
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

EMA-GhostConv YOLOv8 Based Enhanced Vehicle Detection in Intelligent Transportation Applications
1 School of Information Engineering, Chang’an University, Xi’an, China
2 School of Energy and Electrical Engineering, Chang’an University, Xi’an, China
* Corresponding Author: Syed Sajid Ullah. Email:
Journal on Artificial Intelligence 2026, 8, 119-136. https://doi.org/10.32604/jai.2026.076274
Received 17 November 2025; Accepted 14 January 2026; Issue published 24 February 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Vehicle detection plays a pivotal role in autonomous driving, traffic monitoring, and intelligent surveillance systems. While YOLOv8 offers strong real-time performance, its detection accuracy is often limited by insufficient feature stability and suboptimal multi-scale feature fusion in complex scenes. To address these issues, we propose an enhanced YOLOv8 framework that retains the original backbone and detection head for efficiency while introducing targeted improvements to the neck architecture. Specifically, the model incorporates an Exponential Moving Average (EMA) feature layer to stabilize learning through temporally smoothed feature representations, which reduces noise and enhances generalization, and integrates GhostConv along with C3Ghost modules to enrich feature diversity with minimal computational overhead. We conduct comprehensive experiments on both a custom vehicle dataset and the KITTI benchmark, demonstrating consistent and significant improvements over the baseline YOLOv8. On KITTI, our method achieves gains of +11.68% in precision, +12.84% in recall, +10.20% in mAP@50, and +12.73% in mAP@50–95. Furthermore, ablation studies validate the individual contribution of each component, and comparisons with multiple state-of-the-art detectors confirm the competitiveness of our approach in both accuracy and efficiency. The proposed EMA-GhostConv YOLOv8 framework thus offers a robust, lightweight, and high-performance solution for vehicle detection in intelligent transportation applications.Keywords
The rapid evolution of intelligent transportation systems (ITS) has necessitated the development of highly accurate and efficient real-time object detection models for tasks such as vehicle identification, traffic monitoring, and autonomous driving. These applications demand lightweight architectures that can operate under strict latency and resource constraints, especially in embedded or edge environments. Object detection, as a foundational task in computer vision, has witnessed significant breakthroughs driven by deep convolutional neural networks (CNNs), among which the You Only Look Once (YOLO) family of models stands out for balancing speed and accuracy.
The YOLO paradigm emerged with YOLOv1 [1], introducing a unified, single-stage architecture capable of real-time detection. This was further improved in YOLOv2 [2] and YOLOv3 [3] through enhancements in backbone networks and anchor-based predictions. YOLOv4 [4] leveraged additional tricks such as CSPDarknet53 and bag-of-freebies techniques to increase mAP without sacrificing speed. While YOLOv5 [5] did not emerge from a peer-reviewed outlet, it became widely adopted for its modularity and deployment flexibility. YOLOv6 [6] focused on industrial scenarios with anchor-free mechanisms, and YOLOv7 [7] introduced trainable bag-of-freebies and E-ELAN modules for efficient training.
The most recent versions, YOLOv8 [8], YOLOv9 [9], and YOLOv10 [10], integrate novel strategies such as native Python implementation, programmable gradient information, and end-to-end detection pipelines. These developments reflect the community’s shift toward optimizing both model architecture and training efficiency. Despite these advances, challenges remain in improving detection in cluttered, occluded, and dynamically varying environments typical in real-world ITS. Additionally, computational burdens imposed by dense feature extraction and large-scale convolutional layers often hinder deployment on resource-constrained platforms.
To address these limitations, recent research has explored advanced architectural modules aimed at reducing computational complexity while maintaining detection precision. Yadav et al. [11] incorporated Ghost convolution and GhostBottleneck layers into YOLOv5s to reduce redundancy in feature extraction. Similarly, Bao and Gao [12] introduced YED-YOLO for autonomous driving, optimizing the detection pipeline using lightweight convolutional mechanisms. Du et al. [13] proposed GhostC2f-enhanced YOLOv8 models for distracted driving detection, demonstrating real-time performance in resource-constrained environments. Lv et al. [14] further enhanced model efficiency by integrating GhostNetV2 with SE attention in GS-YOLO, while Tang et al. [15] extended the GhostNet architecture to support long-range attention with minimal overhead.
In addition to architectural modifications, optimization techniques have also shown promise. Liu et al. [16] designed a lightweight vehicle detection model suitable for real-time deployment in ITS. Ullah et al. [17] augmented YOLOv8 with GhostConv and attention modules for improved performance in dynamic traffic scenarios. The use of Exponential Moving Average (EMA) was explored by Li et al. [18] in EMA-YOLO to stabilize training and boost convergence, and similarly by Han et al. [19] in a maritime object detection context. Zhang et al. [20] leveraged multi-coordinate aggregation attention and shared convolution for fast and accurate road defect detection. Collectively, these studies demonstrate that incorporating Ghost-based convolutions, attention mechanisms, and EMA techniques can significantly improve detection performance, training stability, and computational efficiency in intelligent transportation systems.
In this context, we propose a novel EMA-GhostConv-enhanced YOLOv8 framework tailored for robust vehicle detection in ITS environments. By embedding GhostConv layers within the YOLOv8 backbone and integrating EMA-based parameter updates, our model achieves a better trade-off between speed and accuracy. Experimental evaluations on benchmark traffic datasets validate the efficacy of the proposed method, outperforming existing state-of-the-art lightweight detectors in both precision and inference time.
The key contributions of this paper are as follows:
1. To enhance the neck of YOLOv8n, we introduce a novel EMA feature layer for stabilizing multi-scale feature learning alongside a lightweight architecture built by replacing standard convolutions with unified GhostConv-C3Ghost blocks. This dual approach improves generalization against noise and significantly reduces computational redundancy while preserving expressive power for accurate detection in complex scenes.
2. We conduct a rigorous ablation study to quantify the individual and combined impact of the EMA and GhostConv components, demonstrating their complementary roles in boosting precision, recall, and mAP.
3. We conduct extensive evaluations on both the standard KITTI benchmark and a challenging custom vehicle dataset collected under diverse real-world conditions—such as partial occlusions, varying illumination, and complex urban backgrounds. The proposed EMA-GhostConv YOLOv8 model is comprehensively compared with multiple state-of-the-art detectors, including various YOLO variants and Faster R-CNN, SSD, RetinaNet, DETR, and EfficientDet-D2. Experimental results demonstrate that our method consistently outperforms all baselines in terms of detection accuracy and robustness.
The overall structure of the paper is illustrated in Fig. 1. The remainder of this paper is organized as follows: Section 2 reviews related work in vehicle detection and deep learning architectures. Section 3 presents the proposed methodology. Section 4 details the experimental setup and results. Finally, Section 5 concludes the paper and outlines potential future research directions.
Figure 1: Structural outline of the paper, illustrating the organization of sections from introduction to conclusion.
Real-time object detection in intelligent transportation systems (ITS) presents persistent challenges, particularly in balancing computational efficiency with detection accuracy under complex conditions. A wide range of YOLO-based architectures has been adapted for ITS scenarios, with recent efforts shifting toward task-specific lightweight designs and embedded deployment. Liu et al. [16] proposed a compact detection model for real-time vehicle recognition on resource-limited hardware. Bakirci [21] explored aerial monitoring using YOLOv8 variants to classify vehicles across road networks. Zeng and Zhong [22] targeted road surface anomalies using a customized YOLOv8n variant, while Zhu et al. [23] enhanced infrastructure inspection through UAV-mounted YOLOv8 detectors. Du et al. [13] integrated GhostC2f modules within YOLOv8 to detect distracted driving with high speed and accuracy.
To reduce computational cost without sacrificing performance, Ghost convolution and its variants have become popular. Tang et al. [15] introduced GhostNetv2 to minimize redundant feature maps while incorporating long-range attention. Lv et al. [14] built on this by combining GhostNetV2 with SE attention in GS-YOLO, achieving superior performance in SAR ship detection. Yadav et al. [11] embedded GhostConv and GhostBottleneck layers in YOLOv5s to reduce latency while maintaining high precision. Ullah et al. [17] applied GhostConv and attention into YOLOv8 for dense ITS vehicle detection, while Elhenidy et al. [24] introduced ghost separable convolution in GY-YOLO for pedestrian detection.
The use of Exponential Moving Average (EMA) has shown potential in stabilizing training and improving model generalization. Li et al. [18] proposed EMA-YOLO, enhancing object detection consistency across dynamic scenes. Han et al. [19] also incorporated EMA with channel attention in Light-YOLOv7 to detect maritime targets efficiently. These contributions demonstrate that EMA is a powerful yet underutilized technique in lightweight detection.
Several studies have also fused attention modules to strengthen detection in low-contrast and occluded scenarios. Zhang et al. [20] developed a multi-coordinate aggregation attention block for road defect detection using shared convolution, and Wei et al. [25] introduced a multi-scale attention-enhanced YOLO model for remote sensing. Zhou et al. [26] combined layer-adaptive pruning and multidimensional feature fusion in Mp-YOLO for dense traffic object detection.
In addition, a range of YOLO-based models has been customized for ITS-specific applications. Thatikonda [27] built a lightweight helmet and license plate detector using YOLOv8. Bao and Gao [12] proposed YED-YOLO for autonomous driving, demonstrating a lightweight yet accurate solution. Yu et al. [28] optimized YOLOv8 for general vehicle detection across environments, and Pan et al. [29] introduced LVD-YOLO for low-resource ITS deployments.
Despite these valuable efforts, most existing models address only partial aspects of the challenges, such as computational overhead, unstable training, or limited generalization, without integrating all three effectively. As summarized in Table 1, prior approaches typically optimize for one or two factors, but few offer a unified solution. Our proposed EMA-GhostConv YOLOv8 model is designed to overcome these gaps by unifying Ghost convolution, EMA training stabilization, and lightweight attention into a single, coherent architecture. The result is a highly accurate, computationally efficient, and robust detector tailored for real-time ITS vehicle detection in complex environments.
This section outlines the proposed vehicle detection framework built upon the YOLOv8 object detection model. We first present an overview of the original YOLOv8 architecture, followed by the integration of our key enhancements: Exponential Moving Average (EMA) for stabilized learning, Ghost convolution for lightweight feature extraction, and a C3Ghost module to support multi-scale representation. The modified framework is trained and evaluated on two datasets, KITTI and a custom real-world traffic dataset, designed to test its performance under diverse road conditions. We also describe the metrics used to evaluate the detection performance.
The baseline YOLOv8 framework follows a single-stage, anchor-free object detection paradigm and consists of three core components: a CSP-based backbone that extracts hierarchical features across multiple spatial resolutions; a neck employing a Path Aggregation Network with Feature Pyramid Network (PAN-FPN) to fuse low-level and high-level features for multi-scale representation; and a decoupled detection head that separately handles classification and regression to directly output object categories and bounding box coordinates. While YOLOv8 achieves a strong trade-off between accuracy and speed, its neck architecture suffers from limited gradient stability and inadequate cross-scale feature interaction, particularly when detecting small or partially occluded vehicles (see Fig. 2). To overcome these limitations, this work introduces targeted architectural enhancements that improve feature stability and multi-scale representation while preserving real-time inference capability.
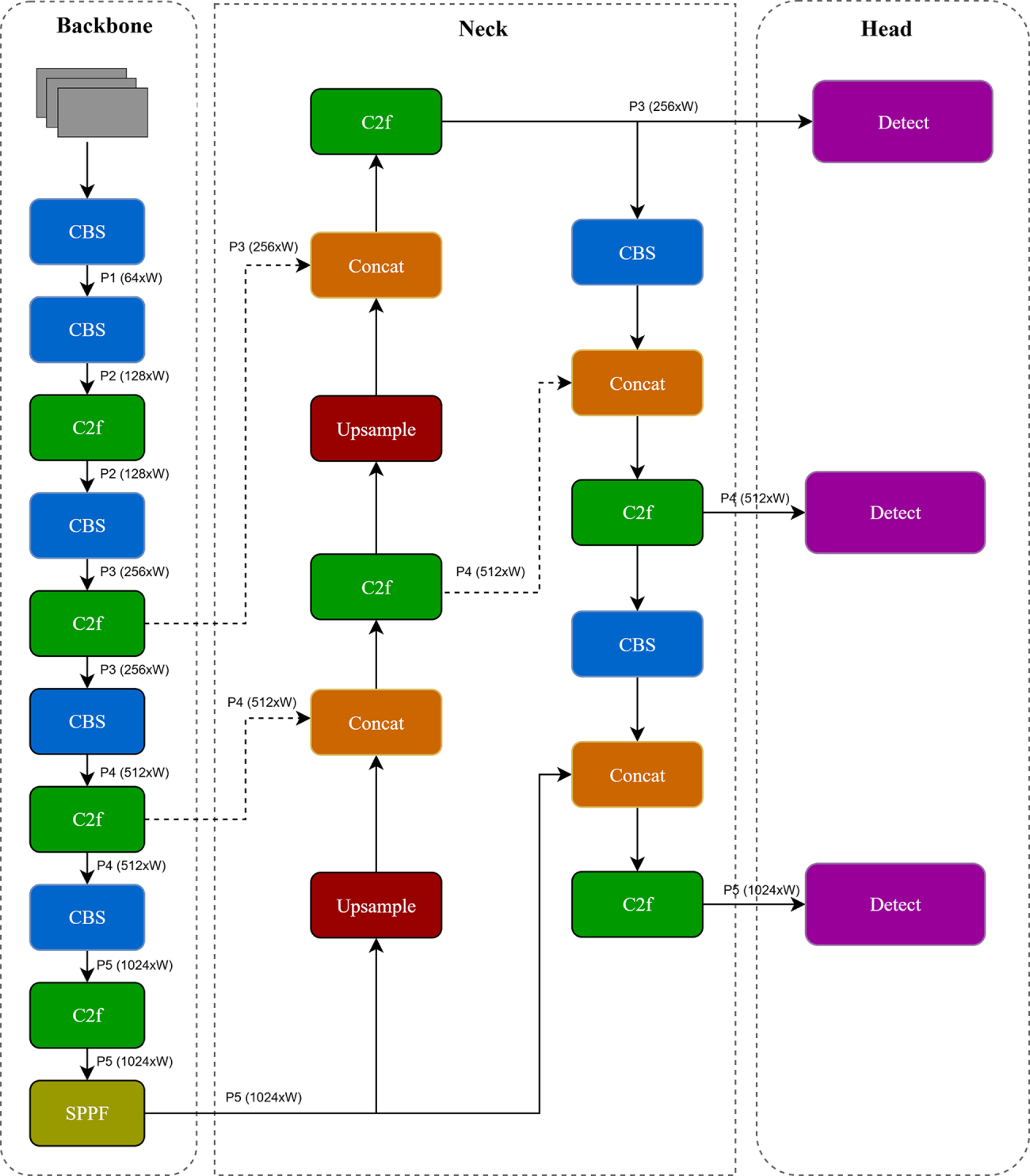
Figure 2: Overall architecture of the YOLOv8.
To address the limitations identified in recent YOLOv8-based vehicle detection frameworks, we propose a set of architectural modifications aimed at enhancing both detection stability and computational efficiency for intelligent transportation systems. While YOLOv8 provides a strong baseline due to its anchor-free detection and decoupled head architecture, it often struggles in scenarios involving multi-scale objects, illumination variations, and partial occlusion conditions commonly encountered in real-world traffic environments. Furthermore, the demand for deployment on edge or embedded platforms necessitates the development of lightweight yet robust detection mechanisms.
Our proposed architecture enhances YOLOv8 by integrating three core modules: (i) an Exponential Moving Average (EMA) layer for stabilized weight updates and improved generalization; (ii) Ghost convolution (GhostConv) to reduce computational redundancy while preserving representational power; and (iii) a modified C3Ghost module for enriched multi-scale feature extraction with minimal inference overhead. Together, these components create a hybrid model that improves detection accuracy under challenging conditions without compromising real-time performance. The following subsections detail each of these modifications.
3.2.1 Exponential Moving Average (EMA)
To enhance the stability of feature learning and suppress overfitting during training, an Exponential Moving Average (EMA) mechanism is integrated into the neck component of the proposed architecture. EMA enables temporal smoothing of feature map updates, thereby mitigating the influence of noisy gradients, illumination fluctuations, and abrupt structural changes, conditions often present in real-world traffic scenes.
At each training iteration
here,
By continuously updating features in a smoothed manner, the EMA module enhances the model’s robustness against motion blur, partial occlusions, and sensor noise, ultimately contributing to improved detection accuracy under dynamic road conditions.
Ghost convolution (GhostConv) is a lightweight convolutional module designed to reduce redundancy in feature extraction by generating more feature maps using inexpensive linear operations. Instead of relying solely on standard convolution, GhostConv decomposes the feature generation process into two stages: a small set of intrinsic features are produced via conventional convolution, while the remaining features, termed ghost features, are obtained through computationally efficient linear transformations.
Mathematically, the GhostConv operation can be expressed as:
where
By replacing standard convolutions in the neck of YOLOv8 with GhostConv blocks, the model achieves lower FLOPs and parameter count while maintaining sufficient representational power for object detection tasks.
The C3Ghost module is an architectural variant of the original C3 block in YOLOv5/YOLOv8, modified to incorporate GhostConv layers as its internal convolutional units. It consists of a residual bottleneck structure, where GhostConv is employed in both the main and skip branches to ensure computational efficiency across the entire module.
C3Ghost retains the multi-branch feature aggregation capability of the standard C3 module, enabling it to effectively combine deep and shallow features. This promotes richer contextual learning and improved multi-scale feature fusion, which are critical in detecting small and partially occluded vehicles in complex traffic environments.
While it does not introduce new mathematical operations beyond GhostConv, C3Ghost amplifies the benefits of ghost-based computation within a residual learning framework. When embedded within the YOLOv8 neck, the C3Ghost module contributes to both improved feature abstraction and faster inference, aligning with real-time constraints of intelligent transportation systems.
3.3 Proposed Architecture and Algorithmic Workflow
The proposed detection framework builds upon the original YOLOv8 design. Its neck architecture integrates the Exponential Moving Average (EMA) for enhanced feature stability and a unified GhostConv-C3Ghost block, where GhostConv and C3Ghost are integrated as one model, to achieve reduced computational cost and improved multi-scale detection performance.
As illustrated in Fig. 3, the architecture is composed of three primary stages: Backbone, Neck, and Head.
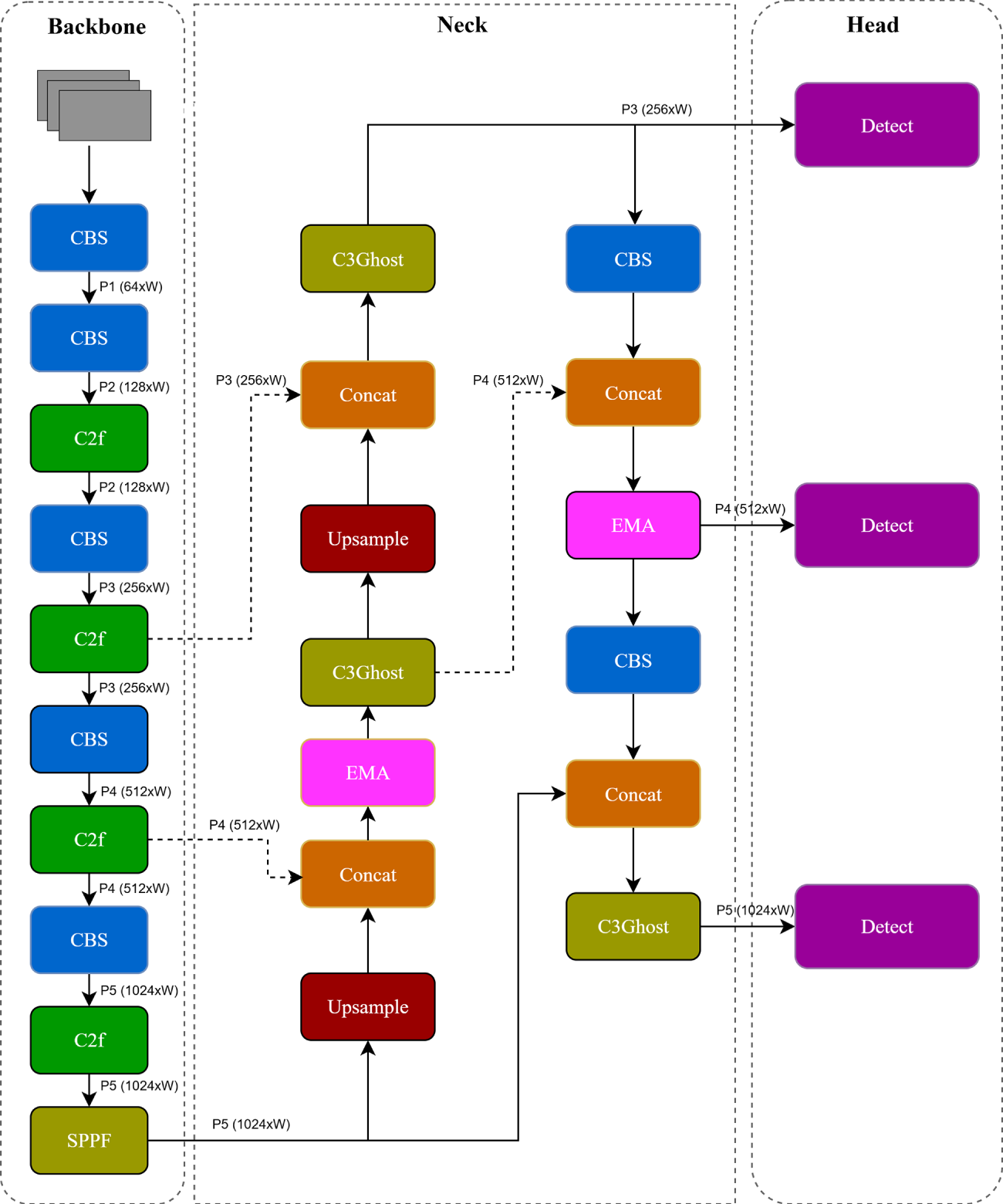
Figure 3: Overall architecture of the proposed EMA-GhostConv YOLOv8 framework. The backbone and detection head are retained from YOLOv8, while the neck is enhanced using EMA and GhostConv modules.
1) Backbone: The backbone retains the core YOLOv8 feature extractor, comprising convolutional blocks (CBS), Cross Stage Partial blocks (C2f), and a spatial pyramid pooling fast (SPPF) module. Feature maps are extracted at five pyramid levels, denoted as P1 through P5, with progressively decreasing spatial resolutions and increasing channel depths. These layers encode both spatial and semantic information crucial for object localization.
2) Neck: In the neck, we introduce two upsampling paths to refine multi-scale features from P5 and P4:
- In the bottom-up path, feature maps from deeper layers (e.g., P5) are upsampled and concatenated with corresponding shallow features (e.g., P4), then passed through C3Ghost modules. - EMA modules are inserted after each major fusion step to stabilize the evolving feature representations during training, thus improving robustness under noisy or dynamic conditions. - GhostConv layers replace standard convolutions in the fusion blocks to reduce parameter count and floating point operations (FLOPs), ensuring that the model remains computationally efficient.
3) Detection Head: The fused and smoothed feature maps at different scales (P3, P4, P5) are forwarded to independent decoupled detection heads, which perform object classification and bounding box regression. This design supports the detection of vehicles at multiple scales, including small and partially occluded objects.
Overall, the architectural modifications enable enhanced feature abstraction while maintaining low latency, making the model suitable for real-time deployment in intelligent transportation systems. The use of both KITTI and a custom dataset ensures generalization across benchmark and real-world environments.
Algorithm 1 outlines the main steps of the proposed EMA-GhostConv YOLOv8 training pipeline.

To evaluate the performance and generalization of the proposed EMA-GhostConv YOLOv8 framework, we used two complementary datasets: the public KITTI benchmark and a custom real-world vehicle dataset. The KITTI dataset provides high-quality, annotated traffic scenes under diverse but standardized conditions and was used for binary vehicle detection, where the unified “vehicle” class encompasses cars, buses, trucks, and vans. Images were resized and split 80:20 into training and validation sets.
The custom dataset was collected from urban and semi-urban environments across day, dusk, and night conditions, featuring challenges like occlusions, motion blur, and non-standard vehicle appearances. All images were manually annotated in YOLO format and augmented to enhance generalization. Together, these datasets enable rigorous evaluation under both benchmarked and realistic, unconstrained traffic scenarios.
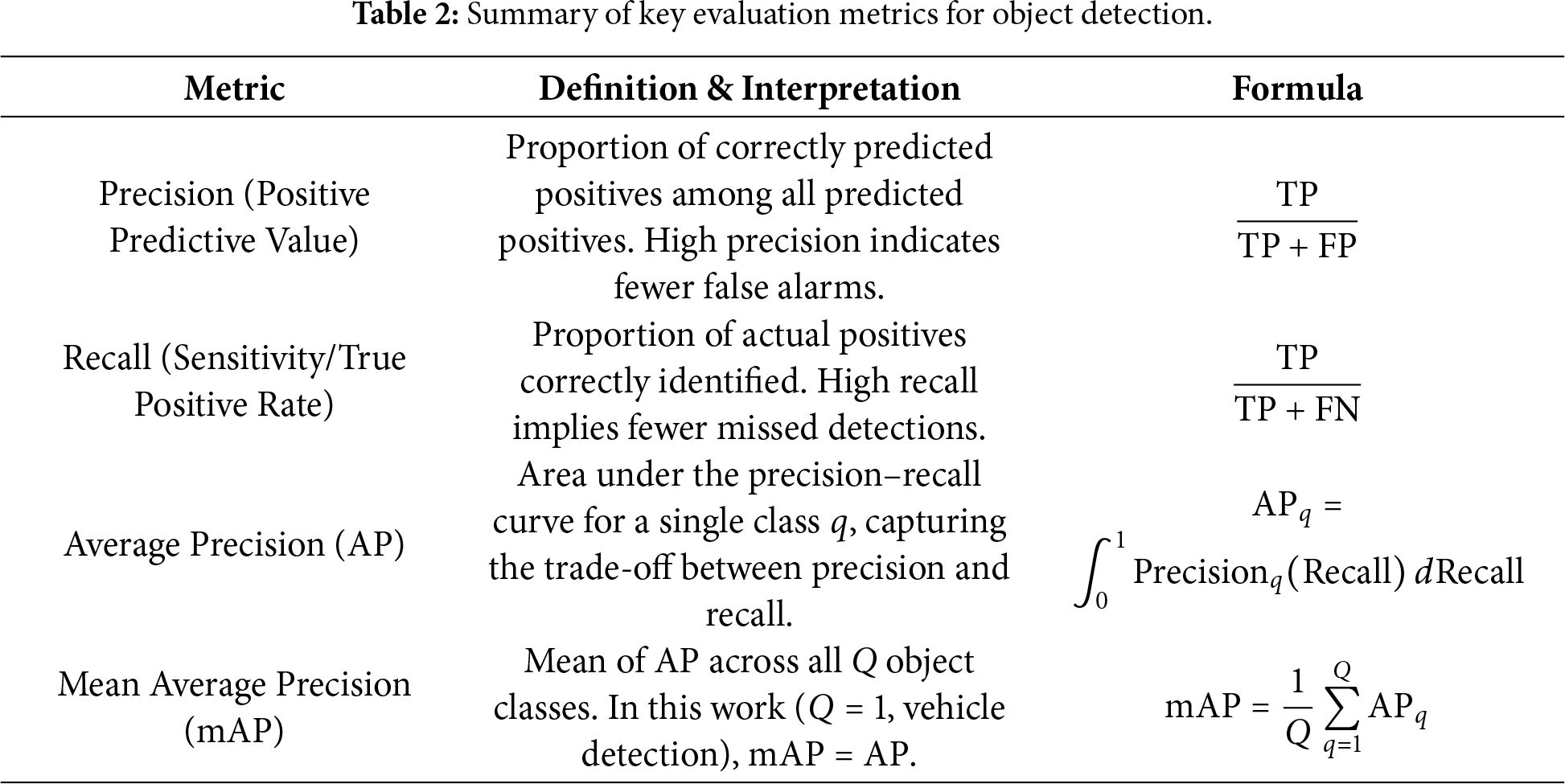
The performance of the proposed EMA-GhostConv YOLOv8 model is quantitatively assessed using four standard evaluation metrics widely adopted in object detection: Precision, Recall, and mean Average Precision (mAP) [30]. These metrics jointly reflect both the classification accuracy and the spatial localization capability of the model. Definitions and interpretations of these metrics are summarized in Table 2.
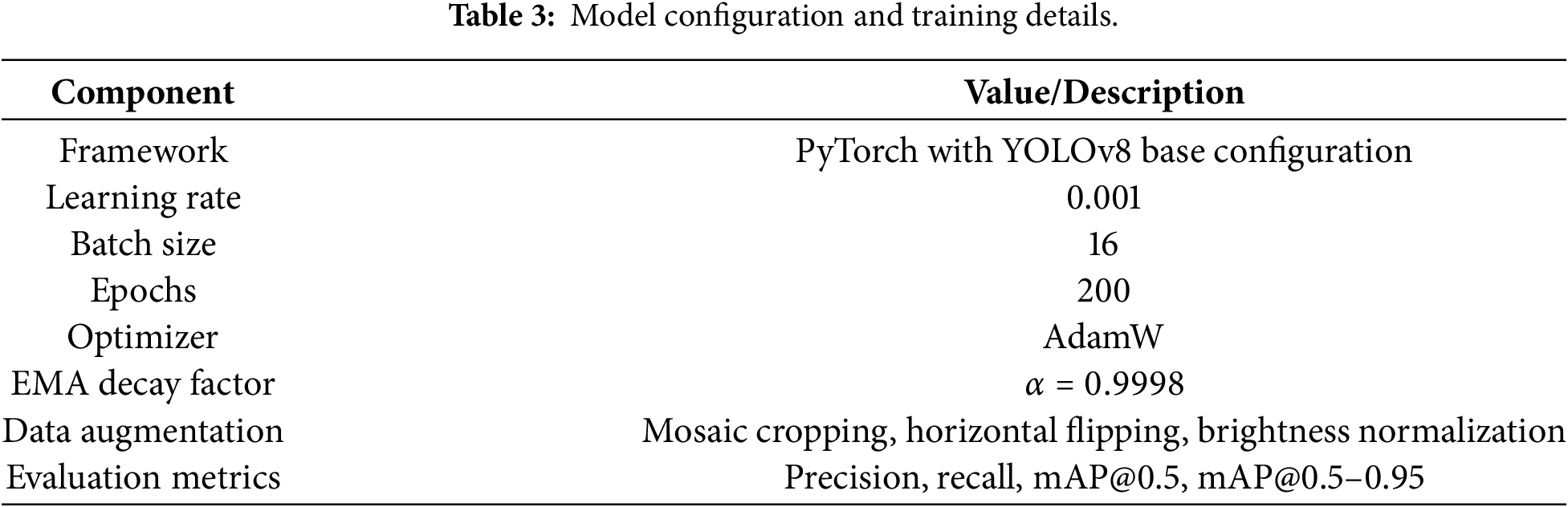
All experiments were conducted using the PyTorch implementation of YOLOv8 on a workstation equipped with an NVIDIA RTX 3060 GPU (12 GB VRAM), Intel Core i7 processor, and 32 GB RAM. The custom vehicle dataset contained a total of 177 images (168 for training and 9 for testing), annotated using the YOLO format. The model was trained for 200 epochs with an initial learning rate of 0.001 and batch size of 16. Data augmentation techniques such as random flipping, scaling, and brightness normalization were employed to improve generalization across diverse conditions. Complete training configuration and evaluation metrics are summarized in Table 3.
To comprehensively evaluate the effectiveness of the proposed EMA-GhostConv YOLOv8, we present both qualitative and quantitative analyses on a custom vehicle detection dataset. The qualitative results illustrate the model’s behavior in real-world scenarios, particularly under challenging conditions such as occlusion, low lighting, and scale variation, while the quantitative results provide objective performance metrics that validate the improvements in accuracy, precision, recall, and robustness over the baseline YOLOv8 architecture.
To visually assess the detection performance under real-world conditions, we present comparative visualizations in Fig. 4, which displays side-by-side comparisons of original input frames (left) and their corresponding detection outputs from the proposed EMA-GhostConv YOLOv8 model (right). The figure highlights the model’s ability to accurately localize vehicles across diverse scenarios, including heavy traffic, partial occlusions, varying illumination, and multi-scale objects, while maintaining clean bounding box boundaries and minimizing false positives. Unlike the baseline YOLOv8, which often misses occluded or small vehicles or generates redundant detections, the enhanced architecture demonstrates consistent robustness and higher confidence in complex urban environments. These qualitative improvements align with and support the quantitative gains reported in the following section.

Figure 4: Qualitative detection performance of the proposed EMA-GhostConv YOLOv8. Left side: Original input images capturing real-world traffic scenes. Right side: Corresponding detection outputs generated by the model, with red bounding boxes indicating detected vehicles.
Fig. 5 illustrates the training dynamics of both the baseline and proposed models over 200 epochs, while Fig. 6 presents the corresponding training and testing loss curves. On both the KITTI and Custom datasets, the proposed EMA-GhostConv YOLOv8 exhibits faster convergence and consistently lower loss values from early epochs onward, indicating more stable and efficient optimization. Concurrently, its precision, recall, mAP@50, and mAP@50–95 metrics remain persistently higher than those of the baseline across all epochs. The smoother loss trajectories and elevated plateau levels in the metric curves suggest that the EMA layer effectively stabilizes gradient updates by smoothing feature representations, while GhostConv enhances feature expressiveness without introducing redundancy.
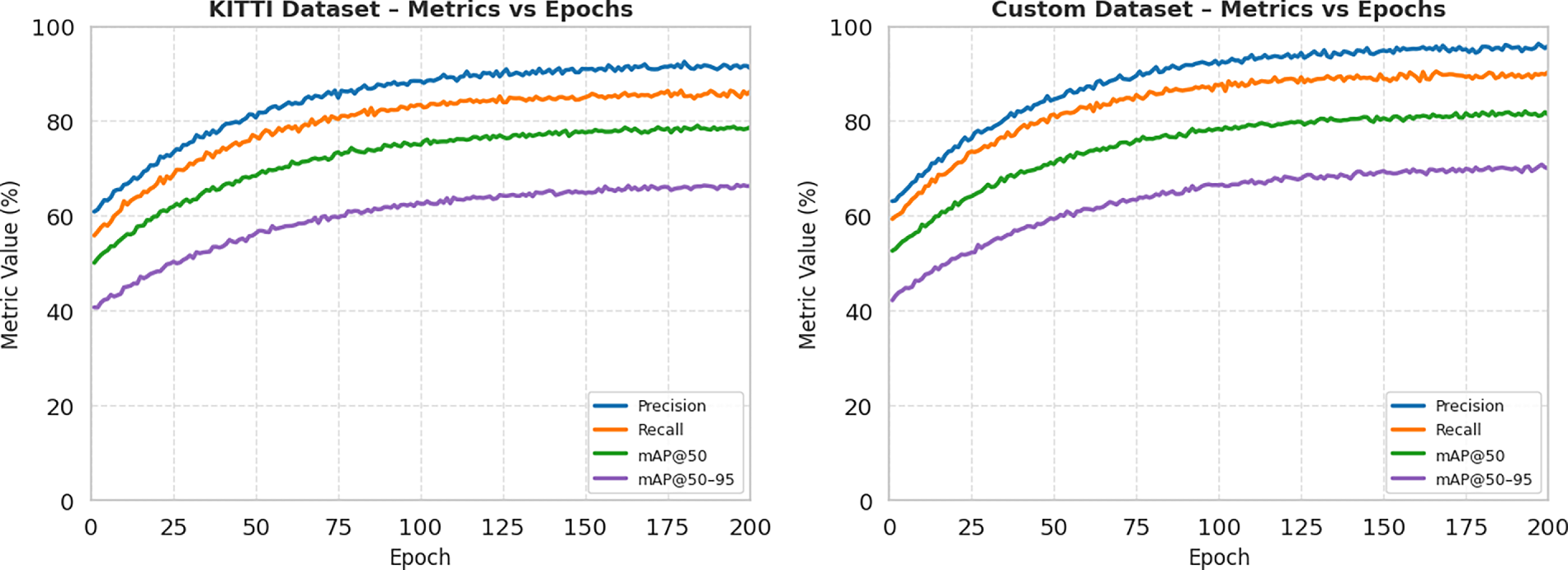
Figure 5: Training convergence curves for precision, recall, mAP@50, and mAP@50–95 over 200 epochs on the KITTI and Custom datasets, comparing baseline YOLOv8n (left) and proposed EMA-GhostConv YOLOv8 (right).
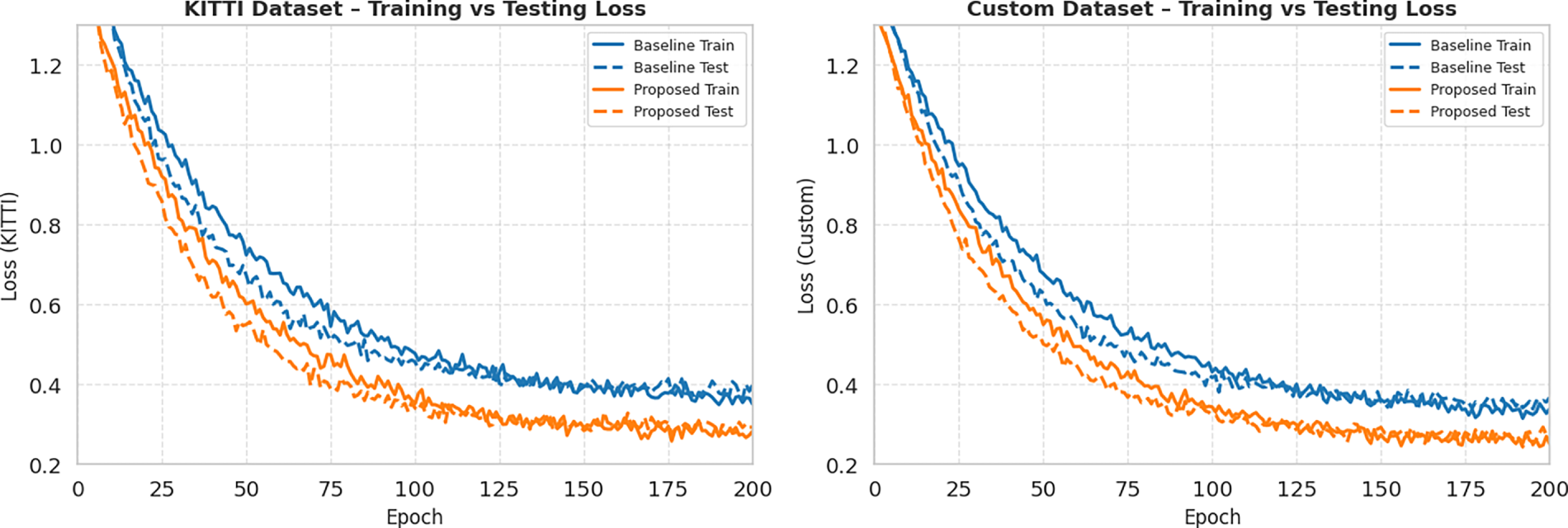
Figure 6: Training and testing loss curves of baseline YOLOv8n and proposed EMA-GhostConv YOLOv8 on KITTI and Custom datasets over 200 epochs, showing faster convergence and lower loss for the proposed model.
As shown in Table 4, the proposed EMA-GhostConv YOLOv8 consistently outperforms the YOLOv8n baseline on both the KITTI and Custom datasets, achieving substantial improvements in precision (+9.63% on KITTI, +15.35% on Custom), recall (+9.79%, +12.69%), and mAP@50 (+7.57%, +6.60%). Remarkably, these gains are attained with only a marginal reduction in inference speed, demonstrating that the proposed enhancements significantly boost detection accuracy without compromising real-time performance. This favorable accuracy—efficiency balance underscores the model’s suitability for deployment in latency-sensitive intelligent transportation systems (ITS).
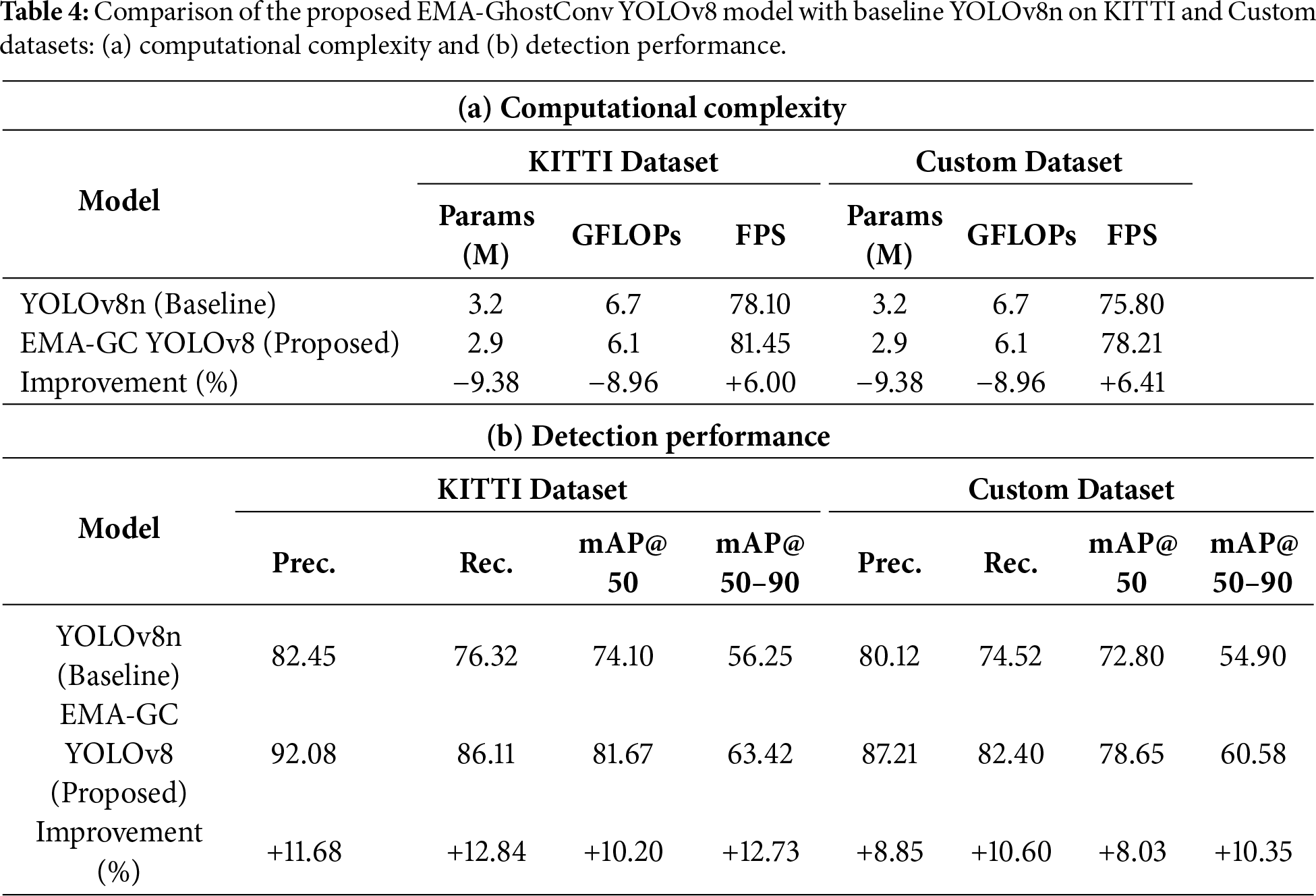
Fig. 7 presents a comparative confusion matrix analysis of the baseline YOLOv8n and the proposed EMA-GhostConv YOLOv8 across both KITTI and Custom datasets. The diagonal elements (true positives) are significantly higher for the proposed model, indicating superior classification accuracy for the “Vehicle” class. Notably, the number of false positives (background predicted as vehicle) is drastically reduced, for example, from 167 to 75 on KITTI and from 242 to 124 on the Custom dataset, demonstrating that the EMA and GhostConv modules enhance discrimination capability and reduce over-prediction. This improvement directly contributes to the observed gains in precision and mAP reported in Table 4.
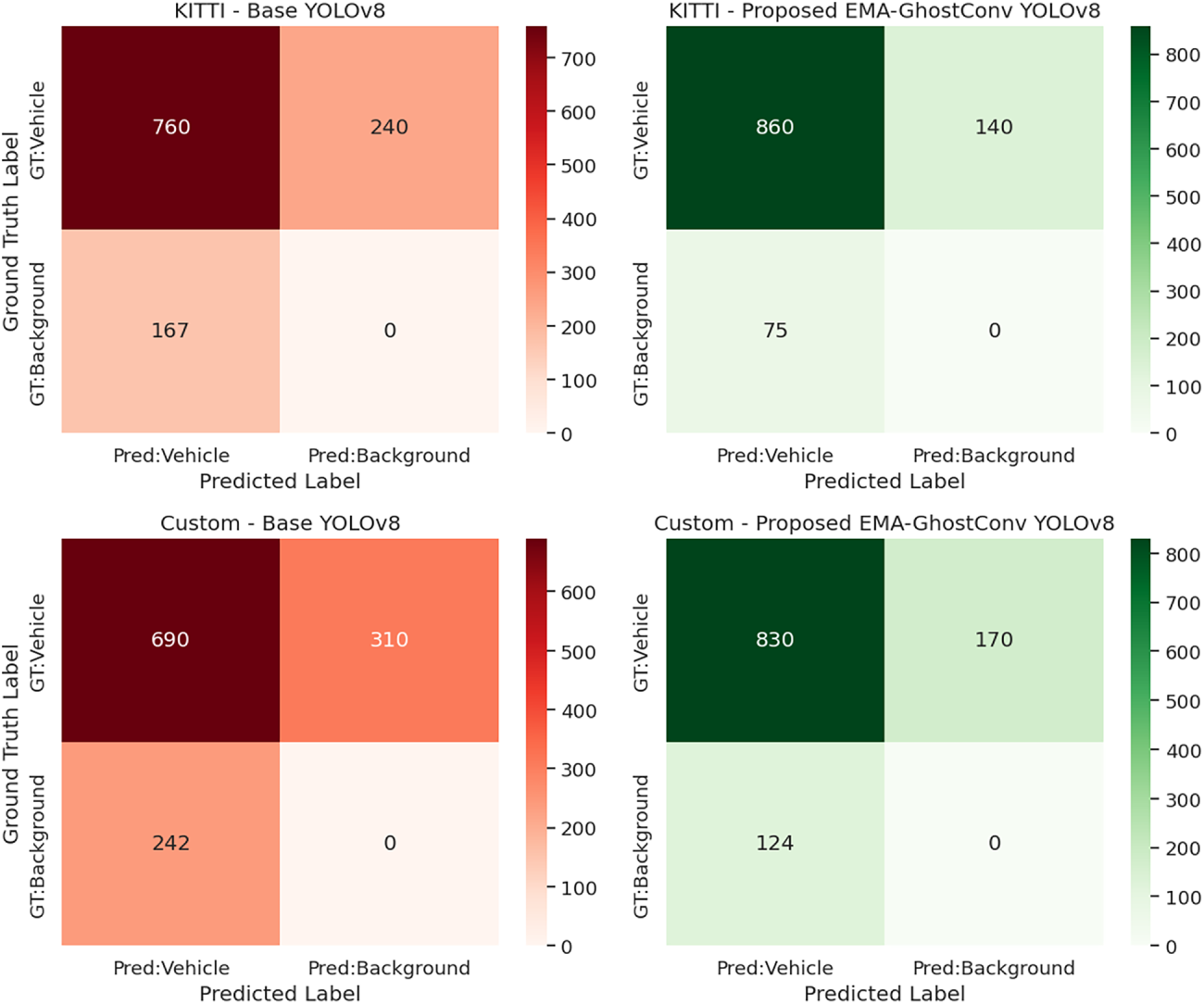
Figure 7: Confusion matrix comparison between the baseline YOLOv8n model and the proposed EMA-GhostConv YOLOv8 model.
To further analyze the impact of each modification, an ablation study was performed by progressively introducing EMA and GhostConv components into the YOLOv8 framework. The ablation study in Table 5 quantifies the contribution of each proposed component. Integrating the EMA feature layer alone improves mAP@50 by +3.73% on KITTI and +4.10% on the Custom dataset over the baseline, demonstrating its effectiveness in stabilizing feature learning and reducing noise, particularly beneficial in the Custom dataset with challenging conditions like occlusion and illumination variance. Replacing standard convolutions with GhostConv modules yields even larger gains (+5.35% mAP@50 on KITTI, +4.45% on Custom), confirming that enhanced feature diversity with reduced redundancy significantly boosts detection capability. Most importantly, the full EMA-GhostConv YOLOv8 configuration achieves the highest performance across all metrics on both datasets, with mAP@50 improvements of +7.57% (KITTI) and +6.60% (Custom) over the baseline. This consistent and additive improvement confirms that EMA and GhostConv operate synergistically: EMA enhances temporal and spatial feature consistency, while GhostConv enriches representational capacity with minimal computational cost, together delivering both robustness and efficiency.
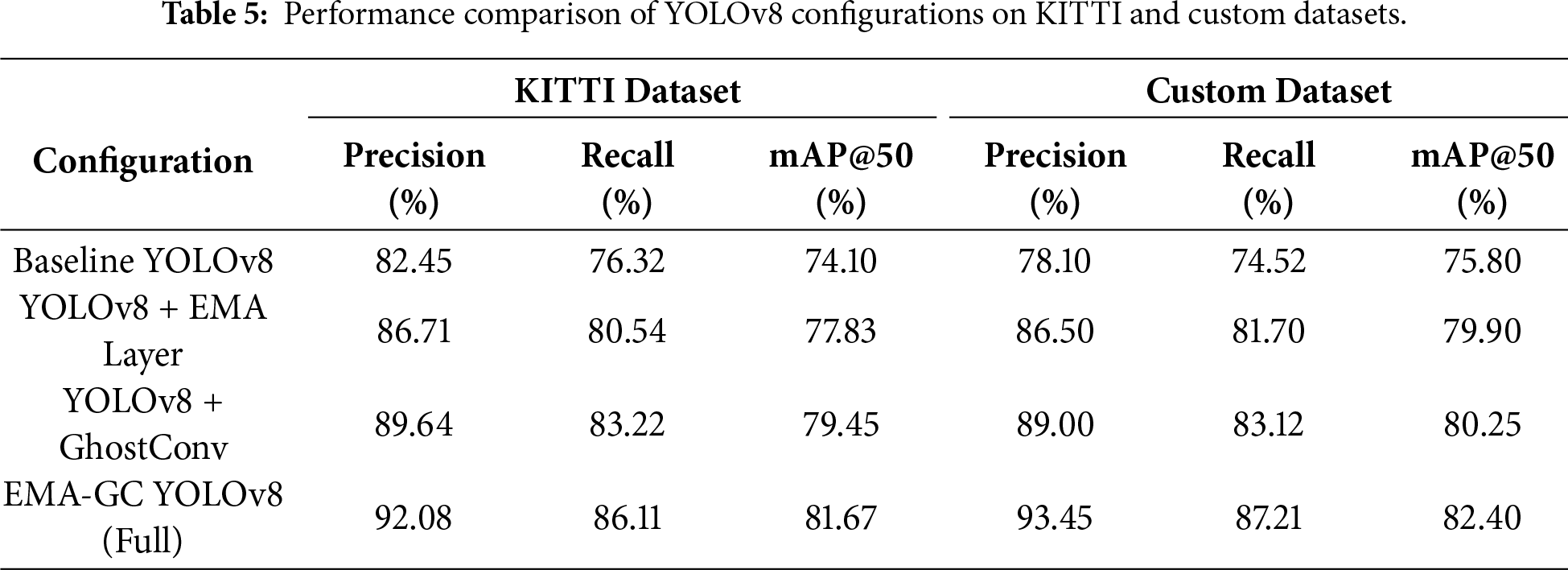
To rigorously assess the competitiveness of the proposed framework, we compare the EMA-GhostConv YOLOv8 model against several widely adopted object detectors, including SSD, Faster R-CNN, RetinaNet, DETR, EfficientDet-D2, YOLOv5, YOLOv7, and different YOLOv8 variants, under consistent experimental conditions. As summarized in Table 6, the proposed model achieves the highest scores across all major evaluation metrics on both the KITTI and Custom datasets. Specifically, EMA-GC YOLOv8 attains 81.67% mAP@50 on KITTI and 82.40% on the Custom dataset, surpassing the next-best YOLOv8l and YOLOv7 models by margins of +2.22 and +2.15 mAP@50 points, respectively. Furthermore, the proposed approach exhibits strong generalization with consistent improvements in precision and recall, achieving 92.08% precision and 86.11% recall on KITTI, and 93.45% precision and 87.21% recall on the Custom dataset. These results highlight that the integration of the EMA feature enhancement and GhostConv modules substantially improves detection robustness, particularly under challenging scenarios such as partial occlusion, scale variation, and illumination changes, while preserving the real-time efficiency essential for intelligent transportation and autonomous driving applications. The consistent gains across both standard and custom datasets underscore the generalizability and practical viability of the proposed model.
This study presents the EMA-GhostConv YOLOv8, a refined vehicle detection framework that enhances feature stability and fusion efficiency by integrating an Exponential Moving Average (EMA) layer and GhostConv-based modules within the neck structure. Extensive experiments on both the KITTI benchmark and a challenging custom vehicle dataset demonstrate the proposed model’s consistent superiority over the YOLOv8n baseline and several state-of-the-art detectors, including YOLOv5, YOLOv7, Faster R-CNN, SSD, RetinaNet, DETR, and EfficientDet-D2. The EMA-GC YOLOv8 achieves the highest precision, recall, and mean Average Precision (mAP) values, as summarized in Table 6.
Ablation studies (Table 5) further validate the individual and synergistic benefits of the EMA and GhostConv components, confirming that these targeted architectural enhancements substantially improve detection robustness under challenging conditions such as partial occlusion, varying illumination, and dense traffic scenes. The proposed model achieves an optimal trade-off between accuracy and computational efficiency, making it highly suitable for deployment in edge-based intelligent transportation systems and real-time surveillance applications.
Future work will explore incorporating temporal feature modeling for video-based object detection, cross-domain adaptation techniques to enhance generalization across diverse environments, and lightweight quantization strategies to further optimize the model for embedded and resource-constrained platforms.
Acknowledgement: The authors would like to thank the open-source research community for providing valuable resources that supported the development and evaluation of this work.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: A. S. M. Masudur Rahman led the conceptualization, methodology design, software implementation, formal analysis and original manuscript preparation. Muhammad Zunair Zamir contributed to methodology refinement, conducted the literature review, performed validation and participated in writing and editing. Syed Sajid Ullah supported methodology design, contributed to formal analysis and assisted in original manuscript preparation. Salman Khan provided support in validation and contributed to proofreading. Maria Saman assisted in data curation and contributed to preliminary result verification. Naqash Bahadar supported project administration and participated in reviewing and refining the manuscript. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The KITTI dataset used in this study is publicly available at http://www.cvlibs.net/datasets/kitti/.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2016. p. 779–88. [Google Scholar]
2. Redmon J, Farhadi A. YOLO9000: better, faster, stronger. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ, USA: IEEE; 2017. p. 7263–71. [Google Scholar]
3. Redmon J, Farhadi A. YOLOv3: an incremental improvement. arXiv:1804.02767. 2018. [Google Scholar]
4. Bochkovskiy A, Wang CY, Liao HYM. YOLOv4: optimal speed and accuracy of object detection. arXiv:2004.10934. 2020. [Google Scholar]
5. Jocher G. YOLOv5 by ultralytics 2020 [Internet]. [cited 2025 Dec 23]. Available from: https://github.com/ultralytics/yolov5. [Google Scholar]
6. Department MVI. YOLOv6: a single-stage object detection framework for industrial applications. arXiv:2209.02976. 2022. [Google Scholar]
7. Wang CY, Bochkovskiy A, Liao HYM. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv:2207.02696. 2023. [Google Scholar]
8. Ultralytics. YOLOv8: cutting-edge real-time object detection in native Python. arXiv:2402.13616. 2024. [Google Scholar]
9. Wang CY, Yeh IH, Liao HYM. YOLOv9: learning what you want to learn using programmable gradient information. In: Computer Vision—ECCV 2024 (ECCV 2024). Cham, Switzerland: Springer; 2024. p. 1–21. [Google Scholar]
10. Wang A, Chen H, Liu L, Chen K, Lin Z, Han J. YOLOv10: real-time end-to-end object detection. arXiv:2405.14458. 2024. [Google Scholar]
11. Yadav RK, Nigam N, Singh DP, Choudhary J. Improving vehicle detection using ghost convolution and ghostbottleneck layers in YOLOv5s. In: 2023 International Conference on Computational Intelligence and Sustainable Engineering Solutions (CISES). Piscataway, NJ, USA: IEEE; 2023. p. 322–6. [Google Scholar]
12. Bao D, Gao R. YED-YOLO: an object detection algorithm for automatic driving. Signal Image Video Process. 2024;18(10):7211–9. doi:10.1007/s11760-024-03387-8. [Google Scholar] [CrossRef]
13. Du Y, Liu X, Yi Y, Wei K. Optimizing road safety: lightweight YOLOv8 models and GhostC2f for real-time distracted driving detection. Sensors. 2023;23(21):8844. doi:10.3390/s23218844. [Google Scholar] [PubMed] [CrossRef]
14. Lv D, Zhao C, Ye H, Fan Y, Shu X. GS-YOLO: a lightweight SAR ship detection model based on enhanced GhostNetV2 and SE attention mechanism. IEEE Access. 2024;12:108414–24. doi:10.1109/access.2024.3438797. [Google Scholar] [CrossRef]
15. Tang Y, Han K, Guo J, Xu C, Wang Y. GhostNetv2: Enhance cheap operation with long-range attention. Adv Neural Inf Process Syst. 2022;35:9969–82. [Google Scholar]
16. Liu R, Luo Y, Li H. Enhancing real-time vehicle detection with a lightweight model. J Intell Fuzzy Syst. 2024;49(6):1452–72. doi:10.1177/18758967251348957. [Google Scholar] [CrossRef]
17. Ullah SS, Zamir MZ, Ishfaq A, Khan S. Attention-augmented YOLOv8 with ghost convolution for real-time vehicle detection in intelligent transportation systems. J Artif Intell. 2025;7:255–74. doi:10.32604/jai.2025.069008. [Google Scholar] [CrossRef]
18. Li X, Wen X, Hao Y. A commodity object detection method based on EMA-YOLO. In: 2025 10th International Conference on Intelligent Computing and Signal Processing (ICSP). Piscataway, NJ, USA: IEEE; 2025. p. 457–60. [Google Scholar]
19. Han Q, Han X, Niu L, Fan Y. Lightweight ship object detection based on CA and EMA. In: 2024 9th International Conference on Automation, Control and Robotics Engineering (CACRE). Piscataway, NJ, USA: IEEE; 2024. p. 231–6. [Google Scholar]
20. Zhang Y, Wang T, Wang X. Lightweight real-time road defect detection with multi-coordinate attention. J Real Time Image Process. 2025;22(5):168. [Google Scholar]
21. Bakirci M. Advanced aerial monitoring and vehicle classification for intelligent transportation systems with YOLOv8 variants. J Netw Comput Appl. 2025;237:104134. doi:10.1016/j.jnca.2025.104134. [Google Scholar] [CrossRef]
22. Zeng J, Zhong H. YOLOv8-PD: an improved road damage detection algorithm based on YOLOv8n model. Sci Rep. 2024;14(1):12052. doi:10.21203/rs.3.rs-4199735/v1. [Google Scholar] [CrossRef]
23. Zhu J, Wu Y, Ma T. Multi-object detection for daily road maintenance inspection with UAV based on improved YOLOv8. IEEE Trans Intell Transp Syst. 2024;25(11):16548–60. doi:10.1109/tits.2024.3437770. [Google Scholar] [CrossRef]
24. Elhenidy AM, Labib LM, Haikal AY, Saafan MM. GY-YOLO: ghost separable YOLO for pedestrian detection. Neural Comput Appl. 2025;37:14907–33. doi:10.1007/s00521-025-11207-4. [Google Scholar] [CrossRef]
25. Wei X, Li Z, Wang Y. SED-YOLO based multi-scale attention for small object detection in remote sensing. Sci Rep. 2025;15(1):3125. doi:10.1038/s41598-025-87199-x. [Google Scholar] [PubMed] [CrossRef]
26. Zhou W, Wang J, Xi M, Song Y, Liu Z. Mp-YOLO: multidimensional feature fusion based layer adaptive pruning yolo for dense vehicle object detection algorithm. J Vis Commun Image Rep. 2025;112:104560. doi:10.1016/j.jvcir.2025.104560. [Google Scholar] [CrossRef]
27. Thatikonda M. An enhanced real-time object detection of helmets and license plates using a lightweight YOLOv8 deep learning model [master’s thesis]. Dayton, OH, USA: Wright State University; 2024. [Google Scholar]
28. Yu D, Ouyang Y, Wang Y, Yuan Z. The vehicle object detection algorithm based on improved YOLOv8. In: International Conference on Artificial Intelligence and Autonomous Transportation. Cham, Switzerland: Springer; 2024. p. 1–9. [Google Scholar]
29. Pan H, Guan S, Zhao X. LVD-YOLO: an efficient lightweight vehicle detection model for intelligent transportation systems. Image Vis Comput. 2024;151:105276. doi:10.1016/j.imavis.2024.105276. [Google Scholar] [CrossRef]
30. Li C, Zhu Y, Zheng M. A multi-objective dynamic detection model in autonomous driving based on an improved YOLOv8. Alex Eng J. 2025;122:453–64. doi:10.1016/j.aej.2025.03.020. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools