Global-Local Embedding Gating Network for Part-Wise Text-to-Motion Generation
Chanyoung Kim, Jion Kim, Byeong-Seok Shin*
Department of Electrical and Computer Engineering, Inha University, Incheon, Republic of Korea
* Corresponding Author: Byeong-Seok Shin. Email: 
Computers, Materials & Continua https://doi.org/10.32604/cmc.2026.080992
Received 20 February 2026; Accepted 20 April 2026; Published online 30 April 2026
Abstract
Diffusion-based methods have substantially improved the performance of full-body Text-to-Motion (T2M) generation from natural language descriptions. Despite this progress, accurately capturing the fine-grained semantics of composite prompts remains challenging. Approaches that rely solely on a single global text condition often fail to retain part-specific semantic cues, leading to deviations in the motions of certain body parts from the intended descriptions. Recent methods have attempted to address this by incorporating both global and local conditions, yet these are typically combined using fixed ratios or applied in separate stages, which restricts their adaptability to evolving semantic requirements during generation. To address these constraints, this work proposes the Embedding Gating Network (EGN), which dynamically modulates the contributions of global and local information according to the current noisy motion state and the diffusion timestep. By conditioning the gating mechanism on the intermediate noisy motion estimate, EGN adjusts the relative importance of global and local information to emphasize semantics that remain underrepresented at each denoising step. The conditioned signals are processed through independent part-wise generation pathways to minimize semantic interference, while a lightweight fusion module enables inter-part information exchange to preserve structural coherence across the full body. Experiments on the HumanML3D benchmark show that the proposed method consistently improves text-motion alignment over existing full-body and part-based baselines, without compromising motion quality or diversity. Analysis of the learned gating coefficients reveals that local conditions primarily contribute to the formation of part-wise structural outlines during early denoising stages, whereas global conditions become increasingly influential, integrating cross-part semantics and refining full-body consistency as denoising advances. These findings indicate that dynamically modulating conditioning signals during generation is an effective alternative to fixed-ratio conditioning.
Graphical Abstract
Keywords
Motion generation; diffusion model; human motion synthesis; text-to-motion; condition embedding
 Open Access
Open Access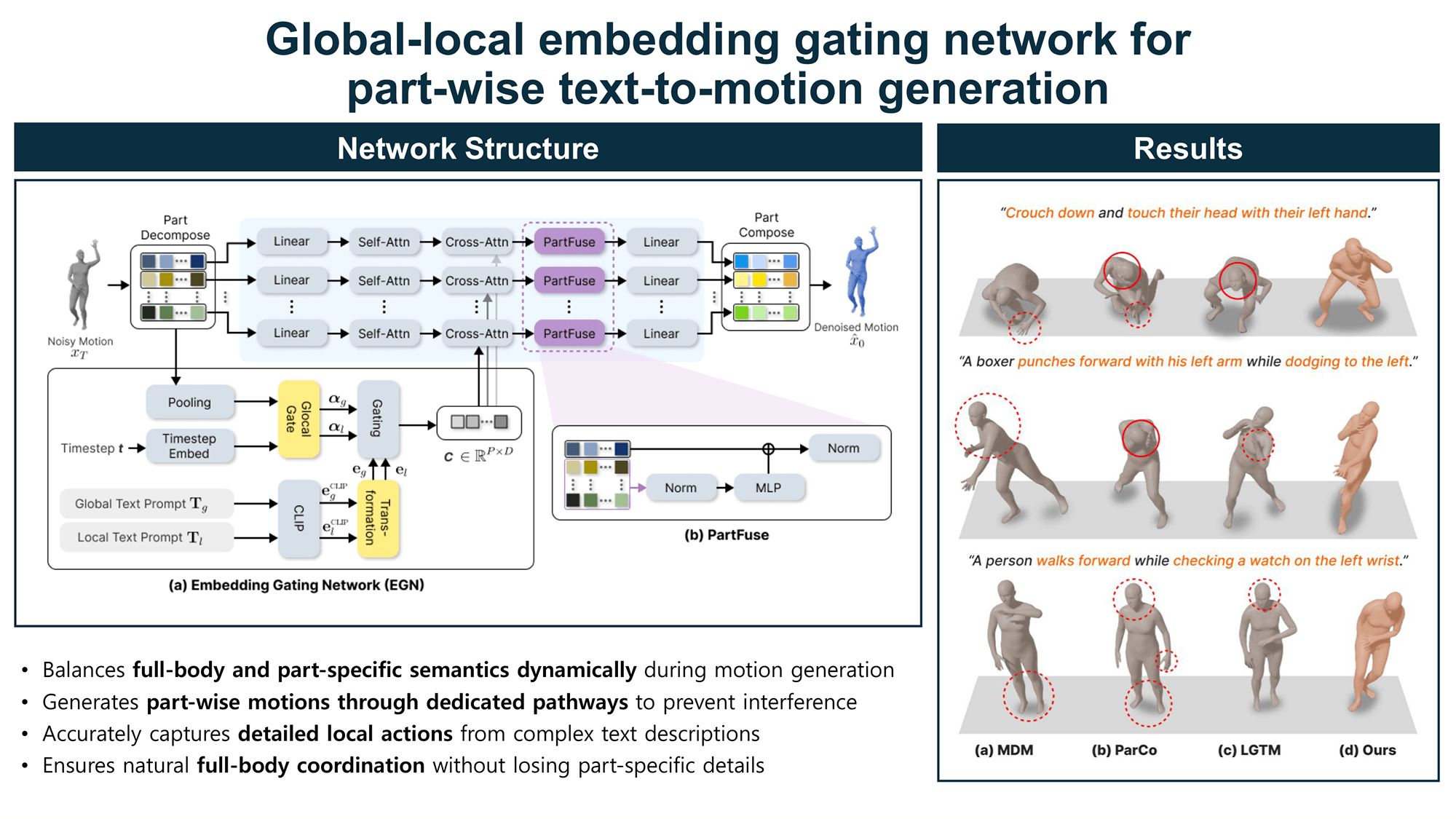

 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Download PDF
Download PDF Downloads
Downloads
 Citation Tools
Citation Tools