
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Research on the Development Model of University Archives Cultural Products Based on Deep Learning
School of Information Management, Nanjing University, Nanjing, 210023, China
* Corresponding Author: Qiong Luo. Email:
Computer Systems Science and Engineering 2023, 46(3), 3141-3158. https://doi.org/10.32604/csse.2023.038017
Received 24 November 2022; Accepted 17 February 2023; Issue published 03 April 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The products of an archival culture in colleges and universities are the final result of the development of archival cultural resources, and the development of archival cultural effects in colleges and universities should be an important part of improving the artistic level of libraries. The existing RippleNet model doesn’t consider the influence of key nodes on recommendation results, and the recommendation accuracy is not high. Therefore, based on the RippleNet model, this paper introduces the influence of complex network nodes into the model and puts forward the Cn RippleNet model. The performance of the model is verified by experiments, which provide a theoretical basis for the promotion and recommendation of its cultural products of universarchives, solve the problem that RippleNet doesn’t consider the influence of key nodes on recommendation results, and improve the recommendation accuracy. This paper also combs the development course of archival cultural products in detail. Finally, based on the Cn-RippleNet model, the cultural effect of university archives is recommended and popularized.Keywords
In recent years, culture and artistic work have become hot topics worldwide. It is necessary to boldly promote the reform of the cultural system, promote the overall prosperity of cultural undertakings, and the rapid development of cultural industries [1]. As a cultural institution in China, archives should fully develop archival artistic performances, show archival cultural resources to the public in more ways, and develop archival cultural products, which is the most direct and effective means to close the relationship between archives and the public. Therefore, perfecting the development process of archival cultural products, sorting out the development steps, and supplementing the information technology used in development have profound and significant practical significance for the development of archives [2–4].
At present, all local archives actively respond to national policies, such as the exhibition of archival culture, lectures on archival culture, compilation and research of archival publications, construction and opening of archival cultural databases, etc. More and more archival cultural products have been developed, and the cultural function of archives is gradually realized [5]. However, due to the diversity and massive amount of archival resources, and the lack of informatization talents in some libraries, archival resources can’t be used in a timely and effective way. The development of archival resources in archives only focuses on a few archival resources, and practical information in archives has not been deeply excavated, which leads to the low cultural influence of the currently developed archival cultural products [6–8]. At the same time, many archival cultural products designed by archives contain too much political color, ignoring other cultural characteristics in libraries. Although China’s archival cultural products have achieved results, a systematic development process has not been worked out, and archives lack a comprehensive grasp of the technologies involved in the development of archival cultural products [9,10]. China’s libraries have increasingly recognized its cultural characteristics, but how to establish archives culture and realize the archives culture industry has become the critical direction for archives to enter the public’s field of vision. With the continuous development of computer technology and the guidance of national policies, the electronic work of paper archives is being carried out nationwide [11]. Libraries are changing from single, low-efficiency paper archives to diversified, high-efficiency electronic archives, and become electronic archives of big data convenient for transmission, retrieval, and use on the Internet [12]. At present, the electrification of libraries has led to the continuous explosive increase of electronic archives data, and the functions of information retrieval, updating, and use of electronic archives have gradually become just needed in the market [13]. However, ordinary users lack systematic learning in the field of libraries, and can’t clearly express accurate keywords in information retrieval, resulting in the search results not meeting expectations [14]. These keywords have a specific semantic relationship in the field of archives. According to this relationship, the related files can be recommended by using the corresponding recommendation methods, so that users can get more files needed by users in the recommendation list [15,16]. After the collaborative filtering (CF) algorithm, which was studied earlier, was proposed, the recommendation system has become a hot research direction in the industry [17]. Traditional recommendation algorithms are mainly divided into collaborative filtering recommendation algorithms, content-based recommendation algorithms, and hybrid recommendation. Each algorithm has its advantages and disadvantages. The hybrid recommendation algorithm uses a combination of multiple recommendation methods to solve the algorithm deficiencies of a single recommendation model [18]. Yang Wenlong summarized some hybrid recommendation algorithms in his research on mixed recommendation methods: weighted hybrid recommendation algorithm, cross harmonic recommendation algorithm, feature extended recommendation algorithm, and meta-model hybrid recommendation algorithm. The above hybrid algorithm can solve the sparse matrix and cold start problem at the same time to a certain extent while maintaining the high accuracy of the recommendation results.
According to the above, based on the RippleNet model, this paper introduces the influence of complex network nodes into the model and puts forward the Cn-RippleNet model. This paper constructs and explains the model of the development of university archival culture products, and sorts out the development process of archival culture products. At the same time, according to the present situation of the development of archival cultural products in China and modern information technology, a comprehensive development plan has been made, including the construction of an archival cultural database, the development process of books, audio-visual archival cultural products, archival cultural creative products, and Internet archival cultural products, and finally recommends and promotes the effects of university archival culture based on the Cn-RippleNet model.
2 Proposal and Verification of Cn-RippleNet Model
2.1 Establishment of Cn-RippleNet Model
2.1.1 Building a Complex Network Based on Knowledge Map
This paper uses the knowledge maps of university archives, books, and social archives in RippleNet. The above knowledge maps are all text files, and the data constituting the above knowledge maps are the relationships among entities [19].
RippleNet designed a model for user feature extraction on the knowledge map, which is called Ripp1eNet-prop. RippleNet-prop put forward the idea of spreading users’ preferences on the knowledge map for the first time, taking the entities corresponding to users’ favorite items as the starting point and spreading outward from the center layer by layer in the knowledge map, similar to water waves, in which triples refer to (head entities, relationships, tail entities) in the knowledge map [20]. This process is equivalent to starting from these starting points and traversing breadth first on the graph represented by the knowledge map. The number of layers of water waves is equivalent to the traversed depth. When the traversed depth is 0, only the favorite items of users are included. For the first time, the triples with depths of 0 and 1 are considered to be traversed, and for the second time, the triples with depths of 1 and 2 are considered to be traversed. The smaller the traversal depth, the closer the distance between the discovered entities and the user’s favorite items on the knowledge map, the higher the similarity between these entities and the user’s favorite items, and the more representative of the user’s preferences. This Apollo-like structure also has an “interference effect” [21]. RippleNet-prop extracts user features from the knowledge map through its model structure and then assists recommendations.
When users extract features, they regard the knowledge map as a directed graph, while when extracting features of articles, they regard the knowledge map as an undirected graph. The reason for this difference is that in the process of user feature extraction, the knowledge map spreads from multiple starting points at the same time, and the head entities and relationships of each diffusion path are different. When calculating path weights, the head entities and relationships are considered at the same time. Because the head entities should be considered, the knowledge map is regarded as a directed graph. In the process of article feature extraction, On the knowledge map, it only spreads from one starting point, and each diffusion path only has differences in relation [22]. When calculating the path weight, only a relation is considered, and the direction of the path is not important at this time, so the knowledge map can be regarded as an undirected graph [23]. It is a set of entities directly connected with V in the knowledge map. Because the number of direct adjacent entities of each entity in the actual knowledge map is different in size, to make the machine learning model handle this kind of data conveniently, the adjacent entities of each entity are randomly sampled, with a fixed sampling number of K, and the set of adjacent entities of V after sampling is S(v).
Through data training, it is determined that the entity where the connected subnet is located is generated by MaxSubNet and GraphLink graph chain. As shown in Fig. 1, the storage mode of the largest connected subnet does not change [24]. As can be seen from Fig. 1, there are two points in the innermost layer, which gradually spread out. The enmity between the two points is the second layer, and the entity in the third layer is the point between the second layers, which increases layer by layer to cover the whole subnet.
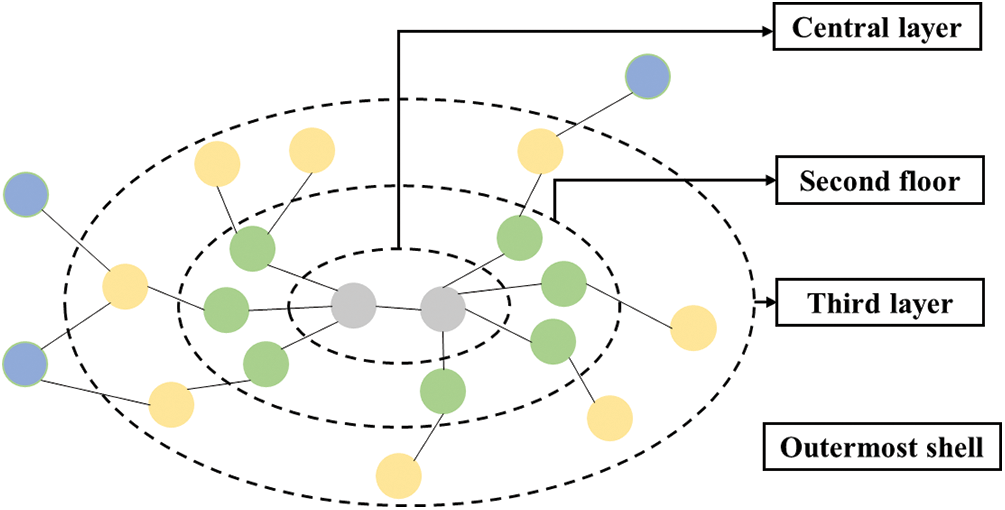
Figure 1: Model structure of the largest connected subnet
2.1.2 Cn-RippleNet Model of Complex Network
Because the model structure formed by the knowledge map of university archives is an undirected network, its calculation formula is:
In the RippleNet model, a circular recursion method is adopted to create a training set of related entities of archives recommendation, as shown below:
After the relevant entities are calculated, this paper defines all K-hop ripple sets of u as follows:
In each Hop, the entity in the Ripple set will be used as the weight and the embedded matrix head of the Ripple set
Thereby obtaining the correlation probability p:
Correlation probability can be regarded as the measure of item v and head entity h, R in relation space [23]. Because different kinds of relationship types will calculate different similarities, the relational data R also participates in the calculation of correlation probability. After obtaining the correlation probability, all tail entities tail in
Finally, combining user embedding and project embedding, the predicted click probability is the output:
The model structure is shown in Fig. 2, This model has networked the domain knowledge map, calculated the influence of entities in the knowledge map, and integrated them into the network of the knowledge map, making the recommendation results more consistent with people’s preferences, solving the problem that RippleNet did not consider the influence of key nodes on the recommendation results, thus increasing the recommendation accuracy.
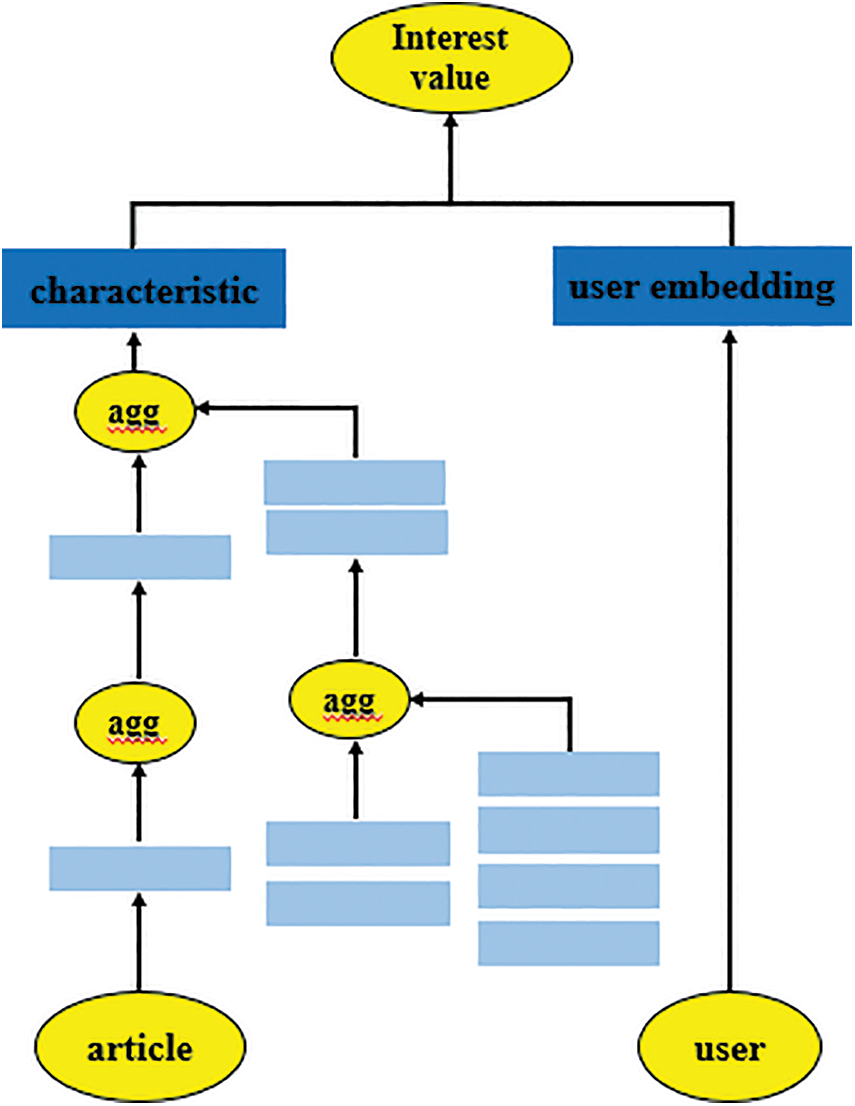
Figure 2: Cn RippleNet model structure
2.2 Cn-RippleNet Model Verification
2.2.1 Cn-RippleNet Model of Complex Network
In this experiment, the following two data sets are used for the experiment: university archives and Book-Crossing, which are commonly used in university archives and book recommendations, respectively, as shown in Table 1. Among them, the University archives data set contains millions of ratings of real users on the website. Book-Crossing also contains 100,000 books, and all the books are rated by users in the book exchange community. In this paper, the knowledge map constructed for each data set in the RippleNet model is adopted.
In this paper, ACC (Accuracy) and AUC (Area Under Curve) is used as the evaluation indexes of the experiment. AUC comes from ROC, that is, the area of the lower half of the ROC curve, and its value is less than 1. ROC graph is used to judge whether a binary classifier is good or bad. The abscissa of the obtained graph is FPR (false positive rate) and the ordinate is TPR (true positive rate). Connecting these coordinate pairs forms the ROC graph. Finally, the area of AUC is calculated to get a value of 0.5 to 1. The larger the AUC, the better the classification effect.
Parameters of Cn-RippleNet model number are archive data: dim = 4, hop = 2,
2.2.2 Experimental Results and Analysis
In this paper, the working conditions of the data set are calculated by Cn-RippleNet. The calculated results of the Cn-RippleNet model are better when the dimensions dim = 16, lr = 0.02, as shown in Table 2. Compared with other recommendation models based on knowledge maps, Cn-RippleNet has obvious advantages in both data sets, showing the best advantages. The reason is that Cn-RippleNet combines path-based and embedding-based methods, makes use of the side information of the knowledge map and the influence of nodes and gives weight to the entities in the network, which can give better recommendations to the recommendation system and get more accurate recommendation results. Compared with RippleNet, in the university archive data set, the improved Cn-RippleNe model has higher AUC and ACC evaluation indexes than the RippleNet model, while in the Book-Crossing data set, the AUC and ACC evaluation indexes are higher than 20%. This shows that the recommendation effect of RippleNet considering the influence of nodes is more accurate. Therefore, this paper thinks that Cn-RippleNet has a better effect after the method of merging the influence of nodes according to the path.
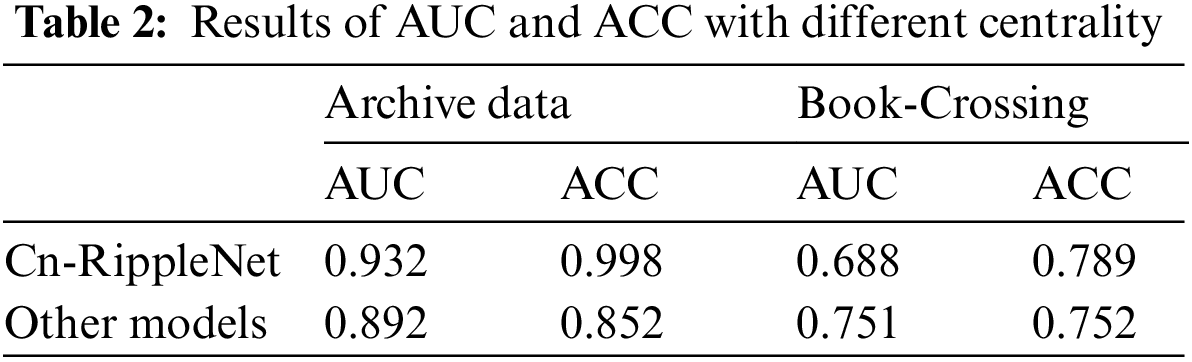
It can be seen from Figs. 3 and 4 that the evaluation index AUC reaches 0.929 when the value of Hop is 2, and the evaluation index AUC is only 0.91 when the value of Hop is 4, indicating that the impact of Hop number on performance is not as high as possible. It can be seen from Figs. 5 and 6 that it can also be concluded that the higher the Dim value, the better, and the evaluation index AUC of Dim reaches the maximum at 16: 00. Table 2 It can be seen that under these two data sets, in the experimental comparison of degree centrality, intermediate centrality and near centrality, all results of degree centrality are better than others.
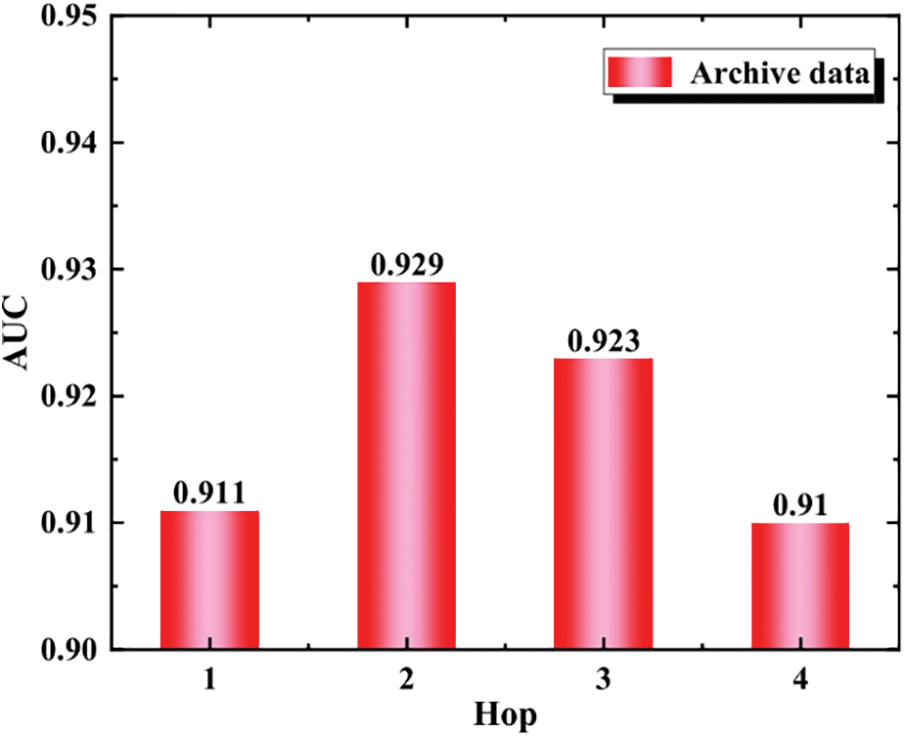
Figure 3: AUC of different hops in archive data
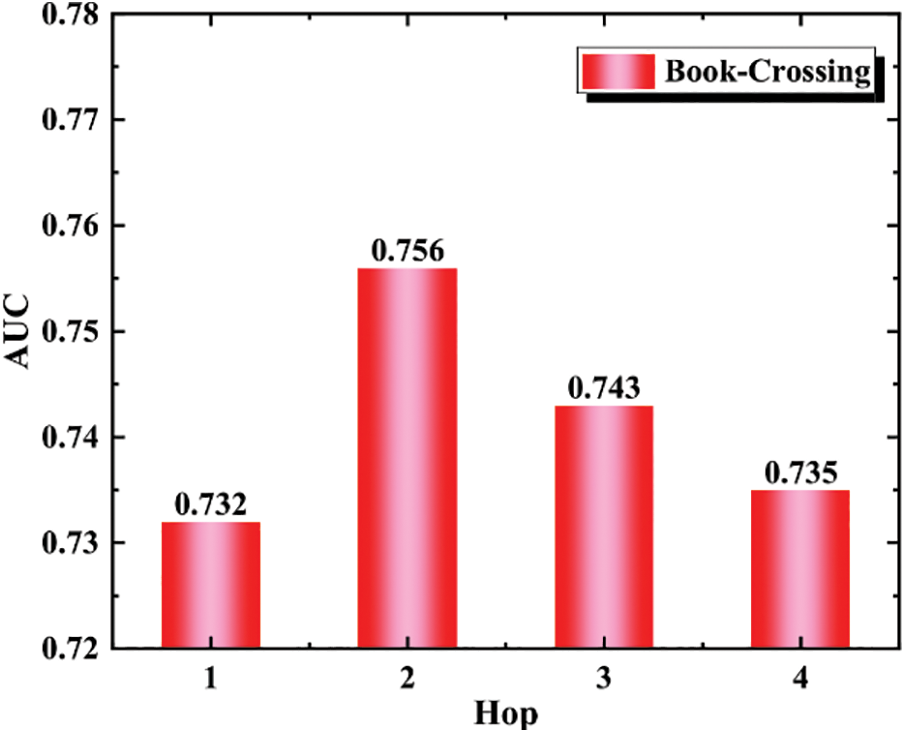
Figure 4: AUC of different hops in book-crossing
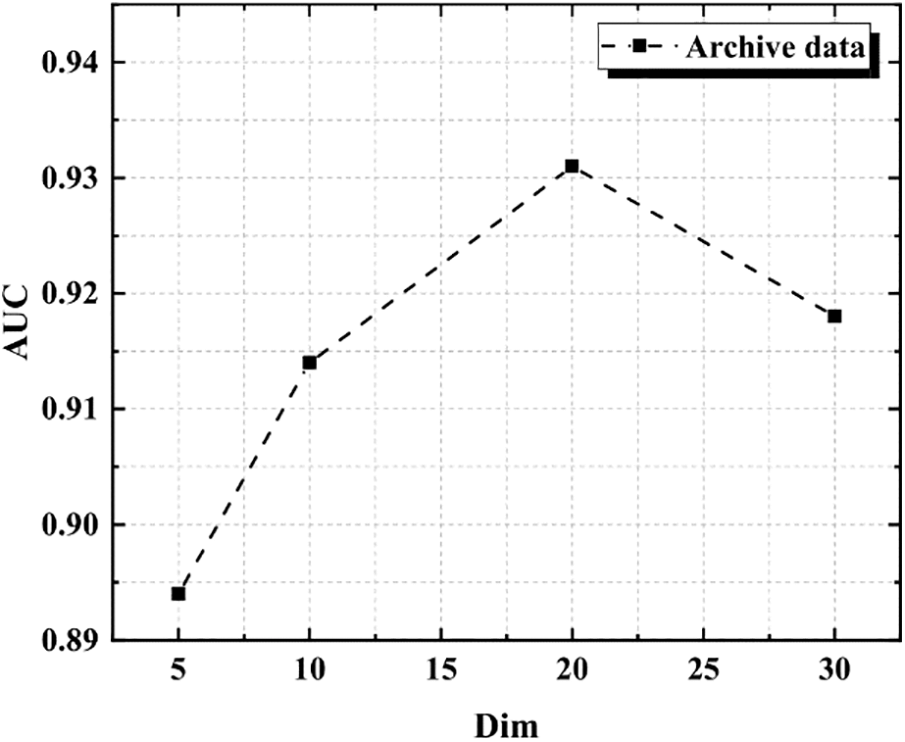
Figure 5: AUC of different dims of archive data
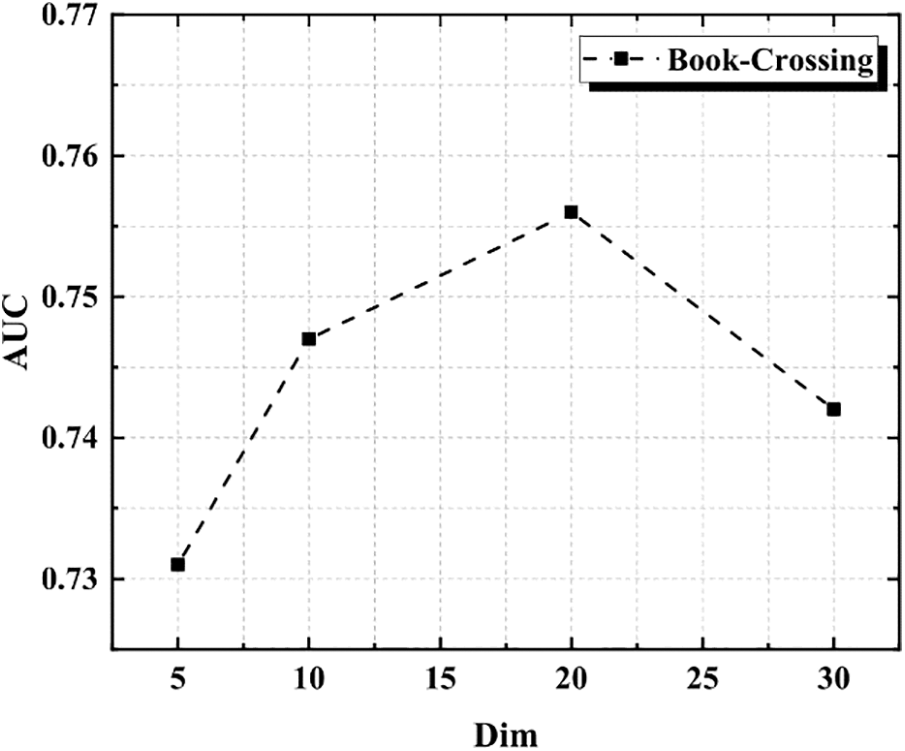
Figure 6: AUC of different dims of book-crossing
3 Construction of University Archives Cultural Product Development Process
3.1 The Model Structure of Cultural Product Development
According to the cultural characteristics of archives and the model structure of general product development, the author divides the model structure of archival cultural product development into a resource layer, formation layer, application layer, and user layer, as shown in Fig. 7. The model structure of the development of archival cultural products involves two development processes: the development of archival cultural resources, that is, the construction of an archival cultural database is the preliminary arrangement of archival resources, and the development of archival cultural products, which can also be called the redevelopment of archival cultural resources, and is the direct result of the development of archival resources.

Figure 7: Model framework of archival cultural product development
3.1.1 Cultural Product Resource Layer of Archives
China is an ancient civilization with a long history, with various cultural resources. The contents of archival cultural resources are very rich. These resources can not only be used as educational resources, literary and artistic creation resources, memory heritage resources, national cultural resources, cultural industry resources, and cultural leisure resources but also be indirectly developed as scientific research resources. The resource layer of archival cultural products is the lowest layer of the development model structure of archival cultural products, which provides a lot of information resources for the development of archival cultural products, and is the foundation to ensure the smooth development of archival cultural products.
3.1.2 Archival Cultural Product Formation Layer
The formation of archival cultural products is in the development stage of archival resources in the development of archival cultural products, which lays the foundation for the effective utilization of archival cultural resources in the future. At this stage, we first select a large number of archives resources with obvious cultural value for content mining, then aggregate different resources using theme maps, etc., to ensure the complete knowledge content and form a variety of cultural development materials, and finally put them into archives culture database to provide direct and comprehensive knowledge inquiry services for future development.
Using the theme map to aggregate the scattered archival cultural resources according to specific requirements and rules can effectively classify the archival cultural resources of the same materials and form a scientific and complete archival cultural database. And store it in the archive culture library to complete the aggregation of a material, as shown in Fig. 8, the formation process of the archive culture library. Commonly used theme map development tools include OKS, TM4J, tiny Tim, XTM4XMLDB, etc.

Figure 8: Formation process of archive culture library
To make the archives and cultural resources that can be opened and shared can be used by more people, the related data can usually be used to improve the construction of the database. Association data is a description specification. The unique Uniform Resource Locating System (HTTP URI) is used as the generic name of archival cultural resources, and the data is described in the triple RDF format of “subject-predicate-object”. Through HTTP URI, the data are linked and associated, and a new data network is constructed to realize the intelligent application of an archival cultural database. There are three kinds of data access methods for data opening established by associated data: SPARQL Endpoint; a query language for directly accessing archival culture database; Restful API interface to realize the purpose of ordinary users accessing the database through indirect access. This kind of query interface can obtain encapsulated data; Direct access to open archives of cultural data websites through HTTP URI.
3.1.3 Application Layer of Archival Products
After reasonable development in the early stage, the archival cultural resources enter the formal stage of archival cultural product development. According to different types of archival cultural resources in the archival cultural library, the contents are deeply processed and refined, and different types of archival cultural products are developed in combination with the needs of users. In the application layer, according to the classification of archival cultural products, archival cultural products are classified according to carrier types, which can be roughly divided into three categories: archival books audio-visual products, archival cultural creative products, and archival Internet cultural products. Among them, archival books, and audio-visual products are traditional archival cultural products, while cultural and creative products and Internet cultural products are relatively new products.
When developing the application layer, the Internet archive culture product development will directly use the data in the archive culture database. To ensure the security and stability of the database and improve the efficiency of product development, a specific Restful API interface can be used in data acquisition to directly obtain related data, such as “names”, “dynasties”, “places” and other data in the character material database. Fig. 9 The use of Restful API in the product development of Internet archives and cultural products.

Figure 9: The use of Restful API in the development of Internet archival cultural products
3.1.4 User Layer of Cultural Products
The user layer of archival cultural products is at the top of the development model structure of archival cultural products. Based on the particularity of archival undertakings, the audience users of archival cultural products are divided into two categories: insiders and the public. Most archival cultural products are oriented to society. However, due to the reasons of archival security and intellectual property rights, some archival cultural products, such as internal journals and magazines, some historical data summaries, some conference compilations, etc., are distributed inside the archives, which can be viewed and used by people in the archives or those who meet the requirements.
To improve the quality of archival cultural products, it is necessary to investigate the actual utilization of published products, such as the sales volume of books, cultural and creative products, the broadcast volume of audio-visual products, the downloads and visits of Internet products, and the identity information of users, etc. If necessary, more detailed data can be obtained by questionnaire survey, and data analysis software can be used to analyze the data, to obtain the application effect and audience of the developed products from the data, which will provide data support for the next step of perfecting archival cultural products and developing new products.
3.2 Collection of Cultural Product Development Resources
The collection of archival cultural resources is the most basic work for the development of archival cultural products. Only high-quality archival cultural resources can have high utilization value, and good cultural products can be developed. To ensure the quality of archival cultural resources, we usually need to pay attention to the following two points. First, the emergence of archives determines its dispersion characteristics, so we should have foresight and planning when collecting, and taking the initiative to collect; Secondly, when choosing archives, we should pay attention to pertinence, and we need to choose those with high cultural value. To achieve the above points, when collecting archival cultural resources, it is necessary to collect them through various channels.
3.2.1 Collection of Library-Archives Resources
Librarians should have a good grasp of the basic information of collections in archives, and when collecting archives resources, they should select the archives with special collections or special cultural significance. When judging the cultural significance of archives, it needs to be judged by experts and scholars with relevant professional knowledge backgrounds to ensure the quality of resources.
3.2.2 Collection of Internet Archive Resources
The collection of Internet archival resources to obtain archival cultural resources through the Internet, and its sources include World Memory Heritage Network, local archival information networks, China HowNet, Wanfang Database, archival Internet social media, search engines, and so on. As we are in the era of Internet information explosion when collecting Internet archives resources, the progress of manual search alone is slow, and we need to use crawler tools to automatically crawl web information, such as commonly used crawler tools such as Nutch, Larbin, Heritrix, HTTrack, Wget, WebFountain, or crawler code based on Python programming language, etc. When collecting Internet archives information resources, we should choose the appropriate tools according to the specific needs. For example, when the collected data needs to be redeveloped, you can use Nutch; which can customize the crawler by using plug-ins; Heritrix can be used to ensure the completeness and coverage of grabbing; When crawling incremental Web pages such as online social media, WebFountain is generally used to ensure the maximum freshness of web pages. Avoid using HTTrack and Wget when the compatibility and extensibility of tools are required. As far as the current technology is concerned, crawler technology saves a lot of information collection time, but precision can’t be guaranteed. To ensure the balance between precision and recall, experts in related fields still need to participate in the collection of Internet archives and cultural resources.
3.2.3 Collection of Social Resources
Social resource collection is a supplement to the collection of library collections and Internet archives, and it is a social worker. Archives are produced in society, and some archives are scattered all over society due to various irresistible factors, waiting for us to discover them. Whether it is for collecting specific projects or enriching collections, archives should collect valuable archives, for example, historical materials scattered in the hands of state organs, social organizations, or individuals, materials reflecting the development of ethnic minorities and certain regions, representative works of famous literary and artistic creations reflecting major historical themes, archives of famous people who have made outstanding contributions to society [25], relevant documents formed by intangible cultural heritage, and commemorative objects with historical representativeness, etc. Specific collection methods include free donation, deposit, purchase, reproduction, etc [26].
At the later stage of resource collection, a file resource bank will be formed to keep these resources [27]. The above three methods of resource collection, usually can’t be used alone, but they need to be carried out together to reflect scientificity and integrity. To ensure a better recall rate, some countries or regions have launched cooperative plans, and archives have cooperated with other cultural institutions to build and share resources. For example, many national museums, libraries, and archives jointly form the LAM (Library, Archives, and Museum) Alliance, in which resources are jointly developed and shared. Taiwan Province has also launched the E-Learning and Digital Archives Program (LDAP), which involves the joint participation of 19 departments including Archives Administration, Ministry of Culture, Academia Sinica, Taiwan Province Film Archive, Taiwan Palace Museum, etc., starting with the digitization of the lowest archives. The deep integration of metadata, the combination of development technology, and creativity show the public the application of Taiwan Province’s local culture in many fields, such as humanities, society, natural environment, etc., which provides great convenience for further development of these resources in the future.
3.3 Collection of Cultural Product Development Resources
3.3.1 Books, Audio-Visual Products
Archives audio-visual products belong to the mainstream archives cultural products at present, and most archives have many books and audio-visual achievements. UNESCO stipulated in 1961: 5–49 pages of printed matter are booklets, and 50 pages or more of printed matter are books. Audio-visual archival cultural products include audio-visual products and video products. Audio-visual products include audio tapes, records, and compact discs, while video products include video tapes and compact discs. Generally, audio-visual cultural products need to be jointly produced by other departments, such as TV stations and cultural publishing enterprises. The development process of archival audio-visual cultural products is rough as follows:
① Topic selection and preparation. The topic selection of archival audio-visual products is related to the working goal and direction of archivists, as well as the quality of publications and public expectations. When choosing a topic, we should consider social needs, material basis, and editorial strength. Social needs include: First, considering the timeliness of topic selection, the subject matter should be combined with social hotspots and cultural research hotspots. Secondly, pay attention to the strategic theme. The development of archival books and audio-visual products is not only to spread archival documents but also to improve social and cultural quality and make efforts to build cultural power. Finally, choose the pertinence of the subject matter, actively choose the subject matter with strong social value, and excavate and develop it, such as genealogy, intangible cultural heritage, oral history, etc. Material basis refers to the number, type, and cultural value of selected subject files. Only the archives resources with considerable quantity, rich variety, and high social and cultural value have development value. Editor’s strength refers to the team that develops cultural products, including archives, relevant cultural organizations, TV stations, etc., and does what it can according to its team situation. After the topic selection and before the processing, there will be some preparatory work, such as the research of the selected subject and the determination of the material selection outline. The research on the selected subject matter includes the principles and policies related to the subject matter, the analysis of the same type of products, etc. For audio-visual archival cultural products, it also involves the prior interview of documentary interviewees, etc.
② Manufacture and processing. The editing and processing of books-like archival cultural products include the transcription, punctuation and segmentation, title setting, and arrangement of archival documents in the archival cultural library. Transcription of original documents is the first step of processing. Transcription includes manual copying, computer input, and film image intake. Most of China’s historical archives have no punctuation and segmentation, so they need to be properly calibrated to be understood. The title is a preliminary understanding of the content of the article, which needs to be created by combining integrity and literacy. The arrangement is the process of displaying the archival culture in an orderly manner, which can be arranged and displayed according to time, events, and regions. The production of audio-visual archival cultural products includes writing scripts, shooting, and post-production. First of all, by extracting the materials that have been sorted out in the archive culture library, the scripts and scripts are written according to the direction of topic selection. Secondly, according to the script, the script setting for shooting, TV films also need to choose actors. Finally, after the shooting is finished, all the data, images, sounds, etc. are edited and spliced.
3.3.2 Cultural and Creative Products of Archives
According to the “fifth dimension theory of archives” put forward by Yvon Lemay, a Canadian archivist, there is a fifth dimension “Exploitation” besides Activity, purpose, Time and material, and creative development is a new idea of archives development and utilization. By the general definition of museum cultural creative products, cultural creative products are also called cultural derivative products or souvenirs. The cultural and creative products of archives, it is rooted in the collection archives and cultural themes of archives and developed by using modern product design methods and concepts, including stationery, daily necessities, etc. When developing such products, special cultural symbols in archival cultural resources are generally sought for in-depth development, such as special characters, seals, characters, etc., to reflect regional culture, history, and culture, national customs, etc., and the designed products need to be collectible or practical. The development of archival creative products involves the professional knowledge of art design, so most of them are designed and developed by specialized cultural creative enterprises.
4 Design and Promotion of Cultural Products of University Archives Based on Cn-RippleNet Model
Integrated user data, candidate archive files, archive knowledge base, sorting layer, and recall layer together form an archive recommendation system. The organizational structure of the recommendation system is shown in Fig. 10. In the data part, the user’s preference is judged through the establishment of the user’s portrait, and the basis for recommending the model is given. The candidate archive stores all the recommended archive directories and archive data. Because of its huge archive of data to be recommended, its function is to cooperate with the recall layer and user data to conduct the first round of recommendation screening. The knowledge base is the triple set constructed above, which is used to assist the Cn-RippleNet model in recommending archives at the ranking level [28]. Further, determine the recommended list based on the recall layer.
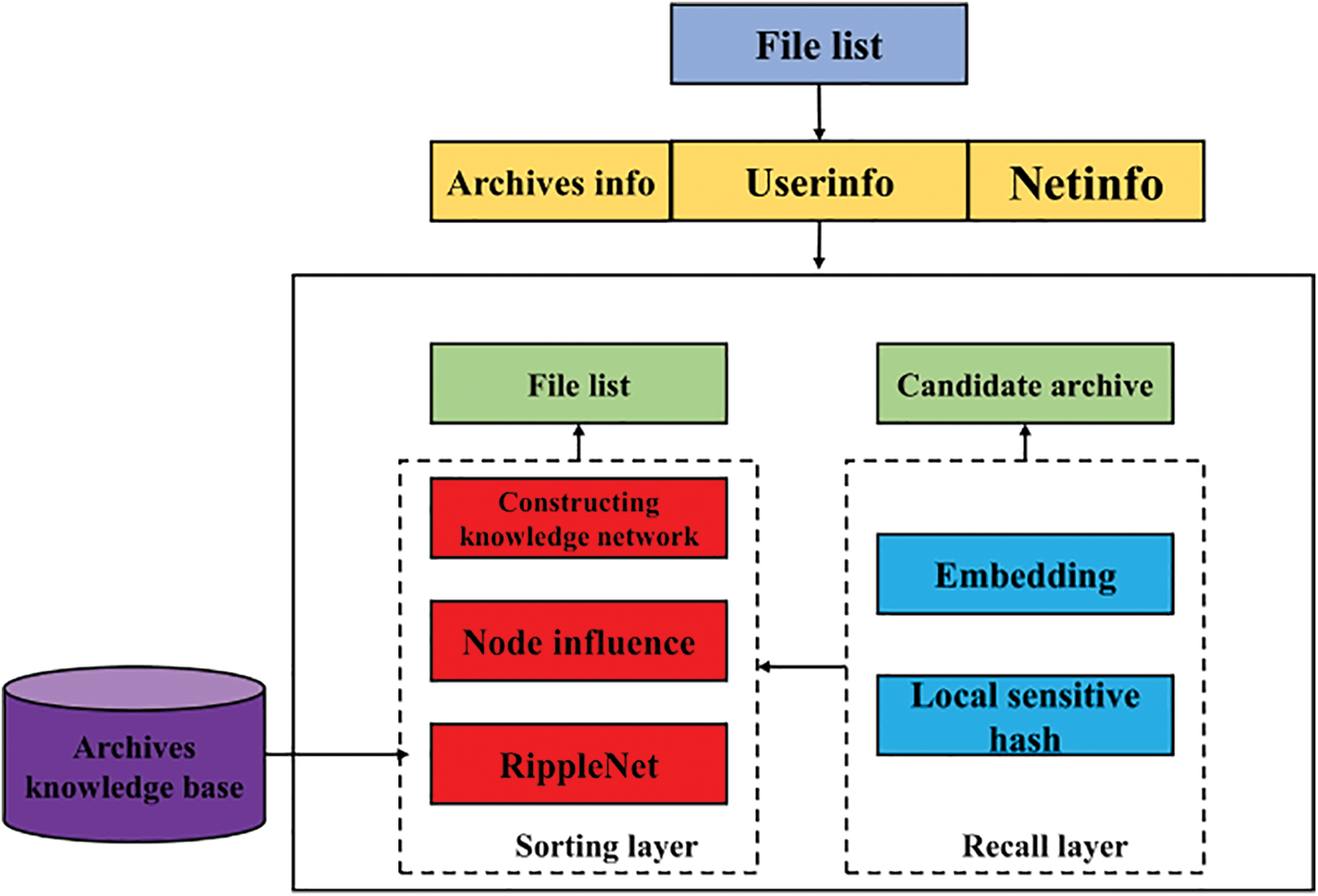
Figure 10: Architecture of archive recommendation system based on Cn-RippleNet model
4.2 User Data Preprocessing Module
If you want to get user data information, you must first build a user information portrait. Through the information filled in when the account is created, we can get the corresponding basic user information, such as gender, age, etc. This part of the information will be recorded and stored in the database as part of the user’s portrait. On this basis, we need to obtain the user’s historical interaction data through the user’s search records, click history, and other human-computer interaction behaviors, and use it as the basis of user preference in the initial recommendation.
There are three kinds of information in the module, namely file information, user information, and network information. Information is the basic information of the files in the candidate archives, including the file name, file type, classification, subordinate department, and other basic information. The user information is all the information entered by the user when registering and logging in, and contains the historical click and search information of the user. The network mainly obtains the user’s T address and confirms the user’s province and city according to the P address. Three kinds of data information are combined into the article portrait and user portrait of the whole recommendation system. The most important recommendation information comes from the data when users search.
The recall layer is a part of the recommendation system. The purpose of the recall layer is to find out a large number of candidate sets from all the items, which are the candidate sets of the items that the user may like, and it is responsible for the first screening of the items. In the recall stage, due to a large amount of data to be screened, a part of it is often screened from all items. Considering the need to improve the efficiency of screening, it takes a simple algorithm with time complexity to screen at the recall level.
Because it is necessary to express each user and each recommended item, the current mainstream methods are vector and embedding [29,30]. Embedding is also used in the previous research, so this method can be used in the whole recommendation system and can be used in the whole recommendation system. However, when calculating the item set with more than one million levels of data, linearly calculating the similarity between Embedding will result in a huge waste of computing resources and time. To solve this problem, quickly find two similar Embedding. In this paper, the most mainstream method to solve approximate Embedding in the industry, local sensitive hashing, is adopted.
Through the operation of the recall layer, the recommendation system has reduced the scale of the candidate item set, and on this basis, we make the final ranking. In this paper, the recommendation method based on the Cn-RippleNet model is considered for file recommendation. In the previous content, we established the archive knowledge base based on the archive directory and archive text according to the construction method of archive knowledge triplet based on deep learning, which will be used as the basis here. As the knowledge map of the Cn-RippleNet algorithm, the ripple diffusion calculation with user preference as the seed set is carried out.
Firstly, a complex network based on an archive knowledge map is constructed, and the subnet extraction algorithm based on the set operation (SNESO) is adopted. According to this algorithm, the triple is traversed, and the largest connected subnet is established, which is convenient to analyze the complex network and obtain its degree value, degree centrality, and other key data. Because of the huge amount of data and the long running time of the algorithm, this paper analyzes and calculates all entity relationships in the form of digital ID, which can speed up the calculation speed of the generation algorithm.
In this paper, a Cn-RippleNet model integrating the influence of complex network nodes is proposed and verified by experiments. It is found that the evaluation index AUC reaches 0.929 when the value of Hop is 2, and the evaluation index AUC is only 0.91 when the value of Hop is 4, which shows that the impact of Hop number on performance is not as high as possible, and it can also be concluded that the value of Dim is not as high as possible. The model networked the domain knowledge map calculated the influence of the entities in the knowledge map and integrated it into the knowledge map network, which solved the problem that RippleNet didn’t consider the influence of key nodes on the recommendation results, thus increasing the recommendation accuracy. Based on the Cn-RippleNet model, a file recommendation system is constructed. In the sorting layer, the Cn-RippleNet model is used to simulate the user’s preferences, and the results of the recall layer are sorted to get the final sorting result. In this paper, the node influence algorithm is not considered, so in future work, we can consider refining the relationship of the largest connected subnet of the knowledge map and giving different weights to different relationships. A more novel node influence algorithm can also be considered. The difficulty of this study lies in the proposal of a recommendation model that integrates the influence of complex network nodes, and the verification of this model. The limitation of the model proposed in this paper is that the relationship between the largest connected subnets of the knowledge map is not very detailed, therefore, the next step is to refine the relation of the largest connected subnet of the knowledge map, giving different weights to different relationships, and consider adding a more novel node influence algorithm.
Funding Statement: The authors received no specific funding for this study.
Availability of Data and Materials: The experimental data used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. A. Flinn, “Community histories, community archives: Some opportunities and challenges,” Journal of the Society of Archivists, vol. 28, no. 2, pp. 129–156, 2017. [Google Scholar]
2. Z. Lv and H. Shi, “The exploring on university archives management system based on information system,” Journal of Physics: Conference Series, vol. 1150, no. 3, pp. 032017, 2020. [Google Scholar]
3. S. G. Gunanto, “Preliminary identification of Indonesian digital heritage archives (IDHA) as a digital preservation for indonesian culture,” 2020. [Online]. Available: SSRN,3807631 [Google Scholar]
4. J. M. Yap, “The role of academic archives: Prospects and possibilities,” Journal of the Society of Archivists, vol. 11, no. 3, pp. 12–21, 2018. [Google Scholar]
5. Y. J. Chiu, Y. C. Hu and J. J. Du, “Evaluating art licensing for digital archives using fuzzy integral,” Mathematics, vol. 8, no. 12, pp. 2206, 2020. [Google Scholar]
6. M. J. Eischen, C. Spiker and N. Wallin, “Nostalgic femininity/from flowers to warriors: Japanese woodblock prints in the St,” Catherine University Archives & Special Collections, vol. 8, no. 12, pp. 16–18, 2019. [Google Scholar]
7. J. Hu, X. Weng, L. Yang, S. Lei and H. Niu, “Centrifugal modeling test on failure characteristics of soil-rock mixture slope under rainfall,” Engineering Failure Analysis, vol. 142, no. 10, pp. 106775, 2022. [Google Scholar]
8. H. Li and J. Yin, “Optimization of university archives management under the application of blockchain technology in the digital age,” Mobile Information Systems, vol. 8, no. 5, pp. 44–60, 2022. [Google Scholar]
9. R. Krishnaswamy, K. Subramaniam, V. Nandini, K. Vijayalakshmi, S. Kadry et al., “Metaheuristic based clustering with deep learning model for big data classification,” Computer Systems Science and Engineering, vol. 44, no. 1, pp. 391–406, 2023. [Google Scholar]
10. A. Ghezzi, “Filing the world: Archives as cultural heritage and the power of remembering,” International Journal of Constitutional Law, vol. 19, no. 5, pp. 1738–1755, 2021. [Google Scholar]
11. E. Henningsen and H. Larsen, “The mystification of digital technology in Norwegian policies on archives, libraries and museums: Digitalization as policy imperative,” Current Cultural Research, vol. 4, no. 22, pp. 9–16, 2020. [Google Scholar]
12. S. Parrinello and F. Picchio, “Documenting the cultural heritage routes. The creation of informative models of historical russian churches on upper kama region,” International Archives of the Photogrammetry, vol. 118, no. 25, pp. 21–28, 2019. [Google Scholar]
13. G. Arrigoni and T. Schofield, “Framing collaborative processes of digital transformation in cultural organisations: From literary archives to augmented reality,” Museum Management and Curatorship, vol. 35, no. 4, pp. 424–445, 2020. [Google Scholar]
14. F. Wardani, “Finding a place for art archives: Reflections on archiving Indonesian and Southeast Asian art,” Wacana, vol. 20, no. 2, pp. 209–232, 2019. [Google Scholar]
15. J. Laznow, “The angel and the cholent: Food representation from the israel folktale archives,” Journal of American Folklore, vol. 135, no. 537, pp. 360–362, 2022. [Google Scholar]
16. I. Ibrus and M. Ojamaa, “The creativity of digital (audiovisual) archives: A dialogue between media archaeology and cultural semiotics,” Theory, Culture & Society, vol. 37, no. 3, pp. 49–70, 2020. [Google Scholar]
17. J. A. Konstan, B. N. Miller and D. Maltz, “Grouplens: Applying collaborative filtering to usenet news,” Communications of the ACM, vol. 40, no. 3, pp. 77–87, 1997. [Google Scholar]
18. Y. Tian, B. Zheng and Y. Wang, “College library personalized recommendation system based on hybrid recommendation algorithm,” Procedia the International Academy for Production Engineering, vol. 83, no. 4, pp. 490–494, 2019. [Google Scholar]
19. C. T. Chisita, M. Shoko and A. M. Rusero, “Media, libraries, and archives: Unearthing the missing link in zimbabwe,” Cooperation and Collaboration Initiatives for Libraries and Related Institutions. IGI Global, vol. 51, no. 6, pp. 243–272, 2020. [Google Scholar]
20. Y. Ma, B. Dai and B. Ding, “University archives autonomous management control system under the internet of things and deep learning professional certification,” Computational Intelligence & Neuroscience, vol. 2022, no. 5, pp. 9–16, 2022. [Google Scholar]
21. E. Tsvetkova, “Mobile access to digitalised objects of cultural and historical heritage,” ICERI2019 Proceedings. IATED, vol. 8, no. 5, pp. 4814–4818, 2019. [Google Scholar]
22. Y. Luo, B. Sha and T. Xu, “A recommended method based on the weighted RippleNet network mode,” Journal of Physics: Conference Series. IOP Publishing, vol. 2025, no. 1, pp. 012011, 2021. [Google Scholar]
23. M. Ballarin, C. Balletti and P. Vernier, “Replicas in cultural heritage: 3D printing and the museum experience,” The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, vol. 42, no. 5, pp. 2, 2018. [Google Scholar]
24. Z. G. Stein, D. N. Khey and S. T. Jordan, “Archives and the incarceral state,” Academic Libraries and Collaborative Research Services, vol. 2, no. 1, pp. 125, 2022. [Google Scholar]
25. Y. Luo, T. Xu and Z. Xu, “Recommendation method based on Cn-RippleNet model of joint complex network,” Journal of Northwestern Polytechnical University, vol. 39, no. 5, pp. 1070–1076, 2021. [Google Scholar]
26. N. Saurombe, “Raising awareness about public archives in East and Southern Africa through social media,” Research Anthology on Applying Social Networking Strategies to Classrooms and Libraries. IGI Global, vol. 4, no. 1, pp. 1427–1448, 2023. [Google Scholar]
27. Y. J. Wong, S. Y. Wang and E. M. Klann, “The emperor with no clothes: A critique of collectivism and individualism,” Archives of Scientific Psychology, vol. 6, no. 1, pp. 251–260, 2018. [Google Scholar]
28. I. Rotherham, “Forest & wood as historic archives of people, place & past,” European Forests Our Cultural Heritage, vol. 11,no. 4, pp. 7–10, 2018. [Google Scholar]
29. K. Santos, E. Loures and F. Piechnicki, “Opportunities assessment of product development process in Industry 4. 0,” Procedia Manufacturing, vol. 11, no. 2, pp. 1358–1365, 2017. [Google Scholar]
30. S. Vu and Q. Le, “A deep learning based approach for context-aware multi-criteria recommender systems,” Computer Systems Science and Engineering, vol. 44, no. 1, pp. 471–483, 2023. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools