To reduce the possibility of suffering the aforementioned computer vision syndromes (CVS), doctors and professors recommend using the 20/20/20 rule when working with computers and mobile phones, which is to look 20 feet away from the screen for 20 seconds every 20 minutes [4], or when feeling eye strain, alleviate it simply by closing the eyes for a while. However, even when people are aware of the case, it is hard to follow the solutions while concentrating on their work. Thus, users prefer a fast and accurate diagnosis that can relieve their patients discomfort, spare them unnecessary expenses and exposure to potential side effects associated with some treatments. Mohan et al. [5] and his colleagues measured eye fatigue through a survey using a questionnaire that asked children and parents about their usage of digital devices before and during the Covid-19 pandemic. However, this survey only presented the number of children that were suffering some symptoms and the incidence of digital eye strain, giving no specific solutions. Currently, there are several software packages that help users manage their rest breaks and exercises [6], but they all have serious limitations in activity level detection. This activity level is usually determined from keyboard or mouse use and does not correctly represent the behavior when the user is statically observing the screen. Therefore, it is important to relieve eye fatigue at the appropriate time to help online teachers or learners check their eye conditions, as well as to be alert when having symptoms of eye diseases or using digital electronic devices continuously for a long time.
In recent years, deep learning using deep artificial neural networks has gained increasing attention for its image recognition abilities. As a result, artificial intelligence (AI) has been widely applied to handle problems directly related to humans, such as intelligent education [7], medical [8,9], network security [10], users’ behavior and the environment [11,12]. Thus, their application has improved our society. In ophthalmology, it has so far mainly been used in the analysis of data from the retinal to segment regions of interest in images, diagnosis automation and prediction of disease outcomes [13]. Several reviews have been published that discuss the application of AI in the detection of eye diseases. Although deep convolutional neural networks (CNN) have gained considerable attention in image processing, including retinal image quality [14], Mu et al. [15] recently proposed an improved model for the early recognition of ophthalmopathy in retinal fundus images based on the visual geometry group (VGG) training network of densely connected layers. Worah et al. [16] indicated algorithms using CNN for blink detection and compared it with a normal threshold for announcements to individuals. This system warns people that they may have CVS without specificity or incidence. Machine learning algorithms have also been utilized in interferometry and slit-lamp images for lipid layer classification based on morphological features [17], lipid layer thickness estimation [18], ocular redness assessment [19], and tear meniscus height measurement [20]. Ramos et al. [21] employed machine learning in an attempt to detect dry areas in tear break-up time videos as well as estimate and conclude that shorter break-up time indicates an unstable tear film and a higher probability of dry eye disease. Kim et al. [22] also used CNN for accurate pupil detection concerning pupil accommodation speed, blink frequency and eye-closed duration. However, this methodology involves using infrared cameras, which is not suitable for people staying home during this pandemic. As a result, this technique has low applicability in supporting online learners.
All studies that focus on the clinical diagnosis of eye diseases using retinal images require specialized medical imaging techniques. Further than that, we are not aware of any review on applying machine learning on detecting fatigue during e-learning for daily routine. To address these issues, we propose an improved MobileNetV2 [23] pre-trained model called EyeNet that can be deployed on personal computers for detecting and recognizing patients’ eye conditions as well as alerting them when having any symptoms of eye diseases or after having used digital electronic devices continuously for a long time. In reality, the eye images from our dataset have low resolution and require a model that contains large parameters to learn and accurately predict the results, so we applied knowledge distillation (KD). This works well with a high-accuracy teaching model that helps train the EyeNet model to become efficient on all devices. This study will use deep learning to make predictions about eye diseases, mostly the symptoms of eye strain after using a digital screen for educational purposes. The major contributions of this paper are as follows:
• We built the proposed model, called EyeNet, by improving the MobileNetV2 to deploy software on low-configuration hardware such as personal computers.
• Applied KD using ResNet-18 [24] as the teacher model to teach our EyeNet model so that our model achieves better accuracy on almost any personal devices.
• We use a dataset of eye strain symptoms to train the EyeNet, refer to their characteristics to evaluate the conditions before they turn worse.
• Deploy an application that detects tired eyes and provides treatment solutions for users in terms of improving eye conditions while learning and working online.
Since our application is targeted at general users, we decided to capture input data using cameras available on normal electronic devices used for learning and working without any additional hardware. This application would be able to process videos in real-time under varying indoor conditions like in the office.
In Fig. 1 we created a basic visualization of the system’s components. The proposed system does not require any supplementary or external devices to be functional, since it works with the video stream from a camera. Most modern laptops or cellphones have built-in front cameras anyway and they generally have a high enough image quality for our model to work. The model is already pre-trained on our machine before deployment on the client’s side and we will describe the techniques that we used to make the deployment possible on as many devices as possible below.
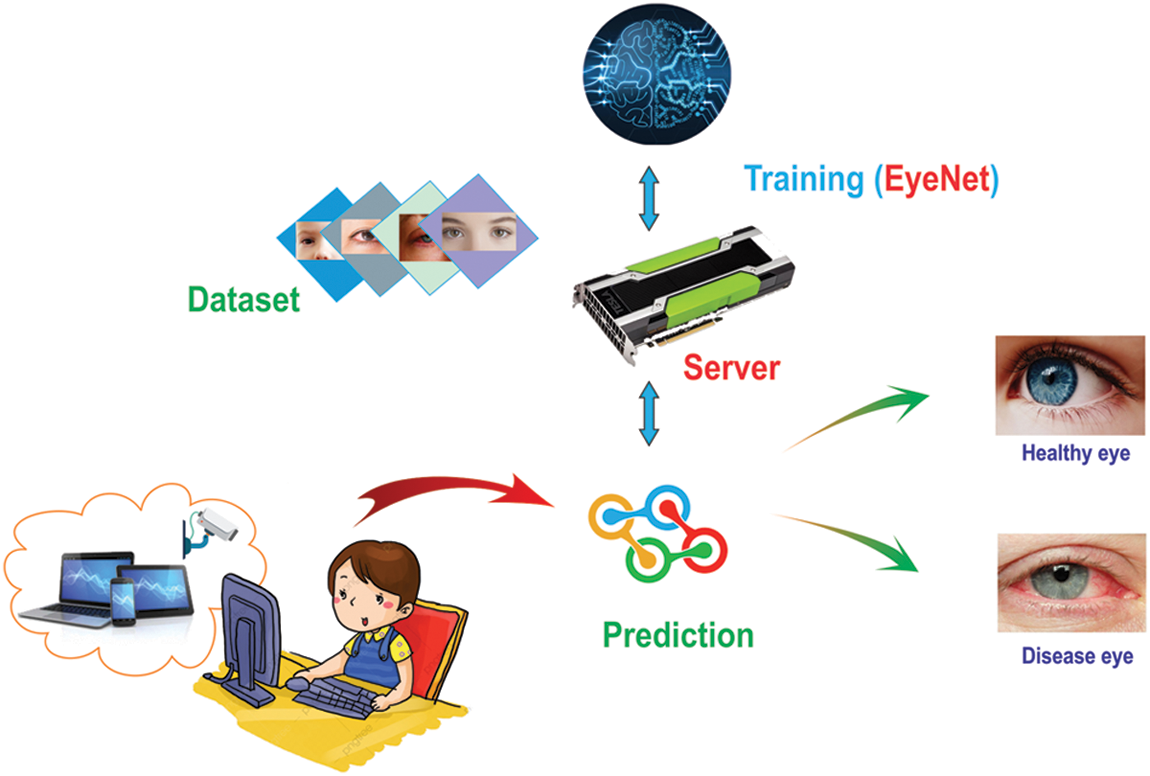
Figure 1: System diagram
An eye dataset was collected and trained on our server in order to detect whether the eyes in the photos are in fatigue condition or not. We will clarify the method we use to collect this dataset below. We used our EyeNet, trained with KD to improve the efficiency in recognizing strained eyes after online classes. The model’s size is carefully calculated to be as light-weighted as possible so that it can be available on most mobile devices. When the app predicts fatigue conditions, it will give a warning on the screen to remind the users to have some treatments to keep their eyes in healthy condition.
The dataset contains free images on Google and from surveys at different online classes. All students were voluntarily used for research purposes in our project. The survey was conducted as follows:
• At the end of each session, volunteers were required to turn on the camera and look at the computer screen on the e-learning platforms; a short video clip with all the participants’ faces will be recorded.
• The volunteers were asked about their eye condition and symptoms, and then assessed the level of engaging eye strain.
• Depending on their answers, the records would then be labeled as “Normal” or “Fatigue”
From video footage of the sessions, we extracted participants’ frames and label their eyes manually with corresponding labels which were mentioned before. The whole process is shown in Fig. 2.
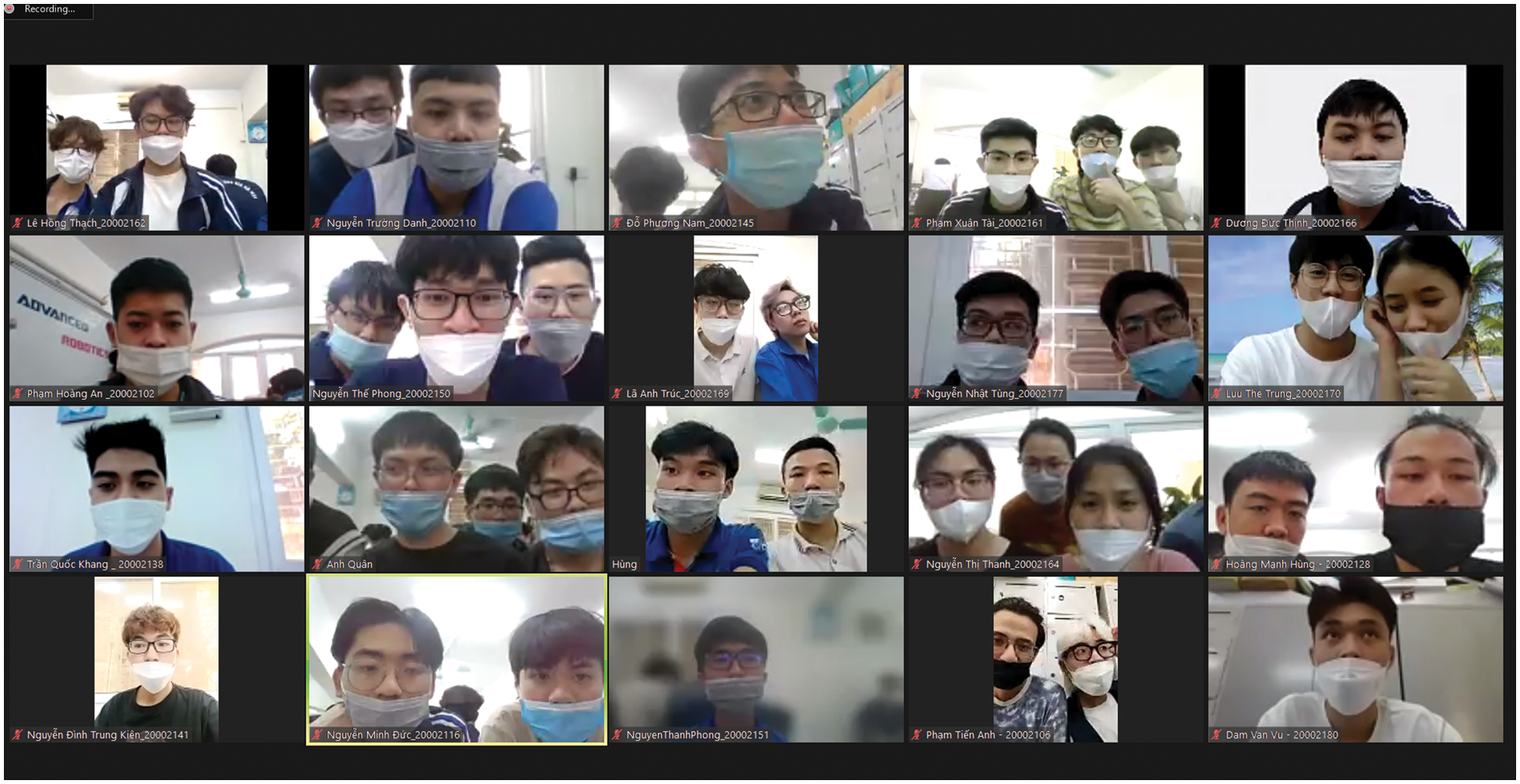
Figure 2: Data collection from online classes
During online studying, aside from the element of varying light angles, blurred pictures may also occur in cases of non-standard cameras. Data augmentation using techniques such as flipping, rotating, randomly shearing, zooming and adjusting images’ contrast are essential in such circumstances.
Before starting the training phase, we removed poor quality images to prevent the algorithm from learning unrelated features such as decentralization, blinking, low signal-to-noise ratio, or ambiguous reactions about eye strain from user responses. After cleaning, we got 611 fatigue eye images and 817 normal eye images. The data was then randomly divided into two parts, with 80% of the images assigned to the training group and 20% assigned to the validation group. The data is shown in Tab. 1.
3.3 EyeNet Base on MobileNetV2 Model
CNN is a prominent classifier of deep learning that is used to analyze images and extract features from them in less computational time. It takes images as input, assigns learnable weights, biases them into different objects, and classifies them into different classes. CNN usually consists of convolutional layers, pooling layers, and fully-connected layers [25]. The features are extracted by one or more convolution layers and pooling layers. Then, all the feature maps from the last convolution layer are transformed into one-dimensional vectors for full connection. Finally, the output layer classifies the input images. The network adjusts the weight parameters by backpropagation and minimizes the square difference between the classification results and the expected outputs.
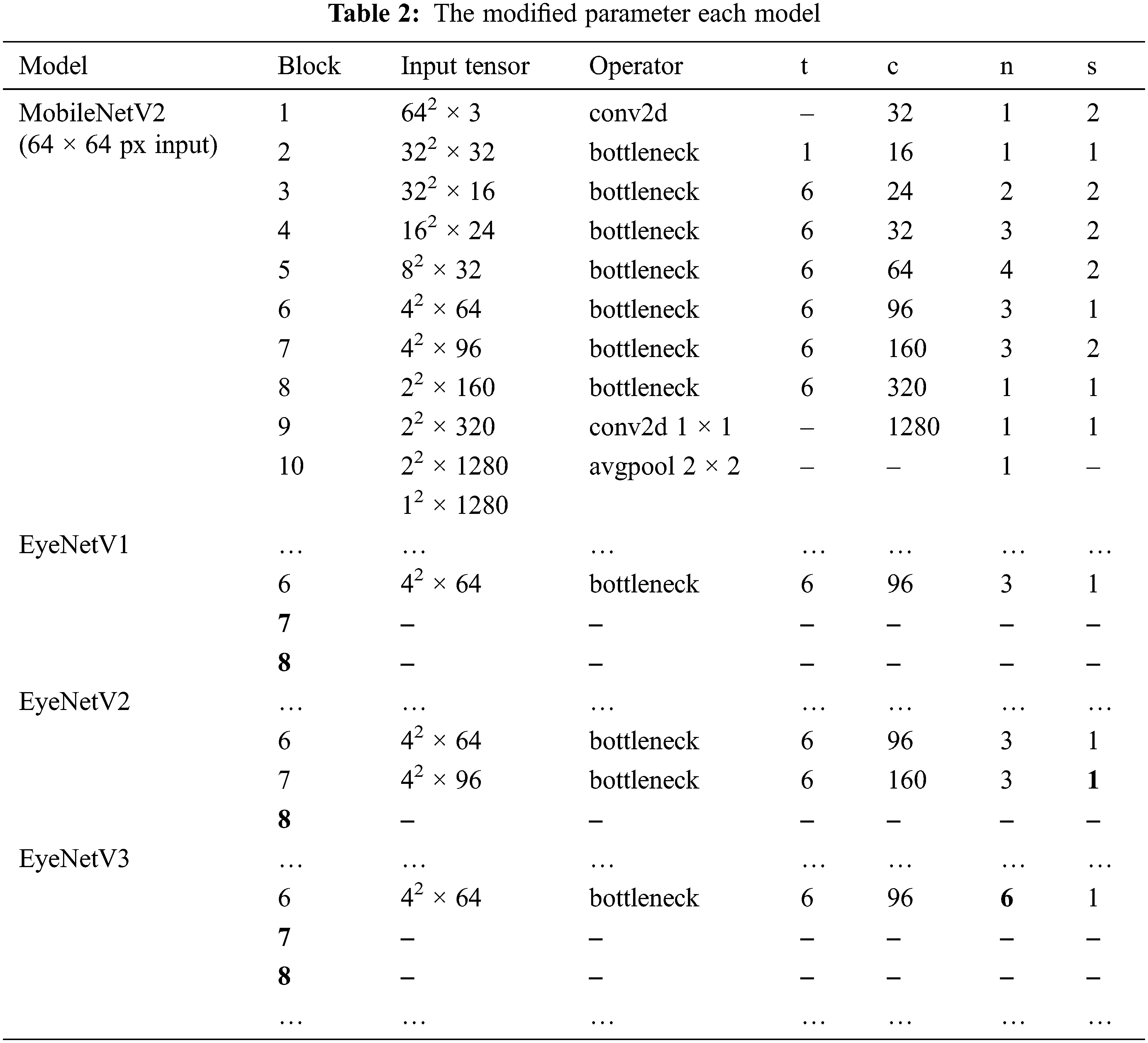
Performing tasks on mobile terminals and embedded devices requires a small, light, fast and accurate model, so in 2017 MobileNet [26] was introduced. By applying depth-wise separable convolutions (DSC), MobileNet can decrease the number of parameters and computational complexity with less loss of classification precision. While standard convolution performs the channel-wise and spatial-wise computation in one step, DSC splits the computation into two steps: depthwise convolution applies a single convolutional filter per each input channel, and pointwise convolution is used to create a linear combination of the output of the depthwise convolution. DSC is continually utilized in MobileNetV2, attaching to the fine-tuned shortcut connections allowing to decrease the number of input and output channels of each block residual. This model is based on an inverted residual structure, which is different from traditional residual architectures. They also use depth-separated convolutional transforms to minimize the number of model parameters, which significantly reduces the model size.
The original MobileNetV2 model has an input image resolution of 224 x 224 pixels. After model blocks, images are extracted into feature maps with dimensions of 112 x 112, 56 x 56, 28 x 28, 14 x 14, and 7 x 7 respectively. The final convolutional layer 7 x 7 applied average pooling to aggregate feature into a 1280-dimensional vector, which then is passed through the fully-connected layer with the
When we experimented with our dataset that contains small-sized images, the accuracy when using the optimal EyeNetV3 was not as high as expected. Therefore, it is crucial to have a technique to advance the precision of the recently built model, explaining why we applied KD.
Knowledge distillation (KD), first proposed by Buciluǎ et al. [27] 2006 and generalized by Hinton et al. [28] 2015, took the idea of people’s learning process where a big pre-trained model or model ensemble called teacher transmit information to a smaller student model. It is shown in [28] that using KD often allows for better performance than simply training the student model from the same data by supervised learning. In our proposal, we use ResNet-18 in the teacher model so that teachers can be trained on a prepared eye’s dataset mentioned above. This dataset has enough capacity and the teacher network can learn with all the circumstances. After it has achieved the expected accuracy, we employed a teacher to train the student using the EyeNet model. This method is shown in Fig. 3.
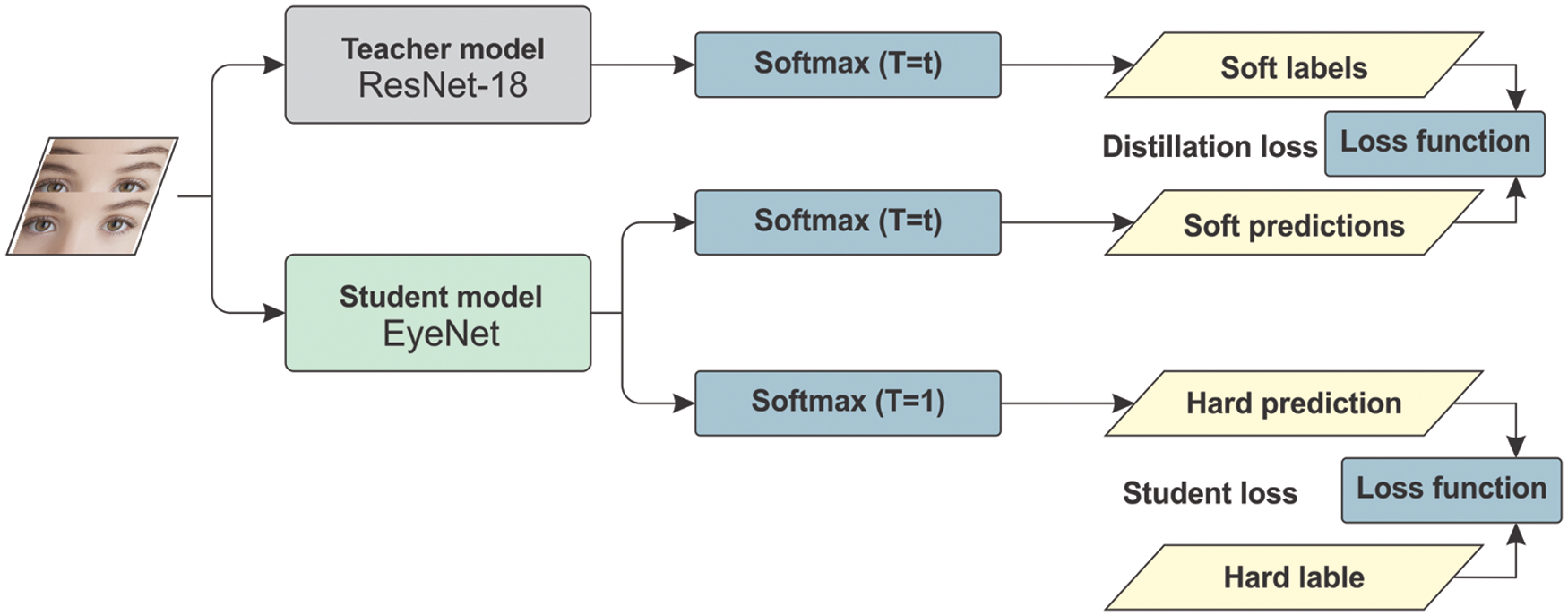
Figure 3: EyeNet base knowledge distillation
In distillation, knowledge is transferred from the teacher model to the student by minimizing a loss function in which the target is the distribution of class probabilities predicted by the teacher model. That is the output of a
where
When computing the loss function vs. the soft targets, we use the same value of T to compute the
Hinton et al. [28] found that it is also beneficial to train the distilled model to produce the correct labels based on ground truth in addition to the soft labels. Hence, the overall loss function incorporating both distillation and student losses is calculated as:
where
In our proposal, we chose ResNet-18 as the teacher model while EyeNetV3 was chosen as the student model. ResNet-18 is one of the most powerful CNN architectures and has demonstrated outstanding representation and generalization abilities in the medical imaging analytic area However, ResNet-18 increases the complexity of architecture and requires huge computational power during training. Therefore, it is a suitable choice for the teacher model in our project. On the other hand, EyeNetV3 as an advanced version of our student models benefits from its reduced network size and number of parameters, and it has been proven as an effective feature extractor for eye strain detection while studying online.
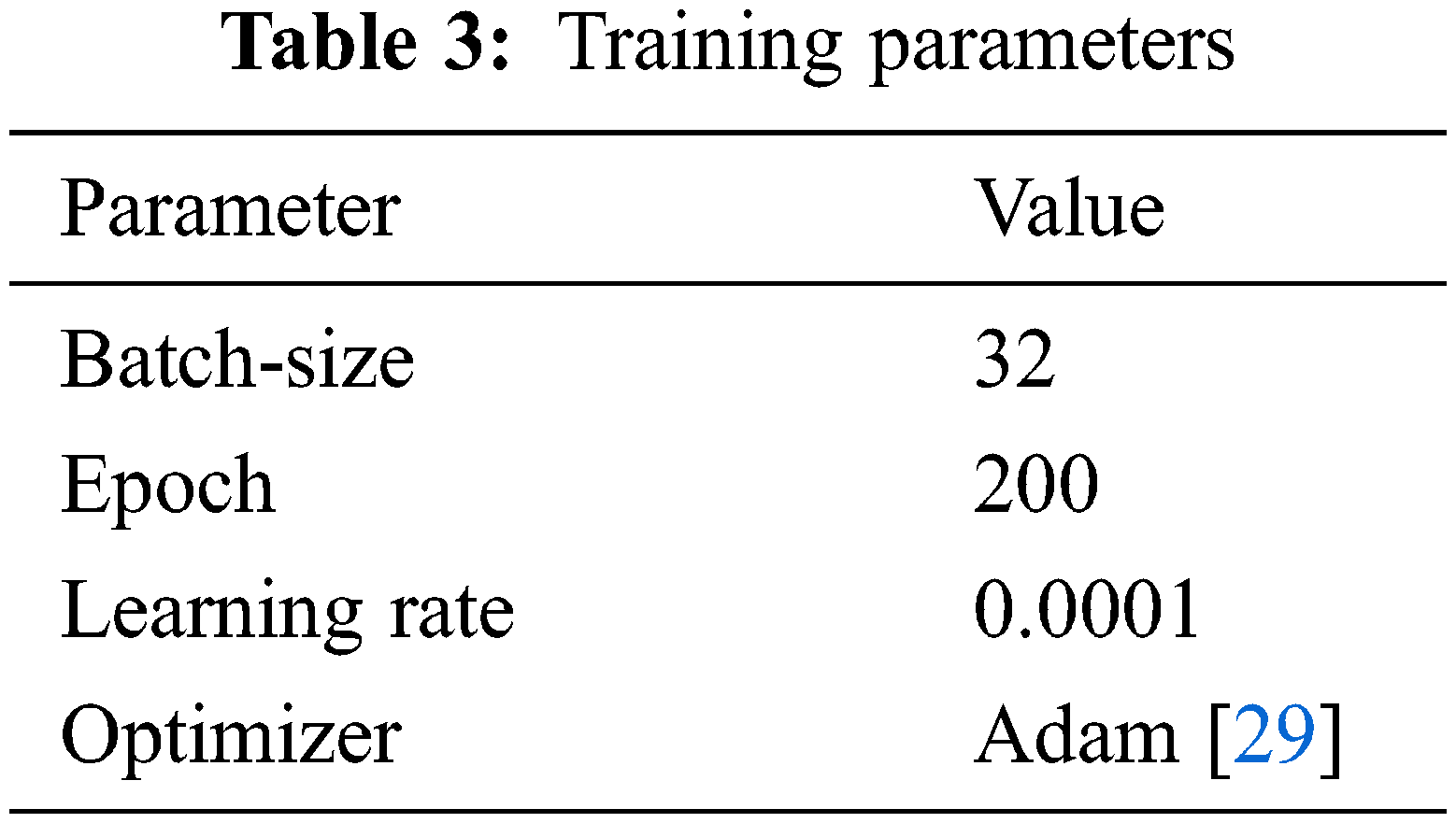
We performed training for our model in two stages, the first stage was optimizing the student model and the last one was KD from the teacher to student model. To execute EyeNet optimization, we used the cross-entropy loss in KD. Firstly, we trained a teacher model as ResNet-18 and used the best model on the trainer’s validation loss during training. After training the teacher model, we froze the teacher model and trained our EyeNetV3 student model according to the knowledge of distillation with the changing hyperparameter and used the best checkpoint based on validation loss. The parameters during the training process are shown in Tab. 3. All the experiments were implemented with Google Colaboratory, Python 3 programming language and Pytorch library to simulate the model. The following are the system specifications: random access memory (RAM) of 13 GB, memory of 32 GB, graphics processing unit (GPU) of Nvidia Tesla K80 with 16 GB memory and compute unified device architecture (CUDA) version 11.2.
In the final, the model weight and architecture can be saved with the
4.1 EyeNet Performance Evaluation
There are several metrics to evaluate the effectiveness of a model. In this research, we choose the 2 most representative ones, which are the accuracy and F1-score, calculated based on the model’s performance on the test set. With a ground truth of 286 samples in total, in which there are 163 negative and 123 positive samples, our calculations are based on these 4 fundamental values:
True positive (TP): The number of samples that the model predicted to be positive, and in fact are positive.
False positive (FP): The number of samples that the model predicted to be positive, but in fact are negative.
True negative (TN): The number of samples that the model predicted to be negative, and in fact are negative.
False negative (FN): The number of samples that the model predicted to be negative, but in fact are positive.
From these 4 fundamental values, several other values can be calculated for different purposes, such as:
Sensitivity, also known as true positive rate (TPR), represents the probability of a positive prediction being true:
Specificity, also known as true negative rate (TNR) which represents the probability of a negative prediction to be true:
Precision, also known as positive predictive value (PPV), stands for the rate of the correct positive predictions over all positive predictions:
Here we choose the the accuracy and F1-score since they are more representative, showing the overall performance when it comes to both positive and negative tests with relatively simple formulas:
Accuracy (ACC):
F1-score:
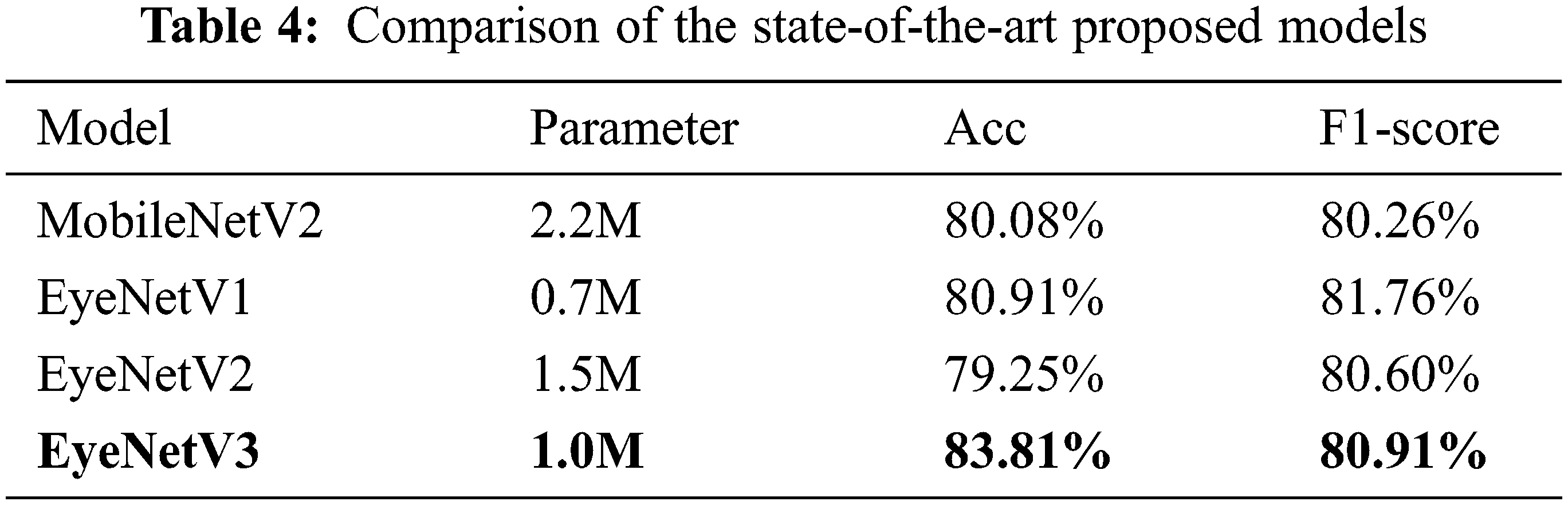
The comparison given in Tab. 4 provides the results of our models with EyeNetV3 which produce the best outcome among all the four proposed models including original MobileNetV2, where the accuracy and F1 are 83.81% and 80.91%, respectively. Although EyeNetV3 has a higher F1-score, the number of parameters is not too large (over 1 million), which is well within the capability of even modern low end devices. The proposed model exhibits superiority over the challenging datasets eyestrain.
Removing the 7th and 8th blocks will greatly reduce parameters, which is beneficial for mobile models, but increasing the number of iterations in a bottleneck will increase the ability to extract features, which makes the accuracy of the model faster convergence as shown in Fig. 4 with the EyeNetV3 model.
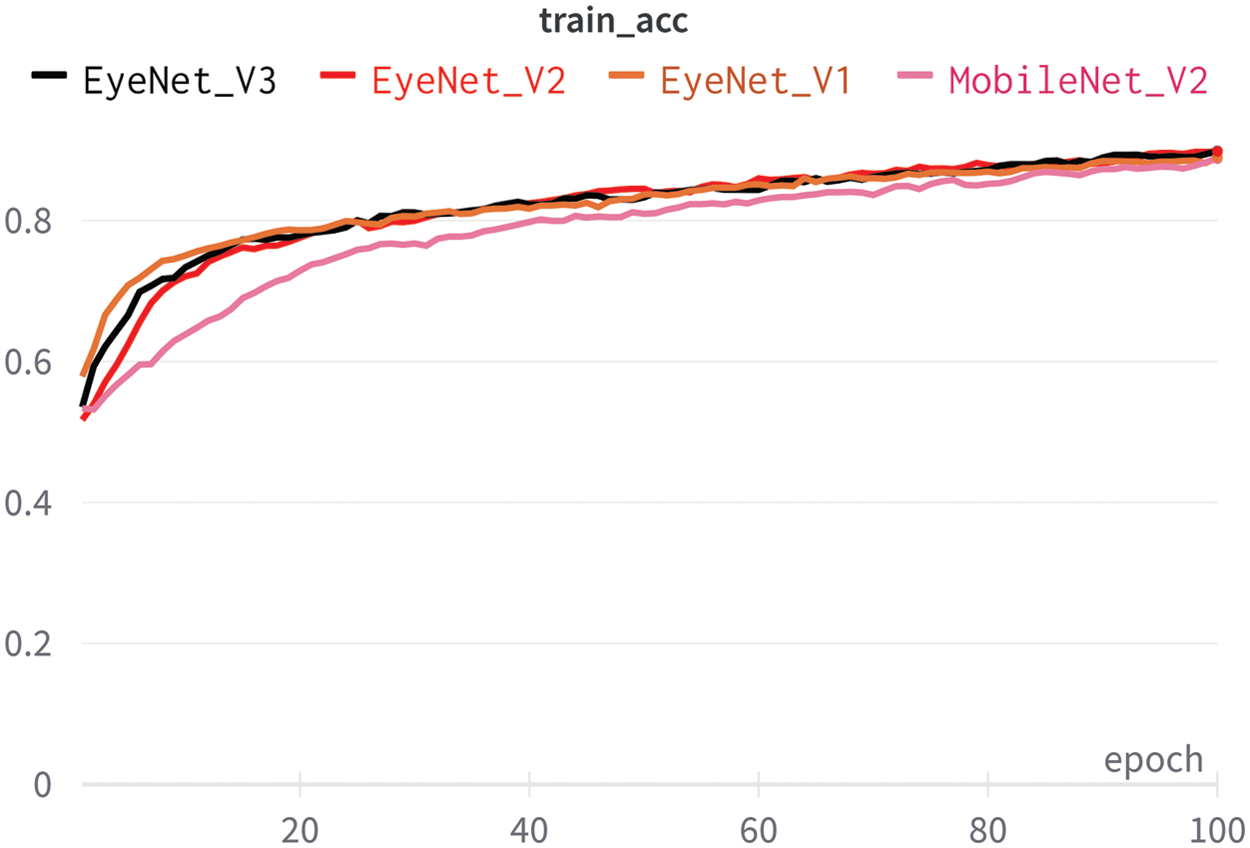
Figure 4: Accuracy from proposed classification models that are trained
4.2 Comparison of Knowledge Distillation to Baseline Approach
We compared the performance of the KD method with the original one in our dataset to improve the robustness against input visual corruption in the context of eye strain detection and classification. To study the effect of the temperature on the KD method, we initially set hyperparameters alpha and beta with a ratio of 50:50. We discover the best temperature by simulating and experimenting with different temperature values, as shown in Tab. 5, when the accuracy acc and F1-score of the KD technique are 85.06% and 85.20%, respectively. This makes sense if we consider that as we raise the temperature, the resulting soft-label distribution becomes richer in information, and a very small student model might not be able to capture all of this information from the teacher model.
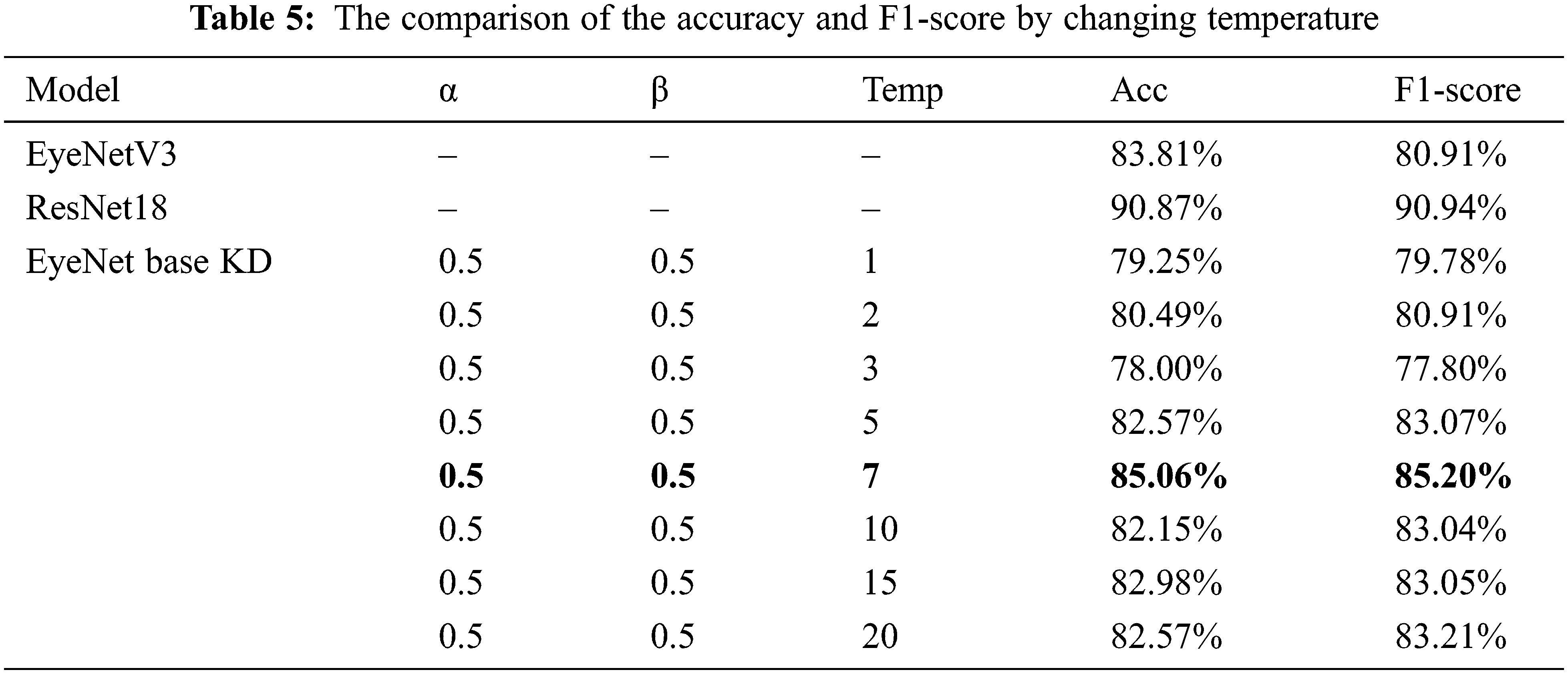
After acquiring the optimal temperature value for the KD applied model, we proceeded to modify the hyperparameters α, β to evaluate knowledge transferring from the teacher to the student. Results of accuracy and F1–score obtained from these modifications are shown in Tab. 6.
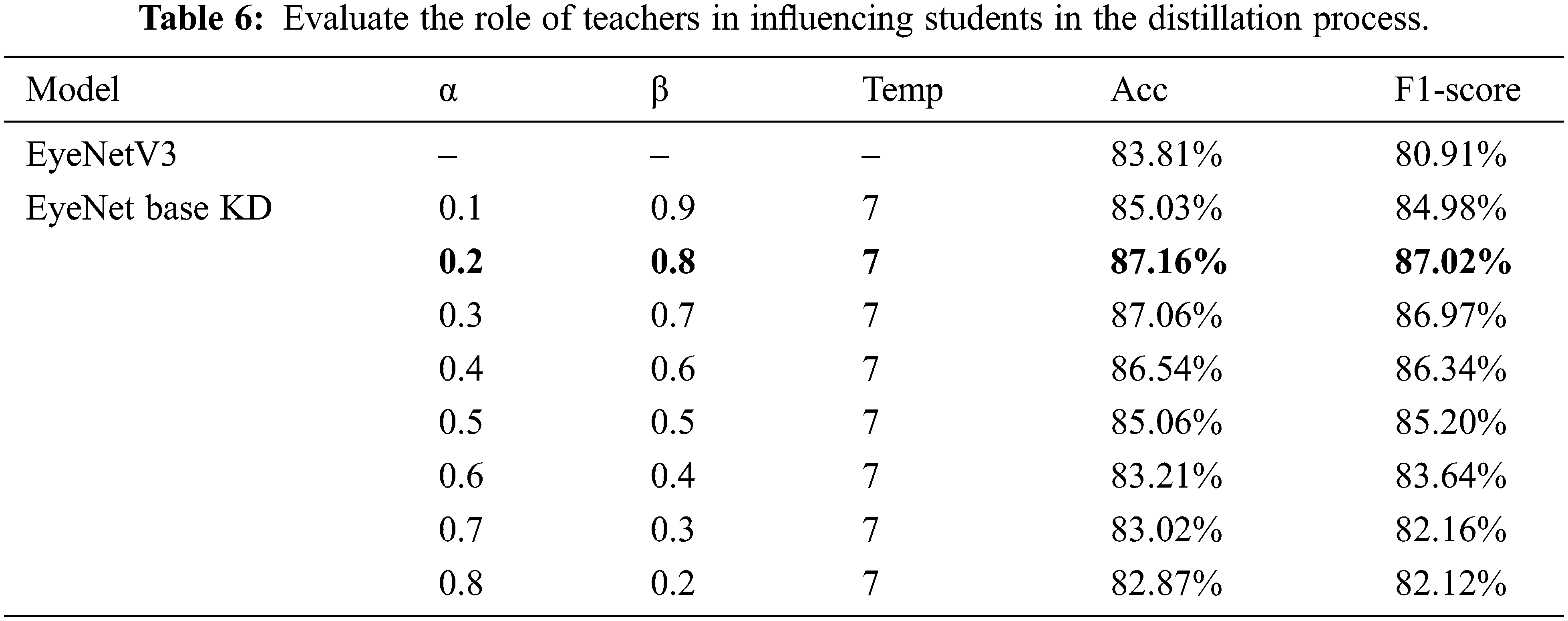
The results after training show that the influence of the β coefficient on accuracy is very large, which reflects the great role of the teacher in the process of imparting knowledge to students. Finally, to extract features into the eye strain recognition software when learning online, we choose the following hyperparameters to select into our model, α with 0.2, β with 0.8 and
4.3 Eye Strain Detection Testing
Fig. 5 shows the sample image frames taken during the online classroom at the end of the lesson. After surveying students’ feedback on their eye condition, there was clear evidence that fatigue was detectable by our application.
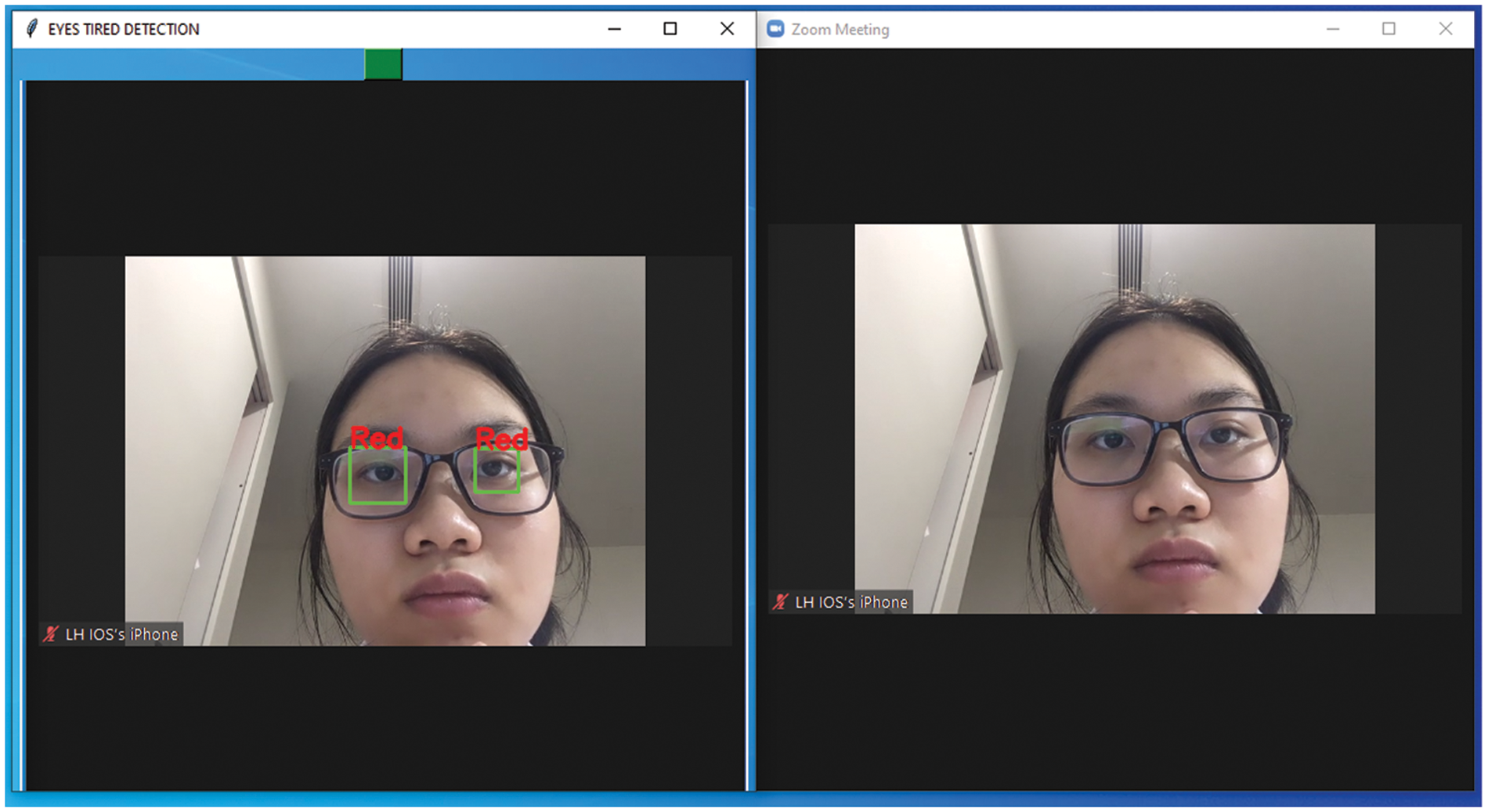
Figure 5: Eye strain detection application
In the condition of online classes, even the resolution of the laptop’s camera affects the quality of the data received, as the input images are sometimes blurred, causing the prediction probability to decrease. The proposed method for assessing eye fatigue is more difficult than those that focus on eye studies using special ophthalmic equipment. However, combining it with classroom management experience can help us overcome this obstacle by making the right decisions about changing the length of online learning. Depends on various external conditions such as the types of illnesses, input image qualities, types of images (radiography, normal images, positron emission tomography (PET) scan, etc.) and the others, the accuracy of those models that target ophthalmic illnesses using image detection can vary from 64%~82% on diabetic retinopathy [31] or 70%~80% on age-related macular degeneration [32]. From those statistics, we believe that our results show the effectiveness of this approach. This can be one stepping stone for further research regarding the improvement in quality of online learning, an indispensable part of the education system in the future.
Due to the Covid-19 pandemic, online classes have become more popular in the education system. Maintaining the same learning standards will be a challenge for both teachers and students, especially as eye fatigue increases rapidly due to high exposure to digital screens. To address this problem, this paper proposes to apply the KD method to improve lightweight models that can be used in an application capable of predicting eye strain in students when they have to study continuously on digital learning platforms. In KD, we use ResNet-18 as the teacher model and EyeNet as the student model in a small labeled dataset of eye disease images. By tuning hyperparameters are important in the KD process to evaluate the influence of the teacher model on students and by changing these, we propose to improve the distillation process while training. In our task, we noticed that KD is a good idea based on human learning. That is, students need guidance from the teacher just as the smaller student model needs to learn from the larger teacher model. Teachers not only teach students through output but also intervene in the student-specific learning process on each layer. With the results presented when experimenting, we confirm that this work can help people who are constantly exposed to digital screens by reducing the risk of eye strain during online learning.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Schools still closed for nearly 77 million students 18 months into pandemic, https://www.unicef.org/, Accessed 17 Nov 2021. [Google Scholar]
2. P. Sahu, “Closure of universities due to coronavirus disease 2019 (COVID-19Impact on education and mental health of students and academic staff,” Cureus, vol. 12, no. 4, pp. 6, 2020.http://dx.doi.org/10.7759/cureus.7541. [Google Scholar]
3. A. L. Sheppard and J. S. Wolffsohn, “Digital eye strain: Prevalence, measurement and amelioration,” BMJ Open Ophthalmology, vol. 3, no. 1, pp. 10, 2018.http://dx.doi.org/10.1136/bmjophth-2018-000146. [Google Scholar]
4. How to protect eyes from mobile and computer screens, https://kraffeye.com/,Accessed 11 Oct 2021. [Google Scholar]
5. A. Mohan, P. Sen, C. Shah, E. Jain and S. Jain, “Prevalence and risk factor assessment of digital eye strain among children using online e-learning during the COVID-19 pandemic: Digital eye strain among kids (DESK study-1),” Indian Journal of Ophthalmology, vol. 69, no. 1, pp. 140–144, 2021. [Google Scholar]
6. EyeShield, Nimble software, http://www.nimblesoftware.com/desktop/eyeshield,Accessed 17 Nov 2021. [Google Scholar]
7. K. Zhang and A. B. Aslan, “AI technologies for education: Recent research & future directions,” Computers and Education: Artificial Intelligence, vol. 2, no. 2, pp. 100025, 2021. [Google Scholar]
8. S. Secinaro, D. Calandra, A. Secinaro, V. Muthurangu and P. Biancone, “The role of artificial intelligence in healthcare: A structured literature review,” BMC Medical Informatics and Decision Making, vol. 21, no. 1, pp. 1, 2021. [Google Scholar]
9. A. L. Beam and I. S. Kohane, “Big data and machine learning in health care,” Journal of the American Medical Association, vol. 319, no. 13, pp. 1317–1318, 2018. [Google Scholar]
10. R. Raimundo and A. Rosário, “The impact of artificial intelligence on data system security: A literature review,” Sensors, vol. 21, no. 21, pp. 7029, 2021. [Google Scholar]
11. S. E. Haupt, D. J. Gagne, W. W. Hsieh, V. Krasnopolsky, A. McGovern et al., “The history and practice of AI in the environmental sciences,” Bulletin of the American Meteorological Society, vol. 103, no. 5, pp. 1351–1357, 2021. [Google Scholar]
12. H. Panwar, P. K. Gupta, M. K. Siddiqui, R. Morales-Menendez, P. Bhardwaj et al., “Aquavision: Automating the detection of waste in water bodies using deep transfer learning,” Case Studies in Chemical and Environmental Engineering, vol. 2, no. 57, pp. 100026, 2020. [Google Scholar]
13. U. Schmidt-Erfurth, A. Sadeghipour, B. S. Gerendas, S. M. Waldstein and H. Bogunović, “Artificial intelligence in retina,” Progress in Retinal and Eye Research, vol. 67, pp. 1–29, 2018. [Google Scholar]
14. D. Mahapatra, P. K. Roy, S. Sedai and R. Garnavi, “Retinal image quality classification using saliency maps and CNNs,” International Workshop on Machine Learning in Medical Imaging, vol. 10019, pp. 172–179, 2016. [Google Scholar]
15. Y. Mu, Y. Sun, T. Hu, H. Gong, S. Li et al., “Improved model of eye disease recognition based on VGG model,” Intelligent Automation & Soft Computing, vol. 28, no. 3, pp. 729–737, 2021. [Google Scholar]
16. G. Worah, M. Kothari, A. Khan and M. Naik, “Monitor eye-care system using blink detection a convolutional neural net approach,” International Journal of Engineering Research & Technology, vol. 6, no. 11, pp. 12–16, 2017. [Google Scholar]
17. L. B. Cruz, J. C. Souza, J. A. Sousa, A. M. Santos, A. C. Paiva et al., “Interferometer eye image classification for dry eye categorization using phylogenetic diversity indexes for texture analysis,” Computer Methods and Programs in Biomedicine, vol. 188, no. 3, pp. 105269, 2020. [Google Scholar]
18. Pin-I. Fu, F. Po-Chiung, H. Ren-Wen, C. Tsai-Ling, C. Wan-Hua et al., “Determination of tear lipid film thickness based on a reflected placido disk tear film analyzer,” Diagnostics, vol. 10, no. 6, pp. 353, 2020. [Google Scholar]
19. J. Rodriguez, P. Johnston, G. Ousler, M. Smith and M. Abelson, “Automated grading system for evaluation of ocular redness associated with dry eye,” Clinical Ophthalmology, vol. 7, pp. 1197–1204, 2013. [Google Scholar]
20. J. Yang, X. Zhu, Y. Liu, X. Jiang, J. Fu et al., “TMIS: A new image-based software application for the measurement of tear meniscus height,” Acta Ophthalmologica, vol. 97, no. 7, pp. e973–e980, 2019. [Google Scholar]
21. L. Ramos, N. Barreira, A. Mosquera, M. G. Penedo, E. Yebra-Pimentel et al., “Analysis of parameters for the automatic computation of the tear film break-up time test based on CCLRU standards,” Computer Methods and Programs in Biomedicine, vol. 113, no. 3, pp. 715–724, 2014. [Google Scholar]
22. T. Kim and E. C. Lee, “Experimental verification of objective visual fatigue measurement based on accurate pupil detection of infrared eye image and multi-feature analysis,” Sensors, vol. 20, no. 17, pp. 4814, 2020. [Google Scholar]
23. M. Sandler, A. Howard, M. Zhu, A. Zhmoginov and L. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” Arxiv, vol. 37, pp. 4510–4520, 2018. [Google Scholar]
24. K. He, X. Zhang, S. Ren and J. Sun, “Deep residual learning for image recognition,” Arxiv, 2015https://doi.org/10.48550/arXiv.1512.03385. [Google Scholar]
25. Y. LeCun, L. Bottou, Y. Bengio and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998. [Google Scholar]
26. A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang et al., “MobileNets: Efficient convolutional neural networks for mobile vision applications,” Arxiv, 2017https://doi.org/10.48550/arXiv.1704.04861. [Google Scholar]
27. C. Buciluǎ, R. Caruana and A. Niculescu-Mizil, “Model compression,” in Proc. of the 12th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, New York, NY, United States, pp. 535–541, 2006. [Google Scholar]
28. G. Hinton, O. Vinyals and J. Dean, “Distilling the knowledge in a neural network,” Arxiv, 2015https://doi.org/10.48550/arXiv.1503.02531. [Google Scholar]
29. D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” Arxiv, 2017https://doi.org/10.48550/arXiv.1412.6980. [Google Scholar]
30. Open neural network exchange, 2017, https://onnx.ai,Accessed Jan, 2022. [Google Scholar]
31. R. Rajalakshmi, R. Subashini, R. M. Anjana and V. Mohan, “Automated diabetic retinopathy detection in smartphone-based fundus photography using artificial intelligence,” Eye, vol. 32, no. 6, pp. 1138–1144, 2018. [Google Scholar]
32. H. Bogunović, S. M. Waldstein, T. Schlegl, G. Langs, A. Sadeghipour et al., “Prediction of anti-VEGF treatment requirements in neovascular AMD using a machine learning approach,” Investigative Ophthalmology & Visual Science, vol. 58, no. 7, pp. 3240–3248, 2017. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools