
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Night Vision Object Tracking System Using Correlation Aware LSTM-Based Modified Yolo Algorithm
1 Department of Computer Science and Engineering, K.L.N. College of Engineering, 630612, Tamilnadu, India
2 Department of Electronics and Communication Engineering, Thiagarajar College of Engineering, Madurai, 625015, Tamilnadu, India
* Corresponding Author: R. Anandha Murugan. Email:
Intelligent Automation & Soft Computing 2023, 36(1), 353-368. https://doi.org/10.32604/iasc.2023.032355
Received 15 May 2022; Accepted 28 June 2022; Issue published 29 September 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Improved picture quality is critical to the effectiveness of object recognition and tracking. The consistency of those photos is impacted by night-video systems because the contrast between high-profile items and different atmospheric conditions, such as mist, fog, dust etc. The pictures then shift in intensity, colour, polarity and consistency. A general challenge for computer vision analyses lies in the horrid appearance of night images in arbitrary illumination and ambient environments. In recent years, target recognition techniques focused on deep learning and machine learning have become standard algorithms for object detection with the exponential growth of computer performance capabilities. However, the identification of objects in the night world also poses further problems because of the distorted backdrop and dim light. The Correlation aware LSTM based YOLO (You Look Only Once) classifier method for exact object recognition and determining its properties under night vision was a major inspiration for this work. In order to create virtual target sets similar to daily environments, we employ night images as inputs; and to obtain high enhanced image using histogram based enhancement and iterative wiener filter for removing the noise in the image. The process of the feature extraction and feature selection was done for electing the potential features using the Adaptive internal linear embedding (AILE) and uplift linear discriminant analysis (ULDA). The region of interest mask can be segmented using the Recurrent-Phase Level set Segmentation. Finally, we use deep convolution feature fusion and region of interest pooling to integrate the presently extremely sophisticated quicker Long short term memory based (LSTM) with YOLO method for object tracking system. A range of experimental findings demonstrate that our technique achieves high average accuracy with a precision of 99.7% for object detection of SSAN datasets that is considerably more than that of the other standard object detection mechanism. Our approach may therefore satisfy the true demands of night scene target detection applications. We very much believe that our method will help future research.Keywords
The identification of night-object objects in the view of the machine was crucial because of its tough problems, especially for military border monitoring and sophisticated driver assistance systems. Many night vision gadgets automatically drive, but regrettably the visibility of input pictures is good under the light. Various atmospheric conditions that modify the primary features of the light source because of the dispersion of medium-aerosols influence the quality of these images (intensity, color, polarization, consistency). It gives us many drawbacks, particularly where protection also involves useful knowledge in the low-enlightenment picture received. The low-light picture has issues with low visibility, low contrast and noise in low lighting conditions due to its low light or inadequate exposure. While indoor and outdoor performance benefits computer vision systems, inside and outdoor contexts they confront problems at night. The major safety problem in the event of collisions in vehicle constructions induced by darkness, is a good solution. Wide datasets have been developed to satisfy the rising need for designing new models of detection of night objects under poor atmospheric conditions in recent decades. However, video datasets for moving object detection tasks are still missing which can provide a balance in deteriorated exterior scenes in the atmosphere, particularly at night. However, in low lighting or vision conditions like complete darkness and bad atmosphere they are unreliable because the representation of objects is not as noticeable as photographs reported in the usual atmosphere. Many trials of methods for detecting objects with infrared cameras like Near Infrared (NIR) and Far infrared (FIR) have been undertaken to overcome nighttime visual and camera limitations. The NIR cameras are resistant to the dark and less expensive than the FIR. But Charge Coupled Device (CCD) camera has similar drawbacks in the NIR as car headlights intervene. In addition, the reduction in visual, CCD and NIR radiation by atmospheric aerosols is owing to their short wavelengths. On the other hand, FIR cameras allow robust object identification regardless of the environment, since the spectrum wavelength increases the effects from the unfavorable atmosphere. Less study into moving object tracking at night was conducted with thermal images under varying ambient conditions due to the high cost of a FIR sensor. One of the simplest options is to upgrade technology, such as infrared surveillance or increase camera aperture. But the cost would be too high for these hardware upgrades. Much attention is still also based on applications for software algorithms. Much of today’s work on low-lighting focuses on optimizing images in order to enhance the low visual qualities of images. However, not enough attention has yet been obtained for high-level activities, including object identification in low-light conditions.
Detection of objects is very difficult in low light conditions. While several efficient detection algorithms with deep learning developments have been proposed, they cannot work best under low light conditions. Owing to the unequal distribution of luminance, although with additional light sources the specifics of object are still difficult to discern. The basic explanation we believe is that existing mainstream detectors have been equipped for regular lighting data. So far, in low enlightenment settings there is no unique remedy for vision activities. Therefore, the key goal in the current analysis is to establish an automatic system for forecasting an object in the night. The method will correctly classify the objects. Hence in the current study the main objective is to develop an automated method to forecast an object in a night time environment. The procedure can identify the objects in a precise manner. The images can be collected and by using the suggested recurrent phase level set segmentation and correlation aware LSTM based YOLO classifier for background subtraction and target object detection. This may be structured for the remainder of the paper. Section 2 provides a summary of the related work. Section 3 describes the problem statement. Section 4 describes the methods used for object detection. Section 5 shows the experimental outcomes. The document is closed at Section 6.
Xiao et al., [1] Propose a Night Vision Detector (NVD) for low-luminance object detection with a specially built pyramid network feature and background fusion network. Due to extensive testing on ExDARK and selected COCO*, a public real light scene dataset, some useful comparison conclusions were obtained on the one hand and unique solutions have been established for low-illumination object detection on the other. Nowosielski et al., [2] proposed night-vision system with thermal imaging processes for pedestrian tracking using an Ubuntu MATE Operating System patented ODROID XU4 microcomputer. Ashiba et al., [3] Presents a proposed solution to enhancing night vision images in Infrared (IR). This technique is based on a trilateral improvement of the contrast, in which the IR-night view images are segmented, enhanced and refreshed in three steps. The IR picture is divided into threshold segments in the first step. The second step that is at the heart of the enhancement approach is based on additive wavelet transformation (AWT). Homographic improvement is carried out in detail elements, while on the approximation plane the plateau histogram is equalized. Afterwards, the image is rebuilt and subjected to a high pass filter after processing. The efficiency measures for assessment of the proposed solution are the average curve, sobel edge and spectral entropy. Sowmyalakshmi et al., [4] presented the best background subtraction algorithms are defined by means of genetic algorithms, parameter background subtraction are optimised and the optimum number of pre and post-processing operations are determined. Mehmood et al., [5] Built a smart home automation system based on Cloud of Thing (CoT) model view controller (MVC). Nobis et al., [6] proposed Camera Radar Fusion Net (CRF-Net) immediately learns the most advantageous degree of sensor data fusion in order to detect the effect. They also present BlackIn, a Dropout-inspired teaching technique that focuses learning on a single form of sensor. Kim et al., [7] suggest a system to comprehend purchasing activities using video sensors, detection and monitoring in real time of products in an unmanned product cabinet. Park et al., [8] Proposes a reliable and reliable system for the infrarot identification of CCTV pictures at night. Kim et al., [9] give a framework that helps collect images of general tracking cameras used in multiple locations using networks for better image quality and networks for object detection. Shakeel et al., [10] Propose a novel deep learning approach based on the revolutionary neural networks to tackle this problem (CNN). The approach stated that sleepiness should be recognised as an item and that open and enclosed views should be distinguished from an entry driver video source. The MobileNet CNN Architecture of the Single Shot Multibox Detector (SSD) is utilised for this purpose. Schneider et al., [11] Proved the possibility to identify, measure and locate animals in cameras, by means of a training and comparison of two deep learning object identification classifiers-Faster R-CNN and YOLO v2.0-with the Reconyx Camera Trap and Gold Standard Snapshot Serengeti data sets. Komatsu et al., [12] Offer a passive 3D imaging approach with an integrated imaging (LWIR) camera. 3D imaging helps increase visualization and indentation in unfavorable situations like low light levels and partial occlusion by rebuilding the object plane scene. Kuanar [13] Propose a method based on a neural network (CNN) that learns and wisely divides the area. The downstream encoder systems then employ these categorization effects in order to select the best coding units in each block, which therefore lowers the number of prediction modes. Aladem et al., [14] Four ways for enhancing photographs show and research under harsh night settings. For a broad range of vision systems such as auction detection, picture collection, positioning, mapping and deep object detectors, the findings are significant. Bhatia et al., [15] study the effectiveness and precision of pothole detection thermal imaging. The shadowing issue and classification accuracy of human object sequences must be addressed, according to the findings of the literature review. Existing strategies have yielded results by putting congested and crowded situations at risk.
Since much work was done to detect object in sequential video frames in this area. The key challenges are developed in the video monitoring system either because of certain environmental circumstances or because of external influences.
• Dynamic or Disordered
• Context and foreground perception is expected to be background as foreground (e.g., camouflage).
• Variable intensity due to progressive or abrupt shifts leading to false pixel detection
Both these challenges in literature are very critical. The concept behind using the context strategy is that a moving subject should be separated in real time situations from unvarying or shifting parts of the background. Effective segmentation and classification methods may also boost these essential issues or problem. This technique for the identification of subjects under night-time scenarios has been greatly established.
The key aim of this analysis is to identify important moving details in a video setting in each consecutive frame. Our key objective is to detect the video frame object. Generally, Human, Car, Bike, Animal, Truck and Van are topics of concern. The foreground is also known. In video tracking, the context elimination technique is often used to track the meaningful moving target or its behavior. In this work, we have used a novel segmentation and classification methodology for background subtraction technique for detecting moving objects in video. ASL ETH FLIR dataset [16], LITIV2012 Dataset [17] , KAIST Multispectral Pedestrian Detection Benchmark [18], OSU Thermal Pedestrian Database from OTCBVS Benchmark Dataset Collection, Terravic Motion IR Database [19]-, CVC-09: FIR Sequence Pedestrian Dataset [20], and VOT-TIR2015 [21], CCTN RGB IR [22] dataset were used to detect pedestrians. We use the dataset of SSAN here.
The vision of the night is a crucial component and has a major impact on our eye efficiency. During the dark hours night vision research has gradually developed, in particular in image enhancement, but a database is a baseline. Our data set includes items for night vision, and a night dark video is classified as bright if the changes in light are modest or substantial. Night-vision movies featuring a range of illumination objects were filmed under a number of situations. The IR illumination is the greatest difficulty with night viewing films. Our CCTV system uses the IR Led light that can be accessed by a 920-pixel image sensor camera at a maximum distance of 25 m. Different situation CCTV images with different objects like human, vehicle, motorcycle, bike, van & etc. have been considered. We took about 50 movies with 25FPS frame rates for each object. We consider various objects walk at night time and also we consider the rain fall, illumination from other light sources also. For night vision research scientists, we have produced an exclusive dataset of reference points. Fig. 1 shows the architecture of proposed methodology.
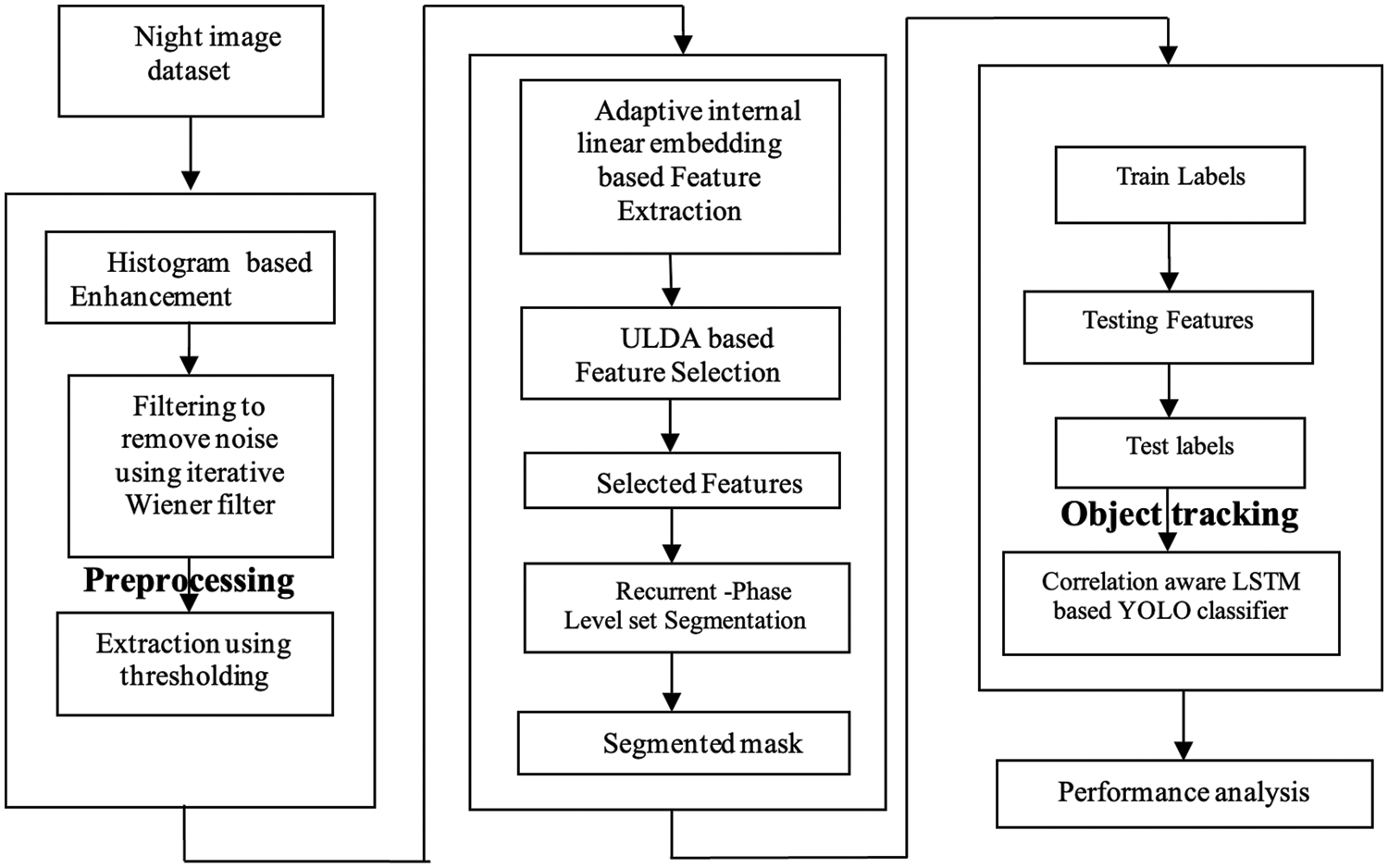
Figure 1: Schematic representation of the proposed methodology
The first step of the object detection is the pre-processing. To ensure the durability and usability of a database, preprocessing is important. For this, any step seems to be essential to the workflow of image processing. The process carries out pre-processing of unnecessary error identification using filters and histogram equalizing techniques. Here, with night image the noises can be removed in this step. The iterative wiener filter is a non-linear optical filtering technique that is frequently used to remove noise from a picture or signal. A reduction of noise is a typical efficiency improvement preprocessing approach. Pre-processing is performed to enhance the contrast of the image in the night image. Typically, histogram equalization is achieved to increase image consistency. Histogram Equalization is a computerized process used to enhance the contrast of pictures. The most typical sensitivity values are improved effectively, i.e., the image intensity range is broadened. In order to boost relations between regions, it allows less local contrast. Therefore, after implementation of the histogram equalization, the average contrast of the images is improved.
Let p denote the normalized histogram of each possible intensity. Hence,
Here, y = 0, 1,…, y − 1
The histogram equalized image can be defined as
where, base represents the nearest integer. This is equivalent to transforming the pixel intensity,
Here, finally the probability distributed uniformity function can be represented as
While the result indicates that the equalization process used is exactly flat histograms, it can soften them and improve them. Although the result reveals that equalization used is an exactly flat histogram, it will ease and boost it. We apply a threshold method to refine the SS color image from the context after minimizing the images’ unnecessary noise. After applying thresholds, the binary image is generated, which simplifies image processing. In most dental images, we detect a shading effect manifested by an increase in the color’s strength. Therefore, it is not preferable to just take a single threshold value because it will cause lost information pixels. The histogram of the filtered image includes the percentage of pixels below a given level of grey, which decreases the noise level to zero. The threshold procedure is used to measure a threshold for each pixel in the image using certain local statistics, including mean, pixel median, and the threshold at a time. In the case of poorly intensity images, it is the key benefit of this thresholding process. The pixels in a standardized neighborhood are set to the bottom line for the extraction of the object.
Here to choose the characteristics A common manifold learning technique is the Adaptive Internal Embedding Algorithm (AILE). AILE is primarily designed to handle nonlinear local fitting problems throughout the world, based on the assumption that data from a multiplied nonlinear system may be interpreted as linear in a limited area. AILE translates its input into a single universally coordinated lower dimensional system by computing low dimension inputs that protect the neighborhood without any local minimum. By using local symmetries of linear reconstruction, AILE can learn the global structure of nonlinear divers. Local linear assembly is defined by linear reactivation coefficients for each data point from its surrounding areas as well as by linear coefficients, i.e., weight matrix. AILE seeks the samples of training data by their class significance to be better differentiated (or discriminated against). In particular, the template aims to identify a linear combination of input variables, which allows for a maximum separation of samples across classes (average or mean) and a minimal division within each class of samples. The AILE is processed in the following. The first step of the linear analysis of discrimination must create a matrix based on the formation of samples from the AILE function space. The AILE has the C class (C
Afterward the matrix was constructed,
Generally the matrix can be developed for the purpose of selecting the features. The pointed features are calculated by the calculation of the covariance matrix. Finally the Map high-dimensional features can be mapped to the embedded coordinate,
4.4 Uplift LDA Based Feature Selection
In order to select the appropriate features for object detection in the defined experimental field, decision model has been created. The selected and grouped 26 input variables are sort out into 6 primary variables. In the course of extracting features 26 input variables were gathered in order to build the decision-making model to help users to decide on feature selection at the respective locations. Six of the 26 input variables are selected using a Uplift LDA (Linear discriminant Analysis) by utilizing the feature selection method. Then the features can be visualized using the ULDA system. An orthogonal transformation-driven function design methodology is the primary component of the syste. The number of key elements is fewer than the original criteria. Input value can be limited by ULDA. The parameter value of every class can be shown in this ULDA function map. ULDA condenses information from a wide variety of variables into less variables by introducing some sort of transformation theory. Correlation implies information is repetitive and that if this consistency, information may be compact. Consider the two F1 and F2 features which are distributed uniformly on [−1, 1] binary and the O output class and which are given below,
In this dilemma are the data points provided in the shady regions. The problem is linear separable and the required features of F1 + F2 can easily be chosen. The LDA is done with N-dimensional vectors on the collection of data providers, indicating the path of the function space. This vector provides the best information about the problem and provides the latest function to the output class that projections it into space (F1, F2). By using the following equation the correlation between the features can be defined
After that some the important crop features that can be extracted that can be depicted below.
This method helps to process the data and extracting the features of the crop from the data in an effective manner.
Then for the Segmentation, the recurrent phase level set segmentation method can be used for the subtraction of the background in the night time images. The level set’s fundamental concept is to depict the hyper-surface curves and surfaces as a zero level range. It provides more precise numerical and fast topological tests. The surface-smoothing method
where,
d is the shortest distance between the point x on the surface and curve.
The general level set function is defined as follows in Eq. (14)
where,
F is the independent function depends on the information of images.
To improve the segmentation process, the independent internal term and the external independent term shall be considered. The gradient flow that reduces the cumulative power function is this growth.
where,
E is the controlling parameter.
σ is the Dirac delta function
g is the edge indicator function defined by
I is an image, and gj is the Gaussian kernel with standard deviation.
This model’s network design consists of 24 convergence layers and two fully linked levels. Wherever the convolutionary strata extract characteristics, the fully linked strata estimate the position and probability of the border strata. First, we divide the entire image into a n/n grid. Each cell is connected to two bounding boxes and to their respective secrecy category to identify a maximum of two items in a single grid cell. If an item has a grid cell, the middle cell is selected as the prediction. An array without an item has 0 trust value whereas a bounding box near an item is trustworthy in line with the bounding box value as shown in Tab. 1.

The Correlation aware LSTM based YOLO can be suggested for object classification. Here in this process the object can be identified and it can be tracked depend upon its posing. One of the main problems with night scene images is that they were shot on many occasions for several years. So the views usually shift a bit so that the two images may become affinity until they are furnished. The transition into a sub-set involves an affinity. The shear transformation is not considered since shear is negligible in night images. Thus the transformation becomes,
If an image has been submitted, we generate multiple sub-images for each image in the database with the same number of images as the query. The images and databases are numbered with 1, 2, … and so on to the right. Then the imaging in which the object can be identified, and the Euclidean distance can be calculated.
Finally, a ranking is generated for the abnormality matching distance of data base images,
where the ED signifies the Euclidean distance, q denotes the query image, and s is the image’s score value.
The CNN classification was concluded as
The overall process of the suggested classifier was depicted in Fig. 2.
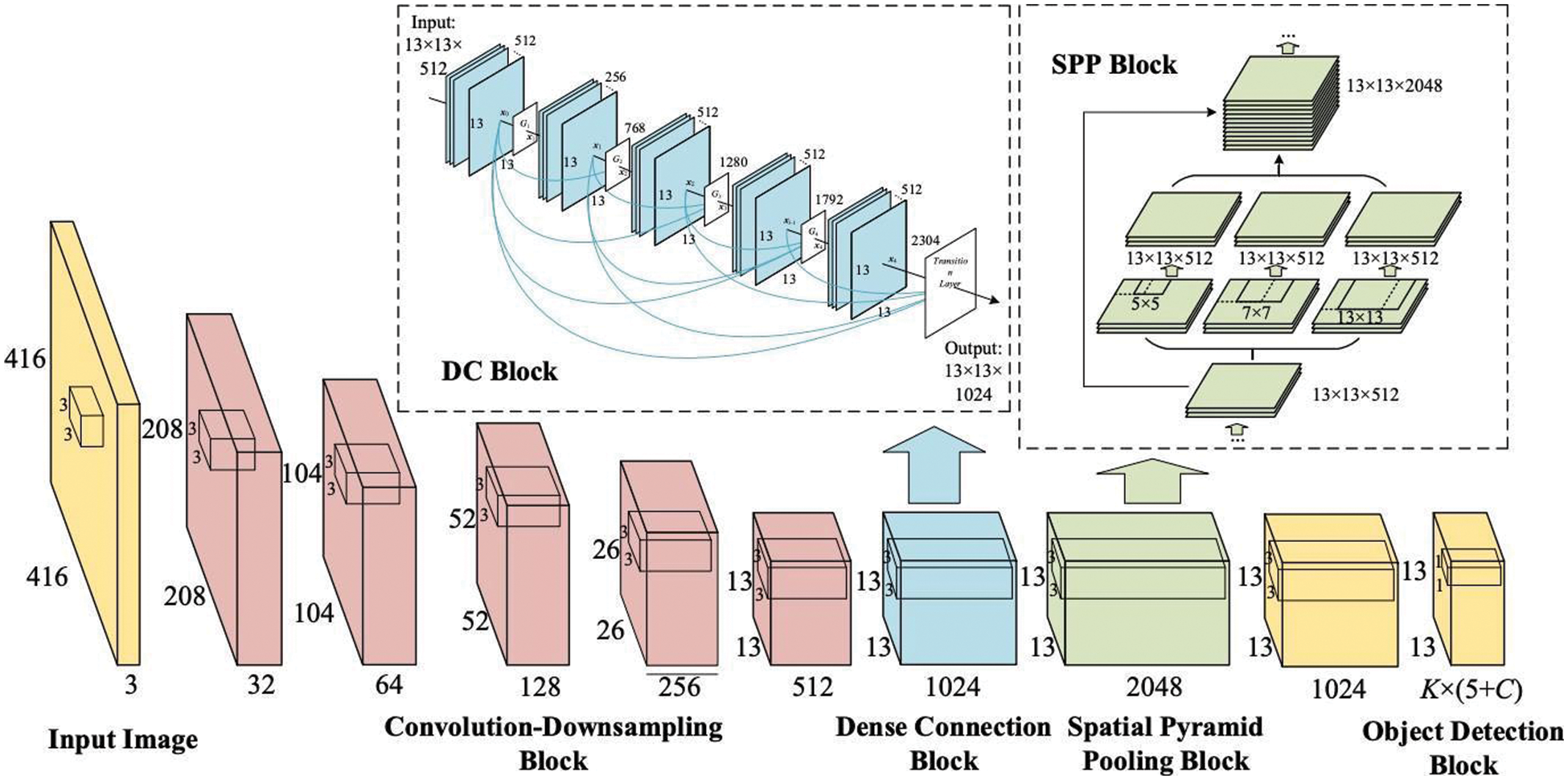
Figure 2: Process of the classification

As part of the paper the test results were represented in this section, the results are seems to be more experimental. It can be seen that the recurrent phase level set segmentation and Correlation aware LSTM based YOLO was presented here in this paper. The prediction result of the test image is compared with the label image, and the pixel accuracy, class average accuracy and average IU are calculated. In terms of calculation speed, the comparison method takes about 1500 ms to process each image, while the method in this paper only needs 90 ms, which is significantly less than the comparison method and meets real-time requirements. It can be seen that the method in this paper has a higher recognition rate for each category. However, there is a problem with both the method in this article and the comparison method, that is, the recognition rate of the image is sparse but equally important. The distance is far, and manual calibration is rough. In the follow-up work, we will increase the number of samples in these categories and improve the quality of calibration.
This section has analyzed the efficiency of the proposed method. At this moment, implementing the Correlation aware LSTM based YOLO can be used for training and testing, as depicted in Fig. 3. Here we may then run the trained class on unknown documents by running samples of classes through classification to train them to which classes each belong. Some parameters were measured and analyzed to assess the output of the implemented method. The performance analysis is performed using various performance metrics evaluated for the system proposed and contrasted with the rest of the prevailing research study [23]. The idea is contrasted with other algorithm and methods for identification, though based on significant performance metrics. Due to their higher success than other existing methods, the Correlation aware LSTM based YOLO detection classifier was used for the night time object detection mission. Tab. 2 represents the segmented and the classified output by implementing the novel mechanism. Tab. 3 represents perfromance evaluation of the proposed classifier.
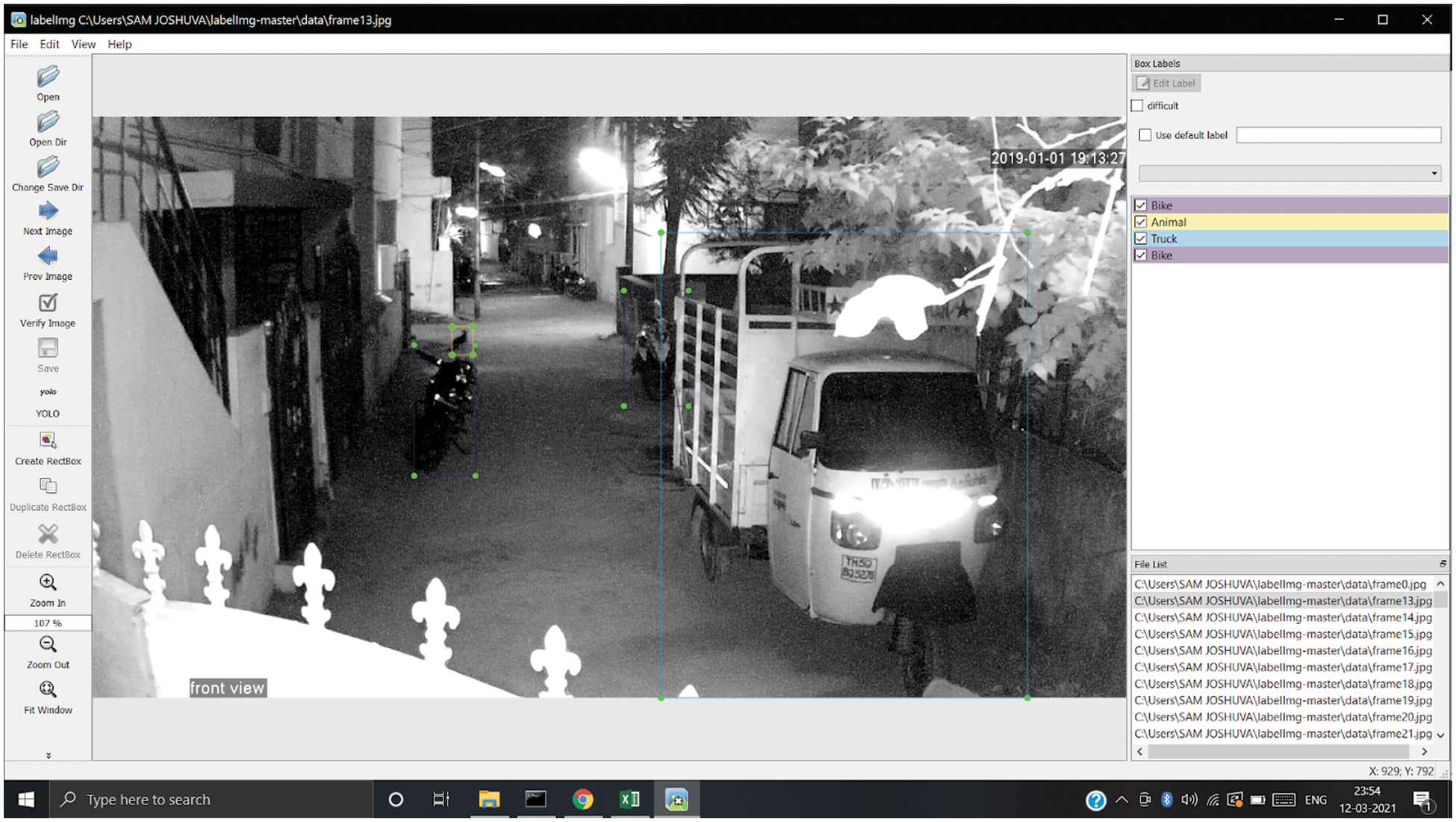
Figure 3: Training process of the suggested classifier

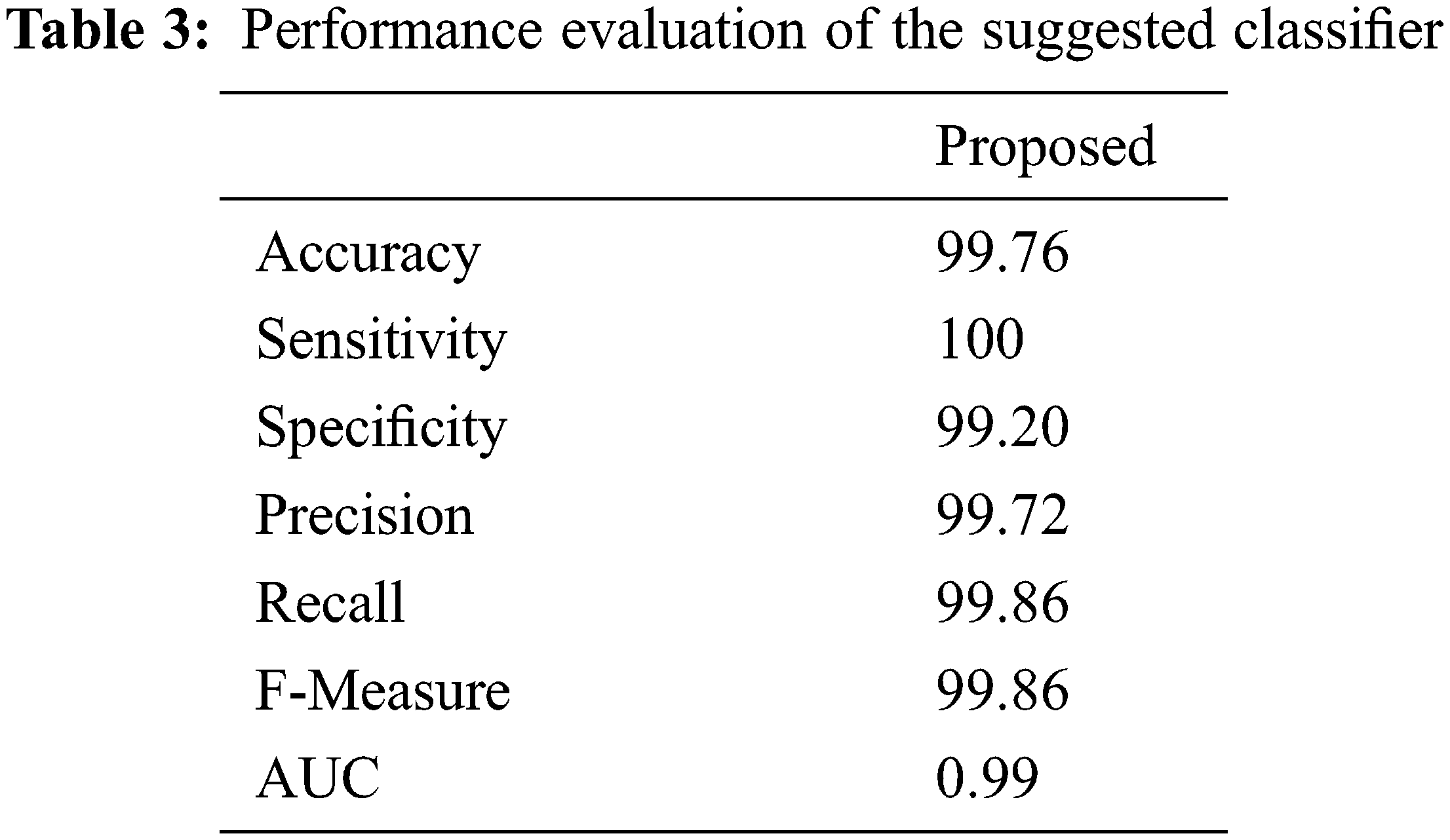
Fig. 4 represents that the data set graphical values of the proposed classifier output. With the use of the suggested classifier, the best performance can get achieved. The findings suggest that the improved performance of the proposed method. A total performance of 99.2% specificity, 100% sensitivity, 99.7% precision, 100% recall, 99.8% F-measure is observed with 0.99% AUC. The accuracy of the suggested classifier will be raised upto 99.79%.
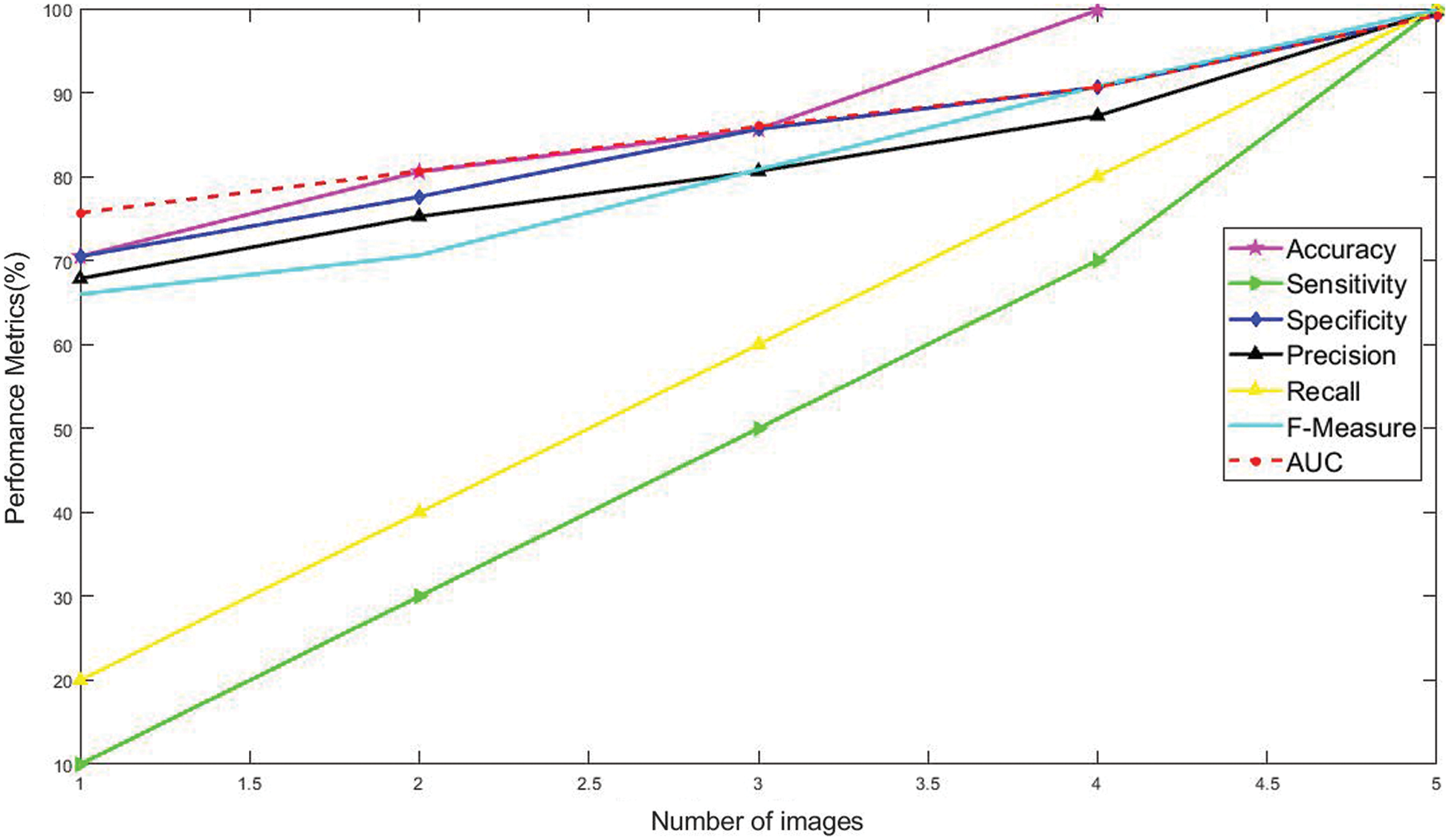
Figure 4: Number of images vs. performance metrics
The detection performance of the suggested model trained on our dataset was tested on SSAN datasets and it can be compared with the existing object detection methodology TIRNet [23], Faster R-CNN [24], YOLO V3 [25–27] to prove the efficiency of the suggested system The outputof the IoU shown in Tab. 4.
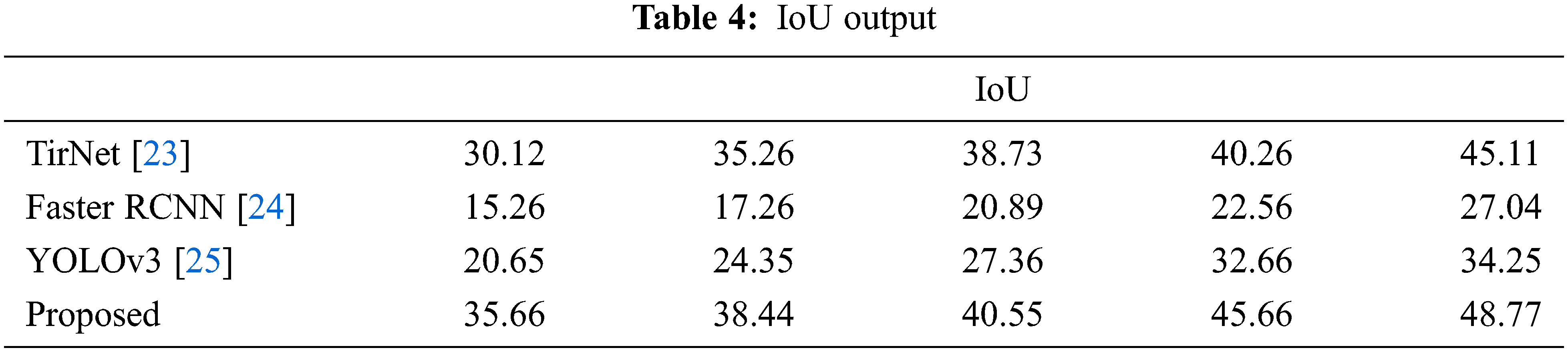
Intersection over Union is an assessment metric used to quantify accuracy on a specific data set of the proposed object detector. We can cross the box and the anticipated box in the ground truth. It should be seen from the results collected that the proposed model has a higher IoU value compared to other current techniques on the dataset mAP output shown in Tab. 5.
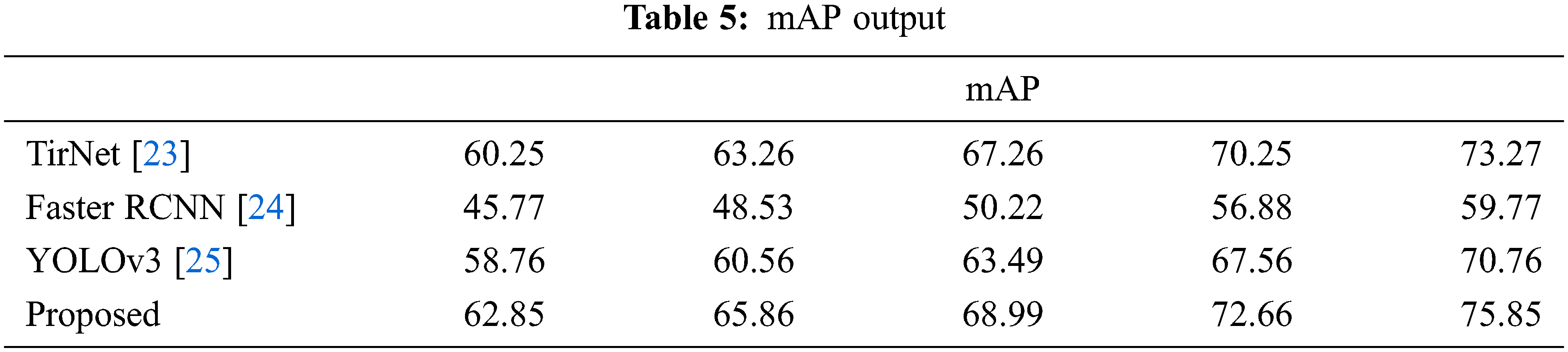
Mean average precision (mAP) is a common measure of the performance of the proposed model on object identification tasks or is only occasionally referenced as an AP. From the collected results it should be shown that, compared to other current models, the proposed model can precisely detect objects within a short time.
The average of several IoU is referred to as the AP. Tab. 6 shows that, when compared to other existing mechanisms, the detection performance of the suggested mechanism with a low threshold value of 0.6 IoU results in a good prediction accuracy.
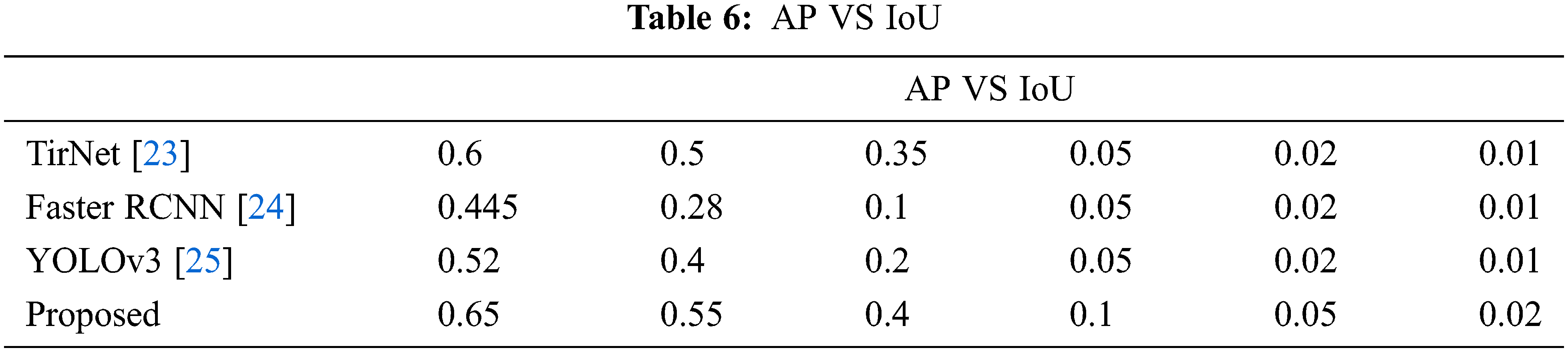
It is used to calculate the true predictions from all correctly predicted data. The harmonic mean of precision and recall is the F1 score shown in Tab. 7. This will generally reveals the process of the segmentation score. Here by using the recurrent phase level set segmentation the object can be segmented precisely by subtracting background.
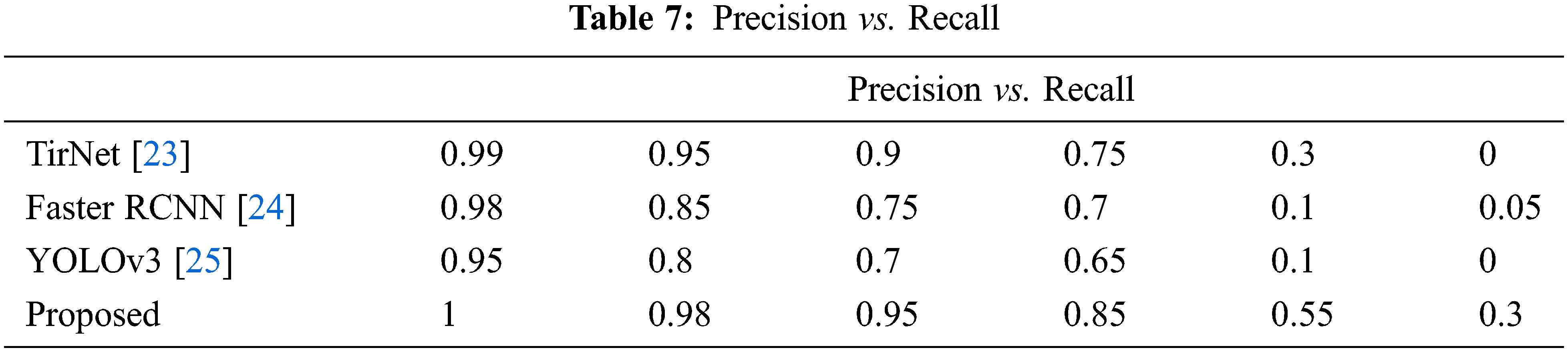
The findings suggest that the improved performance of the proposed method. The comparative findings of the conventional and the suggested technique are seen in Tab. 8. It is apparent from the outcomes achieved that as opposed to other current approaches, the proposed approach outperforms well.
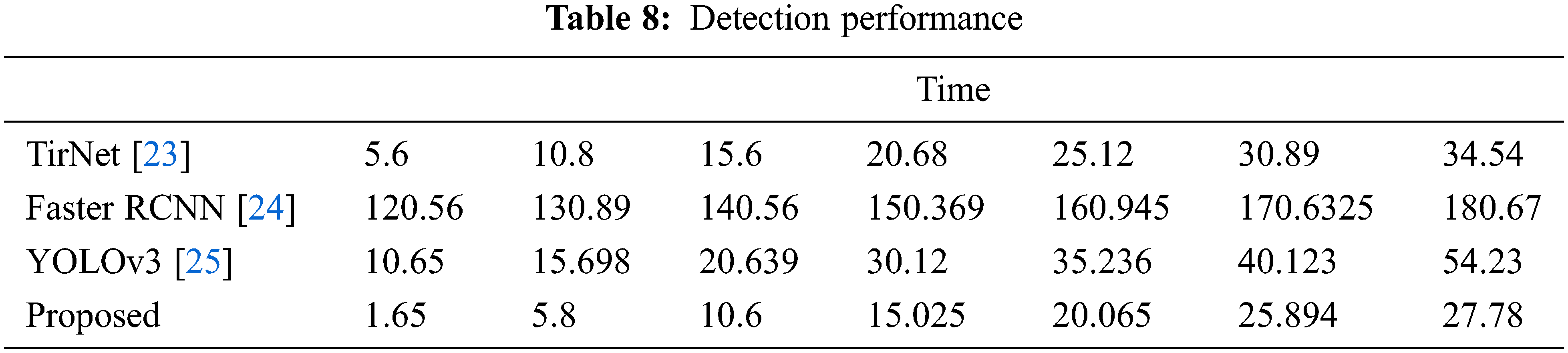
The findings of the common YOLO-Methodology were improved in this paper and were tested in monitoring scenarios to identify objects and trace them in regular night visual images. The experiment was performed on a custom data set where various authors will explain. We have done a tentative study of the chosen state-of-the-art detectors, such as TirNet, Faster RCNN and YOLOv3, in order to find the best detector for detecting people in thermal or natural imagery. Input images are excellent. The LSTM-based YOLO, TirNet, Faster R-CNN, and YOLOv3-control detectors obtained comparable detection results at night-views, but the LSTM-based YOLO was considerably faster and more used in the research. The proposed model, however, achieved high average accuracy with a precision of 99.7% at 100% recall. This recommended model was still able to detect objects in a variety of thermal/night vision pictures, thus it was a decent place to start when building a model. Future scope of research work will be applied to the real time CCTV systems to perform the night time detections.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Y. Xiao, A. Jiang, J. Ye and I. A. Wang, “Making of night vision: Object detection under low-illumination,” IEEE Access, vol. 8, no. 2, pp. 123075–123086, 2020. [Google Scholar]
2. A. Nowosielski, K. Małecki, P. Forczmański, A. Smoliński and K. J. I. S. J. Krzywicki, “Embedded night-vision system for pedestrian detection,” IEEE Sensors Journal, vol. 2, no. 15, pp. 325–336, 2020. [Google Scholar]
3. M. Ashiba, M. S. Tolba, A. S. El-Fishawy and M. T. Abd El-Samie, “Hybrid enhancement of infrared night vision imaging system,” Multimedia Tools and Application, vol. 79, no. 4, pp. 6085–6108, 2020. [Google Scholar]
4. R. Sowmyalakshmi, M. Ibrahim Waly, M. Yacin Sikkandar, T. Jayasankar, S. Sayeed Ahmad et al., “An optimal lempel ziv markov based microarray image compression algorithm,” Computers, Materials & Continua, vol. 69, no. 2, pp. 2245–2260, 2021. [Google Scholar]
5. F. Mehmood, I. Ullah, S. Ahmad and D. H. Kim, “Object detection mechanism based on deep learning algorithm using embedded IoT devices for smart home appliances control in CoT,” Journal of Ambient Intelligence and Humanized Computing, vol. 12, no. 4, pp. 1–17, 2019. [Google Scholar]
6. F. Nobis, M. Geisslinger, M. Weber, J. Betz and M. Lienkamp, “A deep learning-based radar and camera sensor fusion architecture for object detection,” in 2019 Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, vol. 4, no. 6, pp. 1–7, 2019. [Google Scholar]
7. D. H. Kim, S. Lee, J. Jeon and B. C. J. E. S. W. A. Song, “Real-time purchase behavior recognition system based on deep learning-based object detection and tracking for an unmanned product cabinet,” Expert Systems with Applications, vol. 143, no. 5, pp. 113063–113075, 2020. [Google Scholar]
8. J. Park, J. Chen, Y. K. Cho, D. Y. Kang and B. J. J. S. Son, “CNN-Based person detection using infrared images for night-time intrusion warning systems,” Sensors, vol. 20, no. 5, pp. 34–49, 2020. [Google Scholar]
9. I. S. Kim, Y. Jeong, S. H. Kim, J. S. Jang and S. K. Jung, “Deep learning based effective surveillance system for low-illumination environments,” in 2019 Eleventh Int. Conf. on Ubiquitous and Future Networks (ICUFN), Zagreb, Croatia, vol. 14, no. 2, pp. 141–143, 2014. [Google Scholar]
10. M. F. Shakeel, N. A. Bajwa, A. M. Anwaar, A. Sohail and A. Khan, “Detecting driver drowsiness in real time through deep learning based object detection,” in Int. Work-Conf. on Artificial Neural Networks, Zagreb, Croatia, vol. 4, no. 6, pp. 283–296, 2019. [Google Scholar]
11. S. Schneider, G. W. Taylor and S. Kremer, “Deep learning object detection methods for ecological camera trap data,” in 2018 15th Conf. on Computer and Robot Vision (CRV), Toronto, ON, vol. 5, no. 8, pp. 321–328, 2019. [Google Scholar]
12. S. Komatsu, A. Markman, A. Mahalanobis, K. Chen and B. J. A. O. Javidi, “Three-dimensional integral imaging and object detection using long-wave infrared imaging,” Applied Optics, vol. 56, no. 9, pp. 120–126, 2017. [Google Scholar]
13. S. P. Kuanar, “Deep learning based fast mode decision in HEVC intra prediction using region wise feature classification,” Ph.d Thesis Dissertation, University of Texas, lington, United States, vol. 5, no. 52, pp. 322–339, 2018. [Google Scholar]
14. M. Aladem, S. Baek and R. Rawashdeh, “Evaluation of image enhancement techniques for vision-based navigation under low illumination,” Journal of Robotics, vol. 2019, pp. 1–16, 2019. [Google Scholar]
15. Y. Bhatia, R. Rai, V. Gupta, N. Aggarwal and A. Akula, “Convolutional neural networks based potholes detection using thermal imaging,” Journal of King Saud University-Computer and Information Sciences, vol. 12, no. 56, pp. 525–541, 2019. [Google Scholar]
16. J. Portmann, S. Lynen, M. Chli and R. Siegwart, “People detection and tracking from aerial thermal views,” in 2014 IEEE Int. Conf. on Robotics and Automation (ICRA), Hong Kong, China, vol. 4, no. 81, pp. 1794–1800, 2014. [Google Scholar]
17. G. -A. Bilodeau, A. Torabi, P. -L. St-Charles and I. P. Riahi, “Thermal–visible registration of human silhouettes: A similarity measure performance evaluation,” Nfrared Physics & Technology, vol. 64, no. 8, pp. 79–86, 2014. [Google Scholar]
18. J. W. Davis and M. A. Keck, “A Two-stage template approach to person detection in thermal imagery,” in 2005 Seventh IEEE Workshops on Applications of Computer Vision (WACV/MOTION’05), Breckenridge, Colorado, USA, vol. 1, pp. 364–369, 2005. [Google Scholar]
19. S. B. Miezianko, Terravic Research Infrared Database, Springer, Cham, Switzerland, vol. 4, no. 61, pp. 652–671, 2005. [Google Scholar]
20. Y. Socarrás, S. Ramos, D. Vázquez, A. M. López and T. Gevers, “Adapting pedestrian detection from synthetic to far infrared images,” in IEEE ICCV Workshops, Amsterdam, vol. 4, no. 62, pp. 585–597, 2013. [Google Scholar]
21. M. Felsberg, A. Berg, G. Hager, J. Ahlberg, M. Kristan et al., “The thermal infrared visual object tracking VOT-TIR2015 challenge results,” in Proc. of the IEEE Int. Conf. on Computer Vision Workshops, Santigo, Chile, vol. 7, no. 92, pp. 76–88, 2015. [Google Scholar]
22. J. Redmon and A. J. A. P. A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv, vol. 4, no. 7, pp. 789–799, 2018. [Google Scholar]
23. X. Dai, X. Yuan and X. J. A. I. Wei, “TIRNet: Object detection in thermal infrared images for autonomous driving,” IEEE Access, vol. 4, no. 9, pp. 1–18, 2020. [Google Scholar]
24. S. Ren, K. He, R. Girshick and J. J. I. P. A. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” Advances in Neural Information Processing Systems, vol. 39, no. 2, pp. 1137–1149, 2016. [Google Scholar]
25. M. Krišto, M. Ivasic-Kos and M. J. I. A. Pobar, “Thermal object detection in difficult weather conditions using YOLO,” IEEE Access, vol. 8, no. 8, pp. 125459–125476, 2020. [Google Scholar]
26. H. Sun and R. Grishman, “Lexicalized dependency paths based supervised learning for relation extraction,” Computer Systems Science and Engineering, vol. 43, no. 3, pp. 861–870, 2022. [Google Scholar]
27. H. Sun and R. Grishman, “Employing lexicalized dependency paths for active learning of relation extraction,” Intelligent Automation & Soft Computing, vol. 34, no. 3, pp. 1415–1423, 2022. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools