
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Human Activity Recognition Using Weighted Average Ensemble by Selected Deep Learning Models
1 Department of Computer Science, University of Wah, Wah Cantt, Pakistan
2 Department of Computer Science, National Excellence Institute, Islamabad, Pakistan
3 Department of Computer Science, University of Rasul, Mandi Bahaud Din, Pakistan
4 Department of Information Systems, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, Saudi Arabia
5 Department of Computer Science, COMSATS University Islamabad, Wah Campus, Wah Cantt, Pakistan
6 Department of Software Engineering, Faculty of Computing and Information Technology, University of Sargodha, Sargodha, Pakistan
* Corresponding Author: Romana Aziz. Email:
Computer Modeling in Engineering & Sciences 2026, 146(2), 34 https://doi.org/10.32604/cmes.2026.071669
Received 09 August 2025; Accepted 14 January 2026; Issue published 26 February 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Human Activity Recognition (HAR) is a novel area for computer vision. It has a great impact on healthcare, smart environments, and surveillance while is able to automatically detect human behavior. It plays a vital role in many applications, such as smart home, healthcare, human computer interaction, sports analysis, and especially, intelligent surveillance. In this paper, we propose a robust and efficient HAR system by leveraging deep learning paradigms, including pre-trained models, CNN architectures, and their average-weighted fusion. However, due to the diversity of human actions and various environmental influences, as well as a lack of data and resources, achieving high recognition accuracy remain elusive. In this work, a weighted average ensemble technique is employed to fuse three deep learning models: EfficientNet, ResNet50, and a custom CNN. The results of this study indicate that using a weighted average ensemble strategy for developing more effective HAR models may be a promising idea for detection and classification of human activities. Experiments by using the benchmark dataset proved that the proposed weighted ensemble approach outperformed existing approaches in terms of accuracy and other key performance measures. The combined average-weighted ensemble of pre-trained and CNN models obtained an accuracy of 98%, compared to 97%, 96%, and 95% for the customized CNN, EfficientNet, and ResNet50 models, respectively.Keywords
HAR is an emerging area of artificial intelligence that recognises and classifies human actions utilising data from sensors, cameras, and wearable devices. Its applications include healthcare, Smart homes, Surveillance, Violent activity detection [1], Academia, driver behaviors and fitness monitoring. HAR systems analyse motion patterns to detect different types of activities. HAR activities are classified as either normal or abnormal. Normal activities are those which are described as regular or daily, for instance, walking, sitting, standing, running, climbing stairs, and so on. Such activities illustrate standard human motion patterns and are widely utilized to train models for behavior understanding. On the other hand, unusual events are unpredictable or anomalous events, such as falling, fighting, elements of sudden collapse, or even some strange dance movements, which are culturally consistent and could be regarded as anomalies but of a different nature.
In surveillance and security, HAR also helps identify suspicious behaviors and enhance security protocols. It also allows for more natural interfaces in interactive media and human-computer interaction. Growing demands for automation, personalized services, and real-time monitoring have raised HAR as a key research area that challenges more accuracy, adaptability, and efficiency.
In HAR, accurately identifying and categorising complex human activities, such as fights, snatching, and running, remains difficult, especially when each activity has multiple subtypes with significant intra-class variation. Most existing HAR systems struggle to distinguish visually similar actions, handle occlusions, and remain robust in dynamic, real-world environments with multiple viewpoints.
Deep learning and pre-trained methods have shown significant success in feature extraction, and Convolutional Neural Networks (CNNs) have been effective in acquiring spatial patterns for activity identification [2]. Beyond the limits of conventional models, CNNs are a powerful way for analyzing spatial and image data. Additionally, CNNs preserve spatial relationships, ensuring coherence even when objects are repositioned. It is better suited for image classification and object detection tasks because it can handle noise and slight data variations, learn deeper features in deeper networks, and perform well on large and complex datasets. Detection of these challenging activities creates problems because the discussed activities are heterogeneous, complex, and not simple [3].
To overcome these challenges, this study first examines the performance of CNN-based architectures and pre-trained models separately, then presents an average-weighted fusion method that capitalizes on their respective advantages. The fusion strategy attains higher recognition accuracy by exploiting the spatial learning capabilities of CNNs and enhanced feature extraction of pre-trained models.
The main objective of this research is to develop a deep learning-based framework for classifying human activities using a labelled dataset comprising three primary activity classes: fighting, snatching, and running, each with five distinct subtypes. This research aims to create a robust human activity detection system capable of detecting safety-critical events. It explores and fine-tunes advanced deep learning models to assess their performance in precisely classifying three different classes, using five variations of each class. The majority of the literature focuses on relatively simple actions such as walking, jogging, clapping, and wrestling, which limits their applicability to real-world, high-risk circumstances. There are models specifically designed to identify complex, safety-critical actions, such as violent or abnormal behaviour (e.g., cellphone theft or fighting), which are very important for surveillance and security applications.
To address this limitation, we selected a benchmark dataset that encompasses cellphone snatching, fighting, and running activities. Deep learning was also used with CNNs and three pre-trained models, which were combined using a Weighted Average Ensemble to achieve robust and accurate classification of critical actions. The results of experiments demonstrate that the proposed fusion scheme has better performance than stand-alone models, implying the need to consider a holistic view in improving HAR performance. The study focuses on abnormal and high-risk activities (e.g., cellphone snatching, fighting, and running) that are rarely addressed in HAR research. Additionally, it utilized the Weighted Average Ensemble of CNNs with three pre-trained models, which improves generalization and reliability for surveillance-oriented HAR.
The main research contributions include:
• We investigated many cutting-edge pre-trained deep learning models for classifying human activities, evaluating their strengths and limitations in extracting useful information.
• We proposed the CNN model for the classification and detection of given types of activities in the used dataset.
• To improve classification performance, we implemented an average-weighted fusion of pre-trained and CNN models, which combines functional characteristics from both architectures.
• Developed efficient image preprocessing methods, such as cropping and resizing, to standardise input dimensions and maintain motion-related information.
• An effective preprocessing technique has been proposed to improve feature visibility and recognition accuracy in deep learning models by enhancing the low-resolution and low-contrast images.
The remaining sections of the paper are organized as follows: Section 2 presents a literature review; Section 3 briefly describes the proposed methodology; Section 4 discusses the results and their implications; Section 5 highlights the discussion and finally, Section 6 provides the conclusion.
This section examines current studies on human activity recognition that employed machine learning, deep learning, and Internet of Things (IoT)-based techniques. HAR uses information gathered from sensors, cameras and other sources to categorise and recognise human activities. This section summarizes some of the significant recent contributions to HAR across different approaches, datasets, results, and challenges. The work aimed to develop the model and report on its accuracy using a test population of individuals aged 19 to 48 years. Various procedures were applied to clean and process the data, as well as to identify different patterns of human activities. In terms of model learning, it performed better than other types of models, including machine learning models, with the highest accuracy rate of 88.6% among machine learning models. It was also the best deep learning model, achieving an accuracy of 84.5% on Gated Recurrent Unit (GRU) [4].
The purpose of this work [5] was to develop an activity recognition method, based on deep learning, by extracting features from the raw input data. Two Hybrid Learning Algorithms (HLA) are proposed to identify sequential and spatial patterns using CNN and Recurrent Neural Networks (RNNs). A hybrid optimisation method, combining the Whale Optimisation Algorithm and the Grey Wolf Optimiser, enhanced feature selection. This evolved the entire optimization process.
In this work, Ref. [6] proposed a dynamic method for HAR that combines a deep bidirectional long-term memory and the pre-trained feature extraction technique. Initially, Convolutional Neural Network models, particularly MobileNetV2, were used to extract deep-level characteristics from video frames. These extracted features were subsequently analyzed using an optimized Deep BiLSTM network which effectively captured dependencies and increased prediction accuracy. During testing phase, an iterative fine-tuning approach was employed to update high-level parameters and enhance flexibility in response to various conditions. The model’s performance was assessed using three benchmark datasets: UCF Sport [7], UCF11 [8], and JHMDB [9], with accuracies of 76.30%, 93.3%, and 99.20%, respectively.
This work [10] used XGBoost to build an activity recognition system. Initially, a Hue, Saturation, Value (HSV) colour transformation was used to improve video frame clarity, followed by noise reduction. Silhouettes were extracted using multiple object tracking (MOT) and Video Inference for Body Estimation (VIBE) methods. For feature extraction, Textone maps and Features from the Accelerated Segment Test (FAST) [11] were used. Independent Component Analysis (ICA) was then used to determine the most informative components for feature discrimination. Finally, the composed features were loaded into XGBoost for categorization as relevant human activities. Experiments conducted using the Stony Brook University (SBU) [12] Interaction dataset achieved a recognition rate of 91%. The AI-based behavior biometrics framework used a dynamic attention fusion unit and a temporal-spatial fusion method to improve the detection of human activity in surveillance systems. The system records temporal, geographical, and behavioral dependencies in video data streams and extracts important features employing a lightweight EfficientNetB0 backbone. The system outperformed state-of-the-art techniques, showing high accuracies of 80.342%, 98.987%, 98.734%, and 98.927%, respectively, using four publicly accessible datasets (HMDB51 [13], UCF50 [14], UCF101 [15], and YouTube Action [8]).
Some artificial intelligence models have been created to recognise human activity but have produced poor results in HAR in real-world, long-term settings. Because they have extracted insufficient temporal and spatial features [16]. RNN and the CNN model are applied to examine the best efficiency of daily activities, such as walking, and to attain the best figure of accuracy [17]. One feature of the Wi-Fi signal is Channel State Information (CSI), which identifies various human activities. Human activity data was collected using a Raspberry Pi 4 and applied techniques, including 1D-CNN, LSTM, and Bi-directional LSTM, to achieve 95% accuracy [18]. Similarly, 100% success is achieved in recognising human posture and action using a CNN model, as compared to the Microsoft Research (MSR) and Kinect Activity Recognition Dataset (KARD) [19]. A novel acceleration-based HAR method is employed in conjunction with the CNN model, utilising a large dataset of 31,688 samples. Here, eight distinctive human activities were examined and achieved 93.8% accuracy [20]. Furthermore, an advanced system for human image tracking (HIT) was developed to detect both simple and complex user movements. A smart camera was used to collect the dataset for the model of a region-based CNN. As a result, 98.53% accuracy was achieved through the proposed model [21]. Another deep learning model, CNN-LSTM, was identified to recognise normal individuals and straightforward actions, including driving and eating. Here, CNN was used to extract features from sensor data, and an LSTM was used to obtain long-term dependencies between two events. The proposed model achieved a maximum recognition rate of 95.8% [22]. In some places, a combination of three models was used, including LSTM, CNN, and CNN-LSTM, to organize human activities. These models were trained on a dataset comprising six classes of activities, collected from 36 people. Activities included walking, sitting, jogging, standing, and climbing stairs. The created model was evaluated using the TensorFlow framework, and the testing accuracy was 94.51% for the CNN, 96.61% for the LSTM, and 97.76% for the CNN-LSTM. The accuracy was checked by a precision of 97.75%, a recall of 97.77%, F1-Measure 97.76%, and an area under the curve of 100% for the CNN-LSTM model [23].
The model’s effectiveness in personalised and adaptive learning environments was validated through experimental results on datasets, including the recently created Human Activities and Postural Transitions (HAPT) dataset [24], which achieved better classification accuracy (97.84% for transitional activities and 99.04% for dynamic activities) than state-of-the-art methods.
The research introduced an ensemble deep learning approach for capturing temporal correlations in sensory data. We proposed a hybrid LSTM-GRU architecture with dropout and batch normalization and evaluated it on the UCI-HAR and Wireless Sensor Data Mining (WISDM) [25] datasets.
The method was developed to promote a culture of fluid, scalable, and ubiquitous learning The results on HAPT outperformed all the state-of-the-art methods (97.84% for transitional activities and 99.04% for dynamic activities), which demonstrates its effectiveness in the personalized and adaptively learning applications [26]. The authors proposed the method by using the motion capturing system with marker-based motion capturing system (MBMCS) and marker-less motion capturing system (MLMCS), and compared them for the analysis of human gait of a person and activity recognition. Results demonstrate that MBMCS performs up to 99.3% accuracy for person recognition and 98.1% for activity recognition using K-Nearest Neighbors, while MLMCS provides a cost-effective solution with comparable performance and the potential for further improvement by advanced feature extraction [27]. The existing work has been described in Table 1.

3 Proposed Research Methodology
The proposed methodology has been discussed in this section. The diagram of the proposed framework is shown in Fig. 1. The basic steps of the proposed method are given below:
(a) Data set selection
(b) Pre-processing,
(c) Feature extraction and classification
(d) Performance measures
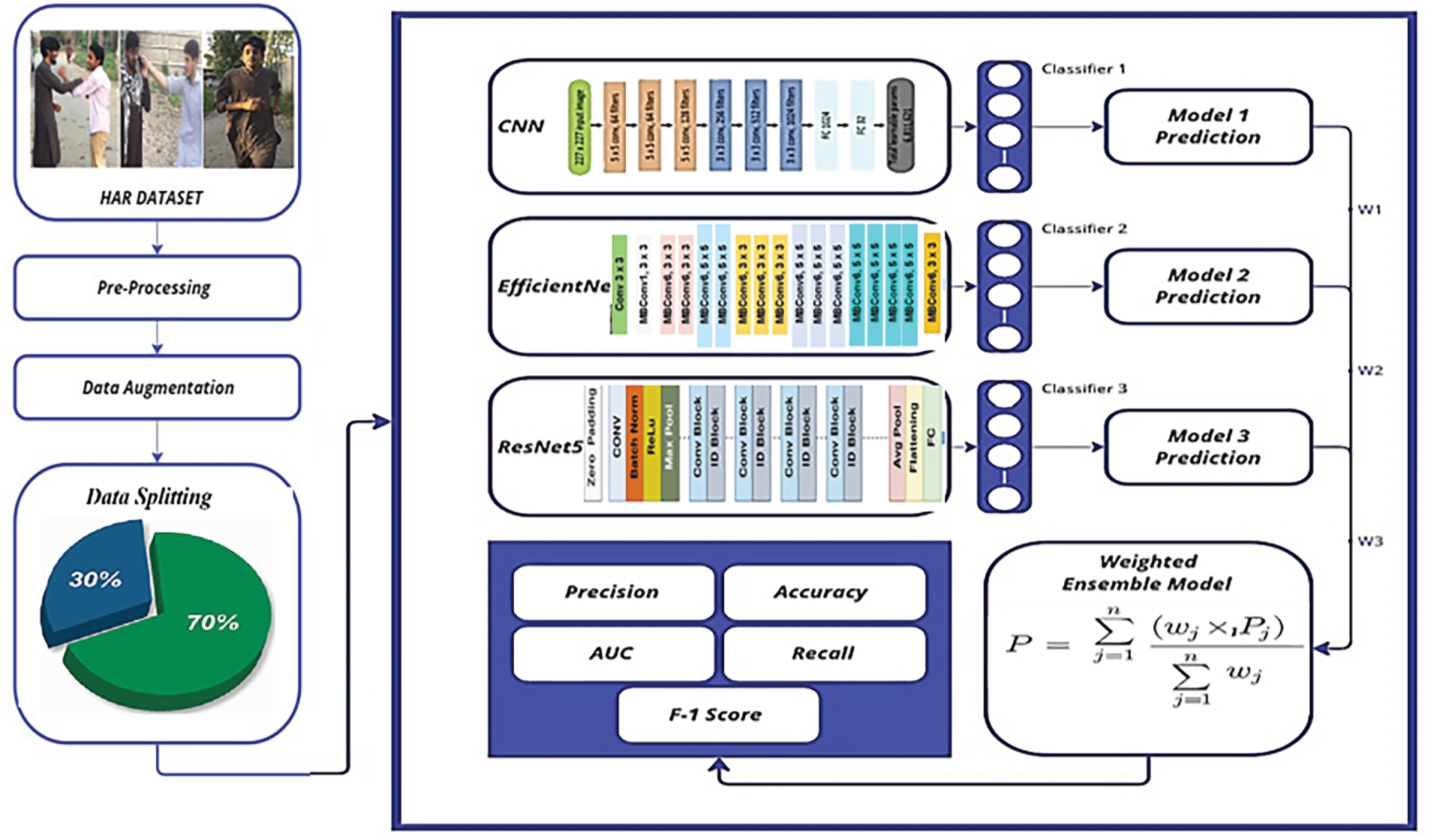
Figure 1: Proposed framework for the weighted ensemble model using selected deep learning methods.
The dataset serves as a standard for recognising human behaviours, with a focus on violence detection, including frames for cell phone snatching, fighting, and running.
A brief description of the selected dataset is provided in this section, including sample images of each class with varying variations, as shown in Fig. 2.

Figure 2: Dataset samples of three classes with five different forms [28].
In the pre-processing, raw data were cleaned and organized so that it would be easier for the proposed model to understand [29]. It makes it easier to identify and correct errors, fill in missing portions, and improve the overall quality of the selected data. Pre-processing steps focused on the selected datasets. The selected dataset of human activity recognition consists of the following tasks: running, fighting, and snatching. Cropping removes unnecessary parts of the image frame, such as the background, so the focus remains on the person acting. This allows the model to focus only on essential activities. After cropping, all frames are resized to a fixed size. Since varying images frequently have varying sizes, scaling ensures the model analyzes each input consistently, thereby reducing memory use. Adjusting the resolution entails either increasing the clarity for greater detail or decreasing it to accelerate training. High-resolution displays can capture finer information (such as hand movements in fighting). In contrast, low-resolution displays can capture larger movements (such as running) while allowing the model to run faster. The following steps have been utilized for the pre-processing:
• To focus on the region of interest (ROI) where human activity occurs, cropping is also applied to some images where it is needed to remove unnecessary background elements.
• Images in the given dataset were in different sizes and were resized according to the proposed CNN model and other pretrained models.
• As in the given dataset, a few images are of low resolution and contrast. So, the Histogram processing is used to upgrade the brightness [30] and contrast of image data. It modifies the pixel values to enhance parts in dark or light ranges for better visibility. This assists in clearly managing human actions within the frames. The transformation using histogram equalization is given as
3.3 Feature Extraction and Classification
We employed the pre-trained models EfficientNet [31], ResNet50 [32], and the proposed CNN [33] model for feature extraction and classification.
EfficientNet is a collection of CNNs designed to improve accuracy and efficiency through compound scaling. It carefully balances depth, width, and resolution to improve performance while retaining computational efficiency. The architecture enhances feature representation with Mobile Inverted Bottleneck Convolution layers and Squeeze-and-Excitation blocks. EfficientNet achieves higher accuracy with fewer parameters, making it a good choice for a variety of computer vision applications, especially Human Activity recognition.
3.3.2 Fine-Tune Residual Network (ResNet50)
ResNet is a deep network with 50 layers designed to address the challenges of training deep networks, introducing residual learning by using residual blocks to mitigate the vanishing gradient problem and enable the training of deeper networks. Each residual block comprises skip connections that avoid one or more layers, permitting the network to learn residual mappings. This architecture enables the network to learn an identity function, which helps in preserving the gradient flow during backpropagation and improves training efficiency. The symbols used in the equation are explained in Table 2.
Deep neural networks, such as CNNs, are widely used for tasks like image categorisation and object detection. When features have been extracted and dimensionality reduced, the fully connected layer can evaluate the degree to which values and class labels are related. The convolutional layer is responsible for creating feature maps by extracting features from the input pictures. By using techniques such as max pooling and average pooling, the spatial dimensions are compressed in the pooling layer without losing valuable data. CNNs, which were inspired by the human visual cortex, are particularly good at maintaining the spatial relationships between pixels and identifying fine-grained details in images.
The proposed CNN model applied with six layers is designed to efficiently handle the detection task of driver positions from the dataset while maintaining a balance between computational complexity and accuracy, as shown in Fig. 2. This model consists of input layers, convolutional layers, max-pooling layers, a flattened layer, a dense layer, an activation function, and an output layer. Each layer plays a distinct role in the pipeline’s processing, contributing to the model’s ability to learn from the input data.
The first layer receives the input image on which the selected model is trained.
This layer utilised the set of learnable filters on the input image. This layer captures local patterns, such as edges and texture, and can be computed as in Eq. (2). Multiple layers are used to extract features from the input layer, each with ten filters of size 3 × 3. To create feature maps that capture the spatial hierarchies of features, this layer applies filters to the input. The symbols used in the equation are explained in Table 2.
A max pooling layer with a 2 × 2 pool size comes after each convolutional layer to reduce the spatial dimensions of the feature maps while keeping the features and reducing the computational complexity. This helps in making the model more robust to variation in the input.
A flattened layer receives the output from the last max pooling layer and converts the multi-dimensional feature map into a one-dimensional vector. This step prepared the data for a fully connected layer.
The fully Connected Layer, also called the dense layer, flattened layer, is fed into a series of fully connected layers as follows:
• Dense layer including 3 neurons
• Dense layer including 64 neurons
• Dense layer including 128 neurons
• Dense layer including 512 neurons
• Dense layer including 1024 neurons
Each fully connected layer applies a linear transformation followed by a non-linear activation function to capture the complex patterns and relationships in the data.
The final dense layer with two units is followed by a SoftMax activation function (which normalizes the outputs into a probability distribution) to construct a probability distribution over the output classes, enabling classification into one of the two categories, as shown in Eq. (3).
The symbols used in the equation are explained in Table 2.
The output of the softmax layer is the last classification result, indicating the class to which the input image belongs. Also known as CNN mode, this approach combines convolution, max pooling, fully connected, and softmax layers to capture features and patterns in the required input image. The proposed CNN model architecture is shown in Fig. 3.
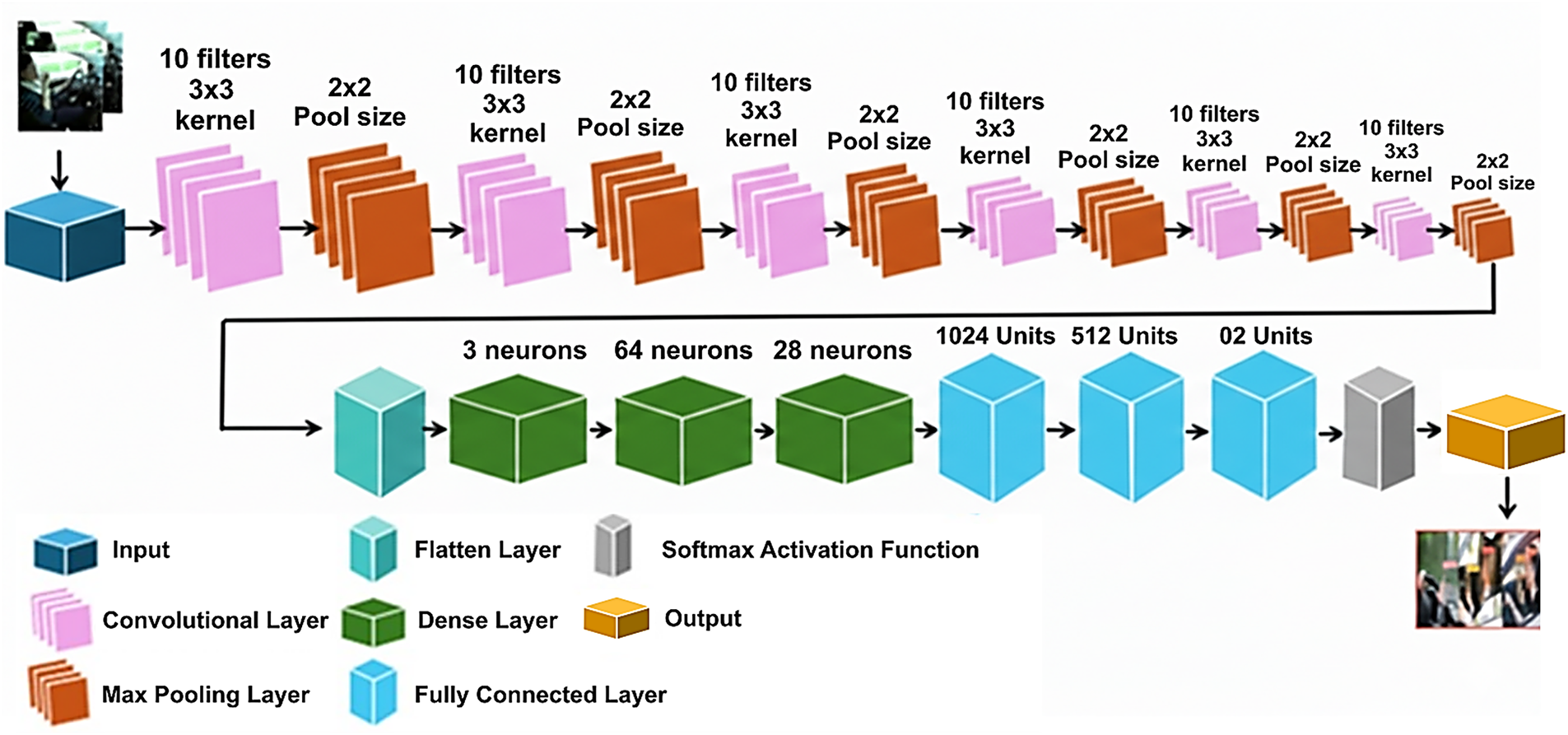
Figure 3: Proposed CNN model architecture.
3.5 Weighted Average Ensemble Model for Human Activity Recognition (HAR)
Ensemble learning, a machine learning technique, combines different models to improve cumulative predictive performance. The fundamental idea is that aggregating the results of other models improves the final prediction’s reliability, accuracy, and generalizability. In this study, ensemble learning with an average-weighted fusion of EfficientNet, ResNet50, and CNN models improves Human Activity Recognition (HAR) by utilizing their related capabilities. EfficientNet brings fine-grained spatial information compression, ResNet50 generates hierarchical motion representations through deep residual connections, and CNNs learn local spatial features from raw sensor data or video frames. The ensemble trades accuracy for stability by weighting its predictions with the best weight assignments. This prevents overfitting and helps capture diverse activity patterns for better generalization. In this work, an ensemble approach is employed to enhance human activity recognition. The approach had three branches, with five variations each. In this research, two pre-trained and one customized CNN deep learning model were initially constructed, and their performances were thoroughly evaluated on the dataset. The findings demonstrated that ResNet50, EfficientNet, and our own CNN were best suited to acquiring the complex features within images of human activities. Based on this baseline assessment, we developed an ensemble model by aggregating the prediction powers of the three base classifiers. We selected the weighted average ensemble, which leverages the variety of multiple models to generate a more reliable and accurate prediction system. Every base classifier in this ensemble paradigm makes predictions, which are weighted based on how well it performs on a validation set. The weighted averaging technique maximizes the ensemble’s overall performance by ensuring that classifiers with higher predictive abilities have a greater influence in the final decision-making process.
The weighted average ensemble for combining predictions from multiple models can be represented mathematically as:
where:
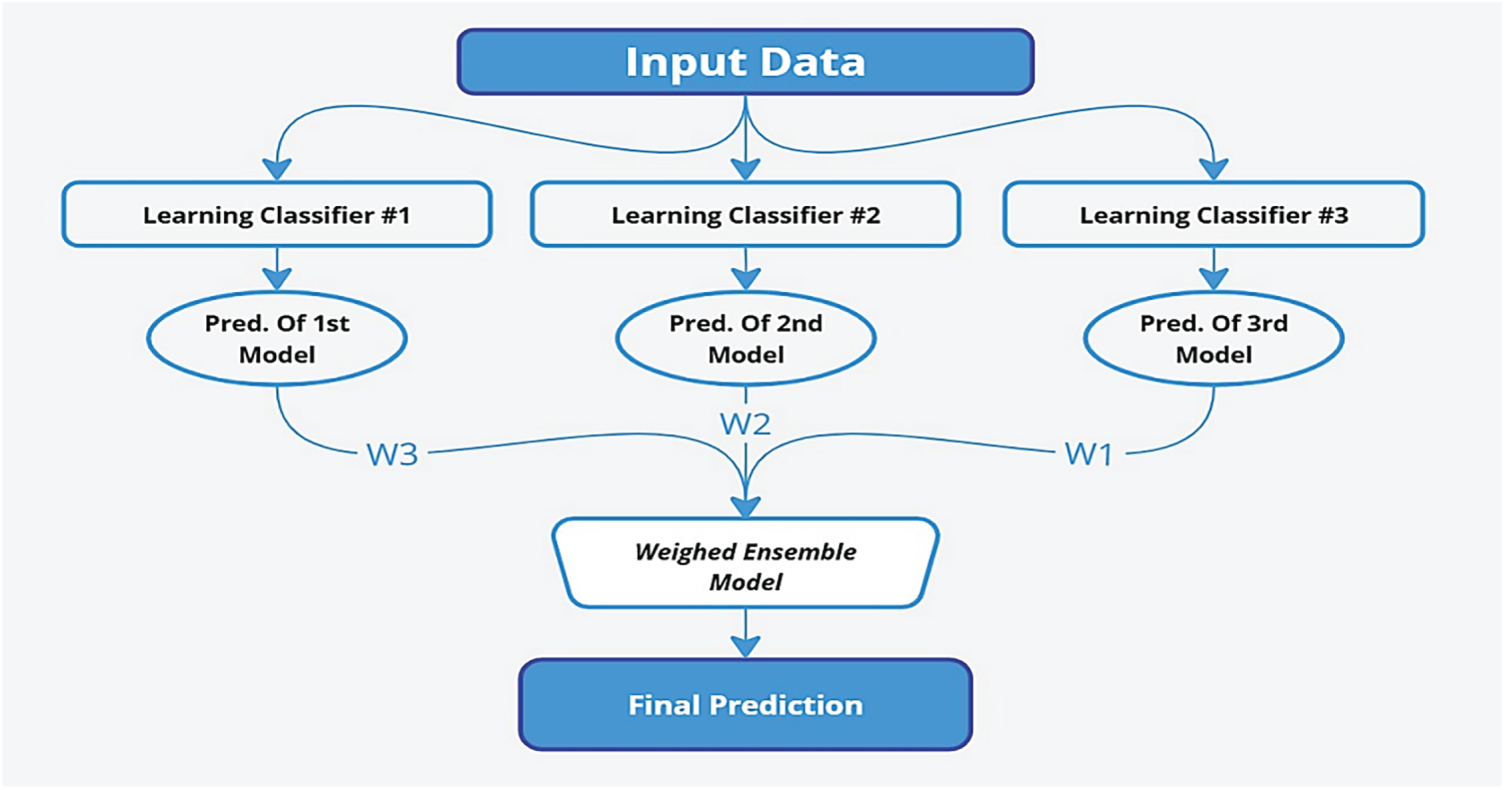
Figure 4: Model structure for weighted average ensemble.
For the experimental setup of our study, we begin by selecting a dataset for empirical analysis. This ensures the integrity and balance of pre-processing, standardising image size and shape. The Experimental setup has been discussed in Table 3.
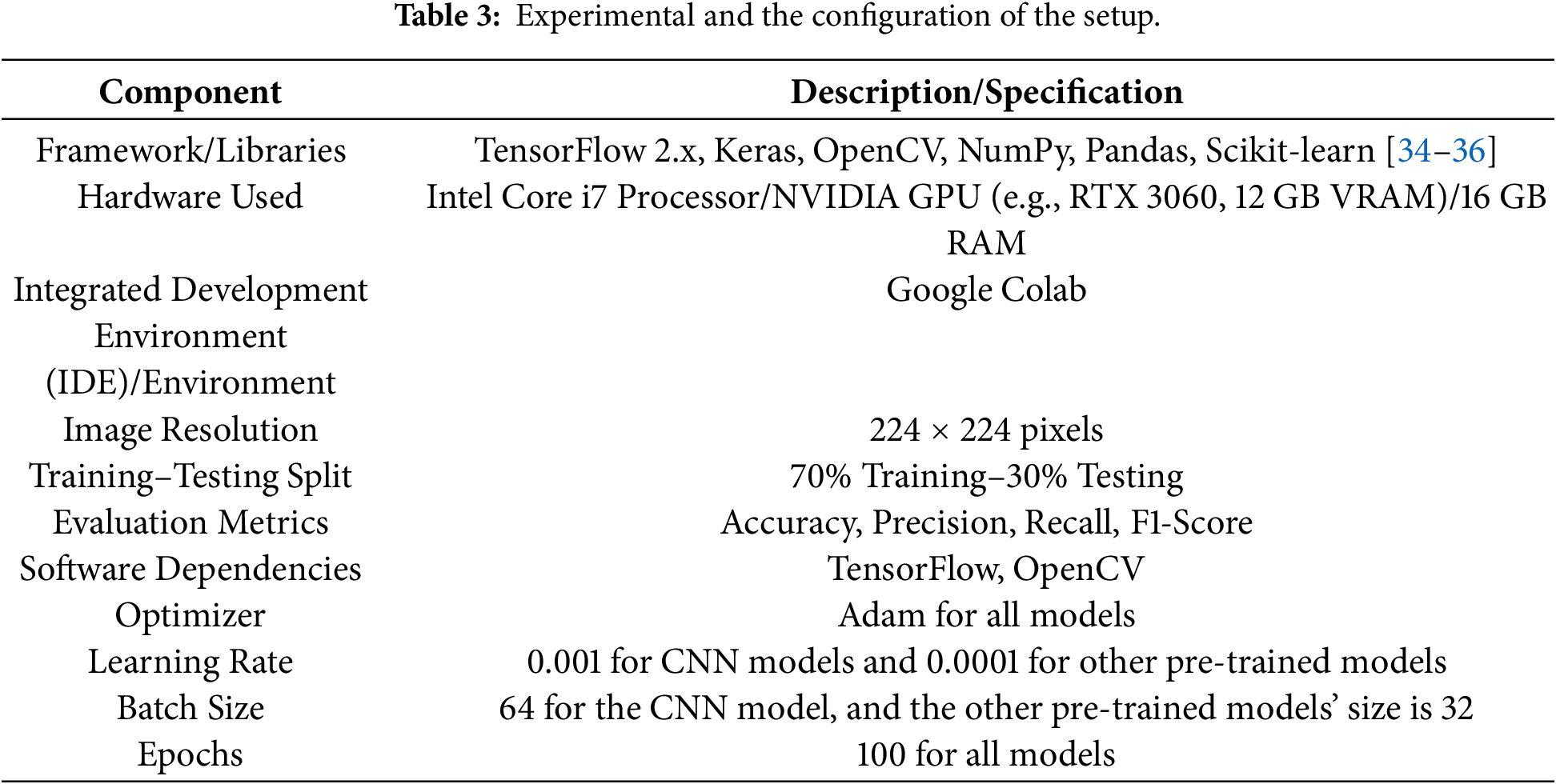
Additionally, we outline the standard measures used to compare the applied method with existing studies. The following performance has been used for the analysis of the results.
The study results were evaluated using three DL models: ResNet50, EfficientNet, and the proposed CNN. Then, these models were fused by averaging for further performance enhancement. ResNet50 with its residual learning framework had excellent feature extraction, however, it struggled to capture more complicated activity sequences. EfficientNet is also a compound scaling method which compares to ResNet50 and is computationally efficient while achieving better accuracy performance. The proposed CNN model for human activity recognition through salient activity features has shown promising results which are tailored accordingly. However, as the models were complementary, some variations existed at the level of the different activity classes, as the unique strengths and weaknesses of each model applied. An average-weighted fusion scheme was simulated to address such a concern. ResNet50, EfficientNet and Prose CNN predictions are weighted based on the performances of the individual models. Benefitting from complementary of three models, the integrated approach improves the classification accuracy, precision, sensitivity as well as the F1 value significantly. In the case of human activity recognition, such an ensemble method has been proven to improve accuracy and to reduce classification errors and over-fitting. Our experiments demonstrate that fusion strategy is a simple yet effective approach to boost the accuracy of activity detection tasks by mitigating the limitations of single models.
4.1 Accuracy and Model Loss Plot for Training and Validation Using Selected Model
The model loss and accuracy graphs were crucial for the analysis of the performance measure during the training and testing of our Human Activity Recognition system using both pre-trained and weighted average ensemble models. The loss graph illustrates how the training and validation loss values change over time, showing how well the model learns from the data.
Similarly, the accuracy graph illustrates the evolution of training and validation accuracy over time. Both curves exhibit an upward trend, indicating that the model is improving at accurately classifying human activity. Due to prior learning, the accuracy and loss curves for the pre-trained model converged more quickly, whereas the suggested CNN model needed more epochs but still performed competitively. Comparing the performance, modifying hyperparameters, and choosing the best model configuration were all made easier by these visualisations. The model loss and accuracy graphs using ResNet, EfficientNet, the proposed CNN, and the proposed weighted average ensemble method are shown in Fig. 5.
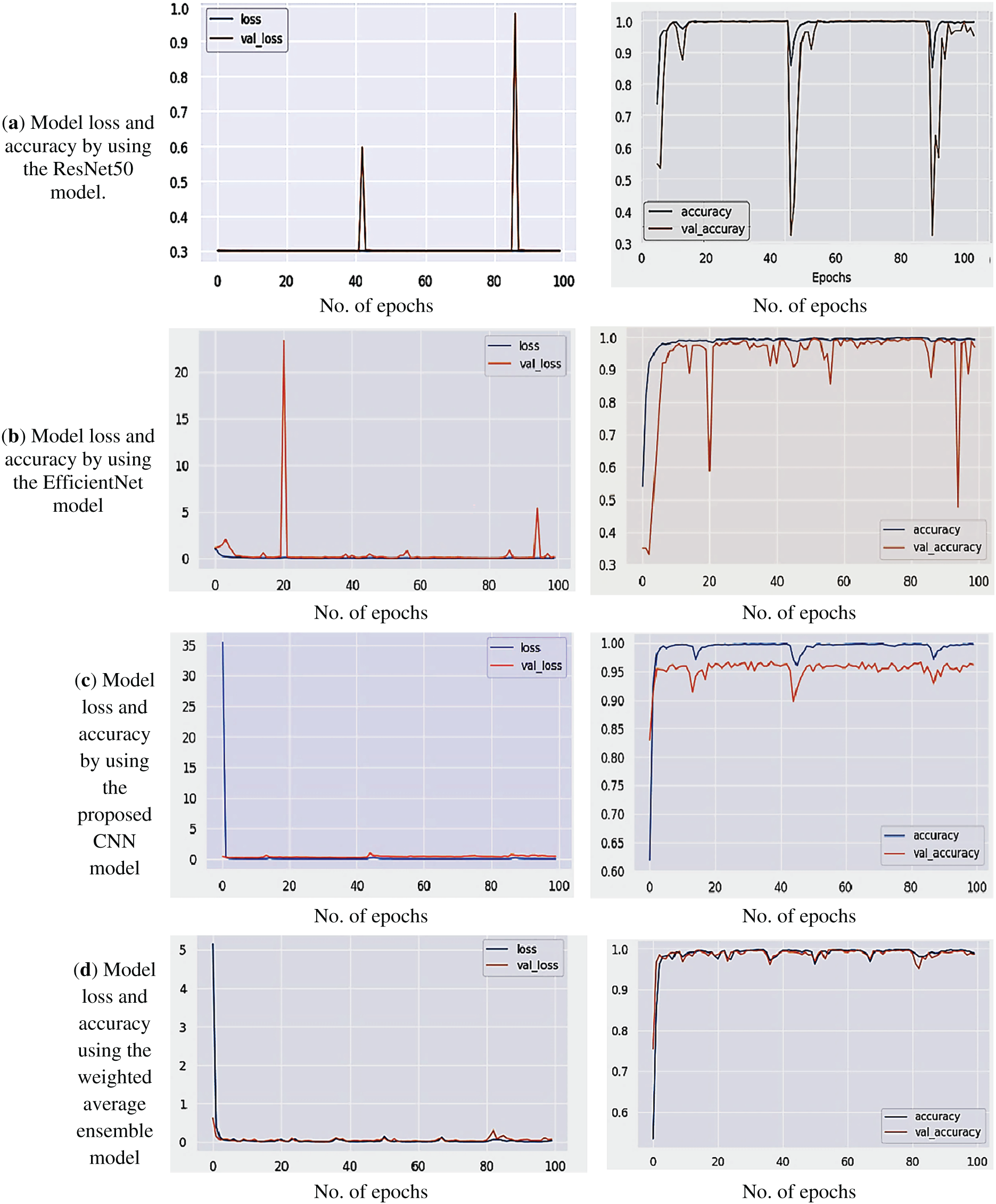
Figure 5: Model loss and model accuracy using: (a) ResNet, (b) EfficientNet, (c) proposed CNN, and (d) Weighted average ensemble.
4.2 Confusion Matrix Using Selected Model
The confusion matrix is an essential resource for assessing the class-wise accuracy and identifying misclassification movements by examining the confusion matrices of selected models, such as ResNet101, EfficientNet, proposed CNNs, and then the average weighted ensemble method hybrid architectures. Thus, the confusion matrix directs additional tuning or data balancing and aids in identifying model generalization flaws. The most accurate architecture for deployment can also be chosen by comparing the confusion matrices of various models. The confusion matrix analysis results were shown in Fig. 6 by using all selected models.
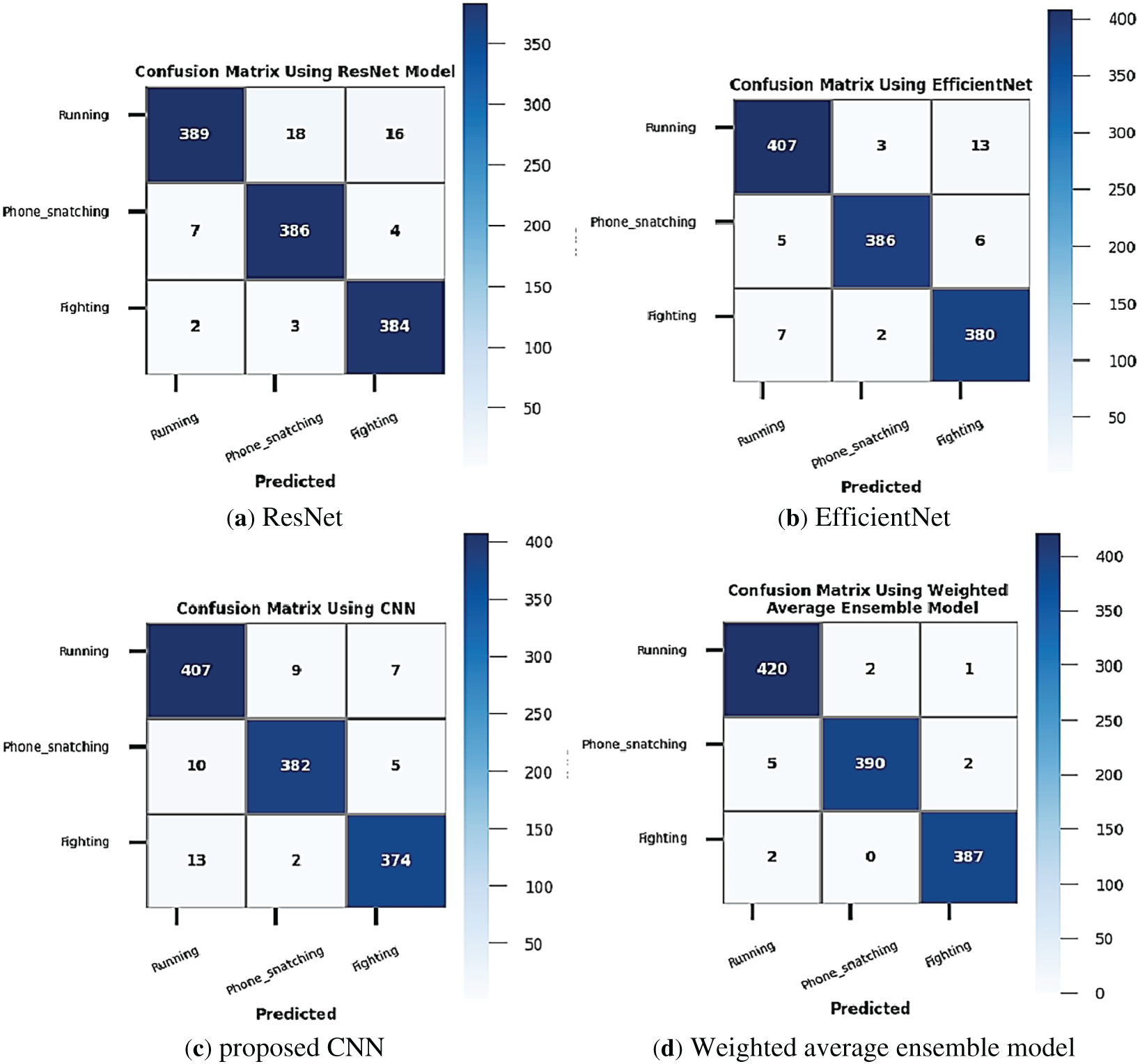
Figure 6: Confusion matrix by using all selected models: (a) ResNet, (b) EfficientNet, (c) proposed CNN, and (d) Weighted average ensemble.
4.3 Accuracy, Precision, Recall, and F-Score by Using the Selected Model
By using ResNet, EfficientNet, CNN, and a weighted average ensemble model, the accuracy, precision, recall, and F-measure values are presented in Table 4.
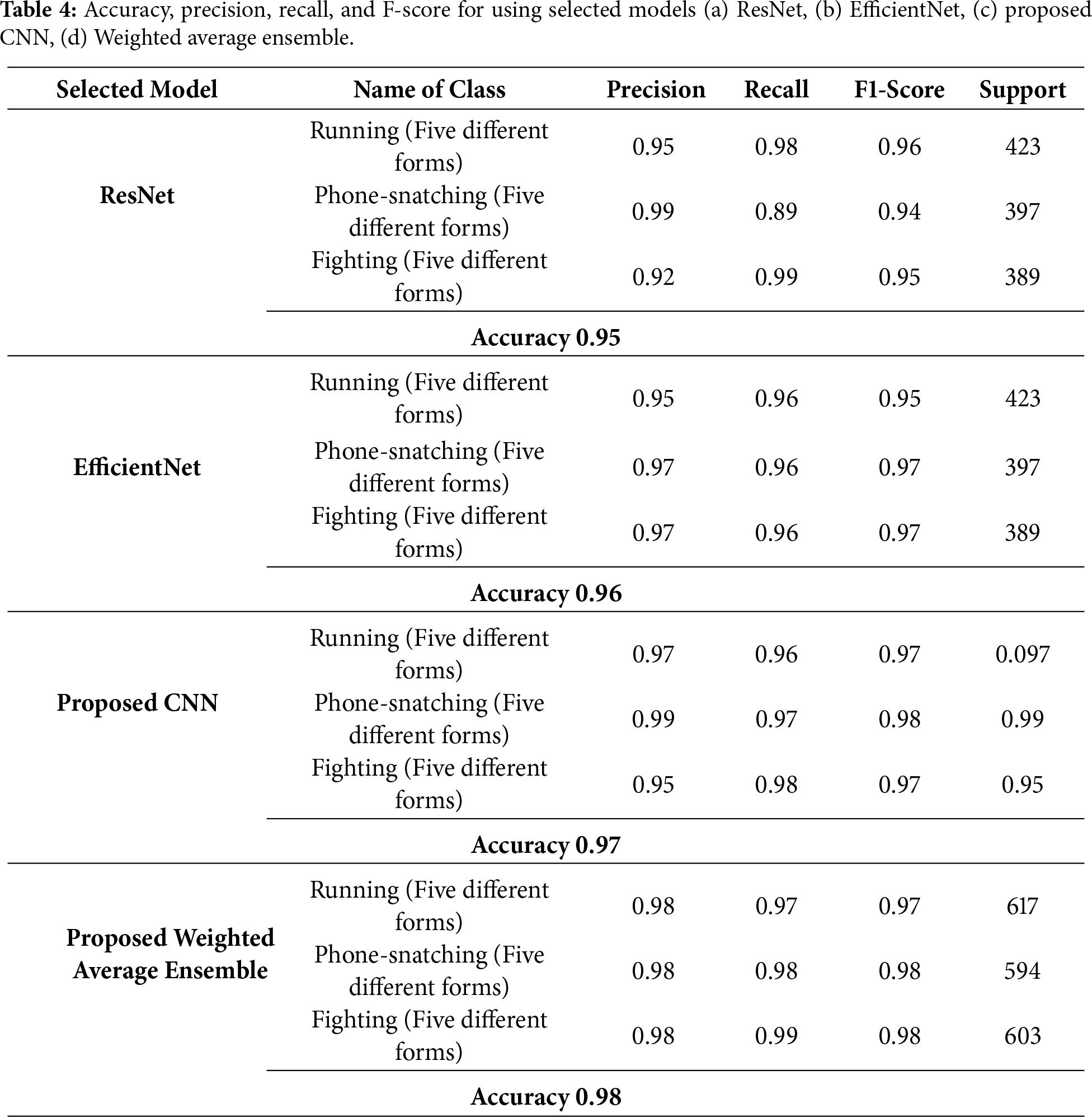
The proposed weighted average ensemble framework for HAR combines various deep learning architectures to improve classification accuracy and model robustness. CNN can help to detect low-level spatial features, ResNet handles this by using skip connections to learn deeper features, whereas EfficientNet provides optimized scaling to balance accuracy and computational efficiency. The weighted average ensemble aggregates predictions and assigns importance based on model performance, combining the individual models’ strengths. Comparisons of the results using ResNet, EfficientNet, CNN, and the Proposed model with Weighted Average Ensemble have been shown in Fig. 7.
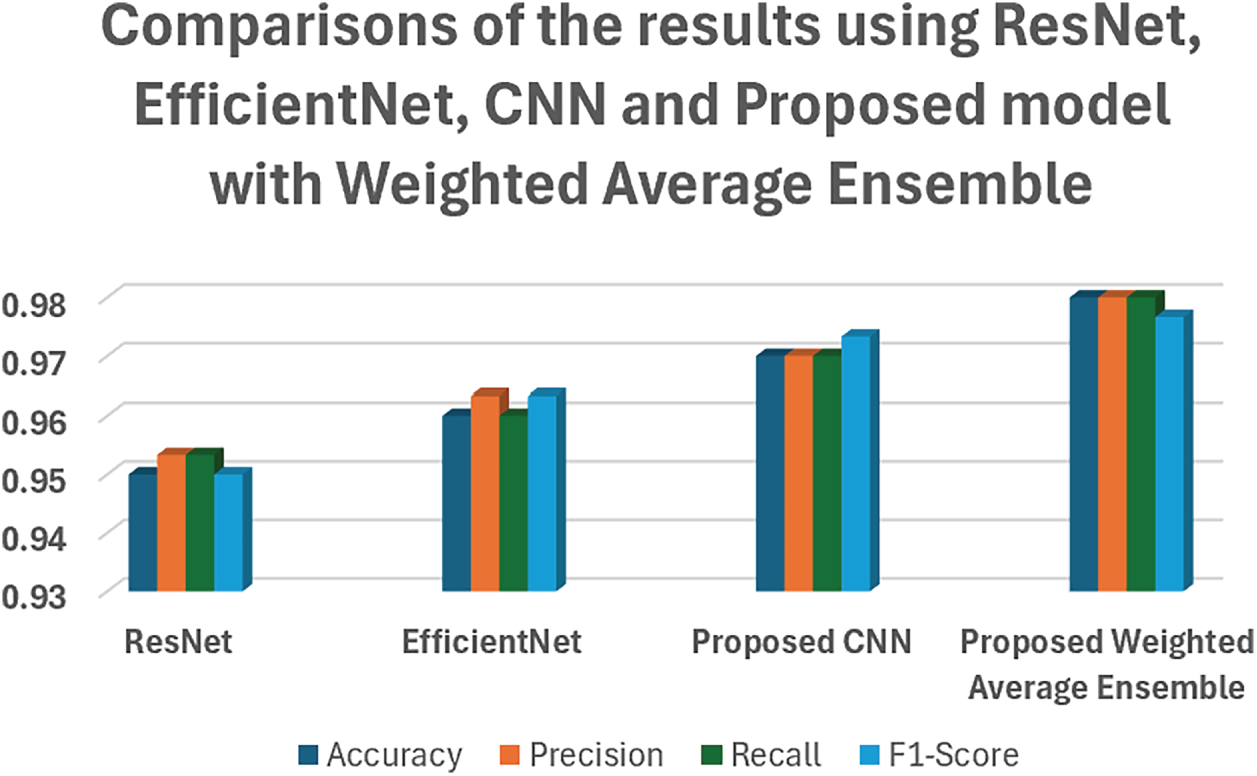
Figure 7: Comparison of the results of the proposed model with weighted average ensemble with other models.
We aimed to effectively classify and recognise these complex activity patterns using deep learning models. To this end, we evaluated several state-of-the-art convolutional neural networks, including ResNet, EfficientNet, a custom-designed CNN model, and a proposed model integrated with a weighted-average ensemble approach. The experimental results demonstrated that while standard pre-trained models performed reasonably well, the proposed CNN model showed improved classification performance by capturing more discriminative spatial features. In addition, combining several models with the weighted-average ensemble method achieved the best accuracy and stability for all activity types and subtypes. In summary, the proposed ensemble model achieved superior performance than the other baseline models, suggesting that it is able to effectively capture the complexity and diversity of real-world activity recognition. These results demonstrate that ensemble-based deep learning methods are very promising to enhance the performance and robustness of HAR systems, especially in such safety-critical applications as public security, crime prevention, and surveillance. The proposed method yielded encouraging results, but the speed of processing and the overall efficiency may be further enhanced. When the focus of future work will be on performing real-time experiments, considering the problem of imbalanced data, and extending the current model to predict more human activities in diverse domains. Multimodal sensor data and self-supervised learning methods can be incorporated to demonstrate an even higher level of robustness and generalization.
Acknowledgement: This work was supported by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2026R765), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Funding Statement: This work was supported by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2026R765), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author Contributions: Waseem Akhtar: Data preparation, data analysis, literature review, initial draft, methodology. Mahwish Ilyas: Data preparation, manuscript revision, experiments and implementation. Romana Aziz: Supervision, final draft review, correspondence, manuscript improvement. Ghadah Aldehim: Critical review, conceptualization, visualization. Tassawar Iqbal: Analysis, improved the writing editing and revision. Muhammad Ramzan: Methodology enhancement, and results interpretation. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The dataset used in this research is available at: https://data.mendeley.com/datasets/67bbcr5ssp/1.
Ethics Approval: No need for the ethics approval, as the published dataset has been used in this research work.
Conflicts of Interest: The authors declare no conflicts of interest to report.
References
1. Ramzan M, Abid A, Khan HU, Awan SM, Ismail A, Ahmed M, et al. A review on state-of-the-art violence detection techniques. IEEE Access. 2019;7:107560–75. doi:10.1109/ACCESS.2019.2932114. [Google Scholar] [CrossRef]
2. Pathmaperuma MH, Rahulamathavan Y, Dogan S, Kondoz A. CNN for user activity detection using encrypted in-app mobile data. Future Internet. 2022;14(2):67. doi:10.3390/fi14020067. [Google Scholar] [CrossRef]
3. Kumar P, Suresh S. Deep-HAR: an ensemble deep learning model for recognizing the simple, complex, and heterogeneous human activities. Multimed Tools Appl. 2023;82(20):30435–62. doi:10.1007/s11042-023-14492-0. [Google Scholar] [PubMed] [CrossRef]
4. Chadha J, Jain A, Kumar Y, Modi N. Hybrid deep learning approaches for human activity recognition and postural transitions using mobile device sensors. SN Comput Sci. 2024;5(7):925. doi:10.1007/s42979-024-03300-7. [Google Scholar] [CrossRef]
5. Thakur D, Dangi S, Lalwani P. A novel hybrid deep learning approach with GWO-WOA optimization technique for human activity recognition. Biomed Signal Process Control. 2025;99(3):106870. doi:10.1016/j.bspc.2024.106870. [Google Scholar] [CrossRef]
6. Hassan N, Miah ASM, Shin J. A deep bidirectional LSTM model enhanced by transfer-learning-based feature extraction for dynamic human activity recognition. Appl Sci. 2024;14(2):603. doi:10.3390/app14020603. [Google Scholar] [CrossRef]
7. Rodriguez MD, Ahmed J, Shah M. Action MACH a spatio-temporal Maximum Average Correlation Height filter for action recognition. In: Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition; 2008 Jun 23–28; Anchorage, AK, USA. doi:10.1109/CVPR.2008.4587727. [Google Scholar] [CrossRef]
8. Liu J, Luo J, Shah M. Recognizing realistic actions from videos in the wild. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition; 2009 Jun 20–25; Miami, FL, USA. doi:10.1109/cvpr.2009.5206744. [Google Scholar] [CrossRef]
9. Jhuang H, Gall J, Zuffi S, Schmid C, Black MJ. Towards understanding action recognition. In: Proceedings of the 2013 IEEE International Conference on Computer Vision; 2013 Dec 1–8; Sydney, Australia. doi:10.1109/iccv.2013.396. [Google Scholar] [CrossRef]
10. Bukht TFN, Jalal A. A robust model of human activity recognition using independent component analysis and XGBoost. In: Proceedings of the 2024 5th International Conference on Advancements in Computational Sciences (ICACS); 2024 Feb 19–20; Lahore, Pakistan. doi:10.1109/ICACS60934.2024.10473238. [Google Scholar] [CrossRef]
11. Rosten E, Drummond T. Machine learning for high-speed corner detection. In: Computer Vision—ECCV 2006. Berlin/Heidelberg, Germany: Springer; 2006. p. 430–43. doi:10.1007/11744023_34. [Google Scholar] [CrossRef]
12. Yun K, Honorio J, Chattopadhyay D, Berg TL, Samaras D. Two-person interaction detection using body-pose features and multiple instance learning. In: Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops; 2012 Jun 16–21; Providence, RI, USA. doi:10.1109/CVPRW.2012.6239234. [Google Scholar] [CrossRef]
13. Kuehne H, Jhuang H, Garrote E, Poggio T, Serre T. HMDB: a large video database for human motion recognition. In: Proceedings of the 2011 International Conference on Computer Vision; 2011 Nov 6–13; Barcelona, Spain. doi:10.1109/ICCV.2011.6126543. [Google Scholar] [CrossRef]
14. Reddy KK, Shah M. Recognizing 50 human action categories of web videos. Mach Vis Appl. 2013;24(5):971–81. doi:10.1007/s00138-012-0450-4. [Google Scholar] [CrossRef]
15. Soomro K, Zamir AR, Shah M. UCF101: a dataset of 101 human actions classes from videos in the wild. Orlando, FL, USA: University of Central Florida; 2012. [Google Scholar]
16. Hussain A, Khan SU, Khan N, Shabaz M, Baik SW. AI-driven behavior biometrics framework for robust human activity recognition in surveillance systems. Eng Appl Artif Intell. 2024;127:107218. doi:10.1016/j.engappai.2023.107218. [Google Scholar] [CrossRef]
17. Batool S, Khan MH, Farid MS. An ensemble deep learning model for human activity analysis using wearable sensory data. Appl Soft Comput. 2024;159:111599. doi:10.1016/j.asoc.2024.111599. [Google Scholar] [CrossRef]
18. Abbaspour S, Fotouhi F, Sedaghatbaf A, Fotouhi H, Vahabi M, Linden M. A comparative analysis of hybrid deep learning models for human activity recognition. Sensors. 2020;20(19):5707. doi:10.3390/s20195707. [Google Scholar] [PubMed] [CrossRef]
19. Fard Moshiri P, Shahbazian R, Nabati M, Ali Ghorashi S. A CSI-based human activity recognition using deep learning. Sensors. 2021;21(21):7225. doi:10.3390/s21217225. [Google Scholar] [PubMed] [CrossRef]
20. Çalışkan A. Detecting human activity types from 3D posture data using deep learning models. Biomed Signal Process Control. 2023;81:104479. doi:10.1016/j.bspc.2022.104479. [Google Scholar] [CrossRef]
21. Chen Y, Xue Y. A deep learning approach to human activity recognition based on single accelerometer. In: Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics; 2015 Oct 9–12; Hong Kong, China. doi:10.1109/SMC.2015.263. [Google Scholar] [CrossRef]
22. Poulose A, Kim JH, Han DS. HIT HAR: human image threshing machine for human activity recognition using deep learning models. Comput Intell Neurosci. 2022;2022:1808990. doi:10.1155/2022/1808990. [Google Scholar] [PubMed] [CrossRef]
23. Wang H, Zhao J, Li J, Tian L, Tu P, Cao T, et al. Wearable sensor-based human activity recognition using hybrid deep learning techniques. Secur Commun Netw. 2020;2020:2132138. doi:10.1155/2020/2132138. [Google Scholar] [CrossRef]
24. Anguita D, Ghio A, Oneto L, Parra X, Reyes-Ortiz JL. A public domain dataset for human activity recognition using smartphones. In: Proceedings of the European Symposium on Artificial Neural Networks; 2013 Apr 24–26; Bruges, Belgium. [Google Scholar]
25. Kwapisz JR, Weiss GM, Moore SA. Activity recognition using cell phone accelerometers. SIGKDD Explor Newsl. 2011;12(2):74–82. doi:10.1145/1964897.1964918. [Google Scholar] [CrossRef]
26. Maharana K, Mondal S, Nemade B. A review: data pre-processing and data augmentation techniques. Glob Transit Proc. 2022;3(1):91–9. doi:10.1016/j.gltp.2022.04.020. [Google Scholar] [CrossRef]
27. Binish Zahra S, Adnan Khan M, Abbas S, Masood Khan K, Al Ghamdi MA, Almotiri SH. Marker-based and marker-less motion capturing video data: person & activity identification comparison based on machine learning approaches. Comput Mater Contin. 2021;66(2):1269–82. doi:10.32604/cmc.2020.012778. [Google Scholar] [CrossRef]
28. Saddique M, Muneer I. Dataset for human activity recognition. Version 1. Mendeley Data. 2024. doi:10.17632/67BBCR5SSP.1. [Google Scholar] [CrossRef]
29. Deng W, Xie G. Image contrast enhancement and brightness preservation based on an adaptive histogram correction framework. Appl Opt. 2025;64(13):3502–15. doi:10.1364/AO.557280. [Google Scholar] [PubMed] [CrossRef]
30. Wang W, Yang Y. A histogram equalization model for color image contrast enhancement. Signal Image Video Process. 2024;18(2):1725–32. doi:10.1007/s11760-023-02881-9. [Google Scholar] [CrossRef]
31. Tan M, Le QV. EfficientNet: rethinking model scaling for convolutional neural networks. In: Proceedings of the 36th International Conference on Machine Learning (ICML); 2019 Jun 10–15; Long Beach, CA, USA. [Google Scholar]
32. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27–30; Las Vegas, NV, USA. doi:10.1109/CVPR.2016.90. [Google Scholar] [CrossRef]
33. Gu J, Wang Z, Kuen J, Ma L, Shahroudy A, Shuai B, et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018;77:354–77. doi:10.1016/j.patcog.2017.10.013. [Google Scholar] [CrossRef]
34. Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Corrado GS, et al. TensorFlow: large-scale machine learning on heterogeneous systems [Internet]. [cited 2026 Jan 13]. Available from: https://www.tensorflow.org. [Google Scholar]
35. Bradski G, Kaehler A. Learning OpenCV: computer vision with the OpenCV library. Sebastopol, CA, USA: O’Reilly Media; 2008. [Google Scholar]
36. Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, et al. Scikit-learn: machine learning in Python. J Mach Learn Res. 2011;12:2825–30. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools