
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Enhancing Classification Algorithm Recommendation in Automated Machine Learning: A Meta-Learning Approach Using Multivariate Sparse Group Lasso
1 School of Software, Dalian University of Technology, Dalian, 116620, China
2 Faculty of Information and Communication Technology, Universiti Tunku Abdul Rahman, Kampar, 31900, Malaysia
3 College of Computing and Informatics, University of Sharjah, Sharjah, 27272, United Arab Emirates
4 Department of Computer Systems Engineering, University of Engineering and Applied Sciences, Swat, 19200, Pakistan
* Corresponding Authors: Xianchao Zhang. Email: ; Ramesh Kumar Ayyasamy. Email:
(This article belongs to the Special Issue: Emerging Artificial Intelligence Technologies and Applications)
Computer Modeling in Engineering & Sciences 2025, 142(2), 1611-1636. https://doi.org/10.32604/cmes.2025.058566
Received 14 September 2024; Accepted 28 November 2024; Issue published 27 January 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The rapid growth of machine learning (ML) across fields has intensified the challenge of selecting the right algorithm for specific tasks, known as the Algorithm Selection Problem (ASP). Traditional trial-and-error methods have become impractical due to their resource demands. Automated Machine Learning (AutoML) systems automate this process, but often neglect the group structures and sparsity in meta-features, leading to inefficiencies in algorithm recommendations for classification tasks. This paper proposes a meta-learning approach using Multivariate Sparse Group Lasso (MSGL) to address these limitations. Our method models both within-group and across-group sparsity among meta-features to manage high-dimensional data and reduce multicollinearity across eight meta-feature groups. The Fast Iterative Shrinkage-Thresholding Algorithm (FISTA) with adaptive restart efficiently solves the non-smooth optimization problem. Empirical validation on 145 classification datasets with 17 classification algorithms shows that our meta-learning method outperforms four state-of-the-art approaches, achieving 77.18% classification accuracy, 86.07% recommendation accuracy and 88.83% normalized discounted cumulative gain.Keywords
The increasing implementation of machine learning (ML) in diverse fields has greatly transformed data-driven decision-making. However, the growing number of available algorithms makes selecting the most suitable one for a particular task challenging. This challenge, known as the Algorithm Selection Problem (ASP), is becoming more complex and computationally demanding [1]. Conventional approaches, which rely on comprehensive trial-and-error techniques are not only time-consuming and resource-intensive but also require a high level of expertise, specifically when dealing with large datasets and multiple algorithms [2].
In response to these challenges, Automated Machine Learning (AutoML) is a rapidly expanding field within machine learning that attempts to overcome these challenges and automates the entire process of applying machine learning to real world problems [3]. AutoML systems are designed to recommend not just the most suitable machine learning algorithms but also optimal hyperparameters and preprocessing methods for a specific dataset. By intelligently narrowing down the search space and offering customized recommendations, AutoML greatly decreases the manual effort and expertise needed, hence enhancing the accessibility of advanced machine learning techniques for both novice and experienced practitioners.
Recently, meta-learning has been receiving huge attention as one of the most promising ways to advance algorithm selection within the AutoML pipeline [4]. Generally described as learning to learn [5,6], meta-learning learns from past experiences derived from a wide range of machine learning tasks to recommend the most appropriate algorithm or set of algorithms to use on a given task. For algorithm recommendation systems, meta-learning is the process of building a knowledge base by systematically analyzing a wide variety of datasets, their descriptive meta-features, and the performance of different algorithms on the datasets. The acquired knowledge is then used to train a meta-model that learns the complex associations between meta-features and algorithm performance. To recommend an appropriate algorithm for a particular dataset, the first step is to extract and analyze its meta-features. Based on this extracted information, a trained meta-model can then predict which algorithms are likely to perform best on the given dataset. In essence, meta-learning operates as an “algorithm selection expert,” providing tailored recommendations by analyzing the data. This approach streamlines the machine learning process by helping users identify the most suitable algorithms without requiring extensive trial and error or specialized domain knowledge [7,8].
Meta-learning has demonstrated its effectiveness in recommending algorithms across a variety of fields. In time series forecasting, for instance, it assists in identifying the most appropriate algorithms for accurate predictions [9]. Similarly, in clustering tasks, meta-learning aids in selecting methods that best suit specific datasets [10]. In the domain of classification, notably the most studied domain in meta-learning for algorithm recommendation, has seen numerous studies demonstrating its success for example in these studies [11–14]. Furthermore, meta-learning has also been vital in identifying optimal pre-processing techniques, improving the overall performance of machine learning workflows [15–18]. Additionally, it has significantly contributed to automating hyper-parameter tuning, allowing for the selection of optimal configurations that enhance algorithm performance [5,19,20].
Although considerable advances have been made in the area of AutoML for algorithm recommendation, especially in classification, many current methods often overlook the group structures that exist within meta-features. These meta-features are typically organized based on their origins or the relationships they represent [1]. In the literature, meta-features are grouped according to their relationships with various dataset attributes, such as statistical properties, information-theoretic characteristics, or model-based attributes. However, current methods frequently treat these meta-features in isolation [21]. This neglect of group structures introduces challenges, most notably high dimensionality. When meta-features from the same group are treated independently, it complicates the feature space and leads to redundancy, thereby increasing computational costs and reducing the efficiency of feature selection. The overlap of information within these groups can degrade the performance of meta-models by incorporating an excess of irrelevant or redundant features.
In addition to high dimensionality, sparsity within meta-feature spaces adds another layer of complexity. Meta-features are often sparse, with only a few features or groups proving truly informative [3]. This aspect of sparsity is currently not yet properly exploited. Current methods do not handle both intra-group and inter-group sparsity. Ignoring this dual-level sparsity may lead to risks of overfitting models by selecting too many features or underfitting, where the most relevant groups are not being captured. Furthermore, the failure to address sparsity across groups diminishes the interpretability and effectiveness of algorithm recommendations. It becomes difficult to identify which specific groups of meta-features are most influential, obscuring the decision-making process of the model and making it challenging to determine which meta-features contribute most to predictive performance.
To overcome these limitations, this paper proposes a novel approach to algorithm recommendation within the context of meta-learning by framing it as a multivariate sparse group lasso regression task (Meta-MSGL). This approach directly addresses the challenges of managing high-dimensional, sparse, and structured meta-feature spaces, improving both the efficiency of feature selection and the accuracy of algorithm recommendations. The key contributions of this paper are as follows:
1. Multivariate Sparse Group Lasso (MSGL) for Meta-Learning: We propose the Meta-MSGL framework, which extends traditional Lasso and Group Lasso methods by introducing multivariate sparse group regularization. This allows the model to handle both individual and group-level sparsity, which is particularly important for addressing high-dimensional meta-features and mitigating multicollinearity, a challenge not fully addressed in previous algorithm recommendation methods.
2. Effective Meta-Feature Selection: Unlike prior works that either treat meta-features independently or lack structured regularization, our method simultaneously considers meta-feature groups, leading to improved accuracy in classifier selection by reducing redundancy and selecting only the most relevant groups of meta-features.
3. Robust Performance Across Diverse Datasets: Through extensive empirical evaluation on 145 datasets, we demonstrate that Meta-MSGL outperforms established baseline methods across key metrics, including average classification accuracy (ACA), average recommendations accuracy (ARA), and normalized discounted cumulative gain (NDCG). The structured feature selection and regularization lead to more reliable algorithm recommendations, particularly in high-dimensional spaces.
The remainder of this paper is organized as follows: Section 2 provides an overview of existing meta-learning methods for algorithm recommendation. In Section 3, we provide details of the proposed meta-learning framework. Section 4 outlines our experimental design and results. Finally, in Section 5, we conclude the paper.
2 Background and Related Works
In AutoML, various methodologies regarding meta-learning for algorithm recommendation have been explored. This section reviews main approaches, including multi-label methods, instance-based methods, and regression-based methods.
Wang et al. [22] introduces a multilabel learning-based approach for recommending classification algorithms, treating the task as a multilabel problem. Meta-data is generated by evaluating 13 classification algorithms across 84 UCI datasets, with five groups of meta-features characterizing the datasets. A multiple comparison procedure, specifically the Friedman test followed by Holm’s procedure, is used to label algorithms (meta-labels) for each dataset. The recommendation model is then constructed using the multilabel k-nearest neighbors (ML-kNN) algorithm [23], with
Zhu et al. [11] proposed the EML (Ensemble of ML-KNN) method for classification algorithm recommendation, addressing key limitations in existing methods that often rely on single learners or simple combinations of meta-features. The EML method is structured as a two-layer learning framework where the first layer (Tier-1) constructs 31 different meta-datasets by combining five types of meta-features, each used to train an ML-KNN model. The outputs from these models serve as features for the second layer (Tier-2), where binary classifiers are trained using AdaBoost with C4.5 as the base classifier. This ensemble approach improves recommendation accuracy by leveraging the diversity and accuracy of multiple ML-KNN models. Empirical validation on 183 datasets using 20 classification algorithms demonstrated that EML outperforms existing methods (ML-KNN, random walk with restart (RWR), and OBOE (Collaborative Filtering for AutoML Model Selection) across several metrics, including Hamming Loss, F-measure, Accuracy, and Hit Ratio.
Zhu et al. [24] propose a classification algorithm recommendation method based on link prediction within a heterogeneous network called the Data and Algorithm Relationship (DAR) Network, utilizing 131 datasets, five groups of meta-features, and 21 classification algorithms. The method involves three steps: meta-data collection, DAR network construction, and algorithm recommendation via link prediction. The DAR Network consists of two node types (datasets and algorithms) and two edge types (dataset-algorithm and dataset-dataset). Dataset nodes are connected to their
Yang et al. [25] developed OBOE, a collaborative filtering method for time-constrained model selection and hyperparameter tuning. OBOE constructs a low-rank approximation of an error matrix, predicting model performance based on latent meta-features inferred from cross-validated errors. This method offers quick, accurate recommendations under time constraints, but its effectiveness may be limited if the error matrix does not exhibit low-rank properties.
Although the multi-label approaches have shown success, they have several limitations such as training meta-models separately on each group of meta-features, which restricts the full utilization of feature diversity. Moreover, depending on statistical tests such as the Friedman test for meta-label estimation may fail to consider potentially significant algorithms, therefore restricting the recommendations. The method that takes into account all meta-features at the same time could improve the accuracy and adaptability of meta-models and provide more extensive recommendations for algorithms and comprehensive algorithm suggestions.
Instance-based approaches utilize the notion of similarity, through the analysis of dataset meta-features, to suggest appropriate algorithms. These methods are adaptable and scalable, as demonstrated by the European METAL project, which led to the development of the Data Mining Advisor (DMA). DMA uses the K-Nearest Neighbors (KNN) algorithm as a meta-learner, extracting meta-knowledge from 67 datasets and 10 algorithms. It recommends algorithms by identifying the K most similar datasets in the meta-knowledge database and aggregating performance data from these datasets. A key advantage of this approach is its ability to manage small training sets and incorporate new meta-examples without retraining the meta-model, making it effective in expanding meta-knowledge bases [26].
Wang et al. [2] proposed a clustering-based approach where datasets are grouped based on feature vectors using the EM algorithm. This method evaluates the performance of 17 classification algorithms on 84 UCI datasets, grouping similar datasets in the meta-knowledge database via clustering. To recommend an algorithm for a new dataset, the system identifies the closest cluster and suggests algorithms that perform well in that cluster. However, the complexity of feature extraction, clustering, and the reliance on training data quality poses challenges, especially when new datasets or algorithms are introduced.
Although instance-based methods offer advantages, they encounter challenges. Determining the optimal value for the parameter k is sometimes challenging, as it directly influences recommendation accuracy and computational efficiency. Moreover, these methods might exhibit limitations in terms of scalability when dealing with large meta-knowledge bases and high-dimensional meta-features. To address these difficulties, several authors, such as Lee et al. [27] and Wang et al. [2], have investigated the incorporation of unsupervised learning approaches with instance-based methods. Their objective is to enhance the adaptability and generalizability of these methods.
In the context of meta-learning for algorithm recommendation, regression methods have been found beneficial in modeling the association between meta-features and algorithm performance. Such models are very flexible, handle continuous target variables well, and suit a wide variety of algorithm recommendation tasks, making them very popular for performance prediction and algorithm selection. For instance, using ridge regression, Leyva et al. [28] found it is possible to predict classifier performance more accurately than with simpler models. In another work, Garcia et al. [29] conducted work involving random forest regression, which shows how flexible different regression methods are in this context.
Reif et al. [30] conducted a comprehensive assessment of the predictive capability of regression models among five separate groups of meta-features: simple, statistical, information-theoretic, model-based, and landmarking. This evaluation was conducted utilizing data from 54 UCI datasets. The work integrated an automated feature selection technique that improved the regression models, thereby increasing prediction accuracy and decreasing computational expenses.
Lai et al. [31] introduced a scalable digital twin framework that utilizes an adaptive ensemble surrogate model to predict performance across varying conditions. While their method focuses on real-time system optimization, our approach specifically targets algorithm recommendation in AutoML pipelines, leveraging multivariate sparse group Lasso to handle high-dimensional meta-features.
Furthermore, Bensusan et al. [32] examined linear regression models to determine the association between meta-features and the performance of algorithms. Although simple regression methods offered meaningful insights, their research emphasized the need to develop more advanced models to tackle non-linear connections. The primary advantage of regression-based methods in the field of AutoML is to offer readily available and easily understandable performance estimates. In addition to providing dependable predictions across diverse datasets, they also aid in the identification of the most influential meta-features, therefore contributing to the development of more precise and efficient models and facilitating informed decision-making in algorithm selection.
AutoML systems, such as Auto-sklearn [33] and A Tree-based Pipeline Optimization Tool for Automating Machine Learning (TPOT) [34], have introduced more advanced techniques for model selection and hyperparameter optimization. These frameworks automate the machine learning pipeline by integrating diverse classifiers and search strategies to identify optimal configurations for different tasks. However, these systems primarily focus on general model selection and hyperparameter tuning and do not specifically target the problem of meta-feature selection in the context of algorithm recommendation. In contrast, our approach, Meta-MSGL, leverages multivariate sparse group Lasso to handle high-dimensional meta-features while addressing the challenges of multicollinearity and redundant meta-features, leading to more precise algorithm recommendations.
3 Methodological Framework (Meta-MSGL): Multivariate Sparse Grouped Lasso Regression
In this study, we propose a novel framework for classification algorithm recommendation, leveraging the Multivariate Sparse Group Lasso (MSGL) regression. This approach is designed to handle the high dimensionality and multicollinearity that often arise in meta-feature-based algorithm recommendations. Our key contribution lies in modeling both intra-group and inter-group sparsity within meta-features, allowing for more efficient and accurate classification algorithm recommendations across diverse datasets. Unlike existing methods that treat meta-features independently or fail to fully exploit group structures, MSGL enables the simultaneous selection of relevant features both within and across predefined meta-feature groups. By imposing structured sparsity, our method improves performance and computational efficiency.
To solve this challenging optimization problem, we employ the Fast Iterative Shrinkage-Thresholding Algorithm (FISTA) with adaptive restart, which efficiently handles the non-smooth regularization terms involved in MSGL. This innovation ensures that the model is not only accurate but also interpretable, as it allows us to identify the most critical meta-features for algorithm recommendation.
In this section, we describe the methodology used in this study. We first introduce the necessary notations and present the basic formal definition of algorithm selection. We then frame this problem as a multi-objective, multivariate sparse group lasso regression task and explain our approach to solving it. To present our approach, we first define the following notations:
•
•
•
•
•
Given these notations, and following the framework proposed by Smith [35], the algorithm recommendation process can be formally defined as follows:
1. Construct a mapping function
2. For a new dataset
In the field of algorithm selection through meta-learning, the construction of the mapping function is a process that seeks to align the inherent biases and capabilities of candidate algorithms with the meta-features characterizing classification tasks. Each algorithm operates under specific data assumptions, such as linearity, smoothness, or feature independence, influencing its performance across diverse scenarios. As elaborated in Section 2, various methodologies have been employed to construct such a mapping function, each leveraging distinct underlying assumptions and computational paradigms, including instance-based approaches, multi-label learning techniques, and ranking-based approaches. In this paper, we formulate the meta-learning task of classifier recommendation as an optimization problem, specifically a multi-objective multivariate sparse group lasso regression task.
3.1 MSGL Optimization Problem: A Detailed Derivation
To establish a formal definition of our problem, we introduce two fundamental matrices that represent the data utilized for our meta-learning process: the Meta-Feature matrix (
Here
The Meta-Label matrix, denoted by
Here
For the accurate construction of the mapping function
where
While OLS regression is a powerful tool, it can lead to overfitting when the number of features is large relative to the number of observations. To overcome this issue, we introduce regularization techniques. In particular, we employ the Lasso (Least Absolute Shrinkage and Selection Operator) regularization, which adds an L1 penalty on the coefficients:
where
In many real-world scenarios, features naturally exhibit inherent grouping structures. This is especially relevant in our meta-learning problem, where meta-features are categorized into eight predefined groups based on established literature, which have been consistently validated across various studies [19]. Conventional Lasso regularization does not explicitly consider this group structure, which can lead to sub-optimal feature selection [36]. To address this, we introduce the group Lasso regularization, which adds L2 penalty on groups of coefficients. This approach leverages domain-specific groupings to enforce sparsity at both the individual feature and group levels.
where
By integrating the OLS loss with both Lasso and group Lasso regularization, we formulate our final optimization problem, thus defining the grouped multivariate sparse Lasso:
The above general optimization problem we aim to solve is derived from the principles of penalized regression, specifically the multivariate sparse grouped Lasso [37].
The first term in the equation,
Each term in the summation quantifies the squared difference between the observed performance of the
The second term,
This factor quantifies the extent of coefficients associated with a particular meta-feature. Incorporating this term into the objective function, weighted by
The third term,
The balance between prediction accuracy and model complexity is determined by the hyper-parameters
The overall loss function, combining both the data-fitting term and regularization terms, plays a key role in controlling model complexity and ensuring the selection of relevant meta-features. By minimizing the squared error between the predicted and actual performance values, the model achieves high predictive accuracy. Simultaneously, the
By minimizing the combined objective function, the resulting coefficient matrix
3.2 Fast Iterative Shrinkage-Thresholding Algorithm for MSGL (FISTA)
The multivariate sparse group Lasso regression problem we have formulated is the main component of our meta-learning framework. However, appropriately solving this problem requires an adequate optimization approach due to its inherent complexity, which involves both individual and group-level sparsity. To manage this complexity, it is important to employ an algorithm capable of efficiently handling the smooth and non-differentiable components of the objective function. In this part, we present the mathematical formulation of the Fast Iterative Shrinkage-Thresholding Algorithm (FISTA) with adaptive restart. We follow the approach proposed by Beck et al. [38] and enhanced by the adaptive restart scheme of Donoghue et al. [39]. This optimization algorithm is particularly well-suited to solving our MSGL problem because it ensures accurate minimization of the objective function while maintaining both predictive accuracy and computational efficiency. We here provide a step-by-step derivation of the algorithm and show how it addresses our specific optimization problem.
FISTA is designed to minimize composite objective functions of the form
This term represents the squared Frobenius norm of the residuals, where
This term incorporates the Lasso and group Lasso regularizations, promoting sparsity in individual meta-features and groups of meta-features. By minimizing
The gradient of
The gradient indicates the direction in which
The above operator works well in addressing the non-smooth component of our objective function through the implementation of a proximal gradient step. It ensures that the updated solution maintains the sparsity properties induced by the regularization terms. In our case,
To improve the performance of FISTA, we have implemented an adaptive restart strategy based on the recommendation made by Donoghue et al. [39]. This technique can automatically restart the algorithm when the objective function shows a specific non-monotonic behavior. This facilitates faster convergence by ensuring that the iterations do not become stuck.
The FISTA algorithm starts by initializing the coefficient matrix
During each iteration
To avoid potential stalling, the algorithm includes an adaptive restart mechanism. If the condition
In summary, the combination of FISTA with adaptive restart offers an efficient solution to our MSGL optimization problem. By effectively minimizing the composite objective function, this approach balances the trade-offs between prediction accuracy, sparsity, and computational efficiency, resulting in a robust and interpretable model (Algorithm 1).

Within this subsection, we show how Meta-MSGL is used for the recommending classifiers. To illustrate, we consider
The training of the GMSL model begins with the initialization of the matrix
The vector
Here
3.4 Algorithm Recommendation Using Meta-MSGL
For a new dataset
1. Meta-feature Extraction: Extract relevant meta-features of
2. Performance Estimation: Using the selected meta-features, the trained meta-model estimates the performance of each algorithm:
where
The algorithm(s) predicted to achieve the best performance on
This ranking serves as an elementary step to prioritize algorithms. The configuration with the highest predicted value is recommended for
3.5 Metafeature Extraction and Selection
Our methodology employs an extensive set of meta-features across eight categories: General, Statistical, Landmarking, Information Theory, Clustering, Model-Based, Itemset, and Complexity. Unlike prior studies with limited meta-features, our approach effectively handles the high dimensionality and multicollinearity inherent in these diverse groups. Due to space limitations, we cannot provide detailed descriptions, mathematical formulations, and extensive discussions of the eight meta-feature groups here. For a comprehensive overview of these meta-features, including their formulations and detailed descriptions, we refer readers to [40,41].
Inconsistencies in extraction techniques can affect reproducibility across studies [42]. To address this, we utilize the standardized reproducible meta-feature extraction (MFE) framework [43] available in R and Python, specifically using the Python package pymfe for meta-feature extraction. Post-extraction, we apply preprocessing steps: (1) normalize measures to
We have shown the multicollinearity by calculating correlation matrices and eigenvalues from meta-features extracted from 145 UCI datasets in Fig. 1. Some eigenvalues nearing zero indicate high correlation, potentially degrading linear regression model performance if not addressed. The Meta-MSGL method facilitates the selection of the most informative meta-features, mitigating multicollinearity and reducing redundancy. By managing a broad range of meta-features, our methodology significantly enhances the accuracy and reliability of classification algorithm selection in AutoML systems.

Figure 1: Multicollinearity is present between the different groups (eight) of meta-features. The near-zero eigenvalues indicate that some meta-feature variables are strongly correlated with each other
In this section, we conduct an empirical investigation to evaluate the effectiveness of our proposed approach. We begin by detailing the experimental setup which includes the datasets, classification algorithms, and evaluation metrics used. We then present the results, highlight key findings, and compare the performance of our approach with four existing benchmark methods.
4.1 Datasets and Candidate Algorithms
This study utilizes 145 classification datasets sourced from OpenML [44], with 105 datasets allocated for training and validation, and 40 datasets randomly selected as the test set. The datasets were split such that 80% of the datasets were used for model training and cross-validation, while 20% were reserved for independent testing. The training set was further divided into training and validation subsets using 10-fold cross-validation to tune the hyperparameters
To ensure a thorough evaluation, we included 17 classification algorithms in our meta-learning setup. These algorithms are widely used in previous studies on classifier selection. The algorithms include probabilistic learners such as Bayesian Network (weka.classifiers.bayes.BayesNet) and Naive Bayes (weka.classifiers.bayes.NaiveBayes), tree-based learners like C4.5 (weka.classifiers.trees.J48), Random Tree (weka.classifiers.trees.RandomTree), and Random Forest (weka.classifiers.trees.RandomForest), rule-based learners including Ripper (weka.classifiers.rules.JRip) and PART (weka.classifiers.rules.PART), an instance-based learner, K-Nearest Neighbors (weka.classifiers.lazy.KStar), and a Support Vector Machine, SMO (weka.classifiers.functions.SMO). We also included several ensemble methods, such as AdaBoostM1 combined with Naive Bayes, KStar, PART, and J48, as well as Bagging combined with Naive Bayes, KStar, PART, and J48. This diverse selection of algorithms enables a thorough assessment of different classification methods, ensuring the collection of high-quality meta-data essential for adequate training the meta-learner.
We used WEKA version 3.8.2 [45], a Java-based open-source data mining software, to implement these candidate classifiers at the meta-level. We followed the default settings provided by WEKA for each classifier. This included using a polynomial kernel for the Support Vector Machine and a linear search for the K-Nearest Neighbors algorithm, aligning with configurations used in previous studies.
4.2 Evaluation Against Benchmark Approaches
To assess the effectiveness of our proposed method, we compared it with four established baseline methods, each representing a different approach to recommending classification algorithms:
1. Wang et al. (2014) - Meta-MLkNN: This method uses multilabel learning, treating the task of recommending classification algorithms as a multilabel problem, implemented through the ML-kNN algorithm [22].
2. Zhu et al. (2018) - Meta-DAR: This method uses link prediction within a heterogeneous network called the Data and Algorithm Relationship (DAR) Network to recommend classifiers [24].
3. Zhu et al. (2021) - Meta-EML: An ensemble approach that uses ML-KNN as the base learner to recommend classification algorithms based on meta-features [11].
4. Giraud-Carrier et al. (2005) - Meta-DMA: An instance-based method developed under the European METAL project, using KNN to recommend algorithms [46].
Each of the above baseline method is described in detail in the Section 2. These baseline methods were chosen because they are well-known in the literature, allowing for a thorough comparison with our proposed method.
4.3 Performance Evaluation Metrics
Our study evaluates the effectiveness of each method using three widely recognized metrics: classification accuracy rate (CA), recommendation accuracy rate (RA), and normalized discounted cumulative gain (NDCG). These metrics are commonly used in meta-learning (MtL) research for algorithm recommender systems, as demonstrated in studies such as [42,47]. Each of these metrics provides insight into the effectiveness of the different meta-learning frameworks for algorithm recommendation. Below, we define each of these metrics:
1. Classification Accuracy Rate (CA): CA is frequently employed to assess the efficacy of a recommended classification algorithm
The average cumulative accuracy (ACA) across N datasets is defined as:
The notation
2. Recommendation Accuracy (RA): While Classification Accuracy (CA) is a key metric for algorithm selection, it may not always differentiate well between multiple algorithms that achieve similar CA values on a given problem. To address this limitation, Recommendation Accuracy (RA) evaluates how close a recommended algorithm is to the optimal solution. Let
This formula normalizes the CA of a given algorithm within the range of possible CA values for that problem. RA values range from
Similar to RA, ARA values range from
3. Normalized Discounted Cumulative Gain (NDCG)
The Normalized Discounted Cumulative Gain (NDCG) is a metric used to assess the quality of ranked lists, particularly in recommender systems, by evaluating how closely the predicted rankings of items align with their ideal rankings based on true relevance. For a given dataset (query)
Again, NDCG@p values lie within the range
Our experimental analysis comprises two distinct phases. In the first phase, we conduct an in-depth examination of the Meta-MSGL model, focusing on three key questions. (1) Which meta-features are essential for constructing the Meta-MSGL model? (2) Can meta-features selection help mitigate multicollinearity in the Meta-MSGL model? (3) How does meta-feature selection influence the recommendation performance of Meta-MSGL? In the second phase, we directly compare the performance of Meta-MSGL against four baseline meta-learning methods. This comprehensive two-phase approach allows us to thoroughly evaluate the strengths and weaknesses of Meta-MSGL, specifically within the context of meta-learning for classification algorithm recommendation.
4.4.1 Evaluating the Effectiveness of Metafeature Selection in Meta-MSGL
A comprehensive grid search was conducted to determine the optimal settings and assess the impact of various meta-features on the meta-model. It involved extensive experimentation with different parameter combinations. Here, we present the results of varying the regularization parameter
Fig. 2 illustrates these results, showing the ratio of retained measures to the total number of measures for each

Figure 2: The influence of
A similar pattern is observed for
Across both
In summary, retaining complexity-based, model-based, simple, and information-theoretic features is crucial for preserving the model’s predictive performance across varying levels of regularization. Each of these meta-feature groups plays a key role in improving the model’s decision-making process. For example, complexity and model-based features provide essential insights into the structure and behavior of datasets, while information-theoretic features capture relationships between variables that enhance algorithm selection. The reduced significance of statistical and structural features suggests that they contribute less to the meta-learning task, often introducing redundancy. This highlights the value of incorporating diverse, relevant meta-feature groups to optimize meta-learning models and improve both accuracy and interpretability.
4.4.2 Analysis of Eigenvalues to Assess Multicollinearity Reduction
Here we evaluate the effectiveness of the Meta-MSGL model in reducing multicollinearity by analyzing the smallest eigenvalues of the correlation matrix for selected meta-features. The results for both

Figure 3: Smallest six eigenvalues of the meta feature correlation matrix for the various
4.4.3 Impact of Meta-features Selection on Meta-MSGL Performance
Here, we illustrate how meta-feature selection impacts the performance of Meta-MSGL. The ACA, ARA, and hit rate (HR) results are presented in Fig. 4. The impact of feature selection on the Meta-MSGL performance is evident. When all meta-features are used with
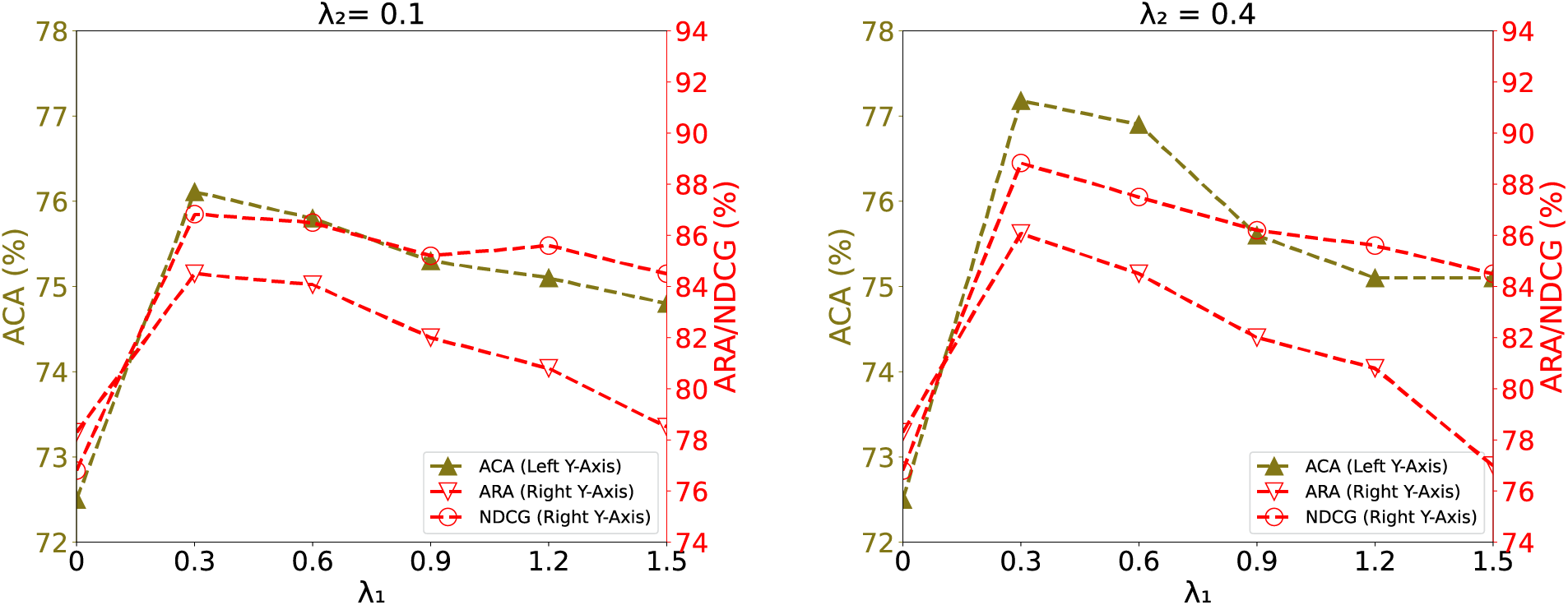
Figure 4: Analyzing SGLasso recommendations: how varying sparsity affects accuracy
The optimal performance is observed at
4.5 Comparisons With MtL Baselines
In this section, we compare the performance of Meta-MSGL with several baseline meta-learning methods, namely Meta-EML, Meta-MLkNN, Meta-DAR, and Meta-DMA, using three key metrics: ACA, ARA, and NDCG. The results, summarized in Table 1, are averaged across all testing datasets.

The performance of Meta-MSGL is consistently high on the three metrics. The achieved ACA is 77.18% ARA is 86.07% and the average normalized discounted cumulative gain is 88.83%. The results indicate that Meta-MSGL is able to reliably produce recommendations and sustain good classification performance across the datasets. The high NDCG score further confirms its efficiency in prioritizing algorithms based on predictive performance on datasets. Meta-EML performs comparably to Meta-MSGL particularly in the ARA and NDCG metrics achieving scores of 83.52% and 84.75%, respectively. Although it falls slightly short of the performance of Meta-MSGL the minor difference indicates that Meta-EML is still effective in most scenarios on ARA and NDCG metrics. In contrast, the performance of Meta-MLkNN is significantly lower compared to Meta-MSGL and Meta-EML. It achieved an ACA of 72.25% ARA of 79.53% and NDCG of 80.15%. This suggests that Meta-MLkNN recommendations are less reliable on many datasets.
Meta-DAR and Meta-DMA show consistently lower performance compared to the other methods with ACA scores of 66.48% and 64.88%, respectively. Their ARA and NDCG scores are also significantly lower. Meta-DAR achieves 72.58% and 74.90%, while Meta-DMA scores 70.02% and 69.87%. These results highlight limitations in their ability to handle diverse datasets effectively. Its lower NDCG scores on NDCG@3 indicate that Meta-DAR and Meta-DMA have a limitation in not only providing adequate recommendations for the best predictive algorithm in each testing data set but also in the top three recommended algorithms.
4.5.1 Classification Accuracy (CA)
To further illustrate the performance differences across each testing problem, we present scatter plots in Figs. 5–7. In these plots, the datasets are ordered in ascending order according to the performance of Meta-MSGL. In terms of the CA metric on each testing dataset, Meta-MSGL performed better compared to the baseline methods on most of the datasets. It should be noted that algorithm recommended by Meta-MSGL achieves accuracy levels higher than 90% on 9 datasets and retains high accuracy on 22 datasets when a more moderate accuracy level of 80% is taken into account. The results indicate that Meta-MSGL is not only able to recommend algorithms that attain performance comparable to the best available candidate for a specific dataset but also consistently achieves high classification accuracy.

Figure 5: Comparison of CA performance across individual testing datasets among Meta-MSGL, Meta-EML, Meta-MLkNN, Meta-DAR, and Meta-DMA

Figure 6: Comparison of RA performance across individual testing datasets among Meta-MSGL, Meta-EML, Meta-MLkNN, Meta-DAR, and Meta-DMA

Figure 7: Comparison of NDGC performance across individual testing datasets among Meta-MSGL, Meta-EML, Meta-MLkNN, Meta-DAR, and Meta-DMA
Meta-EML and Meta-MLkNN also acheived reliable performance by reaching over 90% accuracy on 6 and 5 datasets, respectively. However they display greater variability than Meta-MSGL particularly in datasets like column3C and thoracic-surgery where their performance is less stable. When the accuracy threshold is reduced to 80% Meta-EML remains competitive by achieving this level on 18 datasets, while Meta-MLkNN achieves it on 14 datasets. This indicates that although both Meta-EML and Meta-MLkNN are effective, their sensitivity to certain dataset characteristics may affect their overall reliability in consistently maintaining high accuracy across diverse datasets.
In contrast, Meta-DAR and Meta-DMA show poor performance by reaching the 90% accuracy threshold in only one dataset each and even not achieving 80% in most cases. Their lower classification accuracy values highlight significant limitations in adapting to diverse datasets. As a result, these methods may recommend algorithms that are not well-suited to the task, which leads to poorer classification accuracy across a broader range of datasets.
4.5.2 Recommendation Accuracy (RA)
Fig. 6 presents scatter plot to show the variations in performance among the meta-learning methods on the RA metric for each testing problem. As can be observed Meta-MSGL performs better than the baseline methods on the majority of the datasets. It achieves above 90% recommendation accuracy in 17 datasets and exceeds 80% on 31 datasets, which indicates its advantage over the baselines. In comparison, Meta-EML exhibits competitive performance closely following Meta-MSGL achieving 90% RA on 15 datasets and exceeding 80% on 29 datasets. Although slightly less effective than Meta-MSGL Meta-EML remains a strong contender showcasing its ability to recommend algorithms with high accuracy in a substantial number of cases. This indicates that Meta-EML’s meta-learning approach while effective does not match the precision of Meta-MSGL in all scenarios. Although Meta-EML performance is not as high as Meta-MSGL, it still demonstrates its capability to accurately recommend algorithms on most of the datasets.
Meta-MLkNN shows a noticeable drop in performance reaching the 90% accuracy threshold in only 9 datasets and exceeding 80% in 21 datasets. This suggests that Meta-MLkNN is less effective in consistently identifying and recommending algorithms. In addition, Meta-DAR and Meta-DMA showed considerably lower performance. Meta-DAR achieved 90% accuracy on only 5 datasets and Meta-DMA on 3. When considering the 80% accuracy threshold, Meta-DAR and Meta-DMA reached it in only 10 and 11 datasets respectively. The overall evaluation indicates that while Meta-MSGL and Meta-EML consistently recommend algorithms effectively for most datasets, Meta-MLkNN, Meta-DAR, and Meta-DMA show notable inconsistency and decreased efficacy.
4.5.3 Normalized Discounted Cumulative Gain (NDCG)
The Normalized Discounted Cumulative Gain (NDCG@3) metric assesses the ranking quality of the recommendations, highlighting the importance of correctly ordering the top 3 relevant algorithms according to their performance. Meta-MSGL consistently demonstrates superior ranking capabilities, maintaining high NDCG scores on most datasets. As can be noted from Fig. 7, Meta-MSGL consistently demonstrated superior ranking capabilities with high NDCG scores across diverse datasets, exceeding 90% in 19 datasets. This indicates the Meta-MSGL accurately identifies and ranks top-performing algorithms, ensuring recommendations are both reliable and informative.
Meta-EML and Meta-MLkNN also achieve considerably high NDCG scores, but not as high as Meta-MSGL. Meta-EML exceeds 90% in 10 datasets, while Meta-MLkNN achieves this in 4. These methods perform generally well on NDCG metric implying that, while they may not always provide the highest-ranked algorithm, their rankings are generally close to optimal. However, their performance variability indicates that they do not consistently match Meta-MSGL performance on this metric. In contrast, Meta-DAR and Meta-DMA exhibit significantly lower NDCG scores, failing to reach the 90% threshold in any dataset. Their weaker performance in ranking algorithms effectively reflects their limitations in utilizing the available meta-features.
Overall, the results on NDCG metric show that Meta-MSGL is the most effective method for ensuring that recommended algorithms are both accurate and correctly prioritized. Meta-EML and Meta-MLkNN offer reasonably good rankings but are less reliable, whereas Meta-DAR and Meta-DMA performanc is much lower.
While Meta-MSGL demonstrates superior performance across a wide range of datasets, certain datasets present unique challenges that affect its recommendation accuracy. Specifically, datasets with high dimensionality, class imbalance, or substantial noise can introduce variability in the performance of the model. For instance, datasets such as ‘thoracic-surgery’ and ‘column3C’ exhibit variability in classification accuracy due to significant noise and imbalance between classes, which complicates the recommendation process. Meta-MSGL’s ability to mitigate these challenges is attributed to its multivariate sparse group Lasso framework, which effectively reduces the impact of irrelevant meta-features. However, in cases where the meta-features are highly correlated or exhibit high variance, the method’s ability to discern subtle differences in algorithm performance may be affected. Future work could explore more refined noise-handling techniques or alternative meta-feature extraction methods to further enhance the model’s robustness to such dataset-specific characteristics.
4.5.4 Statistical Validation of Meta-MSGL Performance
To evaluate the statistical significance of the performance differences between Meta-MSGL and the baseline methods, we conducted Wilcoxon signed-rank tests at a significance level of 0.05. The results, presented in Table 2 provide insight into whether the observed performance advantages of Meta-MSGL are statistically significant. The null hypothesis in each case affirms that Meta-MSGL performs either worse or equally compared to the other baseline methods (Meta-EML, Meta-MLkNN, Meta-DAR, and Meta-DMA) across the three key metrics: CA, RA and NDCG.

The test reveal that Meta-MSGL significantly outperforms the baseline methods on the three evaluation metrics. Meta-MSGL shows a consistent and statistically significant advantage, secifically when compared to Meta-MLkNN, Meta-DAR, and Meta-DMA, with p-values of 0.0 across all metrics. When compared to Meta-EML, Meta-MSGL also demonstrates significant improvements, especially in RA and NDCG, though the competition is closer, as reflected in the slightly higher p-values. These results confirm that Meta-MSGL superior performance is not only practical but also statistically significant, making it the most reliable choice for algorithm selection and ranking tasks.
While the proposed Meta-MSGL model demonstrates strong performance in classification algorithm recommendation, it is not without limitations. First, the model’s performance is sensitive to the choice of regularization parameters
In this paper, we have introduced a novel framework to address critical challenges in automated machine learning (AutoML), specifically focusing on the classification algorithm recommendation problem within the context of meta-learning. By leveraging multivariate sparse group lasso, our approach effectively manages the high-dimensional, sparse, and structured nature of meta-feature spaces. This dual-level sparsity, enforced both within and across groups, enhances the accuracy of feature selection and algorithm recommendations. This results in more precise and effective algorithm recommendations, addressing the limitations of existing methods that treat meta-features in isolation and fail to account for the interrelatedness of these features.
The empirical validation of our approach on a diverse set of benchmark datasets has demonstrated its superior performance compared to state-of-the-art meta-learning methods. However, our model does present some limitations, particularly regarding its sensitivity to the regularization parameters
Future work can address these limitations by integrating our framework with adaptive meta-learning techniques, such as dynamic hyperparameter tuning and incremental learning for continuous adaptation to new data. Further, expanding the considered meta-features and datasets, as well as enhancing the method’s scalability and efficiency, will open new opportunities for improving the performance and applicability of the framework across various domains.
Acknowledgment: The authors would like to thank Universiti Tunku Abdul Rahman, Kampar, Malaysia, and the School of Software, Dalian University of Technology, Dalian, China for supporting this study.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm their contributions to the paper as follows: Irfan Khan conceived and conducted the study, designed the experiments, and prepared the draft manuscript. Xianchao Zhang provided supervision and guidance throughout the research. Ramesh Kumar Ayyasamy offered technical assistance and support during the study. Saadat M. Alhashmi and Azizur Rahim contributed by reviewing the manuscript and providing critical feedback. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: All data supporting the findings of this study are provided within the paper. For any additional information or further inquiries, the authors may be contacted.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Deng L, Xiao M. A new automatic hyperparameter recommendation approach under low-rank tensor completion e framework. IEEE Transact Pattern Anal Mach Intell. 2023;45(4):4038–50. doi:10.1109/TPAMI.2022.3195658. [Google Scholar] [PubMed] [CrossRef]
2. Wang G, Song Q, Zhu X. An improved data characterization method and its application in classification algorithm recommendation. Appl Intell. 2015;43:892–912. doi:10.1007/s10489-015-0689-3. [Google Scholar] [CrossRef]
3. Khan I, Zhang X, Ayyasamy RK, Ali R. AutoFe-Sel: a meta-learning based methodology for recommending feature subset selection algorithms. KSII Trans Internet Inf Syst. 2023 Jul;17(7):1773–93. doi:10.3837/tiis.2023.07.002. [Google Scholar] [CrossRef]
4. Carneiro D, Guimar M, Carvalho M, Novais P. Using meta-learning to predict performance metrics in machine learning problems. Expert Syst. 2023;40(1):e12900. doi:10.1111/exsy.12900. [Google Scholar] [CrossRef]
5. Marinho TL, Carvalho D, Pimentel BA. Optimization on selecting XGBoost hyperparameters using meta-learning. Expert Syst. 2024 Apr;41(9):e13611. doi:10.1111/exsy.13611. [Google Scholar] [CrossRef]
6. Jiang K, Cao B, Fan J. A robust framework for multimodal sentiment analysis with noisy labels generated from distributed data annotation. Comput Mod Eng Sci. 2024;139(3):1–10. doi:10.32604/cmes.2023.046348. [Google Scholar] [CrossRef]
7. Xu C, Zhu Y, Zhu P, Cui L. Meta-learning-based sample discrimination framework for improving dynamic selection of classifiers under label noise. Knowl Based Sys. 2024;295:111811. doi:10.1016/j.knosys.2024.111811. [Google Scholar] [CrossRef]
8. Khan I, Zhang X, Kumar R, Alhashmi SM, Ali R. MtL-NFW: a meta-learning framework for automated noise filter selection and hyperparameter optimization in auto-ML. Research Square. 2024 Jul. doi:10.21203/rs.3.rs-4638344/v1. [Google Scholar] [CrossRef]
9. Abanda A, Mori U, Lozano JA. Time series classifier recommendation by a meta-learning approach. Pattern Recognit. 2022;128(1):108671. doi:10.1016/j.patcog.2022.108671. [Google Scholar] [CrossRef]
10. Pimentel BA, de Carvalho ACPLF. A new data characterization for selecting clustering algorithms using meta-learning. Informat Sci. 2019;477:203–19. doi:10.1016/j.ins.2018.10.043. [Google Scholar] [CrossRef]
11. Zhu X, Ying C, Wang J, Li J, Lai X, Wang G. Ensemble of ML-KNN for classification algorithm recommendation. Knowl Based Syst. 2021;221(1):106933. doi:10.1016/j.knosys.2021.106933. [Google Scholar] [CrossRef]
12. Pio PB, Rivolli A, Carvalho ACPLFD, Garcia LPF. A review on preprocessing algorithm selection with meta-learning. Knowl Inf Syst. 2023;66(1):1–28. doi:10.1007/s10115-023-01970-y. [Google Scholar] [CrossRef]
13. Shao X, Wang H, Zhu X, Xiong F, Mu T, Zhang Y. EFFECT: explainable framework for meta-learning in automatic classification algorithm selection. Informat Sci. 2023;622(92):211–34. doi:10.1016/j.ins.2022.11.144. [Google Scholar] [CrossRef]
14. Garouani M, Ahmad A, Bouneffa M, Hamlich M. Autoencoder “kNN meta” model based data character-ization approach for an automated selection of AI algorithms. J Big Data. 2023;10(1):1–18. doi:10.1186/s40537-023-00687-7. [Google Scholar] [CrossRef]
15. Garcia LPF, de Carvalho ACPLF, Lorena AC. Noise detection in the meta-learning level. Neurocomputing. 2016;176:14–25. doi:10.1016/j.neucom.2014.12.100. [Google Scholar] [CrossRef]
16. Tornede A, Gehring L, Tornede T, Wever M, Hüllermeier E. Algorithm selection on a meta level. USA: Springer; 2023. doi:10.1007/s10994-022-06161-4 [Google Scholar] [CrossRef]
17. Oreski D, Oreski S, Klicek B. Effects of dataset characteristics on the performance of feature selection techniques. Appl Soft Comput. 2017;52:109–19. doi:10.1016/j.asoc.2016.12.023. [Google Scholar] [CrossRef]
18. Corrales DC, Ledezma A, Corrales JC. A case-based reasoning system for recommendation of data cleaning algorithms in classification and regression tasks. Appl Soft Comput. 2020;90(4):106180. doi:10.1016/j.asoc.2020.106180. [Google Scholar] [CrossRef]
19. Deng L, Chen WS, Xiao M. Metafeature selection via multivariate sparse-group lasso learning for automatic hyperparameter configuration recommendation. IEEE Trans Neural Netw Learn Syst. 2024;35(9):12540–52. doi:10.1109/TNNLS.2023.3263506. [Google Scholar] [PubMed] [CrossRef]
20. Mantovani RG, Rossi ALD, Alcobaça E, Vanschoren J, de Carvalho ACPLF. A meta-learning recommender system for hyperparameter tuning: predicting when tuning improves SVM classifiers. Informat Sci. 2019;501(13):193–221. doi:10.1016/j.ins.2019.06.005. [Google Scholar] [CrossRef]
21. Horváth T, Mantovani RG, de Carvalho ACPLF. Hyper-parameter initialization of classification algorithms using dynamic time warping: a perspective on PCA meta-features. Appl Soft Comput. 2023;134(2):109969. doi:10.1016/j.asoc.2022.109969. [Google Scholar] [CrossRef]
22. Wang G, Song Q, Zhang X, Zhang K. A generic multilabel learning-based classification algorithm recommendation method. ACM Transact Knowl Disc Data. 2014;9:1–30. doi:10.1145/262947. [Google Scholar] [CrossRef]
23. Zhang ML, Zhou ZH. ML-KNN: a lazy learning approach to multi-label learning. Pattern Recognit. 2007;40(7):2038–48. doi:10.1016/j.patcog.2006.12.019. [Google Scholar] [CrossRef]
24. Zhu X, Yang X, Ying C, Wang G. A new classification algorithm recommendation method based on link prediction. Knowl-Based Syst. 2018;159:171–85. doi:10.1016/j.knosys.2018.07.015. [Google Scholar] [CrossRef]
25. Yang C, Akimoto Y, Kim DW, Udell M. OBOE: collaborative filtering for AutoML model selection. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019; Anchorage AK, USA. p. 1173–83. [Google Scholar]
26. Sousa AFM, Prudêncio RBC, Ludermir TB, Soares C. Active learning and data manipulation techniques for generating training examples in meta-learning. Neurocomputing. 2016;194:45–55. doi:10.1016/j.neucom.2016.02.007. [Google Scholar] [CrossRef]
27. Lee JW, Giraud-Carrier C. Automatic selection of classification learning algorithms for data mining practitioners. Intell Data Anal. 2013;17:665–78. doi:10.3233/IDA-130599. [Google Scholar] [CrossRef]
28. Leyva E, Caises Y, González A, Pérez R. On the use of meta-learning for instance selection: an architecture and an experimental study. Informat Sci. 2014;266:16–30. doi:10.1016/j.ins.2014.01.007. [Google Scholar] [CrossRef]
29. Garcia LPF, Lorena AC, Matwin S, Carvalho AD. Ensembles of label noise filters: a ranking approach. Data Min Knowl Disc. 2016;30(5):1192–216. doi:10.1007/s10618-016-0475-9. [Google Scholar] [CrossRef]
30. Reif M, Shafait F, Goldstein M, Breuel T, Dengel A. Automatic classifier selection for non-experts. Pattern Anal Appl. 2014;17(1):83–96. doi:10.1007/s10044-012-0280-z. [Google Scholar] [CrossRef]
31. Lai X, He X, Pang Y, Zhang F, Zhou D, Sun W, et al. A scalable digital twin framework based on a novel adaptive ensemble surrogate model. J Mech Des. 2022 Nov;145(2):021701. doi:10.1115/1.4056077. [Google Scholar] [CrossRef]
32. Bensusan H, Kalousis A. Estimating the predictive accuracy of a classifier. In: De Raedt L, Flach P, editors. Machine learning: ECML 2001. Berlin, Heidelberg: Springer; 2007. vol. 2167, p. 25–36. doi:10.1007/3-540-44795-4_3. [Google Scholar] [CrossRef]
33. Feurer M, Klein A, Eggensperger K, Springenberg JT, Blum M, Hutter F. Efficient and robust automated machine learning. Adv Neural Inf Process Syst. 2015;2015:2962–70. [Google Scholar]
34. Olson RS, Moore JH. TPOT: a tree-based pipeline optimization tool for automating machine learning. In: International Conference on Machine Learning. New York, NY, USA; 2016. p. 66–74. [Google Scholar]
35. Smith-Miles KA. Cross-disciplinary perspectives on meta-learning for algorithm selection. ACM Comput Surv. 2008;41:1–25. doi:10.1145/1456650.14566. [Google Scholar] [CrossRef]
36. Tugnait JK. Sparse-group lasso for graph learning from multi-attribute data. IEEE Transact Signal Process. 2021;69:1771–86. doi:10.1109/TSP.2021.3057699. [Google Scholar] [CrossRef]
37. Li Y, Nan B, Zhu J. Multivariate sparse group lasso for the multivariate multiple linear regression with an arbitrary group structure. Biometrics. 2015;71(2):354–63. doi:10.1111/biom.12292. [Google Scholar] [PubMed] [CrossRef]
38. Beck A, Teboulle M. A fast iterative shrinkage-thresholding algorithm. Soci Indust Appl Math J Imag Sci. 2009;2(1):183–202. doi:10.1137/080716542. [Google Scholar] [CrossRef]
39. O’Donoghue B, Candès E. Adaptive restart for accelerated gradient schemes. Foundat Computat Mathem. 2015;15(3):715–32. doi:10.1007/s10208-013-9150-3. [Google Scholar] [CrossRef]
40. Smith MR, Martinez T, Giraud-Carrier C. An instance level analysis of data complexity. Mach Learn. 2014;95(2):225–56. doi:10.1007/s10994-013-5422-z. [Google Scholar] [CrossRef]
41. Rivolli A, Garcia LPF, Soares C, Vanschoren J, Carvalho ACPLFD. Meta-features for meta-learning. Knowl-Based Syst. 2022;240(2):101–8. doi:10.1016/j.knosys.2021.108101. [Google Scholar] [CrossRef]
42. Khan I, Zhang X, Rehman M, Ali R. A literature survey and empirical study of meta-learning for classifier selection. IEEE Access. 2020;8:10262–81. doi:10.1109/ACCESS.2020.2964726. [Google Scholar] [CrossRef]
43. Alcobaça E, Siqueira F, Rivolli A, Garcia LPF, Oliva JT, de Carvalho ACPLF. MFE: towards reproducible meta-feature extraction. J Mach Learn Res. 2020;21(111):1–5. [Google Scholar]
44. Rijn JNV, Bischl B, Torgo L, Gao B, Umaashankar V, Fischer S, et al. OpenML: a collaborative science platform. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases. 2013; Prague, Czech Republic. p. 645–9. [Google Scholar]
45. Kotthoff L, Leyton-brown K. Auto-WEKA 2.0: automatic model selection and hyperparameter optimization in WEKA. J Mach Learn Res. 2017;18:1–5. [Google Scholar]
46. Giraud-Carrier C. The data mining advisor: meta-learning at the service of practitioners. In: Fourth International Conference on Machine Learning and Applications (ICMLA'05). 2005; Los Angeles, CA, USA. p. 113–9. [Google Scholar]
47. Deng L, Xiao MQ. Latent feature learning via autoencoder training for automatic classification configuration recommendation. Knowl Based Syst. 2023;261(3):110218. doi:10.1016/j.knosys.2022.110218. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools