
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Deep Learning Driven Feature Based Steganalysis Approach
1 College of Computer Science and Information Engineering, Hefei University of Technology, Hefei, 230009, China
2 College of Information Engineering, Anhui Broadcasting Movie and Television College, Hefei, 230011, China
3 Department of Informatics, Faculty of Natural & Mathematical Sciences, King’s College London, London, WC2R2LS, UK
* Corresponding Author: Baohong Ling. Email:
Intelligent Automation & Soft Computing 2023, 37(2), 2213-2225. https://doi.org/10.32604/iasc.2023.029983
Received 16 March 2022; Accepted 25 May 2022; Issue published 21 June 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The goal of steganalysis is to detect whether the cover carries the secret information which is embedded by steganographic algorithms. The traditional steganalysis detector is trained on the stego images created by a certain type of steganographic algorithm, whose detection performance drops rapidly when it is applied to detect another type of steganographic algorithm. This phenomenon is called as steganographic algorithm mismatch in steganalysis. To resolve this problem, we propose a deep learning driven feature-based approach. An advanced steganalysis neural network is used to extract steganographic features, different pairs of training images embedded with steganographic algorithms can obtain diverse features of each algorithm. Then a multi-classifier implemented as lightgbm is used to predict the matching algorithm. Experimental results on four types of JPEG steganographic algorithms prove that the proposed method can improve the detection accuracy in the scenario of steganographic algorithm mismatch.Keywords
Steganography is a technique to hide secret information in public carriers (text, image, audio, video etc) for specific purposes [1–6], and this secret information is difficult to be identified with human eyes and technical means. Digital images [7–9], especially JPEG (Joint Photographic Experts Group) images, are one of the most widely spread media on the internet. The corresponding JPEG steganographic algorithms are developing rapidly, from traditional embedding algorithms such as Outguess [10], MB [11] and nsF5 [12] to the adaptive algorithms based on syndrome-tellis codes (STC) [13] technique, such as J-UNIWARD [14], UED [15] and UERD [16], which make steganalysis more difficult.
As the opposite of steganography, the goal of steganalysis is to detect whether the cover carries secret information. With the rapid development of machine learning (including deep learning) [17–21], steganalysis models began to be constructed using these tools. Kodovský et al. proposed the ensemble classifier implemented as random forests to build a steganalyzer with improved detection accuracy [22], Zeng et al. proposed a hybrid deep learning framework for large-scale JPEG steganalysis [23], and it was the first time that quantization and truncation were applied to deep learning based steganalysis. More recently, Boroumand et al. proposed SRNet [24], which can automatically compute noise residuals without using high-pass filters and obtain superior performance. However, in the real environment, we do not know which steganographic algorithm is used for embedding in advance. Without this important prior knowledge, we will face the problem of steganographic algorithm mismatch, and it is difficult to train and obtain the corresponding effective steganalysis model.
To solve or alleviate the algorithm mismatch problem, Pevný et al. summarized some approaches for the construction of universal steganalysis [25], the one-against-all classifier was trained on the image set which contains the stego images created by a variety of known (existing) steganographic algorithms, the one-class classifier used anomaly detection to identify stego images and the approach of multi-classifier was trained by a group of binary classifiers. For example, to construct a support vector machine (SVM) classifier for recognizing which steganographic algorithm was used [26–28], Pevný et al. used different handcrafted features such as calibrated DCT (Discrete Cosine Transform) features [29] and Markov features [30]. However, with the growth of feature dimensions, SVM is no longer the most appropriate choice. At the same time, deep neural network shows the excellent capabilities of feature extraction, and this end-to-end method does not need handcrafted features anymore.
Based on transfer learning, Kong et al. designed an iterative multi-order feature alignment (IMFA) algorithm to reduce the maximum mean discrepancy of feature distributions between training and testing sets [31]. Feng et al. presented a contribution-based feature transfer (CFT) algorithm to learn two transformations to transfer learning set features by evaluating both the sample feature and dimensional feature [32]. In this paper, we propose a different approach to relieve the impacts of steganographic algorithm mismatch. We first use the deep convolutional neural network as a feature extractor to obtain more representative steganographic features from different dimensions, then train a multi-classifier for different steganographic features, and finally use the steganalysis model based on the matched steganographic algorithm to detect the suspicious images. We conduct experiments on several classical JPEG steganographic algorithms which contain both traditional and adaptive algorithms. The experimental results show that the proposed method significantly improves the detection accuracy of steganalysis in the case of steganographic algorithm mismatch.
Section 2 describes the details of the proposed method. Section 3 presents the experimental configuration and results, and Section 4 concludes this paper.
In this section, we introduce our proposed approach in detail. First, we construct a steganographic library consisting of different types of stego and cover images, then we use convolutional neural networks trained by different pairs of training images to extract diverse features automatically. Based on the feature library, we train a multi-classifier for different steganographic algorithms. Finally, we estimate the most suspicious steganography method used in the testing images and detect the testing images by the matched steganalysis model. Fig. 1 shows the framework of the proposed blind steganalysis method.
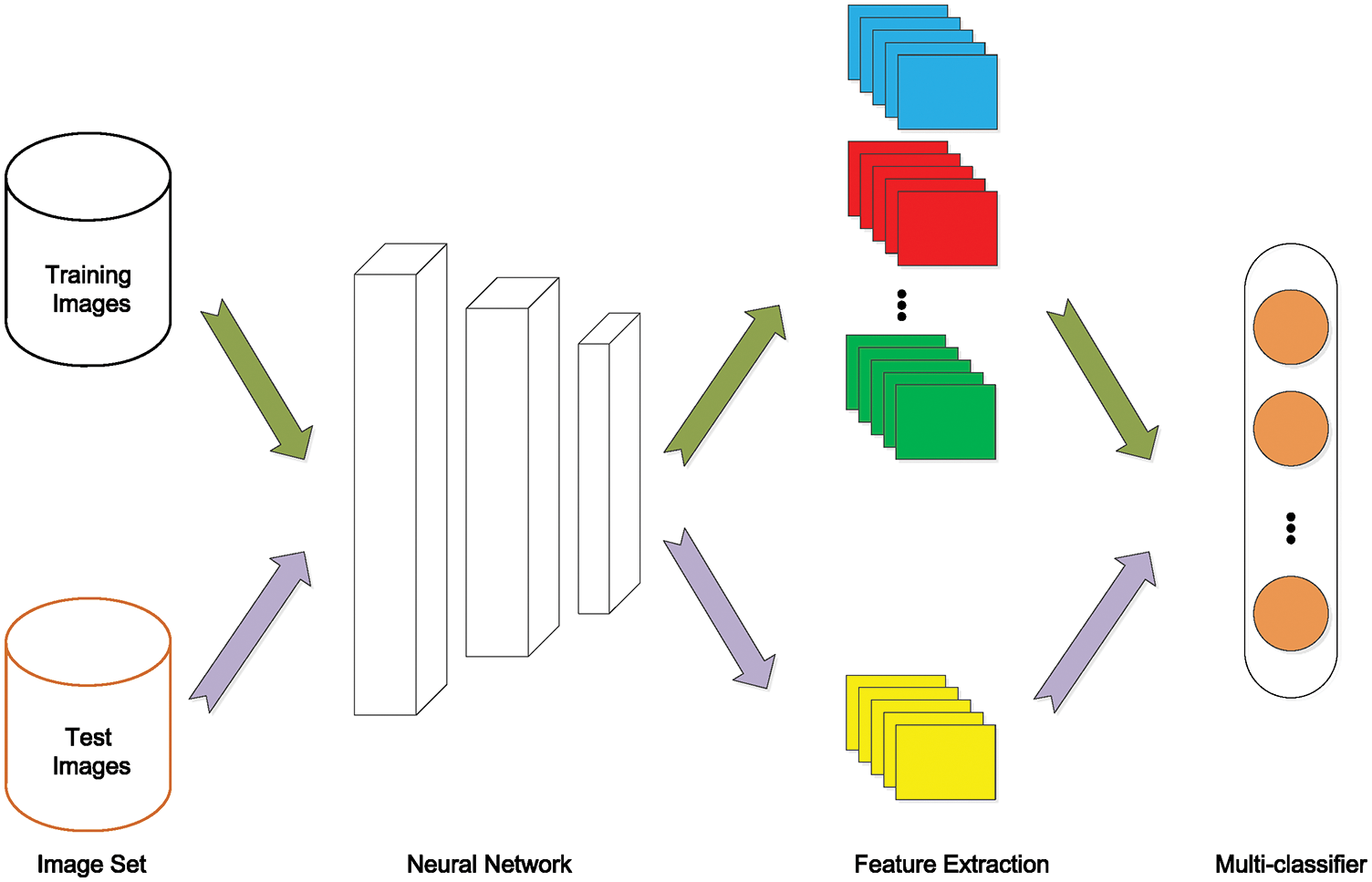
Figure 1: The framework of the proposed deep learning driven feature-based steganalysis method
Here, the symbol
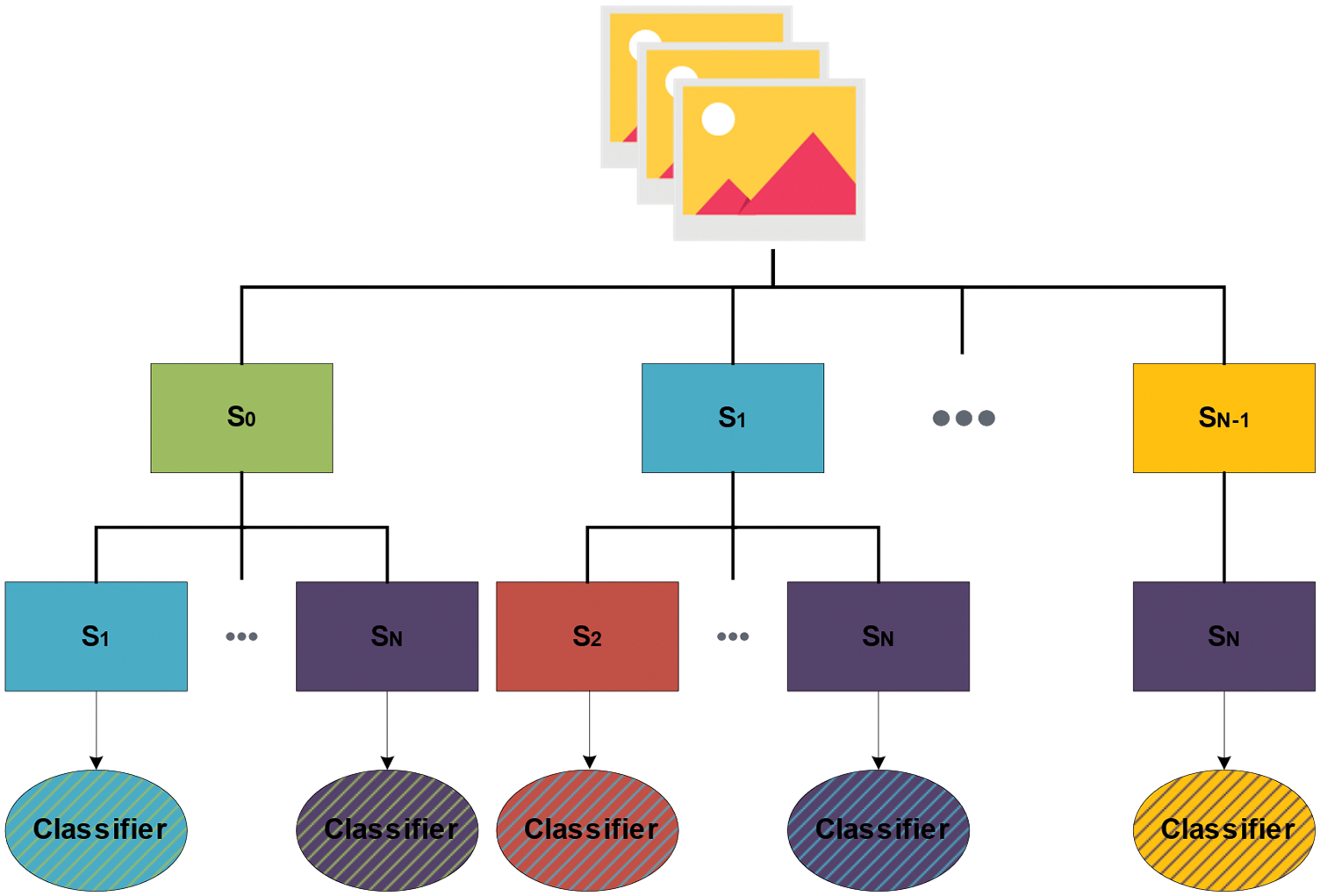
Figure 2: Different pairs of stego images to train classifiers
As for the testing set, all
Due to its excellent detection ability, we use SRNet [24] as our feature extractor and the structure of feature extractor is shown in Fig. 3. We intercept the feature map of the twelfth layer of SRNet as steganography features. To obtain more diverse image feature representations, we use different reduction strategies, including max, min and mean as shown in Fig. 4. Combining these sub-features can produce new features such as max_mean, min_mean, max_min and max_min_mean. The combination is done by directly concatenating different types of features. We conduct experiments presented in Section 3 to choose the optimal sub-feature combination.
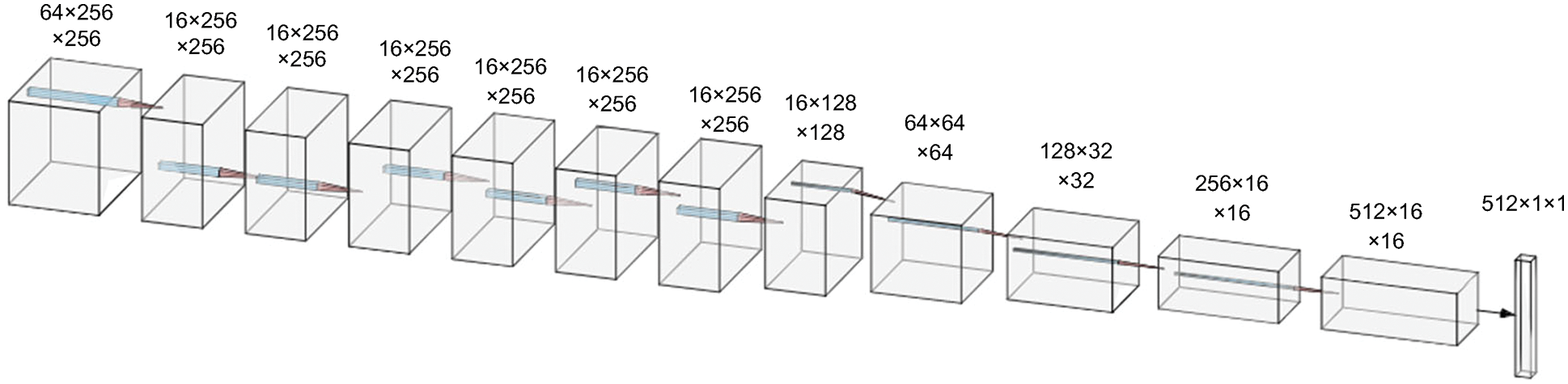
Figure 3: The structure of feature extractor
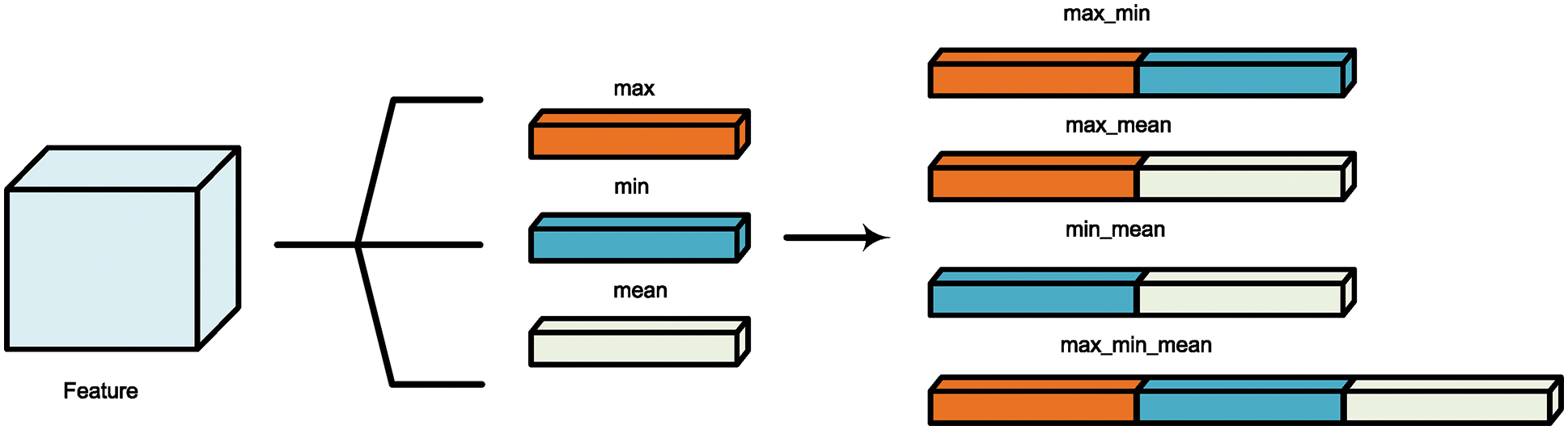
Figure 4: Different reduction strategies of feature map
We train a multi-classifier fed by
where

Figure 5: Algorithm to obtain the best matched steganographic algorithm
Finally, we use the model of the best matched steganographic algorithm to detect test images. We can achieve a relatively high accuracy as without algorithm mismatching if the matching result is correct.
In the experiments, the Graphics card we use is RTX2080 TI with 11 G memory. The raw dataset is BOSSbase 1.01 [34], which has a total of 10000 grayscale images. These images are divided into three parts, 60% as a training set and the rest are equally used as a validation set and a testing set, respectively.
The images are first resized from their original size 512 × 512 to 256 × 256, then are compressed with JPEG quality factors (QF) 75 and 95. The embedding rates are set from 0.1 to 0.4 bits per non-zero AC DCT coefficient (bpnzac). For each combination of embedding rate and quality factor, we use four types of steganographic algorithms in the frequency domain, J-UNIWARD [14], UED [15], UERD [16] and nsF5 [12], and the steganographic algorithm feature library is composed of five types of steganographic algorithm features (including cover). Totally, there are 6000 × 5 × 4 × 2 = 240000 groups of stego features.
All feature extractors are built via curriculum training [35]. We first train the network for 0.4 bpnzac as it is the easiest task for extractors, and these parameters are seeded for the network for 0.3 bpnzac, and the rest can be inferred in the same manner. The feature extractors are trained for 200 k iterations with an initial learning rate of 0.001 and another 50 k iterations with the learning rate are cut to one-tenth of the original.
There are some special features in the training, the network for J-UNIWARD with JPEG quality factor 95 at 0.4 bpnzac is seeded by the network trained for J-UNIWARD with JPEG quality factor 75 at 0.4 bpnzac. When we train the network of two types of stego images, we experience convergence problems, so we initialize the network with the parameters trained by stego and cover images as usual.
In the experiments, we choose some traditional classifiers. We take the testing set with QF 95 and embedding rate 0.1 bpnzac as an example to compare their effects. The matching ratios of experiments are shown in Table 1. The higher the value, the stronger the confidence of being successfully matched. Red numbers indicate that the corresponding algorithm predictions are not accurate. Support vector machine, lightgbm and neural network are denoted as SVM, LGB and NN, respectively. We use the default parameters of SVM and LGB in this experiment. As for NN, we design a three-layer fully connected network with activation function of ReLU [36], a loss function of cross entropy and an optimizer of RMSprop [37]. Among these classifiers, lightgbm can match the steganography algorithm most correctly and achieve a highest confidence level, so we use lightgbm as our multi-classifier.
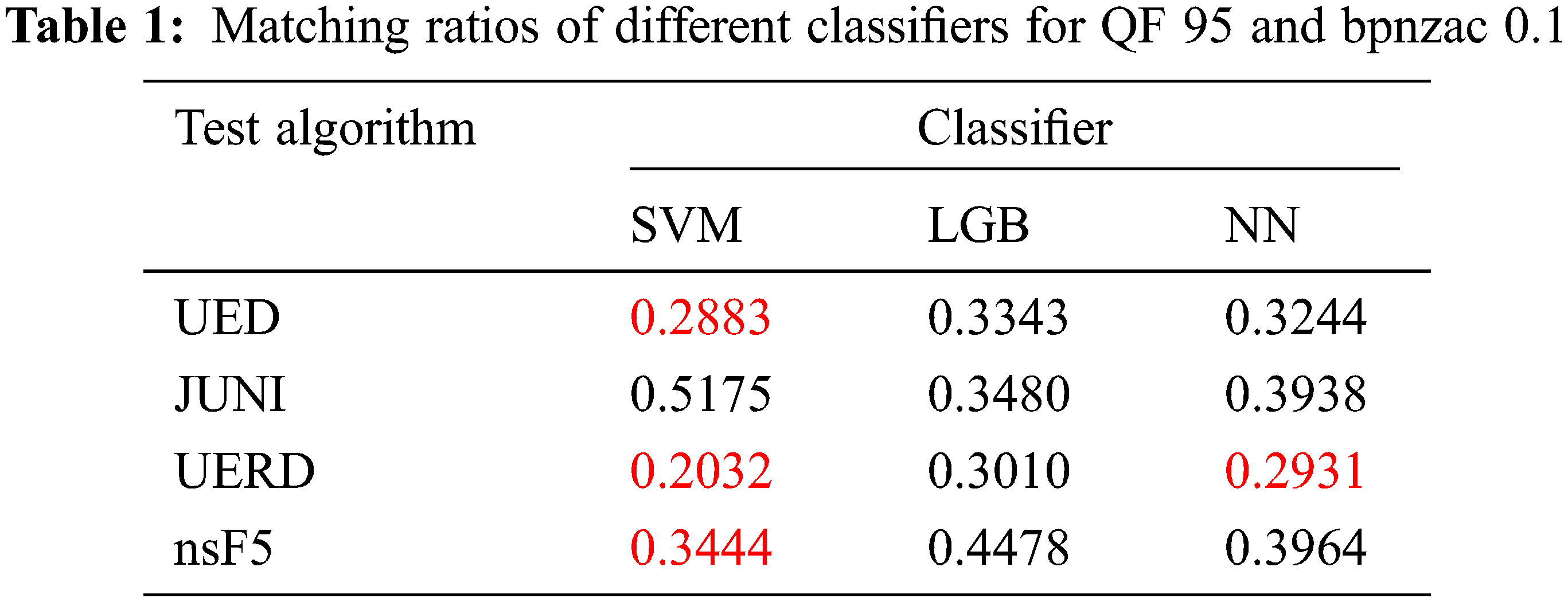
3.3 Optimal Sub-Feature Combination
To obtain more diverse representations of image features, we conduct experiments to compare the matching performance of steganographic algorithm by using different combinations of sub-features. We also take the testing set with QF 95 and embedding rate 0.1 bpnzac as an example. Figs. 6–9 show the matching results of different steganographic algorithms. The results show that all the combinations of sub-features achieve excellent performance except the combination of min_max. Considering the time consumption, we prefer to choose the single sub-feature. Among the three single sub-features, we use sub-feature mean in the following experiments because it has the most powerful capability of matching steganographic algorithm.
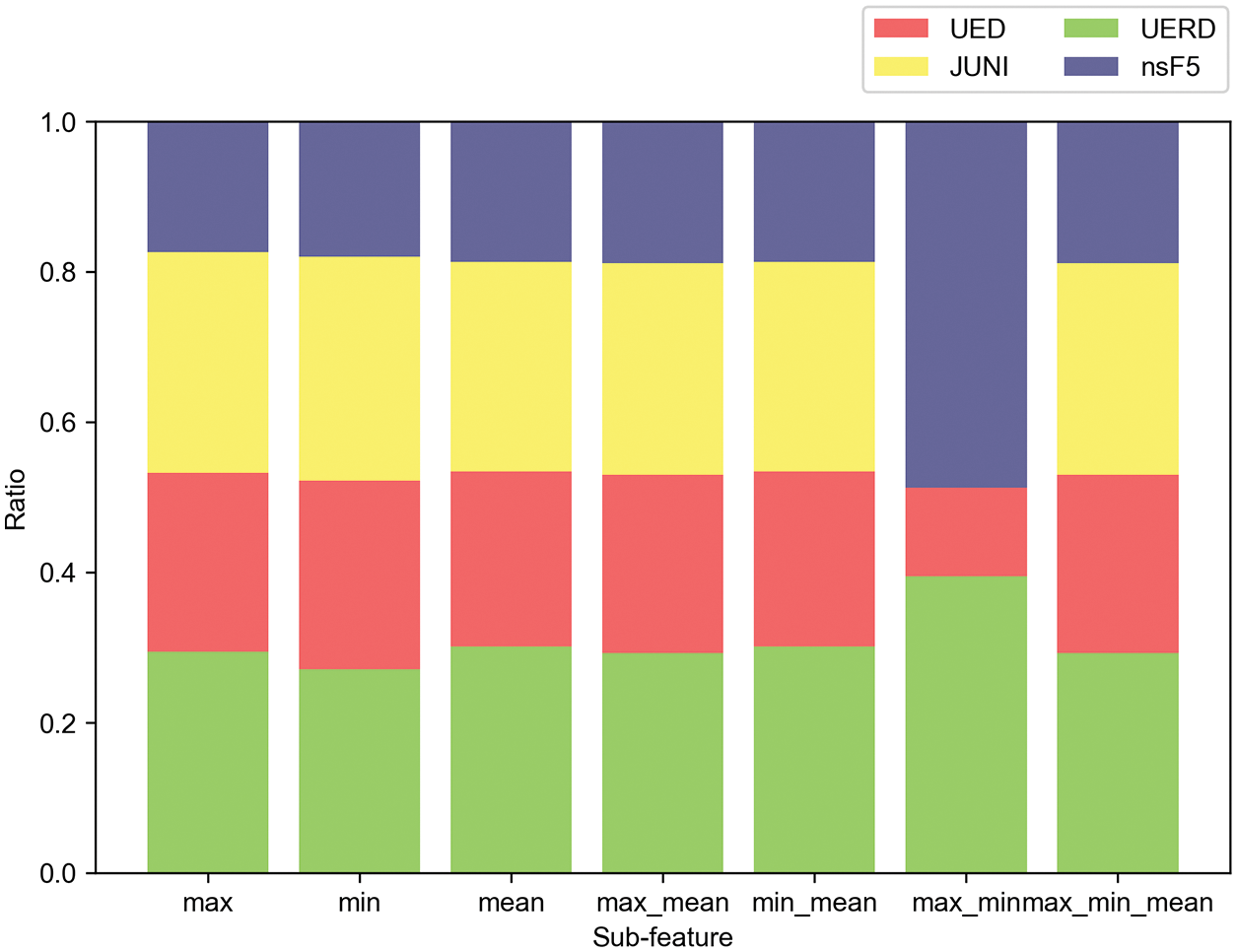
Figure 6: Matching ratio of each sub-feature combination for UERD
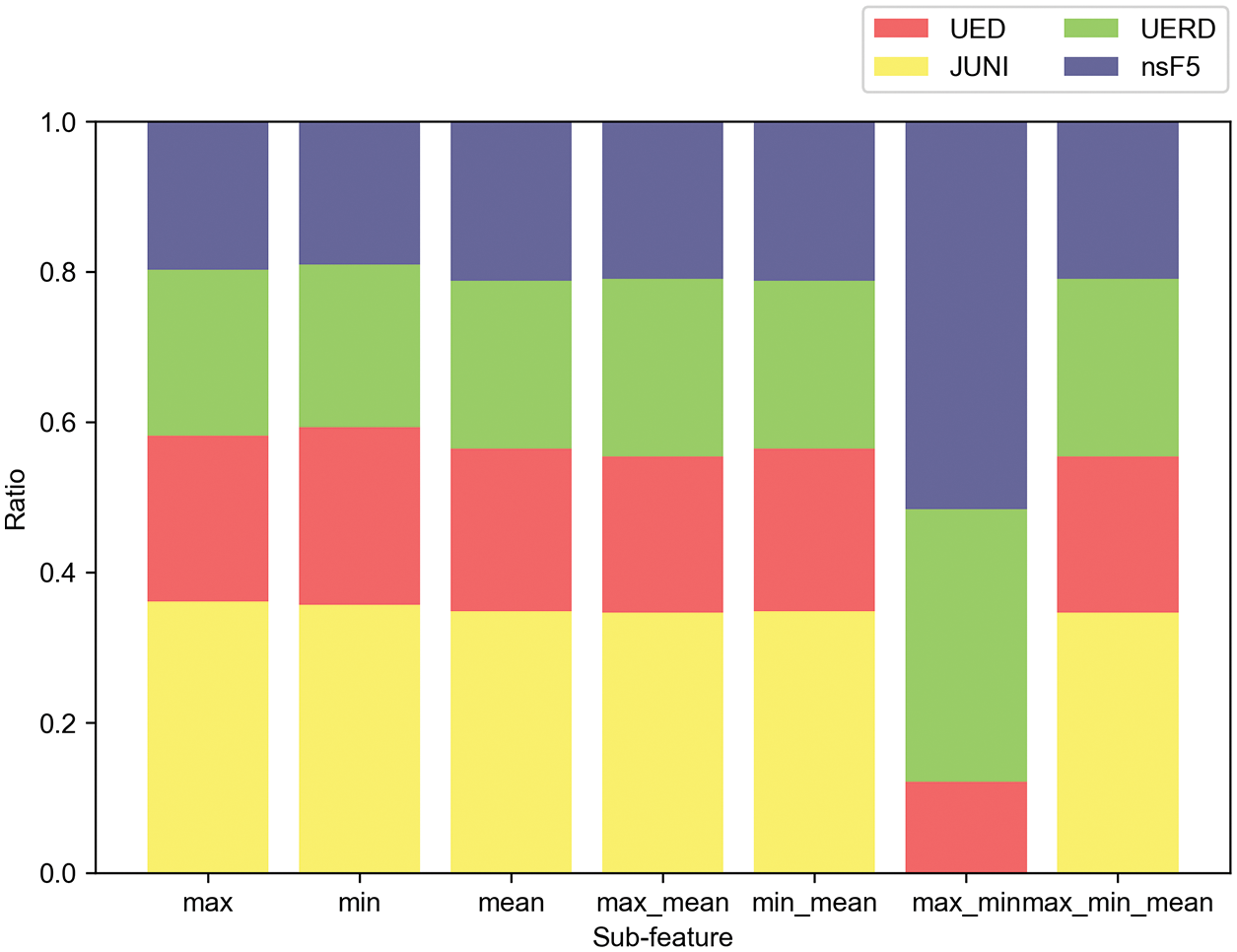
Figure 7: Matching ratio of each sub-feature combination for JUNI
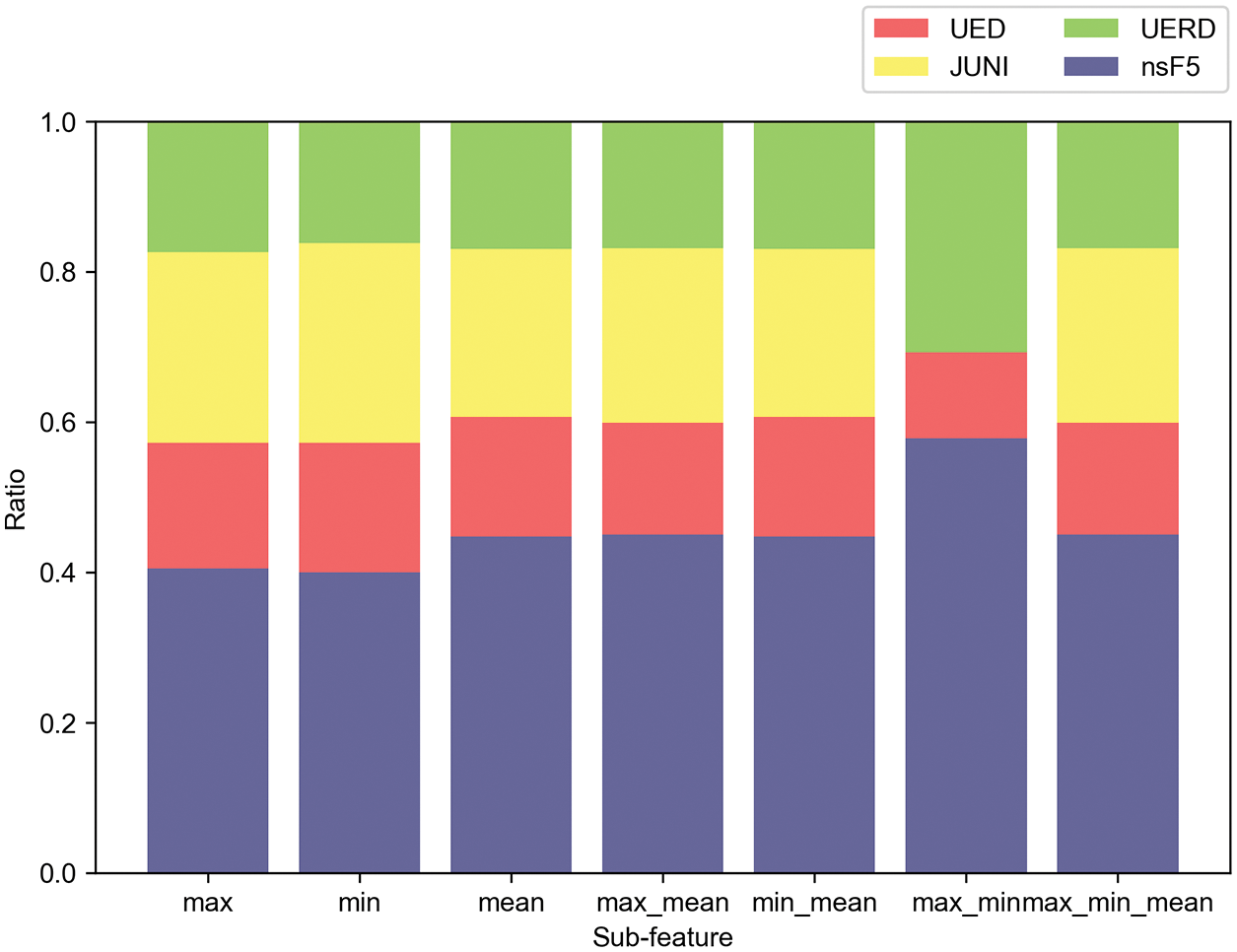
Figure 8: Matching ratio of each sub-feature combination for nsF5
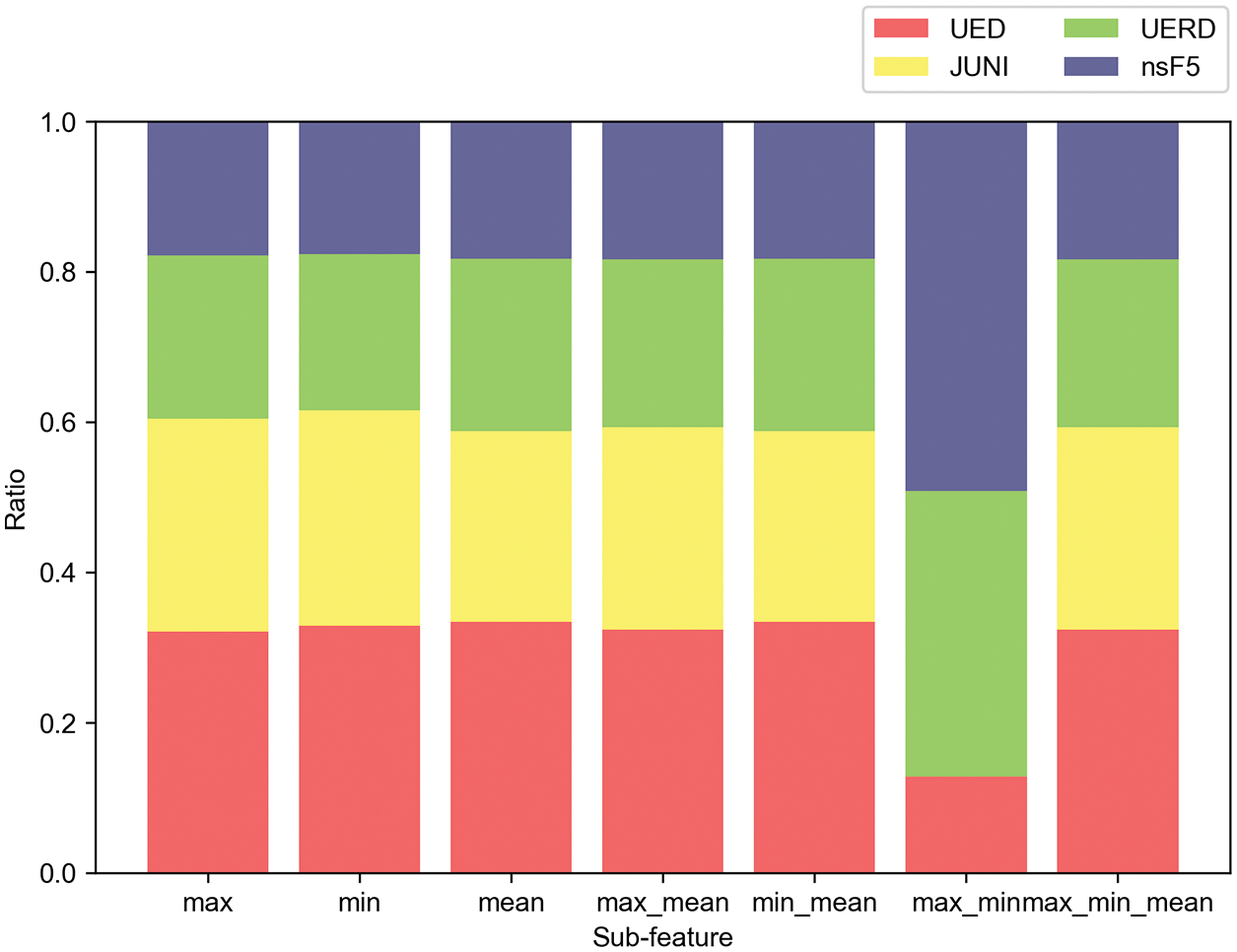
Figure 9: Matching ratio of each sub-feature combination for UED
3.4 Steganography Matching Results
In this section, we conduct the experiments to verify the effectiveness of the steganographic algorithm matching method. In detail, for each of the four steganographic algorithms, J-UNIWARD, UED, UERD and nsF5, we use all 2000 pairs of images with cover images coming from the aforementioned testing set. The experiments of different QFs and embedding rates are conducted separately. Algorithm J-UNIWARD is denoted as JUNI. Tables 2 and 3 show the matching results of the four JPEG steganographic algorithms when QF = 75 and QF = 95, respectively.
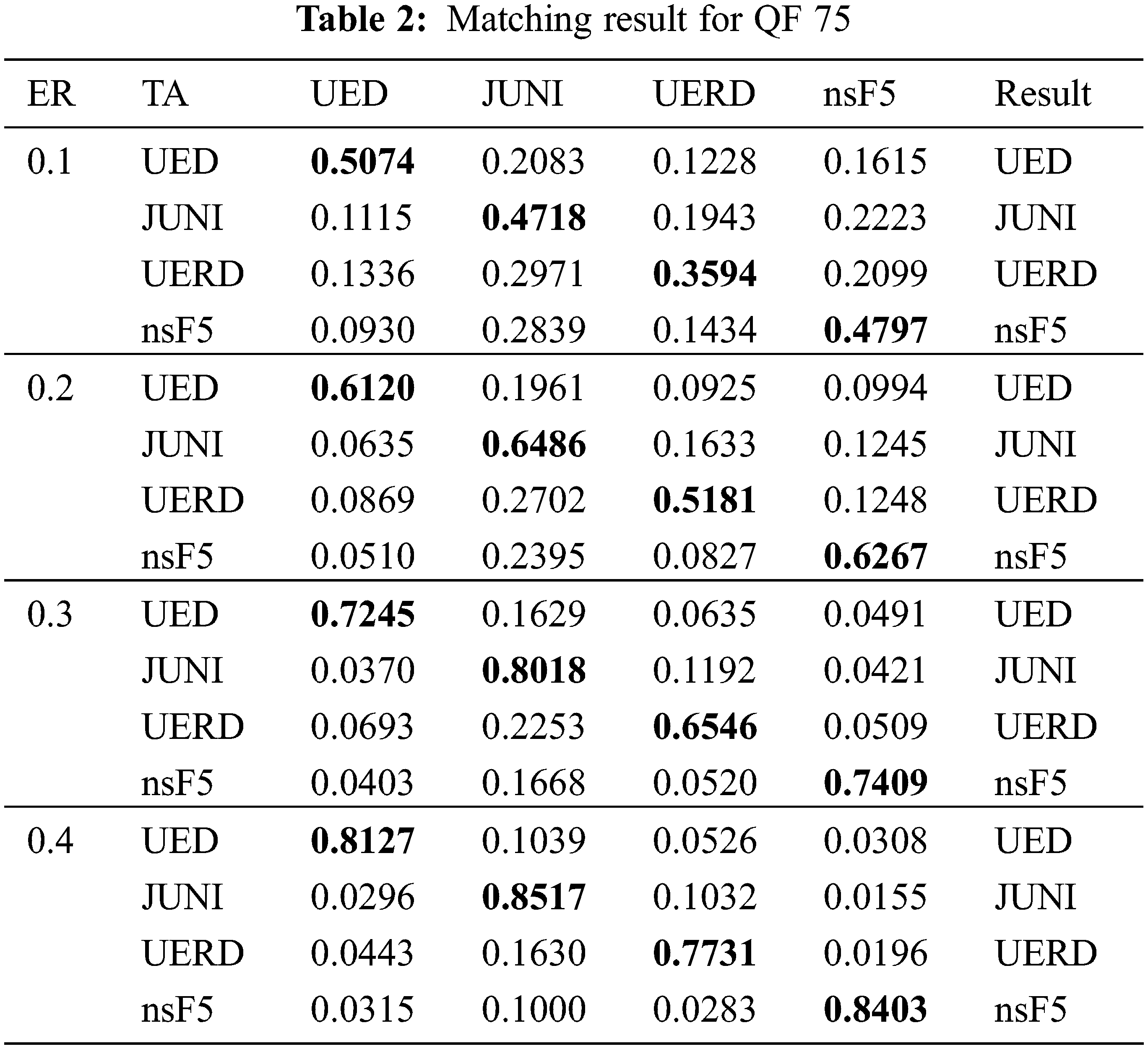
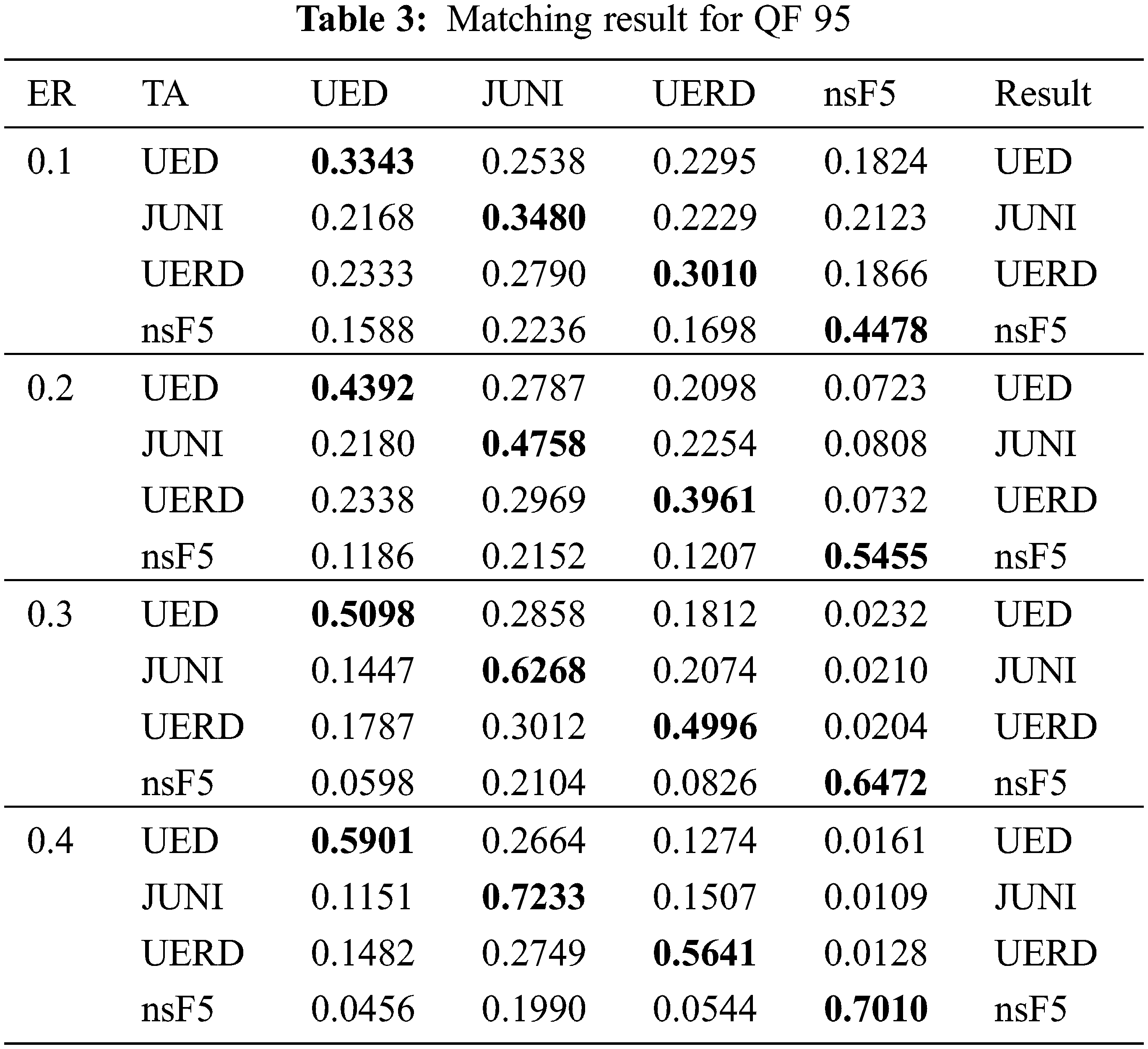
For both Tables of 2 and 3, the first column
3.5 Blind Steganalysis Results
In this section, we use our proposed method to evaluate the detection accuracy of steganalysis in the case of algorithm mismatch. We compare our work with state-of-the-art works, including the subspace learning-based method [38] and SRNet with algorithm mismatch. The detection performance is measured as follows:
Tables 4 and 5 present the detection results with QFs 75 and 95 of 0.1 bpnzac, respectively. As we can see in both tables, our method has a significant improvement over the detection of SRNet with algorithm mismatch, the performances of different steganographic algorithms are improved by more than 15% with QF 75 and approximately 10% with QF 95 averagely. Compared with the method proposed by [38], our method also achieves better performance in the majority of cases. We also conduct experiments on other conditions. Table 6 presents the detection results with embedding rates ranging from 0.2 to 0.4, the first column


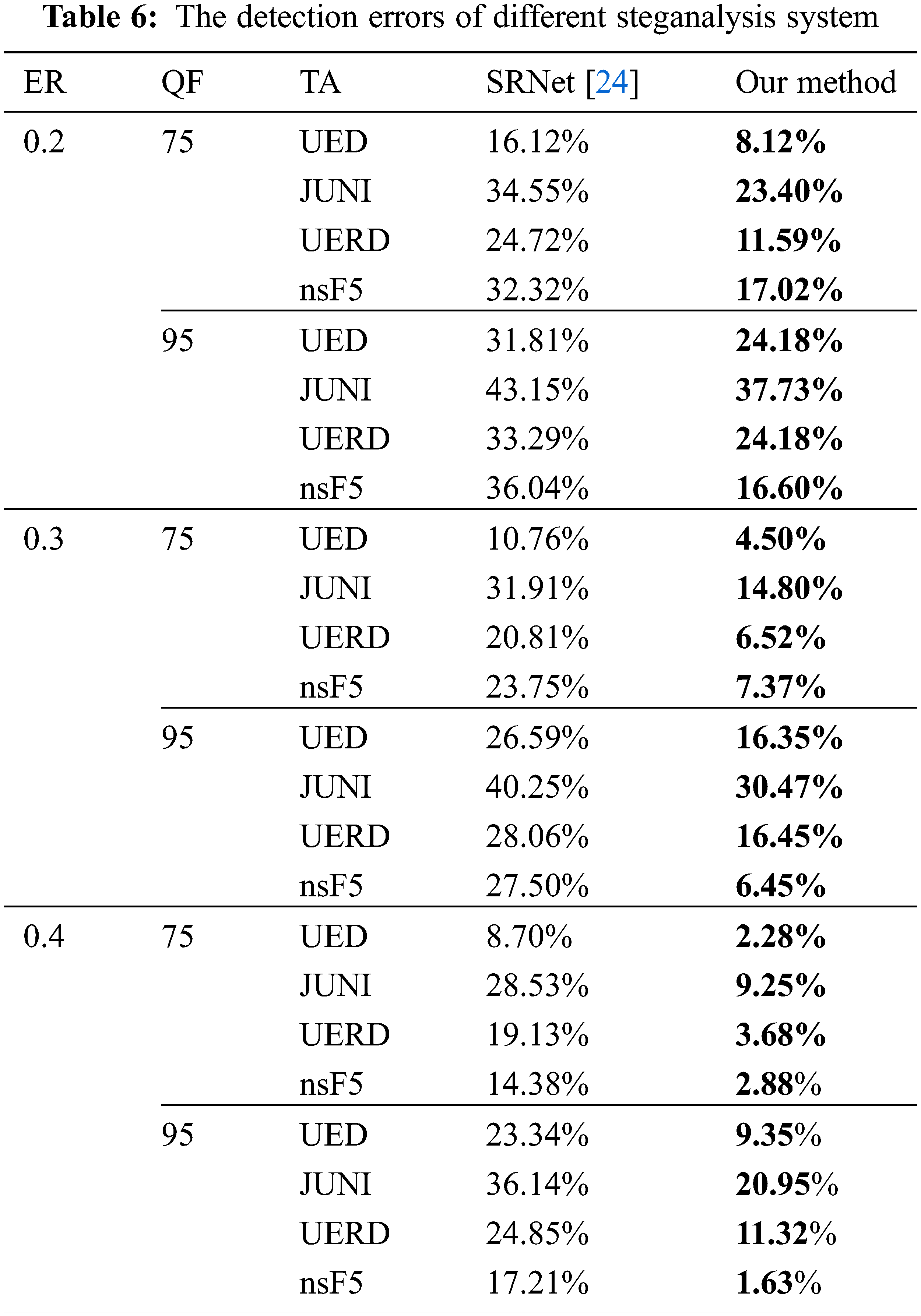
The core of our method is to extract multi-dimensional steganographic features so that the multi-classifier can match the steganographic algorithm of the testing set. The reason why matching can be successful is that for each steganographic algorithm, we have the features extracted by the feature extractor obtained through training by pairs, which can help multi-classifier to distinguish different steganographic algorithms. When the feature extractor does not extract any useful features, the multi-classifier can only produce random prediction, and the probability of each steganography algorithm is
In this paper, we propose a deep learning driven feature-based multi-classifier model to solve the steganalysis problem in the case of algorithm mismatch. Representative steganographic features extracted by neural networks are designed to train a multi-classifier for finding the most matched steganographic algorithm, then the model trained by this steganographic algorithm is used to detect the test images. Experimental results show that the proposed method outperforms state-of-the-art works significantly.
However, this method still has some problems, for example, the process of feature extracting takes a long time because deep neural networks need to be trained, and it can only handle steganographic algorithms that are already known. Therefore, designing a lightweight network to extract the features without the loss of accuracy is one of our future works. In addition, implementing incremental learning to deal with new steganographic algorithms is also under consideration.
Funding Statement: This work was supported by the National Natural Science Foundation of China (NSFC) under grant No. U1836102, Anhui Science and Technology Key Special Program under the grant No.201903a05020016, and 2020 Domestic Visiting and Training Program for Outstanding Young Backbone Talents in Colleges and Universities under the grant No. gxgnfx2020132.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. S. Dhawan and R. Gupta, “Analysis of various data security techniques of steganography: A survey,” Information Security Journal: A Global Perspective, vol. 30, no. 2, pp. 63–87, 2021. [Google Scholar]
2. L. Shi, Z. Wang, Z. Qian, N. Huang, P. Puteaux et al., “Distortion function for emoji image steganography,” Computers, Materials & Continua, vol. 59, no. 3, pp. 943–953, 2019. [Google Scholar]
3. Y. Tong, Y. Liu, J. Wang and G. Xin, “Text steganography on RNN-generated lyrics,” Mathematical Biosciences and Engineering, vol. 16, no. 5, pp. 5451–5463, 2019. [Google Scholar] [PubMed]
4. S. Rahman, F. Masood, W. U. Khan, N. Ullah and F. Qudus, “A novel approach of image steganography for secure communication based on lsb substitution technique,” Computers, Materials & Continua, vol. 64, no. 1, pp. 31–61, 2020. [Google Scholar]
5. A. M. Alhomoud, “Image steganography in spatial domain: current status, techniques, and trends,” Intelligent Automation & Soft Computing, vol. 27, no. 1, pp. 69–88, 2021. [Google Scholar]
6. D. Datta, L. Garg, K. Srinivasan, A. Inoue, G. T. Reddy et al., “An efficient sound and data steganography based secure authentication system,” Computers, Materials & Continua, vol. 67, no. 1, pp. 723–751, 2021. [Google Scholar]
7. J. Wang, M. Cheng, P. Wu and B. Chen, “A survey on digital image steganography,” Journal of Information Hiding and Privacy Protection, vol. 1, no. 2, pp. 87–93, 2019. [Google Scholar]
8. A. Baumy, A. D. Algarni, M. Abdalla, W. El-Shafai, F. E. Abd EI-Samie et al., “Efficient forgery detection approaches for digital color images,” Computers, Materials & Continua, vol. 71, no. 2, pp. 3257–3276, 2022. [Google Scholar]
9. Z. Yan, P. Yang, R. Ni, Y. Zhao and H. Qi, “CNN-based forensic method on contrast enhancement with JPEG post-processing,” Computers, Materials & Continua, vol. 69, no. 3, pp. 3205–3216, 2021. [Google Scholar]
10. N. Provos, “Defending against statistical steganalysis,” in Proc. Usenix Security Symp., Washington DC, vol. 10, pp. 323–336, 2001. [Google Scholar]
11. P. Sallee, “Model-based steganography,” in Proc. Int. Workshop on Digital Watermarking, Berlin, Heidelberg, Springer, pp. 154–167, 2003. [Google Scholar]
12. J. Fridrich, T. Pevný and J. Kodovský, “Statistically undetectable jpeg steganography: Dead ends challenges, and opportunities,” in Proc. of the 9th Workshop on Multimedia & Security, New York, ACM, pp. 3–14, 2007. [Google Scholar]
13. T. Filler, J. Judas and J. Fridrich, “Minimizing additive distortion in steganography using syndrome-trellis codes,” IEEE Transactions on Information Forensics and Security, vol. 6, no. 3, pp. 920–935, 2011. [Google Scholar]
14. V. Holub and J. Fridrich, “Digital image steganography using universal distortion,” in Proc. of the First ACM Workshop on Information Hiding and Multimedia Security, Montpellier, France, pp. 59–68, 2013. [Google Scholar]
15. L. Guo, J. Ni and Y. Q. Shi, “Uniform embedding for efficient JPEG steganography,” IEEE Transactions on Information Forensics and Security, vol. 9, no. 5, pp. 814–825, 2014. [Google Scholar]
16. L. Guo, J. Ni, W. Su, C. Tang and Y. Q. Shi, “Using statistical image model for JPEG steganography: Uniform embedding revisited,” IEEE Transactions on Information Forensics and Security, vol. 10, no. 12, pp. 2669–2680, 2015. [Google Scholar]
17. Q. Zhang, L. T. Yang, Z. Chen and P. Li, “A survey on deep learning for big data,” Information Fusion, vol. 42, no. 9, pp. 146–157, 2018. [Google Scholar]
18. Y. Zhang and Z. Wang, “Hybrid malware detection approach with feedback-directed machine learning,” Information Sciences, vol. 63, no. 139103, pp. 1–139103, 2020. [Google Scholar]
19. Z. Li, J. Zhang, K. Zhang and Z. Li, “Visual tracking with weighted adaptive local sparse appearance model via spatio-temporal context learning,” IEEE Transactions on Image Processing, vol. 27, no. 9, pp. 4478–4489, 2018. [Google Scholar] [PubMed]
20. W. Sun, X. Chen, X. R. Zhang, G. Z. Dai, P. S. Chang et al., “A multi-feature learning model with enhanced local attention for vehicle re-identification,” Computers, Materials & Continua, vol. 69, no. 3, pp. 3549–3561, 2021. [Google Scholar]
21. X. R. Zhang, J. Zhou, W. Sun and S. K. Jha, “A lightweight CNN based on transfer learning for COVID-19 diagnosis,” Computers, Materials & Continua, vol. 72, no. 1, pp. 1123–1137, 2022. [Google Scholar]
22. J. Kodovský, J. Fridrich and V. Holub, “Ensemble classifiers for steganalysis of digital media,” IEEE Transactions on Information Forensics and Security, vol. 7, no. 2, pp. 432–444, 2011. [Google Scholar]
23. J. Zeng, S. Tan, B. Li and J. Huang, “Large-scale JPEG image steganalysis using hybrid deep-learning framework,” IEEE Transactions on Information Forensics and Security, vol. 13, no. 5, pp. 1200–1214, 2017. [Google Scholar]
24. M. Boroumand, M. Chen and J. Fridrich, “Deep residual network for steganalysis of digital images,” IEEE Transactions on Information Forensics and Security, vol. 14, no. 5, pp. 1181–1193, 2018. [Google Scholar]
25. T. Pevný and J. Fridrich, “Novelty detection in blind steganalysis,” in Proc. of the 10th ACM Workshop on Multimedia and Security, Oxford, UK, pp. 167–176, 2008. [Google Scholar]
26. T. Pevný and J. Fridrich, “Towards multi-class blind steganalyzer for JPEG images,” in Proc. Int. Workshop on Digital Watermarking, Berlin, Heidelberg, Springer, pp. 39–53, 2005. [Google Scholar]
27. T. Pevný and J. Fridrich, “Merging Markov and DCT features for multi-class JPEG steganalysis,” Proc. Security, Steganaography, and Watermarking of Multimedia Contents IX, vol. 6505, no. 2, pp. 650503, 2007. [Google Scholar]
28. T. Pevný and J. Fridrich, “Multi-class blind steganalysis for JPEG images,” Proc. Security, Steganaography, and Watermarking of Multimedia Contents VIII, vol. 6072, no. 2, pp. 60720O, 2006. [Google Scholar]
29. J. Fridrich, “Feature-based steganalysis for JPEG images and its implications for future design of steganographic schemes,” in Proc. Int. Workshop on Information Hiding, Berlin, Heidelberg, Springer, pp. 67–81, 2004. [Google Scholar]
30. Y. Q. Shi, C. Chen and W. Chen, “A Markov process based approach to effective attacking JPEG steganography,” in Proc. Int. Workshop on Information Hiding, Berlin, Heidelberg, Springer, pp. 249–264, 2006. [Google Scholar]
31. X. Kong, C. Feng, M. Li and Y. Guo, “Iterative multi-order feature alignment for JPEG mismatched steganalysis,” Neurocomputing, vol. 214, no. 1, pp. 458–470, 2016. [Google Scholar]
32. C. Feng, X. Kong, M. Li, Y. Yang and Y. Guo, “Contribution-based feature transfer for JPEG mismatched steganalysis,” in Proc. 2017 IEEE Int. Conf. on Image Processing (ICIP), Beijing, China, pp. 500–504, 2017. [Google Scholar]
33. G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen et al., “Lightgbm: A highly efficient gradient boosting decision tree,” in Proc. Advances in Neural Information Processing Systems, Long Beach, USA, pp. 3146–3154, 2017. [Google Scholar]
34. P. Bas, T. Filler and T. Pevný, “break our steganographic system: The ins and outs of organizing boss,” in Proc. Int. Workshop on Information Hiding, Berlin, Heidelberg, Springer, pp. 59–70, 2011. [Google Scholar]
35. Y. Bengio, J. Louradour, R. Collobert and J. Weston, “Curriculum learning,” in Proc. of the 26th Annual Int. Conf. on Machine Learning, New York, NY, USA, pp. 41–48, 2009. [Google Scholar]
36. V. Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” in Proc ICML, Haifa, Isreal, pp. 807–814, 2010. [Google Scholar]
37. T. Tieleman and G. Hinton, “Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude,” COURSERA: Neural Networks for Machine Learning, vol. 4, no. 2, pp. 26–31, 2012. [Google Scholar]
38. Y. Xue, L. Yang, J. Wen, S. Niu and P. Zhong, “A subspace learning-based method for JPEG mismatched steganalysis,” Multimedia Tools and Applications, vol. 78, no. 7, pp. 8151–8166, 2019. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools