
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Data Analytics on Unpredictable Pregnancy Data Records Using Ensemble Neuro-Fuzzy Techniques
1 Faculty of Information and Communication Engineering, Anna University, Chennai, 600025, India
2 Department of Computer Science and Engineering, KSR College of Engineering, Tiruchengode, 637215, India
* Corresponding Author: C. Vairavel. Email:
Computer Systems Science and Engineering 2023, 46(2), 2159-2175. https://doi.org/10.32604/csse.2023.036598
Received 06 October 2022; Accepted 08 December 2022; Issue published 09 February 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The immune system goes through a profound transformation during pregnancy, and certain unexpected maternal complications have been correlated to this transition. The ability to correctly examine, diagnoses, and predict pregnancy-hastened diseases via the available big data is a delicate problem since the range of information continuously increases and is scalable. Many approaches for disease diagnosis/classification have been established with the use of data mining concepts. However, such methods do not provide an appropriate classification/diagnosis model. Furthermore, single learning approaches are used to create the bulk of these systems. Classification issues may be made more accurate by combining predictions from many different techniques. As a result, we used the Ensembling of Neuro-Fuzzy (E-NF) method to perform a high-level classification of medical diseases. E-NF is a layered computational model with self-learning and self-adaptive capabilities to deal with specific problems, such as the handling of imprecise and ambiguous data that may lead to uncertainty concerns that specifically emerge during the classification stage. Preprocessing data, Training phase, Ensemble phase, and Testing phase make up the complete procedure for the suggested task. Data preprocessing includes feature extraction and dimensionality reduction. Besides such processes, the training phase includes the fuzzification process of medical data. Moreover, training of input data was done using four types of NF techniques: Fuzzy Adaptive Learning Control Network (FALCON), Adaptive Network-based Fuzzy Inference System (ANFIS), Self Constructing Neural Fuzzy Inference Network (SONFIN) and/Evolving Fuzzy Neural Network (EFuNN). Later, in the ensemble phase, all the NF methods’ predicted outcomes are integrated, and finally, the test results are evaluated in the testing phase. The outcomes indicate that the method could predict impaired glucose tolerance, preeclampsia, gestational hypertensive abnormalities, bacteriuria, and iron deficiency anaemia better than the others. In addition, the model exposed the capability to be utilized as an autonomous learning strategy, specifically in the early stages of pregnancy, examinations, and clinical guidelines for disease interventions.Keywords
Successful pregnancy depends on a series of interconnected biological changes, including placentation, fetal immunological reactions, and metabolic stability. Rapid advancements in rising technology have enabled accessibility to multi-omics bioinformatics that could yield more significant knowledge of healthy and pathological conceptions when linked with health and therapeutic facts. The unification of such diverse information via the use of cutting-edge Machine Learning (ML) techniques can allow the prognosis of both short-range and long-range health patterns during the development stages of a fetus and the formulation of therapies that could avoid or reduce the severity of issues.
Women’s anatomy undergoes substantial transformations throughout the maternity period, and tragically, many maternal problems may emerge. In addition, there are several frequent but severe side effects, including impaired glucose tolerance and preeclampsia, gestational hypertension abnormalities, bacteriuria, and iron deficiency anaemia.
Impaired glucose tolerance: Although the haemoglobin glucose levels are raised (140 to 199 mg/dL), it does not meet the criteria for diabetes classification. Usually, the muscular cells of pregnant women cannot react to the hormone that has been secreted. Thus, the subject finds it difficult to utilize the glucose in their bloodstream. A fetus’s health may be seriously harmed if the mother’s sugar regulation goes off course throughout gestation.
Gestational Hypertensive Abnormalities: An increase in haemoglobin hypertension during gestation is known as gestational hypertension (prenatal hypertension). As many as 3% of all pregnancies are affected by this condition. Around 135–140 days of pregnancy, gestational hypertension is the first sign of hypertension. Such a diagnosis usually represents the blood pressure range at systolic ≥140 mmHg/diastolic ≥90 mmHg. If a woman’s blood pressure stays high for more than 12 weeks after giving birth, she may be diagnosed with chronic high blood pressure. Table 1 depicts the three prominent ranges.

Preeclampsia: Among the several forms of hypertension (increased bloodstream stress) that may afflict a pregnant woman is preeclampsia (sometimes referred to as toxaemia). Inflammation and elevated hypertension are common symptoms of pregnant women suffering from toxaemia. In addition, gestational hypertension and high proteinuria are found to be significant signs of preeclampsia in pregnant women.
In some cases, it may progress to eclampsia, a dangerous complication that can put both mother and foetus at risk or, in exceptional circumstances, prove fatal. A few significant risk factors of preeclampsia are exhibited in Fig. 1.
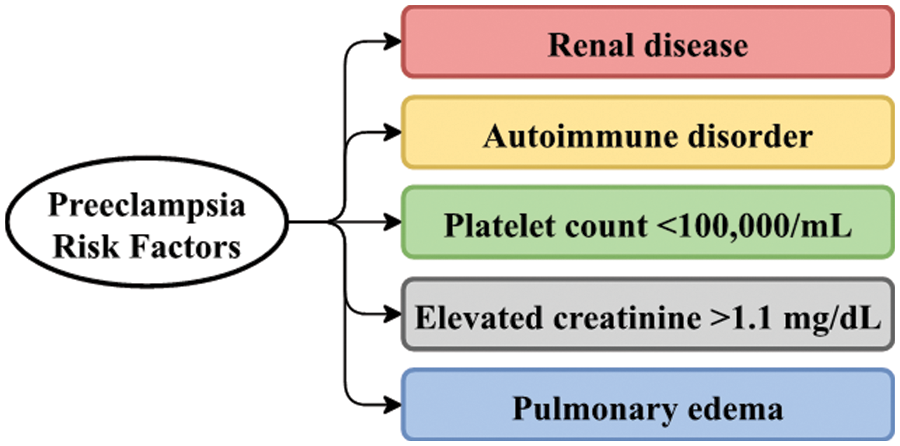
Figure 1: Risk factors of preeclampsia
Bacteriuria: Extreme inflammation of the lining, severe cystitis, and rheumatic diseases may occur during pregnancy, with bacteriuria infection progressing up the urinary tract. In addition, under-nutrition and premature labor may result from the presence of bacteriuria in the urine of pregnant women. A prevalence of pre-existing impaired glucose tolerance, past bacterial infection, elevated parity, as well as poor socioeconomic position have all been linked with a higher incidence of bacteriuria.
Iron Deficiency Anaemia: Preterm birth seems to be more frequent in pregnancy with extreme anaemia (12 g/dL) throughout gestation (such a scenario is possible, especially if the preterm happens before 37 gestation weeks). Anaemia caused by iron deficit during gestation is also linked with lower foetal growth and postnatal distress in expectant mothers. The mother and the fetus’s health are severely affected by iron deficiency anaemia during gestation; it is associated with an elevated risk of foetal morbidity.
Making presumptions, limiting diagnostic errors, and significantly enhancing the accuracy of different diagnoses may benefit from artificial intelligence (AI) [1]. Machine Learning is a subpart of Artificial Intelligence (AI) and has become an eminent domain in the computer science sector. Information from diverse data sets may now be linked effectively using such approaches, making correlations among them that previously seemed unattainable [2,3]. Because of the vast amount and complexity of medical data, Machine Learning is acknowledged as a viable tool for diagnosing or forecasting medical consequences.
The assessment of massive data in the medical sector is a delicate matter that must be performed accurately in order to facilitate the forecasting, identification, and investigation of disorders. Thus, creating and using Machine Learning [4] categorization strategies that accurately and efficiently identify conditions is critical. The increased utilization of high computational approaches in healthcare data analytics has significantly impacted Machine Learning in the past few years. However, a multitude of diagnostic difficulties must always be solved to help physicians properly diagnose the disorder. These include developing assessment methods that are accurate, consistent, and efficient. Most healthcare records are filled with inappropriate, contradictory, replicated, and missing information, which makes it challenging to build a sound classifier system from such datasets. The accuracy of any classifier’s predictions of disorder is indicative of the consistency of the healthcare records as well as the algorithms that are utilized throughout the categorization phase. As a result, in order to accurately forecast and predict disorders, classifiers must be used to assess critical medical information.
In Machine Learning and trend prediction, categorization is crucial for extracting information from actual concerns. With the help of the dataset, a model is built to predict the feature values at various levels of classification properly. However, due to their inherent inflexibility in dealing with more complicated situations, ANNs (artificial neural networks) [5] and other self-contained classification techniques cannot be expected to function consistently and provide more integrated solutions with optimal accuracy.
Because of its massive parallelism, ANN is a computationally intensive framework capable of self-learning and self-adaptation. However, ANN is poorly suited to deal with challenges, such as contradictory, unclear, and imperfect information, over which inconsistency concerns may develop at any level of categorization. Using Fuzzy Logic (FL) [6] as a solution, numerical input characteristics are transformed into linguistic equivalents, also referred to as terms, e.g., extreme, moderate, or low risks. In the fuzzification procedure, every feature is turned into a membership number within the range of defined linguistic qualities. Accordingly, the data points are used to retrieve all linguistic characteristics (2 or 3-fold the number of attribute values). Fuzzy Logic may also be used to determine the association number (membership value) of various linguistic concepts in order to deal with the unpredictability issue. ANN is capable of learning the pattern independently through the facts and afterwards self-adapting the networking system appropriately. However, it is unable to comprehend the learned information from the facts. On the other hand, Fuzzy Logic cannot evaluate information through learning strategies, yet it is pretty good at interpreting language words. A linguistic factor is a term often used to show how much a subject fits into a specific group.
A rule-based architecture implies that training the classifier takes a longer duration. Moreover, framing the appropriate rules for predicting the objective outcome is also critical. The Neuro-Fuzzy framework (NF) [7] is a hybridized concept that combines the benefits of both FL and ANN to deal with the difficulties of uncertainties and imperfect data input. Broadly speaking, NF processes include any combo of fuzzy reasoning and neural rationale approaches. According to [8], the various combinations of these strategies fall under the broad categories that were depicted in Fig. 2. Among such varieties, few NF strategies are found to be effective, which were evident through their consequential attainment of desired outcomes. They are FALCON, SONFIN, and EFuNN are examples of blended systems that combine the advantages of ANNs and FLs.
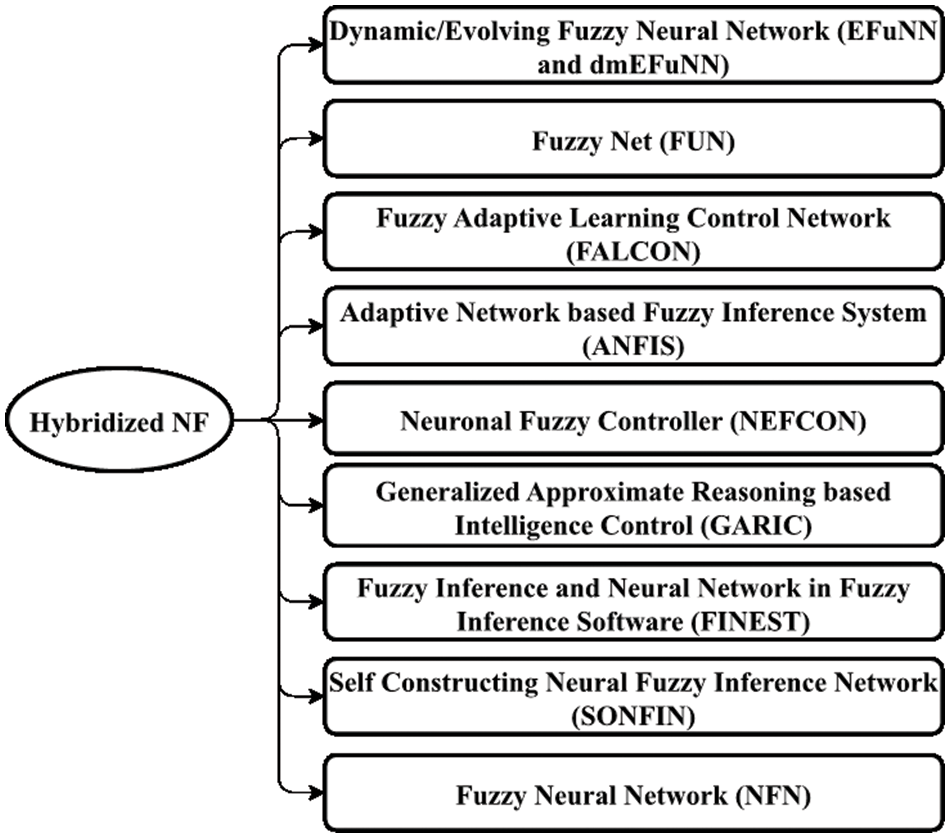
Figure 2: Different types of hybridized NF
Accurate evaluation of pregnancy-induced disorders might be challenging for any physician since a large number of variables must be considered. As a matter of fact, creating technologies for the automated and precise identification of diseases caused by pregnancy might be beneficial to physicians in reaching decisions about such disorders/diseases. Since ensemble learning approaches, also known as “combined task forces” of classifiers in the process of classification and prediction, may enhance the precision of traditional predictive approaches, a novel model is employed in this research that performs the ensembles of suitable hybridized NFs to boost the prognostic accuracy of pregnancy-induced disorder detection systems. With the capacity to represent very complicated correlations among reported variables (features) and processed predictors, E-NF has become popular for predicting the future of pregnancies. However, the overwhelming proportion of past research has concentrated on modeling strategies that combine single or multiple data sources, including therapeutic and generated statistical information from additional sources. This study explored two groups of datasets for data analytics: the Apollo-University of Cambridge Repository [9] and the Preeclampsia datasets from BioGPS [10].
This study builds, trains, and enhances a learning platform, including managing a vast quantity of observations, developing a learning strategy, and testing. Subsequently, the test findings are reviewed in the testing stage after incorporating them into the ensemble process using the entire NF approaches.
A crucial risk is involved while examining various machine learning algorithms for classifying problems of any kind. It’s significant to mention, however, that such a choice is highly reliant on the dataset’s dimensionality and complexity, as well as various features. Since cause and effect can’t be proven using ML, it can only present potential possibilities for determinism. Moreover, only a limited number of models can be used to solve specific issues. It was found that [11] constructed a decision-making framework that employed two classes of decision: one for indicating preterm labor and the alternative one for showing an irregularly delayed pregnancy. Likewise, a study from [12] employed e-health information to forecast premature births. In order to categorize the severity of preterm delivery, both positive, as well as negative categories were used.
Research on both hypertensive as well as preeclampsia problems has been conducted, with multiple trials specifically focusing on both conditions [13]. 11.5 per cent of the research falls under this group. Research on preeclampsia usually emphasizes its early detection. However, hypertension diseases are studied for a variety of reasons, including screening and early detection, mortality correlation, and adverse effects on pregnancy and foetal development. Most of the research in this domain focused on categorization (88.9%), but the other studies (11.1%) suggested decision guidance platforms, mobile apps, and an e-health infrastructure. Around 44.4% used information via medical databases.
Sensors were used to collect real-time data (blood pressure readings) in approximately 22.2% of the research. Around 11.1% of the investigations acquired data through perinatal staged questionnaires and smartphone utilization. Survey information was utilized in 16.6% of the research, while healthcare-associated electronics were used in 11.1% of the investigations. In 11.1 percent of the study, experts’ experience was consulted. Existing research employed facts from previous medical archives and questionnaires. Feature extraction processes were discussed in 22% of analyzed research findings, with three prominent studies reporting on the functioning of incomplete information from which parametric estimation procedures were utilized by [14] single-chained attribution of weighted mean was implemented by [15] and outcome with the mean significance of records was adapted.
Only minimal studies were used for feature selection techniques [16]. Of all studies in this category, 22.2% proposed usable systems. The research work from [17] presented a complete IDSS for preeclampsia prediction and maternal care alongside three different applications for each role (A smart tablet/smartphone app for subjects and healthcare practitioners, as well as a web app for healthcare professionals and a standalone installer (desktop) for supervisors). The research work from [18] developed a mobile application which was used to report for preeclampsia prediction and home monitoring. Research from [19] proposed a mobile application to monitor the health status of pregnant women suffering from hypertensive disorders. Both patients and healthcare professionals could use the mobile application. An e-health system proposed in [20] for hypertension detection could also be used via a web application by healthcare professionals. In all mentioned studies, BPsensing devices were used by pregnant women. Table 2 represents some recent ML-based pregnancy complication predictive models using e-medical images and records.
Data preprocessing, training with several hybridized NF techniques with extracted features, ensemble stage (stacking), and ultimately testing are all addressed in this discussion section in depth.
As an initial step for data preparation, we employed PCA-based feature extraction concerning dimensionality reduction factors. Such a process enables the preparatory phase to better explore the complexities of the pregnancy-induced hypertension prediction issue, especially at significant risk instances. This study’s prediction model was built using Python as well as the scikit-learn module. Table 3 represents the vital feature components of the datasets.

3.2 Dimensionality Reduction Using PCA
A high combination of multiple variables may result in a massive amount of higher dimensional feature space; making each data point in the dimensional space (records) a tiny and disproportionate sampling. Systematic dimensionality reduction can be accomplished with the help of the linear algebraic approach, and one such optimal technique is principal component analysis (PCA). The “curse of dimensionality” [28] may significantly influence the effectiveness of ML algorithms when applied to large datasets with a large number of primary features (input). PCA is utilized to determine the most influential characteristics for training the model to solve this problem. It removes all the unrepresentative features that aren’t essential to the concept and retains crucial and distinct features. Using PCA, we could normalize the critical characteristics from the imprecise and uncertain features obtained from the source datasets. The entire process is highlighted in four steps, they are
i) A Covariance Matrix is an initial step in determining the correlations among various features.
ii) In the second step, the eigenvalues and eigenvectors of the Matrices are derived using eigen decomposition or transformation matrix.
iii) The third step uses eigenvectors to transform the information into principal components.
iv) In the end, Eigenvalues are used to quantify the relevance of these associations and maintain the most relevant primary components.
In this approach, an enlarged feature space is represented as a feature matrix |M| with ‘n’ observations and ‘m’ attributes. Computations are formulated to determine the mean value of each feature in the sample. Next, reducing factors (subtraction) removes every feature from the calculated mean. The subsequent step is to determine the correlation/covariance matrix. Thus, the eigenvectors and their associative eigenvalues are estimated using the computed correlation matrix. Finally, an eigen-decomposition is applied to the extracted data to determine the PCA, as seen in Eqs. (1) and (2).
The eigenvector
This Tc matrix comprises the reduced and normalized features that are remarkably significant in the contribution of crucial network operations. All the extracted normalized features are fed into the NF systems to predict pregnancy-induced illnesses.
4 Parallel Training of Input Data
A hybrid NF system is a fuzzy-based neural network that employs a training and learning technique that relies on multi-variate parameters or is influenced by the ANN theory (centred on inference optimization) to evaluate its variables (intuitionistic fuzzy and its inference) via the analysis of trends observed. One way to understand an NF system is as a collective compilation of fuzzy rules and sequential training of the evolved model. Such a method may either be built entirely via mapping input-output data points or can be proceeded with using a comprehensive assessment through prior information, as fuzzy rules do. Fusion of FL control with NN yields a more straightforward system to understand and recognize the objective outcome from observed patterns. In this research, some prominent hybridized NF systems are considered to train and predict pregnancy-induced disorders. They are ANFIS, EFuNN, FALCON, and SONFIN. The following subsection elaborates on the core mechanism of all those considered NF systems.
ANFIS [29] implements a Takagi-Sugeno Fuzzy Inference Mechanism (FIM) that comprises five layers. To begin with the first layer, the input feature vectors are mapped to the corresponding MF (membership function) to obtain a membership value. The second layer represents the first-level hidden layer, where the predecessors of the regulations (predefined rules) are determined using the operative segment T-norm. The rule intensities are then fine-tuned in the next hidden layer, which is preceded by its next-level hidden layer, where the subsequent effects of the regulations are computed. Finally, the last layer determines the overall outcome by summing up all the incoming processed information. Using a backpropagation training strategy and the least-squares approach, ANFIS determines the source MF features. The recurrent trained model comprises two elements for each phase. To begin, the input sequences are transmitted, and subsequent variables are determined using the recursive least square approach, whereas the features of the antecedents are deemed immutable. Iterative training algorithms such as backpropagation have been used to fine-tune the variables of the assumptions, but their outcomes are left unchanged. The overall outcome in ANFIS can be stated as a continuous function of the subsequent components. It is also feasible to rewrite the result (f) as,
Thus, Eq. (4) exhibits a linear relationship with the following sequential variables (i1, j1, k1….. in, jn, kn).
The five-layered construction of the FALCON is proposed by [30]. Every output has a pair of linguistic endpoints attached to it. The first one is used for the patterns, while the latter one is utilized to represent the actual outcome. The dimensional input vectors are mapped to the relative MF in the first-level hidden layer. The predecessors of the regulations (rules) are defined in the next-level layer (second), which is then preceded by the consequents described in the next layer (third). FALCON makes use of a training engine that is a hybrid comprised of unlabeled data to establish the initial MFs and preliminary inference system. Similarly, a training strategy is entirely centred on learning rate to optimize and alter the eventual parametric values of each MF to generate the objective output. Finally, these learning procedures are used in conjunction with one another to provide the required outcome. The following Eq. (5) provides the final outcome of FALCON using a defuzzification process in which wpq denotes the input of the pth linguistic result (O) from its qth input.
where
Only during the training process all the neurons are evolved and involved in training procedures of the Evolving Fuzzy Neural Network (EFuNN) [31,32]. Here, data from the first layer is sent to the second layer, which determines levels of the appropriateness of predetermined MF. Further, the layer at the third level incorporates fuzzy rule-based neurons, which express hypotheses of unprocessed-processed information as a relationship to hyper-spheres drawn from the fuzzified input-output space dimensions. Using a hybrid training approach, each rule-based neuron that is specified with two vector fields of weight matrix is tuned. The fourth layer measures the degree of sensitivity between the output MF and the input data. Finally, the defuzzification process and attainment of crisp outcomes are performed at the fifth layer.
The hybrid concept of SONFIN implements an improved Takagi-Sugeno FIM. The input vector is segmented in a participatory way, employing a positioned grouping approach in the preliminary section of the procedure [33]. A singular, unique value is determined using a clustering algorithm that is allocated initially to each defined rule for the purpose of identifying its form throughout the subsequent phase of the workflow. Several vital parameters (input variables) are introduced progressively as a supplementary process in the learning process. Thus, it can generate a linear model of independent factors for every rule, which is determined by projection-based correlated measures. The subsequent variables are optimized using the least square method or recurrent minimal space methods, and the primary variable factors are effectively corrected using the backpropagation algorithm. The outcome layer, which performs the defuzzification process, integrates the previous layer’s output (recommended) and produces the ultimate resultant, the following computation exhibited in Eq. (6).
Using the ensemble paradigm, a set of hybridized NF models is trained, and the outcome of every model is processed to obtain a final prediction on pregnancy-induced disorders. Recursively learning the prediction variance of the preceding model is the premise of the proposed stacking ensemble concept. Multiple versions of existing models and predictive features can be combined using the stacking method instead of boosting, bagging, or other homogenous ensemble procedures. Unlike the heterogeneous voting-based ensemble approach, the stacking ensemble strategy allows the meta-learner to acquire knowledge and retrain the evolved meta-model from the base layer. Thus, the stackable ensemble approach has superior performance to others.
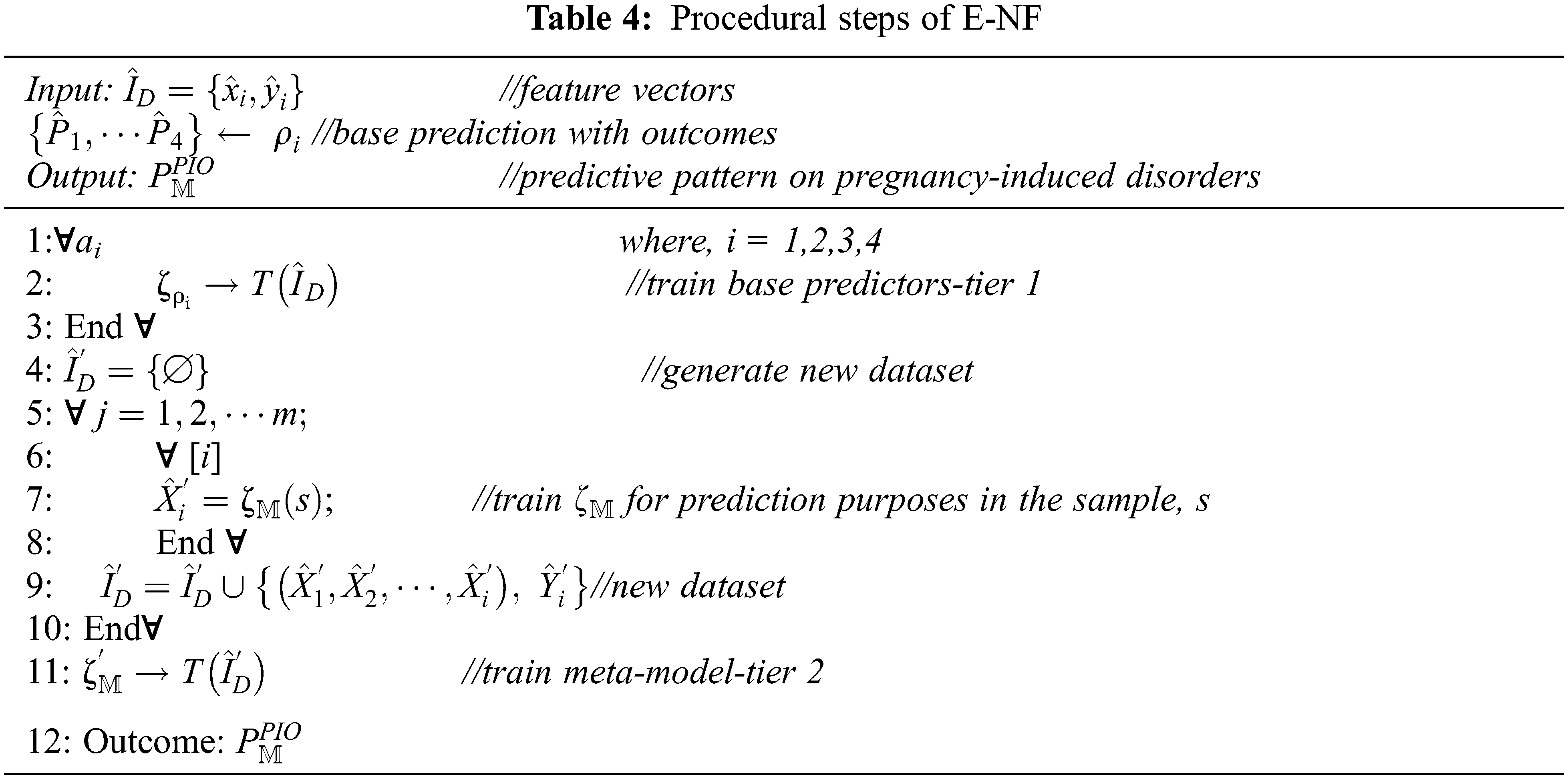
As demonstrated in Fig. 3, the stackable ensemble training process has a two-tiered layout. The first tier comprises the multiple base predictors (ANIFIS, EFuNN, FALCON, and SONFIN), where the training process is accomplished using a normalized input feature. Thus, each model possesses a set of predictive datasets for a varying range of trials. The second tier incorporates the outcome of the first tier and tends to form a new dataset for training the meta-model. Predictive results on pregnancy-induced disorders are generated using the newly evolved dataset. Table 4 represents the procedural steps of E-NF.
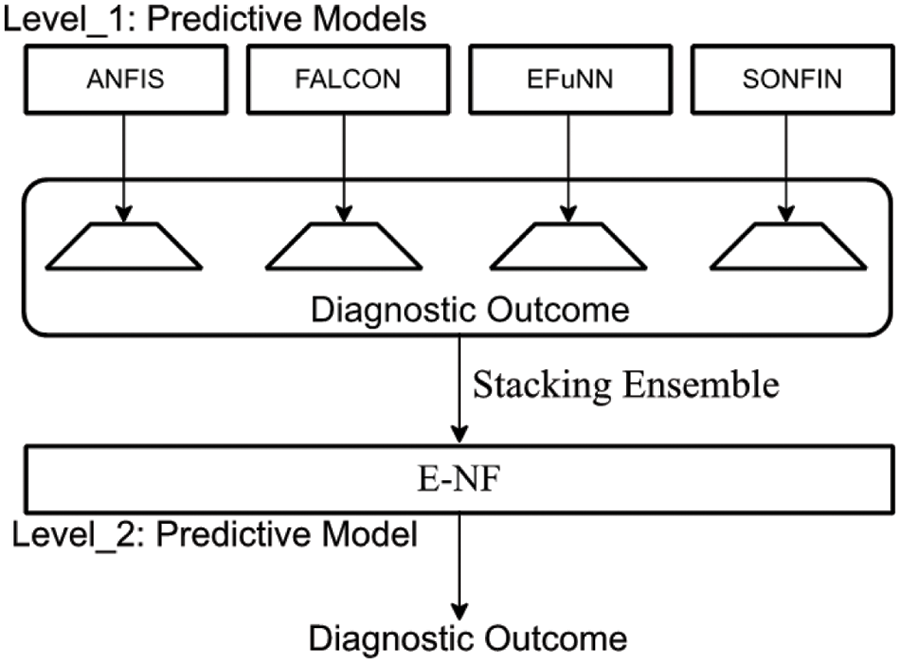
Figure 3: Architecture of E-NF
This section demonstrates the efficacy of four NF models and the sequential E-NF in predicting pregnancy-related diseases by making use of two healthcare data resources. BioGPS [10] and Apollo-University of Cambridge Repository [9] was used for the experimental purpose. Extraction of features and dimensionality reductions has been performed upon those healthcare records before they are made usable. Python 3.6.5 is used to implement the considered predictive methods. System characteristics include an Intel I7-[Core i7-3520M CPU] with a processor speed of 3.60 GHz as well as 8 GB of memory. The essential hyper-parameters are considered to evaluate this research’s outcomes. A learning rate of 0.002 has been configured for each model. The overall count of accessible features determines the involvement of input neurons which can be used to process data from the dataset. Moreover, a dataset’s target class count specifies the overall neurons count in the output section. Finally, the process halting criterion of the proposed system is determined by the number of iterations they have executed (1000 epochs).
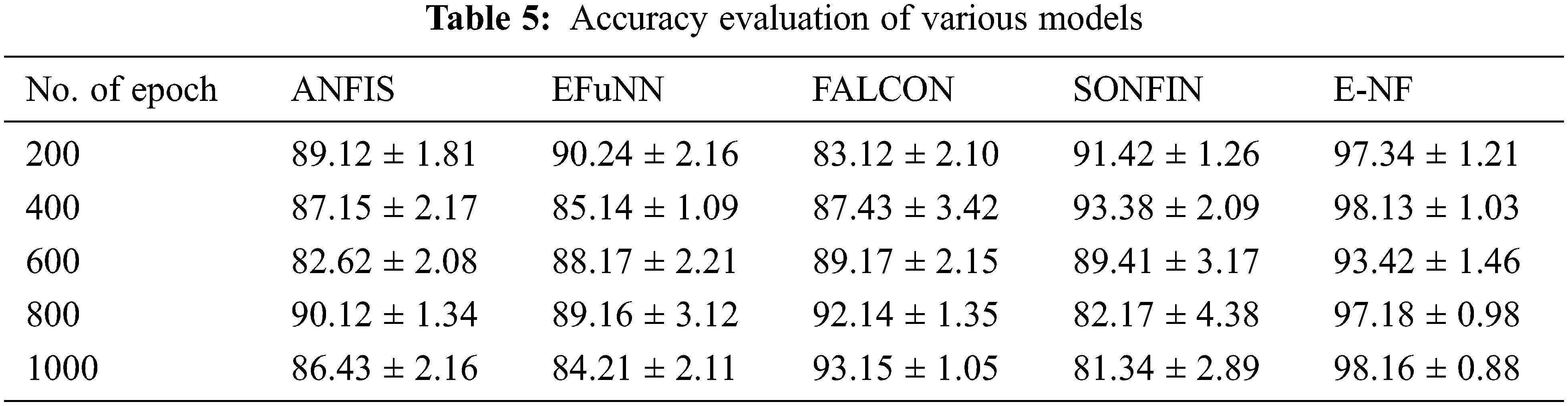
Fig. 4a shows the accuracy of various NF predictions, where the E-NF (96.84%) exhibits around 9.85% more predictive accuracy than other models. Other NF models like ANIFIS, EFuNN, FALCON, SONFIN reported 87.08%, 87.38%, 89.00%, 87.54%, respectively. It is also evident that the performance of E-NF is consistent regardless of the increment of epochs. In contrast, the performance degrades for other models as the epoch increases eventually, which is evident from the outcome displayed in Table 5. Fig. 4bexhibits the superiority of proposed models in the prediction process compared to the existing model, which is discussed in Section 2 elaborately.
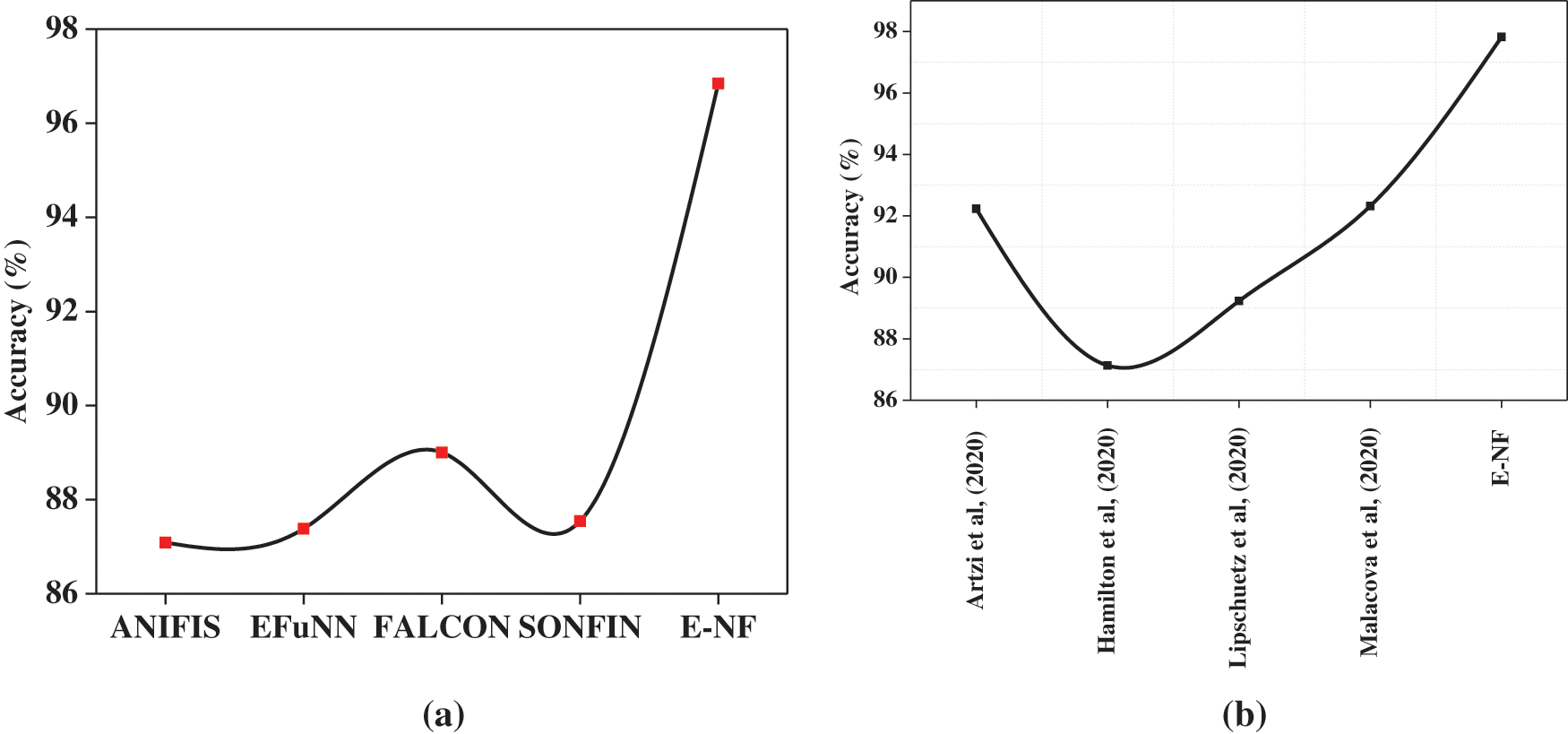
Figure 4: (a) Analysis of model’s predictive accuracy among various NF, (b) analysis of model’s predictive accuracy with existing models
The suggested model’s functionality is assessed and compared to other hybridized NF strategies using data analytics. Furthermore, it clarifies the kind of data and its relevance in light of various modeling schemes. The two considered datasets are compared using the parametric test. When using ML, overfitting is a prevalent concern. It can emerge at any moment in different contexts. A decrease in error does not influence the effectiveness of the proposed model anymore, especially during the optimization process, which contributes to the collinearity of the training sample. Predominately, NF uses backpropagation mechanisms to reduce the error gap between observed and predicted results. Input feature vectors that aren’t necessary are removed with the inclusion of the dimensional reduction approach via PCA.
We utilized the Receiver Operating Characteristic (ROC) plot to compare several prediction models and the E-NF approach. In addition, the findings indicated that the AUC (Area Under Curve) of all ROC-measured techniques is over 0.95 on average. As seen in Fig. 5, AUC values are shown for (a) ANFIS, (b) EFuNN, (c) E-NF, (d) SONFIN, and (e) FALCON. Employing 7-cross validation, the AUC is obtained for all prediction models after 250 epochs. Three layers of feed-forward neural backpropagation are used in each NF approach.
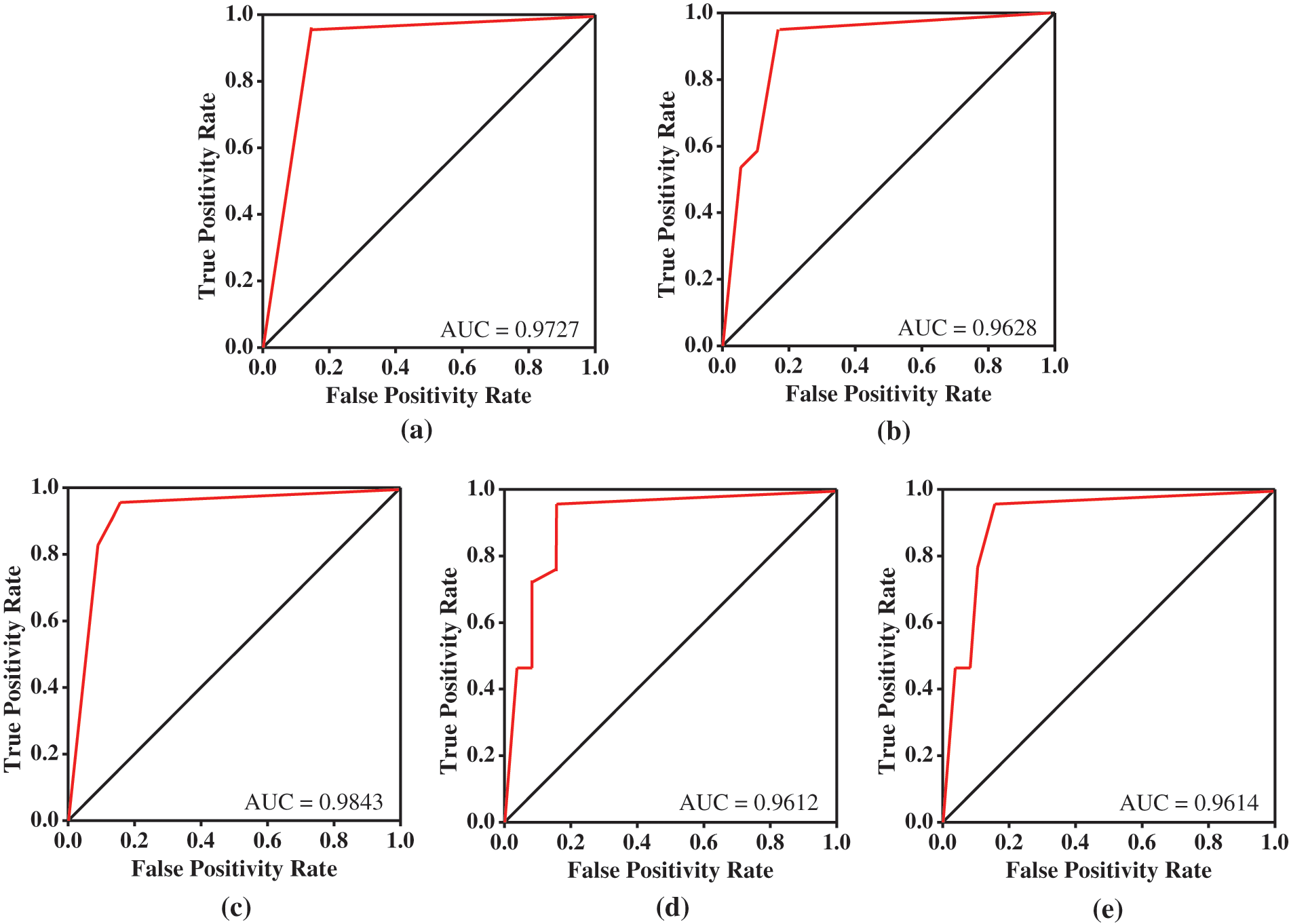
Figure 5: RoC of (a) ANFIS, (b) EFuNN, (c) E-NF, (d) SONFIN, and (e) FALCON
Furthermore, the three-layered NF-based models and E-NF were trained using the robust backpropagation learning approach. Because each technique employs input feature vectors modified by PCA with dimensionality reduction capabilities, the results show that there are only negligible variations in predicting accuracy between each model except E-NF, which shows a significant difference. The associated consequential benefit of PCA-based dimensionality reduction has been the model’s ability to forecast pregnancy-related disorders accurately. So, the results of this research show that E-NF is better than ANFIS, EFuNN, FALCON, and SONFIN.
The statistical and analytical report of the proposed model is exhibited in Table 6. The outcome has been assessed against five commonly occurring disorders during the gestation period. The p-value of the entire concerned model’s prediction process is found to be more acceptable (p = <0.00001) since the outcome is significant at 0.05. As the gestation week increases, the likelihood of prevalence of disorders increases, but prediction varies among the considered models, which are evident for Pre-eclampsia and Bacteriuria. Moreover, Fig. 6 illustrates the average training and testing error of E-NF in predicting all five disorders is 0.03156% and 0.04142%, respectively, which is significantly lower than 0.05. Thus, an optimal outcome is produced even if the sampling rate and the number of epochs are increased.
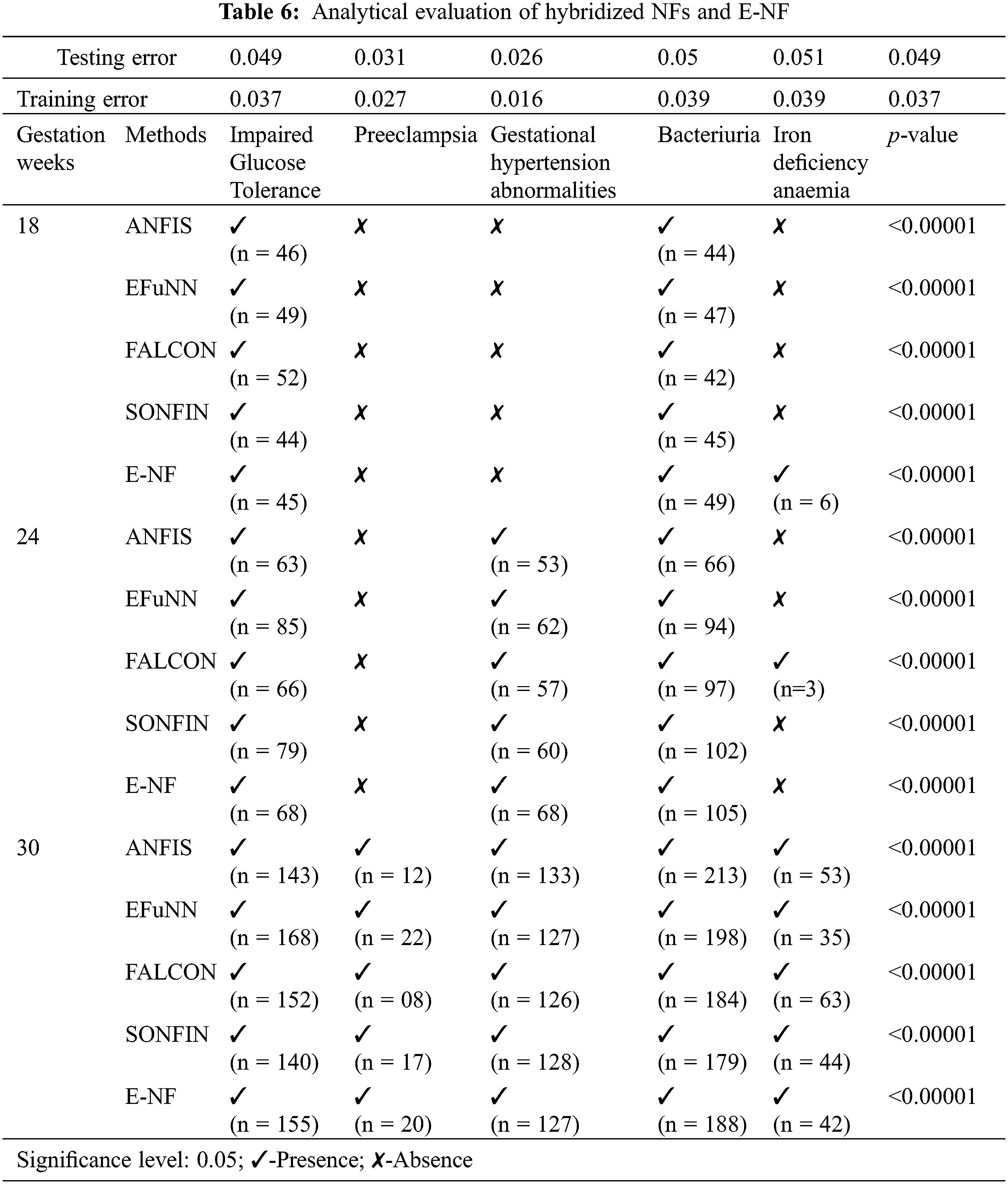
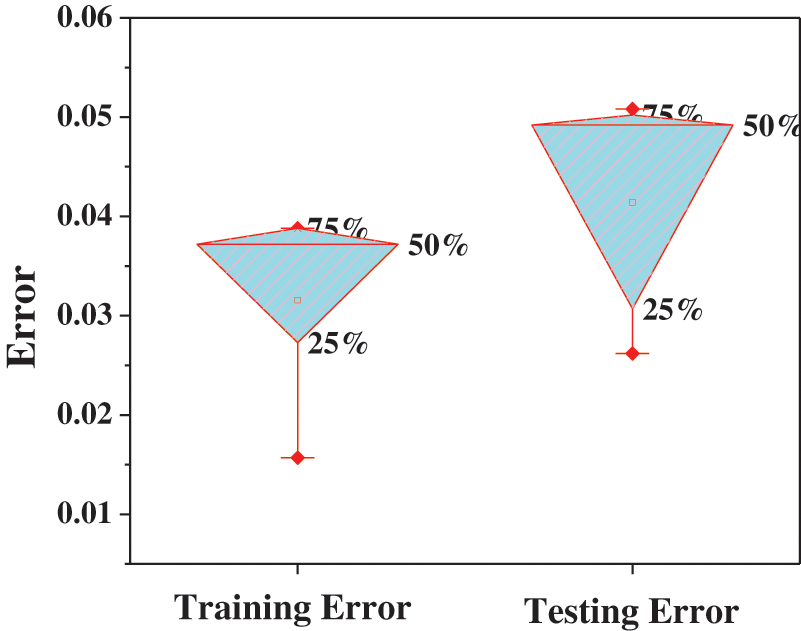
Figure 6: Error gap evaluation
7 Conclusion and Future Research
The Ensemble NF model for predicting pregnancy-induced illnesses is presented in this paper, where the input characteristics are normalized using a PCA to address inaccurate and ambiguous input data. The fuzzification process in NF models (FALCON, EFuNN, SONFIN, and ANFIS) ensures decision support beyond uncertain facts. Still, it increases the model’s complexity since it takes longer to train each model due to the extension of the fuzzy space. The neural network uses these fuzzified values to improve the learning and training process. This model’s flaw is in the fuzzification procedure, which does not use target-labeled attributes and relies on neural networking to handle the discrepancy. The results show that the E-NF approach accurately predicted impaired glucose tolerance, preeclampsia, gestational hypertension, bacteriuria, and iron deficiency anaemia.
Moreover, the proposed model maintains the minimal average training (0.0325) and testing error (0.0427). As a self-learning technique, the model can be used in the prenatal period, diagnostics, and medical recommendations for disorder interventions as well. In future work, we plan to incorporate security measures on the eve of storing and accessing the predictive results via handheld devices.
Acknowledgement: The author, with a deep sense of gratitude, would thank the supervisor for his guidance and constant support rendered during this research.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare they have no conflicts of interest to report regarding the present study.
References
1. M. A. Makary and M. Daniel, “Medical error—the third leading cause of death in the us,” BMJ, vol. 353, no. 35, pp. 2139, 2016. [Google Scholar]
2. M. Darcy, A. K. Louie and L. W. Roberts, “Machine learning and the profession of medicine,” JAMA, vol. 315, no. 6, pp. 551, 2016. [Google Scholar]
3. Z. Obermeyer and E. J. Emanuel, “Predicting the future—big data, machine learning, and clinical medicine,” England Journal of Medicine, vol. 375, no. 13, pp. 1216–1219, 2016. [Google Scholar]
4. IV, J. F. E., D. Michie, D. J. Spiegelhalter and C. C. Taylor, “Machine learning, neural, and statistical classification,” Journal of the American Statistical Association, vol. 91, no. 433, pp. 436, 1996. [Google Scholar]
5. K. M. Karthick Raghunath and G. R. Anantha Raman, “Neuro-fuzzy-based bidirectional and biobjective reactive routing schema for critical wireless sensor networks,” Sensor Data Analysis and Management, vol. 7, no. 78, pp. 3–96, 2021. [Google Scholar]
6. L. A. Zadeh, “Fuzzy sets,” Information and Control, vol. 8, no. 3, pp. 338–353, 1965. [Google Scholar]
7. V. V. Kumar, K. M. K. Raghunath, N. Rajesh and M. Venkatesan, “Paddy plant disease recognition, risk analysis, and classification using deep convolution neuro-fuzzy network,” Journal of Mobile Multimedia, vol. 15, no. 50, pp. 1829, 2021. [Google Scholar]
8. D. Nauck and R. Kruse, “Neuro-fuzzy systems for function approximation,” Fuzzy Sets and Systems, vol. 101, no. 2, pp. 261–271, 1999. [Google Scholar]
9. C. J. Petry, K. K. Ong, I. A. Hughes, C. L. Acerini and D. B. Dunger, “Associations between bacterial infections and blood pressure in pregnancy,” Pregnancy Hypertension, vol. 10, no. 16, pp. 202–206, 2017. [Google Scholar]
10. Preeclampsia Datasets | BioGPS. (n.d.“Biogps.org,” 2019. Available: http://biogps.org/dataset/tag/preeclampsia/. [Google Scholar]
11. H. Rawashdeh, S. Awawdeh, F. Shannag, E. Henawi, H. Fariset et al., “Intelligent system based on data mining techniques for prediction of preterm birth for women with cervical cerclage,” Computational Biology and Chemistry, vol. 85, no. 2, pp. 1072, 2020. [Google Scholar]
12. C. Gao, S. Osmundson, D. R. Velez Edwards, G. P. Jackson, B. A. Malin et al., “Deep learning predicts extreme preterm birth from electronic health records,” Journal of Biomedical Informatics, vol. 100, no. 10, pp. 103334, 2019. [Google Scholar]
13. M. W. L. Moreira, J. J. P. Rodrigues, F. H. C. Carvalho, N. Chilamkurti, J. Al Muhtadi et al., “Biomedical data analytics in mobile-health environments for high-risk pregnancy outcome prediction,” Journal of Ambient Intelligence and Humanized Computing, vol. 10, no. 10, pp. 4121–4134, 2019. [Google Scholar]
14. J. H. Jhee, S. Lee, Y. Park, Y. A. Kim, S. W. Kang et al., “Prediction model development of late-onset preeclampsia using machine learning-based methods,” PLoS One, vol. 14, no. 8, pp. 221202, 2019. [Google Scholar]
15. A. Sandström, J. M. Snowden, J. Höijer, M. Bottai and A. K. Wikström, “Clinical risk assessment in early pregnancy for preeclampsia in nulliparous women: A population based cohort study,” PLoS One, vol. 14, no. 11, pp. 25716, 2019. [Google Scholar]
16. L. Yoffe, A. Gilam, O. Yaron, A. Polsky, L. Farberov et al., “Early detection of preeclampsia using circulating small non-coding RNA,” Scientific Reports, vol. 8, no. 1, pp. 216, 2018. [Google Scholar]
17. M. Abubakar, A. Bibi, R. Hussain, Z. Bibi, A. Gul et al., “Towards providing full spectrum antenatal health care in low and middle income countries,” in Proc. Biomedical Engineering Systems and Technologies, Rome, Italy, pp. 478–483, 2016. [Google Scholar]
18. M. Velikova, J. Peter and N. Spaanderman, “A predictive bayesian network model for home management of preeclampsia,” Journal of Biological Chemistry, vol. 112, no. 22, pp. 179–183, 2011. [Google Scholar]
19. M. W. L. Moreira, J. J. P. C. Rodrigues, A. M. B. Oliveiraand and K. Saleem, “Smart mobile system for pregnancy care using body sensors,” in Proc. on Selected Topics in Mobile & Wireless Networking (MoWNeT), Tangier Morocco, pp. 1–4, 2016. [Google Scholar]
20. I. Marin and N. Goga, “Hypertension detection based on machine learning,” in Proc. on the Engineering of Computer Based Systems, Bucharest Romania, pp. 1–4, 2019. [Google Scholar]
21. N. S. Artzi, S. Shilo, E. Hadar, H. Rossman, S. Barbashet et al., “Prediction of gestational diabetes based on nationwide electronic health records,” Nature Medicine, vol. 26, no. 1, pp. 71–76, 2020. [Google Scholar]
22. M. W. L. Moreira, J. J. P. C. Rodrigues, V. Furtado, N. Kumar and V. V. Korotaev, “Averaged one-dependence estimators on edge devices for smart pregnancy data analysis,” Computers & Electrical Engineering, vol. 77, no. 41, pp. 435–444, 2019. [Google Scholar]
23. S. Kuhle, B. Maguire, H. Zhang, D. Hamilton, A. C. Allen et al., “Comparison of logistic regression with machine learning methods for the prediction of fetal growth abnormalities: A retrospective cohort study,” BMC Pregnancy and Childbirth, vol. 18, no. 1, pp. 1971, 2018. [Google Scholar]
24. K. J. Rittenhouse, B. Vwalika, A. Keil, J. Winston, M. Stoner et al., “Improving preterm newborn identification in low-resource settings with machine learning,” PLoS One, vol. 14, no. 2, pp. 201, 2019. [Google Scholar]
25. D. Shigemi, S. Yamaguchi, S. Aso and H. Yasunaga, “Predictive model for macrosomia using maternal parameters without sonography information,” The Journal of Maternal-Fetal & Neonatal Medicine, vol. 32, no. 22, pp. 3859–3863, 2018. [Google Scholar]
26. K. Paydar, S. R. NiakanKalhori, M. Akbarian and A. Sheikhtaheri, “A clinical decision support system for prediction of pregnancy outcome in pregnant women with systemic lupus erythematosus,” International Journal of Medical Informatics, vol. 97, no. 10, pp. 239–246, 2017. [Google Scholar]
27. L. Chen, “Curse of dimensionality,” Encyclopedia of Database Systems, vol. 3, no. 8, pp. 545–546, 2009. [Google Scholar]
28. D. Rutkowska, “Neuro-fuzzy architectures based on the Mamdani approach,” Studies in Fuzziness and Soft Computing, vol. 10, no. 4, pp. 105–126, 2012. [Google Scholar]
29. C. T. Lin and C. S. G. Lee, “Neural-network-based fuzzy logic control and decision system,” IEEE Transactions on Computers, vol. 40, no. 12, pp. 1320–1336, 1991. [Google Scholar]
30. N. Detlef, R. Kruse and F. Klawonn, Foundations of Neuro-Fuzzy Systems. New York, United States: John Wiley, 1997. [Online]. Available at: https://dl.acm.org/doi/book/10.5555/550675. [Google Scholar]
31. N. Kasabov, V. Jain and L. Benuskova, “Integrating evolving brain–gene ontology and connectionist-based system for modeling and knowledge discovery,” Neural Networks, vol. 21, no. 2, pp. 266–275, 2008. [Google Scholar]
32. H. R. Berenji and P. Khedkar, “Learning and tuning fuzzy logic controllers through reinforcements,” IEEE Transactions on Neural Networks, vol. 3, no. 5, pp. 724–740, 1992. [Google Scholar]
33. M. Abbassi, L. G. Greer and F. G. Cunningham, “Pregnancy and laboratory studies: A reference table for clinicians,” Obstetrics & Gynecology, vol. 115, no. 4, pp. 868–869, 2010. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools