
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Novel Multimodal Biometric Feature Extraction for Precise Human Identification
1 Department of Computer Science and Engineering, SRM Institute of Science and Technology, Kattankulathur, 603203, Tamil Nadu, India
2 Department of Computational Intelligence, SRM Institute of Science and Technology, Kattankulathur, 603203, Tamil Nadu, India
* Corresponding Author: M. S. Abirami. Email:
Intelligent Automation & Soft Computing 2023, 36(2), 1349-1363. https://doi.org/10.32604/iasc.2023.032604
Received 23 May 2022; Accepted 08 July 2022; Issue published 05 January 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In recent years, biometric sensors are applicable for identifying important individual information and accessing the control using various identifiers by including the characteristics like a fingerprint, palm print, iris recognition, and so on. However, the precise identification of human features is still physically challenging in humans during their lifetime resulting in a variance in their appearance or features. In response to these challenges, a novel Multimodal Biometric Feature Extraction (MBFE) model is proposed to extract the features from the noisy sensor data using a modified Ranking-based Deep Convolution Neural Network (RDCNN). The proposed MBFE model enables the feature extraction from different biometric images that includes iris, palm print, and lip, where the images are preprocessed initially for further processing. The extracted features are validated after optimal extraction by the RDCNN by splitting the datasets to train the feature extraction model and then testing the model with different sets of input images. The simulation is performed in matlab to test the efficacy of the modal over multi-modal datasets and the simulation result shows that the proposed method achieves increased accuracy, precision, recall, and F1 score than the existing deep learning feature extraction methods. The performance improvement of the MBFE Algorithm technique in terms of accuracy, precision, recall, and F1 score is attained by 0.126%, 0.152%, 0.184%, and 0.38% with existing Back Propagation Neural Network (BPNN), Human Identification Using Wavelet Transform (HIUWT), Segmentation Methodology for Non-cooperative Recognition (SMNR), Daugman Iris Localization Algorithm (DILA) feature extraction techniques respectively.Keywords
In light of the recent events taking place in the world, especially concerning the increasing activity of international terrorism, there is a greater focus on security issues. One of the most important aspects of security is identifying a person. The task of identifying a person becomes important even in many everyday situations [1]. We are increasingly facing fraud cases by people impersonating others while trying to enter hotel rooms, accessing the computer network, or making purchases online. Biometric recognition of an object based on the measurement of individual and permanent individual parameters is one of the possible methods of identification [2].
The main characteristics of a person can be divided into two groups-Behavior and Physiology. Behavioral characteristics include, for example, the way you speak, the style of handwriting you use on a computer keyboard, and the group of personal physiological parameters such as palm prints, palm geometry, iris or retina, and facial expressions. Practical methods of biometrics rely heavily on physiological characteristics because behavioral patterns are still subject to change depending on the individual condition [3]. For example, a cold not only changes the tone of voice but also the way people speak: even those who can speak avoid unwanted conversations. Several other issues related to the feature extraction model of multimodal biometrics have been analyzed well with the current scenario and the problem has been identified related to it and provides an optimal solution based on it.
At the same time, many parts of the human body are very unique and can be used to identify. So, when looking for a friend in a meeting, we use some common face recognition algorithms implemented by our intelligence. A particular simplified method is most possible with the help of a computer [4]. A person’s face is captured by the camera and some facial shapes match the information in the database. The human eye is a collection of many unique data. By focusing the camera accordingly, the eye can be drawn to compare with the image of the iris model [5]. Biometric properties are the geometry and topography of its surface. Palm prints play a special role. Palm prints were legally accepted for personal identification over a century ago, and palm print identification has been actively used in the criminal field since the 20thcentury [6].
To improve prediction accuracy and robustness, multimodal biometric systems [7–12] combine many biometric modalities. Ranking Deep convolution neural networks (RDCNN) is used in this paper to construct a feature extraction model for noisy sensor data. It is possible to extract features from all biometric images using the suggested multimodal feature extraction model with a suitable pre-processing application. To verify the recovered features, the CNN first partitions the data sets into training and testing datasets, so that the derived features may be tested on a variety of images and datasets.
The organization of the manuscript is structured as follows; the following section includes the review related to deep learning-based multimodal biometric feature extraction. Section 3 conveys the background of the study with various technical comparisons. Section 4 includes an elaborative presentation of the RDCNN. Section 5 presents the result and discussion based on multimodal biometrics with its measures of accuracy, precision, recall, and f1-score. Finally, a conclusion about the proposed RDCNN is presented in Section 5.
Various researches have been carried out based on biometric feature extraction which lacks prediction accuracy, robustness and more functionalities. This section conveys a review of existing techniques utilized for multimodal feature extraction with their drawback and inefficiencies in biometric feature extraction.
Vyas et al. [13] introduced a feature extraction for the multimodal biometrics with a score level fusion approach to integrating the performances of Iris and palm print with various databases which shows the performance with their EER as low as 0.4%–0.8% and AUC as high as 99.7%–99.9%.
Ren et al. [14] Together have developed an algorithm that was developed to further enhance the sensitivity of the Daugman Iris Localization algorithm to improve retinal visibility. Its special, enhanced retina calculation accurately calculates the edges of the retina being generated. This algorithm has also improved the diagnostic methods that are blocked by its effects on the retina.
Proença et al. [15] received images of high-sensitivity areas of the retina as input. Based on this the images were divided into a small server or square-shaped groups. These groups occupy very rare retinal volumes and calculate their volumes and then provide comparisons. Its improved method was quantity calculations.
Sahmoud et al. [16] calculated the status of a variety of biometric systems in an unconstrained environment. The authors Pittsburgh conducted experiments based on the input of indistinguishable biometric information from humans. Its accuracy varied according to the bio inputs. The accuracy was calculated less when giving the total number of inputs generated based on different biometric modules. Higher results were realized when calculating alone, and combined calculation was found to be less effective.
Wildes [17] developed a method of calculating maximum accuracy by incorporating biodata that includes security features. i.e., each module was individually sensitive. Made comparisons based on it. Those comparisons showed its accuracy. That is, it ensured that no one other than that particular user could get in there.
Boles et al. [18] developed an improved human organ-based biometric system. Its basic sensitivity was very fast. Its basic predictions were taken from the inputs given by the lines and calculated with changes in its sensitivity. These calculations were compared with other forms of input and the results were calculated with the best features in others. The results were released based on this calculation. Thus, while the particular individual features were better its other forms indicated the speed of the method and led to a lack of accuracy in the results.
Lim et al. [19] proposed an improved algorithm based on vector and classifier. It is sensitive sensors that take the given inputs intact and compute their important patterns and perform calculations based on them. Thus, changes in its magnitude and significant changes are calculated.
Li et al. [20] proposed Learning sparse and discriminative multimodal feature codes (SDMFCs), which take into consideration both intermodal and intramodal particular and common information. To begin capturing the information about the textures included within local patches, first a local difference matrix is established through the use of multimodal finger photographs. The next stage is to restrict the data coming from many modalities in order to learn a discriminative and condensed binary code concurrently. To categorise fingers, an SDMFC-based multimodal finger recognition system has been created. This system uses the local histograms of each division block in the learned binary codes together.
Li et al. [21] proposed Joint discriminative sparse coding for the supervised multimodal feature learning of hand-based multimodal recognition. This method’s applications include the fusion of finger veins and finger knuckle prints, palm veins and palmprints, and palm veins and dorsal-hand veins, amongst other applications. The JDSC method projects the raw data onto a common space in such a way that the distance between classes is both maximised and minimised while, at the same time, the correlation among the inter-modality of the within-class is maximised. Sparse binary codes assessed by the projection matrix have the potential to be more effective in multimodal recognition tasks when the discriminative strength of the data being measured increases.
The above-reviewed techniques comprise shortcomings such as lacking in the speed of accuracy, complications, and inaccuracy in extraction addressed by performing accurate feature extraction with efficient duration using the proposed RDCNN methodology. The background of the proposed multimodal feature extraction technique is presented in the following section.
The biometrics are unique to each person, cannot be changed, and are used in areas where identification errors are unacceptable when arranging access under criminal law or with the highest level of security. Historically, optical sensor systems have been used for palm printing, but for a long time they were very expensive, bulky, and not reliable enough. In the late 1990s, the advent of low-cost, different-policy palm print data collection devices led to the advancement of palmprint identification technologies from limited use to widespread use in many new areas [20–22].
Some emerging technologies are experiencing this phenomenon. Virtual Reality is an outstanding example of this concept. It was already in the public domain before the organization’s formation. It keeps coming back, but the majority of us are refusing to acknowledge it. Another example is the use of biometric security measures [23]. The future will look drastically different when computers can read our lips and recognize each individual. We are all storing an increasing amount of information about our lives in digital form [24]. Biometric security encompasses much more than just facial recognition. Hand geometry, eye scans, and lip-reading are just a few of the additional ways of identifying a person that has been developed [25].
Lip images are similar to palm patterns in terms of their resemblance. Using our lips as a recognition tool, our computers and cellphones can identify us in yet another way. According to the findings of the study, lip print can be used as an alternative to biometric security as an alternative to visual passwords, they were able to unlock their smartphones and get into their accounts. This technology needs to be improved before it can be used on a large scale in the future. There is unquestionably space for improvement in this situation. Various aspects must be considered to successfully interpret the lips, such as poor illumination or braces. People might be able to use computers that can read lips shortly, even though it isn’t very likely.
The primary task of police in all countries of the world is to find criminals and establish their involvement in certain criminal activities. Palm prints, also known as the papillary method, are used as irrefutable evidence of a suspect’s guilt. You know, the probability of meeting people along the same lines is simply very low. Many of the palm prints are not serious scientific works and the various technical implementations of palmprint identification systems are tabulated in Tab. 1. What is the scientific basis for palm printing? Experts have only two of them:

No identical palm prints have yet been found in any database or file cabinet, not even the computer program;
■ The shapes on the fingers of identical twins are not identical.
These two facts are enough to turn palm printing into an accurate science. In fact, over time, experts have come up with more and more questions about it. Naturally, in this case, the fat balance of the skin and the degree of cleanliness of the user’s hands play no role. In addition, in this case, a very small structure is obtained.
The overall Comparative characteristics of multiple security devices are tabulated in Tab. 2. If we talk about the disadvantages of this radical proposal, it is important for the silicon chip to have the function of a sealed shell and for additional coatings to reduce the sensitivity of the system. In addition, strong external electromagnetic radiation can have some effect on the film. There is another way to implement the settings. At the center of their Tactile Sense system is an electro-optical polymer. This material is sensitive to the difference in the electric field between the ridges of the skin and the tubes. The electric field gradient is converted into a high-resolution optical image, which is then converted to digital format, which is then transferred to the PC via a parallel port or USB interface [26]. This method is also insensitive to the condition of the skin and its level of contamination, including chemicals. However, the reader has a smaller size and can be configured on a computer keyboard, for example. According to the manufacturers, this system has a very low price (several tens of dollars).
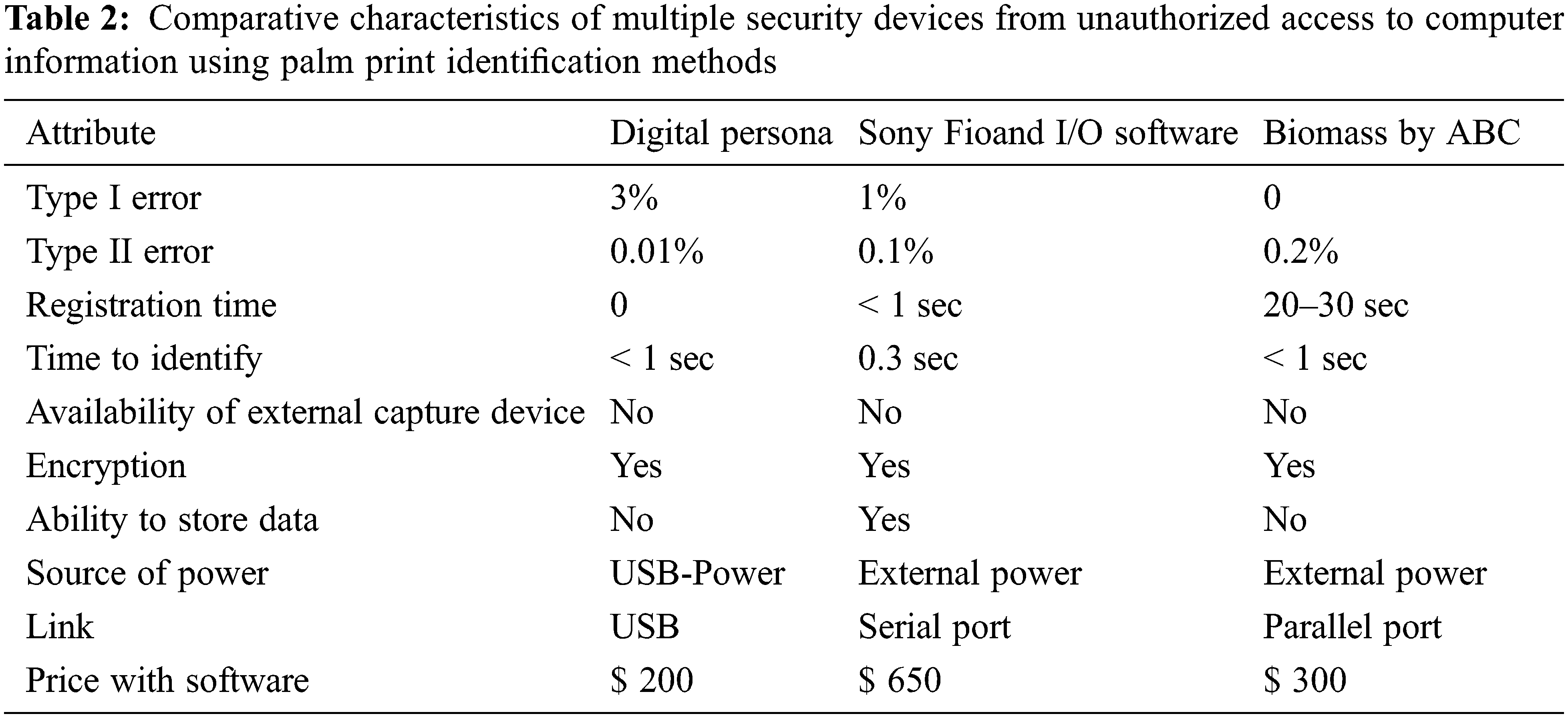
The type I error (incorrect rejection rate)-is the probability that the registered user will be denied access. The type II error (incorrect acceptance rate)-is the probability of allowing an unregistered user. Common solutions to protect the premises from unauthorized access. The analog video signal is processed by a verification unit, which reduces the noise in the image, and converts it into a digital format, after which a set of characteristics unique to this palm print is extracted from it [27]. This data uniquely identifies a person. Data is stored and converted into a unique palm print template for a specific person. On further reading, the new palm prints are compared with those stored in the database. In the simplest case, when processing an image, characteristic points are selected in it (for example, the coordinates of the end of the split of the papillary lines, the junction of the turns). Up to 70 such points can be identified and each can be characterized by two, three or more parameters. As a result, up to five hundred values of different characteristics can be obtained from one axis. The most complex processing algorithms connect the characteristic points of the image with the vectors and describe their properties and interactions. As a rule, data collection from palm prints can take up to 1 KB.
Another and most common form of biometric authentication is iris scanners. The shapes in our eyes are unique and do not change in a person’s life, allowing them to recognize a particular person. The verification process is more complicated as a higher number of dots are analyzed compared to palm print scanners, which indicates the reliability of the system. However, in this case, it can be difficult for those with glasses or contact lenses-they need to be removed for the scanner to work properly. Retinal scanning is an alternative way of using the human eye for biometric authentication. The scanner shines into the eyesight and shows the structure of the blood vessels, which is shell-like, unique to each of us. Iris and retina scanners can be easily deceived by a high-quality image of a person printed on colored paper [28]. However, most modern scanners can recognize a 2D model and distinguish it from a 3D one; in this case, you need to place a contact lens on the image, which simulates glare (light reflection).
4 RDCNN Based Multimodal Biometric Feature Extraction
The proposed Multimodal Biometric Feature Extraction Algorithm (MBFEA) contains all the conventional modules with a standard system and a systematic representation of RDCNN architecture is shown in Fig. 1 and its evaluation is shown in Fig. 2.
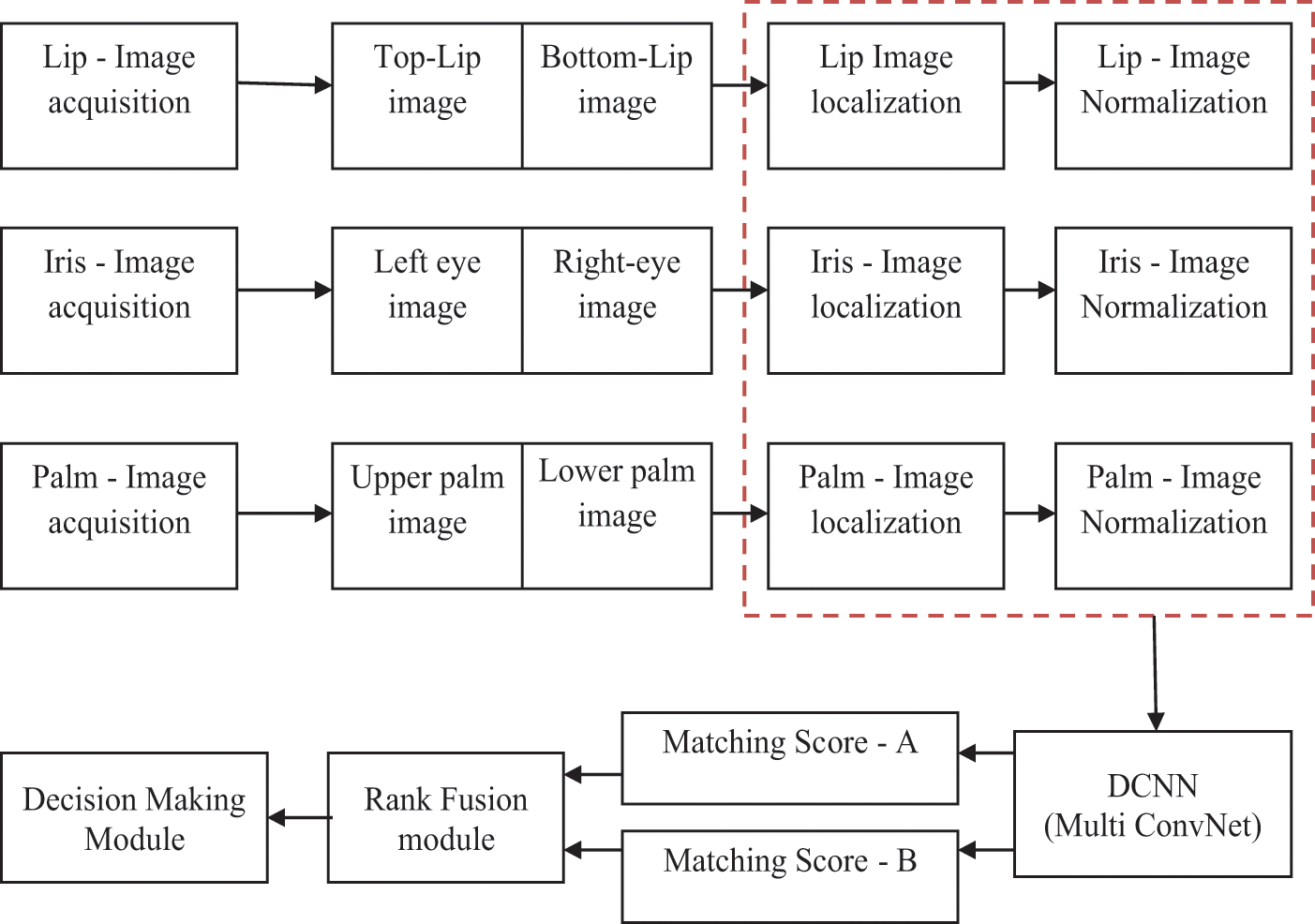
Figure 1: Systematic representation of RDCNN architecture
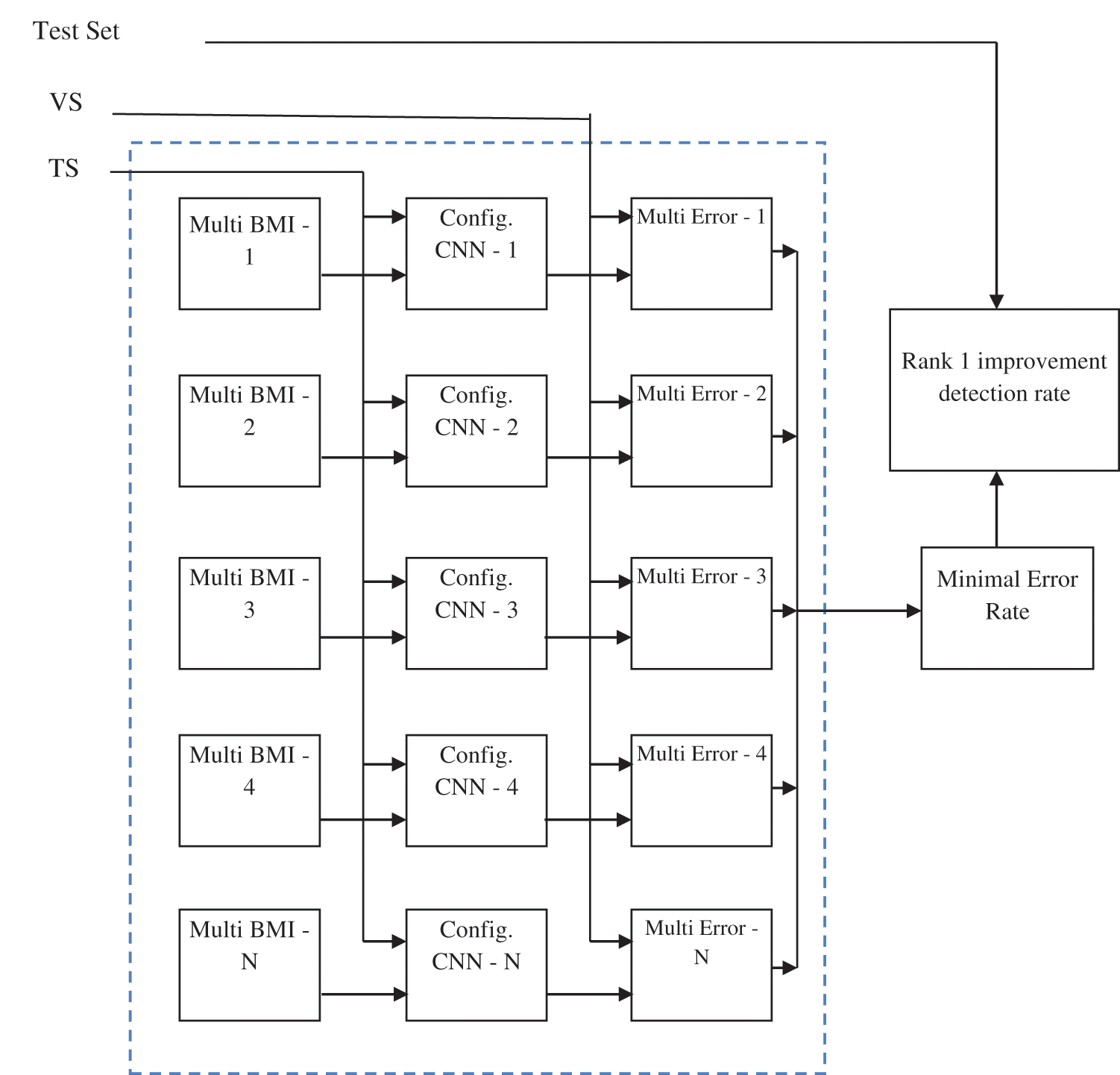
Figure 2: Evolution and ranking methodology of the RDCNN system
The capture volume module will capture the values of the input images and sensor inputs. These units performed well and produce highly efficient input images. The feature extraction module was classifying the multi bio-metric inputs as two different performances [29]. The localization and normalization are the two different operations. The localization task classifies and splits the images as per the given parameter comparison and the normalization will perform the added images while spitted the localization process.
A comparative volume module compared the stored data and the given multi-biometric images. If the input images and stored pattern matching images were equal to each other then it will send the information to the decision-making unit otherwise it neglects the task or sends the warning message to the input units. The Decision-making module performs the decision-making while the inputs and performance operations are in the correct direction. If the matching inputs are perfect then it allows to perform the instruction otherwise it can drop the works.
When it comes to authenticating a biometric system, only a single piece of information must be provided. As the name implies, a multimodal biometric system accepts data from a variety of biometric sources. A multimodal biometric system, when used for authentication, allows the user to supply a broader range and variety of information than a single-modal biometric system [30–32] and it is shown in Fig. 3. They must contend with a variety of challenges, including confidentiality, the universality of models, user comfort when controlling the computer, and the duplication of attacks on stored information, among others. Some of these problems may be solved by using a biometric system that can be used in many different ways.
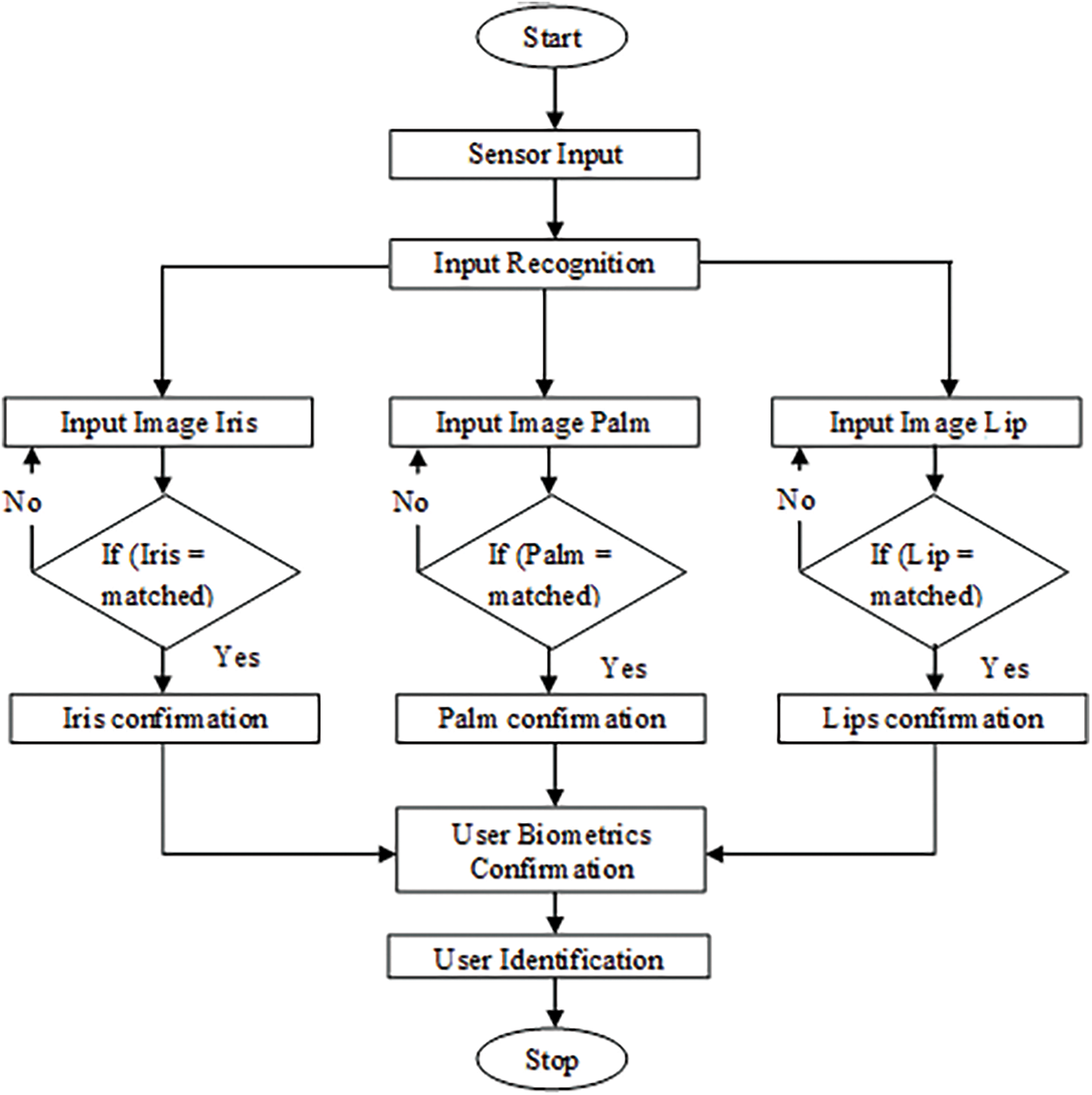
Figure 3: Systematic flow diagram of multimodal biometric feature extraction
The commencement plan of the complication coating is distinct as the follows, where the maximum of foregone conclusion is used for the estimation of the commencement plan:
where,
* represents the Convolution;
Multimodal systems can provide knowledge of the livelihood of the included model through the use of livelihood detection techniques. It is capable of detecting and dealing with fraud.
Multimodal biometric systems that integrate or link information at an early stage are considered more effective than systems that integrate information at a later stage. The obvious reason for this is that there is more accurate information at the initial stage than the applicability scores of the comparative modules.

Fusion Displays in a Multimodal Biometric System: Within a multimodal biometric system, the number of properties and components can vary. They may be as follows:
Single biometric characteristic, multiple sensors.
Single biometric attribute, multiple classifiers (say, very small based match and system-based match).
Single biometric characteristic, multiple units (say, multiple fingers).
Many biometric characteristics of a person (say, iris, palm print, etc.).
These properties are then enabled to verify the user identity.
The proposed Multimodal Biometric Feature Extraction Algorithm (MBFEA) was compared with the existing Daugman Iris Localization Algorithm (DILA), Segmentation Methodology for Non-cooperative Recognition (SMNR), Human Identification Using Wavelet Transform (HIUWT), and an advanced BPNN face recognition based on curvelet transform (BPNN) Back Propagation Neural Network.
Dataset: The study uses various biometric images that include iris images collected from the Kaggle repository named MMU iris dataset and which consists of 460 available images. The palm print images are obtained from the COEP Palm Print Database which consists of 1344 images. Finally, the lip print images are collected from SUT-LIPS-DB-A Database of Lips Traces. Furthermore, images such as Iris, Palmprint, and Mouth are acquired from 20 different persons in real-time in which each trait consists of 5 sample images such that 100 iris images, 100 palm print images, and 100 lip images. For training, 80% of the images are considered from the iris, palm print, and lip print datasets. The remaining 20% of the datasets are utilized for testing purposes.
The simulation is conducted in MATLAB to test the efficacy of the feature extraction model against different performance metrics on a high-end computing engine that includes 16 GB of RAM running on an i5 core processor with a 16GB GPU. The study is validated in terms of 5 different parameters that include Multi Biometric accuracy, Multi Biometric precision, Multi Biometric recall, Multi Biometric F1-Score, and computation time. Before understanding the quality rate of the parameters, will know about the following,
TP–It is the perfect predicted correct or above the calibration level.
TN–It is the negative predictive value below the calibration level.
FP–When the exact values are in calibration level and the predicted samples are at the same level.
FN–When the exact values are in calibration level but the predicted samples are at a different level.
The Multi Biometric accuracy is the parameter that describes the ratio between perfectly predicted Multi Biometric input images from the given samples to the total number of collected image samples. When the rate of Multi Biometric accuracy is high then the given output image sample gets a high-quality rate.
Fig. 4 demonstrates the various measurement comparison of the Multi Biometric accuracy values between the existing DILA, SMNR, HIUWT, BPNN, and proposed MBFEA. The accuracy value is attained by 77%, 88%, 90%, 84%, and 97%, in terms of DILA, SMNR, HIUWT, BPNN, and proposed MBFEA respectively.
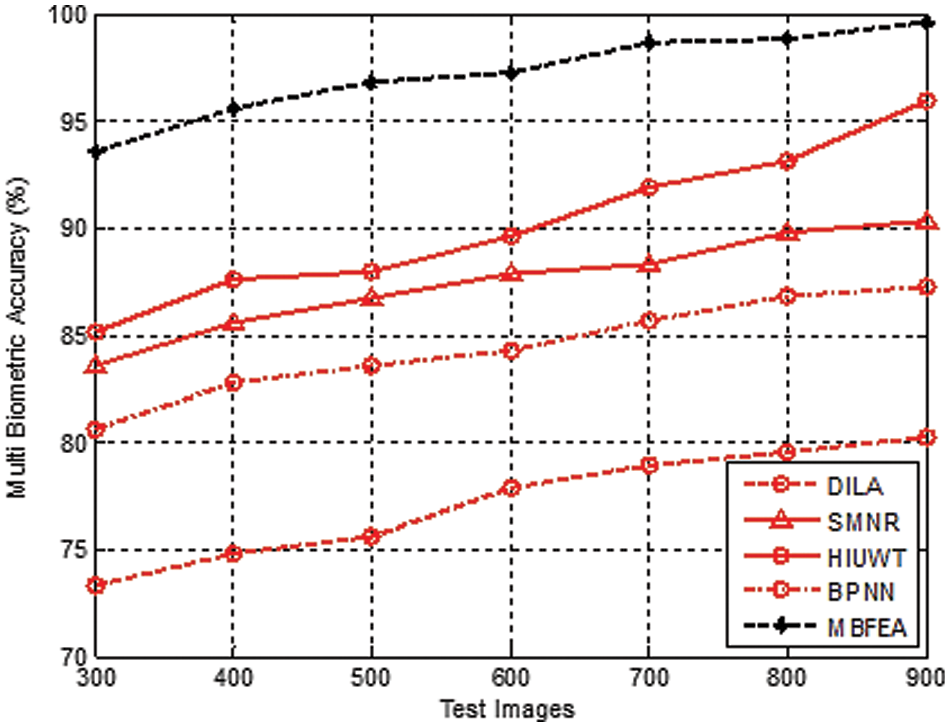
Figure 4: Measurement of multi biometric accuracy
Multi Biometric precision measurement is the ratio between the positive true samples and total true samples. The total true samples are calculated by the sum of positive true samples and false-positive samples.
Fig. 5 demonstrates the various measurement comparison of the Multi Biometric precision values between the existing DILA, SMNR, HIUWT, BPNN, and proposed MBFEA. The Precision value is attained by 67%, 78%, 80%, 74%, and 88%, in terms of DILA, SMNR, HIUWT, BPNN, and proposed MBFEA respectively.
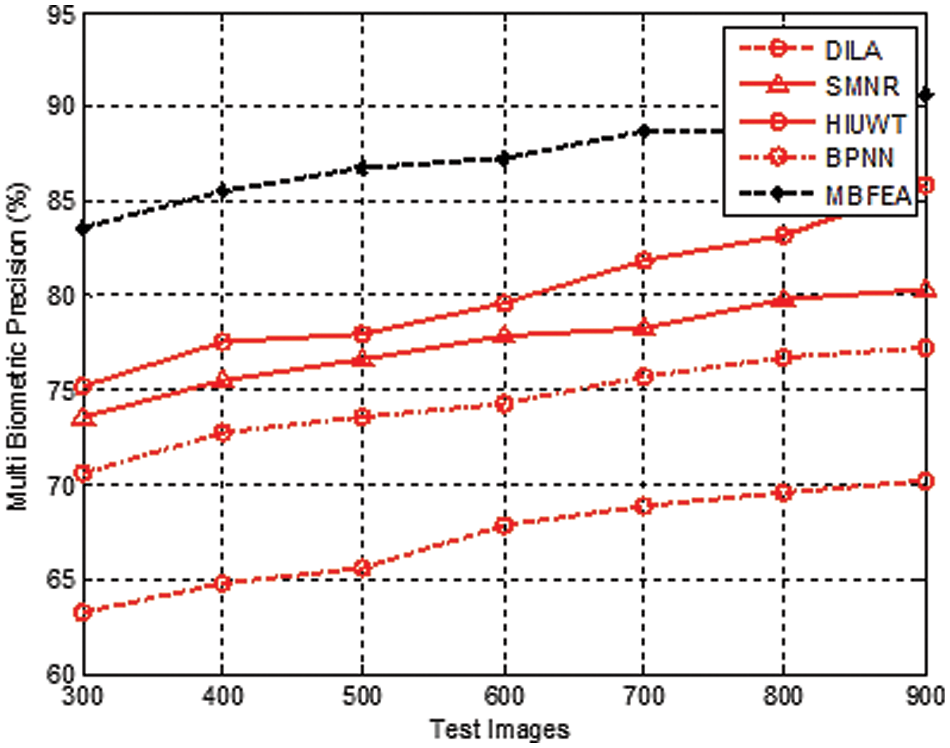
Figure 5: Measurement of multi biometric precision
Multi Biometric Recall measurement is the ratio between the positive true samples and the sum of positive true samples and false-negative true samples.
Fig. 6 demonstrates the various measurement comparison of the Multi Biometric recall values between the existing DILA, SMNR, HIUWT, BPNN and proposed MBFEA. The recall value is attained by 76%, 85%, 79%, 79% and 98%, in terms of DILA, SMNR, HIUWT, BPNN and proposed MBFEA respectively.
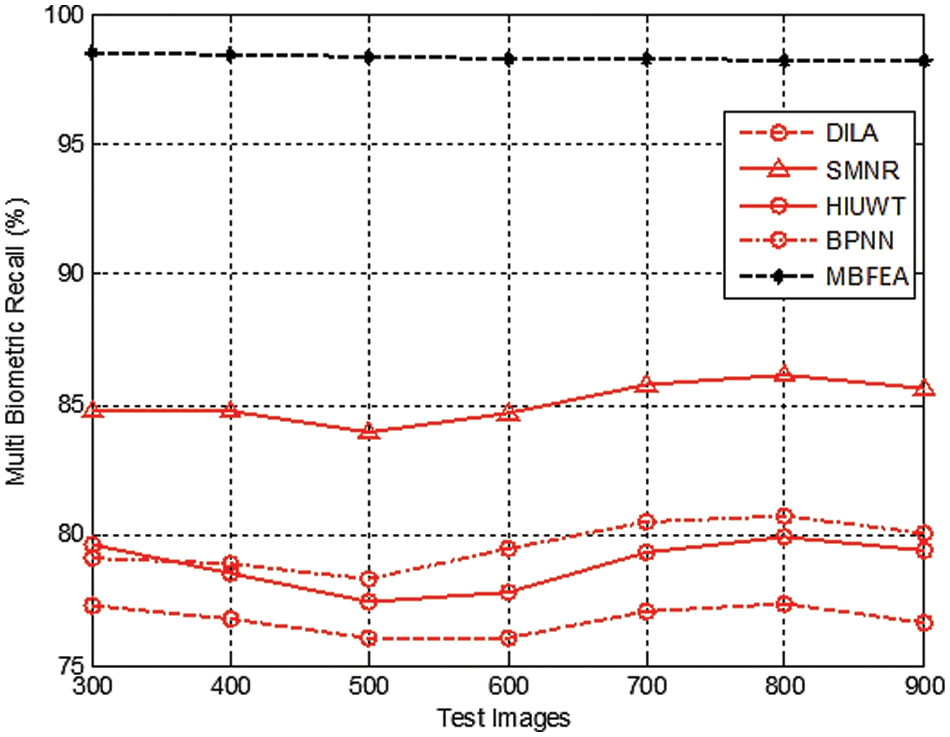
Figure 6: Measurement of multi biometric recall
It is measured by the average sample values of Multi Biometric precision and Multi Biometric recall of the samples.
Fig. 7 demonstrates the various measurement comparison of the Multi Biometric F1-Score values between the existing DILA, SMNR, HIUWT, BPNN and proposed MBFEA.
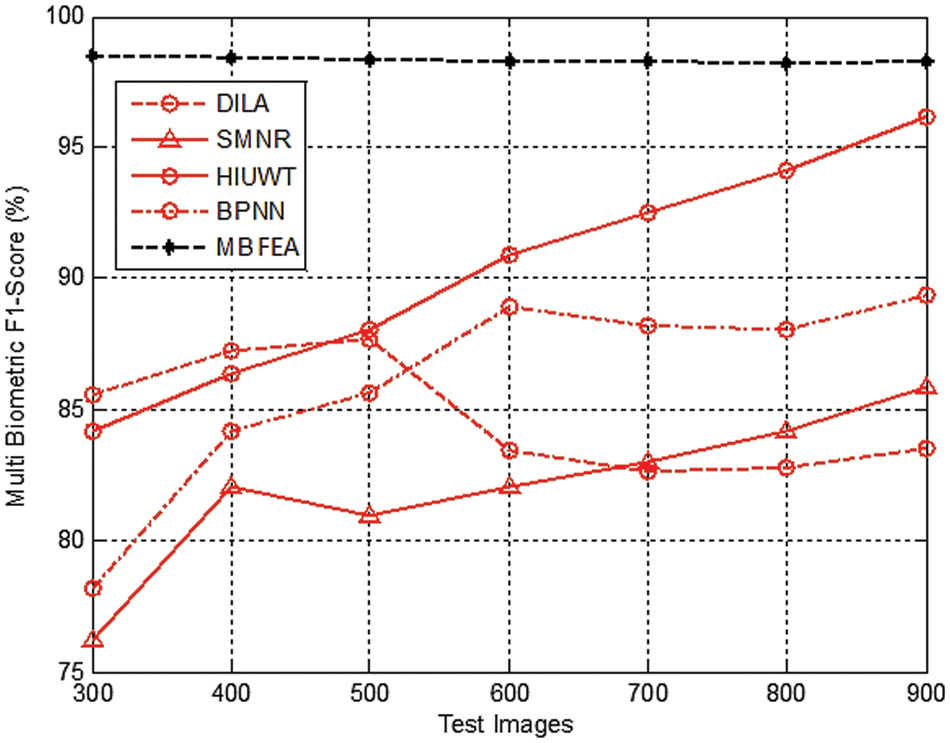
Figure 7: Measurement of multi biometric F1-score
The computation duration is nothing but the time taken to calculate the prediction of two different images.
Fig. 8 demonstrates the various measurement comparison of the Multi Biometric Computational duration values between the existing DILA, SMNR, HIUWT, BPNN, and proposed MBFEA. The computation time taken for feature extraction with 900 test images of the proposed MBFEA, DILA, SMNR, HIUWT, and BPNN techniques is efficiently achieved by 98.7, 94.2, 95.6, 96.2, 97.3, 92.3, and 84.5 respectively show in Fig. 9.
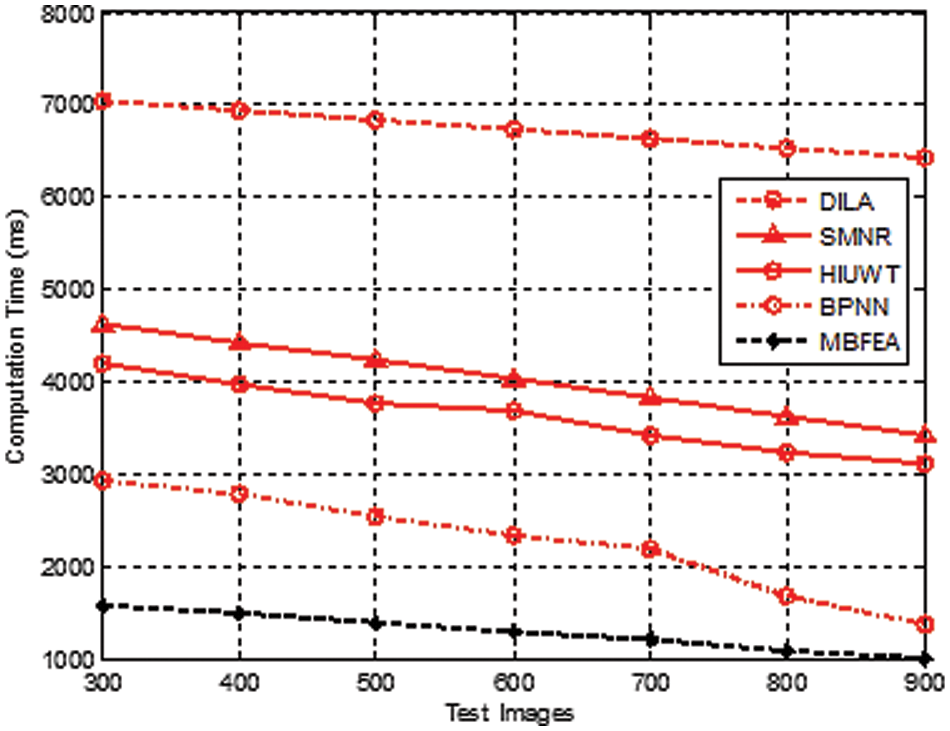
Figure 8: Measurement of computational time
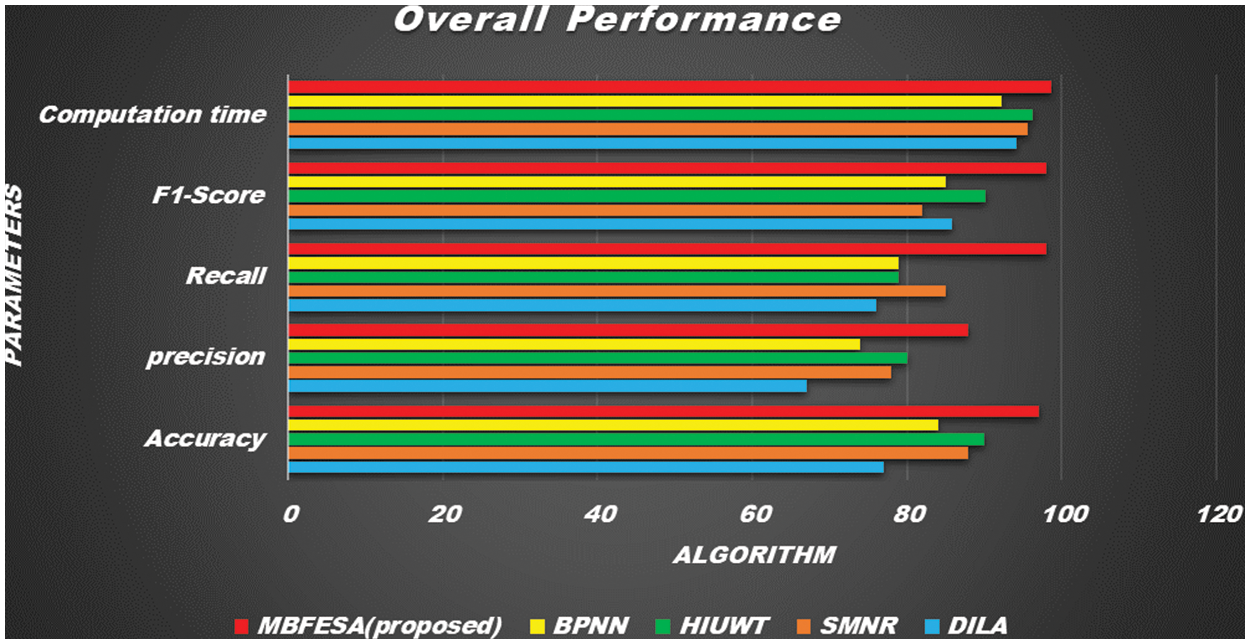
Figure 9: Overall performance of the output parameters with existing algorithm
The overall performance of the various output parameters
Biometric methods in general vary and Each of these methods has different sensitivities. The different sounds taken based on these sensitivities reveal different types of calculations. These methods individually have special features. But its overall computational capacity reveals a lower level of accuracy. And the multifaceted practical possibilities in the methods of combining more than one method complicate how many citizens over a year create problems in its precision. The proposed MBFE Algorithm was compared with the existing methods like DILA, SMNR, HIUWT, and BPNN. The proposed multi-biometric calculation using the feature extraction identification method gets better accuracy, good precision, recall, improved F1 score, and reduced computation time. As compared with existing techniques such as BPNN, HIUWT, SMNR, and DILA, the performance of the MBFE Algorithm technique improved by 0.126%, 0.152%, 0.184%, and 0.384%, respectively. From the results it is concluded that the proposed method achieves a higher rate of accuracy, precision, recall and F1-score with reduced computational time than the other existing methods.
This method further enhances the security features and ensures its security character. In future, security is a major aspect that can be considered for the estimation of biometric authentication over various types of attacks.
Acknowledgement: The authors with a deep sense of gratitude would thank the supervisor for her guidance and constant support rendered during this research.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. S. Ding, H. Zhu, W. Jia and C. Su, “A survey on feature extraction for pattern recognition,” Artificial Intelligence Review, vol. 37, no. 3, pp. 169–180, 2012. [Google Scholar]
2. Y. Jihua, H. Dan, X. Guomiao and C. Yahui, “An advanced BPNN face recognition based on curvelet transform and 2DPCA,” in Proc. 8th Int. Conf. on Computer Science & Education, Colombo, pp. 1019–1022, 2013. [Google Scholar]
3. H. Khalajzadeh, M. Mansouri and M. Teshnehlab, “Face recognition using convolutional neural network and simple logistic classifier,” in Soft Computing in Industrial Applications, vol. 223, Cham: Springer, pp. 197–207, 2014. [Google Scholar]
4. M. Zeng, L. T. Nguyen, B. Yu, O. J. Mengshoel, J. Zhu et al., “Convolutional neural networks for human activity recognition using mobile sensors,” in Proc. 6th Int. Conf. on Mobile Computing, Applications and Services, USA, pp. 197–205, 2014. [Google Scholar]
5. A. R. Syafeeza, M. K. Hani, S. S. Liew and R. Bakhteri, “Convolutional neural network for face recognition with pose and illumination variation,” International Journal of Engineering & Technology, vol. 6, no. 1, pp. 0975–4024, 2014. [Google Scholar]
6. M. Leghari, S. Memon, L. D. Dhomeja, A. H. Jalbani and A. A. Chandio, “Deep feature fusion of fingerprint and online signature for multimodal biometrics,” Computers, vol. 10, no. 2, pp. 01–15, 2021. [Google Scholar]
7. M. S. Lohith, Y. S. K. Manjunath and M. N. Eshwarappa, “Multimodal biometric person authentication using face, ear and periocular region based on convolution neural networks,” International Journal of Image and Graphics, vol. 3, pp. 235, 2021. [Google Scholar]
8. E. A. Alkeem, C. Y. Yeun, J. Yun, P. D. Yoo, M. Chae et al., “Robust deep identification using ECG and multimodal biometrics for industrial internet of things,” Ad Hoc Networks, vol. 121, pp. 102581, 2021. [Google Scholar]
9. D. R. Ramji, C. A. Palagan, A. Nithya, A. Appathurai and E. J. Alex, “Soft computing based color image demosaicing for medical image processing,” Multimedia Tools and Applications, vol. 79, no. 15, pp. 10047–10063, 2020. [Google Scholar]
10. S. H. Choudhury, A. Kumar and S. H. Laskar, “Adaptive management of multimodal biometrics—a deep learning and metaheuristic approach,” Applied Soft Computing, vol. 106, pp. 107344, 2021. [Google Scholar]
11. S. Tyagi, B. Chawla, R. Jain and S. Srivastava, “Multimodal biometric system using deep learning based on face and finger vein fusion,” Journal of Intelligent & Fuzzy Systems, vol. 42, no. 2, pp. 943–955, 2022. [Google Scholar]
12. P. Shende and Y. Dandawate, “Convolutional neural network-based feature extraction using multimodal for high security application,” Evolutionary Intelligence, vol. 14, no. 2, pp. 1023–1033, 2021. [Google Scholar]
13. R. Vyas, T. Kanumuri, G. Sheoran and P. Dubey, “Accurate feature extraction for multimodal biometrics combining iris and palmprint,” Journal of Ambient Intelligence and Humanized Computing, pp. 1–9, 2021. https://doi.org/10.1007/s12652-021-03190-0. [Google Scholar]
14. X. Ren, Z. Peng, Q. Zeng, C. Peng, J. Zhang et al., “An improved method for daugman iris localization algorithm,” Computers in Biology and Medicine, vol. 38, no. 1, pp. 111–115, 2008. [Google Scholar]
15. H. Proença and L. A. Alexandre, “Iris segmentation methodology for non-cooperative recognition,” IEE Proceedings-Vision, Image and Signal Processing, vol. 153, no. 2, pp. 199–205, 2006. [Google Scholar]
16. S. A. Sahmoud and I. S. Abuhaiba, “Efficient iris segmentation method in unconstrained environments,” Pattern Recognition, vol. 46, no. 12, pp. 3174–3185, 2013. [Google Scholar]
17. R. P. Wildes, “Iris recognition: An emerging biometric technology,” in Proc. of the IEEE, vol. 85, no. 9, pp. 1348–1363, 1997. [Google Scholar]
18. W. W. Boles and B. Boashash, “A human identification technique using images of the iris and wavelet transform,” IEEE Transactions on Signal Processing, vol. 46, no. 4, pp. 1185–1188, 1998. [Google Scholar]
19. S. Lim, K. Lee, O. Byeon and T. Kim, “Efficient iris recognition through improvement of feature vector and classifier,” ETRI Journal, vol. 23, no. 2, pp. 61–70, 2001. [Google Scholar]
20. S. Li, B. Zhang, L. Fei, S. Zhao and Y. Zhou, “Learning sparse and discriminative multimodal feature codes for finger recognition,” IEEE Transactions on Multimedia, vol. 5, pp. 1–7, 2021. [Google Scholar]
21. S. Li and B. Zhang, “Joint discriminative sparse coding for robust hand-based multimodal recognition,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 3186–3198, 2021. [Google Scholar]
22. A. N. Uwaechia and D. A. Ramli, “A comprehensive survey on ECG signals as new biometric modality for human authentication: Recent advances and future challenges,” IEEE Access, vol. 9, pp. 97760–97802, 2021. [Google Scholar]
23. L. Zhang, Z. Liu, X. Zhu, Z. Song, X. Yang et al., “Weakly aligned feature fusion for multimodal object detection,” IEEE Transactions on Neural Networks and Learning Systems, vol. 5, pp. 1–15, 2021. [Google Scholar]
24. B. Chen, Q. Cao, M. Hou, Z. Zhang, G. Lu et al., “Multimodal emotion recognition with temporal and semantic consistency,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3592–3603, 2021. [Google Scholar]
25. R. Mothi and M. Karthikeyan, “Protection of bio medical iris image using watermarking and cryptography with WPT,” Measurement, vol. 136, pp. 67–73, 2019. [Google Scholar]
26. S. Itani, S. Kita and Y. Kajikawa, “Multimodal personal ear authentication using acoustic ear feature for smartphone security,” IEEE Transactions on Consumer Electronics, vol. 68, pp. 77–84, 2021. [Google Scholar]
27. A. Nithya, A. Appathurai, N. Venkatadri, D. R. Ramji and C. A. Palagan, “Kidney disease detection and segmentation using artificial neural network and multi-kernel k-means clustering for ultrasound images,” Measurement, vol. 149, pp. 106952, 2020. [Google Scholar]
28. V. Talreja, M. C. Valenti and N. M. Nasrabadi, “Deep hashing for secure multimodal biometrics,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 1306–1321, 2020. [Google Scholar]
29. M. J. M. Jimenez, F. M. Castro, R. D. Escano, V. Kalogeiton and N. Guil, “UGaitNet: Multimodal gait recognition with missing input modalities,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 5452–5462, 2021. [Google Scholar]
30. R. Sundarasekar and A. Appathurai, “Automatic brain tumor detection and classification based on IoT and machine learning techniques,” Fluctuation and Noise Letters, pp. 2250030, vol. 11, pp. 23–29, 2022. [Google Scholar]
31. W. Sun, G. C. Zhang, X. R. Zhang, X. Zhang and N. N. Ge, “Fine-grained vehicle type classification using lightweight convolutional neural network with feature optimization and joint learning strategy,” Multimedia Tools and Applications, vol. 80, no. 20, pp. 30803–30816, 2021. [Google Scholar]
32. W. Sun, X. Chen, X. R. Zhang, G. Z. Dai, P. S. Chang et al., “A Multi-feature learning model with enhanced local attention for vehicle re-identification,” Computers, Materials & Continua, vol. 69, no. 3, pp. 3549–3560, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools