
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Ensemble Voting-Based Anomaly Detection for a Smart Grid Communication Infrastructure
1 Department of Computer Science, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, 21589, Saudi Arabia
2 Self-Development Skills Department, Common First Year Deanship, King Saud University, Riyadh, 12211, Saudi Arabia
* Corresponding Author: Hend Alshede. Email:
Intelligent Automation & Soft Computing 2023, 36(3), 3257-3278. https://doi.org/10.32604/iasc.2023.035874
Received 08 September 2022; Accepted 04 November 2022; Issue published 15 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Advanced Metering Infrastructure (AMI) is the metering network of the smart grid that enables bidirectional communications between each consumer’s premises and the provider’s control center. The massive amount of data collected supports the real-time decision-making required for diverse applications. The communication infrastructure relies on different network types, including the Internet. This makes the infrastructure vulnerable to various attacks, which could compromise security or have devastating effects. However, traditional machine learning solutions cannot adapt to the increasing complexity and diversity of attacks. The objective of this paper is to develop an Anomaly Detection System (ADS) based on deep learning using the CIC-IDS2017 dataset. However, this dataset is highly imbalanced; thus, a two-step sampling technique: random under-sampling and the Synthetic Minority Oversampling Technique (SMOTE), is proposed to balance the dataset. The proposed system utilizes a multiple hidden layer Auto-encoder (AE) for feature extraction and dimensional reduction. In addition, an ensemble voting based on both Random Forest (RF) and Convolutional Neural Network (CNN) is developed to classify the multiclass attack categories. The proposed system is evaluated and compared with six different state-of-the-art machine learning and deep learning algorithms: Random Forest (RF), Light Gradient Boosting Machine (LightGBM), eXtreme Gradient Boosting (XGboost), Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM), and bidirectional LSTM (biLSTM). Experimental results show that the proposed model enhances the detection for each attack class compared with the other machine learning and deep learning models with overall accuracy (98.29%), precision (99%), recall (98%), F1 score (98%), and the UNDetection rate (UND) (8%).Keywords
The Advanced Metering Infrastructure (AMI) is a core component of the smart grid to enable bidirectional communication between a consumer’s premises and the control center of the utility company [1]. The collected data supports various functionalities of the smart grid, such as energy consumption forecasting, energy theft detection, power quality monitoring, and dynamic energy pricing [2]. AMI communication architecture relies on three main types of communication networks: Home Area Network (HAN), Neighborhood Area Network (NAN), and Wide Area Network (WAN) [3]. Different communication technologies and protocols are used along with the Internet of Things (IoT), which has recently emerged as an enabling technology for smart grids [4]. The bidirectional end-to-end communication between smart meters and a utility company makes these networks highly vulnerable to cyberattacks [5]. Unethical customers, publicity seekers, and curious or motivated eavesdroppers might target the communication infrastructure for a variety of malicious reasons to cause local or regional consequences, such as customer information leakage, electricity theft, energy price manipulation, and system disruption, which could damage the economy or endanger human life [6].
For the smart grid, it is essential to secure the communication infrastructure to ensure the continuous and reliable flow of information and electricity [7]. Traditional security solutions such as encryption, firewalls, authorization, and authentication mechanisms are not enough to protect the AMI. Thus, Intrusion Detection Systems (IDSs) are vital for protecting AMI. IDSs are used to monitor the network traffic flow to detect various kinds of attacks [8]. IDSs can detect abnormal events and alert administrators to take appropriate measures [9].
IDSs are classified into two main types: Host-based (HIDS) or Network-based (NIDS). NIDSs analyze and investigate incoming network traffic. In contrast, HIDSs monitor node devices for malicious activity. NIDSs have three categories based on detection approaches: signature-based, anomaly-based, and hybrid-based. Signature-based detection systems use a known pattern of malicious behavior stored in a database that contains predefined malicious signatures. Anomaly-based Detection Systems (ADSs) identify attacks by looking for deviations in network traffic. The hybrid IDSs combine signature-based and anomaly-based approaches. Usually, ADSs are preferred over the signature-based one because the former can address new and undefined attacks [10]. Therefore, this paper proposes the development of ADS to detect multiple attack types against AMI communication infrastructure.
Machine learning and deep learning models are currently used to detect cyberattacks [11]. However, machine learning-based IDSs cannot process large amounts of nonlinear high-dimensional data, and it can be difficult to adapt the system to increasingly complex and diversified attacks [12]. Deep learning models do not suffer from these problems; therefore, they have been gradually applied to IDSs [13]. Considering the periodic, high-traffic, and nonlinear characteristics of AMI traffic, the objective of this paper is to develop a deep learning-based ADS to detect and classify multiple attack types that target the AMI communication infrastructure.
AMI has some distinguishing characteristics that are not parts of a conventional information technology environment, such as high-quantity and nonlinear high-dimensional data, imbalanced network traffic, and constant exposure to various attack methods. The CIC-IDS2017 dataset [14], represents the most valuable contemporary dataset satisfying the unique requirements of AMI and has accordingly been used in this paper to reflect real-world attack criteria and include the most recently updated network attacks. The main contributions of this paper are as follows:
C.1. The use of Auto-Encoder (AE) for feature extraction and dimensional reduction.
C.2. The use of two-step sampling to balance the high-class imbalance of the dataset. Random under-sampling and Synthetic Minority Oversampling Technique (SMOTE).
C.3 The development of ensemble voting Random Forest–Convolutional Neural Network (RF–CNN) to classify a wide range of attacks.
The rest of the paper is organized as follows. In Section 2, related works are reviewed. In Section 3, the proposed methodology is described. The results and discussion are presented in Section 4. Finally, the conclusion and future works are presented in Section 5.
Subsection 2.1 briefly describes designing an ADS for different network environments. Subsection 2.2 discusses designing an ADS specifically for an AMI environment. In Subsection 2.3, different works discussing the CIC-IDS2017 dataset are considered.
2.1 Anomaly-based Intrusion Detection Systems (ADS) Related Works
ADSs can be classified into many types, such as statistics, data mining, machine learning, and deep learning. Some approaches combine two or more techniques [15]. This section reviews ADSs that are based on machine learning or deep learning.
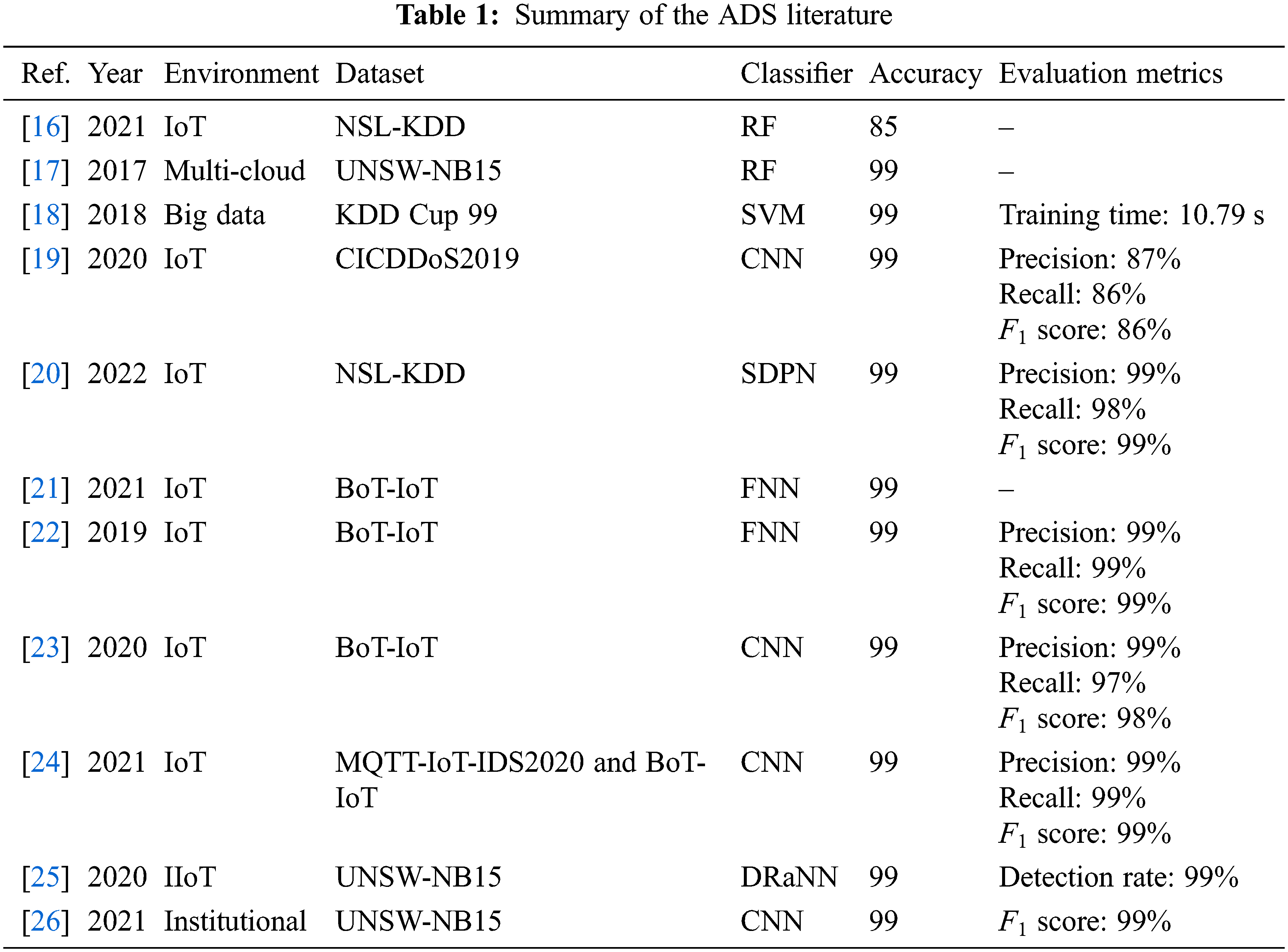
Based on machine learning, Anwer et al. [16] developed a framework for detecting attacks in network flow. Their framework used three widespread machine learning classifiers: a Support Vector Machine (SVM), Gradient Boosted Decision Trees (GBDT), and RF. RF achieved the highest accuracy of 85.34%. The NSL-KDD dataset was used in the development of this framework. The authors validated their model based on accuracy only. Salman et al. [17] demonstrated the feasibility of supervised machine learning models for anomaly IDS and for classifying attacks using the UNSW dataset. In their experiments, RF had an accuracy of 99%. Othman et al. [18] used ChiSqSelector and an SVM classifier on an Apache Spark Big Data platform. They used the KDD Cup 99 dataset to train and test the model. The findings showed that the model had a very high accuracy of about 99%.
Based on deep learning, Hussain et al. [19] used CICDDoS2019 to simulate an IoT system. They developed an IDS with a CNN classifier to detect Denial of Service (DoS) and Distributed Denial of Service (DDoS) attacks. It had an extremely high accuracy of about 99.99%. Otoum et al. [20] achieved an accuracy of 99.02% with an IDS based on a Stacked Deep Polynomial Network (SDPN), which was used to detect attacks in IoT systems using the NSL-KDD dataset.
By contrast, Ge et al. [21] studied an IoT environment. They developed an IDS based on a Feed-forward Neural Network (FNN) using the BoT-IoT dataset. These authors achieved an accuracy of 99.79%. Ge et al. [22] used the BoT-IoT dataset in another study. They designed an IDS that could detect DoS, DDoS, reconnaissance, and information theft in IoT systems. They collected the BoT-IoT dataset. Their FNN classifier had an accuracy of 99%. Derhab et al. [23] described a detection model for IoT networks based on a CNN classifier, which had an accuracy of 99.99% with the BoT-IoT dataset.
Ullah et al. [24] devised an IDS for detecting attacks in an IoT. They used a CNN classifier with the MQTT-IoT-IDS2020, BoT-IoT, and IoT-23 datasets. The results were excellent, with an accuracy of 99.97%. Moreover, Latif et al. [25] achieved an accuracy of 99.54%. They focused on the Industrial IoT (IIoT). The classifier was based on a Deep Random Neural Network (DRaNN) trained with the UNSW-NB15 dataset. Tufan et al. [26] developed an ADS based on a CNN model to protect institutional network systems. They trained the model on the UNSW-NB15 dataset. The system had a high accuracy of 99%. Table 1 summarizes the literature on ADSs.
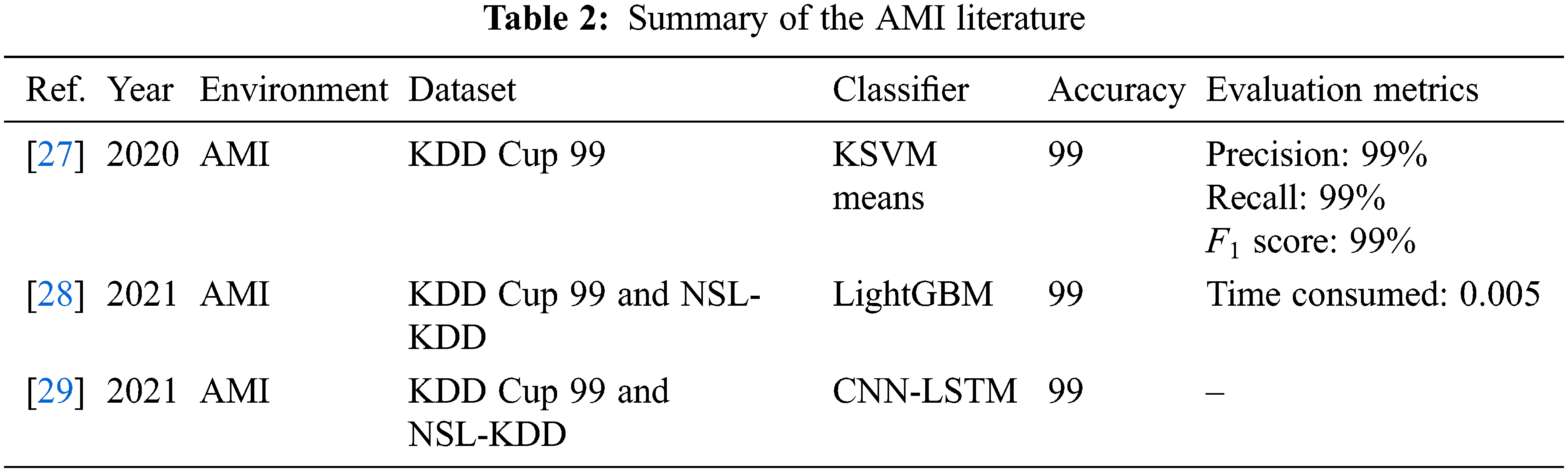
For the AMI environment, Rose et al. [27] presented a hybrid ADS to reduce the time complexity of an AMI environment. The proposed machine learning model was based on SVM and K-means clustering (KSVM means). This system was evaluated using the KDD Cup 99 dataset and achieved good results in terms of accuracy, precision, and the F1 score (99%). Yao et al. [28] developed an ADS for a Smart Distribution Network (SDN). This IDS is based on a Light Gradient-Boosting Machine (LightGBM). Firstly, the system used borderline SMOTE to balance the dataset, and then it extracted features using an AE. The model was trained using the LightGBM machine learning approach. The authors used two datasets and achieved an accuracy of 99.90% with the KDD Cup 99 dataset and 99.70% with NSL-KDD.
Yao et al. [29] introduced an ADS trained with deep learning in an AMI environment. The proposed system was based on CNN and LSTM as the deep learning models. This combination increased the system’s capability and performance. The accuracy results were 99.95% and 99.79%, respectively for the KDD Cup 99 and NSL-KDD datasets. Table 2 summarizes the AMI literature.
The following are the main observations regarding the ADS literature reviewed for an AMI environment:
G.1 Most of the reviewed systems apply to datasets created a long time ago (KDD Cup99 in 1999 and NSL-KDD in 2009). However, the behavior of some attacks has changed since then, specifically becoming more akin to normal behavior, which negatively impacts the system performance due to their inability to detect these new attack forms.
G.2 As the number and types of attacks increase deep learning-based attack detection solutions are considered promising for enhancing performance in many application areas. However, little research (to the best of our knowledge) has been done on detecting attacks in an AMI environment.
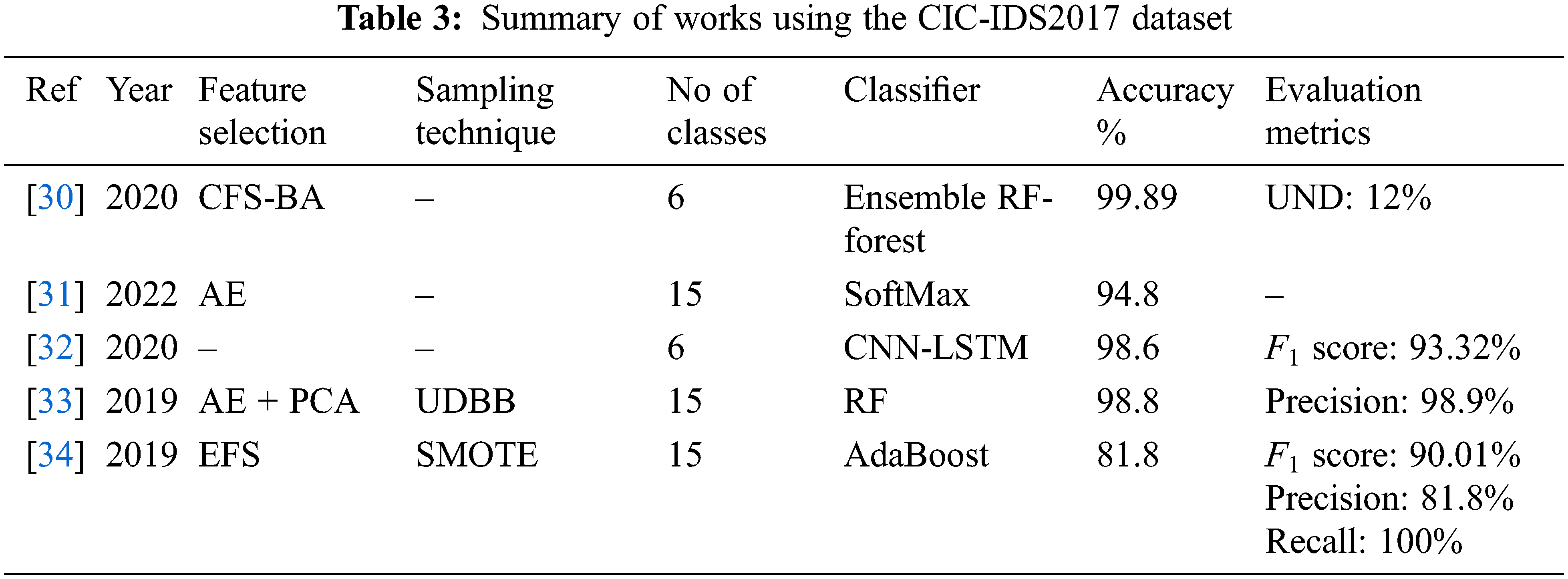
The CIC-IDS2017 dataset contains normal traffic and flows with 14 attack types. It has been used by many researchers to develop ADSs. Zhou et al. [30] used CIC-IDS2017 to design an IDS. Their model was based on feature extraction and ensemble algorithms. Firstly, they defined a dimensionality reduction algorithm called CFS-BA. This algorithm uses feature correlations to select the optimal subset. The authors used penalized attributes (PA) in an ensemble approach with two algorithms, RF and Forest, in a new model called Forest PA. Finally, the model used voting on the probability distributions to detect attacks. Their proposed CFS-BA-Forest PA model performed better than state-of-the-art models with an accuracy of 99.89% and an UN-Detected rate (UND) of 12%.
Choobdar et al. [31] also used the CIC-IDS2017 dataset to develop an IDS for Software Defined Networks (SDN). The proposed IDS was built in three stages. In the first stage, a sparse stacked AE was used for feature extraction. The second stage used the SoftMax algorithm to train and test the model. Finally, the system parameters were optimized. The system performance was evaluated with NSL-KDD as well as CIC-IDS2017. It had an average accuracy of 94.8%.
Sun et al. [32] trained an IDS using CIC-IDS2017. They used a hybrid model with a CNN and LSTM for feature extraction and classification. This deep learning-based IDS reached an overall accuracy of 98.67%.
Abdulhammed et al. [33] designed an IDS based on CIC-IDS2017. This work adopted two feature dimensionality-reduction methods: AE and Principal Component Analysis (PCA). They used Uniform Distribution Based Balancing (UDBB) to balance the high data distribution. The resulting subset from both techniques was then used to build the IDS with different algorithms: RF, Bayesian Network, Linear Discriminant Analysis (LDA), and Quadratic Discriminant Analysis (QDA). The main contribution of this approach is that it reduced the number of dimensions in CIC-IDS2017 from 81 to 10, whilst achieving high accuracy of 98.8%.
Finally, Yulianto et al. [34] tackled the high-class imbalance of the CIC-IDS2017 dataset. They constructed an IDS based on SMOTE, PCA, and Ensemble Feature Selection (EFS). AdaBoost was used to enhance performance. The proposed model had accuracy, precision, recall, and F1 scores of 81.83%, 81.83%, 100%, and 90.01%, respectively. Table 3 summarizes the literature on the CIC-IDS2017 dataset.
The main observations about the papers reviewed on the CIC-IDS2017 dataset are as follows:
G.3 The dataset has highly imbalanced data. However, few works have been found that balance the data distribution.
G.4 Only one study [32] applied a deep learning model but without any feature selection or data sampling techniques. Moreover, this system classified only 6 classes.
G.5 Most of the studies have been concerned with detecting cyberattacks with high detection accuracy only. However, little work has focused on minimizing the UND, which measures how many attack flows are considered normal traffic. This work focuses on minimizing the UND due to the devastating physical effects of an attack in an AMI environment.
This section presents the research methodology in two main subsections: the dataset description (which describes the training set in detail), and the proposed framework (which explains the proposed model in detail).
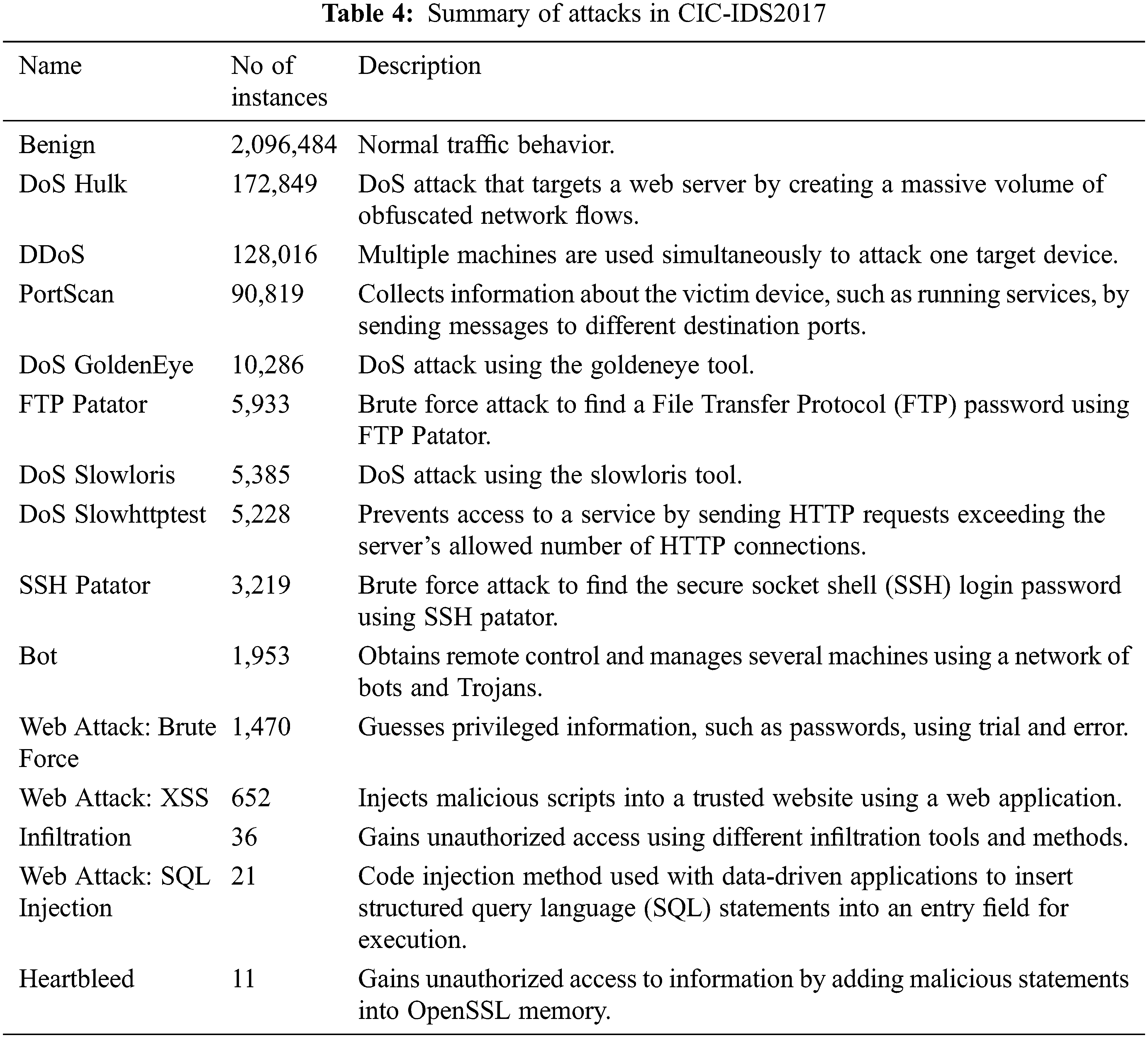
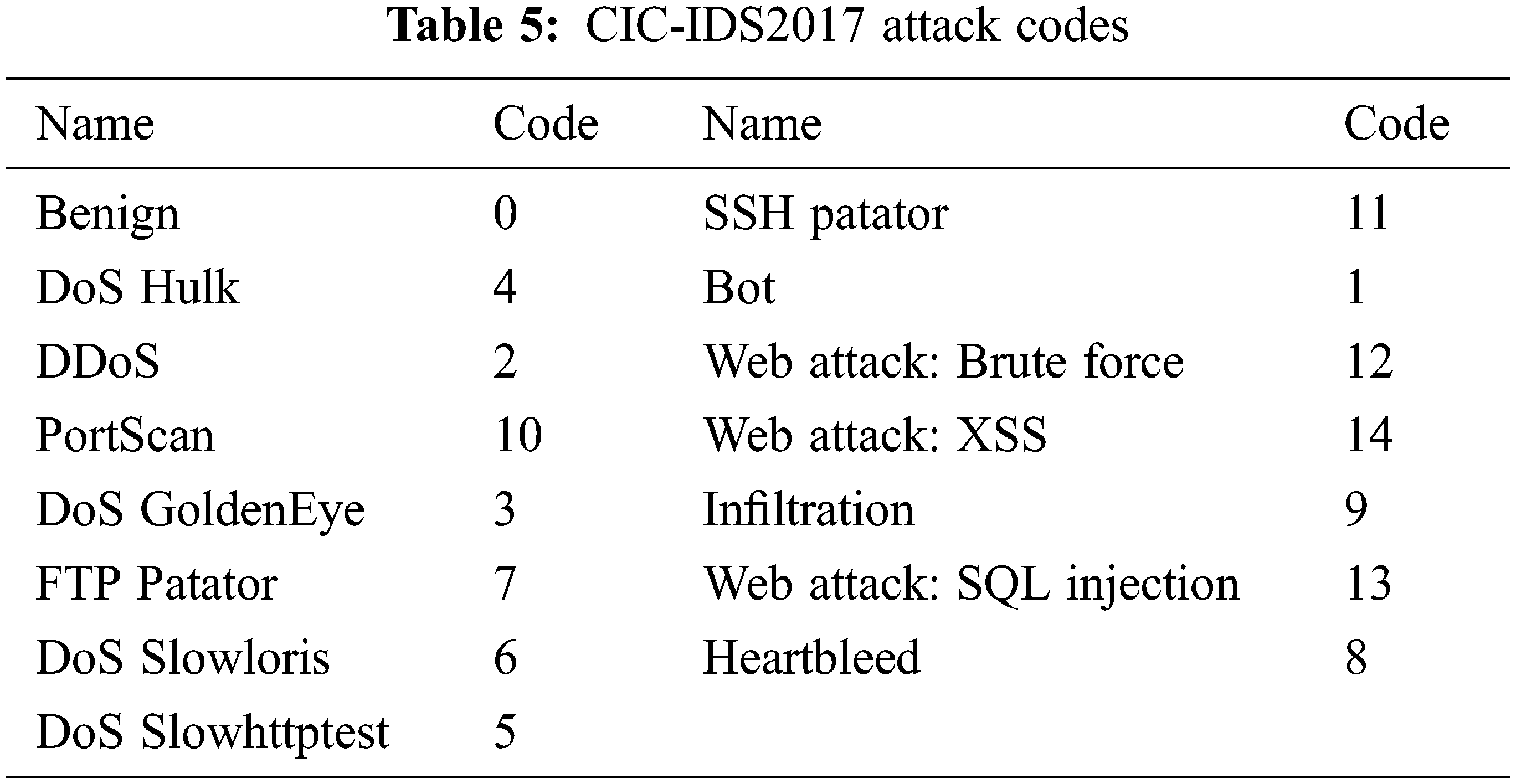
CIC-IDS2017 was assembled by the Canadian Institute of Cybersecurity (CIC). It consists of the latest threats and features. It is one of the most important datasets since it includes more recent threat types that are not represented in the older datasets. Additionally, it has examples of the most up-to-date attack scenarios which fulfill all the criteria of real-world attacks. However, like real-world network data, it has a high degree of class imbalance. It contains 2,522,362 different network flows. Of these, 2,096,484 are benign (83.12% of the data). There are 425,878 attack flows (16.88% of the data) with 79 different features. It covers normal flow and 14 attack types. These attacks are briefly described in Table 4.
The proposed framework consists of the following steps: (1) features are extracted with a deep learning approach, (2) the dataset is balanced in two steps (random under-sampling and SMOTE), and (3) a threat is detected by ensemble soft voting-based on RF and CNN to classify the data. The model can successfully identify a normal flow and 14 attack types. Fig. 1 illustrates the proposed model framework, which has the following phases:
• Dara pre-processing: This step transforms the raw data in the original dataset into a suitable input format for the machine learning and deep learning models.
• Normalization: The Min-Max method is proposed.
• Dataset splitting: Of the data, 70% is used for training and 30% is used for testing.
• Data distribution balancing: To enhance performance, the data distribution is balanced through under-sampling and SMOTE oversampling.
• Dimensionality reduction: To reduce the dataset’s dimensionality, the most relevant features are selected with an AE. This step decreases the complexity and processing time for this high-dimensional dataset.
• Classifier training: To improve performance, the RF and CNN results undergo ensemble voting.
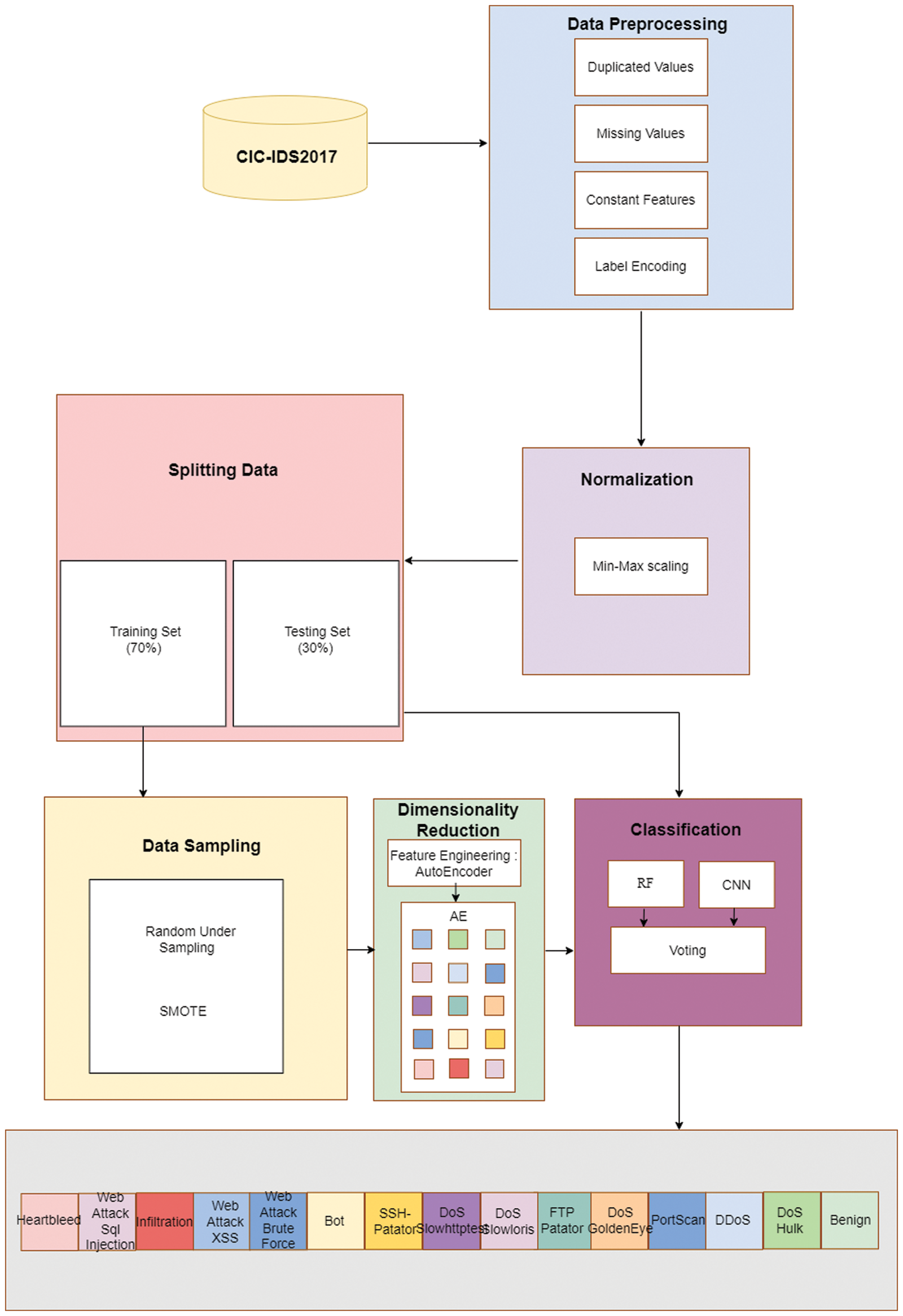
Figure 1: Proposed framework
The first step in building the model is to pre-process the data. This step addresses the noise and missing values in the data, both of which can degrade the model performance of the model. Four primary pre-processing steps are applied:
• Deleting Duplicate Rows: If a dataset has duplicate rows, the processing time when training or testing the model is increased owing to the redundant effort. Therefore, duplicates were removed to decrease the overhead. In this step, 308,381 duplicate rows were deleted from this dataset.
• Handling Missing Values: Many techniques have been proposed for filling lost or missing values. In this work, missing values were deleted to obtain a more accurate result.
• Removing Constant Features: Some features have the same values for all instances in the dataset. Eight such features were removed to decrease the training overhead: Bwd PSH Flags’,’ Bwd URG Flags’,’Fwd Avg Bytes/Bulk’,’ Fwd Avg Packets/Bulk’, ‘Fwd Avg Bulk Rate’, ‘Bwd Avg Bytes/Bulk’,’ Bwd Avg Packets/Bulk’, ‘Bwd Avg Bulk Rate’.
• Encoding: The last step in the data pre-processing phase is to encode the text values as numbers because the classifier cannot work with text. In this dataset, only the label feature, which represents the attack type, had text values, which were encoded as in Table 5.
Normalization or standardization transforms the data, so it is contained in a unit sphere. Min-Max normalization was used to standardize all features values using the following formula [35]:
where
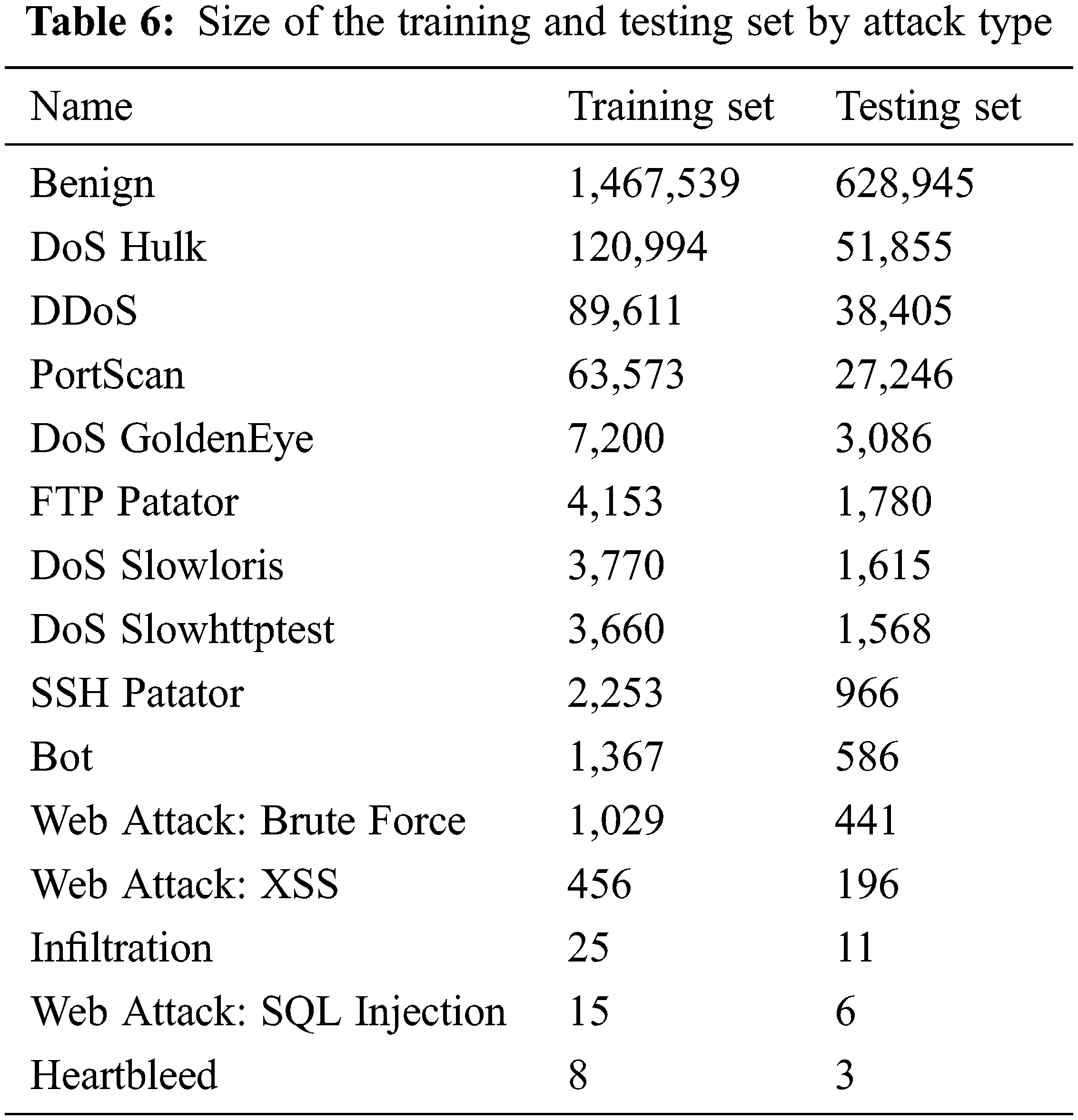
In this work, 70% of the samples were placed in the training set and 30% in the testing set. This distribution was done according to attack type, as listed in Table 6.
3.2.4 Data Distribution Balancing
The proposed model uses two sampling steps. Firstly, a random under-sampling technique is applied only for class (0) (benign traffic). In this step, the samples were randomly deleted samples from the largest class. Secondly, SMOTE was run against all the other classes except class (4) (DoS Hulk). SMOTE was used to increase the size of these classes to that of class (4), which had 120,994 flows. SMOTE reduces the negative impact of both under and over-sampling by integrating both to generate a balanced dataset [36]. Fig. 2 represents the training dataset before and after applying the proposed data balancing technique, with 120,994 samples for each type of class. Algorithm 1 describes the proposed two-step sampling.
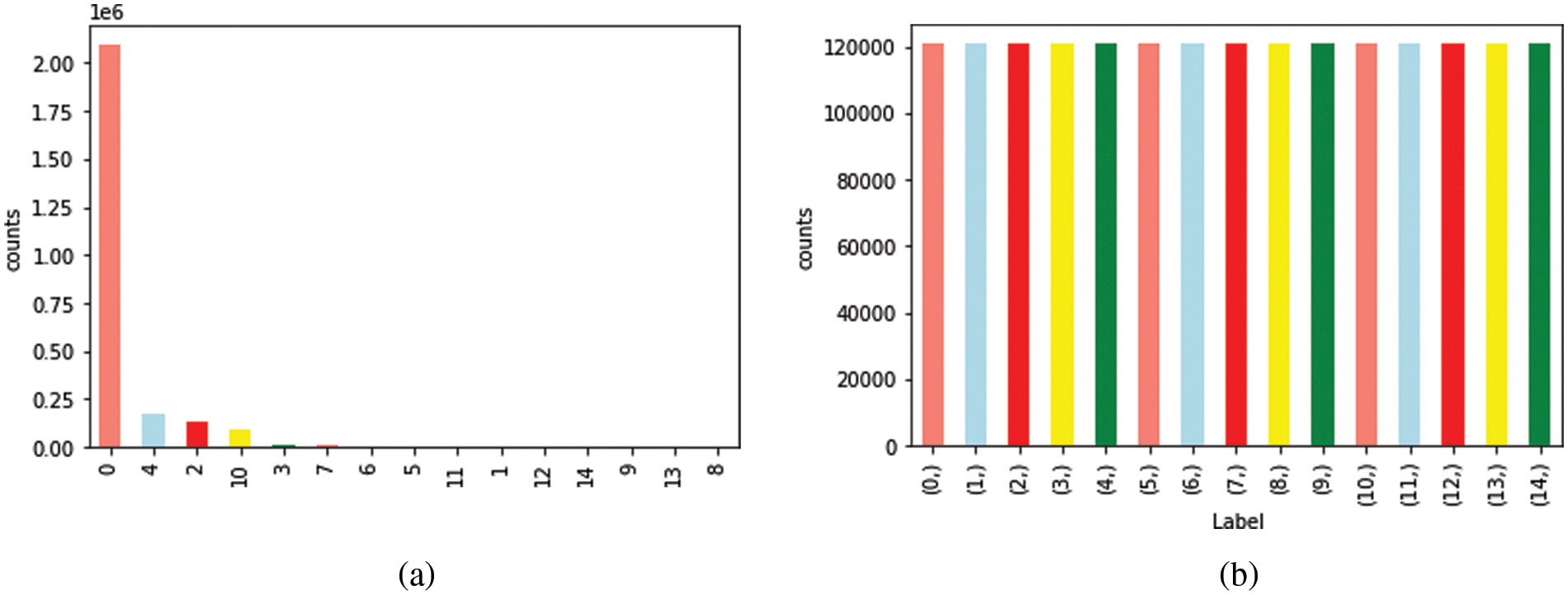
Figure 2: Training dataset: (a) original distribution and (b) two-step balanced data

3.2.5 Dimensional Reduction and Feature Selection
CIC-IDS2017 is a high-dimensional dataset. In this phase, AE-based feature extraction, which is an unsupervised neural network is used for dimensional reduction. It has an encoder and a decoder. Fig. 3 shows the hierarchical structure of the AE. It selects and reconstructs the input features to extract the main features [37].
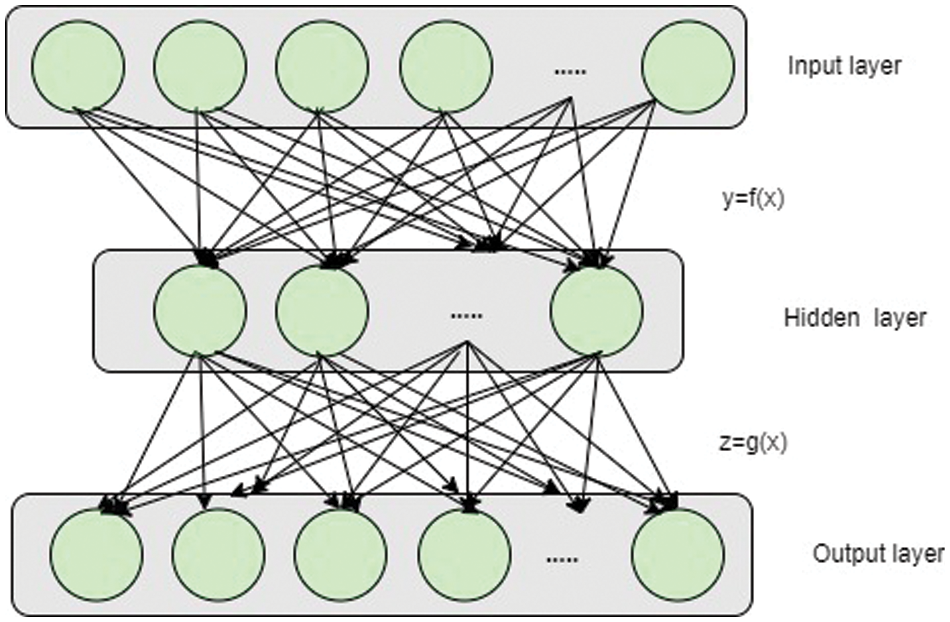
Figure 3: Hierarchical structure of the AE
Let the information in the input layer be x, that in the hidden layer y, and that in the output layer z. The following formulae represent the encoding and decoding of the AE:
where
3.2.6 Proposed Ensemble Voting RF–CNN Classification Model
Ensemble approaches combine the base classifiers in a final ensemble model for better results. There are different types of ensemble approaches. This work uses soft ensemble voting to assess the RF and CNN results. RF produces high results in terms of accuracy, precision, recall, and F1 score, whereas a CNN is the best model for detecting a few sample attacks and has the lowest UND. In soft voting, the average probability of a class is the prediction output. Soft voting is described as [38]:
where
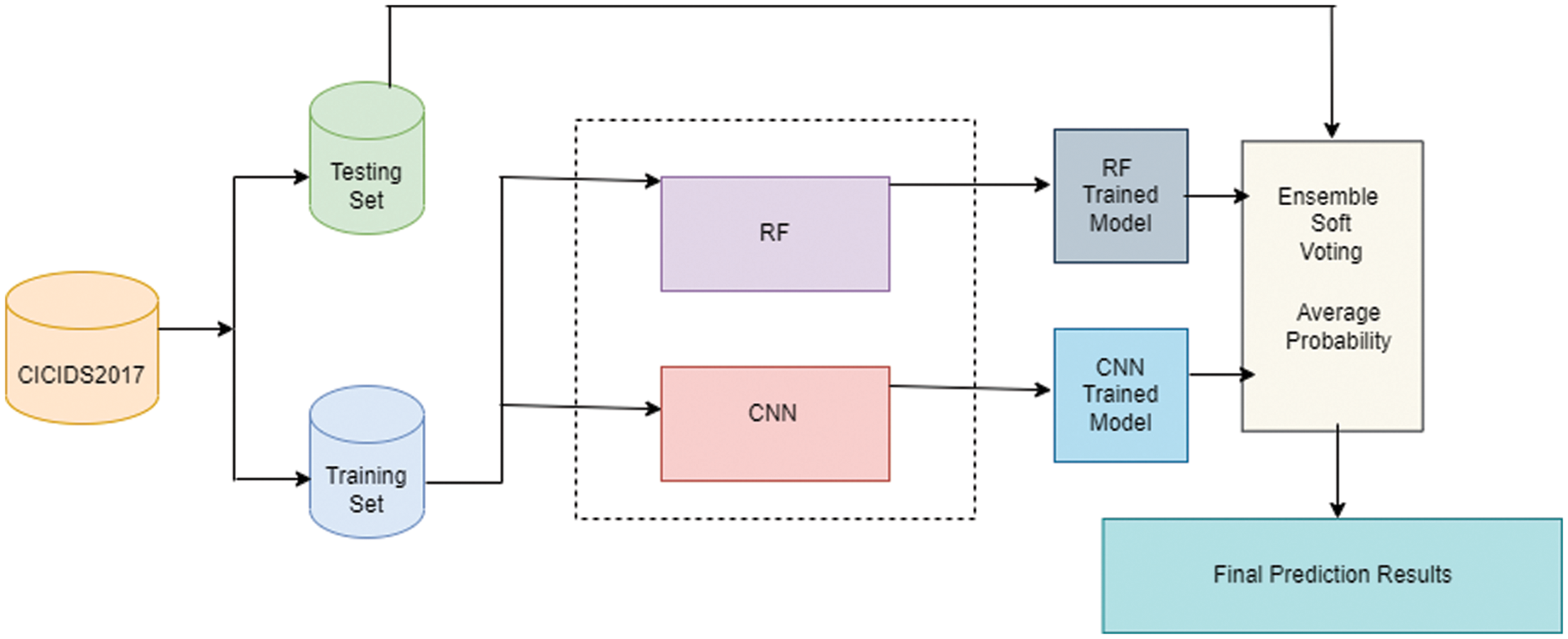
Figure 4: Conceptual architecture of the proposed ensemble soft voting RF–CNN

The proposed model uses RF and a CNN to classify attacks. The RF algorithm uses many Decision Trees (DT). It has higher accuracy compared to other traditional machine learning algorithms because it makes fewer classification errors. Other advantages of using RF include the following [39]:
(1) It can save generated forests for later use.
(2) It does not suffer from the overfitting problem.
(3) It automatically calculates accuracy and variable importance.
The final decision is the majority vote by all trees in the RF model. Fig. 5 shows the proposed architecture of the RF model.
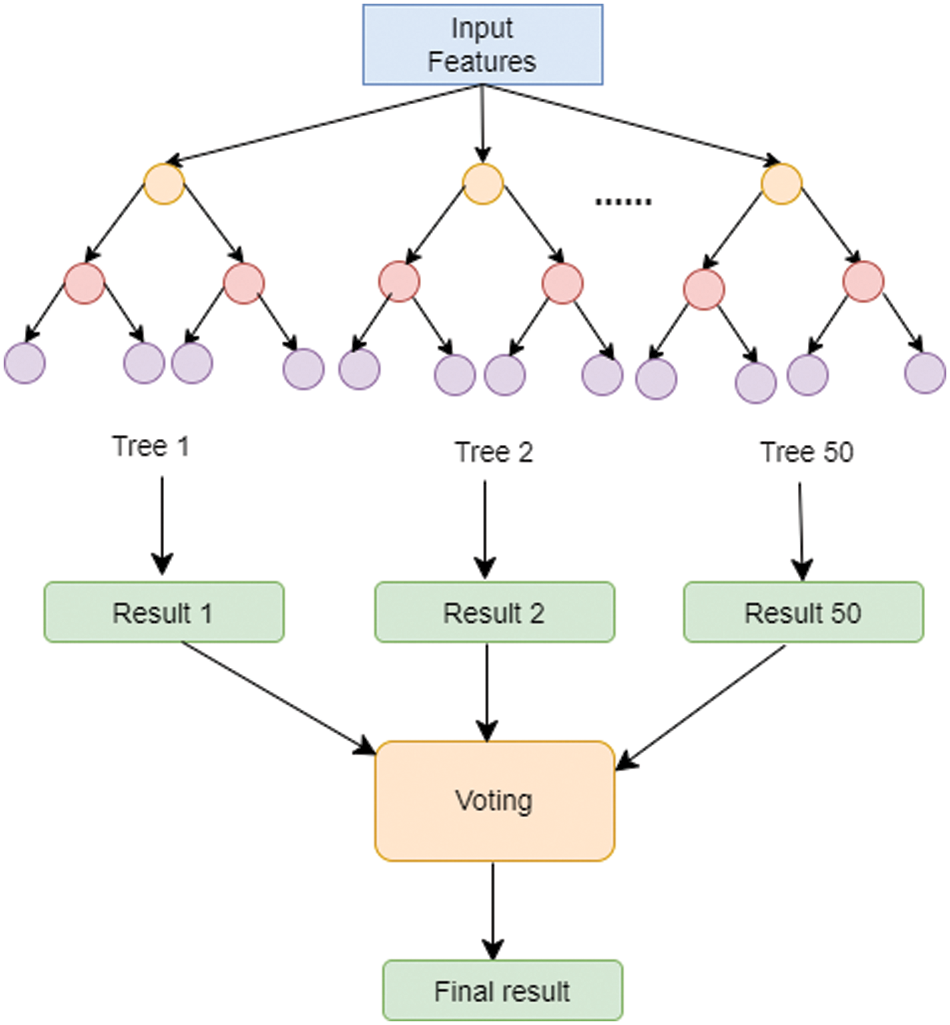
Figure 5: Architecture of the proposed RF model
Many experiments were run to find the best number of trees (k) with the highest classification accuracy. Each experiment used a random value of k in the range of (10, 100). When k = 50, the accuracy was highest at about 98.54%. For k above 50, the accuracy did not increase. The other RF parameters are shown in Table 7.

CNNs are widely used deep learning algorithms. A CNN has the following types of layers: (1) convolution layers, which extract the main features, (2) pooling layers, which decrease the size of the convolved features to reduce the cost, (3) fully connected layers, which determine the class for the input layer, and (4) an output layer. A CNN has a feature learning stage and a classification stage. Each stage uses one or more layers. The feature learning stage usually combines convolutional layers and pooling layers. This stage extracts the main features from the data. These extracted features are fed into the classification stage, which has a fully connected layer to determine the class for the input layer. The architecture of a CNN with N-layers and input vector
An optimized set of weight vectors
Overfitting often occurs if all the features are connected to the fully connected layer. A dropout layer is used to overcome this problem. It drops a few neurons from the neural network during training to decrease the size of the model [40].
The proposed CNN model has four convolutional layers. The numbers of filters were 64, 128, 256, and 512, respectively. For each layer, the activation function is a Rectified Linear Unit (ReLU) with a kernel size of 3 and strides of 1. The ReLU is calculated as:
Each convolutional layer is followed by a pooling layer with a pooling size of 2 and Max-pooling methods. The formula of the max-pooling layer is calculated as [41]:
where
where z is arbitrary with real values

Figure 6: Architecture of the proposed CNN model
As is evident from Subsection 3.1, the dataset in question is highly imbalanced. It has 2,522,362 instances of network traffic, 2,096,484 (83.12%) of which were normal traffic flows whilst 425,878 (16.88%) were instances of malicious traffic flows. Owing to the preponderance of normal traffic flows and the comparatively small number of attack flows, errors in detection would not significantly reduce the overall accuracy of the model. Accordingly, increasing the accuracy or other performance metrics in the model would produce misleading results thus suggesting an inability to detect attacks because of the imbalanced dataset, which in turn means the ADS may not be able to detect all attacks. Moreover, this research focused on enhancing the detection per class and the UND, which more accurately reflects the system’s ability to identify attacks, as a low UND indicates the model can detect most incoming attacks.
Building on the related works described in Section 2 and examining the effect of the proposed two-step data distribution balancing algorithm, this work utilizes six state-of-the-art machine learning and deep learning algorithms: RF, LightGBM, XGboost, CNN, LSTM, and biLSTM. The efficacy of these algorithms is evaluated with the original dataset and dimensional reduction. The results are listed in Table 9. All six algorithms achieved high precision, recall, F1 score, and accuracy due to a large number of normal samples compared to the attacks in the testing set.
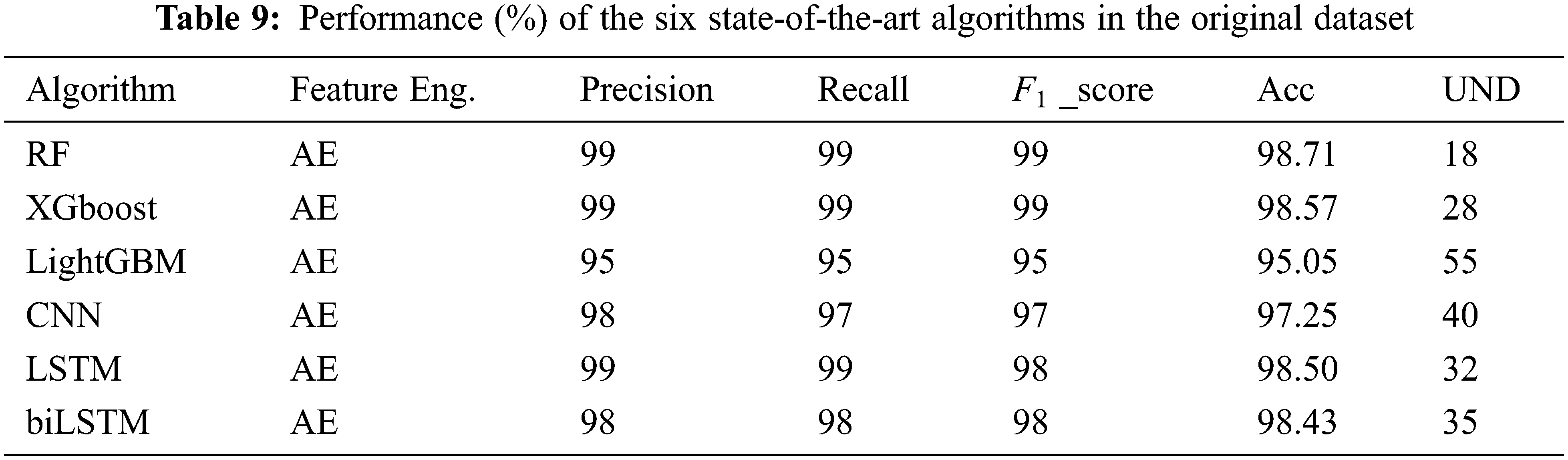
Hence, although these models can classify most normal flows accurately, the high UND values suggest that many attacks were undetected because the models had not been trained correctly. This result is clear in Table 10, which shows the detection accuracy for each class for the six algorithms with the original dataset. Fig. 7 represents these results graphically.
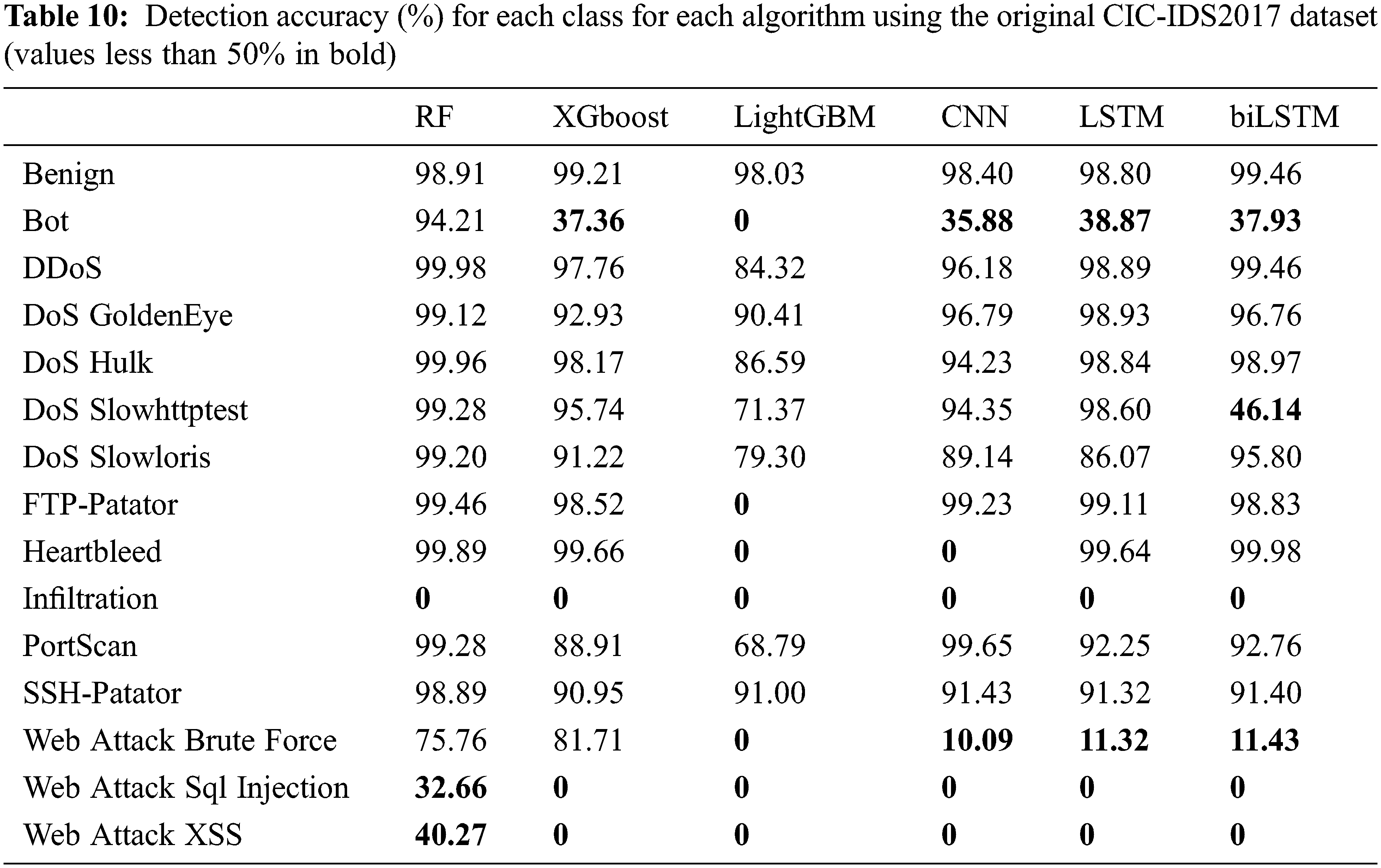
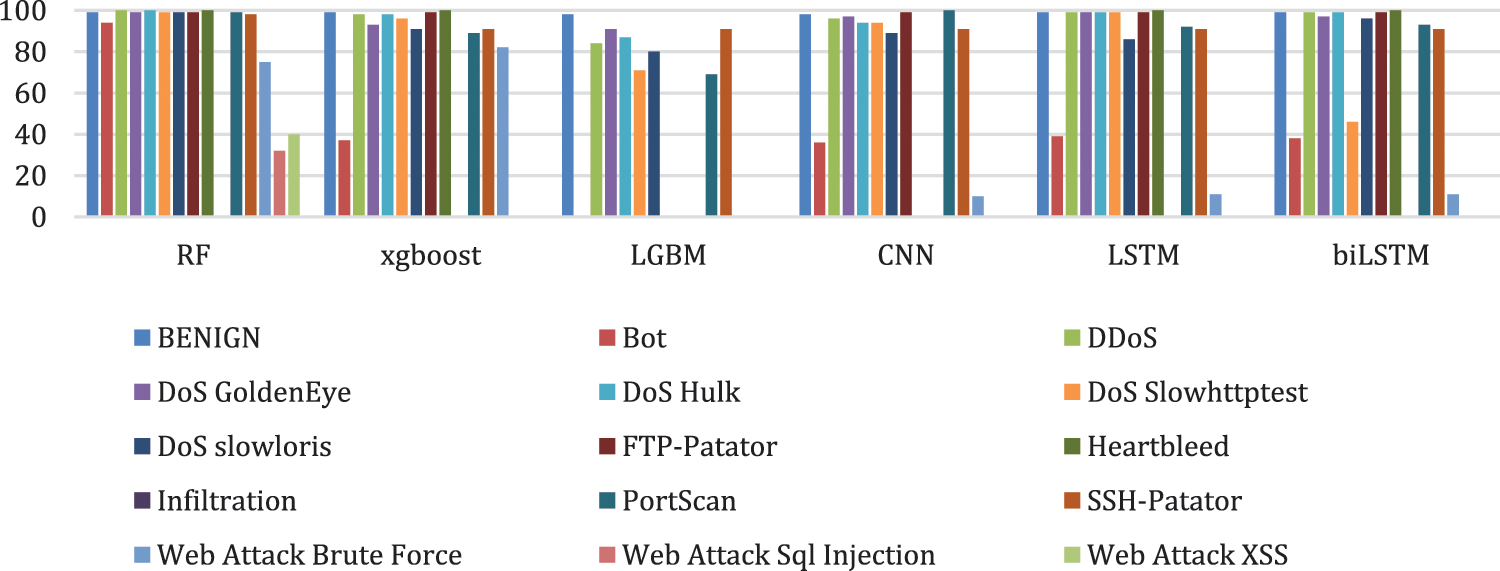
Figure 7: Detection accuracy for each class for each algorithm using the original CIC-IDS2017 dataset
The algorithms were next trained and evaluated after the proposed data distribution balancing, as shown in Table 11. The final row shows the results for the proposed method. The proposed two-step sampling leads to a noteworthy improvement in the UND with high accuracy score, indicating the improved ability of each model to detect attacks. Table 12 lists the accuracy per class for the algorithms after the two-step sampling. This data is represented graphically in Fig. 8.
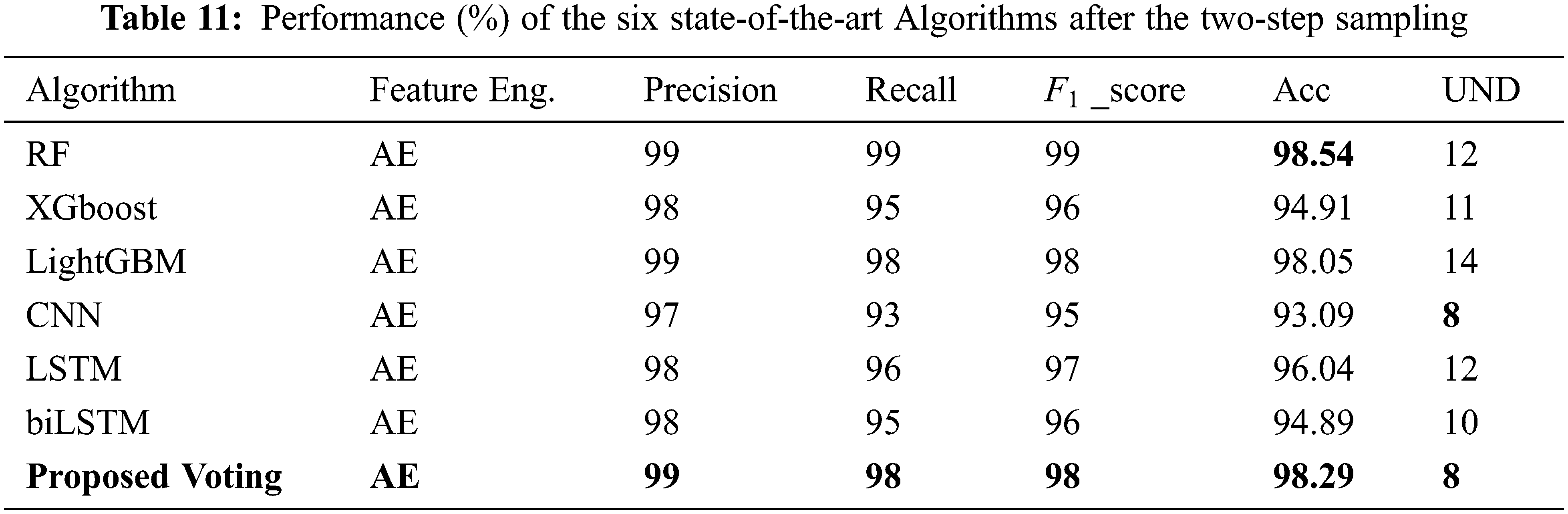
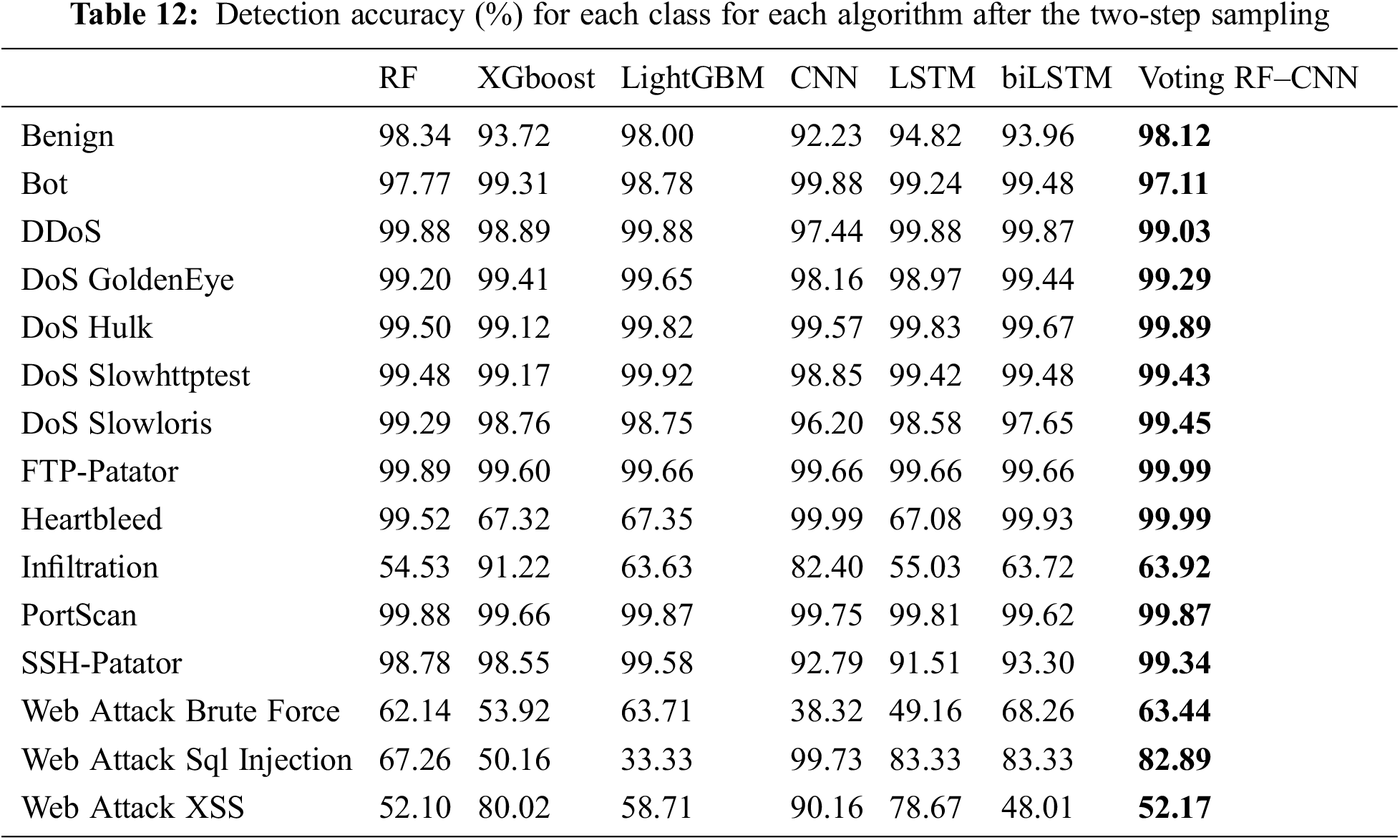
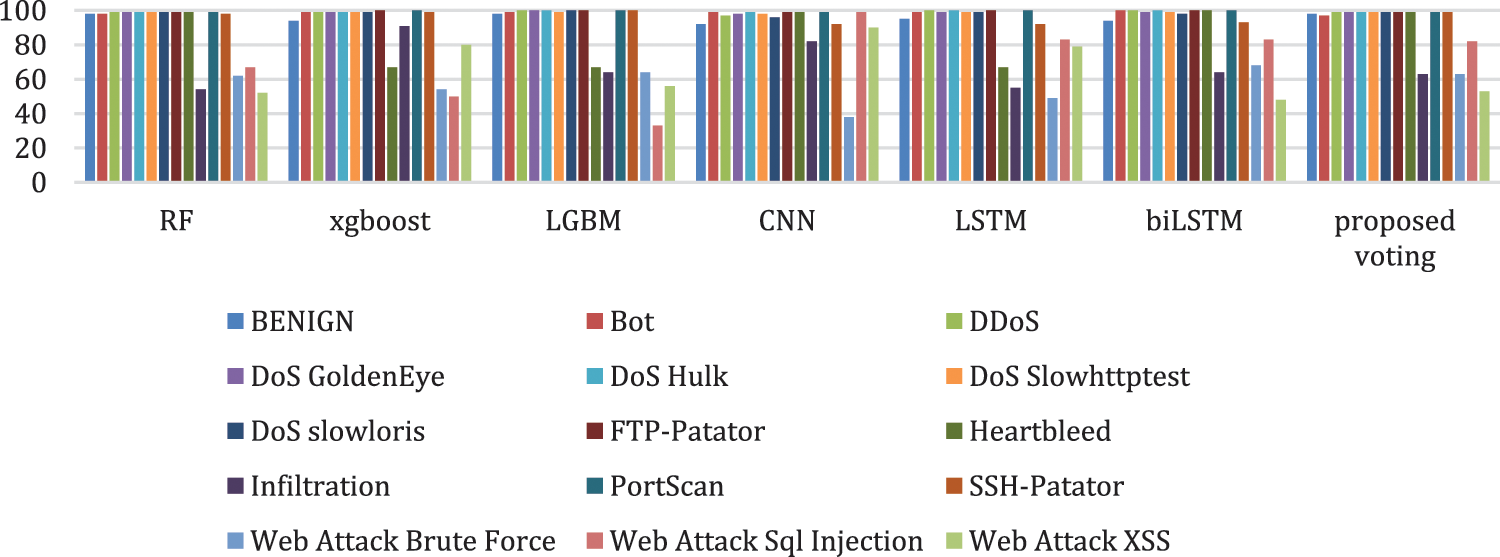
Figure 8: Detection accuracy for each class for each algorithm after the two-step sampling
Table 12 shows that, compared to RF, the proposed voting model had better detection performance against DoS GoldenEye, DoS Hulk, DoS Slowloris, FTP Patator, Heartbleed, Infiltration, SSH Patator, Web attack: Brute force, Web attack: XSS, and Web attack: SQL injection. Furthermore, the proposed voting model had better accuracy than did the CNN for benign flows and against DDoS, DoS GoldenEye, DoS Hulk, DoS Slowhttptest, DoS Slowloris, FTP Patator, PortScan, SSH Patator, and Web attack: Brute force. The proposed voting model classified benign traffic with 98.12% accuracy, which was very close to models that are trained with all the benign flows in the original dataset, as shown in Table 10. Fig. 9 shows the confusion matrix for the proposed model. The proposed model can detect attacks better than both other machine learning and deep learning models.
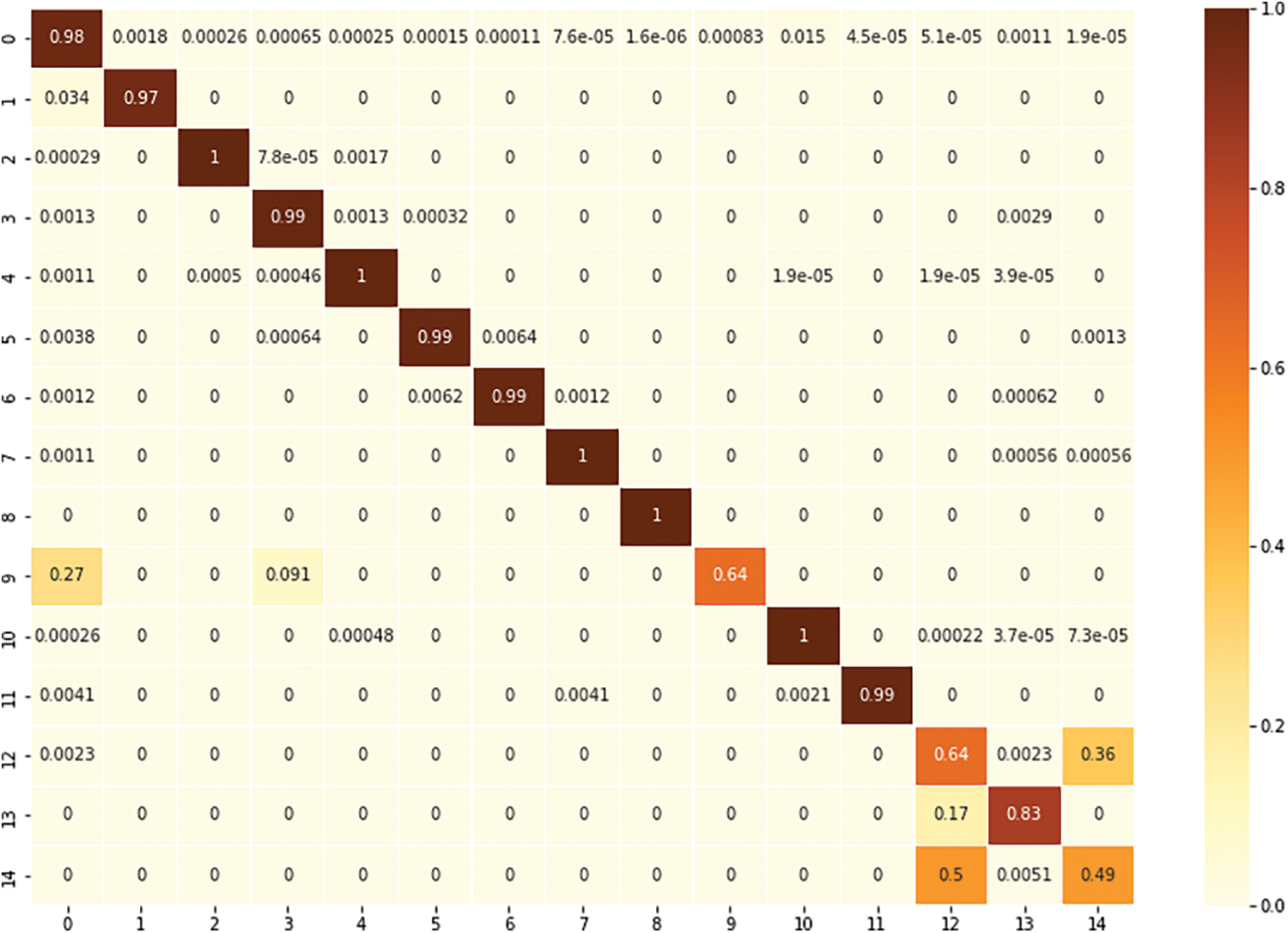
Figure 9: Confusion matrix for the proposed ensemble voting RF–CNN model
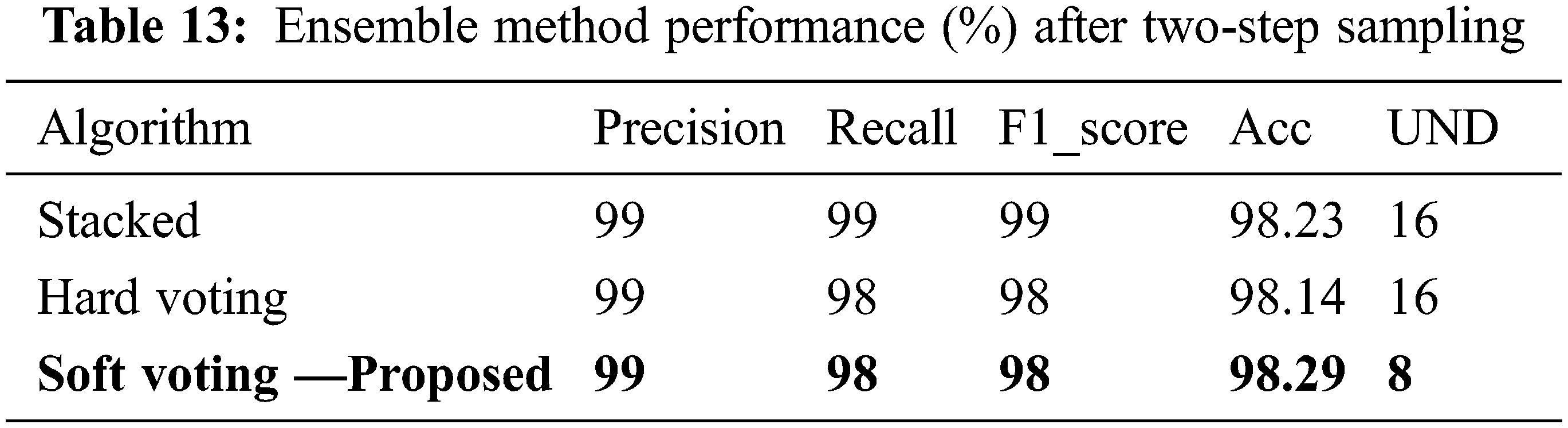
Three ensemble strategies were assessed in this work: soft voting, hard voting, and stacked ensemble. The results are displayed in Table 13. Soft voting was the most effective ensemble strategy.
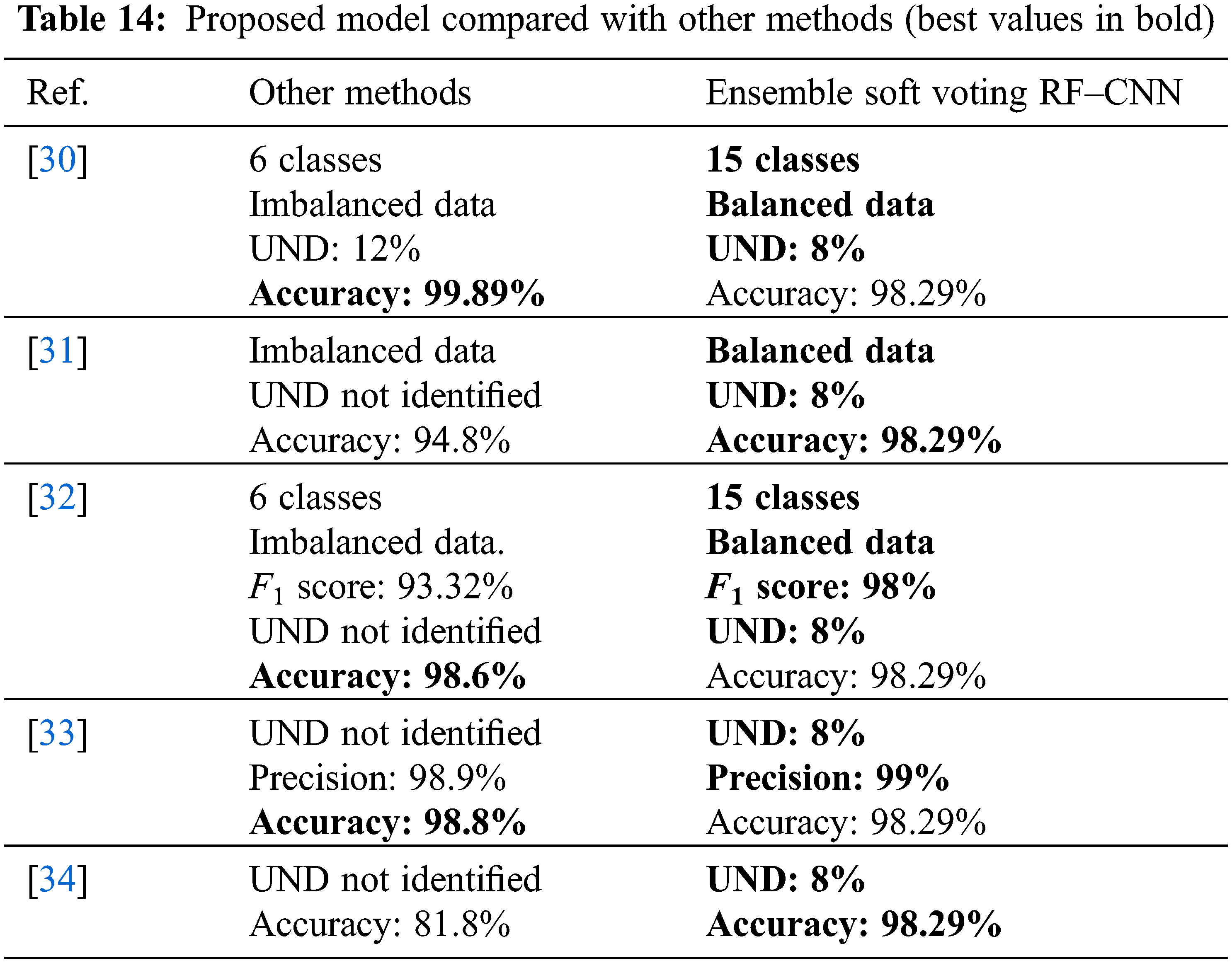
Finally, Table 14 compares the proposed model with the other detection methods (listed in Table 3) tested with the same dataset. Each method’s efficacy was assessed according to the number of attacks detected and classified. An ability to classify various attack types is reflective of a model’s strength. Furthermore, although accuracy and UND are important metrics when designing an ADS for an AMI environment, accuracy can become skewed if the data are imbalanced. UND and accuracy per class, by contrast, reflect a system’s ability to distinguish malicious traffic from normal flows, particularly in small-scale attacks that lack training. An AMI is a critical and sensitive system: indeed, an attack against it may cause serious damage, and the network may take a long time to recover. Therefore, AMIs must be very careful about which network flows they accept. Table 14 reveals that the proposed model performed better than the other methods, with one, minor exception. The method described in [33] had a higher accuracy but lower precision and the UND was not identified.
A smart grid is proposed to enhance the efficiency, reliability, stability, and security of traditional energy power systems. An AMI exchanges sensitive information through various types of communication networks with different technologies, which exposes it to different types of attacks. Detecting anomalies in network flow patterns is a difficult task, especially in the security management of a large network. The current IDSs have various drawbacks, such as high False Positive and False Negative, difficult feature engineering, and low efficiency when pre-processing the data. These problems arise because the range of possible normal behaviors of the multiple devices on the network is very large and dynamic. Additionally, many ADSs cannot process complex data and have poor classification performance.
To improve anomaly detection, this paper proposed ensemble voting based on deep learning algorithms to enhance system performance. The proposed system was developed in four stages: data preprocessing, dimensional reduction using AE-based feature engineering, data distribution balancing using under-sampling and SMOTE oversampling, and multiclass classification using the ensemble voting RF–CNN model. The findings show that the proposed model can detect 14 different attack types better than other machine learning and deep learning models. It had high performance in terms of accuracy, precision, recall, F1 score, and UND. It could be used to build an efficient IDS for an AMI network. In future work, we recommend training the model on more attacks from other datasets. Moreover, we recommend enhancing the capability of the model to deal with zero-day attacks.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. V. Tudor, M. Almgren and M. Papatriantafilou, “The influence of dataset characteristics on privacy preserving methods in the advanced metering infrastructure,” Computers & Security, vol. 76, ISSN 0167-4048, pp. 178–196, 2018. [Google Scholar]
2. J. L. Gallardo, M. A. Ahmed and N. Jara, “Clustering algorithm-based network planning for advanced metering infrastructure in smart grid,” IEEE Access, vol. 9, pp. 48992–49006, 2021. [Google Scholar]
3. W. Tong, L. Lu, Z. Li, J. Lin and X. Jin, “A survey on intrusion detection system for advanced metering infrastructure,” in Proc. 6th Int. Conf. on Instrumentation and Measurement, Computer, Communication and Control, IMCCC, Harbin, China, pp. 33–37, 2016. [Google Scholar]
4. W. Wisetsri, S. Qamar, G. Verma, D. Verma, V. Kakar et al., “Electricity theft detection and localization in smart grids for industry 4.0,” Intelligent Automation & Soft Computing, vol. 33, no. 3, pp. 1473–1483, 2022. [Google Scholar]
5. G. Bendiab, K. P. Grammatikakis, I. Koufos, N. Kolokotronis and S. Shiaeles, “Advanced metering infrastructures: Security risks and mitigation,” in Proc. of the 15th Int. Conf. on Availability, Reliability and Security, Dublin, Ireland, New York, NY, USA, ACM, Association for Computing Machinery, pp. 2–21, 2020. [Google Scholar]
6. S. Tufail, I. Parvez, S. Batool and A. Sarwat, “A survey on cybersecurity challenges, detection, and mitigation techniques for the smart grid,” Energies, vol. 14, no. 18, pp. 1–22, 2021. [Google Scholar]
7. C. Bekara, “Security issues and challenges for the IoT-based smart grid,” Procedia Computer Science, vol. 34, ISSN 1877-0509, pp. 532–537, 2014. [Google Scholar]
8. J. Li, J. Huang, L. Tian and J. Wang, “Application of new active defense technology in power information network security,” IOP Conference Series: Materials Science and Engineering, vol. 750, no. 1, pp. 012156, 2020. [Google Scholar]
9. L. Wei, L. P. Rondon, A. Moghadasi and A. I. Sarwat, “Review of cyber-physical attacks and counter defense mechanisms for advanced metering infrastructure in smart grid,” in Proc. IEEE Power Engineering Society Transmission and Distribution Conf., Denver, USA, pp. 1–9, 2018. [Google Scholar]
10. R. R. Chaudhari and S. P. Patil, “Intrusion detection system: Classification, techniques and datasets to implement,” International Research Journal of Engineering and Technology, vol. 4, no. 2, pp. 1860–1866, 2017. [Google Scholar]
11. S. M. Naser, Y. H. Ali and D. A. J. Obe, “Deep learning model for cyber-attacks detection method in wireless sensor networks,” Periodicals of Engineering and Natural Sciences, vol. 10, no. 2, pp. 251–259, 2022. [Google Scholar]
12. S. Angra and S. Ahuja, “Machine learning and its applications: A review,” in Proc. Int. Conf. on Big Data Analytics and Computational Intelligence, Cirala, India, pp. 57–60, 2017. [Google Scholar]
13. I. H. Sarker, “Deep learning: A comprehensive overview on techniques, taxonomy, applications and research directions,” SN Computer Science, vol. 2, no. 6, pp. 1–20, 2021. [Google Scholar]
14. Intrusion detection evaluation dataset (CIC-IDS2017Canadian Institute for Cybersecurity 2017. https://www.unb.ca/cic/datasets/ids-2017.html (accessed Feb. 26, 2022). [Google Scholar]
15. M. Hachimi, G. Kaddoum, G. Gagnon and P. Illy, “Multi-stage jamming attacks detection using deep learning combined with kernelized support vector machine in 5G cloud radio access networks,” in Proc. Int. Symp. on Networks, Computers and Communications, Montreal, QC, USA, pp. 1–5, 2020. [Google Scholar]
16. M. Anwer, S. M. Khan, M. U. Farooq and W. Waseemullah, “Attack detection in IoT using machine learning,” Engineering, Technology & Applied Science Research, vol. 11, no. 3, pp. 7273–7278, 2021. [Google Scholar]
17. T. Salman, D. Bhamare, A. Erbad, R. Jain and M. Samaka, “Machine learning for anomaly detection and categorization in multi-cloud environments,” in Proc. 4th IEEE Int. Conf. on Cyber Security and Cloud Computing, CSCloud 2017 and 3rd IEEE Int. Conf. of Scalable and Smart Cloud, New York, NY, USA, pp. 97–103, 2017. [Google Scholar]
18. S. M. Othman, F. M. Ba-Alwi, N. T. Alsohybe and A. Y. Al-Hashida, “Intrusion detection model using machine learning algorithm on big data environment,” Journal of Big Data, vol. 5, no. 1, pp. 2–12, 2018. [Google Scholar]
19. F. Hussain, S. G. Abbas, M. Husnain, U. U. Fayyaz, F. Shahzad et al., “IoT DoS and DDoS attack detection using ResNet,” in Proc. 3rd IEEE Int. Multi-Topic Conf., INMIC 2020, Bahawalpur, Pakistan, pp. 1–6, 2020. [Google Scholar]
20. Y. Otoum, D. Liu and A. Nayak, “DL-IDS: A deep learning–based intrusion detection framework for securing IoT,” Transactions on Emerging Telecommunications Technologies, vol. 33, no. 3, pp. 2–16, 2022. [Google Scholar]
21. M. Ge, N. F. Syed, X. Fu, Z. Baig and A. Robles-Kelly, “Towards a deep learning-driven intrusion detection approach for internet of things,” Computer Networks, vol. 186, pp. 107784, 2021. [Google Scholar]
22. M. Ge, X. Fu, N. Syed, Z. Baig, G. Teo et al., “Deep learning-based intrusion detection for IoT networks,” in Proc. IEEE Pacific Rim Int. Symp. on Dependable Computing, Kyoto, Japan, vol. 2, pp. 256–265, 2019. [Google Scholar]
23. A. Derhab, A. Aldweesh, A. Z. Emam and F. A. Khan, “Intrusion detection system for internet of things based on temporal convolution neural network and efficient feature engineering,” Wireless Communications and Mobile Computing, vol. 2020, no. 6689134, pp. 2–16, 2020. [Google Scholar]
24. I. Ullah and Q. H. Mahmoud, “Design and development of a deep learning-based model for anomaly detection in IoT networks,” IEEE Access, vol. 9, pp. 103906–103926, 2021. [Google Scholar]
25. S. Latif, Z. Idrees, Z. Zou and J. Ahmad, “DRaNN: A deep random neural network model for intrusion detection in industrial IoT,” in Proc. Int. Conf. on UK-China Emerging Technologies, Glasgow, UK, 20–21, pp. 1–4, 2020. [Google Scholar]
26. E. Tufan, C. Tezcan and C. Acartürk, “Anomaly-based intrusion detection by machine learning: A case study on probing attacks to an institutional network,” IEEE Access, vol. 9, pp. 50078–50092, 2021. [Google Scholar]
27. T. Rose, K. Kifayat, S. Abbas and M. Asim, “A hybrid anomaly-based intrusion detection system to improve time complexity in the internet of energy environment,” Journal of Parallel and Distributed Computing, vol. 145, pp. 124–139, 2020. [Google Scholar]
28. R. Yao, N. Wang, Z. Liu, P. Chen, D. Ma et al., “Intrusion detection system in the smart distribution network: A feature engineering-based AE-LightGBM approach,” Energy Reports, vol. 7, pp. 353–361, 2021. [Google Scholar]
29. R. Yao, N. Wang, Z. Liu, P. Chen and X. Sheng, “Intrusion detection system in the advanced metering infrastructure: A cross-layer feature-fusion CNN-LSTM-based approach,” Sensors, vol. 21, no. 2, pp. 1–17, 2021. [Google Scholar]
30. Y. Zhou, G. Cheng, S. Jiang and M. Dai, “Building an efficient intrusion detection system based on feature selection and ensemble classifier,” Computer Networks, vol. 174, pp. 1–21, 2020. [Google Scholar]
31. P. Choobdar, M. Naderan and M. Naderan, “Detection and multi-class classification of intrusion in software-defined networks using stacked auto-encoders and CICIDS2017 dataset,” Wireless Personal Communications, vol. 123, no. 1, pp. 437–471, 2022. [Google Scholar]
32. P. Sun, P. Liu, Q. Li, C. Liu, X. Lu et al., “DL-IDS: Extracting features using CNN-LSTM hybrid network for intrusion detection system,” Security and Communication Networks, vol. 2020, ID 8890306, pp. 1–11, 2020. [Google Scholar]
33. R. Abdulhammed, H. Musafer, A. Alessa, M. Faezipour and A. Abuzneid, “Features dimensionality reduction approaches for machine learning based network intrusion detection,” Electronics, vol. 8, no. 3, pp. 2–27, 2019. [Google Scholar]
34. A. Yulianto, P. Sukarno and N. A. Suwastika, “Improving AdaBoost-based intrusion detection system (IDS) performance on CICIDS2017 dataset,” Journal of Physics: Conference Series, vol. 1192, no. 1, pp. 2–9, 2019. [Google Scholar]
35. M. Haggag, M. M. Tantawy and M. M. S. El-Soudani, “Implementing a deep learning model for intrusion detection on apache spark platform,” IEEE Access, vol. 8, pp. 163660–163672, 2020. [Google Scholar]
36. A. Aldegheishem, M. Anwar, N. Javaid, N. Alrajeh, M. Shafiq et al., “Towards sustainable energy efficiency with intelligent electricity theft detection in smart grids emphasising enhanced neural networks,” IEEE Access, vol. 9, pp. 25036–25061, 2021. [Google Scholar]
37. Y. Wei, J. Jang-Jaccard, F. Sabrina, A. Singh, W. Xu et al., “AE-MLP: A hybrid deep learning approach for DDoS detection and classification,” IEEE Access, vol. 9, pp. 146810–146821, 2021. [Google Scholar]
38. S. Karlos, G. Kostopoulos and S. Kotsiantis, “A soft-voting ensemble-based co-training scheme using static selection for binary classification problems,” Algorithms, vol. 13, no. 1, pp. 26, 2020. [Google Scholar]
39. N. Farnaaz and M. A. Jabbar, “Random forest modeling for network intrusion detection system,” Procedia Computer Science, vol. 89, pp. 213–217, 2016. [Google Scholar]
40. C. E. Galván-Tejada, L. Calzada, A. Domínguez, R. Quintanar, H. García et al., “Estimation of indoor location through magnetic field data: An approach based on convolutional neural networks,” ISPRS Int J Geoinf, vol. 9, no. 4, pp. 226, 2020. [Google Scholar]
41. R. Almarshdi, L. Nassef, E. Fadel and N. Alowidi, “Hybrid deep learning based attack detection for imbalanced data classification,” Intelligent Automation & Soft Computing, vol. 35, no. 1, pp. 297–320, 2023. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools