
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Fuzzy-HLSTM (Hierarchical Long Short-Term Memory) for Agricultural Based Information Mining
1 Department of Computer Science, College of Science and Arts, Sharurah, Najran University, Najran, Saudi Arabia
2 Department of Computer Science, College of Computer Science & Information Systems, Najran University, Najran, Saudi Arabia
3 Computer Skills Department, Deanship of Preparatory Year, Najran University, Najran, Saudi Arabia
* Corresponding Author: Ahmed Abdu Alattab. Email:
Computers, Materials & Continua 2023, 74(2), 2397-2413. https://doi.org/10.32604/cmc.2023.030924
Received 06 April 2022; Accepted 26 May 2022; Issue published 31 October 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
This research proposes a machine learning approach using fuzzy logic to build an information retrieval system for the next crop rotation. In case-based reasoning systems, case representation is critical, and thus, researchers have thoroughly investigated textual, attribute-value pair, and ontological representations. As big databases result in slow case retrieval, this research suggests a fast case retrieval strategy based on an associated representation, so that, cases are interrelated in both either similar or dissimilar cases. As soon as a new case is recorded, it is compared to prior data to find a relative match. The proposed method is worked on the number of cases and retrieval accuracy between the related case representation and conventional approaches. Hierarchical Long Short-Term Memory (HLSTM) is used to evaluate the efficiency, similarity of the models, and fuzzy rules are applied to predict the environmental condition and soil quality during a particular time of the year. Based on the results, the proposed approaches allows for rapid case retrieval with high accuracy.Keywords
Farming is undergoing a revolution field to the latest technologies that appear to be highly promising because it allows the key sector to reach new levels of farm profitability and productivity. Agriculture is involving precision affecting inputs when it needed good farming. The 3rd wave of the current agriculture revolution is being enhanced by the availability of larger amounts of data. It is difficult for farmers to know what crops are most suited as per their soil’s quality, nutrients, and structure. In this study, a data mining technique for soil quality analysis is proposed to assist farmers. Thus, the method reduces efforts on monitoring the soil quality to anticipate the crop suited for cultivation based on the soil type and to optimize crop production. This research concentrates on the establishment of site-specific characteristics as the impact on soil quality and explains the influence of soil quality enhancements on enhancing agronomic. Furthermore, this research determines the next crop rotation based on the query generated and prediction of the current soil quality. The soil nutrient dataset is compiled using information from quality experiments [1].
Crop rotation has long been shown to be beneficial to the environment, but farmers are typically motivated by economics and the capacity to control pest, weed, and bug populations by using synthetic fertilizers or pesticides to sow the same crop repeatedly [2]. There are externalities (like harmful pests migrating across fields or excessive fertilizer application contaminating rivers) or there would be long-term consequences if land users don’t consider how their activities affect soil fertility, which contributes to natural resource deterioration [3].
In many countries agriculture has a significant financial impact, and it is one of the most common tasks. It is often referred to as the most flexible way to make money, because 60.45% of the country's land area is devoted to agriculture. The process of upgrading the agricultural industry is extensive in the current day. In this way, farmers get an edge and save money while increasing their income [4,5]. The yield can be calculated and based on the knowledge of a rancher about the land and harvest. Farmers are working on accumulating a steady stream of crops as the environment changes. Many farmers are given the present scenario and need additional information about the new yields [6]. Better knowledge and assessment of crop execution in natural circumstances increase the profitability of a farm’s operations, but they have no idea how much money they make from farming. The approach described in this study necessitates the inclusion of client-specific data. Nitrogen, Phosphorous, and Potassium are all nutrients needed for the growth of a plant found in soil [7–9].
Agriculture is influenced by a variety of parameters including climate, geography, historical, geographical, biological, political, and socioeconomic influences. As a result, the agricultural output is varying dramatically and widely throughout the nation. Agriculture is affected by a type of factors that are irrelevant to one another. Consequently, there is a danger and a decrease in the constant production of food. The environment has a major impact on agricultural productivity. There is a great deal of variation in agricultural yields throughout the year due to weather conditions [10]. The weather and the soil’s qualities are combined to provide a wide range of yields. Weather-related production losses can be mitigated by crop agronomic management practices such as planting, fertilizer application, irrigation tillage, etc. [11].
Fig. 1 illustrates how data from several aspects such as weather, legislation, regulations, the number, and qualifications of personnel can be processed by Artificial intelligence (AI) algorithms in an expert system [12].
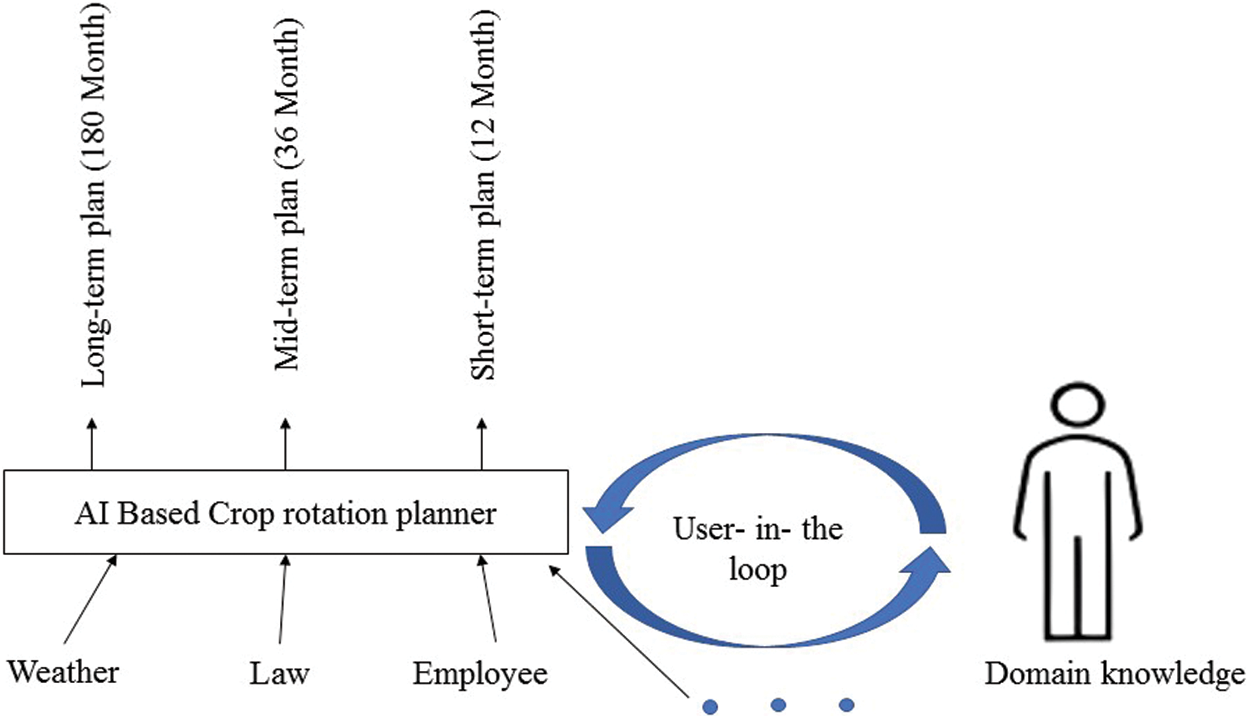
Figure 1: Cultivating a crop rotation strategy that includes a user in the loop
There must be a short, medium, and long-term strategy for crop management for the expert systems to dynamically offer the prospective consequences of today’s agricultural operations, as shown in Fig. 1. As a result, crop rotation expert systems are developed short, mid, and long-term crop rotation plans [13]. All three plans feature yield, water, fertilizer, insecticides, and profit estimates in addition to suggested agricultural actions. Three-year plans are making it easier to see the effects of various agricultural practices, such as the adoption of a no-tillage approach, and the associated environmental, financial, and technical advantages [14].
Several sensors are utilized in smart agriculture to gather data. Converting sensor readings into usable information is one of the challenges in dealing with the data. For this sake, “Case-Based Reasoning (CBR)” is a good approach for creating intelligent agricultural systems to enhance knowledge management when metadata descriptions are utilized as characterizations. Case studies are used to illustrate the categorizations that detail problems and their solutions [15]. Consequently, combining case-based reasoning with sensor technologies is beneficial to intelligent agricultural systems [16]. The application of machine learning algorithms in the agricultural supply chains, and the main four clusters (production, processing, distribution, and preproduction) are becoming more important. The ML was utilized at the preproduction stage and the use of technology is mostly for crop forecasting. Yield, soil quality, and irrigation needs are all things to think about [17].
Machine learning (ML) can be used in the manufacturing stage. The third cluster of the processing phase approach is dedicated to disease detection and forecasting [18]. ML algorithms might be used in the distribution cluster, especially to review production planning to obtain a safe and high-quality product. Consumer research is the first preproduction cluster in the agricultural supply chain. The objectives of these accurate agriculture solutions is to better educate stakeholders and farmers about their requirements (such as nutrients and fertilizers) by applying machine learning algorithms to predict effective models [19], encourage farmers to make the most beneficial yield forecasting decisions and to improve their agricultural methods. As an example, Bayesian network described using terms like decision tree, clustering, deep learning, and regression have recently been used to predict agricultural output [20].
Existing farm systems are unable to meet the demands of today’s generation owing to the absence of key criteria such as processing speed, data storage capacity, and the resources utilized in “computer-based agriculture systems”. There is a necessity to construct a cloud-based autonomous data system that provides Agricultural as a Service (AaaS) to overcome the challenge of current agriculture systems. In this part, researchers show the architecture of Agri-Info and a QoS-aware “cloud-based autonomic” data system for agriculture that maintains various forms of agricultural-related data across many domains. Fig. 3 depicts the architecture of Agri-Info [20]. The main goals of this suggested system are given as:
i) Analyze the data utilizing creating fuzzy rules and fuzzy logic.
ii) Collect data from various IoT devices.
iii) Automatically respond to user queries based on the data kept in the Fuzzy Rule Base.
iv) Store fuzzy rules and user data in a cloud repository (Fuzzy Rule Base) for future decisions.
v) Automatically assign resources based on QoS necessities of dissimilar needs.
Agri-architecture Info is divided into two subsystems
i) User subsystem
ii) Cloud subsystem
• User Subsystem
This subsystem is a user interface via which various types of users connect with Agri-Info to supply and receive relevant data on agriculture depending on several domains. It considers nine distinct sets of data from several agricultural domains such as livestock, productivity, soil, pest, crop, weather, fertilizer, irrigation, and equipment. Users are divided into three groups [20]:
i) Agricultural experts,
ii) Agriculture officers,
iii) Farmers
• Cloud Subsystem
This subsystem includes the cloud-based platform for agribusiness web services. Agriculture information submitted by users from various agricultural domains can be processed using an online or mobile agriculture service. As indicated in Tab. 1, Agri-Info collected a variety of qualities based on particular agricultural information given by users across agriculture online services.

These facts are saved in a cloud repository in separate classes for each domain, each with its unique identifier which is used to Agri-Info monitors, analyses, and process the data constantly. It has created separate classes and subclasses for each domain to better categorize information. User data is classified in a storage repository based on fuzzy rules and distinct specified domain classes. This data is sent on to agricultural professionals and officials for ultimate certification via IoT devices [21].
This part shows the related work of various authors for a Query-based information retrieval system for the crop rotation decision using learning techniques.
Duboisy et al. [22] focused on potato cultivation, and a crop where irrigation is critical. The author modeled soil water potential as a prediction as to the supervised learning issue. The task looks complicated because there are numerous possible inputs and outputs. The experiment is run using data collected over 3 years and shows how to use include variety to spontaneously construct models with appropriate characteristics and high performance.
Shreejana [23] assessed that in agriculture across the globe, Diversified Crop Rotation (DCR) has a positive impact on productivity. Improved soil quality and increased system production might be achieved by using this method. Many crops’ rotations yield tolerance to drought and other difficult growing circumstances that might be improved by increasing soil water absorption and storing the number of valuable soil organisms. It is benefits to farmers include less risk, uncertainty, improved soil health, and a more sustainable environment. Crop rotations are including a variety of crops to help farmers diversify their revenue streams. Soil health is also improved due to the unique structure, function, and link between plant communities and the soil in DCR, which reduces insect, weed, and disease prevalence, and increases the structure of the soil. It is developing more common to use DCR to ensure the long-term viability of agricultural production. This analysis presents evidence of the importance of DCR, barriers to adapting it, and proposed solutions to these issues.
Sun et al. [24] suggested that the intelligent transportation nowadays is mainly reliant on Vehicle Type Classification (VTC). Earlier VTC systems operated on the monitoring center’s host machine due to the models’ complexity and resource requirements. Recent advancements in IoT hardware, such as systems of heterogeneous embedded devices, software, cloud optimization solutions, and lightweight computer vision algorithms allow a connected (smart) farm to accumulate and effectively analyze data from a variety of sources. It is feasible to gather information from several farming operations at various time scales involving in near real-time, and by interconnecting the IoT sensors, which are often spread across wide swathes of farmland. This information can subsequently be utilized to generate actionable insights, such as the correct application of soil additives, resulting in less waste and contamination. When federated learning techniques are used to combine data from multiple farms, such insights would be even more powerful. In a “wireless sensor network (WSN)”, IoT devices efficient in sensing various types of data can communicate with one another. Large amounts of data are created from a range of field operations in row crop systems. Fertilizer application, soil sampling, planting, scouting, spraying, harvesting, distribution, and processing are examples of these operations.
Patel et al. [25] examined three components of Indian traditional agriculture that are cultivation, locally available sustainable crop protection measures, and biological pest management. Mixed cropping, crop rotation, agroforestry, double cropping, and the exploitation of resources with host-pathogen interaction and local varieties are a few of India’s most famous conventional agricultural methods that must be strengthened in the interest of food security and the environment. It is enhancing nutrition quality such techniques perform an important role in ensuring agriculture’s long-term viability.
Wang et al. [26] looked at using acceleration, location, and machine learning to identify estrus in dairy cows. The data were collected from 12 cows for 12 days. It gathered 25,684 data on position and acceleration. Several machine-learning algorithms were tried to automatically detect cows in estrus using “Principal Component Analysis (PCA)” of twelve behavioral measures.
Liang et al. [27] highlighted that are being developed how irrigation water allocation contributes to the high-efficacy concert of the accuracy irrigation approaches such as the infrastructure, models, the management approaches currently in use, and the management approaches. Some of the most cutting-edge methods for constructing a long-term, integrated, and evolutionary irrigation system while also delivering the high quality and effectiveness required for full precision irrigation application are data-driven irrigation organizations. It is cloud-based irrigation control and performance-proven water allocation.
Saiz-Rubio et al. [28] analyzed for farmers to make an optimized decision to save money but protect the environment, and alter the food to match and sustainably the coming population development. Data is used in the form of data-driven farm management to increase efficiency while decreasing resource waste and pollution. The basis for future organic agriculture is laid by data-driven agriculture paired with robotic solutions that include artificial intelligence methods. Data asset in agricultural fields to variable rate applications is a vital step in sophisticated farm management systems.
Lagos-Ortiz et al. [29] investigated in the agricultural context, and a wide range of pests and illnesses harm crops. Furthermore, the quantity of information accessible on these issues is growing exponentially. Farmers have difficulty making judgments based on the big and changing quantity of data. Agri-Ent and a knowledge-based web platform are presented in the paper to assist farmers in making decisions about the control of agricultural insect pests. There are four levels in the Agri-Ent functional architecture such as data, semantics, web services, and presentation. These specialists’ expertise is officially documented using ontologies in this platform, which also does insect pest diagnostics.
Neha et al. [30] developed a crop yield prediction model using “linear and non-linear regressor models” with 5-fold cross authentication. The kernel in this case was based on the Radial Basis Function., This method forecasted agricultural production from 2013 to 2017. This system is unable to accurately predict the future due to the lack of data. Other professional training approaches have fared better than Regression.
Opera [31] described a framework for environmentally intelligent management information systems. Bayesian networks and data mining as a base of knowledge are created and used in decision-making processes using taxonomies. Ontologies have also been simplified via research efforts for non-experts.
The primary goal of a smart agriculture system is to increase the productivity of a given field of crops. The following are the two primary streams that have been selected in this research, it involves (i) anticipating the most suited crop for the next crop rotation and (ii) improving the irrigation system of the land via the use of selective irrigation techniques. The above-mentioned purpose is realized by the regular monitoring of the field. The monitoring method entails gathering information on the soil properties present in the field to be monitored. A wireless sensor network (WSN) is set up to gather the data and look back at it by uploading it to the cloud regularly. Machine learning (ML) is an important part of artificial intelligence. Instead of explicitly programming is a computer to solve the problem. The benefit of the approach is detecting and adjusting for any outliers in the data collection. Sensor readings were recorded for twelve months, and this enormous volume of data was transmitted into a database for storage. The ML model was trained using the parameter’s maximum and lowest values. This dataset was used to train two separate machine learning models using RMSProp optimizer and the validation losses were determined using MSE. Validation losses of 9.2752 and 48.52 s for GRU and 2.1354 and 57.62 s for LSTM were considered for ML models. The suggested model can predict more accurately and reliably the soil parameter patterns for future tenures using a learning-based classification strategy. Predicting a great crop for planting gets easier when the future pattern is known for a certain amount of time. It is allowing the farmer to rely less on personal intuition and more on a predetermined strategy for farming. After a comparison of the inferred findings with the ideal parameters, the best-suited crop is sent to the customer via a Short Messaging Service (SMS). Predicting the best time to manure, apply fertilizer, and apply pesticides are increase the performance of smart agriculture in the future [32].
The work is based on the information retrieval process over the small dataset using the case association. The user input is directly considered in the form of the case and is re-directed towards the similarity evaluation and mining of the past cases concerning the similarity between the cases. It is based on the earlier study conducted on the major gap, and firstly the cases generated from the user query are not having any specifications. Secondly, similarity evaluation should be made more realistic using machine learning to turn the focus from fast retrieval over small data to fast and efficient evaluation over large datasets. Thirdly, the threshold definition is computed using some pre-defined set of rules which remain the same all around the processing, which means no change with the change in the type and category of the dataset.
In the current work, the major focus is on three major gaps identified and progress has been focused to resolve the problems. As a solution for the problem first, there is a harsh requirement of the query expansion, because about 70%–80% of the target users of the platform are not well-aware of the technological words related to agriculture features. Second, the major prospect of the previous work is towards the fast retrieval of cases, and the accuracy of the system is never considered for large datasets. For efficient and fast similarity evaluation, Hierarchical Long Short-Term Memory (HLSTM) is considered the output of each neuron varies on the current input and background of prior concealed state output. Third, the threshold definition is decided based on some fuzzy rules which are dynamic and can be added and rejected when change is encountered for the type and category of the dataset.
This system has several holes when it comes to estimating the yield of a field. A single day’s analysis of soil factors is not sufficient to forecast a crop’s success. Crop yields cannot be predicted using the technique since plant development takes time. As a result, the following strategy is utilized to overcome the disadvantage and complete the task.
5.1 Hierarchical Long Short-Term Memory
Over a complicated sequence, it is found through numerous layers of sequential hierarchy. In general, the HLSTM’s first recurrent layer converts a sentence into a sentence vector for example, word vectors [33]:
where LSTM (·) is described as the LSTM operation for simplicity,
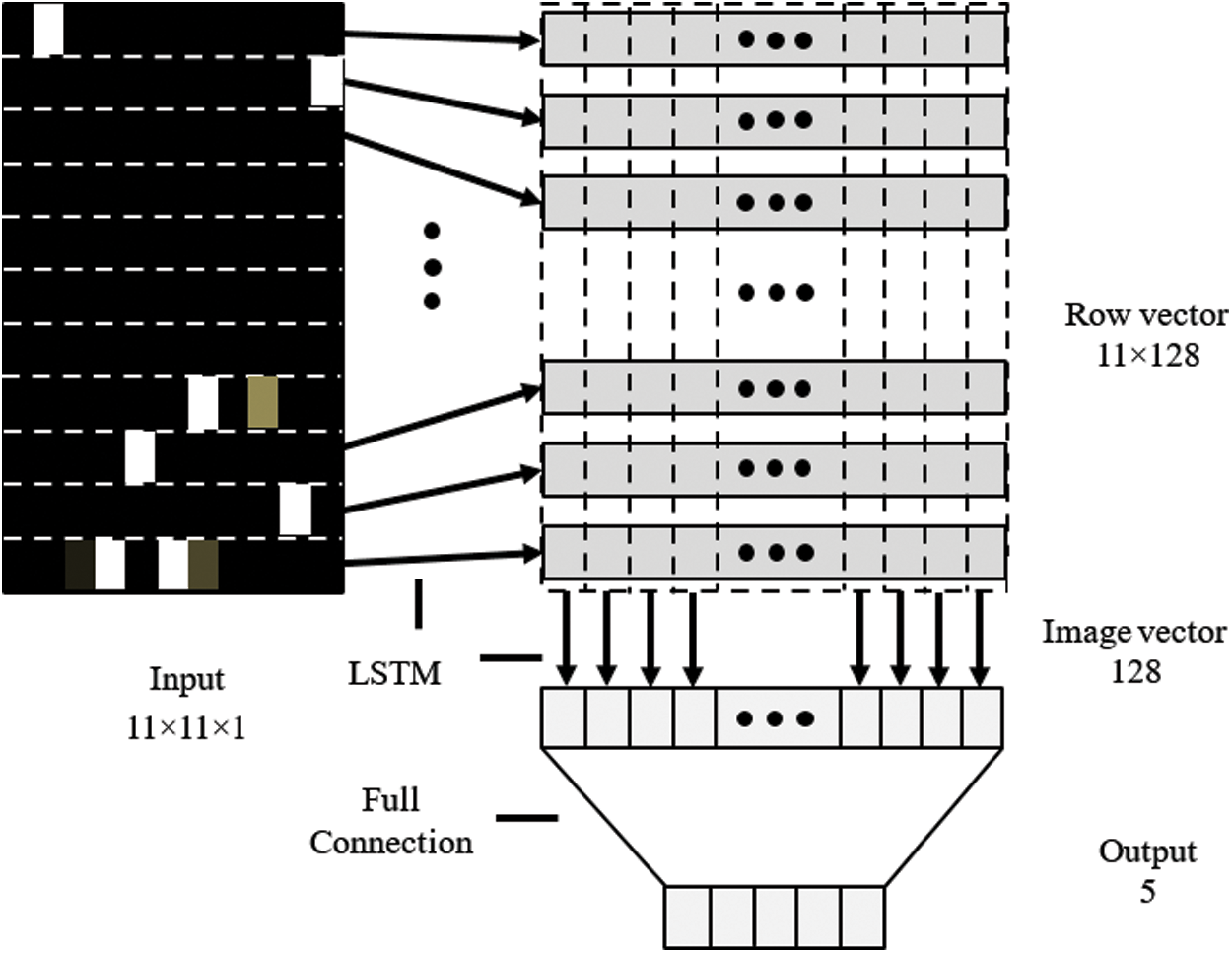
Figure 2: The architecture of the HLSTM
Fig. 2 shows that each record in the preprocessed data has 121 values, allowing it to be turned into an 11 × 11-pixel grayscale picture. The first LSTM layer translates each column of shape (11, 1) pixels to a column vector of form (128) in the HLSTM-based interruption recognition model. The subsequent LSTM layer converts 11 shape column vectors (11, 128) into an image vector that represents the whole image. Ultimately, the whole connection layer is included for prediction.
A fuzzy rule is a statement that is true or false. In fuzzy logic, there exist rules of inference that determine the output variable’s value depending on the values of the input variables. Following are all fuzzy rules utilized in fuzzy logic.
The expertise of a professional in any linked area use might be termed fuzzy control rule. If the control of the closed-loop method is utilized, and the fuzzy rule is characterized by a series of the type IF-THEN, which leads to procedures defining what case must be done in the presently stated information, that contains feedback and input. The law governing the design or construction of the set of fuzzy rules is centered on a human’s experience or knowledge, which varies depending on the specific usage. A fuzzy IF-THEN rule connects a situation defined by fuzzy sets and linguistic variables to a result. The IF component is mostly applied to collect experience via elastic circumstances, while the THEN part could be used to provide an output in semantic variable form. The fuzzy inference method frequently utilizes this IF-THEN rule to determine the degree to which the incoming data meets the rule’s condition. In Fig. 3, the method for calculating the difference in degree among a fuzzy condition LOW (temperature) and fuzzy input T (temperature) [35].
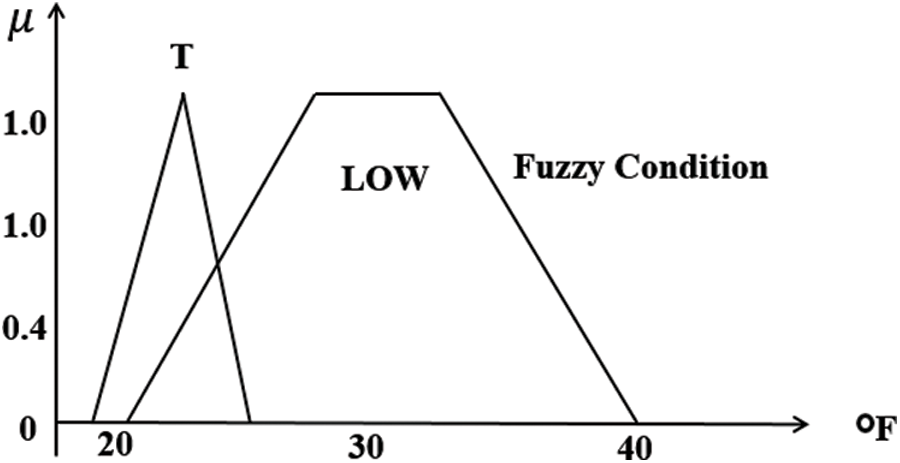
Figure 3: Fuzzy input with the fuzzy circumstance
The function could also be used to express this computation.
where M = Difference in degree and “
Fuzzy mapping rules offer an efficient mapping between the output and the input using linguistic variables. A fuzzy mapping rule is built on the foundation of a graph of fuzzy, that depicts the relationship between the fuzzy output and input. It might be difficult to extract a specific link between output and input, or the relationship between those outputs and inputs can be quite intricate even when it is created the real-world products. Fuzzy mapping rules are a viable option for certain cases. Fuzzy rules mapping is act comparably to human insight, intuition, and all fuzzy rule mapping only values a small portion of the function. The collection of fuzzy mapping rules should be used to assess the full function. Continuing with AC as an instance, a fuzzy rule mapping is developed as follows: IF temperature is LOW, THEN the heater motor must be turned FAST. Different rules should be created for different input temperatures.
The input variables have many dimensions in most real-world applications. For example, the inputs comprise both the present temperature and temperature rate difference in AC. The fuzzy control rules should be expanded to consider numerous inputs while calculating the output.
Temperature inputs vary at a different pace, and those inputs are linked to IF portions of IF-THEN rules. It is known as the control output, and 3D variable that is found at the intersection of every row and every column, and it is linked to the THEN component of IF-THEN rules. As if the existing temperature is LOW and the current temperature alter rate is likewise LOW, and the speed heater motor must be FAST to quickly raise the temperature.
It is expressed using the IF-THEN rule, which states that if the temperature is low and the rate of change is low, THEN the production must be FAST. Various additional laws are abided by a related method, that is extremely close to the intuition of a human being. A total of nine rules are created in the air conditioner. Input and output should be split into smaller parts for applications that should be required high control precision, and more rules of fuzzy [36–38].
A generalized logic is suggesting a correlation between output and input. It is described by an implication rule of fuzzy. All restricted essence of fuzzy logic is the basis of a fuzzy implication rule. Multiple-valued logic and Traditional two-valued logic are connected to fuzzy implication rules. Continuing with the AC as an illustration, the conclusion is that if the temperature is low, then the heating motor must be quick. The temperature is HIGH, based on the inference and a reality. The conclusion is the heating engine should slow down, or SLOW.
• Similarity Relation–Fuzzification
Comparison is a crucial topic for which a simple model is frequently discovered to be insufficient. The gradual property of the fuzzy sets shows the perception of the gradual property. The fuzzy equivalence relation is used to illustrate the connection among items of a fuzzy set from the perspective of a fuzzy equivalence relation. Fuzzy sets were considered stimulating ideas by designating resemblance described as a basis of fuzzy equivalence relation. A fuzzy set cannot differentiate two elements if they are both members of the same set or its complement. The generation of the fuzzy set membership functions using the equivalence fuzzy relation is explained as follows:
• Definition 1
A fuzzy similarity relation on set V is the mapping E: V x V
where the unit interval is denoted as [0,1] with the normal ordering. Occasionally, E is known as a similarity relation. Contextually, a few theorems and definitions are hereby remembered.
• Definition 2
A fuzzy set
• Definition 3
Let E is a “fuzzy equivalence relation” on V and let
The fuzzy set
In Fig. 4, the planned related case representation allowed fast case retrieval by associating with the help of the similar, the dissimilar cases especially, and as an alternative to measuring the likeness of every case in the case base. The procedure is explained by the pair of an attribute-value, and the case is formulized by the vector. Features of the vectors are matched with each other and added up with the weights as general identical.
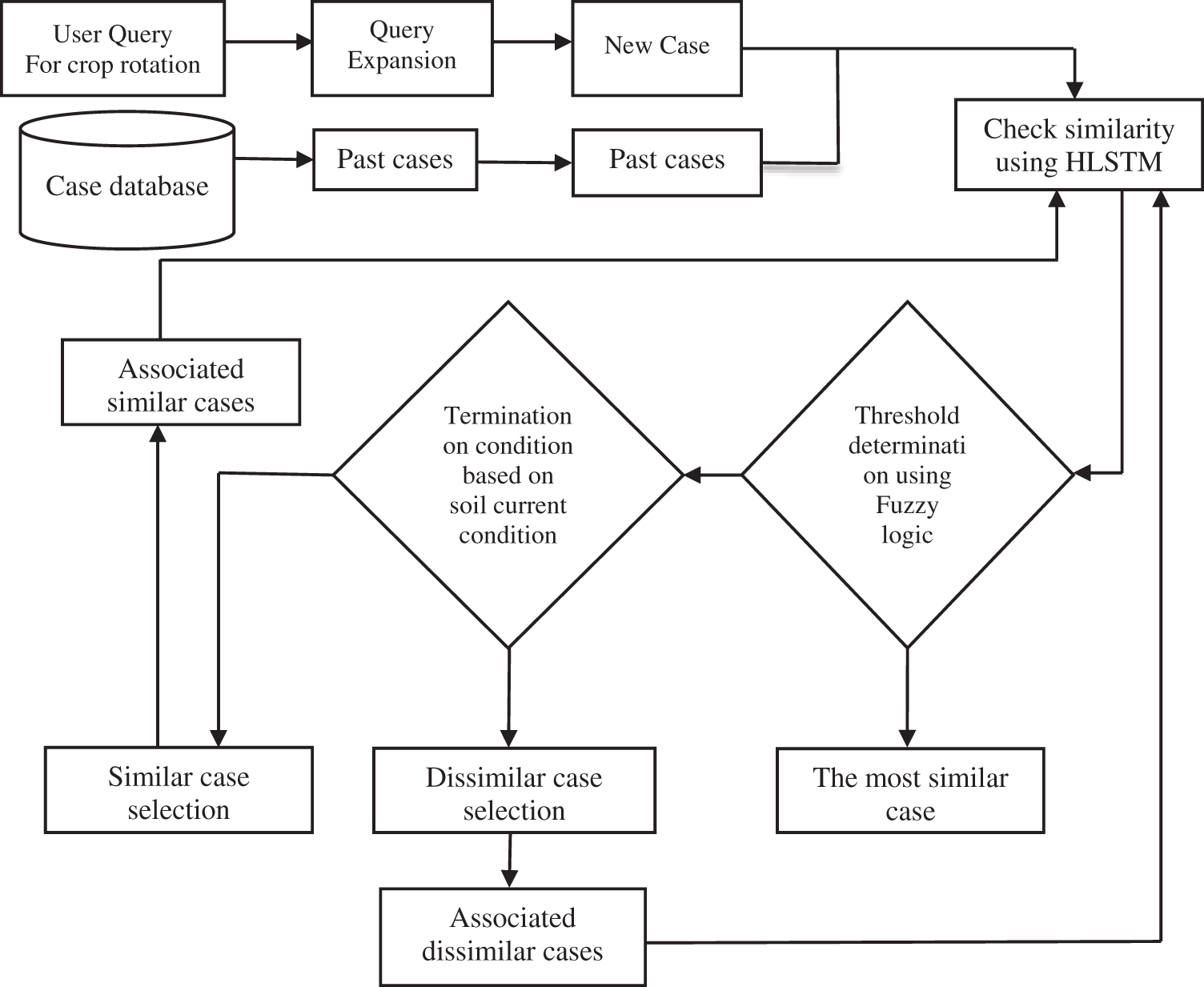
Figure 4: Architecture diagram for the proposed system
Step 1: Check the user query for crop rotation, after the query has been identified. It would be expanded, if the user query is different, and it would be treated as a new case. The case database stores past user requests for crop rotation, and hierarchical long short-term memory compares the similarity between the two cases.
Step 2: In this step, threshold determination is done based on the fuzzy rules. The fuzzy rules set is based on the soil quality and environmental parameters.
Step 3: As part of the threshold determination stage, this includes determining which instances have the greatest number of similarities when there is a 75% or more similarity between the two cases. The source case is rewarded with a supplementary case that suggests which case is the most comparable to the source case.
Step 4: When there are more similar instances than there are dissimilar cases available for selection, the source case with the highest comparability value is selected, and its associated cases are examined in the next repeat of the procedure. If the number of different cases is more than the number of identical cases, the source case with the greatest depth of connection value would be picked as the source case. In the next iteration, the associated dissimilar situations would be compared to the result in the previous iteration.
Step 5: There are two case selections in this step such as similar and dissimilar. The crop rotation contains termination conditions that are dependent on the soil such as soil humidity and weather conditions. When the similarity between the two cases is less than 50% (past case), the case is said to be dissimilar to the source case, and when the resemblance between the two cases is more than 50% (present case), the case is said to be identical to the source case.
The intended model is a learning-based categorization technique, and the prediction is more accurate, and assists in more reliably estimating the whole soil parameter pattern for future tenure. The future pattern is established for a certain time, which is simple to select a suitable crop that can be sown. It would aid in the development of a more pre-deterministic approach to agriculture rather than relying on human instinct. In the implementation results, different parameters like atmospheric temperature, soil temperature, and humidity are predicted using fuzzy set rules. Then there are also calculated the accuracy of the model and the error.
Result 1: The given Fig. 5 depicts the prediction of the atmospheric temperature for June to August in the year 2022. The minimum temperature is predicted approximately 15 to 20 degrees and the maximum temperature is between 30 to 40 degrees.
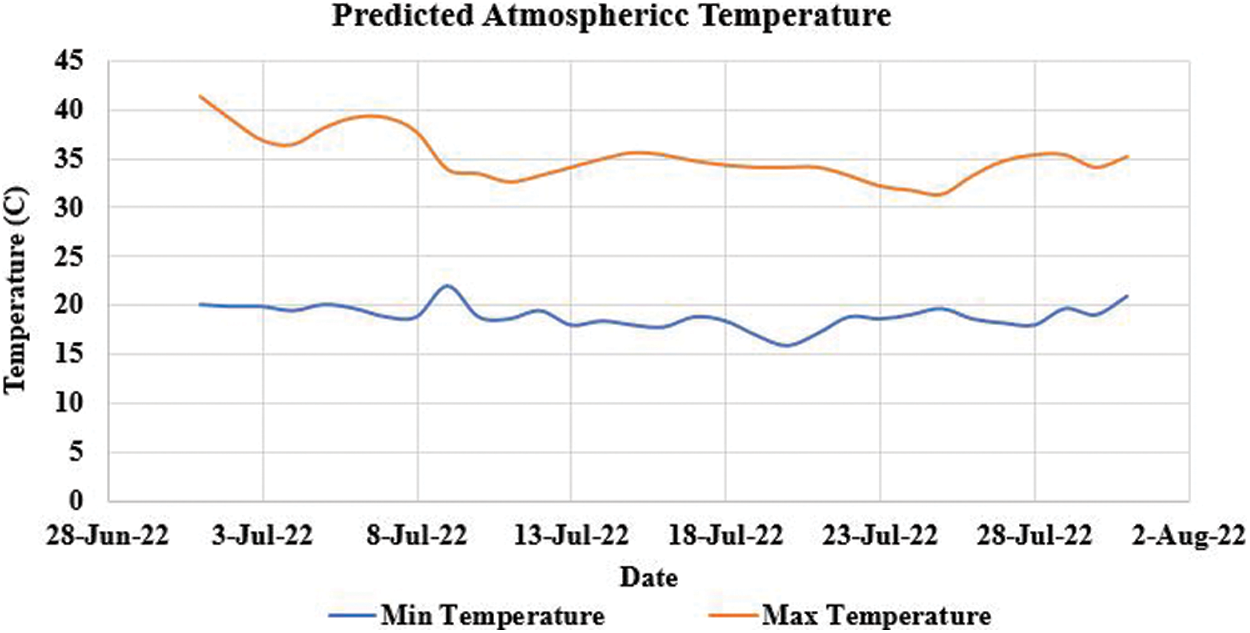
Figure 5: Atmospheric temperature prediction
Result 2: The given Fig. 6 depicts the prediction of the soil temperature for June to August in the year 2022. The minimum temperature is predicted approximately 15 to 20 degrees and the maximum temperature is between 25 to 40 degrees.
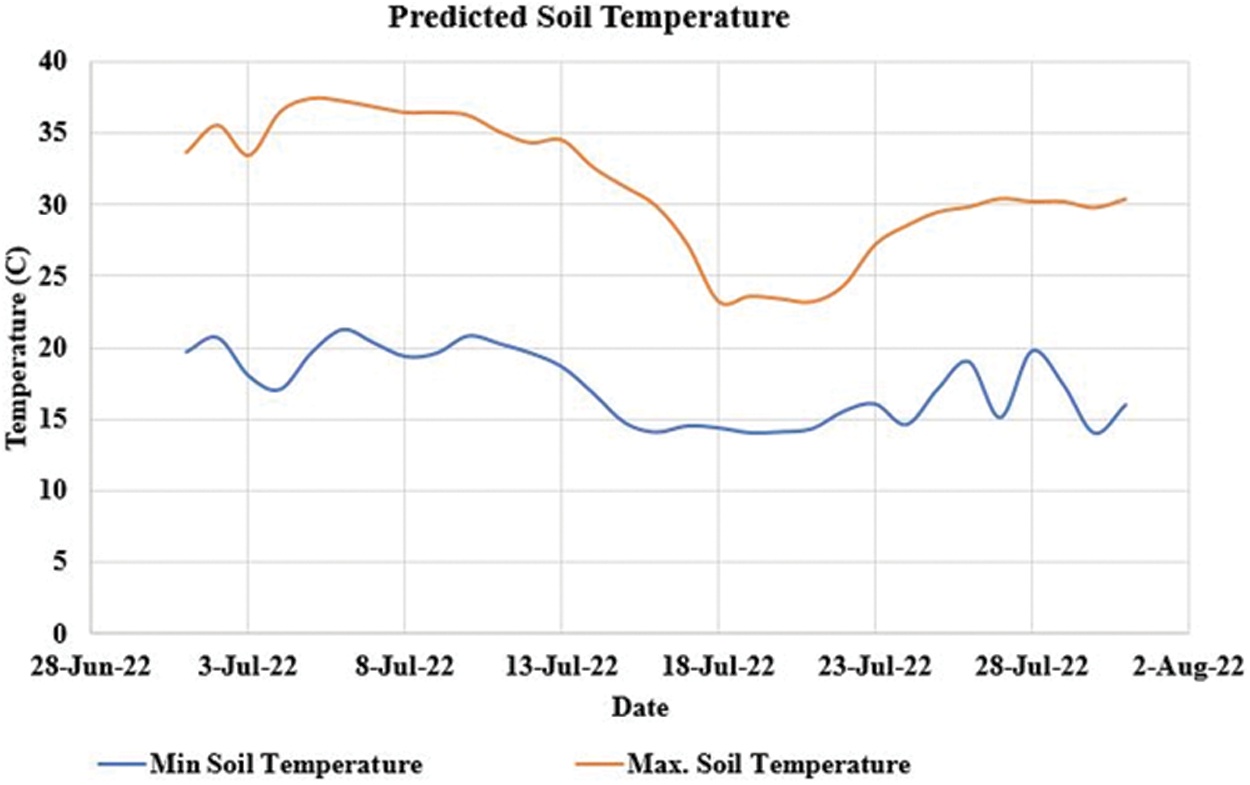
Figure 6: Soil temperature prediction
Result 3: The given Fig. 7 depicts the prediction of humidity in the atmosphere for June to August in the year 2022. The minimum temperature is predicted to be approximately 45 to 65 percent and the maximum temperature is between 70 to 100 percent.
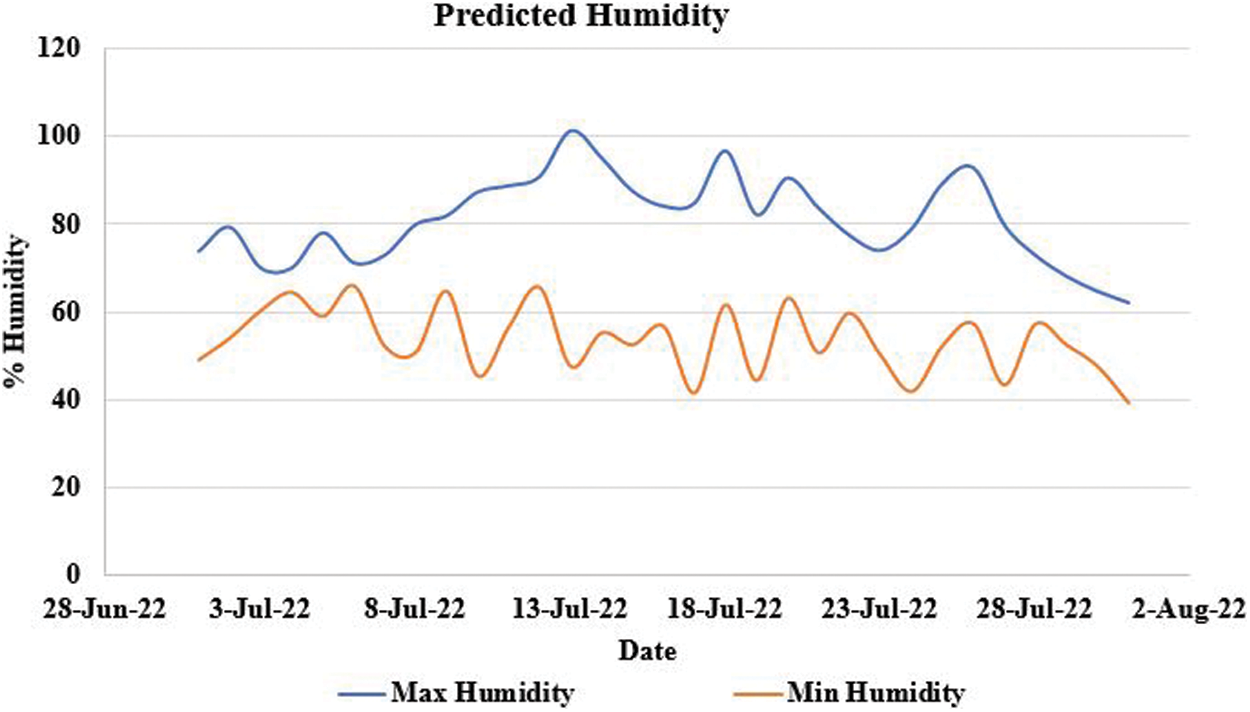
Figure 7: Humidity prediction
Result 4: The given Fig. 8 depicts the accuracy of the model which is 97.03%. The accuracy of the model is calculated from the defined confusion matrices.

Figure 8: Accuracy of the model
Result 5: The given Fig. 9 depicts the mean square error concerning increasing epochs. Eq. 6 shows the formula to evaluate the mean square error. Here, N total number of observations in the dataset. The sigma symbol denotes the difference between actual and predicted values taken on every
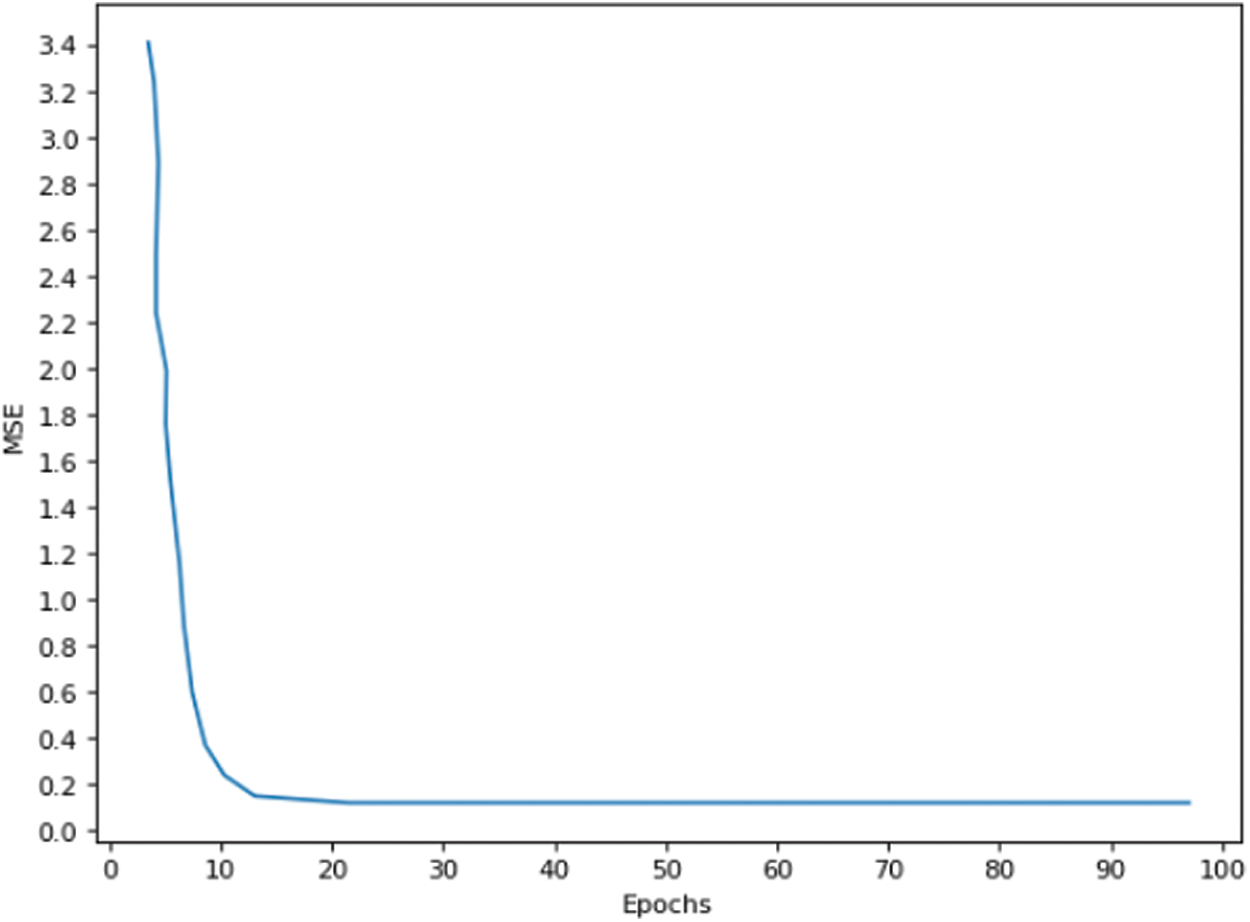
Figure 9: MSE vs. Epochs
The given figure illustrates that with increasing the epochs mean square error values are trending toward zero.
Comparative Analysis
Tab. 2 depicts the comparative analysis of the performance parameters between the existing result and the proposed method. The accuracy of the existing method is 97% and the MSE value with the increasing epochs is 0.5 approximately. Whereas in the proposed model accuracy is 97.3 percent and the MSE value is 0.2.

Agricultural cases in a case-based reasoning system were the subject of this research, which also included a proposal for a related case representation approach for crop rotation. A high number of cases in a case base might lead to inefficient retrieval since traditional case representation techniques do not consider the association ties between those instances. As a result, the strategy described in this research was followed by a case representation method. The peculiarity of the concept is exploring the interconnections between cases, which is different from the standard attribute-value pair format. Fast case retrieval is made possible by the fact that comparable instances are prioritized for comparison. Dissimilar connections are useful in the early stages of case recollection. Fast case retrieval is achieved by using the suggested case representation approach, which visits a smaller number of instances while ensuring correctness at the same time. When it comes to case-based reasoning, effective case retrieval is critical, and the rest of the processes cannot advance without it. It is using the case-based reasoning methodology based on the query for the next crop. Therefore, the suggested related case is a representation method for providing farmers with decision assistance for managing agricultural operations that might help enhance farmer-centric retrieval systems. Furthermore, the concept provides a means of efficiently managing agricultural knowledge. In the presented work prediction is done based on the environmental conditions and the soil effectivity and quality.
For the future aspect, the key challenges faced, and the huge amount of data in the database are latency and capacity. A distributed framework based on fog architecture could be built to increase reaction time. Unlike the cloud, where processing and services are centered on a single node, fog architecture pushes computing and services to the network’s logical extremes. Furthermore, the efficiency of smart agriculture can be increased by forecasting the best time for manuring, fertilizer application, and pesticide application.
Acknowledgement: The authors would like to express their gratitude to the ministry of education and the deanship of scientific research-Najran University-Kingdom of Saudi Arabia for their Financial and Technical support under code number (code NU/-/SERC/10/643).
Funding Statement: This research work was supported by the Deanship of Scientific Research-Najran University, Ministry of Education, Kingdom of Saudi Arabia under code NU/-/SERC/10/643.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. S. David, “Farm profits and adoption of precision agriculture,” United States Department of Agriculture Report. 1477-2016-121190:46, 2016. [Online]. Available: http://ageconsearch.umn.edu/record/249773. [Google Scholar]
2. L. Zhiyi, X. Xu, D. Zhang and P. Zhang, “Cross-modal hashing retrieval based on deep residual network,” Computer Systems Science and Engineering, vol. 36, no. 2, pp. 383–405, 2021. [Google Scholar]
3. W. Sun, X. Chen, X. R. Zhang, G. Z. Dai, P. S. Chang et al., “A multi-feature learning model with enhanced local attention for vehicle re-identification,” Computers, Materials & Continua, vol. 69, no. 3, pp. 3549–3560, 2021. [Google Scholar]
4. M. R. Bendre, R. C. Thool and V. R. Thool, “Big data in precision agriculture: Weather forecasting for future farming,” in 1st Int. Conf. on Next Generation Computing Technologies (NGCT), Dehradun, Uttrakhand, India, IEEE, pp. 744–750, 2015. [Google Scholar]
5. N. Suma, S. R. Samson, S. Saranya, G. Shanmugapriya and R. Subhashri, “IOT based smart agriculture monitoring system,” International Journal on Recent and Innovation Trends in Computing and Communication, vol. 5, no. 2, pp. 177–181, 2017. [Google Scholar]
6. S. Agarwal and S. Tarar, “A hybrid approach for crop yield prediction using machine learning and deep learning algorithms,” Journal of Physics: Conference Series, vol. 1714, no. 1, pp. 012012, IOP Publishing, 2021. [Google Scholar]
7. C. Michal, S. D’Antonio, J. Keller and R. Kozik, “Progress in features, data, patterns and similarity analysis,” Journal of Universal Computer Science, vol. 26, no. 6, pp. 647–648, 2020. [Google Scholar]
8. C. Dimkpa, P. Bindraban, J. E. McLean, L. Gatere, U. Singh et al., “Methods for rapid testing of plant and soil nutrients,” in Sustainable Agriculture Reviews, Springer, Cham, vol. 25, pp. 1–43, 2017. [Google Scholar]
9. N. Anastasija, J. Bicevskis, Z. Bicevska and I. Oditis, “User-oriented approach to data quality evaluation,” Journal of Universal Computer Science, vol. 26, no. 1, pp. 107–126, 2020. [Google Scholar]
10. S. Zihao, H. Wang, K. Liu, P. Liu, M. Ba et al., “RP-NBSR: A novel network attack detection model based on machine learning,” Computer Systems Science and Engineering, vol. 37, no. 1, pp. 121–133, 2021. [Google Scholar]
11. M. Subhadra, D. Mishra and G. H. Santra, “Applications of machine learning techniques in agricultural crop production: A review paper,” Indian Journal of Science and Technology, vol. 9, no. 38, pp. 1–14, 2016. [Google Scholar]
12. T. Gomiero, “Soil degradation, land scarcity and food security: Reviewing a complex challenge,” Sustainability, vol. 8, no. 3, pp. 281, 2016. [Google Scholar]
13. N. Z. Jhanjhi, M. Humayun and S. N. Almuayqil, “Cyber security and privacy issues in industrial internet of things,” Computer Systems Science & Engineering, vol. 37, no. 3, pp. 361–380, 2021. [Google Scholar]
14. J. G. Brindha and E. S. Gopi, Maximizing profits in crop planning using socio evolution and learning optimization. Singapore: Socio-cultural Inspired Metaheuristics, Springer, pp. 151–174, 2019. [Google Scholar]
15. B. Marius, M. Zipperle and A. Karduck, “Intelligent choice of machine learning methods for predictive maintenance of intelligent machines,” Computer Systems Science and Engineering, vol. 35, no. 2, pp. 81–89, 2020. [Google Scholar]
16. K. M. Alhyasat., K. Ibrahim, A. Al Omari and M. A. Bakar, “Extended Rama distribution, properties and applications,” Computer Systems Science and Engineering, vol. 39, no. 1, pp. 55–67, 2021. [Google Scholar]
17. R. B. Ayed, K. Ennouri, F. B. Amar, F. Moreau, M. A. Triki et al., “Bayesian and phylogenic approaches for studying relationships among table olive cultivars,” Biochemical Genetics, vol. 55, no. 4, pp. 300–313, 2017. [Google Scholar]
18. B. Marius, M. Zipperle and A. Karduck, “Intelligent choice of machine learning methods for predictive maintenance of intelligent machines,” Computer Systems Science and Engineering, vol. 35, no. 2, pp. 81–89, 2020. [Google Scholar]
19. Q. Jingcheng, M. Zhu, Y. Zhao and X. He, “Short-term wind speed prediction with a two-layer attention-based LSTM,” Computer Systems Science and Engineering, vol. 39, no. 2, pp. 197–209, 2021. [Google Scholar]
20. S. Singh, I. Chana and R. Buyya, “Agri-Info: Cloud based autonomic system for delivering agriculture as a service,” Internet of Things, vol. 9, no. 4, pp. 100–131, 2020. [Google Scholar]
21. S. S. Gill and R. Buyya, “Resource provisioning-based scheduling framework for execution of heterogeneous and clustered workloads in clouds: From fundamental to autonomic offering,” Journal of Grid Computing, vol. 17, no. 3, pp. 385–417, 2019. [Google Scholar]
22. A. Duboisy, F. Teytaud and S. Verel, “Short term soil moisture forecasts for potato crop farming: A machine learning approach,” Computers and Electronics in Agriculture, vol. 180, no. 12, pp. 105902, 2021. [Google Scholar]
23. K. C. Shreejana, “Effect of transplanting dates on yield attributing characters of tomato (Lycopersicon esculentum Mill.) variety,” Archives of Agriculture and Environmental Science, vol. 6, no. 4, pp. 453–458, 2021. [Google Scholar]
24. W. Sun, G. C. Zhang, X. R. Zhang, X. Zhang and N. N. Ge, “Fine-grained vehicle type classification using lightweight convolutional neural network with feature optimization and joint learning strategy,” Multimedia Tools and Applications, vol. 80, no. 20, pp. 30803–30816, 2021. [Google Scholar]
25. S. K. Patel, A. Sharma and G. S. Singh, “Traditional agricultural practices in India: An approach for environmental sustainability and food security,” Energy, Ecology and Environment, vol. 5, no. 4, pp. 253–271, 2020. [Google Scholar]
26. J. Wang, M. Bell, X. Liu and G. Liu, “Machine-learning techniques can enhance dairy cow estrus detection using location and acceleration data,” Animals, vol. 10, no. 7, pp. 1160, 2020. [Google Scholar]
27. Z. Liang, X. Liu, J. Xiong and J. Xiao, “Water allocation and integrative management of precision irrigation: A systematic review,” Water, vol. 12, no. 11, pp. 3135, 2020. [Google Scholar]
28. V. Saiz-Rubio and F. Rovira-Más, “From smart farming towards agriculture 5.0: A review on crop data management,” Agronomy, vol. 10, no. 2, pp. 207, 2020. [Google Scholar]
29. K. Lagos-Ortiz, M. P. Salas-Zárate, M. A. Paredes-Valverde, J. A. García-Díaz and R. Valencia-Garcia, “AgriEnt: A knowledge-based web platform for managing insect pests of field crops,” Applied Sciences, vol. 10, no. 3, pp. 1040, 2020. [Google Scholar]
30. R. Neha, R. Solanki, D. Bein, J. Andro-Vasko and W. Bein, “Prediction of crop cultivation,” in 2019 IEEE 9th Annual Computing and Communication Workshop and Conf. (CCWC), Las Vegas, NV, USA, pp. 227–232, 2019. [Google Scholar]
31. M. Oprea, “A knowledge modelling framework for intelligent environmental decision support systems and its application to some environmental problems,” Environmental Modelling & Software, vol. 110, no. 4, pp. 72–94, 2018. [Google Scholar]
32. S. A. M. Varman, A. R. Baskaran, S. Aravindh and E. Prabhu, “Deep learning and IoT for smart agriculture using WSN,” in 2017 IEEE Int. Conf. on Computational Intelligence and Computing Research (ICCIC), Tamilnadu, India, pp. 1–6, 2017. [Google Scholar]
33. S. Shekhar and R. Sharma, “A pun identification framework for retrieving equivocation terms based on HLSTM learning model,” IOP Conference Series: Materials Science and Engineering, vol. 1131, no. 1, pp. 012011, 2021. [Google Scholar]
34. Y. Du, W. Wang and L. Wang, “Hierarchical recurrent neural network for skeleton based action recognition,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, pp. 1110–1118, 2015. [Google Scholar]
35. D. R. Michele, M. T. Knudsen and J. E. Hermansen, “A comparison of land use change models: Challenges and future developments,” Journal of Cleaner Production, vol. 113, no. 1, pp. 183–193, 2016. [Google Scholar]
36. P. K. Priya and N. Yuvaraj, “An IoT based gradient descent approach for precision crop suggestion using MLP,” Journal of Physics: Conference Series, vol. 1362, no. 1, pp. 012038, 2019. [Google Scholar]
37. L. Campanile, M. Iacono, F. Marulli, M. Mastroianni and N. Mazzocca, “Toward a fuzzy-based approach for computational load offloading of IOT devices,” Journal of Universal Computer Science, vol. 26, no. 11, pp. 1455–1474, 2020. [Google Scholar]
38. L. Apiecionek and M. Biedziak, “Fuzzy adaptive data packets control algorithm for IoT system protection,” Journal of Universal Computer Science, vol. 26, no. 11, pp. 1435–1454, 2020. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools