
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Automated Arabic Text Classification Using Hyperparameter Tuned Hybrid Deep Learning Model
1 Department of Language Preparation, Arabic Language Teaching Institute, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
2 Department of Information Systems, College of Computing and Information System, Umm Al-Qura University, Saudi Arabia
3 Department of Computer Science, College of Computing and Information Technology, Shaqra University, Shaqra, Saudi Arabia
4 Prince Saud AlFaisal Institute for Diplomatic Studies, Saudi Arabia
5 Department of Information Technology, College of Computers and Information Technology, Taif University, Taif P.O. Box 11099, Taif, 21944, Saudi Arabia
6 Department of Electrical Engineering, Faculty of Engineering & Technology, Future University in Egypt, New Cairo, 11845, Egypt
7 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Saeed Masoud Alshahrani. Email:
Computers, Materials & Continua 2023, 74(3), 5447-5465. https://doi.org/10.32604/cmc.2023.033564
Received 20 June 2022; Accepted 09 September 2022; Issue published 28 December 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The text classification process has been extensively investigated in various languages, especially English. Text classification models are vital in several Natural Language Processing (NLP) applications. The Arabic language has a lot of significance. For instance, it is the fourth mostly-used language on the internet and the sixth official language of the United Nations. However, there are few studies on the text classification process in Arabic. A few text classification studies have been published earlier in the Arabic language. In general, researchers face two challenges in the Arabic text classification process: low accuracy and high dimensionality of the features. In this study, an Automated Arabic Text Classification using Hyperparameter Tuned Hybrid Deep Learning (AATC-HTHDL) model is proposed. The major goal of the proposed AATC-HTHDL method is to identify different class labels for the Arabic text. The first step in the proposed model is to pre-process the input data to transform it into a useful format. The Term Frequency-Inverse Document Frequency (TF-IDF) model is applied to extract the feature vectors. Next, the Convolutional Neural Network with Recurrent Neural Network (CRNN) model is utilized to classify the Arabic text. In the final stage, the Crow Search Algorithm (CSA) is applied to fine-tune the CRNN model’s hyperparameters, showing the work’s novelty. The proposed AATC-HTHDL model was experimentally validated under different parameters and the outcomes established the supremacy of the proposed AATC-HTHDL model over other approaches.Keywords
Arabic is one of the six prevalently-spoken global languages and its speakers are spread across the nations, especially in the Middle East region. Further, a certain number of Islamic nations to use Arabic as their main language since it is the language of the Qur’an [1,2]. The Arabic language has a total of 28 letters including elmodod and hamzas. Every note contains some notations that denote the position of a letter in a word, i.e., in the beginning, middle or at the end of a word [3,4]. There are no upper-or lower cases in the Arabic language, which is a peculiar characteristic compared to the other languages [5]. The geomorphology of the Arabic language is a complex phenomenon, while the complexity of the language is attributed to the fact that it contains radical letters, suffixes and prefixes.
Further, the letters in the Arabic language do not have consecutive procedures as in other languages. This is because the term assemblies of the letters are dissimilar and hinge on location in a sentence to convey a meaning [6,7]. As mentioned above, the categorization of the texts is extensive in the Arabic language. In contrast, various research works have been conducted earlier to categorize the texts in other languages, such as English language. However, the studies concerning the categorization of the texts in Arabic are limited [8]. Several methods and systems have been developed for classifying English texts which provide brilliant outcomes with high precision, thanks to the nature of the words, language and the letters in the English language [9].
Arabic Natural Language Processing (NLP) is a challenging process due to the challenging morphology and structure of the language. Therefore, the number of studies on Arabic NLP is less than the English NLP [10]. In general, several methods are utilized to improve the applications of NLP, like statistical methods, word embedding, graph representation and Deep Learning (DL) [11]. Text classification is a categorization or labelling procedure focusing on tagging the writing processes and distinguishing its kind or category [12]. Text is classified either as a single-label text or a multi-label text under which many difficult and different categories of labels exist. Several challenges exist in the classification of Arabic text and it cannot be handled using the methods generally used for English NLP. This is because Arabic is an amusing yet difficult language with delicate geomorphology [13]. Various studies indicate that the data is an important complexity in the Arabic text classification process. If a text contains additional structures, it increases the runtime too. So, the preferred solution to overcome this problem is to reduce the number of features. Therefore, feature selection techniques are proposed to select the appropriate features representing the language [14].
1.1 Prior Works on Arabic Text Classification
Boukil et al. [15] introduced a state-of-the-art technique for classifying Arabic texts. In this study, an Arabic stemming approach was introduced for the extraction, selection and reduction of the required characteristics. Next, the Term Frequency-Inverse Document Frequency (TF-IDF) approach was incorporated to provide weightage for the features. In the categorization stage, the DL algorithm was utilized, which is powerful in other fields such as pattern recognition and image processing. Though it is rarely used in text mining approaches, this study used Convolutional Neural Network. Aljedani et al. [16] examined a hierarchical multi-level categorization model with respect to Arabic. In this study, a Hierarchical Multi-level Arabic Text Categorization (HMATC) mechanism was developed based on Machine Learning (ML) method. Also, the study assessed the influence of the feature set dimensions and Feature Selection (FS) methods on the classification accuracy of the method. The Hierarchy of Multi-label categorization (HOMER) approach was improved by examining distinct sets of multi-label categories, clustering algorithms and dissimilar cluster counts to enhance the outcomes of the hierarchical classification.
Elnagar et al. [17] presented a novel unbiased, and rich dataset for single-label (SANAD) and multi-label (NADiA) Arabic text classification process. These datasets were made easily accessible to the researchers in Arabic computation linguistics. Furthermore, the study presented a wide range of DL analytical approaches for the Arabic text classification and estimated the model’s efficacy. The proposed model had a distinctive feature compared to the existing models, i.e., no pre-processing stage was required in the proposed model, and it was completely based on the DL method. In literature [18], a better methodology was proposed for the Arabic text classification process in which the Chi-square FS method was applied to improve the accuracy of the classification process. In addition, the study compared the chi-square values with three other conventional FS metrics as Chi-square, mutual data and information gain. Sainte et al. [19] could not execute the Arabic text classification process comprehensively due to the difficulty of the Arabic language. A new firefly algorithm-related FS technique was developed in this study. This technique was effectively employed in dissimilar combinatorial challenges. But the model did not include the FS model to perform Arabic Text categorization.
The current study has developed an Automated Arabic Text Classification using Hyperparameter-Tuned Hybrid Deep Learning (AATC-HTHDL) model. The major goal of the developed AATC-HTHDL algorithm is to identify different class labels for the Arabic text. It includes distinct levels of operations. At first, the data is pre-processed to transform the input data into a useful format. Secondly, the TF-IDF model is applied to extract the feature vectors. Next, the Convolutional Neural Network with Recurrent Neural Network (CRNN) method is utilized for the classification of the Arabic text. Finally, the Crow Search Algorithm (CSA) is used for fine tuning the hyperparameters involved in the CRNN model. The results from the experimental analysis conducted upon the proposed AATC-HTHDL model were investigated under distinct aspects.
The proposed AATC-HTHDL model effectively identifies different class labels for the Arabic text. It encompasses different stages of operations. At first, data pre-processing is performed to transform the input data into a useful format. Secondly, the TF-IDF model is applied to extract the feature vectors. Next, the CRNN model is utilized for Arabic text classification. Finally, the CSA is used to fine-tune the hyperparameters involved in the CRNN model. Fig. 1 depicts the block diagram of the AATC-HTHDL approach.
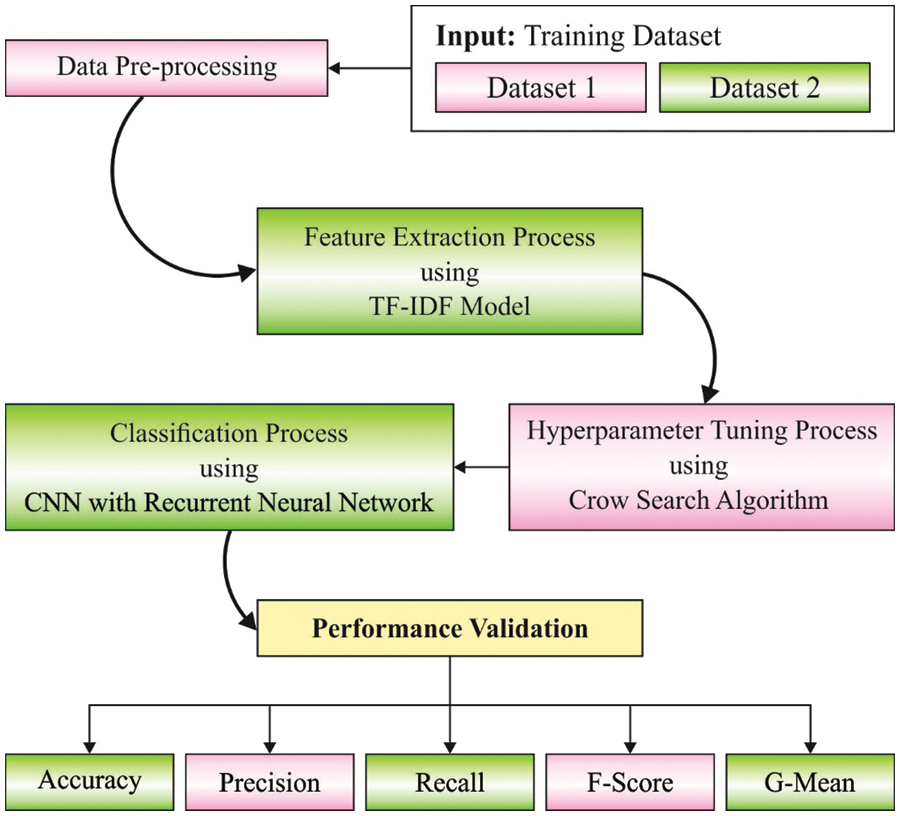
Figure 1: Block diagram of the AATC-HTHDL approach
2.1 Stage I: Data Pre-Processing
Primarily, the data is pre-processed to transform the input data into a useful format. In general, the tokenization procedure considers the dataset and divides it into distinct tokens. The tokens of single-or 2-characters length, numerical values and the non-Arabic characters are avoided from the dataset so that it does not affect the performance of the classifier [20]. Regular expressions help perform the tokenization process, whereas stop words are nothing but general functional words, for instance, prepositions, conjunctions and so on. Mostly, these words appear in a text with less impact on the classification procedure. A list of Arabic stop-words is collected, and such words are removed from the text. The NLP application developers eliminate such stop-words from the search engine indices so that the size of the indices gets extensively reduced. This phenomenon enhances recall and the precision results. Then, stemming, a mapping procedure is performed on the derivative words into a base format, i.e., stem that has been shared. Stemming employs the morphological heuristics to remove the affixes from the words before indexing it. For instance, the Arabic words  ,
,  and
and  share the same root
share the same root 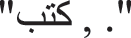 .
.
In this stage, the TF-IDF model is applied to extract the feature vectors. Generally, the TF-IDF model operates by defining a similar frequency of the words in a document, in comparison with inverse ratio of the words over an entire corpus [21]. Indeed, this computation defines the significance of a word, provided in a specific document. A conventional word, in a few documents or a single document, is appropriate to have a high TF-IDF number than the conventional words like prepositions and articles. Assume a group of documents D and a word w, while
In this expression,
Given that
The above equation is satisfied by a small constant like
At last, visualize that
2.3 Stage III: CRNN Based Classification
For effectual classification of the Arabic text, the CRNN model is exploited in this study. The Convolutional Neural Network (CNN) model yields better performance in the development of features from spatial datasets like images. However, the CNN model cannot handle consecutive datasets. On the contrary, the Recurrent Neural Network (RNN)-based model possesses stronger abilities in terms of modelling the consecutive datasets like text [22]. Based on the simulation from features, the authors propose to combine RNN and CNN as a novel mechanism and term it as CRNN. When grouping RNN and CNN, the CNN method is placed in front of the RNN method which results in the creation of the CRNN method.
Here, the additional grouping is performed to place the RNN in front of the CNN and it results in the formation of the RCNN mechanism.
Here, the input dataset x denotes the short and sequential sentences. A novel and a better CNN-RNN mechanism is developed in this study. In the presented method, the CNN approach is placed in front of the RNN approach. A strong pooling layer moves towards the back of the Long Short Term Memory (LSTM)-RNN layer. In other terms, the LSTM layer processes the textual features that are attained by the convolutional layer and extracts the time-based features of the input dataset. Then, with the help of the maximal pooling layer, the text and its temporal characteristics are grouped, highlighted and compressed. The principle of the presented mechanism is that the problem is consecutive yet shorter. Hence, a better CRNN method places the pooling layer with prominent features behind the LSTM layer. It also highlights the textual features as well as the temporal features.
2.4 Stage IV: CSA Based Parameter Tuning
In this final stage, the CSA method is used to fine-tune the hyperparameters of the CRNN method. CSA is a population-based stochastic searching technique [23]. The presented method is a recently-established optimization approach that is used to resolve complex engineering-based optimization problems. It is inspired from the smart performance of the crows. The principles of the CSA model are listed herewith.
In line with the abovementioned assumptions, the central method of the CSA has three fundamental stages such as initialization, generation of a novel location and updating the crow’s memory. In the beginning, an initialized population of the crows, characterized by
a. State 1: The crow
b. State 2: The crow
Based on the states mentioned above, the location of the crows is upgraded as follows.
In Eq. (7), rj represents a uniform distribution fuzzy value within
In Eq. (8),
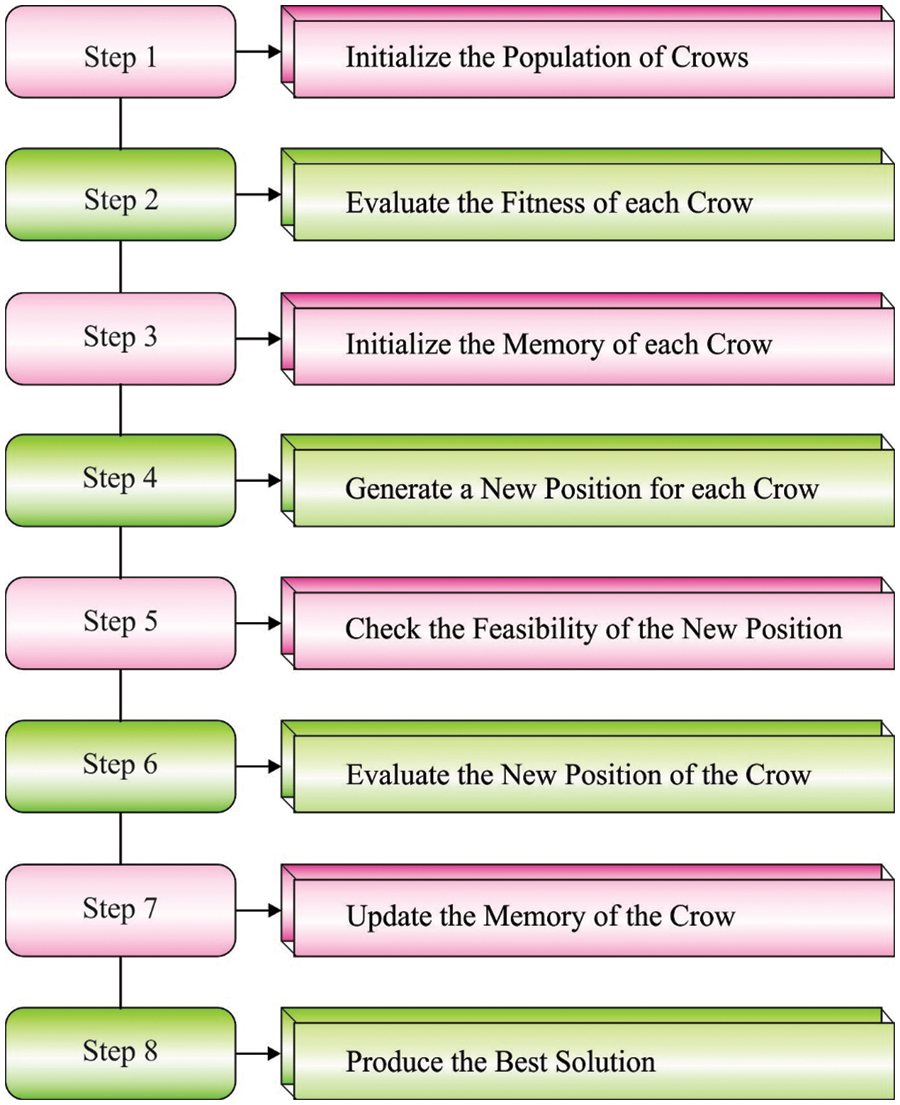
Figure 2: Flowchart of the CSA method
The CSA method derives a Fitness Function (FF) to achieve the enhanced classification outcomes. It uses a positive numeral to indicate the superior outcomes of the candidate solution. In this work, the reduced classification error rate is considered as the fitness function and is provided in Eq. (9). The finest solution contains the least error rate whereas the poor solution possesses the highest error rate.
In this section, a detailed analysis was conducted upon the proposed AATC-HTHDL model using two datasets and the results are discussed herewith. The details related to the dataset-1 are shown in Table 1. The dataset holds 5,690 samples under four class labels.
Fig. 3 depicts the confusion matrices formed by the proposed AATC-HTHDL model on the applied dataset-1. The figure reports that the proposed AATC-HTHDL model proficiently recognized the samples under four distinct class labels.
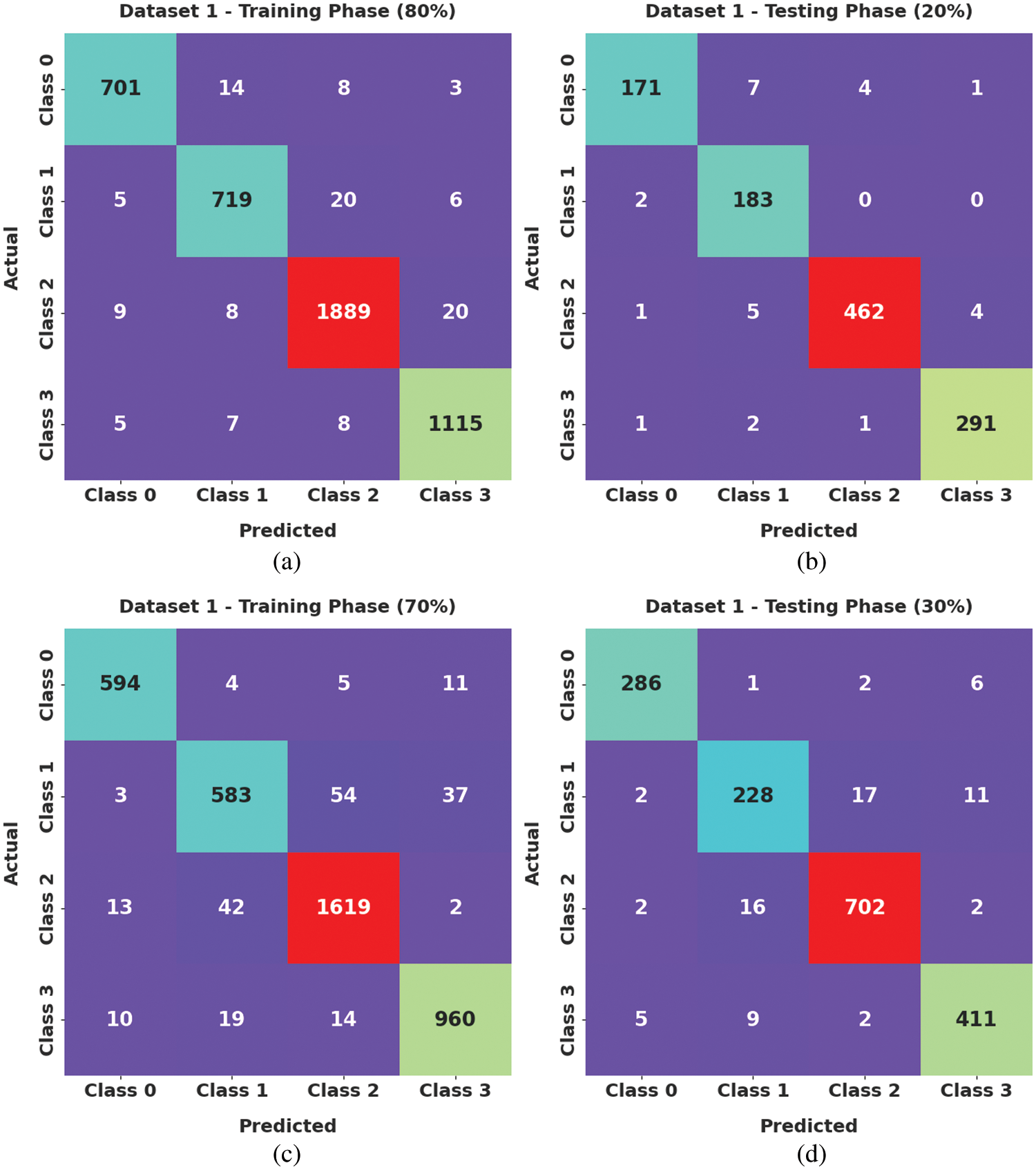
Figure 3: Confusion matrices of the AATC-HTHDL approach under dataset-1 (a) 80% of TR data, (b) 20% of TS data, (c) 70% of TR data, and (d) 30% of TS data
Table 2 shows the detailed classification output achieved by the proposed AATC-HTHDL model on 80% of Training (TR) data and 20% of Testing (TS) datasets. The obtained values denote that the proposed AATC-HTHDL model produced an improved performance. With 80% of TR data, the presented AATC-HTHDL model achieved an average
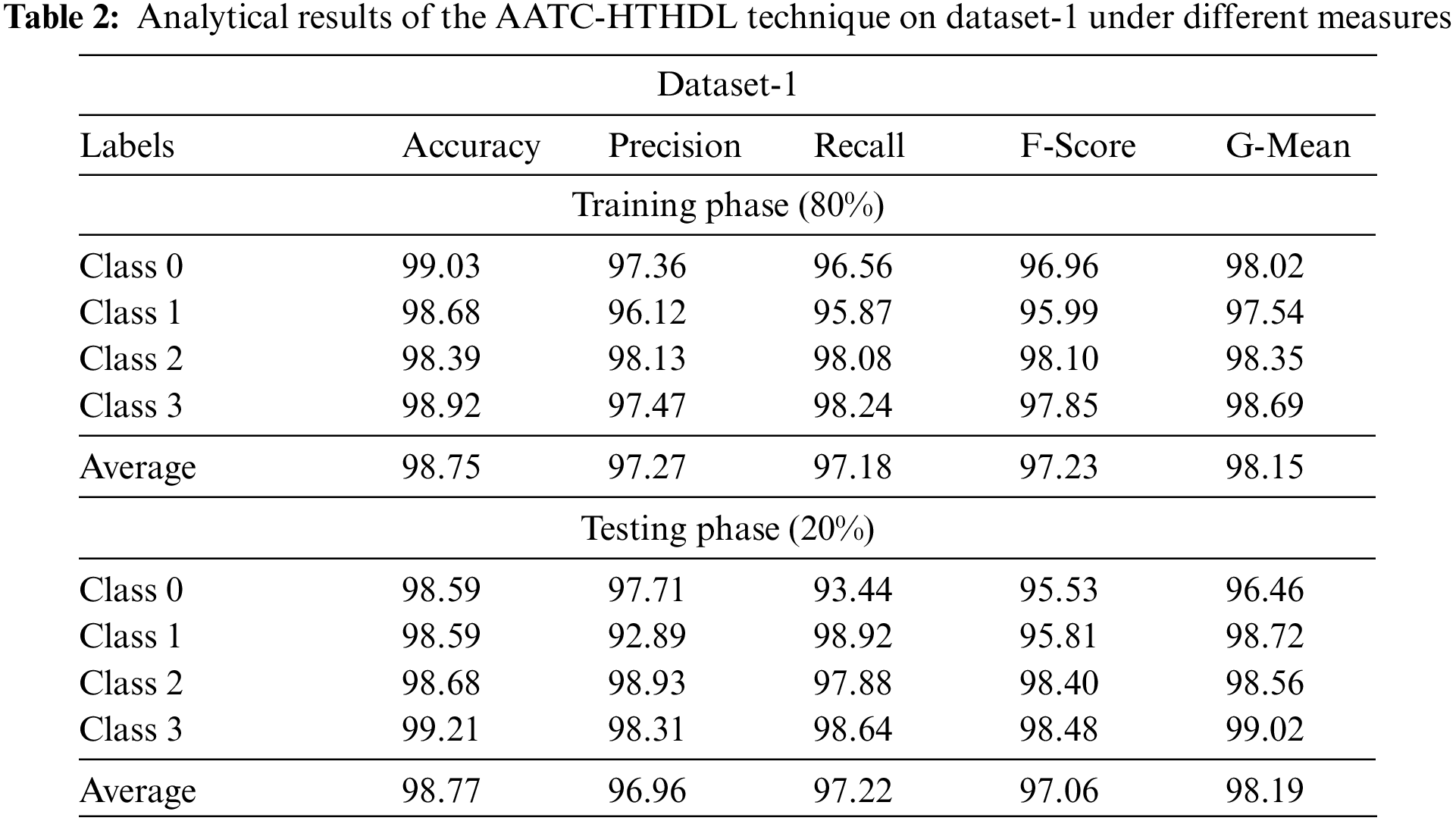
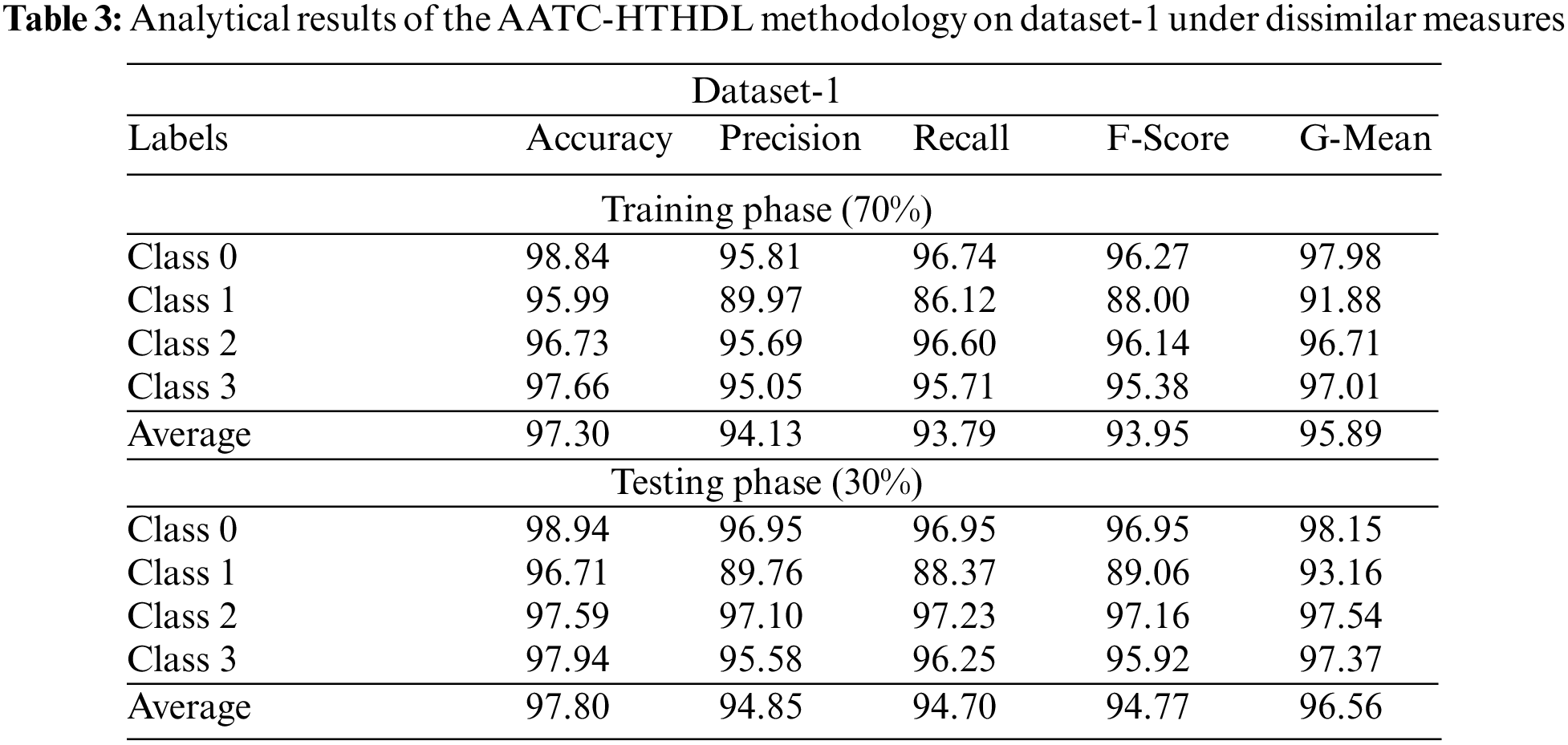
Table 3 shows the detailed classification outcomes achieved by the proposed AATC-HTHDL model on 70% of TR data and 30% of TS datasets. The obtained values indicate that the proposed AATC-HTHDL model achieved an improved performance. With 70% of TR data, the proposed AATC-HTHDL model provided an average
Both Training Accuracy (TA) and Validation Accuracy (VA) values, achieved by the proposed AATC-HTHDL methodology on dataset-1, are established in Fig. 4. The experimental results imply that the proposed AATC-HTHDL algorithm accomplished the highest TA and VA values whereas the VA values were higher than the TA values.
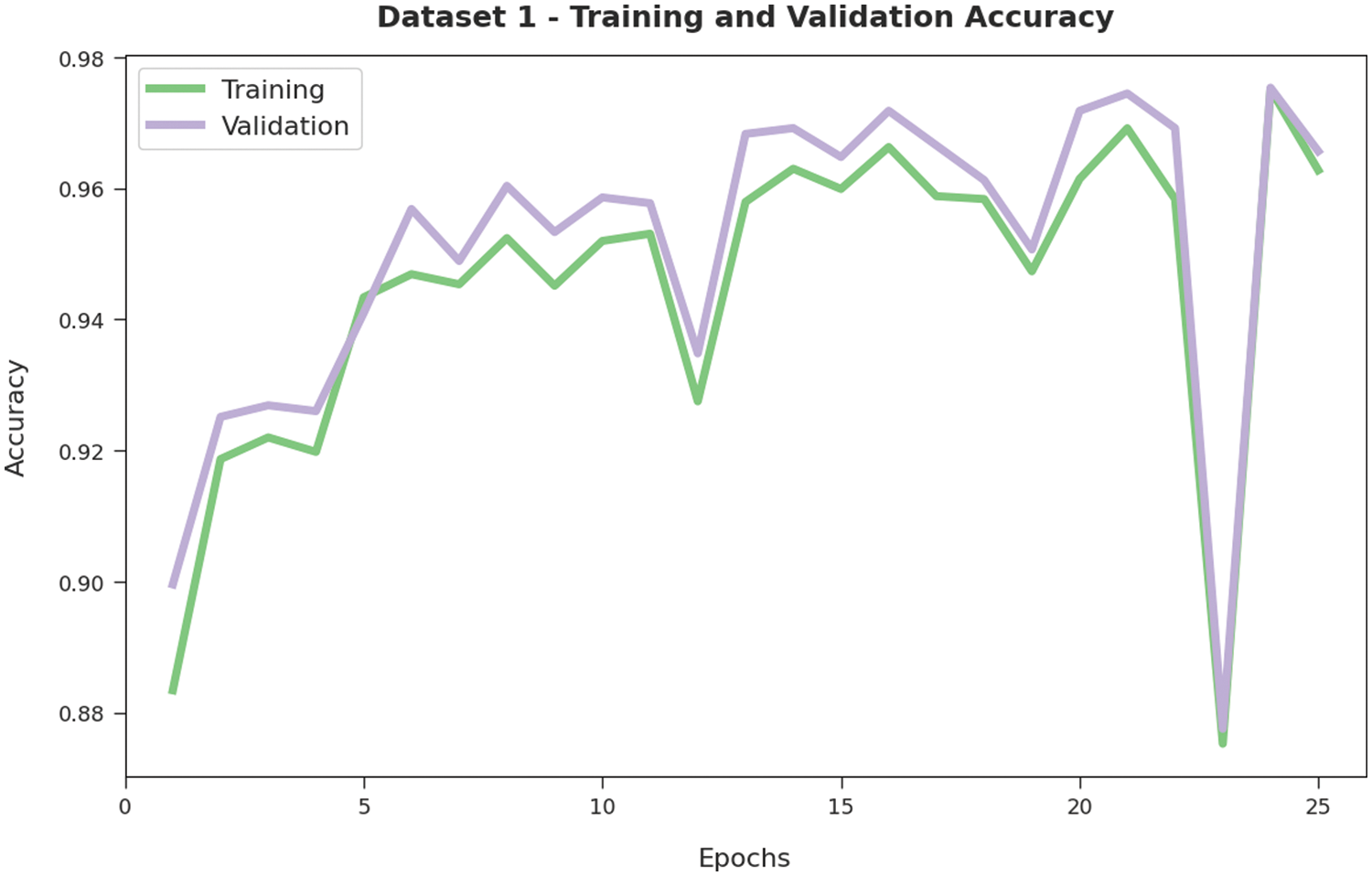
Figure 4: TA and VA analyses results of the AATC-HTHDL approach on dataset-1
Both Training Loss (TL) and Validation Loss (VL) values, obtained by the proposed AATC-HTHDL approach on dataset-1, are illustrated in Fig. 5. The experimental results infer that the proposed AATC-HTHDL technique achieved the minimal TL and VL values whereas the VL values were lesser compared to TL values.
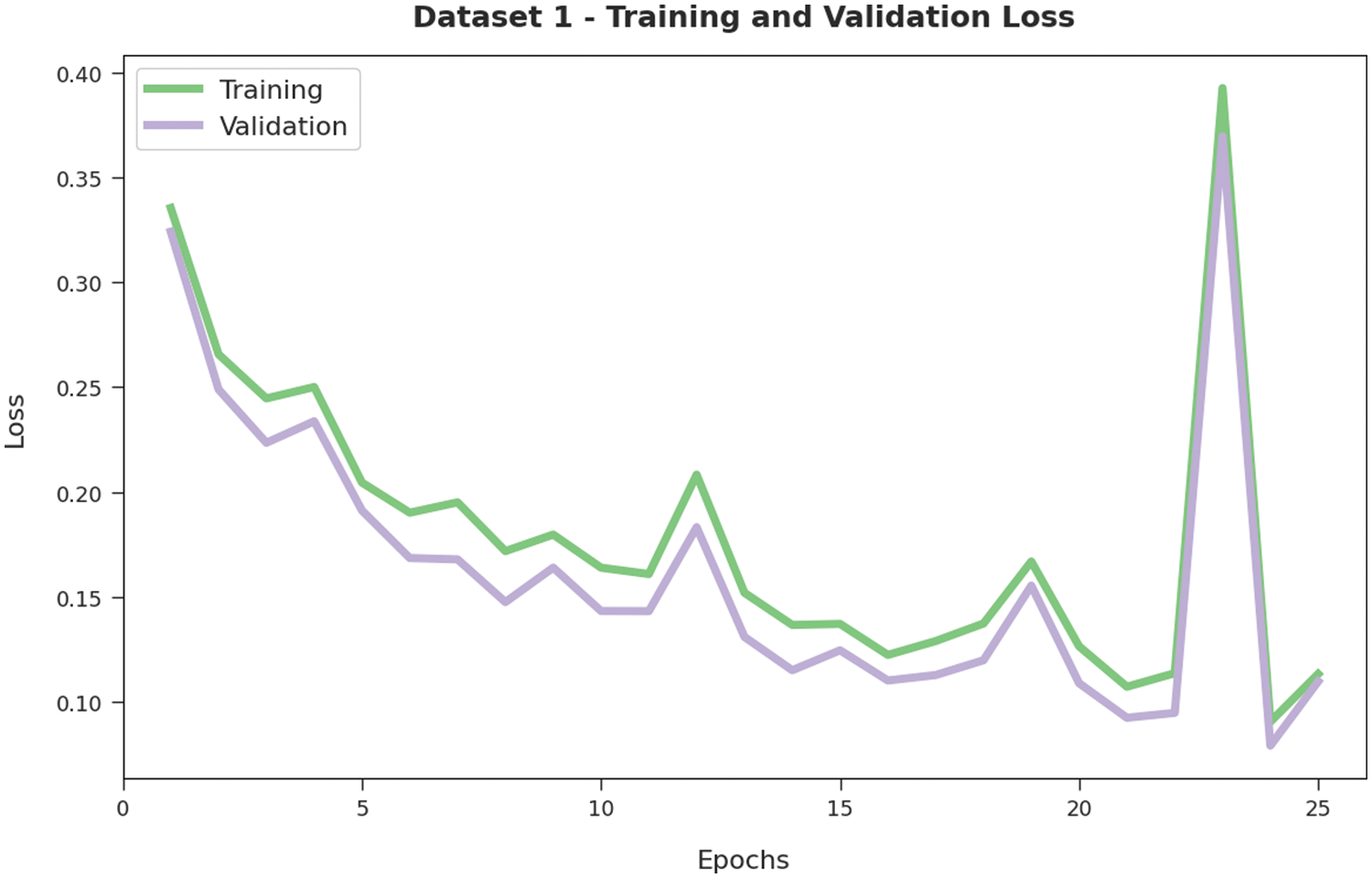
Figure 5: TL and VL analyses results of the AATC-HTHDL approach on dataset-1
The details related to the dataset-2 are given in Table 4. The dataset has 1,445 samples under eight class labels.
Fig. 6 exhibits the confusion matrices generated by the proposed AATC-HTHDL approach on the applied dataset i.e., dataset-2. The obtained values denote that the proposed AATC-HTHDL technique proficiently recognized the samples under eight dissimilar class labels.
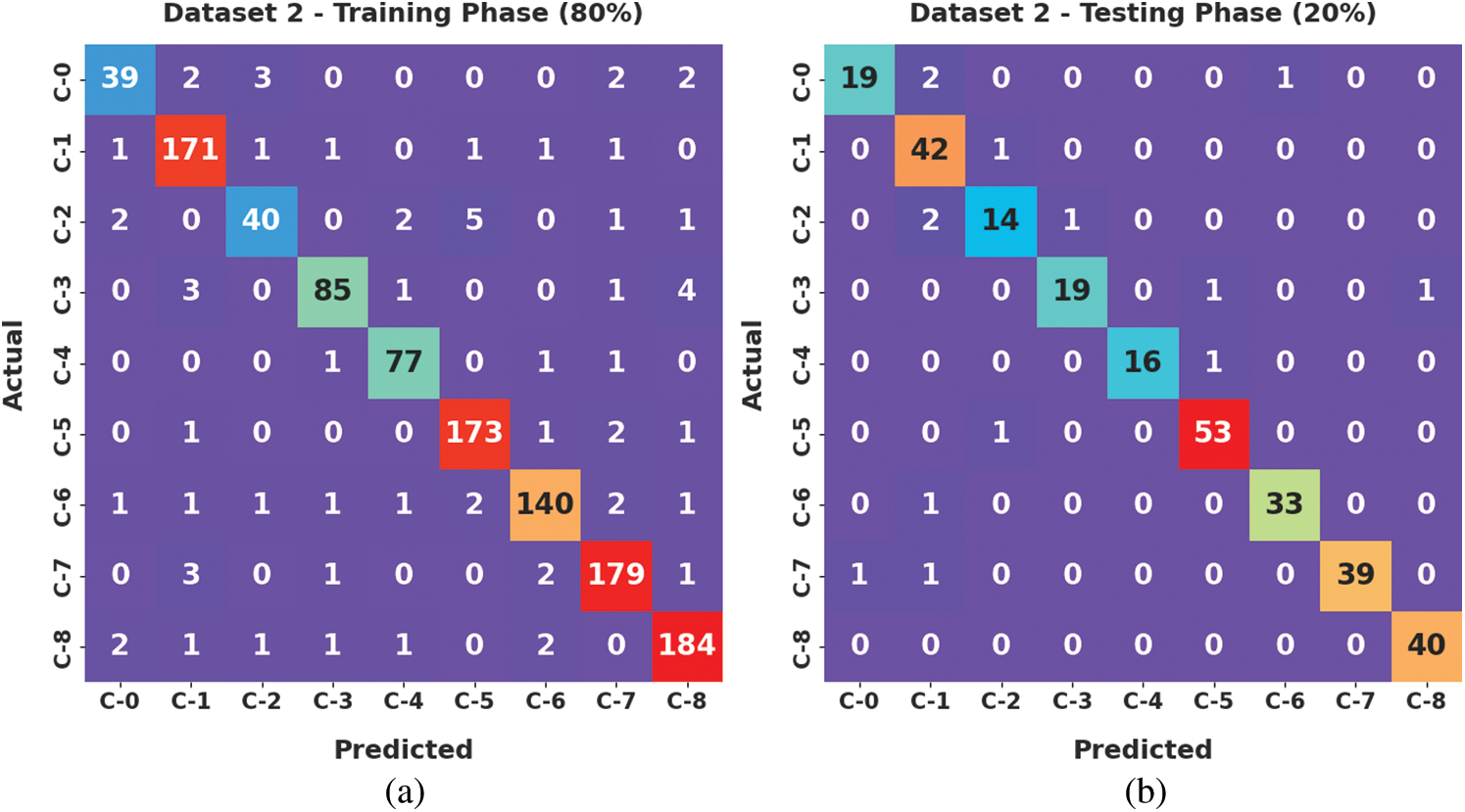
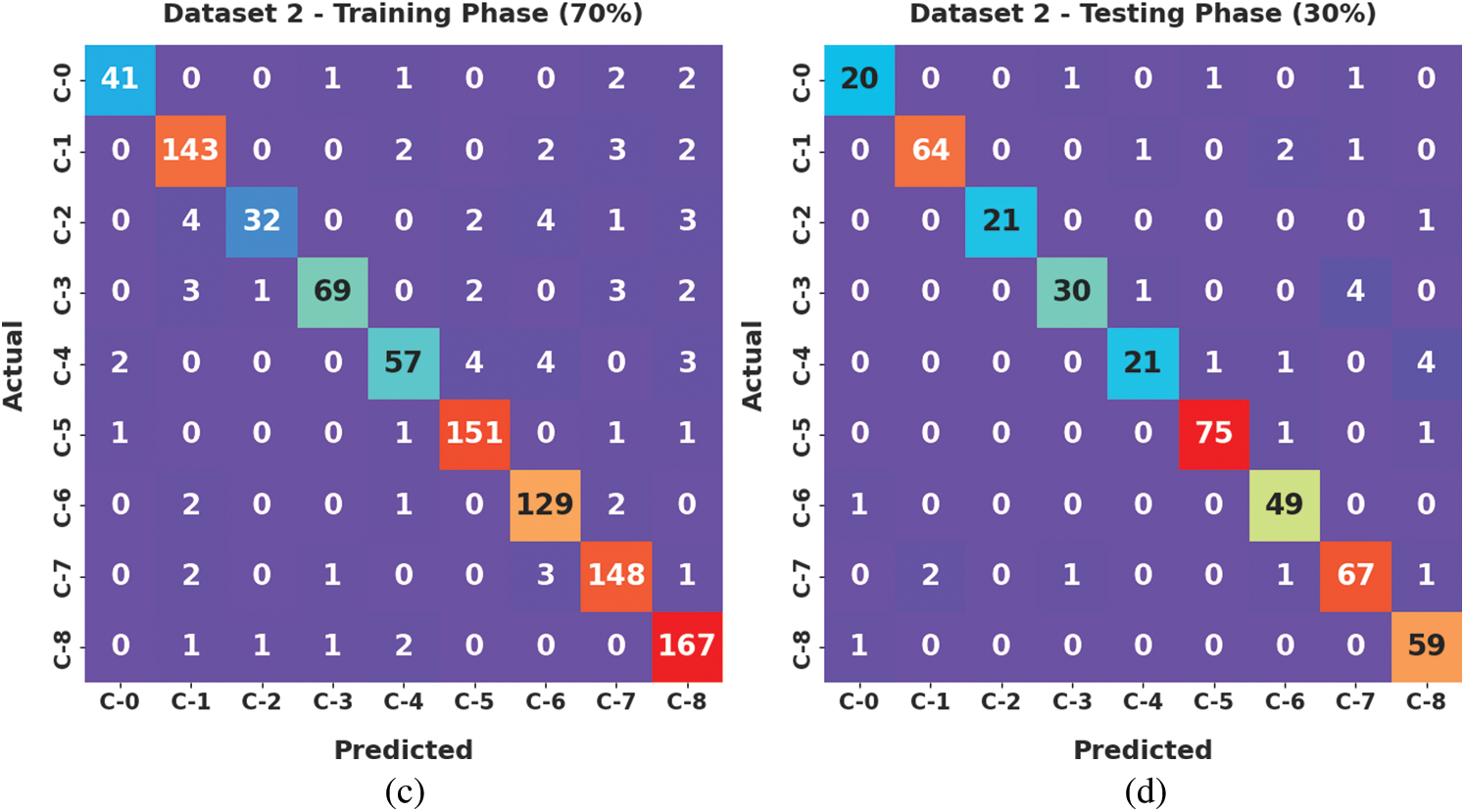
Figure 6: Confusion matrices of the AATC-HTHDL approach under dataset-2 (a) 80% of TR data, (b) 20% of TS data, (c) 70% of TR data, and (d) 30% of TS data
Table 5 depicts the detailed classification outcomes of the proposed AATC-HTHDL method on 80% of TR data and 20% of TS datasets. The figure reports that the presented AATC-HTHDL method achieved a better performance. With 80% of TR data, the AATC-HTHDL approach achieved an average
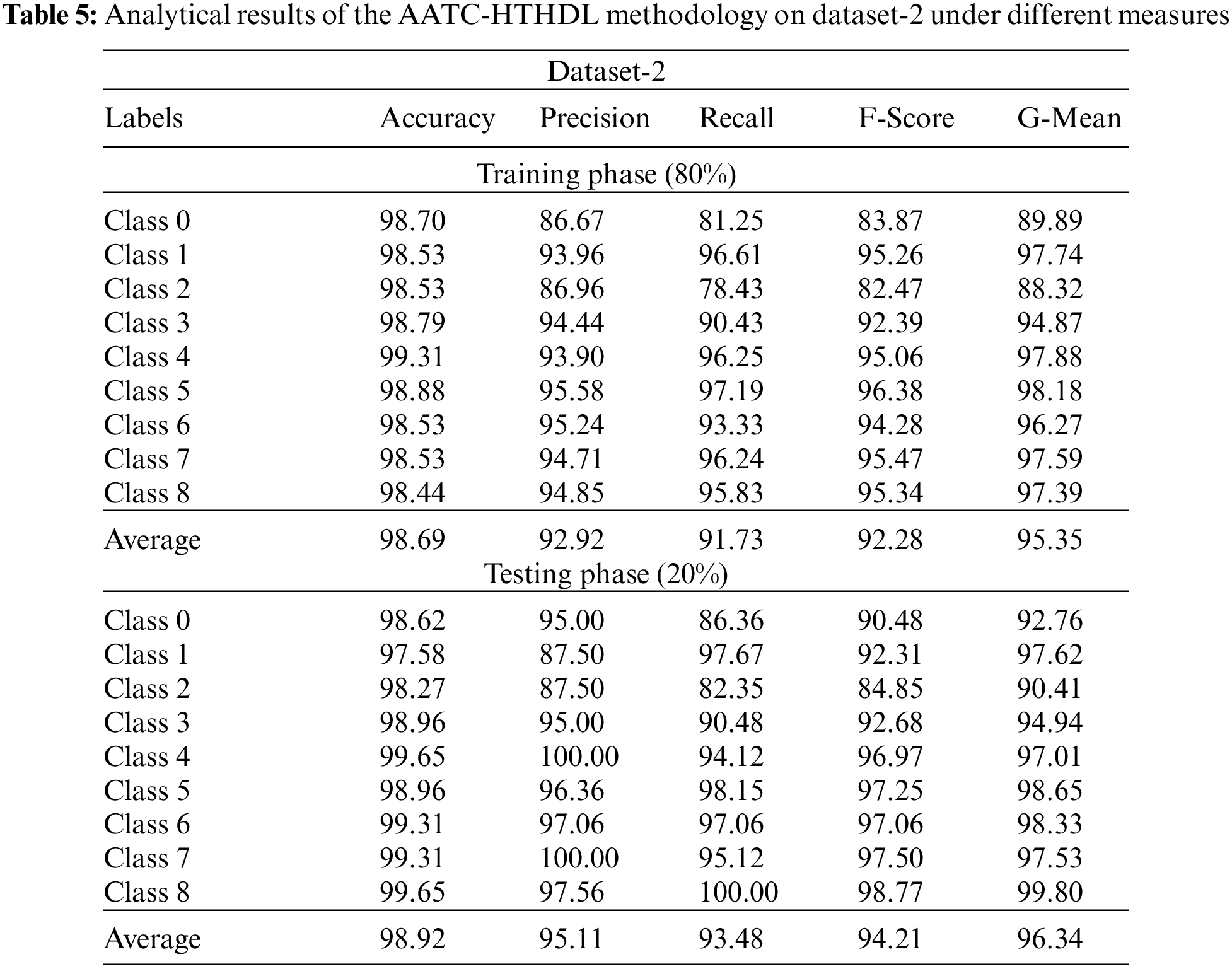
Table 6 shows the detailed classification outcomes of the proposed AATC-HTHDL method on 70% of TR dataset and 30% of TS dataset. The values obtained denote that the proposed AATC-HTHDL approach achieved a better performance. With 70% of TR data, the proposed AATC-HTHDL technique accomplished an average
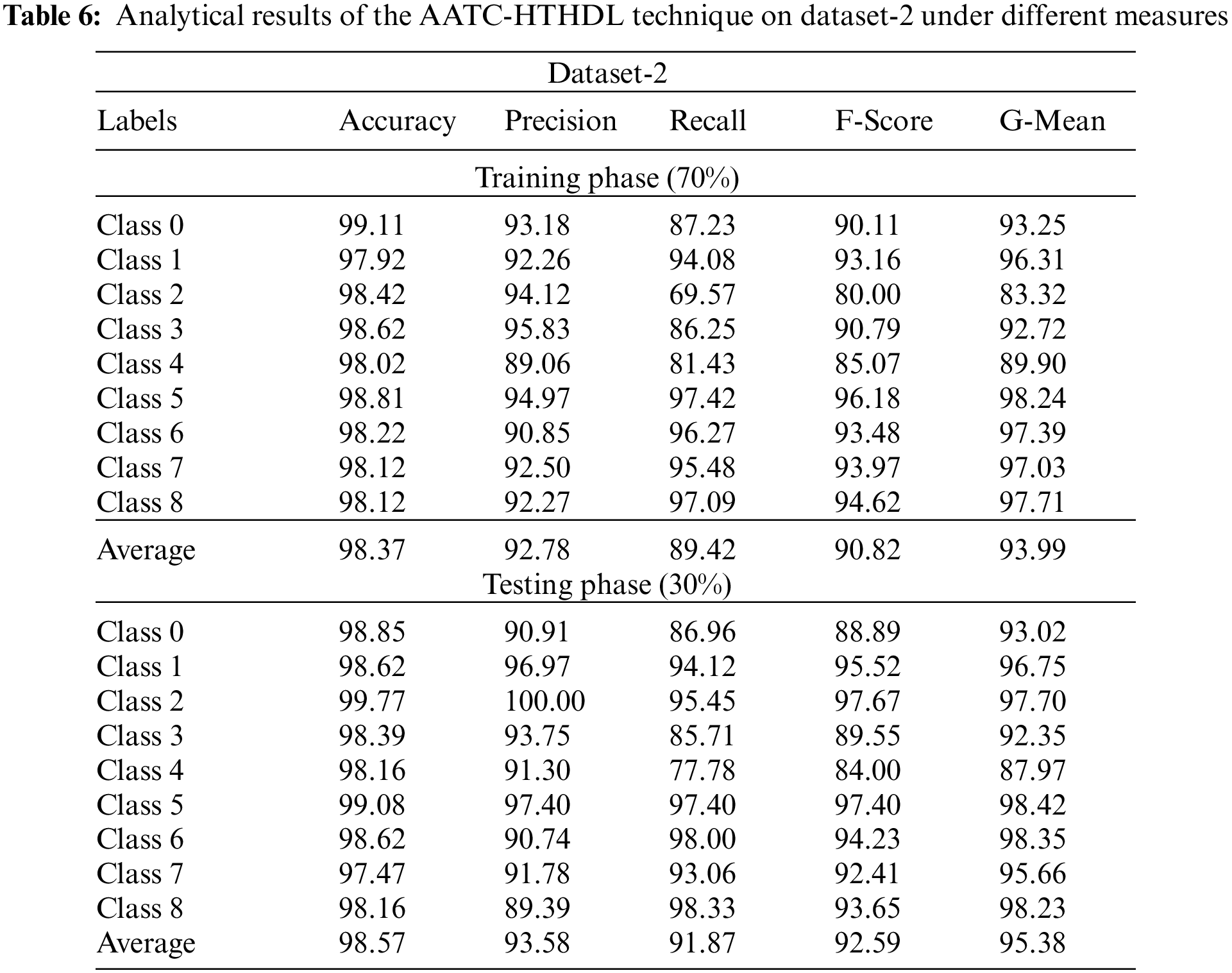
Both TA and VA values, attained by the proposed AATC-HTHDL approach on dataset-2, are established in Fig. 7. The experimental results imply that the proposed AATC-HTHDL algorithm accomplished the highest TA and VA values whereas the VA values were higher than the TA values.
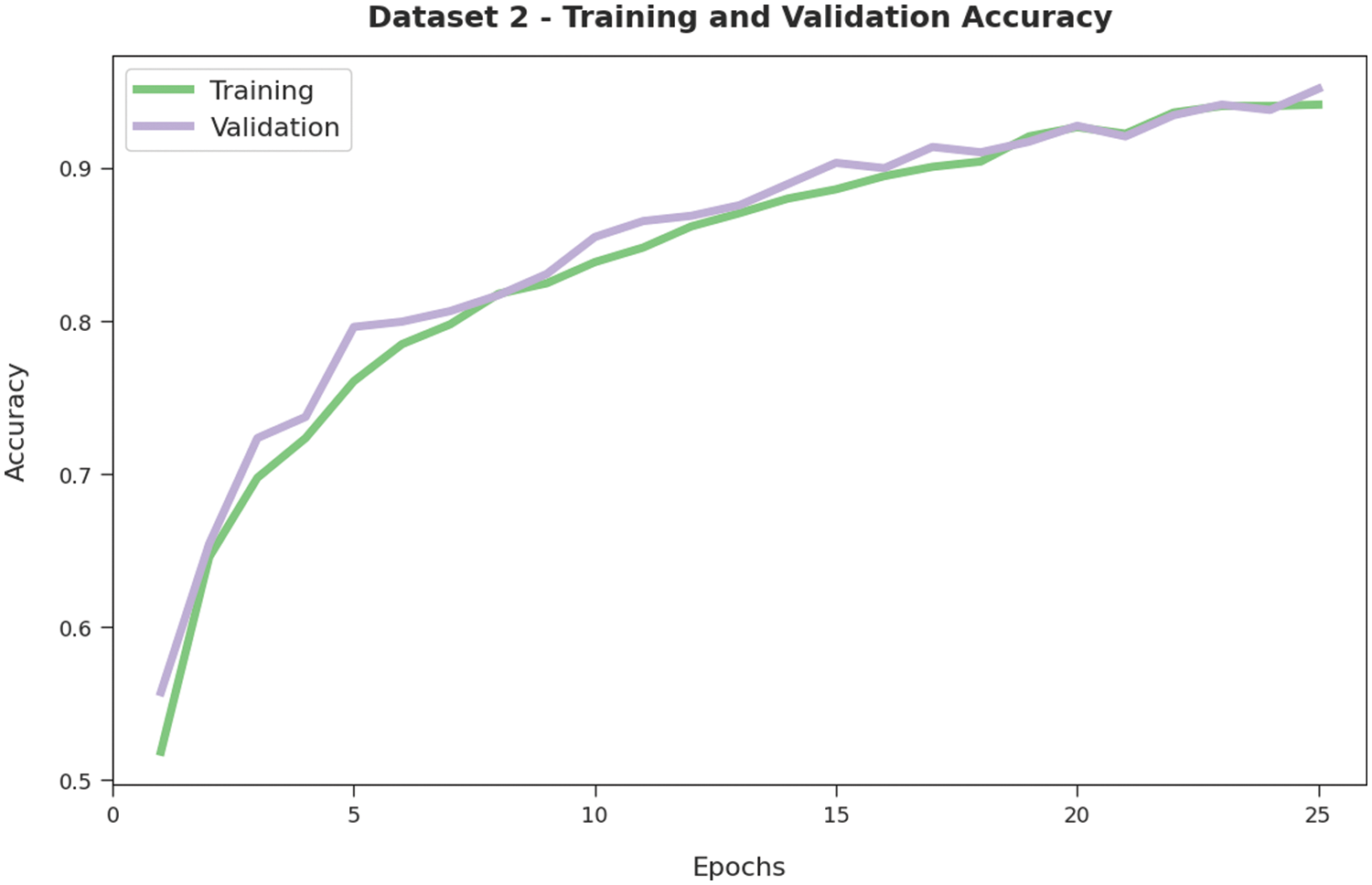
Figure 7: TA and VA analyses results of the AATC-HTHDL method on dataset-2
Both TL and VL values, achieved by the proposed AATC-HTHDL approach on dataset-2, are illustrated in Fig. 8. The experimental results infer that the proposed AATC-HTHDL technique achieved the minimal TL and VL values while the VL values were lesser than the TL values.
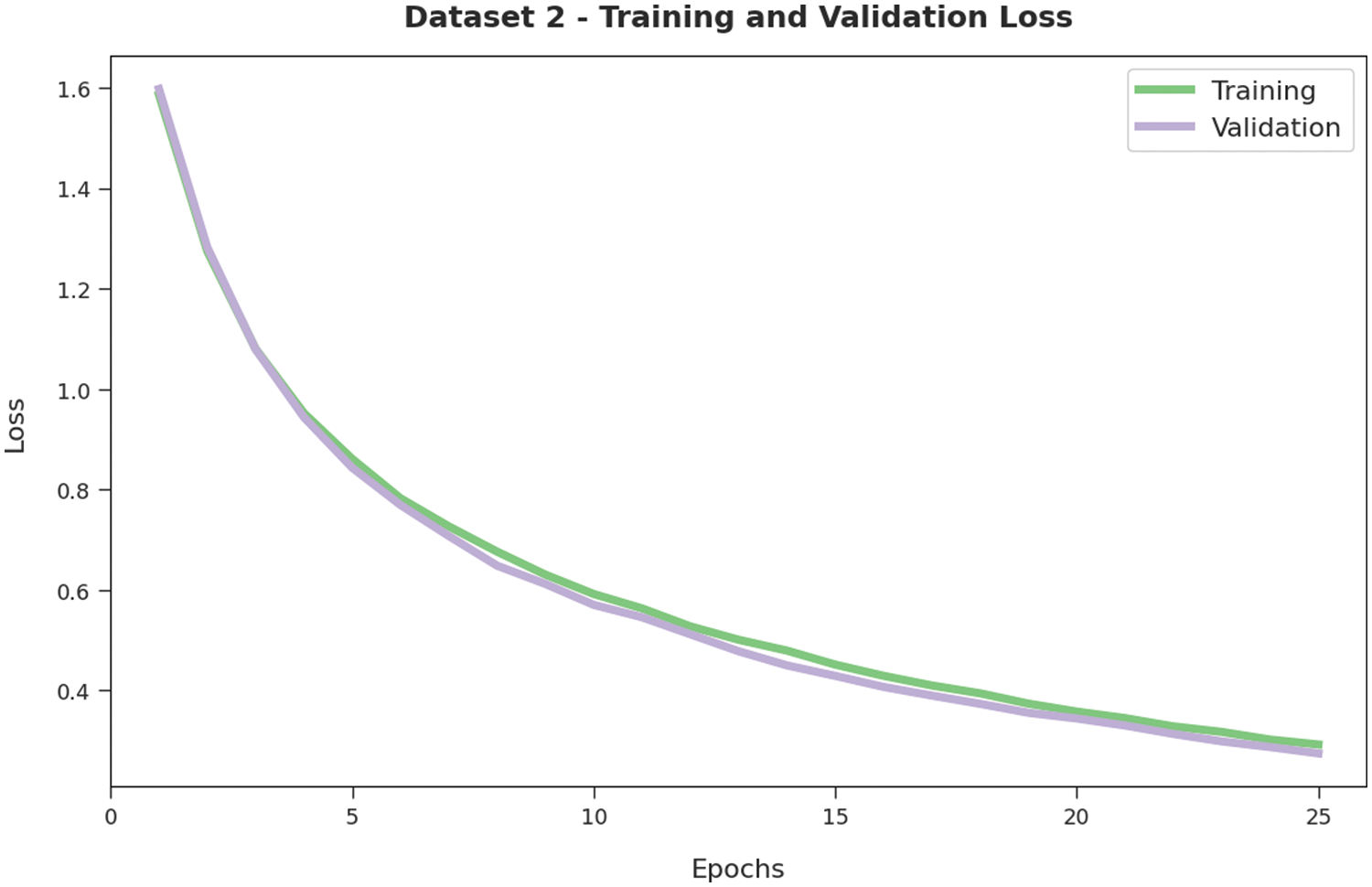
Figure 8: TL and VL analyses results of the AATC-HTHDL approach on dataset-2
In order to validate the improved performance of the proposed AATC-HTHDL model, a comparative analysis was conducted between the proposed model and the rest of the existing models such as Logistic Regression (LR), Support Vector Machine (SVM), Generative Adversarial Network (GAN), Artificial Neural Network (ANN) and Ant Colony Optimization (ACO) on dataset-1 and the results are portrayed in Table 7 and Fig. 9 [24]. The results demonstrate that the proposed AATC-HTHDL model achieved an excellent performance. For instance, in terms of
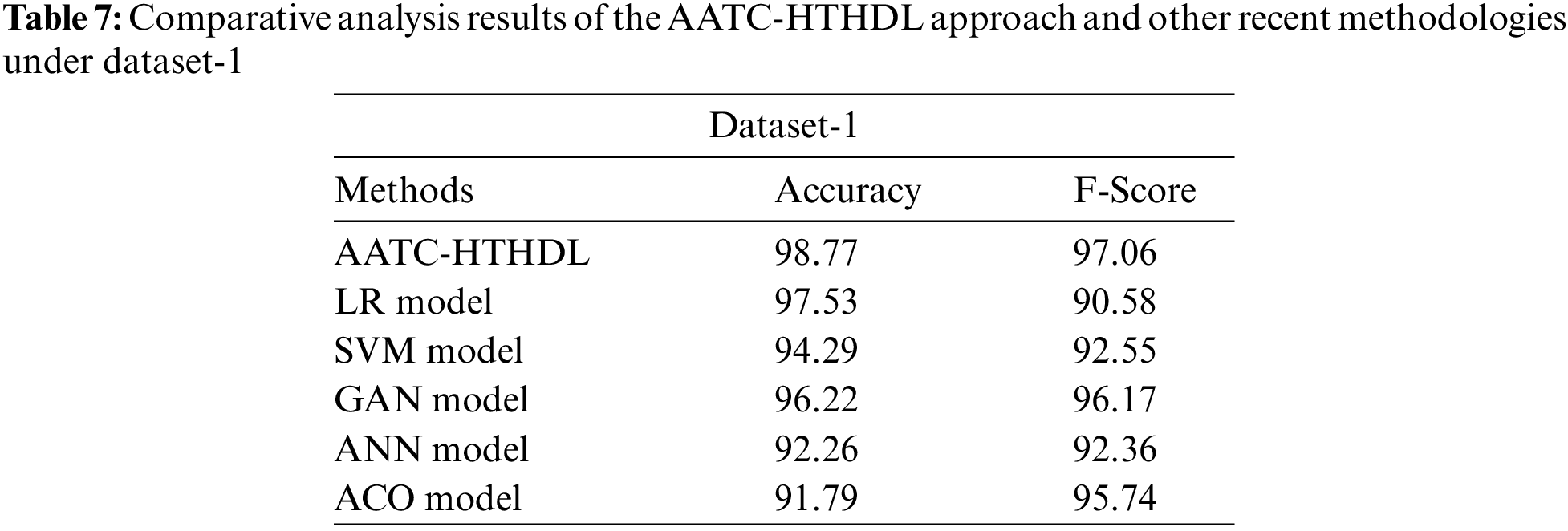
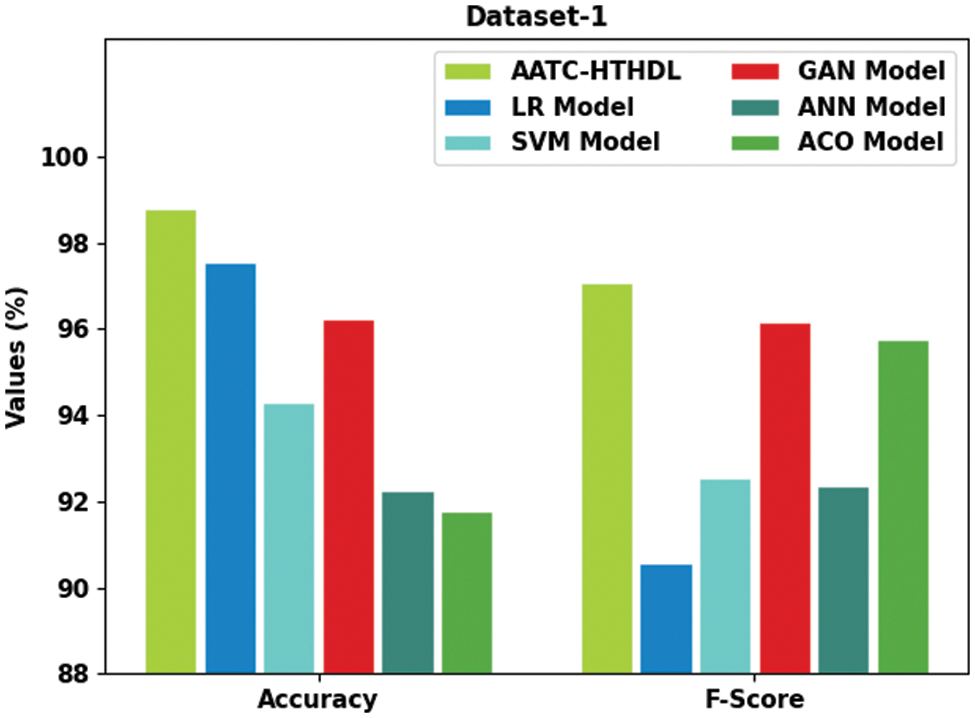
Figure 9: Comparative analysis results of the AATC-HTHDL approach upon dataset-1
In order to validate the enhanced outcomes of the proposed AATC-HTHDL approach, a comparative analysis was conducted between the proposed model and the existing models on dataset-2 and the results are demonstrated in Table 8 and Fig. 10. The results illustrate that the presented AATC-HTHDL approach achieved an excellent performance. For instance, in terms of
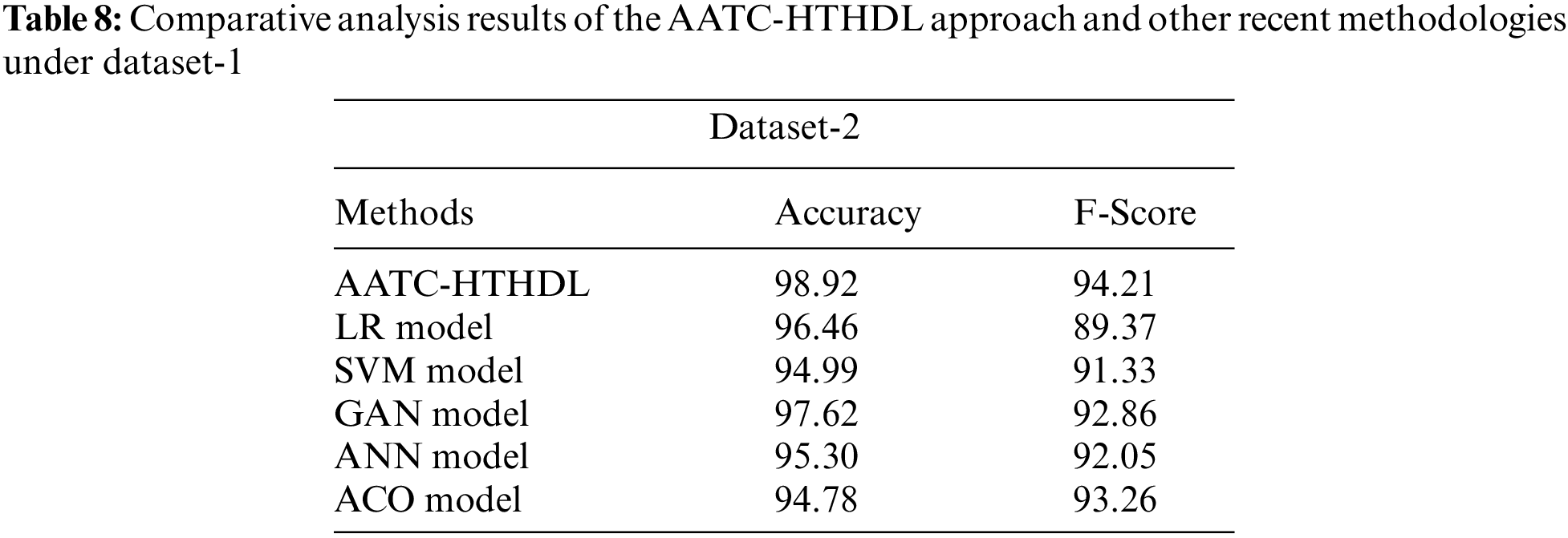
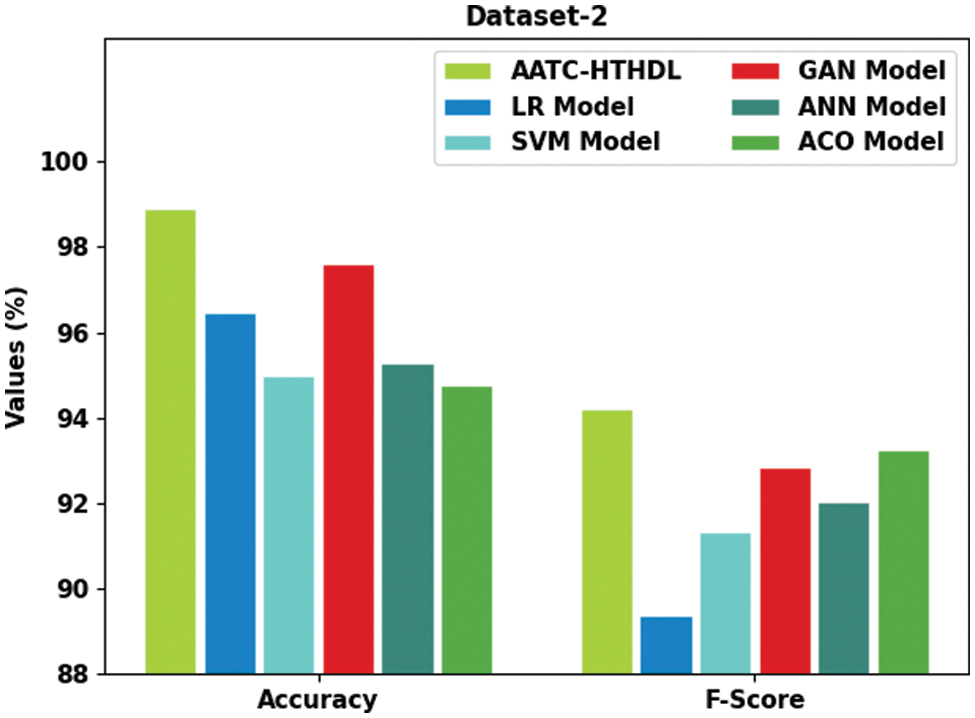
Figure 10: Comparative analysis results of the AATC-HTHDL approach on dataset-2
Based on the analytical results and the discussions made above, it can be inferred that the proposed AATC-HTHDL model achieved a better performance compared to other models.
In the current study, the AATC-HTHDL model has been developed to identify different class labels for the Arabic text. It encompasses different stages of operations. At first, the data is pre-processed to transform the input data into a useful format. Secondly, the TF-IDF model is applied to extract the feature vectors. Next, the CRNN model is utilized for the Arabic text classification process. Finally, the CSA is used for fine-tuning the hyperparameters involved in the CRNN model. The proposed AATC-HTHDL model was experimentally validated and the outcomes were investigated under distinct aspects. The comparison study outcomes highlight the promising performance of the presented AATC-HTHDL model over other approaches. In the future, feature selection and feature reduction methodologies can be applied to improve the classification performance of the projected technique.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4210118DSR31). The author would like to thank the Deanship of Scientific Research at Shaqra University for supporting this work.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. A. M. F. A. Sbou, “A survey of arabic text classification models,” International Journal of Electrical and Computer Engineering, vol. 8, no. 6, pp. 4352, 2018. [Google Scholar]
2. A. Wahdan, S. A. L. Hantoobi, S. A. Salloum and K. Shaalan, “A systematic review of text classification research based on deep learning models in arabic language,” International Journal of Electrical and Computer Engineering, vol. 10, no. 6, pp. 6629, 2020. [Google Scholar]
3. F. N. Al-Wesabi, “Proposing high-smart approach for content authentication and tampering detection of arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. [Google Scholar]
4. H. Chantar, M. Mafarja, H. Alsawalqah, A. A. Heidari, I. Aljarah et al., “Feature selection using binary grey wolf optimizer with elite-based crossover for arabic text classification,” Neural Computing and Applications, vol. 32, no. 16, pp. 12201–12220, 2020. [Google Scholar]
5. F. N. Al-Wesabi, “A hybrid intelligent approach for content authentication and tampering detection of arabic text transmitted via internet,” Computers, Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. [Google Scholar]
6. A. E. Kah and I. Zeroual, “The effects of pre-processing techniques on arabic text classification,” International Journal of Advanced Trends in Computer Science and Engineering, vol. 10, no. 1, pp. 41–48, 2021. [Google Scholar]
7. F. N. Al-Wesabi, A. Abdelmaboud, A. A. Zain, M. M. Almazah and A. Zahary, “Tampering detection approach of arabic-text based on contents interrelationship,” Intelligent Automation & Soft Computing, vol. 27, no. 2, pp. 483–498, 2021. [Google Scholar]
8. F. N. Al-Wesabi, “Entropy-based watermarking approach for sensitive tamper detection of arabic text,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. [Google Scholar]
9. M. A. Ahmed, R. A. Hasan, A. H. Ali and M. A. Mohammed, “The classification of the modern arabic poetry using machine learning,” TELKOMNIKA, vol. 17, no. 5, pp. 2667, 2019. [Google Scholar]
10. F. S. Al-Anzi and D. AbuZeina, “Beyond vector space model for hierarchical arabic text classification: A markov chain approach,” Information Processing & Management, vol. 54, no. 1, pp. 105–115, 2018. [Google Scholar]
11. X. Luo, “Efficient English text classification using selected machine learning techniques,” Alexandria Engineering Journal, vol. 60, no. 3, pp. 3401–3409, 2021. [Google Scholar]
12. A. Adel, N. Omar, M. Albared and A. Al-Shabi, “Feature selection method based on statistics of compound words for arabic text classification,” The International Arab Journal of Information Technology, vol. 16, no. 2, pp. 178–185, 2019. [Google Scholar]
13. H. N. Alshaer, M. A. Otair, L. Abualigah, M. Alshinwan and A. M. Khasawneh, “Feature selection method using improved CHI square on arabic text classifiers: Analysis and application,” Multimedia Tools and Applications, vol. 80, no. 7, pp. 10373–10390, 2021. [Google Scholar]
14. R. Janani and S. Vijayarani, “Automatic text classification using machine learning and optimization algorithms,” Soft Computing, vol. 25, no. 2, pp. 1129–1145, 2020. [Google Scholar]
15. S. Boukil, M. Biniz, F. E. Adnani, L. Cherrat and A. E. E. Moutaouakkil, “Arabic text classification using deep learning technics,” International Journal of Grid and Distributed Computing, vol. 11, no. 9, pp. 103–114, 2018. [Google Scholar]
16. N. Aljedani, R. Alotaibi and M. Taileb, “HMATC: Hierarchical multi-label arabic text classification model using machine learning,” Egyptian Informatics Journal, vol. 22, no. 3, pp. 225–237, 2021. [Google Scholar]
17. A. Elnagar, R. A. Debsi and O. Einea, “Arabic text classification using deep learning models,” Information Processing & Management, vol. 57, no. 1, pp. 102121, 2020. [Google Scholar]
18. S. Bahassine, A. Madani, M. A. Sarem and M. Kissi, “Feature selection using an improved Chi-square for arabic text classification,” Journal of King Saud University-Computer and Information Sciences, vol. 32, no. 2, pp. 225–231, 2020. [Google Scholar]
19. S. L. M. Sainte and N. Alalyani, “Firefly algorithm based feature selection for arabic text classification,” Journal of King Saud University-Computer and Information Sciences, vol. 32, no. 3, pp. 320–328, 2020. [Google Scholar]
20. E. Al-Thwaib, B. H. Hammo and S. Yagi, “An academic arabic corpus for plagiarism detection: Design, construction and experimentation,” International Journal of Educational Technology in Higher Education, vol. 17, no. 1, pp. 1, 2020. [Google Scholar]
21. S. Douzi, F. AlShahwan, M. Lemoudden and B. Ouahidi, “Hybrid email spam detection model using artificial intelligence,” International Journal of Machine Learning and Computing, vol. 10, no. 2, pp. 316–322, 2020. [Google Scholar]
22. S. Yusuf, A. Alshdadi, M. Alassafi, R. AlGhamdi and A. Samad, “Predicting catastrophic temperature changes based on past events via a CNN-LSTM regression mechanism,” Neural Computing and Applications, vol. 33, no. 15, pp. 9775–9790, 2021. [Google Scholar]
23. T. Gadekallu, M. Alazab, R. Kaluri, P. K. R. Maddikunta, S. Bhattacharya et al., “Hand gesture classification using a novel CNN-crow search algorithm,” Complex & Intelligent Systems, vol. 7, pp. 1855–1868, 2021. [Google Scholar]
24. K. Sundus, F. Al-Haj and B. Hammo, “A deep learning approach for arabic text classification,” in 2019 2nd Int. Conf. on new Trends in Computing Sciences (ICTCS), Amman, Jordan, pp. 1–7, 2019. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools